Régression logistique, diagramme de Voronoï, k-Means#
Ce qui suit explore les liens entre une régression logistique, les diagrammes de Voronoï pour construire un classifieur qui allie la régression logistique et les clustering type k-means. Le point de départ est une conjecture : les régions créées par une régression logistique sont convexes.
Diagramme de Voronoï#
Un diagramme de Voronoï
est le diagramme issu des intersections des médiatrices entre  points.
points.

On définit un ensemble de points  .
La zone d’influence de chaque point est défini par
.
La zone d’influence de chaque point est défini par
 .
Si d est la distance euclidienne, la frontière entre deux
points
.
Si d est la distance euclidienne, la frontière entre deux
points  est un segment sur la droite d’équation
est un segment sur la droite d’équation
 :
:

Ce système constitue  droites ou hyperplans si
l’espace vectoriel est en dimension plus que deux.
Le diagramme de Voronoï est formé par des segments de chacune
de ces droites. On peut retourner le problème. On suppose
qu’il existe hyperplans,
existe-t-il n points de telle sorte que les hyperplans
initiaux sont les frontières du diagramme de Voronoï formé
par ces n points ? Les paragraphes qui suivent expliquent
explorent cette hypothèse.
droites ou hyperplans si
l’espace vectoriel est en dimension plus que deux.
Le diagramme de Voronoï est formé par des segments de chacune
de ces droites. On peut retourner le problème. On suppose
qu’il existe hyperplans,
existe-t-il n points de telle sorte que les hyperplans
initiaux sont les frontières du diagramme de Voronoï formé
par ces n points ? Les paragraphes qui suivent expliquent
explorent cette hypothèse.
Régression logistique#
scikit-learn a rendu populaire le jeu de données Iris qui consiste à classer des fleurs en trois classes en fonction des dimensions de leurs pétales.
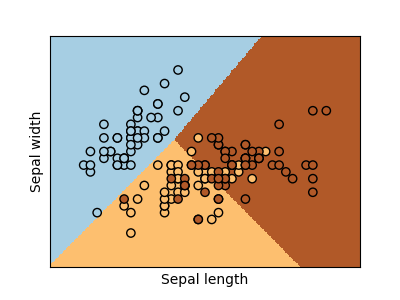
<<<
from sklearn.datasets import load_iris
data = load_iris()
X, y = data.data[:, :2], data.target
from sklearn.linear_model import LogisticRegression
clr = LogisticRegression()
clr.fit(X, y)
print("coef_", clr.coef_)
print("intercept_", clr.intercept_)
>>>
coef_ [[-2.709 2.324]
[ 0.613 -1.571]
[ 2.096 -0.753]]
intercept_ [ 7.913 1.845 -9.758]
La fonction de prédiction est assez simple :
 . La classe d’appartenance
du point x est déterminé par
. La classe d’appartenance
du point x est déterminé par  .
La frontière entre deux classes i, j est définie
par les deux conditions :
.
La frontière entre deux classes i, j est définie
par les deux conditions :
 .
On retrouve bien hyperplans.
On définit la matrice A comme une matrice
ligne
.
On retrouve bien hyperplans.
On définit la matrice A comme une matrice
ligne  où n est le nombre
de classes. L’équation de l’hyperplan entre deux classes devient :
où n est le nombre
de classes. L’équation de l’hyperplan entre deux classes devient :

Il y a peu de chance que cela fonctionne comme cela. Avant de continuer, assurons-nous que les régions associées aux classes sont convexes. C’est une condition nécessaire mais pas suffisante pour avoir un diagramme de Voronoï.
Soit  et
et  appartenant à la classe i.
On sait que
appartenant à la classe i.
On sait que  et
et  .
On considère un point
.
On considère un point  sur le segment
sur le segment ![[X_1, X_2]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSA0MC42NDI1NjYgMTEuOTU1MTY4JyB3aWR0aD0nNDAuNjQyNTY2cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2cxLTQ5Jy8+CjxwYXRoIGQ9J00yLjI0NzU3MiAtMS42MjU5MDNDMi4zNzUwOTMgLTEuNzQ1NDU1IDIuNzA5ODM4IC0yLjAwODQ2OCAyLjgzNzM2IC0yLjEyMDA1QzMuMzMxNTA3IC0yLjU3NDM0NiAzLjgwMTc0MyAtMy4wMTI3MDIgMy44MDE3NDMgLTMuNzM3OTgzQzMuODAxNzQzIC00LjY4NjQyNiAzLjAwNDczMiAtNS4zMDAxMjUgMi4wMDg0NjggLTUuMzAwMTI1QzEuMDUyMDU1IC01LjMwMDEyNSAwLjQyMjQxNiAtNC41NzQ4NDQgMC40MjI0MTYgLTMuODY1NTA0QzAuNDIyNDE2IC0zLjQ3NDk2OSAwLjczMzI1IC0zLjQxOTE3OCAwLjg0NDgzMiAtMy40MTkxNzhDMS4wMTIyMDQgLTMuNDE5MTc4IDEuMjU5Mjc4IC0zLjUzODczIDEuMjU5Mjc4IC0zLjg0MTU5NEMxLjI1OTI3OCAtNC4yNTYwNCAwLjg2MDc3MiAtNC4yNTYwNCAwLjc2NTEzMSAtNC4yNTYwNEMwLjk5NjI2NCAtNC44Mzc4NTggMS41MzAyNjIgLTUuMDM3MTExIDEuOTIwNzk3IC01LjAzNzExMUMyLjY2MjAxNyAtNS4wMzcxMTEgMy4wNDQ1ODMgLTQuNDA3NDcyIDMuMDQ0NTgzIC0zLjczNzk4M0MzLjA0NDU4MyAtMi45MDkwOTEgMi40NjI3NjUgLTIuMzAzMzYyIDEuNTIyMjkxIC0xLjMzODk3OUwwLjUxODA1NyAtMC4zMDI4NjRDMC40MjI0MTYgLTAuMjE1MTkzIDAuNDIyNDE2IC0wLjE5OTI1MyAwLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMgLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2IC0xLjI2NzI0OCAzLjQ2Njk5OSAtMC44Njg3NDIgMy4zNzEzNTcgLTAuNzE3MzFDMy4zMjM1MzcgLTAuNjUzNTQ5IDIuNzE3ODA4IC0wLjY1MzU0OSAyLjU5MDI4NiAtMC42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzIgLTEuNjI1OTAzWicgaWQ9J2cxLTUwJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMi05MycvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzAtNTknLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2cwLTg4Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDIuMTA1OTU4JyB4bGluazpocmVmPScjZzAtODgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzUxLjgyMTE4NScgeGxpbms6aHJlZj0nI2cxLTQ5JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PSc1Ni41NTM1JyB4bGluazpocmVmPScjZzAtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYxLjc5NzY1OScgeGxpbms6aHJlZj0nI2cwLTg4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3MS41MTI4ODYnIHhsaW5rOmhyZWY9JyNnMS01MCcgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nNzYuMjQ1MjAxJyB4bGluazpocmVmPScjZzItOTMnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) , donc il existe
, donc il existe
 tel que
tel que  et
et
 . On vérifie que :
. On vérifie que :

Donc le point X appartient bien à classe i et celle-ci est convexe. La régression logistique forme une partition convexe de l’espace des features.
Théorème T1 : convexité des classes formées par une régression logistique
On définit l’application  qui associe la plus grande coordonnée
qui associe la plus grande coordonnée
 .
A est une matrice
.
A est une matrice  ,
B est un vecteur de
,
B est un vecteur de  ,
c est le nombre de parties.
L’application f définit une partition convexe
de l’espace vectoriel .
,
c est le nombre de parties.
L’application f définit une partition convexe
de l’espace vectoriel .
Revenons au cas de Voronoï. La classe prédite dépend de
 . On veut trouver n points
. On veut trouver n points
 tels que chaque couple
tels que chaque couple  soit équidistant de la frontière qui sépare leurs classes.
Il faut également les projections des deux points sur
la frontière se confondent et donc que les vecteurs
soit équidistant de la frontière qui sépare leurs classes.
Il faut également les projections des deux points sur
la frontière se confondent et donc que les vecteurs
 et
et  sont colinéaires.
sont colinéaires.

La seconde équation en cache en fait plusieurs puisqu’elle est valable
sur plusieurs dimensions mais elles sont redondantes.
Il suffit de choisir un vecteur  non perpendiculaire
à de sorte que
qu’il n’est pas perpendiculaire au vecteur et de
considérer la projection de cette équation sur ce vecteur.
C’est pourquoi on réduit le système au suivant qui est
équivalent au précédent si le vecteur est bien choisi.
non perpendiculaire
à de sorte que
qu’il n’est pas perpendiculaire au vecteur et de
considérer la projection de cette équation sur ce vecteur.
C’est pourquoi on réduit le système au suivant qui est
équivalent au précédent si le vecteur est bien choisi.

Diagramme de Voronoï et partition convexe#
Faisons un peu de géométrie avant de résoudre ce problème car celui-ci
a dans la plupart des cas plus d’équations que d’inconnues.
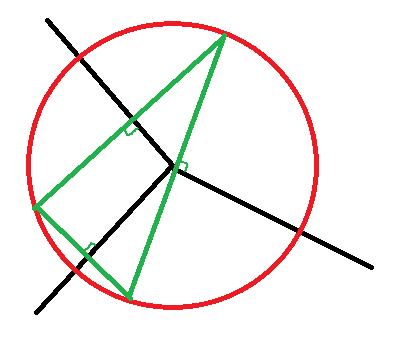
Chaque frontière entre deux classes est la médiatrice d’un segment
![[P_i, P_j]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMzA5Mzg1cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSAzNC42MDE0NDYgMTIuMzA5Mzg1JyB3aWR0aD0nMzQuNjAxNDQ2cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuMzc1MDkzIC00Ljk3MzM1QzIuMzc1MDkzIC01LjE0ODY5MiAyLjI0NzU3MiAtNS4yNzYyMTQgMi4wNjQyNTkgLTUuMjc2MjE0QzEuODU3MDM2IC01LjI3NjIxNCAxLjYyNTkwMyAtNS4wODQ5MzIgMS42MjU5MDMgLTQuODQ1ODI4QzEuNjI1OTAzIC00LjY3MDQ4NiAxLjc1MzQyNSAtNC41NDI5NjQgMS45MzY3MzcgLTQuNTQyOTY0QzIuMTQzOTYgLTQuNTQyOTY0IDIuMzc1MDkzIC00LjczNDI0NyAyLjM3NTA5MyAtNC45NzMzNVpNMS4yMTE0NTcgLTIuMDQ4MzE5TDAuNzgxMDcxIC0wLjk0ODQ0M0MwLjc0MTIyIC0wLjgyODg5MiAwLjcwMTM3IC0wLjczMzI1IDAuNzAxMzcgLTAuNTk3NzU4QzAuNzAxMzcgLTAuMjA3MjIzIDEuMDA0MjM0IDAuMDc5NzAxIDEuNDI2NjUgMC4wNzk3MDFDMi4xOTk3NTEgMC4wNzk3MDEgMi41MjY1MjYgLTEuMDM2MTE1IDIuNTI2NTI2IC0xLjEzOTcyNkMyLjUyNjUyNiAtMS4yMTk0MjcgMi40NjI3NjUgLTEuMjQzMzM3IDIuNDA2OTc0IC0xLjI0MzMzN0MyLjMxMTMzMyAtMS4yNDMzMzcgMi4yOTUzOTIgLTEuMTg3NTQ3IDIuMjcxNDgyIC0xLjEwNzg0NkMyLjA4ODE2OSAtMC40NzAyMzcgMS43NjEzOTUgLTAuMTQzNDYyIDEuNDQyNTkgLTAuMTQzNDYyQzEuMzQ2OTQ5IC0wLjE0MzQ2MiAxLjI1MTMwOCAtMC4xODMzMTMgMS4yNTEzMDggLTAuMzk4NTA2QzEuMjUxMzA4IC0wLjU4OTc4OCAxLjMwNzA5OCAtMC43MzMyNSAxLjQxMDcxIC0wLjk4MDMyNEMxLjQ5MDQxMSAtMS4xOTU1MTcgMS41NzAxMTIgLTEuNDEwNzEgMS42NTc3ODMgLTEuNjI1OTAzTDEuOTA0ODU3IC0yLjI3MTQ4MkMxLjk3NjU4OCAtMi40NTQ3OTUgMi4wNzIyMjkgLTIuNzAxODY4IDIuMDcyMjI5IC0yLjgzNzM2QzIuMDcyMjI5IC0zLjIzNTg2NiAxLjc1MzQyNSAtMy41MTQ4MTkgMS4zNDY5NDkgLTMuNTE0ODE5QzAuNTczODQ4IC0zLjUxNDgxOSAwLjIzOTEwMyAtMi4zOTkwMDQgMC4yMzkxMDMgLTIuMjk1MzkyQzAuMjM5MTAzIC0yLjIyMzY2MSAwLjI5NDg5NCAtMi4xOTE3ODEgMC4zNTg2NTUgLTIuMTkxNzgxQzAuNDYyMjY3IC0yLjE5MTc4MSAwLjQ3MDIzNyAtMi4yMzk2MDEgMC40OTQxNDcgLTIuMzE5MzAzQzAuNzE3MzEgLTMuMDc2NDYzIDEuMDgzOTM1IC0zLjI5MTY1NiAxLjMyMzAzOSAtMy4yOTE2NTZDMS40MzQ2MiAtMy4yOTE2NTYgMS41MTQzMjEgLTMuMjUxODA2IDEuNTE0MzIxIC0zLjAyODY0M0MxLjUxNDMyMSAtMi45NDg5NDEgMS41MDYzNTEgLTIuODM3MzYgMS40MjY2NSAtMi41OTgyNTdMMS4yMTE0NTcgLTIuMDQ4MzE5WicgaWQ9J2cwLTEwNScvPgo8cGF0aCBkPSdNMy4yOTE2NTYgLTQuOTczMzVDMy4yOTE2NTYgLTUuMTI0NzgyIDMuMTcyMTA1IC01LjI3NjIxNCAyLjk4MDgyMiAtNS4yNzYyMTRDMi43NDE3MTkgLTUuMjc2MjE0IDIuNTM0NDk2IC01LjA1MzA1MSAyLjUzNDQ5NiAtNC44NDU4MjhDMi41MzQ0OTYgLTQuNjk0Mzk2IDIuNjU0MDQ3IC00LjU0Mjk2NCAyLjg0NTMzIC00LjU0Mjk2NEMzLjA4NDQzMyAtNC41NDI5NjQgMy4yOTE2NTYgLTQuNzY2MTI3IDMuMjkxNjU2IC00Ljk3MzM1Wk0xLjYyNTkwMyAwLjM5ODUwNkMxLjUwNjM1MSAwLjg4NDY4MiAxLjExNTgxNiAxLjQwMjc0IDAuNjI5NjM5IDEuNDAyNzRDMC41MDIxMTcgMS40MDI3NCAwLjM4MjU2NSAxLjM3MDg1OSAwLjM2NjYyNSAxLjM2Mjg4OUMwLjYxMzY5OSAxLjI0MzMzNyAwLjY0NTU3OSAxLjAyODE0NCAwLjY0NTU3OSAwLjk1NjQxM0MwLjY0NTU3OSAwLjc2NTEzMSAwLjUwMjExNyAwLjY2MTUxOSAwLjMzNDc0NSAwLjY2MTUxOUMwLjEwMzYxMSAwLjY2MTUxOSAtMC4xMTE1ODIgMC44NjA3NzIgLTAuMTExNTgyIDEuMTIzNzg2Qy0wLjExMTU4MiAxLjQyNjY1IDAuMTgzMzEzIDEuNjI1OTAzIDAuNjM3NjA5IDEuNjI1OTAzQzEuMTIzNzg2IDEuNjI1OTAzIDIuMDAwNDk4IDEuMzIzMDM5IDIuMjM5NjAxIDAuMzY2NjI1TDIuOTU2OTEyIC0yLjQ4NjY3NUMyLjk4MDgyMiAtMi41ODIzMTYgMi45OTY3NjIgLTIuNjQ2MDc3IDIuOTk2NzYyIC0yLjc2NTYyOUMyLjk5Njc2MiAtMy4yMDM5ODUgMi42NDYwNzcgLTMuNTE0ODE5IDIuMTgzODExIC0zLjUxNDgxOUMxLjMzODk3OSAtMy41MTQ4MTkgMC44NDQ4MzIgLTIuMzk5MDA0IDAuODQ0ODMyIC0yLjI5NTM5MkMwLjg0NDgzMiAtMi4yMjM2NjEgMC45MDA2MjMgLTIuMTkxNzgxIDAuOTY0Mzg0IC0yLjE5MTc4MUMxLjA1MjA1NSAtMi4xOTE3ODEgMS4wNjAwMjUgLTIuMjE1NjkxIDEuMTE1ODE2IC0yLjMzNTI0M0MxLjM1NDkxOSAtMi44ODUxODEgMS43NjEzOTUgLTMuMjkxNjU2IDIuMTU5OSAtMy4yOTE2NTZDMi4zMjcyNzMgLTMuMjkxNjU2IDIuNDIyOTE0IC0zLjE4MDA3NSAyLjQyMjkxNCAtMi45MTcwNjFDMi40MjI5MTQgLTIuODA1NDc5IDIuMzk5MDA0IC0yLjY5Mzg5OCAyLjM3NTA5MyAtMi41ODIzMTZMMS42MjU5MDMgMC4zOTg1MDZaJyBpZD0nZzAtMTA2Jy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMi05MycvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzEtNTknLz4KPHBhdGggZD0nTTMuNTM4NzMgLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExIC0zLjgwMTc0MyA4Ljg0NjgyNCAtNS4wMjExNzEgOC44NDY4MjQgLTYuMzg0MDZDOC44NDY4MjQgLTcuMzE2NTYzIDguMDU3NzgzIC04LjE2NTM4IDYuNTUxNDMyIC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3IC04LjE2NTM4IDIuNTIyNTQgLTguMTY1MzggMi41MjI1NCAtNy45MzgyMzJDMi41MjI1NCAtNy44MTg2OCAyLjYzMDEzNyAtNy44MTg2OCAyLjgwOTQ2NSAtNy44MTg2OEMzLjUzODczIC03LjgxODY4IDMuNTM4NzMgLTcuNzIzMDM5IDMuNTM4NzMgLTcuNTkxNTMyQzMuNTM4NzMgLTcuNTY3NjIxIDMuNTM4NzMgLTcuNDk1ODkgMy40OTA5MDkgLTcuMzE2NTYzTDEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjY2OTQ4OSAwIDAuNzQxMjIgMEMwLjk2ODM2OSAwIDEuMjA3NDcyIC0wLjAyMzkxIDEuNDM0NjIgLTAuMDIzOTFIMi44MzMzNzVDMy4wNjA1MjMgLTAuMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4IC0wLjIyNzE0OEMzLjc2NTg3OCAtMC4zNDY3IDMuNjU4MjgxIC0wLjM0NjcgMy40Nzg5NTQgLTAuMzQ2N0MyLjc2MTY0NCAtMC4zNDY3IDIuNzQ5Njg5IC0wLjQzMDM4NiAyLjc0OTY4OSAtMC41NDk5MzhDMi43NDk2ODkgLTAuNjA5NzE0IDIuNzYxNjQ0IC0wLjY5MzQgMi43NzM1OTkgLTAuNzUzMTc2TDMuNTM4NzMgLTMuODAxNzQzWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4yMDQ3MzJDNy4xMDEzNyAtNy44MTg2OCA3Ljg0MjU5IC03LjUzMTc1NiA3Ljg0MjU5IC02LjYzNTExOEM3Ljg0MjU5IC02LjMyNDI4NCA3LjY4NzE3MyAtNS4zMDgwOTUgNy4xMzcyMzUgLTQuNzU4MTU3QzYuOTMzOTk4IC00LjU0Mjk2NCA2LjM2MDE0OSAtNC4wODg2NjcgNS4yNzIyMjkgLTQuMDg4NjY3SDMuNTg2NTVMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2cxLTgwJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDIuMTA1OTU4JyB4bGluazpocmVmPScjZzEtODAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzQ5LjY1MTIyNicgeGxpbms6aHJlZj0nI2cwLTEwNScgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nNTMuMDMyNDk3JyB4bGluazpocmVmPScjZzEtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzU4LjI3NjY1NicgeGxpbms6aHJlZj0nI2cxLTgwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2NS44MjE5MjQnIHhsaW5rOmhyZWY9JyNnMC0xMDYnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzcwLjIwNDA4MScgeGxpbms6aHJlZj0nI2cyLTkzJyB5PSc2NS43NTM0MjUnLz4KPC9nPgo8L3N2Zz4=) . Le dessin suivant trace un diagramme de Voronoï à
trois points. L’intersection est le centre des médiatrices du triangle
formé par les points de Voronoï. Pour les trouver, on trace un cercle,
n’importe lequel, puis une droite perpendiculaire à l’une des médiatrice.
On obtient deux points. Le troisième est obtenu en traçant une seconde
perpendiculaire et par construsction, la troisième droite est perpendiculaire
à la troisième médiatrice. Et on nomme les angles.
. Le dessin suivant trace un diagramme de Voronoï à
trois points. L’intersection est le centre des médiatrices du triangle
formé par les points de Voronoï. Pour les trouver, on trace un cercle,
n’importe lequel, puis une droite perpendiculaire à l’une des médiatrice.
On obtient deux points. Le troisième est obtenu en traçant une seconde
perpendiculaire et par construsction, la troisième droite est perpendiculaire
à la troisième médiatrice. Et on nomme les angles.
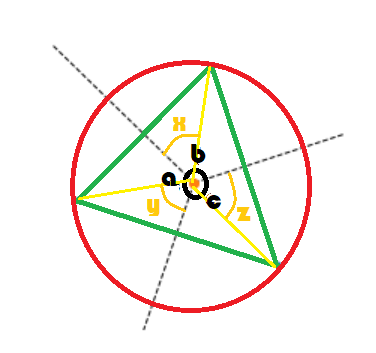
Les triangles formés par les côtés jaunes sont isocèles. On en déduit que
 . On en déduit aussi que :
. On en déduit aussi que :

On en conclut que  et
et
 . Il existe une infinité de triplets de 3 points
qui aboutissent à ce diagramme de Voronoï. Il suffit de changer
la taille du cercle. On montre aussi qu’en dimension 2 et 3 classes,
il existe toujours une solution au problème posé.
Maintenant, si on considère la configuration suivante avec des points
disposés de telle sorte que le diagramme de Voronoï est un maillage
hexagonal.
. Il existe une infinité de triplets de 3 points
qui aboutissent à ce diagramme de Voronoï. Il suffit de changer
la taille du cercle. On montre aussi qu’en dimension 2 et 3 classes,
il existe toujours une solution au problème posé.
Maintenant, si on considère la configuration suivante avec des points
disposés de telle sorte que le diagramme de Voronoï est un maillage
hexagonal.  et
et  .
Il n’existe qu’un ensemble de points qui peut produire ce maillage
comme diagramme de Voronoï. Mais si on ajoute une petite zone
(dans le cercle vert ci-dessous), il est impossible que ce diagramme
soit un diagramme de Voronoï bien que cela soit une partition convexe.
.
Il n’existe qu’un ensemble de points qui peut produire ce maillage
comme diagramme de Voronoï. Mais si on ajoute une petite zone
(dans le cercle vert ci-dessous), il est impossible que ce diagramme
soit un diagramme de Voronoï bien que cela soit une partition convexe.
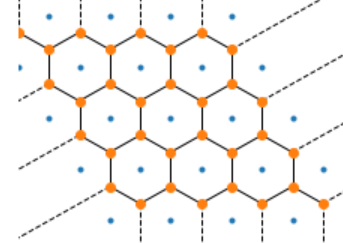
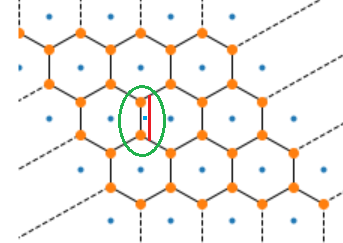
On revient à la détermination du diagramme de Voronoï associé à une régression logistique. On a montré qu’il n’existe pas tout le temps pour n’importe quelle partition convexe. Mais cela ne veut pas dire que tel est le cas pour une régression logistique.
Régression logistique et partition convexe#
On a montré que la régression logistique réalise une
partition convexe de l’espace vectoriel des variables.
On note L(n) l’ensemble des partitions à n classes.
Le diagramme de Voronoï correspondent également à un
sous-ensemble V(n).  , that is the
question.
, that is the
question.
On peut se poser la question de savoir si L(n) un sous-ensemble ou tout l’ensemble auquel cas la réponse à la question précédente est triviale. Considérons d’abord deux parties voisines d’une partition convexe formée par une fonction telle que celle décrite par le théorème sur la convexité des classes formées par une régression logistique.
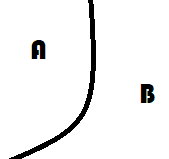
L’image qui précède montre une partition qui n’est pas convexe.
La partie A l’est mais pas la partie B. En fait, il est facile
de montrer que la seule frontière admissible entre deux parties convexe
est un hyperplan. Si la partition contient n partie,
il y a au pire frontières,
ce qui correspond également au nombre d’hyperplans définis
par la fonction de prédiction associée à la régression logistique.
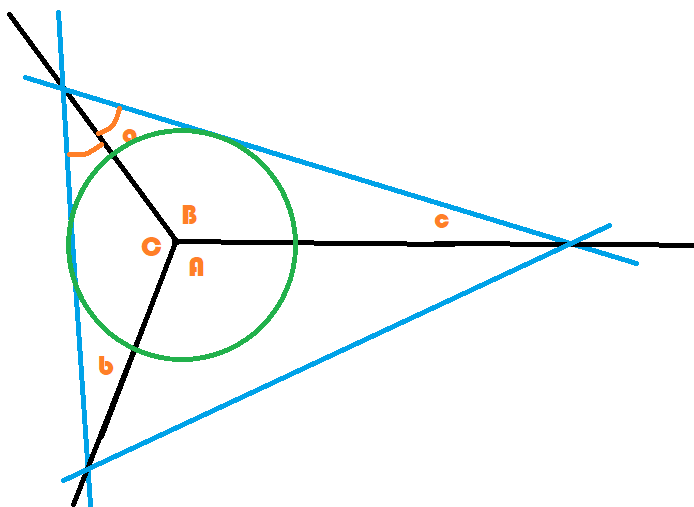
L’image qui précède présente une classification en trois
zones (droites noires). On a choisi une droite bleue au hasard.
En prenant son symétrique par rapport à une des droites noires (D),
on a deux droites  ,
,  . L’ensemble des points
. L’ensemble des points
 correspond à la droite noire.
Il doit être de même pour les trois droites bleues, autrement
dit, l’intersection des droites est le centre du cercle inscrit
dans le triangle bleu ce qui n’est visiblement pas le cas sur l’image.
Il paraît vraisemblable de dire que les régressions logisitiques ne permettent
pas de former toutes les partitions convexes. On pourrait le montrer mais
cela ne permettrait pas de répondre à la question initiale
?
correspond à la droite noire.
Il doit être de même pour les trois droites bleues, autrement
dit, l’intersection des droites est le centre du cercle inscrit
dans le triangle bleu ce qui n’est visiblement pas le cas sur l’image.
Il paraît vraisemblable de dire que les régressions logisitiques ne permettent
pas de former toutes les partitions convexes. On pourrait le montrer mais
cela ne permettrait pas de répondre à la question initiale
?
Voronoï et régression logistique#
On sait que  quelque soit la dimension,
que
quelque soit la dimension,
que  en dimension 2. La matrice L
définit une régression logistique. Le diagramme de Voronoï qui
lui correspond est solution du système d’équations qui suit :
en dimension 2. La matrice L
définit une régression logistique. Le diagramme de Voronoï qui
lui correspond est solution du système d’équations qui suit :
(1)#
Avec choisi de telle sorte que les
vecteur et ne soit pas
coliénaires. Ce système inclut des équations
entre classes ou régions qui ne sont pas voisines.
Il y a potentiellement
équations pour n inconnues. Il n’est pas évident de dire
si ce système à une solution. Voyons plutôt l’ensemble des droites
formées par un diagramme de Voronoï. Un point appartient à un segment
s’il est à égale distance de deux points.

Pour une partition convexe formée à partir de droite, comme c’est le cas d’une régression linéaire, un point appartient à un segment s’il est à égale distance de deux droites. L’ensemble de ces points correspond à deux droites, les deux bissectrices.
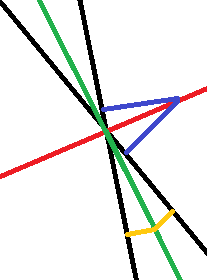
Seule l’une de ces droites est la bonne.
L’équation d’une droite est donnée par
 .
.

On choisit l’une de ces droites.

On peut voir que si tous les points sont situés
sur la boule unité, à savoir  ,
la régression logistique s’écrit simplement avec
,
la régression logistique s’écrit simplement avec
 et
et  .
On revient au système d’équations linéaires
(1) et on en cherche une solution
approchée un peu à la façon
RANSAC
avec une régression linéaire et la norme L1.
Il n’existe pas toujours de diagramme de Voronoï équivalent
à la partition convexe réalisée par une regréssion logistique.
Il est facile de trouver un contre-exemple en essayant de résoudre
le système précédent. C’est ce que fait la fonction
.
On revient au système d’équations linéaires
(1) et on en cherche une solution
approchée un peu à la façon
RANSAC
avec une régression linéaire et la norme L1.
Il n’existe pas toujours de diagramme de Voronoï équivalent
à la partition convexe réalisée par une regréssion logistique.
Il est facile de trouver un contre-exemple en essayant de résoudre
le système précédent. C’est ce que fait la fonction
voronoi_estimation_from_lr.
La fonction essaye avec quelques approximations et heuristiques
de déterminer les points du diagramme de Voronoï. Si elle réussit
du premier coup, c’est qu’il y avait équivalence ce qui arrive peu souvent.
Il faudrait refaire les calculs à la main et non de façon approchée pour
valider un contre exemple. Une prochaine fois peut-être.
Ce qu’il faut retenir est que la régression logistique
réalise une partition convexe de l’espace des variables.
Notebooks#
Le notebook qui suit reprend les différents éléments théoriques présentés ci-dessus. Il continue l’étude d’une régression logistique et donne une intuition de ce qui marche ou pas avec un tel modèle. Notamment, le modèle est plus performant si les classes sont réparties sur la boule unité de l’espace des features.