1A.algo - Programmation dynamique et plus court chemin (correction)#
Links: notebook, html, python, slides, GitHub
Correction.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
On récupère le fichier matrix_distance_7398.txt depuis
matrix_distance_7398.zip
qui contient des distances entre différentes villes (pas toutes).
import pyensae.datasource
pyensae.datasource.download_data("matrix_distance_7398.zip", website = "xd")
['matrix_distance_7398.txt']
import pandas
df = pandas.read_csv("matrix_distance_7398.txt", sep="\t", header=None, names=["v1","v2","distance"])
matrice = df.values
matrice[:5]
array([['Boulogne-Billancourt', 'Beauvais', 85597],
['Courbevoie', 'Sevran', 26564],
['Colombes', 'Alfortville', 36843],
['Bagneux', 'Marcq-En-Baroeul', 233455],
['Suresnes', 'Gennevilliers', 10443]], dtype=object)
Exercice 1#
vil = { }
for row in matrice :
vil [row[0]] = 0
vil [row[1]] = 1
vil = list(vil.keys())
print (len(vil))
196
Exercice 2#
La distance n’existe pas encore. L’exception du court programme suivant le montre. Rejoindre Bordeaux depuis Charleville nécessite plusieurs étapes.
dist = { }
for row in matrice :
a = row[0]
b = row[1]
dist[a,b] = dist[b,a] = row[2]
print (len(dist))
7888
print ( dist["Charleville-Mezieres","Bordeaux"] ) # elle n'existe pas encore
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-6-0227958f5453> in <module>()
----> 1 print ( dist["Charleville-Mezieres","Bordeaux"] ) # elle n'existe pas encore
KeyError: ('Charleville-Mezieres', 'Bordeaux')
Exercice 3#
On peut remplir facilement toutes les cases correspondant aux villes reliées à Charleville-Mézières, c’est-à-dire toutes les villes accessibles en une étape.
d = { }
d['Charleville-Mezieres'] = 0
for v in vil : d[v] = 1e10
for v,w in dist :
if v == 'Charleville-Mezieres':
d[w] = dist[v,w]
print(len(d))
196
Exercice 4#
Si on découvre que ![d[w] > d[v] + dist[w,v]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAxMTYuNDU2NjEgMTEuOTU1MTY4JyB3aWR0aD0nMTE2LjQ1NjYxcHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTQuNzcwMTEyIC0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMSAtMi43NjE2NDQgOC40NTIzMDQgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjk3NjgzN0M4LjQ1MjMwNCAtMy4yMDM5ODUgOC4yNDkwNjYgLTMuMjAzOTg1IDguMDY5NzM4IC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTIgLTYuNjcwOTg0IDQuNzcwMTEyIC02Ljg4NjE3NyA0LjU1NDkxOSAtNi44ODYxNzdDNC4zMjc3NzEgLTYuODg2MTc3IDQuMzI3NzcxIC02LjY4MjkzOSA0LjMyNzc3MSAtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0QzAuODYwNzcyIC0zLjIwMzk4NSAwLjY0NTU3OSAtMy4yMDM5ODUgMC42NDU1NzkgLTIuOTg4NzkyQzAuNjQ1NTc5IC0yLjc2MTY0NCAwLjg0ODgxNyAtMi43NjE2NDQgMS4wMjgxNDQgLTIuNzYxNjQ0SDQuMzI3NzcxVjAuNTM3OTgzQzQuMzI3NzcxIDAuNzA1MzU1IDQuMzI3NzcxIDAuOTIwNTQ4IDQuNTQyOTY0IDAuOTIwNTQ4QzQuNzcwMTEyIDAuOTIwNTQ4IDQuNzcwMTEyIDAuNzE3MzEgNC43NzAxMTIgMC41Mzc5ODNWLTIuNzYxNjQ0WicgaWQ9J2cxLTQzJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnMS05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMS05MycvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzAtNTknLz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjcyNTc3OEM4LjEwNTYwNCAtMi44MzMzNzUgOC4xMTc1NTkgLTIuOTA1MTA2IDguMTE3NTU5IC0yLjk4ODc5MkM4LjExNzU1OSAtMy4wNjA1MjMgOC4wOTM2NDkgLTMuMTQ0MjA5IDcuODc4NDU2IC0zLjIzOTg1MUwxLjQxMDcxIC02LjIxNjY4N0MxLjI1NTI5MyAtNi4yODg0MTggMS4yMzEzODIgLTYuMzAwMzc0IDEuMjA3NDcyIC02LjMwMDM3NEMxLjA2NDAxIC02LjMwMDM3NCAwLjk4MDMyNCAtNi4xODA4MjIgMC45ODAzMjQgLTYuMDg1MTgxQzAuOTgwMzI0IC01Ljk0MTcxOSAxLjA3NTk2NSAtNS44OTM4OTggMS4yMzEzODIgLTUuODIyMTY3TDcuMzc2MzM5IC0yLjk4ODc5MkwxLjIxOTQyNyAtMC4xNDM0NjJDMC45ODAzMjQgLTAuMDM1ODY2IDAuOTgwMzI0IDAuMDQ3ODIxIDAuOTgwMzI0IDAuMTE5NTUyQzAuOTgwMzI0IDAuMjE1MTkzIDEuMDY0MDEgMC4zMzQ3NDUgMS4yMDc0NzIgMC4zMzQ3NDVDMS4yMzEzODIgMC4zMzQ3NDUgMS4yNDMzMzcgMC4zMjI3OSAxLjQxMDcxIDAuMjUxMDU5TDcuODc4NDU2IC0yLjcyNTc3OFonIGlkPSdnMC02MicvPgo8cGF0aCBkPSdNNi4wMTM0NSAtNy45OTgwMDdDNi4wMjU0MDUgLTguMDQ1ODI4IDYuMDQ5MzE1IC04LjExNzU1OSA2LjA0OTMxNSAtOC4xNzczMzVDNi4wNDkzMTUgLTguMjk2ODg3IDUuOTI5NzYzIC04LjI5Njg4NyA1LjkwNTg1MyAtOC4yOTY4ODdDNS44OTM4OTggLTguMjk2ODg3IDUuMzA4MDk1IC04LjI0OTA2NiA1LjI0ODMxOSAtOC4yMzcxMTFDNS4wNDUwODEgLTguMjI1MTU2IDQuODY1NzUzIC04LjIwMTI0NSA0LjY1MDU2IC04LjE4OTI5QzQuMzUxNjgxIC04LjE2NTM4IDQuMjY3OTk1IC04LjE1MzQyNSA0LjI2Nzk5NSAtNy45MzgyMzJDNC4yNjc5OTUgLTcuODE4NjggNC4zNjM2MzYgLTcuODE4NjggNC41MzEwMDkgLTcuODE4NjhDNS4xMTY4MTIgLTcuODE4NjggNS4xMjg3NjcgLTcuNzExMDgzIDUuMTI4NzY3IC03LjU5MTUzMkM1LjEyODc2NyAtNy41MTk4MDEgNS4xMDQ4NTcgLTcuNDI0MTU5IDUuMDkyOTAyIC03LjM4ODI5NEw0LjM2MzYzNiAtNC40ODMxODhDNC4yMzIxMyAtNC43OTQwMjIgMy45MDkzNCAtNS4yNzIyMjkgMy4yODc2NzEgLTUuMjcyMjI5QzEuOTM2NzM3IC01LjI3MjIyOSAwLjQ3ODIwNyAtMy41MjY3NzUgMC40NzgyMDcgLTEuNzU3NDFDMC40NzgyMDcgLTAuNTczODQ4IDEuMTcxNjA2IDAuMTE5NTUyIDEuOTg0NTU4IDAuMTE5NTUyQzIuNjQyMDkyIDAuMTE5NTUyIDMuMjAzOTg1IC0wLjM5NDUyMSAzLjUzODczIC0wLjc4OTA0MUMzLjY1ODI4MSAtMC4wODM2ODYgNC4yMjAxNzQgMC4xMTk1NTIgNC41Nzg4MjkgMC4xMTk1NTJTNS4yMjQ0MDggLTAuMDk1NjQxIDUuNDM5NjAxIC0wLjUyNjAyN0M1LjYzMDg4NCAtMC45MzI1MDMgNS43OTgyNTcgLTEuNjYxNzY4IDUuNzk4MjU3IC0xLjcwOTU4OUM1Ljc5ODI1NyAtMS43NjkzNjUgNS43NTA0MzYgLTEuODE3MTg2IDUuNjc4NzA1IC0xLjgxNzE4NkM1LjU3MTEwOCAtMS44MTcxODYgNS41NTkxNTMgLTEuNzU3NDEgNS41MTEzMzMgLTEuNTc4MDgyQzUuMzMyMDA1IC0wLjg3MjcyNyA1LjEwNDg1NyAtMC4xMTk1NTIgNC42MTQ2OTUgLTAuMTE5NTUyQzQuMjY3OTk1IC0wLjExOTU1MiA0LjI0NDA4NSAtMC40MzAzODYgNC4yNDQwODUgLTAuNjY5NDg5QzQuMjQ0MDg1IC0wLjcxNzMxIDQuMjQ0MDg1IC0wLjk2ODM2OSA0LjMyNzc3MSAtMS4zMDMxMTNMNi4wMTM0NSAtNy45OTgwMDdaTTMuNTk4NTA2IC0xLjQyMjY2NUMzLjUzODczIC0xLjIxOTQyNyAzLjUzODczIC0xLjE5NTUxNyAzLjM3MTM1NyAtMC45NjgzNjlDMy4xMDgzNDQgLTAuNjMzNjI0IDIuNTgyMzE2IC0wLjExOTU1MiAyLjAyMDQyMyAtMC4xMTk1NTJDMS41MzAyNjIgLTAuMTE5NTUyIDEuMjU1MjkzIC0wLjU2MTg5MyAxLjI1NTI5MyAtMS4yNjcyNDhDMS4yNTUyOTMgLTEuOTI0NzgyIDEuNjI1OTAzIC0zLjI2Mzc2MSAxLjg1MzA1MSAtMy43NjU4NzhDMi4yNTk1MjcgLTQuNjAyNzQgMi44MjE0MiAtNS4wMzMxMjYgMy4yODc2NzEgLTUuMDMzMTI2QzQuMDc2NzEyIC01LjAzMzEyNiA0LjIzMjEzIC00LjA1MjgwMiA0LjIzMjEzIC0zLjk1NzE2MUM0LjIzMjEzIC0zLjk0NTIwNSA0LjE5NjI2NCAtMy43ODk3ODggNC4xODQzMDkgLTMuNzY1ODc4TDMuNTk4NTA2IC0xLjQyMjY2NVonIGlkPSdnMC0xMDAnLz4KPHBhdGggZD0nTTMuMzgzMzEzIC0xLjcwOTU4OUMzLjM4MzMxMyAtMS43NjkzNjUgMy4zMzU0OTIgLTEuODE3MTg2IDMuMjYzNzYxIC0xLjgxNzE4NkMzLjE1NjE2NCAtMS44MTcxODYgMy4xNDQyMDkgLTEuNzgxMzIgMy4wODQ0MzMgLTEuNTc4MDgyQzIuNzczNTk5IC0wLjQ5MDE2MiAyLjI4MzQzNyAtMC4xMTk1NTIgMS44ODg5MTcgLTAuMTE5NTUyQzEuNzQ1NDU1IC0wLjExOTU1MiAxLjU3ODA4MiAtMC4xNTU0MTcgMS41NzgwODIgLTAuNTE0MDcyQzEuNTc4MDgyIC0wLjgzNjg2MiAxLjcyMTU0NCAtMS4xOTU1MTcgMS44NTMwNTEgLTEuNTU0MTcyTDIuNjg5OTEzIC0zLjc3NzgzM0MyLjcyNTc3OCAtMy44NzM0NzQgMi44MDk0NjUgLTQuMDg4NjY3IDIuODA5NDY1IC00LjMxNTgxNkMyLjgwOTQ2NSAtNC44MTc5MzMgMi40NTA4MDkgLTUuMjcyMjI5IDEuODY1MDA2IC01LjI3MjIyOUMwLjc2NTEzMSAtNS4yNzIyMjkgMC4zMjI3OSAtMy41Mzg3MyAwLjMyMjc5IC0zLjQ0MzA4OEMwLjMyMjc5IC0zLjM5NTI2OCAwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NjE4OTMgLTMuMzM1NDkyIDAuNTczODQ4IC0zLjM4MzMxMyAwLjYyMTY2OSAtMy41NTA2ODVDMC45MDg1OTMgLTQuNTU0OTE5IDEuMzYyODg5IC01LjAzMzEyNiAxLjgyOTE0MSAtNS4wMzMxMjZDMS45MzY3MzcgLTUuMDMzMTI2IDIuMTM5OTc1IC01LjAyMTE3MSAyLjEzOTk3NSAtNC42Mzg2MDVDMi4xMzk5NzUgLTQuMzI3NzcxIDEuOTg0NTU4IC0zLjkzMzI1IDEuODg4OTE3IC0zLjY3MDIzN0wxLjA1MjA1NSAtMS40NDY1NzVDMC45ODAzMjQgLTEuMjU1MjkzIDAuOTA4NTkzIC0xLjA2NDAxIDAuOTA4NTkzIC0wLjg0ODgxN0MwLjkwODU5MyAtMC4zMTA4MzQgMS4yNzkyMDMgMC4xMTk1NTIgMS44NTMwNTEgMC4xMTk1NTJDMi45NTI5MjcgMC4xMTk1NTIgMy4zODMzMTMgLTEuNjI1OTAzIDMuMzgzMzEzIC0xLjcwOTU4OVpNMy4yODc2NzEgLTcuNDYwMDI1QzMuMjg3NjcxIC03LjYzOTM1MiAzLjE0NDIwOSAtNy44NTQ1NDUgMi44ODExOTYgLTcuODU0NTQ1QzIuNjA2MjI3IC03Ljg1NDU0NSAyLjI5NTM5MiAtNy41OTE1MzIgMi4yOTUzOTIgLTcuMjgwNjk3QzIuMjk1MzkyIC02Ljk4MTgxOCAyLjU0NjQ1MSAtNi44ODYxNzcgMi42ODk5MTMgLTYuODg2MTc3QzMuMDEyNzAyIC02Ljg4NjE3NyAzLjI4NzY3MSAtNy4xOTcwMTEgMy4yODc2NzEgLTcuNDYwMDI1WicgaWQ9J2cwLTEwNScvPgo8cGF0aCBkPSdNMi43MjU3NzggLTIuMzkxMDM0QzIuOTI5MDE2IC0yLjM1NTE2OCAzLjI1MTgwNiAtMi4yODM0MzcgMy4zMjM1MzcgLTIuMjcxNDgyQzMuNDc4OTU0IC0yLjIyMzY2MSA0LjAxNjkzNiAtMi4wMzIzNzkgNC4wMTY5MzYgLTEuNDU4NTMxQzQuMDE2OTM2IC0xLjA4NzkyIDMuNjgyMTkyIC0wLjExOTU1MiAyLjI5NTM5MiAtMC4xMTk1NTJDMi4wNDQzMzQgLTAuMTE5NTUyIDEuMTQ3Njk2IC0wLjE1NTQxNyAwLjkwODU5MyAtMC44MTI5NTFDMS4zODY4IC0wLjc1MzE3NiAxLjYyNTkwMyAtMS4xMjM3ODYgMS42MjU5MDMgLTEuMzg2OEMxLjYyNTkwMyAtMS42Mzc4NTggMS40NTg1MzEgLTEuNzY5MzY1IDEuMjE5NDI3IC0xLjc2OTM2NUMwLjk1NjQxMyAtMS43NjkzNjUgMC42MDk3MTQgLTEuNTY2MTI3IDAuNjA5NzE0IC0xLjAyODE0NEMwLjYwOTcxNCAtMC4zMjI3OSAxLjMyNzAyNCAwLjExOTU1MiAyLjI4MzQzNyAwLjExOTU1MkM0LjEwMDYyMyAwLjExOTU1MiA0LjYzODYwNSAtMS4yMTk0MjcgNC42Mzg2MDUgLTEuODQxMDk2QzQuNjM4NjA1IC0yLjAyMDQyMyA0LjYzODYwNSAtMi4zNTUxNjggNC4yNTYwNCAtMi43Mzc3MzNDMy45NTcxNjEgLTMuMDI0NjU4IDMuNjcwMjM3IC0zLjA4NDQzMyAzLjAyNDY1OCAtMy4yMTU5NEMyLjcwMTg2OCAtMy4yODc2NzEgMi4xODc3OTYgLTMuMzk1MjY4IDIuMTg3Nzk2IC0zLjkzMzI1QzIuMTg3Nzk2IC00LjE3MjM1NCAyLjQwMjk4OSAtNS4wMzMxMjYgMy41Mzg3MyAtNS4wMzMxMjZDNC4wNDA4NDcgLTUuMDMzMTI2IDQuNTMxMDA5IC00Ljg0MTg0MyA0LjY1MDU2IC00LjQxMTQ1N0M0LjEyNDUzMyAtNC40MTE0NTcgNC4xMDA2MjMgLTMuOTU3MTYxIDQuMTAwNjIzIC0zLjk0NTIwNUM0LjEwMDYyMyAtMy42OTQxNDcgNC4zMjc3NzEgLTMuNjIyNDE2IDQuNDM1MzY3IC0zLjYyMjQxNkM0LjYwMjc0IC0zLjYyMjQxNiA0LjkzNzQ4NCAtMy43NTM5MjMgNC45Mzc0ODQgLTQuMjU2MDRTNC40ODMxODggLTUuMjcyMjI5IDMuNTUwNjg1IC01LjI3MjIyOUMxLjk4NDU1OCAtNS4yNzIyMjkgMS41NjYxMjcgLTQuMDQwODQ3IDEuNTY2MTI3IC0zLjU1MDY4NUMxLjU2NjEyNyAtMi42NDIwOTIgMi40NTA4MDkgLTIuNDUwODA5IDIuNzI1Nzc4IC0yLjM5MTAzNFonIGlkPSdnMC0xMTUnLz4KPHBhdGggZD0nTTIuNDAyOTg5IC00LjgwNTk3OEgzLjUwMjg2NEMzLjczMDAxMiAtNC44MDU5NzggMy44NDk1NjQgLTQuODA1OTc4IDMuODQ5NTY0IC01LjAyMTE3MUMzLjg0OTU2NCAtNS4xNTI2NzcgMy43Nzc4MzMgLTUuMTUyNjc3IDMuNTM4NzMgLTUuMTUyNjc3SDIuNDg2Njc1TDIuOTI5MDE2IC02Ljg5ODEzMkMyLjk3NjgzNyAtNy4wNjU1MDQgMi45NzY4MzcgLTcuMDg5NDE1IDIuOTc2ODM3IC03LjE3MzEwMUMyLjk3NjgzNyAtNy4zNjQzODQgMi44MjE0MiAtNy40NzE5OCAyLjY2NjAwMiAtNy40NzE5OEMyLjU3MDM2MSAtNy40NzE5OCAyLjI5NTM5MiAtNy40MzYxMTUgMi4xOTk3NTEgLTcuMDUzNTQ5TDEuNzMzNDk5IC01LjE1MjY3N0gwLjYwOTcxNEMwLjM3MDYxIC01LjE1MjY3NyAwLjI2MzAxNCAtNS4xNTI2NzcgMC4yNjMwMTQgLTQuOTI1NTI5QzAuMjYzMDE0IC00LjgwNTk3OCAwLjM0NjcgLTQuODA1OTc4IDAuNTczODQ4IC00LjgwNTk3OEgxLjYzNzg1OEwwLjg0ODgxNyAtMS42NDk4MTNDMC43NTMxNzYgLTEuMjMxMzgyIDAuNzE3MzEgLTEuMTExODMxIDAuNzE3MzEgLTAuOTU2NDEzQzAuNzE3MzEgLTAuMzk0NTIxIDEuMTExODMxIDAuMTE5NTUyIDEuNzgxMzIgMC4xMTk1NTJDMi45ODg3OTIgMC4xMTk1NTIgMy42MzQzNzEgLTEuNjI1OTAzIDMuNjM0MzcxIC0xLjcwOTU4OUMzLjYzNDM3MSAtMS43ODEzMiAzLjU4NjU1IC0xLjgxNzE4NiAzLjUxNDgxOSAtMS44MTcxODZDMy40OTA5MDkgLTEuODE3MTg2IDMuNDQzMDg4IC0xLjgxNzE4NiAzLjQxOTE3OCAtMS43NjkzNjVDMy40MDcyMjMgLTEuNzU3NDEgMy4zOTUyNjggLTEuNzQ1NDU1IDMuMzExNTgyIC0xLjU1NDE3MkMzLjA2MDUyMyAtMC45NTY0MTMgMi41MTA1ODUgLTAuMTE5NTUyIDEuODE3MTg2IC0wLjExOTU1MkMxLjQ1ODUzMSAtMC4xMTk1NTIgMS40MzQ2MiAtMC40MTg0MzEgMS40MzQ2MiAtMC42ODE0NDVDMS40MzQ2MiAtMC42OTM0IDEuNDM0NjIgLTAuOTIwNTQ4IDEuNDcwNDg2IC0xLjA2NDAxTDIuNDAyOTg5IC00LjgwNTk3OFonIGlkPSdnMC0xMTYnLz4KPHBhdGggZD0nTTUuNDYzNTEyIC00LjQ3MTIzM0M1LjQ2MzUxMiAtNS4yMjQ0MDggNS4wODA5NDYgLTUuMjcyMjI5IDQuOTg1MzA1IC01LjI3MjIyOUM0LjY5ODM4MSAtNS4yNzIyMjkgNC40MzUzNjcgLTQuOTg1MzA1IDQuNDM1MzY3IC00Ljc0NjIwMkM0LjQzNTM2NyAtNC42MDI3NCA0LjUxOTA1NCAtNC41MTkwNTQgNC41NjY4NzQgLTQuNDcxMjMzQzQuNjg2NDI2IC00LjM2MzYzNiA0Ljk5NzI2IC00LjA0MDg0NyA0Ljk5NzI2IC0zLjQxOTE3OEM0Ljk5NzI2IC0yLjkxNzA2MSA0LjI3OTk1IC0wLjExOTU1MiAyLjg0NTMzIC0wLjExOTU1MkMyLjExNjA2NSAtMC4xMTk1NTIgMS45NzI2MDMgLTAuNzI5MjY1IDEuOTcyNjAzIC0xLjE3MTYwNkMxLjk3MjYwMyAtMS43NjkzNjUgMi4yNDc1NzIgLTIuNjA2MjI3IDIuNTcwMzYxIC0zLjQ2Njk5OUMyLjc2MTY0NCAtMy45NTcxNjEgMi44MDk0NjUgLTQuMDc2NzEyIDIuODA5NDY1IC00LjMxNTgxNkMyLjgwOTQ2NSAtNC44MTc5MzMgMi40NTA4MDkgLTUuMjcyMjI5IDEuODY1MDA2IC01LjI3MjIyOUMwLjc2NTEzMSAtNS4yNzIyMjkgMC4zMjI3OSAtMy41Mzg3MyAwLjMyMjc5IC0zLjQ0MzA4OEMwLjMyMjc5IC0zLjM5NTI2OCAwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NjE4OTMgLTMuMzM1NDkyIDAuNTczODQ4IC0zLjM4MzMxMyAwLjYyMTY2OSAtMy41NTA2ODVDMC45MDg1OTMgLTQuNTc4ODI5IDEuMzc0ODQ0IC01LjAzMzEyNiAxLjgyOTE0MSAtNS4wMzMxMjZDMS45MzY3MzcgLTUuMDMzMTI2IDIuMTM5OTc1IC01LjAzMzEyNiAyLjEzOTk3NSAtNC42Mzg2MDVDMi4xMzk5NzUgLTQuMzI3NzcxIDIuMDA4NDY4IC0zLjk4MTA3MSAxLjgyOTE0MSAtMy41MjY3NzVDMS4yNTUyOTMgLTEuOTk2NTEzIDEuMjU1MjkzIC0xLjYyNTkwMyAxLjI1NTI5MyAtMS4zMzg5NzlDMS4yNTUyOTMgLTEuMDc1OTY1IDEuMjkxMTU4IC0wLjU4NTgwMyAxLjY2MTc2OCAtMC4yNTEwNTlDMi4wOTIxNTQgMC4xMTk1NTIgMi42ODk5MTMgMC4xMTk1NTIgMi43OTc1MDkgMC4xMTk1NTJDNC43ODIwNjcgMC4xMTk1NTIgNS40NjM1MTIgLTMuNzg5Nzg4IDUuNDYzNTEyIC00LjQ3MTIzM1onIGlkPSdnMC0xMTgnLz4KPHBhdGggZD0nTTQuMTEyNTc4IC0wLjcyOTI2NUM0LjM3NTU5MiAtMC4wMTE5NTUgNS4xMTY4MTIgMC4xMTk1NTIgNS41NzExMDggMC4xMTk1NTJDNi40Nzk3MDEgMC4xMTk1NTIgNy4wMTc2ODQgLTAuNjY5NDg5IDcuMzUyNDI4IC0xLjQ5NDM5NkM3LjYyNzM5NyAtMi4xODc3OTYgOC4wNjk3MzggLTMuNzY1ODc4IDguMDY5NzM4IC00LjQ3MTIzM0M4LjA2OTczOCAtNS4yMDA0OTggNy42OTkxMjggLTUuMjcyMjI5IDcuNTkxNTMyIC01LjI3MjIyOUM3LjMwNDYwOCAtNS4yNzIyMjkgNy4wNDE1OTQgLTQuOTg1MzA1IDcuMDQxNTk0IC00Ljc0NjIwMkM3LjA0MTU5NCAtNC42MDI3NCA3LjEyNTI4IC00LjUxOTA1NCA3LjE4NTA1NiAtNC40NzEyMzNDNy4yOTI2NTMgLTQuMzYzNjM2IDcuNjAzNDg3IC00LjA0MDg0NyA3LjYwMzQ4NyAtMy40MTkxNzhDNy42MDM0ODcgLTMuMDEyNzAyIDcuMjY4NzQyIC0xLjg4ODkxNyA3LjAxNzY4NCAtMS4zMjcwMjRDNi42ODI5MzkgLTAuNTk3NzU4IDYuMjQwNTk4IC0wLjExOTU1MiA1LjYxODkyOSAtMC4xMTk1NTJDNC45NDk0NCAtMC4xMTk1NTIgNC43MzQyNDcgLTAuNjIxNjY5IDQuNzM0MjQ3IC0xLjE3MTYwNkM0LjczNDI0NyAtMS41MTgzMDYgNC44NDE4NDMgLTEuOTM2NzM3IDQuODg5NjY0IC0yLjEzOTk3NUw1LjM5MTc4MSAtNC4xNDg0NDNDNS40NTE1NTcgLTQuMzg3NTQ3IDUuNTU5MTUzIC00LjgwNTk3OCA1LjU1OTE1MyAtNC44NTM3OThDNS41NTkxNTMgLTUuMDMzMTI2IDUuNDE1NjkxIC01LjE1MjY3NyA1LjIzNjM2NCAtNS4xNTI2NzdDNC44ODk2NjQgLTUuMTUyNjc3IDQuODA1OTc4IC00Ljg1Mzc5OCA0LjczNDI0NyAtNC41NjY4NzRDNC42MTQ2OTUgLTQuMTAwNjIzIDQuMTEyNTc4IC0yLjA4MDE5OSA0LjA2NDc1NyAtMS44MTcxODZDNC4wMTY5MzYgLTEuNjEzOTQ4IDQuMDE2OTM2IC0xLjQ4MjQ0MSA0LjAxNjkzNiAtMS4yMTk0MjdDNC4wMTY5MzYgLTAuOTMyNTAzIDMuNjM0MzcxIC0wLjQ3ODIwNyAzLjYyMjQxNiAtMC40NTQyOTZDMy40OTA5MDkgLTAuMzIyNzkgMy4yOTk2MjYgLTAuMTE5NTUyIDIuOTI5MDE2IC0wLjExOTU1MkMxLjk4NDU1OCAtMC4xMTk1NTIgMS45ODQ1NTggLTEuMDE2MTg5IDEuOTg0NTU4IC0xLjIxOTQyN0MxLjk4NDU1OCAtMS42MDE5OTMgMi4wNjgyNDQgLTIuMTI4MDIgMi42MDYyMjcgLTMuNTUwNjg1QzIuNzQ5Njg5IC0zLjkyMTI5NSAyLjgwOTQ2NSAtNC4wNzY3MTIgMi44MDk0NjUgLTQuMzE1ODE2QzIuODA5NDY1IC00LjgxNzkzMyAyLjQ1MDgwOSAtNS4yNzIyMjkgMS44NjUwMDYgLTUuMjcyMjI5QzAuNzY1MTMxIC01LjI3MjIyOSAwLjMyMjc5IC0zLjUzODczIDAuMzIyNzkgLTMuNDQzMDg4QzAuMzIyNzkgLTMuMzk1MjY4IDAuMzcwNjEgLTMuMzM1NDkyIDAuNDU0Mjk2IC0zLjMzNTQ5MkMwLjU2MTg5MyAtMy4zMzU0OTIgMC41NzM4NDggLTMuMzgzMzEzIDAuNjIxNjY5IC0zLjU1MDY4NUMwLjkyMDU0OCAtNC42MDI3NCAxLjM4NjggLTUuMDMzMTI2IDEuODI5MTQxIC01LjAzMzEyNkMxLjk0ODY5MiAtNS4wMzMxMjYgMi4xMzk5NzUgLTUuMDIxMTcxIDIuMTM5OTc1IC00LjYzODYwNUMyLjEzOTk3NSAtNC41Nzg4MjkgMi4xMzk5NzUgLTQuMzI3NzcxIDEuOTM2NzM3IC0zLjgwMTc0M0MxLjM3NDg0NCAtMi4zMDczNDcgMS4yNTUyOTMgLTEuODE3MTg2IDEuMjU1MjkzIC0xLjM2Mjg4OUMxLjI1NTI5MyAtMC4xMDc1OTcgMi4yODM0MzcgMC4xMTk1NTIgMi44OTMxNTEgMC4xMTk1NTJDMy4wOTYzODkgMC4xMTk1NTIgMy42MzQzNzEgMC4xMTk1NTIgNC4xMTI1NzggLTAuNzI5MjY1WicgaWQ9J2cwLTExOScvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nNTYuNDEzMjY3JyB4bGluazpocmVmPScjZzAtMTAwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2Mi40OTU5NicgeGxpbms6aHJlZj0nI2cxLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2NS43NDc2MjEnIHhsaW5rOmhyZWY9JyNnMC0xMTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc0LjQzNzE2MicgeGxpbms6aHJlZj0nI2cxLTkzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MS4wMDk2NTInIHhsaW5rOmhyZWY9JyNnMC02MicgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nOTMuNDM1MTMzJyB4bGluazpocmVmPScjZzAtMTAwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5OS41MTc4MjYnIHhsaW5rOmhyZWY9JyNnMS05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTAyLjc2OTQ4NycgeGxpbms6aHJlZj0nI2cwLTExOCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA4Ljg1NzcwNicgeGxpbms6aHJlZj0nI2cxLTkzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTQuNzY2MDMxJyB4bGluazpocmVmPScjZzEtNDMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyNi41MjczNDYnIHhsaW5rOmhyZWY9JyNnMC0xMDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEzMi42MTAwMzknIHhsaW5rOmhyZWY9JyNnMC0xMDUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEzNi42MDM0NzEnIHhsaW5rOmhyZWY9JyNnMC0xMTUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE0Mi4xMTc0NzcnIHhsaW5rOmhyZWY9JyNnMC0xMTYnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE0Ni4zNDQ2MzYnIHhsaW5rOmhyZWY9JyNnMS05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTQ5LjU5NjI5OCcgeGxpbms6aHJlZj0nI2cwLTExOScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTU4LjI4NTgzOCcgeGxpbms6aHJlZj0nI2cwLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNjMuNTI5OTk3JyB4bGluazpocmVmPScjZzAtMTE4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNjkuNjE4MjE2JyB4bGluazpocmVmPScjZzEtOTMnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) , cela veut dire qu’il
faut mettre à jour le tableau
, cela veut dire qu’il
faut mettre à jour le tableau  car il ne contient pas la
distance optimale. On répète cela pour toutes les paires
car il ne contient pas la
distance optimale. On répète cela pour toutes les paires  .
.
for v,w in dist :
d2 = d[v] + dist[v,w]
if d2 < d[w] :
d[w] = d2
print ( d["Bordeaux"] )
798824
On trouve 813197 mètres pour la distance (Charleville-Mezieres, Bordeaux). Ce n’est pas forcément la meilleure. Pour être sûr, il faut répéter la même itération autant de fois qu’il y a de villes (car le plus long chemin contient autant d’étapes qu’il y a de villes).
for i in range(0,len(d)) :
for v,w in dist :
d2 = d[v] + dist[v,w]
if d2 < d[w] :
d[w] = d2
print ( d["Bordeaux"] )
795670
Exercice facultatif#
Pour montrer que l’algorithme suggéré permettra d’obtenir la solution optimale, il faut montrer qu’il n’est pas nécessaire d’envisager aucun autre ordre que celui des skieurs et des paires triés par taille croissante. Cela ne veut pas dire qu’un autre ordre ne sera pas optimal, cela veut dire que pour obtenir l’appariement de coût optimal, il existe une solution pour laquelle skieurs et skis sont rangés dans l’ordre.
On considère donc un appariement  qui associé le skieur
qui associé le skieur
 à la paire
à la paire  . Il suffit que montrer que
:
. Il suffit que montrer que
:

Pour montrer cela, on fait un raisonnement par l’absurde : pour
 et
et  quelconques, on suppose qu’il existe un
appariement optimal tel que
quelconques, on suppose qu’il existe un
appariement optimal tel que  et
et
 . Le coût
. Le coût  de cet
appariement est :
de cet
appariement est :

Le coût de l’appariement en permutant les skieurs et
(donc en les rangeant dans l’ordre croissant) est :

On calcule :

Premier cas  et
et
 et :
et :

Second cas  et
et
 et :
et :

Dans les deux cas, on montre donc qu’il existe un appariement meilleur
ou équivalent en permutant les deux skieurs et ,
c’est-à-dire en les triant par ordre croissant de taille. Nous avons
donc montré que, si les paires de ski sont triées par ordre croissant de
taille, il existe necéssairement un appariement optimal pour lequel les
skieurs sont aussi triés par ordre croissant. Lors de la recherche de
cet appariement optimal, on peut se restreindre à ces cas de figure.
Exercice 5#

Lorsqu’on considère le meilleur appariement des paires  et
des skieurs
et
des skieurs  , il n’y a que deux choix possibles pour la
paire
, il n’y a que deux choix possibles pour la
paire  :
:
soit elle n’est associée à aucun skieur et dans ce cas :
 ,
,soit elle est associée au skieur
 (et à aucun autre) :
(et à aucun autre) :
 .
.
Exercice 6#
import random
skieurs = [ random.gauss(1.75, 0.1) for i in range(0,10) ]
paires = [ random.gauss(1.75, 0.1) for i in range(0,15) ]
skieurs.sort()
paires.sort()
p = { }
p [-1,-1] = 0
for n,taille in enumerate(skieurs) : p[n,-1] = p[n-1,-1] + taille
for m,paire in enumerate(paires ) : p[-1,m] = 0
for n,taille in enumerate(skieurs) :
for m,paire in enumerate(paires) :
p1 = p.get ( (n ,m-1), 1e10 )
p2 = p.get ( (n-1,m-1), 1e10 ) + abs(taille - paire)
p[n,m] = min(p1,p2)
print (p[len(skieurs)-1,len(paires)-1])
0.40180280093469833
Exercice 7#
Il faut imaginer que  peut être représenté sous forme de
matrice et qu’à chaque fois, on prend le meilleur chemin parmi 2 :
peut être représenté sous forme de
matrice et qu’à chaque fois, on prend le meilleur chemin parmi 2 :
Chemin horizontal : on ne choisit pas la paire
.Chemin diagonal : on choisit la paire
pour le skieur
from pyquickhelper.helpgen import NbImage
NbImage('graph_notebook_ski.png')
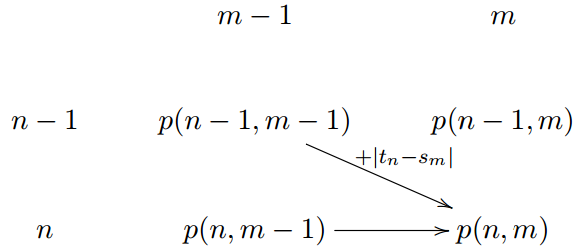
\xymatrix{ & m-1 & m \\ n-1 & p(n-1,m-1) \ar[dr]^{ + \abs{t_n - s_m}} & p(n-1,m) \\ n & p(n,m-1) \ar[r] & p(n,m) \\ }
p = { }
p [-1,-1] = 0
best = { }
for n,taille in enumerate(skieurs) : p[n,-1] = p[n-1,-1] + taille
for m,paire in enumerate(paires ) : p[-1,m] = 0
for n,taille in enumerate(skieurs) :
for m,paire in enumerate(paires) :
p1 = p.get ( (n ,m-1), 1e10 )
p2 = p.get ( (n-1,m-1), 1e10 ) + abs(taille - paire)
p[n,m] = min(p1,p2)
if p[n,m] == p1 : best [n,m] = n,m-1
else : best [n,m] = n-1,m-1
print (p[len(skieurs)-1,len(paires)-1])
chemin = [ ]
pos = len(skieurs)-1,len(paires)-1
while pos in best :
print (pos)
chemin.append(pos)
pos = best[pos]
chemin.reverse()
print (chemin)
0.40180280093469833
(9, 14)
(8, 13)
(7, 12)
(6, 11)
(5, 10)
(4, 9)
(3, 8)
(2, 7)
(1, 6)
(0, 5)
(0, 4)
[(0, 4), (0, 5), (1, 6), (2, 7), (3, 8), (4, 9), (5, 10), (6, 11), (7, 12), (8, 13), (9, 14)]
Exercice 8#
Les deux algorithmes ont un coût quadratique.
Prolongements : degré de séparation sur Facebook#
import pyensae.datasource # utiliser pyensae >= 0.8
files = pyensae.datasource.download_data("facebook.tar.gz",website="http://snap.stanford.edu/data/")
import pandas
df = pandas.read_csv("facebook/1912.edges", sep=" ", names=["v1","v2"])
print(df.shape)
df.head()
(60050, 2)
| v1 | v2 | |
|---|---|---|
| 0 | 2290 | 2363 |
| 1 | 2346 | 2025 |
| 2 | 2140 | 2428 |
| 3 | 2201 | 2506 |
| 4 | 2425 | 2557 |