2A.ml - Problèmes classiques de machine learning illustrés#
Links: notebook, html, python, slides, GitHub
Revue des problèmes classiques de machines learning, classification, régression, ranking. Exercices sur la classification multi-classes.
from jyquickhelper import add_notebook_menu
add_notebook_menu(last_level=3)
%matplotlib inline
import matplotlib.pyplot as plt
Dans les exemples qui suivent :
 est une fonction d’erreur
est une fonction d’erreur et un jeu de coefficients
et un jeu de coefficients la prédiction pour l’observation
la prédiction pour l’observation  ,
représente les paramètres
,
représente les paramètres est un jeu de données
est un jeu de données
Note
Les exemples suivants ne divisent pas les données en base d’apprentissage / base de test. Les modèles sont appris et testés sur les mêmes données ce qu’on ne fait jamais en pratique mais cela permet de voir précisément ce que le modèle apprend. La résolution des problèmes d’optimisation suppose que les données sont homogènes (elles suivent la même lois) et indépendantes.
Supervisés#
Regression#
add_notebook_menu(menu_id="reg", first_level=3, last_level=4, keep_item=0)
données#
, avec  et
et
 .
.
sortie#
 ,
, 
optimisation#

Dans le cas standard, la fonction d’erreur est quadratique :
 et correspond au
problème de modélisation
et correspond au
problème de modélisation  avec
avec
 bruit gaussien.
bruit gaussien.
évaluation#

exemple#
import numpy.random
X = numpy.random.random((100, 1))
xx = numpy.random.normal(size=(100, 1)) / 10
Y = X*X + xx
fig, ax = plt.subplots()
ax.plot(X, Y, ".", label="data")
ax.legend()
ax.set_title("Courbe façon nuage de points");
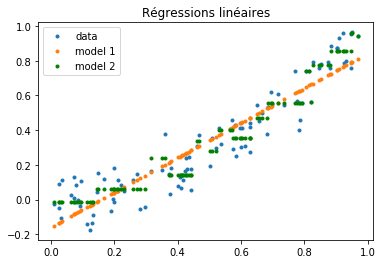
On compare deux modèles, une régression linéaire et un arbre de décision.
# model 1
from sklearn.linear_model import LinearRegression
clr = LinearRegression()
clr.fit(X, Y)
Yp = clr.predict(X)
# model 2
from sklearn.tree import DecisionTreeRegressor
clr2 = DecisionTreeRegressor(max_depth=4)
clr2.fit(X, Y)
Yp2 = clr2.predict(X)
fig, ax = plt.subplots()
ax.plot(X, Y, ".", label="data")
ax.plot(X, Yp, ".", label="model 1")
ax.plot(X, Yp2, "g.", label="model 2")
ax.legend()
ax.set_title("Régressions linéaires");
graphe erreur XY#
fig, ax = plt.subplots()
ax.plot(Y, Yp, ".", label="model 1")
ax.plot(Y, Yp2, "g.", label="model 2")
mm = [numpy.min(Y), numpy.max(Y)]
ax.plot(mm, mm,"--")
ax.set_xlabel("Y attendu")
ax.set_ylabel("Y prédit")
ax.legend()
ax.set_title("Régression linéaire");
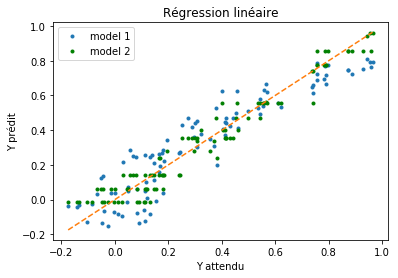
Plus ce nuage est confondu avec la droite, plus il est performant. S’il y a trop de points, on peut trier les erreurs par ordre croissant :
err1 = ((Y - Yp)).reshape((len(Y),))
err1.sort()
err2 = ((Y - Yp2.reshape((len(Y), 1)))).reshape((len(Y),))
err2.sort()
fig, ax = plt.subplots()
ax.plot(err1, label="model 1")
ax.plot(err2, label="model 2")
ax.set_xlabel("observations")
ax.set_ylabel("erreur")
ax.set_title("Répartition des erreurs");
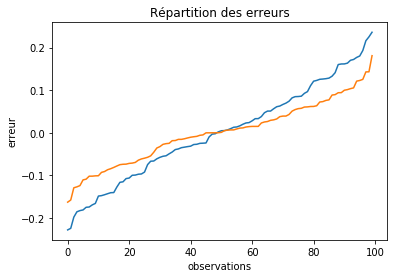
L’erreur correspond alors à l’aire sous la courbe.
Classification binaire#
add_notebook_menu(menu_id="classif", first_level=3, last_level=4, keep_item=1)
données#
, avec et
 .
.
sortie#
 avec
avec  la classe prédite et
la classe prédite et
![p_i^c \in [0,1]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSA0OC4xMDYzMTQgMTEuOTU1MTY4JyB3aWR0aD0nNDguMTA2MzE0cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTUuMzU1OTE1IC0zLjgyNTY1NEM1LjM1NTkxNSAtNC44MTc5MzMgNS4yOTYxMzkgLTUuNzg2MzAxIDQuODY1NzUzIC02LjY5NDg5NEM0LjM3NTU5MiAtNy42ODcxNzMgMy41MTQ4MTkgLTcuOTUwMTg3IDIuOTI5MDE2IC03Ljk1MDE4N0MyLjIzNTYxNiAtNy45NTAxODcgMS4zODY4IC03LjYwMzQ4NyAwLjk0NDQ1OCAtNi42MTEyMDhDMC42MDk3MTQgLTUuODU4MDMyIDAuNDkwMTYyIC01LjExNjgxMiAwLjQ5MDE2MiAtMy44MjU2NTRDMC40OTAxNjIgLTIuNjY2MDAyIDAuNTczODQ4IC0xLjc5MzI3NSAxLjAwNDIzNCAtMC45NDQ0NThDMS40NzA0ODYgLTAuMDM1ODY2IDIuMjk1MzkyIDAuMjUxMDU5IDIuOTE3MDYxIDAuMjUxMDU5QzMuOTU3MTYxIDAuMjUxMDU5IDQuNTU0OTE5IC0wLjM3MDYxIDQuOTAxNjE5IC0xLjA2NDAxQzUuMzMyMDA1IC0xLjk2MDY0OCA1LjM1NTkxNSAtMy4xMzIyNTQgNS4zNTU5MTUgLTMuODI1NjU0Wk0yLjkxNzA2MSAwLjAxMTk1NUMyLjUzNDQ5NiAwLjAxMTk1NSAxLjc1NzQxIC0wLjIwMzIzOCAxLjUzMDI2MiAtMS41MDYzNTFDMS4zOTg3NTUgLTIuMjIzNjYxIDEuMzk4NzU1IC0zLjEzMjI1NCAxLjM5ODc1NSAtMy45NjkxMTZDMS4zOTg3NTUgLTQuOTQ5NDQgMS4zOTg3NTUgLTUuODM0MTIyIDEuNTkwMDM3IC02LjUzOTQ3N0MxLjc5MzI3NSAtNy4zNDA0NzMgMi40MDI5ODkgLTcuNzExMDgzIDIuOTE3MDYxIC03LjcxMTA4M0MzLjM3MTM1NyAtNy43MTEwODMgNC4wNjQ3NTcgLTcuNDM2MTE1IDQuMjkxOTA1IC02LjQwNzk3QzQuNDQ3MzIzIC01LjcyNjUyNiA0LjQ0NzMyMyAtNC43ODIwNjcgNC40NDczMjMgLTMuOTY5MTE2QzQuNDQ3MzIzIC0zLjE2ODEyIDQuNDQ3MzIzIC0yLjI1OTUyNyA0LjMxNTgxNiAtMS41MzAyNjJDNC4wODg2NjcgLTAuMjE1MTkzIDMuMzM1NDkyIDAuMDExOTU1IDIuOTE3MDYxIDAuMDExOTU1WicgaWQ9J2czLTQ4Jy8+CjxwYXRoIGQ9J00zLjQ0MzA4OCAtNy42NjMyNjNDMy40NDMwODggLTcuOTM4MjMyIDMuNDQzMDg4IC03Ljk1MDE4NyAzLjIwMzk4NSAtNy45NTAxODdDMi45MTcwNjEgLTcuNjI3Mzk3IDIuMzE5MzAzIC03LjE4NTA1NiAxLjA4NzkyIC03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODkgLTYuODM4MzU2IDEuOTYwNjQ4IC02LjgzODM1NiAyLjYxODE4MiAtNy4xNDkxOTFWLTAuOTIwNTQ4QzIuNjE4MTgyIC0wLjQ5MDE2MiAyLjU4MjMxNiAtMC4zNDY3IDEuNTMwMjYyIC0wLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MSAtMC4wMjM5MSAyLjY0MjA5MiAtMC4wMjM5MSAzLjAzNjYxMyAtMC4wMjM5MVM0LjU3ODgyOSAtMC4wMjM5MSA0LjkwMTYxOSAwVi0wLjM0NjdINC41MzEwMDlDMy40Nzg5NTQgLTAuMzQ2NyAzLjQ0MzA4OCAtMC40OTAxNjIgMy40NDMwODggLTAuOTIwNTQ4Vi03LjY2MzI2M1onIGlkPSdnMy00OScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzMtOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzMtOTMnLz4KPHBhdGggZD0nTTYuNTUxNDMyIC0yLjc0OTY4OUM2Ljc1NDY3IC0yLjc0OTY4OSA2Ljk2OTg2MyAtMi43NDk2ODkgNi45Njk4NjMgLTIuOTg4NzkyUzYuNzU0NjcgLTMuMjI3ODk1IDYuNTUxNDMyIC0zLjIyNzg5NUgxLjQ4MjQ0MUMxLjYyNTkwMyAtNC44Mjk4ODggMy4wMDA3NDcgLTUuOTc3NTg0IDQuNjg2NDI2IC01Ljk3NzU4NEg2LjU1MTQzMkM2Ljc1NDY3IC01Ljk3NzU4NCA2Ljk2OTg2MyAtNS45Nzc1ODQgNi45Njk4NjMgLTYuMjE2Njg3UzYuNzU0NjcgLTYuNDU1NzkxIDYuNTUxNDMyIC02LjQ1NTc5MUg0LjY2MjUxNkMyLjYxODE4MiAtNi40NTU3OTEgMC45OTIyNzkgLTQuOTAxNjE5IDAuOTkyMjc5IC0yLjk4ODc5MlMyLjYxODE4MiAwLjQ3ODIwNyA0LjY2MjUxNiAwLjQ3ODIwN0g2LjU1MTQzMkM2Ljc1NDY3IDAuNDc4MjA3IDYuOTY5ODYzIDAuNDc4MjA3IDYuOTY5ODYzIDAuMjM5MTAzUzYuNzU0NjcgMCA2LjU1MTQzMiAwSDQuNjg2NDI2QzMuMDAwNzQ3IDAgMS42MjU5MDMgLTEuMTQ3Njk2IDEuNDgyNDQxIC0yLjc0OTY4OUg2LjU1MTQzMlonIGlkPSdnMC01MCcvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzItNTknLz4KPHBhdGggZD0nTTAuNTE0MDcyIDEuNTE4MzA2QzAuNDMwMzg2IDEuODc2OTYxIDAuMzgyNTY1IDEuOTcyNjAzIC0wLjEwNzU5NyAxLjk3MjYwM0MtMC4yNTEwNTkgMS45NzI2MDMgLTAuMzcwNjEgMS45NzI2MDMgLTAuMzcwNjEgMi4xOTk3NTFDLTAuMzcwNjEgMi4yMjM2NjEgLTAuMzU4NjU1IDIuMzE5MzAzIC0wLjIyNzE0OCAyLjMxOTMwM0MtMC4wNzE3MzEgMi4zMTkzMDMgMC4wOTU2NDEgMi4yOTUzOTIgMC4yNTEwNTkgMi4yOTUzOTJIMC43NjUxMzFDMS4wMTYxODkgMi4yOTUzOTIgMS42MjU5MDMgMi4zMTkzMDMgMS44NzY5NjEgMi4zMTkzMDNDMS45NDg2OTIgMi4zMTkzMDMgMi4wOTIxNTQgMi4zMTkzMDMgMi4wOTIxNTQgMi4xMDQxMUMyLjA5MjE1NCAxLjk3MjYwMyAyLjAwODQ2OCAxLjk3MjYwMyAxLjgwNTIzIDEuOTcyNjAzQzEuMjU1MjkzIDEuOTcyNjAzIDEuMjE5NDI3IDEuODg4OTE3IDEuMjE5NDI3IDEuNzkzMjc1QzEuMjE5NDI3IDEuNjQ5ODEzIDEuNzU3NDEgLTAuNDA2NDc2IDEuODI5MTQxIC0wLjY4MTQ0NUMxLjk2MDY0OCAtMC4zNDY3IDIuMjgzNDM3IDAuMTE5NTUyIDIuOTA1MTA2IDAuMTE5NTUyQzQuMjU2MDQgMC4xMTk1NTIgNS43MTQ1NyAtMS42Mzc4NTggNS43MTQ1NyAtMy4zOTUyNjhDNS43MTQ1NyAtNC40OTUxNDMgNS4wOTI5MDIgLTUuMjcyMjI5IDQuMTk2MjY0IC01LjI3MjIyOUMzLjQzMTEzMyAtNS4yNzIyMjkgMi43ODU1NTQgLTQuNTMxMDA5IDIuNjU0MDQ3IC00LjM2MzYzNkMyLjU1ODQwNiAtNC45NjEzOTUgMi4wOTIxNTQgLTUuMjcyMjI5IDEuNjEzOTQ4IC01LjI3MjIyOUMxLjI2NzI0OCAtNS4yNzIyMjkgMC45OTIyNzkgLTUuMTA0ODU3IDAuNzY1MTMxIC00LjY1MDU2QzAuNTQ5OTM4IC00LjIyMDE3NCAwLjM4MjU2NSAtMy40OTA5MDkgMC4zODI1NjUgLTMuNDQzMDg4UzAuNDMwMzg2IC0zLjMzNTQ5MiAwLjUxNDA3MiAtMy4zMzU0OTJDMC42MDk3MTQgLTMuMzM1NDkyIDAuNjIxNjY5IC0zLjM0NzQ0NyAwLjY5MzQgLTMuNjIyNDE2QzAuODcyNzI3IC00LjMyNzc3MSAxLjA5OTg3NSAtNS4wMzMxMjYgMS41NzgwODIgLTUuMDMzMTI2QzEuODUzMDUxIC01LjAzMzEyNiAxLjk0ODY5MiAtNC44NDE4NDMgMS45NDg2OTIgLTQuNDgzMTg4QzEuOTQ4NjkyIC00LjE5NjI2NCAxLjkxMjgyNyAtNC4wNzY3MTIgMS44NjUwMDYgLTMuODYxNTE5TDAuNTE0MDcyIDEuNTE4MzA2Wk0yLjU4MjMxNiAtMy43MzAwMTJDMi42NjYwMDIgLTQuMDY0NzU3IDMuMDAwNzQ3IC00LjQxMTQ1NyAzLjE5MjAzIC00LjU3ODgyOUMzLjMyMzUzNyAtNC42OTgzODEgMy43MTgwNTcgLTUuMDMzMTI2IDQuMTcyMzU0IC01LjAzMzEyNkM0LjY5ODM4MSAtNS4wMzMxMjYgNC45Mzc0ODQgLTQuNTA3MDk4IDQuOTM3NDg0IC0zLjg4NTQzQzQuOTM3NDg0IC0zLjMxMTU4MiA0LjYwMjc0IC0xLjk2MDY0OCA0LjMwMzg2MSAtMS4zMzg5NzlDNC4wMDQ5ODEgLTAuNjkzNCAzLjQ1NTA0NCAtMC4xMTk1NTIgMi45MDUxMDYgLTAuMTE5NTUyQzIuMDkyMTU0IC0wLjExOTU1MiAxLjk2MDY0OCAtMS4xNDc2OTYgMS45NjA2NDggLTEuMTk1NTE3QzEuOTYwNjQ4IC0xLjIzMTM4MiAxLjk4NDU1OCAtMS4zMjcwMjQgMS45OTY1MTMgLTEuMzg2OEwyLjU4MjMxNiAtMy43MzAwMTJaJyBpZD0nZzItMTEyJy8+CjxwYXRoIGQ9J00zLjI1OTc3NiAtMy4wNTI1NTNDMi45MzMwMDEgLTMuMDEyNzAyIDIuODI5MzkgLTIuNzY1NjI5IDIuODI5MzkgLTIuNjA2MjI3QzIuODI5MzkgLTIuMzc1MDkzIDMuMDM2NjEzIC0yLjMxMTMzMyAzLjE0MDIyNCAtMi4zMTEzMzNDMy4xODAwNzUgLTIuMzExMzMzIDMuNTg2NTUgLTIuMzQzMjEzIDMuNTg2NTUgLTIuODI5MzlTMy4wNjA1MjMgLTMuNTE0ODE5IDIuNTgyMzE2IC0zLjUxNDgxOUMxLjQ1MDU2IC0zLjUxNDgxOSAwLjM1MDY4NSAtMi40MTQ5NDQgMC4zNTA2ODUgLTEuMjk5MTI4QzAuMzUwNjg1IC0wLjU0MTk2OCAwLjg2ODc0MiAwLjA3OTcwMSAxLjc1MzQyNSAwLjA3OTcwMUMzLjAxMjcwMiAwLjA3OTcwMSAzLjY3NDIyMiAtMC43MjUyOCAzLjY3NDIyMiAtMC44Mjg4OTJDMy42NzQyMjIgLTAuOTAwNjIzIDMuNTk0NTIxIC0wLjk1NjQxMyAzLjU0NjcgLTAuOTU2NDEzUzMuNDc0OTY5IC0wLjkzMjUwMyAzLjQzNTExOCAtMC44ODQ2ODJDMi44MDU0NzkgLTAuMTQzNDYyIDEuOTEyODI3IC0wLjE0MzQ2MiAxLjc2OTM2NSAtMC4xNDM0NjJDMS4zMzg5NzkgLTAuMTQzNDYyIDAuOTk2MjY0IC0wLjQwNjQ3NiAwLjk5NjI2NCAtMS4wMTIyMDRDMC45OTYyNjQgLTEuMzYyODg5IDEuMTU1NjY2IC0yLjIwNzcyMSAxLjUzMDI2MiAtMi43MDE4NjhDMS44ODA5NDYgLTMuMTQ4MTk0IDIuMjc5NDUyIC0zLjI5MTY1NiAyLjU5MDI4NiAtMy4yOTE2NTZDMi42ODU5MjggLTMuMjkxNjU2IDMuMDUyNTUzIC0zLjI4MzY4NiAzLjI1OTc3NiAtMy4wNTI1NTNaJyBpZD0nZzEtOTknLz4KPHBhdGggZD0nTTIuMzc1MDkzIC00Ljk3MzM1QzIuMzc1MDkzIC01LjE0ODY5MiAyLjI0NzU3MiAtNS4yNzYyMTQgMi4wNjQyNTkgLTUuMjc2MjE0QzEuODU3MDM2IC01LjI3NjIxNCAxLjYyNTkwMyAtNS4wODQ5MzIgMS42MjU5MDMgLTQuODQ1ODI4QzEuNjI1OTAzIC00LjY3MDQ4NiAxLjc1MzQyNSAtNC41NDI5NjQgMS45MzY3MzcgLTQuNTQyOTY0QzIuMTQzOTYgLTQuNTQyOTY0IDIuMzc1MDkzIC00LjczNDI0NyAyLjM3NTA5MyAtNC45NzMzNVpNMS4yMTE0NTcgLTIuMDQ4MzE5TDAuNzgxMDcxIC0wLjk0ODQ0M0MwLjc0MTIyIC0wLjgyODg5MiAwLjcwMTM3IC0wLjczMzI1IDAuNzAxMzcgLTAuNTk3NzU4QzAuNzAxMzcgLTAuMjA3MjIzIDEuMDA0MjM0IDAuMDc5NzAxIDEuNDI2NjUgMC4wNzk3MDFDMi4xOTk3NTEgMC4wNzk3MDEgMi41MjY1MjYgLTEuMDM2MTE1IDIuNTI2NTI2IC0xLjEzOTcyNkMyLjUyNjUyNiAtMS4yMTk0MjcgMi40NjI3NjUgLTEuMjQzMzM3IDIuNDA2OTc0IC0xLjI0MzMzN0MyLjMxMTMzMyAtMS4yNDMzMzcgMi4yOTUzOTIgLTEuMTg3NTQ3IDIuMjcxNDgyIC0xLjEwNzg0NkMyLjA4ODE2OSAtMC40NzAyMzcgMS43NjEzOTUgLTAuMTQzNDYyIDEuNDQyNTkgLTAuMTQzNDYyQzEuMzQ2OTQ5IC0wLjE0MzQ2MiAxLjI1MTMwOCAtMC4xODMzMTMgMS4yNTEzMDggLTAuMzk4NTA2QzEuMjUxMzA4IC0wLjU4OTc4OCAxLjMwNzA5OCAtMC43MzMyNSAxLjQxMDcxIC0wLjk4MDMyNEMxLjQ5MDQxMSAtMS4xOTU1MTcgMS41NzAxMTIgLTEuNDEwNzEgMS42NTc3ODMgLTEuNjI1OTAzTDEuOTA0ODU3IC0yLjI3MTQ4MkMxLjk3NjU4OCAtMi40NTQ3OTUgMi4wNzIyMjkgLTIuNzAxODY4IDIuMDcyMjI5IC0yLjgzNzM2QzIuMDcyMjI5IC0zLjIzNTg2NiAxLjc1MzQyNSAtMy41MTQ4MTkgMS4zNDY5NDkgLTMuNTE0ODE5QzAuNTczODQ4IC0zLjUxNDgxOSAwLjIzOTEwMyAtMi4zOTkwMDQgMC4yMzkxMDMgLTIuMjk1MzkyQzAuMjM5MTAzIC0yLjIyMzY2MSAwLjI5NDg5NCAtMi4xOTE3ODEgMC4zNTg2NTUgLTIuMTkxNzgxQzAuNDYyMjY3IC0yLjE5MTc4MSAwLjQ3MDIzNyAtMi4yMzk2MDEgMC40OTQxNDcgLTIuMzE5MzAzQzAuNzE3MzEgLTMuMDc2NDYzIDEuMDgzOTM1IC0zLjI5MTY1NiAxLjMyMzAzOSAtMy4yOTE2NTZDMS40MzQ2MiAtMy4yOTE2NTYgMS41MTQzMjEgLTMuMjUxODA2IDEuNTE0MzIxIC0zLjAyODY0M0MxLjUxNDMyMSAtMi45NDg5NDEgMS41MDYzNTEgLTIuODM3MzYgMS40MjY2NSAtMi41OTgyNTdMMS4yMTE0NTcgLTIuMDQ4MzE5WicgaWQ9J2cxLTEwNScvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nNTYuNDEzMjY3JyB4bGluazpocmVmPScjZzItMTEyJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2Mi4yODg0MScgeGxpbms6aHJlZj0nI2cxLTk5JyB5PSc2MS40MTQ5ODgnLz4KPHVzZSB4PSc2Mi4yODg0MScgeGxpbms6aHJlZj0nI2cxLTEwNScgeT0nNjguNzA4OTQnLz4KPHVzZSB4PSc2OS43NzUxNTEnIHhsaW5rOmhyZWY9JyNnMC01MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODEuMDY2MTE5JyB4bGluazpocmVmPScjZzMtOTEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzg0LjMxNzc4JyB4bGluazpocmVmPScjZzMtNDgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzkwLjE3MDc3MScgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5NS40MTQ5MycgeGxpbms6aHJlZj0nI2czLTQ5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMDEuMjY3OTInIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) la probabilité d’appartenance à la classe
la probabilité d’appartenance à la classe
 ou score de confiance.
ou score de confiance.  et
et
 .
.
optimisation#
Le problème d’optimisation dépend du modèle. On note
 , la probabilité que
, la probabilité que
 appartienne la la classe 1.
appartienne la la classe 1.
régression logistique
On optimise la vraisemblance déterminée par
 .
.
arbre
On écrit rarement le critère à optimiser pour l’arbre dans sa totalité
mais seulement pour une feuille de l’arbre qu’on cherche à découper. On
optimise une métrique
(Gini,
entropie,
variance).
Si on note  la proportion d’éléments bien classés par cette
feuille. Le critère optimisé est :
la proportion d’éléments bien classés par cette
feuille. Le critère optimisé est :  .
.
from pyquickhelper.helpgen import NbImage
NbImage("dt.png", width=600)

La pertinence de la division d’un noeud de l’arbre consiste à trouver un
seuil de coupure pour une variable qui diminue le critère d’impureté
 . Dans le cas de cette arbre :
. Dans le cas de cette arbre :

évaluation#
exemple#
import numpy.random
X = numpy.random.normal(size=(100, 2))
Y = numpy.random.randint(2, size=(100, ))
X[Y==1,0] += 1.2
X[Y==1,1] += 1.2
fix, ax = plt.subplots()
ax.plot(X[Y==0,0], X[Y==0,1], "o")
ax.plot(X[Y==1,0], X[Y==1,1], "o")
ax.set_title("Nuage de points avec deux classes");
# model 1
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X, Y)
Yp = clf.predict(X)
# model 1
from sklearn.tree import DecisionTreeClassifier
clf2 = DecisionTreeClassifier(max_depth=3)
clf2.fit(X, Y)
Yp2 = clf2.predict(X)
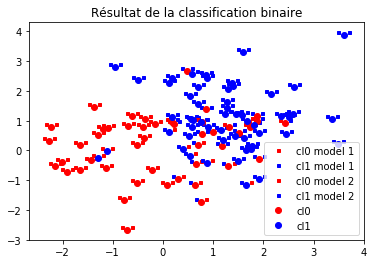
fig, ax = plt.subplots()
ax.plot(X[Yp==0,0]+0.1, X[Yp==0,1]+0.1, "rs", label="cl0 model 1", ms=3)
ax.plot(X[Yp==1,0]+0.1, X[Yp==1,1]+0.1, "bs", label="cl1 model 1", ms=3)
ax.plot(X[Yp2==0,0]-0.1, X[Yp2==0,1]+0.1, "rs", label="cl0 model 2", ms=3)
ax.plot(X[Yp2==1,0]-0.1, X[Yp2==1,1]+0.1, "bs", label="cl1 model 2", ms=3)
ax.plot(X[Y==0,0], X[Y==0,1], "ro", label="cl0")
ax.plot(X[Y==1,0], X[Y==1,1], "bo", label="cl1")
ax.legend()
ax.set_title("Résultat de la classification binaire");
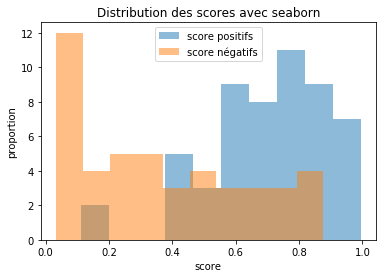
distribution des scores#
from sklearn.metrics import roc_curve, auc
Ypr = clf.predict_proba(X)
score_pos = Ypr[Y == 1, 1]
score_neg = Ypr[Y == 0, 1]
import numpy
numpy.average(score_neg), numpy.average(score_pos)
(0.36854464309856544, 0.7010128988674563)
On utilise seaborn.
f, ax = plt.subplots()
ax.hist(score_pos, label="score positifs", alpha=0.5)
ax.hist(score_neg, label="score négatifs", alpha=0.5)
ax.set_xlabel("score")
ax.set_ylabel("proportion")
ax.legend()
ax.set_title("Distribution des scores avec seaborn");
graphe erreur ROC#
from sklearn.metrics import roc_curve, auc
# model 1
Ypr = clf.predict_proba(X)
fpr, tpr, thresholds = roc_curve(Y, Ypr[:,1]) # on choisit la classe 1
# model 2
Ypr2 = clf2.predict_proba(X)
fpr2, tpr2, thresholds2 = roc_curve(Y, Ypr2[:,1]) # on choisit la classe 1
auc(fpr, tpr), auc(fpr2, tpr2)
(0.8337359098228664, 0.8836553945249597)
import pandas
df = pandas.DataFrame({"seuil":thresholds, "fpr":fpr, "tpr": tpr })[["seuil", "fpr", "tpr"]]
pandas.concat([df.head(), df.tail()])
| seuil | fpr | tpr | |
|---|---|---|---|
| 0 | 0.994020 | 0.000000 | 0.018519 |
| 1 | 0.878538 | 0.000000 | 0.203704 |
| 2 | 0.876186 | 0.021739 | 0.203704 |
| 3 | 0.844416 | 0.021739 | 0.277778 |
| 4 | 0.837452 | 0.043478 | 0.277778 |
| 28 | 0.166698 | 0.739130 | 0.962963 |
| 29 | 0.143926 | 0.739130 | 0.981481 |
| 30 | 0.111130 | 0.782609 | 0.981481 |
| 31 | 0.110802 | 0.782609 | 1.000000 |
| 32 | 0.032959 | 1.000000 | 1.000000 |
fix, ax = plt.subplots()
ax.plot(fpr, tpr, ".-", label="model 1 auc=%0.2f" % auc(fpr, tpr))
ax.plot(fpr2, tpr2, ".-", label="model 2 auc=%0.2f" % auc(fpr2, tpr2))
ax.set_xlabel("FPR = False Positive Rate")
ax.set_ylabel("TPR = True Positive Rate")
ax.legend()
ax.set_title("Courbe ROC");
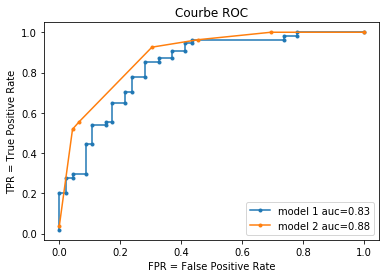
La courbe ROC est définie par l’ensemble des points
 pour
pour ![s \in [0,1]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSA0My41NzkyNjUgMTEuOTU1MTY4JyB3aWR0aD0nNDMuNTc5MjY1cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTUuMzU1OTE1IC0zLjgyNTY1NEM1LjM1NTkxNSAtNC44MTc5MzMgNS4yOTYxMzkgLTUuNzg2MzAxIDQuODY1NzUzIC02LjY5NDg5NEM0LjM3NTU5MiAtNy42ODcxNzMgMy41MTQ4MTkgLTcuOTUwMTg3IDIuOTI5MDE2IC03Ljk1MDE4N0MyLjIzNTYxNiAtNy45NTAxODcgMS4zODY4IC03LjYwMzQ4NyAwLjk0NDQ1OCAtNi42MTEyMDhDMC42MDk3MTQgLTUuODU4MDMyIDAuNDkwMTYyIC01LjExNjgxMiAwLjQ5MDE2MiAtMy44MjU2NTRDMC40OTAxNjIgLTIuNjY2MDAyIDAuNTczODQ4IC0xLjc5MzI3NSAxLjAwNDIzNCAtMC45NDQ0NThDMS40NzA0ODYgLTAuMDM1ODY2IDIuMjk1MzkyIDAuMjUxMDU5IDIuOTE3MDYxIDAuMjUxMDU5QzMuOTU3MTYxIDAuMjUxMDU5IDQuNTU0OTE5IC0wLjM3MDYxIDQuOTAxNjE5IC0xLjA2NDAxQzUuMzMyMDA1IC0xLjk2MDY0OCA1LjM1NTkxNSAtMy4xMzIyNTQgNS4zNTU5MTUgLTMuODI1NjU0Wk0yLjkxNzA2MSAwLjAxMTk1NUMyLjUzNDQ5NiAwLjAxMTk1NSAxLjc1NzQxIC0wLjIwMzIzOCAxLjUzMDI2MiAtMS41MDYzNTFDMS4zOTg3NTUgLTIuMjIzNjYxIDEuMzk4NzU1IC0zLjEzMjI1NCAxLjM5ODc1NSAtMy45NjkxMTZDMS4zOTg3NTUgLTQuOTQ5NDQgMS4zOTg3NTUgLTUuODM0MTIyIDEuNTkwMDM3IC02LjUzOTQ3N0MxLjc5MzI3NSAtNy4zNDA0NzMgMi40MDI5ODkgLTcuNzExMDgzIDIuOTE3MDYxIC03LjcxMTA4M0MzLjM3MTM1NyAtNy43MTEwODMgNC4wNjQ3NTcgLTcuNDM2MTE1IDQuMjkxOTA1IC02LjQwNzk3QzQuNDQ3MzIzIC01LjcyNjUyNiA0LjQ0NzMyMyAtNC43ODIwNjcgNC40NDczMjMgLTMuOTY5MTE2QzQuNDQ3MzIzIC0zLjE2ODEyIDQuNDQ3MzIzIC0yLjI1OTUyNyA0LjMxNTgxNiAtMS41MzAyNjJDNC4wODg2NjcgLTAuMjE1MTkzIDMuMzM1NDkyIDAuMDExOTU1IDIuOTE3MDYxIDAuMDExOTU1WicgaWQ9J2cyLTQ4Jy8+CjxwYXRoIGQ9J00zLjQ0MzA4OCAtNy42NjMyNjNDMy40NDMwODggLTcuOTM4MjMyIDMuNDQzMDg4IC03Ljk1MDE4NyAzLjIwMzk4NSAtNy45NTAxODdDMi45MTcwNjEgLTcuNjI3Mzk3IDIuMzE5MzAzIC03LjE4NTA1NiAxLjA4NzkyIC03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODkgLTYuODM4MzU2IDEuOTYwNjQ4IC02LjgzODM1NiAyLjYxODE4MiAtNy4xNDkxOTFWLTAuOTIwNTQ4QzIuNjE4MTgyIC0wLjQ5MDE2MiAyLjU4MjMxNiAtMC4zNDY3IDEuNTMwMjYyIC0wLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MSAtMC4wMjM5MSAyLjY0MjA5MiAtMC4wMjM5MSAzLjAzNjYxMyAtMC4wMjM5MVM0LjU3ODgyOSAtMC4wMjM5MSA0LjkwMTYxOSAwVi0wLjM0NjdINC41MzEwMDlDMy40Nzg5NTQgLTAuMzQ2NyAzLjQ0MzA4OCAtMC40OTAxNjIgMy40NDMwODggLTAuOTIwNTQ4Vi03LjY2MzI2M1onIGlkPSdnMi00OScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzItOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzItOTMnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2cxLTU5Jy8+CjxwYXRoIGQ9J00yLjcyNTc3OCAtMi4zOTEwMzRDMi45MjkwMTYgLTIuMzU1MTY4IDMuMjUxODA2IC0yLjI4MzQzNyAzLjMyMzUzNyAtMi4yNzE0ODJDMy40Nzg5NTQgLTIuMjIzNjYxIDQuMDE2OTM2IC0yLjAzMjM3OSA0LjAxNjkzNiAtMS40NTg1MzFDNC4wMTY5MzYgLTEuMDg3OTIgMy42ODIxOTIgLTAuMTE5NTUyIDIuMjk1MzkyIC0wLjExOTU1MkMyLjA0NDMzNCAtMC4xMTk1NTIgMS4xNDc2OTYgLTAuMTU1NDE3IDAuOTA4NTkzIC0wLjgxMjk1MUMxLjM4NjggLTAuNzUzMTc2IDEuNjI1OTAzIC0xLjEyMzc4NiAxLjYyNTkwMyAtMS4zODY4QzEuNjI1OTAzIC0xLjYzNzg1OCAxLjQ1ODUzMSAtMS43NjkzNjUgMS4yMTk0MjcgLTEuNzY5MzY1QzAuOTU2NDEzIC0xLjc2OTM2NSAwLjYwOTcxNCAtMS41NjYxMjcgMC42MDk3MTQgLTEuMDI4MTQ0QzAuNjA5NzE0IC0wLjMyMjc5IDEuMzI3MDI0IDAuMTE5NTUyIDIuMjgzNDM3IDAuMTE5NTUyQzQuMTAwNjIzIDAuMTE5NTUyIDQuNjM4NjA1IC0xLjIxOTQyNyA0LjYzODYwNSAtMS44NDEwOTZDNC42Mzg2MDUgLTIuMDIwNDIzIDQuNjM4NjA1IC0yLjM1NTE2OCA0LjI1NjA0IC0yLjczNzczM0MzLjk1NzE2MSAtMy4wMjQ2NTggMy42NzAyMzcgLTMuMDg0NDMzIDMuMDI0NjU4IC0zLjIxNTk0QzIuNzAxODY4IC0zLjI4NzY3MSAyLjE4Nzc5NiAtMy4zOTUyNjggMi4xODc3OTYgLTMuOTMzMjVDMi4xODc3OTYgLTQuMTcyMzU0IDIuNDAyOTg5IC01LjAzMzEyNiAzLjUzODczIC01LjAzMzEyNkM0LjA0MDg0NyAtNS4wMzMxMjYgNC41MzEwMDkgLTQuODQxODQzIDQuNjUwNTYgLTQuNDExNDU3QzQuMTI0NTMzIC00LjQxMTQ1NyA0LjEwMDYyMyAtMy45NTcxNjEgNC4xMDA2MjMgLTMuOTQ1MjA1QzQuMTAwNjIzIC0zLjY5NDE0NyA0LjMyNzc3MSAtMy42MjI0MTYgNC40MzUzNjcgLTMuNjIyNDE2QzQuNjAyNzQgLTMuNjIyNDE2IDQuOTM3NDg0IC0zLjc1MzkyMyA0LjkzNzQ4NCAtNC4yNTYwNFM0LjQ4MzE4OCAtNS4yNzIyMjkgMy41NTA2ODUgLTUuMjcyMjI5QzEuOTg0NTU4IC01LjI3MjIyOSAxLjU2NjEyNyAtNC4wNDA4NDcgMS41NjYxMjcgLTMuNTUwNjg1QzEuNTY2MTI3IC0yLjY0MjA5MiAyLjQ1MDgwOSAtMi40NTA4MDkgMi43MjU3NzggLTIuMzkxMDM0WicgaWQ9J2cxLTExNScvPgo8cGF0aCBkPSdNNi41NTE0MzIgLTIuNzQ5Njg5QzYuNzU0NjcgLTIuNzQ5Njg5IDYuOTY5ODYzIC0yLjc0OTY4OSA2Ljk2OTg2MyAtMi45ODg3OTJTNi43NTQ2NyAtMy4yMjc4OTUgNi41NTE0MzIgLTMuMjI3ODk1SDEuNDgyNDQxQzEuNjI1OTAzIC00LjgyOTg4OCAzLjAwMDc0NyAtNS45Nzc1ODQgNC42ODY0MjYgLTUuOTc3NTg0SDYuNTUxNDMyQzYuNzU0NjcgLTUuOTc3NTg0IDYuOTY5ODYzIC01Ljk3NzU4NCA2Ljk2OTg2MyAtNi4yMTY2ODdTNi43NTQ2NyAtNi40NTU3OTEgNi41NTE0MzIgLTYuNDU1NzkxSDQuNjYyNTE2QzIuNjE4MTgyIC02LjQ1NTc5MSAwLjk5MjI3OSAtNC45MDE2MTkgMC45OTIyNzkgLTIuOTg4NzkyUzIuNjE4MTgyIDAuNDc4MjA3IDQuNjYyNTE2IDAuNDc4MjA3SDYuNTUxNDMyQzYuNzU0NjcgMC40NzgyMDcgNi45Njk4NjMgMC40NzgyMDcgNi45Njk4NjMgMC4yMzkxMDNTNi43NTQ2NyAwIDYuNTUxNDMyIDBINC42ODY0MjZDMy4wMDA3NDcgMCAxLjYyNTkwMyAtMS4xNDc2OTYgMS40ODI0NDEgLTIuNzQ5Njg5SDYuNTUxNDMyWicgaWQ9J2cwLTUwJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHhsaW5rOmhyZWY9JyNnMS0xMTUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY1LjI0ODEwMicgeGxpbms6aHJlZj0nI2cwLTUwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3Ni41MzkwNycgeGxpbms6aHJlZj0nI2cyLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3OS43OTA3MzInIHhsaW5rOmhyZWY9JyNnMi00OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODUuNjQzNzIyJyB4bGluazpocmVmPScjZzEtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzkwLjg4Nzg4MScgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5Ni43NDA4NzEnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) . Le score de
classification désigne le score de la classe de classification dans la
classe 1. Pour un seuil
. Le score de
classification désigne le score de la classe de classification dans la
classe 1. Pour un seuil  , on note:
, on note:
 est l’ensemble des observations pour lesquelles le score
de classification est supérieur à et la réponse attendue
est 1
est l’ensemble des observations pour lesquelles le score
de classification est supérieur à et la réponse attendue
est 1 est l’ensemble des observations pour lesquelles le score
de classification est supérieur à et la réponse attendue
est 0
est l’ensemble des observations pour lesquelles le score
de classification est supérieur à et la réponse attendue
est 0 est l’ensemble des observations pour lesquelles le
score de classification est supérieur à et la prédiction
est 1 et la classe attendue est 1
est l’ensemble des observations pour lesquelles le
score de classification est supérieur à et la prédiction
est 1 et la classe attendue est 1 est l’ensemble des observations pour lesquelles le
score de classification est supérieur à et la prédiction
est 0 et la classe attendue 0
est l’ensemble des observations pour lesquelles le
score de classification est supérieur à et la prédiction
est 0 et la classe attendue 0
 et
et

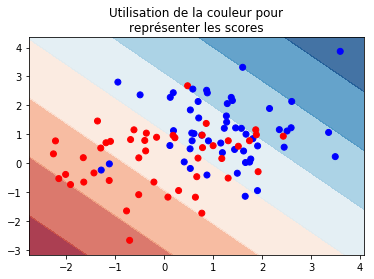
graphe frontière#
Si le nombre de features est supérieur à 2, il faut appliquer une ACP pour réduire les dimmensions.
# nuage de points
from matplotlib.colors import ListedColormap
cm = plt.cm.RdBu
cm_bright = ListedColormap(['#FF0000', '#0000FF'])
fig, ax = plt.subplots()
# grille
h = .02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = numpy.meshgrid(numpy.arange(x_min, x_max, h),
numpy.arange(y_min, y_max, h))
# valeur pour cette grille
if hasattr(clf, "decision_function"):
Z = clf.decision_function(numpy.c_[xx.ravel(), yy.ravel()])
else:
Z = clf.predict_proba(numpy.c_[xx.ravel(), yy.ravel()])[:, 1]
#
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
ax.scatter(X[:, 0], X[:, 1], c=Y, cmap=cm_bright)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_title("Utilisation de la couleur pour\nreprésenter les scores");
# nuage de points
from matplotlib.colors import ListedColormap
cm = plt.cm.RdBu
cm_bright = ListedColormap(['#FF0000', '#0000FF'])
fig, ax = plt.subplots()
# grille
h = .02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = numpy.meshgrid(numpy.arange(x_min, x_max, h),
numpy.arange(y_min, y_max, h))
# valeur pour cette grille
if hasattr(clf2, "decision_function"):
Z = clf2.decision_function(numpy.c_[xx.ravel(), yy.ravel()])
else:
Z = clf2.predict_proba(numpy.c_[xx.ravel(), yy.ravel()])[:, 1]
#
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
ax.scatter(X[:, 0], X[:, 1], c=Y, cmap=cm_bright)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_title("Couleur, score et arbres");
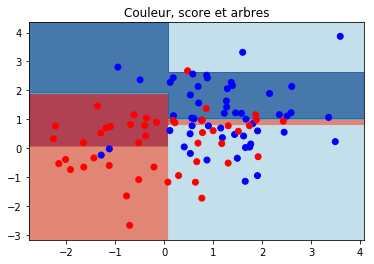
matrice de confusion#
from sklearn.metrics import confusion_matrix
confusion_matrix(Y, Yp)
array([[31, 15],
[ 7, 47]], dtype=int64)
confusion_matrix(Y, Yp2)
array([[32, 14],
[ 4, 50]], dtype=int64)
Plusieurs dimensions#
Régression#

Addition des erreurs sur les différentes dimensions
Classification#
 où
où  est un ensemble sur lequel il n’y a pas
de relation d’ordre.
est un ensemble sur lequel il n’y a pas
de relation d’ordre.
On transforme le problème en plusieurs problèmes de classification binaire.
Ranking#
add_notebook_menu(menu_id="rank", first_level=3, last_level=4, keep_item=3)
données#
 , avec
, avec  et
et
 .
.
 est un identifiant qui permet de regroupes les observations
ensemble. Au sein d’un groupe,
est un identifiant qui permet de regroupes les observations
ensemble. Au sein d’un groupe,  détermine l’ordre dans lequel
les observations doivent être triées.
détermine l’ordre dans lequel
les observations doivent être triées.
sortie#
 , ce score permet de trier les observations au sein d’un
groupe.
, ce score permet de trier les observations au sein d’un
groupe.
optimisation#
Deux approches :
score : on émet l’hypothèse qu’il existe un score qui permet de trier les éléments entre eux, la connaissance du groupe
est superflu, le problème de ranking devient un problème de
régression où on cherche à apprendre le score.pair-wise : le score n’est pas connu, tout ce qu’on sait faire est d’exprimer une préférence entre les éléments
 et
et
 . On transforme le problème le problème de ranking
en un problème de classification binaire, pour chaque chaque pair
d’oboservations au sein du même groupe, on aprend la préférence.
. On transforme le problème le problème de ranking
en un problème de classification binaire, pour chaque chaque pair
d’oboservations au sein du même groupe, on aprend la préférence.
évaluation#
corrélation entre les positions attendues et prédites au sein du même groupe d’observations
Non supervisés#
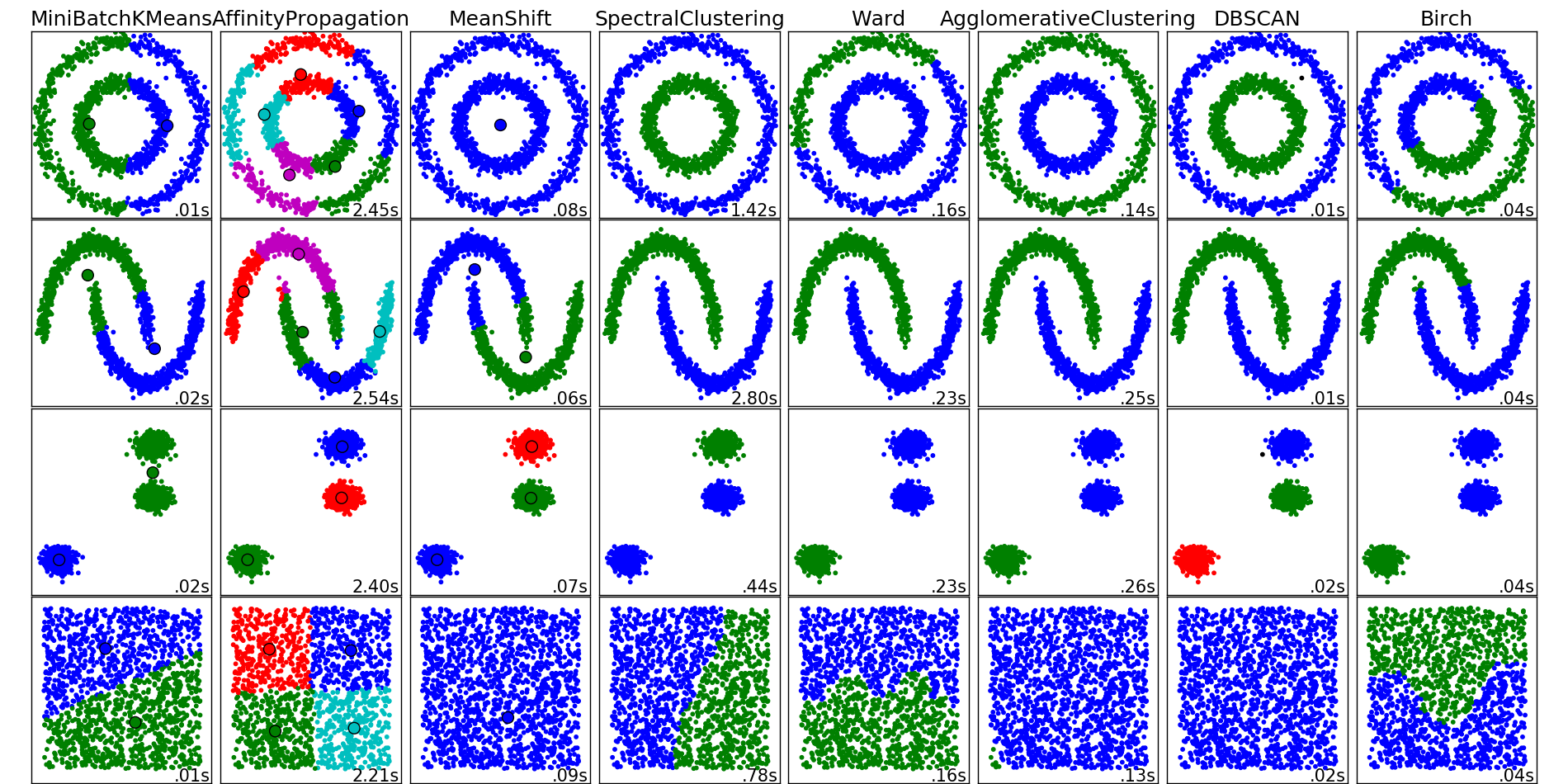
Clustering#
Principales différences entre algorithmes :
espace veectoriel / espace métrique (distance uniquement)
nombre de clusters fixés à l’avance ou déterminé en cours de route
coût
from pyquickhelper.helpgen import NbImage
NbImage("sphx_glr_plot_cluster_comparison_001.png")
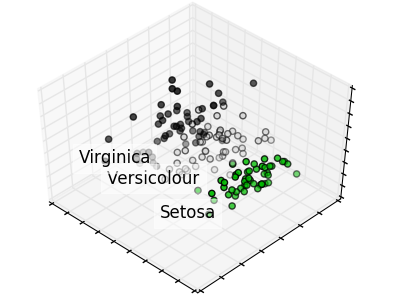
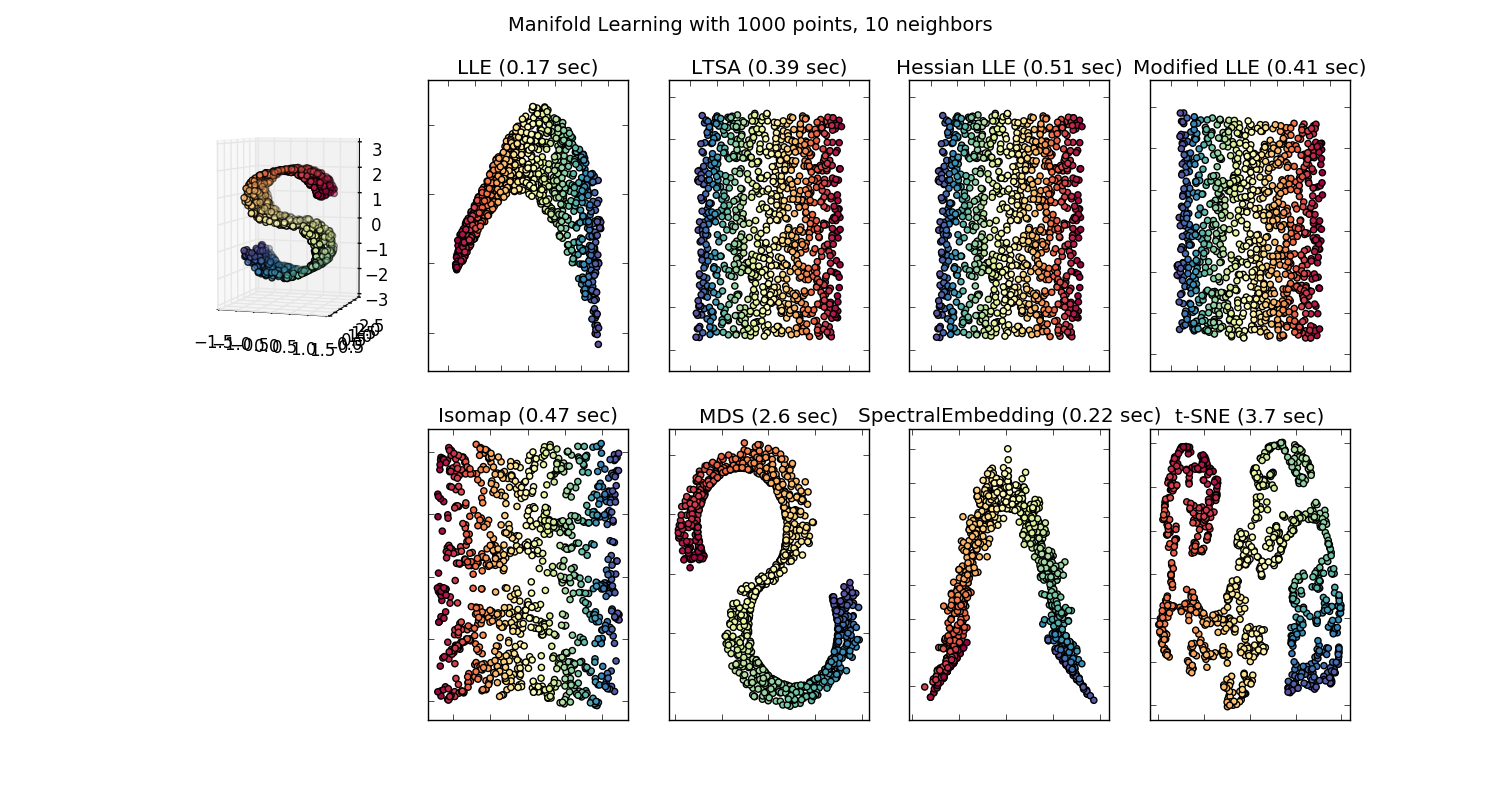
Réduction de dimensions#
NbImage("sphx_glr_plot_pca_iris_001.png")
NbImage("sphx_glr_plot_compare_methods_001.png")
Ridge / Lasso / Régularisation#
Ces deux méthodes
Ridge
et
Lasso
ont été développés pour ces modèles linéaires. On retrouve des idées
similaires pour l’optimisation d’autres modèles en particulier
Ridge
qui revient à ajouter une pénalité de régularisation des coefficients
lors de l’apprentissage. C’est le cas du paramètre alpha qui
apparaît lorsqu’on définit un réseau de
neurones
avec scikit-learn.
Learner / Transformer / Pipeline#
Le module scikit-learn fait apparaître le terme de transformeur :
StandardScaler
est un transformeur (ou transformer en anglais). Ce type d’objet
transforme les données mais ne produisent le résultat final. Un
Pipeline
empile une liste de transformeurs et un estimateur final (classifieur,
régresseur). Une ACP est un transformeur car elle modifie les entrées
avant un apprentissage.
from pyquickhelper.helpgen import NbImage
NbImage("pipeline.png")
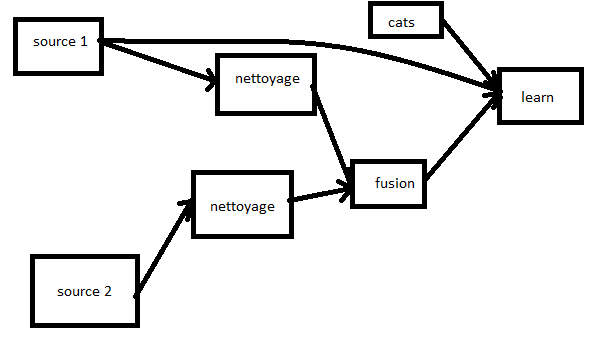
Un pipeline simple :
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
Y = data.target
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
pipe = Pipeline([("acp", PCA()),
("logreg", LogisticRegression())])
pipe.fit(X, Y)
Pipeline(memory=None,
steps=[('acp', PCA(copy=True, iterated_power='auto', n_components=None, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)), ('logreg', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))])
pred = pipe.predict(X)
pred[:5]
array([0, 0, 0, 0, 0])
Lors de la prédiction, les variables passent par la même chaîne de traitement. Les méthodes pour les transformer et estimator sont différents :
estimator : fit + predict
transformer : fit (optionnel) + transform
La méthode fit ne s’applique pas à tous les transformers. Il n’y a pas toujours de coefficients à estimer. La plupart des transformer sont non supervisés (pas besoin de Y) mais certains le sont comme t-SNE.
Exercice 1 : classifier avec plusieurs classes#
La plupart des modèles ne savant pas gérer le cas multi-class, seulement le cas de la classification binaire.
Et si on transformait le label en une variable…
Il faut comparer ces trois approches.
Exercice 2 : grand nombre de classes ?#
Pourquoi un grand nombre de classes aboutit-il nécessairement à un cas de jeu de données imbalanced ? Que proposez-vous pour y remédier ?
Exercice 3 : ranking#
Résoudre un problème de ranking.