2A.data - Classification, régression, anomalies - correction#
Links: notebook, html, python, slides, GitHub
Le jeu de données Wine Quality Data Set contient 5000 vins décrits par leurs caractéristiques chimiques et évalués par un expert. Peut-on s’approcher de l’expert à l’aide d’un modèle de machine learning.
%matplotlib inline
import matplotlib.pyplot as plt
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Les données#
On peut les récupérer sur github…data_2a.
from ensae_teaching_cs.data import wines_quality
from pandas import read_csv
df = read_csv(wines_quality(local=True, filename=True))
df.head()
| fixed_acidity | volatile_acidity | citric_acid | residual_sugar | chlorides | free_sulfur_dioxide | total_sulfur_dioxide | density | pH | sulphates | alcohol | quality | color | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 | red |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 | red |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 | red |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 | 6 | red |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 | red |
ax = df['quality'].hist(bins=16)
ax.set_title("Distribution des notes");
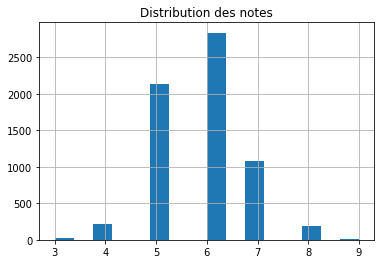
Il y a peu de très mauvais ou très bons vins. On découpe en apprentissage / test ce qui va nécessairement rendre leur prédiction complexe : un modèle reproduit en quelque sorte ce qu’il voit.
from sklearn.model_selection import train_test_split
X = df.drop("quality", axis=1)
y = df["quality"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
X_train.shape, X_test.shape
((3248, 12), (3249, 12))
from pandas import DataFrame
def distribution(y_train, y_test):
df_train = DataFrame(dict(color=y_train))
df_test = DataFrame(dict(color=y_test))
df_train['ctrain'] = 1
df_test['ctest'] = 1
h_train = df_train.groupby('color').count()
h_test = df_test.groupby('color').count()
merge = h_train.join(h_test, how='outer')
merge["ratio"] = merge.ctest / merge.ctrain
return merge
distribution(y_train, y_test)
| ctrain | ctest | ratio | |
|---|---|---|---|
| color | |||
| 3 | 12 | 18 | 1.500000 |
| 4 | 94 | 122 | 1.297872 |
| 5 | 1076 | 1062 | 0.986989 |
| 6 | 1429 | 1407 | 0.984605 |
| 7 | 536 | 543 | 1.013060 |
| 8 | 98 | 95 | 0.969388 |
| 9 | 3 | 2 | 0.666667 |
ax = y_train.hist(bins=24, label="train", align="right")
y_test.hist(bins=24, label="test", ax=ax, align="left")
ax.set_title("Distribution des notes")
ax.legend();
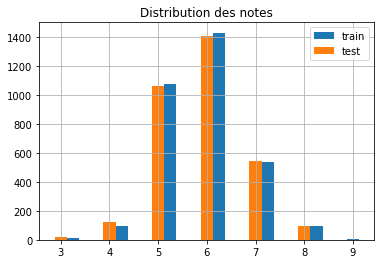
Avec un peu de chance, les notes extrêmes sont présentes dans les bases d’apprentissages et de tests mais une note seule a peu d’influence sur un modèle. Pour s’assurer une meilleur répartition train / test, on peut s’assurer que chaque note est bien répartie de chaque côté. On se sert du paramètre stratify.
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.5)
X_train.shape, X_test.shape
ax = y_train.hist(bins=24, label="train", align="right")
y_test.hist(bins=24, label="test", ax=ax, align="left")
ax.set_title("Distribution des notes - statifiée")
ax.legend();
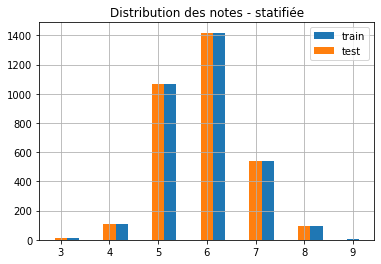
distribution(y_train, y_test)
| ctrain | ctest | ratio | |
|---|---|---|---|
| color | |||
| 3 | 15 | 15 | 1.000000 |
| 4 | 108 | 108 | 1.000000 |
| 5 | 1069 | 1069 | 1.000000 |
| 6 | 1418 | 1418 | 1.000000 |
| 7 | 539 | 540 | 1.001855 |
| 8 | 96 | 97 | 1.010417 |
| 9 | 3 | 2 | 0.666667 |
La répartition des notes selon apprentissage / test est plus uniforme.
Premier modèle#
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
try:
logreg.fit(X_train, y_train)
except Exception as e:
print(e)
could not convert string to float: 'white'
Une colonne n’est pas numérique. On utilise un OneHotEncoder.
from sklearn.preprocessing import OneHotEncoder
one = OneHotEncoder()
one.fit(X_train[['color']])
tr = one.transform(X_test[["color"]])
tr
<3249x2 sparse matrix of type '<class 'numpy.float64'>'
with 3249 stored elements in Compressed Sparse Row format>
La matrice est sparse ou creuse.
tr.todense()[:5]
matrix([[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.]])
Ensuite il faut fusionner ces deux colonnes avec les données ou une seule puisqu’elles sont corrélées. Ou alors on écrit un pipeline…
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
numeric_features = [c for c in X_train if c != 'color']
pipe = Pipeline([
("prep", ColumnTransformer([
("color", Pipeline([
('one', OneHotEncoder()),
('select', ColumnTransformer([('sel1', 'passthrough', [0])]))
]), ['color']),
("others", "passthrough", numeric_features)
])),
])
pipe.fit(X_train)
pipe.transform(X_test)[:2]
array([[0.0000e+00, 6.0000e+00, 3.4000e-01, 2.4000e-01, 5.4000e+00,
6.0000e-02, 2.3000e+01, 1.2600e+02, 9.9510e-01, 3.2500e+00,
4.4000e-01, 9.0000e+00],
[0.0000e+00, 6.7000e+00, 4.1000e-01, 2.7000e-01, 2.6000e+00,
3.3000e-02, 2.5000e+01, 8.5000e+01, 9.9086e-01, 3.0500e+00,
3.4000e-01, 1.1700e+01]])
from jyquickhelper import RenderJsDot
from mlinsights.plotting import pipeline2dot
dot = pipeline2dot(pipe, X_train)
RenderJsDot(dot)
Il reste quelques bugs. On ajoute un classifieur.
pipe = Pipeline([
("prep", ColumnTransformer([
("color", Pipeline([
('one', OneHotEncoder()),
('select', ColumnTransformer([('sel1', 'passthrough', [0])]))
]), ['color']),
("others", "passthrough", numeric_features)
])),
("lr", LogisticRegression(max_iter=1000)),
])
pipe.fit(X_train, y_train)
C:Python395_x64libsite-packagessklearnlinear_model_logistic.py:814: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
Pipeline(steps=[('prep',
ColumnTransformer(transformers=[('color',
Pipeline(steps=[('one',
OneHotEncoder()),
('select',
ColumnTransformer(transformers=[('sel1',
'passthrough',
[0])]))]),
['color']),
('others', 'passthrough',
['fixed_acidity',
'volatile_acidity',
'citric_acid',
'residual_sugar',
'chlorides',
'free_sulfur_dioxide',
'total_sulfur_dioxide',
'density', 'pH', 'sulphates',
'alcohol'])])),
('lr', LogisticRegression(max_iter=1000))])
from sklearn.metrics import classification_report
print(classification_report(y_test, pipe.predict(X_test)))
precision recall f1-score support
3 0.00 0.00 0.00 15
4 0.00 0.00 0.00 108
5 0.60 0.61 0.60 1069
6 0.52 0.72 0.60 1418
7 0.40 0.14 0.21 540
8 0.00 0.00 0.00 97
9 0.00 0.00 0.00 2
accuracy 0.54 3249
macro avg 0.22 0.21 0.20 3249
weighted avg 0.49 0.54 0.50 3249
C:Python395_x64libsite-packagessklearnmetrics_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior. _warn_prf(average, modifier, msg_start, len(result)) C:Python395_x64libsite-packagessklearnmetrics_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior. _warn_prf(average, modifier, msg_start, len(result)) C:Python395_x64libsite-packagessklearnmetrics_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior. _warn_prf(average, modifier, msg_start, len(result))
Pas extraordinaire.
from sklearn.ensemble import RandomForestClassifier
pipe = Pipeline([
("prep", ColumnTransformer([
("color", Pipeline([
('one', OneHotEncoder()),
('select', ColumnTransformer([('sel1', 'passthrough', [0])]))
]), ['color']),
("others", "passthrough", numeric_features)
])),
("lr", RandomForestClassifier()),
])
pipe.fit(X_train, y_train)
print(classification_report(y_test, pipe.predict(X_test)))
precision recall f1-score support
3 0.00 0.00 0.00 15
4 0.73 0.07 0.13 108
5 0.70 0.71 0.70 1069
6 0.62 0.76 0.68 1418
7 0.65 0.44 0.52 540
8 0.83 0.30 0.44 97
9 0.00 0.00 0.00 2
accuracy 0.65 3249
macro avg 0.50 0.33 0.35 3249
weighted avg 0.66 0.65 0.63 3249
C:Python395_x64libsite-packagessklearnmetrics_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior. _warn_prf(average, modifier, msg_start, len(result)) C:Python395_x64libsite-packagessklearnmetrics_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior. _warn_prf(average, modifier, msg_start, len(result)) C:Python395_x64libsite-packagessklearnmetrics_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use zero_division parameter to control this behavior. _warn_prf(average, modifier, msg_start, len(result))
Beaucoup mieux.
Courbe ROC pour chaque classe#
from sklearn.metrics import roc_curve, auc
labels = pipe.steps[1][1].classes_
y_score = pipe.predict_proba(X_test)
fpr = dict()
tpr = dict()
roc_auc = dict()
for i, cl in enumerate(labels):
fpr[cl], tpr[cl], _ = roc_curve(y_test == cl, y_score[:, i])
roc_auc[cl] = auc(fpr[cl], tpr[cl])
fig, ax = plt.subplots(1, 1, figsize=(8,4))
for k in roc_auc:
ax.plot(fpr[k], tpr[k], label="c%d = %1.2f" % (k, roc_auc[k]))
ax.legend();
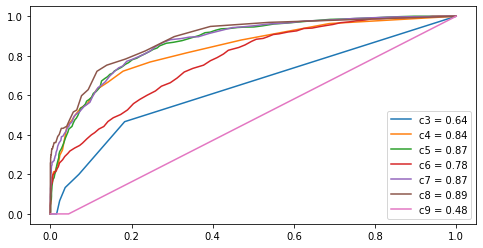
Ces chiffres peuvent paraître élevés mais ce n’est pas formidable quand même.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, pipe.predict(X_test), labels=labels)
array([[ 0, 0, 3, 12, 0, 0, 0],
[ 0, 8, 60, 38, 2, 0, 0],
[ 2, 3, 755, 303, 6, 0, 0],
[ 0, 0, 242, 1083, 91, 2, 0],
[ 0, 0, 20, 280, 236, 4, 0],
[ 0, 0, 0, 42, 26, 29, 0],
[ 0, 0, 0, 2, 0, 0, 0]], dtype=int64)
Ce n’est pas très joli…
def confusion_matrix_df(y_test, y_true):
conf = confusion_matrix(y_test, y_true)
labels = list(sorted(set(y_test)))
df = DataFrame(conf, columns=labels)
df.set_index(labels)
return df
confusion_matrix_df(y_test, pipe.predict(X_test))
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 3 | 12 | 0 | 0 | 0 |
| 1 | 0 | 8 | 60 | 38 | 2 | 0 | 0 |
| 2 | 2 | 3 | 755 | 303 | 6 | 0 | 0 |
| 3 | 0 | 0 | 242 | 1083 | 91 | 2 | 0 |
| 4 | 0 | 0 | 20 | 280 | 236 | 4 | 0 |
| 5 | 0 | 0 | 0 | 42 | 26 | 29 | 0 |
| 6 | 0 | 0 | 0 | 2 | 0 | 0 | 0 |
Mais cela veut dire que pour un score élevé, le taux de bonne classification s’améliore.
import numpy
ind = numpy.max(pipe.predict_proba(X_test), axis=1) >= 0.6
confusion_matrix_df(y_test[ind], pipe.predict(X_test)[ind])
| 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 2 | 1 | 0 | 0 |
| 1 | 0 | 5 | 21 | 6 | 0 | 0 |
| 2 | 0 | 0 | 517 | 77 | 1 | 0 |
| 3 | 0 | 0 | 109 | 539 | 7 | 0 |
| 4 | 0 | 0 | 7 | 71 | 141 | 0 |
| 5 | 0 | 0 | 0 | 10 | 3 | 25 |
Les petites classes ont disparu : le modèle n’est pas sûr du tout pour les classes 3, 4, 9. On voit aussi que le modèle se trompe souvent d’une note, il serait sans doute plus judicieux de passer à un modèle de régression plutôt que de classification. Cependant, un modèle de régression ne fournit pas de score de confiance. Sans doute serait-il possible d’en construire avec un modèle de détection d’anomalie…
Anomalies#
Une anomalie est un point aberrant. Cela revient à dire que sa probabilité qu’un tel événement se reproduise est faible. Un modèle assez connu est EllipticEnvelope. On suppose que si le modèle détecte une anomalie, un modèle de prédiction aura plus de mal à prédire. On réutilise le pipeline précédent en changeant juste la dernière étape.
from sklearn.covariance import EllipticEnvelope
one = Pipeline([
("prep", ColumnTransformer([
("color", Pipeline([
('one', OneHotEncoder()),
('select', ColumnTransformer([('sel1', 'passthrough', [0])]))
]), ['color']),
("others", "passthrough", numeric_features)
])),
("lr", EllipticEnvelope()),
])
one.fit(X_train)
ano = one.predict(X_test)
ano
array([1, 1, 1, ..., 1, 1, 1])
from pandas import DataFrame
df = DataFrame(dict(note=y_test, ano=one.decision_function(X_test),
pred=pipe.predict(X_test),
errors=y_test == pipe.predict(X_test),
proba_max=numpy.max(pipe.predict_proba(X_test), axis=1),
))
df["anoclip"] = df.ano.apply(lambda x: max(x, -200))
df.head()
| note | ano | pred | errors | proba_max | anoclip | |
|---|---|---|---|---|---|---|
| 3776 | 7 | 114.263113 | 5 | False | 0.68 | 114.263113 |
| 5800 | 6 | 113.160338 | 6 | True | 0.82 | 113.160338 |
| 4028 | 6 | 107.483432 | 6 | True | 0.55 | 107.483432 |
| 3311 | 6 | 112.045947 | 5 | False | 0.46 | 112.045947 |
| 4716 | 7 | 118.097584 | 6 | False | 0.59 | 118.097584 |
import seaborn
seaborn.lmplot(x="anoclip", y="proba_max", hue="errors",
truncate=True, height=5, data=df,
logx=True, fit_reg=False);
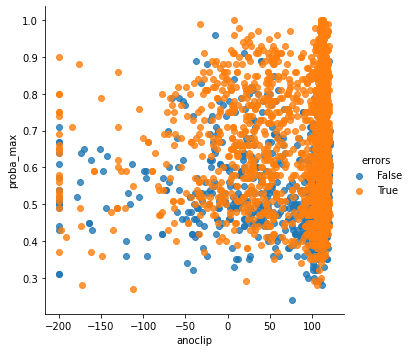
df.corr()
| note | ano | pred | errors | proba_max | anoclip | |
|---|---|---|---|---|---|---|
| note | 1.000000 | 0.111448 | 0.615705 | -0.069233 | -0.080223 | 0.167420 |
| ano | 0.111448 | 1.000000 | 0.099407 | 0.025075 | 0.012574 | 0.640359 |
| pred | 0.615705 | 0.099407 | 1.000000 | -0.035231 | -0.149703 | 0.168249 |
| errors | -0.069233 | 0.025075 | -0.035231 | 1.000000 | 0.345579 | 0.034597 |
| proba_max | -0.080223 | 0.012574 | -0.149703 | 0.345579 | 1.000000 | 0.008371 |
| anoclip | 0.167420 | 0.640359 | 0.168249 | 0.034597 | 0.008371 | 1.000000 |
Les résultats précédents ne sont pas probants. On peut changer de modèle de détection d’anomalies mais les conclusions restent les mêmes. Le score d’anomalie n’est pas relié au score de prédiction.
fig, ax = plt.subplots(1, 2, figsize=(14, 4))
df.proba_max.hist(ax=ax[0], bins=50)
df.anoclip.hist(ax=ax[1], bins=50)
ax[0].set_title("Distribution du score de classification")
ax[1].set_title("Distribution du score d'anomalie");
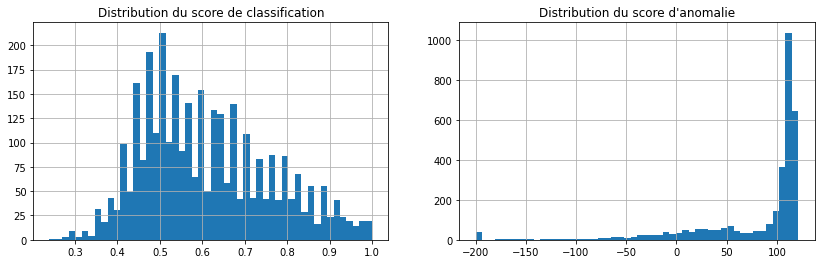
C’est joli mais ils n’ont rien à voir. Et c’était prévisible car le modèle de prédiction qu’on utilise est tout-à-fait capable de prédire ce qu’est une anomalie.
pipe_ano = Pipeline([
("prep", ColumnTransformer([
("color", Pipeline([
('one', OneHotEncoder()),
('select', ColumnTransformer([('sel1', 'passthrough', [0])]))
]), ['color']),
("others", "passthrough", numeric_features)
])),
("lr", RandomForestClassifier()),
])
pipe_ano.fit(X_train, one.predict(X_train))
confusion_matrix_df(one.predict(X_test), pipe_ano.predict(X_test))
| -1 | 1 | |
|---|---|---|
| 0 | 276 | 57 |
| 1 | 31 | 2885 |
Le modèle d’anomalie n’apporte donc aucune information nouvelle. Cela signifie que le modèle prédictif initial n’améliorerait pas sa prédiction en utilisant le score d’anomalie. Il n’y a donc aucune chance que les erreurs ou les score de prédiction soient corrélés au score d’anomalie d’une manière ou d’une autre.
Score de confiance pour une régression#
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
pipe_reg = Pipeline([
("prep", ColumnTransformer([
("color", Pipeline([
('one', OneHotEncoder()),
('select', ColumnTransformer([('sel1', 'passthrough', [0])]))
]), ['color']),
("others", "passthrough", numeric_features)
])),
("lr", RandomForestRegressor()),
])
pipe_reg.fit(X_train, y_train)
r2_score(y_test, pipe_reg.predict(X_test))
0.45446782471634095
Pas super. Mais…
error = y_test - pipe_reg.predict(X_test)
score = numpy.max(pipe.predict_proba(X_test), axis=1)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
seaborn.kdeplot(score, error, ax=ax[1])
ax[1].set_ylim([-1.5, 1.5])
ax[1].set_title("Densité")
ax[0].plot(score, error, ".")
ax[0].set_xlabel("score de confiance du classifieur")
ax[0].set_ylabel("Erreur de prédiction")
ax[0].set_title("Lien entre classification et prédiction");
C:Python395_x64libsite-packagesseaborn_decorators.py:36: FutureWarning: Pass the following variable as a keyword arg: y. From version 0.12, the only valid positional argument will be data, and passing other arguments without an explicit keyword will result in an error or misinterpretation. warnings.warn(
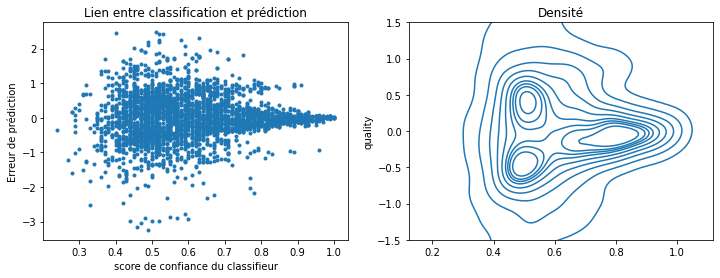
Comme prévu le modèle ne se trompe pas plus dans un sens que dans l’autre.
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
seaborn.kdeplot(score, error.abs(), ax=ax[1])
ax[1].set_ylim([0, 1.5])
ax[1].set_title("Densité")
ax[0].plot(score, error.abs(), ".")
ax[0].set_xlabel("score de confiance du classifieur")
ax[0].set_ylabel("Erreur de prédiction")
ax[0].set_title("Lien entre classification et prédiction");
C:Python395_x64libsite-packagesseaborn_decorators.py:36: FutureWarning: Pass the following variable as a keyword arg: y. From version 0.12, the only valid positional argument will be data, and passing other arguments without an explicit keyword will result in an error or misinterpretation. warnings.warn(
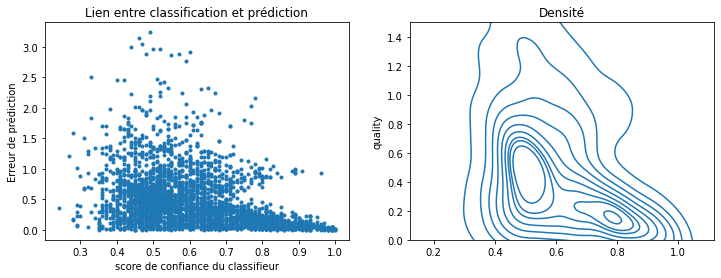
On vient de construire un indicateur de confiance pour un modèle de régression. On voit aussi que l’erreur de prédiction est concentrée autour de 0.5 lorsque le score est faible. C’est normal dans la mesure où la probabilité est faible lorsque le classifieur n’est pas sûr, c’est-à-dire que l’observation à prédire est proche de la frontière entre deux classes. Ces classes sont centrées autour des notes entières, les frontières sont au milieu, soit approximativement 3.5, 4.5, … Ce n’est pas une preuve mais seulement la vérifie que l’intervalle de confiance qu’on vient de fabriquer n’est pas complètement aberrant.