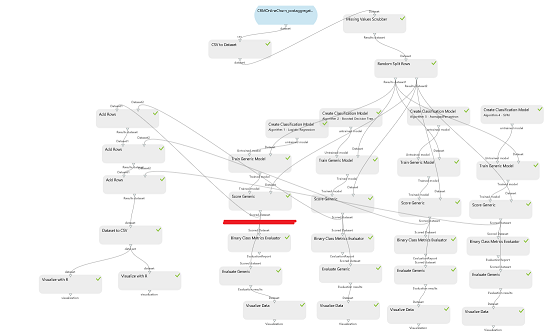
Quelques pistes sur le fonctionnement des moteurs de recommandations sur le web.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
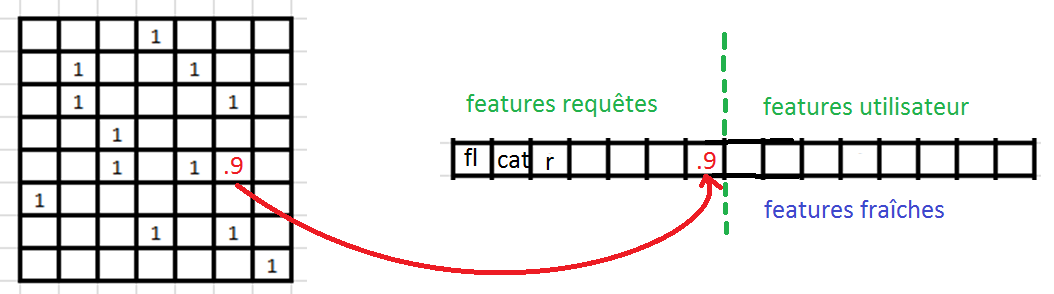
Online
Offline
Construction d'une liste de recommandations à utiliser online $\sim O(100M)$.
Métrique
Personnalisation renforcée
Apprentissage par renforcement