Gradient Boosting#
Links: notebook, html, python, slides, GitHub
Le notebook explore l’algorithme du Gradient Boosting.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
%matplotlib inline
Premier exemple#
On considère les paramètres par défaut de la classe GradientBoostingRegressor.
from numpy.random import randn, random
from pandas import DataFrame
from sklearn.model_selection import train_test_split
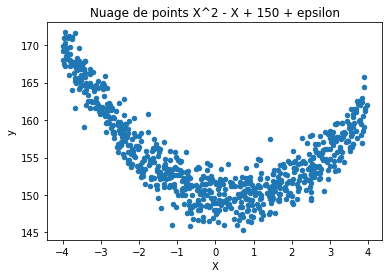
rnd = randn(1000)
X = random(1000) * 8 - 4
y = X ** 2 - X + rnd * 2 + 150 # X^2 - X + 150 + epsilon
X = X.reshape((-1, 1))
X_train, X_test, y_train, y_test = train_test_split(X, y)
df = DataFrame({'X': X_train.ravel(), 'y': y_train})
ax = df.plot(x='X', y='y', kind='scatter')
ax.set_title("Nuage de points X^2 - X + 150 + epsilon");
from sklearn.ensemble import GradientBoostingRegressor
model = GradientBoostingRegressor(max_depth=1)
model.fit(X_train, y_train)
GradientBoostingRegressor(alpha=0.9, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=0.1, loss='ls', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_iter_no_change=None, presort='deprecated',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
import numpy
ind = numpy.argsort(X_test, axis=0)
y_ = model.predict(X_test)
df = DataFrame({'X': X_test[ind].ravel(),
'y': y_test[ind].ravel(),
'y^': y_[ind].ravel()})
ax = df.plot(x='X', y='y', kind='scatter')
df.plot(x='X', y='y^', kind='line', ax=ax, color="r")
ax.set_title("Prédictions avec GradientBoostingRegressor");
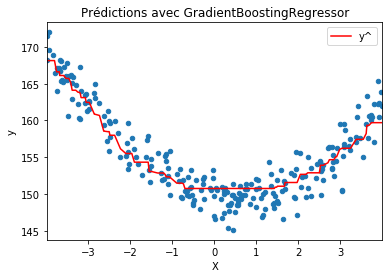
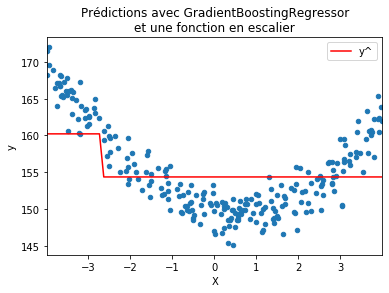
Rien d’imprévu jusque là. Essayons autre chose. On regarde avec une seule itération.
model = GradientBoostingRegressor(max_depth=1, n_estimators=1, learning_rate=0.5)
model.fit(X_train, y_train)
GradientBoostingRegressor(alpha=0.9, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=0.5, loss='ls', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=1,
n_iter_no_change=None, presort='deprecated',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
y_ = model.predict(X_test)
df = DataFrame({'X': X_test[ind].ravel(),
'y': y_test[ind].ravel(),
'y^': y_[ind].ravel()})
ax = df.plot(x='X', y='y', kind='scatter')
df.plot(x='X', y='y^', kind='line', ax=ax, color="r")
ax.set_title("Prédictions avec GradientBoostingRegressor\net une fonction en escalier");
Essayons de montrer l’évolution de la courbe prédite en fonction du nombre de marches et revenons à 100 estimateurs.
model = GradientBoostingRegressor(max_depth=1)
model.fit(X_train, y_train)
GradientBoostingRegressor(alpha=0.9, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=0.1, loss='ls', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_iter_no_change=None, presort='deprecated',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
for i in range(0, model.estimators_.shape[0] + 1, 10):
if i == 0:
df = DataFrame({'X': X_test[ind].ravel(),
'y': y_test[ind].ravel()})
ax = df.plot(x='X', y='y', kind='scatter', figsize=(10, 4))
y_ = model.init_.predict(X_test)
color = 'b'
else:
y_ = sum([model.init_.predict(X_test)] +
[model.estimators_[k, 0].predict(X_test) * model.learning_rate
for k in range(0, i)])
color = 'r'
df = DataFrame({'X': X_test[ind].ravel(),
'y^': y_[ind].ravel()})
df.plot(x='X', y='y^', kind='line', ax=ax, color=color, label='i=%d' % i)
ax.set_title("Prédictions");
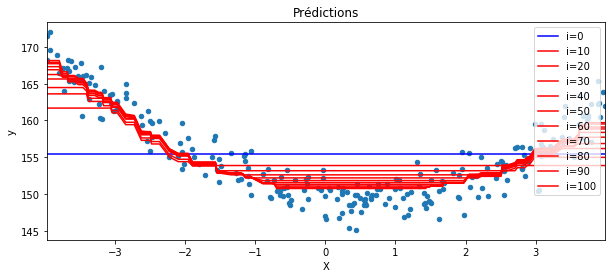
learning rate et itérations#
Et si on choisissait un learning_rate, plus petit ou plus grand…
model01 = GradientBoostingRegressor(max_depth=1, learning_rate=0.01)
model01.fit(X_train, y_train)
modela = GradientBoostingRegressor(max_depth=1, learning_rate=1.2)
modela.fit(X_train, y_train)
modelb = GradientBoostingRegressor(max_depth=1, learning_rate=1.99)
modelb.fit(X_train, y_train)
GradientBoostingRegressor(alpha=0.9, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=1.99, loss='ls', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_iter_no_change=None, presort='deprecated',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 3, figsize=(12, 4))
ind = numpy.argsort(X_test, axis=0)
for i, mod in enumerate([model01, modela, modelb]):
df = DataFrame({'X': X_test[ind].ravel(),
'y': y_test[ind].ravel(),
'y^': mod.predict(X_test)[ind].ravel()})
df.plot(x='X', y='y', kind='scatter', ax=ax[i])
df.plot(x='X', y='y^', kind='line', ax=ax[i], color="r")
ax[i].set_title("learning_rate=%f" % mod.learning_rate);
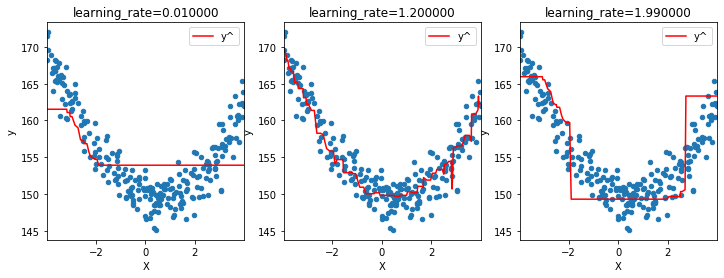
Une trop faible valeur de learning_rate semble retenir le modèle de converger, une grande valeur produit des effets imprévisibles. Pour comprendre pourquoi, il faut détailler l’algorithme…
L’algorithme#
Inspiration#
L’algorithme est inspiré de l’algorithme de la descente de gradient. On
considère une fonction réelle  et on calcule le gradient
et on calcule le gradient
 pour construire une suite :
pour construire une suite :

La suite  converge vers le minimum de la fonction
converge vers le minimum de la fonction
 . On applique cela à une fonction d’erreur issue d’un problème
de régression.
. On applique cela à une fonction d’erreur issue d’un problème
de régression.

Le plus souvent, on applique cette méthode à une fonction  qui
dépend d’un paramètre
qui
dépend d’un paramètre 

Et c’est la suite
 qui converge vers le minimum de la fonction de sorte que la
fonction
qui converge vers le minimum de la fonction de sorte que la
fonction  approxime au mieux les points
approxime au mieux les points
 . Mais, on pourrait tout-à-fait résoudre ce problème
dans un espace de fonctions et non un espace de paramètres :
. Mais, on pourrait tout-à-fait résoudre ce problème
dans un espace de fonctions et non un espace de paramètres :

Le gradient  est facile à calculer
puisqu’il ne dépend pas de
est facile à calculer
puisqu’il ne dépend pas de  . On pourrait donc construire la
fonction de régression comme une suite additive de fonctions
. On pourrait donc construire la
fonction de régression comme une suite additive de fonctions
 .
.

Et nous pourrions construire la fonction  comme solution d’un
problème de régression défini par les couples
comme solution d’un
problème de régression défini par les couples  avec :
avec :

Voilà l’idée.
Algorithme#
Je reprends ici la page wikipedia. On cherche à construire un modèle qui
minimise l’erreur  . On
note
. On
note  le learning rate.
le learning rate.
Etape 1 : on cale un premier modèle de régression, ici, simplement
une constante, en optimisant
 .
.
 est une constante.
est une constante.
On note ensuite  où
où  est la fonction constante construire lors de la
première étape.
est la fonction constante construire lors de la
première étape.
Etape 2 : on calcule ensuite les erreurs
 et l’opposé du gradient
et l’opposé du gradient
![r_{im} = - \left[ \frac{\partial l(y_i, F_m(x_i)) }{\partial F_m(x_i)} \right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjEuNTE5NTIycHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDUzLjc5ODI0OSAxMDcuNjE2ODggMjEuNTE5NTIyJyB3aWR0aD0nMTA3LjYxNjg4cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuMDgwMTk5IC0zLjczMDAxMkMyLjA4MDE5OSAtMy44NzM0NzQgMS45NzI2MDMgLTMuOTY5MTE2IDEuODM1MTE4IC0zLjk2OTExNkMxLjY3MzcyNCAtMy45NjkxMTYgMS41MDAzNzQgLTMuODEzNjk5IDEuNTAwMzc0IC0zLjY0MDM0OUMxLjUwMDM3NCAtMy40OTA5MDkgMS42MDc5NyAtMy40MDEyNDUgMS43Mzk0NzcgLTMuNDAxMjQ1QzEuOTMwNzYgLTMuNDAxMjQ1IDIuMDgwMTk5IC0zLjU4MDU3MyAyLjA4MDE5OSAtMy43MzAwMTJaTTEuNzIxNTQ0IC0xLjY0MzgzNkMxLjc0NTQ1NSAtMS43MDM2MTEgMS43OTkyNTMgLTEuODQ3MDczIDEuODIzMTYzIC0xLjkwMDg3MkMxLjg0MTA5NiAtMS45NTQ2NyAxLjg2NTAwNiAtMi4wMTQ0NDYgMS44NjUwMDYgLTIuMTE2MDY1QzEuODY1MDA2IC0yLjQ1MDgwOSAxLjU2NjEyNyAtMi42MzYxMTUgMS4yNjcyNDggLTIuNjM2MTE1QzAuNjU3NTM0IC0yLjYzNjExNSAwLjM2NDYzMyAtMS44NDcwNzMgMC4zNjQ2MzMgLTEuNzE1NTY3QzAuMzY0NjMzIC0xLjY4NTY3OSAwLjM4ODU0MyAtMS42MzE4OCAwLjQ3MjIyOSAtMS42MzE4OFMwLjU3Mzg0OCAtMS42Njc3NDYgMC41OTE3ODEgLTEuNzIxNTQ0QzAuNzU5MTUzIC0yLjMwMTM3IDEuMDc1OTY1IC0yLjQzODg1NCAxLjI0MzMzNyAtMi40Mzg4NTRDMS4zNjI4ODkgLTIuNDM4ODU0IDEuNDA0NzMyIC0yLjM2MTE0NiAxLjQwNDczMiAtMi4yMjM2NjFDMS40MDQ3MzIgLTIuMTA0MTEgMS4zNjg4NjcgLTIuMDE0NDQ2IDEuMzU2OTEyIC0xLjk3MjYwM0wxLjA0NjA3NyAtMS4yMDc0NzJDMC45NzQzNDYgLTEuMDM0MTIyIDAuOTc0MzQ2IC0xLjAyMjE2NyAwLjg5NjYzOCAtMC44MTg5MjlDMC44MTg5MjkgLTAuNjM5NjAxIDAuNzg5MDQxIC0wLjU2MTg5MyAwLjc4OTA0MSAtMC40NjAyNzRDMC43ODkwNDEgLTAuMTU1NDE3IDEuMDY0MDEgMC4wNTk3NzYgMS4zOTI3NzcgMC4wNTk3NzZDMS45OTY1MTMgMC4wNTk3NzYgMi4yOTUzOTIgLTAuNzI5MjY1IDIuMjk1MzkyIC0wLjg2MDc3MkMyLjI5NTM5MiAtMC44NzI3MjcgMi4yODk0MTUgLTAuOTQ0NDU4IDIuMTgxODE4IC0wLjk0NDQ1OEMyLjA5ODEzMiAtMC45NDQ0NTggMi4wOTIxNTQgLTAuOTE0NTcgMi4wNTYyODkgLTAuODAwOTk2QzEuOTYwNjQ4IC0wLjQ5NjEzOSAxLjcxNTU2NyAtMC4xMzc0ODQgMS40MTA3MSAtMC4xMzc0ODRDMS4zMDMxMTMgLTAuMTM3NDg0IDEuMjQ5MzE1IC0wLjIwOTIxNSAxLjI0OTMxNSAtMC4zNTI2NzdDMS4yNDkzMTUgLTAuNDcyMjI5IDEuMjg1MTgxIC0wLjU2MTg5MyAxLjM2Mjg4OSAtMC43NDcxOThMMS43MjE1NDQgLTEuNjQzODM2WicgaWQ9J2cyLTEwNScvPgo8cGF0aCBkPSdNMi44MjczOTcgLTAuNTE0MDcyQzIuNzk3NTA5IC0wLjM4ODU0MyAyLjc0MzcxMSAtMC4xNzkzMjggMi43NDM3MTEgLTAuMTM3NDg0QzIuNzQzNzExIC0wLjAwNTk3OCAyLjg0NTMzIDAuMDU5Nzc2IDIuOTUyOTI3IDAuMDU5Nzc2UzMuMTYyMTQyIC0wLjAxMTk1NSAzLjIwOTk2MyAtMC4xMDE2MTlDMy4yMjE5MTggLTAuMTM3NDg0IDMuMjc1NzE2IC0wLjM0NjcgMy4zMDU2MDQgLTAuNDY2MjUyTDMuNDM3MTExIC0xLjAwNDIzNEMzLjQ3ODk1NCAtMS4xNTk2NTEgMy41MDI4NjQgLTEuMjY3MjQ4IDMuNTM4NzMgLTEuNDA0NzMyQzMuNTkyNTI4IC0xLjYwNzk3IDMuODAxNzQzIC0xLjkyNDc4MiA0LjAyMjkxNCAtMi4xNDU5NTNDNC4xNDI0NjYgLTIuMjU5NTI3IDQuMzk5NTAyIC0yLjQzODg1NCA0LjcyMjI5MSAtMi40Mzg4NTRDNS4xMDQ4NTcgLTIuNDM4ODU0IDUuMTA0ODU3IC0yLjEzMzk5OCA1LjEwNDg1NyAtMi4wMjA0MjNDNS4xMDQ4NTcgLTEuNjY3NzQ2IDQuODQ3ODIxIC0xLjAyODE0NCA0Ljc0MDIyNCAtMC43NTkxNTNDNC43MDQzNTkgLTAuNjU3NTM0IDQuNjYyNTE2IC0wLjU2MTg5MyA0LjY2MjUxNiAtMC40NjAyNzRDNC42NjI1MTYgLTAuMTU1NDE3IDQuOTM3NDg0IDAuMDU5Nzc2IDUuMjY2MjUyIDAuMDU5Nzc2QzUuODY5OTg4IDAuMDU5Nzc2IDYuMTY4ODY3IC0wLjcyOTI2NSA2LjE2ODg2NyAtMC44NjA3NzJDNi4xNjg4NjcgLTAuODcyNzI3IDYuMTYyODg5IC0wLjk0NDQ1OCA2LjA1NTI5MyAtMC45NDQ0NThDNS45NzE2MDYgLTAuOTQ0NDU4IDUuOTY1NjI5IC0wLjkxNDU3IDUuOTI5NzYzIC0wLjgwMDk5NkM1LjgyMjE2NyAtMC40NTQyOTYgNS41NjUxMzEgLTAuMTM3NDg0IDUuMjkwMTYyIC0wLjEzNzQ4NEM1LjIwNjQ3NiAtMC4xMzc0ODQgNS4xMjI3OSAtMC4xNzMzNSA1LjEyMjc5IC0wLjM1MjY3N0M1LjEyMjc5IC0wLjQ3MjIyOSA1LjE2NDYzMyAtMC41Nzk4MjYgNS4yMTg0MzEgLTAuNzA1MzU1QzUuMjg0MTg0IC0wLjg3MjcyNyA1LjU3NzA4NiAtMS41OTYwMTUgNS41NzcwODYgLTEuOTQyNzE1QzUuNTc3MDg2IC0yLjQzMjg3NyA1LjIwNjQ3NiAtMi42MzYxMTUgNC43NTIxNzkgLTIuNjM2MTE1QzQuNDIzNDEyIC0yLjYzNjExNSA0LjAyODg5MiAtMi41MTY1NjMgMy42NDAzNDkgLTIuMDA4NDY4QzMuNjA0NDgzIC0yLjQ1MDgwOSAzLjI1MTgwNiAtMi42MzYxMTUgMi44MTU0NDIgLTIuNjM2MTE1QzIuNTE2NTYzIC0yLjYzNjExNSAyLjEzMzk5OCAtMi41NDA0NzMgMS43NTE0MzIgLTIuMDY4MjQ0QzEuNzIxNTQ0IC0yLjUyMjU0IDEuMzAzMTEzIC0yLjYzNjExNSAxLjA3NTk2NSAtMi42MzYxMTVTMC42OTM0IC0yLjQ5ODYzIDAuNTg1ODAzIC0yLjMwNzM0N0MwLjQzMDM4NiAtMi4wNTYyODkgMC4zNjQ2MzMgLTEuNzM5NDc3IDAuMzY0NjMzIC0xLjcyMTU0NEMwLjM2NDYzMyAtMS42NTU3OTEgMC40MTg0MzEgLTEuNjMxODggMC40NzIyMjkgLTEuNjMxODhDMC41Njc4NyAtMS42MzE4OCAwLjU3Mzg0OCAtMS42NzM3MjQgMC42MDM3MzYgLTEuNzY5MzY1QzAuNzIzMjg4IC0yLjI0MTU5NCAwLjg2Njc1IC0yLjQzODg1NCAxLjA1ODAzMiAtMi40Mzg4NTRDMS4yNjEyNyAtMi40Mzg4NTQgMS4yNzMyMjUgLTIuMjI5NjM5IDEuMjczMjI1IC0yLjEzMzk5OFMxLjIxMzQ1IC0xLjc5OTI1MyAxLjE3MTYwNiAtMS42MzE4OEMxLjEyOTc2MyAtMS40NzA0ODYgMS4wNjk5ODggLTEuMjI1NDA1IDEuMDQwMSAtMS4wOTM4OThDMC45OTgyNTcgLTAuOTQ0NDU4IDAuOTYyMzkxIC0wLjc4OTA0MSAwLjkyMDU0OCAtMC42Mzk2MDFDMC44Nzg3MDUgLTAuNDcyMjI5IDAuODA2OTc0IC0wLjE3MzM1IDAuODA2OTc0IC0wLjEzNzQ4NEMwLjgwNjk3NCAtMC4wMDU5NzggMC45MDg1OTMgMC4wNTk3NzYgMS4wMTYxODkgMC4wNTk3NzZTMS4yMjU0MDUgLTAuMDExOTU1IDEuMjczMjI1IC0wLjEwMTYxOUMxLjI4NTE4MSAtMC4xMzc0ODQgMS4zMzg5NzkgLTAuMzQ2NyAxLjM2ODg2NyAtMC40NjYyNTJMMS41MDAzNzQgLTEuMDA0MjM0QzEuNTQyMjE3IC0xLjE1OTY1MSAxLjU2NjEyNyAtMS4yNjcyNDggMS42MDE5OTMgLTEuNDA0NzMyQzEuNjU1NzkxIC0xLjYwNzk3IDEuODY1MDA2IC0xLjkyNDc4MiAyLjA4NjE3NyAtMi4xNDU5NTNDMi4yMDU3MjkgLTIuMjU5NTI3IDIuNDYyNzY1IC0yLjQzODg1NCAyLjc4NTU1NCAtMi40Mzg4NTRDMy4xNjgxMiAtMi40Mzg4NTQgMy4xNjgxMiAtMi4xMzM5OTggMy4xNjgxMiAtMi4wMjA0MjNDMy4xNjgxMiAtMS44NzY5NjEgMy4xMDgzNDQgLTEuNjM3ODU4IDMuMDYwNTIzIC0xLjQ0NjU3NUwyLjgyNzM5NyAtMC41MTQwNzJaJyBpZD0nZzItMTA5Jy8+CjxwYXRoIGQ9J00xLjQ5MDQxMSAtMC4xMTk1NTJDMS40OTA0MTEgMC4zOTg1MDYgMS4zNzg4MjkgMC44NTI4MDIgMC44ODQ2ODIgMS4zNDY5NDlDMC44NTI4MDIgMS4zNzA4NTkgMC44MzY4NjIgMS4zODY4IDAuODM2ODYyIDEuNDI2NjVDMC44MzY4NjIgMS40OTA0MTEgMC45MDA2MjMgMS41MzgyMzIgMC45NTY0MTMgMS41MzgyMzJDMS4wNTIwNTUgMS41MzgyMzIgMS43MTM1NzQgMC45MDg1OTMgMS43MTM1NzQgLTAuMDIzOTFDMS43MTM1NzQgLTAuNTMzOTk4IDEuNTIyMjkxIC0wLjg4NDY4MiAxLjE3MTYwNiAtMC44ODQ2ODJDMC44OTI2NTMgLTAuODg0NjgyIDAuNzMzMjUgLTAuNjYxNTE5IDAuNzMzMjUgLTAuNDQ2MzI2QzAuNzMzMjUgLTAuMjIzMTYzIDAuODg0NjgyIDAgMS4xNzk1NzcgMEMxLjM3MDg1OSAwIDEuNDkwNDExIC0wLjExMTU4MiAxLjQ5MDQxMSAtMC4xMTk1NTJaJyBpZD0nZzMtNTknLz4KPHBhdGggZD0nTTMuODk3Mzg1IC0yLjc0MTcxOUMzLjc4NTgwMyAtMy4xNzIxMDUgMy40ODI5MzkgLTMuNjQyMzQxIDIuNzU3NjU5IC0zLjY0MjM0MUMyLjAwMDQ5OCAtMy42NDIzNDEgMS41MjIyOTEgLTMuMjkxNjU2IDEuMTM5NzI2IC0yLjk2NDg4MkMwLjMzNDc0NSAtMi4yNzE0ODIgMC4zMzQ3NDUgLTEuMzQ2OTQ5IDAuMzM0NzQ1IC0xLjI3NTIxOEMwLjMzNDc0NSAtMC43ODEwNzEgMC43MTczMSAwLjE2NzM3MiAxLjkyODc2NyAwLjE2NzM3MkMyLjU5MDI4NiAwLjE2NzM3MiAzLjI5OTYyNiAtMC4xNTk0MDIgMy44NDE1OTQgLTAuODkyNjUzQzQuMzY3NjIxIC0xLjYwOTk2MyA0Ljc1ODE1NyAtMi43ODk1MzkgNC43NTgxNTcgLTMuNTg2NTVDNC43NTgxNTcgLTQuODc3NzA5IDMuOTUzMTc2IC01LjY5ODYzIDIuODkzMTUxIC01LjY5ODYzQzEuNjY1NzUzIC01LjY5ODYzIDEuMjk5MTI4IC00LjY3ODQ1NiAxLjI5OTEyOCAtNC40MzEzODJDMS4yOTkxMjggLTQuMjQwMSAxLjQ0MjU5IC00LjEzNjQ4OCAxLjYwOTk2MyAtNC4xMzY0ODhDMS44NjUwMDYgLTQuMTM2NDg4IDIuMDU2Mjg5IC00LjM2NzYyMSAyLjA1NjI4OSAtNC41NzQ4NDRDMi4wNTYyODkgLTQuNjc4NDU2IDIuMDMyMzc5IC00Ljg2MTc2OCAxLjcxMzU3NCAtNC44Njk3MzhDMi4wMzIzNzkgLTUuMzg3Nzk2IDIuNTU4NDA2IC01LjQ5MTQwNyAyLjg4NTE4MSAtNS40OTE0MDdDMy42MDI0OTEgLTUuNDkxNDA3IDQuMTEyNTc4IC00LjkzMzQ5OSA0LjExMjU3OCAtNC4wMDg5NjZDNC4xMTI1NzggLTMuNTcwNjEgNC4wMTY5MzYgLTMuMTQ4MTk0IDMuOTA1MzU1IC0yLjc0MTcxOUgzLjg5NzM4NVpNMS45NDQ3MDcgLTAuMDcxNzMxQzEuMDUyMDU1IC0wLjA3MTczMSAxLjAwNDIzNCAtMC44Mjg4OTIgMS4wMDQyMzQgLTAuOTg4Mjk0QzEuMDA0MjM0IC0xLjI5OTEyOCAxLjIzNTM2NyAtMi4xNDM5NiAxLjMxNTA2OCAtMi4zNDMyMTNDMS41MjIyOTEgLTIuODEzNDUgMi4wMTY0MzggLTMuNDE5MTc4IDIuNzgxNTY5IC0zLjQxOTE3OEMzLjQ1MTA1OSAtMy40MTkxNzggMy43Mzc5ODMgLTIuOTA5MDkxIDMuNzM3OTgzIC0yLjM1MTE4M0MzLjczNzk4MyAtMS43Mzc0ODQgMy4xODAwNzUgLTAuMDcxNzMxIDEuOTQ0NzA3IC0wLjA3MTczMVonIGlkPSdnMy02NCcvPgo8cGF0aCBkPSdNMi41MTg1NTUgLTIuNTgyMzE2SDMuMzQ3NDQ3QzQuMDAwOTk2IC0yLjU4MjMxNiA0LjAzMjg3NyAtMi40NTQ3OTUgNC4wMzI4NzcgLTIuMjIzNjYxQzQuMDMyODc3IC0yLjE2Nzg3IDQuMDMyODc3IC0yLjA4ODE2OSAzLjk3NzA4NiAtMS44ODA5NDZDMy45NjkxMTYgLTEuODQ5MDY2IDMuOTYxMTQ2IC0xLjc4NTMwNSAzLjk2MTE0NiAtMS43NjEzOTVDMy45NjExNDYgLTEuNzUzNDI1IDMuOTYxMTQ2IC0xLjY0OTgxMyA0LjA4MDY5NyAtMS42NDk4MTNDNC4xNzYzMzkgLTEuNjQ5ODEzIDQuMjAwMjQ5IC0xLjcyOTUxNCA0LjIyNDE1OSAtMS44MzMxMjZMNC42NDY1NzUgLTMuNTM4NzNDNC42NTQ1NDUgLTMuNTU0NjcgNC42Nzg0NTYgLTMuNjU4MjgxIDQuNjc4NDU2IC0zLjY2NjI1MkM0LjY3ODQ1NiAtMy42OTgxMzIgNC42NTQ1NDUgLTMuNzc3ODMzIDQuNTUwOTM0IC0zLjc3NzgzM0M0LjQ1NTI5MyAtMy43Nzc4MzMgNC40MzkzNTIgLTMuNzA2MTAyIDQuNDE1NDQyIC0zLjYxMDQ2MUM0LjI1NjA0IC0yLjk4ODc5MiA0LjA3MjcyNyAtMi44NDUzMyAzLjM2MzM4NyAtMi44NDUzM0gyLjU5MDI4NkwzLjA5MjQwMyAtNC44NTM3OThDMy4xNjQxMzQgLTUuMTQwNzIyIDMuMTcyMTA1IC01LjE1NjY2MyAzLjQ5ODg3OSAtNS4xNTY2NjNINC42NzA0ODZDNS42MTg5MjkgLTUuMTU2NjYzIDUuODg5OTEzIC00Ljk1NzQxIDUuODg5OTEzIC00LjI3MTk4QzUuODg5OTEzIC00LjEwNDYwOCA1Ljg1MDA2MiAtMy44OTczODUgNS44NTAwNjIgLTMuNzQ1OTUzQzUuODUwMDYyIC0zLjY1MDMxMSA1LjkwNTg1MyAtMy42MTA0NjEgNS45Njk2MTQgLTMuNjEwNDYxQzYuMDgxMTk2IC0zLjYxMDQ2MSA2LjA4OTE2NiAtMy42ODIxOTIgNi4xMDUxMDYgLTMuODE3Njg0TDYuMjQ4NTY4IC01LjE3MjYwM0M2LjI1NjUzOCAtNS4yMTI0NTMgNi4yNTY1MzggLTUuMjY4MjQ0IDYuMjU2NTM4IC01LjMwODA5NUM2LjI1NjUzOCAtNS40MTk2NzYgNi4xNjA4OTcgLTUuNDE5Njc2IDYuMDE3NDM1IC01LjQxOTY3NkgxLjkyODc2N0MxLjc4NTMwNSAtNS40MTk2NzYgMS42ODE2OTQgLTUuNDE5Njc2IDEuNjgxNjk0IC01LjI3NjIxNEMxLjY4MTY5NCAtNS4xNTY2NjMgMS43NzczMzUgLTUuMTU2NjYzIDEuOTEyODI3IC01LjE1NjY2M0MxLjk2ODYxOCAtNS4xNTY2NjMgMi4wODAxOTkgLTUuMTU2NjYzIDIuMjE1NjkxIC01LjE0MDcyMkMyLjM4MzA2NCAtNS4xMjQ3ODIgMi40MDY5NzQgLTUuMTA4ODQyIDIuNDA2OTc0IC01LjAyOTE0MUMyLjQwNjk3NCAtNC45ODkyOSAyLjM5OTAwNCAtNC45NTc0MSAyLjM3NTA5MyAtNC44Njk3MzhMMS4zMTUwNjggLTAuNjI5NjM5QzEuMjQzMzM3IC0wLjMyNjc3NSAxLjIyNzM5NyAtMC4yNjMwMTQgMC42Mzc2MDkgLTAuMjYzMDE0QzAuNDg2MTc3IC0wLjI2MzAxNCAwLjM5MDUzNSAtMC4yNjMwMTQgMC4zOTA1MzUgLTAuMTExNTgyQzAuMzkwNTM1IC0wLjA3OTcwMSAwLjQxNDQ0NiAwIDAuNTE4MDU3IDBDMC42ODU0MyAwIDAuODc2NzEyIC0wLjAyMzkxIDEuMDUyMDU1IC0wLjAyMzkxSDIuMTUxOTNDMi4zMDMzNjIgLTAuMDE1OTQgMi41OTAyODYgMCAyLjc0MTcxOSAwQzIuNzk3NTA5IDAgMi45MDkwOTEgMCAyLjkwOTA5MSAtMC4xNTE0MzJDMi45MDkwOTEgLTAuMjYzMDE0IDIuODEzNDUgLTAuMjYzMDE0IDIuNjQ2MDc3IC0wLjI2MzAxNFMyLjQxNDk0NCAtMC4yNjMwMTQgMi4yMzE2MzEgLTAuMjc4OTU0QzIuMDE2NDM4IC0wLjMwMjg2NCAxLjk5MjUyOCAtMC4zMjY3NzUgMS45OTI1MjggLTAuNDIyNDE2QzEuOTkyNTI4IC0wLjQzMDM4NiAxLjk5MjUyOCAtMC40NzgyMDcgMi4wMjQ0MDggLTAuNTk3NzU4TDIuNTE4NTU1IC0yLjU4MjMxNlonIGlkPSdnMy03MCcvPgo8cGF0aCBkPSdNMi4zNzUwOTMgLTQuOTczMzVDMi4zNzUwOTMgLTUuMTQ4NjkyIDIuMjQ3NTcyIC01LjI3NjIxNCAyLjA2NDI1OSAtNS4yNzYyMTRDMS44NTcwMzYgLTUuMjc2MjE0IDEuNjI1OTAzIC01LjA4NDkzMiAxLjYyNTkwMyAtNC44NDU4MjhDMS42MjU5MDMgLTQuNjcwNDg2IDEuNzUzNDI1IC00LjU0Mjk2NCAxLjkzNjczNyAtNC41NDI5NjRDMi4xNDM5NiAtNC41NDI5NjQgMi4zNzUwOTMgLTQuNzM0MjQ3IDIuMzc1MDkzIC00Ljk3MzM1Wk0xLjIxMTQ1NyAtMi4wNDgzMTlMMC43ODEwNzEgLTAuOTQ4NDQzQzAuNzQxMjIgLTAuODI4ODkyIDAuNzAxMzcgLTAuNzMzMjUgMC43MDEzNyAtMC41OTc3NThDMC43MDEzNyAtMC4yMDcyMjMgMS4wMDQyMzQgMC4wNzk3MDEgMS40MjY2NSAwLjA3OTcwMUMyLjE5OTc1MSAwLjA3OTcwMSAyLjUyNjUyNiAtMS4wMzYxMTUgMi41MjY1MjYgLTEuMTM5NzI2QzIuNTI2NTI2IC0xLjIxOTQyNyAyLjQ2Mjc2NSAtMS4yNDMzMzcgMi40MDY5NzQgLTEuMjQzMzM3QzIuMzExMzMzIC0xLjI0MzMzNyAyLjI5NTM5MiAtMS4xODc1NDcgMi4yNzE0ODIgLTEuMTA3ODQ2QzIuMDg4MTY5IC0wLjQ3MDIzNyAxLjc2MTM5NSAtMC4xNDM0NjIgMS40NDI1OSAtMC4xNDM0NjJDMS4zNDY5NDkgLTAuMTQzNDYyIDEuMjUxMzA4IC0wLjE4MzMxMyAxLjI1MTMwOCAtMC4zOTg1MDZDMS4yNTEzMDggLTAuNTg5Nzg4IDEuMzA3MDk4IC0wLjczMzI1IDEuNDEwNzEgLTAuOTgwMzI0QzEuNDkwNDExIC0xLjE5NTUxNyAxLjU3MDExMiAtMS40MTA3MSAxLjY1Nzc4MyAtMS42MjU5MDNMMS45MDQ4NTcgLTIuMjcxNDgyQzEuOTc2NTg4IC0yLjQ1NDc5NSAyLjA3MjIyOSAtMi43MDE4NjggMi4wNzIyMjkgLTIuODM3MzZDMi4wNzIyMjkgLTMuMjM1ODY2IDEuNzUzNDI1IC0zLjUxNDgxOSAxLjM0Njk0OSAtMy41MTQ4MTlDMC41NzM4NDggLTMuNTE0ODE5IDAuMjM5MTAzIC0yLjM5OTAwNCAwLjIzOTEwMyAtMi4yOTUzOTJDMC4yMzkxMDMgLTIuMjIzNjYxIDAuMjk0ODk0IC0yLjE5MTc4MSAwLjM1ODY1NSAtMi4xOTE3ODFDMC40NjIyNjcgLTIuMTkxNzgxIDAuNDcwMjM3IC0yLjIzOTYwMSAwLjQ5NDE0NyAtMi4zMTkzMDNDMC43MTczMSAtMy4wNzY0NjMgMS4wODM5MzUgLTMuMjkxNjU2IDEuMzIzMDM5IC0zLjI5MTY1NkMxLjQzNDYyIC0zLjI5MTY1NiAxLjUxNDMyMSAtMy4yNTE4MDYgMS41MTQzMjEgLTMuMDI4NjQzQzEuNTE0MzIxIC0yLjk0ODk0MSAxLjUwNjM1MSAtMi44MzczNiAxLjQyNjY1IC0yLjU5ODI1N0wxLjIxMTQ1NyAtMi4wNDgzMTlaJyBpZD0nZzMtMTA1Jy8+CjxwYXRoIGQ9J00yLjA4ODE2OSAtNS4yOTIxNTRDMi4wOTYxMzkgLTUuMzA4MDk1IDIuMTIwMDUgLTUuNDExNzA2IDIuMTIwMDUgLTUuNDE5Njc2QzIuMTIwMDUgLTUuNDU5NTI3IDIuMDg4MTY5IC01LjUzMTI1OCAxLjk5MjUyOCAtNS41MzEyNThMMS4xODc1NDcgLTUuNDY3NDk3QzAuODkyNjUzIC01LjQ0MzU4NyAwLjgyODg5MiAtNS40MzU2MTYgMC44Mjg4OTIgLTUuMjkyMTU0QzAuODI4ODkyIC01LjE4MDU3MyAwLjk0MDQ3MyAtNS4xODA1NzMgMS4wMzYxMTUgLTUuMTgwNTczQzEuNDE4NjggLTUuMTgwNTczIDEuNDE4NjggLTUuMTMyNzUyIDEuNDE4NjggLTUuMDYxMDIxQzEuNDE4NjggLTUuMDM3MTExIDEuNDE4NjggLTUuMDIxMTcxIDEuMzc4ODI5IC00Ljg3NzcwOUwwLjM5MDUzNSAtMC45MjQ1MzNDMC4zNTg2NTUgLTAuNzk3MDExIDAuMzU4NjU1IC0wLjY3NzQ2IDAuMzU4NjU1IC0wLjY2OTQ4OUMwLjM1ODY1NSAtMC4xNzUzNDIgMC43NjUxMzEgMC4wNzk3MDEgMS4xNjM2MzYgMC4wNzk3MDFDMS41MDYzNTEgMC4wNzk3MDEgMS42ODk2NjQgLTAuMTkxMjgzIDEuNzc3MzM1IC0wLjM2NjYyNUMxLjkyMDc5NyAtMC42Mjk2MzkgMi4wNDAzNDkgLTEuMDk5ODc1IDIuMDQwMzQ5IC0xLjEzOTcyNkMyLjA0MDM0OSAtMS4xODc1NDcgMi4wMTY0MzggLTEuMjQzMzM3IDEuOTEyODI3IC0xLjI0MzMzN0MxLjg0MTA5NiAtMS4yNDMzMzcgMS44MTcxODYgLTEuMjAzNDg3IDEuODE3MTg2IC0xLjE5NTUxN0MxLjgwMTI0NSAtMS4xNzE2MDYgMS43NjEzOTUgLTEuMDI4MTQ0IDEuNzM3NDg0IC0wLjk0MDQ3M0MxLjYxNzkzMyAtMC40NzgyMDcgMS40NjY1MDEgLTAuMTQzNDYyIDEuMTc5NTc3IC0wLjE0MzQ2MkMwLjk4ODI5NCAtMC4xNDM0NjIgMC45MzI1MDMgLTAuMzI2Nzc1IDAuOTMyNTAzIC0wLjUxODA1N0MwLjkzMjUwMyAtMC42Njk0ODkgMC45NTY0MTMgLTAuNzU3MTYxIDAuOTgwMzI0IC0wLjg2MDc3MkwyLjA4ODE2OSAtNS4yOTIxNTRaJyBpZD0nZzMtMTA4Jy8+CjxwYXRoIGQ9J00xLjU5NDAyMiAtMS4zMDcwOThDMS42MTc5MzMgLTEuNDI2NjUgMS42OTc2MzQgLTEuNzI5NTE0IDEuNzIxNTQ0IC0xLjg0OTA2NkMxLjc0NTQ1NSAtMS45Mjg3NjcgMS43OTMyNzUgLTIuMTIwMDUgMS44MDkyMTUgLTIuMTk5NzUxQzEuODI1MTU2IC0yLjIzOTYwMSAyLjA4ODE2OSAtMi43NTc2NTkgMi40Mzg4NTQgLTMuMDIwNjcyQzIuNzA5ODM4IC0zLjIyNzg5NSAyLjk3Mjg1MiAtMy4yOTE2NTYgMy4xOTYwMTUgLTMuMjkxNjU2QzMuNDkwOTA5IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4xMTYzMTQgMy42NTAzMTEgLTIuNzQ5Njg5QzMuNjUwMzExIC0yLjU1ODQwNiAzLjYwMjQ5MSAtMi4zNzUwOTMgMy41MTQ4MTkgLTIuMDE2NDM4QzMuNDU5MDI5IC0xLjgwOTIxNSAzLjMyMzUzNyAtMS4yNzUyMTggMy4yNzU3MTYgLTEuMDYwMDI1TDMuMTU2MTY0IC0wLjU4MTgxOEMzLjExNjMxNCAtMC40NDYzMjYgMy4wNjA1MjMgLTAuMjA3MjIzIDMuMDYwNTIzIC0wLjE2NzM3MkMzLjA2MDUyMyAwLjAxNTk0IDMuMjExOTU1IDAuMDc5NzAxIDMuMzE1NTY3IDAuMDc5NzAxQzMuNDU5MDI5IDAuMDc5NzAxIDMuNTc4NTggLTAuMDE1OTQgMy42MzQzNzEgLTAuMTExNTgyQzMuNjU4MjgxIC0wLjE1OTQwMiAzLjcyMjA0MiAtMC40MzAzODYgMy43NjE4OTMgLTAuNTk3NzU4TDMuOTQ1MjA1IC0xLjMwNzA5OEMzLjk2OTExNiAtMS40MjY2NSA0LjA0ODgxNyAtMS43Mjk1MTQgNC4wNzI3MjcgLTEuODQ5MDY2QzQuMTg0MzA5IC0yLjI3OTQ1MiA0LjE4NDMwOSAtMi4yODc0MjIgNC4zNjc2MjEgLTIuNTUwNDM2QzQuNjMwNjM1IC0yLjk0MDk3MSA1LjAwNTIzIC0zLjI5MTY1NiA1LjUzOTIyOCAtMy4yOTE2NTZDNS44MjYxNTIgLTMuMjkxNjU2IDUuOTkzNTI0IC0zLjEyNDI4NCA1Ljk5MzUyNCAtMi43NDk2ODlDNS45OTM1MjQgLTIuMzExMzMzIDUuNjU4NzggLTEuMzk0NzcgNS41MDczNDcgLTEuMDEyMjA0QzUuNDI3NjQ2IC0wLjgwNDk4MSA1LjQwMzczNiAtMC43NDkxOTEgNS40MDM3MzYgLTAuNTk3NzU4QzUuNDAzNzM2IC0wLjE0MzQ2MiA1Ljc3ODMzMSAwLjA3OTcwMSA2LjEyMTA0NiAwLjA3OTcwMUM2LjkwMjExNyAwLjA3OTcwMSA3LjIyODg5MiAtMS4wMzYxMTUgNy4yMjg4OTIgLTEuMTM5NzI2QzcuMjI4ODkyIC0xLjIxOTQyNyA3LjE2NTEzMSAtMS4yNDMzMzcgNy4xMDkzNCAtMS4yNDMzMzdDNy4wMTM2OTkgLTEuMjQzMzM3IDYuOTk3NzU4IC0xLjE4NzU0NyA2Ljk3Mzg0OCAtMS4xMDc4NDZDNi43ODI1NjUgLTAuNDQ2MzI2IDYuNDQ3ODIxIC0wLjE0MzQ2MiA2LjE0NDk1NiAtMC4xNDM0NjJDNi4wMTc0MzUgLTAuMTQzNDYyIDUuOTUzNjc0IC0wLjIyMzE2MyA1Ljk1MzY3NCAtMC40MDY0NzZTNi4wMTc0MzUgLTAuNzY1MTMxIDYuMDk3MTM2IC0wLjk2NDM4NEM2LjIxNjY4NyAtMS4yNjcyNDggNi41NjczNzIgLTIuMTgzODExIDYuNTY3MzcyIC0yLjYzMDEzN0M2LjU2NzM3MiAtMy4yMjc4OTUgNi4xNTI5MjcgLTMuNTE0ODE5IDUuNTc5MDc4IC0zLjUxNDgxOUM1LjAyOTE0MSAtMy41MTQ4MTkgNC41NzQ4NDQgLTMuMjI3ODk1IDQuMjE2MTg5IC0yLjczMzc0OEM0LjE1MjQyOCAtMy4zNzEzNTcgMy42NDIzNDEgLTMuNTE0ODE5IDMuMjI3ODk1IC0zLjUxNDgxOUMyLjg2MTI3IC0zLjUxNDgxOSAyLjM3NTA5MyAtMy4zODcyOTggMS45MzY3MzcgLTIuODEzNDVDMS44ODA5NDYgLTMuMjkxNjU2IDEuNDk4MzgxIC0zLjUxNDgxOSAxLjEyMzc4NiAtMy41MTQ4MTlDMC44NDQ4MzIgLTMuNTE0ODE5IDAuNjQ1NTc5IC0zLjM0NzQ0NyAwLjUxMDA4NyAtMy4wNzY0NjNDMC4zMTg4MDQgLTIuNzAxODY4IDAuMjM5MTAzIC0yLjMxMTMzMyAwLjIzOTEwMyAtMi4yOTUzOTJDMC4yMzkxMDMgLTIuMjIzNjYxIDAuMjk0ODk0IC0yLjE5MTc4MSAwLjM1ODY1NSAtMi4xOTE3ODFDMC40NjIyNjcgLTIuMTkxNzgxIDAuNDcwMjM3IC0yLjIyMzY2MSAwLjUyNjAyNyAtMi40MzA4ODRDMC42MjE2NjkgLTIuODIxNDIgMC43NjUxMzEgLTMuMjkxNjU2IDEuMDk5ODc1IC0zLjI5MTY1NkMxLjMwNzA5OCAtMy4yOTE2NTYgMS4zNTQ5MTkgLTMuMDkyNDAzIDEuMzU0OTE5IC0yLjkxNzA2MUMxLjM1NDkxOSAtMi43NzM1OTkgMS4zMTUwNjggLTIuNjIyMTY3IDEuMjUxMzA4IC0yLjM1OTE1M0MxLjIzNTM2NyAtMi4yOTUzOTIgMS4xMTU4MTYgLTEuODI1MTU2IDEuMDgzOTM1IC0xLjcxMzU3NEwwLjc4OTA0MSAtMC41MTgwNTdDMC43NTcxNjEgLTAuMzk4NTA2IDAuNzA5MzQgLTAuMTk5MjUzIDAuNzA5MzQgLTAuMTY3MzcyQzAuNzA5MzQgMC4wMTU5NCAwLjg2MDc3MiAwLjA3OTcwMSAwLjk2NDM4NCAwLjA3OTcwMUMxLjEwNzg0NiAwLjA3OTcwMSAxLjIyNzM5NyAtMC4wMTU5NCAxLjI4MzE4OCAtMC4xMTE1ODJDMS4zMDcwOTggLTAuMTU5NDAyIDEuMzcwODU5IC0wLjQzMDM4NiAxLjQxMDcxIC0wLjU5Nzc1OEwxLjU5NDAyMiAtMS4zMDcwOThaJyBpZD0nZzMtMTA5Jy8+CjxwYXRoIGQ9J00zLjk5MzAyNiAtMy4xODAwNzVDMy42NDIzNDEgLTMuMDkyNDAzIDMuNjI2NDAxIC0yLjc4MTU2OSAzLjYyNjQwMSAtMi43NDk2ODlDMy42MjY0MDEgLTIuNTc0MzQ2IDMuNzYxODkzIC0yLjQ1NDc5NSAzLjkzNzIzNSAtMi40NTQ3OTVTNC4zODM1NjIgLTIuNTkwMjg2IDQuMzgzNTYyIC0yLjkzMzAwMUM0LjM4MzU2MiAtMy4zODcyOTggMy44ODE0NDUgLTMuNTE0ODE5IDMuNTg2NTUgLTMuNTE0ODE5QzMuMjExOTU1IC0zLjUxNDgxOSAyLjkwOTA5MSAtMy4yNTE4MDYgMi43MjU3NzggLTIuOTQwOTcxQzIuNTUwNDM2IC0zLjM2MzM4NyAyLjEzNTk5IC0zLjUxNDgxOSAxLjgwOTIxNSAtMy41MTQ4MTlDMC45NDA0NzMgLTMuNTE0ODE5IDAuNDU0Mjk2IC0yLjUxODU1NSAwLjQ1NDI5NiAtMi4yOTUzOTJDMC40NTQyOTYgLTIuMjIzNjYxIDAuNTEwMDg3IC0yLjE5MTc4MSAwLjU3Mzg0OCAtMi4xOTE3ODFDMC42Njk0ODkgLTIuMTkxNzgxIDAuNjg1NDMgLTIuMjMxNjMxIDAuNzA5MzQgLTIuMzI3MjczQzAuODkyNjUzIC0yLjkwOTA5MSAxLjM3MDg1OSAtMy4yOTE2NTYgMS43ODUzMDUgLTMuMjkxNjU2QzIuMDk2MTM5IC0zLjI5MTY1NiAyLjI0NzU3MiAtMy4wNjg0OTMgMi4yNDc1NzIgLTIuNzgxNTY5QzIuMjQ3NTcyIC0yLjYyMjE2NyAyLjE1MTkzIC0yLjI1NTU0MiAyLjA4ODE2OSAtMi4wMDA0OThDMi4wMzIzNzkgLTEuNzY5MzY1IDEuODU3MDM2IC0xLjA2MDAyNSAxLjgxNzE4NiAtMC45MDg1OTNDMS43MDU2MDQgLTAuNDc4MjA3IDEuNDE4NjggLTAuMTQzNDYyIDEuMDYwMDI1IC0wLjE0MzQ2MkMxLjAyODE0NCAtMC4xNDM0NjIgMC44MjA5MjIgLTAuMTQzNDYyIDAuNjUzNTQ5IC0wLjI1NTA0NEMxLjAyMDE3NCAtMC4zNDI3MTUgMS4wMjAxNzQgLTAuNjc3NDYgMS4wMjAxNzQgLTAuNjg1NDNDMS4wMjAxNzQgLTAuODY4NzQyIDAuODc2NzEyIC0wLjk4MDMyNCAwLjcwMTM3IC0wLjk4MDMyNEMwLjQ4NjE3NyAtMC45ODAzMjQgMC4yNTUwNDQgLTAuNzk3MDExIDAuMjU1MDQ0IC0wLjQ5NDE0N0MwLjI1NTA0NCAtMC4xMjc1MjIgMC42NDU1NzkgMC4wNzk3MDEgMS4wNTIwNTUgMC4wNzk3MDFDMS40NzQ0NzEgMC4wNzk3MDEgMS43NjkzNjUgLTAuMjM5MTAzIDEuOTEyODI3IC0wLjQ5NDE0N0MyLjA4ODE2OSAtMC4xMDM2MTEgMi40NTQ3OTUgMC4wNzk3MDEgMi44MzczNiAwLjA3OTcwMUMzLjcwNjEwMiAwLjA3OTcwMSA0LjE4NDMwOSAtMC45MTY1NjMgNC4xODQzMDkgLTEuMTM5NzI2QzQuMTg0MzA5IC0xLjIxOTQyNyA0LjEyMDU0OCAtMS4yNDMzMzcgNC4wNjQ3NTcgLTEuMjQzMzM3QzMuOTY5MTE2IC0xLjI0MzMzNyAzLjk1MzE3NiAtMS4xODc1NDcgMy45MjkyNjUgLTEuMTA3ODQ2QzMuNzY5ODYzIC0wLjU3Mzg0OCAzLjMxNTU2NyAtMC4xNDM0NjIgMi44NTMzIC0wLjE0MzQ2MkMyLjU5MDI4NiAtMC4xNDM0NjIgMi4zOTkwMDQgLTAuMzE4ODA0IDIuMzk5MDA0IC0wLjY1MzU0OUMyLjM5OTAwNCAtMC44MTI5NTEgMi40NDY4MjQgLTAuOTk2MjY0IDIuNTU4NDA2IC0xLjQ0MjU5QzIuNjE0MTk3IC0xLjY4MTY5NCAyLjc4OTUzOSAtMi4zODMwNjQgMi44MjkzOSAtMi41MzQ0OTZDMi45NDA5NzEgLTIuOTQ4OTQxIDMuMjE5OTI1IC0zLjI5MTY1NiAzLjU3ODU4IC0zLjI5MTY1NkMzLjYxODQzMSAtMy4yOTE2NTYgMy44MjU2NTQgLTMuMjkxNjU2IDMuOTkzMDI2IC0zLjE4MDA3NVonIGlkPSdnMy0xMjAnLz4KPHBhdGggZD0nTTQuMTI4NTE4IC0zLjAwNDczMkM0LjE2MDM5OSAtMy4xMTYzMTQgNC4xNjAzOTkgLTMuMTMyMjU0IDQuMTYwMzk5IC0zLjE4ODA0NUM0LjE2MDM5OSAtMy4zODcyOTggNC4wMDA5OTYgLTMuNDM1MTE4IDMuOTA1MzU1IC0zLjQzNTExOEMzLjg2NTUwNCAtMy40MzUxMTggMy42ODIxOTIgLTMuNDI3MTQ4IDMuNTc4NTggLTMuMjE5OTI1QzMuNTYyNjQgLTMuMTgwMDc1IDMuNDkwOTA5IC0yLjg5MzE1MSAzLjQ1MTA1OSAtMi43MjU3NzhMMi45NzI4NTIgLTAuODEyOTUxQzIuOTY0ODgyIC0wLjc4OTA0MSAyLjYyMjE2NyAtMC4xNDM0NjIgMi4wNDAzNDkgLTAuMTQzNDYyQzEuNjQ5ODEzIC0wLjE0MzQ2MiAxLjUxNDMyMSAtMC40MzAzODYgMS41MTQzMjEgLTAuNzg5MDQxQzEuNTE0MzIxIC0xLjI1MTMwOCAxLjc4NTMwNSAtMS45NjA2NDggMS45Njg2MTggLTIuNDIyOTE0QzIuMDQ4MzE5IC0yLjYyMjE2NyAyLjA3MjIyOSAtMi42OTM4OTggMi4wNzIyMjkgLTIuODM3MzZDMi4wNzIyMjkgLTMuMjc1NzE2IDEuNzIxNTQ0IC0zLjUxNDgxOSAxLjM1NDkxOSAtMy41MTQ4MTlDMC41NjU4NzggLTMuNTE0ODE5IDAuMjM5MTAzIC0yLjM5MTAzNCAwLjIzOTEwMyAtMi4yOTUzOTJDMC4yMzkxMDMgLTIuMjIzNjYxIDAuMjk0ODk0IC0yLjE5MTc4MSAwLjM1ODY1NSAtMi4xOTE3ODFDMC40NjIyNjcgLTIuMTkxNzgxIDAuNDcwMjM3IC0yLjIzOTYwMSAwLjQ5NDE0NyAtMi4zMTkzMDNDMC43MDEzNyAtMy4wMTI3MDIgMS4wNDQwODUgLTMuMjkxNjU2IDEuMzMxMDA5IC0zLjI5MTY1NkMxLjQ1MDU2IC0zLjI5MTY1NiAxLjUyMjI5MSAtMy4yMTE5NTUgMS41MjIyOTEgLTMuMDI4NjQzQzEuNTIyMjkxIC0yLjg2MTI3IDEuNDU4NTMxIC0yLjY3Nzk1OCAxLjQwMjc0IC0yLjUzNDQ5NkMxLjA3NTk2NSAtMS42ODk2NjQgMC45NDA0NzMgLTEuMjgzMTg4IDAuOTQwNDczIC0wLjkwODU5M0MwLjk0MDQ3MyAtMC4xMjc1MjIgMS41MzAyNjIgMC4wNzk3MDEgMi4wMDA0OTggMC4wNzk3MDFDMi4zNzUwOTMgMC4wNzk3MDEgMi42NDYwNzcgLTAuMDg3NjcxIDIuODM3MzYgLTAuMjcwOTg0QzIuNzI1Nzc4IDAuMTc1MzQyIDIuNjQ2MDc3IDAuNDg2MTc3IDIuMzQzMjEzIDAuODY4NzQyQzIuMDgwMTk5IDEuMTk1NTE3IDEuNzYxMzk1IDEuNDAyNzQgMS40MDI3NCAxLjQwMjc0QzEuMjY3MjQ4IDEuNDAyNzQgMC45NjQzODQgMS4zNzg4MjkgMC44MDQ5ODEgMS4xMzk3MjZDMS4yMjczOTcgMS4xMDc4NDYgMS4yNTkyNzggMC43NDkxOTEgMS4yNTkyNzggMC43MDEzN0MxLjI1OTI3OCAwLjUxMDA4NyAxLjExNTgxNiAwLjQwNjQ3NiAwLjk0ODQ0MyAwLjQwNjQ3NkMwLjc3MzEwMSAwLjQwNjQ3NiAwLjQ5NDE0NyAwLjU0MTk2OCAwLjQ5NDE0NyAwLjkzMjUwM0MwLjQ5NDE0NyAxLjMwNzA5OCAwLjgzNjg2MiAxLjYyNTkwMyAxLjQwMjc0IDEuNjI1OTAzQzIuMjE1NjkxIDEuNjI1OTAzIDMuMTMyMjU0IDAuOTcyMzU0IDMuMzcxMzU3IDAuMDA3OTdMNC4xMjg1MTggLTMuMDA0NzMyWicgaWQ9J2czLTEyMScvPgo8cGF0aCBkPSdNNC42NTA1NiAtNC44ODk2NjRDNC4yNzk5NSAtNC44MTc5MzMgNC4wODg2NjcgLTQuNTU0OTE5IDQuMDg4NjY3IC00LjI5MTkwNUM0LjA4ODY2NyAtNC4wMDQ5ODEgNC4zMTU4MTYgLTMuOTA5MzQgNC40ODMxODggLTMuOTA5MzRDNC44MTc5MzMgLTMuOTA5MzQgNS4wOTI5MDIgLTQuMTk2MjY0IDUuMDkyOTAyIC00LjU1NDkxOUM1LjA5MjkwMiAtNC45Mzc0ODQgNC43MjIyOTEgLTUuMjcyMjI5IDQuMTI0NTMzIC01LjI3MjIyOUMzLjY0NjMyNiAtNS4yNzIyMjkgMy4wOTYzODkgLTUuMDU3MDM2IDIuNTk0MjcxIC00LjMyNzc3MUMyLjUxMDU4NSAtNC45NjEzOTUgMi4wMzIzNzkgLTUuMjcyMjI5IDEuNTU0MTcyIC01LjI3MjIyOUMxLjA4NzkyIC01LjI3MjIyOSAwLjg0ODgxNyAtNC45MTM1NzQgMC43MDUzNTUgLTQuNjUwNTZDMC41MDIxMTcgLTQuMjIwMTc0IDAuMzIyNzkgLTMuNTAyODY0IDAuMzIyNzkgLTMuNDQzMDg4QzAuMzIyNzkgLTMuMzk1MjY4IDAuMzcwNjEgLTMuMzM1NDkyIDAuNDU0Mjk2IC0zLjMzNTQ5MkMwLjU0OTkzOCAtMy4zMzU0OTIgMC41NjE4OTMgLTMuMzQ3NDQ3IDAuNjMzNjI0IC0zLjYyMjQxNkMwLjgxMjk1MSAtNC4zMzk3MjYgMS4wNDAxIC01LjAzMzEyNiAxLjUxODMwNiAtNS4wMzMxMjZDMS44MDUyMyAtNS4wMzMxMjYgMS44ODg5MTcgLTQuODI5ODg4IDEuODg4OTE3IC00LjQ4MzE4OEMxLjg4ODkxNyAtNC4yMjAxNzQgMS43NjkzNjUgLTMuNzUzOTIzIDEuNjg1Njc5IC0zLjM4MzMxM0wxLjM1MDkzNCAtMi4wOTIxNTRDMS4zMDMxMTMgLTEuODY1MDA2IDEuMTcxNjA2IC0xLjMyNzAyNCAxLjExMTgzMSAtMS4xMTE4MzFDMS4wMjgxNDQgLTAuODAwOTk2IDAuODk2NjM4IC0wLjIzOTEwMyAwLjg5NjYzOCAtMC4xNzkzMjhDMC44OTY2MzggLTAuMDExOTU1IDEuMDI4MTQ0IDAuMTE5NTUyIDEuMjA3NDcyIDAuMTE5NTUyQzEuMzM4OTc5IDAuMTE5NTUyIDEuNTY2MTI3IDAuMDM1ODY2IDEuNjM3ODU4IC0wLjIwMzIzOEMxLjY3MzcyNCAtMC4yOTg4NzkgMi4xMTYwNjUgLTIuMTA0MTEgMi4xODc3OTYgLTIuMzc5MDc4QzIuMjQ3NTcyIC0yLjY0MjA5MiAyLjMxOTMwMyAtMi44OTMxNTEgMi4zNzkwNzggLTMuMTU2MTY0QzIuNDI2ODk5IC0zLjMyMzUzNyAyLjQ3NDcyIC0zLjUxNDgxOSAyLjUxMDU4NSAtMy42NzAyMzdDMi41NDY0NTEgLTMuNzc3ODMzIDIuODY5MjQgLTQuMzYzNjM2IDMuMTY4MTIgLTQuNjI2NjVDMy4zMTE1ODIgLTQuNzU4MTU3IDMuNjIyNDE2IC01LjAzMzEyNiA0LjExMjU3OCAtNS4wMzMxMjZDNC4zMDM4NjEgLTUuMDMzMTI2IDQuNDk1MTQzIC00Ljk5NzI2IDQuNjUwNTYgLTQuODg5NjY0WicgaWQ9J2c0LTExNCcvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzYtNjEnLz4KPHBhdGggZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIDAuNzI1MjggMS4zMzg5NzkgLTAuNzU3MTYxIDEuMzM4OTc5IC0xLjk5MjUyOEMxLjMzODk3OSAtNC4yODc5MiAyLjI4NzQyMiAtNS4zNjM4ODUgMi42OTM4OTggLTUuNzMwNTExQzIuODA1NDc5IC01LjgzNDEyMiAyLjgxMzQ1IC01Ljg0MjA5MiAyLjgxMzQ1IC01Ljg4MTk0M1MyLjc4MTU2OSAtNS45Nzc1ODQgMi43MDE4NjggLTUuOTc3NTg0QzIuNTc0MzQ2IC01Ljk3NzU4NCAyLjE3NTg0MSAtNS41NzExMDggMi4xMTIwOCAtNS40OTkzNzdDMS4wNDQwODUgLTQuMzgzNTYyIDAuODIwOTIyIC0yLjk0ODk0MSAwLjgyMDkyMiAtMS45OTI1MjhDMC44MjA5MjIgLTAuMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicgaWQ9J2c1LTQwJy8+CjxwYXRoIGQ9J00yLjQ2Mjc2NSAtMS45OTI1MjhDMi40NjI3NjUgLTIuNzQ5Njg5IDIuMzM1MjQzIC0zLjY1ODI4MSAxLjg0MTA5NiAtNC41OTg3NTVDMS40NTA1NiAtNS4zMzIwMDUgMC43MjUyOCAtNS45Nzc1ODQgMC41ODE4MTggLTUuOTc3NTg0QzAuNTAyMTE3IC01Ljk3NzU4NCAwLjQ3ODIwNyAtNS45MjE3OTMgMC40NzgyMDcgLTUuODgxOTQzQzAuNDc4MjA3IC01Ljg1MDA2MiAwLjQ3ODIwNyAtNS44MzQxMjIgMC41NzM4NDggLTUuNzM4NDgxQzEuNjg5NjY0IC00LjY3ODQ1NiAxLjk0NDcwNyAtMy4yMTk5MjUgMS45NDQ3MDcgLTEuOTkyNTI4QzEuOTQ0NzA3IDAuMjk0ODk0IDAuOTk2MjY0IDEuMzc4ODI5IDAuNTg5Nzg4IDEuNzQ1NDU1QzAuNDg2MTc3IDEuODQ5MDY2IDAuNDc4MjA3IDEuODU3MDM2IDAuNDc4MjA3IDEuODk2ODg3UzAuNTAyMTE3IDEuOTkyNTI4IDAuNTgxODE4IDEuOTkyNTI4QzAuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgMC4zOTg1MDYgMi40NjI3NjUgLTEuMDM2MTE1IDIuNDYyNzY1IC0xLjk5MjUyOFonIGlkPSdnNS00MScvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzEtMCcvPgo8cGF0aCBkPSdNMi43MDE4NjggMjEuMDI5MTQxSDUuNDE1NjkxVjIwLjQ2NzI0OEgzLjI2Mzc2MVYwLjA4MzY4Nkg1LjQxNTY5MVYtMC40NzgyMDdIMi43MDE4NjhWMjEuMDI5MTQxWicgaWQ9J2cwLTEwNCcvPgo8cGF0aCBkPSdNMi4zNjcxMjMgMjAuNDY3MjQ4SDAuMjE1MTkzVjIxLjAyOTE0MUgyLjkyOTAxNlYtMC40NzgyMDdIMC4yMTUxOTNWMC4wODM2ODZIMi4zNjcxMjNWMjAuNDY3MjQ4WicgaWQ9J2cwLTEwNScvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nNTYuNDEzMjY3JyB4bGluazpocmVmPScjZzQtMTE0JyB5PSc2Ny41NDY3OTQnLz4KPHVzZSB4PSc2MS42ODg1NzQnIHhsaW5rOmhyZWY9JyNnMy0xMDUnIHk9JzY5LjM0MDA1NycvPgo8dXNlIHg9JzY0LjU3MTcxNCcgeGxpbms6aHJlZj0nI2czLTEwOScgeT0nNjkuMzQwMDU3Jy8+Cjx1c2UgeD0nNzUuODgxMjAyJyB4bGluazpocmVmPScjZzYtNjEnIHk9JzY3LjU0Njc5NCcvPgo8dXNlIHg9Jzg4LjMwNjY4MycgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzY3LjU0Njc5NCcvPgo8dXNlIHg9Jzk5LjU5NzY3NycgeGxpbms6aHJlZj0nI2cwLTEwNCcgeT0nNTQuMjc2NDQ0Jy8+Cjx1c2UgeD0nMTA2LjQzODcwNycgeGxpbms6aHJlZj0nI2czLTY0JyB5PSc2MS44NDgxOTMnLz4KPHVzZSB4PScxMTEuMzcwMjcyJyB4bGluazpocmVmPScjZzMtMTA4JyB5PSc2MS44NDgxOTMnLz4KPHVzZSB4PScxMTMuOTkyMzk3JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzYxLjg0ODE5MycvPgo8dXNlIHg9JzExNy4yODU2NScgeGxpbms6aHJlZj0nI2czLTEyMScgeT0nNjEuODQ4MTkzJy8+Cjx1c2UgeD0nMTIxLjQ3MTQnIHhsaW5rOmhyZWY9JyNnMi0xMDUnIHk9JzYzLjA2MzI3MicvPgo8dXNlIHg9JzEyNC42MzMxNTgnIHhsaW5rOmhyZWY9JyNnMy01OScgeT0nNjEuODQ4MTkzJy8+Cjx1c2UgeD0nMTI2Ljk4NTQ4MicgeGxpbms6aHJlZj0nI2czLTcwJyB5PSc2MS44NDgxOTMnLz4KPHVzZSB4PScxMzIuMzQ0NjEyJyB4bGluazpocmVmPScjZzItMTA5JyB5PSc2Mi44NDQ0NTcnLz4KPHVzZSB4PScxMzkuMzgwNjk2JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzYxLjg0ODE5MycvPgo8dXNlIHg9JzE0Mi42NzM5NDknIHhsaW5rOmhyZWY9JyNnMy0xMjAnIHk9JzYxLjg0ODE5MycvPgo8dXNlIHg9JzE0Ny40NDA4NDgnIHhsaW5rOmhyZWY9JyNnMi0xMDUnIHk9JzYzLjA2MzI3MicvPgo8dXNlIHg9JzE1MC42MDI2MDYnIHhsaW5rOmhyZWY9JyNnNS00MScgeT0nNjEuODQ4MTkzJy8+Cjx1c2UgeD0nMTUzLjg5NTg2JyB4bGluazpocmVmPScjZzUtNDEnIHk9JzYxLjg0ODE5MycvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNTAuNzUwNDA2JyB4PScxMDYuNDM4NzA3JyB5PSc2NC4zMTg5MDgnLz4KPHVzZSB4PScxMTUuODkyOTM5JyB4bGluazpocmVmPScjZzMtNjQnIHk9JzcxLjY2OTQyNicvPgo8dXNlIHg9JzEyMC44MjQ1MDQnIHhsaW5rOmhyZWY9JyNnMy03MCcgeT0nNzEuNjY5NDI2Jy8+Cjx1c2UgeD0nMTI2LjE4MzYzNCcgeGxpbms6aHJlZj0nI2cyLTEwOScgeT0nNzIuNjY1NjknLz4KPHVzZSB4PScxMzMuMjE5NzE4JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzcxLjY2OTQyNicvPgo8dXNlIHg9JzEzNi41MTI5NzEnIHhsaW5rOmhyZWY9JyNnMy0xMjAnIHk9JzcxLjY2OTQyNicvPgo8dXNlIHg9JzE0MS4yNzk4NycgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nNzIuODg0NTA1Jy8+Cjx1c2UgeD0nMTQ0LjQ0MTYyOCcgeGxpbms6aHJlZj0nI2c1LTQxJyB5PSc3MS42Njk0MjYnLz4KPHVzZSB4PScxNTguMzg0NjI3JyB4bGluazpocmVmPScjZzAtMTA1JyB5PSc1NC4yNzY0NDQnLz4KPC9nPgo8L3N2Zz4=)
Etape 3 : on choisit la fonction  de telle sorte
qu’elle approxime au mieux les résidus
de telle sorte
qu’elle approxime au mieux les résidus  .
.
Etape 4 : on choisit le coefficient  de telle
sorte qu’il minimise l’expression
de telle
sorte qu’il minimise l’expression
 .
.
On retourne l’étape 2 autant de fois qu’il y a d’itérations. Lorsque
l’erreur est une erreur quadratique  , les
résidus deviennent
, les
résidus deviennent  . Par conséquent,
la fonction
. Par conséquent,
la fonction  approxime au mieux ce qu’il manque pour atteindre
l’objectif. Un learning rate égal à 1 fait que la somme des prédictions
de chaque fonction
approxime au mieux ce qu’il manque pour atteindre
l’objectif. Un learning rate égal à 1 fait que la somme des prédictions
de chaque fonction  oscille autour de la vraie valeur, une
faible valeur donne l’impression d’une fonction qui converge à petits
pas, une grande valeur accroît l’amplitude des oscillations au point
d’empêcher l’algorithme de converger.
oscille autour de la vraie valeur, une
faible valeur donne l’impression d’une fonction qui converge à petits
pas, une grande valeur accroît l’amplitude des oscillations au point
d’empêcher l’algorithme de converger.
On voit aussi que l’algorithme s’intéresse d’abord aux points où le gradient est le plus fort, donc en principe aux erreurs les plus grandes.
Régression quantile#
Dans ce cas, l’erreur quadratique est remplacée par une erreur en valeur absolue. Les résidus dans ce cas sont égaux à -1 ou 1.
alpha = 0.5
model = GradientBoostingRegressor(alpha=alpha, loss='quantile', max_depth=1, learning_rate=0.1)
model.fit(X_train, y_train)
model01 = GradientBoostingRegressor(alpha=alpha, loss='quantile', max_depth=1, learning_rate=0.01)
model01.fit(X_train, y_train)
modela = GradientBoostingRegressor(alpha=alpha, loss='quantile', max_depth=1, learning_rate=1.2)
modela.fit(X_train, y_train)
modelb = GradientBoostingRegressor(alpha=alpha, loss='quantile', max_depth=1, learning_rate=1.99)
modelb.fit(X_train, y_train)
modelc = GradientBoostingRegressor(alpha=alpha, loss='quantile', max_depth=1, learning_rate=2.01)
modelc.fit(X_train, y_train)
GradientBoostingRegressor(alpha=0.5, ccp_alpha=0.0, criterion='friedman_mse',
init=None, learning_rate=2.01, loss='quantile',
max_depth=1, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_iter_no_change=None, presort='deprecated',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0, warm_start=False)
fig, ax = plt.subplots(1, 5, figsize=(12, 4))
ind = numpy.argsort(X_test, axis=0)
for i, mod in enumerate([model, model01, modela, modelb, modelc]):
df = DataFrame({'X': X_test[ind].ravel(),
'y': y_test[ind].ravel(),
'y^': mod.predict(X_test)[ind].ravel()})
df.plot(x='X', y='y', kind='scatter', ax=ax[i])
df.plot(x='X', y='y^', kind='line', ax=ax[i], color="r")
ax[i].set_title("learning_rate=%1.2f" % mod.learning_rate);
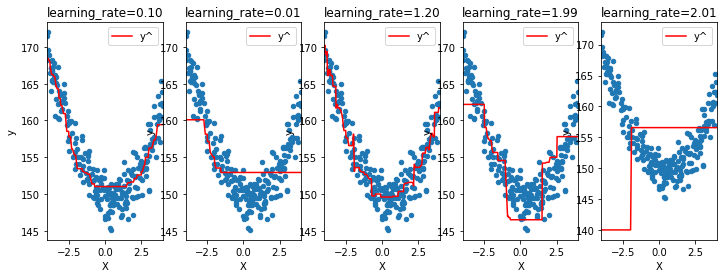
Concrètement, le paramètre max_depth=1 correspond à une simple
fonction  et le modèle final est une
somme pondérée de fonctions indicatrices.
et le modèle final est une
somme pondérée de fonctions indicatrices.
learning_rate et sur-apprentissage#
from sklearn.ensemble import RandomForestRegressor
from tqdm import tqdm
def experiment(models, tries=25):
scores = []
for _ in tqdm(range(tries)):
rnd = randn(1000)
X = random(1000) * 8 - 4
y = X ** 2 - X + rnd * 2 + 150 # X^2 - X + 150 + epsilon
X = X.reshape((-1, 1))
X_train, X_test, y_train, y_test = train_test_split(X, y)
scs = []
for model in models:
model.fit(X_train, y_train)
sc = model.score(X_test, y_test)
scs.append(sc)
scores.append(scs)
return scores
scores = experiment([
GradientBoostingRegressor(max_depth=1, n_estimators=100),
RandomForestRegressor(max_depth=1, n_estimators=100)
])
scores[:3]
100%|██████████| 25/25 [00:07<00:00, 3.33it/s]
[[0.8694704613325202, 0.6154817789660219],
[0.8483182026025287, 0.5448822271424512],
[0.8461792771831131, 0.4989444940263401]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="GradientBoostingRegressor")
ax.plot([_[1] for _ in scores], label="RandomForestRegressor")
ax.set_title("Comparaison pour une somme pondérée de fonctions en escalier")
ax.legend();
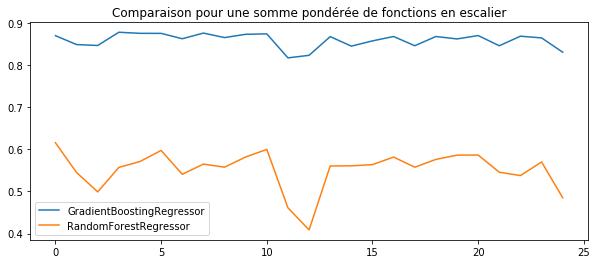
Ce résultat est attendu car la forêt aléatoire est une moyenne de modèle de régression tous appris dans les mêmes conditions alors que le gradient boosting s’intéresse à l’erreur après la somme des premiers régresseurs. Voyons avec des arbres de décision et non plus des fonctions en escaliers.
from sklearn.tree import DecisionTreeRegressor
scores = experiment([
GradientBoostingRegressor(max_depth=5, n_estimators=100),
RandomForestRegressor(max_depth=5, n_estimators=100),
DecisionTreeRegressor(max_depth=5)
])
100%|██████████| 25/25 [00:09<00:00, 2.57it/s]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="GradientBoostingRegressor")
ax.plot([_[1] for _ in scores], label="RandomForestRegressor")
ax.plot([_[2] for _ in scores], label="DecisionTreeRegressor")
ax.set_title("Comparaison pour une somme pondérée d'arbres de décisions")
ax.legend();
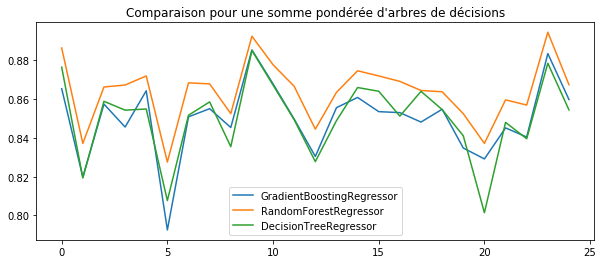
Le modèle GradientBoostingRegressor est clairement moins bon quand le modèle sous-jacent - l’arbre de décision - est performant. On voit que la forêt aléatoire est meilleure qu’un arbre de décision seul. Cela signifie qu’elle généralise mieux et que l’arbre de décision fait du sur apprentissage. De même, le GradientBoostingRegressor est plus exposé au sur-apprentissage.
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
GradientBoostingRegressor(max_depth=5, n_estimators=100, learning_rate=0.05),
GradientBoostingRegressor(max_depth=5, n_estimators=100, learning_rate=0.1),
GradientBoostingRegressor(max_depth=5, n_estimators=100, learning_rate=0.2),
])
scores[:2]
100%|██████████| 25/25 [00:15<00:00, 1.58it/s]
[[0.8775118863156427,
0.8658450142103171,
0.8606599637847404,
0.8364389493877071],
[0.8688453584981832,
0.8702540086892945,
0.8637637833529082,
0.8473494773500022]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor")
ax.plot([_[1] for _ in scores], label="GBR(5, lr=0.05)")
ax.plot([_[2] for _ in scores], label="GBR(5, lr=0.1)")
ax.plot([_[3] for _ in scores], label="GBR(5, lr=0.2)")
ax.set_title("Comparaison pour différents learning_rate")
ax.legend();
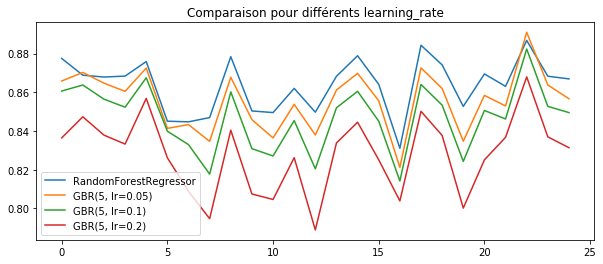
Diminuer learning_rate est clairement une façon d’éviter le sur-apprentissage mais les graphes précédents ont montré qu’il fallait plus d’itérations lorsque le learning rate est petit.
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
GradientBoostingRegressor(max_depth=1, n_estimators=100, learning_rate=0.05),
GradientBoostingRegressor(max_depth=1, n_estimators=100, learning_rate=0.1),
GradientBoostingRegressor(max_depth=1, n_estimators=100, learning_rate=0.2),
])
scores[:2]
100%|██████████| 25/25 [00:11<00:00, 2.30it/s]
[[0.8729919074479062,
0.8153190929633006,
0.8674320406867211,
0.8718834705539096],
[0.8442950556922886,
0.815363804525106,
0.8474302187940742,
0.8444000149837192]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor")
ax.plot([_[1] for _ in scores], label="GBR(1, lr=0.05)")
ax.plot([_[2] for _ in scores], label="GBR(1, lr=0.1)")
ax.plot([_[3] for _ in scores], label="GBR(1, lr=0.2)")
ax.set_title("Comparaison pour différents learning_rate et des fonctions en escalier")
ax.legend();
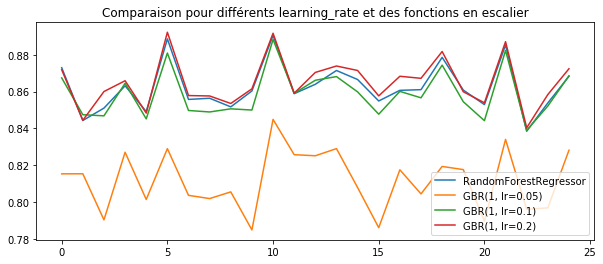
Plus le modèle sous-jacent est simple, plus le learning_rate peut être élevé car les modèles simples ne font pas de sur-apprentissage.
Gradient Boosting avec d’autres librairies#
Une somme pondérée de régression linéaire reste une regréssion linéaire. Il est impossible de tester ce scénario avec scikit-learn puisque seuls les arbres de décisions sont implémentés. Mais il existe d’autres librairies qui implémente le gradient boosting.
XGBoost#
from xgboost import XGBRegressor
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
XGBRegressor(max_depth=1, n_estimators=100, learning_rate=0.05, objective='reg:squarederror'),
XGBRegressor(max_depth=1, n_estimators=100, learning_rate=0.1, objective='reg:squarederror'),
XGBRegressor(max_depth=1, n_estimators=100, learning_rate=0.2, objective='reg:squarederror'),
])
scores[:2]
100%|██████████| 25/25 [00:08<00:00, 2.94it/s]
[[0.8679202687780997,
0.790334034357459,
0.8529726388853197,
0.8635076525988759],
[0.8714386434767272,
0.8076555688846012,
0.876320858210121,
0.8795969068127192]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor(5)")
ax.plot([_[1] for _ in scores], label="XGB(1, lr=0.05)")
ax.plot([_[2] for _ in scores], label="XGB(1, lr=0.1)")
ax.plot([_[3] for _ in scores], label="XGB(1, lr=0.2)")
ax.set_title("Comparaison pour différents learning_rate\net des fonctions en escalier "
"avec XGBoost")
ax.legend();
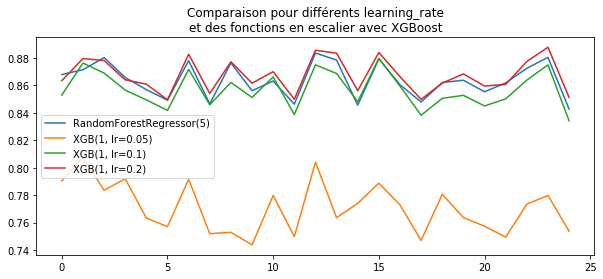
Les résultats sont sensiblement les mêmes.
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
XGBRegressor(max_depth=5, n_estimators=100, learning_rate=0.05, objective='reg:squarederror'),
XGBRegressor(max_depth=5, n_estimators=100, learning_rate=0.1, objective='reg:squarederror'),
XGBRegressor(max_depth=5, n_estimators=100, learning_rate=0.2, objective='reg:squarederror'),
])
scores[:2]
100%|██████████| 25/25 [00:10<00:00, 2.34it/s]
[[0.8850200020052564,
0.8491004361723402,
0.8816335539385363,
0.8760849465925536],
[0.8653185803997192,
0.8402218872212899,
0.8683639698989838,
0.8661907635378407]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor(5)")
ax.plot([_[1] for _ in scores], label="XGB(5, lr=0.05)")
ax.plot([_[2] for _ in scores], label="XGB(5, lr=0.1)")
ax.plot([_[3] for _ in scores], label="XGB(5, lr=0.2)")
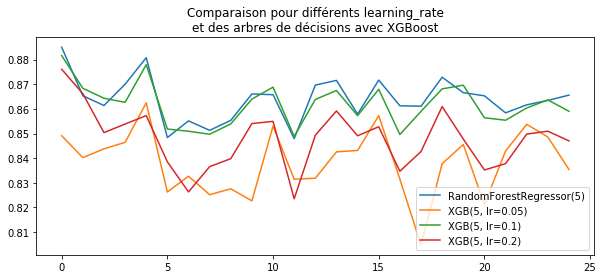
ax.set_title("Comparaison pour différents learning_rate\net des arbres de décisions "
"avec XGBoost")
ax.legend();
LightGbm#
from lightgbm import LGBMRegressor
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
LGBMRegressor(max_depth=1, n_estimators=100, learning_rate=0.05),
LGBMRegressor(max_depth=1, n_estimators=100, learning_rate=0.1),
LGBMRegressor(max_depth=1, n_estimators=100, learning_rate=0.2),
])
scores[:2]
100%|██████████| 25/25 [00:08<00:00, 3.03it/s]
[[0.8893616908044297,
0.8261124421322801,
0.8817998121916502,
0.8926218231962352],
[0.856474322673725,
0.7988728741682812,
0.8481012917344808,
0.8589885895995628]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor(5)")
ax.plot([_[1] for _ in scores], label="LGB(1, lr=0.05)")
ax.plot([_[2] for _ in scores], label="LGB(1, lr=0.1)")
ax.plot([_[3] for _ in scores], label="LGB(1, lr=0.2)")
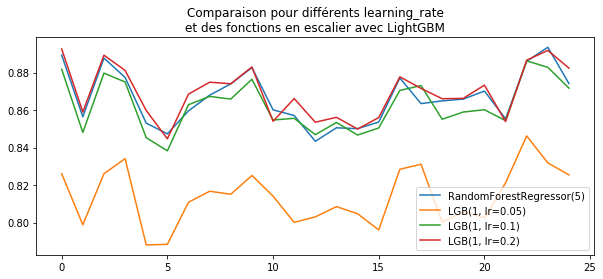
ax.set_title("Comparaison pour différents learning_rate\net des fonctions en escalier "
"avec LightGBM")
ax.legend();
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
LGBMRegressor(max_depth=5, n_estimators=100, learning_rate=0.05),
LGBMRegressor(max_depth=5, n_estimators=100, learning_rate=0.1),
LGBMRegressor(max_depth=5, n_estimators=100, learning_rate=0.2),
])
scores[:2]
100%|██████████| 25/25 [00:10<00:00, 2.26it/s]
[[0.8609320085819122,
0.8634839814757147,
0.8597595136945096,
0.8551285081930242],
[0.8326411682697042,
0.8292392382894543,
0.8280682654753115,
0.8224006022576665]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor(5)")
ax.plot([_[1] for _ in scores], label="LGB(5, lr=0.05)")
ax.plot([_[2] for _ in scores], label="LGB(5, lr=0.1)")
ax.plot([_[3] for _ in scores], label="LGB(5, lr=0.2)")
ax.set_title("Comparaison pour différents learning_rate\net des arbres de décisions "
"avec LightGBM")
ax.legend();
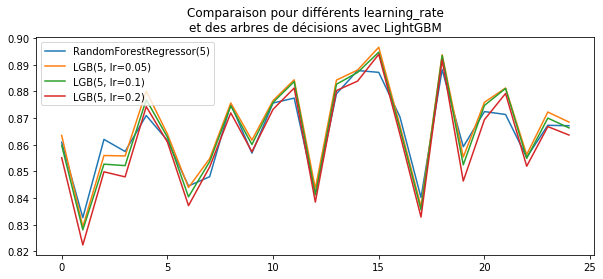
LightGBM paraît moins sensible au learning_rate que XGBoost.
CatBoost#
CatBoost est une des plus récentes. Elle est sensée être plus efficace pour les catégories ce qui n’est pas le cas ici.
from catboost import CatBoostRegressor
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
CatBoostRegressor(max_depth=1, n_estimators=100, learning_rate=0.05, verbose=False),
CatBoostRegressor(max_depth=1, n_estimators=100, learning_rate=0.1, verbose=False),
CatBoostRegressor(max_depth=1, n_estimators=100, learning_rate=0.2, verbose=False),
])
scores[:2]
100%|██████████| 25/25 [00:24<00:00, 1.00it/s]
[[0.8630013062715012,
0.8171496530214813,
0.8705211410285828,
0.8756897741529662],
[0.8655349009959259,
0.8082932897705987,
0.8614224979710696,
0.866454702226169]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor(5)")
ax.plot([_[1] for _ in scores], label="CAT(1, lr=0.05)")
ax.plot([_[2] for _ in scores], label="CAT(1, lr=0.1)")
ax.plot([_[3] for _ in scores], label="CAT(1, lr=0.2)")
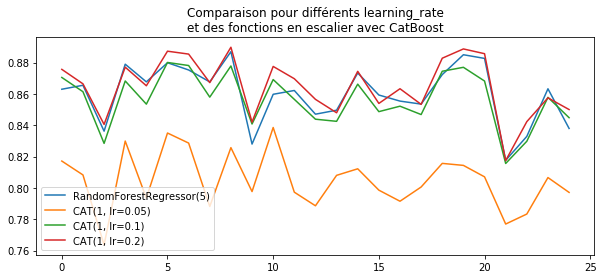
ax.set_title("Comparaison pour différents learning_rate\net des fonctions en escalier "
"avec CatBoost")
ax.legend();
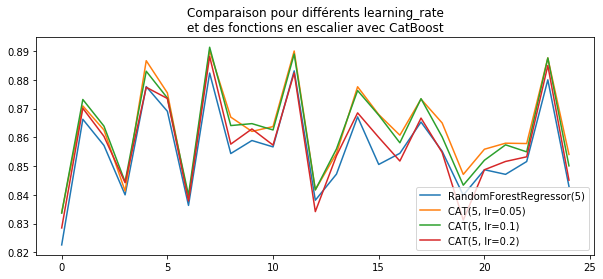
scores = experiment([
RandomForestRegressor(max_depth=5, n_estimators=100),
CatBoostRegressor(max_depth=5, n_estimators=100, learning_rate=0.05, verbose=False),
CatBoostRegressor(max_depth=5, n_estimators=100, learning_rate=0.1, verbose=False),
CatBoostRegressor(max_depth=5, n_estimators=100, learning_rate=0.2, verbose=False),
])
scores[:2]
100%|██████████| 25/25 [00:31<00:00, 1.27s/it]
[[0.8225527835029143,
0.83387879282829,
0.8336031459553583,
0.8284593124477894],
[0.8662884568803738,
0.870941831673826,
0.8731751692649438,
0.8701201310203557]]
fig, ax = plt.subplots(1, 1, figsize=(10, 4))
ax.plot([_[0] for _ in scores], label="RandomForestRegressor(5)")
ax.plot([_[1] for _ in scores], label="CAT(5, lr=0.05)")
ax.plot([_[2] for _ in scores], label="CAT(5, lr=0.1)")
ax.plot([_[3] for _ in scores], label="CAT(5, lr=0.2)")
ax.set_title("Comparaison pour différents learning_rate\net des fonctions en escalier "
"avec CatBoost")
ax.legend();