k-means#
Dénomination française : algorithme des centres mobiles.
Principe#
Les centres mobiles ou nuées dynamiques sont un algorithme de classification non supervisée. A partir d’un ensemble de points, il détermine pour un nombre de classes fixé, une répartition des points qui minimise un critère appelé inertie ou variance intra-classe.
Algorithme A1 : centre mobile, k-means
On considère un ensemble de points :

A chaque point est associée une classe :
 .
On définit les barycentres des classes :
.
On définit les barycentres des classes :
 .
.
Initialisation
L’initialisation consiste à choisir pour chaque point une classe aléatoirement dans
 . On pose
. On pose  .
.
Calcul des barycentres


Calcul de l’inertie

 et
et 
Attribution des classes


 est la distance entre
est la distance entre  et
et 
Retour à l’étape du calcul des barycentres jusqu’à convergence de l’inertie  .
.
Théorème T1 : convergence des k-means
Quelque soit l’initialisation choisie, la suite  construite par l’algorithme des k-means
converge.
construite par l’algorithme des k-means
converge.
La démonstration du théorème nécessite le lemme suivant.
Lemme L1 : inertie minimum
Soit  ,
,
 points de
points de  , le minimum de la quantité
, le minimum de la quantité
 :
:

est atteint pour  le barycentre des points
le barycentre des points  .
.
Soit ,
points de .

On peut maintenant démontrer le théorème.
L’étape d’attribution des classes consiste à attribuer à chaque
point le barycentre le plus proche. On définit  par :
par :

On en déduit que :

Le lemme précédent appliqué à chacune des classes  ,
permet d’affirmer que
,
permet d’affirmer que  .
Par conséquent, la suite est décroissante et minorée par
0, elle est donc convergente.
.
Par conséquent, la suite est décroissante et minorée par
0, elle est donc convergente.
L’algorithme des centres mobiles cherche à attribuer à chaque
point de l’ensemble une classe parmi les  disponibles.
La solution trouvée dépend de l’initialisation et n’est pas forcément
celle qui minimise l’inertie intra-classe : l’inertie finale est
un minimum local. Néanmoins, elle assure que la partition est formée
de classes convexes : soit
disponibles.
La solution trouvée dépend de l’initialisation et n’est pas forcément
celle qui minimise l’inertie intra-classe : l’inertie finale est
un minimum local. Néanmoins, elle assure que la partition est formée
de classes convexes : soit  et
et  deux classes différentes,
on note
deux classes différentes,
on note  et
et  les enveloppes convexes des points qui
constituent ces deux classes, alors
les enveloppes convexes des points qui
constituent ces deux classes, alors
 .
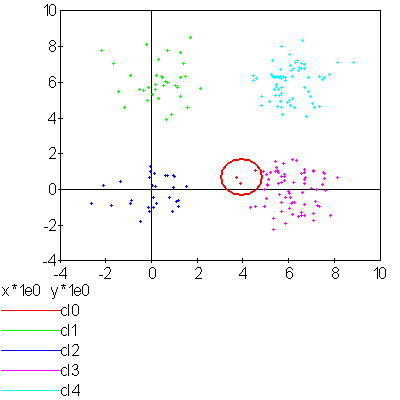
La figure suivante présente un exemple d’utilisation de l’algorithme
des centres mobiles. Des points sont générés aléatoirement
dans le plan et répartis en quatre groupes.
.
La figure suivante présente un exemple d’utilisation de l’algorithme
des centres mobiles. Des points sont générés aléatoirement
dans le plan et répartis en quatre groupes.
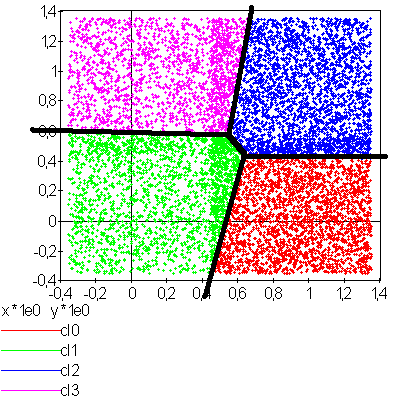
C’est une application des centres mobiles avec une classification en quatre classes d’un ensemble aléatoire de points plus dense sur la partie droite du graphe. Les quatre classes ainsi formées sont convexes.
Homogénéité des dimensions#
Les coordonnées des points
 sont généralement non homogènes :
les ordres de grandeurs de chaque dimension sont différents.
C’est pourquoi il est conseillé de centrer et normaliser chaque dimension.
On note :
sont généralement non homogènes :
les ordres de grandeurs de chaque dimension sont différents.
C’est pourquoi il est conseillé de centrer et normaliser chaque dimension.
On note :  :
:

Les points centrés et normalisés sont :

L’algorithme des centres mobiles est appliqué sur l’ensemble
 .
Il est possible ensuite de décorréler les variables ou d’utiliser
une distance dite de Malahanobis définie par
.
Il est possible ensuite de décorréler les variables ou d’utiliser
une distance dite de Malahanobis définie par
 où
où  désigne la transposée de
désigne la transposée de  et
et  est une matrice symétrique définie positive.
Dans le cas de variables corrélées, la matrice
est une matrice symétrique définie positive.
Dans le cas de variables corrélées, la matrice
 où
où  est la matrice
de variance-covariance des variables aléatoires
est la matrice
de variance-covariance des variables aléatoires  .
.
Améliorations de l’initialisation#
K-means++#
L’article [Arthur2007] montre que l’initialisation aléatoire n’est pas efficace et est sensible aux outliers ou points aberrants. L’étape d’initialisation est remplacée par la suivante :
Algorithme A2 : initialisation k-means++
Cette étape d’initialisation viendra remplacer celle définie dans l’algorithme k-means. On considère un ensemble de points :

A chaque point est associée une classe :
.
Pour  centres, on choisit
au hasard dans l’ensemble
centres, on choisit
au hasard dans l’ensemble  .
Pour les suivants :
.
Pour les suivants :

On choisit aléatoirement
 avec la probabilité
avec la probabilité


On revient à l’étape 2 jusqu’à ce que
 .
.
La fonction  est définie par la distance du point
est définie par la distance du point  au centre
au centre  choisi parmi les premiers centres.
choisi parmi les premiers centres.
 .
.
La suite de l’algorithme k-means++ reprend les mêmes étapes que k-means.
Cette initilisation éloigne le prochain centre le plus possibles des centres déjà choisis. L’article montre que :
Théorème T2 : Borne supérieure de l’erreur produite par k-means++
On définit l’inertie par
 .
Si
.
Si  définit l’inertie optimale alors
définit l’inertie optimale alors
 .
.
La démonstration est disponible dans l’article [Arthur2007].
K-means||#
L’article [Bahmani2012] propose une autre initialisation que K-means++ mais plus rapide et parallélisable.
Algorithme A3 : initialisation k-means||
Cette étape d’initialisation viendra remplacer celle définie dans l’algorithme k-means. On considère un ensemble de points :
A chaque point est associée une classe :
.
Pour centres, on choisit  au hasard dans l’ensemble .
au hasard dans l’ensemble .
 fois :
fois : échantillon aléatoire issue de de probabilité
échantillon aléatoire issue de de probabilité 

La fonction  est définie par la distance du point
au plus proche centre
est définie par la distance du point
au plus proche centre  :
:
 .
Cette étape ajoute à l’ensemble des centres
.
Cette étape ajoute à l’ensemble des centres  un nombre aléatoire de centres à chaque étape.
L’ensemble contiendra plus de centres.
un nombre aléatoire de centres à chaque étape.
L’ensemble contiendra plus de centres.
Pour tout
, on assigne le poids 
On clusterise l’ensemble des points
en clusters
(avec un k-means classique par exemple)
Au lieu d’ajouter les centres un par un comme dans l’algorithme
k-means++, plusieurs sont ajoutés à chaque fois,
plus  est grand, plus ce nombre est grand. Le tirage d’un échantillon
aléatoire consiste à inclure chaque point avec la probabilité
.
est grand, plus ce nombre est grand. Le tirage d’un échantillon
aléatoire consiste à inclure chaque point avec la probabilité
.
Estimation de probabilités#
A partir de cette classification en classes, on construit un
vecteur de probabilités pour chaque point  en supposant que la loi de sachant sa classe
en supposant que la loi de sachant sa classe  est une loi
normale multidimensionnelle. La classe de est
notée
est une loi
normale multidimensionnelle. La classe de est
notée  . On peut alors écrire :
. On peut alors écrire :

On en déduit que :

La densité des obervations est alors modélisée par une mélange de lois normales, chacune centrée au barycentre de chaque classe. Ces probabilités peuvent également être apprises par un réseau de neurones classifieur où servir d’initialisation à un algorithme EM.
Sélection du nombre de classes#
Critère de qualité#
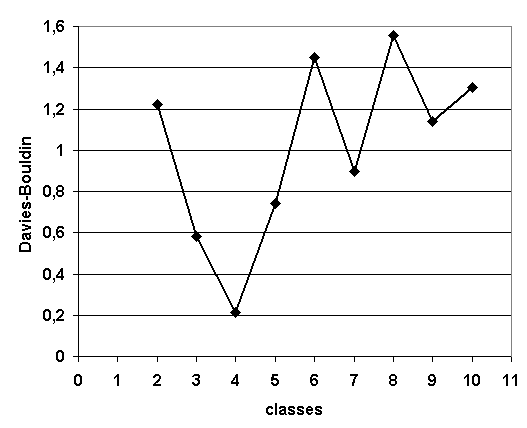
L’algorithme des centres mobiles effectue une classification non supervisée à condition de connaître au préalable le nombre de classes et cette information est rarement disponible. Une alternative consiste à estimer la pertinence des classifications obtenues pour différents nombres de classes, le nombre de classes optimal est celui qui correspond à la classification la plus pertinente. Cette pertinence ne peut être estimée de manière unique, elle dépend des hypothèses faites sur les éléments à classer, notamment sur la forme des classes qui peuvent être convexes ou pas, être modélisées par des lois normales multidimensionnelles, à matrice de covariances diagonales, … Les deux critères qui suivent sont adaptés à l’algorithme des centres mobiles. Le critère de Davies-Bouldin (voir [Davies1979]) est minimum lorsque le nombre de classes est optimal.

Avec :
|
nombre de classes |
|---|---|
|
écart-type des distances des observations de la classe |
|
centre de la classe |



Le critère de Goodman-Kruskal (voir [Goodman1954]) est quant à lui maximum lorsque le nombre de classes est optimal. Il est toutefois plus coûteux à calculer.

Avec :

Où  sont dans la même classe et
sont dans la même classe et  sont dans des classes différentes.
sont dans des classes différentes.
|
|
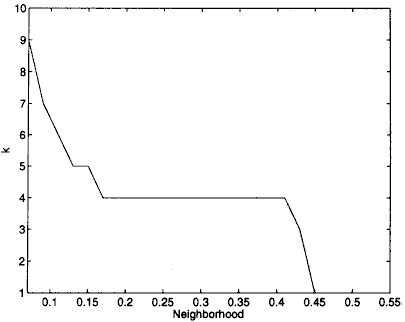
Classification en quatre classes : nombre de classes sélectionnées par le critère de Davies-Bouldin dont les valeurs sont illustrées par le graphe apposé à droite.
Maxima de la fonction densité#
L’article [Herbin2001] propose une méthode différente pour estimer
le nombre de classes, il s’agit tout d’abord d’estimer la fonction
densité du nuage de points qui est une fonction de
 . Cette estimation est effectuée au moyen
d’une méthode non paramètrique telle que les estimateurs à noyau
(voir [Silverman1986])
Soit
. Cette estimation est effectuée au moyen
d’une méthode non paramètrique telle que les estimateurs à noyau
(voir [Silverman1986])
Soit  un nuage de points inclus dans une image,
on cherche à estimer la densité
un nuage de points inclus dans une image,
on cherche à estimer la densité  au pixel :
au pixel :

Où :

 est un paramètre estimée avec la règle de Silverman.
L’exemple utilisé dans cet article est un problème de segmentation
d’image qui ne peut pas être résolu par la méthode des nuées
dynamiques puisque la forme des classes n’est pas convexe,
ainsi que le montre la figure suivante. La fonction de densité
est un paramètre estimée avec la règle de Silverman.
L’exemple utilisé dans cet article est un problème de segmentation
d’image qui ne peut pas être résolu par la méthode des nuées
dynamiques puisque la forme des classes n’est pas convexe,
ainsi que le montre la figure suivante. La fonction de densité
 est seuillée de manière à obtenir une fonction
est seuillée de manière à obtenir une fonction
 définie par :
définie par :

L’ensemble  est composée de
est composée de  composantes connexes notées
composantes connexes notées
 , la classe d’un point
est alors l’indice de la composante connexe à la
laquelle il appartient ou la plus proche le cas échéant.
, la classe d’un point
est alors l’indice de la composante connexe à la
laquelle il appartient ou la plus proche le cas échéant.

|

|
Exemple de classification non supervisée appliquée à un problème
de segmentation d’image, la première figure montre la densité obtenue,
la seconde figure illustre la classification obtenue, figure extraite de [Herbin2001].
Cette méthode paraît néanmoins difficilement applicable lorsque la
dimension de l’espace vectoriel atteint de grande valeur. L’exemple de l’image
est pratique, elle est déjà découpée en région représentées par les pixels,
l’ensemble  correspond à
l’ensemble des pixels pour lesquels
correspond à
l’ensemble des pixels pour lesquels  .
.
Décroissance du nombre de classes#
L’article [Kothari1999] propose une méthode permettant de
faire décroître le nombre de classes afin de choisir le nombre
approprié. L’algorithme des centres mobiles
proposent de faire décroître l’inertie notée  définie pour un ensemble de points noté
définie pour un ensemble de points noté  et
et  classes. La classe d’un élément
est notée
classes. La classe d’un élément
est notée  . Les centres des classes sont notés
. Les centres des classes sont notés
 .
L’inertie de ce nuage de points est définie par :
.
L’inertie de ce nuage de points est définie par :

On définit tout d’abord une distance
 , puis l’ensemble
, puis l’ensemble
 ,
,
 est donc l’ensemble des voisins des
centres dont la distance avec
est donc l’ensemble des voisins des
centres dont la distance avec  est inférieur à
est inférieur à  .
L’article [Kothari1999] propose de minimiser le coût
.
L’article [Kothari1999] propose de minimiser le coût  suivant :
suivant :

Lorsque est nul, ce facteur est égal à l’inertie :
 et ce terme est minimal lorsqu’il y a autant de
classes que d’éléments dans . Lorsque
tend vers l’infini,
et ce terme est minimal lorsqu’il y a autant de
classes que d’éléments dans . Lorsque
tend vers l’infini,  où :
où :

Ici encore, il est possible de montrer que ce terme
 est minimal lorsqu’il n’existe plus qu’une
seule classe. Le principe de cette méthode consiste à faire varier
le paramètre , plus le paramètre augmente,
plus le nombre de classes devra être réduit. Néanmoins, il existe
des intervalles pour lequel ce nombre de classes est stable,
le véritable nombre de classes de l’ensemble
sera considéré comme celui correspondant au plus grand intervalle
stable.
est minimal lorsqu’il n’existe plus qu’une
seule classe. Le principe de cette méthode consiste à faire varier
le paramètre , plus le paramètre augmente,
plus le nombre de classes devra être réduit. Néanmoins, il existe
des intervalles pour lequel ce nombre de classes est stable,
le véritable nombre de classes de l’ensemble
sera considéré comme celui correspondant au plus grand intervalle
stable.
|
|
(a) |
(b) |
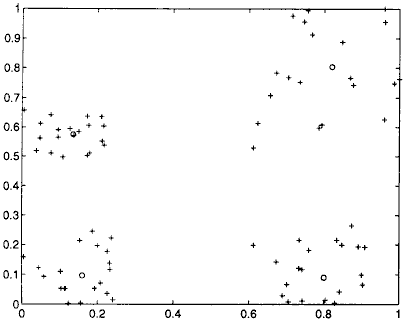
Evolutation du nombre de classes en fonction du paramètre lors de la
minimisation du critère , figure extraite de [Kothari1999].
La première image représente le nuage de points illustrant quatre classes sans recouvrement.
La seconde image montre que quatre classes est l’état le plus longtemps stable
lorsque croît.
Le coût est une somme de coût dont
l’importance de l’un par rapport à l’autre est contrôle
par les paramètres  . Le problème de
minimisation de est résolu par l’algorithme qui suit.
Il s’appuie sur la méthode des multiplicateurs de Lagrange.
. Le problème de
minimisation de est résolu par l’algorithme qui suit.
Il s’appuie sur la méthode des multiplicateurs de Lagrange.
Algorithme A4 : sélection du nombre de classes
(voir [Kothari1999])
Les notations sont celles utilisés dans les paragraphes précédents. On suppose que le
paramètre évolue dans l’intervalle  à intervalle régulier
à intervalle régulier  .
Le nombre initial de classes est noté et il est supposé surestimer le véritable
nombre de classes. Soit
.
Le nombre initial de classes est noté et il est supposé surestimer le véritable
nombre de classes. Soit ![\eta \in \left]0,1\right[](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSA0NC4yNjk3MTUgMTEuOTU1MTY4JyB3aWR0aD0nNDQuMjY5NzE1cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTUuMzU1OTE1IC0zLjgyNTY1NEM1LjM1NTkxNSAtNC44MTc5MzMgNS4yOTYxMzkgLTUuNzg2MzAxIDQuODY1NzUzIC02LjY5NDg5NEM0LjM3NTU5MiAtNy42ODcxNzMgMy41MTQ4MTkgLTcuOTUwMTg3IDIuOTI5MDE2IC03Ljk1MDE4N0MyLjIzNTYxNiAtNy45NTAxODcgMS4zODY4IC03LjYwMzQ4NyAwLjk0NDQ1OCAtNi42MTEyMDhDMC42MDk3MTQgLTUuODU4MDMyIDAuNDkwMTYyIC01LjExNjgxMiAwLjQ5MDE2MiAtMy44MjU2NTRDMC40OTAxNjIgLTIuNjY2MDAyIDAuNTczODQ4IC0xLjc5MzI3NSAxLjAwNDIzNCAtMC45NDQ0NThDMS40NzA0ODYgLTAuMDM1ODY2IDIuMjk1MzkyIDAuMjUxMDU5IDIuOTE3MDYxIDAuMjUxMDU5QzMuOTU3MTYxIDAuMjUxMDU5IDQuNTU0OTE5IC0wLjM3MDYxIDQuOTAxNjE5IC0xLjA2NDAxQzUuMzMyMDA1IC0xLjk2MDY0OCA1LjM1NTkxNSAtMy4xMzIyNTQgNS4zNTU5MTUgLTMuODI1NjU0Wk0yLjkxNzA2MSAwLjAxMTk1NUMyLjUzNDQ5NiAwLjAxMTk1NSAxLjc1NzQxIC0wLjIwMzIzOCAxLjUzMDI2MiAtMS41MDYzNTFDMS4zOTg3NTUgLTIuMjIzNjYxIDEuMzk4NzU1IC0zLjEzMjI1NCAxLjM5ODc1NSAtMy45NjkxMTZDMS4zOTg3NTUgLTQuOTQ5NDQgMS4zOTg3NTUgLTUuODM0MTIyIDEuNTkwMDM3IC02LjUzOTQ3N0MxLjc5MzI3NSAtNy4zNDA0NzMgMi40MDI5ODkgLTcuNzExMDgzIDIuOTE3MDYxIC03LjcxMTA4M0MzLjM3MTM1NyAtNy43MTEwODMgNC4wNjQ3NTcgLTcuNDM2MTE1IDQuMjkxOTA1IC02LjQwNzk3QzQuNDQ3MzIzIC01LjcyNjUyNiA0LjQ0NzMyMyAtNC43ODIwNjcgNC40NDczMjMgLTMuOTY5MTE2QzQuNDQ3MzIzIC0zLjE2ODEyIDQuNDQ3MzIzIC0yLjI1OTUyNyA0LjMxNTgxNiAtMS41MzAyNjJDNC4wODg2NjcgLTAuMjE1MTkzIDMuMzM1NDkyIDAuMDExOTU1IDIuOTE3MDYxIDAuMDExOTU1WicgaWQ9J2cyLTQ4Jy8+CjxwYXRoIGQ9J00zLjQ0MzA4OCAtNy42NjMyNjNDMy40NDMwODggLTcuOTM4MjMyIDMuNDQzMDg4IC03Ljk1MDE4NyAzLjIwMzk4NSAtNy45NTAxODdDMi45MTcwNjEgLTcuNjI3Mzk3IDIuMzE5MzAzIC03LjE4NTA1NiAxLjA4NzkyIC03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODkgLTYuODM4MzU2IDEuOTYwNjQ4IC02LjgzODM1NiAyLjYxODE4MiAtNy4xNDkxOTFWLTAuOTIwNTQ4QzIuNjE4MTgyIC0wLjQ5MDE2MiAyLjU4MjMxNiAtMC4zNDY3IDEuNTMwMjYyIC0wLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MSAtMC4wMjM5MSAyLjY0MjA5MiAtMC4wMjM5MSAzLjAzNjYxMyAtMC4wMjM5MVM0LjU3ODgyOSAtMC4wMjM5MSA0LjkwMTYxOSAwVi0wLjM0NjdINC41MzEwMDlDMy40Nzg5NTQgLTAuMzQ2NyAzLjQ0MzA4OCAtMC40OTAxNjIgMy40NDMwODggLTAuOTIwNTQ4Vi03LjY2MzI2M1onIGlkPSdnMi00OScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzItOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzItOTMnLz4KPHBhdGggZD0nTTUuNjc4NzA1IC0zLjMxMTU4MkM1LjczODQ4MSAtMy41NTA2ODUgNS43NzQzNDYgLTMuNjk0MTQ3IDUuNzc0MzQ2IC00LjAxNjkzNkM1Ljc3NDM0NiAtNC43MzQyNDcgNS4zNTU5MTUgLTUuMjcyMjI5IDQuNDQ3MzIzIC01LjI3MjIyOUMzLjM4MzMxMyAtNS4yNzIyMjkgMi44MjE0MiAtNC41MTkwNTQgMi42MDYyMjcgLTQuMjIwMTc0QzIuNTcwMzYxIC00LjkwMTYxOSAyLjA4MDE5OSAtNS4yNzIyMjkgMS41NTQxNzIgLTUuMjcyMjI5QzEuMjA3NDcyIC01LjI3MjIyOSAwLjkzMjUwMyAtNS4xMDQ4NTcgMC43MDUzNTUgLTQuNjUwNTZDMC40OTAxNjIgLTQuMjIwMTc0IDAuMzIyNzkgLTMuNDkwOTA5IDAuMzIyNzkgLTMuNDQzMDg4UzAuMzcwNjEgLTMuMzM1NDkyIDAuNDU0Mjk2IC0zLjMzNTQ5MkMwLjU0OTkzOCAtMy4zMzU0OTIgMC41NjE4OTMgLTMuMzQ3NDQ3IDAuNjMzNjI0IC0zLjYyMjQxNkMwLjgxMjk1MSAtNC4zMjc3NzEgMS4wNDAxIC01LjAzMzEyNiAxLjUxODMwNiAtNS4wMzMxMjZDMS43OTMyNzUgLTUuMDMzMTI2IDEuODg4OTE3IC00Ljg0MTg0MyAxLjg4ODkxNyAtNC40ODMxODhDMS44ODg5MTcgLTQuMjIwMTc0IDEuNzY5MzY1IC0zLjc1MzkyMyAxLjY4NTY3OSAtMy4zODMzMTNMMS4zNTA5MzQgLTIuMDkyMTU0QzEuMzAzMTEzIC0xLjg2NTAwNiAxLjE3MTYwNiAtMS4zMjcwMjQgMS4xMTE4MzEgLTEuMTExODMxQzEuMDI4MTQ0IC0wLjgwMDk5NiAwLjg5NjYzOCAtMC4yMzkxMDMgMC44OTY2MzggLTAuMTc5MzI4QzAuODk2NjM4IC0wLjAxMTk1NSAxLjAyODE0NCAwLjExOTU1MiAxLjIwNzQ3MiAwLjExOTU1MkMxLjM1MDkzNCAwLjExOTU1MiAxLjUxODMwNiAwLjA0NzgyMSAxLjYxMzk0OCAtMC4xMzE1MDdDMS42Mzc4NTggLTAuMTkxMjgzIDEuNzQ1NDU1IC0wLjYwOTcxNCAxLjgwNTIzIC0wLjg0ODgxN0wyLjA2ODI0NCAtMS45MjQ3ODJMMi40NjI3NjUgLTMuNTAyODY0QzIuNDg2Njc1IC0zLjU3NDU5NSAyLjc4NTU1NCAtNC4xNzIzNTQgMy4yMjc4OTUgLTQuNTU0OTE5QzMuNTM4NzMgLTQuODQxODQzIDMuOTQ1MjA1IC01LjAzMzEyNiA0LjQxMTQ1NyAtNS4wMzMxMjZDNC44ODk2NjQgLTUuMDMzMTI2IDUuMDU3MDM2IC00LjY3NDQ3MSA1LjA1NzAzNiAtNC4xOTYyNjRDNS4wNTcwMzYgLTMuODQ5NTY0IDUuMDA5MjE1IC0zLjY1ODI4MSA0Ljk0OTQ0IC0zLjQzMTEzM0wzLjU2MjY0IDIuMDY4MjQ0QzMuNTUwNjg1IDIuMTI4MDIgMy41MjY3NzUgMi4xOTk3NTEgMy41MjY3NzUgMi4yNzE0ODJDMy41MjY3NzUgMi40NTA4MDkgMy42NzAyMzcgMi41NzAzNjEgMy44NDk1NjQgMi41NzAzNjFDMy45NTcxNjEgMi41NzAzNjEgNC4yMDgyMTkgMi41MjI1NCA0LjMwMzg2MSAyLjE2Mzg4NUw1LjY3ODcwNSAtMy4zMTE1ODJaJyBpZD0nZzEtMTcnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2cxLTU5Jy8+CjxwYXRoIGQ9J002LjU1MTQzMiAtMi43NDk2ODlDNi43NTQ2NyAtMi43NDk2ODkgNi45Njk4NjMgLTIuNzQ5Njg5IDYuOTY5ODYzIC0yLjk4ODc5MlM2Ljc1NDY3IC0zLjIyNzg5NSA2LjU1MTQzMiAtMy4yMjc4OTVIMS40ODI0NDFDMS42MjU5MDMgLTQuODI5ODg4IDMuMDAwNzQ3IC01Ljk3NzU4NCA0LjY4NjQyNiAtNS45Nzc1ODRINi41NTE0MzJDNi43NTQ2NyAtNS45Nzc1ODQgNi45Njk4NjMgLTUuOTc3NTg0IDYuOTY5ODYzIC02LjIxNjY4N1M2Ljc1NDY3IC02LjQ1NTc5MSA2LjU1MTQzMiAtNi40NTU3OTFINC42NjI1MTZDMi42MTgxODIgLTYuNDU1NzkxIDAuOTkyMjc5IC00LjkwMTYxOSAwLjk5MjI3OSAtMi45ODg3OTJTMi42MTgxODIgMC40NzgyMDcgNC42NjI1MTYgMC40NzgyMDdINi41NTE0MzJDNi43NTQ2NyAwLjQ3ODIwNyA2Ljk2OTg2MyAwLjQ3ODIwNyA2Ljk2OTg2MyAwLjIzOTEwM1M2Ljc1NDY3IDAgNi41NTE0MzIgMEg0LjY4NjQyNkMzLjAwMDc0NyAwIDEuNjI1OTAzIC0xLjE0NzY5NiAxLjQ4MjQ0MSAtMi43NDk2ODlINi41NTE0MzJaJyBpZD0nZzAtNTAnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cxLTE3JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0OC4zNzk1ODEnIHhsaW5rOmhyZWY9JyNnMC01MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNTkuNjcwNTQ5JyB4bGluazpocmVmPScjZzItOTMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYyLjkyMjIxMScgeGxpbms6aHJlZj0nI2cyLTQ4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2OC43NzUyMDEnIHhsaW5rOmhyZWY9JyNnMS01OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzQuMDE5MzYnIHhsaW5rOmhyZWY9JyNnMi00OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzkuODcyMzUnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) ,
ce paramètre doit être choisi de telle sorte que dans
l’algorithme qui suit, l’évolution des centres
,
ce paramètre doit être choisi de telle sorte que dans
l’algorithme qui suit, l’évolution des centres  soit autant assurée par le premier de la fonction de coût que par le second.
soit autant assurée par le premier de la fonction de coût que par le second.
initialisation

On tire aléatoirement les centres des classes  .
.
préparation
On définit les deux suites entières  ,
,  ,
et les deux suites de vecteur
,
et les deux suites de vecteur  ,
,
 .
.

calcul des mises à jour
 .
.








convergence
Tant que l’étape précédente n’a pas convergé vers une version stable des centres,
, retour à l’étape précédente. Sinon, tous les couples de classes  vérifiant
vérifiant  sont fusionnés :
sont fusionnés :
 .
Si
.
Si  , retour à l’étape de préparation.
, retour à l’étape de préparation.
terminaison
Le nombre de classes est celui ayant prévalu pour le plus grand nombre de valeur de .
Extension des nuées dynamiques#
Classes elliptiques#
La version de l’algorithme des nuées dynamique proposée dans l’article [Cheung2003] suppose que les classes ne sont plus de forme circulaire mais suivent une loi normale quelconque. La loi de l’échantillon constituant le nuage de points est de la forme :

Avec  . On définit :
. On définit :

L’algorithme qui suit a pour objectif de minimiser la quantité pour un échantillon  :
:

Algorithme A5 : nuées dynamiques généralisées
Les notations sont celles utilisées dans ce paragraphe. Soient  ,
,
 deux réels tels que
deux réels tels que  .
La règle préconisée par l’article [Cheung2003] est
.
La règle préconisée par l’article [Cheung2003] est  .
.
initialisation
 .
Les paramètres
.
Les paramètres  sont initialisés
grâce à un algorithme des k-means ou FSCL.
sont initialisés
grâce à un algorithme des k-means ou FSCL.
 et
et  .
.
récurrence
Soit  choisi aléatoirement dans .
choisi aléatoirement dans .






terminaison
Tant que  change pour au moins un des points .
change pour au moins un des points .
Lors de la mise à jour de ,
l’algorithme précédent propose la mise à jour de  alors que le calcul de
alors que le calcul de  implique
implique  ,
par conséquent, il est préférable de mettre à jour directement la matrice
:
,
par conséquent, il est préférable de mettre à jour directement la matrice
:

Rival Penalized Competitive Learning (RPCL)#
L’algorithme suivant développé dans [Xu1993], est une variante de celui des centres mobiles. Il entreprend à la fois la classification et la sélection du nombre optimal de classes à condition qu’il soit inférieur à une valeur maximale à déterminer au départ de l’algorithme. Un mécanisme permet d’éloigner les centres des classes peu pertinentes de sorte qu’aucun point ne leur sera affecté.
Algorithme A6 : RPCL
Soient , vecteurs à classer en au
plus  classes de centres
classes de centres  .
Soient deux réels
.
Soient deux réels  et
et  tels que
tels que  .
.
initialisation
Tirer aléatoirement les centres .

calcul de poids
Choisir aléatoirement un point .




mise à jour


terminaison
S’il existe un indice  pour lequel
pour lequel  alors retourner à l’étape de calcul de poids ou que les centres des classes jugées inutiles
ont été repoussés vers l’infini.
alors retourner à l’étape de calcul de poids ou que les centres des classes jugées inutiles
ont été repoussés vers l’infini.
Pour chaque point, le centre de la classe la plus proche en est rapproché
tandis que le centre de la seconde classe la plus proche en est éloigné
mais d’une façon moins importante (condition  ).
Après convergence, les centres des classes inutiles ou non pertinentes
seront repoussés vers l’infini. Par conséquent, aucun point n’y sera rattaché.
).
Après convergence, les centres des classes inutiles ou non pertinentes
seront repoussés vers l’infini. Par conséquent, aucun point n’y sera rattaché.
L’algorithme doit être lancé plusieurs fois. L’algorithme RPCL peut terminer sur un résultat comme celui de la figure suivante où un centre reste coincé entre plusieurs autres. Ce problème est moins important lorsque la dimension de l’espace est plus grande.
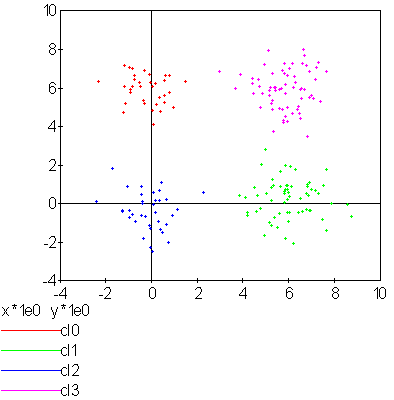
Application de l’algorithme RPCL : la classe 0 est incrusté entre les quatre autres et son centre ne peut se « faufiler » vers l’infini.
RPCL-based local PCA#
L’article [Liu2003] propose une extension de l’algorithme RPCL et suppose que les classes ne sont plus de forme circulaire mais suivent une loi normale quelconque. Cette méthode est utilisée pour la détection de ligne considérées ici comme des lois normales dégénérées en deux dimensions, la matrice de covariance définit une ellipse dont le grand axe est très supérieur au petit axe, ce que montre la figure suivante. Cette méthode est aussi présentée comme un possible algorithme de squelettisation.

Figure extraite de [Liu2003], l’algorithme est utilisé pour la détection de lignes considérées ici comme des lois normales dont la matrice de covariance définit une ellipse dégénérée dont le petit axe est très inférieur au grand axe. Les traits fin grisés correspondent aux classes isolées par l’algorithme RPCL-based local PCA.
On modélise le nuage de points par une mélange de lois normales :
Avec  .
.
On suppose que le nombre de classes initiales surestime le
véritable nombre de classes. L’article [Liu2003] s’intéresse
au cas particulier où les matrices de covariances vérifient
 avec
avec  .
.
On définit également :
L’algorithme utilisé est similaire à l’algortihme RPCL.
La distance  utilisée lors de l’étape de calcul des poids
afin de trouver la classe la plus probable pour un point
donné est remplacée par l’expression :
utilisée lors de l’étape de calcul des poids
afin de trouver la classe la plus probable pour un point
donné est remplacée par l’expression :

L’étape de mise à jour des coefficients est remplacée par :

Où  joue le rôle d’un paramètre et est remplacé
successivement par
joue le rôle d’un paramètre et est remplacé
successivement par  ,
,  ,
,  ,
,  ,
,  :
:

Frequency Sensitive Competitive Learning (FSCL)#
L’algorithme Frequency Sensitive Competitive Learning est présenté dans [Balakrishnan1996]. Par rapport à l’algorithme des centres mobiles classique, lors de l’estimation des centres des classes, l’algorithme évite la formation de classes sous-représentées.
Algorithme A7 : FSCL
Soit un nuage de points ,
soit vecteurs  initialisés de manière aléatoires.
Soit
initialisés de manière aléatoires.
Soit  croissante par rapport à
croissante par rapport à  .
Soit une suite de réels
.
Soit une suite de réels  ,
soit une suite
,
soit une suite  décroissante où
décroissante où  représente le nombre d’itérations.
Au début
représente le nombre d’itérations.
Au début  .
.
meilleur candidat
Pour un vecteur choisi aléatoirement dans
l’ensemble , on détermine :

mise à jour


Retour à l’étape précédente jusqu’à ce que les nombres
 convergent.
convergent.
Exemple de fonctions pour  ,
,  (voir [Balakrishnan1996]) :
(voir [Balakrishnan1996]) :

Cet algorithme ressemble à celui des cartes topographiques de Kohonen
sans toutefois utiliser un maillage entre les neurones
(ici les vecteurs  ). Contrairement à l’algorithme RPCL,
les neurones ne sont pas repoussés s’ils ne sont pas choisis mais la fonction
croissante
). Contrairement à l’algorithme RPCL,
les neurones ne sont pas repoussés s’ils ne sont pas choisis mais la fonction
croissante  par rapport à assure que plus un neurone
est sélectionné, moins il a de chance de l’être,
bien que cet avantage disparaisse au fur et à mesure des itérations.
par rapport à assure que plus un neurone
est sélectionné, moins il a de chance de l’être,
bien que cet avantage disparaisse au fur et à mesure des itérations.
k-means norme L1#
L’algorithme dans sa version la plus courante optimise l’inertie définie
par  , qui est
en quelque sorte une inertie L2. Que devriendrait l’algorithme
si la norme choisie était une norme L1, il faudrait alors choisir
à chaque itération t des points qui minimise la quantité :
, qui est
en quelque sorte une inertie L2. Que devriendrait l’algorithme
si la norme choisie était une norme L1, il faudrait alors choisir
à chaque itération t des points qui minimise la quantité :
 où
où
 est la norme L1 entre deux points X,Y :
est la norme L1 entre deux points X,Y :
 . Avant de continuer,
on rappelle un théorème :
. Avant de continuer,
on rappelle un théorème :
propriété P1 : Médiane et valeur absolue
Soit  un ensembl de n réels quelconque.
On note
un ensembl de n réels quelconque.
On note  la médiane
de l’ensemble de points A. Alors la médiane m
minimise la quantité
la médiane
de l’ensemble de points A. Alors la médiane m
minimise la quantité  .
.
C’est cette propriété qui est utilisée pour définir ce qu’est
la régression quantile et sa démonstration
est présentée à la page Médiane et valeur absolue. Il ne reste
plus qu’à se servir de ce résultat pour mettre à jour l’algorithme
centre mobile, k-means. L’étape qui
consiste à affecter un point à un cluster représenté par un point
ne pose pas de problème si on utilise cette nouvelle norme. Il ne reste
plus qu’à déterminer le point qui représente un cluster sachant
les points qui le constituent. Autrement dit, il faut déterminer
le point qui minimiser la pseudo-inertie définie comme suit
pour un ensemble de points  appartenant à un
espace vectoriel de dimension k.
appartenant à un
espace vectoriel de dimension k.

On cherche le point G qui minimise la quantité  .
Comme
.
Comme  ,
on en déduit qu’on peut chercher la coordonnée
,
on en déduit qu’on peut chercher la coordonnée  indépendemment
les unes des autres. On en déduit
que le barycentre de norme L1 d’un ensemble de points dans un
espace vectoriel de dimension d a pour coordonnées les d
médianes extraites sur chacune des dimensions.
L’algorithme est implémenté dans le module mlinsights
en s’inspirant du code KMeans.
indépendemment
les unes des autres. On en déduit
que le barycentre de norme L1 d’un ensemble de points dans un
espace vectoriel de dimension d a pour coordonnées les d
médianes extraites sur chacune des dimensions.
L’algorithme est implémenté dans le module mlinsights
en s’inspirant du code KMeans.
Bibliographie#
k-means++: the advantages of careful seeding (2007), Arthur, D.; Vassilvitskii, S., Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics Philadelphia, PA, USA. pp. 1027–1035. PDF.
Comparative performance of the FSCL neural net and K-means algorithm for market segmentation (1996), P. V. Sundar Balakrishnan, Martha Cooper, Varghese S. Jacob, Phillip A. Lewis, European Journal of Operation Research, volume 93, pages 346-357
Scalable K-Means++ (2012), Bahman Bahmani, Benjamin Moseley, Andrea Vattani, Ravi Kumar, Sergei Vassilvitskii, Proceedings of the VLDB Endowment (PVLDB), Vol. 5, No. 7, pp. 622-633 (2012) PDF, arXiv
 -Means: A new generalized k-means clustering algorithm (2003),
Yiu-Ming Cheung,
Pattern Recognition Letters, volume 24, 2883-2893
-Means: A new generalized k-means clustering algorithm (2003),
Yiu-Ming Cheung,
Pattern Recognition Letters, volume 24, 2883-2893
A cluster Separation Measure (1979), D. L. Davies, D. W. Bouldin, IEEE Trans. Pattern Analysis and Machine Intelligence (PAMI), volume 1(2)
Measures of associations for cross-validations (1954), L. Goodman, W. Kruskal, J. Am. Stat. Assoc., volume 49, pages 732-764
Estimation of the number of clusters and influence zones (2001), M. Herbin, N. Bonnet, P. Vautrot, Pattern Recognition Letters, volume 22, pages 1557-1568
On finding the number of clusters (1999), Ravi Kothari, Dax Pitts, Pattern Recognition Letters, volume 20, pages 405-416
Strip line detection and thinning by RPCL-based local PCA (2003), Zhi-Yong Liu, Kai-Chun Chiu, Lei Xu, Pattern Recognition Letters volume 24, pages 2335-2344
Density Estimation for Statistics and Data Analysis (1986), B. W. Silverman, Monographs on Statistics and Applied Probability, Chapman and Hall, London, volume 26
Rival penalized competitive learning for clustering analysis, rbf net and curve detection (1993), L. Xu, A. Krzyzak, E. Oja, IEEE Trans. Neural Networks, volume (4), pages 636-649