Apprentissage sans labels#
Rappels#
L’apprentissage supervisé nécessite des données
annotées. Chaque exemple est un couple
 où X est ce qu’on mesure ou
ce qui est connu, Y est la réponse qu’on veut prédire.
La prédiction passe le plus souvent par la construction
d’une fonction paramétrique
où X est ce qu’on mesure ou
ce qui est connu, Y est la réponse qu’on veut prédire.
La prédiction passe le plus souvent par la construction
d’une fonction paramétrique  .
.
Pour apprendre une telle fonction, on dispose d’une base d’apprentissage
 . C’est-à-dire qu’on connaît la prédiction
pour un ensemble de points. On souhaite
déterminer les coefficients
. C’est-à-dire qu’on connaît la prédiction
pour un ensemble de points. On souhaite
déterminer les coefficients  qui minimise
une certaine fonction d’erreur
qui minimise
une certaine fonction d’erreur  qui est nulle lorsque la prédiction et parfaite
(
qui est nulle lorsque la prédiction et parfaite
( ) en chaque point.
) en chaque point.
Plus on a de points ou d’observations, plus on a d’informations pour déterminer les coefficients
. Pour un réseau de neurones, on considère souvent qu’il faut dix fois d’observations
que de coefficients pour bien apprendre ou plutôt pour ne pas apprendre par coeur.
Pas de labels ?#
Créer un modèle de prédiction implique qu’on sache formaliser le problème, qu’on sache extraire ce qu’on observe et ce qu’on doit prédire. Ce n’est pas toujours évident. Essayons par exemple de construire un modèle qui reconnaît ce qu’il y a sur une image. On peut commencer par distinguer entre chien et chats ou reconnaître un décor ou encore des visages :

On ne sait pas encore construire la machine capable de reconnaître n’importe quoi. Que fait-on s’il y a un chat et un chien sur la même image ? Doit-on construire un modèle plus complexe ou décider que le modèle n’est pas prévu pour donner une réponse fiable dans ce cas ? La formalisation est souvent le résultat d’un compromis entre l’utilité du problème, la facilité avec laquelle on pense le résultat, la capacité de construire ces labels. Il arrive parfois qu’on ne sache pas construire ces labels. Sauriez-vous distinguer la signature accoustique d’une baleine de celle d’un cachalot ?
On ne sait pas labelliser.#
On est obligé d’apprendre en faisant. On part toujours de ce qu’on sait. Si on doit construire une classification sans savoir ce que sont les deux classes à prédire, on va essayer de regrouper les observations en deux classes puis essayer de comprendre si les deux groupes ainsi formés ont quelque chose à voir avec le problème initial quitte à ne pas savoir tout classer. On peut aussi essayer de trouver une autre source d’information pour construire quelques labels.
On veut parfois construire un système d’alerte qui doit prédire si une anomalie survient ? Mais on ne sait pas ce que c’est une anomalie. On regarde alors les événements extrêmes pour cerner un peu mieux puis petit à petit définir ce qu’on attend du modèle de prédiction.
On a peu de labels.#
On sait que la complexité du modèle nécessite plus d’exemples que ceux
dont on dispose. On a quelques couples  pour lesquels
on connaît la réponse et beaucoup de
pour lesquels
on connaît la réponse et beaucoup de  pour lesquels on ne sait pas.
On commence par construire un petit modèle et on regarde sa réponse sur les exemples
sans labels. Que se passe-t-il quand il est très sûr de lui (score de confiance élevé)
ou pas du tout (score de confiance nul) ? On s’aperçoit parfois que les labels produits
sont assez faibles et on les incorpore à la base d’apprentissage pour construire
un modèle plus imposant.
pour lesquels on ne sait pas.
On commence par construire un petit modèle et on regarde sa réponse sur les exemples
sans labels. Que se passe-t-il quand il est très sûr de lui (score de confiance élevé)
ou pas du tout (score de confiance nul) ? On s’aperçoit parfois que les labels produits
sont assez faibles et on les incorpore à la base d’apprentissage pour construire
un modèle plus imposant.
Un autre idée consiste à réutiliser un modèle déjà appris pour autre chose et celui-ci disposait d’une grande base d’apprentissage. Cela marche beaucoup dans la classification d’images. Il existe des modèles disponibles sur internet comme VGG. Il ne font pas exactement ce qu’on veut mais on peut essayer d’utiliser ce qu’ils ont appris. C’est l”apprentissage par transfert ou transfert learning.
On a des labels bruités.#
Pas mal de gens mettent leurs photos sur internet en y apposant une légende. Pour ceux qui les stockent, c’est une manne très intéressante pour faire de la classification d’images. La légende n’est pas nécessairement reliée au problème en question mais existe un moyen de transformer automatiquement tout ou partie de ces labels en quelque chose qui soit utile ?
Un clic sur internet n’est pas nécessairement signe que le lien est intéressant. Il peut être suivi d’un quick back auquel l’internaute a jugé rapidement que cela ne l’était pas. On a dès lors la tentation de filtrer entre les bons et les mauvais clics ou de construire des modèles où ce qui est observé dépend du vrai label mais qui est caché.
Dans les deux cas, on cherche à comprendre si le bruit des labels est en partie systématique et si tel est le cas, comment se servir de ce label biaisé.
Revue non exhaustive d’outils et modèles#
Il n’existe pas de réponse systèmatique au manque de labels. Il est important de bien comprendre les données pour choisir les bons outils et modèles qui seront le plus pertinent. Voici quelques pistes de réflexions.
Réduction de dimension#
Les labels sont en trop petit nombre et le modèle de prédiction n’arrive pas à généraliser.
L’espace des features  est trop grand. L’idée consiste à trouver un espace
de features plus petits dans lequel deux observations similaires sont plus proches que
dans l’ensemble de départ. On peut classer les chiffres à partir des pixels,
des images 8x8 dans l’exemple ci-dessous.
est trop grand. L’idée consiste à trouver un espace
de features plus petits dans lequel deux observations similaires sont plus proches que
dans l’ensemble de départ. On peut classer les chiffres à partir des pixels,
des images 8x8 dans l’exemple ci-dessous.

Ou on peut essayer de trouver un espace à deux dimensions dans lequel c’est plus simple comme avec une projection t-SNE.
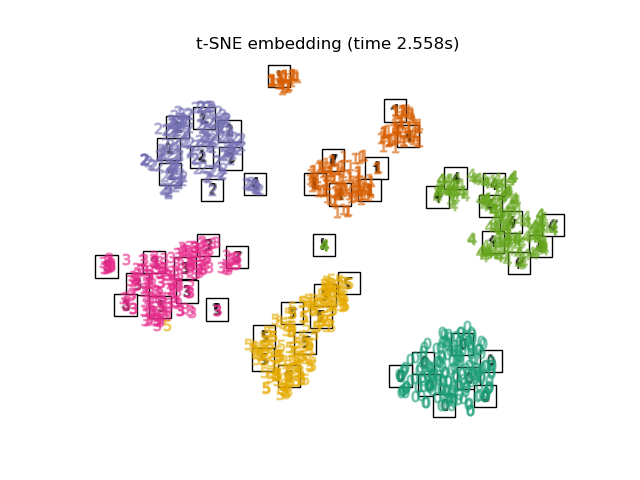
Cette représentation en plus petite dimensions sont en quelque sorte une compression de l’information avec perte. On espère que cette perte est essentiellement du bruit et qu’il reste l’information pertinente.
Non supervisé
La méthode la plus connue est l’ACP ou Analyse en Composantes Principales, Sparse PCA, Kernal PCA. On peut évoquer aussi Sparce Coding (lire Online Dictionary Learning for Sparse Coding). Il s’agit de représenter chaque élément de la base d’apprentissage comme une combinaison linéaire sparse d’un petit d’éléments représentatifs.
Supervisé
La première idée s’addresse à un problème de classification. On souhaite construire un espace dans lequel les classes du problèmes de classification sont les plus éloignées possibles. C’est l’objectif de la transformation t-SNE mais ce n’est pas la seule Manifold learning. La seconde idée reprend l’idée de compression avec perte et l’applique sous la forme d’un réseau avec les auto-encoders.
auto-encoders
L’article Adversarial Autoencoders illustre comment cette technique est utilisée (voir Adversarial Autoencoders (with Pytorch) pour un exemple de code).

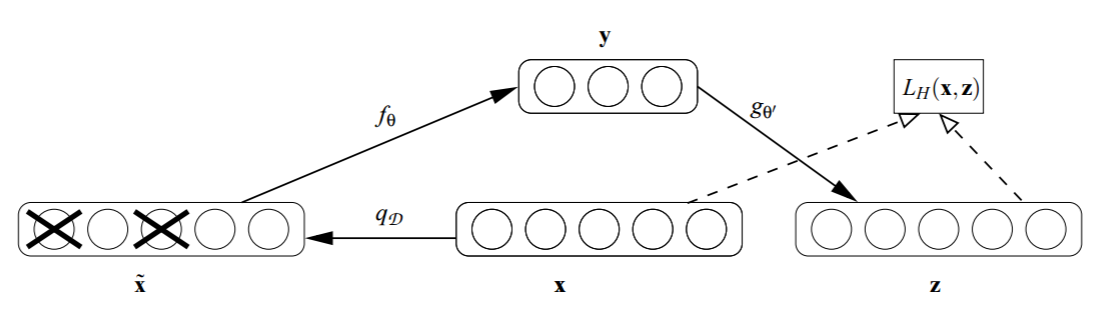
Autoencoder#
Image extraite de Adversarial Autoencoders (with Pytorch).
Le réseau de neurones inclut une couche cachée dont la dimension est réduite. Il apprend à compresser et restituer un grand nombre d’image. Les labels ne sont pas utilisées. La sortie de la couche cachée est utilisée comme entrée d’un modèle supervisé utilisant les labels mais plus facile à entraîner puisque l’espace d’entrée a été réduit.
L’article Why Does Unsupervised Pre-training Help Deep Learning? montre cette étape de compression ou pre-training aide même dans le cas où les labels ne manquent pas. L’article Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion étudie la possibilité de préentraîner chaque couche d’un réseau de neurones avec un auto-encoder (SDA). Celui-ci n’apprend pas seulement à reconstruire une image x à partir d’elle-même mais aussi à reconstuire x à partir d’une image bruitée de x.
Autoencoder#
L’idée de bruiter les données pour mieux apprendre est aussi présente dans l’article Learning with Marginalized Corrupted Features qui a inspiré Marginalizing Stacked Linear Denoising Autoencoders qui se présente comme une version plus rapide des SDA car en partie linéaire. Les Variational Autoencoders introduisent une contrainte sur la couche cachée dont les sorties doivent suivre une certaine loi souvent gaussiennes. C’est en quelque sorte un paramètre de régularisation. Pour finir un tutoriel mathématiques sur les auto-encoders : Tutorial on Variational Autoencoders qui évoque aussi les auto-encodeurs booléens qui sont utilisés pour faire du clustering dans l’article Autoencoders, Unsupervised Learning, and Deep Architectures. La couche intermédiaire booléene indique dans quel cluster classer une observation.
Compress Sensing
L’article Compressed sensing and single-pixel cameras explique assez clairement ce qu’est le compress sensing ou acquisition comprimée. Il prend le cas de la compression d’images qui réussit parfois à compresser une image à 90% avec des ondelettes. L’image est représentée avec seulement 10% de l’information initiale. Seulement, calculer ces 10% restant est parfois coûteux. Le compress sensing se pose la question de savoir si toute l’information initiale est réellement utile pour calculer ces 10% compressé. De façon évidente, une multitude d’images pourraient correspondre à ces mêmes 10% compressés et retrouver la bonne image initiale repose sur le fait que le signal original est sparse et obéit à quelques contraintes.
A partir de là, rien n’empêche d’utiliser ce type de technique à des problèmes de machine learning. C’est le cas de l’article Multi-Label Prediction via Compressed Sensing qui étudie le cas où le nombre de classes possibles pour une observation est excessivement grand. Le compress sensing est utilisé pour prédire un nombre réduit de labels et retrouver les labels originaux ensuite. L’estimation du processus de reconstruction des labels originaux repose sur des algorithmes tels que Orthogonal Matching Pursuit (OMP) (Signal Recovery From Random Measurements Via Orthogonal Matching Pursuit), FoBa (Forward-Backward Greedy Algorithms for General Convex Smooth Functions over A Cardinality Constraint (slides), CoSaMP (COSAMP: Iterative Signal Recovery From Incomplete And Inaccurate Sample ), toutes variantes du Matching Pursuit (Matching Pursuits With Time-Frequency Dictionaries).
On suppose que  et qu’il existe une matrice
et qu’il existe une matrice
 où
où  .
.
 est le signal compressé et
est le signal compressé et  le signal original.
Il est possible de reconstruire sachant
le signal original.
Il est possible de reconstruire sachant  et
et  s’il existe une base
s’il existe une base  dans laquelle
dans laquelle
 avec
avec  est K-sparse
(pas plus de K valeurs non nulles).
est K-sparse
(pas plus de K valeurs non nulles).  . Trouver
et
. Trouver
et  est le sujet du problème
Single Measurement Vector (SMV)
ou sa version distribuée
Multiple Measurement Vectors (MMV)
(Sparse Representations For Multiple Measrument Vectors (MMV) in an Over-Complete Dictionary).
Voir aussi Poursuite de base
est le sujet du problème
Single Measurement Vector (SMV)
ou sa version distribuée
Multiple Measurement Vectors (MMV)
(Sparse Representations For Multiple Measrument Vectors (MMV) in an Over-Complete Dictionary).
Voir aussi Poursuite de base
L’article Distributed Compressive Sensing: A Deep Learning Approach associe deep learning avec les modèles LSTM et compress sensing. C’est un article où on construit une architecture pour extraire l’information qu’on souhaite comme capturer la dépendance entre les observations successives d’une séquence.
Apprentissage semi-supervisé#
Generative Adversarial Networks (GAN)
L’article Generative Adversarial Networks
décrit une façon de créer à la fois fonction qui imite les données d’entrées
et une autre capable de faire la distinction entre les données
simulées et les vraies données. Cela se traduit par le programme
d’optimisation qui suit. La fonction  estime la densité
des données et
estime la densité
des données et  est une fonction qui les imitent.
est une fonction qui les imitent.
![\min_G \max_D V(D,G) = \mathbb{E}_{x \sim p_{data}(x)} [\ln D(x)] + \mathbb{E}_{z \sim p(z)} [ \ln (1-D(G(z)))]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTYuNDA1MTRwdCcgdmVyc2lvbj0nMS4xJyB2aWV3Qm94PSc2NC42MzI2MTIgODEuNzYwMDUgMzM2Ljk4NjM3IDE2LjQwNTE0JyB3aWR0aD0nMzM2Ljk4NjM3cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjc0OTY4OUM4LjA4MTY5NCAtMi43NDk2ODkgOC4yOTY4ODcgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjk4ODc5MlM4LjA4MTY5NCAtMy4yMjc4OTUgNy44Nzg0NTYgLTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzIgLTMuMjI3ODk1IDAuOTkyMjc5IC0zLjIyNzg5NSAwLjk5MjI3OSAtMi45ODg3OTJTMS4yMDc0NzIgLTIuNzQ5Njg5IDEuNDEwNzEgLTIuNzQ5Njg5SDcuODc4NDU2WicgaWQ9J2cyLTAnLz4KPHBhdGggZD0nTTEuMzMxMDA5IC0wLjYyOTYzOUMxLjI1OTI3OCAtMC4zMjY3NzUgMS4yNDMzMzcgLTAuMjYzMDE0IDAuNjUzNTQ5IC0wLjI2MzAxNEMwLjUwMjExNyAtMC4yNjMwMTQgMC40MDY0NzYgLTAuMjYzMDE0IDAuNDA2NDc2IC0wLjExMTU4MkMwLjQwNjQ3NiAwIDAuNTEwMDg3IDAgMC42NDU1NzkgMEgzLjM4NzI5OEM1LjA2ODk5MSAwIDYuNzQyNzE1IC0xLjYwOTk2MyA2Ljc0MjcxNSAtMy4zODcyOThDNi43NDI3MTUgLTQuNjA2NzI1IDUuOTI5NzYzIC01LjQ0MzU4NyA0Ljc0MjIxNyAtNS40NDM1ODdIMS45NTI2NzdDMS44MDkyMTUgLTUuNDQzNTg3IDEuNzA1NjA0IC01LjQ0MzU4NyAxLjcwNTYwNCAtNS4yOTIxNTRDMS43MDU2MDQgLTUuMTgwNTczIDEuODAxMjQ1IC01LjE4MDU3MyAxLjkzNjczNyAtNS4xODA1NzNDMi4xOTk3NTEgLTUuMTgwNTczIDIuNDMwODg0IC01LjE4MDU3MyAyLjQzMDg4NCAtNS4wNTMwNTFDMi40MzA4ODQgLTUuMDIxMTcxIDIuNDIyOTE0IC01LjAxMzIgMi4zOTkwMDQgLTQuOTA5NTg5TDEuMzMxMDA5IC0wLjYyOTYzOVpNMy4wOTI0MDMgLTQuODg1Njc5QzMuMTY0MTM0IC01LjE1NjY2MyAzLjE3MjEwNSAtNS4xODA1NzMgMy40OTg4NzkgLTUuMTgwNTczSDQuNDYzMjYzQzUuMzk1NzY2IC01LjE4MDU3MyA2LjAyNTQwNSAtNC42NDY1NzUgNi4wMjU0MDUgLTMuNjc0MjIyQzYuMDI1NDA1IC0zLjQxMTIwOCA1LjkxMzgyMyAtMi4xMTIwOCA1LjIyMDQyMyAtMS4yMTk0MjdDNC44Njk3MzggLTAuNzczMTAxIDQuMTg0MzA5IC0wLjI2MzAxNCAzLjI0MzgzNiAtMC4yNjMwMTRIMi4wNTYyODlDMS45ODQ1NTggLTAuMjc4OTU0IDEuOTYwNjQ4IC0wLjI3ODk1NCAxLjk2MDY0OCAtMC4zMzQ3NDVDMS45NjA2NDggLTAuMzk4NTA2IDEuOTc2NTg4IC0wLjQ2MjI2NyAxLjk5MjUyOCAtMC41MTAwODdMMy4wOTI0MDMgLTQuODg1Njc5WicgaWQ9J2c0LTY4Jy8+CjxwYXRoIGQ9J002LjM1MjE3OSAtNS4zOTU3NjZDNi4zNjAxNDkgLTUuNDI3NjQ2IDYuMzc2MDkgLTUuNDc1NDY3IDYuMzc2MDkgLTUuNTE1MzE4QzYuMzc2MDkgLTUuNTcxMTA4IDYuMzI4MjY5IC01LjYxMDk1OSA2LjI3MjQ3OCAtNS42MTA5NTlTNi4xOTI3NzcgLTUuNTg3MDQ5IDYuMTI5MDE2IC01LjUxNTMxOEw1LjU3MTEwOCAtNC45MDE2MTlDNS4yMDQ0ODMgLTUuNDExNzA2IDQuNjg2NDI2IC01LjYxMDk1OSA0LjE0NDQ1OCAtNS42MTA5NTlDMi4yNzk0NTIgLTUuNjEwOTU5IDAuNDIyNDE2IC0zLjg4OTQxNSAwLjQyMjQxNiAtMi4wNjQyNTlDMC40MjI0MTYgLTAuNzMzMjUgMS40MTA3MSAwLjE2NzM3MiAyLjc2NTYyOSAwLjE2NzM3MkMzLjYyNjQwMSAwLjE2NzM3MiA0LjI2NDAxIC0wLjE0MzQ2MiA0LjU1ODkwNCAtMC40ODYxNzdDNC42NTQ1NDUgLTAuMjMxMTMzIDQuODQ1ODI4IC0wLjAwNzk3IDQuOTI1NTI5IC0wLjAwNzk3QzQuOTU3NDEgLTAuMDA3OTcgNC45OTcyNiAtMC4wMjM5MSA1LjAxMzIgLTAuMDU1NzkxQzUuMDYxMDIxIC0wLjE5MTI4MyA1LjI1MjMwNCAtMS4wMDQyMzQgNS4zMDgwOTUgLTEuMjI3Mzk3QzUuMzc5ODI2IC0xLjU0NjIwMiA1LjQzNTYxNiAtMS43NjkzNjUgNS40ODM0MzcgLTEuODMzMTI2QzUuNTU1MTY4IC0xLjkyODc2NyA1LjcwNjYgLTEuOTM2NzM3IDUuOTQ1NzA0IC0xLjkzNjczN0M1Ljk4NTU1NCAtMS45MzY3MzcgNi4xMDUxMDYgLTEuOTM2NzM3IDYuMTA1MTA2IC0yLjA4MDE5OUM2LjEwNTEwNiAtMi4xNTk5IDYuMDQ5MzE1IC0yLjE5OTc1MSA1Ljk4NTU1NCAtMi4xOTk3NTFDNS45Mjk3NjMgLTIuMTk5NzUxIDUuODM0MTIyIC0yLjE3NTg0MSA1LjA2MTAyMSAtMi4xNzU4NDFDNC44NjE3NjggLTIuMTc1ODQxIDQuNTkwNzg1IC0yLjE3NTg0MSA0LjQ3MTIzMyAtMi4xODM4MTFTNC4wMzI4NzcgLTIuMTk5NzUxIDMuOTEzMzI1IC0yLjE5OTc1MUMzLjg2NTUwNCAtMi4xOTk3NTEgMy43NDU5NTMgLTIuMTk5NzUxIDMuNzQ1OTUzIC0yLjA0ODMxOUMzLjc0NTk1MyAtMS45MzY3MzcgMy44MzM2MjQgLTEuOTM2NzM3IDQuMDQwODQ3IC0xLjkzNjczN0M0LjIwODIxOSAtMS45MzY3MzcgNC41MTEwODMgLTEuOTM2NzM3IDQuNzAyMzY2IC0xLjg2NTAwNkM0LjcxMDMzNiAtMS44NDkwNjYgNC43MTgzMDYgLTEuODAxMjQ1IDQuNzE4MzA2IC0xLjc2OTM2NUM0LjcxODMwNiAtMS43Mjk1MTQgNC42NzA0ODYgLTEuNTU0MTcyIDQuNjQ2NTc1IC0xLjQ1MDU2QzQuNTk4NzU1IC0xLjI0MzMzNyA0LjUxMTA4MyAtMC45MDg1OTMgNC40NzkyMDMgLTAuODI4ODkyQzQuMjI0MTU5IC0wLjI5NDg5NCAzLjQ1MTA1OSAtMC4wOTU2NDEgMi45MDExMjEgLTAuMDk1NjQxQzIuMTEyMDggLTAuMDk1NjQxIDEuMTg3NTQ3IC0wLjUxMDA4NyAxLjE4NzU0NyAtMS44MDkyMTVDMS4xODc1NDcgLTIuNDcwNzM1IDEuNDU4NTMxIC0zLjYxODQzMSAyLjE1OTkgLTQuMzgzNTYyQzIuOTI1MDMxIC01LjIxMjQ1MyAzLjc4NTgwMyAtNS4zNDc5NDUgNC4yMDAyNDkgLTUuMzQ3OTQ1QzUuMTcyNjAzIC01LjM0Nzk0NSA1LjYxODkyOSAtNC41ODI4MTQgNS42MTg5MjkgLTMuNzc3ODMzQzUuNjE4OTI5IC0zLjY2NjI1MiA1LjU4NzA0OSAtMy41MjI3OSA1LjU4NzA0OSAtMy40MjcxNDhDNS41ODcwNDkgLTMuMzIzNTM3IDUuNjkwNjYgLTMuMzIzNTM3IDUuNzIyNTQgLTMuMzIzNTM3QzUuODI2MTUyIC0zLjMyMzUzNyA1Ljg0MjA5MiAtMy4zNTU0MTcgNS44NzM5NzMgLTMuNDk4ODc5TDYuMzUyMTc5IC01LjM5NTc2NlonIGlkPSdnNC03MScvPgo8cGF0aCBkPSdNMC40MTQ0NDYgMC45NjQzODRDMC4zNTA2ODUgMS4yMTk0MjcgMC4zMzQ3NDUgMS4yODMxODggMC4wMTU5NCAxLjI4MzE4OEMtMC4wOTU2NDEgMS4yODMxODggLTAuMTkxMjgzIDEuMjgzMTg4IC0wLjE5MTI4MyAxLjQzNDYyQy0wLjE5MTI4MyAxLjUwNjM1MSAtMC4xMTk1NTIgMS41NDYyMDIgLTAuMDc5NzAxIDEuNTQ2MjAyQzAgMS41NDYyMDIgMC4wMzE4OCAxLjUyMjI5MSAwLjYyMTY2OSAxLjUyMjI5MUMxLjE5NTUxNyAxLjUyMjI5MSAxLjM2Mjg4OSAxLjU0NjIwMiAxLjQxODY4IDEuNTQ2MjAyQzEuNDUwNTYgMS41NDYyMDIgMS41NzAxMTIgMS41NDYyMDIgMS41NzAxMTIgMS4zOTQ3N0MxLjU3MDExMiAxLjI4MzE4OCAxLjQ1ODUzMSAxLjI4MzE4OCAxLjM2Mjg4OSAxLjI4MzE4OEMwLjk4MDMyNCAxLjI4MzE4OCAwLjk4MDMyNCAxLjIzNTM2NyAwLjk4MDMyNCAxLjE2MzYzNkMwLjk4MDMyNCAxLjEwNzg0NiAxLjEyMzc4NiAwLjU0MTk2OCAxLjM2Mjg4OSAtMC4zOTA1MzVDMS40NjY1MDEgLTAuMjA3MjIzIDEuNzEzNTc0IDAuMDc5NzAxIDIuMTQzOTYgMC4wNzk3MDFDMy4xMjQyODQgMC4wNzk3MDEgNC4xNDQ0NTggLTEuMDUyMDU1IDQuMTQ0NDU4IC0yLjIwNzcyMUM0LjE0NDQ1OCAtMi45OTY3NjIgMy42MzQzNzEgLTMuNTE0ODE5IDIuOTk2NzYyIC0zLjUxNDgxOUMyLjUxODU1NSAtMy41MTQ4MTkgMi4xMzU5OSAtMy4xODgwNDUgMS45MDQ4NTcgLTIuOTQ4OTQxQzEuNzM3NDg0IC0zLjUxNDgxOSAxLjIwMzQ4NyAtMy41MTQ4MTkgMS4xMjM3ODYgLTMuNTE0ODE5QzAuODM2ODYyIC0zLjUxNDgxOSAwLjYzNzYwOSAtMy4zMzE1MDcgMC41MTAwODcgLTMuMDg0NDMzQzAuMzI2Nzc1IC0yLjcyNTc3OCAwLjIzOTEwMyAtMi4zMTkzMDMgMC4yMzkxMDMgLTIuMjk1MzkyQzAuMjM5MTAzIC0yLjIyMzY2MSAwLjI5NDg5NCAtMi4xOTE3ODEgMC4zNTg2NTUgLTIuMTkxNzgxQzAuNDYyMjY3IC0yLjE5MTc4MSAwLjQ3MDIzNyAtMi4yMjM2NjEgMC41MjYwMjcgLTIuNDMwODg0QzAuNjI5NjM5IC0yLjgzNzM2IDAuNzczMTAxIC0zLjI5MTY1NiAxLjA5OTg3NSAtMy4yOTE2NTZDMS4yOTkxMjggLTMuMjkxNjU2IDEuMzU0OTE5IC0zLjEwODM0NCAxLjM1NDkxOSAtMi45MTcwNjFDMS4zNTQ5MTkgLTIuODM3MzYgMS4zMjMwMzkgLTIuNjQ2MDc3IDEuMzA3MDk4IC0yLjU4MjMxNkwwLjQxNDQ0NiAwLjk2NDM4NFpNMS44ODA5NDYgLTIuNDU0Nzk1QzEuOTIwNzk3IC0yLjU5MDI4NiAxLjkyMDc5NyAtMi42MDYyMjcgMi4wNDAzNDkgLTIuNzQ5Njg5QzIuMzQzMjEzIC0zLjEwODM0NCAyLjY4NTkyOCAtMy4yOTE2NTYgMi45NzI4NTIgLTMuMjkxNjU2QzMuMzcxMzU3IC0zLjI5MTY1NiAzLjUyMjc5IC0yLjkwMTEyMSAzLjUyMjc5IC0yLjU0MjQ2NkMzLjUyMjc5IC0yLjI0NzU3MiAzLjM0NzQ0NyAtMS4zOTQ3NyAzLjEwODM0NCAtMC45MjQ1MzNDMi45MDExMjEgLTAuNDk0MTQ3IDIuNTE4NTU1IC0wLjE0MzQ2MiAyLjE0Mzk2IC0wLjE0MzQ2MkMxLjYwMTk5MyAtMC4xNDM0NjIgMS40NzQ0NzEgLTAuNzY1MTMxIDEuNDc0NDcxIC0wLjgyMDkyMkMxLjQ3NDQ3MSAtMC44MzY4NjIgMS40OTA0MTEgLTAuOTI0NTMzIDEuNDk4MzgxIC0wLjk0ODQ0M0wxLjg4MDk0NiAtMi40NTQ3OTVaJyBpZD0nZzQtMTEyJy8+CjxwYXRoIGQ9J00zLjk5MzAyNiAtMy4xODAwNzVDMy42NDIzNDEgLTMuMDkyNDAzIDMuNjI2NDAxIC0yLjc4MTU2OSAzLjYyNjQwMSAtMi43NDk2ODlDMy42MjY0MDEgLTIuNTc0MzQ2IDMuNzYxODkzIC0yLjQ1NDc5NSAzLjkzNzIzNSAtMi40NTQ3OTVTNC4zODM1NjIgLTIuNTkwMjg2IDQuMzgzNTYyIC0yLjkzMzAwMUM0LjM4MzU2MiAtMy4zODcyOTggMy44ODE0NDUgLTMuNTE0ODE5IDMuNTg2NTUgLTMuNTE0ODE5QzMuMjExOTU1IC0zLjUxNDgxOSAyLjkwOTA5MSAtMy4yNTE4MDYgMi43MjU3NzggLTIuOTQwOTcxQzIuNTUwNDM2IC0zLjM2MzM4NyAyLjEzNTk5IC0zLjUxNDgxOSAxLjgwOTIxNSAtMy41MTQ4MTlDMC45NDA0NzMgLTMuNTE0ODE5IDAuNDU0Mjk2IC0yLjUxODU1NSAwLjQ1NDI5NiAtMi4yOTUzOTJDMC40NTQyOTYgLTIuMjIzNjYxIDAuNTEwMDg3IC0yLjE5MTc4MSAwLjU3Mzg0OCAtMi4xOTE3ODFDMC42Njk0ODkgLTIuMTkxNzgxIDAuNjg1NDMgLTIuMjMxNjMxIDAuNzA5MzQgLTIuMzI3MjczQzAuODkyNjUzIC0yLjkwOTA5MSAxLjM3MDg1OSAtMy4yOTE2NTYgMS43ODUzMDUgLTMuMjkxNjU2QzIuMDk2MTM5IC0zLjI5MTY1NiAyLjI0NzU3MiAtMy4wNjg0OTMgMi4yNDc1NzIgLTIuNzgxNTY5QzIuMjQ3NTcyIC0yLjYyMjE2NyAyLjE1MTkzIC0yLjI1NTU0MiAyLjA4ODE2OSAtMi4wMDA0OThDMi4wMzIzNzkgLTEuNzY5MzY1IDEuODU3MDM2IC0xLjA2MDAyNSAxLjgxNzE4NiAtMC45MDg1OTNDMS43MDU2MDQgLTAuNDc4MjA3IDEuNDE4NjggLTAuMTQzNDYyIDEuMDYwMDI1IC0wLjE0MzQ2MkMxLjAyODE0NCAtMC4xNDM0NjIgMC44MjA5MjIgLTAuMTQzNDYyIDAuNjUzNTQ5IC0wLjI1NTA0NEMxLjAyMDE3NCAtMC4zNDI3MTUgMS4wMjAxNzQgLTAuNjc3NDYgMS4wMjAxNzQgLTAuNjg1NDNDMS4wMjAxNzQgLTAuODY4NzQyIDAuODc2NzEyIC0wLjk4MDMyNCAwLjcwMTM3IC0wLjk4MDMyNEMwLjQ4NjE3NyAtMC45ODAzMjQgMC4yNTUwNDQgLTAuNzk3MDExIDAuMjU1MDQ0IC0wLjQ5NDE0N0MwLjI1NTA0NCAtMC4xMjc1MjIgMC42NDU1NzkgMC4wNzk3MDEgMS4wNTIwNTUgMC4wNzk3MDFDMS40NzQ0NzEgMC4wNzk3MDEgMS43NjkzNjUgLTAuMjM5MTAzIDEuOTEyODI3IC0wLjQ5NDE0N0MyLjA4ODE2OSAtMC4xMDM2MTEgMi40NTQ3OTUgMC4wNzk3MDEgMi44MzczNiAwLjA3OTcwMUMzLjcwNjEwMiAwLjA3OTcwMSA0LjE4NDMwOSAtMC45MTY1NjMgNC4xODQzMDkgLTEuMTM5NzI2QzQuMTg0MzA5IC0xLjIxOTQyNyA0LjEyMDU0OCAtMS4yNDMzMzcgNC4wNjQ3NTcgLTEuMjQzMzM3QzMuOTY5MTE2IC0xLjI0MzMzNyAzLjk1MzE3NiAtMS4xODc1NDcgMy45MjkyNjUgLTEuMTA3ODQ2QzMuNzY5ODYzIC0wLjU3Mzg0OCAzLjMxNTU2NyAtMC4xNDM0NjIgMi44NTMzIC0wLjE0MzQ2MkMyLjU5MDI4NiAtMC4xNDM0NjIgMi4zOTkwMDQgLTAuMzE4ODA0IDIuMzk5MDA0IC0wLjY1MzU0OUMyLjM5OTAwNCAtMC44MTI5NTEgMi40NDY4MjQgLTAuOTk2MjY0IDIuNTU4NDA2IC0xLjQ0MjU5QzIuNjE0MTk3IC0xLjY4MTY5NCAyLjc4OTUzOSAtMi4zODMwNjQgMi44MjkzOSAtMi41MzQ0OTZDMi45NDA5NzEgLTIuOTQ4OTQxIDMuMjE5OTI1IC0zLjI5MTY1NiAzLjU3ODU4IC0zLjI5MTY1NkMzLjYxODQzMSAtMy4yOTE2NTYgMy44MjU2NTQgLTMuMjkxNjU2IDMuOTkzMDI2IC0zLjE4MDA3NVonIGlkPSdnNC0xMjAnLz4KPHBhdGggZD0nTTEuMTU1NjY2IC0wLjY5MzRDMS40NDI1OSAtMC45ODgyOTQgMS41MzAyNjIgLTEuMDc1OTY1IDIuMjMxNjMxIC0xLjY1Nzc4M0MyLjMxOTMwMyAtMS43Mjk1MTQgMi44NzcyMSAtMi4xOTE3ODEgMy4wOTI0MDMgLTIuMzk5MDA0QzMuNTk0NTIxIC0yLjg5MzE1MSAzLjkwNTM1NSAtMy4zMzE1MDcgMy45MDUzNTUgLTMuNDE5MTc4QzMuOTA1MzU1IC0zLjQ5MDkwOSAzLjg0MTU5NCAtMy41MTQ4MTkgMy43ODU4MDMgLTMuNTE0ODE5QzMuNzA2MTAyIC0zLjUxNDgxOSAzLjY5ODEzMiAtMy40OTg4NzkgMy42MTg0MzEgLTMuMzc5MzI4QzMuMzcxMzU3IC0zLjAxMjcwMiAzLjE5NjAxNSAtMi45NDg5NDEgMy4wNTI1NTMgLTIuOTQ4OTQxQzIuOTAxMTIxIC0yLjk0ODk0MSAyLjgwNTQ3OSAtMy4wMTI3MDIgMi42NDYwNzcgLTMuMTcyMTA1QzIuNDM4ODU0IC0zLjM3MTM1NyAyLjI3OTQ1MiAtMy41MTQ4MTkgMi4wMjQ0MDggLTMuNTE0ODE5QzEuMzg2OCAtMy41MTQ4MTkgMC45ODgyOTQgLTIuNzk3NTA5IDAuOTg4Mjk0IC0yLjU4MjMxNkMwLjk4ODI5NCAtMi41NzQzNDYgMC45ODgyOTQgLTIuNDg2Njc1IDEuMTE1ODE2IC0yLjQ4NjY3NUMxLjE5NTUxNyAtMi40ODY2NzUgMS4yMTE0NTcgLTIuNTE4NTU1IDEuMjQzMzM3IC0yLjYwNjIyN0MxLjM0Njk0OSAtMi44MzczNiAxLjY4OTY2NCAtMi45MTcwNjEgMS45Mjg3NjcgLTIuOTE3MDYxQzIuMTEyMDggLTIuOTE3MDYxIDIuMzAzMzYyIC0yLjg2OTI0IDIuNDk0NjQ1IC0yLjgxMzQ1QzIuODI5MzkgLTIuNzI1Nzc4IDIuOTAxMTIxIC0yLjcyNTc3OCAzLjA4NDQzMyAtMi43MjU3NzhDMi45MTcwNjEgLTIuNTUwNDM2IDIuNjkzODk4IC0yLjMyNzI3MyAyLjA4MDE5OSAtMS44MjUxNTZDMS43NDU0NTUgLTEuNTQ2MjAyIDEuNDEwNzEgLTEuMjc1MjE4IDEuMTk1NTE3IC0xLjA2Nzk5NUMwLjYwNTcyOSAtMC40ODYxNzcgMC4zNTA2ODUgLTAuMDk1NjQxIDAuMzUwNjg1IC0wLjAxNTk0QzAuMzUwNjg1IDAuMDU1NzkxIDAuNDA2NDc2IDAuMDc5NzAxIDAuNDcwMjM3IDAuMDc5NzAxQzAuNTQ5OTM4IDAuMDc5NzAxIDAuNTY1ODc4IDAuMDU1NzkxIDAuNjA1NzI5IDBDMC43NjUxMzEgLTAuMjM5MTAzIDEuMDEyMjA0IC0wLjQ4NjE3NyAxLjMxNTA2OCAtMC40ODYxNzdDMS40OTgzODEgLTAuNDg2MTc3IDEuNTc4MDgyIC0wLjQxNDQ0NiAxLjcyOTUxNCAtMC4yNjMwMTRDMS45ODQ1NTggLTAuMDE1OTQgMi4xMjgwMiAwLjA3OTcwMSAyLjM1OTE1MyAwLjA3OTcwMUMzLjE4ODA0NSAwLjA3OTcwMSAzLjY5MDE2MiAtMC45MDg1OTMgMy42OTAxNjIgLTEuMTU1NjY2QzMuNjkwMTYyIC0xLjIyNzM5NyAzLjYzNDM3MSAtMS4yNTkyNzggMy41NzA2MSAtMS4yNTkyNzhDMy40ODI5MzkgLTEuMjU5Mjc4IDMuNDY2OTk5IC0xLjIxMTQ1NyAzLjQzNTExOCAtMS4xMzE3NTZDMy4yODM2ODYgLTAuNzMzMjUgMi44NDUzMyAtMC41MTgwNTcgMi40NDY4MjQgLTAuNTE4MDU3QzIuMjk1MzkyIC0wLjUxODA1NyAyLjEyMDA1IC0wLjU1NzkwOCAxLjg4MDk0NiAtMC42MjE2NjlDMS41NDYyMDIgLTAuNzA5MzQgMS40NjY1MDEgLTAuNzA5MzQgMS4zNDY5NDkgLTAuNzA5MzRDMS4yNjcyNDggLTAuNzA5MzQgMS4yMTk0MjcgLTAuNzA5MzQgMS4xNTU2NjYgLTAuNjkzNFonIGlkPSdnNC0xMjInLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnNy00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzctNDEnLz4KPHBhdGggZD0nTTQuNzcwMTEyIC0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMSAtMi43NjE2NDQgOC40NTIzMDQgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjk3NjgzN0M4LjQ1MjMwNCAtMy4yMDM5ODUgOC4yNDkwNjYgLTMuMjAzOTg1IDguMDY5NzM4IC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTIgLTYuNjcwOTg0IDQuNzcwMTEyIC02Ljg4NjE3NyA0LjU1NDkxOSAtNi44ODYxNzdDNC4zMjc3NzEgLTYuODg2MTc3IDQuMzI3NzcxIC02LjY4MjkzOSA0LjMyNzc3MSAtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0QzAuODYwNzcyIC0zLjIwMzk4NSAwLjY0NTU3OSAtMy4yMDM5ODUgMC42NDU1NzkgLTIuOTg4NzkyQzAuNjQ1NTc5IC0yLjc2MTY0NCAwLjg0ODgxNyAtMi43NjE2NDQgMS4wMjgxNDQgLTIuNzYxNjQ0SDQuMzI3NzcxVjAuNTM3OTgzQzQuMzI3NzcxIDAuNzA1MzU1IDQuMzI3NzcxIDAuOTIwNTQ4IDQuNTQyOTY0IDAuOTIwNTQ4QzQuNzcwMTEyIDAuOTIwNTQ4IDQuNzcwMTEyIDAuNzE3MzEgNC43NzAxMTIgMC41Mzc5ODNWLTIuNzYxNjQ0WicgaWQ9J2c3LTQzJy8+CjxwYXRoIGQ9J00zLjQ0MzA4OCAtNy42NjMyNjNDMy40NDMwODggLTcuOTM4MjMyIDMuNDQzMDg4IC03Ljk1MDE4NyAzLjIwMzk4NSAtNy45NTAxODdDMi45MTcwNjEgLTcuNjI3Mzk3IDIuMzE5MzAzIC03LjE4NTA1NiAxLjA4NzkyIC03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODkgLTYuODM4MzU2IDEuOTYwNjQ4IC02LjgzODM1NiAyLjYxODE4MiAtNy4xNDkxOTFWLTAuOTIwNTQ4QzIuNjE4MTgyIC0wLjQ5MDE2MiAyLjU4MjMxNiAtMC4zNDY3IDEuNTMwMjYyIC0wLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MSAtMC4wMjM5MSAyLjY0MjA5MiAtMC4wMjM5MSAzLjAzNjYxMyAtMC4wMjM5MVM0LjU3ODgyOSAtMC4wMjM5MSA0LjkwMTYxOSAwVi0wLjM0NjdINC41MzEwMDlDMy40Nzg5NTQgLTAuMzQ2NyAzLjQ0MzA4OCAtMC40OTAxNjIgMy40NDMwODggLTAuOTIwNTQ4Vi03LjY2MzI2M1onIGlkPSdnNy00OScvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzctNjEnLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2c3LTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2c3LTkzJy8+CjxwYXRoIGQ9J000LjYxNDY5NSAtMy4xOTIwM0M0LjYxNDY5NSAtMy44Mzc2MDkgNC42MTQ2OTUgLTQuMzE1ODE2IDQuMDg4NjY3IC00Ljc4MjA2N0MzLjY3MDIzNyAtNS4xNjQ2MzMgMy4xMzIyNTQgLTUuMzMyMDA1IDIuNjA2MjI3IC01LjMzMjAwNUMxLjYyNTkwMyAtNS4zMzIwMDUgMC44NzI3MjcgLTQuNjg2NDI2IDAuODcyNzI3IC0zLjkwOTM0QzAuODcyNzI3IC0zLjU2MjY0IDEuMDk5ODc1IC0zLjM5NTI2OCAxLjM3NDg0NCAtMy4zOTUyNjhDMS42NjE3NjggLTMuMzk1MjY4IDEuODY1MDA2IC0zLjU5ODUwNiAxLjg2NTAwNiAtMy44ODU0M0MxLjg2NTAwNiAtNC4zNzU1OTIgMS40MzQ2MiAtNC4zNzU1OTIgMS4yNTUyOTMgLTQuMzc1NTkyQzEuNTMwMjYyIC00Ljg3NzcwOSAyLjEwNDExIC01LjA5MjkwMiAyLjU4MjMxNiAtNS4wOTI5MDJDMy4xMzIyNTQgLTUuMDkyOTAyIDMuODM3NjA5IC00LjYzODYwNSAzLjgzNzYwOSAtMy41NjI2NFYtMy4wODQ0MzNDMS40MzQ2MiAtMy4wNDg1NjggMC41MjYwMjcgLTIuMDQ0MzM0IDAuNTI2MDI3IC0xLjEyMzc4NkMwLjUyNjAyNyAtMC4xNzkzMjggMS42MjU5MDMgMC4xMTk1NTIgMi4zNTUxNjggMC4xMTk1NTJDMy4xNDQyMDkgMC4xMTk1NTIgMy42ODIxOTIgLTAuMzU4NjU1IDMuOTA5MzQgLTAuOTMyNTAzQzMuOTU3MTYxIC0wLjM3MDYxIDQuMzI3NzcxIDAuMDU5Nzc2IDQuODQxODQzIDAuMDU5Nzc2QzUuMDkyOTAyIDAuMDU5Nzc2IDUuNzg2MzAxIC0wLjEwNzU5NyA1Ljc4NjMwMSAtMS4wNjQwMVYtMS43MzM0OTlINS41MjMyODhWLTEuMDY0MDFDNS41MjMyODggLTAuMzgyNTY1IDUuMjM2MzY0IC0wLjI4NjkyNCA1LjA2ODk5MSAtMC4yODY5MjRDNC42MTQ2OTUgLTAuMjg2OTI0IDQuNjE0Njk1IC0wLjkyMDU0OCA0LjYxNDY5NSAtMS4wOTk4NzVWLTMuMTkyMDNaTTMuODM3NjA5IC0xLjY4NTY3OUMzLjgzNzYwOSAtMC41MTQwNzIgMi45NjQ4ODIgLTAuMTE5NTUyIDIuNDUwODA5IC0wLjExOTU1MkMxLjg2NTAwNiAtMC4xMTk1NTIgMS4zNzQ4NDQgLTAuNTQ5OTM4IDEuMzc0ODQ0IC0xLjEyMzc4NkMxLjM3NDg0NCAtMi43MDE4NjggMy40MDcyMjMgLTIuODQ1MzMgMy44Mzc2MDkgLTIuODY5MjRWLTEuNjg1Njc5WicgaWQ9J2c3LTk3Jy8+CjxwYXRoIGQ9J00yLjA4MDE5OSAtNy4zNjQzODRDMi4wODAxOTkgLTcuNjc1MjE4IDEuODI5MTQxIC03Ljk1MDE4NyAxLjQ5NDM5NiAtNy45NTAxODdDMS4xODM1NjIgLTcuOTUwMTg3IDAuOTIwNTQ4IC03LjY5OTEyOCAwLjkyMDU0OCAtNy4zNzYzMzlDMC45MjA1NDggLTcuMDE3Njg0IDEuMjA3NDcyIC02Ljc5MDUzNSAxLjQ5NDM5NiAtNi43OTA1MzVDMS44NjUwMDYgLTYuNzkwNTM1IDIuMDgwMTk5IC03LjEwMTM3IDIuMDgwMTk5IC03LjM2NDM4NFpNMC40MzAzODYgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4zMDMxMTMgLTQuNzIyMjkxIDEuMzAzMTEzIC00LjEzNjQ4OFYtMC44ODQ2ODJDMS4zMDMxMTMgLTAuMzQ2NyAxLjE3MTYwNiAtMC4zNDY3IDAuMzk0NTIxIC0wLjM0NjdWMEMwLjcyOTI2NSAtMC4wMjM5MSAxLjMwMzExMyAtMC4wMjM5MSAxLjY0OTgxMyAtMC4wMjM5MUMxLjc4MTMyIC0wLjAyMzkxIDIuNDc0NzIgLTAuMDIzOTEgMi44ODExOTYgMFYtMC4zNDY3QzIuMTA0MTEgLTAuMzQ2NyAyLjA1NjI4OSAtMC40MDY0NzYgMi4wNTYyODkgLTAuODcyNzI3Vi01LjI3MjIyOUwwLjQzMDM4NiAtNS4xNDA3MjJaJyBpZD0nZzctMTA1Jy8+CjxwYXRoIGQ9J00yLjA1NjI4OSAtOC4yOTY4ODdMMC4zOTQ1MjEgLTguMTY1MzhWLTcuODE4NjhDMS4yMDc0NzIgLTcuODE4NjggMS4zMDMxMTMgLTcuNzM0OTk0IDEuMzAzMTEzIC03LjE0OTE5MVYtMC44ODQ2ODJDMS4zMDMxMTMgLTAuMzQ2NyAxLjE3MTYwNiAtMC4zNDY3IDAuMzk0NTIxIC0wLjM0NjdWMEMwLjcyOTI2NSAtMC4wMjM5MSAxLjMxNTA2OCAtMC4wMjM5MSAxLjY3MzcyNCAtMC4wMjM5MVMyLjYzMDEzNyAtMC4wMjM5MSAyLjk2NDg4MiAwVi0wLjM0NjdDMi4xOTk3NTEgLTAuMzQ2NyAyLjA1NjI4OSAtMC4zNDY3IDIuMDU2Mjg5IC0wLjg4NDY4MlYtOC4yOTY4ODdaJyBpZD0nZzctMTA4Jy8+CjxwYXRoIGQ9J004LjU3MTg1NiAtMi45MDUxMDZDOC41NzE4NTYgLTQuMDE2OTM2IDguNTcxODU2IC00LjM1MTY4MSA4LjI5Njg4NyAtNC43MzQyNDdDNy45NTAxODcgLTUuMjAwNDk4IDcuMzg4Mjk0IC01LjI3MjIyOSA2Ljk4MTgxOCAtNS4yNzIyMjlDNS45ODk1MzkgLTUuMjcyMjI5IDUuNDg3NDIyIC00LjU1NDkxOSA1LjI5NjEzOSAtNC4wODg2NjdDNS4xMjg3NjcgLTUuMDA5MjE1IDQuNDgzMTg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNDYzNTEyIC0wLjM0NjcgNS4zMjAwNSAtMC4zNDY3IDUuMzIwMDUgLTAuODg0NjgyVi0zLjEwODM0NEM1LjMyMDA1IC00LjM2MzYzNiA2LjE0NDk1NiAtNS4wMzMxMjYgNi44ODYxNzcgLTUuMDMzMTI2UzcuNzk0NzcgLTQuNDIzNDEyIDcuNzk0NzcgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM3Ljc5NDc3IC0wLjM0NjcgNy42NjMyNjMgLTAuMzQ2NyA2Ljg4NjE3NyAtMC4zNDY3VjBDNy4xOTcwMTEgLTAuMDIzOTEgNy44NDI1OSAtMC4wMjM5MSA4LjE3NzMzNSAtMC4wMjM5MUM4LjUyNDAzNSAtMC4wMjM5MSA5LjE2OTYxNCAtMC4wMjM5MSA5LjQ4MDQ0OCAwVi0wLjM0NjdDOC44ODI2OSAtMC4zNDY3IDguNTgzODExIC0wLjM0NjcgOC41NzE4NTYgLTAuNzA1MzU1Vi0yLjkwNTEwNlonIGlkPSdnNy0xMDknLz4KPHBhdGggZD0nTTUuMzIwMDUgLTIuOTA1MTA2QzUuMzIwMDUgLTQuMDE2OTM2IDUuMzIwMDUgLTQuMzUxNjgxIDUuMDQ1MDgxIC00LjczNDI0N0M0LjY5ODM4MSAtNS4yMDA0OTggNC4xMzY0ODggLTUuMjcyMjI5IDMuNzMwMDEyIC01LjI3MjIyOUMyLjU3MDM2MSAtNS4yNzIyMjkgMi4xMTYwNjUgLTQuMjc5OTUgMi4wMjA0MjMgLTQuMDQwODQ3SDIuMDA4NDY4Vi01LjI3MjIyOUwwLjM4MjU2NSAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMTk1NTE3IC00Ljc5NDAyMiAxLjI5MTE1OCAtNC43MTAzMzYgMS4yOTExNTggLTQuMTI0NTMzVi0wLjg4NDY4MkMxLjI5MTE1OCAtMC4zNDY3IDEuMTU5NjUxIC0wLjM0NjcgMC4zODI1NjUgLTAuMzQ2N1YwQzAuNjkzNCAtMC4wMjM5MSAxLjMzODk3OSAtMC4wMjM5MSAxLjY3MzcyNCAtMC4wMjM5MUMyLjAyMDQyMyAtMC4wMjM5MSAyLjY2NjAwMiAtMC4wMjM5MSAyLjk3NjgzNyAwVi0wLjM0NjdDMi4yMTE3MDYgLTAuMzQ2NyAyLjA2ODI0NCAtMC4zNDY3IDIuMDY4MjQ0IC0wLjg4NDY4MlYtMy4xMDgzNDRDMi4wNjgyNDQgLTQuMzYzNjM2IDIuODkzMTUxIC01LjAzMzEyNiAzLjYzNDM3MSAtNS4wMzMxMjZTNC41NDI5NjQgLTQuNDIzNDEyIDQuNTQyOTY0IC0zLjY5NDE0N1YtMC44ODQ2ODJDNC41NDI5NjQgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3IDMuNjM0MzcxIC0wLjM0NjdWMEMzLjk0NTIwNSAtMC4wMjM5MSA0LjU5MDc4NSAtMC4wMjM5MSA0LjkyNTUyOSAtMC4wMjM5MUM1LjI3MjIyOSAtMC4wMjM5MSA1LjkxNzgwOCAtMC4wMjM5MSA2LjIyODY0MyAwVi0wLjM0NjdDNS42MzA4ODQgLTAuMzQ2NyA1LjMzMjAwNSAtMC4zNDY3IDUuMzIwMDUgLTAuNzA1MzU1Vi0yLjkwNTEwNlonIGlkPSdnNy0xMTAnLz4KPHBhdGggZD0nTTMuMzQ3NDQ3IC0yLjgyMTQyQzMuNjk0MTQ3IC0zLjI3NTcxNiA0LjE5NjI2NCAtMy45MjEyOTUgNC40MjM0MTIgLTQuMTcyMzU0QzQuOTEzNTc0IC00LjcyMjI5MSA1LjQ3NTQ2NyAtNC44MDU5NzggNS44NTgwMzIgLTQuODA1OTc4Vi01LjE1MjY3N0M1LjM0Mzk2IC01LjEyODc2NyA1LjMyMDA1IC01LjEyODc2NyA0Ljg1Mzc5OCAtNS4xMjg3NjdDNC4zOTk1MDIgLTUuMTI4NzY3IDQuMzc1NTkyIC01LjEyODc2NyAzLjc3NzgzMyAtNS4xNTI2NzdWLTQuODA1OTc4QzMuOTMzMjUgLTQuNzgyMDY3IDQuMTI0NTMzIC00LjcxMDMzNiA0LjEyNDUzMyAtNC40MzUzNjdDNC4xMjQ1MzMgLTQuMjMyMTMgNC4wMTY5MzYgLTQuMTAwNjIzIDMuOTQ1MjA1IC00LjAwNDk4MUwzLjE4MDA3NSAtMy4wMzY2MTNMMi4yNDc1NzIgLTQuMjY3OTk1QzIuMjExNzA2IC00LjMxNTgxNiAyLjEzOTk3NSAtNC40MjM0MTIgMi4xMzk5NzUgLTQuNTA3MDk4QzIuMTM5OTc1IC00LjU3ODgyOSAyLjE5OTc1MSAtNC43OTQwMjIgMi41NTg0MDYgLTQuODA1OTc4Vi01LjE1MjY3N0MyLjI1OTUyNyAtNS4xMjg3NjcgMS42NDk4MTMgLTUuMTI4NzY3IDEuMzI3MDI0IC01LjEyODc2N0MwLjkzMjUwMyAtNS4xMjg3NjcgMC45MDg1OTMgLTUuMTI4NzY3IDAuMTc5MzI4IC01LjE1MjY3N1YtNC44MDU5NzhDMC43ODkwNDEgLTQuODA1OTc4IDEuMDE2MTg5IC00Ljc4MjA2NyAxLjI2NzI0OCAtNC40NTkyNzhMMi42NjYwMDIgLTIuNjMwMTM3QzIuNjg5OTEzIC0yLjYwNjIyNyAyLjczNzczMyAtMi41MzQ0OTYgMi43Mzc3MzMgLTIuNDk4NjNTMS44MDUyMyAtMS4yOTExNTggMS42ODU2NzkgLTEuMTM1NzQxQzEuMTU5NjUxIC0wLjQ5MDE2MiAwLjYzMzYyNCAtMC4zNTg2NTUgMC4xMTk1NTIgLTAuMzQ2N1YwQzAuNTczODQ4IC0wLjAyMzkxIDAuNTk3NzU4IC0wLjAyMzkxIDEuMTExODMxIC0wLjAyMzkxQzEuNTY2MTI3IC0wLjAyMzkxIDEuNTkwMDM3IC0wLjAyMzkxIDIuMTg3Nzk2IDBWLTAuMzQ2N0MxLjkwMDg3MiAtMC4zODI1NjUgMS44NTMwNTEgLTAuNTYxODkzIDEuODUzMDUxIC0wLjcyOTI2NUMxLjg1MzA1MSAtMC45MjA1NDggMS45MzY3MzcgLTEuMDE2MTg5IDIuMDU2Mjg5IC0xLjE3MTYwNkMyLjIzNTYxNiAtMS40MjI2NjUgMi42MzAxMzcgLTEuOTEyODI3IDIuOTE3MDYxIC0yLjI4MzQzN0wzLjg5NzM4NSAtMS4wMDQyMzRDNC4xMDA2MjMgLTAuNzQxMjIgNC4xMDA2MjMgLTAuNzE3MzEgNC4xMDA2MjMgLTAuNjQ1NTc5QzQuMTAwNjIzIC0wLjU0OTkzOCA0LjAwNDk4MSAtMC4zNTg2NTUgMy42ODIxOTIgLTAuMzQ2N1YwQzMuOTkzMDI2IC0wLjAyMzkxIDQuNTc4ODI5IC0wLjAyMzkxIDQuOTEzNTc0IC0wLjAyMzkxQzUuMzA4MDk1IC0wLjAyMzkxIDUuMzMyMDA1IC0wLjAyMzkxIDYuMDQ5MzE1IDBWLTAuMzQ2N0M1LjQxNTY5MSAtMC4zNDY3IDUuMjAwNDk4IC0wLjM3MDYxIDQuOTEzNTc0IC0wLjc1MzE3NkwzLjM0NzQ0NyAtMi44MjE0MlonIGlkPSdnNy0xMjAnLz4KPHBhdGggZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIDAuNzI1MjggMS4zMzg5NzkgLTAuNzU3MTYxIDEuMzM4OTc5IC0xLjk5MjUyOEMxLjMzODk3OSAtNC4yODc5MiAyLjI4NzQyMiAtNS4zNjM4ODUgMi42OTM4OTggLTUuNzMwNTExQzIuODA1NDc5IC01LjgzNDEyMiAyLjgxMzQ1IC01Ljg0MjA5MiAyLjgxMzQ1IC01Ljg4MTk0M1MyLjc4MTU2OSAtNS45Nzc1ODQgMi43MDE4NjggLTUuOTc3NTg0QzIuNTc0MzQ2IC01Ljk3NzU4NCAyLjE3NTg0MSAtNS41NzExMDggMi4xMTIwOCAtNS40OTkzNzdDMS4wNDQwODUgLTQuMzgzNTYyIDAuODIwOTIyIC0yLjk0ODk0MSAwLjgyMDkyMiAtMS45OTI1MjhDMC44MjA5MjIgLTAuMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicgaWQ9J2c2LTQwJy8+CjxwYXRoIGQ9J00yLjQ2Mjc2NSAtMS45OTI1MjhDMi40NjI3NjUgLTIuNzQ5Njg5IDIuMzM1MjQzIC0zLjY1ODI4MSAxLjg0MTA5NiAtNC41OTg3NTVDMS40NTA1NiAtNS4zMzIwMDUgMC43MjUyOCAtNS45Nzc1ODQgMC41ODE4MTggLTUuOTc3NTg0QzAuNTAyMTE3IC01Ljk3NzU4NCAwLjQ3ODIwNyAtNS45MjE3OTMgMC40NzgyMDcgLTUuODgxOTQzQzAuNDc4MjA3IC01Ljg1MDA2MiAwLjQ3ODIwNyAtNS44MzQxMjIgMC41NzM4NDggLTUuNzM4NDgxQzEuNjg5NjY0IC00LjY3ODQ1NiAxLjk0NDcwNyAtMy4yMTk5MjUgMS45NDQ3MDcgLTEuOTkyNTI4QzEuOTQ0NzA3IDAuMjk0ODk0IDAuOTk2MjY0IDEuMzc4ODI5IDAuNTg5Nzg4IDEuNzQ1NDU1QzAuNDg2MTc3IDEuODQ5MDY2IDAuNDc4MjA3IDEuODU3MDM2IDAuNDc4MjA3IDEuODk2ODg3UzAuNTAyMTE3IDEuOTkyNTI4IDAuNTgxODE4IDEuOTkyNTI4QzAuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgMC4zOTg1MDYgMi40NjI3NjUgLTEuMDM2MTE1IDIuNDYyNzY1IC0xLjk5MjUyOFonIGlkPSdnNi00MScvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzUtNTknLz4KPHBhdGggZD0nTTEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjYzMzYyNCAwIDAuODcyNzI3IDBINC42NjI1MTZDNy4wNzc0NiAwIDkuNDMyNjI4IC0yLjQ5ODYzIDkuNDMyNjI4IC01LjE2NDYzM0M5LjQzMjYyOCAtNi44ODYxNzcgOC40MDQ0ODMgLTguMTY1MzggNi42OTQ4OTQgLTguMTY1MzhIMi44NTcyODVDMi42MzAxMzcgLTguMTY1MzggMi41MjI1NCAtOC4xNjUzOCAyLjUyMjU0IC03LjkzODIzMkMyLjUyMjU0IC03LjgxODY4IDIuNjMwMTM3IC03LjgxODY4IDIuODA5NDY1IC03LjgxODY4QzMuNTM4NzMgLTcuODE4NjggMy41Mzg3MyAtNy43MjMwMzkgMy41Mzg3MyAtNy41OTE1MzJDMy41Mzg3MyAtNy41Njc2MjEgMy41Mzg3MyAtNy40OTU4OSAzLjQ5MDkwOSAtNy4zMTY1NjNMMS44NzY5NjEgLTAuODg0NjgyWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4zMzYyMzlDNy40NjAwMjUgLTcuODE4NjggOC40ODgxNjkgLTcuMjA4OTY2IDguNDg4MTY5IC01LjU1OTE1M0M4LjQ4ODE2OSAtNC45NjEzOTUgOC4yNDkwNjYgLTIuODgxMTk2IDcuMDg5NDE1IC0xLjU2NjEyN0M2Ljc1NDY3IC0xLjE3MTYwNiA1Ljg0NjA3NyAtMC4zNDY3IDQuNDcxMjMzIC0wLjM0NjdIMy4xMDgzNDRDMi45NDA5NzEgLTAuMzQ2NyAyLjkxNzA2MSAtMC4zNDY3IDIuODQ1MzMgLTAuMzU4NjU1QzIuNzEzODIzIC0wLjM3MDYxIDIuNzAxODY4IC0wLjM5NDUyMSAyLjcwMTg2OCAtMC40OTAxNjJDMi43MDE4NjggLTAuNTczODQ4IDIuNzI1Nzc4IC0wLjY0NTU3OSAyLjc0OTY4OSAtMC43NTMxNzZMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2c1LTY4Jy8+CjxwYXRoIGQ9J004LjkxODU1NSAtOC4zMDg4NDJDOC45MTg1NTUgLTguNDE2NDM4IDguODM0ODY5IC04LjQxNjQzOCA4LjgxMDk1OSAtOC40MTY0MzhTOC43MzkyMjggLTguNDE2NDM4IDguNjQzNTg3IC04LjI5Njg4N0w3LjgxODY4IC03LjMwNDYwOEM3Ljc1ODkwNCAtNy40MDAyNDkgNy41MTk4MDEgLTcuODE4NjggNy4wNTM1NDkgLTguMDkzNjQ5QzYuNTM5NDc3IC04LjQxNjQzOCA2LjAyNTQwNSAtOC40MTY0MzggNS44NDYwNzcgLTguNDE2NDM4QzMuMjg3NjcxIC04LjQxNjQzOCAwLjU5Nzc1OCAtNS44MTAyMTIgMC41OTc3NTggLTIuOTg4NzkyQzAuNTk3NzU4IC0xLjAxNjE4OSAxLjk2MDY0OCAwLjI1MTA1OSAzLjc1MzkyMyAwLjI1MTA1OUM0LjYxNDY5NSAwLjI1MTA1OSA1LjcwMjYxNSAtMC4wMzU4NjYgNi4zMDAzNzQgLTAuNzg5MDQxQzYuNDMxODggLTAuMzM0NzQ1IDYuNjk0ODk0IC0wLjAxMTk1NSA2Ljc3ODU4IC0wLjAxMTk1NUM2LjgzODM1NiAtMC4wMTE5NTUgNi44NTAzMTEgLTAuMDQ3ODIxIDYuODYyMjY3IC0wLjA0NzgyMUM2Ljg3NDIyMiAtMC4wNzE3MzEgNi45Njk4NjMgLTAuNDkwMTYyIDcuMDI5NjM5IC0wLjcwNTM1NUw3LjIyMDkyMiAtMS40NzA0ODZDNy4zMTY1NjMgLTEuODY1MDA2IDcuMzY0Mzg0IC0yLjAzMjM3OSA3LjQ0ODA3IC0yLjM5MTAzNEM3LjU2NzYyMSAtMi44NDUzMyA3LjU5MTUzMiAtMi44ODExOTYgOC4yNDkwNjYgLTIuODkzMTUxQzguMjk2ODg3IC0yLjg5MzE1MSA4LjQ0MDM0OSAtMi44OTMxNTEgOC40NDAzNDkgLTMuMTIwMjk5QzguNDQwMzQ5IC0zLjIzOTg1MSA4LjMyMDc5NyAtMy4yMzk4NTEgOC4yODQ5MzIgLTMuMjM5ODUxQzguMDgxNjk0IC0zLjIzOTg1MSA3Ljg1NDU0NSAtMy4yMTU5NCA3LjYzOTM1MiAtMy4yMTU5NEg2Ljk5Mzc3M0M2LjQ5MTY1NiAtMy4yMTU5NCA1Ljk2NTYyOSAtMy4yMzk4NTEgNS40NzU0NjcgLTMuMjM5ODUxQzUuMzY3ODcgLTMuMjM5ODUxIDUuMjI0NDA4IC0zLjIzOTg1MSA1LjIyNDQwOCAtMy4wMjQ2NThDNS4yMjQ0MDggLTIuOTA1MTA2IDUuMzIwMDUgLTIuOTA1MTA2IDUuMzIwMDUgLTIuODkzMTUxSDUuNjE4OTI5QzYuNTYzMzg3IC0yLjg5MzE1MSA2LjU2MzM4NyAtMi43OTc1MDkgNi41NjMzODcgLTIuNjE4MTgyQzYuNTYzMzg3IC0yLjYwNjIyNyA2LjMzNjIzOSAtMS4zOTg3NTUgNi4xMDkwOTEgLTEuMDQwMUM1LjY1NDc5NSAtMC4zNzA2MSA0LjcxMDMzNiAtMC4wOTU2NDEgNC4wMDQ5ODEgLTAuMDk1NjQxQzMuMDg0NDMzIC0wLjA5NTY0MSAxLjU5MDAzNyAtMC41NzM4NDggMS41OTAwMzcgLTIuNjQyMDkyQzEuNTkwMDM3IC0zLjQ0MzA4OCAxLjg3Njk2MSAtNS4yNzIyMjkgMy4wMzY2MTMgLTYuNjIzMTYzQzMuNzg5Nzg4IC03LjQ4MzkzNSA0LjkwMTYxOSAtOC4wNjk3MzggNS45NTM2NzQgLTguMDY5NzM4QzcuMzY0Mzg0IC04LjA2OTczOCA3Ljg2NjUwMSAtNi44NjIyNjcgNy44NjY1MDEgLTUuNzYyMzkxQzcuODY2NTAxIC01LjU3MTEwOCA3LjgxODY4IC01LjMwODA5NSA3LjgxODY4IC01LjE0MDcyMkM3LjgxODY4IC01LjAzMzEyNiA3LjkzODIzMiAtNS4wMzMxMjYgNy45NzQwOTcgLTUuMDMzMTI2QzguMTA1NjA0IC01LjAzMzEyNiA4LjExNzU1OSAtNS4wNDUwODEgOC4xNjUzOCAtNS4yNjAyNzRMOC45MTg1NTUgLTguMzA4ODQyWicgaWQ9J2c1LTcxJy8+CjxwYXRoIGQ9J003LjQwMDI0OSAtNi44MzgzNTZDNy44MDY3MjUgLTcuNDgzOTM1IDguMTc3MzM1IC03Ljc3MDg1OSA4Ljc4NzA0OSAtNy44MTg2OEM4LjkwNjYgLTcuODMwNjM1IDkuMDAyMjQyIC03LjgzMDYzNSA5LjAwMjI0MiAtOC4wNDU4MjhDOS4wMDIyNDIgLTguMDkzNjQ5IDguOTc4MzMxIC04LjE2NTM4IDguODcwNzM1IC04LjE2NTM4QzguNjU1NTQyIC04LjE2NTM4IDguMTQxNDY5IC04LjE0MTQ2OSA3LjkyNjI3NiAtOC4xNDE0NjlDNy41Nzk1NzcgLTguMTQxNDY5IDcuMjIwOTIyIC04LjE2NTM4IDYuODg2MTc3IC04LjE2NTM4QzYuNzkwNTM1IC04LjE2NTM4IDYuNjcwOTg0IC04LjE2NTM4IDYuNjcwOTg0IC03LjkzODIzMkM2LjY3MDk4NCAtNy44MzA2MzUgNi43Nzg1OCAtNy44MTg2OCA2LjgyNjQwMSAtNy44MTg2OEM3LjI2ODc0MiAtNy43ODI4MTQgNy4zMTY1NjMgLTcuNTY3NjIxIDcuMzE2NTYzIC03LjQyNDE1OUM3LjMxNjU2MyAtNy4yNDQ4MzIgNy4xNDkxOTEgLTYuOTY5ODYzIDcuMTM3MjM1IC02Ljk1NzkwOEwzLjM4MzMxMyAtMS4wMDQyMzRMMi41NDY0NTEgLTcuNDQ4MDdDMi41NDY0NTEgLTcuNzk0NzcgMy4xNjgxMiAtNy44MTg2OCAzLjI5OTYyNiAtNy44MTg2OEMzLjQ3ODk1NCAtNy44MTg2OCAzLjU4NjU1IC03LjgxODY4IDMuNTg2NTUgLTguMDQ1ODI4QzMuNTg2NTUgLTguMTY1MzggMy40NTUwNDQgLTguMTY1MzggMy40MTkxNzggLTguMTY1MzhDMy4yMTU5NCAtOC4xNjUzOCAyLjk3NjgzNyAtOC4xNDE0NjkgMi43NzM1OTkgLTguMTQxNDY5SDIuMTA0MTFDMS4yMzEzODIgLTguMTQxNDY5IDAuODcyNzI3IC04LjE2NTM4IDAuODYwNzcyIC04LjE2NTM4QzAuNzg5MDQxIC04LjE2NTM4IDAuNjQ1NTc5IC04LjE2NTM4IDAuNjQ1NTc5IC03Ljk1MDE4N0MwLjY0NTU3OSAtNy44MTg2OCAwLjcyOTI2NSAtNy44MTg2OCAwLjkyMDU0OCAtNy44MTg2OEMxLjUzMDI2MiAtNy44MTg2OCAxLjU2NjEyNyAtNy43MTEwODMgMS42MDE5OTMgLTcuNDEyMjA0TDIuNTU4NDA2IC0wLjAzNTg2NkMyLjU5NDI3MSAwLjIxNTE5MyAyLjU5NDI3MSAwLjI1MTA1OSAyLjc2MTY0NCAwLjI1MTA1OUMyLjkwNTEwNiAwLjI1MTA1OSAyLjk2NDg4MiAwLjIxNTE5MyAzLjA4NDQzMyAwLjAyMzkxTDcuNDAwMjQ5IC02LjgzODM1NlonIGlkPSdnNS04NicvPgo8cGF0aCBkPSdNNS42NjY3NSAtNC44Nzc3MDlDNS4yODQxODQgLTQuODA1OTc4IDUuMTQwNzIyIC00LjUxOTA1NCA1LjE0MDcyMiAtNC4yOTE5MDVDNS4xNDA3MjIgLTQuMDA0OTgxIDUuMzY3ODcgLTMuOTA5MzQgNS41MzUyNDMgLTMuOTA5MzRDNS44OTM4OTggLTMuOTA5MzQgNi4xNDQ5NTYgLTQuMjIwMTc0IDYuMTQ0OTU2IC00LjU0Mjk2NEM2LjE0NDk1NiAtNS4wNDUwODEgNS41NzExMDggLTUuMjcyMjI5IDUuMDY4OTkxIC01LjI3MjIyOUM0LjMzOTcyNiAtNS4yNzIyMjkgMy45MzMyNSAtNC41NTQ5MTkgMy44MjU2NTQgLTQuMzI3NzcxQzMuNTUwNjg1IC01LjIyNDQwOCAyLjgwOTQ2NSAtNS4yNzIyMjkgMi41OTQyNzEgLTUuMjcyMjI5QzEuMzc0ODQ0IC01LjI3MjIyOSAwLjcyOTI2NSAtMy43MDYxMDIgMC43MjkyNjUgLTMuNDQzMDg4QzAuNzI5MjY1IC0zLjM5NTI2OCAwLjc3NzA4NiAtMy4zMzU0OTIgMC44NjA3NzIgLTMuMzM1NDkyQzAuOTU2NDEzIC0zLjMzNTQ5MiAwLjk4MDMyNCAtMy40MDcyMjMgMS4wMDQyMzQgLTMuNDU1MDQ0QzEuNDEwNzEgLTQuNzgyMDY3IDIuMjExNzA2IC01LjAzMzEyNiAyLjU1ODQwNiAtNS4wMzMxMjZDMy4wOTYzODkgLTUuMDMzMTI2IDMuMjAzOTg1IC00LjUzMTAwOSAzLjIwMzk4NSAtNC4yNDQwODVDMy4yMDM5ODUgLTMuOTgxMDcxIDMuMTMyMjU0IC0zLjcwNjEwMiAyLjk4ODc5MiAtMy4xMzIyNTRMMi41ODIzMTYgLTEuNDk0Mzk2QzIuNDAyOTg5IC0wLjc3NzA4NiAyLjA1NjI4OSAtMC4xMTk1NTIgMS40MjI2NjUgLTAuMTE5NTUyQzEuMzYyODg5IC0wLjExOTU1MiAxLjA2NDAxIC0wLjExOTU1MiAwLjgxMjk1MSAtMC4yNzQ5NjlDMS4yNDMzMzcgLTAuMzU4NjU1IDEuMzM4OTc5IC0wLjcxNzMxIDEuMzM4OTc5IC0wLjg2MDc3MkMxLjMzODk3OSAtMS4wOTk4NzUgMS4xNTk2NTEgLTEuMjQzMzM3IDAuOTMyNTAzIC0xLjI0MzMzN0MwLjY0NTU3OSAtMS4yNDMzMzcgMC4zMzQ3NDUgLTAuOTkyMjc5IDAuMzM0NzQ1IC0wLjYwOTcxNEMwLjMzNDc0NSAtMC4xMDc1OTcgMC44OTY2MzggMC4xMTk1NTIgMS40MTA3MSAwLjExOTU1MkMxLjk4NDU1OCAwLjExOTU1MiAyLjM5MTAzNCAtMC4zMzQ3NDUgMi42NDIwOTIgLTAuODI0OTA3QzIuODMzMzc1IC0wLjExOTU1MiAzLjQzMTEzMyAwLjExOTU1MiAzLjg3MzQ3NCAwLjExOTU1MkM1LjA5MjkwMiAwLjExOTU1MiA1LjczODQ4MSAtMS40NDY1NzUgNS43Mzg0ODEgLTEuNzA5NTg5QzUuNzM4NDgxIC0xLjc2OTM2NSA1LjY5MDY2IC0xLjgxNzE4NiA1LjYxODkyOSAtMS44MTcxODZDNS41MTEzMzMgLTEuODE3MTg2IDUuNDk5Mzc3IC0xLjc1NzQxIDUuNDYzNTEyIC0xLjY2MTc2OEM1LjE0MDcyMiAtMC42MDk3MTQgNC40NDczMjMgLTAuMTE5NTUyIDMuOTA5MzQgLTAuMTE5NTUyQzMuNDkwOTA5IC0wLjExOTU1MiAzLjI2Mzc2MSAtMC40MzAzODYgMy4yNjM3NjEgLTAuOTIwNTQ4QzMuMjYzNzYxIC0xLjE4MzU2MiAzLjMxMTU4MiAtMS4zNzQ4NDQgMy41MDI4NjQgLTIuMTYzODg1TDMuOTIxMjk1IC0zLjc4OTc4OEM0LjEwMDYyMyAtNC41MDcwOTggNC41MDcwOTggLTUuMDMzMTI2IDUuMDU3MDM2IC01LjAzMzEyNkM1LjA4MDk0NiAtNS4wMzMxMjYgNS40MTU2OTEgLTUuMDMzMTI2IDUuNjY2NzUgLTQuODc3NzA5WicgaWQ9J2c1LTEyMCcvPgo8cGF0aCBkPSdNMS41MTgzMDYgLTAuOTY4MzY5QzIuMDMyMzc5IC0xLjU1NDE3MiAyLjQ1MDgwOSAtMS45MjQ3ODIgMy4wNDg1NjggLTIuNDYyNzY1QzMuNzY1ODc4IC0zLjA4NDQzMyA0LjA3NjcxMiAtMy4zODMzMTMgNC4yNDQwODUgLTMuNTYyNjRDNS4wODA5NDYgLTQuMzg3NTQ3IDUuNDk5Mzc3IC01LjA4MDk0NiA1LjQ5OTM3NyAtNS4xNzY1ODhTNS40MDM3MzYgLTUuMjcyMjI5IDUuMzc5ODI2IC01LjI3MjIyOUM1LjI5NjEzOSAtNS4yNzIyMjkgNS4yNzIyMjkgLTUuMjI0NDA4IDUuMjEyNDUzIC01LjE0MDcyMkM0LjkxMzU3NCAtNC42MjY2NSA0LjYyNjY1IC00LjM3NTU5MiA0LjMxNTgxNiAtNC4zNzU1OTJDNC4wNjQ3NTcgLTQuMzc1NTkyIDMuOTMzMjUgLTQuNDgzMTg4IDMuNzA2MTAyIC00Ljc3MDExMkMzLjQ1NTA0NCAtNS4wNjg5OTEgMy4yNTE4MDYgLTUuMjcyMjI5IDIuOTA1MTA2IC01LjI3MjIyOUMyLjAzMjM3OSAtNS4yNzIyMjkgMS41MDYzNTEgLTQuMTg0MzA5IDEuNTA2MzUxIC0zLjkzMzI1QzEuNTA2MzUxIC0zLjg5NzM4NSAxLjUxODMwNiAtMy44MjU2NTQgMS42MjU5MDMgLTMuODI1NjU0QzEuNzIxNTQ0IC0zLjgyNTY1NCAxLjczMzQ5OSAtMy44NzM0NzQgMS43NjkzNjUgLTMuOTU3MTYxQzEuOTcyNjAzIC00LjQzNTM2NyAyLjU0NjQ1MSAtNC41MTkwNTQgMi43NzM1OTkgLTQuNTE5MDU0QzMuMDI0NjU4IC00LjUxOTA1NCAzLjI2Mzc2MSAtNC40MzUzNjcgMy41MTQ4MTkgLTQuMzI3NzcxQzMuOTY5MTE2IC00LjEzNjQ4OCA0LjE2MDM5OSAtNC4xMzY0ODggNC4yNzk5NSAtNC4xMzY0ODhDNC4zNjM2MzYgLTQuMTM2NDg4IDQuNDExNDU3IC00LjEzNjQ4OCA0LjQ3MTIzMyAtNC4xNDg0NDNDNC4wNzY3MTIgLTMuNjgyMTkyIDMuNDMxMTMzIC0zLjEwODM0NCAyLjg5MzE1MSAtMi42MTgxODJMMS42ODU2NzkgLTEuNTA2MzUxQzAuOTU2NDEzIC0wLjc2NTEzMSAwLjUxNDA3MiAtMC4wNTk3NzYgMC41MTQwNzIgMC4wMjM5MUMwLjUxNDA3MiAwLjA5NTY0MSAwLjU3Mzg0OCAwLjExOTU1MiAwLjY0NTU3OSAwLjExOTU1MlMwLjcyOTI2NSAwLjEwNzU5NyAwLjgxMjk1MSAtMC4wMzU4NjZDMS4wMDQyMzQgLTAuMzM0NzQ1IDEuMzg2OCAtMC43NzcwODYgMS44MjkxNDEgLTAuNzc3MDg2QzIuMDgwMTk5IC0wLjc3NzA4NiAyLjE5OTc1MSAtMC42OTM0IDIuNDM4ODU0IC0wLjM5NDUyMUMyLjY2NjAwMiAtMC4xMzE1MDcgMi44NjkyNCAwLjExOTU1MiAzLjI1MTgwNiAwLjExOTU1MkM0LjQyMzQxMiAwLjExOTU1MiA1LjA5MjkwMiAtMS4zOTg3NTUgNS4wOTI5MDIgLTEuNjczNzI0QzUuMDkyOTAyIC0xLjcyMTU0NCA1LjA4MDk0NiAtMS43OTMyNzUgNC45NjEzOTUgLTEuNzkzMjc1QzQuODY1NzUzIC0xLjc5MzI3NSA0Ljg1Mzc5OCAtMS43NDU0NTUgNC44MTc5MzMgLTEuNjI1OTAzQzQuNTU0OTE5IC0wLjkyMDU0OCAzLjg0OTU2NCAtMC42MzM2MjQgMy4zODMzMTMgLTAuNjMzNjI0QzMuMTMyMjU0IC0wLjYzMzYyNCAyLjg5MzE1MSAtMC43MTczMSAyLjY0MjA5MiAtMC44MjQ5MDdDMi4xNjM4ODUgLTEuMDE2MTg5IDIuMDMyMzc5IC0xLjAxNjE4OSAxLjg3Njk2MSAtMS4wMTYxODlDMS43NTc0MSAtMS4wMTYxODkgMS42MjU5MDMgLTEuMDE2MTg5IDEuNTE4MzA2IC0wLjk2ODM2OVonIGlkPSdnNS0xMjInLz4KPHBhdGggZD0nTTMuMDk2Mzg5IC00LjAxNjkzNkMzLjM5NTI2OCAtNC4wMTY5MzYgMy45NjkxMTYgLTQuMDE2OTM2IDQuMzg3NTQ3IC0zLjc2NTg3OEM0Ljk2MTM5NSAtMy4zOTUyNjggNS4wMDkyMTUgLTIuNzQ5Njg5IDUuMDA5MjE1IC0yLjY3Nzk1OEM1LjAyMTE3MSAtMi41MTA1ODUgNS4wMjExNzEgLTIuMzU1MTY4IDUuMjI0NDA4IC0yLjM1NTE2OFM1LjQyNzY0NiAtMi41MjI1NCA1LjQyNzY0NiAtMi43Mzc3MzNWLTUuOTc3NTg0QzUuNDI3NjQ2IC02LjE2ODg2NyA1LjQyNzY0NiAtNi4zNjAxNDkgNS4yMjQ0MDggLTYuMzYwMTQ5UzUuMDA5MjE1IC02LjE4MDgyMiA1LjAwOTIxNSAtNi4wODUxODFDNC45Mzc0ODQgLTQuNTQyOTY0IDMuNzE4MDU3IC00LjQ1OTI3OCAzLjA5NjM4OSAtNC40NDczMjNWLTYuOTY5ODYzQzMuMDk2Mzg5IC03Ljc3MDg1OSAzLjMyMzUzNyAtNy43NzA4NTkgMy42MTA0NjEgLTcuNzcwODU5SDQuMTg0MzA5QzUuNzk4MjU3IC03Ljc3MDg1OSA2LjU5OTI1MyAtNi45NDU5NTMgNi42NzA5ODQgLTYuMTIxMDQ2QzYuNjgyOTM5IC02LjAyNTQwNSA2LjY5NDg5NCAtNS44NDYwNzcgNi44ODYxNzcgLTUuODQ2MDc3QzcuMDg5NDE1IC01Ljg0NjA3NyA3LjA4OTQxNSAtNi4wMzczNiA3LjA4OTQxNSAtNi4yNDA1OThWLTcuNzk0NzdDNy4wODk0MTUgLTguMTY1MzggNy4wNjU1MDQgLTguMTg5MjkgNi42OTQ4OTQgLTguMTg5MjlIMC41NzM4NDhDMC4zNTg2NTUgLTguMTg5MjkgMC4xNjczNzIgLTguMTg5MjkgMC4xNjczNzIgLTcuOTc0MDk3QzAuMTY3MzcyIC03Ljc3MDg1OSAwLjM5NDUyMSAtNy43NzA4NTkgMC40OTAxNjIgLTcuNzcwODU5QzEuMTcxNjA2IC03Ljc3MDg1OSAxLjIxOTQyNyAtNy42NzUyMTggMS4yMTk0MjcgLTcuMDg5NDE1Vi0xLjA5OTg3NUMxLjIxOTQyNyAtMC41Mzc5ODMgMS4xODM1NjIgLTAuNDE4NDMxIDAuNTQ5OTM4IC0wLjQxODQzMUMwLjM3MDYxIC0wLjQxODQzMSAwLjE2NzM3MiAtMC40MTg0MzEgMC4xNjczNzIgLTAuMjE1MTkzQzAuMTY3MzcyIDAgMC4zNTg2NTUgMCAwLjU3Mzg0OCAwSDYuOTEwMDg3QzcuMTM3MjM1IDAgNy4yNTY3ODcgMCA3LjI5MjY1MyAtMC4xNjczNzJDNy4zMDQ2MDggLTAuMTc5MzI4IDcuNjM5MzUyIC0yLjE3NTg0MSA3LjYzOTM1MiAtMi4yMzU2MTZDNy42MzkzNTIgLTIuMzY3MTIzIDcuNTMxNzU2IC0yLjQ1MDgwOSA3LjQzNjExNSAtMi40NTA4MDlDNy4yNjg3NDIgLTIuNDUwODA5IDcuMjIwOTIyIC0yLjI5NTM5MiA3LjIyMDkyMiAtMi4yODM0MzdDNy4xNDkxOTEgLTEuOTcyNjAzIDcuMDI5NjM5IC0xLjQ3MDQ4NiA2LjE1NjkxMiAtMC45NTY0MTNDNS41MzUyNDMgLTAuNTg1ODAzIDQuOTI1NTI5IC0wLjQxODQzMSA0LjI2Nzk5NSAtMC40MTg0MzFIMy42MTA0NjFDMy4zMjM1MzcgLTAuNDE4NDMxIDMuMDk2Mzg5IC0wLjQxODQzMSAzLjA5NjM4OSAtMS4yMTk0MjdWLTQuMDE2OTM2Wk02LjY3MDk4NCAtNy43NzA4NTlWLTcuMTk3MDExQzYuNDY3NzQ2IC03LjQyNDE1OSA2LjI0MDU5OCAtNy42MTU0NDIgNS45ODk1MzkgLTcuNzcwODU5SDYuNjcwOTg0Wk00LjMzOTcyNiAtNC4yNjc5OTVDNC41MzEwMDkgLTQuMzUxNjgxIDQuNzk0MDIyIC00LjUzMTAwOSA1LjAwOTIxNSAtNC43ODIwNjdWLTMuNzc3ODMzQzQuNzIyMjkxIC00LjEwMDYyMyA0LjM1MTY4MSAtNC4yNTYwNCA0LjMzOTcyNiAtNC4yNTYwNFYtNC4yNjc5OTVaTTEuNjM3ODU4IC03LjExMzMyNUMxLjYzNzg1OCAtNy4yNTY3ODcgMS42Mzc4NTggLTcuNTU1NjY2IDEuNTQyMjE3IC03Ljc3MDg1OUgyLjgwOTQ2NUMyLjY3Nzk1OCAtNy40OTU4OSAyLjY3Nzk1OCAtNy4xMDEzNyAyLjY3Nzk1OCAtNi45OTM3NzNWLTEuMTk1NTE3QzIuNjc3OTU4IC0wLjc2NTEzMSAyLjc2MTY0NCAtMC41MjYwMjcgMi44MDk0NjUgLTAuNDE4NDMxSDEuNTQyMjE3QzEuNjM3ODU4IC0wLjYzMzYyNCAxLjYzNzg1OCAtMC45MzI1MDMgMS42Mzc4NTggLTEuMDc1OTY1Vi03LjExMzMyNVpNNi4wODUxODEgLTAuNDE4NDMxVi0wLjQzMDM4NkM2LjQ2Nzc0NiAtMC42MjE2NjkgNi43OTA1MzUgLTAuODcyNzI3IDcuMDI5NjM5IC0xLjA4NzkyQzcuMDE3Njg0IC0xLjA0MDEgNi45MzM5OTggLTAuNTE0MDcyIDYuOTIyMDQyIC0wLjQxODQzMUg2LjA4NTE4MVonIGlkPSdnMC02OScvPgo8cGF0aCBkPSdNNi4xMDUxMDYgLTIuNzE3ODA4QzYuMTA1MTA2IC0yLjk3Mjg1MiA2LjAxNzQzNSAtMy4wMDQ3MzIgNS45Nzc1ODQgLTMuMDA0NzMyQzUuODY2MDAyIC0zLjAwNDczMiA1Ljg1MDA2MiAtMi44MDU0NzkgNS44NTAwNjIgLTIuNjg1OTI4QzUuODE4MTgyIC0yLjExMjA4IDUuMzg3Nzk2IC0xLjQ4MjQ0MSA0LjY5NDM5NiAtMS40ODI0NDFDNC4yMTYxODkgLTEuNDgyNDQxIDMuODMzNjI0IC0xLjc2OTM2NSAzLjM2MzM4NyAtMi4xOTk3NTFDMi44NTMzIC0yLjY3Nzk1OCAyLjQzMDg4NCAtMy4wMTI3MDIgMS44ODA5NDYgLTMuMDEyNzAyQzAuOTY0Mzg0IC0zLjAxMjcwMiAwLjQ3MDIzNyAtMi4wNTYyODkgMC40NzAyMzcgLTEuMjc1MjE4QzAuNDcwMjM3IC0xLjAwNDIzNCAwLjU2NTg3OCAtMC45ODAzMjQgMC41OTc3NTggLTAuOTgwMzI0QzAuNjUzNTQ5IC0wLjk4MDMyNCAwLjcxNzMxIC0xLjAzNjExNSAwLjcyNTI4IC0xLjIzNTM2N0MwLjc1NzE2MSAtMi4wMDg0NjggMS4yOTExNTggLTIuNTAyNjE1IDEuODgwOTQ2IC0yLjUwMjYxNUMyLjM1OTE1MyAtMi41MDI2MTUgMi43NDE3MTkgLTIuMjE1NjkxIDMuMjExOTU1IC0xLjc4NTMwNUMzLjcyMjA0MiAtMS4zMDcwOTggNC4xNDQ0NTggLTAuOTcyMzU0IDQuNjk0Mzk2IC0wLjk3MjM1NEM1LjU5NTAxOSAtMC45NzIzNTQgNi4xMDUxMDYgLTEuOTA0ODU3IDYuMTA1MTA2IC0yLjcxNzgwOFonIGlkPSdnMS0yNCcvPgo8cGF0aCBkPSdNMy4xMDIzNjYgLTEuOTE4ODA0QzMuMTMyMjU0IC0yLjA1NjI4OSAzLjE5MjAzIC0yLjI4MzQzNyAzLjE5MjAzIC0yLjMyNTI4QzMuMTkyMDMgLTIuNDU2Nzg3IDMuMDkwNDExIC0yLjUyMjU0IDIuOTgyODE0IC0yLjUyMjU0QzIuODE1NDQyIC0yLjUyMjU0IDIuNzEzODIzIC0yLjM2NzEyMyAyLjY5NTg5IC0yLjI3NzQ2QzIuNjEyMjA0IC0yLjQxNDk0NCAyLjQwODk2NiAtMi42MzYxMTUgMi4wMzgzNTYgLTIuNjM2MTE1QzEuMjczMjI1IC0yLjYzNjExNSAwLjQ0ODMxOSAtMS44MzUxMTggMC40NDgzMTkgLTAuOTU2NDEzQzAuNDQ4MzE5IC0wLjMxMDgzNCAwLjkwMjYxNSAwLjA1OTc3NiAxLjQxMDcxIDAuMDU5Nzc2QzEuODExMjA4IDAuMDU5Nzc2IDIuMTUxOTMgLTAuMjE1MTkzIDIuMzAxMzcgLTAuMzY0NjMzQzIuNDE0OTQ0IDAuMDExOTU1IDIuODE1NDQyIDAuMDU5Nzc2IDIuOTQ2OTQ5IDAuMDU5Nzc2QzMuMTYyMTQyIDAuMDU5Nzc2IDMuMzE3NTU5IC0wLjA1OTc3NiAzLjQzMTEzMyAtMC4yNDUwODFDMy41ODA1NzMgLTAuNDg0MTg0IDMuNjY0MjU5IC0wLjgzMDg4NCAzLjY2NDI1OSAtMC44NjA3NzJDMy42NjQyNTkgLTAuODcyNzI3IDMuNjU4MjgxIC0wLjk0NDQ1OCAzLjU1MDY4NSAtMC45NDQ0NThDMy40NjEwMjEgLTAuOTQ0NDU4IDMuNDQ5MDY2IC0wLjkwMjYxNSAzLjQyNTE1NiAtMC44MDY5NzRDMy4zMjk1MTQgLTAuNDQyMzQxIDMuMjAzOTg1IC0wLjEzNzQ4NCAyLjk3MDg1OSAtMC4xMzc0ODRDMi43Njc2MjEgLTAuMTM3NDg0IDIuNzQ5Njg5IC0wLjM1MjY3NyAyLjc0OTY4OSAtMC40NDIzNDFDMi43NDk2ODkgLTAuNTIwMDUgMi44MDk0NjUgLTAuNzU5MTUzIDIuODUxMzA4IC0wLjkxNDU3TDMuMTAyMzY2IC0xLjkxODgwNFpNMi4zMjUyOCAtMC43ODMwNjRDMi4yOTUzOTIgLTAuNjc1NDY3IDIuMjk1MzkyIC0wLjY2MzUxMiAyLjIxMTcwNiAtMC41NzM4NDhDMS44ODI5MzkgLTAuMjAzMjM4IDEuNTc4MDgyIC0wLjEzNzQ4NCAxLjQyODY0MyAtMC4xMzc0ODRDMS4xODk1MzkgLTAuMTM3NDg0IDAuOTU2NDEzIC0wLjI5ODg3OSAwLjk1NjQxMyAtMC43MjMyODhDMC45NTY0MTMgLTAuOTY4MzY5IDEuMDgxOTQzIC0xLjU1NDE3MiAxLjI3MzIyNSAtMS44OTQ4OTRDMS40NTI1NTMgLTIuMjE3Njg0IDEuNzU3NDEgLTIuNDM4ODU0IDIuMDQ0MzM0IC0yLjQzODg1NEMyLjQ5MjY1MyAtMi40Mzg4NTQgMi42MDYyMjcgLTEuOTY2NjI1IDIuNjA2MjI3IC0xLjkyNDc4MkwyLjU4ODI5NCAtMS44NDEwOTZMMi4zMjUyOCAtMC43ODMwNjRaJyBpZD0nZzMtOTcnLz4KPHBhdGggZD0nTTMuNjE2NDM4IC0zLjk2OTExNkMzLjYyMjQxNiAtMy45OTMwMjYgMy42MzQzNzEgLTQuMDI4ODkyIDMuNjM0MzcxIC00LjA1ODc4QzMuNjM0MzcxIC00LjE1NDQyMSAzLjUxNDgxOSAtNC4xNDg0NDMgMy40NDMwODggLTQuMTQyNDY2TDIuNzczNTk5IC00LjA4ODY2N0MyLjY3MTk4IC00LjA4MjY5IDIuNTk0MjcxIC00LjA3NjcxMiAyLjU5NDI3MSAtMy45MzkyMjhDMi41OTQyNzEgLTMuODQzNTg3IDIuNjcxOTggLTMuODQzNTg3IDIuNzYxNjQ0IC0zLjg0MzU4N0MyLjk0MDk3MSAtMy44NDM1ODcgMi45ODI4MTQgLTMuODMxNjMxIDMuMDYwNTIzIC0zLjgwMTc0M0MzLjA1NDU0NSAtMy43MTIwOCAzLjA1NDU0NSAtMy43MDAxMjUgMy4wMzY2MTMgLTMuNjIyNDE2QzIuOTExMDgzIC0zLjEwODM0NCAyLjgxNTQ0MiAtMi43MDc4NDYgMi42OTU4OSAtMi4yNzc0NkMyLjYxMjIwNCAtMi40MTQ5NDQgMi40MDg5NjYgLTIuNjM2MTE1IDIuMDM4MzU2IC0yLjYzNjExNUMxLjI3MzIyNSAtMi42MzYxMTUgMC40NDgzMTkgLTEuODM1MTE4IDAuNDQ4MzE5IC0wLjk1NjQxM0MwLjQ0ODMxOSAtMC4zMTA4MzQgMC45MDI2MTUgMC4wNTk3NzYgMS40MTA3MSAwLjA1OTc3NkMxLjgxMTIwOCAwLjA1OTc3NiAyLjE1MTkzIC0wLjIxNTE5MyAyLjMwMTM3IC0wLjM2NDYzM0MyLjQxNDk0NCAwLjAxMTk1NSAyLjgxNTQ0MiAwLjA1OTc3NiAyLjk0Njk0OSAwLjA1OTc3NkMzLjE2MjE0MiAwLjA1OTc3NiAzLjMxNzU1OSAtMC4wNTk3NzYgMy40MzExMzMgLTAuMjQ1MDgxQzMuNTgwNTczIC0wLjQ4NDE4NCAzLjY2NDI1OSAtMC44MzA4ODQgMy42NjQyNTkgLTAuODYwNzcyQzMuNjY0MjU5IC0wLjg3MjcyNyAzLjY1ODI4MSAtMC45NDQ0NTggMy41NTA2ODUgLTAuOTQ0NDU4QzMuNDYxMDIxIC0wLjk0NDQ1OCAzLjQ0OTA2NiAtMC45MDI2MTUgMy40MjUxNTYgLTAuODA2OTc0QzMuMzI5NTE0IC0wLjQ0MjM0MSAzLjIwMzk4NSAtMC4xMzc0ODQgMi45NzA4NTkgLTAuMTM3NDg0QzIuNzY3NjIxIC0wLjEzNzQ4NCAyLjc0OTY4OSAtMC4zNTI2NzcgMi43NDk2ODkgLTAuNDQyMzQxQzIuNzQ5Njg5IC0wLjUyMDA1IDIuNzQ5Njg5IC0wLjUzNzk4MyAyLjc3OTU3NyAtMC42NDU1NzlMMy42MTY0MzggLTMuOTY5MTE2Wk0yLjMyNTI4IC0wLjc4MzA2NEMyLjI5NTM5MiAtMC42NzU0NjcgMi4yOTUzOTIgLTAuNjYzNTEyIDIuMjExNzA2IC0wLjU3Mzg0OEMxLjg4MjkzOSAtMC4yMDMyMzggMS41NzgwODIgLTAuMTM3NDg0IDEuNDI4NjQzIC0wLjEzNzQ4NEMxLjE4OTUzOSAtMC4xMzc0ODQgMC45NTY0MTMgLTAuMjk4ODc5IDAuOTU2NDEzIC0wLjcyMzI4OEMwLjk1NjQxMyAtMC45NjgzNjkgMS4wODE5NDMgLTEuNTU0MTcyIDEuMjczMjI1IC0xLjg5NDg5NEMxLjQ1MjU1MyAtMi4yMTc2ODQgMS43NTc0MSAtMi40Mzg4NTQgMi4wNDQzMzQgLTIuNDM4ODU0QzIuNDkyNjUzIC0yLjQzODg1NCAyLjYwNjIyNyAtMS45NjY2MjUgMi42MDYyMjcgLTEuOTI0NzgyTDIuNTg4Mjk0IC0xLjg0MTA5NkwyLjMyNTI4IC0wLjc4MzA2NFonIGlkPSdnMy0xMDAnLz4KPHBhdGggZD0nTTEuNjA3OTcgLTIuMzM3MjM1SDIuMjU5NTI3QzIuMzc5MDc4IC0yLjMzNzIzNSAyLjQ2Mjc2NSAtMi4zMzcyMzUgMi40NjI3NjUgLTIuNDg2Njc1QzIuNDYyNzY1IC0yLjU3NjMzOSAyLjM4NTA1NiAtMi41NzYzMzkgMi4yNzc0NiAtMi41NzYzMzlIMS42Njc3NDZMMS44NzY5NjEgLTMuNDAxMjQ1QzEuOTAwODcyIC0zLjQ5MDkwOSAxLjkwMDg3MiAtMy41MjY3NzUgMS45MDA4NzIgLTMuNTMyNzUyQzEuOTAwODcyIC0zLjY3NjIxNCAxLjc4NzI5OCAtMy43MzU5OSAxLjY5MTY1NiAtMy43MzU5OUMxLjYxOTkyNSAtMy43MzU5OSAxLjQ2NDUwOCAtMy42OTQxNDcgMS40MTA3MSAtMy41MDI4NjRMMS4xNzc1ODQgLTIuNTc2MzM5SDAuNTMyMDA1QzAuNDA2NDc2IC0yLjU3NjMzOSAwLjQwMDQ5OCAtMi41NzAzNjEgMC4zNzY1ODggLTIuNTUyNDI4QzAuMzQ2NyAtMi41Mjg1MTggMC4zMjI3OSAtMi40NTA4MDkgMC4zMjI3OSAtMi40MjA5MjJDMC4zNDA3MjIgLTIuMzM3MjM1IDAuMzk0NTIxIC0yLjMzNzIzNSAwLjUxNDA3MiAtMi4zMzcyMzVIMS4xMTc4MDhMMC43NjUxMzEgLTAuOTI2NTI2QzAuNzI5MjY1IC0wLjc4OTA0MSAwLjY4MTQ0NSAtMC41ODU4MDMgMC42ODE0NDUgLTAuNTE0MDcyQzAuNjgxNDQ1IC0wLjE2NzM3MiAwLjk5MjI3OSAwLjA1OTc3NiAxLjM1NjkxMiAwLjA1OTc3NkMyLjA0NDMzNCAwLjA1OTc3NiAyLjQ1MDgwOSAtMC43NTkxNTMgMi40NTA4MDkgLTAuODYwNzcyQzIuNDUwODA5IC0wLjg3ODcwNSAyLjQzODg1NCAtMC45NDQ0NTggMi4zMzcyMzUgLTAuOTQ0NDU4QzIuMjU5NTI3IC0wLjk0NDQ1OCAyLjI0NzU3MiAtMC45MTQ1NyAyLjIxNzY4NCAtMC44NDI4MzlDMi4wMTQ0NDYgLTAuMzk0NTIxIDEuNjczNzI0IC0wLjEzNzQ4NCAxLjM4MDgyMiAtMC4xMzc0ODRDMS4xNTk2NTEgLTAuMTM3NDg0IDEuMTUzNjc0IC0wLjM1ODY1NSAxLjE1MzY3NCAtMC40MzYzNjRDMS4xNTM2NzQgLTAuNTIwMDUgMS4xNTM2NzQgLTAuNTMyMDA1IDEuMTgzNTYyIC0wLjY0NTU3OUwxLjYwNzk3IC0yLjMzNzIzNVonIGlkPSdnMy0xMTYnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzY0LjYzMjYxMicgeGxpbms6aHJlZj0nI2c3LTEwOScgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nNzQuMzg3NTk2JyB4bGluazpocmVmPScjZzctMTA1JyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PSc3Ny42MzkyNTcnIHhsaW5rOmhyZWY9JyNnNy0xMTAnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzcxLjA4ODI2MicgeGxpbms6aHJlZj0nI2c0LTcxJyB5PSc5OC4xNjUxOScvPgo8dXNlIHg9Jzg2LjEzNTA3OCcgeGxpbms6aHJlZj0nI2c3LTEwOScgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nOTUuODkwMDYxJyB4bGluazpocmVmPScjZzctOTcnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzEwMS43NDMwNTInIHhsaW5rOmhyZWY9JyNnNy0xMjAnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzkzLjQzNjg0MycgeGxpbms6aHJlZj0nI2c0LTY4JyB5PSc5OC4xNjUxOScvPgo8dXNlIHg9JzEwOS45MTM3MDYnIHhsaW5rOmhyZWY9JyNnNS04NicgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMTE5LjMzOTM4NScgeGxpbms6aHJlZj0nI2c3LTQwJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScxMjMuODkxNzEnIHhsaW5rOmhyZWY9JyNnNS02OCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMTMzLjkzNjE4NScgeGxpbms6aHJlZj0nI2c1LTU5JyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScxMzkuMTgwMzQ0JyB4bGluazpocmVmPScjZzUtNzEnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzE0OC40MTM5NjgnIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMTU2LjI4NzEyMycgeGxpbms6aHJlZj0nI2c3LTYxJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScxNjguNzEyNjA0JyB4bGluazpocmVmPScjZzAtNjknIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzE3Ni42ODI3NDInIHhsaW5rOmhyZWY9JyNnNC0xMjAnIHk9JzkyLjU4NjEzNicvPgo8dXNlIHg9JzE4MS40NDk2NDEnIHhsaW5rOmhyZWY9JyNnMS0yNCcgeT0nOTIuNTg2MTM2Jy8+Cjx1c2UgeD0nMTg4LjAzNjE0OCcgeGxpbms6aHJlZj0nI2c0LTExMicgeT0nOTIuNTg2MTM2Jy8+Cjx1c2UgeD0nMTkyLjI5ODkyNScgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nOTMuOTkxOTgyJy8+Cjx1c2UgeD0nMTk2LjEzOTM4JyB4bGluazpocmVmPScjZzMtOTcnIHk9JzkzLjk5MTk4MicvPgo8dXNlIHg9JzIwMC4xNzM1NTUnIHhsaW5rOmhyZWY9JyNnMy0xMTYnIHk9JzkzLjk5MTk4MicvPgo8dXNlIHg9JzIwMy4wMjM5NjMnIHhsaW5rOmhyZWY9JyNnMy05NycgeT0nOTMuOTkxOTgyJy8+Cjx1c2UgeD0nMjA3LjU1NjI0JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzkyLjU4NjEzNicvPgo8dXNlIHg9JzIxMC44NDk0OTMnIHhsaW5rOmhyZWY9JyNnNC0xMjAnIHk9JzkyLjU4NjEzNicvPgo8dXNlIHg9JzIxNS42MTYzOTInIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nOTIuNTg2MTM2Jy8+Cjx1c2UgeD0nMjE5LjQwNzc3NycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScyMjIuNjU5NDM5JyB4bGluazpocmVmPScjZzctMTA4JyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScyMjUuOTExMScgeGxpbms6aHJlZj0nI2c3LTExMCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMjM0LjQwNjkyJyB4bGluazpocmVmPScjZzUtNjgnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzI0NC40NTEzOTUnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMjQ5LjAwMzcyMScgeGxpbms6aHJlZj0nI2c1LTEyMCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMjU1LjY1NTgwOCcgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScyNjAuMjA4MTM0JyB4bGluazpocmVmPScjZzctOTMnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzI2Ni4xMTY0NTgnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMjc3Ljg3Nzc3MycgeGxpbms6aHJlZj0nI2cwLTY5JyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PScyODUuODQ3OTEyJyB4bGluazpocmVmPScjZzQtMTIyJyB5PSc5Mi41ODYxMzYnLz4KPHVzZSB4PScyOTAuMTIzNTk2JyB4bGluazpocmVmPScjZzEtMjQnIHk9JzkyLjU4NjEzNicvPgo8dXNlIHg9JzI5Ni43MTAxMDInIHhsaW5rOmhyZWY9JyNnNC0xMTInIHk9JzkyLjU4NjEzNicvPgo8dXNlIHg9JzMwMC45NzI4OCcgeGxpbms6aHJlZj0nI2c2LTQwJyB5PSc5Mi41ODYxMzYnLz4KPHVzZSB4PSczMDQuMjY2MTMzJyB4bGluazpocmVmPScjZzQtMTIyJyB5PSc5Mi41ODYxMzYnLz4KPHVzZSB4PSczMDguNTQxODE3JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzkyLjU4NjEzNicvPgo8dXNlIHg9JzMxMi4zMzMyMDInIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMzE1LjU4NDg2MycgeGxpbms6aHJlZj0nI2c3LTEwOCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMzE4LjgzNjUyNScgeGxpbms6aHJlZj0nI2c3LTExMCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMzI1LjMzOTg0NycgeGxpbms6aHJlZj0nI2c3LTQwJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PSczMjkuODkyMTczJyB4bGluazpocmVmPScjZzctNDknIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzMzOC40MDE4MjcnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PSczNTAuMzU2OTg3JyB4bGluazpocmVmPScjZzUtNjgnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzM2MC40MDE0NjInIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMzY0Ljk1Mzc4OCcgeGxpbms6aHJlZj0nI2c1LTcxJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PSczNzQuMTg3NDEyJyB4bGluazpocmVmPScjZzctNDAnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzM3OC43Mzk3MzcnIHhsaW5rOmhyZWY9JyNnNS0xMjInIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzM4NC43MTAzNDQnIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nOTAuNzI2NDI2Jy8+Cjx1c2UgeD0nMzg5LjI2MjY2OScgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc5MC43MjY0MjYnLz4KPHVzZSB4PSczOTMuODE0OTk1JyB4bGluazpocmVmPScjZzctNDEnIHk9JzkwLjcyNjQyNicvPgo8dXNlIHg9JzM5OC4zNjczMjEnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nOTAuNzI2NDI2Jy8+CjwvZz4KPC9zdmc+)
Pour en savoir un peu plus : NIPS 2016 Tutorial: Generative Adversarial Networks et une présentation Generative Adversarial Networks (GANs). On peut se servir de cette idée pour multiplier les exemples.
Apprentissage semi-supervisé
Le même article Adversarial Autoencoders étend l’idée principale à un cas semi-supervisé. Comme les labels ne sont pas présent sur toute la base, le modèle est transformé pour faire apparaître une variable cachée qui la représente.

Autoencoder#
Image extraite de Adversarial Autoencoders.
L’apprentissage est modifié de telle sorte que la distribution de cette variable cachée suive celle de la variable label. Une dernière partie basé sur les Generative Adversarial Networks s’assure que cette variable cachée et la couche cachée de compression représente deux informations différente, que toute l’information liée au label est porté par la variable cachée introduite.
Génération d’images ou de modèles#
Particle filtering est une technique qu’on utilise beaucoup en reconstruction d’images 3D à partir d’image 2D observées : quel modèle 3D serait à la source des projections observées (deux dans le cas de la vision stéréophonique) ? Il est tentant d’étendre cette technique à plusieurs modèles Coupling of Particle Filters ou des modèles plus complexes Inference in generative models using the Wasserstein distance (voir aussi distance Wasserstein).
Le deep learning est de plus en plus utilisé pour inférer voire inventer des images comme avec Deep Dream. D’autres modèles plus utiles sont développés pour squelettiser des images. sketch-rnn squelettise les caractères Kanji, pix2pix effectue la transformation inverse en ajoutant la texture à un objet squelettisé.
Le deep learning sert aussi à calculer des distances entre images Visual Analogy TensorFlow. On peut également segmenter très finement une image SharpMask.
Transfer learning ou apprentissage par transfert#
Le transfer learning revient à apprendre un modèle avec des données et à l’appliquer sur un problème différent. La version paresseuse consiste à réutiliser un modèle appris pour autre chose que le problème auxquel on songe à l’appliquer. L’application la plus fréquente consiste à prendre un réseaux de neurones profond appris pour une tâche autre, à enlever la dernière couche pour utiliser les sorties comme nouvelles variables.
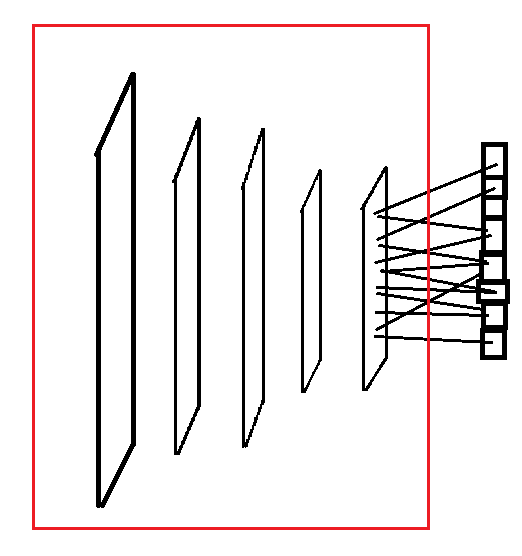
Transfer learning#
On garde les premières couches spécialisées dans le traitement de l’image. Elles extraient des informations pertinentes pour la dernière couche qui effectuent la classification. C’est cette dernière qu’on change sans réapprendre les premières.
L’article Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach est un exemple sur les systèmes de recommandation. Le chapite du livre Transfer Learning, l’article A Survey on Transfer Learning ou encore Transfer Learning for Reinforcement Learning Domains: A Survey recensent plusieurs scénarios.
L’article Learning Transferable Features with Deep Adaptation Networks propose quant à lui d’adapter un réseaux de neurones existant et publié AlexNet en figeant les premières couches, en ajustant les couches intermédiaires et en remplaçant les dernières. L’algorithme proposé s’appuie sur des méthodes à noyau et l’article A Kernel Two-Sample Test.
Online training#
On peut comprendre Online Training de deux façons différentes.
Continuous Training
La première consiste à la conception d’un modèle qui est mise à jour régulièrement sur de nouvelles données. Il doit également être capable d’oublier les plus vieilles données d’apprentissage. Le modèle Averaged Perceptron met continuellement ses poids à jour, il les corrige avec les erreurs d’observées. Pour peu qu’on parcourt les observations dans un sens chronologiquement, les observations les plus récentes auront plus d’influence. La méthode la plus courante est d’utiliser une fenêtre glissante sur les données. Chaque semaine, chaque mois, la base d’apprentissage est composées des données enregistrées sur la dernières années. De cette façon le modèle apprend avec 80% des données déjà vu et 20% de nouvelles. Cela garantit une forme de continuité dans les résultats. Tout l’enjeu est de réduire le coût d’apprentissage en mettant à jour le modèle plutôt que de le réapprendre complètement.
Bootstrapping
La seconde direction consiste à commencer à constuire un modèle avec peu de données. Le modèle croît en complexité au fur et à mesure qu’on lui ajoute des caractèristiques comme dans l’article Online Incremental Feature Learning with Denoising Autoencoders. Encore une fois, l’enjeu est de pouvoir réutiliser les apprentissages précédents pour arriver au plus vite à un modèles ayant de bonnes performances. On appelle cela faire du bootstrapping ou self training Training Deep Neural Networks On Noisy Labels With Bootstrapping.
Ce processus est intéressant lorsqu’on a des données mais peu de données avec des labels. On se sert alors de la prédiction du premier modèle sur les données sans labels. Les scores extrêmes (le modèle est confiant ou pas du tout confiance) permettent en règle générale de construire automatiquement des labels pour une partie de ces données sans labels. Une fois la base d’apprentissage agrandie, un second modèle est entraîné. Il suffit de recommencer jusqu’à ce que le modèle ait de bonnes performances.
Label corrompus ou peu fiables#
Le cas auquel on pense en premier est celui de label imprécis. Est-ce que la qualité des labels nuit à la qualité de l’apprentissage et comment y remédier ?
Données bruitées
L’approche est souvent bayésienne : The Dawid-Skene model with priors ou une version améliorée qui s’appuie sur l’algorithme EM : Spectral Methods meet EM: A Provably Optimal Algorithm for Crowdsourcing. On peut lire pour aller vite : Bayesian Bias Mitigation for Crowdsourcing (one minute summary). Un article Learning with Noisy Labels dans la même veine, le suivant Learning from Corrupted Binary Labels via Class-Probability Estimation s’intéresse à la métrique AUC. Pour finir, apprentissage semi-supervisé ou labels corrompus ne sont pas très loin : Generalized Expectation Criteria for Semi-Supervised Learning with Weakly Labeled Data.
Données cachées
L’article Unsupervised Supervised Learning I: Estimating Classification and Regression Errors without Labels (suite) aborde le cas de plusieurs hôpitaux qui apprennent chacun un modèle sur le même problème mais avec chacun leurs données qu’ils ne peuvent partager. Comment savoir si un modèle appris par un hôpital va marcher sur les données d’un autre ? C’est à ce type de question que cet article répond.
Grand nombre de labels
Une classification en un nombre très grand de classes est nécessairement moins précise que la même classification avec les mêmes classes regroupées. Plus il y a de classes, plus la précision est faible. Certains labels sont aussi très peu représentés. L’article Training Highly Multiclass Classifiers discute de ce point. Il aborde différentes métriques et fonctions d’erreur plus adaptées à ce type de configuration.
L’article Multitask Learning without Label Correspondences aborde le cas où on apprend plusieurs classifieurs sur des jeux de données qui se ressemblent avec des ensembles de classes différents.