Rappels sur scikit-learn et le machine learning (correction)#
Links: notebook, html, python, slides, GitHub
Quelques exercices simples sur scikit-learn. Le notebook est long pour ceux qui débutent en machine learning et sans doute sans suspens pour ceux qui en ont déjà fait.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
%matplotlib inline
Des données synthétiques#
On simule un jeu de données aléatoires.
from numpy import random
n = 1000
X = random.rand(n, 2)
X[:5]
array([[0.33151303, 0.70686719],
[0.13039027, 0.58941167],
[0.612744 , 0.37799233],
[0.20215973, 0.11095186],
[0.56857961, 0.10783821]])
y = X[:, 0] * 3 - 2 * X[:, 1] ** 2 + random.rand(n)
y[:5]
array([0.10121972, 0.49414321, 2.19975264, 0.74372472, 2.27103021])
Exercice 1 : diviser en base d’apprentissage et de test#
Simple train_test_split.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Exercice 2 : caler une régression linéaire#
Et calculer le coefficient  . Pour ceux qui ne savent pas se
servir d’un moteur de recherche :
LinearRegression,
r2_score.
. Pour ceux qui ne savent pas se
servir d’un moteur de recherche :
LinearRegression,
r2_score.
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
from sklearn.metrics import r2_score
score = r2_score(y_test, reg.predict(X_test))
score
0.908988490753245
Exercice 3 : améliorer le modèle en appliquant une transformation bien choisie#
Le modèle de départ est :  . Il
suffit de rajouter des featues polynômiales avec
PolynomialFeatures.
. Il
suffit de rajouter des featues polynômiales avec
PolynomialFeatures.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures()
poly.fit(X_train)
X_train2 = poly.transform(X_train)
reg2 = LinearRegression()
reg2.fit(X_train2, y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
score2 = r2_score(y_test, reg2.predict(poly.transform(X_test)))
score2
0.9362394073926681
Le coefficient est plus élevé car on utilise les mêmes
variables que le modèle. Il n’est théoriquement pas possible d’aller au
delà.
Exercice 4 : caler une forêt aléatoire#
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_train, y_train)
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0, warm_start=False)
r2_score(y_test, rf.predict(X_test))
0.9153506166386053
Le modèle linéaire est le meilleur modèle dans notre cas puisque les
données ont été construites de la sorte. Il est attendu que le
ne soit pas plus élevé tout du moins pas significativement
plus élevé. On regarde avec les features polynômiales…
rf2 = RandomForestRegressor()
rf2.fit(X_train2, y_train)
r2_score(y_test, rf2.predict(poly.transform(X_test)))
0.9119002367619022
Avant de tirer des conclusions hâtives, il faudrait recommencer plusieurs fois l’expérience avant de dire que la performance est plus ou moins élevée avec ces features ce que ce notebook ne fera pas puisque la réponse théorique est connue dans ce cas.
Exercice 5 : un peu de math#
Comparer les deux modèles sur les données suivantes ? Que remarquez-vous ? Expliquez pourquoi ?
X_test2 = random.rand(n, 2) + 0.5
y_test2 = X_test2[:, 0] * 3 - 2 * X_test2[:, 1] ** 2 + random.rand(n)
res = []
for model in [reg, reg2, rf, rf2]:
name = model.__class__.__name__
try:
pred = model.predict(X_test)
pred2 = model.predict(X_test2)
except Exception:
pred = model.predict(poly.transform(X_test))
pred2 = model.predict(poly.transform(X_test2))
name += " + X^2"
res.append(dict(name=name, r2=r2_score(y_test, pred),
r2_jeu2=r2_score(y_test2, pred2)))
import pandas
df = pandas.DataFrame(res)
df
| name | r2 | r2_jeu2 | |
|---|---|---|---|
| 0 | LinearRegression | 0.908988 | 0.682467 |
| 1 | LinearRegression + X^2 | 0.936239 | 0.948110 |
| 2 | RandomForestRegressor | 0.915351 | 0.493273 |
| 3 | RandomForestRegressor + X^2 | 0.911900 | 0.517105 |
Le seul modèle qui s’en tire vraiment est la régression linéaire avec les features polynômiales. Comme il équivaut au modèle théorique, il est normal qu’il ne se plante pas trop même si ses coefficients ne sont pas identique au modèle théorique (il faudrait plus de données pour que cela converge).
reg2.coef_, reg2.intercept_
(array([ 0. , 2.81692538, -0.29768531, 0.08662761, 0.13367719,
-1.7515442 ]), 0.5889925538787228)
Pour les autes modèles, voyons déjà visuellement ce qu’il se passe.
Exercice 6 : faire un graphe avec…#
Je laisse le code décrire l’approche choisie pour illustrer les carences des modèles précédents. Le commentaire suit le graphique pour les paresseux.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(14, 4))
a, b = 0.9, 1.1
index1 = (X_test2[:, 0] >= a) & (X_test2[:, 0] <= b)
index2 = (X_test2[:, 1] >= a) & (X_test2[:, 1] <= b)
yth = X_test2[:, 0] * 3 - 2 * X_test2[:, 1]
ax[0].set_xlabel("X1")
ax[0].set_ylabel("Y")
ax[0].plot(X_test2[index2, 0], yth[index2], '.', label='Y théorique')
ax[1].set_xlabel("X2")
ax[1].set_ylabel("Y")
ax[1].plot(X_test2[index1, 1], yth[index1], '.', label='Y théorique')
for model in [reg, reg2, rf, rf2]:
name = model.__class__.__name__
try:
pred2 = model.predict(X_test2)
except Exception:
pred2 = model.predict(poly.transform(X_test2))
name += " + X^2"
ax[0].plot(X_test2[index2, 0], pred2[index2], '.', label=name)
ax[1].plot(X_test2[index1, 1], pred2[index1], '.', label=name)
ax[0].legend()
ax[1].legend();
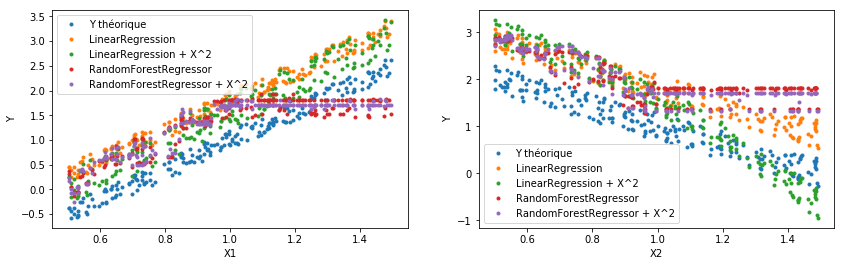
Le graphe étudie les variables des modèles selon une coordonnées tout en
restreignant l’autre dans un intervalle donné. On voit tout de suite que
la forêt aléatoire devient constante au delà d’un certain seuil. C’est
encore une fois tout à fait normal puisque la base d’apprentissage ne
contient des  que dans l’intervalle
que dans l’intervalle ![[0, 1]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAyMy40NTM0NjIgMTEuOTU1MTY4JyB3aWR0aD0nMjMuNDUzNDYycHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2cwLTU5Jy8+CjxwYXRoIGQ9J001LjM1NTkxNSAtMy44MjU2NTRDNS4zNTU5MTUgLTQuODE3OTMzIDUuMjk2MTM5IC01Ljc4NjMwMSA0Ljg2NTc1MyAtNi42OTQ4OTRDNC4zNzU1OTIgLTcuNjg3MTczIDMuNTE0ODE5IC03Ljk1MDE4NyAyLjkyOTAxNiAtNy45NTAxODdDMi4yMzU2MTYgLTcuOTUwMTg3IDEuMzg2OCAtNy42MDM0ODcgMC45NDQ0NTggLTYuNjExMjA4QzAuNjA5NzE0IC01Ljg1ODAzMiAwLjQ5MDE2MiAtNS4xMTY4MTIgMC40OTAxNjIgLTMuODI1NjU0QzAuNDkwMTYyIC0yLjY2NjAwMiAwLjU3Mzg0OCAtMS43OTMyNzUgMS4wMDQyMzQgLTAuOTQ0NDU4QzEuNDcwNDg2IC0wLjAzNTg2NiAyLjI5NTM5MiAwLjI1MTA1OSAyLjkxNzA2MSAwLjI1MTA1OUMzLjk1NzE2MSAwLjI1MTA1OSA0LjU1NDkxOSAtMC4zNzA2MSA0LjkwMTYxOSAtMS4wNjQwMUM1LjMzMjAwNSAtMS45NjA2NDggNS4zNTU5MTUgLTMuMTMyMjU0IDUuMzU1OTE1IC0zLjgyNTY1NFpNMi45MTcwNjEgMC4wMTE5NTVDMi41MzQ0OTYgMC4wMTE5NTUgMS43NTc0MSAtMC4yMDMyMzggMS41MzAyNjIgLTEuNTA2MzUxQzEuMzk4NzU1IC0yLjIyMzY2MSAxLjM5ODc1NSAtMy4xMzIyNTQgMS4zOTg3NTUgLTMuOTY5MTE2QzEuMzk4NzU1IC00Ljk0OTQ0IDEuMzk4NzU1IC01LjgzNDEyMiAxLjU5MDAzNyAtNi41Mzk0NzdDMS43OTMyNzUgLTcuMzQwNDczIDIuNDAyOTg5IC03LjcxMTA4MyAyLjkxNzA2MSAtNy43MTEwODNDMy4zNzEzNTcgLTcuNzExMDgzIDQuMDY0NzU3IC03LjQzNjExNSA0LjI5MTkwNSAtNi40MDc5N0M0LjQ0NzMyMyAtNS43MjY1MjYgNC40NDczMjMgLTQuNzgyMDY3IDQuNDQ3MzIzIC0zLjk2OTExNkM0LjQ0NzMyMyAtMy4xNjgxMiA0LjQ0NzMyMyAtMi4yNTk1MjcgNC4zMTU4MTYgLTEuNTMwMjYyQzQuMDg4NjY3IC0wLjIxNTE5MyAzLjMzNTQ5MiAwLjAxMTk1NSAyLjkxNzA2MSAwLjAxMTk1NVonIGlkPSdnMS00OCcvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzEtNDknLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2cxLTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2cxLTkzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHhsaW5rOmhyZWY9JyNnMS05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNTkuNjY0OTI4JyB4bGluazpocmVmPScjZzEtNDgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY1LjUxNzkxOScgeGxpbms6aHJlZj0nI2cwLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3MC43NjIwNzgnIHhsaW5rOmhyZWY9JyNnMS00OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzYuNjE1MDY4JyB4bGluazpocmVmPScjZzEtOTMnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) . En
dehors, chaque arbre de décision produit une valeur constante tout
simplement parce que ce sont des fonctions en escalier : une forêt
aléatoire est une moyenne de fonctions en escalier, elle est bornée.
Quant à la première régression linéaire, elle ne peut saisir les effets
du second degré, elle est linéaire par rapport aux variables de départ.
Elle s’écarte moins mais elle s’écarte quand même de la variable à
prédire.
. En
dehors, chaque arbre de décision produit une valeur constante tout
simplement parce que ce sont des fonctions en escalier : une forêt
aléatoire est une moyenne de fonctions en escalier, elle est bornée.
Quant à la première régression linéaire, elle ne peut saisir les effets
du second degré, elle est linéaire par rapport aux variables de départ.
Elle s’écarte moins mais elle s’écarte quand même de la variable à
prédire.
Cet exercice a pour but d’illustrer qu’un modèle de machine learning est estimé sur un jeu de données qui suit une certaine distribution. Lorsque les données sur lesquelles le modèle est utilisé pour prédire ne suivent plus cette loi, les modèles retournent des réponses qui ont toutes les chances d’être fausses et ce, de manière différente selon les modèles.
C’est pour cela qu’on dit qu’il faut réapprendre régulièrement les modèles de machine learning, surtout s’ils sont appliqués sur des données générées par l’activité humaine et non des données issues de problèmes physiques.
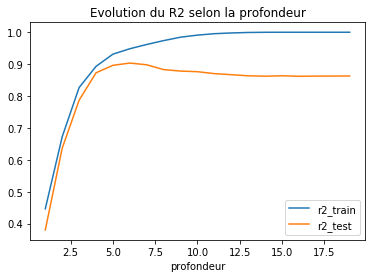
Exercice 7 : illuster l’overfitting avec un arbre de décision#
Sur le premier jeu de données.
from sklearn.tree import DecisionTreeRegressor
res = []
for md in range(1, 20):
tree = DecisionTreeRegressor(max_depth=md)
tree.fit(X_train, y_train)
r2_train = r2_score(y_train, tree.predict(X_train))
r2_test = r2_score(y_test, tree.predict(X_test))
res.append(dict(profondeur=md, r2_train=r2_train, r2_test=r2_test))
df = pandas.DataFrame(res)
df.head()
| profondeur | r2_test | r2_train | |
|---|---|---|---|
| 0 | 1 | 0.380103 | 0.446387 |
| 1 | 2 | 0.636346 | 0.672284 |
| 2 | 3 | 0.786778 | 0.826594 |
| 3 | 4 | 0.872799 | 0.892911 |
| 4 | 5 | 0.896276 | 0.931297 |
ax = df.plot(x='profondeur', y=['r2_train', 'r2_test'])
ax.set_title("Evolution du R2 selon la profondeur");
Exercice 8 : augmenter le nombre de features et régulariser une régression logistique#
L’objectif est de regarder l’impact de la régularisation des coefficients d’une régression logistique lorsque le nombre de features augmentent. On utilise les features polynômiales et une régression Ridge ou Lasso.
from sklearn.linear_model import Ridge, Lasso
import numpy.linalg as nplin
import numpy
def coef_non_nuls(coef):
return sum(numpy.abs(coef) > 0.001)
res = []
for d in range(1, 21):
poly = PolynomialFeatures(degree=d)
poly.fit(X_train)
X_test2 = poly.transform(X_test)
reg = LinearRegression()
reg.fit(poly.transform(X_train), y_train)
r2_reg = r2_score(y_test, reg.predict(X_test2))
rid = Ridge(alpha=10)
rid.fit(poly.transform(X_train), y_train)
r2_rid = r2_score(y_test, rid.predict(X_test2))
las = Lasso(alpha=0.01)
las.fit(poly.transform(X_train), y_train)
r2_las = r2_score(y_test, las.predict(X_test2))
res.append(dict(degre=d, nb_features=X_test2.shape[1],
r2_reg=r2_reg, r2_las=r2_las, r2_rid=r2_rid,
norm_reg=nplin.norm(reg.coef_),
norm_rid=nplin.norm(rid.coef_),
norm_las=nplin.norm(las.coef_),
nnul_reg=coef_non_nuls(reg.coef_),
nnul_rid=coef_non_nuls(rid.coef_),
nnul_las=coef_non_nuls(las.coef_),
))
df = pandas.DataFrame(res)
df
| degre | nb_features | nnul_las | nnul_reg | nnul_rid | norm_las | norm_reg | norm_rid | r2_las | r2_reg | r2_rid | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 3 | 2 | 2 | 2 | 3.403924 | 3.568168e+00 | 3.079896 | 0.906854 | 0.908988 | 0.892232 |
| 1 | 2 | 6 | 4 | 5 | 5 | 3.280738 | 3.334211e+00 | 2.350989 | 0.934247 | 0.936239 | 0.919758 |
| 2 | 3 | 10 | 4 | 9 | 9 | 3.280888 | 5.090698e+00 | 2.072340 | 0.934247 | 0.935657 | 0.921656 |
| 3 | 4 | 15 | 4 | 14 | 14 | 3.280963 | 1.180973e+01 | 1.992448 | 0.934248 | 0.934934 | 0.921532 |
| 4 | 5 | 21 | 4 | 20 | 20 | 3.281022 | 6.657031e+01 | 1.972762 | 0.934248 | 0.935177 | 0.921656 |
| 5 | 6 | 28 | 4 | 27 | 26 | 3.281037 | 3.242570e+02 | 1.965189 | 0.934248 | 0.934388 | 0.921823 |
| 6 | 7 | 36 | 4 | 35 | 35 | 3.281040 | 1.428490e+03 | 1.958965 | 0.934248 | 0.933246 | 0.921927 |
| 7 | 8 | 45 | 4 | 44 | 43 | 3.281041 | 1.441240e+04 | 1.952981 | 0.934248 | 0.931307 | 0.921976 |
| 8 | 9 | 55 | 4 | 55 | 53 | 3.281041 | 4.893616e+13 | 1.947737 | 0.934248 | 0.616562 | 0.921997 |
| 9 | 10 | 66 | 4 | 65 | 65 | 3.281041 | 4.659569e+05 | 1.943600 | 0.934248 | 0.929751 | 0.922013 |
| 10 | 11 | 78 | 4 | 77 | 75 | 3.281041 | 2.360073e+06 | 1.940623 | 0.934248 | 0.925344 | 0.922035 |
| 11 | 12 | 91 | 4 | 91 | 88 | 3.281041 | 1.708086e+07 | 1.938666 | 0.934248 | 0.921123 | 0.922067 |
| 12 | 13 | 105 | 4 | 105 | 99 | 3.281041 | 9.955733e+07 | 1.937518 | 0.934248 | 0.874136 | 0.922108 |
| 13 | 14 | 120 | 4 | 120 | 111 | 3.281041 | 6.854497e+08 | 1.936961 | 0.934248 | 0.927716 | 0.922158 |
| 14 | 15 | 136 | 4 | 136 | 127 | 3.281041 | 3.786997e+09 | 1.936808 | 0.934248 | 0.842488 | 0.922212 |
| 15 | 16 | 153 | 4 | 153 | 145 | 3.281041 | 4.467998e+10 | 1.936913 | 0.934248 | 0.664588 | 0.922269 |
| 16 | 17 | 171 | 4 | 171 | 161 | 3.281041 | 2.361809e+11 | 1.937165 | 0.934248 | -0.726442 | 0.922325 |
| 17 | 18 | 190 | 4 | 190 | 179 | 3.281041 | 1.599035e+12 | 1.937489 | 0.934248 | 0.582385 | 0.922379 |
| 18 | 19 | 210 | 4 | 210 | 203 | 3.281041 | 4.455355e+13 | 1.937834 | 0.934248 | -25.406536 | 0.922429 |
| 19 | 20 | 231 | 4 | 231 | 223 | 3.281041 | 2.262080e+13 | 1.938168 | 0.934248 | -21.684447 | 0.922475 |
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
df.plot(x="nb_features", y=["r2_reg", "r2_las", "r2_rid"], ax=ax[0])
ax[0].set_xlabel("Nombre de features")
ax[0].set_ylim([0, 1])
ax[0].set_title("r2")
df.plot(x="nb_features", y=["nnul_reg", "nnul_las", "nnul_rid"], ax=ax[1])
ax[1].set_xlabel("Nombre de features")
ax[1].set_title("Nombre de coefficients non nuls");
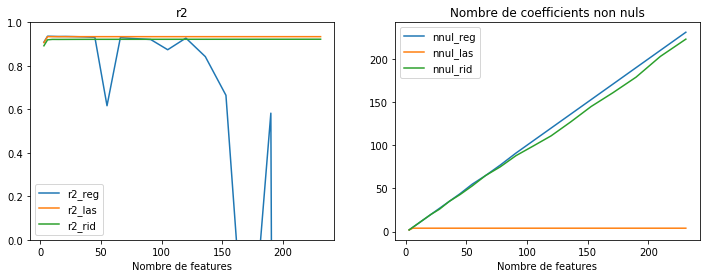
Numériquement, la régression linéaire devient difficile à estimer lorsque le nombre de features augmente. Théoriquement, il ne devrait pas y avoir de baisse de performances mais le graphe montre des erreurs évidentes. Cela se traduit par une norme des coefficients qui explose. La régularisation parvient à contraindre les modèles. La régression Ridge produira beaucoup de petits coefficients non nuls, la régression Lasso préfèrera concentrer la norme sur quelques coefficients seulement. Cette observation n’est vraie que dans le cas d’une régression linéaire avec une erreur quadratique.