Note
Click here to download the full example code
Compares implementations of Tranpose#
This example compares the numpy.transpose from numpy, to onnxruntime implementation. If available, tensorflow and pytorch are included as well.
Available optimisation#
The code shows which parallelisation optimisation could be used, AVX or SSE and the number of available processors. Both numpy and torch have lazy implementations, the function switches dimensions and strides but does not move any data. That’s why function contiguous was called in both cases.
import numpy
import pandas
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import OnnxTranspose
from cpyquickhelper.numbers import measure_time
from tqdm import tqdm
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
AVX-omp=8
Transpose implementations#
Function einsum is used from tensorflow and pytorch instead of transpose. The equation reflects the required transposition.
try:
from tensorflow import transpose as tf_transpose, convert_to_tensor
except ImportError:
tf_transpose = None
try:
from torch import einsum as torch_einsum, from_numpy
except ImportError:
torch_einsum = None
def build_ort_transpose(perm, op_version=12):
node = OnnxTranspose('x', perm=perm, op_version=op_version,
output_names=['z'])
onx = node.to_onnx(inputs=[('x', FloatTensorType())],
target_opset=op_version)
sess = InferenceSession(onx.SerializeToString())
return lambda x, y: sess.run(None, {'x': x})
def loop_fct(fct, xs, ys):
for x, y in zip(xs, ys):
fct(x, y)
def perm2eq(perm):
first = "".join(chr(97 + i) for i in range(len(perm)))
second = "".join(first[p] for p in perm)
return f"{first}->{second}"
def benchmark_op(perm, repeat=5, number=5, name="Transpose", shape_fct=None):
if shape_fct is None:
def shape_fct(dim): return (3, dim, 1, 512)
ort_fct = build_ort_transpose(perm)
res = []
for dim in tqdm([8, 16, 32, 64, 100, 128, 200,
256, 400, 512, 1024]):
shape = shape_fct(dim)
n_arrays = 10 if dim < 512 else 4
xs = [numpy.random.rand(*shape).astype(numpy.float32)
for _ in range(n_arrays)]
ys = [perm for _ in range(n_arrays)]
equation = perm2eq(perm)
info = dict(perm=perm, shape=shape)
# numpy
ctx = dict(
xs=xs, ys=ys,
fct=lambda x, y: numpy.ascontiguousarray(numpy.transpose(x, y)),
loop_fct=loop_fct)
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'numpy'
obs.update(info)
res.append(obs)
# onnxruntime
ctx['fct'] = ort_fct
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort'
obs.update(info)
res.append(obs)
if tf_transpose is not None:
# tensorflow
ctx['fct'] = tf_transpose
ctx['xs'] = [convert_to_tensor(x) for x in xs]
ctx['ys'] = [convert_to_tensor(y) for y in ys]
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'tf'
obs.update(info)
res.append(obs)
# tensorflow with copy
ctx['fct'] = lambda x, y: tf_transpose(
convert_to_tensor(x)).numpy()
ctx['xs'] = xs
ctx['ys'] = ys
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'tf_copy'
obs.update(info)
res.append(obs)
if torch_einsum is not None:
# torch
ctx['fct'] = lambda x, y: torch_einsum(equation, x).contiguous()
ctx['xs'] = [from_numpy(x) for x in xs]
ctx['ys'] = ys # [from_numpy(y) for y in ys]
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'torch'
obs.update(info)
res.append(obs)
# Dataframes
shape_name = str(shape).replace(str(dim), "N")
df = pandas.DataFrame(res)
df.columns = [_.replace('dim', 'N') for _ in df.columns]
piv = df.pivot('N', 'fct', 'average')
rs = piv.copy()
for c in ['ort', 'torch', 'tf', 'tf_copy']:
if c in rs.columns:
rs[c] = rs['numpy'] / rs[c]
rs['numpy'] = 1.
# Graphs.
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
piv.plot(logx=True, logy=True, ax=ax[0],
title="%s benchmark\n%r - %r - %s"
" lower better" % (name, shape_name, perm, equation))
ax[0].legend(prop={"size": 9})
rs.plot(logx=True, logy=True, ax=ax[1],
title="%s Speedup, baseline=numpy\n%r - %r - %s"
" higher better" % (name, shape_name, perm, equation))
ax[1].plot([min(rs.index), max(rs.index)], [0.5, 0.5], 'g--')
ax[1].plot([min(rs.index), max(rs.index)], [2., 2.], 'g--')
ax[1].legend(prop={"size": 9})
return df, rs, ax
dfs = []
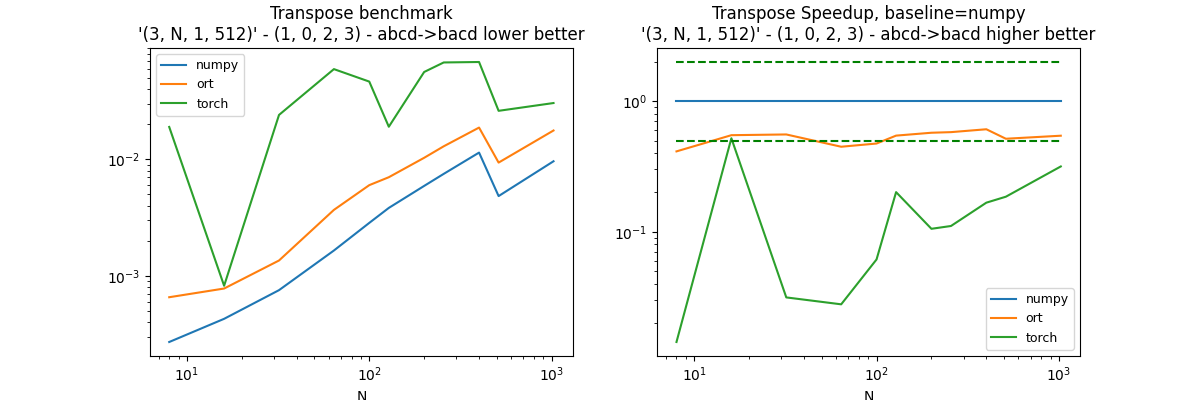
First permutation: (1, 0, 2, 3)#
perm = (1, 0, 2, 3)
df, piv, ax = benchmark_op(perm)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/11 [00:00<?, ?it/s]
9%|9 | 1/11 [00:00<00:05, 1.99it/s]
27%|##7 | 3/11 [00:01<00:03, 2.50it/s]
36%|###6 | 4/11 [00:02<00:05, 1.20it/s]
45%|####5 | 5/11 [00:04<00:06, 1.03s/it]
55%|#####4 | 6/11 [00:05<00:04, 1.05it/s]
64%|######3 | 7/11 [00:06<00:04, 1.25s/it]
73%|#######2 | 8/11 [00:09<00:04, 1.57s/it]
82%|########1 | 9/11 [00:11<00:03, 1.89s/it]
91%|######### | 10/11 [00:12<00:01, 1.65s/it]
100%|##########| 11/11 [00:14<00:00, 1.63s/it]
100%|##########| 11/11 [00:14<00:00, 1.32s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:153: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:185: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
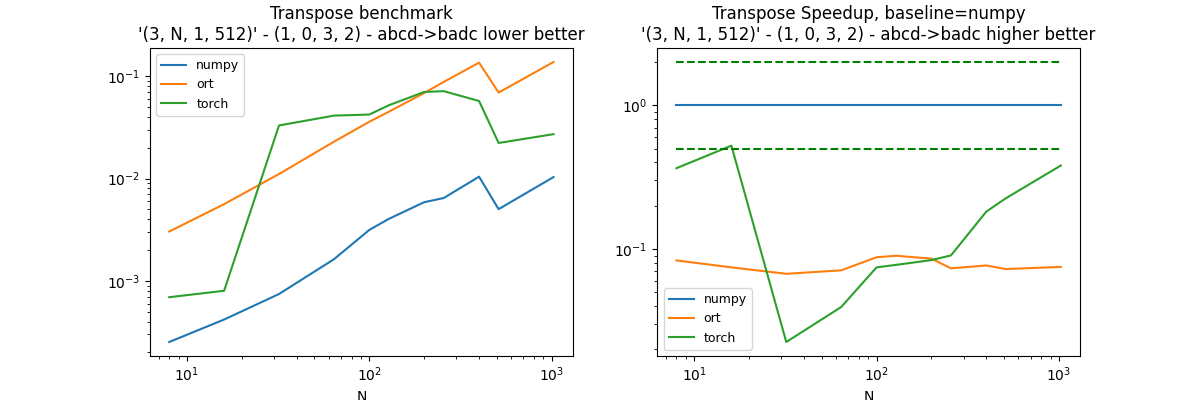
Second permutation: (0, 1, 3, 2)#
perm = (1, 0, 3, 2)
df, piv, ax = benchmark_op(perm)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/11 [00:00<?, ?it/s]
9%|9 | 1/11 [00:00<00:01, 9.51it/s]
18%|#8 | 2/11 [00:00<00:01, 6.69it/s]
27%|##7 | 3/11 [00:01<00:04, 1.67it/s]
36%|###6 | 4/11 [00:03<00:07, 1.02s/it]
45%|####5 | 5/11 [00:05<00:08, 1.40s/it]
55%|#####4 | 6/11 [00:07<00:09, 1.80s/it]
64%|######3 | 7/11 [00:11<00:09, 2.42s/it]
73%|#######2 | 8/11 [00:15<00:09, 3.00s/it]
82%|########1 | 9/11 [00:20<00:07, 3.70s/it]
91%|######### | 10/11 [00:23<00:03, 3.33s/it]
100%|##########| 11/11 [00:27<00:00, 3.70s/it]
100%|##########| 11/11 [00:27<00:00, 2.54s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:153: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:194: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
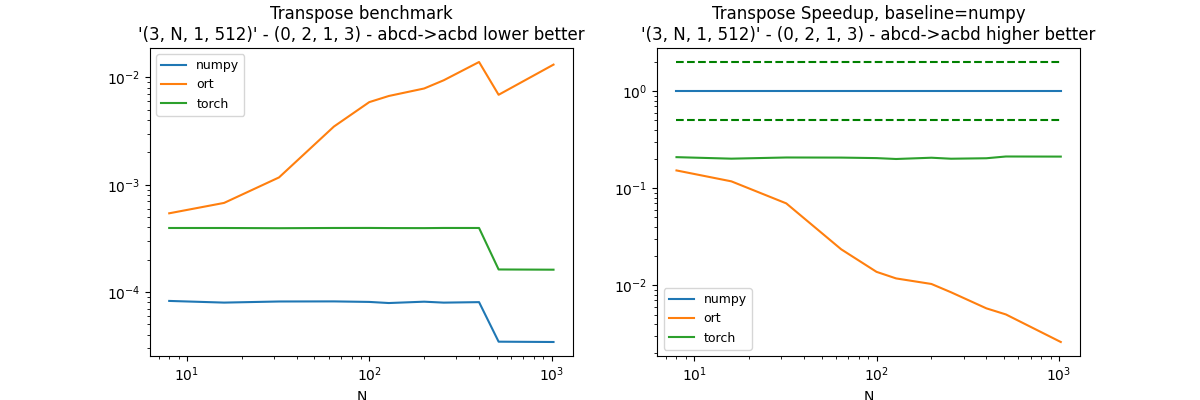
Third permutation: (0, 2, 1, 3)#
This transposition is equivalent to a reshape because it only moves the empty axis. The comparison is entirely fair as the cost for onnxruntime includes a copy from numpy to onnxruntime, a reshape = another copy, than a copy back to numpy. Tensorflow and pytorch seems to have a lazy implementation in this case.
perm = (0, 2, 1, 3)
df, piv, ax = benchmark_op(perm)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/11 [00:00<?, ?it/s]
27%|##7 | 3/11 [00:00<00:00, 24.24it/s]
55%|#####4 | 6/11 [00:00<00:00, 7.92it/s]
73%|#######2 | 8/11 [00:01<00:00, 5.14it/s]
82%|########1 | 9/11 [00:01<00:00, 3.85it/s]
91%|######### | 10/11 [00:02<00:00, 3.86it/s]
100%|##########| 11/11 [00:02<00:00, 3.18it/s]
100%|##########| 11/11 [00:02<00:00, 4.28it/s]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:153: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:211: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
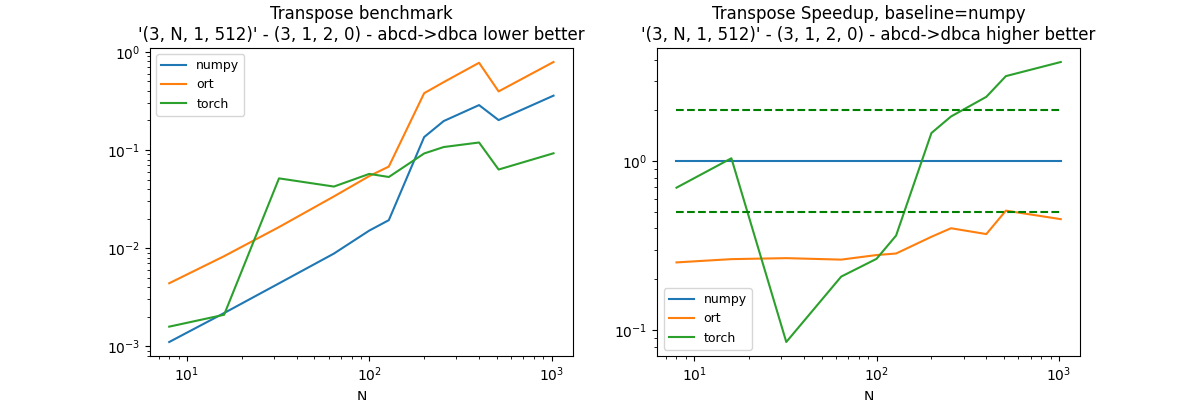
Fourth permutation: (3, 1, 2, 0)#
perm = (3, 1, 2, 0)
df, piv, ax = benchmark_op(perm)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/11 [00:00<?, ?it/s]
9%|9 | 1/11 [00:00<00:01, 5.48it/s]
18%|#8 | 2/11 [00:00<00:02, 3.77it/s]
27%|##7 | 3/11 [00:02<00:07, 1.03it/s]
36%|###6 | 4/11 [00:04<00:10, 1.44s/it]
45%|####5 | 5/11 [00:07<00:12, 2.07s/it]
55%|#####4 | 6/11 [00:11<00:12, 2.58s/it]
64%|######3 | 7/11 [00:26<00:26, 6.72s/it]
73%|#######2 | 8/11 [00:46<00:32, 10.95s/it]
82%|########1 | 9/11 [01:16<00:33, 16.80s/it]
91%|######### | 10/11 [01:32<00:16, 16.74s/it]
100%|##########| 11/11 [02:03<00:00, 21.15s/it]
100%|##########| 11/11 [02:03<00:00, 11.26s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:153: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:220: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
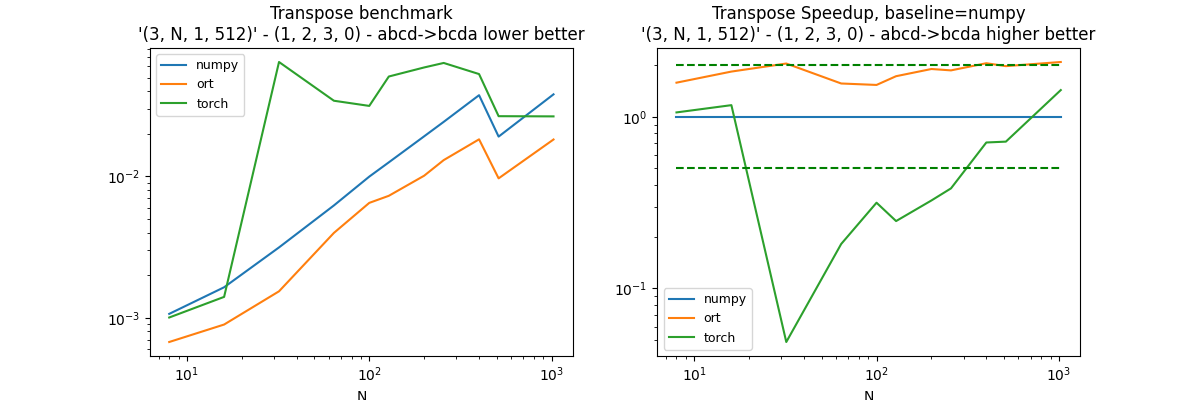
Fifth permutation: (1, 2, 3, 0)#
perm = (1, 2, 3, 0)
df, piv, ax = benchmark_op(perm)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/11 [00:00<?, ?it/s]
18%|#8 | 2/11 [00:00<00:00, 11.01it/s]
36%|###6 | 4/11 [00:03<00:06, 1.13it/s]
45%|####5 | 5/11 [00:04<00:05, 1.01it/s]
55%|#####4 | 6/11 [00:06<00:06, 1.24s/it]
64%|######3 | 7/11 [00:08<00:06, 1.55s/it]
73%|#######2 | 8/11 [00:11<00:05, 1.87s/it]
82%|########1 | 9/11 [00:13<00:04, 2.17s/it]
91%|######### | 10/11 [00:15<00:01, 1.96s/it]
100%|##########| 11/11 [00:17<00:00, 2.04s/it]
100%|##########| 11/11 [00:17<00:00, 1.60s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:153: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:229: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
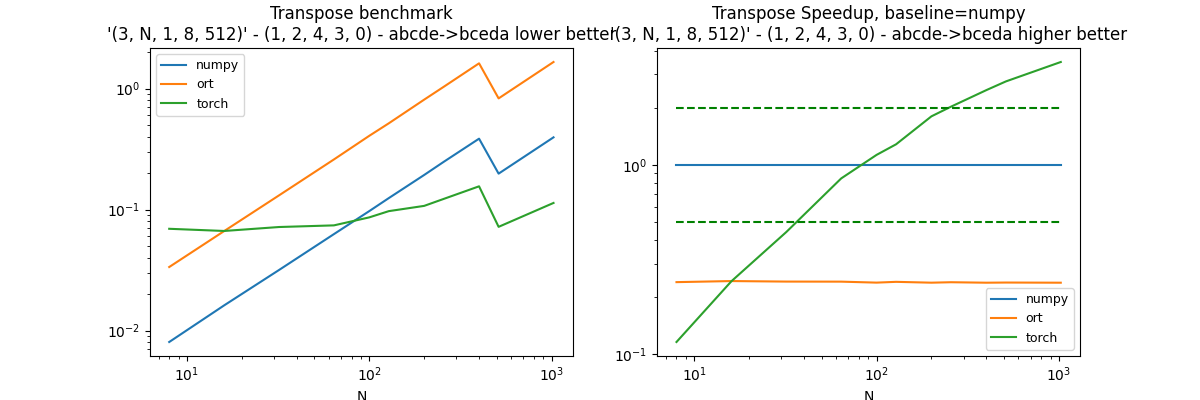
Six th permutation: (1, 2, 4, 3, 0)#
perm = (1, 2, 4, 3, 0)
df, piv, ax = benchmark_op(perm, shape_fct=lambda dim: (3, dim, 1, 8, 512))
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/11 [00:00<?, ?it/s]
9%|9 | 1/11 [00:02<00:28, 2.80s/it]
18%|#8 | 2/11 [00:06<00:30, 3.38s/it]
27%|##7 | 3/11 [00:12<00:36, 4.56s/it]
36%|###6 | 4/11 [00:22<00:47, 6.75s/it]
45%|####5 | 5/11 [00:37<00:58, 9.75s/it]
55%|#####4 | 6/11 [00:56<01:04, 12.84s/it]
64%|######3 | 7/11 [01:24<01:11, 17.92s/it]
73%|#######2 | 8/11 [02:00<01:10, 23.64s/it]
82%|########1 | 9/11 [02:55<01:06, 33.48s/it]
91%|######### | 10/11 [03:24<00:31, 31.82s/it]
100%|##########| 11/11 [04:19<00:00, 39.03s/it]
100%|##########| 11/11 [04:19<00:00, 23.58s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:153: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_transpose.py:238: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
Conclusion#
All libraries have similar implementations. onnxruntime measures includes 2 mores copies, one to copy from numpy container to onnxruntime container, another one to copy back from onnxruntime container to numpy. Parallelisation should be investigated.
merged = pandas.concat(dfs)
name = "transpose"
merged.to_csv(f"plot_{name}.csv", index=False)
merged.to_excel(f"plot_{name}.xlsx", index=False)
plt.savefig(f"plot_{name}.png")
plt.show()

Total running time of the script: ( 7 minutes 38.602 seconds)