2A.i - Jupyter et calcul distribué#
Links: notebook, html, python, slides, GitHub
Jupyter a été découpé en plusieurs extensions comme ipyparallel qui permet de distribuer un calcul sur plusieurs processus. Ce notebook montre comment faire sur une seule machine.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Avec de commencer, quelques mots de vocabulaire :
thread : il est possible de paralléliser un traitement au sein d’un même programme ou processus, c’est un thread. Les threads ont accès aux mêmes variables.
processus : c’est un programme, chaque processus a sa propre mémoire non partagée avec d’autres processus.
Une fontion utile pour récupérer les processus qui tournent#
Voir psutil.
import psutil
def find_process(name):
for proc in psutil.process_iter():
try: pinfo = proc.as_dict(attrs=['pid', 'name'])
except psutil.NoSuchProcess: pass
else:
if name in pinfo["name"]:
return pinfo, proc
return None, None
i, p = find_process('ipcluster')
i, p
(None, None)
Calcul distribué#
Quelques liens :
Overview and getting started with ipyrallel La distribution d’un programme implique l’exécution en parallèle de morceaux de programme, sur la même machine ou sur des machines différentes. Dans le cas de cette séance, ce sera sur la même machine mais le principe reste le même : une machine centrale (serveur) envoie des données et le traitement associé sur d’autres machines (clients). Pour que les clients comprennent qu’ils doivent exécuter un programme, ils doivent continuellement attendre qu’on leur envoie des instructions : un client est lancé puis attend des instructions. Pour lancer des clients localement sur cette machine, on doit aller dans le répertoire :
import os,sys
if hasattr(sys, 'real_prefix'):
exe = sys.real_prefix
else:
exe = sys.base_exec_prefix
f = os.path.join(exe, "Scripts")
f
'c:\python35_x64\Scripts'
[ _ for _ in os.listdir(f) if "cluster" in _ ]
['ipcluster.exe']
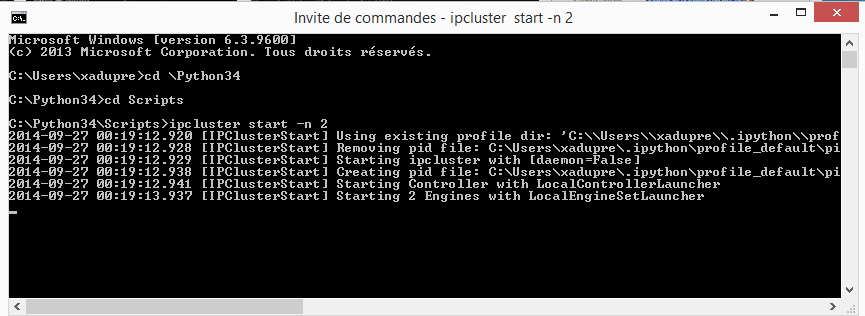
Il faut exécuter l’instruction ipcluster start -n 2 depuis une ligne
de commande. Celle-ci vient avec le module
ipyparallel 2
signifie deux clients puis on vérifie que ceux-ci sont bien en train de
s’exécuter. Sous Windows, il faut ouvrir une fenêtre de commande avec la
commande
cmd.
# ipcluster start -n 2
On obtient quelque chose similaire à ceci :
from pyquickhelper.helpgen import NbImage
NbImage("cmdipc.png")
On utilise une astuce pour le lancer depuis un noteboook :
if find_process("ipcluster")[0] is None:
print("start ipcluster")
from pyquickhelper.loghelper import run_cmd
if sys.platform.startswith("win"):
cmd = os.path.join(f, "ipcluster")
else:
cmd = "ipcluster"
cmd += " start -n 2"
run_cmd(cmd, wait=False)
else:
print("déjà démarré", find_process("ipcluster"))
start ipcluster
On attend que le processus démarre.
import time
time.sleep(5)
On vérifie que les deux clients sont accessibles depuis de notebook :
from ipyparallel import Client
clients = Client()
clients.block = True # use synchronous computations
print(clients.ids) # on s'attend à deux clients
[0, 1]
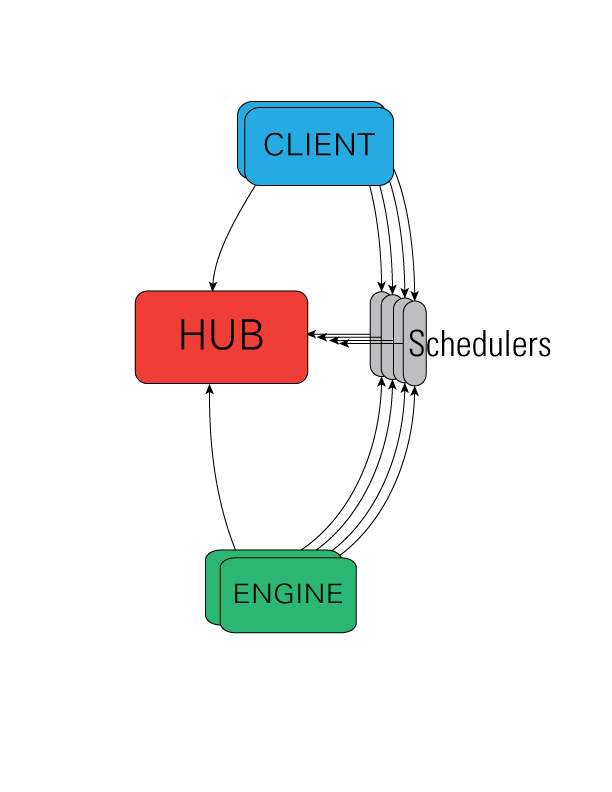
Tout va bien. L’ensemble fonctionne comme le dessin ci-dessous :
from IPython.core.display import Image
Image("http://ipython.org/ipython-doc/stable/_images/wideView.png", width=300)
Exemple simple#
On teste l’exemple du tutoriel :
clients[:].apply_sync(lambda : "Hello, World")
['Hello, World', 'Hello, World']
Et un autre pour paralléliser l’exécution d’une fonction : map_sync.
def addition(m):
return m + 1
parallel_result = clients[:].map_sync(addition, range(32))
parallel_result[:5]
[1, 2, 3, 4, 5]
Exemple plus subtile#
On crée une autre fonction plus complexe qu’on souhaite paralléliser :
def inverse_matrice(m) :
return numpy.linalg.inv ( m )
Ensuite, on créer 100 matrices à inverser :
import numpy
ms = [ numpy.random.random ( (5,5) ) for i in range(0,10) ]
On fait de même pour paralléliser la fonction. Selon les différentes installation, cela provoaque une erreur ou cela n’aboutit pas.
# mat = clients[:].map_sync(inverse_matrice, ms)
Car le module numpy a été importé dans ce notebook mais il ne l’a
pas été sur les processus distribués :
with clients[:].sync_imports():
import numpy
importing numpy on engine(s)
On réessaye :
mat = clients[:].map_sync(inverse_matrice, ms)
mat[:2]
[array([[ 0.44355592, -1.51704114, 0.78806645, 1.46110877,
-0.91563883],
[ 2.75547106, -7.29685701, 6.23665899, 7.79916234,
-15.77432008],
[ -2.86686696, 4.24283253, -2.76788208, -4.2635678 ,
10.16315185],
[ 3.66888355, -4.75685452, 4.39946704, 4.01960793,
-12.05135127],
[ -7.28746322, 16.05911264, -13.53209716, -14.15627803,
33.21478412]]),
array([[ 6.25664148, 15.66280127, 12.06488389, -13.3586936 ,
-16.76660498],
[ 0.35637738, -4.10233268, -4.27594773, 2.7287904 ,
4.91983962],
[-15.0833757 , -30.39031239, -18.9426754 , 28.14733333,
30.08489302],
[ 0.2343882 , -0.76741284, -3.21725047, 1.67819449,
2.19797219],
[ 6.31315111, 13.48306181, 9.00514844, -13.46040096,
-12.49950715]])]
Autre écriture et mesure de temps#
Puis on crée une view load balanced :
view = clients.load_balanced_view()
Qu’on utilise pour dispatcher les résultats sur plusieurs processus :
results = view.map(inverse_matrice, ms)
len(results)
10
On recommence à exécuter le code suivant :
results = view.map(inverse_matrice, ms)
len(results)
10
On compare avec un traitement non distribué :
%timeit list(map(inverse_matrice, ms))
The slowest run took 33.95 times longer than the fastest. This could mean that an intermediate result is being cached.
1000 loops, best of 3: 296 µs per loop
%timeit view.map(inverse_matrice, ms)
1 loop, best of 3: 294 ms per loop
Le processus distribué est plus long : cela prend du temps de communiquer les matrices depuis ce notebook vers les engines. Ce temps est manifestement plus long. C’est pourquoi on distribue généralement des processus dont le calcul est significativement plus lent que le temps de communication. Selon ce schéma, on préfère envoyer des noms de fichiers au processus pour ce recevoir des résultats courts. Pour distribuer, il faut faire attention au ratio communication/calcul. La fonction suivante ne reçoit rien, fait beaucoup de calcul et retourne une matrice 10x10.
def average_random_matrix(i):
mean = None
for n in range(0,100000):
m = numpy.random.random ( (10,10) )
if mean is None : mean = m
else : mean += m
return mean / n
%timeit list(map(average_random_matrix, range(0,10)))
1 loop, best of 3: 5.16 s per loop
%timeit view.map(average_random_matrix, range(0,10))
1 loop, best of 3: 3.23 s per loop
La distribution commence à montrer un gain de temps. Elle ne devient généralement intéressante que si un traitement numérique dure au moins quelques secondes.
Autres options pour distribuer les calculs#
IPython n’est pas le seul module à proposer un méchanisme de parallélisation. Un problème récurrent et souvent très agaçant est l’erreur qui oblige à tout recommencer depuis le depuis. On parallélise pour gagner du temps et une erreur se produit au bout de trois heures à cause d’une division par zéro par exemple. Il existe des modules qui sauvent les résultats intermédiaires et ne recommencent pas les calculs déjà effectués :
joblib : très simple d’utilisation, le module parallélise des tâches sur plusieurs processus sans que vous ayez à vous soucier des échanges entre processus.
luigi : c’est un système pour les long workflow (plusieurs heures ou jours), il permet de voir visuellement l’avancement.
Il existe d’autres options comme pyina. Une des premières solutions capable de faire cela était RPyC. Lorsqu’on veut distribuer sur plusieurs machines, il faut faire attention à :
Les machines sont-elles sur un réseau local ou distantes (Azure, Amazon, …) ?
Les communications doivent-elles encryptées ?
Quelques pointeurs :
Un peu plus sur les threads#
Le module threading propose une interface pour créer des threads. C’est utile pour exécuter des fonctions en parallèle. Toutefois, comme le langage Python n’est pas un langage multithreadé (voir Global Interpreter Lock, il ne sera pas plus rapide du point de vue vitesse de calcul. La fonction suivante montre comment à partir de la librairie standard threading on peut paralléliser un traitement (voir ParallelThread).
import numpy
ms = [ numpy.random.random ( (5,5) ) for i in range(0,100000) ]
def inverse_matrice(m) :
return numpy.linalg.inv ( m )
from ensae_teaching_cs.td_2a import ParallelThread
%timeit res = ParallelThread.parallel( inverse_matrice, [ (m,) for m in ms ], 4, delay_sec = 0.1 )
1 loop, best of 3: 3.12 s per loop
Ce code sera plus lent que d’appeler la fonction directement car il faudra en plus passer du temps à attendre la fin des autres threads ou fils d’exécution.
%timeit list(map(inverse_matrice, ms))
1 loop, best of 3: 2.95 s per loop
Exercice 1 : Distribuer un calcul#
import pyensae.datasource
pyensae.datasource.download_data("td8_velib.zip")
['stations.txt', 'td8_velib.txt']
import pandas
df = pandas.read_csv("td8_velib.txt", sep="\t")
df.shape
(1103787, 7)
df.columns
Index(['collect_date', 'last_update', 'available_bike_stands',
'available_bikes', 'number', 'heure', 'minute'],
dtype='object')
df = df.sort_values("collect_date")
df.head()
| collect_date | last_update | available_bike_stands | available_bikes | number | heure | minute | |
|---|---|---|---|---|---|---|---|
| 40729 | 2013-09-10 11:27:43.390054 | 2013-09-10 11:25:19 | 7 | 15 | 22005 | 11 | 25 |
| 40467 | 2013-09-10 11:27:43.390054 | 2013-09-10 11:25:19 | 19 | 0 | 13037 | 11 | 25 |
| 40525 | 2013-09-10 11:27:43.390054 | 2013-09-10 11:25:19 | 20 | 2 | 9021 | 11 | 25 |
| 40351 | 2013-09-10 11:27:43.390054 | 2013-09-10 11:25:19 | 16 | 2 | 19038 | 11 | 25 |
| 40070 | 2013-09-10 11:27:43.390054 | 2013-09-10 11:20:19 | 19 | 0 | 13037 | 11 | 20 |
La colonne number indique le numéro d’une station de vélo. On peut
calculer le pourcentage de places disponibles sur l’ensemble des places
de chaque station, on moyenne ce pourcentage pour chaque heure de la
journée. Pour chaque station, on a un vecteur qui correspond à un
pourcentage pour chaque heure de la journée. On veut constuire la
matrice de corrélation de ces vecteurs, si possible en distribuant.
Fin : on arrête le cluster#
import os,sys
if hasattr(sys, 'real_prefix'):
exe = sys.real_prefix
else:
exe = sys.base_exec_prefix
f = os.path.join(exe, "Scripts")
f
'c:\python35_x64\Scripts'
if find_process("ipcluster")[0] is not None:
print("stop ipcluster")
from pyquickhelper.loghelper import run_cmd
if sys.platform.startswith("win"):
cmd = os.path.join(f, "ipcluster")
else:
cmd = "ipcluster"
cmd += " stop"
out, err = run_cmd(cmd, wait=True)
print(out.replace(os.environ["USERNAME"], "USERNAME"))
else:
print("aucun processus ipcluster trouvé")
stop ipcluster