FAQ#
FAQ cvxopt#
TypeError: “q” must be a “d” matrix with one column
Cette erreur survient même lorsque la dimension de la matrice q en question
est la dimension attendue. Dans le cas présent, elle est définie comme suit :
q=matrix([[0,0,0]])
Mais la fonction coneqp retourne l’erreur :
Traceback (most recent call last):
File "toutbiss.py", line 236, in <module>
liste_composition,liquide = actualisation(liste_df,index,liquide,liste_composition,
nb_jours_rendement,nb_jours_volatilite,volatilite_max)
File "toutbiss.py", line 136, in actualisation
objectif_repartition=volatilite_quadra2(liste_df,index,nb_jours_rendement,nb_jours_volatilite,volatilite_max)
File "toutbiss.py", line 121, in volatilite_quadra2
sol=solvers.coneqp(P=P,q=q,G=G,h=h,b=b,A=A)
File "C:\Python35_x64\lib\site-packages\cvxopt\coneprog.py", line 1852, in coneqp
raise TypeError("'q' must be a 'd' matrix with one column")
TypeError: 'q' must be a 'd' matrix with one column
C’est dû au fait que le module fait la différence entre les entiers et les réels. Il suffit juste d’écrire :
q=matrix([[0.0,0.0,0.0]])
Bien sûr, si l’erreur est vraiment un problème de dimension, cette correction n’aidera pas.
(entrée originale : faq_cvxopt.py:docstring of ensae_teaching_cs.faq.faq_cvxopt.optimisation, line 3)
ValueError: Rank[|A|] < p or Rank[|[P; A; G]|] < n)
La fonction coneqp déclenche parfois cette erreur :
Traceback (most recent call last):
File "C:\Python35_x64\lib\site-packages\cvxopt\coneprog.py", line 2271, in coneqp
try: f3 = kktsolver(W)
File "C:\Python35_x64\lib\site-packages\cvxopt\coneprog.py", line 1996, in kktsolver
return factor(W, P)
File "C:\Python35_x64\lib\site-packages\cvxopt\misc.py", line 1457, in factor
lapack.potrf(F['S'])
ArithmeticError: 3
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "toutbiss.py", line 237, in <module>
liste_composition,liquide = actualisation(liste_df,index,liquide,liste_composition,
nb_jours_rendement,nb_jours_volatilite,volatilite_max)
File "toutbiss.py", line 137, in actualisation
objectif_repartition=volatilite_quadra2(liste_df,index,nb_jours_rendement,nb_jours_volatilite,volatilite_max)
File "toutbiss.py", line 122, in volatilite_quadra2
sol=solvers.coneqp(P=P,q=q,G=G,h=h,b=b,A=A)
File "C:\Python35_x64\lib\site-packages\cvxopt\coneprog.py", line 2274, in coneqp
raise ValueError("Rank(A) < p or Rank([P; A; G]) < n")
ValueError: Rank(A) < p or Rank([P; A; G]) < n
Le message est explicite mais si aucune de ces conditions n’est vérifiée, cela peut vouloir dire qu’une autre hypothèse du problème à résoudre n’est pas vérifiée :
la symétrie d’une matrice
le fait qu’une matrice doit être définie semi-positive
(entrée originale : faq_cvxopt.py:docstring of ensae_teaching_cs.faq.faq_cvxopt.optimisation, line 41)
FAQ Cython#
Compiler une function Cython ?
Cette fonction compile un script
Cython.
Cette extension permet d’implémenter des fonctions Python dans un
pseudo-langage proche du C.
Il faut suivre les instructions décrite dans le tutorial
The Basics of Cython
pour réussir à utiliser une fonction codée en Cython.
C’est ce que fait la fonction compile_cython_single_script.
Etant donné que la partie en pseudo C est compilée afin de la rendre beaucoup plus rapide, la partie la plus difficile est généralement celle qui consiste à faire en sorte que l’interpréteur Python trouve le <b>bon</b> compilateur. Ce compilateur est nécessairement le même que celui utilisé pour compiler Python et celui-ci change à chaque version. Voir Compiling Python on Windows et faire attention à la version de Python que vous utilisez.
(entrée originale : faq_cython.py:docstring of ensae_teaching_cs.faq.faq_cython.compile_cython_single_script, line 25)
FAQ Geo coordinates and Maps#
Les fichiers GEOFLA ne contiennent pas de longitude, latitude ?
Les coordonnées contenues dans les fichiers GEOFLA ne sont pas toujours des longitudes, latitudes mais des coordonnées exprimées dans un système de projection conique Lambert 93. Il faut convertir les coordonnées avant de pouvoir tracer la carte ou changer la projection utilisée par cartopy : Lambert Conformal Projection.
(entrée originale : geo_helper.py:docstring of ensae_teaching_cs.helpers.geo_helper.lambert93_to_WGPS, line 13)
FAQ Hadoop#
La version de Python est différente dans putty
Lorsqu’on ouvre une fenêtre putty, on crée une passerelle vers une autre machine, le plus souvent linux. Ce qu’on voit à l’intérieur de la fenêtre est la ligne de commande de cette machine. Ce n’est pas vraiment la ligne de commande mais plutôt une représentation. Les commandes sont envoyés à la machine distance via le protocole SSH. Je renvoie au TD Map/Reduce avec PIG qui montre comment se server de putty pour envoyer des commandes vers le cluster. Il est aussi possible de créer sa propre fenêtre putty à l’intérieur d’un notebook (voir Communication with a remote Linux machine through SSH).
Mais comment fait-on pour exécuter un script python sur la machine distance ?
Deux options. On l’écrit sur sa machine locale avec l’éditeur dont on a l’habitude puis on transfère le fichier sur la machine distante pour l’exécuter avec la commande
python <fichier.py>
La seconde option consiste à ouvrir un édieur de texte à l’intérieur de la fenêtre putty. Tout se fait avec des raccourcis puisque la souris est inutilisable. On peut utiliser les éditeurs vi ou nano.
Une astuce : pour éviter de sortir de l’éditeur nano ou vi à chaque fois qu’on souhaite exécuter le script, il suffit d’ouvrir une seconde fenêtre putty. La première sert à éditer, la seconde à exécuter le script.
(entrée originale : faq_hadoop.py:docstring of ensae_teaching_cs.faq.faq_hadoop.putty_different_python, line 1)
FAQ Jupyter#
Accéder ou modifier une variable du notebook depuis une commande magique
Comment ajouter un lien vers un fichier local pour le télécharger ?
Accéder ou modifier une variable du notebook depuis une commande magique
Lorsqu’on écrit un notebook, toutes les variables qu’on crée sont
en quelque sorte globales puisqu’on peut y accéder depuis chaque cellule
mais leur périmètre est limité au notebook.
Lorsqu’on crée un commande magique, il est possible d’accéder à ce contexte local
via le membre self.shell.user_ns. De cette façon, on peut accéder au contenu d’une
variable, le modifier ou en ajouter une.
class CustomMagics(Magics):
@line_magic
def custom_cmd(self, line):
context = self.shell.user_ns
#...
(entrée originale : faq_jupyter.py:docstring of ensae_teaching_cs.faq.faq_jupyter.jupyter_get_variable, line 14)
Comment ajouter un lien vers un fichier local pour le télécharger ?
Voir notebook 2A.soft - Convert a notebook into a document.
(entrée originale : faq_jupyter.py:docstring of ensae_teaching_cs.faq.faq_jupyter.jupyter_convert_notebooks, line 15)
Comment convertir le notebook en cours au format HTML ?
Voir notebook 2A.soft - Convert a notebook into a document.
(entrée originale : faq_jupyter.py:docstring of ensae_teaching_cs.faq.faq_jupyter.jupyter_convert_notebooks, line 9)
Lancer le serveur de notebooks
On suppose que le module Jupyter a été bien installé.
Depuis août 2015, IPython est devenu Jupyter qui n’est pas plus automatiquement
associé à Python mais propose des notebooks pour de nombreux langages.
Il faut installer le module jupyter (pip install jupyter).
Plusieurs options :
Utiliser la ligne de commande usuelle :
jupyter-notebook. Ce script (ou programme jupyter-notebook.exe sous Windows est inclus dans le répertoire Scripts du répertoire d’installation. Voir également Travailler avec IPython notebook, Open the notebook with a different browser Il est possible de créer un fichier .bat pour automatiser la ligne de commande et l’ajouter en tant qu’icône sur le bureau.Utiliser la fonction
jupyter_open_notebookfrom ensae_teaching_cs.faq import jupyter_open_notebook nbfile = "notebook.ipynb" jupyter_open_notebook(nbfile)
Utiliser le raccourci proposé par la distribution choisi pour installer Python.
(entrée originale : faq_jupyter.py:docstring of ensae_teaching_cs.faq.faq_jupyter.jupyter_open_notebook, line 10)
Le notebook ne répond plus
On utilise les notebooks via un navigateur web mais ce n’est pas lui qui exécute le code Python, c’est un serveur. Ce serveur tourne soit une machine distante, soit une machine locale. Il s’agit d’une fenêtre terminale où l’on peut voir des informations s’afficher à chaque qu’on ouvre, qu’on ferme, qu’on enregistre un notebook. Si cette fenêtre est fermée, il n’existe plus de serveur de notebook qui puisse exécuter le code inclus dans le notebook. Il ne se passe plus rien, les modifications sont perdues. Il faut redémarrer le serveur, qu’il soit distant ou local.
(entrée originale : faq_jupyter.py:docstring of ensae_teaching_cs.faq.faq_jupyter.jupyter_open_notebook, line 37)
Récupérer le fichier du notebook depuis le notebook
Voir How to I get the current Jupyter Notebook name Il suffit d’insérer la cellule suivante dans le notebook
%%javascript
var kernel = IPython.notebook.kernel;
var body = document.body,
attribs = body.attributes;
var command = "theNotebook = os.path.join(" + "r'"+attribs['data-project'].value+"'," +
"r'"+attribs['data-notebook-path'].value+"'," + "r'"+attribs['data-notebook-name'].value+"')";
kernel.execute(command);
On peut vérifier que cela fonctionne
theNotebook
(entrée originale : faq_jupyter.py:docstring of ensae_teaching_cs.faq.faq_jupyter.notebook_path, line 1)
FAQ matplotlib#
Changer le style de graphique pour ggplot
Voir Customizing plots with style sheets
import matplotlib.pyplot as plt
plt.style.use('ggplot')
(entrée originale : faq_matplotlib.py:docstring of ensae_teaching_cs.faq.faq_matplotlib.graph_style, line 5)
Comment ajuster les labels non numériques d’un graphe ?
Lorsqu’on trace un graphique et qu’on veut ajouter des labels non numériques sur l’axe des abscisses (en particulier des dates), matplotlib ne fait pas apparaître tous les labels. Ainsi, si on a 50 points, 50 abscisses et 50 labels, seuls les premiers labels apparaîtront comme ceci :
import matplotlib.pyplot as plt
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27,
28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]
y = [1, 3, 10, 6, 3, 5, 3, 6, 4, 2, 3, 2, 11, 10, 4, 5, 2, 5, 4, 1, 1, 1, 3, 15, 5, 2, 1, 5, 3, 1, 3,
2, 4, 5, 2, 12, 12, 5, 11, 2, 19, 21, 5, 2]
xl = ['2014-w04', '2014-w05', '2014-w06', '2014-w07', '2014-w08', '2014-w09',
'2014-w10', '2014-w11',
'2014-w12', '2014-w13', '2014-w14', '2014-w15', '2014-w16',
'2014-w17', '2014-w18', '2014-w19', '2014-w20', '2014-w21', '2014-w22', '2014-w23',
'2014-w24', '2014-w25', '2014-w27',
'2014-w29', '2014-w30', '2014-w31', '2014-w32', '2014-w34', '2014-w35', '2014-w36',
'2014-w38', '2014-w39', '2014-w41',
'2014-w42', '2014-w43', '2014-w44', '2014-w45', '2014-w46', '2014-w47', '2014-w48',
'2014-w49', '2014-w50', '2014-w51', '2014-w52']
plt.close('all')
fig,ax = plt.subplots(nrows=1,ncols=1,figsize=(10,4))
ax.bar( x,y )
ax.set_xticklabels( xl )
ax.grid(True)
ax.set_title("commits")
plt.show()
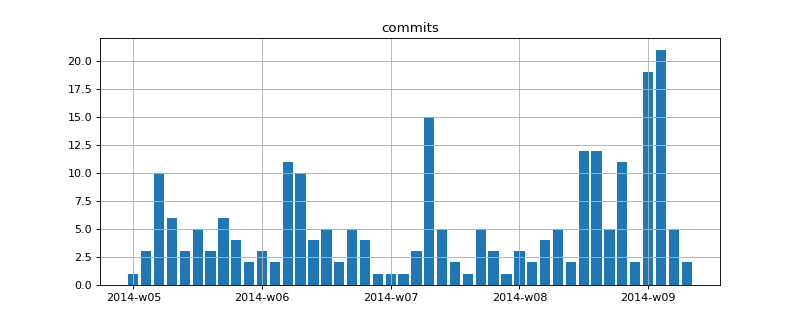{kind=link}
{kind=link}
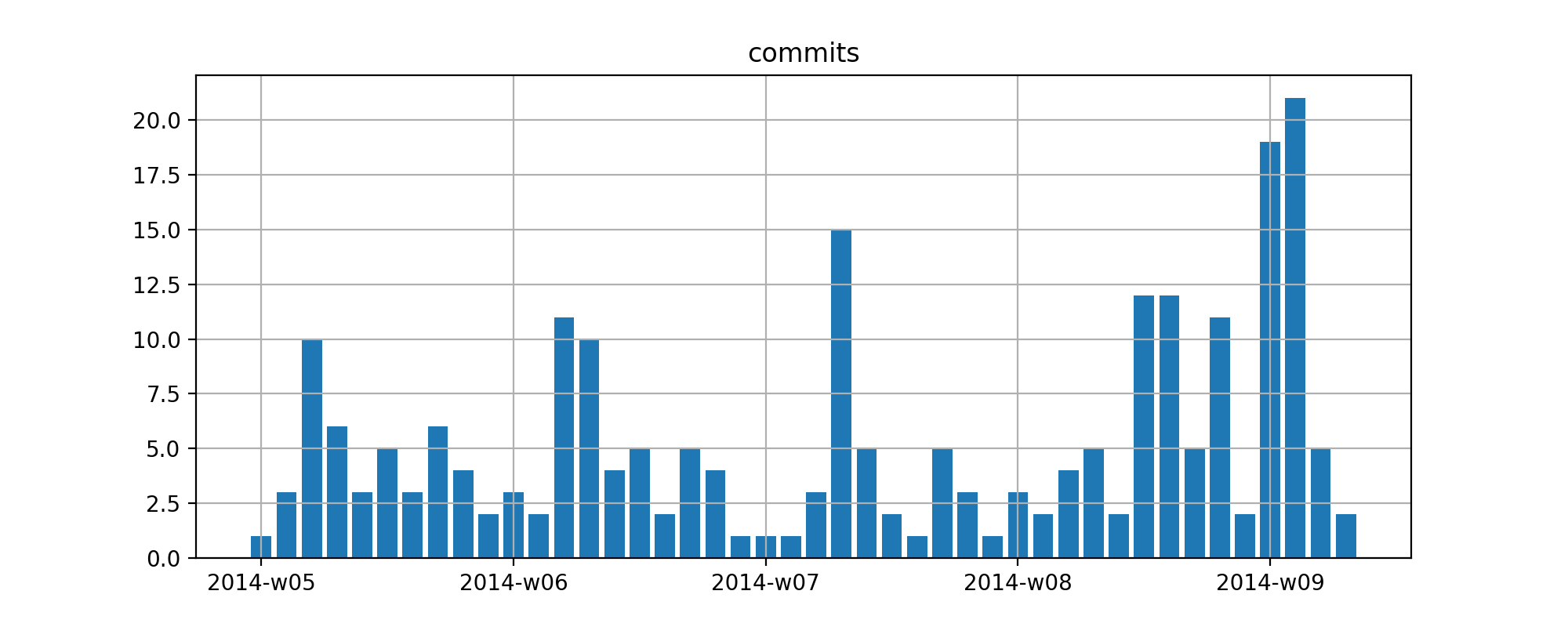
Or c’est cela qu’on veut :
import matplotlib.pyplot as plt
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31,
32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]
y = [1, 3, 10, 6, 3, 5, 3, 6, 4, 2, 3, 2, 11, 10, 4, 5, 2, 5, 4, 1, 1, 1, 3, 15, 5, 2, 1, 5,
3, 1, 3, 2, 4, 5, 2, 12, 12, 5, 11, 2, 19, 21, 5, 2]
xl = ['2014-w04', '2014-w05', '2014-w06', '2014-w07', '2014-w08', '2014-w09',
'2014-w10', '2014-w11', '2014-w12', '2014-w13', '2014-w14',
'2014-w15', '2014-w16', '2014-w17', '2014-w18', '2014-w19',
'2014-w20', '2014-w21', '2014-w22', '2014-w23', '2014-w24', '2014-w25',
'2014-w27', '2014-w29', '2014-w30', '2014-w31', '2014-w32', '2014-w34',
'2014-w35', '2014-w36', '2014-w38', '2014-w39', '2014-w41',
'2014-w42', '2014-w43', '2014-w44', '2014-w45', '2014-w46', '2014-w47',
'2014-w48', '2014-w49', '2014-w50', '2014-w51', '2014-w52']
plt.close('all')
fig,ax = plt.subplots(nrows=1,ncols=1,figsize=(10,4))
ax.bar( x,y )
tig = ax.get_xticks()
labs = [ ]
for t in tig:
if t in x: labs.append(xl[x.index(t)])
else: labs.append("")
ax.set_xticklabels( labs )
ax.grid(True)
ax.set_title("commits")
plt.show()
{kind=link}
{kind=link}
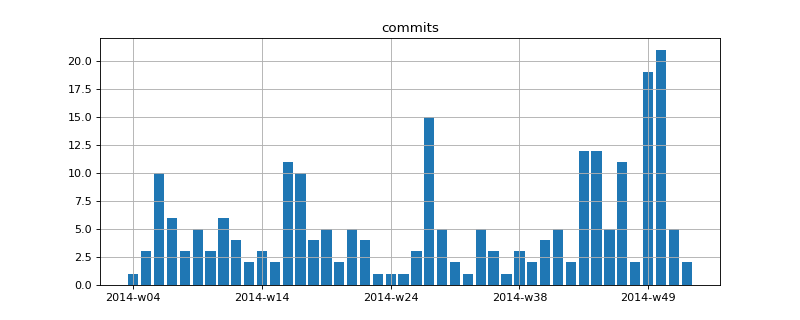
Pour cela il faut d’abord utiliser la méthode get_xticks pour récupérer d’abord les graduations et n’afficher les labels que pour celles-ci (voir aussi Custom ticks autoscaled when using imshow?). Voici un exemple de code
import matplotlib.pyplot as plt
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,
30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43]
y = [1, 3, 10, 6, 3, 5, 3, 6, 4, 2, 3, 2, 11, 10, 4, 5, 2, 5, 4, 1, 1, 1, 3, 15, 5, 2, 1, 5, 3, 1, 3, 2,
4, 5, 2, 12, 12, 5, 11, 2, 19, 21, 5, 2]
xl = ['2014-w04', '2014-w05', '2014-w06', '2014-w07', '2014-w08', '2014-w09', '2014-w10', '2014-w11', '2014-w12', '2014-w13',
'2014-w14', '2014-w15', '2014-w16', '2014-w17', '2014-w18', '2014-w19', '2014-w20', '2014-w21',
'2014-w22', '2014-w23', '2014-w24', '2014-w25',
'2014-w27', '2014-w29', '2014-w30', '2014-w31', '2014-w32', '2014-w34', '2014-w35', '2014-w36',
'2014-w38', '2014-w39', '2014-w41', '2014-w42',
'2014-w43', '2014-w44', '2014-w45', '2014-w46', '2014-w47', '2014-w48', '2014-w49',
'2014-w50', '2014-w51', '2014-w52']
plt.close('all')
fig,ax = plt.subplots(nrows=1,ncols=1,figsize=(10,4))
ax.bar( x,y )
tig = ax.get_xticks()
labs = [ ]
for t in tig:
if t in x:
labs.append(xl[x.index(t)])
else:
# une graduation peut être en dehors des labels proposés
labs.append("")
ax.set_xticklabels( labs )
ax.grid(True)
ax.set_title("commits")
plt.show()
(entrée originale : faq_matplotlib.py:docstring of ensae_teaching_cs.faq.faq_matplotlib.graph_with_label, line 14)
Comment changer l’emplacement de la légende ?
On cherche ici à changer l’emplacement de la légende alors que celle-ci a déjà été définie par ailleurs. C’est pratique lorsque celle-ci cache une partie du graphe qu’on veut absolument montrer. On ne dispose que de l’objet ax de type Axes. On utilise pour cela la méthode legend et le code suivant :
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles, labels, loc="lower center")
Les différentes options pour le nouvel emplacement sont énoncées dans l’aide associée à la méthode legend.
(entrée originale : faq_matplotlib.py:docstring of ensae_teaching_cs.faq.faq_matplotlib.change_legend_location, line 7)
Comment éviter les dates qui se superposent ?
La méthode autofmt_xdate permet d’éviter les problèmes de dates qui se superposent.
fig, ax = plt.subplots(...)
# ...
fig.autofmt_xdate()
(entrée originale : faq_matplotlib.py:docstring of ensae_teaching_cs.faq.faq_matplotlib.avoid_overlapping_dates, line 4)
Plante après plusieurs graphes
Il peut arriver que matplotlib fasse planter python sans qu’aucune exception ne soit générée. L’article matplotlib crashing Python suggère la solution suivante
import matplotlib.pyplot as plt
plt.close('all')
Voir close.
(entrée originale : faq_matplotlib.py:docstring of ensae_teaching_cs.faq.faq_matplotlib.close_all, line 3)
FAQ pandas#
Caractères bizarres en utf8 et sous Windows (BOM) ?
Sous Windows, certains logiciels comme Notepad
permettent d’enregister un fichier sous différents encodings.
Avec l’encoding UTF8, on a parfois un problème avec le premier caractère
\ufeff car Notepad ajoute ce qu’on appelle un BOM.
Par exemple
import pandas
df = pandas.read_csv("dataframe.txt",sep="\t", encoding="utf8")
print(df)
Provoque une erreur des plus énervantes
UnicodeEncodeError: 'charmap' codec can't encode character '\ufeff' in position 0: character maps to <undefined>
Pour contrecarrer ceci, il suffit de modifier l’encoding par utf-8-sig
import pandas
df = pandas.read_csv("dataframe.txt",sep="\t", encoding="utf-8-sig")
print(df)
(entrée originale : faq_pandas.py:docstring of ensae_teaching_cs.faq.faq_pandas.read_csv, line 10)
Comment comparer deux dataframe?
Ecrire df1 == df2 ne compare pas deux dataframes entre deux
car le sens n’est pas forcément le même pour tout le monde.
Même si les valeurs sont les mêmes, est-ce l’ordre des colonnes
est important ?
Il faut le faire soi-même pour une comparaison spécifique à
vos besoins. Le code ci-dessus
compare d’abord les dimensions, ensuite compare l’ordre
des colonnes puis enfin les valeurs
if df1.shape != df2.shape:
return False
l1 = list(df1.columns)
l2 = list(df2.columns)
l1.sort()
l2.sort()
if l1 != l2:
return False
df1 = df1[l1]
df2 = df2[l2]
t = (df1 == df2).all()
s = set(t)
return False not in s
Autres alternatives :
(entrée originale : faq_pandas.py:docstring of ensae_teaching_cs.faq.faq_pandas.df_equal, line 17)
Comment créer un dataframe rapidement ?
Le notebook 2A.i - Mesures de vitesse sur les dataframes compare différentes manières de créer un dataframe ou un array. Quelques enseignemens :
Même si les données sont produites par un générateur, pandas les convertit en liste.
La création d’un array est plus rapide à partir d’un générateur plutôt que d’une liste.
(entrée originale : faq_pandas.py:docstring of ensae_teaching_cs.faq.faq_pandas.speed_dataframe, line 1)
Comment vérifier que deux DataFrame sont égaux (2) ?
Comparer deux DataFrame
avec l’opérateur == ne fonctionne pas.
On obtient un message d’erreur
ValueError: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
Il faut au préalable convertir le Dataframe en le convertissant en liste
df.values.tolist() == df2.values.tolist()
(entrée originale : serialization.py:docstring of ensae_teaching_cs.td_2a.serialization.df2list, line 15)
Copier un dataframe dans le presse-papier - clipboard
Pour récupérer un dataframe dans Excel, on peut utiliser la méthode to_excel puis ouvrir le fichier dans Excel ou le copier dans le presse-papier et le coller dans une feuille ouverte dans Excel. C’est l’objet de la méthode to_clipboard <to_clipboard:
df = pandas.DataFrame ( ... )
df.to_clipboard(sep="\t")
(entrée originale : faq_pandas.py:docstring of ensae_teaching_cs.faq.faq_pandas.df_to_clipboard, line 11)
Enregistrer plusieurs DataFrame dans un seul fichier Excel ?
Le code suivant enregistre deux DataFrame dans un seul fichier Excel.
import pandas
writer = pandas.ExcelWriter('example.xlsx')
df1.to_excel(writer, 'Data 0')
df2.to_excel(writer, 'Data 1')
write.save()
Ou en utilisant cette fonction :
dfs2excel( { 'Data 0':df1, 'Data 1':df2 }, "example.xlsx" )
(entrée originale : serialization.py:docstring of ensae_teaching_cs.td_2a.serialization.dfs2excel, line 27)
top n lignes avec pandas
Grouper puis garder les premières observations de ce groupe est un problème classique. Il n’existe pas de meilleure façon de le faire, cela dépend du nombre d’obervations par groupe. Le moyen le plus simple de le faire avec pandas est :
grouper les lignes
trier les lignes dans chaque groupe
garder les premières lignes dans chaque groupe
Ceci donne
df.groupby(by_keys)
.apply(lambda x: x.sort_values(sort_keys, ascending=ascending).head(head))
.reset_index(drop=True)
La dernière instruction supprimer l’index ce qui donne au dataframe final la même structure que le dataframe initial.
<<<
import pandas
l = [dict(k1="a", k2="b", v=4, i=1),
dict(k1="a", k2="b", v=5, i=1),
dict(k1="a", k2="b", v=4, i=2),
dict(k1="b", k2="b", v=1, i=2),
dict(k1="b", k2="b", v=1, i=3)]
df = pandas.DataFrame(l)
df.groupby(["k1", "k2"]).apply(
lambda x: x.sort_values(["v", "i"], ascending=True).head(1))
print(df)
>>>
k1 k2 v i
0 a b 4 1
1 a b 5 1
2 a b 4 2
3 b b 1 2
4 b b 1 3
(entrée originale : faq_pandas.py:docstring of ensae_teaching_cs.faq.faq_pandas.groupby_topn, line 11)
FAQ python#
Comment itérer sur les résultats d'une expression régulière ?
Comment éviter sys.path.append... quand on développe un module ?
Pourquoi l'installation de pandas (ou numpy) ne marche pas sous Windows avec pip ?
A quoi sert un ``StringIO`` ?
La plupart du temps, lorsqu’on récupère des données, elles sont sur le disque dur de votre ordinateur dans un fichier texte. Lorsqu’on souhaite automatiser un processur qu’on répète souvent avec ce fichier, on écrit une fonction qui prend le nom du fichier en entrée.
def processus_quotidien(nom_fichier) :
# on compte les lignes
nb = 0
with open(nom_fichier,"r") as f :
for line in f :
nb += 1
return nb
Et puis un jour, les données ne sont plus dans un fichier mais sur Internet.
Le plus simple dans ce cas est de recopier ces données sur disque dur et d’appeler la même fonction.
Simple. Un autre les données qu’on doit télécharger font plusieurs gigaoctets. Tout télécharger prend
du temps pour finir pour s’apercevoir qu’elles sont corrompues. On a perdu plusieurs heures pour rien.
On aurait bien voulu que la fonction processus_quotidien commence à traiter les données
dès le début du téléchargement.
Pour cela, on a inventé la notion de stream ou flux qui sert d’interface entre la fonction qui traite les données et la source des données. Le flux lire les données depuis n’importe quel source (fichier, internet, mémoire), la fonction qui les traite n’a pas besoin d’en connaître la provenance.
StringIO est un flux qui considère la mémoire comme source de données.
def processus_quotidien(data_stream):
# on compte toujours les lignes
nb = 0
for line in data_stream :
nb += 1
return nb
La fonction processus_quotidien fonctionne pour des données en mémoire
et sur un fichier.
fichier = __file__
f = open(fichier,"r")
nb = processus_quotidien(f)
print(nb)
text = "ligne1
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.stringio, line 6)
Classe sortable
Il faut prononcer sortable à l’anglaise. Comment rendre une classe sortable ? Pour faire simple, on veut écrire
l = [ o1, o2 ]
l.sort()
Où o1 et o2 sont des objets d’une classe
que vous avez définie
class MaClasse:
...
Pour que cela fonctionne, il suffit juste
de surcharger l’opérateur < ou plus exactement
__lt__. Par exemple
class MaClasse:
def __lt__(self, autre_instance):
if self.jenesaispas < autre.jenesaispas:
return True
elif self.jenesaispas > autre.jenesaispas:
return False:
else:
if self.jenesaispas2 < autre.jenesaispas2:
return True
else:
return False
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.sortable_class, line 1)
Comment gagner du temps lors de la lecture de données ?
Les languages informatiques définissent des structures de données qui permettent une utilisation rapide et cela n’a souvent rien à voir avec la façon dont on lit ces données. La plupart des données apparaissent dans des fichiers texte ou fichiers plat. Pour les utiliser, le programme les charges en mémoires ce qui peut prendre du temps. La première fois qu’on s’en sert, c’st inévitable. La seconde fois, on peut stocker les données telles qu’elles sont en mémoire. Le second chargement est plus rapide.
obj = ... # n'importe quoi de sérialisable
dump_object(obj, "object_sur_disque.bin")
Pour recharger les données, on écrit :
obj = load_object("object_sur_disque.bin")
Le code de ces deux fonctions fait intervenir le module pickle. Il suffit pour la plupart des usages. Pour un usage plus exotique, il faut voir le module dill.
(entrée originale : serialization.py:docstring of ensae_teaching_cs.td_2a.serialization.dump_object, line 6)
Comment itérer sur les résultats d’une expression régulière ?
On utilise la méthode finditer.
found = exp.search(text)
for m in exp.finditer(text):
# ...
Voir également Petites subtilités avec les expressions régulières en Python.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.enumerate_regex_search, line 7)
Comment éviter sys.path.append… quand on développe un module ?
Lorsqu’on développe un module,
on ne veut pas l’installer. On ne veut pas qu’il soit présent dans le répertoire site-packages de la distribution
de Python car cela introduit deux versions : celle qu’on développe et celle qu’on a installer.
Avant, je faisais cela pour créer un petit programme utilisant mon propre module
(et on en trouve quelque trace dans mon code) :
import sys
sys.path.append("c:/moncode/monmodule/src")
import monmodule
Quand je récupère un programme utilisant ce module, il me faudrait ajouter ces petites lignes à chaque fois et c’est barbant. Pour éviter cela, il est possible de dire à l’interpréteur Python d’aller chercher ailleurs pour trouver des modules en ajoutant le chemin à la variable d’environnement PYTHONPATH. Sous Windows :
set PYTHON_PATH=%PYTHON_PATH%;c:\moncode\monmodule\src
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.python_path, line 1)
Obtenir des informations sur les packages installés
Le module pip retourne des informations sur n’importe quel module installé, sa version, sa license
pip show pandas
On peut également l’obtenir depuis l’interpréteur python
import pip
pip.main(["show", "pandas"])
Exemple
Name: pandas
Version: 0.16.0
Summary: Powerful data structures for data analysis, time series,and statistics
Home-page: http://pandas.pydata.org
Author: The PyData Development Team
Author-email: pydata@googlegroups.com
License: BSD
Location: c:\python35_x64\lib\site-packages
Requires: python-dateutil, pytz, numpy
On utilise également pip freeze pour répliquer l’environnement
dans lequel on a développé un programme. pip freeze
produit la liste des modules avec la version utilisée
docutils==0.11
Jinja2==2.7.2
MarkupSafe==0.19
Pygments==1.6
Sphinx==1.2.2
Ce qu’on utilise pour répliquer l’environnement de la manière suivante
pip freeze > requirements.txt
pip install -r requirements.txt
Cette façon de faire fonctionne très bien sous Linux mais n’est pas encore opérationnelle sous Windows à moins d’installer le compilateur C++ utilisée pour compiler Python.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.list_of_installed_packages, line 3)
Pourquoi l’installation de pandas (ou numpy) ne marche pas sous Windows avec pip ?
Python est un langage très lent et c’est pourquoi la plupart des modules de calculs numériques incluent des parties implémentées en langage C++. numpy, pandas, matplotlib, scipy, scikit-learn, …
Sous Linux, le compilateur est intégré au système et l’installation de ces modules via
l’instruction pip install <module> met implicitement le compilateur à contribution.
Sous Windows, il n’existe pas de compilateur C++ par défaut à moins de l’installer.
Il faut faire attention alors d’utiliser exactement le même que celui utilisé
pour compiler Python (voir
Compiling Python on Windows).
C’est pour cela qu’on préfère utiliser des distributions comme Anaconda qui propose par défaut une version de Python accompagnée des modules les plus utilisés. Elle propose également une façon simple d’installer des modules précompilés avec l’instruction
conda install <module_compile>
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.information_about_package, line 17)
Python n’accepte pas les accents
Le langage Python a été conçu en langage anglais. Dès qu’on on ajoute un caractère qui ne fait pas partie de l’alphabet anglais (ponctuation comprise), il déclenche une erreur :
File "faq_cvxopt.py", line 3
SyntaxError: Non-UTF-8 code starting with 'è' in file faq_cvxopt.py on line 4, but no encoding declared;
see http://python.org/dev/peps/pep-0263/ for details
Pour la résoudre, il faut dire à l’interpréteur que des caractères non anglais peuvent apparaître et écrire sur la première ligne du programme :
# -*- coding: latin-1 -*-
Ou pour tout caractère y compris chinois :
# -*- coding: utf-8 -*-
Si vous utilisez l’éditeur SciTE sous Windows, après avoir ajouté cette ligne avec l’encoding utf-8, il est conseillé de fermer le fichier puis de le réouvrir. SciTE le traitera différemment.
L’encodage ``utf-8`` est la norme sur Internet. C’est pourquoi il est préférable d’utiliser celui-ci pour partager son code via une page Web.
(entrée originale : classiques.py:docstring of ensae_teaching_cs.td_1a.classiques.commentaire_accentues, line 3)
Qu’est-ce qu’un test unitaire ?
Un test unitaire
une procédure permettant de vérifier le bon fonctionnement d’une partie précise.
Concrètement, cela consiste à écrire une fonction qui exécute la partie de code
à vérifier. Cette fonction retourne True si le test est valide, c’est-à-dire
que la partie de code s’est comportée comme prévue : elle a retourné le résultat attendu.
Elle déclenche une exception si elle le code à vérifier ne se comporte pas comme prévu.
Par example, si on voulait écrire un test unitaire pour la fonction pow, on pourrait écrire
def test_pow():
assert pow(2,1) == 2 # on vérifie que 2^1 == 0
assert pow(2,0) == 1
assert pow(2,-1) == 0.5
assert pow(2,-1) == 0.5
assert pow(0,0) == 1 # convention, on s'assure qu'elle ne change pas
assert isinstance(pow(-2,3.4), complex)
return True
A quoi ça sert ?
On écrit la fonction x_exp ( ) comme suit
) comme suit
def x_exp(x,y,n):
return y / pow(x,n)
La fonction retourne 0 si  .
Admettons maintenant qu’un dévelopeur veuille changer la convention
.
Admettons maintenant qu’un dévelopeur veuille changer la convention  en
en  .
La fonction précédente produira une erreur à cause d’une division
.
La fonction précédente produira une erreur à cause d’une division 0/0.
Un test unitaire détectera au plus tôt cette erreur.
Les tests unitaires garantissent la qualité d’un logiciel qui est considéré comme bonne si 80% du code est couvert par un test unitaire. Lorsque plusieurs personnes travaillent sur un même programme, un dévelopeur utilisera une fonction faite par un autre. Il s’attend donc à ce que la fonction produise les mêmes résultats avec les mêmes entrées même si on la modifie ultérieurement. Les tests unitaires servent à s’assurer qu’il n’y a pas d’erreur introduite au sein des résultats intermédiaire d’une chaîne de traitement, auquel cas, c’est une cascade d’erreur qui est susceptible de se produite. La source d’une erreur est plus facile à trouver lorsque les tests unitaires sont nombreux.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.test_unitaire, line 1)
Qu’est-ce qu’un type immuable ou immutable ?
Une variable de type immuable ne peut être modifiée. Cela concerne principalement :
int,float,str,tuple
Si une variable est de type immuable, lorsqu’on effectue une opération, on créé implicitement une copie de l’objet.
Les dictionnaires et les listes sont modifiables (ou mutable). Pour une variable
de ce type, lorsqu’on écrit a = b, a et b désigne le même objet même
si ce sont deux noms différentes. C’est le même emplacement mémoire
accessible paur deux moyens (deux identifiants).
Par exemple
a = (2,3)
b = a
a += (4,5)
print( a == b ) # --> False
print(a,b) # --> (2, 3, 4, 5) (2, 3)
a = [2,3]
b = a
a += [4,5]
print( a == b ) # --> True
print(a,b) # --> [2, 3, 4, 5] [2, 3, 4, 5]
Dans le premier cas, le type (tuple) est _immutable_, l’opérateur += cache implicitement une copie.
Dans le second cas, le type (list) est _mutable_, l’opérateur += évite la copie
car la variable peut être modifiée. Même si b=a est exécutée avant l’instruction suivante,
elle n’a pas pour effet de conserver l’état de a avant l’ajout d’élément.
Un autre exemple
a = [1, 2]
b = a
a [0] = -1
print(a) # --> [-1, 2]
print(b) # --> [-1, 2]
Pour copier une liste, il faut expliciter la demander
a = [1, 2]
b = list(a)
a [0] = -1
print(a) # --> [-1, 2]
print(b) # --> [1, 2]
La page Immutable Sequence Types détaille un peu plus le type qui sont mutable et ceux qui sont immutable. Parmi les types standards :
Une instance de classe est mutable. Il est possible de la rendre immutable par quelques astuces :
Enfin, pour les objects qui s’imbriquent les uns dans les autres, une liste de listes, une classe qui incluent des dictionnaires et des listes, on distingue une copie simple d’une copie intégrale (deepcopy). Dans le cas d’une liste de listes, la copie simple recopie uniquement la première liste
import copy
l1 = [ [0,1], [2,3] ]
l2 = copy.copy(l1)
l1 [0][0] = '##'
print(l1,l2) # --> [['##', 1], [2, 3]] [['##', 1], [2, 3]]
l1 [0] = [10,10]
print(l1,l2) # --> [[10, 10], [2, 3]] [['##', 1], [2, 3]]
La copie intégrale recopie également les objets inclus
import copy
l1 = [ [0,1], [2,3] ]
l2 = copy.deepcopy(l1)
l1 [0][0] = '##'
print(l1,l2) # --> [['##', 1], [2, 3]] [[0, 1], [2, 3]]
Les deux fonctions s’appliquent à tout object Python : module copy.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.same_variable, line 8)
Quel est l’entier le plus grand ?
La version 3 du langage Python a supprimé la constante sys.maxint
qui définissait l’entier le plus grand (voir
What’s New In Python 3.0).
De ce fait la fonction getrandbit
retourne un entier aussi grand que l’on veut.
<<<
import random
import sys
x = random.getrandbits(2048)
print(type(x), x)
>>>
<class 'int'> 27182865868248823254698384316186423051027371279810493222381097580899889519504678598551540023775731203179169357507633496992994604285094798617572960290068940572007585192258695869051554324712502686919866448789265031545477679761959111528208368916673142852166159329898578876492336793956706507170265173311752681341765133741014325063609248383314126058630160414822313305647408367000057504672638467964641513878260215379412384263620011161247389807177098496377061131369529354363264537788461358993683591781428460267608706305384057673898696642441368027482948273780861841082203083238296697184124639909390478695206276787416579949555
Les calculs en nombre réels se font toujours avec huit octets de précision. Au delà, il faut utiliser la librairie gmpy2. Il est également recommandé d’utiliser cette librairie pour les grands nombres entiers (entre 20 et 40 chiffres). La librairie est plus rapide que l’implémentation du langage Python (voir Overview of gmpy2).
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.entier_grande_taille, line 1)
Quelle est la différence entre / et // - division ?
Le résultat de la division avec l’opérateur / est toujours réel :
la division de deux entiers 1/2 donne 0.5.
Le résultat de la division avec l’opérateur // est toujours entier.
Il correspond au quotient de la division.
div1 = 1/2
div2 = 4/2
div3 = 1//2
div4 = 1.0//2.0
print(div1,div2,div3,div4) # affiche (0.5, 2.0, 0, 0)
Le reste d’une division entière est obtenue avec l’opérateur %.
print ( 5 % 2 ) # affiche 1
C’est uniquement vrai pour les version Python 3.x.
Pour les versions 2.x, les opérateurs / et // avaient des comportements différents
(voir What’s New In Python 3.0).
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.difference_div, line 1)
Quelle est la différence entre return et print ?
La fonction print sert à afficher un résultat sur la sortie standard.
Elle peut être utilisée à tout moment
mais elle n’a pas d’impact sur le déroulement programme. Le mot-clé return
n’est utilisé que dans une fonction. Lorsque le programme rencontre
une instruction commençant par return, il quitte la fonction
et transmet le résultat à l’instruction qui a appelé la fonction.
La fonction print ne modifie pas votre algorithme. La fonction return
spécifie le résultat de votre fonction : elle modifie l’algorithme.
(entrée originale : classiques.py:docstring of ensae_teaching_cs.td_1a.classiques.dix_entiers_carre, line 5)
Récupérer la liste des modules installés
Le module pip permet d’installer de nouveaux modules mais aussi d’obtenir la liste des packages installés
pip list
On peut également l’obtenir depuis l’interpréteur python
import pip
pip.main(["list"])
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.information_about_package, line 3)
Récupérer le nom du jour à partir d’une date
import datetime
dt = datetime.datetime(2016, 1, 1)
print(dt.strftime("%A"))
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.get_day_name, line 6)
Récupérer le nom du mois à partir d’une date
import datetime
dt = datetime.datetime(2016, 1, 1)
print(dt.strftime("%B"))
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.get_month_name, line 6)
Tabulations ou espace ?
Il est préférable de ne pas utiliser les tabulations et de les remplacer par des espaces. Lorsqu’on passe d’un Editeur à un autre, les espaces ne bougent pas. Les tabulations sont plus ou moins grandes visuellement. L’essentiel est de ne pas mélanger. Dans SciTE, il faut aller dans le menu Options / Change Indentation Settings… Tous les éditeurs ont une option similaire.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.entier_grande_taille, line 24)
Télécharger un fichier depuis un notebook?
L’exemple suivant illustre comment télécharger puis enregister ce fichier sur le disque local. Il ne faut pas que ce fichier dépasse la taille de la mémoire. L’url donné en exemple est celui utilisé sur DropBox.
url = "https://www.dropbox.com/[something]/[filename]?dl=1" # dl=1 is important
import urllib.request
with urllib.request.urlopen(url) as u:
data = u.read()
with open([filename], "wb") as f :
f.write(data)
L’exemple est tiré de Download a file from Dropbox with Python.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.download_from_url, line 9)
propriété
Une property est une écriture qui sert à transformer l’appel d’une méthode de classe en un attribut.
class ClasseAvecProperty:
def __init__(self,x,y):
self._x, self._y = x,y
@property
def x(self):
return self._x
@property
def y(self):
return self._y
@property
def norm2(self):
return self._y**2 + self._x**2
c = ClasseAvecProperty(1,2)
print(c.x)
print(c.y)
x est définit comme une méthode mais elle retourne simplement l’attribut
_x. De cette façon, il est impossible de changer x en écrivant:
c.x = 5
Cela déclenche l’erreur:
Traceback (most recent call last):
File "faq_python.py", line 455, in <module>
c.x = 5
AttributeError: can't set attribute
On fait cela parce que l’écriture est plus courte et que cela évite certaines erreurs.
(entrée originale : faq_python.py:docstring of ensae_teaching_cs.faq.faq_python.property_example, line 1)
FAQ web#
Issue with Selenium and Firefox
Firefox >= v47 does not work on Windows. See Selenium WebDriver and Firefox 47.
Voir ChromeDriver download, Error message: “chromedriver” executable needs to be available in the path.
(entrée originale : faq_web.py:docstring of ensae_teaching_cs.faq.faq_web._get_selenium_browser, line 7)