Benchmark (ONNX) for LogisticRegression#
Overview#
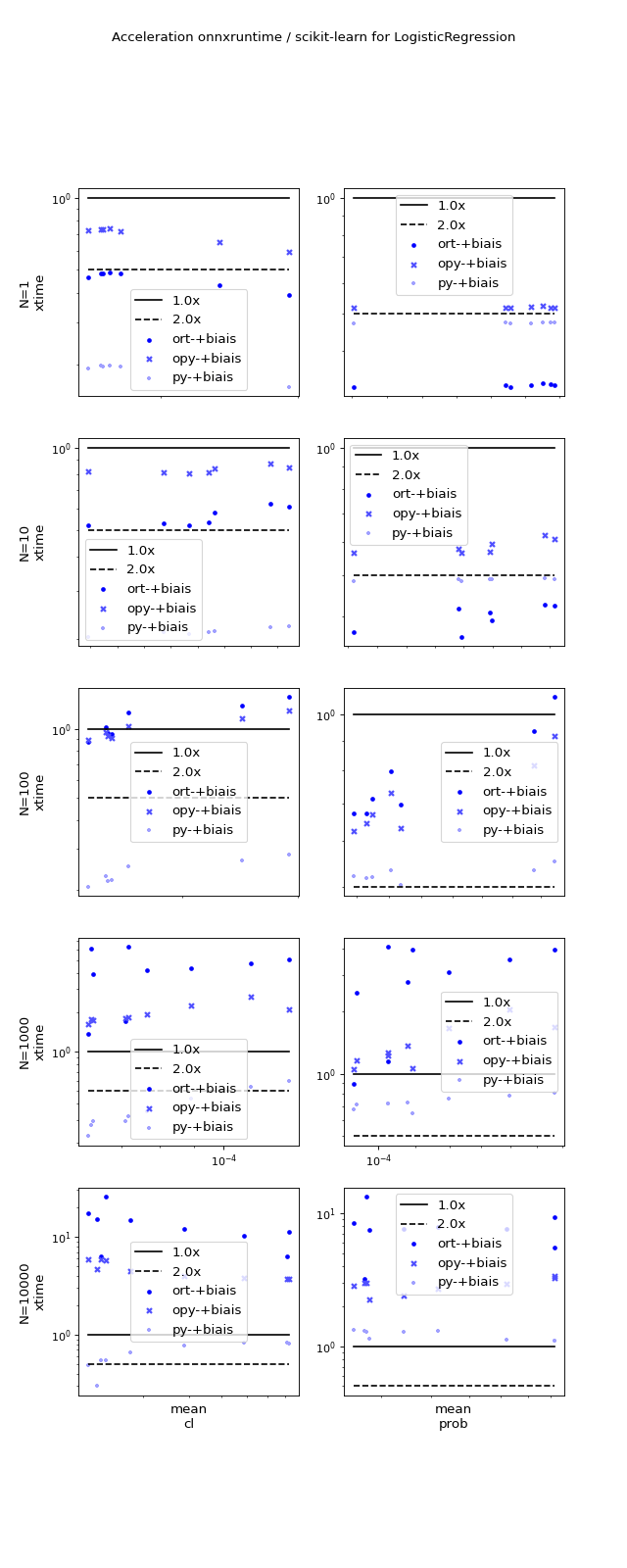
(Source code, png, hires.png, pdf)
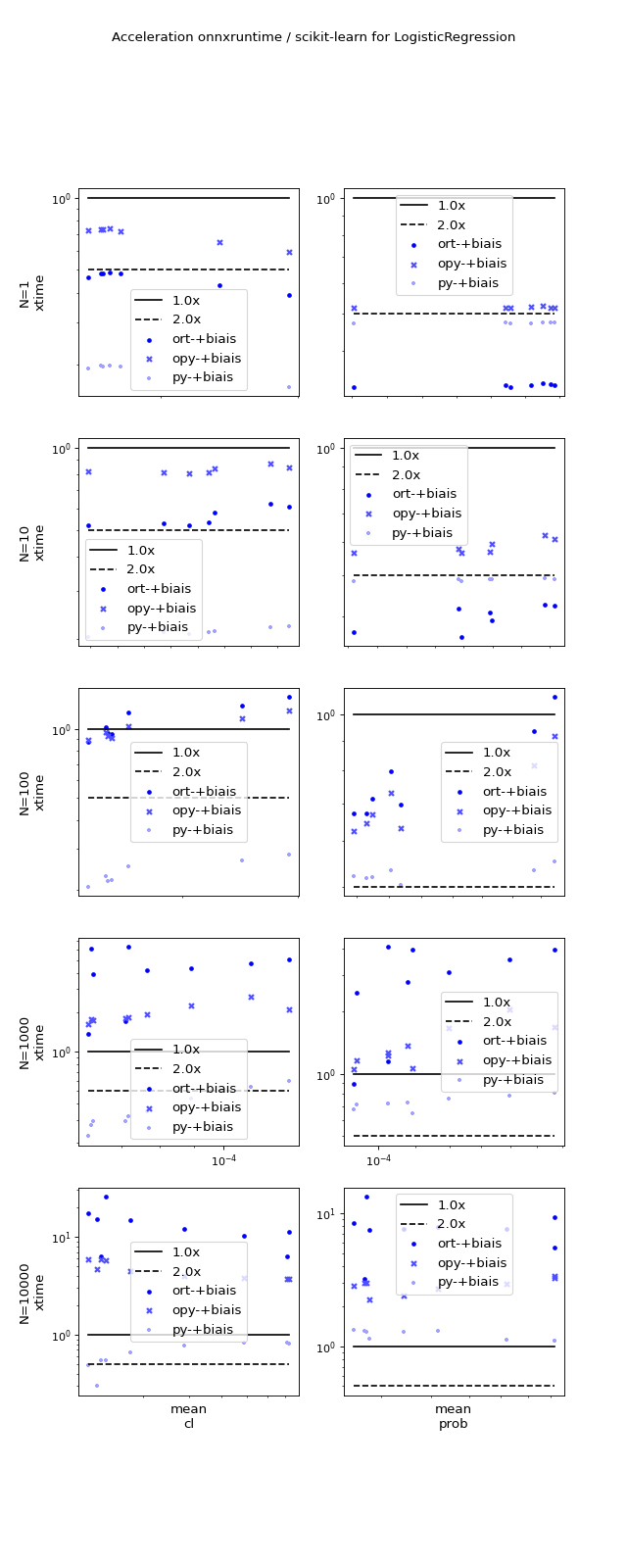{kind=link}
{kind=link}
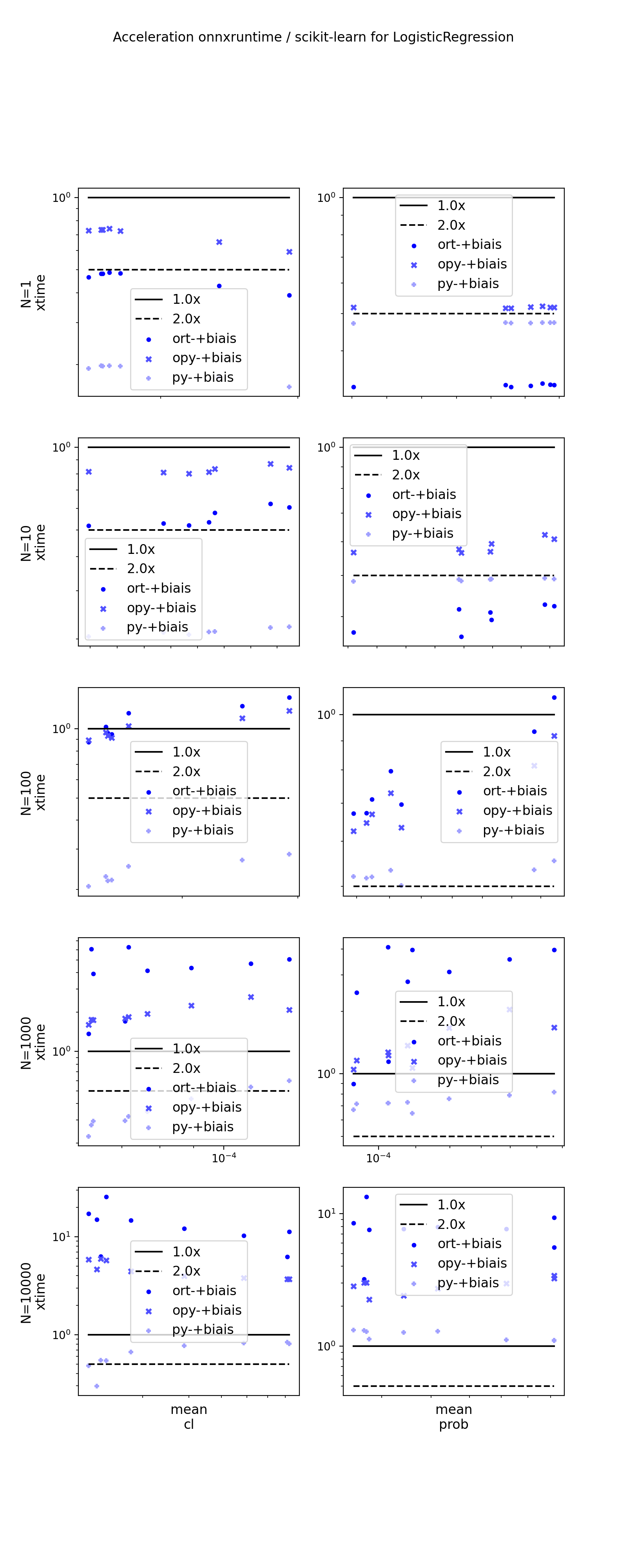
Detailed graphs#
(Source code, png, hires.png, pdf)
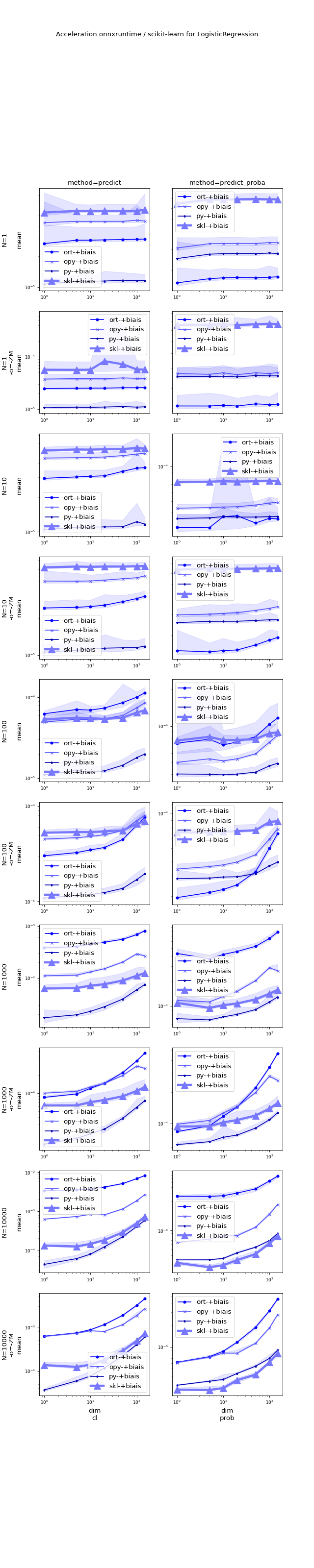{kind=link}
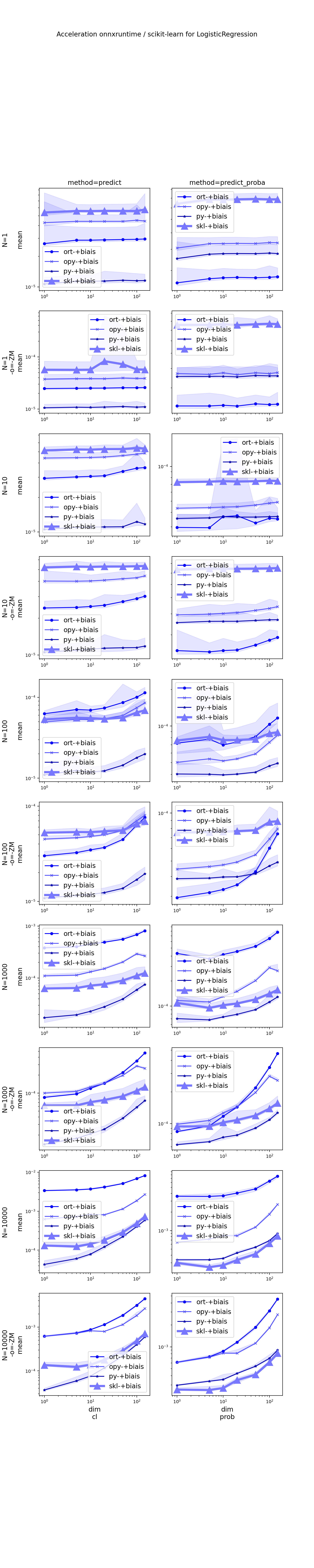{kind=link}
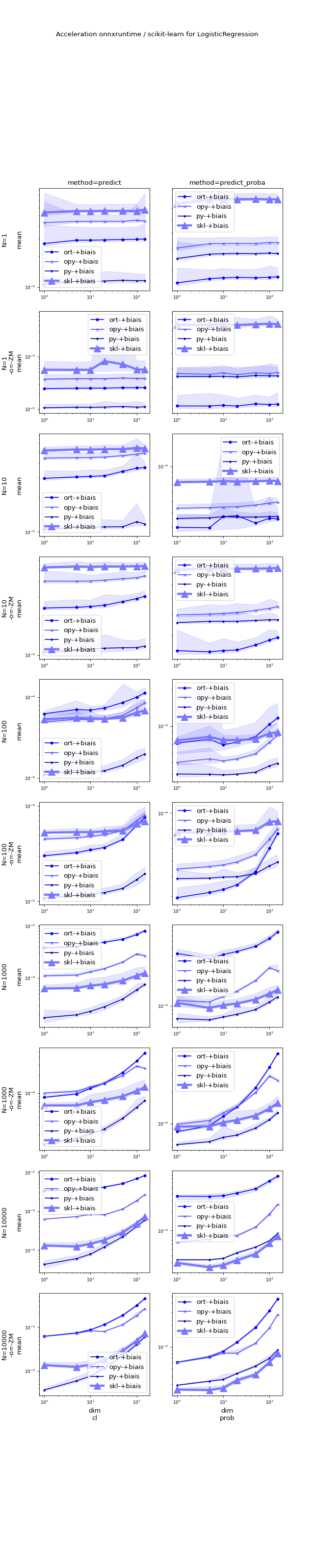
Configuration#
<<<
from pyquickhelper.pandashelper import df2rst
import pandas
name = os.path.join(
__WD__, "../../onnx/results/bench_plot_onnxruntime_logreg.time.csv")
df = pandas.read_csv(name)
print(df2rst(df, number_format=4))
>>>
name |
version |
value |
|---|---|---|
date |
2019-12-11 |
|
python |
3.7.2 (default, Mar 1 2019, 18:34:21) [GCC 6.3.0 20170516] |
|
platform |
linux |
|
OS |
Linux-4.9.0-8-amd64-x86_64-with-debian-9.6 |
|
machine |
x86_64 |
|
processor |
||
release |
4.9.0-8-amd64 |
|
architecture |
(‘64bit’, ‘’) |
|
mlprodict |
0.3 |
|
numpy |
1.17.4 |
openblas, language=c |
onnx |
1.6.34 |
opset=12 |
onnxruntime |
1.1.992 |
CPU-DNNL-MKL-ML |
pandas |
0.25.3 |
|
skl2onnx |
1.6.993 |
|
sklearn |
0.22 |
Raw results#
bench_plot_onnxruntime_logreg.csv
<<<
from pyquickhelper.pandashelper import df2rst
from pymlbenchmark.benchmark.bench_helper import bench_pivot
import pandas
name = os.path.join(
__WD__, "../../onnx/results/bench_plot_onnxruntime_logreg.perf.csv")
df = pandas.read_csv(name)
piv = bench_pivot(df).reset_index(drop=False)
piv['speedup_py'] = piv['skl'] / piv['onxpython_compiled']
piv['speedup_ort'] = piv['skl'] / piv['onxonnxruntime1']
print(df2rst(piv, number_format=4))
method |
skl_nb_base_estimators |
N |
dim |
fit_intercept |
onnx_options |
number |
count |
error_c |
onnx_opset |
error |
onxonnxruntime1 |
onxpython_compiled |
py |
skl |
speedup_py |
speedup_ort |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
1.069e-05 |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
2.669e-05 |
4.287e-05 |
||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.059e-05 |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.471e-05 |
3.76e-05 |
|||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
1.137e-05 |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
2.881e-05 |
4.413e-05 |
||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.086e-05 |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.503e-05 |
3.834e-05 |
|||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
1.136e-05 |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
2.882e-05 |
4.413e-05 |
||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.077e-05 |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.516e-05 |
3.838e-05 |
|||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
1.143e-05 |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
2.903e-05 |
4.416e-05 |
||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.094e-05 |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.521e-05 |
3.833e-05 |
|||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
1.163e-05 |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
2.925e-05 |
4.416e-05 |
||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.119e-05 |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.561e-05 |
3.945e-05 |
|||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
1.152e-05 |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
2.94e-05 |
4.528e-05 |
||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.09e-05 |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.564e-05 |
3.882e-05 |
|||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
1.156e-05 |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
2.959e-05 |
4.444e-05 |
||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.105e-05 |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.582e-05 |
3.872e-05 |
|||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
1.054e-05 |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
2.936e-05 |
4.413e-05 |
||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.057e-05 |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.425e-05 |
4.027e-05 |
|||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
1.095e-05 |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
3.021e-05 |
4.447e-05 |
||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.094e-05 |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.454e-05 |
4.015e-05 |
|||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
1.101e-05 |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
3.053e-05 |
4.465e-05 |
||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.117e-05 |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.493e-05 |
4.035e-05 |
|||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
1.105e-05 |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
3.09e-05 |
4.506e-05 |
||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.138e-05 |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.555e-05 |
4.096e-05 |
|||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
1.109e-05 |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
3.379e-05 |
4.636e-05 |
||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.147e-05 |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.734e-05 |
4.209e-05 |
|||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
1.228e-05 |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
3.6e-05 |
4.775e-05 |
||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.151e-05 |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.896e-05 |
4.285e-05 |
|||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
1.17e-05 |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
3.642e-05 |
4.871e-05 |
||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.183e-05 |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.026e-05 |
4.436e-05 |
|||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
1.099e-05 |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
6.274e-05 |
4.956e-05 |
||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.083e-05 |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.008e-05 |
4.505e-05 |
|||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
1.248e-05 |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
7.084e-05 |
5.352e-05 |
||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.152e-05 |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.248e-05 |
4.654e-05 |
|||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
1.188e-05 |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
6.953e-05 |
5.316e-05 |
||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.18e-05 |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.468e-05 |
4.796e-05 |
|||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
1.234e-05 |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
7.378e-05 |
5.458e-05 |
||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.235e-05 |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.675e-05 |
5.001e-05 |
|||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
1.448e-05 |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
8.632e-05 |
5.965e-05 |
||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.369e-05 |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
4.464e-05 |
5.529e-05 |
|||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
1.796e-05 |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
0.0001006 |
7.452e-05 |
||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.691e-05 |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
6.288e-05 |
6.998e-05 |
|||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
1.993e-05 |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
0.0001141 |
8.552e-05 |
||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.944e-05 |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
7.577e-05 |
8.022e-05 |
|||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
1.731e-05 |
||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.0003814 |
0.0001104 |
|||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.403e-05 |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
8.512e-05 |
0.0001 |
|||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
1.966e-05 |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
0.000401 |
0.0001138 |
||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
1.755e-05 |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
9.707e-05 |
0.0001074 |
|||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
2.294e-05 |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
0.0004501 |
0.0001316 |
||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
2.087e-05 |
|||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
0.0001204 |
0.0001267 |
||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
2.805e-05 |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
0.0004888 |
0.0001511 |
||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
2.498e-05 |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.0001463 |
0.0001456 |
|||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
3.951e-05 |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
0.0005571 |
0.000203 |
||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.804e-05 |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.000221 |
0.0001981 |
|||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
5.946e-05 |
||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
0.0006844 |
0.0002917 |
|||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
5.817e-05 |
|||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0003459 |
0.0002842 |
||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
7.534e-05 |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
0.0008089 |
0.000266 |
||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.518e-05 |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.000469 |
0.0002592 |
|||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
4.316e-05 |
||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.003382 |
0.0006254 |
|||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
3.663e-05 |
|||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
0.0006203 |
0.0006144 |
||||
predict |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
6.075e-05 |
||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
0.003532 |
0.0007306 |
|||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
5.928e-05 |
|||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
0.0007367 |
0.0007244 |
||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
7.909e-05 |
||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
0.003709 |
0.000832 |
|||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.627e-05 |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.0008718 |
0.0008247 |
|||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
0.0001219 |
||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
0.004164 |
0.0008069 |
|||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
0.0001168 |
|||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
0.001144 |
0.0007963 |
||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
0.0002222 |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
0.005127 |
0.001145 |
||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0002228 |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.001864 |
0.001144 |
|||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
0.0004031 |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
0.006849 |
0.001856 |
||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0004002 |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.003146 |
0.001838 |
|||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.000588 |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
0.008204 |
0.002683 |
||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0005972 |
|||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.004459 |
0.002648 |
||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
5.394e-05 |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.668e-05 |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
5.581e-05 |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.637e-05 |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
5.567e-05 |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.674e-05 |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
5.595e-05 |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
8.273e-05 |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
5.59e-05 |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.223e-05 |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
5.58e-05 |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.744e-05 |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
5.765e-05 |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.703e-05 |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
5.142e-05 |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.205e-05 |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
5.243e-05 |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.29e-05 |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
5.225e-05 |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.26e-05 |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
5.278e-05 |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.293e-05 |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
5.289e-05 |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.294e-05 |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
5.402e-05 |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.322e-05 |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
5.346e-05 |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.341e-05 |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
5.337e-05 |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.255e-05 |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
5.596e-05 |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.33e-05 |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
5.538e-05 |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.329e-05 |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
5.406e-05 |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.434e-05 |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
5.609e-05 |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
5.563e-05 |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
6.499e-05 |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
6.501e-05 |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
6.907e-05 |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
6.932e-05 |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
6.292e-05 |
||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
6.228e-05 |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
6.434e-05 |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
6.244e-05 |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
7.162e-05 |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
7.076e-05 |
|||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
7.614e-05 |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.687e-05 |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
8.967e-05 |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
8.874e-05 |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
0.0001106 |
||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.000109 |
|||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.0001248 |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0001266 |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.0001313 |
||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
0.0001357 |
|||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
0.0001246 |
||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
0.0001236 |
|||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
0.0001449 |
||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0001384 |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
0.0001814 |
||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
0.0001786 |
|||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
0.000287 |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0002884 |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
0.0004866 |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0004856 |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.0007249 |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0007134 |
|||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
3.525e-05 |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
2.535e-05 |
4.067e-05 |
||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.55e-05 |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.302e-05 |
3.708e-05 |
|||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
3.741e-05 |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
2.68e-05 |
4.312e-05 |
||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.551e-05 |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.301e-05 |
3.666e-05 |
|||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
3.767e-05 |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
2.713e-05 |
4.322e-05 |
||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.561e-05 |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.326e-05 |
3.748e-05 |
|||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
3.773e-05 |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
2.729e-05 |
4.33e-05 |
||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.529e-05 |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.3e-05 |
3.648e-05 |
|||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
3.768e-05 |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
2.716e-05 |
4.324e-05 |
||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.599e-05 |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.375e-05 |
3.749e-05 |
|||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
3.796e-05 |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
2.732e-05 |
4.38e-05 |
||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.583e-05 |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.35e-05 |
3.707e-05 |
|||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
3.772e-05 |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
2.751e-05 |
4.368e-05 |
||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.583e-05 |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.365e-05 |
3.761e-05 |
|||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
3.548e-05 |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
2.965e-05 |
4.35e-05 |
||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.55e-05 |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.417e-05 |
3.949e-05 |
|||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
3.589e-05 |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
2.948e-05 |
4.403e-05 |
||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.613e-05 |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.377e-05 |
3.989e-05 |
|||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
3.677e-05 |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
3.674e-05 |
4.451e-05 |
||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.616e-05 |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.42e-05 |
4.027e-05 |
|||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
3.645e-05 |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
3.744e-05 |
4.48e-05 |
||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.616e-05 |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.439e-05 |
4.071e-05 |
|||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
3.646e-05 |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
3.238e-05 |
4.637e-05 |
||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.659e-05 |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.613e-05 |
4.202e-05 |
|||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
3.674e-05 |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
3.56e-05 |
4.819e-05 |
||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.69e-05 |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.794e-05 |
4.318e-05 |
|||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
3.687e-05 |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
3.511e-05 |
4.914e-05 |
||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.696e-05 |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.897e-05 |
4.42e-05 |
|||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
4.025e-05 |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
7.23e-05 |
5.026e-05 |
||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.871e-05 |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
2.944e-05 |
4.451e-05 |
|||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
4.002e-05 |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
7.792e-05 |
5.368e-05 |
||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.904e-05 |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.17e-05 |
4.615e-05 |
|||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
3.956e-05 |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
6.988e-05 |
5.167e-05 |
||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.968e-05 |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.312e-05 |
4.73e-05 |
|||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
4.017e-05 |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
7.399e-05 |
5.372e-05 |
||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
3.982e-05 |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
3.545e-05 |
4.929e-05 |
|||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
4.167e-05 |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
8.162e-05 |
5.903e-05 |
||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
4.166e-05 |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
4.283e-05 |
5.477e-05 |
|||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
4.694e-05 |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
0.0001036 |
7.366e-05 |
||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
4.662e-05 |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
6.025e-05 |
6.887e-05 |
|||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
4.936e-05 |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
0.0001168 |
8.403e-05 |
||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
4.92e-05 |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
7.422e-05 |
7.952e-05 |
|||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
7.048e-05 |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.000431 |
0.0001165 |
|||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
6.305e-05 |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
8.39e-05 |
9.875e-05 |
|||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
6.802e-05 |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
0.0003709 |
0.0001122 |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
6.725e-05 |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
9.486e-05 |
0.0001072 |
|||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
7.389e-05 |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
0.0004184 |
0.0001303 |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
7.407e-05 |
|||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
0.0001175 |
0.0001262 |
||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
7.941e-05 |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
0.0004553 |
0.0001502 |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.772e-05 |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.0001437 |
0.0001445 |
|||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
9.054e-05 |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
0.0005251 |
0.0002021 |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
9.066e-05 |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.0002189 |
0.0001975 |
|||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
0.0001119 |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
0.0006531 |
0.0002895 |
|||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0001087 |
|||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0003435 |
0.0002828 |
||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.0001287 |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
0.0007782 |
0.0002665 |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0001267 |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.0004661 |
0.000258 |
|||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.0003355 |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.003605 |
0.0006483 |
|||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
0.0002962 |
|||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
0.0006138 |
0.0006095 |
||||
predict_proba |
-1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
0.0003365 |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
0.003579 |
0.0007279 |
|||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
0.0003367 |
|||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
0.0007305 |
0.0007199 |
||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
0.0003545 |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
0.003675 |
0.000827 |
|||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0003558 |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.0008685 |
0.000819 |
|||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
0.0004358 |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
0.004056 |
0.000826 |
|||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
0.0004307 |
|||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
0.001159 |
0.0008181 |
||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
0.0005382 |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
0.00474 |
0.001137 |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0005412 |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.001852 |
0.00112 |
|||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
0.0006874 |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
0.006357 |
0.001839 |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0006944 |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
0.003131 |
0.001825 |
|||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.0008986 |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
0.007624 |
0.002658 |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0009015 |
|||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.004535 |
0.002773 |
||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
-1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
7.418e-05 |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.586e-05 |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
7.872e-05 |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.587e-05 |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
7.853e-05 |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.662e-05 |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
7.876e-05 |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.566e-05 |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
7.917e-05 |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.657e-05 |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
7.875e-05 |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.711e-05 |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
7.88e-05 |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.67e-05 |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
7.312e-05 |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.347e-05 |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
7.383e-05 |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.463e-05 |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
7.458e-05 |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.438e-05 |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
7.405e-05 |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.437e-05 |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
7.448e-05 |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.451e-05 |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
7.533e-05 |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.475e-05 |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
7.483e-05 |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.508e-05 |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
7.601e-05 |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.559e-05 |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
8.155e-05 |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.592e-05 |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
7.664e-05 |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.656e-05 |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
7.68e-05 |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.704e-05 |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
7.813e-05 |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
7.804e-05 |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
8.712e-05 |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
8.797e-05 |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
8.895e-05 |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
8.894e-05 |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
100 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.000109 |
||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
9.382e-05 |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
9.499e-05 |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
9.423e-05 |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
0.0001024 |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
0.0001026 |
|||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
0.0001074 |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0001081 |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
0.0001203 |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0001193 |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
0.0001408 |
||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0001389 |
|||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.0001568 |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0001567 |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
1000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
0.0003 |
||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
0.0002578 |
|||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
1 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
0.0002555 |
||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
0.0002544 |
|||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
5 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
0.0002749 |
||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0002711 |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
10 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
||||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
0.0003331 |
||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
0.0003483 |
|||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
20 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
0.0004169 |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.000415 |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
50 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
0.0006211 |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
0.0006143 |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
100 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
0.0008158 |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
||||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
||||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
||||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
0 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
0.0008166 |
|||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
-1 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
|||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(37 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (1000 )-(1000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(69 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(15 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(17 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(2 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(28 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(29 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(32 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(34 ‘predict’)’. |
||||||
predict_proba |
1 |
10000 |
150 |
True |
{<class ‘sklearn.linear_model._logistic.LogisticRegression’>: {‘zipmap’: False}} |
1 |
100 |
1 |
12 |
ERROR: Dim (10000 )-(10000 ) - discrepencies between ‘skl’ and ‘onxpython_compiled’ for ‘(48 ‘predict’)’. |
Benchmark code#
bench_plot_onnxruntime_logreg.py
# coding: utf-8
"""
Benchmark of :epkg:`onnxruntime` on LogisticRegression.
"""
# Authors: Xavier Dupré (benchmark)
# License: MIT
import matplotlib
matplotlib.use('Agg')
import os
from time import perf_counter as time
import numpy
import pandas
import matplotlib.pyplot as plt
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.utils._testing import ignore_warnings
from sklearn.utils.extmath import softmax
from scipy.special import expit
from pymlbenchmark.context import machine_information
from pymlbenchmark.benchmark import BenchPerf
from pymlbenchmark.external import OnnxRuntimeBenchPerfTestBinaryClassification
from pymlbenchmark.plotting import plot_bench_results
model_name = "LogisticRegression"
filename = os.path.splitext(os.path.split(__file__)[-1])[0]
class OnnxRuntimeBenchPerfTestBinaryClassification3(OnnxRuntimeBenchPerfTestBinaryClassification):
"""
Overwrites the class to add a pure python implementation
of the logistic regression.
"""
def fcts(self, dim=None, **kwargs):
def predict_py_predict(X, model=self.skl):
coef = model.coef_
intercept = model.intercept_
pred = numpy.dot(X, coef.T) + intercept
return (pred >= 0).astype(numpy.int32)
def predict_py_predict_proba(X, model=self.skl):
coef = model.coef_
intercept = model.intercept_
pred = numpy.dot(X, coef.T) + intercept
decision_2d = numpy.c_[-pred, pred]
return expit(decision_2d)
res = OnnxRuntimeBenchPerfTestBinaryClassification.fcts(
self, dim=dim, **kwargs)
res.extend([
{'method': 'predict', 'lib': 'py', 'fct': predict_py_predict},
{'method': 'predict_proba', 'lib': 'py',
'fct': predict_py_predict_proba},
])
return res
@ignore_warnings(category=FutureWarning)
def run_bench(repeat=100, verbose=False):
pbefore = dict(dim=[1, 5, 10, 20, 50, 100, 150],
fit_intercept=[True],
onnx_options=[None, {LogisticRegression: {'zipmap': False}}])
pafter = dict(N=[1, 10, 100, 1000, 10000])
test = lambda dim=None, **opts: OnnxRuntimeBenchPerfTestBinaryClassification3(
LogisticRegression, dim=dim, **opts)
bp = BenchPerf(pbefore, pafter, test)
with sklearn.config_context(assume_finite=True):
start = time()
results = list(bp.enumerate_run_benchs(repeat=repeat, verbose=verbose,
stop_if_error=False))
end = time()
results_df = pandas.DataFrame(results)
print("Total time = %0.3f sec\n" % (end - start))
return results_df
#########################
# Runs the benchmark
# ++++++++++++++++++
df = run_bench(verbose=True)
df.to_csv("%s.perf.csv" % filename, index=False)
print(df.head())
#########################
# Extract information about the machine used
# ++++++++++++++++++++++++++++++++++++++++++
pkgs = ['numpy', 'pandas', 'sklearn', 'skl2onnx',
'onnxruntime', 'onnx', 'mlprodict']
dfi = pandas.DataFrame(machine_information(pkgs))
dfi.to_csv("%s.time.csv" % filename, index=False)
print(dfi)
#############################
# Plot the results
# ++++++++++++++++
def label_fct(la):
la = la.replace("onxpython_compiled", "opy")
la = la.replace("onxpython", "opy")
la = la.replace("onxonnxruntime1", "ort")
la = la.replace("fit_intercept", "fi")
la = la.replace("True", "1")
la = la.replace("False", "0")
la = la.replace("max_depth", "mxd")
return la
plot_bench_results(df, row_cols=['N', 'onnx_options'], col_cols='method',
x_value='dim', hue_cols='fit_intercept',
title="%s\nBenchmark scikit-learn / onnxruntime" % model_name,
label_fct=label_fct)
plt.savefig("%s.png" % filename)
import sys
if "--quiet" not in sys.argv:
plt.show()