Carte de Kohonen#
Principe#
Les cartes de Kohonen ou Self Organizing Map (SOM) est le terme anglais
pour les cartes de Kohonen.
(voir [Kohonen1997]) sont assimilées à des méthodes neuronales.
Ces cartes sont constituées d’un ensemble de neurones
 lesquels sont reliés par une forme récurrente de
voisinage. Les neurones sont initialement répartis selon ce système
de voisinage. Le réseau évolue ensuite puisque chaque point de l’espace
parmi l’ensemble
lesquels sont reliés par une forme récurrente de
voisinage. Les neurones sont initialement répartis selon ce système
de voisinage. Le réseau évolue ensuite puisque chaque point de l’espace
parmi l’ensemble  attire le neurone le plus proche
vers lui, ce neurone attirant à son tour ses voisins. Cette procédure
est réitérée jusqu’à convergence du réseau en faisant décroître
l’attirance des neurones vers les points du nuage.
attire le neurone le plus proche
vers lui, ce neurone attirant à son tour ses voisins. Cette procédure
est réitérée jusqu’à convergence du réseau en faisant décroître
l’attirance des neurones vers les points du nuage.
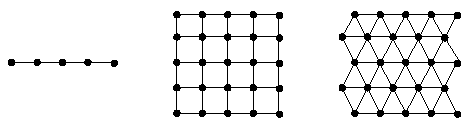
Trois types de voisinages couramment utilisés pour les cartes de Kohonen, voisinages linéaire, rectangulaire, triangulaire.
Algorithme A1 : cartes de Kohonen (SOM)
Soient  des neurones de l’espace vectoriel
des neurones de l’espace vectoriel  . On
désigne par
. On
désigne par  l’ensemble des neurones
voisins de
l’ensemble des neurones
voisins de  pour cette carte de Kohonen.
Par définition, on a
pour cette carte de Kohonen.
Par définition, on a  .
Soit
.
Soit  un nuage de points.
On utilise une suite de réels positifs
un nuage de points.
On utilise une suite de réels positifs
 vérifiant
vérifiant
 et
et
 .
.
initialisation
Les neurones  sont répartis dans l’espace
de manière régulière selon la forme de leur voisinage.
sont répartis dans l’espace
de manière régulière selon la forme de leur voisinage.
 .
.
neurone le plus proche
On choisi aléatoirement un points du nuage
 puis on définit le neurone
puis on définit le neurone
 de telle sorte que :
de telle sorte que :
 .
.
mise à jour
 in
in 


Tant que l’algorithme n’a pas convergé, retour à l’étape du neurone le plus proche.
L’étape de mise à jour peut être modifiée de manière à améliorer la vitesse de convergence (voir [Lo1991]) :

Où  est une fonction à valeur dans l’intervalle
est une fonction à valeur dans l’intervalle
 qui vaut 1 lorsque
qui vaut 1 lorsque  et qui décroît lorsque la distance entre ces deux neurones augmente.
Une fonction typique est :
et qui décroît lorsque la distance entre ces deux neurones augmente.
Une fonction typique est :  .
.
Les cartes de Kohonen sont utilisées en analyse des données afin de projeter un nuage de points dans un espace à deux dimensions d’une manière non linéaire en utilisant un voisinage rectangulaire. Elles permettent également d’effectuer une classification non supervisée en regroupant les neurones là où les points sont concentrés. Les arêtes reliant les neurones ou sommets de la cartes de Kohonen sont soit rétrécies pour signifier que deux neurones sont voisins, soit distendues pour indiquer une séparation entre classes.
Carte de Kohonen et classification#
L’article [Wu2004] aborde le problème d’une classification à
partir du résultat obtenu depuis une carte de Kohonen.
Plutôt que de classer les points, ce sont les neurones qui seront
classés en  classes. Après avoir appliqué
l”algorithme de Kohonen,
la méthode proposée dans [Wu2004] consiste à classer de manière
non supervisée les
classes. Après avoir appliqué
l”algorithme de Kohonen,
la méthode proposée dans [Wu2004] consiste à classer de manière
non supervisée les  neurones obtenus
neurones obtenus  .
Toutefois, ceux-ci ne sont pas tous pris en compte afin d’éviter
les points aberrants. On suppose que
.
Toutefois, ceux-ci ne sont pas tous pris en compte afin d’éviter
les points aberrants. On suppose que  si le
neurone
si le
neurone  est le plus proche du point
, 0 dans le cas contraire. Puis on construit les quantités suivantes :
est le plus proche du point
, 0 dans le cas contraire. Puis on construit les quantités suivantes :

De plus :

Si  ou
ou  ,
le neurone
,
le neurone  n’est pas prise en compte lors de la classification non
supervisée. Une fois celle-ci terminée, chaque élément
est classé selon la classe du neurone le plus proche.
n’est pas prise en compte lors de la classification non
supervisée. Une fois celle-ci terminée, chaque élément
est classé selon la classe du neurone le plus proche.
L’article [Wu2004] propose également un critère permettant de
déterminer le nombre de classes idéale. On note,
 si appartient à la classe
si appartient à la classe  ,
dans le cas contraire,
,
dans le cas contraire,  . On définit
. On définit  le nombre d’éléments de la classe , le vecteur moyenne
le nombre d’éléments de la classe , le vecteur moyenne  associé à la classe :
associé à la classe :

On note au préalable  .
L’article définit ensuite la densité interne pour classes :
.
L’article définit ensuite la densité interne pour classes :

On définit la distance  pour
pour  ,
cette distance est égale à la distance minimale pour un couple de points,
le premier appartenant à la classe
,
cette distance est égale à la distance minimale pour un couple de points,
le premier appartenant à la classe  , le second à la classe
, le second à la classe  :
:

La densité externe est alors définie en fonction du nombre de classes par :

L’article définit ensuite la séparabilité en fonction du nombre de classes :

Enfin, le critère Composing Density Between and With clusters
noté  est défini par :
est défini par :

Ce critère est maximal pour un nombre de classes optimal. Outre les résultats de l’article [Wu2004] sommairement résumés ici, ce dernier revient sur l’histoire des cartes de Kohonen, depuis leur création [Kohonen1982] jusqu’aux derniers développements récents.
Autres utilisation des cartes de Kohenen#
On peut les utiliser pour déterminer le plus court chemin passant par tous les noeuds d’un graphe, c’est à dire appliquer Kohonen au problème du voyageur de commerce.
Bibliographie#
Self-organized formation of topologically correct feature maps (1982), T. Kohonen, Biol. Cybern., volume (43), pages 59-69
Self-Organizing Map (1997) T. Kohonen, Springer
On the rate of convergence in topology preserving neural networks (1991), Z. Lo, B. Bavarian, Biological Cybernetics, volume 63, pages 55-63
Dynamic Self-Organising Map, Nicolas P. Rougier and Yann Boniface