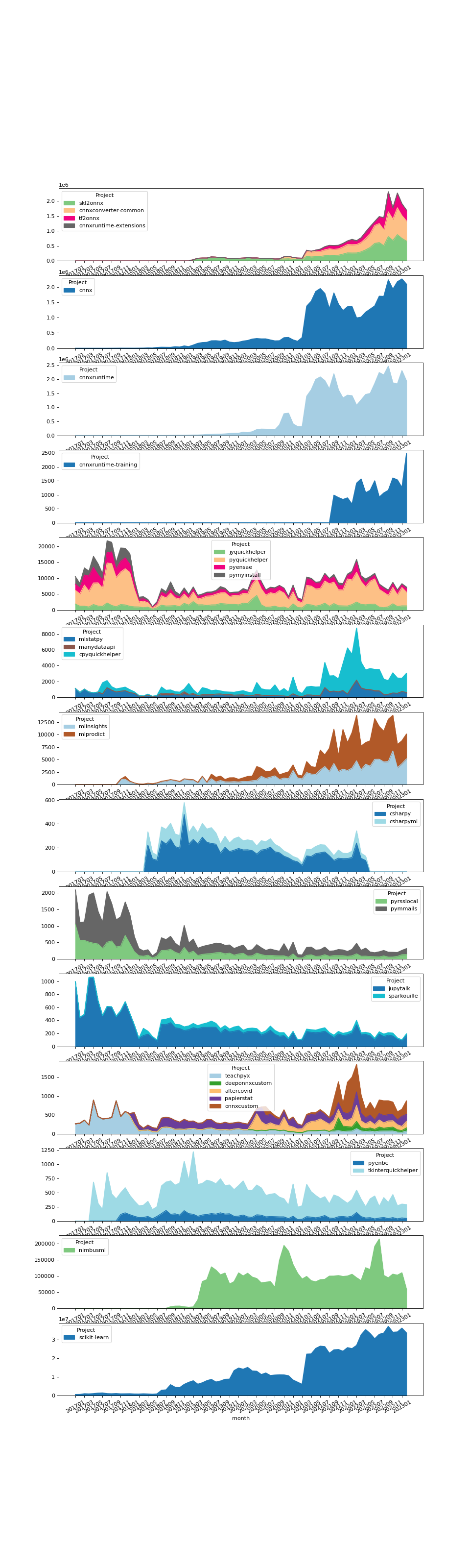
Pypi download#
Le nombre de téléchargements peut être obtenu en exécutant la requête suivante sur Google BigQuery. On peut retrouver la plupart de ces résultats sur pypistat. Exemple avec pypistat/mlinsights.
<<<
query = """
SELECT
file.project AS Project,
COUNT(*) AS num_downloads,
FORMAT_DATE("%Y%m", DATE(timestamp)) AS Month
FROM `bigquery-public-data.pypi.file_downloads`
WHERE
(__CONDITION__)
AND DATE(timestamp) BETWEEN DATE '2022-12-01' AND '2022-12-31'
GROUP BY `Project`, `Month`
ORDER BY `Month`, `Project`
"""
import textwrap
from ensae_teaching_cs.automation import get_teaching_modules
modules = get_teaching_modules(branch=False)
modules.extend([
'onnx', 'onnxruntime', 'skl2onnx', 'nimbusml',
'scikit-learn', 'pandas', 'numpy', 'jupyter', 'matplotlib',
'protobuf', 'nimbusml', 'aftercovid', 'onnxruntime-training',
'onnxconverter-common', 'tf2onnx', 'onnxruntime-extensions'])
modules = [m.split(':')[0] for m in modules]
dont = {'numpy', 'matplotlib', 'pandas', 'jupyter'}
modules = [_ for _ in modules if _ not in dont]
conds = ["file.project = '{0}'".format(m) for m in modules]
cond = " OR ".join(conds)
print(query.replace('__CONDITION__', '\n'.join(
textwrap.wrap(cond, subsequent_indent=' '))))
>>>
SELECT
file.project AS Project,
COUNT(*) AS num_downloads,
FORMAT_DATE("%Y%m", DATE(timestamp)) AS Month
FROM `bigquery-public-data.pypi.file_downloads`
WHERE
(file.project = 'deeponnxcustom' OR file.project = 'onnxcustom' OR
file.project = 'pymlbenchmark' OR file.project =
'ensae_teaching_dl' OR file.project = 'lecture_citation' OR
file.project = 'pyquickhelper' OR file.project = 'jyquickhelper'
OR file.project = 'python3_module_template' OR file.project =
'pymmails' OR file.project = 'pymyinstall' OR file.project =
'pyensae' OR file.project = 'pyrsslocal' OR file.project =
'ensae_projects' OR file.project = 'ensae_teaching_cs' OR
file.project = 'code_beatrix' OR file.project = 'actuariat_python'
OR file.project = 'mlstatpy' OR file.project = 'jupytalk' OR
file.project = 'teachpyx' OR file.project = 'tkinterquickhelper'
OR file.project = 'cpyquickhelper' OR file.project =
'pandas_streaming' OR file.project = 'mlinsights' OR file.project
= 'pyenbc' OR file.project = 'mlprodict' OR file.project =
'mloptonnx' OR file.project = 'papierstat' OR file.project =
'sparkouille' OR file.project = 'manydataapi' OR file.project =
'wrapclib' OR file.project = 'myblog' OR file.project =
'_check_python_install' OR file.project = 'onnxortext' OR
file.project = 'onnx' OR file.project = 'onnxruntime' OR
file.project = 'skl2onnx' OR file.project = 'nimbusml' OR
file.project = 'scikit-learn' OR file.project = 'protobuf' OR
file.project = 'nimbusml' OR file.project = 'aftercovid' OR
file.project = 'onnxruntime-training' OR file.project =
'onnxconverter-common' OR file.project = 'tf2onnx' OR file.project
= 'onnxruntime-extensions')
AND DATE(timestamp) BETWEEN DATE '2022-12-01' AND '2022-12-31'
GROUP BY `Project`, `Month`
ORDER BY `Month`, `Project`
import pandas
import matplotlib.pyplot as plt
url = "pypi_downloads.csv"
df = pandas.read_csv(url)
df = df.groupby(["Project", "month"], as_index=False).sum()
df = df.sort_values(["Project", "month"])
df['month'] = df.month.astype(str)
df = df[df.month >= "2017"]
gr = df.groupby("Project", as_index=False).sum(
numeric_only=True).sort_values(
"num_downloads").reset_index(drop=True)
med = gr.iloc[gr.shape[0]//2, 1]
sets = [
{'skl2onnx', 'onnxmltools',
'tf2onnx', 'onnxconverter-common',
'onnxruntime-extensions'},
{'onnx'},
{'onnxruntime'},
{'onnxruntime-training'},
{'jyquickhelper', 'pymyinstall', 'pyquickhelper', 'pyensae'},
{'manydataapi', 'cpyquickhelper', 'mlstatpy', },
{'mlinsights', 'mlprodict', 'onnxortext'},
{'csharpy', 'csharpyml', },
{'pyrsslocal', 'pymmails', },
{'sparkouille', 'ensae_projects', 'actuariat_python',
'code_beatrix', 'jupytalk'},
{'papierstat', 'teachpyx', 'ensae_teaching_cs',
'ensae_teaching_dl', 'teachpyx',
'aftercovid', 'onnxcustom', 'deeponnxcustom'},
{'tkinterquickhelper', 'pyenbc', },
{'nimbusml', },
{'scikit-learn'},
]
piv = df.pivot(index="month", columns="Project",
values="num_downloads").fillna(0)
fig, ax = plt.subplots(len(sets), 1, figsize=(12,40))
colormaps = ['Accent', "tab10", "Paired", "tab20"]
for i in range(len(sets)):
sub = sets[i].intersection(set(df['Project']))
piv2 = piv[list(sub)]
piv2.plot.area(colormap=colormaps[i % len(colormaps)], ax=ax[i])
ax[i].set_xticks(list(range(0, len(piv2.index), 2)))
ax[i].set_xticklabels(list(piv2.index)[::2], rotation=30)
plt.show()
{kind=link}
{kind=link}