Régression linéaire par morceaux#
Le paragraphe Régression linéaire
étudie le lien entre le coefficient  et la corrélation pour finalement illustrer
une façon de réaliser une régression linéaire par
morceaux. L’algorithme s’appuie sur un arbre
de régression pour découper en morceaux ce qui
n’est pas le plus satisfaisant car l’arbre
cherche à découper en segment en approximant
la variable à régresser Y par une constante sur chaque
morceaux et non une droite.
On peut se poser la question de comment faire
pour construire un algorithme qui découpe en approximant
Y par une droite et non une constante. Le plus dur
n’est pas de le faire mais de le faire efficacement.
Et pour comprendre là où je veux vous emmener, il faudra
un peu de mathématiques.
et la corrélation pour finalement illustrer
une façon de réaliser une régression linéaire par
morceaux. L’algorithme s’appuie sur un arbre
de régression pour découper en morceaux ce qui
n’est pas le plus satisfaisant car l’arbre
cherche à découper en segment en approximant
la variable à régresser Y par une constante sur chaque
morceaux et non une droite.
On peut se poser la question de comment faire
pour construire un algorithme qui découpe en approximant
Y par une droite et non une constante. Le plus dur
n’est pas de le faire mais de le faire efficacement.
Et pour comprendre là où je veux vous emmener, il faudra
un peu de mathématiques.
Une implémentation de ce type de méthode est proposée dans la pull request Model trees (M5P and co) qui répond à au problème posée dans Model trees (M5P) et originellement implémentée dans Building Model Trees. Cette dernière implémentation réestime les modèles comme l’implémentation décrite au paragraphe Implémentation naïve d’une régression linéaire par morceaux mais étendue à tout type de modèle.
Exploration#
Problème et regréssion linéaire dans un espace à une dimension#
Tout d’abord, une petite illustration du problème avec la classe PiecewiseRegression implémentée selon l’API de scikit-learn.
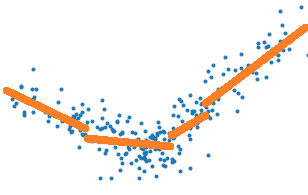
Cette régression par morceaux est obtenue grâce à un arbre
de décision. Celui-ci trie le nuage de points  par ordre croissant selon les X, soit
par ordre croissant selon les X, soit  .
L’arbre coupe en deux lorsque la différence des erreurs quadratiques est
maximale, erreur quadratique obtenue en approximant Y par sa moyenne
sur l’intervalle considéré. On note l’erreur quadratique :
.
L’arbre coupe en deux lorsque la différence des erreurs quadratiques est
maximale, erreur quadratique obtenue en approximant Y par sa moyenne
sur l’intervalle considéré. On note l’erreur quadratique :

La dernière ligne applique la formule  qui est facile à redémontrer.
L’algorithme de l’arbre de décision coupe un intervalle en
deux et détermine l’indice k qui minimise la différence :
qui est facile à redémontrer.
L’algorithme de l’arbre de décision coupe un intervalle en
deux et détermine l’indice k qui minimise la différence :

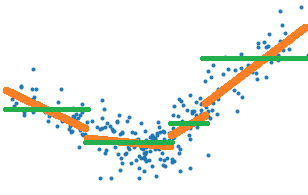
L’arbre de décision optimise la construction d’une fonction en escalier qui représente au mieux le nuage de points, les traits verts sur le graphe suivant, alors qu’il faudrait choisir une erreur quadratique qui corresponde aux traits oranges.
Il suffirait donc de remplacer l’erreur E par celle obtenue
par une régression linéaire. Mais si c’était aussi simple,
l’implémentation de sklearn.tree.DecisionTreeRegressor
la proposerait. Alors pourquoi ?
La raison principale est que cela coûte trop cher en
temps de calcul. Pour trouver l’indice k, il faut calculer
toutes les erreurs 
 , ce qui
coûte très cher lorsque cette erreur est celle d’une régression
linéaire parce qu’il est difficile de simplifier la différence :
, ce qui
coûte très cher lorsque cette erreur est celle d’une régression
linéaire parce qu’il est difficile de simplifier la différence :

Arbre de régression constante
On s’intéresse au terme  dans le cas
le nuage de points est représenté par une constante sur chaque segment.
C’est l’hypothèse faite par l’algorithme classique de construction
d’un arbre de régression (segments verts sur le premier dessin) :
dans le cas
le nuage de points est représenté par une constante sur chaque segment.
C’est l’hypothèse faite par l’algorithme classique de construction
d’un arbre de régression (segments verts sur le premier dessin) :

On en déduit que :

On voit que cette formule ne fait intervenir que  ,
elle est donc très rapide à calculer et c’est pour cela qu’apprendre un arbre
de décision peut s’apprendre en un temps raisonnable. Cela repose sur la possibilité
de calculer le critère optimisé par récurrence. On voit également que ces formules
ne font pas intervenir X, elles sont donc généralisables au cas
multidimensionnel. Il suffira de trier les couples
selon chaque dimension et déterminer le meilleur seuil de coupure
d’abord sur chacune des dimensions puis de prendre le meilleur
de ces seuils sur toutes les dimensions. Le problème est résolu.
,
elle est donc très rapide à calculer et c’est pour cela qu’apprendre un arbre
de décision peut s’apprendre en un temps raisonnable. Cela repose sur la possibilité
de calculer le critère optimisé par récurrence. On voit également que ces formules
ne font pas intervenir X, elles sont donc généralisables au cas
multidimensionnel. Il suffira de trier les couples
selon chaque dimension et déterminer le meilleur seuil de coupure
d’abord sur chacune des dimensions puis de prendre le meilleur
de ces seuils sur toutes les dimensions. Le problème est résolu.
Le notebook Custom Criterion for DecisionTreeRegressor
implémente une version pas efficace du critère
MSE
et compare la vitesse d’exécution avec l’implémentation de scikit-learn.
Il implémente ensuite le calcul rapide de scikit-learn pour
montrer qu’on obtient un temps comparable.
Le résultat est sans équivoque. La version rapide n’implémente pas
 mais plutôt les sommes
mais plutôt les sommes
 ,
,  dans un sens
et dans l’autre. En gros,
le code stocke les séries des numérateurs et des dénominateurs
pour les diviser au dernier moment.
dans un sens
et dans l’autre. En gros,
le code stocke les séries des numérateurs et des dénominateurs
pour les diviser au dernier moment.
Arbre de régression linéaire
Le cas d’une régression est plus complexe. Prenons d’abord le cas où il n’y a qu’un seule dimension, il faut d’abord optimiser le problème :

On dérive pour aboutir au système d’équations suivant :

Ce qui aboutit à :

Pour construire un algorithme rapide pour apprendre un arbre de décision
avec cette fonction de coût, il faut pouvoir calculer
 en fonction de
en fonction de  ou d’autres quantités intermédiaires qui ne font pas intervenir
les valeurs
ou d’autres quantités intermédiaires qui ne font pas intervenir
les valeurs  . D’après ce qui précède,
cela paraît tout-à-fait possible. Mais dans le
cas multidimensionnel,
il faut déterminer le vecteur A qui minimise
. D’après ce qui précède,
cela paraît tout-à-fait possible. Mais dans le
cas multidimensionnel,
il faut déterminer le vecteur A qui minimise  ce qui donne
ce qui donne  . Si on note
. Si on note  la matrice
M tronquée pour ne garder que ses k premières lignes, il faudrait pouvoir
calculer rapidement :
la matrice
M tronquée pour ne garder que ses k premières lignes, il faudrait pouvoir
calculer rapidement :

La documentation de sklearn.tree.DecisionTreeRegressor
ne mentionne que deux critères pour apprendre un arbre de décision
de régression, MSE pour
sklearn.metrics.mean_squared_error et MAE pour
sklearn.metrics.mean_absolute_error. Les autres critères n’ont
probablement pas été envisagés. L’article [Acharya2016] étudie la possibilité
de ne pas calculer la matrice  pour tous les k.
Le paragraphe Streaming Linear Regression utilise
le fait que la matrice A est la solution d’un problème d’optimisation
quadratique et propose un algorithme de mise à jour de la matrice A
(cas unidimensionnel). Cet exposé va un peu plus loin
pour proposer une version qui ne calcule pas de matrices inverses.
pour tous les k.
Le paragraphe Streaming Linear Regression utilise
le fait que la matrice A est la solution d’un problème d’optimisation
quadratique et propose un algorithme de mise à jour de la matrice A
(cas unidimensionnel). Cet exposé va un peu plus loin
pour proposer une version qui ne calcule pas de matrices inverses.
Implémentation naïve d’une régression linéaire par morceaux#
On part du cas général qui écrit la solution d’une régression
linéaire comme étant la matrice
et on adapte l’implémentation de scikit-learn pour
optimiser l’erreur quadratique obtenue. Ce n’est pas simple mais
pas impossible. Il faut entrer dans du code cython et, pour
éviter de réécrire une fonction qui multiplie et inverse une matrice,
on peut utiliser la librairie LAPACK. Je ne vais pas plus loin
ici car cela serait un peu hors sujet mais ce n’était pas une partie
de plaisir. Cela donne :
piecewise_tree_regression_criterion_linear.pyx
C’est illustré toujours par le notebook
DecisionTreeRegressor optimized for Linear Regression.
Aparté sur la continuité de la régression linéaire par morceaux#
Approcher la fonction  quand x et y
sont réels est un problème facile, trop facile… A voir le dessin,
précédent, il est naturel de vouloir recoller les morceaux lorsqu’on
passe d’un segment à l’autre. Il s’agit d’une optimisation sous contrainte.
Il est possible également d’ajouter une contrainte de régularisation
qui tient compte de cela. On exprime cela comme suit avec une régression
linéaire à deux morceaux.
quand x et y
sont réels est un problème facile, trop facile… A voir le dessin,
précédent, il est naturel de vouloir recoller les morceaux lorsqu’on
passe d’un segment à l’autre. Il s’agit d’une optimisation sous contrainte.
Il est possible également d’ajouter une contrainte de régularisation
qui tient compte de cela. On exprime cela comme suit avec une régression
linéaire à deux morceaux.

Le cas multidimensionnel est loin d’être aussi simple. Avec une dimension, chaque zone a deux voisines. En deux dimensions, chaque zone peut en avoir plus de deux. La figure suivante montre une division de l’espace dans laquelle la zone centrale a cinq voisins.
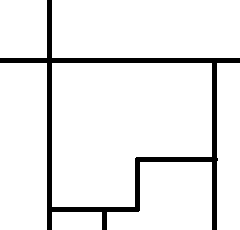
Peut-on facilement approcher une fonction  par un plan en trois dimensions ? A moins que tous les sommets soient
déjà dans le même plan, c’est impossible. La zone en question n’est
peut-être même pas convexe. Une régression linéaire par morceaux
et continue en plusieurs dimensions n’est pas un problème facile.
Cela n’empêche pas pour autant d’influencer la détermination de chaque
morceaux avec une contrainte du type de celle évoquée plus haut
mais pour écrire la contrainte lorsque les zones sont construites
à partir des feuilles d’un arbre de décision, il faut déterminer
quelles sont les feuilles voisines.
Et ça c’est un problème intéressant !
par un plan en trois dimensions ? A moins que tous les sommets soient
déjà dans le même plan, c’est impossible. La zone en question n’est
peut-être même pas convexe. Une régression linéaire par morceaux
et continue en plusieurs dimensions n’est pas un problème facile.
Cela n’empêche pas pour autant d’influencer la détermination de chaque
morceaux avec une contrainte du type de celle évoquée plus haut
mais pour écrire la contrainte lorsque les zones sont construites
à partir des feuilles d’un arbre de décision, il faut déterminer
quelles sont les feuilles voisines.
Et ça c’est un problème intéressant !
Régression linéaire et corrélation#
On reprend le calcul multidimensionnel mais on s’intéresse au
cas où la matrice  est diagonale qui correspond au cas
où les variables
est diagonale qui correspond au cas
où les variables  ne sont pas corrélées.
Si
ne sont pas corrélées.
Si  ,
la matrice
,
la matrice  s’exprime plus simplement
s’exprime plus simplement  .
On en déduit que :
.
On en déduit que :

Cette expression donne un indice sur la résolution d’une régression linéaire
pour laquelle les variables sont corrélées. Il suffit d’appliquer d’abord une
ACP
(Analyse en Composantes Principales) et de calculer les coefficients
 associés à des valeurs propres non nulles. On écrit alors
associés à des valeurs propres non nulles. On écrit alors
 où la matrice P vérifie
où la matrice P vérifie  .
.
Idée de l’algorithme#
On s’intéresser d’abord à la recherche d’un meilleur point de coupure.
Pour ce faire, les éléments  sont triés le plus souvent
selon l’ordre défini par une dimension. On note E l’erreur de prédiction
sur cette échantillon
sont triés le plus souvent
selon l’ordre défini par une dimension. On note E l’erreur de prédiction
sur cette échantillon  .
On définit ensuite
.
On définit ensuite  .
D’après cette notation,
.
D’après cette notation,  . La construction de l’arbre
de décision passe par la détermination de
. La construction de l’arbre
de décision passe par la détermination de  qui vérifie :
qui vérifie :

Autrement dit, on cherche le point de coupure qui maximise la différence entre la prédiction obtenue avec deux régressions linéaires plutôt qu’une. On sait qu’il existe une matrice P qui vérifie :

Où  est une matrice
diagonale. On a posé
est une matrice
diagonale. On a posé  ,
donc
,
donc  .
On peut réécrire le problème
de régression comme ceci :
.
On peut réécrire le problème
de régression comme ceci :

Comme  :
:

Avec  . C’est la même régression
après un changement de repère et on la résoud de la même manière :
. C’est la même régression
après un changement de repère et on la résoud de la même manière :

La notation  désigne la ligne i et
désigne la ligne i et
![M_{[k]}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMDIxNjA0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU3LjU4NDA1OSAyMC42NTEwNzQgMTIuMDIxNjA0JyB3aWR0aD0nMjAuNjUxMDc0cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuMzI3MjczIC01LjI5MjE1NEMyLjMzNTI0MyAtNS4zMDgwOTUgMi4zNTkxNTMgLTUuNDExNzA2IDIuMzU5MTUzIC01LjQxOTY3NkMyLjM1OTE1MyAtNS40NTk1MjcgMi4zMjcyNzMgLTUuNTMxMjU4IDIuMjMxNjMxIC01LjUzMTI1OEMyLjE5OTc1MSAtNS41MzEyNTggMS45NTI2NzcgLTUuNTA3MzQ3IDEuNzY5MzY1IC01LjQ5MTQwN0wxLjMyMzAzOSAtNS40NTk1MjdDMS4xNDc2OTYgLTUuNDQzNTg3IDEuMDY3OTk1IC01LjQzNTYxNiAxLjA2Nzk5NSAtNS4yOTIxNTRDMS4wNjc5OTUgLTUuMTgwNTczIDEuMTc5NTc3IC01LjE4MDU3MyAxLjI3NTIxOCAtNS4xODA1NzNDMS42NTc3ODMgLTUuMTgwNTczIDEuNjU3NzgzIC01LjEzMjc1MiAxLjY1Nzc4MyAtNS4wNjEwMjFDMS42NTc3ODMgLTUuMDM3MTExIDEuNjU3NzgzIC01LjAyMTE3MSAxLjYxNzkzMyAtNC44Nzc3MDlMMC40ODYxNzcgLTAuMzQyNzE1QzAuNDU0Mjk2IC0wLjIyMzE2MyAwLjQ1NDI5NiAtMC4xNzUzNDIgMC40NTQyOTYgLTAuMTY3MzcyQzAuNDU0Mjk2IC0wLjAzMTg4IDAuNTY1ODc4IDAuMDc5NzAxIDAuNzE3MzEgMC4wNzk3MDFDMC45ODgyOTQgMC4wNzk3MDEgMS4wNTIwNTUgLTAuMTc1MzQyIDEuMDgzOTM1IC0wLjI4NjkyNEMxLjE2MzYzNiAtMC42MjE2NjkgMS4zNzA4NTkgLTEuNDY2NTAxIDEuNDU4NTMxIC0xLjgwMTI0NUMxLjg5Njg4NyAtMS43NTM0MjUgMi40MzA4ODQgLTEuNjAxOTkzIDIuNDMwODg0IC0xLjE0NzY5NkMyLjQzMDg4NCAtMS4xMDc4NDYgMi40MzA4ODQgLTEuMDY3OTk1IDIuNDE0OTQ0IC0wLjk4ODI5NEMyLjM5MTAzNCAtMC44ODQ2ODIgMi4zNzUwOTMgLTAuNzczMTAxIDIuMzc1MDkzIC0wLjczMzI1QzIuMzc1MDkzIC0wLjI2MzAxNCAyLjcyNTc3OCAwLjA3OTcwMSAzLjE4ODA0NSAwLjA3OTcwMUMzLjUyMjc5IDAuMDc5NzAxIDMuNzMwMDEyIC0wLjE2NzM3MiAzLjgzMzYyNCAtMC4zMTg4MDRDNC4wMjQ5MDcgLTAuNjEzNjk5IDQuMTUyNDI4IC0xLjA5MTkwNSA0LjE1MjQyOCAtMS4xMzk3MjZDNC4xNTI0MjggLTEuMjE5NDI3IDQuMDg4NjY3IC0xLjI0MzMzNyA0LjAzMjg3NyAtMS4yNDMzMzdDMy45MzcyMzUgLTEuMjQzMzM3IDMuOTIxMjk1IC0xLjE5NTUxNyAzLjg4OTQxNSAtMS4wNTIwNTVDMy43ODU4MDMgLTAuNjc3NDYgMy41Nzg1OCAtMC4xNDM0NjIgMy4yMDM5ODUgLTAuMTQzNDYyQzIuOTk2NzYyIC0wLjE0MzQ2MiAyLjk0ODk0MSAtMC4zMTg4MDQgMi45NDg5NDEgLTAuNTMzOTk4QzIuOTQ4OTQxIC0wLjYzNzYwOSAyLjk1NjkxMiAtMC43MzMyNSAyLjk5Njc2MiAtMC45MTY1NjNDMy4wMDQ3MzIgLTAuOTQ4NDQzIDMuMDM2NjEzIC0xLjA3NTk2NSAzLjAzNjYxMyAtMS4xNjM2MzZDMy4wMzY2MTMgLTEuODE3MTg2IDIuMjE1NjkxIC0xLjk2MDY0OCAxLjgwOTIxNSAtMi4wMTY0MzhDMi4xMDQxMSAtMi4xOTE3ODEgMi4zNzUwOTMgLTIuNDYyNzY1IDIuNDcwNzM1IC0yLjU2NjM3NkMyLjkwOTA5MSAtMi45OTY3NjIgMy4yNjc3NDYgLTMuMjkxNjU2IDMuNjUwMzExIC0zLjI5MTY1NkMzLjc1MzkyMyAtMy4yOTE2NTYgMy44NDk1NjQgLTMuMjY3NzQ2IDMuOTEzMzI1IC0zLjE4ODA0NUMzLjQ4MjkzOSAtMy4xMzIyNTQgMy40ODI5MzkgLTIuNzU3NjU5IDMuNDgyOTM5IC0yLjc0OTY4OUMzLjQ4MjkzOSAtMi41NzQzNDYgMy42MTg0MzEgLTIuNDU0Nzk1IDMuNzkzNzczIC0yLjQ1NDc5NUM0LjAwODk2NiAtMi40NTQ3OTUgNC4yNDgwNyAtMi42MzAxMzcgNC4yNDgwNyAtMi45NTY5MTJDNC4yNDgwNyAtMy4yMjc4OTUgNC4wNTY3ODcgLTMuNTE0ODE5IDMuNjU4MjgxIC0zLjUxNDgxOUMzLjE5NjAxNSAtMy41MTQ4MTkgMi43ODE1NjkgLTMuMTY0MTM0IDIuMzI3MjczIC0yLjcwOTgzOEMxLjg2NTAwNiAtMi4yNTU1NDIgMS42NjU3NTMgLTIuMTY3ODcgMS41MzgyMzIgLTIuMTEyMDhMMi4zMjcyNzMgLTUuMjkyMTU0WicgaWQ9J2cwLTEwNycvPgo8cGF0aCBkPSdNMTAuODU1MjkzIC03LjI5MjY1M0MxMC45NjI4ODkgLTcuNjk5MTI4IDEwLjk4NjggLTcuODE4NjggMTEuODM1NjE2IC03LjgxODY4QzEyLjA2Mjc2NSAtNy44MTg2OCAxMi4xNzAzNjEgLTcuODE4NjggMTIuMTcwMzYxIC04LjA0NTgyOEMxMi4xNzAzNjEgLTguMTY1MzggMTIuMDg2Njc1IC04LjE2NTM4IDExLjg1OTUyNyAtOC4xNjUzOEgxMC40MjQ5MDdDMTAuMTI2MDI3IC04LjE2NTM4IDEwLjExNDA3MiAtOC4xNTM0MjUgOS45ODI1NjUgLTcuOTYyMTQyTDUuNjE4OTI5IC0xLjA2NDAxTDQuNzIyMjkxIC03LjkwMjM2NkM0LjY4NjQyNiAtOC4xNjUzOCA0LjY3NDQ3MSAtOC4xNjUzOCA0LjM2MzYzNiAtOC4xNjUzOEgyLjg4MTE5NkMyLjY1NDA0NyAtOC4xNjUzOCAyLjU0NjQ1MSAtOC4xNjUzOCAyLjU0NjQ1MSAtNy45MzgyMzJDMi41NDY0NTEgLTcuODE4NjggMi42NTQwNDcgLTcuODE4NjggMi44MzMzNzUgLTcuODE4NjhDMy41NjI2NCAtNy44MTg2OCAzLjU2MjY0IC03LjcyMzAzOSAzLjU2MjY0IC03LjU5MTUzMkMzLjU2MjY0IC03LjU2NzYyMSAzLjU2MjY0IC03LjQ5NTg5IDMuNTE0ODE5IC03LjMxNjU2M0wxLjk4NDU1OCAtMS4yMTk0MjdDMS44NDEwOTYgLTAuNjQ1NTc5IDEuNTY2MTI3IC0wLjM4MjU2NSAwLjc2NTEzMSAtMC4zNDY3QzAuNzI5MjY1IC0wLjM0NjcgMC41ODU4MDMgLTAuMzM0NzQ1IDAuNTg1ODAzIC0wLjEzMTUwN0MwLjU4NTgwMyAwIDAuNjkzNCAwIDAuNzQxMjIgMEMwLjk4MDMyNCAwIDEuNTkwMDM3IC0wLjAyMzkxIDEuODI5MTQxIC0wLjAyMzkxSDIuNDAyOTg5QzIuNTcwMzYxIC0wLjAyMzkxIDIuNzczNTk5IDAgMi45NDA5NzEgMEMzLjAyNDY1OCAwIDMuMTU2MTY0IDAgMy4xNTYxNjQgLTAuMjI3MTQ4QzMuMTU2MTY0IC0wLjMzNDc0NSAzLjAzNjYxMyAtMC4zNDY3IDIuOTg4NzkyIC0wLjM0NjdDMi41OTQyNzEgLTAuMzU4NjU1IDIuMjExNzA2IC0wLjQzMDM4NiAyLjIxMTcwNiAtMC44NjA3NzJDMi4yMTE3MDYgLTAuOTgwMzI0IDIuMjExNzA2IC0wLjk5MjI3OSAyLjI1OTUyNyAtMS4xNTk2NTFMMy45MDkzNCAtNy43NDY5NDlIMy45MjEyOTVMNC45MTM1NzQgLTAuMzIyNzlDNC45NDk0NCAtMC4wMzU4NjYgNC45NjEzOTUgMCA1LjA2ODk5MSAwQzUuMjAwNDk4IDAgNS4yNjAyNzQgLTAuMDk1NjQxIDUuMzIwMDUgLTAuMjAzMjM4TDEwLjEyNjAyNyAtNy44MDY3MjVIMTAuMTM3OTgzTDguNDA0NDgzIC0wLjg4NDY4MkM4LjI5Njg4NyAtMC40NjYyNTIgOC4yNzI5NzYgLTAuMzQ2NyA3LjQzNjExNSAtMC4zNDY3QzcuMjA4OTY2IC0wLjM0NjcgNy4wODk0MTUgLTAuMzQ2NyA3LjA4OTQxNSAtMC4xMzE1MDdDNy4wODk0MTUgMCA3LjE5NzAxMSAwIDcuMjY4NzQyIDBDNy40NzE5OCAwIDcuNzExMDgzIC0wLjAyMzkxIDcuOTE0MzIxIC0wLjAyMzkxSDkuMzI1MDMxQzkuNTI4MjY5IC0wLjAyMzkxIDkuNzc5MzI4IDAgOS45ODI1NjUgMEMxMC4wNzgyMDcgMCAxMC4yMDk3MTQgMCAxMC4yMDk3MTQgLTAuMjI3MTQ4QzEwLjIwOTcxNCAtMC4zNDY3IDEwLjEwMjExNyAtMC4zNDY3IDkuOTIyNzkgLTAuMzQ2N0M5LjE5MzUyNCAtMC4zNDY3IDkuMTkzNTI0IC0wLjQ0MjM0MSA5LjE5MzUyNCAtMC41NjE4OTNDOS4xOTM1MjQgLTAuNTczODQ4IDkuMTkzNTI0IC0wLjY1NzUzNCA5LjIxNzQzNSAtMC43NTMxNzZMMTAuODU1MjkzIC03LjI5MjY1M1onIGlkPSdnMS03NycvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzItOTMnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cxLTc3JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc1MC4xNzkxMDcnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNTIuNTMxNDMxJyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1Ny4xNTMwNDcnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+CjwvZz4KPC9zdmc+) désigne la colonne.
On en déduit que le coefficient de la régression
désigne la colonne.
On en déduit que le coefficient de la régression
 est égal à :
est égal à :
![\gamma_k = \frac{<Z_{[k]},Y>}{<Z_{[k]},Z_{[k]}>} =
\frac{<(XP')_{[k]},Y>}{<(XP')_{[k]},(XP')_{[k]}>}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjkuNTMzOTYycHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMTE5LjkxMDUzNCA3OC43MDQ4NTcgMjI1LjIzNDk5NyAyOS41MzM5NjInIHdpZHRoPScyMjUuMjM0OTk3cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMC00OCcvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2c0LTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnNC00MScvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzQtNjEnLz4KPHBhdGggZD0nTTQuNTE5MDU0IC0xLjQ1ODUzMUM0LjQ5NTE0MyAtMi4wNDQzMzQgNC40NzEyMzMgLTIuOTY0ODgyIDQuMDE2OTM2IC00LjA0MDg0N0MzLjc3NzgzMyAtNC42Mzg2MDUgMy4zNzEzNTcgLTUuMjcyMjI5IDIuNDk4NjMgLTUuMjcyMjI5QzEuMDI4MTQ0IC01LjI3MjIyOSAwLjIyNzE0OCAtMy4zOTUyNjggMC4yMjcxNDggLTMuMDg0NDMzQzAuMjI3MTQ4IC0yLjk3NjgzNyAwLjMxMDgzNCAtMi45NzY4MzcgMC4zNDY3IC0yLjk3NjgzN0MwLjQ1NDI5NiAtMi45NzY4MzcgMC40NTQyOTYgLTMuMDAwNzQ3IDAuNTE0MDcyIC0zLjE1NjE2NEMwLjc2NTEzMSAtMy44OTczODUgMS41MzAyNjIgLTQuNDgzMTg4IDIuMzU1MTY4IC00LjQ4MzE4OEM0LjAxNjkzNiAtNC40ODMxODggNC4yNTYwNCAtMi42MzAxMzcgNC4yNTYwNCAtMS40NDY1NzVDNC4yNTYwNCAtMC42OTM0IDQuMTcyMzU0IC0wLjQ0MjM0MSA0LjEwMDYyMyAtMC4yMDMyMzhDMy44NzM0NzQgMC41Mzc5ODMgMy40Nzg5NTQgMi4wMjA0MjMgMy40Nzg5NTQgMi4zNTUxNjhDMy40Nzg5NTQgMi40NTA4MDkgMy41MTQ4MTkgMi41NTg0MDYgMy42MTA0NjEgMi41NTg0MDZDMy43ODk3ODggMi41NTg0MDYgMy44OTczODUgMi4xNjM4ODUgNC4wMjg4OTIgMS42ODU2NzlDNC4zMTU4MTYgMC42MzM2MjQgNC4zODc1NDcgMC4xMDc1OTcgNC40NDczMjMgLTAuMzcwNjFDNC40ODMxODggLTAuNjU3NTM0IDUuMTY0NjMzIC0yLjYzMDEzNyA2LjEwOTA5MSAtNC41MDcwOThDNi4xOTI3NzcgLTQuNjk4MzgxIDYuMzYwMTQ5IC01LjAyMTE3MSA2LjM2MDE0OSAtNS4wNTcwMzZDNi4zNjAxNDkgLTUuMDY4OTkxIDYuMzQ4MTk0IC01LjE1MjY3NyA2LjI0MDU5OCAtNS4xNTI2NzdDNi4yMTY2ODcgLTUuMTUyNjc3IDYuMTU2OTEyIC01LjE1MjY3NyA2LjEzMzAwMSAtNS4xMDQ4NTdDNi4xMDkwOTEgLTUuMDgwOTQ2IDUuNjkwNjYgLTQuMjY3OTk1IDUuMzMyMDA1IC0zLjQ1NTA0NEM1LjE1MjY3NyAtMy4wNDg1NjggNC45MTM1NzQgLTIuNTEwNTg1IDQuNTE5MDU0IC0xLjQ1ODUzMVonIGlkPSdnMi0xMycvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzItNTknLz4KPHBhdGggZD0nTTcuODc4NDU2IC01LjgyMjE2N0M4LjA5MzY0OSAtNS45MTc4MDggOC4xMTc1NTkgLTYuMDAxNDk0IDguMTE3NTU5IC02LjA3MzIyNUM4LjExNzU1OSAtNi4yMDQ3MzIgOC4wMjE5MTggLTYuMzAwMzc0IDcuODkwNDExIC02LjMwMDM3NEM3Ljg2NjUwMSAtNi4zMDAzNzQgNy44NTQ1NDUgLTYuMjg4NDE4IDcuNjg3MTczIC02LjIxNjY4N0wxLjIxOTQyNyAtMy4yMzk4NTFDMS4wMDQyMzQgLTMuMTQ0MjA5IDAuOTgwMzI0IC0zLjA2MDUyMyAwLjk4MDMyNCAtMi45ODg3OTJDMC45ODAzMjQgLTIuOTA1MTA2IDAuOTkyMjc5IC0yLjgzMzM3NSAxLjIxOTQyNyAtMi43MjU3NzhMNy42ODcxNzMgMC4yNTEwNTlDNy44NDI1OSAwLjMyMjc5IDcuODY2NTAxIDAuMzM0NzQ1IDcuODkwNDExIDAuMzM0NzQ1QzguMDIxOTE4IDAuMzM0NzQ1IDguMTE3NTU5IDAuMjM5MTAzIDguMTE3NTU5IDAuMTA3NTk3QzguMTE3NTU5IDAuMDM1ODY2IDguMDkzNjQ5IC0wLjA0NzgyMSA3Ljg3ODQ1NiAtMC4xNDM0NjJMMS43MjE1NDQgLTIuOTc2ODM3TDcuODc4NDU2IC01LjgyMjE2N1onIGlkPSdnMi02MCcvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzI1Nzc4QzguMTA1NjA0IC0yLjgzMzM3NSA4LjExNzU1OSAtMi45MDUxMDYgOC4xMTc1NTkgLTIuOTg4NzkyQzguMTE3NTU5IC0zLjA2MDUyMyA4LjA5MzY0OSAtMy4xNDQyMDkgNy44Nzg0NTYgLTMuMjM5ODUxTDEuNDEwNzEgLTYuMjE2Njg3QzEuMjU1MjkzIC02LjI4ODQxOCAxLjIzMTM4MiAtNi4zMDAzNzQgMS4yMDc0NzIgLTYuMzAwMzc0QzEuMDY0MDEgLTYuMzAwMzc0IDAuOTgwMzI0IC02LjE4MDgyMiAwLjk4MDMyNCAtNi4wODUxODFDMC45ODAzMjQgLTUuOTQxNzE5IDEuMDc1OTY1IC01Ljg5Mzg5OCAxLjIzMTM4MiAtNS44MjIxNjdMNy4zNzYzMzkgLTIuOTg4NzkyTDEuMjE5NDI3IC0wLjE0MzQ2MkMwLjk4MDMyNCAtMC4wMzU4NjYgMC45ODAzMjQgMC4wNDc4MjEgMC45ODAzMjQgMC4xMTk1NTJDMC45ODAzMjQgMC4yMTUxOTMgMS4wNjQwMSAwLjMzNDc0NSAxLjIwNzQ3MiAwLjMzNDc0NUMxLjIzMTM4MiAwLjMzNDc0NSAxLjI0MzMzNyAwLjMyMjc5IDEuNDEwNzEgMC4yNTEwNTlMNy44Nzg0NTYgLTIuNzI1Nzc4WicgaWQ9J2cyLTYyJy8+CjxwYXRoIGQ9J00zLjUzODczIC0zLjgwMTc0M0g1LjU0NzE5OEM3LjE5NzAxMSAtMy44MDE3NDMgOC44NDY4MjQgLTUuMDIxMTcxIDguODQ2ODI0IC02LjM4NDA2QzguODQ2ODI0IC03LjMxNjU2MyA4LjA1Nzc4MyAtOC4xNjUzOCA2LjU1MTQzMiAtOC4xNjUzOEgyLjg1NzI4NUMyLjYzMDEzNyAtOC4xNjUzOCAyLjUyMjU0IC04LjE2NTM4IDIuNTIyNTQgLTcuOTM4MjMyQzIuNTIyNTQgLTcuODE4NjggMi42MzAxMzcgLTcuODE4NjggMi44MDk0NjUgLTcuODE4NjhDMy41Mzg3MyAtNy44MTg2OCAzLjUzODczIC03LjcyMzAzOSAzLjUzODczIC03LjU5MTUzMkMzLjUzODczIC03LjU2NzYyMSAzLjUzODczIC03LjQ5NTg5IDMuNDkwOTA5IC03LjMxNjU2M0wxLjg3Njk2MSAtMC44ODQ2ODJDMS43NjkzNjUgLTAuNDY2MjUyIDEuNzQ1NDU1IC0wLjM0NjcgMC45MDg1OTMgLTAuMzQ2N0MwLjY4MTQ0NSAtMC4zNDY3IDAuNTYxODkzIC0wLjM0NjcgMC41NjE4OTMgLTAuMTMxNTA3QzAuNTYxODkzIDAgMC42Njk0ODkgMCAwLjc0MTIyIDBDMC45NjgzNjkgMCAxLjIwNzQ3MiAtMC4wMjM5MSAxLjQzNDYyIC0wLjAyMzkxSDIuODMzMzc1QzMuMDYwNTIzIC0wLjAyMzkxIDMuMzExNTgyIDAgMy41Mzg3MyAwQzMuNjM0MzcxIDAgMy43NjU4NzggMCAzLjc2NTg3OCAtMC4yMjcxNDhDMy43NjU4NzggLTAuMzQ2NyAzLjY1ODI4MSAtMC4zNDY3IDMuNDc4OTU0IC0wLjM0NjdDMi43NjE2NDQgLTAuMzQ2NyAyLjc0OTY4OSAtMC40MzAzODYgMi43NDk2ODkgLTAuNTQ5OTM4QzIuNzQ5Njg5IC0wLjYwOTcxNCAyLjc2MTY0NCAtMC42OTM0IDIuNzczNTk5IC0wLjc1MzE3NkwzLjUzODczIC0zLjgwMTc0M1pNNC4zOTk1MDIgLTcuMzUyNDI4QzQuNTA3MDk4IC03Ljc5NDc3IDQuNTU0OTE5IC03LjgxODY4IDUuMDIxMTcxIC03LjgxODY4SDYuMjA0NzMyQzcuMTAxMzcgLTcuODE4NjggNy44NDI1OSAtNy41MzE3NTYgNy44NDI1OSAtNi42MzUxMThDNy44NDI1OSAtNi4zMjQyODQgNy42ODcxNzMgLTUuMzA4MDk1IDcuMTM3MjM1IC00Ljc1ODE1N0M2LjkzMzk5OCAtNC41NDI5NjQgNi4zNjAxNDkgLTQuMDg4NjY3IDUuMjcyMjI5IC00LjA4ODY2N0gzLjU4NjU1TDQuMzk5NTAyIC03LjM1MjQyOFonIGlkPSdnMi04MCcvPgo8cGF0aCBkPSdNNS42Nzg3MDUgLTQuODUzNzk4TDQuNTU0OTE5IC03LjQ3MTk4QzQuNzEwMzM2IC03Ljc1ODkwNCA1LjA2ODk5MSAtNy44MDY3MjUgNS4yMTI0NTMgLTcuODE4NjhDNS4yODQxODQgLTcuODE4NjggNS40MTU2OTEgLTcuODMwNjM1IDUuNDE1NjkxIC04LjAzMzg3M0M1LjQxNTY5MSAtOC4xNjUzOCA1LjMwODA5NSAtOC4xNjUzOCA1LjIzNjM2NCAtOC4xNjUzOEM1LjAzMzEyNiAtOC4xNjUzOCA0Ljc5NDAyMiAtOC4xNDE0NjkgNC41OTA3ODUgLTguMTQxNDY5SDMuODk3Mzg1QzMuMTY4MTIgLTguMTQxNDY5IDIuNjQyMDkyIC04LjE2NTM4IDIuNjMwMTM3IC04LjE2NTM4QzIuNTM0NDk2IC04LjE2NTM4IDIuNDE0OTQ0IC04LjE2NTM4IDIuNDE0OTQ0IC03LjkzODIzMkMyLjQxNDk0NCAtNy44MTg2OCAyLjUyMjU0IC03LjgxODY4IDIuNjc3OTU4IC03LjgxODY4QzMuMzcxMzU3IC03LjgxODY4IDMuNDE5MTc4IC03LjY5OTEyOCAzLjUzODczIC03LjQxMjIwNEw0Ljk2MTM5NSAtNC4wODg2NjdMMi4zNjcxMjMgLTEuMzE1MDY4QzEuOTM2NzM3IC0wLjg0ODgxNyAxLjQyMjY2NSAtMC4zOTQ1MjEgMC41Mzc5ODMgLTAuMzQ2N0MwLjM5NDUyMSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjExOTU1MkMwLjI5ODg3OSAtMC4wODM2ODYgMC4zMTA4MzQgMCAwLjQ0MjM0MSAwQzAuNjA5NzE0IDAgMC43ODkwNDEgLTAuMDIzOTEgMC45NTY0MTMgLTAuMDIzOTFIMS41MTgzMDZDMS45MDA4NzIgLTAuMDIzOTEgMi4zMTkzMDMgMCAyLjY4OTkxMyAwQzIuNzczNTk5IDAgMi45MTcwNjEgMCAyLjkxNzA2MSAtMC4yMTUxOTNDMi45MTcwNjEgLTAuMzM0NzQ1IDIuODMzMzc1IC0wLjM0NjcgMi43NjE2NDQgLTAuMzQ2N0MyLjUyMjU0IC0wLjM3MDYxIDIuMzY3MTIzIC0wLjUwMjExNyAyLjM2NzEyMyAtMC42OTM0QzIuMzY3MTIzIC0wLjg5NjYzOCAyLjUxMDU4NSAtMS4wNDAxIDIuODU3Mjg1IC0xLjM5ODc1NUwzLjkyMTI5NSAtMi41NTg0MDZDNC4xODQzMDkgLTIuODMzMzc1IDQuODE3OTMzIC0zLjUyNjc3NSA1LjA4MDk0NiAtMy43ODk3ODhMNi4zMzYyMzkgLTAuODQ4ODE3QzYuMzQ4MTk0IC0wLjgyNDkwNyA2LjM5NjAxNSAtMC43MDUzNTUgNi4zOTYwMTUgLTAuNjkzNEM2LjM5NjAxNSAtMC41ODU4MDMgNi4xMzMwMDEgLTAuMzcwNjEgNS43NTA0MzYgLTAuMzQ2N0M1LjY3ODcwNSAtMC4zNDY3IDUuNTQ3MTk4IC0wLjMzNDc0NSA1LjU0NzE5OCAtMC4xMTk1NTJDNS41NDcxOTggMCA1LjY2Njc1IDAgNS43MjY1MjYgMEM1LjkyOTc2MyAwIDYuMTY4ODY3IC0wLjAyMzkxIDYuMzcyMTA1IC0wLjAyMzkxSDcuNjg3MTczQzcuOTAyMzY2IC0wLjAyMzkxIDguMTI5NTE0IDAgOC4zMzI3NTIgMEM4LjQxNjQzOCAwIDguNTQ3OTQ1IDAgOC41NDc5NDUgLTAuMjI3MTQ4QzguNTQ3OTQ1IC0wLjM0NjcgOC40MjgzOTQgLTAuMzQ2NyA4LjMyMDc5NyAtMC4zNDY3QzcuNjAzNDg3IC0wLjM1ODY1NSA3LjU3OTU3NyAtMC40MTg0MzEgNy4zNzYzMzkgLTAuODYwNzcyTDUuNzk4MjU3IC00LjU2Njg3NEw3LjMxNjU2MyAtNi4xOTI3NzdDNy40MzYxMTUgLTYuMzEyMzI5IDcuNzExMDgzIC02LjYxMTIwOCA3LjgxODY4IC02LjczMDc2QzguMzMyNzUyIC03LjI2ODc0MiA4LjgxMDk1OSAtNy43NTg5MDQgOS43NzkzMjggLTcuODE4NjhDOS44OTg4NzkgLTcuODMwNjM1IDEwLjAxODQzMSAtNy44MzA2MzUgMTAuMDE4NDMxIC04LjAzMzg3M0MxMC4wMTg0MzEgLTguMTY1MzggOS45MTA4MzQgLTguMTY1MzggOS44NjMwMTQgLTguMTY1MzhDOS42OTU2NDEgLTguMTY1MzggOS41MTYzMTQgLTguMTQxNDY5IDkuMzQ4OTQxIC04LjE0MTQ2OUg4Ljc5OTAwNEM4LjQxNjQzOCAtOC4xNDE0NjkgNy45OTgwMDcgLTguMTY1MzggNy42MjczOTcgLTguMTY1MzhDNy41NDM3MTEgLTguMTY1MzggNy40MDAyNDkgLTguMTY1MzggNy40MDAyNDkgLTcuOTUwMTg3QzcuNDAwMjQ5IC03LjgzMDYzNSA3LjQ4MzkzNSAtNy44MTg2OCA3LjU1NTY2NiAtNy44MTg2OEM3Ljc0Njk0OSAtNy43OTQ3NyA3Ljk1MDE4NyAtNy42OTkxMjggNy45NTAxODcgLTcuNDcxOThMNy45MzgyMzIgLTcuNDQ4MDdDNy45MjYyNzYgLTcuMzY0Mzg0IDcuOTAyMzY2IC03LjI0NDgzMiA3Ljc3MDg1OSAtNy4xMDEzN0w1LjY3ODcwNSAtNC44NTM3OThaJyBpZD0nZzItODgnLz4KPHBhdGggZD0nTTcuMDI5NjM5IC02LjgzODM1Nkw3LjMwNDYwOCAtNy4xMTMzMjVDNy44MzA2MzUgLTcuNjUxMzA4IDguMjcyOTc2IC03Ljc4MjgxNCA4LjY5MTQwNyAtNy44MTg2OEM4LjgyMjkxNCAtNy44MzA2MzUgOC45MzA1MTEgLTcuODQyNTkgOC45MzA1MTEgLTguMDQ1ODI4QzguOTMwNTExIC04LjE2NTM4IDguODEwOTU5IC04LjE2NTM4IDguNzg3MDQ5IC04LjE2NTM4QzguNjQzNTg3IC04LjE2NTM4IDguNDg4MTY5IC04LjE0MTQ2OSA4LjM0NDcwNyAtOC4xNDE0NjlINy44NTQ1NDVDNy41MDc4NDYgLTguMTQxNDY5IDcuMTM3MjM1IC04LjE2NTM4IDYuODAyNDkxIC04LjE2NTM4QzYuNzE4ODA0IC04LjE2NTM4IDYuNTg3Mjk4IC04LjE2NTM4IDYuNTg3Mjk4IC03LjkzODIzMkM2LjU4NzI5OCAtNy44MzA2MzUgNi43MDY4NDkgLTcuODE4NjggNi43NDI3MTUgLTcuODE4NjhDNy4xMDEzNyAtNy43OTQ3NyA3LjEwMTM3IC03LjYxNTQ0MiA3LjEwMTM3IC03LjU0MzcxMUM3LjEwMTM3IC03LjQxMjIwNCA3LjAwNTcyOSAtNy4yMzI4NzcgNi43NjY2MjUgLTYuOTU3OTA4TDMuOTIxMjk1IC0zLjY5NDE0N0wyLjU3MDM2MSAtNy4zMjg1MThDMi40OTg2MyAtNy40OTU4OSAyLjQ5ODYzIC03LjUxOTgwMSAyLjQ5ODYzIC03LjU0MzcxMUMyLjQ5ODYzIC03Ljc5NDc3IDIuOTg4NzkyIC03LjgxODY4IDMuMTMyMjU0IC03LjgxODY4UzMuNDA3MjIzIC03LjgxODY4IDMuNDA3MjIzIC04LjAzMzg3M0MzLjQwNzIyMyAtOC4xNjUzOCAzLjI5OTYyNiAtOC4xNjUzOCAzLjIyNzg5NSAtOC4xNjUzOEMzLjAyNDY1OCAtOC4xNjUzOCAyLjc4NTU1NCAtOC4xNDE0NjkgMi41ODIzMTYgLTguMTQxNDY5SDEuMjU1MjkzQzEuMDQwMSAtOC4xNDE0NjkgMC44MTI5NTEgLTguMTY1MzggMC42MDk3MTQgLTguMTY1MzhDMC41MjYwMjcgLTguMTY1MzggMC4zOTQ1MjEgLTguMTY1MzggMC4zOTQ1MjEgLTcuOTM4MjMyQzAuMzk0NTIxIC03LjgxODY4IDAuNTAyMTE3IC03LjgxODY4IDAuNjgxNDQ1IC03LjgxODY4QzEuMjY3MjQ4IC03LjgxODY4IDEuMzc0ODQ0IC03LjcxMTA4MyAxLjQ4MjQ0MSAtNy40MzYxMTVMMi45NjQ4ODIgLTMuNDU1MDQ0QzIuOTc2ODM3IC0zLjQxOTE3OCAzLjAxMjcwMiAtMy4yODc2NzEgMy4wMTI3MDIgLTMuMjUxODA2UzIuNDI2ODk5IC0wLjg2MDc3MiAyLjM5MTAzNCAtMC43NDEyMkMyLjI5NTM5MiAtMC40MTg0MzEgMi4xNzU4NDEgLTAuMzU4NjU1IDEuNDEwNzEgLTAuMzQ2N0MxLjIwNzQ3MiAtMC4zNDY3IDEuMTExODMxIC0wLjM0NjcgMS4xMTE4MzEgLTAuMTE5NTUyQzEuMTExODMxIDAgMS4yNDMzMzcgMCAxLjI3OTIwMyAwQzEuNDk0Mzk2IDAgMS43NDU0NTUgLTAuMDIzOTEgMS45NzI2MDMgLTAuMDIzOTFIMy4zODMzMTNDMy41OTg1MDYgLTAuMDIzOTEgMy44NDk1NjQgMCA0LjA2NDc1NyAwQzQuMTQ4NDQzIDAgNC4yOTE5MDUgMCA0LjI5MTkwNSAtMC4yMTUxOTNDNC4yOTE5MDUgLTAuMzQ2NyA0LjIwODIxOSAtMC4zNDY3IDQuMDA0OTgxIC0wLjM0NjdDMy4yNjM3NjEgLTAuMzQ2NyAzLjI2Mzc2MSAtMC40MzAzODYgMy4yNjM3NjEgLTAuNTYxODkzQzMuMjYzNzYxIC0wLjY0NTU3OSAzLjM1OTQwMiAtMS4wMjgxNDQgMy40MTkxNzggLTEuMjY3MjQ4TDMuODQ5NTY0IC0yLjk4ODc5MkMzLjkyMTI5NSAtMy4yMzk4NTEgMy45MjEyOTUgLTMuMjYzNzYxIDQuMDI4ODkyIC0zLjM4MzMxM0w3LjAyOTYzOSAtNi44MzgzNTZaJyBpZD0nZzItODknLz4KPHBhdGggZD0nTTguMzY4NjE4IC03Ljc5NDc3QzguNDQwMzQ5IC03Ljg3ODQ1NiA4LjUwMDEyNSAtNy45NTAxODcgOC41MDAxMjUgLTguMDY5NzM4QzguNTAwMTI1IC04LjE1MzQyNSA4LjQ4ODE2OSAtOC4xNjUzOCA4LjIxMzIgLTguMTY1MzhIMy4yNzU3MTZDMy4wMDA3NDcgLTguMTY1MzggMi45ODg3OTIgLTguMTUzNDI1IDIuOTE3MDYxIC03LjkzODIzMkwyLjI1OTUyNyAtNS43ODYzMDFDMi4yMjM2NjEgLTUuNjY2NzUgMi4yMjM2NjEgLTUuNjQyODM5IDIuMjIzNjYxIC01LjYxODkyOUMyLjIyMzY2MSAtNS41NzExMDggMi4yNTk1MjcgLTUuNDk5Mzc3IDIuMzQzMjEzIC01LjQ5OTM3N0MyLjQzODg1NCAtNS40OTkzNzcgMi40NjI3NjUgLTUuNTQ3MTk4IDIuNTEwNTg1IC01LjcwMjYxNUMyLjk1MjkyNyAtNi45OTM3NzMgMy41Mzg3MyAtNy44MTg2OCA1LjQyNzY0NiAtNy44MTg2OEg3LjM4ODI5NEwwLjgzNjg2MiAtMC40MDY0NzZDMC43MjkyNjUgLTAuMjc0OTY5IDAuNjgxNDQ1IC0wLjIyNzE0OCAwLjY4MTQ0NSAtMC4wOTU2NDFDMC42ODE0NDUgMCAwLjc0MTIyIDAgMC45NjgzNjkgMEg2LjA3MzIyNUM2LjM0ODE5NCAwIDYuMzYwMTQ5IC0wLjAxMTk1NSA2LjQzMTg4IC0wLjIyNzE0OEw3LjI2ODc0MiAtMi44NjkyNEM3LjI4MDY5NyAtMi45MDUxMDYgNy4zMDQ2MDggLTIuOTg4NzkyIDcuMzA0NjA4IC0zLjAzNjYxM0M3LjMwNDYwOCAtMy4wOTYzODkgNy4yNTY3ODcgLTMuMTU2MTY0IDcuMTg1MDU2IC0zLjE1NjE2NEM3LjA4OTQxNSAtMy4xNTYxNjQgNy4wNzc0NiAtMy4xNDQyMDkgNi45ODE4MTggLTIuODQ1MzNDNi40Nzk3MDEgLTEuMzAzMTEzIDUuOTUzNjc0IC0wLjM3MDYxIDMuODczNDc0IC0wLjM3MDYxSDEuODA1MjNMOC4zNjg2MTggLTcuNzk0NzdaJyBpZD0nZzItOTAnLz4KPHBhdGggZD0nTTIuMTU5OSAxLjk5MjUyOFYxLjYyNTkwM0gxLjM1NDkxOVYtNS42MTA5NTlIMi4xNTk5Vi01Ljk3NzU4NEgwLjk4ODI5NFYxLjk5MjUyOEgyLjE1OTlaJyBpZD0nZzMtOTEnLz4KPHBhdGggZD0nTTEuMzU0OTE5IC01Ljk3NzU4NEgwLjE4MzMxM1YtNS42MTA5NTlIMC45ODgyOTRWMS42MjU5MDNIMC4xODMzMTNWMS45OTI1MjhIMS4zNTQ5MTlWLTUuOTc3NTg0WicgaWQ9J2czLTkzJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMS0xMDcnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzExOS45MTA1MzQnIHhsaW5rOmhyZWY9JyNnMi0xMycgeT0nOTYuMTg1OTE4Jy8+Cjx1c2UgeD0nMTI1Ljk4MjQzJyB4bGluazpocmVmPScjZzEtMTA3JyB5PSc5Ny45NzkxODEnLz4KPHVzZSB4PScxMzQuNDIzMDA3JyB4bGluazpocmVmPScjZzQtNjEnIHk9Jzk2LjE4NTkxOCcvPgo8dXNlIHg9JzE1Mi4yNjU3NScgeGxpbms6aHJlZj0nI2cyLTYwJyB5PSc4Ny42NzEyMzMnLz4KPHVzZSB4PScxNjQuNjkxMjMxJyB4bGluazpocmVmPScjZzItOTAnIHk9Jzg3LjY3MTIzMycvPgo8dXNlIHg9JzE3Mi43MDM0ODYnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nODkuNTMwOTQzJy8+Cjx1c2UgeD0nMTc1LjA1NTgxJyB4bGluazpocmVmPScjZzEtMTA3JyB5PSc4OS41MzA5NDMnLz4KPHVzZSB4PScxNzkuNjc3NDI1JyB4bGluazpocmVmPScjZzMtOTMnIHk9Jzg5LjUzMDk0MycvPgo8dXNlIHg9JzE4Mi41Mjc4ODEnIHhsaW5rOmhyZWY9JyNnMi01OScgeT0nODcuNjcxMjMzJy8+Cjx1c2UgeD0nMTg3Ljc3MjA0JyB4bGluazpocmVmPScjZzItODknIHk9Jzg3LjY3MTIzMycvPgo8dXNlIHg9JzIwMC40ODYwMzEnIHhsaW5rOmhyZWY9JyNnMi02MicgeT0nODcuNjcxMjMzJy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2NS43Njg0MTQnIHg9JzE0OC4wNDQwMDInIHk9JzkyLjk1ODAzMycvPgo8dXNlIHg9JzE0OC4wNDQwMDInIHhsaW5rOmhyZWY9JyNnMi02MCcgeT0nMTA0LjM4NjU4MScvPgo8dXNlIHg9JzE2MC40Njk0ODMnIHhsaW5rOmhyZWY9JyNnMi05MCcgeT0nMTA0LjM4NjU4MScvPgo8dXNlIHg9JzE2OC40ODE3MzgnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nMTA2LjI0NjI5MScvPgo8dXNlIHg9JzE3MC44MzQwNjInIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PScxNzUuNDU1Njc3JyB4bGluazpocmVmPScjZzMtOTMnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PScxNzguMzA2MTMzJyB4bGluazpocmVmPScjZzItNTknIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PScxODMuNTUwMjkyJyB4bGluazpocmVmPScjZzItOTAnIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PScxOTEuNTYyNTQ3JyB4bGluazpocmVmPScjZzMtOTEnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PScxOTMuOTE0ODcxJyB4bGluazpocmVmPScjZzEtMTA3JyB5PScxMDYuMjQ2MjkxJy8+Cjx1c2UgeD0nMTk4LjUzNjQ4NicgeGxpbms6aHJlZj0nI2czLTkzJyB5PScxMDYuMjQ2MjkxJy8+Cjx1c2UgeD0nMjA0LjcwNzc3MicgeGxpbms6aHJlZj0nI2cyLTYyJyB5PScxMDQuMzg2NTgxJy8+Cjx1c2UgeD0nMjE4LjMyODc1OScgeGxpbms6aHJlZj0nI2c0LTYxJyB5PSc5Ni4xODU5MTgnLz4KPHVzZSB4PScyNDguMDI4MzQ0JyB4bGluazpocmVmPScjZzItNjAnIHk9Jzg3LjY3MTIzMycvPgo8dXNlIHg9JzI2MC40NTM4MjUnIHhsaW5rOmhyZWY9JyNnNC00MCcgeT0nODcuNjcxMjMzJy8+Cjx1c2UgeD0nMjY1LjAwNjE1MScgeGxpbms6aHJlZj0nI2cyLTg4JyB5PSc4Ny42NzEyMzMnLz4KPHVzZSB4PScyNzUuNjYxMjU5JyB4bGluazpocmVmPScjZzItODAnIHk9Jzg3LjY3MTIzMycvPgo8dXNlIHg9JzI4NC44MzIzNTcnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nODMuMzMyNzk2Jy8+Cjx1c2UgeD0nMjg3LjYyNzQzMycgeGxpbms6aHJlZj0nI2c0LTQxJyB5PSc4Ny42NzEyMzMnLz4KPHVzZSB4PScyOTIuMTc5NzU4JyB4bGluazpocmVmPScjZzMtOTEnIHk9Jzg5LjUzMDk0MycvPgo8dXNlIHg9JzI5NC41MzIwODInIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9Jzg5LjUzMDk0MycvPgo8dXNlIHg9JzI5OS4xNTM2OTgnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nODkuNTMwOTQzJy8+Cjx1c2UgeD0nMzAyLjAwNDE1NCcgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc4Ny42NzEyMzMnLz4KPHVzZSB4PSczMDcuMjQ4MzEyJyB4bGluazpocmVmPScjZzItODknIHk9Jzg3LjY3MTIzMycvPgo8dXNlIHg9JzMxOS45NjIzMDQnIHhsaW5rOmhyZWY9JyNnMi02MicgeT0nODcuNjcxMjMzJy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPScxMTMuMTk1NzU1JyB4PScyMzEuOTQ5NzUzJyB5PSc5Mi45NTgwMzMnLz4KPHVzZSB4PScyMzEuOTQ5NzUzJyB4bGluazpocmVmPScjZzItNjAnIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PScyNDQuMzc1MjM0JyB4bGluazpocmVmPScjZzQtNDAnIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PScyNDguOTI3NTYnIHhsaW5rOmhyZWY9JyNnMi04OCcgeT0nMTA0LjM4NjU4MScvPgo8dXNlIHg9JzI1OS41ODI2NjgnIHhsaW5rOmhyZWY9JyNnMi04MCcgeT0nMTA0LjM4NjU4MScvPgo8dXNlIHg9JzI2OC43NTM3NjYnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nMTAwLjkzMjg3MycvPgo8dXNlIHg9JzI3MS41NDg4NDInIHhsaW5rOmhyZWY9JyNnNC00MScgeT0nMTA0LjM4NjU4MScvPgo8dXNlIHg9JzI3Ni4xMDExNjgnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nMTA2LjI0NjI5MScvPgo8dXNlIHg9JzI3OC40NTM0OTInIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PScyODMuMDc1MTA3JyB4bGluazpocmVmPScjZzMtOTMnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PScyODUuOTI1NTYzJyB4bGluazpocmVmPScjZzItNTknIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PScyOTEuMTY5NzIyJyB4bGluazpocmVmPScjZzQtNDAnIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PScyOTUuNzIyMDQ3JyB4bGluazpocmVmPScjZzItODgnIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PSczMDYuMzc3MTU1JyB4bGluazpocmVmPScjZzItODAnIHk9JzEwNC4zODY1ODEnLz4KPHVzZSB4PSczMTUuNTQ4MjU0JyB4bGluazpocmVmPScjZzAtNDgnIHk9JzEwMC45MzI4NzMnLz4KPHVzZSB4PSczMTguMzQzMzMnIHhsaW5rOmhyZWY9JyNnNC00MScgeT0nMTA0LjM4NjU4MScvPgo8dXNlIHg9JzMyMi44OTU2NTUnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nMTA2LjI0NjI5MScvPgo8dXNlIHg9JzMyNS4yNDc5NzknIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PSczMjkuODY5NTk1JyB4bGluazpocmVmPScjZzMtOTMnIHk9JzEwNi4yNDYyOTEnLz4KPHVzZSB4PSczMzYuMDQwODgnIHhsaW5rOmhyZWY9JyNnMi02MicgeT0nMTA0LjM4NjU4MScvPgo8L2c+Cjwvc3ZnPg==)
On en déduit que :
![\norm{Y - X\beta} = \norm{Y - \sum_{k=1}^{C}Z_{[k]}\frac{<Z_{[k]},Y>}{<Z_{[k]},Z_{[k]}>}} =
\norm{Y - \sum_{k=1}^{C}(XP')_{[k]}\frac{<(XP')_{[k]},Y>}{<(XP')_{[k]},(XP')_{[k]}>}}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMzUuODY1ODY5cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDc5LjM2ODkwMSA0MzkuNjE5MTU5IDM1Ljg2NTg2OScgd2lkdGg9JzQzOS42MTkxNTlwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNNi43NjY2MjUgLTYuOTU3OTA4QzYuNzY2NjI1IC03LjY3NTIxOCA2LjE1NjkxMiAtOC40MjgzOTQgNS4wNjg5OTEgLTguNDI4Mzk0QzMuNTI2Nzc1IC04LjQyODM5NCAyLjU0NjQ1MSAtNi41Mzk0NzcgMi4yMzU2MTYgLTUuMjk2MTM5TDAuMzQ2NyAyLjE5OTc1MUMwLjMyMjc5IDIuMjk1MzkyIDAuMzk0NTIxIDIuMzE5MzAzIDAuNDU0Mjk2IDIuMzE5MzAzQzAuNTM3OTgzIDIuMzE5MzAzIDAuNTk3NzU4IDIuMzA3MzQ3IDAuNjA5NzE0IDIuMjQ3NTcyTDEuNDQ2NTc1IC0xLjA5OTg3NUMxLjU2NjEyNyAtMC40MzAzODYgMi4yMjM2NjEgMC4xMTk1NTIgMi45MjkwMTYgMC4xMTk1NTJDNC42Mzg2MDUgMC4xMTk1NTIgNi4yNTI1NTMgLTEuMjE5NDI3IDYuMjUyNTUzIC0zLjAwMDc0N0M2LjI1MjU1MyAtMy40NTUwNDQgNi4xNDQ5NTYgLTMuOTA5MzQgNS44OTM4OTggLTQuMjkxOTA1QzUuNzUwNDM2IC00LjUxOTA1NCA1LjU3MTEwOCAtNC42ODY0MjYgNS4zNzk4MjYgLTQuODI5ODg4QzYuMjQwNTk4IC01LjI4NDE4NCA2Ljc2NjYyNSAtNi4wMTM0NSA2Ljc2NjYyNSAtNi45NTc5MDhaTTQuNjg2NDI2IC00Ljg0MTg0M0M0LjQ5NTE0MyAtNC43NzAxMTIgNC4zMDM4NjEgLTQuNzQ2MjAyIDQuMDc2NzEyIC00Ljc0NjIwMkMzLjkwOTM0IC00Ljc0NjIwMiAzLjc1MzkyMyAtNC43MzQyNDcgMy41Mzg3MyAtNC44MDU5NzhDMy42NTgyODEgLTQuODg5NjY0IDMuODM3NjA5IC00LjkxMzU3NCA0LjA4ODY2NyAtNC45MTM1NzRDNC4zMDM4NjEgLTQuOTEzNTc0IDQuNTE5MDU0IC00Ljg4OTY2NCA0LjY4NjQyNiAtNC44NDE4NDNaTTYuMTQ0OTU2IC03LjA2NTUwNEM2LjE0NDk1NiAtNi40MDc5NyA1LjgyMjE2NyAtNS40NTE1NTcgNS4wNDUwODEgLTUuMDA5MjE1QzQuODE3OTMzIC01LjA5MjkwMiA0LjUwNzA5OCAtNS4xNTI2NzcgNC4yNDQwODUgLTUuMTUyNjc3QzMuOTkzMDI2IC01LjE1MjY3NyAzLjI3NTcxNiAtNS4xNzY1ODggMy4yNzU3MTYgLTQuNzk0MDIyQzMuMjc1NzE2IC00LjQ3MTIzMyAzLjkzMzI1IC00LjUwNzA5OCA0LjEzNjQ4OCAtNC41MDcwOThDNC40NDczMjMgLTQuNTA3MDk4IDQuNzIyMjkxIC00LjU3ODgyOSA1LjAwOTIxNSAtNC42NjI1MTZDNS4zOTE3ODEgLTQuMzUxNjgxIDUuNTU5MTUzIC0zLjk0NTIwNSA1LjU1OTE1MyAtMy4zNDc0NDdDNS41NTkxNTMgLTIuNjU0MDQ3IDUuMzY3ODcgLTIuMDkyMTU0IDUuMTQwNzIyIC0xLjU3ODA4MkM0Ljc0NjIwMiAtMC42OTM0IDMuODEzNjk5IC0wLjExOTU1MiAyLjk4ODc5MiAtMC4xMTk1NTJDMi4xMTYwNjUgLTAuMTE5NTUyIDEuNjYxNzY4IC0wLjgxMjk1MSAxLjY2MTc2OCAtMS42MjU5MDNDMS42NjE3NjggLTEuNzMzNDk5IDEuNjYxNzY4IC0xLjg4ODkxNyAxLjcwOTU4OSAtMi4wNjgyNDRMMi40ODY2NzUgLTUuMjEyNDUzQzIuODgxMTk2IC02Ljc3ODU4IDMuODg1NDMgLTguMTg5MjkgNS4wNDUwODEgLTguMTg5MjlDNS45MDU4NTMgLTguMTg5MjkgNi4xNDQ5NTYgLTcuNTkxNTMyIDYuMTQ0OTU2IC03LjA2NTUwNFonIGlkPSdnNC0xMicvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzQtNTknLz4KPHBhdGggZD0nTTcuODc4NDU2IC01LjgyMjE2N0M4LjA5MzY0OSAtNS45MTc4MDggOC4xMTc1NTkgLTYuMDAxNDk0IDguMTE3NTU5IC02LjA3MzIyNUM4LjExNzU1OSAtNi4yMDQ3MzIgOC4wMjE5MTggLTYuMzAwMzc0IDcuODkwNDExIC02LjMwMDM3NEM3Ljg2NjUwMSAtNi4zMDAzNzQgNy44NTQ1NDUgLTYuMjg4NDE4IDcuNjg3MTczIC02LjIxNjY4N0wxLjIxOTQyNyAtMy4yMzk4NTFDMS4wMDQyMzQgLTMuMTQ0MjA5IDAuOTgwMzI0IC0zLjA2MDUyMyAwLjk4MDMyNCAtMi45ODg3OTJDMC45ODAzMjQgLTIuOTA1MTA2IDAuOTkyMjc5IC0yLjgzMzM3NSAxLjIxOTQyNyAtMi43MjU3NzhMNy42ODcxNzMgMC4yNTEwNTlDNy44NDI1OSAwLjMyMjc5IDcuODY2NTAxIDAuMzM0NzQ1IDcuODkwNDExIDAuMzM0NzQ1QzguMDIxOTE4IDAuMzM0NzQ1IDguMTE3NTU5IDAuMjM5MTAzIDguMTE3NTU5IDAuMTA3NTk3QzguMTE3NTU5IDAuMDM1ODY2IDguMDkzNjQ5IC0wLjA0NzgyMSA3Ljg3ODQ1NiAtMC4xNDM0NjJMMS43MjE1NDQgLTIuOTc2ODM3TDcuODc4NDU2IC01LjgyMjE2N1onIGlkPSdnNC02MCcvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzI1Nzc4QzguMTA1NjA0IC0yLjgzMzM3NSA4LjExNzU1OSAtMi45MDUxMDYgOC4xMTc1NTkgLTIuOTg4NzkyQzguMTE3NTU5IC0zLjA2MDUyMyA4LjA5MzY0OSAtMy4xNDQyMDkgNy44Nzg0NTYgLTMuMjM5ODUxTDEuNDEwNzEgLTYuMjE2Njg3QzEuMjU1MjkzIC02LjI4ODQxOCAxLjIzMTM4MiAtNi4zMDAzNzQgMS4yMDc0NzIgLTYuMzAwMzc0QzEuMDY0MDEgLTYuMzAwMzc0IDAuOTgwMzI0IC02LjE4MDgyMiAwLjk4MDMyNCAtNi4wODUxODFDMC45ODAzMjQgLTUuOTQxNzE5IDEuMDc1OTY1IC01Ljg5Mzg5OCAxLjIzMTM4MiAtNS44MjIxNjdMNy4zNzYzMzkgLTIuOTg4NzkyTDEuMjE5NDI3IC0wLjE0MzQ2MkMwLjk4MDMyNCAtMC4wMzU4NjYgMC45ODAzMjQgMC4wNDc4MjEgMC45ODAzMjQgMC4xMTk1NTJDMC45ODAzMjQgMC4yMTUxOTMgMS4wNjQwMSAwLjMzNDc0NSAxLjIwNzQ3MiAwLjMzNDc0NUMxLjIzMTM4MiAwLjMzNDc0NSAxLjI0MzMzNyAwLjMyMjc5IDEuNDEwNzEgMC4yNTEwNTlMNy44Nzg0NTYgLTIuNzI1Nzc4WicgaWQ9J2c0LTYyJy8+CjxwYXRoIGQ9J00zLjUzODczIC0zLjgwMTc0M0g1LjU0NzE5OEM3LjE5NzAxMSAtMy44MDE3NDMgOC44NDY4MjQgLTUuMDIxMTcxIDguODQ2ODI0IC02LjM4NDA2QzguODQ2ODI0IC03LjMxNjU2MyA4LjA1Nzc4MyAtOC4xNjUzOCA2LjU1MTQzMiAtOC4xNjUzOEgyLjg1NzI4NUMyLjYzMDEzNyAtOC4xNjUzOCAyLjUyMjU0IC04LjE2NTM4IDIuNTIyNTQgLTcuOTM4MjMyQzIuNTIyNTQgLTcuODE4NjggMi42MzAxMzcgLTcuODE4NjggMi44MDk0NjUgLTcuODE4NjhDMy41Mzg3MyAtNy44MTg2OCAzLjUzODczIC03LjcyMzAzOSAzLjUzODczIC03LjU5MTUzMkMzLjUzODczIC03LjU2NzYyMSAzLjUzODczIC03LjQ5NTg5IDMuNDkwOTA5IC03LjMxNjU2M0wxLjg3Njk2MSAtMC44ODQ2ODJDMS43NjkzNjUgLTAuNDY2MjUyIDEuNzQ1NDU1IC0wLjM0NjcgMC45MDg1OTMgLTAuMzQ2N0MwLjY4MTQ0NSAtMC4zNDY3IDAuNTYxODkzIC0wLjM0NjcgMC41NjE4OTMgLTAuMTMxNTA3QzAuNTYxODkzIDAgMC42Njk0ODkgMCAwLjc0MTIyIDBDMC45NjgzNjkgMCAxLjIwNzQ3MiAtMC4wMjM5MSAxLjQzNDYyIC0wLjAyMzkxSDIuODMzMzc1QzMuMDYwNTIzIC0wLjAyMzkxIDMuMzExNTgyIDAgMy41Mzg3MyAwQzMuNjM0MzcxIDAgMy43NjU4NzggMCAzLjc2NTg3OCAtMC4yMjcxNDhDMy43NjU4NzggLTAuMzQ2NyAzLjY1ODI4MSAtMC4zNDY3IDMuNDc4OTU0IC0wLjM0NjdDMi43NjE2NDQgLTAuMzQ2NyAyLjc0OTY4OSAtMC40MzAzODYgMi43NDk2ODkgLTAuNTQ5OTM4QzIuNzQ5Njg5IC0wLjYwOTcxNCAyLjc2MTY0NCAtMC42OTM0IDIuNzczNTk5IC0wLjc1MzE3NkwzLjUzODczIC0zLjgwMTc0M1pNNC4zOTk1MDIgLTcuMzUyNDI4QzQuNTA3MDk4IC03Ljc5NDc3IDQuNTU0OTE5IC03LjgxODY4IDUuMDIxMTcxIC03LjgxODY4SDYuMjA0NzMyQzcuMTAxMzcgLTcuODE4NjggNy44NDI1OSAtNy41MzE3NTYgNy44NDI1OSAtNi42MzUxMThDNy44NDI1OSAtNi4zMjQyODQgNy42ODcxNzMgLTUuMzA4MDk1IDcuMTM3MjM1IC00Ljc1ODE1N0M2LjkzMzk5OCAtNC41NDI5NjQgNi4zNjAxNDkgLTQuMDg4NjY3IDUuMjcyMjI5IC00LjA4ODY2N0gzLjU4NjU1TDQuMzk5NTAyIC03LjM1MjQyOFonIGlkPSdnNC04MCcvPgo8cGF0aCBkPSdNNS42Nzg3MDUgLTQuODUzNzk4TDQuNTU0OTE5IC03LjQ3MTk4QzQuNzEwMzM2IC03Ljc1ODkwNCA1LjA2ODk5MSAtNy44MDY3MjUgNS4yMTI0NTMgLTcuODE4NjhDNS4yODQxODQgLTcuODE4NjggNS40MTU2OTEgLTcuODMwNjM1IDUuNDE1NjkxIC04LjAzMzg3M0M1LjQxNTY5MSAtOC4xNjUzOCA1LjMwODA5NSAtOC4xNjUzOCA1LjIzNjM2NCAtOC4xNjUzOEM1LjAzMzEyNiAtOC4xNjUzOCA0Ljc5NDAyMiAtOC4xNDE0NjkgNC41OTA3ODUgLTguMTQxNDY5SDMuODk3Mzg1QzMuMTY4MTIgLTguMTQxNDY5IDIuNjQyMDkyIC04LjE2NTM4IDIuNjMwMTM3IC04LjE2NTM4QzIuNTM0NDk2IC04LjE2NTM4IDIuNDE0OTQ0IC04LjE2NTM4IDIuNDE0OTQ0IC03LjkzODIzMkMyLjQxNDk0NCAtNy44MTg2OCAyLjUyMjU0IC03LjgxODY4IDIuNjc3OTU4IC03LjgxODY4QzMuMzcxMzU3IC03LjgxODY4IDMuNDE5MTc4IC03LjY5OTEyOCAzLjUzODczIC03LjQxMjIwNEw0Ljk2MTM5NSAtNC4wODg2NjdMMi4zNjcxMjMgLTEuMzE1MDY4QzEuOTM2NzM3IC0wLjg0ODgxNyAxLjQyMjY2NSAtMC4zOTQ1MjEgMC41Mzc5ODMgLTAuMzQ2N0MwLjM5NDUyMSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjExOTU1MkMwLjI5ODg3OSAtMC4wODM2ODYgMC4zMTA4MzQgMCAwLjQ0MjM0MSAwQzAuNjA5NzE0IDAgMC43ODkwNDEgLTAuMDIzOTEgMC45NTY0MTMgLTAuMDIzOTFIMS41MTgzMDZDMS45MDA4NzIgLTAuMDIzOTEgMi4zMTkzMDMgMCAyLjY4OTkxMyAwQzIuNzczNTk5IDAgMi45MTcwNjEgMCAyLjkxNzA2MSAtMC4yMTUxOTNDMi45MTcwNjEgLTAuMzM0NzQ1IDIuODMzMzc1IC0wLjM0NjcgMi43NjE2NDQgLTAuMzQ2N0MyLjUyMjU0IC0wLjM3MDYxIDIuMzY3MTIzIC0wLjUwMjExNyAyLjM2NzEyMyAtMC42OTM0QzIuMzY3MTIzIC0wLjg5NjYzOCAyLjUxMDU4NSAtMS4wNDAxIDIuODU3Mjg1IC0xLjM5ODc1NUwzLjkyMTI5NSAtMi41NTg0MDZDNC4xODQzMDkgLTIuODMzMzc1IDQuODE3OTMzIC0zLjUyNjc3NSA1LjA4MDk0NiAtMy43ODk3ODhMNi4zMzYyMzkgLTAuODQ4ODE3QzYuMzQ4MTk0IC0wLjgyNDkwNyA2LjM5NjAxNSAtMC43MDUzNTUgNi4zOTYwMTUgLTAuNjkzNEM2LjM5NjAxNSAtMC41ODU4MDMgNi4xMzMwMDEgLTAuMzcwNjEgNS43NTA0MzYgLTAuMzQ2N0M1LjY3ODcwNSAtMC4zNDY3IDUuNTQ3MTk4IC0wLjMzNDc0NSA1LjU0NzE5OCAtMC4xMTk1NTJDNS41NDcxOTggMCA1LjY2Njc1IDAgNS43MjY1MjYgMEM1LjkyOTc2MyAwIDYuMTY4ODY3IC0wLjAyMzkxIDYuMzcyMTA1IC0wLjAyMzkxSDcuNjg3MTczQzcuOTAyMzY2IC0wLjAyMzkxIDguMTI5NTE0IDAgOC4zMzI3NTIgMEM4LjQxNjQzOCAwIDguNTQ3OTQ1IDAgOC41NDc5NDUgLTAuMjI3MTQ4QzguNTQ3OTQ1IC0wLjM0NjcgOC40MjgzOTQgLTAuMzQ2NyA4LjMyMDc5NyAtMC4zNDY3QzcuNjAzNDg3IC0wLjM1ODY1NSA3LjU3OTU3NyAtMC40MTg0MzEgNy4zNzYzMzkgLTAuODYwNzcyTDUuNzk4MjU3IC00LjU2Njg3NEw3LjMxNjU2MyAtNi4xOTI3NzdDNy40MzYxMTUgLTYuMzEyMzI5IDcuNzExMDgzIC02LjYxMTIwOCA3LjgxODY4IC02LjczMDc2QzguMzMyNzUyIC03LjI2ODc0MiA4LjgxMDk1OSAtNy43NTg5MDQgOS43NzkzMjggLTcuODE4NjhDOS44OTg4NzkgLTcuODMwNjM1IDEwLjAxODQzMSAtNy44MzA2MzUgMTAuMDE4NDMxIC04LjAzMzg3M0MxMC4wMTg0MzEgLTguMTY1MzggOS45MTA4MzQgLTguMTY1MzggOS44NjMwMTQgLTguMTY1MzhDOS42OTU2NDEgLTguMTY1MzggOS41MTYzMTQgLTguMTQxNDY5IDkuMzQ4OTQxIC04LjE0MTQ2OUg4Ljc5OTAwNEM4LjQxNjQzOCAtOC4xNDE0NjkgNy45OTgwMDcgLTguMTY1MzggNy42MjczOTcgLTguMTY1MzhDNy41NDM3MTEgLTguMTY1MzggNy40MDAyNDkgLTguMTY1MzggNy40MDAyNDkgLTcuOTUwMTg3QzcuNDAwMjQ5IC03LjgzMDYzNSA3LjQ4MzkzNSAtNy44MTg2OCA3LjU1NTY2NiAtNy44MTg2OEM3Ljc0Njk0OSAtNy43OTQ3NyA3Ljk1MDE4NyAtNy42OTkxMjggNy45NTAxODcgLTcuNDcxOThMNy45MzgyMzIgLTcuNDQ4MDdDNy45MjYyNzYgLTcuMzY0Mzg0IDcuOTAyMzY2IC03LjI0NDgzMiA3Ljc3MDg1OSAtNy4xMDEzN0w1LjY3ODcwNSAtNC44NTM3OThaJyBpZD0nZzQtODgnLz4KPHBhdGggZD0nTTcuMDI5NjM5IC02LjgzODM1Nkw3LjMwNDYwOCAtNy4xMTMzMjVDNy44MzA2MzUgLTcuNjUxMzA4IDguMjcyOTc2IC03Ljc4MjgxNCA4LjY5MTQwNyAtNy44MTg2OEM4LjgyMjkxNCAtNy44MzA2MzUgOC45MzA1MTEgLTcuODQyNTkgOC45MzA1MTEgLTguMDQ1ODI4QzguOTMwNTExIC04LjE2NTM4IDguODEwOTU5IC04LjE2NTM4IDguNzg3MDQ5IC04LjE2NTM4QzguNjQzNTg3IC04LjE2NTM4IDguNDg4MTY5IC04LjE0MTQ2OSA4LjM0NDcwNyAtOC4xNDE0NjlINy44NTQ1NDVDNy41MDc4NDYgLTguMTQxNDY5IDcuMTM3MjM1IC04LjE2NTM4IDYuODAyNDkxIC04LjE2NTM4QzYuNzE4ODA0IC04LjE2NTM4IDYuNTg3Mjk4IC04LjE2NTM4IDYuNTg3Mjk4IC03LjkzODIzMkM2LjU4NzI5OCAtNy44MzA2MzUgNi43MDY4NDkgLTcuODE4NjggNi43NDI3MTUgLTcuODE4NjhDNy4xMDEzNyAtNy43OTQ3NyA3LjEwMTM3IC03LjYxNTQ0MiA3LjEwMTM3IC03LjU0MzcxMUM3LjEwMTM3IC03LjQxMjIwNCA3LjAwNTcyOSAtNy4yMzI4NzcgNi43NjY2MjUgLTYuOTU3OTA4TDMuOTIxMjk1IC0zLjY5NDE0N0wyLjU3MDM2MSAtNy4zMjg1MThDMi40OTg2MyAtNy40OTU4OSAyLjQ5ODYzIC03LjUxOTgwMSAyLjQ5ODYzIC03LjU0MzcxMUMyLjQ5ODYzIC03Ljc5NDc3IDIuOTg4NzkyIC03LjgxODY4IDMuMTMyMjU0IC03LjgxODY4UzMuNDA3MjIzIC03LjgxODY4IDMuNDA3MjIzIC04LjAzMzg3M0MzLjQwNzIyMyAtOC4xNjUzOCAzLjI5OTYyNiAtOC4xNjUzOCAzLjIyNzg5NSAtOC4xNjUzOEMzLjAyNDY1OCAtOC4xNjUzOCAyLjc4NTU1NCAtOC4xNDE0NjkgMi41ODIzMTYgLTguMTQxNDY5SDEuMjU1MjkzQzEuMDQwMSAtOC4xNDE0NjkgMC44MTI5NTEgLTguMTY1MzggMC42MDk3MTQgLTguMTY1MzhDMC41MjYwMjcgLTguMTY1MzggMC4zOTQ1MjEgLTguMTY1MzggMC4zOTQ1MjEgLTcuOTM4MjMyQzAuMzk0NTIxIC03LjgxODY4IDAuNTAyMTE3IC03LjgxODY4IDAuNjgxNDQ1IC03LjgxODY4QzEuMjY3MjQ4IC03LjgxODY4IDEuMzc0ODQ0IC03LjcxMTA4MyAxLjQ4MjQ0MSAtNy40MzYxMTVMMi45NjQ4ODIgLTMuNDU1MDQ0QzIuOTc2ODM3IC0zLjQxOTE3OCAzLjAxMjcwMiAtMy4yODc2NzEgMy4wMTI3MDIgLTMuMjUxODA2UzIuNDI2ODk5IC0wLjg2MDc3MiAyLjM5MTAzNCAtMC43NDEyMkMyLjI5NTM5MiAtMC40MTg0MzEgMi4xNzU4NDEgLTAuMzU4NjU1IDEuNDEwNzEgLTAuMzQ2N0MxLjIwNzQ3MiAtMC4zNDY3IDEuMTExODMxIC0wLjM0NjcgMS4xMTE4MzEgLTAuMTE5NTUyQzEuMTExODMxIDAgMS4yNDMzMzcgMCAxLjI3OTIwMyAwQzEuNDk0Mzk2IDAgMS43NDU0NTUgLTAuMDIzOTEgMS45NzI2MDMgLTAuMDIzOTFIMy4zODMzMTNDMy41OTg1MDYgLTAuMDIzOTEgMy44NDk1NjQgMCA0LjA2NDc1NyAwQzQuMTQ4NDQzIDAgNC4yOTE5MDUgMCA0LjI5MTkwNSAtMC4yMTUxOTNDNC4yOTE5MDUgLTAuMzQ2NyA0LjIwODIxOSAtMC4zNDY3IDQuMDA0OTgxIC0wLjM0NjdDMy4yNjM3NjEgLTAuMzQ2NyAzLjI2Mzc2MSAtMC40MzAzODYgMy4yNjM3NjEgLTAuNTYxODkzQzMuMjYzNzYxIC0wLjY0NTU3OSAzLjM1OTQwMiAtMS4wMjgxNDQgMy40MTkxNzggLTEuMjY3MjQ4TDMuODQ5NTY0IC0yLjk4ODc5MkMzLjkyMTI5NSAtMy4yMzk4NTEgMy45MjEyOTUgLTMuMjYzNzYxIDQuMDI4ODkyIC0zLjM4MzMxM0w3LjAyOTYzOSAtNi44MzgzNTZaJyBpZD0nZzQtODknLz4KPHBhdGggZD0nTTguMzY4NjE4IC03Ljc5NDc3QzguNDQwMzQ5IC03Ljg3ODQ1NiA4LjUwMDEyNSAtNy45NTAxODcgOC41MDAxMjUgLTguMDY5NzM4QzguNTAwMTI1IC04LjE1MzQyNSA4LjQ4ODE2OSAtOC4xNjUzOCA4LjIxMzIgLTguMTY1MzhIMy4yNzU3MTZDMy4wMDA3NDcgLTguMTY1MzggMi45ODg3OTIgLTguMTUzNDI1IDIuOTE3MDYxIC03LjkzODIzMkwyLjI1OTUyNyAtNS43ODYzMDFDMi4yMjM2NjEgLTUuNjY2NzUgMi4yMjM2NjEgLTUuNjQyODM5IDIuMjIzNjYxIC01LjYxODkyOUMyLjIyMzY2MSAtNS41NzExMDggMi4yNTk1MjcgLTUuNDk5Mzc3IDIuMzQzMjEzIC01LjQ5OTM3N0MyLjQzODg1NCAtNS40OTkzNzcgMi40NjI3NjUgLTUuNTQ3MTk4IDIuNTEwNTg1IC01LjcwMjYxNUMyLjk1MjkyNyAtNi45OTM3NzMgMy41Mzg3MyAtNy44MTg2OCA1LjQyNzY0NiAtNy44MTg2OEg3LjM4ODI5NEwwLjgzNjg2MiAtMC40MDY0NzZDMC43MjkyNjUgLTAuMjc0OTY5IDAuNjgxNDQ1IC0wLjIyNzE0OCAwLjY4MTQ0NSAtMC4wOTU2NDFDMC42ODE0NDUgMCAwLjc0MTIyIDAgMC45NjgzNjkgMEg2LjA3MzIyNUM2LjM0ODE5NCAwIDYuMzYwMTQ5IC0wLjAxMTk1NSA2LjQzMTg4IC0wLjIyNzE0OEw3LjI2ODc0MiAtMi44NjkyNEM3LjI4MDY5NyAtMi45MDUxMDYgNy4zMDQ2MDggLTIuOTg4NzkyIDcuMzA0NjA4IC0zLjAzNjYxM0M3LjMwNDYwOCAtMy4wOTYzODkgNy4yNTY3ODcgLTMuMTU2MTY0IDcuMTg1MDU2IC0zLjE1NjE2NEM3LjA4OTQxNSAtMy4xNTYxNjQgNy4wNzc0NiAtMy4xNDQyMDkgNi45ODE4MTggLTIuODQ1MzNDNi40Nzk3MDEgLTEuMzAzMTEzIDUuOTUzNjc0IC0wLjM3MDYxIDMuODczNDc0IC0wLjM3MDYxSDEuODA1MjNMOC4zNjg2MTggLTcuNzk0NzdaJyBpZD0nZzQtOTAnLz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMS00OCcvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2c2LTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnNi00MScvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzYtNjEnLz4KPHBhdGggZD0nTTEuNzMzNDk5IDYuOTgxODE4QzEuNzMzNDk5IDcuMTczMTAxIDEuNzMzNDk5IDcuNDI0MTU5IDEuOTg0NTU4IDcuNDI0MTU5QzIuMjQ3NTcyIDcuNDI0MTU5IDIuMjQ3NTcyIDcuMTg1MDU2IDIuMjQ3NTcyIDYuOTgxODE4VjAuMTkxMjgzQzIuMjQ3NTcyIDAgMi4yNDc1NzIgLTAuMjUxMDU5IDEuOTk2NTEzIC0wLjI1MTA1OUMxLjczMzQ5OSAtMC4yNTEwNTkgMS43MzM0OTkgLTAuMDExOTU1IDEuNzMzNDk5IDAuMTkxMjgzVjYuOTgxODE4Wk00LjM4NzU0NyA2Ljk4MTgxOEM0LjM4NzU0NyA3LjE3MzEwMSA0LjM4NzU0NyA3LjQyNDE1OSA0LjYzODYwNSA3LjQyNDE1OUM0LjkwMTYxOSA3LjQyNDE1OSA0LjkwMTYxOSA3LjE4NTA1NiA0LjkwMTYxOSA2Ljk4MTgxOFYwLjE5MTI4M0M0LjkwMTYxOSAwIDQuOTAxNjE5IC0wLjI1MTA1OSA0LjY1MDU2IC0wLjI1MTA1OUM0LjM4NzU0NyAtMC4yNTEwNTkgNC4zODc1NDcgLTAuMDExOTU1IDQuMzg3NTQ3IDAuMTkxMjgzVjYuOTgxODE4WicgaWQ9J2cwLTEzJy8+CjxwYXRoIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgMC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IDAuNTczODQ4IDEyLjAyNjg5OSAwLjc0MTIyIDEyLjEzNDQ5NiAwLjc2NTEzMUMxMi43ODAwNzUgMC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMwLjcyOTI2NSAwIDAuNzE3MzEgMC4wMTE5NTUgMC42ODE0NDUgMC4wODM2ODZDMC42Njk0ODkgMC4xMTk1NTIgMC42Njk0ODkgMC4zNDY3IDAuNjY5NDg5IDAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TDAuODAwOTk2IDE2LjM5MDUzNUMwLjY4MTQ0NSAxNi41MzM5OTggMC42ODE0NDUgMTYuNTkzNzczIDAuNjgxNDQ1IDE2LjYwNTcyOUMwLjY4MTQ0NSAxNi43MzcyMzUgMC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJyBpZD0nZzAtODgnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2c1LTQ5Jy8+CjxwYXRoIGQ9J001LjgyNjE1MiAtMi42NTQwNDdDNS45NDU3MDQgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjY1NDA0NyA2LjEwNTEwNiAtMi44MzczNlM1LjkxMzgyMyAtMy4wMjA2NzIgNS43OTQyNzEgLTMuMDIwNjcySDAuNzgxMDcxQzAuNjYxNTE5IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMy4wMjA2NzIgMC40NzAyMzcgLTIuODM3MzZTMC42Mjk2MzkgLTIuNjU0MDQ3IDAuNzQ5MTkxIC0yLjY1NDA0N0g1LjgyNjE1MlpNNS43OTQyNzEgLTAuOTY0Mzg0QzUuOTEzODIzIC0wLjk2NDM4NCA2LjEwNTEwNiAtMC45NjQzODQgNi4xMDUxMDYgLTEuMTQ3Njk2UzUuOTQ1NzA0IC0xLjMzMTAwOSA1LjgyNjE1MiAtMS4zMzEwMDlIMC43NDkxOTFDMC42Mjk2MzkgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjMzMTAwOSAwLjQ3MDIzNyAtMS4xNDc2OTZTMC42NjE1MTkgLTAuOTY0Mzg0IDAuNzgxMDcxIC0wLjk2NDM4NEg1Ljc5NDI3MVonIGlkPSdnNS02MScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnNS05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzUtOTMnLz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjc0OTY4OUM4LjA4MTY5NCAtMi43NDk2ODkgOC4yOTY4ODcgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjk4ODc5MlM4LjA4MTY5NCAtMy4yMjc4OTUgNy44Nzg0NTYgLTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzIgLTMuMjI3ODk1IDAuOTkyMjc5IC0zLjIyNzg5NSAwLjk5MjI3OSAtMi45ODg3OTJTMS4yMDc0NzIgLTIuNzQ5Njg5IDEuNDEwNzEgLTIuNzQ5Njg5SDcuODc4NDU2WicgaWQ9J2cyLTAnLz4KPHBhdGggZD0nTTIuMDU2Mjg5IC04LjU1OTlDMi4wNTYyODkgLTguNzUxMTgzIDIuMDU2Mjg5IC04Ljk2NjM3NiAxLjgxNzE4NiAtOC45NjYzNzZTMS41NzgwODIgLTguNzAzMzYyIDEuNTc4MDgyIC04LjUyNDAzNVYyLjU0NjQ1MUMxLjU3ODA4MiAyLjczNzczMyAxLjU3ODA4MiAyLjk4ODc5MiAxLjgxNzE4NiAyLjk4ODc5MlMyLjA1NjI4OSAyLjc3MzU5OSAyLjA1NjI4OSAyLjU4MjMxNlYtOC41NTk5Wk00LjM4NzU0NyAtOC41MjQwMzVDNC4zODc1NDcgLTguNzE1MzE4IDQuMzg3NTQ3IC04Ljk2NjM3NiA0LjE0ODQ0MyAtOC45NjYzNzZTMy45MDkzNCAtOC43NTExODMgMy45MDkzNCAtOC41NTk5VjIuNTgyMzE2QzMuOTA5MzQgMi43NzM1OTkgMy45MDkzNCAyLjk4ODc5MiA0LjE0ODQ0MyAyLjk4ODc5MlM0LjM4NzU0NyAyLjcyNTc3OCA0LjM4NzU0NyAyLjU0NjQ1MVYtOC41MjQwMzVaJyBpZD0nZzItMTA3Jy8+CjxwYXRoIGQ9J002LjM0NDIwOSAtNS4zOTU3NjZDNi4zNTIxNzkgLTUuNDI3NjQ2IDYuMzY4MTIgLTUuNDc1NDY3IDYuMzY4MTIgLTUuNTE1MzE4QzYuMzY4MTIgLTUuNTcxMTA4IDYuMzIwMjk5IC01LjYxMDk1OSA2LjI2NDUwOCAtNS42MTA5NTlTNi4xODQ4MDcgLTUuNTg3MDQ5IDYuMTIxMDQ2IC01LjUxNTMxOEw1LjU2MzEzOCAtNC45MDE2MTlDNS40OTE0MDcgLTUuMDA1MjMgNS4wNjg5OTEgLTUuNjEwOTU5IDQuMTM2NDg4IC01LjYxMDk1OUMyLjI4NzQyMiAtNS42MTA5NTkgMC40MjI0MTYgLTMuODk3Mzg1IDAuNDIyNDE2IC0yLjA2NDI1OUMwLjQyMjQxNiAtMC42Nzc0NiAxLjQ3NDQ3MSAwLjE2NzM3MiAyLjc0MTcxOSAwLjE2NzM3MkMzLjc4NTgwMyAwLjE2NzM3MiA0LjY3MDQ4NiAtMC40NzAyMzcgNS4xMDA4NzIgLTEuMDkxOTA1QzUuMzYzODg1IC0xLjQ4MjQ0MSA1LjQ2NzQ5NyAtMS44NjUwMDYgNS40Njc0OTcgLTEuOTEyODI3QzUuNDY3NDk3IC0xLjk4NDU1OCA1LjQxOTY3NiAtMi4wMTY0MzggNS4zNDc5NDUgLTIuMDE2NDM4QzUuMjUyMzA0IC0yLjAxNjQzOCA1LjIzNjM2NCAtMS45NzY1ODggNS4yMTI0NTMgLTEuODg4OTE3QzQuODc3NzA5IC0wLjc4OTA0MSAzLjgwMTc0MyAtMC4wOTU2NDEgMi44NDUzMyAtMC4wOTU2NDFDMi4wMzIzNzkgLTAuMDk1NjQxIDEuMTc5NTc3IC0wLjU3Mzg0OCAxLjE3OTU3NyAtMS43OTMyNzVDMS4xNzk1NzcgLTIuMDQ4MzE5IDEuMjY3MjQ4IC0zLjM3OTMyOCAyLjE1MTkzIC00LjM3NTU5MkMyLjc0OTY4OSAtNS4wNDUwODEgMy41NjI2NCAtNS4zNDc5NDUgNC4xOTIyNzkgLTUuMzQ3OTQ1QzUuMTk2NTEzIC01LjM0Nzk0NSA1LjYxMDk1OSAtNC41NDI5NjQgNS42MTA5NTkgLTMuNzg1ODAzQzUuNjEwOTU5IC0zLjY3NDIyMiA1LjU3OTA3OCAtMy41MjI3OSA1LjU3OTA3OCAtMy40MjcxNDhDNS41NzkwNzggLTMuMzIzNTM3IDUuNjgyNjkgLTMuMzIzNTM3IDUuNzE0NTcgLTMuMzIzNTM3QzUuODE4MTgyIC0zLjMyMzUzNyA1LjgzNDEyMiAtMy4zNTU0MTcgNS44NjYwMDIgLTMuNDk4ODc5TDYuMzQ0MjA5IC01LjM5NTc2NlonIGlkPSdnMy02NycvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzMtMTA3Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSc0NC44MzE4OTYnIHhsaW5rOmhyZWY9JyNnNC04OScgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9JzU2Ljg4MTcyMScgeGxpbms6aHJlZj0nI2cyLTAnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSc2OC44MzY4ODInIHhsaW5rOmhyZWY9JyNnNC04OCcgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9Jzc5LjQ5MTk5JyB4bGluazpocmVmPScjZzQtMTInIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSc4Ni43NjMyNjEnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSc5Ni4wNjE2NTknIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9JzEwOC40ODcxNCcgeGxpbms6aHJlZj0nI2cwLTEzJyB5PSc3OS4zNjg5MDEnLz4KPHVzZSB4PScxMDguNDg3MTQnIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nODYuNTQyMDc1Jy8+Cjx1c2UgeD0nMTA4LjQ4NzE0JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzkzLjcxNTI0OScvPgo8dXNlIHg9JzEwOC40ODcxNCcgeGxpbms6aHJlZj0nI2cwLTEzJyB5PScxMDAuODg4NDIzJy8+Cjx1c2UgeD0nMTA4LjQ4NzE0JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzEwOC4wNjE1OTYnLz4KPHVzZSB4PScxMTUuMTI4OTInIHhsaW5rOmhyZWY9JyNnNC04OScgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9JzEyNy4xNzg3NDYnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScxMDAuMjkwNjI4Jy8+Cjx1c2UgeD0nMTQ0LjQ2ODg4MScgeGxpbms6aHJlZj0nI2czLTY3JyB5PSc4NS4zNDY2MDcnLz4KPHVzZSB4PScxMzkuMTMzOTA3JyB4bGluazpocmVmPScjZzAtODgnIHk9Jzg4LjkzMzE2MycvPgo8dXNlIHg9JzE0MC4wNDcwNjInIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzExNC4zOTMzODInLz4KPHVzZSB4PScxNDQuNjY4Njc4JyB4bGluazpocmVmPScjZzUtNjEnIHk9JzExNC4zOTMzODInLz4KPHVzZSB4PScxNTEuMjU1MTg1JyB4bGluazpocmVmPScjZzUtNDknIHk9JzExNC4zOTMzODInLz4KPHVzZSB4PScxNTguMzk1MDIxJyB4bGluazpocmVmPScjZzQtOTAnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PScxNjYuNDA3Mjc2JyB4bGluazpocmVmPScjZzUtOTEnIHk9JzEwMi4xNTAzMzgnLz4KPHVzZSB4PScxNjguNzU5NicgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nMTAyLjE1MDMzOCcvPgo8dXNlIHg9JzE3My4zODEyMTUnIHhsaW5rOmhyZWY9JyNnNS05MycgeT0nMTAyLjE1MDMzOCcvPgo8dXNlIHg9JzE4MS42NDg5MzMnIHhsaW5rOmhyZWY9JyNnNC02MCcgeT0nOTEuNzc1OTQyJy8+Cjx1c2UgeD0nMTk0LjA3NDQxNCcgeGxpbms6aHJlZj0nI2c0LTkwJyB5PSc5MS43NzU5NDInLz4KPHVzZSB4PScyMDIuMDg2NjY5JyB4bGluazpocmVmPScjZzUtOTEnIHk9JzkzLjYzNTY1MicvPgo8dXNlIHg9JzIwNC40Mzg5OTMnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzkzLjYzNTY1MicvPgo8dXNlIHg9JzIwOS4wNjA2MDgnIHhsaW5rOmhyZWY9JyNnNS05MycgeT0nOTMuNjM1NjUyJy8+Cjx1c2UgeD0nMjExLjkxMTA2NCcgeGxpbms6aHJlZj0nI2c0LTU5JyB5PSc5MS43NzU5NDInLz4KPHVzZSB4PScyMTcuMTU1MjIzJyB4bGluazpocmVmPScjZzQtODknIHk9JzkxLjc3NTk0MicvPgo8dXNlIHg9JzIyOS44NjkyMTUnIHhsaW5rOmhyZWY9JyNnNC02MicgeT0nOTEuNzc1OTQyJy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2NS43Njg0MTQnIHg9JzE3Ny40MjcxODUnIHk9Jzk3LjA2Mjc0MicvPgo8dXNlIHg9JzE3Ny40MjcxODUnIHhsaW5rOmhyZWY9JyNnNC02MCcgeT0nMTA4LjQ5MTI5Jy8+Cjx1c2UgeD0nMTg5Ljg1MjY2NicgeGxpbms6aHJlZj0nI2c0LTkwJyB5PScxMDguNDkxMjknLz4KPHVzZSB4PScxOTcuODY0OTIxJyB4bGluazpocmVmPScjZzUtOTEnIHk9JzExMC4zNTEnLz4KPHVzZSB4PScyMDAuMjE3MjQ1JyB4bGluazpocmVmPScjZzMtMTA3JyB5PScxMTAuMzUxJy8+Cjx1c2UgeD0nMjA0LjgzODg2JyB4bGluazpocmVmPScjZzUtOTMnIHk9JzExMC4zNTEnLz4KPHVzZSB4PScyMDcuNjg5MzE2JyB4bGluazpocmVmPScjZzQtNTknIHk9JzEwOC40OTEyOScvPgo8dXNlIHg9JzIxMi45MzM0NzUnIHhsaW5rOmhyZWY9JyNnNC05MCcgeT0nMTA4LjQ5MTI5Jy8+Cjx1c2UgeD0nMjIwLjk0NTczJyB4bGluazpocmVmPScjZzUtOTEnIHk9JzExMC4zNTEnLz4KPHVzZSB4PScyMjMuMjk4MDU0JyB4bGluazpocmVmPScjZzMtMTA3JyB5PScxMTAuMzUxJy8+Cjx1c2UgeD0nMjI3LjkxOTY3JyB4bGluazpocmVmPScjZzUtOTMnIHk9JzExMC4zNTEnLz4KPHVzZSB4PScyMzQuMDkwOTU1JyB4bGluazpocmVmPScjZzQtNjInIHk9JzEwOC40OTEyOScvPgo8dXNlIHg9JzI0NC4zOTExMTInIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nNzkuMzY4OTAxJy8+Cjx1c2UgeD0nMjQ0LjM5MTExMicgeGxpbms6aHJlZj0nI2cwLTEzJyB5PSc4Ni41NDIwNzUnLz4KPHVzZSB4PScyNDQuMzkxMTEyJyB4bGluazpocmVmPScjZzAtMTMnIHk9JzkzLjcxNTI0OScvPgo8dXNlIHg9JzI0NC4zOTExMTInIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nMTAwLjg4ODQyMycvPgo8dXNlIHg9JzI0NC4zOTExMTInIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nMTA4LjA2MTU5NicvPgo8dXNlIHg9JzI1NC4zNTM2OTknIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9JzI2Ni43NzkxOCcgeGxpbms6aHJlZj0nI2cwLTEzJyB5PSc3OS4zNjg5MDEnLz4KPHVzZSB4PScyNjYuNzc5MTgnIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nODYuNTQyMDc1Jy8+Cjx1c2UgeD0nMjY2Ljc3OTE4JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzkzLjcxNTI0OScvPgo8dXNlIHg9JzI2Ni43NzkxOCcgeGxpbms6aHJlZj0nI2cwLTEzJyB5PScxMDAuODg4NDIzJy8+Cjx1c2UgeD0nMjY2Ljc3OTE4JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzEwOC4wNjE1OTYnLz4KPHVzZSB4PScyNzMuNDIwOTYnIHhsaW5rOmhyZWY9JyNnNC04OScgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9JzI4NS40NzA3ODYnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScxMDAuMjkwNjI4Jy8+Cjx1c2UgeD0nMzAyLjc2MDkyMScgeGxpbms6aHJlZj0nI2czLTY3JyB5PSc4NS4zNDY2MDcnLz4KPHVzZSB4PScyOTcuNDI1OTQ3JyB4bGluazpocmVmPScjZzAtODgnIHk9Jzg4LjkzMzE2MycvPgo8dXNlIHg9JzI5OC4zMzkxMDMnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzExNC4zOTMzODInLz4KPHVzZSB4PSczMDIuOTYwNzE4JyB4bGluazpocmVmPScjZzUtNjEnIHk9JzExNC4zOTMzODInLz4KPHVzZSB4PSczMDkuNTQ3MjI1JyB4bGluazpocmVmPScjZzUtNDknIHk9JzExNC4zOTMzODInLz4KPHVzZSB4PSczMTQuNjk0NTY0JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSczMTkuMjQ2ODg5JyB4bGluazpocmVmPScjZzQtODgnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSczMjkuOTAxOTk3JyB4bGluazpocmVmPScjZzQtODAnIHk9JzEwMC4yOTA2MjgnLz4KPHVzZSB4PSczMzkuMDczMDk2JyB4bGluazpocmVmPScjZzEtNDgnIHk9Jzk1LjM1NDQ0MicvPgo8dXNlIHg9JzM0MS44NjgxNzEnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTAwLjI5MDYyOCcvPgo8dXNlIHg9JzM0Ni40MjA0OTcnIHhsaW5rOmhyZWY9JyNnNS05MScgeT0nMTAyLjE1MDMzOCcvPgo8dXNlIHg9JzM0OC43NzI4MjEnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzEwMi4xNTAzMzgnLz4KPHVzZSB4PSczNTMuMzk0NDM2JyB4bGluazpocmVmPScjZzUtOTMnIHk9JzEwMi4xNTAzMzgnLz4KPHVzZSB4PSczNzMuNTE4OTk3JyB4bGluazpocmVmPScjZzQtNjAnIHk9JzkxLjc3NTk0MicvPgo8dXNlIHg9JzM4NS45NDQ0NzgnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTEuNzc1OTQyJy8+Cjx1c2UgeD0nMzkwLjQ5NjgwMycgeGxpbms6aHJlZj0nI2c0LTg4JyB5PSc5MS43NzU5NDInLz4KPHVzZSB4PSc0MDEuMTUxOTExJyB4bGluazpocmVmPScjZzQtODAnIHk9JzkxLjc3NTk0MicvPgo8dXNlIHg9JzQxMC4zMjMwMScgeGxpbms6aHJlZj0nI2cxLTQ4JyB5PSc4Ny40Mzc1MDUnLz4KPHVzZSB4PSc0MTMuMTE4MDg1JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzkxLjc3NTk0MicvPgo8dXNlIHg9JzQxNy42NzA0MTEnIHhsaW5rOmhyZWY9JyNnNS05MScgeT0nOTMuNjM1NjUyJy8+Cjx1c2UgeD0nNDIwLjAyMjczNScgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nOTMuNjM1NjUyJy8+Cjx1c2UgeD0nNDI0LjY0NDM1MScgeGxpbms6aHJlZj0nI2c1LTkzJyB5PSc5My42MzU2NTInLz4KPHVzZSB4PSc0MjcuNDk0ODA2JyB4bGluazpocmVmPScjZzQtNTknIHk9JzkxLjc3NTk0MicvPgo8dXNlIHg9JzQzMi43Mzg5NjUnIHhsaW5rOmhyZWY9JyNnNC04OScgeT0nOTEuNzc1OTQyJy8+Cjx1c2UgeD0nNDQ1LjQ1Mjk1NycgeGxpbms6aHJlZj0nI2c0LTYyJyB5PSc5MS43NzU5NDInLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzExMy4xOTU3NTUnIHg9JzM1Ny40NDA0MDYnIHk9Jzk3LjA2Mjc0MicvPgo8dXNlIHg9JzM1Ny40NDA0MDYnIHhsaW5rOmhyZWY9JyNnNC02MCcgeT0nMTA4LjQ5MTI5Jy8+Cjx1c2UgeD0nMzY5Ljg2NTg4NycgeGxpbms6aHJlZj0nI2c2LTQwJyB5PScxMDguNDkxMjknLz4KPHVzZSB4PSczNzQuNDE4MjEzJyB4bGluazpocmVmPScjZzQtODgnIHk9JzEwOC40OTEyOScvPgo8dXNlIHg9JzM4NS4wNzMzMicgeGxpbms6aHJlZj0nI2c0LTgwJyB5PScxMDguNDkxMjknLz4KPHVzZSB4PSczOTQuMjQ0NDE5JyB4bGluazpocmVmPScjZzEtNDgnIHk9JzEwNS4wMzc1ODInLz4KPHVzZSB4PSczOTcuMDM5NDk1JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzEwOC40OTEyOScvPgo8dXNlIHg9JzQwMS41OTE4MicgeGxpbms6aHJlZj0nI2c1LTkxJyB5PScxMTAuMzUxJy8+Cjx1c2UgeD0nNDAzLjk0NDE0NCcgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nMTEwLjM1MScvPgo8dXNlIHg9JzQwOC41NjU3NicgeGxpbms6aHJlZj0nI2c1LTkzJyB5PScxMTAuMzUxJy8+Cjx1c2UgeD0nNDExLjQxNjIxNicgeGxpbms6aHJlZj0nI2c0LTU5JyB5PScxMDguNDkxMjknLz4KPHVzZSB4PSc0MTYuNjYwMzc0JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEwOC40OTEyOScvPgo8dXNlIHg9JzQyMS4yMTI3JyB4bGluazpocmVmPScjZzQtODgnIHk9JzEwOC40OTEyOScvPgo8dXNlIHg9JzQzMS44Njc4MDgnIHhsaW5rOmhyZWY9JyNnNC04MCcgeT0nMTA4LjQ5MTI5Jy8+Cjx1c2UgeD0nNDQxLjAzODkwNycgeGxpbms6aHJlZj0nI2cxLTQ4JyB5PScxMDUuMDM3NTgyJy8+Cjx1c2UgeD0nNDQzLjgzMzk4MicgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxMDguNDkxMjknLz4KPHVzZSB4PSc0NDguMzg2MzA4JyB4bGluazpocmVmPScjZzUtOTEnIHk9JzExMC4zNTEnLz4KPHVzZSB4PSc0NTAuNzM4NjMyJyB4bGluazpocmVmPScjZzMtMTA3JyB5PScxMTAuMzUxJy8+Cjx1c2UgeD0nNDU1LjM2MDI0NycgeGxpbms6aHJlZj0nI2c1LTkzJyB5PScxMTAuMzUxJy8+Cjx1c2UgeD0nNDYxLjUzMTUzMicgeGxpbms6aHJlZj0nI2c0LTYyJyB5PScxMDguNDkxMjknLz4KPHVzZSB4PSc0NzEuODMxNjc1JyB4bGluazpocmVmPScjZzAtMTMnIHk9Jzc5LjM2ODkwMScvPgo8dXNlIHg9JzQ3MS44MzE2NzUnIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nODYuNTQyMDc1Jy8+Cjx1c2UgeD0nNDcxLjgzMTY3NScgeGxpbms6aHJlZj0nI2cwLTEzJyB5PSc5My43MTUyNDknLz4KPHVzZSB4PSc0NzEuODMxNjc1JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzEwMC44ODg0MjMnLz4KPHVzZSB4PSc0NzEuODMxNjc1JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzEwOC4wNjE1OTYnLz4KPC9nPgo8L3N2Zz4=)
Algorithme A1 : Arbre de décision optimisé pour les régressions linéaires
On dipose qu’un nuage de points avec
 et
et  . Les points sont
triés selon une dimension. On note X la matrice composée
des lignes
. Les points sont
triés selon une dimension. On note X la matrice composée
des lignes  et le vecteur colonne
et le vecteur colonne
 .
Il existe une matrice
.
Il existe une matrice  telle que
et avec D une matrice diagonale.
On note
telle que
et avec D une matrice diagonale.
On note  la matrice constituée des lignes
a à b. On calcule :
la matrice constituée des lignes
a à b. On calcule :
![MSE(X, y, a, b) = \norm{Y - \sum_{k=1}^{C}(X_{a..b}P')_{[k]}
\frac{<(X_{a..b}P')_{[k]},Y>}{<(X_{a..b}P')_{[k]},(X_{a..b}P')_{[k]}>}}^2](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMzguNTExMzc1cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTcuNDk2MjU3IDc4LjcwNDg1NyAzNTAuNzYwOTQ4IDM4LjUxMTM3NScgd2lkdGg9JzM1MC43NjA5NDhwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMi4xMTIwOCAtMy43Nzc4MzNDMi4xNTE5MyAtMy44ODE0NDUgMi4xODM4MTEgLTMuOTM3MjM1IDIuMTgzODExIC00LjAxNjkzNkMyLjE4MzgxMSAtNC4yNzk5NSAxLjk0NDcwNyAtNC40NTUyOTMgMS43MjE1NDQgLTQuNDU1MjkzQzEuNDAyNzQgLTQuNDU1MjkzIDEuMzE1MDY4IC00LjE3NjMzOSAxLjI4MzE4OCAtNC4wNjQ3NTdMMC4yNzA5ODQgLTAuNjI5NjM5QzAuMjM5MTAzIC0wLjUzMzk5OCAwLjIzOTEwMyAtMC41MTAwODcgMC4yMzkxMDMgLTAuNTAyMTE3QzAuMjM5MTAzIC0wLjQzMDM4NiAwLjI4NjkyNCAtMC40MTQ0NDYgMC4zNjY2MjUgLTAuMzkwNTM1QzAuNTEwMDg3IC0wLjMyNjc3NSAwLjUyNjAyNyAtMC4zMjY3NzUgMC41NDE5NjggLTAuMzI2Nzc1QzAuNTY1ODc4IC0wLjMyNjc3NSAwLjYxMzY5OSAtMC4zMjY3NzUgMC42Njk0ODkgLTAuNDYyMjY3TDIuMTEyMDggLTMuNzc3ODMzWicgaWQ9J2cxLTQ4Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzYtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c2LTQxJy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnNi02MScvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzQtNTknLz4KPHBhdGggZD0nTTcuODc4NDU2IC01LjgyMjE2N0M4LjA5MzY0OSAtNS45MTc4MDggOC4xMTc1NTkgLTYuMDAxNDk0IDguMTE3NTU5IC02LjA3MzIyNUM4LjExNzU1OSAtNi4yMDQ3MzIgOC4wMjE5MTggLTYuMzAwMzc0IDcuODkwNDExIC02LjMwMDM3NEM3Ljg2NjUwMSAtNi4zMDAzNzQgNy44NTQ1NDUgLTYuMjg4NDE4IDcuNjg3MTczIC02LjIxNjY4N0wxLjIxOTQyNyAtMy4yMzk4NTFDMS4wMDQyMzQgLTMuMTQ0MjA5IDAuOTgwMzI0IC0zLjA2MDUyMyAwLjk4MDMyNCAtMi45ODg3OTJDMC45ODAzMjQgLTIuOTA1MTA2IDAuOTkyMjc5IC0yLjgzMzM3NSAxLjIxOTQyNyAtMi43MjU3NzhMNy42ODcxNzMgMC4yNTEwNTlDNy44NDI1OSAwLjMyMjc5IDcuODY2NTAxIDAuMzM0NzQ1IDcuODkwNDExIDAuMzM0NzQ1QzguMDIxOTE4IDAuMzM0NzQ1IDguMTE3NTU5IDAuMjM5MTAzIDguMTE3NTU5IDAuMTA3NTk3QzguMTE3NTU5IDAuMDM1ODY2IDguMDkzNjQ5IC0wLjA0NzgyMSA3Ljg3ODQ1NiAtMC4xNDM0NjJMMS43MjE1NDQgLTIuOTc2ODM3TDcuODc4NDU2IC01LjgyMjE2N1onIGlkPSdnNC02MCcvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzI1Nzc4QzguMTA1NjA0IC0yLjgzMzM3NSA4LjExNzU1OSAtMi45MDUxMDYgOC4xMTc1NTkgLTIuOTg4NzkyQzguMTE3NTU5IC0zLjA2MDUyMyA4LjA5MzY0OSAtMy4xNDQyMDkgNy44Nzg0NTYgLTMuMjM5ODUxTDEuNDEwNzEgLTYuMjE2Njg3QzEuMjU1MjkzIC02LjI4ODQxOCAxLjIzMTM4MiAtNi4zMDAzNzQgMS4yMDc0NzIgLTYuMzAwMzc0QzEuMDY0MDEgLTYuMzAwMzc0IDAuOTgwMzI0IC02LjE4MDgyMiAwLjk4MDMyNCAtNi4wODUxODFDMC45ODAzMjQgLTUuOTQxNzE5IDEuMDc1OTY1IC01Ljg5Mzg5OCAxLjIzMTM4MiAtNS44MjIxNjdMNy4zNzYzMzkgLTIuOTg4NzkyTDEuMjE5NDI3IC0wLjE0MzQ2MkMwLjk4MDMyNCAtMC4wMzU4NjYgMC45ODAzMjQgMC4wNDc4MjEgMC45ODAzMjQgMC4xMTk1NTJDMC45ODAzMjQgMC4yMTUxOTMgMS4wNjQwMSAwLjMzNDc0NSAxLjIwNzQ3MiAwLjMzNDc0NUMxLjIzMTM4MiAwLjMzNDc0NSAxLjI0MzMzNyAwLjMyMjc5IDEuNDEwNzEgMC4yNTEwNTlMNy44Nzg0NTYgLTIuNzI1Nzc4WicgaWQ9J2c0LTYyJy8+CjxwYXRoIGQ9J004LjMwODg0MiAtMi43NzM1OTlDOC4zMjA3OTcgLTIuODA5NDY1IDguMzU2NjYzIC0yLjg5MzE1MSA4LjM1NjY2MyAtMi45NDA5NzFDOC4zNTY2NjMgLTMuMDAwNzQ3IDguMzA4ODQyIC0zLjA2MDUyMyA4LjIzNzExMSAtMy4wNjA1MjNDOC4xODkyOSAtMy4wNjA1MjMgOC4xNjUzOCAtMy4wNDg1NjggOC4xMjk1MTQgLTMuMDEyNzAyQzguMTA1NjA0IC0zLjAwMDc0NyA4LjEwNTYwNCAtMi45NzY4MzcgNy45OTgwMDcgLTIuNzM3NzMzQzcuMjkyNjUzIC0xLjA2NDAxIDYuNzc4NTggLTAuMzQ2NyA0Ljg2NTc1MyAtMC4zNDY3SDMuMTIwMjk5QzIuOTUyOTI3IC0wLjM0NjcgMi45MjkwMTYgLTAuMzQ2NyAyLjg1NzI4NSAtMC4zNTg2NTVDMi43MjU3NzggLTAuMzcwNjEgMi43MTM4MjMgLTAuMzk0NTIxIDIuNzEzODIzIC0wLjQ5MDE2MkMyLjcxMzgyMyAtMC41NzM4NDggMi43Mzc3MzMgLTAuNjQ1NTc5IDIuNzYxNjQ0IC0wLjc1MzE3NkwzLjU4NjU1IC00LjA1MjgwMkg0Ljc3MDExMkM1LjcwMjYxNSAtNC4wNTI4MDIgNS43NzQzNDYgLTMuODQ5NTY0IDUuNzc0MzQ2IC0zLjQ5MDkwOUM1Ljc3NDM0NiAtMy4zNzEzNTcgNS43NzQzNDYgLTMuMjYzNzYxIDUuNjkwNjYgLTIuOTA1MTA2QzUuNjY2NzUgLTIuODU3Mjg1IDUuNjU0Nzk1IC0yLjgwOTQ2NSA1LjY1NDc5NSAtMi43NzM1OTlDNS42NTQ3OTUgLTIuNjg5OTEzIDUuNzE0NTcgLTIuNjU0MDQ3IDUuNzg2MzAxIC0yLjY1NDA0N0M1Ljg5Mzg5OCAtMi42NTQwNDcgNS45MDU4NTMgLTIuNzM3NzMzIDUuOTUzNjc0IC0yLjkwNTEwNkw2LjYzNTExOCAtNS42Nzg3MDVDNi42MzUxMTggLTUuNzM4NDgxIDYuNTg3Mjk4IC01Ljc5ODI1NyA2LjUxNTU2NyAtNS43OTgyNTdDNi40MDc5NyAtNS43OTgyNTcgNi4zOTYwMTUgLTUuNzUwNDM2IDYuMzQ4MTk0IC01LjU4MzA2NEM2LjEwOTA5MSAtNC42NjI1MTYgNS44Njk5ODggLTQuMzk5NTAyIDQuODA1OTc4IC00LjM5OTUwMkgzLjY3MDIzN0w0LjQxMTQ1NyAtNy4zNDA0NzNDNC41MTkwNTQgLTcuNzU4OTA0IDQuNTQyOTY0IC03Ljc5NDc3IDUuMDMzMTI2IC03Ljc5NDc3SDYuNzQyNzE1QzguMjEzMiAtNy43OTQ3NyA4LjUxMjA4IC03LjQwMDI0OSA4LjUxMjA4IC02LjQ5MTY1NkM4LjUxMjA4IC02LjQ3OTcwMSA4LjUxMjA4IC02LjE0NDk1NiA4LjQ2NDI1OSAtNS43NTA0MzZDOC40NTIzMDQgLTUuNzAyNjE1IDguNDQwMzQ5IC01LjYzMDg4NCA4LjQ0MDM0OSAtNS42MDY5NzRDOC40NDAzNDkgLTUuNTExMzMzIDguNTAwMTI1IC01LjQ3NTQ2NyA4LjU3MTg1NiAtNS40NzU0NjdDOC42NTU1NDIgLTUuNDc1NDY3IDguNzAzMzYyIC01LjUyMzI4OCA4LjcyNzI3MyAtNS43Mzg0ODFMOC45NzgzMzEgLTcuODMwNjM1QzguOTc4MzMxIC03Ljg2NjUwMSA5LjAwMjI0MiAtNy45ODYwNTIgOS4wMDIyNDIgLTguMDA5OTYzQzkuMDAyMjQyIC04LjE0MTQ2OSA4Ljg5NDY0NSAtOC4xNDE0NjkgOC42Nzk0NTIgLTguMTQxNDY5SDIuODQ1MzNDMi42MTgxODIgLTguMTQxNDY5IDIuNDk4NjMgLTguMTQxNDY5IDIuNDk4NjMgLTcuOTI2Mjc2QzIuNDk4NjMgLTcuNzk0NzcgMi41ODIzMTYgLTcuNzk0NzcgMi43ODU1NTQgLTcuNzk0NzdDMy41MjY3NzUgLTcuNzk0NzcgMy41MjY3NzUgLTcuNzExMDgzIDMuNTI2Nzc1IC03LjU3OTU3N0MzLjUyNjc3NSAtNy41MTk4MDEgMy41MTQ4MTkgLTcuNDcxOTggMy40Nzg5NTQgLTcuMzQwNDczTDEuODY1MDA2IC0wLjg4NDY4MkMxLjc1NzQxIC0wLjQ2NjI1MiAxLjczMzQ5OSAtMC4zNDY3IDAuODk2NjM4IC0wLjM0NjdDMC42Njk0ODkgLTAuMzQ2NyAwLjU0OTkzOCAtMC4zNDY3IDAuNTQ5OTM4IC0wLjEzMTUwN0MwLjU0OTkzOCAwIDAuNjIxNjY5IDAgMC44NjA3NzIgMEg2Ljg2MjI2N0M3LjEyNTI4IDAgNy4xMzcyMzUgLTAuMDExOTU1IDcuMjIwOTIyIC0wLjIwMzIzOEw4LjMwODg0MiAtMi43NzM1OTlaJyBpZD0nZzQtNjknLz4KPHBhdGggZD0nTTEwLjg1NTI5MyAtNy4yOTI2NTNDMTAuOTYyODg5IC03LjY5OTEyOCAxMC45ODY4IC03LjgxODY4IDExLjgzNTYxNiAtNy44MTg2OEMxMi4wNjI3NjUgLTcuODE4NjggMTIuMTcwMzYxIC03LjgxODY4IDEyLjE3MDM2MSAtOC4wNDU4MjhDMTIuMTcwMzYxIC04LjE2NTM4IDEyLjA4NjY3NSAtOC4xNjUzOCAxMS44NTk1MjcgLTguMTY1MzhIMTAuNDI0OTA3QzEwLjEyNjAyNyAtOC4xNjUzOCAxMC4xMTQwNzIgLTguMTUzNDI1IDkuOTgyNTY1IC03Ljk2MjE0Mkw1LjYxODkyOSAtMS4wNjQwMUw0LjcyMjI5MSAtNy45MDIzNjZDNC42ODY0MjYgLTguMTY1MzggNC42NzQ0NzEgLTguMTY1MzggNC4zNjM2MzYgLTguMTY1MzhIMi44ODExOTZDMi42NTQwNDcgLTguMTY1MzggMi41NDY0NTEgLTguMTY1MzggMi41NDY0NTEgLTcuOTM4MjMyQzIuNTQ2NDUxIC03LjgxODY4IDIuNjU0MDQ3IC03LjgxODY4IDIuODMzMzc1IC03LjgxODY4QzMuNTYyNjQgLTcuODE4NjggMy41NjI2NCAtNy43MjMwMzkgMy41NjI2NCAtNy41OTE1MzJDMy41NjI2NCAtNy41Njc2MjEgMy41NjI2NCAtNy40OTU4OSAzLjUxNDgxOSAtNy4zMTY1NjNMMS45ODQ1NTggLTEuMjE5NDI3QzEuODQxMDk2IC0wLjY0NTU3OSAxLjU2NjEyNyAtMC4zODI1NjUgMC43NjUxMzEgLTAuMzQ2N0MwLjcyOTI2NSAtMC4zNDY3IDAuNTg1ODAzIC0wLjMzNDc0NSAwLjU4NTgwMyAtMC4xMzE1MDdDMC41ODU4MDMgMCAwLjY5MzQgMCAwLjc0MTIyIDBDMC45ODAzMjQgMCAxLjU5MDAzNyAtMC4wMjM5MSAxLjgyOTE0MSAtMC4wMjM5MUgyLjQwMjk4OUMyLjU3MDM2MSAtMC4wMjM5MSAyLjc3MzU5OSAwIDIuOTQwOTcxIDBDMy4wMjQ2NTggMCAzLjE1NjE2NCAwIDMuMTU2MTY0IC0wLjIyNzE0OEMzLjE1NjE2NCAtMC4zMzQ3NDUgMy4wMzY2MTMgLTAuMzQ2NyAyLjk4ODc5MiAtMC4zNDY3QzIuNTk0MjcxIC0wLjM1ODY1NSAyLjIxMTcwNiAtMC40MzAzODYgMi4yMTE3MDYgLTAuODYwNzcyQzIuMjExNzA2IC0wLjk4MDMyNCAyLjIxMTcwNiAtMC45OTIyNzkgMi4yNTk1MjcgLTEuMTU5NjUxTDMuOTA5MzQgLTcuNzQ2OTQ5SDMuOTIxMjk1TDQuOTEzNTc0IC0wLjMyMjc5QzQuOTQ5NDQgLTAuMDM1ODY2IDQuOTYxMzk1IDAgNS4wNjg5OTEgMEM1LjIwMDQ5OCAwIDUuMjYwMjc0IC0wLjA5NTY0MSA1LjMyMDA1IC0wLjIwMzIzOEwxMC4xMjYwMjcgLTcuODA2NzI1SDEwLjEzNzk4M0w4LjQwNDQ4MyAtMC44ODQ2ODJDOC4yOTY4ODcgLTAuNDY2MjUyIDguMjcyOTc2IC0wLjM0NjcgNy40MzYxMTUgLTAuMzQ2N0M3LjIwODk2NiAtMC4zNDY3IDcuMDg5NDE1IC0wLjM0NjcgNy4wODk0MTUgLTAuMTMxNTA3QzcuMDg5NDE1IDAgNy4xOTcwMTEgMCA3LjI2ODc0MiAwQzcuNDcxOTggMCA3LjcxMTA4MyAtMC4wMjM5MSA3LjkxNDMyMSAtMC4wMjM5MUg5LjMyNTAzMUM5LjUyODI2OSAtMC4wMjM5MSA5Ljc3OTMyOCAwIDkuOTgyNTY1IDBDMTAuMDc4MjA3IDAgMTAuMjA5NzE0IDAgMTAuMjA5NzE0IC0wLjIyNzE0OEMxMC4yMDk3MTQgLTAuMzQ2NyAxMC4xMDIxMTcgLTAuMzQ2NyA5LjkyMjc5IC0wLjM0NjdDOS4xOTM1MjQgLTAuMzQ2NyA5LjE5MzUyNCAtMC40NDIzNDEgOS4xOTM1MjQgLTAuNTYxODkzQzkuMTkzNTI0IC0wLjU3Mzg0OCA5LjE5MzUyNCAtMC42NTc1MzQgOS4yMTc0MzUgLTAuNzUzMTc2TDEwLjg1NTI5MyAtNy4yOTI2NTNaJyBpZD0nZzQtNzcnLz4KPHBhdGggZD0nTTMuNTM4NzMgLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExIC0zLjgwMTc0MyA4Ljg0NjgyNCAtNS4wMjExNzEgOC44NDY4MjQgLTYuMzg0MDZDOC44NDY4MjQgLTcuMzE2NTYzIDguMDU3NzgzIC04LjE2NTM4IDYuNTUxNDMyIC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3IC04LjE2NTM4IDIuNTIyNTQgLTguMTY1MzggMi41MjI1NCAtNy45MzgyMzJDMi41MjI1NCAtNy44MTg2OCAyLjYzMDEzNyAtNy44MTg2OCAyLjgwOTQ2NSAtNy44MTg2OEMzLjUzODczIC03LjgxODY4IDMuNTM4NzMgLTcuNzIzMDM5IDMuNTM4NzMgLTcuNTkxNTMyQzMuNTM4NzMgLTcuNTY3NjIxIDMuNTM4NzMgLTcuNDk1ODkgMy40OTA5MDkgLTcuMzE2NTYzTDEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjY2OTQ4OSAwIDAuNzQxMjIgMEMwLjk2ODM2OSAwIDEuMjA3NDcyIC0wLjAyMzkxIDEuNDM0NjIgLTAuMDIzOTFIMi44MzMzNzVDMy4wNjA1MjMgLTAuMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4IC0wLjIyNzE0OEMzLjc2NTg3OCAtMC4zNDY3IDMuNjU4MjgxIC0wLjM0NjcgMy40Nzg5NTQgLTAuMzQ2N0MyLjc2MTY0NCAtMC4zNDY3IDIuNzQ5Njg5IC0wLjQzMDM4NiAyLjc0OTY4OSAtMC41NDk5MzhDMi43NDk2ODkgLTAuNjA5NzE0IDIuNzYxNjQ0IC0wLjY5MzQgMi43NzM1OTkgLTAuNzUzMTc2TDMuNTM4NzMgLTMuODAxNzQzWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4yMDQ3MzJDNy4xMDEzNyAtNy44MTg2OCA3Ljg0MjU5IC03LjUzMTc1NiA3Ljg0MjU5IC02LjYzNTExOEM3Ljg0MjU5IC02LjMyNDI4NCA3LjY4NzE3MyAtNS4zMDgwOTUgNy4xMzcyMzUgLTQuNzU4MTU3QzYuOTMzOTk4IC00LjU0Mjk2NCA2LjM2MDE0OSAtNC4wODg2NjcgNS4yNzIyMjkgLTQuMDg4NjY3SDMuNTg2NTVMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2c0LTgwJy8+CjxwYXRoIGQ9J003LjU5MTUzMiAtOC4zMDg4NDJDNy41OTE1MzIgLTguNDE2NDM4IDcuNTA3ODQ2IC04LjQxNjQzOCA3LjQ4MzkzNSAtOC40MTY0MzhDNy40MzYxMTUgLTguNDE2NDM4IDcuNDI0MTU5IC04LjQwNDQ4MyA3LjI4MDY5NyAtOC4yMjUxNTZDNy4yMDg5NjYgLTguMTQxNDY5IDYuNzE4ODA0IC03LjUxOTgwMSA2LjcwNjg0OSAtNy41MDc4NDZDNi4zMTIzMjkgLTguMjg0OTMyIDUuNTIzMjg4IC04LjQxNjQzOCA1LjAyMTE3MSAtOC40MTY0MzhDMy41MDI4NjQgLTguNDE2NDM4IDIuMTI4MDIgLTcuMDI5NjM5IDIuMTI4MDIgLTUuNjc4NzA1QzIuMTI4MDIgLTQuNzgyMDY3IDIuNjY2MDAyIC00LjI1NjA0IDMuMjUxODA2IC00LjA1MjgwMkMzLjM4MzMxMyAtNC4wMDQ5ODEgNC4wODg2NjcgLTMuODEzNjk5IDQuNDQ3MzIzIC0zLjczMDAxMkM1LjA1NzAzNiAtMy41NjI2NCA1LjIxMjQ1MyAtMy41MTQ4MTkgNS40NjM1MTIgLTMuMjUxODA2QzUuNTExMzMzIC0zLjE5MjAzIDUuNzUwNDM2IC0yLjkxNzA2MSA1Ljc1MDQzNiAtMi4zNTUxNjhDNS43NTA0MzYgLTEuMjQzMzM3IDQuNzIyMjkxIC0wLjA5NTY0MSAzLjUyNjc3NSAtMC4wOTU2NDFDMi41NDY0NTEgLTAuMDk1NjQxIDEuNDU4NTMxIC0wLjUxNDA3MiAxLjQ1ODUzMSAtMS44NTMwNTFDMS40NTg1MzEgLTIuMDgwMTk5IDEuNTA2MzUxIC0yLjM2NzEyMyAxLjU0MjIxNyAtMi40ODY2NzVDMS41NDIyMTcgLTIuNTIyNTQgMS41NTQxNzIgLTIuNTgyMzE2IDEuNTU0MTcyIC0yLjYwNjIyN0MxLjU1NDE3MiAtMi42NTQwNDcgMS41MzAyNjIgLTIuNzEzODIzIDEuNDM0NjIgLTIuNzEzODIzQzEuMzI3MDI0IC0yLjcxMzgyMyAxLjMxNTA2OCAtMi42ODk5MTMgMS4yNjcyNDggLTIuNDg2Njc1TDAuNjU3NTM0IC0wLjAzNTg2NkMwLjY1NzUzNCAtMC4wMjM5MSAwLjYwOTcxNCAwLjEzMTUwNyAwLjYwOTcxNCAwLjE0MzQ2MkMwLjYwOTcxNCAwLjI1MTA1OSAwLjcwNTM1NSAwLjI1MTA1OSAwLjcyOTI2NSAwLjI1MTA1OUMwLjc3NzA4NiAwLjI1MTA1OSAwLjc4OTA0MSAwLjIzOTEwMyAwLjkzMjUwMyAwLjA1OTc3NkwxLjQ4MjQ0MSAtMC42NTc1MzRDMS43NjkzNjUgLTAuMjI3MTQ4IDIuMzkxMDM0IDAuMjUxMDU5IDMuNTAyODY0IDAuMjUxMDU5QzUuMDQ1MDgxIDAuMjUxMDU5IDYuNDU1NzkxIC0xLjI0MzMzNyA2LjQ1NTc5MSAtMi43Mzc3MzNDNi40NTU3OTEgLTMuMjM5ODUxIDYuMzM2MjM5IC0zLjY4MjE5MiA1Ljg4MTk0MyAtNC4xMjQ1MzNDNS42MzA4ODQgLTQuMzc1NTkyIDUuNDE1NjkxIC00LjQzNTM2NyA0LjMxNTgxNiAtNC43MjIyOTFDMy41MTQ4MTkgLTQuOTM3NDg0IDMuNDA3MjIzIC00Ljk3MzM1IDMuMTkyMDMgLTUuMTY0NjMzQzIuOTg4NzkyIC01LjM2Nzg3IDIuODMzMzc1IC01LjY1NDc5NSAyLjgzMzM3NSAtNi4wNjEyN0MyLjgzMzM3NSAtNy4wNjU1MDQgMy44NDk1NjQgLTguMDkzNjQ5IDQuOTg1MzA1IC04LjA5MzY0OUM2LjE1NjkxMiAtOC4wOTM2NDkgNi43MDY4NDkgLTcuMzc2MzM5IDYuNzA2ODQ5IC02LjI0MDU5OEM2LjcwNjg0OSAtNS45Mjk3NjMgNi42NDcwNzMgLTUuNjA2OTc0IDYuNjQ3MDczIC01LjU1OTE1M0M2LjY0NzA3MyAtNS40NTE1NTcgNi43NDI3MTUgLTUuNDUxNTU3IDYuNzc4NTggLTUuNDUxNTU3QzYuODg2MTc3IC01LjQ1MTU1NyA2Ljg5ODEzMiAtNS40ODc0MjIgNi45NDU5NTMgLTUuNjc4NzA1TDcuNTkxNTMyIC04LjMwODg0MlonIGlkPSdnNC04MycvPgo8cGF0aCBkPSdNNS42Nzg3MDUgLTQuODUzNzk4TDQuNTU0OTE5IC03LjQ3MTk4QzQuNzEwMzM2IC03Ljc1ODkwNCA1LjA2ODk5MSAtNy44MDY3MjUgNS4yMTI0NTMgLTcuODE4NjhDNS4yODQxODQgLTcuODE4NjggNS40MTU2OTEgLTcuODMwNjM1IDUuNDE1NjkxIC04LjAzMzg3M0M1LjQxNTY5MSAtOC4xNjUzOCA1LjMwODA5NSAtOC4xNjUzOCA1LjIzNjM2NCAtOC4xNjUzOEM1LjAzMzEyNiAtOC4xNjUzOCA0Ljc5NDAyMiAtOC4xNDE0NjkgNC41OTA3ODUgLTguMTQxNDY5SDMuODk3Mzg1QzMuMTY4MTIgLTguMTQxNDY5IDIuNjQyMDkyIC04LjE2NTM4IDIuNjMwMTM3IC04LjE2NTM4QzIuNTM0NDk2IC04LjE2NTM4IDIuNDE0OTQ0IC04LjE2NTM4IDIuNDE0OTQ0IC03LjkzODIzMkMyLjQxNDk0NCAtNy44MTg2OCAyLjUyMjU0IC03LjgxODY4IDIuNjc3OTU4IC03LjgxODY4QzMuMzcxMzU3IC03LjgxODY4IDMuNDE5MTc4IC03LjY5OTEyOCAzLjUzODczIC03LjQxMjIwNEw0Ljk2MTM5NSAtNC4wODg2NjdMMi4zNjcxMjMgLTEuMzE1MDY4QzEuOTM2NzM3IC0wLjg0ODgxNyAxLjQyMjY2NSAtMC4zOTQ1MjEgMC41Mzc5ODMgLTAuMzQ2N0MwLjM5NDUyMSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjExOTU1MkMwLjI5ODg3OSAtMC4wODM2ODYgMC4zMTA4MzQgMCAwLjQ0MjM0MSAwQzAuNjA5NzE0IDAgMC43ODkwNDEgLTAuMDIzOTEgMC45NTY0MTMgLTAuMDIzOTFIMS41MTgzMDZDMS45MDA4NzIgLTAuMDIzOTEgMi4zMTkzMDMgMCAyLjY4OTkxMyAwQzIuNzczNTk5IDAgMi45MTcwNjEgMCAyLjkxNzA2MSAtMC4yMTUxOTNDMi45MTcwNjEgLTAuMzM0NzQ1IDIuODMzMzc1IC0wLjM0NjcgMi43NjE2NDQgLTAuMzQ2N0MyLjUyMjU0IC0wLjM3MDYxIDIuMzY3MTIzIC0wLjUwMjExNyAyLjM2NzEyMyAtMC42OTM0QzIuMzY3MTIzIC0wLjg5NjYzOCAyLjUxMDU4NSAtMS4wNDAxIDIuODU3Mjg1IC0xLjM5ODc1NUwzLjkyMTI5NSAtMi41NTg0MDZDNC4xODQzMDkgLTIuODMzMzc1IDQuODE3OTMzIC0zLjUyNjc3NSA1LjA4MDk0NiAtMy43ODk3ODhMNi4zMzYyMzkgLTAuODQ4ODE3QzYuMzQ4MTk0IC0wLjgyNDkwNyA2LjM5NjAxNSAtMC43MDUzNTUgNi4zOTYwMTUgLTAuNjkzNEM2LjM5NjAxNSAtMC41ODU4MDMgNi4xMzMwMDEgLTAuMzcwNjEgNS43NTA0MzYgLTAuMzQ2N0M1LjY3ODcwNSAtMC4zNDY3IDUuNTQ3MTk4IC0wLjMzNDc0NSA1LjU0NzE5OCAtMC4xMTk1NTJDNS41NDcxOTggMCA1LjY2Njc1IDAgNS43MjY1MjYgMEM1LjkyOTc2MyAwIDYuMTY4ODY3IC0wLjAyMzkxIDYuMzcyMTA1IC0wLjAyMzkxSDcuNjg3MTczQzcuOTAyMzY2IC0wLjAyMzkxIDguMTI5NTE0IDAgOC4zMzI3NTIgMEM4LjQxNjQzOCAwIDguNTQ3OTQ1IDAgOC41NDc5NDUgLTAuMjI3MTQ4QzguNTQ3OTQ1IC0wLjM0NjcgOC40MjgzOTQgLTAuMzQ2NyA4LjMyMDc5NyAtMC4zNDY3QzcuNjAzNDg3IC0wLjM1ODY1NSA3LjU3OTU3NyAtMC40MTg0MzEgNy4zNzYzMzkgLTAuODYwNzcyTDUuNzk4MjU3IC00LjU2Njg3NEw3LjMxNjU2MyAtNi4xOTI3NzdDNy40MzYxMTUgLTYuMzEyMzI5IDcuNzExMDgzIC02LjYxMTIwOCA3LjgxODY4IC02LjczMDc2QzguMzMyNzUyIC03LjI2ODc0MiA4LjgxMDk1OSAtNy43NTg5MDQgOS43NzkzMjggLTcuODE4NjhDOS44OTg4NzkgLTcuODMwNjM1IDEwLjAxODQzMSAtNy44MzA2MzUgMTAuMDE4NDMxIC04LjAzMzg3M0MxMC4wMTg0MzEgLTguMTY1MzggOS45MTA4MzQgLTguMTY1MzggOS44NjMwMTQgLTguMTY1MzhDOS42OTU2NDEgLTguMTY1MzggOS41MTYzMTQgLTguMTQxNDY5IDkuMzQ4OTQxIC04LjE0MTQ2OUg4Ljc5OTAwNEM4LjQxNjQzOCAtOC4xNDE0NjkgNy45OTgwMDcgLTguMTY1MzggNy42MjczOTcgLTguMTY1MzhDNy41NDM3MTEgLTguMTY1MzggNy40MDAyNDkgLTguMTY1MzggNy40MDAyNDkgLTcuOTUwMTg3QzcuNDAwMjQ5IC03LjgzMDYzNSA3LjQ4MzkzNSAtNy44MTg2OCA3LjU1NTY2NiAtNy44MTg2OEM3Ljc0Njk0OSAtNy43OTQ3NyA3Ljk1MDE4NyAtNy42OTkxMjggNy45NTAxODcgLTcuNDcxOThMNy45MzgyMzIgLTcuNDQ4MDdDNy45MjYyNzYgLTcuMzY0Mzg0IDcuOTAyMzY2IC03LjI0NDgzMiA3Ljc3MDg1OSAtNy4xMDEzN0w1LjY3ODcwNSAtNC44NTM3OThaJyBpZD0nZzQtODgnLz4KPHBhdGggZD0nTTcuMDI5NjM5IC02LjgzODM1Nkw3LjMwNDYwOCAtNy4xMTMzMjVDNy44MzA2MzUgLTcuNjUxMzA4IDguMjcyOTc2IC03Ljc4MjgxNCA4LjY5MTQwNyAtNy44MTg2OEM4LjgyMjkxNCAtNy44MzA2MzUgOC45MzA1MTEgLTcuODQyNTkgOC45MzA1MTEgLTguMDQ1ODI4QzguOTMwNTExIC04LjE2NTM4IDguODEwOTU5IC04LjE2NTM4IDguNzg3MDQ5IC04LjE2NTM4QzguNjQzNTg3IC04LjE2NTM4IDguNDg4MTY5IC04LjE0MTQ2OSA4LjM0NDcwNyAtOC4xNDE0NjlINy44NTQ1NDVDNy41MDc4NDYgLTguMTQxNDY5IDcuMTM3MjM1IC04LjE2NTM4IDYuODAyNDkxIC04LjE2NTM4QzYuNzE4ODA0IC04LjE2NTM4IDYuNTg3Mjk4IC04LjE2NTM4IDYuNTg3Mjk4IC03LjkzODIzMkM2LjU4NzI5OCAtNy44MzA2MzUgNi43MDY4NDkgLTcuODE4NjggNi43NDI3MTUgLTcuODE4NjhDNy4xMDEzNyAtNy43OTQ3NyA3LjEwMTM3IC03LjYxNTQ0MiA3LjEwMTM3IC03LjU0MzcxMUM3LjEwMTM3IC03LjQxMjIwNCA3LjAwNTcyOSAtNy4yMzI4NzcgNi43NjY2MjUgLTYuOTU3OTA4TDMuOTIxMjk1IC0zLjY5NDE0N0wyLjU3MDM2MSAtNy4zMjg1MThDMi40OTg2MyAtNy40OTU4OSAyLjQ5ODYzIC03LjUxOTgwMSAyLjQ5ODYzIC03LjU0MzcxMUMyLjQ5ODYzIC03Ljc5NDc3IDIuOTg4NzkyIC03LjgxODY4IDMuMTMyMjU0IC03LjgxODY4UzMuNDA3MjIzIC03LjgxODY4IDMuNDA3MjIzIC04LjAzMzg3M0MzLjQwNzIyMyAtOC4xNjUzOCAzLjI5OTYyNiAtOC4xNjUzOCAzLjIyNzg5NSAtOC4xNjUzOEMzLjAyNDY1OCAtOC4xNjUzOCAyLjc4NTU1NCAtOC4xNDE0NjkgMi41ODIzMTYgLTguMTQxNDY5SDEuMjU1MjkzQzEuMDQwMSAtOC4xNDE0NjkgMC44MTI5NTEgLTguMTY1MzggMC42MDk3MTQgLTguMTY1MzhDMC41MjYwMjcgLTguMTY1MzggMC4zOTQ1MjEgLTguMTY1MzggMC4zOTQ1MjEgLTcuOTM4MjMyQzAuMzk0NTIxIC03LjgxODY4IDAuNTAyMTE3IC03LjgxODY4IDAuNjgxNDQ1IC03LjgxODY4QzEuMjY3MjQ4IC03LjgxODY4IDEuMzc0ODQ0IC03LjcxMTA4MyAxLjQ4MjQ0MSAtNy40MzYxMTVMMi45NjQ4ODIgLTMuNDU1MDQ0QzIuOTc2ODM3IC0zLjQxOTE3OCAzLjAxMjcwMiAtMy4yODc2NzEgMy4wMTI3MDIgLTMuMjUxODA2UzIuNDI2ODk5IC0wLjg2MDc3MiAyLjM5MTAzNCAtMC43NDEyMkMyLjI5NTM5MiAtMC40MTg0MzEgMi4xNzU4NDEgLTAuMzU4NjU1IDEuNDEwNzEgLTAuMzQ2N0MxLjIwNzQ3MiAtMC4zNDY3IDEuMTExODMxIC0wLjM0NjcgMS4xMTE4MzEgLTAuMTE5NTUyQzEuMTExODMxIDAgMS4yNDMzMzcgMCAxLjI3OTIwMyAwQzEuNDk0Mzk2IDAgMS43NDU0NTUgLTAuMDIzOTEgMS45NzI2MDMgLTAuMDIzOTFIMy4zODMzMTNDMy41OTg1MDYgLTAuMDIzOTEgMy44NDk1NjQgMCA0LjA2NDc1NyAwQzQuMTQ4NDQzIDAgNC4yOTE5MDUgMCA0LjI5MTkwNSAtMC4yMTUxOTNDNC4yOTE5MDUgLTAuMzQ2NyA0LjIwODIxOSAtMC4zNDY3IDQuMDA0OTgxIC0wLjM0NjdDMy4yNjM3NjEgLTAuMzQ2NyAzLjI2Mzc2MSAtMC40MzAzODYgMy4yNjM3NjEgLTAuNTYxODkzQzMuMjYzNzYxIC0wLjY0NTU3OSAzLjM1OTQwMiAtMS4wMjgxNDQgMy40MTkxNzggLTEuMjY3MjQ4TDMuODQ5NTY0IC0yLjk4ODc5MkMzLjkyMTI5NSAtMy4yMzk4NTEgMy45MjEyOTUgLTMuMjYzNzYxIDQuMDI4ODkyIC0zLjM4MzMxM0w3LjAyOTYzOSAtNi44MzgzNTZaJyBpZD0nZzQtODknLz4KPHBhdGggZD0nTTMuNTk4NTA2IC0xLjQyMjY2NUMzLjUzODczIC0xLjIxOTQyNyAzLjUzODczIC0xLjE5NTUxNyAzLjM3MTM1NyAtMC45NjgzNjlDMy4xMDgzNDQgLTAuNjMzNjI0IDIuNTgyMzE2IC0wLjExOTU1MiAyLjAyMDQyMyAtMC4xMTk1NTJDMS41MzAyNjIgLTAuMTE5NTUyIDEuMjU1MjkzIC0wLjU2MTg5MyAxLjI1NTI5MyAtMS4yNjcyNDhDMS4yNTUyOTMgLTEuOTI0NzgyIDEuNjI1OTAzIC0zLjI2Mzc2MSAxLjg1MzA1MSAtMy43NjU4NzhDMi4yNTk1MjcgLTQuNjAyNzQgMi44MjE0MiAtNS4wMzMxMjYgMy4yODc2NzEgLTUuMDMzMTI2QzQuMDc2NzEyIC01LjAzMzEyNiA0LjIzMjEzIC00LjA1MjgwMiA0LjIzMjEzIC0zLjk1NzE2MUM0LjIzMjEzIC0zLjk0NTIwNSA0LjE5NjI2NCAtMy43ODk3ODggNC4xODQzMDkgLTMuNzY1ODc4TDMuNTk4NTA2IC0xLjQyMjY2NVpNNC4zNjM2MzYgLTQuNDgzMTg4QzQuMjMyMTMgLTQuNzk0MDIyIDMuOTA5MzQgLTUuMjcyMjI5IDMuMjg3NjcxIC01LjI3MjIyOUMxLjkzNjczNyAtNS4yNzIyMjkgMC40NzgyMDcgLTMuNTI2Nzc1IDAuNDc4MjA3IC0xLjc1NzQxQzAuNDc4MjA3IC0wLjU3Mzg0OCAxLjE3MTYwNiAwLjExOTU1MiAxLjk4NDU1OCAwLjExOTU1MkMyLjY0MjA5MiAwLjExOTU1MiAzLjIwMzk4NSAtMC4zOTQ1MjEgMy41Mzg3MyAtMC43ODkwNDFDMy42NTgyODEgLTAuMDgzNjg2IDQuMjIwMTc0IDAuMTE5NTUyIDQuNTc4ODI5IDAuMTE5NTUyUzUuMjI0NDA4IC0wLjA5NTY0MSA1LjQzOTYwMSAtMC41MjYwMjdDNS42MzA4ODQgLTAuOTMyNTAzIDUuNzk4MjU3IC0xLjY2MTc2OCA1Ljc5ODI1NyAtMS43MDk1ODlDNS43OTgyNTcgLTEuNzY5MzY1IDUuNzUwNDM2IC0xLjgxNzE4NiA1LjY3ODcwNSAtMS44MTcxODZDNS41NzExMDggLTEuODE3MTg2IDUuNTU5MTUzIC0xLjc1NzQxIDUuNTExMzMzIC0xLjU3ODA4MkM1LjMzMjAwNSAtMC44NzI3MjcgNS4xMDQ4NTcgLTAuMTE5NTUyIDQuNjE0Njk1IC0wLjExOTU1MkM0LjI2Nzk5NSAtMC4xMTk1NTIgNC4yNDQwODUgLTAuNDMwMzg2IDQuMjQ0MDg1IC0wLjY2OTQ4OUM0LjI0NDA4NSAtMC45NDQ0NTggNC4yNzk5NSAtMS4wNzU5NjUgNC4zODc1NDcgLTEuNTQyMjE3QzQuNDcxMjMzIC0xLjg0MTA5NiA0LjUzMTAwOSAtMi4xMDQxMSA0LjYyNjY1IC0yLjQ1MDgwOUM1LjA2ODk5MSAtNC4yNDQwODUgNS4xNzY1ODggLTQuNjc0NDcxIDUuMTc2NTg4IC00Ljc0NjIwMkM1LjE3NjU4OCAtNC45MTM1NzQgNS4wNDUwODEgLTUuMDQ1MDgxIDQuODY1NzUzIC01LjA0NTA4MUM0LjQ4MzE4OCAtNS4wNDUwODEgNC4zODc1NDcgLTQuNjI2NjUgNC4zNjM2MzYgLTQuNDgzMTg4WicgaWQ9J2c0LTk3Jy8+CjxwYXRoIGQ9J00yLjc2MTY0NCAtNy45OTgwMDdDMi43NzM1OTkgLTguMDQ1ODI4IDIuNzk3NTA5IC04LjExNzU1OSAyLjc5NzUwOSAtOC4xNzczMzVDMi43OTc1MDkgLTguMjk2ODg3IDIuNjc3OTU4IC04LjI5Njg4NyAyLjY1NDA0NyAtOC4yOTY4ODdDMi42NDIwOTIgLTguMjk2ODg3IDIuMjExNzA2IC04LjI2MTAyMSAxLjk5NjUxMyAtOC4yMzcxMTFDMS43OTMyNzUgLTguMjI1MTU2IDEuNjEzOTQ4IC04LjIwMTI0NSAxLjM5ODc1NSAtOC4xODkyOUMxLjExMTgzMSAtOC4xNjUzOCAxLjAyODE0NCAtOC4xNTM0MjUgMS4wMjgxNDQgLTcuOTM4MjMyQzEuMDI4MTQ0IC03LjgxODY4IDEuMTQ3Njk2IC03LjgxODY4IDEuMjY3MjQ4IC03LjgxODY4QzEuODc2OTYxIC03LjgxODY4IDEuODc2OTYxIC03LjcxMTA4MyAxLjg3Njk2MSAtNy41OTE1MzJDMS44NzY5NjEgLTcuNTA3ODQ2IDEuNzgxMzIgLTcuMTYxMTQ2IDEuNzMzNDk5IC02Ljk0NTk1M0wxLjQ0NjU3NSAtNS43OTgyNTdDMS4zMjcwMjQgLTUuMzIwMDUgMC42NDU1NzkgLTIuNjA2MjI3IDAuNTk3NzU4IC0yLjM5MTAzNEMwLjUzNzk4MyAtMi4wOTIxNTQgMC41Mzc5ODMgLTEuODg4OTE3IDAuNTM3OTgzIC0xLjczMzQ5OUMwLjUzNzk4MyAtMC41MTQwNzIgMS4yMTk0MjcgMC4xMTk1NTIgMS45OTY1MTMgMC4xMTk1NTJDMy4zODMzMTMgMC4xMTk1NTIgNC44MTc5MzMgLTEuNjYxNzY4IDQuODE3OTMzIC0zLjM5NTI2OEM0LjgxNzkzMyAtNC40OTUxNDMgNC4xOTYyNjQgLTUuMjcyMjI5IDMuMjk5NjI2IC01LjI3MjIyOUMyLjY3Nzk1OCAtNS4yNzIyMjkgMi4xMTYwNjUgLTQuNzU4MTU3IDEuODg4OTE3IC00LjUxOTA1NEwyLjc2MTY0NCAtNy45OTgwMDdaTTIuMDA4NDY4IC0wLjExOTU1MkMxLjYyNTkwMyAtMC4xMTk1NTIgMS4yMDc0NzIgLTAuNDA2NDc2IDEuMjA3NDcyIC0xLjMzODk3OUMxLjIwNzQ3MiAtMS43MzM0OTkgMS4yNDMzMzcgLTEuOTYwNjQ4IDEuNDU4NTMxIC0yLjc5NzUwOUMxLjQ5NDM5NiAtMi45NTI5MjcgMS42ODU2NzkgLTMuNzE4MDU3IDEuNzMzNDk5IC0zLjg3MzQ3NEMxLjc1NzQxIC0zLjk2OTExNiAyLjQ2Mjc2NSAtNS4wMzMxMjYgMy4yNzU3MTYgLTUuMDMzMTI2QzMuODAxNzQzIC01LjAzMzEyNiA0LjA0MDg0NyAtNC41MDcwOTggNC4wNDA4NDcgLTMuODg1NDNDNC4wNDA4NDcgLTMuMzExNTgyIDMuNzA2MTAyIC0xLjk2MDY0OCAzLjQwNzIyMyAtMS4zMzg5NzlDMy4xMDgzNDQgLTAuNjkzNCAyLjU1ODQwNiAtMC4xMTk1NTIgMi4wMDg0NjggLTAuMTE5NTUyWicgaWQ9J2c0LTk4Jy8+CjxwYXRoIGQ9J00zLjE0NDIwOSAxLjMzODk3OUMyLjgyMTQyIDEuNzkzMjc1IDIuMzU1MTY4IDIuMTk5NzUxIDEuNzY5MzY1IDIuMTk5NzUxQzEuNjI1OTAzIDIuMTk5NzUxIDEuMDUyMDU1IDIuMTc1ODQxIDAuODcyNzI3IDEuNjI1OTAzQzAuOTA4NTkzIDEuNjM3ODU4IDAuOTY4MzY5IDEuNjM3ODU4IDAuOTkyMjc5IDEuNjM3ODU4QzEuMzUwOTM0IDEuNjM3ODU4IDEuNTkwMDM3IDEuMzI3MDI0IDEuNTkwMDM3IDEuMDUyMDU1UzEuMzYyODg5IDAuNjgxNDQ1IDEuMTgzNTYyIDAuNjgxNDQ1QzAuOTkyMjc5IDAuNjgxNDQ1IDAuNTczODQ4IDAuODI0OTA3IDAuNTczODQ4IDEuNDEwNzFDMC41NzM4NDggMi4wMjA0MjMgMS4wODc5MiAyLjQzODg1NCAxLjc2OTM2NSAyLjQzODg1NEMyLjk2NDg4MiAyLjQzODg1NCA0LjE3MjM1NCAxLjMzODk3OSA0LjUwNzA5OCAwLjAxMTk1NUw1LjY3ODcwNSAtNC42NTA1NkM1LjY5MDY2IC00LjcxMDMzNiA1LjcxNDU3IC00Ljc4MjA2NyA1LjcxNDU3IC00Ljg1Mzc5OEM1LjcxNDU3IC01LjAzMzEyNiA1LjU3MTEwOCAtNS4xNTI2NzcgNS4zOTE3ODEgLTUuMTUyNjc3QzUuMjg0MTg0IC01LjE1MjY3NyA1LjAzMzEyNiAtNS4xMDQ4NTcgNC45Mzc0ODQgLTQuNzQ2MjAyTDQuMDUyODAyIC0xLjIzMTM4MkMzLjk5MzAyNiAtMS4wMTYxODkgMy45OTMwMjYgLTAuOTkyMjc5IDMuODk3Mzg1IC0wLjg2MDc3MkMzLjY1ODI4MSAtMC41MjYwMjcgMy4yNjM3NjEgLTAuMTE5NTUyIDIuNjg5OTEzIC0wLjExOTU1MkMyLjAyMDQyMyAtMC4xMTk1NTIgMS45NjA2NDggLTAuNzc3MDg2IDEuOTYwNjQ4IC0xLjA5OTg3NUMxLjk2MDY0OCAtMS43ODEzMiAyLjI4MzQzNyAtMi43MDE4NjggMi42MDYyMjcgLTMuNTYyNjRDMi43Mzc3MzMgLTMuOTA5MzQgMi44MDk0NjUgLTQuMDc2NzEyIDIuODA5NDY1IC00LjMxNTgxNkMyLjgwOTQ2NSAtNC44MTc5MzMgMi40NTA4MDkgLTUuMjcyMjI5IDEuODY1MDA2IC01LjI3MjIyOUMwLjc2NTEzMSAtNS4yNzIyMjkgMC4zMjI3OSAtMy41Mzg3MyAwLjMyMjc5IC0zLjQ0MzA4OEMwLjMyMjc5IC0zLjM5NTI2OCAwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NjE4OTMgLTMuMzM1NDkyIDAuNTczODQ4IC0zLjM4MzMxMyAwLjYyMTY2OSAtMy41NTA2ODVDMC45MDg1OTMgLTQuNTU0OTE5IDEuMzYyODg5IC01LjAzMzEyNiAxLjgyOTE0MSAtNS4wMzMxMjZDMS45MzY3MzcgLTUuMDMzMTI2IDIuMTM5OTc1IC01LjAzMzEyNiAyLjEzOTk3NSAtNC42Mzg2MDVDMi4xMzk5NzUgLTQuMzI3NzcxIDIuMDA4NDY4IC0zLjk4MTA3MSAxLjgyOTE0MSAtMy41MjY3NzVDMS4yNDMzMzcgLTEuOTYwNjQ4IDEuMjQzMzM3IC0xLjU2NjEyNyAxLjI0MzMzNyAtMS4yNzkyMDNDMS4yNDMzMzcgLTAuMTQzNDYyIDIuMDU2Mjg5IDAuMTE5NTUyIDIuNjU0MDQ3IDAuMTE5NTUyQzMuMDAwNzQ3IDAuMTE5NTUyIDMuNDMxMTMzIDAuMDExOTU1IDMuODQ5NTY0IC0wLjQzMDM4NkwzLjg2MTUxOSAtMC40MTg0MzFDMy42ODIxOTIgMC4yODY5MjQgMy41NjI2NCAwLjc1MzE3NiAzLjE0NDIwOSAxLjMzODk3OVonIGlkPSdnNC0xMjEnLz4KPHBhdGggZD0nTTEuNzMzNDk5IDYuOTgxODE4QzEuNzMzNDk5IDcuMTczMTAxIDEuNzMzNDk5IDcuNDI0MTU5IDEuOTg0NTU4IDcuNDI0MTU5QzIuMjQ3NTcyIDcuNDI0MTU5IDIuMjQ3NTcyIDcuMTg1MDU2IDIuMjQ3NTcyIDYuOTgxODE4VjAuMTkxMjgzQzIuMjQ3NTcyIDAgMi4yNDc1NzIgLTAuMjUxMDU5IDEuOTk2NTEzIC0wLjI1MTA1OUMxLjczMzQ5OSAtMC4yNTEwNTkgMS43MzM0OTkgLTAuMDExOTU1IDEuNzMzNDk5IDAuMTkxMjgzVjYuOTgxODE4Wk00LjM4NzU0NyA2Ljk4MTgxOEM0LjM4NzU0NyA3LjE3MzEwMSA0LjM4NzU0NyA3LjQyNDE1OSA0LjYzODYwNSA3LjQyNDE1OUM0LjkwMTYxOSA3LjQyNDE1OSA0LjkwMTYxOSA3LjE4NTA1NiA0LjkwMTYxOSA2Ljk4MTgxOFYwLjE5MTI4M0M0LjkwMTYxOSAwIDQuOTAxNjE5IC0wLjI1MTA1OSA0LjY1MDU2IC0wLjI1MTA1OUM0LjM4NzU0NyAtMC4yNTEwNTkgNC4zODc1NDcgLTAuMDExOTU1IDQuMzg3NTQ3IDAuMTkxMjgzVjYuOTgxODE4WicgaWQ9J2cwLTEzJy8+CjxwYXRoIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgMC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IDAuNTczODQ4IDEyLjAyNjg5OSAwLjc0MTIyIDEyLjEzNDQ5NiAwLjc2NTEzMUMxMi43ODAwNzUgMC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMwLjcyOTI2NSAwIDAuNzE3MzEgMC4wMTE5NTUgMC42ODE0NDUgMC4wODM2ODZDMC42Njk0ODkgMC4xMTk1NTIgMC42Njk0ODkgMC4zNDY3IDAuNjY5NDg5IDAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TDAuODAwOTk2IDE2LjM5MDUzNUMwLjY4MTQ0NSAxNi41MzM5OTggMC42ODE0NDUgMTYuNTkzNzczIDAuNjgxNDQ1IDE2LjYwNTcyOUMwLjY4MTQ0NSAxNi43MzcyMzUgMC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJyBpZD0nZzAtODgnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2c1LTQ5Jy8+CjxwYXRoIGQ9J00yLjI0NzU3MiAtMS42MjU5MDNDMi4zNzUwOTMgLTEuNzQ1NDU1IDIuNzA5ODM4IC0yLjAwODQ2OCAyLjgzNzM2IC0yLjEyMDA1QzMuMzMxNTA3IC0yLjU3NDM0NiAzLjgwMTc0MyAtMy4wMTI3MDIgMy44MDE3NDMgLTMuNzM3OTgzQzMuODAxNzQzIC00LjY4NjQyNiAzLjAwNDczMiAtNS4zMDAxMjUgMi4wMDg0NjggLTUuMzAwMTI1QzEuMDUyMDU1IC01LjMwMDEyNSAwLjQyMjQxNiAtNC41NzQ4NDQgMC40MjI0MTYgLTMuODY1NTA0QzAuNDIyNDE2IC0zLjQ3NDk2OSAwLjczMzI1IC0zLjQxOTE3OCAwLjg0NDgzMiAtMy40MTkxNzhDMS4wMTIyMDQgLTMuNDE5MTc4IDEuMjU5Mjc4IC0zLjUzODczIDEuMjU5Mjc4IC0zLjg0MTU5NEMxLjI1OTI3OCAtNC4yNTYwNCAwLjg2MDc3MiAtNC4yNTYwNCAwLjc2NTEzMSAtNC4yNTYwNEMwLjk5NjI2NCAtNC44Mzc4NTggMS41MzAyNjIgLTUuMDM3MTExIDEuOTIwNzk3IC01LjAzNzExMUMyLjY2MjAxNyAtNS4wMzcxMTEgMy4wNDQ1ODMgLTQuNDA3NDcyIDMuMDQ0NTgzIC0zLjczNzk4M0MzLjA0NDU4MyAtMi45MDkwOTEgMi40NjI3NjUgLTIuMzAzMzYyIDEuNTIyMjkxIC0xLjMzODk3OUwwLjUxODA1NyAtMC4zMDI4NjRDMC40MjI0MTYgLTAuMjE1MTkzIDAuNDIyNDE2IC0wLjE5OTI1MyAwLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMgLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2IC0xLjI2NzI0OCAzLjQ2Njk5OSAtMC44Njg3NDIgMy4zNzEzNTcgLTAuNzE3MzFDMy4zMjM1MzcgLTAuNjUzNTQ5IDIuNzE3ODA4IC0wLjY1MzU0OSAyLjU5MDI4NiAtMC42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzIgLTEuNjI1OTAzWicgaWQ9J2c1LTUwJy8+CjxwYXRoIGQ9J001LjgyNjE1MiAtMi42NTQwNDdDNS45NDU3MDQgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjY1NDA0NyA2LjEwNTEwNiAtMi44MzczNlM1LjkxMzgyMyAtMy4wMjA2NzIgNS43OTQyNzEgLTMuMDIwNjcySDAuNzgxMDcxQzAuNjYxNTE5IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMy4wMjA2NzIgMC40NzAyMzcgLTIuODM3MzZTMC42Mjk2MzkgLTIuNjU0MDQ3IDAuNzQ5MTkxIC0yLjY1NDA0N0g1LjgyNjE1MlpNNS43OTQyNzEgLTAuOTY0Mzg0QzUuOTEzODIzIC0wLjk2NDM4NCA2LjEwNTEwNiAtMC45NjQzODQgNi4xMDUxMDYgLTEuMTQ3Njk2UzUuOTQ1NzA0IC0xLjMzMTAwOSA1LjgyNjE1MiAtMS4zMzEwMDlIMC43NDkxOTFDMC42Mjk2MzkgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjMzMTAwOSAwLjQ3MDIzNyAtMS4xNDc2OTZTMC42NjE1MTkgLTAuOTY0Mzg0IDAuNzgxMDcxIC0wLjk2NDM4NEg1Ljc5NDI3MVonIGlkPSdnNS02MScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnNS05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzUtOTMnLz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjc0OTY4OUM4LjA4MTY5NCAtMi43NDk2ODkgOC4yOTY4ODcgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjk4ODc5MlM4LjA4MTY5NCAtMy4yMjc4OTUgNy44Nzg0NTYgLTMuMjI3ODk1SDEuNDEwNzFDMS4yMDc0NzIgLTMuMjI3ODk1IDAuOTkyMjc5IC0zLjIyNzg5NSAwLjk5MjI3OSAtMi45ODg3OTJTMS4yMDc0NzIgLTIuNzQ5Njg5IDEuNDEwNzEgLTIuNzQ5Njg5SDcuODc4NDU2WicgaWQ9J2cyLTAnLz4KPHBhdGggZD0nTTEuNjE3OTMzIC0wLjQzODM1NkMxLjYxNzkzMyAtMC43MDkzNCAxLjM5NDc3IC0wLjg4NDY4MiAxLjE3OTU3NyAtMC44ODQ2ODJDMC45MjQ1MzMgLTAuODg0NjgyIDAuNzMzMjUgLTAuNjc3NDYgMC43MzMyNSAtMC40NDYzMjZDMC43MzMyNSAtMC4xNzUzNDIgMC45NTY0MTMgMCAxLjE3MTYwNiAwQzEuNDI2NjUgMCAxLjYxNzkzMyAtMC4yMDcyMjMgMS42MTc5MzMgLTAuNDM4MzU2WicgaWQ9J2czLTU4Jy8+CjxwYXRoIGQ9J002LjM0NDIwOSAtNS4zOTU3NjZDNi4zNTIxNzkgLTUuNDI3NjQ2IDYuMzY4MTIgLTUuNDc1NDY3IDYuMzY4MTIgLTUuNTE1MzE4QzYuMzY4MTIgLTUuNTcxMTA4IDYuMzIwMjk5IC01LjYxMDk1OSA2LjI2NDUwOCAtNS42MTA5NTlTNi4xODQ4MDcgLTUuNTg3MDQ5IDYuMTIxMDQ2IC01LjUxNTMxOEw1LjU2MzEzOCAtNC45MDE2MTlDNS40OTE0MDcgLTUuMDA1MjMgNS4wNjg5OTEgLTUuNjEwOTU5IDQuMTM2NDg4IC01LjYxMDk1OUMyLjI4NzQyMiAtNS42MTA5NTkgMC40MjI0MTYgLTMuODk3Mzg1IDAuNDIyNDE2IC0yLjA2NDI1OUMwLjQyMjQxNiAtMC42Nzc0NiAxLjQ3NDQ3MSAwLjE2NzM3MiAyLjc0MTcxOSAwLjE2NzM3MkMzLjc4NTgwMyAwLjE2NzM3MiA0LjY3MDQ4NiAtMC40NzAyMzcgNS4xMDA4NzIgLTEuMDkxOTA1QzUuMzYzODg1IC0xLjQ4MjQ0MSA1LjQ2NzQ5NyAtMS44NjUwMDYgNS40Njc0OTcgLTEuOTEyODI3QzUuNDY3NDk3IC0xLjk4NDU1OCA1LjQxOTY3NiAtMi4wMTY0MzggNS4zNDc5NDUgLTIuMDE2NDM4QzUuMjUyMzA0IC0yLjAxNjQzOCA1LjIzNjM2NCAtMS45NzY1ODggNS4yMTI0NTMgLTEuODg4OTE3QzQuODc3NzA5IC0wLjc4OTA0MSAzLjgwMTc0MyAtMC4wOTU2NDEgMi44NDUzMyAtMC4wOTU2NDFDMi4wMzIzNzkgLTAuMDk1NjQxIDEuMTc5NTc3IC0wLjU3Mzg0OCAxLjE3OTU3NyAtMS43OTMyNzVDMS4xNzk1NzcgLTIuMDQ4MzE5IDEuMjY3MjQ4IC0zLjM3OTMyOCAyLjE1MTkzIC00LjM3NTU5MkMyLjc0OTY4OSAtNS4wNDUwODEgMy41NjI2NCAtNS4zNDc5NDUgNC4xOTIyNzkgLTUuMzQ3OTQ1QzUuMTk2NTEzIC01LjM0Nzk0NSA1LjYxMDk1OSAtNC41NDI5NjQgNS42MTA5NTkgLTMuNzg1ODAzQzUuNjEwOTU5IC0zLjY3NDIyMiA1LjU3OTA3OCAtMy41MjI3OSA1LjU3OTA3OCAtMy40MjcxNDhDNS41NzkwNzggLTMuMzIzNTM3IDUuNjgyNjkgLTMuMzIzNTM3IDUuNzE0NTcgLTMuMzIzNTM3QzUuODE4MTgyIC0zLjMyMzUzNyA1LjgzNDEyMiAtMy4zNTU0MTcgNS44NjYwMDIgLTMuNDk4ODc5TDYuMzQ0MjA5IC01LjM5NTc2NlonIGlkPSdnMy02NycvPgo8cGF0aCBkPSdNMy4xMjQyODQgLTMuMDM2NjEzQzMuMDUyNTUzIC0zLjE3MjEwNSAyLjgyMTQyIC0zLjUxNDgxOSAyLjMzNTI0MyAtMy41MTQ4MTlDMS4zODY4IC0zLjUxNDgxOSAwLjM0MjcxNSAtMi40MDY5NzQgMC4zNDI3MTUgLTEuMjI3Mzk3QzAuMzQyNzE1IC0wLjM5ODUwNiAwLjg3NjcxMiAwLjA3OTcwMSAxLjQ5MDQxMSAwLjA3OTcwMUMyLjAwMDQ5OCAwLjA3OTcwMSAyLjQzODg1NCAtMC4zMjY3NzUgMi41ODIzMTYgLTAuNDg2MTc3QzIuNzI1Nzc4IDAuMDYzNzYxIDMuMjY3NzQ2IDAuMDc5NzAxIDMuMzYzMzg3IDAuMDc5NzAxQzMuNzMwMDEyIDAuMDc5NzAxIDMuOTEzMzI1IC0wLjIyMzE2MyAzLjk3NzA4NiAtMC4zNTg2NTVDNC4xMzY0ODggLTAuNjQ1NTc5IDQuMjQ4MDcgLTEuMTA3ODQ2IDQuMjQ4MDcgLTEuMTM5NzI2QzQuMjQ4MDcgLTEuMTg3NTQ3IDQuMjE2MTg5IC0xLjI0MzMzNyA0LjEyMDU0OCAtMS4yNDMzMzdTNC4wMDg5NjYgLTEuMTk1NTE3IDMuOTYxMTQ2IC0wLjk5NjI2NEMzLjg0OTU2NCAtMC41NTc5MDggMy42OTgxMzIgLTAuMTQzNDYyIDMuMzg3Mjk4IC0wLjE0MzQ2MkMzLjIwMzk4NSAtMC4xNDM0NjIgMy4xMzIyNTQgLTAuMjk0ODk0IDMuMTMyMjU0IC0wLjUxODA1N0MzLjEzMjI1NCAtMC42NTM1NDkgMy4yMDM5ODUgLTAuOTI0NTMzIDMuMjUxODA2IC0xLjEyMzc4NlMzLjQxOTE3OCAtMS44MDEyNDUgMy40NTEwNTkgLTEuOTQ0NzA3TDMuNjEwNDYxIC0yLjU1MDQzNkMzLjY1MDMxMSAtMi43NDE3MTkgMy43Mzc5ODMgLTMuMDc2NDYzIDMuNzM3OTgzIC0zLjExNjMxNEMzLjczNzk4MyAtMy4yOTk2MjYgMy41ODY1NSAtMy4zNjMzODcgMy40ODI5MzkgLTMuMzYzMzg3QzMuMzYzMzg3IC0zLjM2MzM4NyAzLjE2NDEzNCAtMy4yODM2ODYgMy4xMjQyODQgLTMuMDM2NjEzWk0yLjU4MjMxNiAtMC44NjA3NzJDMi4xODM4MTEgLTAuMzEwODM0IDEuNzY5MzY1IC0wLjE0MzQ2MiAxLjUxNDMyMSAtMC4xNDM0NjJDMS4xNDc2OTYgLTAuMTQzNDYyIDAuOTY0Mzg0IC0wLjQ3ODIwNyAwLjk2NDM4NCAtMC44OTI2NTNDMC45NjQzODQgLTEuMjY3MjQ4IDEuMTc5NTc3IC0yLjEyMDA1IDEuMzU0OTE5IC0yLjQ3MDczNUMxLjU4NjA1MiAtMi45NTY5MTIgMS45NzY1ODggLTMuMjkxNjU2IDIuMzQzMjEzIC0zLjI5MTY1NkMyLjg2MTI3IC0zLjI5MTY1NiAzLjAxMjcwMiAtMi43MDk4MzggMy4wMTI3MDIgLTIuNjE0MTk3QzMuMDEyNzAyIC0yLjU4MjMxNiAyLjgxMzQ1IC0xLjgwMTI0NSAyLjc2NTYyOSAtMS41OTQwMjJDMi42NjIwMTcgLTEuMjE5NDI3IDIuNjYyMDE3IC0xLjIwMzQ4NyAyLjU4MjMxNiAtMC44NjA3NzJaJyBpZD0nZzMtOTcnLz4KPHBhdGggZD0nTTEuOTQ0NzA3IC01LjI5MjE1NEMxLjk1MjY3NyAtNS4zMDgwOTUgMS45NzY1ODggLTUuNDExNzA2IDEuOTc2NTg4IC01LjQxOTY3NkMxLjk3NjU4OCAtNS40NTk1MjcgMS45NDQ3MDcgLTUuNTMxMjU4IDEuODQ5MDY2IC01LjUzMTI1OEMxLjgxNzE4NiAtNS41MzEyNTggMS41NzAxMTIgLTUuNTA3MzQ3IDEuMzg2OCAtNS40OTE0MDdMMC45NDA0NzMgLTUuNDU5NTI3QzAuNzY1MTMxIC01LjQ0MzU4NyAwLjY4NTQzIC01LjQzNTYxNiAwLjY4NTQzIC01LjI5MjE1NEMwLjY4NTQzIC01LjE4MDU3MyAwLjc5NzAxMSAtNS4xODA1NzMgMC44OTI2NTMgLTUuMTgwNTczQzEuMjc1MjE4IC01LjE4MDU3MyAxLjI3NTIxOCAtNS4xMzI3NTIgMS4yNzUyMTggLTUuMDYxMDIxQzEuMjc1MjE4IC01LjAxMzIgMS4xOTU1MTcgLTQuNjk0Mzk2IDEuMTQ3Njk2IC00LjUxMTA4M0wwLjQ1NDI5NiAtMS43Mzc0ODRDMC4zOTA1MzUgLTEuNDY2NTAxIDAuMzkwNTM1IC0xLjM0Njk0OSAwLjM5MDUzNSAtMS4yMTE0NTdDMC4zOTA1MzUgLTAuMzkwNTM1IDAuODkyNjUzIDAuMDc5NzAxIDEuNTA2MzUxIDAuMDc5NzAxQzIuNDg2Njc1IDAuMDc5NzAxIDMuNTA2ODQ5IC0xLjA1MjA1NSAzLjUwNjg0OSAtMi4yMDc3MjFDMy41MDY4NDkgLTIuOTk2NzYyIDIuOTk2NzYyIC0zLjUxNDgxOSAyLjM1OTE1MyAtMy41MTQ4MTlDMS45MTI4MjcgLTMuNTE0ODE5IDEuNTcwMTEyIC0zLjIyNzg5NSAxLjM5NDc3IC0zLjA3NjQ2M0wxLjk0NDcwNyAtNS4yOTIxNTRaTTEuNTA2MzUxIC0wLjE0MzQ2MkMxLjIxOTQyNyAtMC4xNDM0NjIgMC45MzI1MDMgLTAuMzY2NjI1IDAuOTMyNTAzIC0wLjk0ODQ0M0MwLjkzMjUwMyAtMS4xNjM2MzYgMC45NjQzODQgLTEuMzYyODg5IDEuMDYwMDI1IC0xLjc0NTQ1NUMxLjExNTgxNiAtMS45NzY1ODggMS4xNzE2MDYgLTIuMTk5NzUxIDEuMjM1MzY3IC0yLjQzMDg4NEMxLjI3NTIxOCAtMi41NzQzNDYgMS4yNzUyMTggLTIuNTkwMjg2IDEuMzcwODU5IC0yLjcwOTgzOEMxLjY0MTg0MyAtMy4wNDQ1ODMgMi4wMDA0OTggLTMuMjkxNjU2IDIuMzM1MjQzIC0zLjI5MTY1NkMyLjczMzc0OCAtMy4yOTE2NTYgMi44ODUxODEgLTIuOTAxMTIxIDIuODg1MTgxIC0yLjU0MjQ2NkMyLjg4NTE4MSAtMi4yNDc1NzIgMi43MDk4MzggLTEuMzk0NzcgMi40NzA3MzUgLTAuOTI0NTMzQzIuMjYzNTEyIC0wLjQ5NDE0NyAxLjg4MDk0NiAtMC4xNDM0NjIgMS41MDYzNTEgLTAuMTQzNDYyWicgaWQ9J2czLTk4Jy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMy0xMDcnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzU3LjQ5NjI1NycgeGxpbms6aHJlZj0nI2c0LTc3JyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nNzAuMDY5ODY0JyB4bGluazpocmVmPScjZzQtODMnIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PSc3Ny45NjUxODcnIHhsaW5rOmhyZWY9JyNnNC02OScgeT0nMTAyLjI3MjA4OScvPgo8dXNlIHg9Jzg3LjMzMTM4MicgeGxpbms6aHJlZj0nI2c2LTQwJyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nOTEuODgzNzA4JyB4bGluazpocmVmPScjZzQtODgnIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PScxMDEuODg4NDgzJyB4bGluazpocmVmPScjZzQtNTknIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PScxMDcuMTMyNjQyJyB4bGluazpocmVmPScjZzQtMTIxJyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTEzLjI2OTI5NCcgeGxpbms6aHJlZj0nI2c0LTU5JyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTE4LjUxMzQ1MycgeGxpbms6aHJlZj0nI2c0LTk3JyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTI0LjY1ODM5NycgeGxpbms6aHJlZj0nI2c0LTU5JyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTI5LjkwMjU1NicgeGxpbms6aHJlZj0nI2c0LTk4JyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTM0Ljg3OTY2MScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTQyLjc1MjgxNicgeGxpbms6aHJlZj0nI2c2LTYxJyB5PScxMDIuMjcyMDg5Jy8+Cjx1c2UgeD0nMTU1LjE3ODI5NycgeGxpbms6aHJlZj0nI2cwLTEzJyB5PSc4MS4zNTAzNjInLz4KPHVzZSB4PScxNTUuMTc4Mjk3JyB4bGluazpocmVmPScjZzAtMTMnIHk9Jzg4LjUyMzUzNicvPgo8dXNlIHg9JzE1NS4xNzgyOTcnIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nOTUuNjk2NzEnLz4KPHVzZSB4PScxNTUuMTc4Mjk3JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzEwMi44Njk4ODQnLz4KPHVzZSB4PScxNTUuMTc4Mjk3JyB4bGluazpocmVmPScjZzAtMTMnIHk9JzExMC4wNDMwNTgnLz4KPHVzZSB4PScxNjEuODIwMDc3JyB4bGluazpocmVmPScjZzQtODknIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PScxNzMuODY5OTAzJyB4bGluazpocmVmPScjZzItMCcgeT0nMTAyLjI3MjA4OScvPgo8dXNlIHg9JzE5MS4xNjAwMzgnIHhsaW5rOmhyZWY9JyNnMy02NycgeT0nODcuMzI4MDY4Jy8+Cjx1c2UgeD0nMTg1LjgyNTA2NCcgeGxpbms6aHJlZj0nI2cwLTg4JyB5PSc5MC45MTQ2MjQnLz4KPHVzZSB4PScxODYuNzM4MjInIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzExNi4zNzQ4NDMnLz4KPHVzZSB4PScxOTEuMzU5ODM1JyB4bGluazpocmVmPScjZzUtNjEnIHk9JzExNi4zNzQ4NDMnLz4KPHVzZSB4PScxOTcuOTQ2MzQyJyB4bGluazpocmVmPScjZzUtNDknIHk9JzExNi4zNzQ4NDMnLz4KPHVzZSB4PScyMDMuMDkzNjgxJyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PScyMDcuNjQ2MDA2JyB4bGluazpocmVmPScjZzQtODgnIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PScyMTcuMzYxMjM0JyB4bGluazpocmVmPScjZzMtOTcnIHk9JzEwNC4wNjUzNTInLz4KPHVzZSB4PScyMjEuODU5MjQzJyB4bGluazpocmVmPScjZzMtNTgnIHk9JzEwNC4wNjUzNTInLz4KPHVzZSB4PScyMjQuMjExNTY3JyB4bGluazpocmVmPScjZzMtNTgnIHk9JzEwNC4wNjUzNTInLz4KPHVzZSB4PScyMjYuNTYzODkxJyB4bGluazpocmVmPScjZzMtOTgnIHk9JzEwNC4wNjUzNTInLz4KPHVzZSB4PScyMzAuNjg0NjA4JyB4bGluazpocmVmPScjZzQtODAnIHk9JzEwMi4yNzIwODknLz4KPHVzZSB4PScyMzkuODU1NzA2JyB4bGluazpocmVmPScjZzEtNDgnIHk9Jzk3LjMzNTkwMycvPgo8dXNlIHg9JzI0Mi42NTA3ODInIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTAyLjI3MjA4OScvPgo8dXNlIHg9JzI0Ny4yMDMxMDgnIHhsaW5rOmhyZWY9JyNnNS05MScgeT0nMTA0LjEzMTc5OScvPgo8dXNlIHg9JzI0OS41NTU0MzEnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzEwNC4xMzE3OTknLz4KPHVzZSB4PScyNTQuMTc3MDQ3JyB4bGluazpocmVmPScjZzUtOTMnIHk9JzEwNC4xMzE3OTknLz4KPHVzZSB4PScyODAuNDkzMzU0JyB4bGluazpocmVmPScjZzQtNjAnIHk9JzkzLjc1NzQwMycvPgo8dXNlIHg9JzI5Mi45MTg4MzUnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTMuNzU3NDAzJy8+Cjx1c2UgeD0nMjk3LjQ3MTE2MScgeGxpbms6aHJlZj0nI2c0LTg4JyB5PSc5My43NTc0MDMnLz4KPHVzZSB4PSczMDcuMTg2Mzg4JyB4bGluazpocmVmPScjZzMtOTcnIHk9Jzk1LjU1MDY2NicvPgo8dXNlIHg9JzMxMS42ODQzOTgnIHhsaW5rOmhyZWY9JyNnMy01OCcgeT0nOTUuNTUwNjY2Jy8+Cjx1c2UgeD0nMzE0LjAzNjcyMicgeGxpbms6aHJlZj0nI2czLTU4JyB5PSc5NS41NTA2NjYnLz4KPHVzZSB4PSczMTYuMzg5MDQ1JyB4bGluazpocmVmPScjZzMtOTgnIHk9Jzk1LjU1MDY2NicvPgo8dXNlIHg9JzMyMC41MDk3NjInIHhsaW5rOmhyZWY9JyNnNC04MCcgeT0nOTMuNzU3NDAzJy8+Cjx1c2UgeD0nMzI5LjY4MDg2MScgeGxpbms6aHJlZj0nI2cxLTQ4JyB5PSc4OS40MTg5NjcnLz4KPHVzZSB4PSczMzIuNDc1OTM2JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzkzLjc1NzQwMycvPgo8dXNlIHg9JzMzNy4wMjgyNjInIHhsaW5rOmhyZWY9JyNnNS05MScgeT0nOTUuNjE3MTEzJy8+Cjx1c2UgeD0nMzM5LjM4MDU4NicgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nOTUuNjE3MTEzJy8+Cjx1c2UgeD0nMzQ0LjAwMjIwMScgeGxpbms6aHJlZj0nI2c1LTkzJyB5PSc5NS42MTcxMTMnLz4KPHVzZSB4PSczNDYuODUyNjU3JyB4bGluazpocmVmPScjZzQtNTknIHk9JzkzLjc1NzQwMycvPgo8dXNlIHg9JzM1Mi4wOTY4MTYnIHhsaW5rOmhyZWY9JyNnNC04OScgeT0nOTMuNzU3NDAzJy8+Cjx1c2UgeD0nMzY0LjgxMDgwOCcgeGxpbms6aHJlZj0nI2c0LTYyJyB5PSc5My43NTc0MDMnLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzEzNy45NjI3NDInIHg9JzI1OC4yMjMwMTcnIHk9Jzk5LjA0NDIwMycvPgo8dXNlIHg9JzI1OC4yMjMwMTcnIHhsaW5rOmhyZWY9JyNnNC02MCcgeT0nMTEwLjQ3Mjc1MScvPgo8dXNlIHg9JzI3MC42NDg0OTcnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nMTEwLjQ3Mjc1MScvPgo8dXNlIHg9JzI3NS4yMDA4MjMnIHhsaW5rOmhyZWY9JyNnNC04OCcgeT0nMTEwLjQ3Mjc1MScvPgo8dXNlIHg9JzI4NC45MTYwNScgeGxpbms6aHJlZj0nI2czLTk3JyB5PScxMTIuMjY2MDE0Jy8+Cjx1c2UgeD0nMjg5LjQxNDA2JyB4bGluazpocmVmPScjZzMtNTgnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PScyOTEuNzY2Mzg0JyB4bGluazpocmVmPScjZzMtNTgnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PScyOTQuMTE4NzA4JyB4bGluazpocmVmPScjZzMtOTgnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PScyOTguMjM5NDI1JyB4bGluazpocmVmPScjZzQtODAnIHk9JzExMC40NzI3NTEnLz4KPHVzZSB4PSczMDcuNDEwNTIzJyB4bGluazpocmVmPScjZzEtNDgnIHk9JzEwNy4wMTkwNDMnLz4KPHVzZSB4PSczMTAuMjA1NTk5JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzExMC40NzI3NTEnLz4KPHVzZSB4PSczMTQuNzU3OTI1JyB4bGluazpocmVmPScjZzUtOTEnIHk9JzExMi4zMzI0NjEnLz4KPHVzZSB4PSczMTcuMTEwMjQ4JyB4bGluazpocmVmPScjZzMtMTA3JyB5PScxMTIuMzMyNDYxJy8+Cjx1c2UgeD0nMzIxLjczMTg2NCcgeGxpbms6aHJlZj0nI2c1LTkzJyB5PScxMTIuMzMyNDYxJy8+Cjx1c2UgeD0nMzI0LjU4MjMyJyB4bGluazpocmVmPScjZzQtNTknIHk9JzExMC40NzI3NTEnLz4KPHVzZSB4PSczMjkuODI2NDc4JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzExMC40NzI3NTEnLz4KPHVzZSB4PSczMzQuMzc4ODA0JyB4bGluazpocmVmPScjZzQtODgnIHk9JzExMC40NzI3NTEnLz4KPHVzZSB4PSczNDQuMDk0MDMyJyB4bGluazpocmVmPScjZzMtOTcnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PSczNDguNTkyMDQxJyB4bGluazpocmVmPScjZzMtNTgnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PSczNTAuOTQ0MzY1JyB4bGluazpocmVmPScjZzMtNTgnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PSczNTMuMjk2Njg5JyB4bGluazpocmVmPScjZzMtOTgnIHk9JzExMi4yNjYwMTQnLz4KPHVzZSB4PSczNTcuNDE3NDA2JyB4bGluazpocmVmPScjZzQtODAnIHk9JzExMC40NzI3NTEnLz4KPHVzZSB4PSczNjYuNTg4NTA0JyB4bGluazpocmVmPScjZzEtNDgnIHk9JzEwNy4wMTkwNDMnLz4KPHVzZSB4PSczNjkuMzgzNTgnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTEwLjQ3Mjc1MScvPgo8dXNlIHg9JzM3My45MzU5MDYnIHhsaW5rOmhyZWY9JyNnNS05MScgeT0nMTEyLjMzMjQ2MScvPgo8dXNlIHg9JzM3Ni4yODgyMjknIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzExMi4zMzI0NjEnLz4KPHVzZSB4PSczODAuOTA5ODQ1JyB4bGluazpocmVmPScjZzUtOTMnIHk9JzExMi4zMzI0NjEnLz4KPHVzZSB4PSczODcuMDgxMTMnIHhsaW5rOmhyZWY9JyNnNC02MicgeT0nMTEwLjQ3Mjc1MScvPgo8dXNlIHg9JzM5Ny4zODEyNzMnIHhsaW5rOmhyZWY9JyNnMC0xMycgeT0nODEuMzUwMzYyJy8+Cjx1c2UgeD0nMzk3LjM4MTI3MycgeGxpbms6aHJlZj0nI2cwLTEzJyB5PSc4OC41MjM1MzYnLz4KPHVzZSB4PSczOTcuMzgxMjczJyB4bGluazpocmVmPScjZzAtMTMnIHk9Jzk1LjY5NjcxJy8+Cjx1c2UgeD0nMzk3LjM4MTI3MycgeGxpbms6aHJlZj0nI2cwLTEzJyB5PScxMDIuODY5ODg0Jy8+Cjx1c2UgeD0nMzk3LjM4MTI3MycgeGxpbms6aHJlZj0nI2cwLTEzJyB5PScxMTAuMDQzMDU4Jy8+Cjx1c2UgeD0nNDA0LjAyMzAyMicgeGxpbms6aHJlZj0nI2c1LTUwJyB5PSc4My44NDExNTknLz4KPC9nPgo8L3N2Zz4=)
Un noeud de l’arbre est construit en choisissant le point de coupure qui minimise :

Par la suite on verra que le fait que la matrice soit diagonale est l’élément
principal mais la matrice P ne doit pas nécessairement
vérifier .
Un peu plus en détail dans l’algorithme#
J’ai pensé à plein de choses pour aller plus loin car l’idée
est de quantifier à peu près combien on pert en précision en utilisant
des vecteurs propres estimés avec l’ensemble des données sur une partie
seulement. Je me suis demandé si les vecteurs propres d’une matrice
pouvait être construit à partir d’une fonction continue de la matrice
symétrique de départ. A peu près vrai mais je ne voyais pas une façon
de majorer cette continuité. Ensuite, je me suis dit que les vecteurs
propres de ne devaient pas être loin de ceux de  où
où  est un sous-échantillon aléatoire de l’ensemble
de départ. Donc comme il faut juste avoir une base de vecteurs
orthogonaux, je suis passé à l”orthonormalisation de Gram-Schmidt.
Il n’a pas non plus ce défaut de permuter les dimensions ce qui rend
l’observation de la continuité a little bit more complicated comme
le max dans l”algorithme de Jacobi.
L’idée est se servir cette orthonormalisation pour construire
la matrice P de l’algortihme.
est un sous-échantillon aléatoire de l’ensemble
de départ. Donc comme il faut juste avoir une base de vecteurs
orthogonaux, je suis passé à l”orthonormalisation de Gram-Schmidt.
Il n’a pas non plus ce défaut de permuter les dimensions ce qui rend
l’observation de la continuité a little bit more complicated comme
le max dans l”algorithme de Jacobi.
L’idée est se servir cette orthonormalisation pour construire
la matrice P de l’algortihme.
La matrice  est constituée de
C vecteurs ortonormaux
est constituée de
C vecteurs ortonormaux ![(P_{[1]}, ..., P_{[C]})](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuODE4NjE0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSA2NS42NzY4OTkgMTIuODE4NjE0JyB3aWR0aD0nNjUuNjc2ODk5cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTYuMzQ0MjA5IC01LjM5NTc2NkM2LjM1MjE3OSAtNS40Mjc2NDYgNi4zNjgxMiAtNS40NzU0NjcgNi4zNjgxMiAtNS41MTUzMThDNi4zNjgxMiAtNS41NzExMDggNi4zMjAyOTkgLTUuNjEwOTU5IDYuMjY0NTA4IC01LjYxMDk1OVM2LjE4NDgwNyAtNS41ODcwNDkgNi4xMjEwNDYgLTUuNTE1MzE4TDUuNTYzMTM4IC00LjkwMTYxOUM1LjQ5MTQwNyAtNS4wMDUyMyA1LjA2ODk5MSAtNS42MTA5NTkgNC4xMzY0ODggLTUuNjEwOTU5QzIuMjg3NDIyIC01LjYxMDk1OSAwLjQyMjQxNiAtMy44OTczODUgMC40MjI0MTYgLTIuMDY0MjU5QzAuNDIyNDE2IC0wLjY3NzQ2IDEuNDc0NDcxIDAuMTY3MzcyIDIuNzQxNzE5IDAuMTY3MzcyQzMuNzg1ODAzIDAuMTY3MzcyIDQuNjcwNDg2IC0wLjQ3MDIzNyA1LjEwMDg3MiAtMS4wOTE5MDVDNS4zNjM4ODUgLTEuNDgyNDQxIDUuNDY3NDk3IC0xLjg2NTAwNiA1LjQ2NzQ5NyAtMS45MTI4MjdDNS40Njc0OTcgLTEuOTg0NTU4IDUuNDE5Njc2IC0yLjAxNjQzOCA1LjM0Nzk0NSAtMi4wMTY0MzhDNS4yNTIzMDQgLTIuMDE2NDM4IDUuMjM2MzY0IC0xLjk3NjU4OCA1LjIxMjQ1MyAtMS44ODg5MTdDNC44Nzc3MDkgLTAuNzg5MDQxIDMuODAxNzQzIC0wLjA5NTY0MSAyLjg0NTMzIC0wLjA5NTY0MUMyLjAzMjM3OSAtMC4wOTU2NDEgMS4xNzk1NzcgLTAuNTczODQ4IDEuMTc5NTc3IC0xLjc5MzI3NUMxLjE3OTU3NyAtMi4wNDgzMTkgMS4yNjcyNDggLTMuMzc5MzI4IDIuMTUxOTMgLTQuMzc1NTkyQzIuNzQ5Njg5IC01LjA0NTA4MSAzLjU2MjY0IC01LjM0Nzk0NSA0LjE5MjI3OSAtNS4zNDc5NDVDNS4xOTY1MTMgLTUuMzQ3OTQ1IDUuNjEwOTU5IC00LjU0Mjk2NCA1LjYxMDk1OSAtMy43ODU4MDNDNS42MTA5NTkgLTMuNjc0MjIyIDUuNTc5MDc4IC0zLjUyMjc5IDUuNTc5MDc4IC0zLjQyNzE0OEM1LjU3OTA3OCAtMy4zMjM1MzcgNS42ODI2OSAtMy4zMjM1MzcgNS43MTQ1NyAtMy4zMjM1MzdDNS44MTgxODIgLTMuMzIzNTM3IDUuODM0MTIyIC0zLjM1NTQxNyA1Ljg2NjAwMiAtMy40OTg4NzlMNi4zNDQyMDkgLTUuMzk1NzY2WicgaWQ9J2cwLTY3Jy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnMi00OScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzItOTMnLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnMy00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzMtNDEnLz4KPHBhdGggZD0nTTIuMTk5NzUxIC0wLjU3Mzg0OEMyLjE5OTc1MSAtMC45MjA1NDggMS45MTI4MjcgLTEuMTU5NjUxIDEuNjI1OTAzIC0xLjE1OTY1MUMxLjI3OTIwMyAtMS4xNTk2NTEgMS4wNDAxIC0wLjg3MjcyNyAxLjA0MDEgLTAuNTg1ODAzQzEuMDQwMSAtMC4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEgLTAuMjg2OTI0IDIuMTk5NzUxIC0wLjU3Mzg0OFonIGlkPSdnMS01OCcvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzEtNTknLz4KPHBhdGggZD0nTTMuNTM4NzMgLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExIC0zLjgwMTc0MyA4Ljg0NjgyNCAtNS4wMjExNzEgOC44NDY4MjQgLTYuMzg0MDZDOC44NDY4MjQgLTcuMzE2NTYzIDguMDU3NzgzIC04LjE2NTM4IDYuNTUxNDMyIC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3IC04LjE2NTM4IDIuNTIyNTQgLTguMTY1MzggMi41MjI1NCAtNy45MzgyMzJDMi41MjI1NCAtNy44MTg2OCAyLjYzMDEzNyAtNy44MTg2OCAyLjgwOTQ2NSAtNy44MTg2OEMzLjUzODczIC03LjgxODY4IDMuNTM4NzMgLTcuNzIzMDM5IDMuNTM4NzMgLTcuNTkxNTMyQzMuNTM4NzMgLTcuNTY3NjIxIDMuNTM4NzMgLTcuNDk1ODkgMy40OTA5MDkgLTcuMzE2NTYzTDEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjY2OTQ4OSAwIDAuNzQxMjIgMEMwLjk2ODM2OSAwIDEuMjA3NDcyIC0wLjAyMzkxIDEuNDM0NjIgLTAuMDIzOTFIMi44MzMzNzVDMy4wNjA1MjMgLTAuMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4IC0wLjIyNzE0OEMzLjc2NTg3OCAtMC4zNDY3IDMuNjU4MjgxIC0wLjM0NjcgMy40Nzg5NTQgLTAuMzQ2N0MyLjc2MTY0NCAtMC4zNDY3IDIuNzQ5Njg5IC0wLjQzMDM4NiAyLjc0OTY4OSAtMC41NDk5MzhDMi43NDk2ODkgLTAuNjA5NzE0IDIuNzYxNjQ0IC0wLjY5MzQgMi43NzM1OTkgLTAuNzUzMTc2TDMuNTM4NzMgLTMuODAxNzQzWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4yMDQ3MzJDNy4xMDEzNyAtNy44MTg2OCA3Ljg0MjU5IC03LjUzMTc1NiA3Ljg0MjU5IC02LjYzNTExOEM3Ljg0MjU5IC02LjMyNDI4NCA3LjY4NzE3MyAtNS4zMDgwOTUgNy4xMzcyMzUgLTQuNzU4MTU3QzYuOTMzOTk4IC00LjU0Mjk2NCA2LjM2MDE0OSAtNC4wODg2NjcgNS4yNzIyMjkgLTQuMDg4NjY3SDMuNTg2NTVMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2cxLTgwJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMy00MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDMuNDA2NjIyJyB4bGluazpocmVmPScjZzEtODAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzUwLjk1MTg5JyB4bGluazpocmVmPScjZzItOTEnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzUzLjMwNDIxNCcgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1Ny41MzgzOTcnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNjAuMzg4ODUyJyB4bGluazpocmVmPScjZzEtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY1LjYzMzAxMScgeGxpbms6aHJlZj0nI2cxLTU4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2OC44ODQ2NzMnIHhsaW5rOmhyZWY9JyNnMS01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzIuMTM2MzM0JyB4bGluazpocmVmPScjZzEtNTgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc1LjM4Nzk5NScgeGxpbms6aHJlZj0nI2cxLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MC42MzIxNTQnIHhsaW5rOmhyZWY9JyNnMS04MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODguMTc3NDIyJyB4bGluazpocmVmPScjZzItOTEnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzkwLjUyOTc0NicgeGxpbms6aHJlZj0nI2cwLTY3JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc5Ny4xMjg0MTQnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nOTkuOTc4ODcnIHhsaW5rOmhyZWY9JyNnMy00MScgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) .
Avec les notations que
j’ai utilisées jusqu’à présent :
.
Avec les notations que
j’ai utilisées jusqu’à présent :
![X_{[k]} = (X_{1k}, ..., X_{nk})](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuODE4NjE0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSAxMDMuNjc2MjIgMTIuODE4NjE0JyB3aWR0aD0nMTAzLjY3NjIycHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnMy00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzMtNDEnLz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2czLTYxJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMC0xMDcnLz4KPHBhdGggZD0nTTEuNTk0MDIyIC0xLjMwNzA5OEMxLjYxNzkzMyAtMS40MjY2NSAxLjY5NzYzNCAtMS43Mjk1MTQgMS43MjE1NDQgLTEuODQ5MDY2QzEuODMzMTI2IC0yLjI3OTQ1MiAxLjgzMzEyNiAtMi4yODc0MjIgMi4wMTY0MzggLTIuNTUwNDM2QzIuMjc5NDUyIC0yLjk0MDk3MSAyLjY1NDA0NyAtMy4yOTE2NTYgMy4xODgwNDUgLTMuMjkxNjU2QzMuNDc0OTY5IC0zLjI5MTY1NiAzLjY0MjM0MSAtMy4xMjQyODQgMy42NDIzNDEgLTIuNzQ5Njg5QzMuNjQyMzQxIC0yLjMxMTMzMyAzLjMwNzU5NyAtMS40MDI3NCAzLjE1NjE2NCAtMS4wMTIyMDRDMy4wNTI1NTMgLTAuNzQ5MTkxIDMuMDUyNTUzIC0wLjcwMTM3IDMuMDUyNTUzIC0wLjU5Nzc1OEMzLjA1MjU1MyAtMC4xNDM0NjIgMy40MjcxNDggMC4wNzk3MDEgMy43Njk4NjMgMC4wNzk3MDFDNC41NTA5MzQgMC4wNzk3MDEgNC44Nzc3MDkgLTEuMDM2MTE1IDQuODc3NzA5IC0xLjEzOTcyNkM0Ljg3NzcwOSAtMS4yMTk0MjcgNC44MTM5NDggLTEuMjQzMzM3IDQuNzU4MTU3IC0xLjI0MzMzN0M0LjY2MjUxNiAtMS4yNDMzMzcgNC42NDY1NzUgLTEuMTg3NTQ3IDQuNjIyNjY1IC0xLjEwNzg0NkM0LjQzMTM4MiAtMC40NTQyOTYgNC4wOTY2MzggLTAuMTQzNDYyIDMuNzkzNzczIC0wLjE0MzQ2MkMzLjY2NjI1MiAtMC4xNDM0NjIgMy42MDI0OTEgLTAuMjIzMTYzIDMuNjAyNDkxIC0wLjQwNjQ3NlMzLjY2NjI1MiAtMC43NjUxMzEgMy43NDU5NTMgLTAuOTY0Mzg0QzMuODY1NTA0IC0xLjI2NzI0OCA0LjIxNjE4OSAtMi4xODM4MTEgNC4yMTYxODkgLTIuNjMwMTM3QzQuMjE2MTg5IC0zLjIyNzg5NSAzLjgwMTc0MyAtMy41MTQ4MTkgMy4yMjc4OTUgLTMuNTE0ODE5QzIuNTgyMzE2IC0zLjUxNDgxOSAyLjE2Nzg3IC0zLjEyNDI4NCAxLjkzNjczNyAtMi44MjE0MkMxLjg4MDk0NiAtMy4yNTk3NzYgMS41MzAyNjIgLTMuNTE0ODE5IDEuMTIzNzg2IC0zLjUxNDgxOUMwLjgzNjg2MiAtMy41MTQ4MTkgMC42Mzc2MDkgLTMuMzMxNTA3IDAuNTEwMDg3IC0zLjA4NDQzM0MwLjMxODgwNCAtMi43MDk4MzggMC4yMzkxMDMgLTIuMzExMzMzIDAuMjM5MTAzIC0yLjI5NTM5MkMwLjIzOTEwMyAtMi4yMjM2NjEgMC4yOTQ4OTQgLTIuMTkxNzgxIDAuMzU4NjU1IC0yLjE5MTc4MUMwLjQ2MjI2NyAtMi4xOTE3ODEgMC40NzAyMzcgLTIuMjIzNjYxIDAuNTI2MDI3IC0yLjQzMDg4NEMwLjYyMTY2OSAtMi44MjE0MiAwLjc2NTEzMSAtMy4yOTE2NTYgMS4wOTk4NzUgLTMuMjkxNjU2QzEuMzA3MDk4IC0zLjI5MTY1NiAxLjM1NDkxOSAtMy4wOTI0MDMgMS4zNTQ5MTkgLTIuOTE3MDYxQzEuMzU0OTE5IC0yLjc3MzU5OSAxLjMxNTA2OCAtMi42MjIxNjcgMS4yNTEzMDggLTIuMzU5MTUzQzEuMjM1MzY3IC0yLjI5NTM5MiAxLjExNTgxNiAtMS44MjUxNTYgMS4wODM5MzUgLTEuNzEzNTc0TDAuNzg5MDQxIC0wLjUxODA1N0MwLjc1NzE2MSAtMC4zOTg1MDYgMC43MDkzNCAtMC4xOTkyNTMgMC43MDkzNCAtMC4xNjczNzJDMC43MDkzNCAwLjAxNTk0IDAuODYwNzcyIDAuMDc5NzAxIDAuOTY0Mzg0IDAuMDc5NzAxQzEuMTA3ODQ2IDAuMDc5NzAxIDEuMjI3Mzk3IC0wLjAxNTk0IDEuMjgzMTg4IC0wLjExMTU4MkMxLjMwNzA5OCAtMC4xNTk0MDIgMS4zNzA4NTkgLTAuNDMwMzg2IDEuNDEwNzEgLTAuNTk3NzU4TDEuNTk0MDIyIC0xLjMwNzA5OFonIGlkPSdnMC0xMTAnLz4KPHBhdGggZD0nTTIuMTk5NzUxIC0wLjU3Mzg0OEMyLjE5OTc1MSAtMC45MjA1NDggMS45MTI4MjcgLTEuMTU5NjUxIDEuNjI1OTAzIC0xLjE1OTY1MUMxLjI3OTIwMyAtMS4xNTk2NTEgMS4wNDAxIC0wLjg3MjcyNyAxLjA0MDEgLTAuNTg1ODAzQzEuMDQwMSAtMC4yMzkxMDMgMS4zMjcwMjQgMCAxLjYxMzk0OCAwQzEuOTYwNjQ4IDAgMi4xOTk3NTEgLTAuMjg2OTI0IDIuMTk5NzUxIC0wLjU3Mzg0OFonIGlkPSdnMS01OCcvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzEtNTknLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2cxLTg4Jy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnMi00OScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzItOTMnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cxLTg4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0OC41Njk1MjQnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNTAuOTIxODQ3JyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1NS41NDM0NjMnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNjEuNzE0NzQ4JyB4bGluazpocmVmPScjZzMtNjEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc0LjE0MDIyOScgeGxpbms6aHJlZj0nI2czLTQwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3OC42OTI1NTUnIHhsaW5rOmhyZWY9JyNnMS04OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODguNDA3NzgyJyB4bGluazpocmVmPScjZzItNDknIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzkyLjY0MTk2NScgeGxpbms6aHJlZj0nI2cwLTEwNycgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nOTcuNzYxNzEyJyB4bGluazpocmVmPScjZzEtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEwMy4wMDU4NzEnIHhsaW5rOmhyZWY9JyNnMS01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA2LjI1NzUzMicgeGxpbms6aHJlZj0nI2cxLTU4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMDkuNTA5MTk0JyB4bGluazpocmVmPScjZzEtNTgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzExMi43NjA4NTUnIHhsaW5rOmhyZWY9JyNnMS01OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTE4LjAwNTAxNCcgeGxpbms6aHJlZj0nI2cxLTg4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMjcuNzIwMjQxJyB4bGluazpocmVmPScjZzAtMTEwJyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PScxMzIuODU4NDQ0JyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PScxMzcuOTc4MTkxJyB4bGluazpocmVmPScjZzMtNDEnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) .
On note la matrice identité
.
On note la matrice identité  .
.
![\begin{array}{rcl}
T_{[1]} &=& \frac{ X_{[1]} }{ \norme{X_{[1]}} } \\
P_{[1]} &=& \frac{ I_{[1]} }{ \norme{X_{[1]}} } \\
T_{[2]} &=& \frac{ X_{[2]} - <X_{[2]}, T_{[1]}> T_{[1]} }
{ \norme{X_{[2]} - <X_{[2]}, T_{[1]}> T_{[1]}} } \\
P_{[2]} &=& \frac{ I_{[2]} - <X_{[2]}, T_{[1]}> T_{[1]} }
{ \norme{X_{[2]} - <X_{[2]}, T_{[1]}> T_{[1]}} } \\
... && \\
T_{[k]} &=& \frac{ X_{[k]} - \sum_{i=1}^{k-1} <X_{[k]}, T_{[i]}> T_{[i]} }
{ \norme{ X_{[2]} - \sum_{i=1}^{k-1} <X_{[k]}, T_{[i]}> T_{[i]} } } \\
P_{[k]} &=& \frac{ I_{[k]} - \sum_{i=1}^{k-1} <X_{[k]}, T_{[i]}> T_{[i]} }
{ \norme{ X_{[2]} - \sum_{i=1}^{k-1} <X_{[k]}, T_{[i]}> T_{[i]} } } \\
\end{array}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTUwLjkxODA5NnB0JyB2ZXJzaW9uPScxLjEnIHZpZXdCb3g9JzE1Mi40MDQ2OTQgNzguNzA0ODU3IDE2MC4yNDY2NjMgMTUwLjkxODA5Nicgd2lkdGg9JzE2MC4yNDY2NjNwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNNC43NTgxNTcgLTEuMzM4OTc5QzQuODUzNzk4IC0xLjMzODk3OSA1LjAwMzIzOCAtMS4zMzg5NzkgNS4wMDMyMzggLTEuNDk0Mzk2UzQuODUzNzk4IC0xLjY0OTgxMyA0Ljc1ODE1NyAtMS42NDk4MTNIMC45OTIyNzlDMC44OTY2MzggLTEuNjQ5ODEzIDAuNzQ3MTk4IC0xLjY0OTgxMyAwLjc0NzE5OCAtMS40OTQzOTZTMC44OTY2MzggLTEuMzM4OTc5IDAuOTkyMjc5IC0xLjMzODk3OUg0Ljc1ODE1N1onIGlkPSdnMS0wJy8+CjxwYXRoIGQ9J00yLjA4MDE5OSAtMy43MzAwMTJDMi4wODAxOTkgLTMuODczNDc0IDEuOTcyNjAzIC0zLjk2OTExNiAxLjgzNTExOCAtMy45NjkxMTZDMS42NzM3MjQgLTMuOTY5MTE2IDEuNTAwMzc0IC0zLjgxMzY5OSAxLjUwMDM3NCAtMy42NDAzNDlDMS41MDAzNzQgLTMuNDkwOTA5IDEuNjA3OTcgLTMuNDAxMjQ1IDEuNzM5NDc3IC0zLjQwMTI0NUMxLjkzMDc2IC0zLjQwMTI0NSAyLjA4MDE5OSAtMy41ODA1NzMgMi4wODAxOTkgLTMuNzMwMDEyWk0xLjcyMTU0NCAtMS42NDM4MzZDMS43NDU0NTUgLTEuNzAzNjExIDEuNzk5MjUzIC0xLjg0NzA3MyAxLjgyMzE2MyAtMS45MDA4NzJDMS44NDEwOTYgLTEuOTU0NjcgMS44NjUwMDYgLTIuMDE0NDQ2IDEuODY1MDA2IC0yLjExNjA2NUMxLjg2NTAwNiAtMi40NTA4MDkgMS41NjYxMjcgLTIuNjM2MTE1IDEuMjY3MjQ4IC0yLjYzNjExNUMwLjY1NzUzNCAtMi42MzYxMTUgMC4zNjQ2MzMgLTEuODQ3MDczIDAuMzY0NjMzIC0xLjcxNTU2N0MwLjM2NDYzMyAtMS42ODU2NzkgMC4zODg1NDMgLTEuNjMxODggMC40NzIyMjkgLTEuNjMxODhTMC41NzM4NDggLTEuNjY3NzQ2IDAuNTkxNzgxIC0xLjcyMTU0NEMwLjc1OTE1MyAtMi4zMDEzNyAxLjA3NTk2NSAtMi40Mzg4NTQgMS4yNDMzMzcgLTIuNDM4ODU0QzEuMzYyODg5IC0yLjQzODg1NCAxLjQwNDczMiAtMi4zNjExNDYgMS40MDQ3MzIgLTIuMjIzNjYxQzEuNDA0NzMyIC0yLjEwNDExIDEuMzY4ODY3IC0yLjAxNDQ0NiAxLjM1NjkxMiAtMS45NzI2MDNMMS4wNDYwNzcgLTEuMjA3NDcyQzAuOTc0MzQ2IC0xLjAzNDEyMiAwLjk3NDM0NiAtMS4wMjIxNjcgMC44OTY2MzggLTAuODE4OTI5QzAuODE4OTI5IC0wLjYzOTYwMSAwLjc4OTA0MSAtMC41NjE4OTMgMC43ODkwNDEgLTAuNDYwMjc0QzAuNzg5MDQxIC0wLjE1NTQxNyAxLjA2NDAxIDAuMDU5Nzc2IDEuMzkyNzc3IDAuMDU5Nzc2QzEuOTk2NTEzIDAuMDU5Nzc2IDIuMjk1MzkyIC0wLjcyOTI2NSAyLjI5NTM5MiAtMC44NjA3NzJDMi4yOTUzOTIgLTAuODcyNzI3IDIuMjg5NDE1IC0wLjk0NDQ1OCAyLjE4MTgxOCAtMC45NDQ0NThDMi4wOTgxMzIgLTAuOTQ0NDU4IDIuMDkyMTU0IC0wLjkxNDU3IDIuMDU2Mjg5IC0wLjgwMDk5NkMxLjk2MDY0OCAtMC40OTYxMzkgMS43MTU1NjcgLTAuMTM3NDg0IDEuNDEwNzEgLTAuMTM3NDg0QzEuMzAzMTEzIC0wLjEzNzQ4NCAxLjI0OTMxNSAtMC4yMDkyMTUgMS4yNDkzMTUgLTAuMzUyNjc3QzEuMjQ5MzE1IC0wLjQ3MjIyOSAxLjI4NTE4MSAtMC41NjE4OTMgMS4zNjI4ODkgLTAuNzQ3MTk4TDEuNzIxNTQ0IC0xLjY0MzgzNlonIGlkPSdnNC0xMDUnLz4KPHBhdGggZD0nTTEuOTg0NTU4IC0zLjk2OTExNkMxLjk5MDUzNSAtMy45OTMwMjYgMi4wMDI0OTEgLTQuMDI4ODkyIDIuMDAyNDkxIC00LjA1ODc4QzIuMDAyNDkxIC00LjE1NDQyMSAxLjg4MjkzOSAtNC4xNDg0NDMgMS44MTEyMDggLTQuMTQyNDY2TDEuMTQxNzE5IC00LjA4ODY2N0MxLjA0MDEgLTQuMDgyNjkgMC45NjIzOTEgLTQuMDc2NzEyIDAuOTYyMzkxIC0zLjkzMzI1QzAuOTYyMzkxIC0zLjg0MzU4NyAxLjA0MDEgLTMuODQzNTg3IDEuMTM1NzQxIC0zLjg0MzU4N0MxLjMwOTA5MSAtMy44NDM1ODcgMS4zNTA5MzQgLTMuODI1NjU0IDEuNDI4NjQzIC0zLjgwMTc0M0MxLjQyODY0MyAtMy43MzAwMTIgMS40Mjg2NDMgLTMuNzE4MDU3IDEuNDA0NzMyIC0zLjYyMjQxNkwwLjU2Nzg3IC0wLjI4MDk0NkMwLjU0Mzk2IC0wLjE4NTMwNSAwLjU0Mzk2IC0wLjE1NTQxNyAwLjU0Mzk2IC0wLjE0MzQ2MkMwLjU0Mzk2IDAuMDA1OTc4IDAuNjYzNTEyIDAuMDU5Nzc2IDAuNzUzMTc2IDAuMDU5Nzc2QzAuODEyOTUxIDAuMDU5Nzc2IDAuOTIwNTQ4IDAuMDM1ODY2IDAuOTk4MjU3IC0wLjA3NzcwOUMxLjA0MDEgLTAuMTU1NDE3IDEuMjc5MjAzIC0xLjE0NzY5NiAxLjMyMTA0NiAtMS4zMzg5NzlDMS43MjE1NDQgLTEuMzA5MDkxIDIuMTUxOTMgLTEuMjEzNDUgMi4xNTE5MyAtMC44NjA3NzJDMi4xNTE5MyAtMC44MzA4ODQgMi4xNTE5MyAtMC44MDA5OTYgMi4xMzM5OTggLTAuNzM1MjQzQzIuMTE2MDY1IC0wLjY0NTU3OSAyLjExNjA2NSAtMC42MDk3MTQgMi4xMTYwNjUgLTAuNTYxODkzQzIuMTE2MDY1IC0wLjE2NzM3MiAyLjQ1MDgwOSAwLjA1OTc3NiAyLjc5MTUzMiAwLjA1OTc3NkMzLjM3MTM1NyAwLjA1OTc3NiAzLjU4MDU3MyAtMC44MTI5NTEgMy41ODA1NzMgLTAuODYwNzcyQzMuNTgwNTczIC0wLjg3MjcyNyAzLjU3NDU5NSAtMC45NDQ0NTggMy40NjY5OTkgLTAuOTQ0NDU4QzMuMzgzMzEzIC0wLjk0NDQ1OCAzLjM3MTM1NyAtMC45MDg1OTMgMy4zNDE0NjkgLTAuODA2OTc0QzMuMjgxNjk0IC0wLjU5MTc4MSAzLjExNDMyMSAtMC4xMzc0ODQgMi44MDk0NjUgLTAuMTM3NDg0QzIuNTgyMzE2IC0wLjEzNzQ4NCAyLjU4MjMxNiAtMC4zOTQ1MjEgMi41ODIzMTYgLTAuNDYwMjc0QzIuNTgyMzE2IC0wLjU1NTkxNSAyLjU4MjMxNiAtMC41NjE4OTMgMi42MTIyMDQgLTAuNjgxNDQ1QzIuNjEyMjA0IC0wLjY4NzQyMiAyLjY0MjA5MiAtMC44MDY5NzQgMi42NDIwOTIgLTAuODc4NzA1QzIuNjQyMDkyIC0xLjMzODk3OSAyLjEyMjA0MiAtMS40ODI0NDEgMS42NjE3NjggLTEuNTI0Mjg0QzEuODA1MjMgLTEuNjEzOTQ4IDEuOTMwNzYgLTEuNzA5NTg5IDIuMTY5ODYzIC0xLjkxODgwNEMyLjQ2ODc0MiAtMi4xODE4MTggMi43Nzk1NzcgLTIuNDM4ODU0IDMuMTA4MzQ0IC0yLjQzODg1NEMzLjE4NjA1MiAtMi40Mzg4NTQgMy4yNTc3ODMgLTIuNDIwOTIyIDMuMzExNTgyIC0yLjM2MTE0NkMzLjEwMjM2NiAtMi4zMTkzMDMgMy4wMTI3MDIgLTIuMTUxOTMgMy4wMTI3MDIgLTIuMDI2NDAxQzMuMDEyNzAyIC0xLjgzNTExOCAzLjE2ODEyIC0xLjc5MzI3NSAzLjI1MTgwNiAtMS43OTMyNzVDMy4zODMzMTMgLTEuNzkzMjc1IDMuNTk4NTA2IC0xLjg4ODkxNyAzLjU5ODUwNiAtMi4xODc3OTZDMy41OTg1MDYgLTIuNDQ0ODMyIDMuNDA3MjIzIC0yLjYzNjExNSAzLjExNDMyMSAtMi42MzYxMTVDMi43Mzc3MzMgLTIuNjM2MTE1IDIuMzg1MDU2IC0yLjM0OTE5MSAyLjExMDA4NyAtMi4xMTAwODdDMS43OTkyNTMgLTEuODQxMDk2IDEuNjEzOTQ4IC0xLjY4NTY3OSAxLjM5Mjc3NyAtMS42MDE5OTNMMS45ODQ1NTggLTMuOTY5MTE2WicgaWQ9J2c0LTEwNycvPgo8cGF0aCBkPSdNNS41NzExMDggLTEuODA5MjE1QzUuNjk4NjMgLTEuODA5MjE1IDUuODczOTczIC0xLjgwOTIxNSA1Ljg3Mzk3MyAtMS45OTI1MjhTNS42OTg2MyAtMi4xNzU4NDEgNS41NzExMDggLTIuMTc1ODQxSDEuMDA0MjM0QzAuODc2NzEyIC0yLjE3NTg0MSAwLjcwMTM3IC0yLjE3NTg0MSAwLjcwMTM3IC0xLjk5MjUyOFMwLjg3NjcxMiAtMS44MDkyMTUgMS4wMDQyMzQgLTEuODA5MjE1SDUuNTcxMTA4WicgaWQ9J2cyLTAnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2c4LTQ5Jy8+CjxwYXRoIGQ9J00yLjI0NzU3MiAtMS42MjU5MDNDMi4zNzUwOTMgLTEuNzQ1NDU1IDIuNzA5ODM4IC0yLjAwODQ2OCAyLjgzNzM2IC0yLjEyMDA1QzMuMzMxNTA3IC0yLjU3NDM0NiAzLjgwMTc0MyAtMy4wMTI3MDIgMy44MDE3NDMgLTMuNzM3OTgzQzMuODAxNzQzIC00LjY4NjQyNiAzLjAwNDczMiAtNS4zMDAxMjUgMi4wMDg0NjggLTUuMzAwMTI1QzEuMDUyMDU1IC01LjMwMDEyNSAwLjQyMjQxNiAtNC41NzQ4NDQgMC40MjI0MTYgLTMuODY1NTA0QzAuNDIyNDE2IC0zLjQ3NDk2OSAwLjczMzI1IC0zLjQxOTE3OCAwLjg0NDgzMiAtMy40MTkxNzhDMS4wMTIyMDQgLTMuNDE5MTc4IDEuMjU5Mjc4IC0zLjUzODczIDEuMjU5Mjc4IC0zLjg0MTU5NEMxLjI1OTI3OCAtNC4yNTYwNCAwLjg2MDc3MiAtNC4yNTYwNCAwLjc2NTEzMSAtNC4yNTYwNEMwLjk5NjI2NCAtNC44Mzc4NTggMS41MzAyNjIgLTUuMDM3MTExIDEuOTIwNzk3IC01LjAzNzExMUMyLjY2MjAxNyAtNS4wMzcxMTEgMy4wNDQ1ODMgLTQuNDA3NDcyIDMuMDQ0NTgzIC0zLjczNzk4M0MzLjA0NDU4MyAtMi45MDkwOTEgMi40NjI3NjUgLTIuMzAzMzYyIDEuNTIyMjkxIC0xLjMzODk3OUwwLjUxODA1NyAtMC4zMDI4NjRDMC40MjI0MTYgLTAuMjE1MTkzIDAuNDIyNDE2IC0wLjE5OTI1MyAwLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMgLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2IC0xLjI2NzI0OCAzLjQ2Njk5OSAtMC44Njg3NDIgMy4zNzEzNTcgLTAuNzE3MzFDMy4zMjM1MzcgLTAuNjUzNTQ5IDIuNzE3ODA4IC0wLjY1MzU0OSAyLjU5MDI4NiAtMC42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzIgLTEuNjI1OTAzWicgaWQ9J2c4LTUwJy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2c4LTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnOC05MycvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2c2LTU4Jy8+CjxwYXRoIGQ9J00zLjUzODczIC0zLjgwMTc0M0g1LjU0NzE5OEM3LjE5NzAxMSAtMy44MDE3NDMgOC44NDY4MjQgLTUuMDIxMTcxIDguODQ2ODI0IC02LjM4NDA2QzguODQ2ODI0IC03LjMxNjU2MyA4LjA1Nzc4MyAtOC4xNjUzOCA2LjU1MTQzMiAtOC4xNjUzOEgyLjg1NzI4NUMyLjYzMDEzNyAtOC4xNjUzOCAyLjUyMjU0IC04LjE2NTM4IDIuNTIyNTQgLTcuOTM4MjMyQzIuNTIyNTQgLTcuODE4NjggMi42MzAxMzcgLTcuODE4NjggMi44MDk0NjUgLTcuODE4NjhDMy41Mzg3MyAtNy44MTg2OCAzLjUzODczIC03LjcyMzAzOSAzLjUzODczIC03LjU5MTUzMkMzLjUzODczIC03LjU2NzYyMSAzLjUzODczIC03LjQ5NTg5IDMuNDkwOTA5IC03LjMxNjU2M0wxLjg3Njk2MSAtMC44ODQ2ODJDMS43NjkzNjUgLTAuNDY2MjUyIDEuNzQ1NDU1IC0wLjM0NjcgMC45MDg1OTMgLTAuMzQ2N0MwLjY4MTQ0NSAtMC4zNDY3IDAuNTYxODkzIC0wLjM0NjcgMC41NjE4OTMgLTAuMTMxNTA3QzAuNTYxODkzIDAgMC42Njk0ODkgMCAwLjc0MTIyIDBDMC45NjgzNjkgMCAxLjIwNzQ3MiAtMC4wMjM5MSAxLjQzNDYyIC0wLjAyMzkxSDIuODMzMzc1QzMuMDYwNTIzIC0wLjAyMzkxIDMuMzExNTgyIDAgMy41Mzg3MyAwQzMuNjM0MzcxIDAgMy43NjU4NzggMCAzLjc2NTg3OCAtMC4yMjcxNDhDMy43NjU4NzggLTAuMzQ2NyAzLjY1ODI4MSAtMC4zNDY3IDMuNDc4OTU0IC0wLjM0NjdDMi43NjE2NDQgLTAuMzQ2NyAyLjc0OTY4OSAtMC40MzAzODYgMi43NDk2ODkgLTAuNTQ5OTM4QzIuNzQ5Njg5IC0wLjYwOTcxNCAyLjc2MTY0NCAtMC42OTM0IDIuNzczNTk5IC0wLjc1MzE3NkwzLjUzODczIC0zLjgwMTc0M1pNNC4zOTk1MDIgLTcuMzUyNDI4QzQuNTA3MDk4IC03Ljc5NDc3IDQuNTU0OTE5IC03LjgxODY4IDUuMDIxMTcxIC03LjgxODY4SDYuMjA0NzMyQzcuMTAxMzcgLTcuODE4NjggNy44NDI1OSAtNy41MzE3NTYgNy44NDI1OSAtNi42MzUxMThDNy44NDI1OSAtNi4zMjQyODQgNy42ODcxNzMgLTUuMzA4MDk1IDcuMTM3MjM1IC00Ljc1ODE1N0M2LjkzMzk5OCAtNC41NDI5NjQgNi4zNjAxNDkgLTQuMDg4NjY3IDUuMjcyMjI5IC00LjA4ODY2N0gzLjU4NjU1TDQuMzk5NTAyIC03LjM1MjQyOFonIGlkPSdnNi04MCcvPgo8cGF0aCBkPSdNNC45ODUzMDUgLTcuMjkyNjUzQzUuMDU3MDM2IC03LjU3OTU3NyA1LjA4MDk0NiAtNy42ODcxNzMgNS4yNjAyNzQgLTcuNzM0OTk0QzUuMzU1OTE1IC03Ljc1ODkwNCA1Ljc1MDQzNiAtNy43NTg5MDQgNi4wMDE0OTQgLTcuNzU4OTA0QzcuMTk3MDExIC03Ljc1ODkwNCA3Ljc1ODkwNCAtNy43MTEwODMgNy43NTg5MDQgLTYuNzc4NThDNy43NTg5MDQgLTYuNTk5MjUzIDcuNzExMDgzIC02LjE0NDk1NiA3LjYzOTM1MiAtNS43MDI2MTVMNy42MjczOTcgLTUuNTU5MTUzQzcuNjI3Mzk3IC01LjUxMTMzMyA3LjY3NTIxOCAtNS40Mzk2MDEgNy43NDY5NDkgLTUuNDM5NjAxQzcuODY2NTAxIC01LjQzOTYwMSA3Ljg2NjUwMSAtNS40OTkzNzcgNy45MDIzNjYgLTUuNjkwNjZMOC4yNDkwNjYgLTcuODA2NzI1QzguMjcyOTc2IC03LjkxNDMyMSA4LjI3Mjk3NiAtNy45MzgyMzIgOC4yNzI5NzYgLTcuOTc0MDk3QzguMjcyOTc2IC04LjEwNTYwNCA4LjIwMTI0NSAtOC4xMDU2MDQgNy45NjIxNDIgLTguMTA1NjA0SDEuNDIyNjY1QzEuMTQ3Njk2IC04LjEwNTYwNCAxLjEzNTc0MSAtOC4wOTM2NDkgMS4wNjQwMSAtNy44Nzg0NTZMMC4zMzQ3NDUgLTUuNzI2NTI2QzAuMzIyNzkgLTUuNzAyNjE1IDAuMjg2OTI0IC01LjU3MTEwOCAwLjI4NjkyNCAtNS41NTkxNTNDMC4yODY5MjQgLTUuNDk5Mzc3IDAuMzM0NzQ1IC01LjQzOTYwMSAwLjQwNjQ3NiAtNS40Mzk2MDFDMC41MDIxMTcgLTUuNDM5NjAxIDAuNTI2MDI3IC01LjQ4NzQyMiAwLjU3Mzg0OCAtNS42NDI4MzlDMS4wNzU5NjUgLTcuMDg5NDE1IDEuMzI3MDI0IC03Ljc1ODkwNCAyLjkxNzA2MSAtNy43NTg5MDRIMy43MTgwNTdDNC4wMDQ5ODEgLTcuNzU4OTA0IDQuMTI0NTMzIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy42MjczOTdDNC4xMjQ1MzMgLTcuNTkxNTMyIDQuMTI0NTMzIC03LjU2NzYyMSA0LjA2NDc1NyAtNy4zNTI0MjhMMi40NjI3NjUgLTAuOTMyNTAzQzIuMzQzMjEzIC0wLjQ2NjI1MiAyLjMxOTMwMyAtMC4zNDY3IDEuMDUyMDU1IC0wLjM0NjdDMC43NTMxNzYgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4zNDY3IDAuNjY5NDg5IC0wLjExOTU1MkMwLjY2OTQ4OSAwIDAuODAwOTk2IDAgMC44NjA3NzIgMEMxLjE1OTY1MSAwIDEuNDcwNDg2IC0wLjAyMzkxIDEuNzY5MzY1IC0wLjAyMzkxSDMuNjM0MzcxQzMuOTMzMjUgLTAuMDIzOTEgNC4yNTYwNCAwIDQuNTU0OTE5IDBDNC42ODY0MjYgMCA0LjgwNTk3OCAwIDQuODA1OTc4IC0wLjIyNzE0OEM0LjgwNTk3OCAtMC4zNDY3IDQuNzIyMjkxIC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2N0MzLjMzNTQ5MiAtMC4zNDY3IDMuMzM1NDkyIC0wLjQ1NDI5NiAzLjMzNTQ5MiAtMC42MzM2MjRDMy4zMzU0OTIgLTAuNjQ1NTc5IDMuMzM1NDkyIC0wLjcyOTI2NSAzLjM4MzMxMyAtMC45MjA1NDhMNC45ODUzMDUgLTcuMjkyNjUzWicgaWQ9J2c2LTg0Jy8+CjxwYXRoIGQ9J00yLjE0NTk1MyAtMy43OTU3NjZDMi4xNDU5NTMgLTMuOTc1MDkzIDIuMTIyMDQyIC0zLjk3NTA5MyAxLjk0MjcxNSAtMy45NzUwOTNDMS41NDgxOTQgLTMuNTkyNTI4IDAuOTM4NDgxIC0zLjU5MjUyOCAwLjcyMzI4OCAtMy41OTI1MjhWLTMuMzU5NDAyQzAuODc4NzA1IC0zLjM1OTQwMiAxLjI3MzIyNSAtMy4zNTk0MDIgMS42MzE4OCAtMy41MjY3NzVWLTAuNTA4MDk1QzEuNjMxODggLTAuMzEwODM0IDEuNjMxODggLTAuMjMzMTI2IDEuMDE2MTg5IC0wLjIzMzEyNkgwLjc1OTE1M1YwQzEuMDg3OTIgLTAuMDIzOTEgMS41NTQxNzIgLTAuMDIzOTEgMS44ODg5MTcgLTAuMDIzOTFTMi42ODk5MTMgLTAuMDIzOTEgMy4wMTg2OCAwVi0wLjIzMzEyNkgyLjc2MTY0NEMyLjE0NTk1MyAtMC4yMzMxMjYgMi4xNDU5NTMgLTAuMzEwODM0IDIuMTQ1OTUzIC0wLjUwODA5NVYtMy43OTU3NjZaJyBpZD0nZzctNDknLz4KPHBhdGggZD0nTTMuMjE1OTQgLTEuMTE3ODA4SDIuOTk0NzdDMi45ODI4MTQgLTEuMDM0MTIyIDIuOTIzMDM5IC0wLjYzOTYwMSAyLjgzMzM3NSAtMC41NzM4NDhDMi43OTE1MzIgLTAuNTM3OTgzIDIuMzA3MzQ3IC0wLjUzNzk4MyAyLjIyMzY2MSAtMC41Mzc5ODNIMS4xMDU4NTNMMS44NzA5ODQgLTEuMTU5NjUxQzIuMDc0MjIyIC0xLjMyMTA0NiAyLjYwNjIyNyAtMS43MDM2MTEgMi43OTE1MzIgLTEuODgyOTM5QzIuOTcwODU5IC0yLjA2MjI2NyAzLjIxNTk0IC0yLjM2NzEyMyAzLjIxNTk0IC0yLjc5MTUzMkMzLjIxNTk0IC0zLjUzODczIDIuNTQwNDczIC0zLjk3NTA5MyAxLjczOTQ3NyAtMy45NzUwOTNDMC45NjgzNjkgLTMuOTc1MDkzIDAuNDMwMzg2IC0zLjQ2Njk5OSAwLjQzMDM4NiAtMi45MDUxMDZDMC40MzAzODYgLTIuNjAwMjQ5IDAuNjg3NDIyIC0yLjU2NDM4NCAwLjc1MzE3NiAtMi41NjQzODRDMC45MDI2MTUgLTIuNTY0Mzg0IDEuMDc1OTY1IC0yLjY3MTk4IDEuMDc1OTY1IC0yLjg4NzE3M0MxLjA3NTk2NSAtMy4wMTg2OCAwLjk5ODI1NyAtMy4yMDk5NjMgMC43MzUyNDMgLTMuMjA5OTYzQzAuODcyNzI3IC0zLjUxNDgxOSAxLjIzNzM2IC0zLjc0MTk2OCAxLjY0OTgxMyAtMy43NDE5NjhDMi4yNzc0NiAtMy43NDE5NjggMi42MTIyMDQgLTMuMjc1NzE2IDIuNjEyMjA0IC0yLjc5MTUzMkMyLjYxMjIwNCAtMi4zNjcxMjMgMi4zMzEyNTggLTEuOTMwNzYgMS45MTI4MjcgLTEuNTQ4MTk0TDAuNDk2MTM5IC0wLjI1MTA1OUMwLjQzNjM2NCAtMC4xOTEyODMgMC40MzAzODYgLTAuMTg1MzA1IDAuNDMwMzg2IDBIMy4wMzA2MzVMMy4yMTU5NCAtMS4xMTc4MDhaJyBpZD0nZzctNTAnLz4KPHBhdGggZD0nTTQuODg5NjY0IC0yLjAyNjQwMUM0Ljk3MzM1IC0yLjAyNjQwMSA1LjExMDgzNCAtMi4wMjY0MDEgNS4xMTA4MzQgLTIuMTgxODE4UzQuOTQ5NDQgLTIuMzM3MjM1IDQuODU5Nzc2IC0yLjMzNzIzNUgwLjcyMzI4OEMwLjYzMzYyNCAtMi4zMzcyMzUgMC40NzIyMjkgLTIuMzM3MjM1IDAuNDcyMjI5IC0yLjE4MTgxOFMwLjYwOTcxNCAtMi4wMjY0MDEgMC42OTM0IC0yLjAyNjQwMUg0Ljg4OTY2NFpNNC44NTk3NzYgLTAuNjUxNTU3QzQuOTQ5NDQgLTAuNjUxNTU3IDUuMTEwODM0IC0wLjY1MTU1NyA1LjExMDgzNCAtMC44MDY5NzRTNC45NzMzNSAtMC45NjIzOTEgNC44ODk2NjQgLTAuOTYyMzkxSDAuNjkzNEMwLjYwOTcxNCAtMC45NjIzOTEgMC40NzIyMjkgLTAuOTYyMzkxIDAuNDcyMjI5IC0wLjgwNjk3NFMwLjYzMzYyNCAtMC42NTE1NTcgMC43MjMyODggLTAuNjUxNTU3SDQuODU5Nzc2WicgaWQ9J2c3LTYxJy8+CjxwYXRoIGQ9J00xLjg2NTAwNiAtNC4xNzIzNTRWLTQuNDgzMTg4SDAuODkwNjZWMS40OTQzOTZIMS44NjUwMDZWMS4xODM1NjJIMS4yMDE0OTRWLTQuMTcyMzU0SDEuODY1MDA2WicgaWQ9J2c3LTkxJy8+CjxwYXRoIGQ9J00xLjIwNzQ3MiAtNC40ODMxODhIMC4yMzMxMjZWLTQuMTcyMzU0SDAuODk2NjM4VjEuMTgzNTYySDAuMjMzMTI2VjEuNDk0Mzk2SDEuMjA3NDcyVi00LjQ4MzE4OFonIGlkPSdnNy05MycvPgo8cGF0aCBkPSdNNC4xMjA1NDggNC4xMjg1MThDNC4yMTYxODkgNC4wMjQ5MDcgNC4yMTYxODkgNC4wMDg5NjYgNC4yMTYxODkgMy45ODUwNTZDNC4yMTYxODkgMy45NzcwODYgNC4yMTYxODkgMy45MzcyMzUgNC4xNTI0MjggMy44NTc1MzRMMS40MjY2NSAwLjM2NjYyNUg0Ljc0MjIxN0M1Ljc1NDQyMSAwLjM2NjYyNSA2LjM2ODEyIDAuNDg2MTc3IDYuNzM0NzQ1IDAuNjA1NzI5QzcuMzgwMzI0IDAuODIwOTIyIDcuOTg2MDUyIDEuMjkxMTU4IDguMjE3MTg2IDEuOTEyODI3SDguNDY0MjU5TDcuNzM4OTc5IDBIMC43MTczMUMwLjQ3ODIwNyAwIDAuNDcwMjM3IDAuMDA3OTcgMC40NzAyMzcgMC4yODY5MjRMMy41NDY3IDQuMjQwMUwwLjU0OTkzOCA3LjczMTAwOUMwLjQ3ODIwNyA3LjgxODY4IDAuNDcwMjM3IDcuODE4NjggMC40NzAyMzcgNy44NTg1MzFDMC40NzAyMzcgNy45NzAxMTIgMC41NzM4NDggNy45NzAxMTIgMC43MTczMSA3Ljk3MDExMkg3LjczODk3OUw4LjQ2NDI1OSA1LjkzNzczM0g4LjIxNzE4NkM4LjAyNTkwMyA2LjQ4NzY3MSA3LjQ4MzkzNSA3LjA2OTQ4OSA2LjUxOTU1MiA3LjMxNjU2M0M1Ljk1MzY3NCA3LjQ2MDAyNSA1LjM3OTgyNiA3LjQ4MzkzNSA0Ljc5ODAwNyA3LjQ4MzkzNUgxLjI0MzMzN0w0LjEyMDU0OCA0LjEyODUxOFonIGlkPSdnMC04MCcvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzktNjEnLz4KPHBhdGggZD0nTTIuMDU2Mjg5IC04LjU1OTlDMi4wNTYyODkgLTguNzUxMTgzIDIuMDU2Mjg5IC04Ljk2NjM3NiAxLjgxNzE4NiAtOC45NjYzNzZTMS41NzgwODIgLTguNzAzMzYyIDEuNTc4MDgyIC04LjUyNDAzNVYyLjU0NjQ1MUMxLjU3ODA4MiAyLjczNzczMyAxLjU3ODA4MiAyLjk4ODc5MiAxLjgxNzE4NiAyLjk4ODc5MlMyLjA1NjI4OSAyLjc3MzU5OSAyLjA1NjI4OSAyLjU4MjMxNlYtOC41NTk5Wk00LjM4NzU0NyAtOC41MjQwMzVDNC4zODc1NDcgLTguNzE1MzE4IDQuMzg3NTQ3IC04Ljk2NjM3NiA0LjE0ODQ0MyAtOC45NjYzNzZTMy45MDkzNCAtOC43NTExODMgMy45MDkzNCAtOC41NTk5VjIuNTgyMzE2QzMuOTA5MzQgMi43NzM1OTkgMy45MDkzNCAyLjk4ODc5MiA0LjE0ODQ0MyAyLjk4ODc5MlM0LjM4NzU0NyAyLjcyNTc3OCA0LjM4NzU0NyAyLjU0NjQ1MVYtOC41MjQwMzVaJyBpZD0nZzMtMTA3Jy8+CjxwYXRoIGQ9J00xLjQ5MDQxMSAtMC4xMTk1NTJDMS40OTA0MTEgMC4zOTg1MDYgMS4zNzg4MjkgMC44NTI4MDIgMC44ODQ2ODIgMS4zNDY5NDlDMC44NTI4MDIgMS4zNzA4NTkgMC44MzY4NjIgMS4zODY4IDAuODM2ODYyIDEuNDI2NjVDMC44MzY4NjIgMS40OTA0MTEgMC45MDA2MjMgMS41MzgyMzIgMC45NTY0MTMgMS41MzgyMzJDMS4wNTIwNTUgMS41MzgyMzIgMS43MTM1NzQgMC45MDg1OTMgMS43MTM1NzQgLTAuMDIzOTFDMS43MTM1NzQgLTAuNTMzOTk4IDEuNTIyMjkxIC0wLjg4NDY4MiAxLjE3MTYwNiAtMC44ODQ2ODJDMC44OTI2NTMgLTAuODg0NjgyIDAuNzMzMjUgLTAuNjYxNTE5IDAuNzMzMjUgLTAuNDQ2MzI2QzAuNzMzMjUgLTAuMjIzMTYzIDAuODg0NjgyIDAgMS4xNzk1NzcgMEMxLjM3MDg1OSAwIDEuNDkwNDExIC0wLjExMTU4MiAxLjQ5MDQxMSAtMC4xMTk1NTJaJyBpZD0nZzUtNTknLz4KPHBhdGggZD0nTTUuNzA2NiAtNC4xMTI1NzhDNS44MDIyNDIgLTQuMTYwMzk5IDUuODczOTczIC00LjIwODIxOSA1Ljg3Mzk3MyAtNC4zMTE4MzFTNS43OTQyNzEgLTQuNDk1MTQzIDUuNjkwNjYgLTQuNDk1MTQzQzUuNjY2NzUgLTQuNDk1MTQzIDUuNjUwODA5IC00LjQ5NTE0MyA1LjU0NzE5OCAtNC40MzkzNTJMMC44Njg3NDIgLTIuMTkxNzgxQzAuNzczMTAxIC0yLjE0Mzk2IDAuNzAxMzcgLTIuMDk2MTM5IDAuNzAxMzcgLTEuOTkyNTI4UzAuNzczMTAxIC0xLjg0MTA5NiAwLjg2ODc0MiAtMS43OTMyNzVMNS41NDcxOTggMC40NTQyOTZDNS42NTA4MDkgMC41MTAwODcgNS42NjY3NSAwLjUxMDA4NyA1LjY5MDY2IDAuNTEwMDg3QzUuNzk0MjcxIDAuNTEwMDg3IDUuODczOTczIDAuNDMwMzg2IDUuODczOTczIDAuMzI2Nzc1UzUuODAyMjQyIDAuMTc1MzQyIDUuNzA2NiAwLjEyNzUyMkwxLjMwNzA5OCAtMS45OTI1MjhMNS43MDY2IC00LjExMjU3OFonIGlkPSdnNS02MCcvPgo8cGF0aCBkPSdNNS43MDY2IC0xLjc5MzI3NUM1LjgwMjI0MiAtMS44NDEwOTYgNS44NzM5NzMgLTEuODg4OTE3IDUuODczOTczIC0xLjk5MjUyOFM1LjgwMjI0MiAtMi4xNDM5NiA1LjcwNjYgLTIuMTkxNzgxTDEuMDI4MTQ0IC00LjQzOTM1MkMwLjkyNDUzMyAtNC40OTUxNDMgMC45MDg1OTMgLTQuNDk1MTQzIDAuODg0NjgyIC00LjQ5NTE0M0MwLjc4MTA3MSAtNC40OTUxNDMgMC43MDEzNyAtNC40MTU0NDIgMC43MDEzNyAtNC4zMTE4MzFTMC43NzMxMDEgLTQuMTYwMzk5IDAuODY4NzQyIC00LjExMjU3OEw1LjI2ODI0NCAtMS45OTI1MjhMMC44Njg3NDIgMC4xMjc1MjJDMC43NzMxMDEgMC4xNzUzNDIgMC43MDEzNyAwLjIyMzE2MyAwLjcwMTM3IDAuMzI2Nzc1UzAuNzgxMDcxIDAuNTEwMDg3IDAuODg0NjgyIDAuNTEwMDg3QzAuOTA4NTkzIDAuNTEwMDg3IDAuOTI0NTMzIDAuNTEwMDg3IDEuMDI4MTQ0IDAuNDU0Mjk2TDUuNzA2NiAtMS43OTMyNzVaJyBpZD0nZzUtNjInLz4KPHBhdGggZD0nTTMuMDkyNDAzIC00LjgyMTkxOEMzLjE2NDEzNCAtNS4xMDA4NzIgMy4xODAwNzUgLTUuMTgwNTczIDMuNzc3ODMzIC01LjE4MDU3M0MzLjk2MTE0NiAtNS4xODA1NzMgNC4wNTY3ODcgLTUuMTgwNTczIDQuMDU2Nzg3IC01LjMzMjAwNUM0LjA1Njc4NyAtNS4zMzk5NzUgNC4wNDg4MTcgLTUuNDQzNTg3IDMuOTIxMjk1IC01LjQ0MzU4N0MzLjgwMTc0MyAtNS40NDM1ODcgMy41NTQ2NyAtNS40Mjc2NDYgMy40MjcxNDggLTUuNDE5Njc2SDIuMzI3MjczQzIuMjE1NjkxIC01LjQyNzY0NiAxLjkyODc2NyAtNS40NDM1ODcgMS44MTcxODYgLTUuNDQzNTg3QzEuNzg1MzA1IC01LjQ0MzU4NyAxLjY1Nzc4MyAtNS40NDM1ODcgMS42NTc3ODMgLTUuMjkyMTU0QzEuNjU3NzgzIC01LjE4MDU3MyAxLjc1MzQyNSAtNS4xODA1NzMgMS45MTI4MjcgLTUuMTgwNTczQzIuNDE0OTQ0IC01LjE4MDU3MyAyLjQxNDk0NCAtNS4xMzI3NTIgMi40MTQ5NDQgLTUuMDM3MTExQzIuNDE0OTQ0IC01LjAyMTE3MSAyLjQxNDk0NCAtNC45ODEzMiAyLjM4MzA2NCAtNC44NTM3OThMMS4zMjMwMzkgLTAuNjI5NjM5QzEuMjUxMzA4IC0wLjM0MjcxNSAxLjIyNzM5NyAtMC4yNjMwMTQgMC42Mzc2MDkgLTAuMjYzMDE0QzAuNDQ2MzI2IC0wLjI2MzAxNCAwLjM1ODY1NSAtMC4yNjMwMTQgMC4zNTg2NTUgLTAuMTExNTgyQzAuMzU4NjU1IC0wLjA3MTczMSAwLjM5MDUzNSAwIDAuNDg2MTc3IDBDMC41OTc3NTggMCAwLjg2MDc3MiAtMC4wMTU5NCAwLjk4MDMyNCAtMC4wMjM5MUgyLjA4ODE2OUMyLjE5OTc1MSAtMC4wMTU5NCAyLjQ4NjY3NSAwIDIuNTk4MjU3IDBDMi42NDYwNzcgMCAyLjc1NzY1OSAwIDIuNzU3NjU5IC0wLjE1MTQzMkMyLjc1NzY1OSAtMC4yNjMwMTQgMi42NjIwMTcgLTAuMjYzMDE0IDIuNDk0NjQ1IC0wLjI2MzAxNEMyLjM3NTA5MyAtMC4yNjMwMTQgMi4zMjcyNzMgLTAuMjYzMDE0IDIuMTkxNzgxIC0wLjI3ODk1NFMxLjk5MjUyOCAtMC4zMDI4NjQgMS45OTI1MjggLTAuMzkwNTM1QzEuOTkyNTI4IC0wLjQzMDM4NiAyLjAwMDQ5OCAtMC40MzAzODYgMi4wMjQ0MDggLTAuNTQxOTY4TDMuMDkyNDAzIC00LjgyMTkxOFonIGlkPSdnNS03MycvPgo8cGF0aCBkPSdNMy42MDI0OTEgLTQuODIxOTE4QzMuNjc0MjIyIC01LjEwODg0MiAzLjY4MjE5MiAtNS4xMjQ3ODIgNC4wMDg5NjYgLTUuMTI0NzgySDQuNjE0Njk1QzUuNDQzNTg3IC01LjEyNDc4MiA1LjUzOTIyOCAtNC44NjE3NjggNS41MzkyMjggLTQuNDYzMjYzQzUuNTM5MjI4IC00LjI2NDAxIDUuNDkxNDA3IC0zLjkyMTI5NSA1LjQ4MzQzNyAtMy44ODE0NDVDNS40Njc0OTcgLTMuNzkzNzczIDUuNDU5NTI3IC0zLjcyMjA0MiA1LjQ1OTUyNyAtMy43MDYxMDJDNS40NTk1MjcgLTMuNjAyNDkxIDUuNTMxMjU4IC0zLjU3ODU4IDUuNTc5MDc4IC0zLjU3ODU4QzUuNjY2NzUgLTMuNTc4NTggNS42OTg2MyAtMy42MjY0MDEgNS43MjI1NCAtMy43Nzc4MzNMNS45Mzc3MzMgLTUuMjc2MjE0QzUuOTM3NzMzIC01LjM4Nzc5NiA1Ljg0MjA5MiAtNS4zODc3OTYgNS42OTg2MyAtNS4zODc3OTZIMS4wMDQyMzRDMC44MDQ5ODEgLTUuMzg3Nzk2IDAuNzg5MDQxIC01LjM4Nzc5NiAwLjczMzI1IC01LjIyMDQyM0wwLjI0NzA3MyAtMy44NDE1OTRDMC4yMzExMzMgLTMuODAxNzQzIDAuMjA3MjIzIC0zLjczNzk4MyAwLjIwNzIyMyAtMy42OTAxNjJDMC4yMDcyMjMgLTMuNjI2NDAxIDAuMjYzMDE0IC0zLjU3ODU4IDAuMzI2Nzc1IC0zLjU3ODU4QzAuNDE0NDQ2IC0zLjU3ODU4IDAuNDMwMzg2IC0zLjYxODQzMSAwLjQ3ODIwNyAtMy43NTM5MjNDMC45MzI1MDMgLTUuMDI5MTQxIDEuMTYzNjM2IC01LjEyNDc4MiAyLjM3NTA5MyAtNS4xMjQ3ODJIMi42ODU5MjhDMi45MjUwMzEgLTUuMTI0NzgyIDIuOTMzMDAxIC01LjExNjgxMiAyLjkzMzAwMSAtNS4wNTMwNTFDMi45MzMwMDEgLTUuMDI5MTQxIDIuOTAxMTIxIC00Ljg2OTczOCAyLjg5MzE1MSAtNC44Mzc4NThMMS44NDEwOTYgLTAuNjUzNTQ5QzEuNzY5MzY1IC0wLjM1MDY4NSAxLjc0NTQ1NSAtMC4yNjMwMTQgMC45MTY1NjMgLTAuMjYzMDE0QzAuNjYxNTE5IC0wLjI2MzAxNCAwLjU4MTgxOCAtMC4yNjMwMTQgMC41ODE4MTggLTAuMTExNTgyQzAuNTgxODE4IC0wLjEwMzYxMSAwLjU4MTgxOCAwIDAuNzE3MzEgMEMwLjkzMjUwMyAwIDEuNDgyNDQxIC0wLjAyMzkxIDEuNjk3NjM0IC0wLjAyMzkxSDIuMzc1MDkzQzIuNTk4MjU3IC0wLjAyMzkxIDMuMTU2MTY0IDAgMy4zNzkzMjggMEMzLjQ0MzA4OCAwIDMuNTYyNjQgMCAzLjU2MjY0IC0wLjE1MTQzMkMzLjU2MjY0IC0wLjI2MzAxNCAzLjQ3NDk2OSAtMC4yNjMwMTQgMy4yNTk3NzYgLTAuMjYzMDE0QzMuMDY4NDkzIC0wLjI2MzAxNCAzLjAwNDczMiAtMC4yNjMwMTQgMi43OTc1MDkgLTAuMjc4OTU0QzIuNTQyNDY2IC0wLjMwMjg2NCAyLjUxMDU4NSAtMC4zMzQ3NDUgMi41MTA1ODUgLTAuNDM4MzU2QzIuNTEwNTg1IC0wLjQ3MDIzNyAyLjUxODU1NSAtMC41MDIxMTcgMi41NDI0NjYgLTAuNTgxODE4TDMuNjAyNDkxIC00LjgyMTkxOFonIGlkPSdnNS04NCcvPgo8cGF0aCBkPSdNNC4xNjAzOTkgLTMuMDQ0NTgzQzQuNTQyOTY0IC0zLjQzNTExOCA1LjY3NDcyIC00LjU5ODc1NSA1Ljg2NjAwMiAtNC43NTAxODdDNi4yMDA3NDcgLTUuMDA1MjMgNi40IC01LjE0ODY5MiA2Ljk3Mzg0OCAtNS4xODA1NzNDNy4wMjE2NjkgLTUuMTg4NTQzIDcuMDg1NDMgLTUuMjI4Mzk0IDcuMDg1NDMgLTUuMzMyMDA1QzcuMDg1NDMgLTUuNDAzNzM2IDcuMDEzNjk5IC01LjQ0MzU4NyA2Ljk3Mzg0OCAtNS40NDM1ODdDNi44OTQxNDcgLTUuNDQzNTg3IDYuODQ2MzI2IC01LjQxOTY3NiA2LjIyNDY1OCAtNS40MTk2NzZDNS42MjY4OTkgLTUuNDE5Njc2IDUuNDExNzA2IC01LjQ0MzU4NyA1LjM3MTg1NiAtNS40NDM1ODdDNS4zMzk5NzUgLTUuNDQzNTg3IDUuMjEyNDUzIC01LjQ0MzU4NyA1LjIxMjQ1MyAtNS4yOTIxNTRDNS4yMTI0NTMgLTUuMjg0MTg0IDUuMjEyNDUzIC01LjE4ODU0MyA1LjMzMjAwNSAtNS4xODA1NzNDNS4zODc3OTYgLTUuMTcyNjAzIDUuNjAyOTg5IC01LjE1NjY2MyA1LjYwMjk4OSAtNC45NzMzNUM1LjYwMjk4OSAtNC45MTc1NTkgNS41NzExMDggLTQuODI5ODg4IDUuNTA3MzQ3IC00Ljc2NjEyN0w1LjQ4MzQzNyAtNC43MjYyNzZDNS40NTk1MjcgLTQuNzAyMzY2IDUuNDU5NTI3IC00LjY4NjQyNiA1LjM3OTgyNiAtNC42MTQ2OTVMNC4wNDg4MTcgLTMuMjY3NzQ2TDMuMjM1ODY2IC00Ljk1NzQxQzMuMzQ3NDQ3IC01LjE0ODY5MiAzLjU4NjU1IC01LjE3MjYwMyAzLjY4MjE5MiAtNS4xODA1NzNDMy43MjIwNDIgLTUuMTgwNTczIDMuODMzNjI0IC01LjE4ODU0MyAzLjgzMzYyNCAtNS4zMjQwMzVDMy44MzM2MjQgLTUuMzk1NzY2IDMuNzc3ODMzIC01LjQ0MzU4NyAzLjcwNjEwMiAtNS40NDM1ODdDMy42MjY0MDEgLTUuNDQzNTg3IDMuMzIzNTM3IC01LjQyNzY0NiAzLjI0MzgzNiAtNS40Mjc2NDZDMy4xOTYwMTUgLTUuNDE5Njc2IDIuOTAxMTIxIC01LjQxOTY3NiAyLjczMzc0OCAtNS40MTk2NzZDMS45OTI1MjggLTUuNDE5Njc2IDEuODk2ODg3IC01LjQ0MzU4NyAxLjgyNTE1NiAtNS40NDM1ODdDMS43OTMyNzUgLTUuNDQzNTg3IDEuNjY1NzUzIC01LjQ0MzU4NyAxLjY2NTc1MyAtNS4yOTIxNTRDMS42NjU3NTMgLTUuMTgwNTczIDEuNzY5MzY1IC01LjE4MDU3MyAxLjg5Njg4NyAtNS4xODA1NzNDMi4yOTUzOTIgLTUuMTgwNTczIDIuMzY3MTIzIC01LjEwMDg3MiAyLjQzODg1NCAtNC45NDk0NEwzLjQ5ODg3OSAtMi43MTc4MDhMMS44NjUwMDYgLTEuMDUyMDU1QzEuMzg2OCAtMC41NzM4NDggMS4wMTIyMDQgLTAuMjk0ODk0IDAuNDQ2MzI2IC0wLjI2MzAxNEMwLjM1MDY4NSAtMC4yNTUwNDQgMC4yNTUwNDQgLTAuMjU1MDQ0IDAuMjU1MDQ0IC0wLjExMTU4MkMwLjI1NTA0NCAtMC4wNjM3NjEgMC4yOTQ4OTQgMCAwLjM3NDU5NSAwQzAuNDMwMzg2IDAgMC41MTgwNTcgLTAuMDIzOTEgMS4xMjM3ODYgLTAuMDIzOTFDMS42OTc2MzQgLTAuMDIzOTEgMS45NDQ3MDcgMCAxLjk3NjU4OCAwQzIuMDE2NDM4IDAgMi4xMzU5OSAwIDIuMTM1OTkgLTAuMTUxNDMyQzIuMTM1OTkgLTAuMTY3MzcyIDIuMTI4MDIgLTAuMjU1MDQ0IDIuMDA4NDY4IC0wLjI2MzAxNEMxLjg1NzAzNiAtMC4yNzA5ODQgMS43NDU0NTUgLTAuMzI2Nzc1IDEuNzQ1NDU1IC0wLjQ3MDIzN0MxLjc0NTQ1NSAtMC41OTc3NTggMS44NDEwOTYgLTAuNzAxMzcgMS45NjA2NDggLTAuODIwOTIyQzIuMDk2MTM5IC0wLjk3MjM1NCAyLjUxMDU4NSAtMS4zODY4IDIuNzk3NTA5IC0xLjY2NTc1M0MyLjk4MDgyMiAtMS44NDkwNjYgMy40MjcxNDggLTIuMzExMzMzIDMuNjEwNDYxIC0yLjQ4NjY3NUw0LjUyNzAyNCAtMC41ODE4MThDNC41NjY4NzQgLTAuNTAyMTE3IDQuNTY2ODc0IC0wLjQ5NDE0NyA0LjU2Njg3NCAtMC40ODYxNzdDNC41NjY4NzQgLTAuNDE0NDQ2IDQuMzk5NTAyIC0wLjI3ODk1NCA0LjEzNjQ4OCAtMC4yNjMwMTRDNC4wODA2OTcgLTAuMjYzMDE0IDMuOTc3MDg2IC0wLjI1NTA0NCAzLjk3NzA4NiAtMC4xMTE1ODJDMy45NzcwODYgLTAuMTAzNjExIDMuOTg1MDU2IDAgNC4xMTI1NzggMEM0LjE5MjI3OSAwIDQuNDg3MTczIC0wLjAxNTk0IDQuNTY2ODc0IC0wLjAyMzkxSDUuMDc2OTYxQzUuODEwMjEyIC0wLjAyMzkxIDUuOTIxNzkzIDAgNS45OTM1MjQgMEM2LjAyNTQwNSAwIDYuMTQ0OTU2IDAgNi4xNDQ5NTYgLTAuMTUxNDMyQzYuMTQ0OTU2IC0wLjI2MzAxNCA2LjA0MTM0NSAtMC4yNjMwMTQgNS45MjE3OTMgLTAuMjYzMDE0QzUuNDkxNDA3IC0wLjI2MzAxNCA1LjQ0MzU4NyAtMC4zNTg2NTUgNS4zODc3OTYgLTAuNDc4MjA3TDQuMTYwMzk5IC0zLjA0NDU4M1onIGlkPSdnNS04OCcvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzUtMTA3Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScxNTMuNDc2Mzg5JyB4bGluazpocmVmPScjZzYtODQnIHk9JzkxLjA4OTQ5Jy8+Cjx1c2UgeD0nMTYwLjMzNzM5NCcgeGxpbms6aHJlZj0nI2c4LTkxJyB5PSc5Mi45NDkyMDEnLz4KPHVzZSB4PScxNjIuNjg5NzE4JyB4bGluazpocmVmPScjZzgtNDknIHk9JzkyLjk0OTIwMScvPgo8dXNlIHg9JzE2Ni45MjM5MDEnIHhsaW5rOmhyZWY9JyNnOC05MycgeT0nOTIuOTQ5MjAxJy8+Cjx1c2UgeD0nMTc5LjczNjk5NycgeGxpbms6aHJlZj0nI2c5LTYxJyB5PSc5MS4wODk0OScvPgo8dXNlIHg9JzIwNS45Nzc0MDInIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nODQuMTUxMDkzJy8+Cjx1c2UgeD0nMjEyLjk0MjM1NycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PSc4NS44ODkwMjInLz4KPHVzZSB4PScyMTUuMDQ1NTU2JyB4bGluazpocmVmPScjZzctNDknIHk9Jzg1Ljg4OTAyMicvPgo8dXNlIHg9JzIxOC42OTg0ODEnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nODUuODg5MDIyJy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPScyNy4yNzc1OTInIHg9JzE5OS45OTk4MDInIHk9Jzg3Ljg2MTYwNScvPgo8dXNlIHg9JzE5OS45OTk4MDInIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9Jzk3Ljc4NDM1NScvPgo8dXNlIHg9JzIwNS45Nzc0MDInIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nOTYuNzg4MDkxJy8+Cjx1c2UgeD0nMjEyLjk0MjM1NycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PSc5OC41MjYwMicvPgo8dXNlIHg9JzIxNS4wNDU1NTYnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nOTguNTI2MDInLz4KPHVzZSB4PScyMTguNjk4NDgxJyB4bGluazpocmVmPScjZzctOTMnIHk9Jzk4LjUyNjAyJy8+Cjx1c2UgeD0nMjIxLjI5OTc5NScgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nOTcuNzg0MzU1Jy8+Cjx1c2UgeD0nMTUyLjc5MjEyNycgeGxpbms6aHJlZj0nI2c2LTgwJyB5PScxMTMuMTU3NzgxJy8+Cjx1c2UgeD0nMTYwLjMzNzM5NCcgeGxpbms6aHJlZj0nI2c4LTkxJyB5PScxMTUuMDE3NDkxJy8+Cjx1c2UgeD0nMTYyLjY4OTcxOCcgeGxpbms6aHJlZj0nI2c4LTQ5JyB5PScxMTUuMDE3NDkxJy8+Cjx1c2UgeD0nMTY2LjkyMzkwMScgeGxpbms6aHJlZj0nI2c4LTkzJyB5PScxMTUuMDE3NDkxJy8+Cjx1c2UgeD0nMTc5LjczNjk5NycgeGxpbms6aHJlZj0nI2c5LTYxJyB5PScxMTMuMTU3NzgxJy8+Cjx1c2UgeD0nMjA3LjYyNDAyOCcgeGxpbms6aHJlZj0nI2c1LTczJyB5PScxMDYuMjE5Mzg0Jy8+Cjx1c2UgeD0nMjExLjI5NTczJyB4bGluazpocmVmPScjZzctOTEnIHk9JzEwNy45NTczMTInLz4KPHVzZSB4PScyMTMuMzk4OTI5JyB4bGluazpocmVmPScjZzctNDknIHk9JzEwNy45NTczMTInLz4KPHVzZSB4PScyMTcuMDUxODU0JyB4bGluazpocmVmPScjZzctOTMnIHk9JzEwNy45NTczMTInLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzI3LjI3NzU5MicgeD0nMTk5Ljk5OTgwMicgeT0nMTA5LjkyOTg5NScvPgo8dXNlIHg9JzE5OS45OTk4MDInIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzExOS44NTI2NDYnLz4KPHVzZSB4PScyMDUuOTc3NDAyJyB4bGluazpocmVmPScjZzUtODgnIHk9JzExOC44NTYzODInLz4KPHVzZSB4PScyMTIuOTQyMzU3JyB4bGluazpocmVmPScjZzctOTEnIHk9JzEyMC41OTQzMTEnLz4KPHVzZSB4PScyMTUuMDQ1NTU2JyB4bGluazpocmVmPScjZzctNDknIHk9JzEyMC41OTQzMTEnLz4KPHVzZSB4PScyMTguNjk4NDgxJyB4bGluazpocmVmPScjZzctOTMnIHk9JzEyMC41OTQzMTEnLz4KPHVzZSB4PScyMjEuMjk5Nzk1JyB4bGluazpocmVmPScjZzMtMTA3JyB5PScxMTkuODUyNjQ2Jy8+Cjx1c2UgeD0nMTUzLjQ3NjM4OScgeGxpbms6aHJlZj0nI2c2LTg0JyB5PScxMzUuMjI2MDcyJy8+Cjx1c2UgeD0nMTYwLjMzNzM5NCcgeGxpbms6aHJlZj0nI2c4LTkxJyB5PScxMzcuMDg1NzgyJy8+Cjx1c2UgeD0nMTYyLjY4OTcxOCcgeGxpbms6aHJlZj0nI2c4LTUwJyB5PScxMzcuMDg1NzgyJy8+Cjx1c2UgeD0nMTY2LjkyMzkwMScgeGxpbms6aHJlZj0nI2c4LTkzJyB5PScxMzcuMDg1NzgyJy8+Cjx1c2UgeD0nMTc5LjczNjk5NycgeGxpbms6aHJlZj0nI2c5LTYxJyB5PScxMzUuMjI2MDcyJy8+Cjx1c2UgeD0nMjA1Ljk3NzQwMicgeGxpbms6aHJlZj0nI2c1LTg4JyB5PScxMjguMjg3Njc0Jy8+Cjx1c2UgeD0nMjEyLjk0MjM1NycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScxMzAuMDI1NjAzJy8+Cjx1c2UgeD0nMjE1LjA0NTU1NicgeGxpbms6aHJlZj0nI2c3LTUwJyB5PScxMzAuMDI1NjAzJy8+Cjx1c2UgeD0nMjE4LjY5ODQ4MScgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScxMzAuMDI1NjAzJy8+Cjx1c2UgeD0nMjIxLjI5OTc5NScgeGxpbms6aHJlZj0nI2cyLTAnIHk9JzEyOC4yODc2NzQnLz4KPHVzZSB4PScyMjcuODg2MzAyJyB4bGluazpocmVmPScjZzUtNjAnIHk9JzEyOC4yODc2NzQnLz4KPHVzZSB4PScyMzQuNDcyODA4JyB4bGluazpocmVmPScjZzUtODgnIHk9JzEyOC4yODc2NzQnLz4KPHVzZSB4PScyNDEuNDM3NzYzJyB4bGluazpocmVmPScjZzctOTEnIHk9JzEzMC4wMjU2MDMnLz4KPHVzZSB4PScyNDMuNTQwOTYyJyB4bGluazpocmVmPScjZzctNTAnIHk9JzEzMC4wMjU2MDMnLz4KPHVzZSB4PScyNDcuMTkzODg4JyB4bGluazpocmVmPScjZzctOTMnIHk9JzEzMC4wMjU2MDMnLz4KPHVzZSB4PScyNDkuNzk1MjAyJyB4bGluazpocmVmPScjZzUtNTknIHk9JzEyOC4yODc2NzQnLz4KPHVzZSB4PScyNTIuMTQ3NTI1JyB4bGluazpocmVmPScjZzUtODQnIHk9JzEyOC4yODc2NzQnLz4KPHVzZSB4PScyNTcuMDc3NzIyJyB4bGluazpocmVmPScjZzctOTEnIHk9JzEzMC4wMjU2MDMnLz4KPHVzZSB4PScyNTkuMTgwOTIxJyB4bGluazpocmVmPScjZzctNDknIHk9JzEzMC4wMjU2MDMnLz4KPHVzZSB4PScyNjIuODMzODQ2JyB4bGluazpocmVmPScjZzctOTMnIHk9JzEzMC4wMjU2MDMnLz4KPHVzZSB4PScyNjUuNDM1MTYnIHhsaW5rOmhyZWY9JyNnNS02MicgeT0nMTI4LjI4NzY3NCcvPgo8dXNlIHg9JzI3Mi4wMjE2NjcnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTI4LjI4NzY3NCcvPgo8dXNlIHg9JzI3Ni45NTE4NjMnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTMwLjAyNTYwMycvPgo8dXNlIHg9JzI3OS4wNTUwNjInIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTMwLjAyNTYwMycvPgo8dXNlIHg9JzI4Mi43MDc5ODgnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTMwLjAyNTYwMycvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nOTEuMjg3MDk4JyB4PScxOTkuOTk5ODAyJyB5PScxMzEuOTk4MTg2Jy8+Cjx1c2UgeD0nMTk5Ljk5OTgwMicgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nMTQxLjkyMDkzNycvPgo8dXNlIHg9JzIwNS45Nzc0MDInIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMTQwLjkyNDY3MycvPgo8dXNlIHg9JzIxMi45NDIzNTcnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTQyLjY2MjYwMScvPgo8dXNlIHg9JzIxNS4wNDU1NTYnIHhsaW5rOmhyZWY9JyNnNy01MCcgeT0nMTQyLjY2MjYwMScvPgo8dXNlIHg9JzIxOC42OTg0ODEnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTQyLjY2MjYwMScvPgo8dXNlIHg9JzIyMS4yOTk3OTUnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScxNDAuOTI0NjczJy8+Cjx1c2UgeD0nMjI3Ljg4NjMwMicgeGxpbms6aHJlZj0nI2c1LTYwJyB5PScxNDAuOTI0NjczJy8+Cjx1c2UgeD0nMjM0LjQ3MjgwOCcgeGxpbms6aHJlZj0nI2c1LTg4JyB5PScxNDAuOTI0NjczJy8+Cjx1c2UgeD0nMjQxLjQzNzc2MycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScxNDIuNjYyNjAxJy8+Cjx1c2UgeD0nMjQzLjU0MDk2MicgeGxpbms6aHJlZj0nI2c3LTUwJyB5PScxNDIuNjYyNjAxJy8+Cjx1c2UgeD0nMjQ3LjE5Mzg4OCcgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScxNDIuNjYyNjAxJy8+Cjx1c2UgeD0nMjQ5Ljc5NTIwMicgeGxpbms6aHJlZj0nI2c1LTU5JyB5PScxNDAuOTI0NjczJy8+Cjx1c2UgeD0nMjUyLjE0NzUyNScgeGxpbms6aHJlZj0nI2c1LTg0JyB5PScxNDAuOTI0NjczJy8+Cjx1c2UgeD0nMjU3LjA3NzcyMicgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScxNDIuNjYyNjAxJy8+Cjx1c2UgeD0nMjU5LjE4MDkyMScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNDIuNjYyNjAxJy8+Cjx1c2UgeD0nMjYyLjgzMzg0NicgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScxNDIuNjYyNjAxJy8+Cjx1c2UgeD0nMjY1LjQzNTE2JyB4bGluazpocmVmPScjZzUtNjInIHk9JzE0MC45MjQ2NzMnLz4KPHVzZSB4PScyNzIuMDIxNjY3JyB4bGluazpocmVmPScjZzUtODQnIHk9JzE0MC45MjQ2NzMnLz4KPHVzZSB4PScyNzYuOTUxODYzJyB4bGluazpocmVmPScjZzctOTEnIHk9JzE0Mi42NjI2MDEnLz4KPHVzZSB4PScyNzkuMDU1MDYyJyB4bGluazpocmVmPScjZzctNDknIHk9JzE0Mi42NjI2MDEnLz4KPHVzZSB4PScyODIuNzA3OTg4JyB4bGluazpocmVmPScjZzctOTMnIHk9JzE0Mi42NjI2MDEnLz4KPHVzZSB4PScyODUuMzA5MzAyJyB4bGluazpocmVmPScjZzMtMTA3JyB5PScxNDEuOTIwOTM3Jy8+Cjx1c2UgeD0nMTUyLjc5MjEyNycgeGxpbms6aHJlZj0nI2c2LTgwJyB5PScxNTcuMjk0MzYyJy8+Cjx1c2UgeD0nMTYwLjMzNzM5NCcgeGxpbms6aHJlZj0nI2c4LTkxJyB5PScxNTkuMTU0MDcyJy8+Cjx1c2UgeD0nMTYyLjY4OTcxOCcgeGxpbms6aHJlZj0nI2c4LTUwJyB5PScxNTkuMTU0MDcyJy8+Cjx1c2UgeD0nMTY2LjkyMzkwMScgeGxpbms6aHJlZj0nI2c4LTkzJyB5PScxNTkuMTU0MDcyJy8+Cjx1c2UgeD0nMTc5LjczNjk5NycgeGxpbms6aHJlZj0nI2c5LTYxJyB5PScxNTcuMjk0MzYyJy8+Cjx1c2UgeD0nMjA3LjYyNDAyOCcgeGxpbms6aHJlZj0nI2c1LTczJyB5PScxNTAuMzU1OTY1Jy8+Cjx1c2UgeD0nMjExLjI5NTczJyB4bGluazpocmVmPScjZzctOTEnIHk9JzE1Mi4wOTM4OTQnLz4KPHVzZSB4PScyMTMuMzk4OTI5JyB4bGluazpocmVmPScjZzctNTAnIHk9JzE1Mi4wOTM4OTQnLz4KPHVzZSB4PScyMTcuMDUxODU0JyB4bGluazpocmVmPScjZzctOTMnIHk9JzE1Mi4wOTM4OTQnLz4KPHVzZSB4PScyMTkuNjUzMTY4JyB4bGluazpocmVmPScjZzItMCcgeT0nMTUwLjM1NTk2NScvPgo8dXNlIHg9JzIyNi4yMzk2NzUnIHhsaW5rOmhyZWY9JyNnNS02MCcgeT0nMTUwLjM1NTk2NScvPgo8dXNlIHg9JzIzMi44MjYxODInIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMTUwLjM1NTk2NScvPgo8dXNlIHg9JzIzOS43OTExMzcnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTUyLjA5Mzg5NCcvPgo8dXNlIHg9JzI0MS44OTQzMzYnIHhsaW5rOmhyZWY9JyNnNy01MCcgeT0nMTUyLjA5Mzg5NCcvPgo8dXNlIHg9JzI0NS41NDcyNjEnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTUyLjA5Mzg5NCcvPgo8dXNlIHg9JzI0OC4xNDg1NzUnIHhsaW5rOmhyZWY9JyNnNS01OScgeT0nMTUwLjM1NTk2NScvPgo8dXNlIHg9JzI1MC41MDA4OTknIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTUwLjM1NTk2NScvPgo8dXNlIHg9JzI1NS40MzEwOTUnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTUyLjA5Mzg5NCcvPgo8dXNlIHg9JzI1Ny41MzQyOTQnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTUyLjA5Mzg5NCcvPgo8dXNlIHg9JzI2MS4xODcyMicgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScxNTIuMDkzODk0Jy8+Cjx1c2UgeD0nMjYzLjc4ODUzMycgeGxpbms6aHJlZj0nI2c1LTYyJyB5PScxNTAuMzU1OTY1Jy8+Cjx1c2UgeD0nMjcwLjM3NTA0JyB4bGluazpocmVmPScjZzUtODQnIHk9JzE1MC4zNTU5NjUnLz4KPHVzZSB4PScyNzUuMzA1MjM3JyB4bGluazpocmVmPScjZzctOTEnIHk9JzE1Mi4wOTM4OTQnLz4KPHVzZSB4PScyNzcuNDA4NDM1JyB4bGluazpocmVmPScjZzctNDknIHk9JzE1Mi4wOTM4OTQnLz4KPHVzZSB4PScyODEuMDYxMzYxJyB4bGluazpocmVmPScjZzctOTMnIHk9JzE1Mi4wOTM4OTQnLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzkxLjI4NzA5OCcgeD0nMTk5Ljk5OTgwMicgeT0nMTU0LjA2NjQ3NycvPgo8dXNlIHg9JzE5OS45OTk4MDInIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzE2My45ODkyMjcnLz4KPHVzZSB4PScyMDUuOTc3NDAyJyB4bGluazpocmVmPScjZzUtODgnIHk9JzE2Mi45OTI5NjMnLz4KPHVzZSB4PScyMTIuOTQyMzU3JyB4bGluazpocmVmPScjZzctOTEnIHk9JzE2NC43MzA4OTInLz4KPHVzZSB4PScyMTUuMDQ1NTU2JyB4bGluazpocmVmPScjZzctNTAnIHk9JzE2NC43MzA4OTInLz4KPHVzZSB4PScyMTguNjk4NDgxJyB4bGluazpocmVmPScjZzctOTMnIHk9JzE2NC43MzA4OTInLz4KPHVzZSB4PScyMjEuMjk5Nzk1JyB4bGluazpocmVmPScjZzItMCcgeT0nMTYyLjk5Mjk2MycvPgo8dXNlIHg9JzIyNy44ODYzMDInIHhsaW5rOmhyZWY9JyNnNS02MCcgeT0nMTYyLjk5Mjk2MycvPgo8dXNlIHg9JzIzNC40NzI4MDgnIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMTYyLjk5Mjk2MycvPgo8dXNlIHg9JzI0MS40Mzc3NjMnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTY0LjczMDg5MicvPgo8dXNlIHg9JzI0My41NDA5NjInIHhsaW5rOmhyZWY9JyNnNy01MCcgeT0nMTY0LjczMDg5MicvPgo8dXNlIHg9JzI0Ny4xOTM4ODgnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTY0LjczMDg5MicvPgo8dXNlIHg9JzI0OS43OTUyMDInIHhsaW5rOmhyZWY9JyNnNS01OScgeT0nMTYyLjk5Mjk2MycvPgo8dXNlIHg9JzI1Mi4xNDc1MjUnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTYyLjk5Mjk2MycvPgo8dXNlIHg9JzI1Ny4wNzc3MjInIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTY0LjczMDg5MicvPgo8dXNlIHg9JzI1OS4xODA5MjEnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTY0LjczMDg5MicvPgo8dXNlIHg9JzI2Mi44MzM4NDYnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTY0LjczMDg5MicvPgo8dXNlIHg9JzI2NS40MzUxNicgeGxpbms6aHJlZj0nI2c1LTYyJyB5PScxNjIuOTkyOTYzJy8+Cjx1c2UgeD0nMjcyLjAyMTY2NycgeGxpbms6aHJlZj0nI2c1LTg0JyB5PScxNjIuOTkyOTYzJy8+Cjx1c2UgeD0nMjc2Ljk1MTg2MycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScxNjQuNzMwODkyJy8+Cjx1c2UgeD0nMjc5LjA1NTA2MicgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNjQuNzMwODkyJy8+Cjx1c2UgeD0nMjgyLjcwNzk4OCcgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScxNjQuNzMwODkyJy8+Cjx1c2UgeD0nMjg1LjMwOTMwMicgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nMTYzLjk4OTIyNycvPgo8dXNlIHg9JzE2MC4wMTkzNzMnIHhsaW5rOmhyZWY9JyNnNi01OCcgeT0nMTc2Ljc0MTM2NCcvPgo8dXNlIHg9JzE2My4yNzEwMzQnIHhsaW5rOmhyZWY9JyNnNi01OCcgeT0nMTc2Ljc0MTM2NCcvPgo8dXNlIHg9JzE2Ni41MjI2OTYnIHhsaW5rOmhyZWY9JyNnNi01OCcgeT0nMTc2Ljc0MTM2NCcvPgo8dXNlIHg9JzE1My4wODg5NTcnIHhsaW5rOmhyZWY9JyNnNi04NCcgeT0nMTk1LjU5MDY3NycvPgo8dXNlIHg9JzE1OS45NDk5NjInIHhsaW5rOmhyZWY9JyNnOC05MScgeT0nMTk3LjQ1MDM4NycvPgo8dXNlIHg9JzE2Mi4zMDIyODYnIHhsaW5rOmhyZWY9JyNnNS0xMDcnIHk9JzE5Ny40NTAzODcnLz4KPHVzZSB4PScxNjYuOTIzOTAxJyB4bGluazpocmVmPScjZzgtOTMnIHk9JzE5Ny40NTAzODcnLz4KPHVzZSB4PScxNzkuNzM2OTk3JyB4bGluazpocmVmPScjZzktNjEnIHk9JzE5NS41OTA2NzcnLz4KPHVzZSB4PScyMDUuNzY2Mzg2JyB4bGluazpocmVmPScjZzUtODgnIHk9JzE4OC42NTIyOCcvPgo8dXNlIHg9JzIxMi43MzEzNDEnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTkwLjM5MDIwOCcvPgo8dXNlIHg9JzIxNC44MzQ1NCcgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTkwLjM5MDIwOCcvPgo8dXNlIHg9JzIxOC45MDk1MTInIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTkwLjM5MDIwOCcvPgo8dXNlIHg9JzIyMS41MTA4MjYnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScxODguNjUyMjgnLz4KPHVzZSB4PScyMjguMDk3MzMzJyB4bGluazpocmVmPScjZzAtODAnIHk9JzE4Mi42NzQ2NScvPgo8dXNlIHg9JzIzNy4wMzYxNjMnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzE4NS4wNzY4MjEnLz4KPHVzZSB4PScyNDEuMTExMTM2JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTg1LjA3NjgyMScvPgo8dXNlIHg9JzI0Ni44NjcyODknIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTg1LjA3NjgyMScvPgo8dXNlIHg9JzIzNy4wMzYxNjMnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzE5MS4zMDE5ODEnLz4KPHVzZSB4PScyMzkuNjk5Nzg5JyB4bGluazpocmVmPScjZzctNjEnIHk9JzE5MS4zMDE5ODEnLz4KPHVzZSB4PScyNDUuMjg5ODgyJyB4bGluazpocmVmPScjZzctNDknIHk9JzE5MS4zMDE5ODEnLz4KPHVzZSB4PScyNTEuMDE4MzA3JyB4bGluazpocmVmPScjZzUtNjAnIHk9JzE4OC42NTIyOCcvPgo8dXNlIHg9JzI1Ny42MDQ4MTMnIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMTg4LjY1MjI4Jy8+Cjx1c2UgeD0nMjY0LjU2OTc2OCcgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScxOTAuMzkwMjA4Jy8+Cjx1c2UgeD0nMjY2LjY3Mjk2NycgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTkwLjM5MDIwOCcvPgo8dXNlIHg9JzI3MC43NDc5NCcgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScxOTAuMzkwMjA4Jy8+Cjx1c2UgeD0nMjczLjM0OTI1NCcgeGxpbms6aHJlZj0nI2c1LTU5JyB5PScxODguNjUyMjgnLz4KPHVzZSB4PScyNzUuNzAxNTc3JyB4bGluazpocmVmPScjZzUtODQnIHk9JzE4OC42NTIyOCcvPgo8dXNlIHg9JzI4MC42MzE3NzQnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMTkwLjM5MDIwOCcvPgo8dXNlIHg9JzI4Mi43MzQ5NzMnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzE5MC4zOTAyMDgnLz4KPHVzZSB4PScyODUuMzk4NTk5JyB4bGluazpocmVmPScjZzctOTMnIHk9JzE5MC4zOTAyMDgnLz4KPHVzZSB4PScyODcuOTk5OTI2JyB4bGluazpocmVmPScjZzUtNjInIHk9JzE4OC42NTIyOCcvPgo8dXNlIHg9JzI5NC41ODY0MzInIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTg4LjY1MjI4Jy8+Cjx1c2UgeD0nMjk5LjUxNjYyOScgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScxOTAuMzkwMjA4Jy8+Cjx1c2UgeD0nMzAxLjYxOTgyOCcgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTkwLjM5MDIwOCcvPgo8dXNlIHg9JzMwNC4yODM0NTQnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMTkwLjM5MDIwOCcvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nMTEyLjY1MTU0NycgeD0nMTk5Ljk5OTgwMicgeT0nMTkyLjM2Mjc5MicvPgo8dXNlIHg9JzE5OS45OTk4MDInIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzIwMi4yODU1NDInLz4KPHVzZSB4PScyMDUuOTc3NDAyJyB4bGluazpocmVmPScjZzUtODgnIHk9JzIwMS4yODkyNzgnLz4KPHVzZSB4PScyMTIuOTQyMzU3JyB4bGluazpocmVmPScjZzctOTEnIHk9JzIwMy4wMjcyMDcnLz4KPHVzZSB4PScyMTUuMDQ1NTU2JyB4bGluazpocmVmPScjZzctNTAnIHk9JzIwMy4wMjcyMDcnLz4KPHVzZSB4PScyMTguNjk4NDgxJyB4bGluazpocmVmPScjZzctOTMnIHk9JzIwMy4wMjcyMDcnLz4KPHVzZSB4PScyMjEuMjk5Nzk1JyB4bGluazpocmVmPScjZzItMCcgeT0nMjAxLjI4OTI3OCcvPgo8dXNlIHg9JzIyNy44ODYzMDInIHhsaW5rOmhyZWY9JyNnMC04MCcgeT0nMTk1LjMxMTY0OScvPgo8dXNlIHg9JzIzNi44MjUxMzInIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzE5Ny43MTM4MTknLz4KPHVzZSB4PScyNDAuOTAwMTA1JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTk3LjcxMzgxOScvPgo8dXNlIHg9JzI0Ni42NTYyNTgnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTk3LjcxMzgxOScvPgo8dXNlIHg9JzIzNi44MjUxMzInIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzIwMy45Mzg5NzknLz4KPHVzZSB4PScyMzkuNDg4NzU4JyB4bGluazpocmVmPScjZzctNjEnIHk9JzIwMy45Mzg5NzknLz4KPHVzZSB4PScyNDUuMDc4ODUxJyB4bGluazpocmVmPScjZzctNDknIHk9JzIwMy45Mzg5NzknLz4KPHVzZSB4PScyNTAuODA3Mjc1JyB4bGluazpocmVmPScjZzUtNjAnIHk9JzIwMS4yODkyNzgnLz4KPHVzZSB4PScyNTcuMzkzNzgyJyB4bGluazpocmVmPScjZzUtODgnIHk9JzIwMS4yODkyNzgnLz4KPHVzZSB4PScyNjQuMzU4NzM3JyB4bGluazpocmVmPScjZzctOTEnIHk9JzIwMy4wMjcyMDcnLz4KPHVzZSB4PScyNjYuNDYxOTM2JyB4bGluazpocmVmPScjZzQtMTA3JyB5PScyMDMuMDI3MjA3Jy8+Cjx1c2UgeD0nMjcwLjUzNjkwOScgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScyMDMuMDI3MjA3Jy8+Cjx1c2UgeD0nMjczLjEzODIyMycgeGxpbms6aHJlZj0nI2c1LTU5JyB5PScyMDEuMjg5Mjc4Jy8+Cjx1c2UgeD0nMjc1LjQ5MDU0NicgeGxpbms6aHJlZj0nI2c1LTg0JyB5PScyMDEuMjg5Mjc4Jy8+Cjx1c2UgeD0nMjgwLjQyMDc0MycgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScyMDMuMDI3MjA3Jy8+Cjx1c2UgeD0nMjgyLjUyMzk0MicgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMjAzLjAyNzIwNycvPgo8dXNlIHg9JzI4NS4xODc1NjgnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMjAzLjAyNzIwNycvPgo8dXNlIHg9JzI4Ny43ODg4OTUnIHhsaW5rOmhyZWY9JyNnNS02MicgeT0nMjAxLjI4OTI3OCcvPgo8dXNlIHg9JzI5NC4zNzU0MDEnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMjAxLjI4OTI3OCcvPgo8dXNlIHg9JzI5OS4zMDU1OTgnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMjAzLjAyNzIwNycvPgo8dXNlIHg9JzMwMS40MDg3OTcnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzIwMy4wMjcyMDcnLz4KPHVzZSB4PSczMDQuMDcyNDIzJyB4bGluazpocmVmPScjZzctOTMnIHk9JzIwMy4wMjcyMDcnLz4KPHVzZSB4PSczMDYuNjczNzUnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzIwMi4yODU1NDInLz4KPHVzZSB4PScxNTIuNDA0Njk0JyB4bGluazpocmVmPScjZzYtODAnIHk9JzIxOS45MzkyOTYnLz4KPHVzZSB4PScxNTkuOTQ5OTYyJyB4bGluazpocmVmPScjZzgtOTEnIHk9JzIyMS43OTkwMDYnLz4KPHVzZSB4PScxNjIuMzAyMjg2JyB4bGluazpocmVmPScjZzUtMTA3JyB5PScyMjEuNzk5MDA2Jy8+Cjx1c2UgeD0nMTY2LjkyMzkwMScgeGxpbms6aHJlZj0nI2c4LTkzJyB5PScyMjEuNzk5MDA2Jy8+Cjx1c2UgeD0nMTc5LjczNjk5NycgeGxpbms6aHJlZj0nI2c5LTYxJyB5PScyMTkuOTM5Mjk2Jy8+Cjx1c2UgeD0nMjA3LjQxMzAxMicgeGxpbms6aHJlZj0nI2c1LTczJyB5PScyMTMuMDAwODk5Jy8+Cjx1c2UgeD0nMjExLjA4NDcxNCcgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScyMTQuNzM4ODI3Jy8+Cjx1c2UgeD0nMjEzLjE4NzkxMycgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMjE0LjczODgyNycvPgo8dXNlIHg9JzIxNy4yNjI4ODYnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMjE0LjczODgyNycvPgo8dXNlIHg9JzIxOS44NjQxOTknIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScyMTMuMDAwODk5Jy8+Cjx1c2UgeD0nMjI2LjQ1MDcwNicgeGxpbms6aHJlZj0nI2cwLTgwJyB5PScyMDcuMDIzMjY5Jy8+Cjx1c2UgeD0nMjM1LjM4OTUzNycgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMjA5LjQyNTQ0Jy8+Cjx1c2UgeD0nMjM5LjQ2NDUwOScgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzIwOS40MjU0NCcvPgo8dXNlIHg9JzI0NS4yMjA2NjInIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMjA5LjQyNTQ0Jy8+Cjx1c2UgeD0nMjM1LjM4OTUzNycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMjE1LjY1MDYnLz4KPHVzZSB4PScyMzguMDUzMTYyJyB4bGluazpocmVmPScjZzctNjEnIHk9JzIxNS42NTA2Jy8+Cjx1c2UgeD0nMjQzLjY0MzI1NScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyMTUuNjUwNicvPgo8dXNlIHg9JzI0OS4zNzE2OCcgeGxpbms6aHJlZj0nI2c1LTYwJyB5PScyMTMuMDAwODk5Jy8+Cjx1c2UgeD0nMjU1Ljk1ODE4NycgeGxpbms6aHJlZj0nI2c1LTg4JyB5PScyMTMuMDAwODk5Jy8+Cjx1c2UgeD0nMjYyLjkyMzE0MicgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScyMTQuNzM4ODI3Jy8+Cjx1c2UgeD0nMjY1LjAyNjM0MScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMjE0LjczODgyNycvPgo8dXNlIHg9JzI2OS4xMDEzMTMnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMjE0LjczODgyNycvPgo8dXNlIHg9JzI3MS43MDI2MjcnIHhsaW5rOmhyZWY9JyNnNS01OScgeT0nMjEzLjAwMDg5OScvPgo8dXNlIHg9JzI3NC4wNTQ5NTEnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMjEzLjAwMDg5OScvPgo8dXNlIHg9JzI3OC45ODUxNDcnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMjE0LjczODgyNycvPgo8dXNlIHg9JzI4MS4wODgzNDYnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzIxNC43Mzg4MjcnLz4KPHVzZSB4PScyODMuNzUxOTcyJyB4bGluazpocmVmPScjZzctOTMnIHk9JzIxNC43Mzg4MjcnLz4KPHVzZSB4PScyODYuMzUzMjk5JyB4bGluazpocmVmPScjZzUtNjInIHk9JzIxMy4wMDA4OTknLz4KPHVzZSB4PScyOTIuOTM5ODA2JyB4bGluazpocmVmPScjZzUtODQnIHk9JzIxMy4wMDA4OTknLz4KPHVzZSB4PScyOTcuODcwMDAyJyB4bGluazpocmVmPScjZzctOTEnIHk9JzIxNC43Mzg4MjcnLz4KPHVzZSB4PScyOTkuOTczMjAxJyB4bGluazpocmVmPScjZzQtMTA1JyB5PScyMTQuNzM4ODI3Jy8+Cjx1c2UgeD0nMzAyLjYzNjgyNycgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScyMTQuNzM4ODI3Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPScxMTIuNjUxNTQ3JyB4PScxOTkuOTk5ODAyJyB5PScyMTYuNzExNDExJy8+Cjx1c2UgeD0nMTk5Ljk5OTgwMicgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nMjI2LjYzNDE2MScvPgo8dXNlIHg9JzIwNS45Nzc0MDInIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMjI1LjYzNzg5NycvPgo8dXNlIHg9JzIxMi45NDIzNTcnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMjI3LjM3NTgyNicvPgo8dXNlIHg9JzIxNS4wNDU1NTYnIHhsaW5rOmhyZWY9JyNnNy01MCcgeT0nMjI3LjM3NTgyNicvPgo8dXNlIHg9JzIxOC42OTg0ODEnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMjI3LjM3NTgyNicvPgo8dXNlIHg9JzIyMS4yOTk3OTUnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScyMjUuNjM3ODk3Jy8+Cjx1c2UgeD0nMjI3Ljg4NjMwMicgeGxpbms6aHJlZj0nI2cwLTgwJyB5PScyMTkuNjYwMjY4Jy8+Cjx1c2UgeD0nMjM2LjgyNTEzMicgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMjIyLjA2MjQzOCcvPgo8dXNlIHg9JzI0MC45MDAxMDUnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScyMjIuMDYyNDM4Jy8+Cjx1c2UgeD0nMjQ2LjY1NjI1OCcgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyMjIuMDYyNDM4Jy8+Cjx1c2UgeD0nMjM2LjgyNTEzMicgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMjI4LjI4NzU5OCcvPgo8dXNlIHg9JzIzOS40ODg3NTgnIHhsaW5rOmhyZWY9JyNnNy02MScgeT0nMjI4LjI4NzU5OCcvPgo8dXNlIHg9JzI0NS4wNzg4NTEnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMjI4LjI4NzU5OCcvPgo8dXNlIHg9JzI1MC44MDcyNzUnIHhsaW5rOmhyZWY9JyNnNS02MCcgeT0nMjI1LjYzNzg5NycvPgo8dXNlIHg9JzI1Ny4zOTM3ODInIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMjI1LjYzNzg5NycvPgo8dXNlIHg9JzI2NC4zNTg3MzcnIHhsaW5rOmhyZWY9JyNnNy05MScgeT0nMjI3LjM3NTgyNicvPgo8dXNlIHg9JzI2Ni40NjE5MzYnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzIyNy4zNzU4MjYnLz4KPHVzZSB4PScyNzAuNTM2OTA5JyB4bGluazpocmVmPScjZzctOTMnIHk9JzIyNy4zNzU4MjYnLz4KPHVzZSB4PScyNzMuMTM4MjIzJyB4bGluazpocmVmPScjZzUtNTknIHk9JzIyNS42Mzc4OTcnLz4KPHVzZSB4PScyNzUuNDkwNTQ2JyB4bGluazpocmVmPScjZzUtODQnIHk9JzIyNS42Mzc4OTcnLz4KPHVzZSB4PScyODAuNDIwNzQzJyB4bGluazpocmVmPScjZzctOTEnIHk9JzIyNy4zNzU4MjYnLz4KPHVzZSB4PScyODIuNTIzOTQyJyB4bGluazpocmVmPScjZzQtMTA1JyB5PScyMjcuMzc1ODI2Jy8+Cjx1c2UgeD0nMjg1LjE4NzU2OCcgeGxpbms6aHJlZj0nI2c3LTkzJyB5PScyMjcuMzc1ODI2Jy8+Cjx1c2UgeD0nMjg3Ljc4ODg5NScgeGxpbms6aHJlZj0nI2c1LTYyJyB5PScyMjUuNjM3ODk3Jy8+Cjx1c2UgeD0nMjk0LjM3NTQwMScgeGxpbms6aHJlZj0nI2c1LTg0JyB5PScyMjUuNjM3ODk3Jy8+Cjx1c2UgeD0nMjk5LjMwNTU5OCcgeGxpbms6aHJlZj0nI2c3LTkxJyB5PScyMjcuMzc1ODI2Jy8+Cjx1c2UgeD0nMzAxLjQwODc5NycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMjI3LjM3NTgyNicvPgo8dXNlIHg9JzMwNC4wNzI0MjMnIHhsaW5rOmhyZWY9JyNnNy05MycgeT0nMjI3LjM3NTgyNicvPgo8dXNlIHg9JzMwNi42NzM3NScgeGxpbms6aHJlZj0nI2czLTEwNycgeT0nMjI2LjYzNDE2MScvPgo8L2c+Cjwvc3ZnPg==)
La matrice T vérifie  puisque les vecteurs sont
construits de façon à être orthonormés. Et on vérifie que
puisque les vecteurs sont
construits de façon à être orthonormés. Et on vérifie que
 et donc
et donc  .
C’est implémenté par la fonction
.
C’est implémenté par la fonction
gram_schmidt.
<<<
import numpy
from mlstatpy.ml.matrices import gram_schmidt
X = numpy.array([[1, 0.5, 0], [0, 0.4, 2]], dtype=float).T
U, P = gram_schmidt(X.T, change=True)
U, P = U.T, P.T
m = X @ P
D = m.T @ m
print(D)
>>>
[[1.000e+00 2.776e-17]
[2.776e-17 1.000e+00]]
Cela débouche sur une autre formulation du calcul
d’une régression linéaire à partir d’une orthornormalisation
de Gram-Schmidt qui est implémentée dans la fonction
linear_regression.
<<<
import numpy
from mlstatpy.ml.matrices import linear_regression
X = numpy.array([[1, 0.5, 0], [0, 0.4, 2]], dtype=float).T
y = numpy.array([1, 1.3, 3.9])
beta = linear_regression(X, y, algo="gram")
print(beta)
>>>
[1.008 1.952]
L’avantage est que cette formulation s’exprime uniquement à partir de produits scalaires. Voir le notebook Régression sans inversion.
Synthèse mathématique#
Algorithme A2 : Orthonormalisation de Gram-Schmidt
Soit une matrice  avec
avec
 . Il existe deux matrices telles que
ou
. Il existe deux matrices telles que
ou  .
.
 et
et  .
La matrice T est triangulaire supérieure
et vérifie
.
La matrice T est triangulaire supérieure
et vérifie  (
( est la matrice identité). L’algorithme se décrit
comme suit :
est la matrice identité). L’algorithme se décrit
comme suit :
![\begin{array}{ll}
\forall i \in & range(1, d) \\
& x_i = X_{[i]} - \sum_{j < i} <T_{[j]}, X_{[i]}> T_{[j]} \\
& p_i = P_{[i]} - \sum_{j < i} <T_{[j]}, X_{[i]}> P_{[j]} \\
& T_{[i]} = \frac{x_i}{\norme{x_i}} \\
& P_{[i]} = \frac{p_i}{\norme{p_i}}
\end{array}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nNzQuNTA3OTE4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMTMxLjYzMjcwNSA3OS41MDE4MjUgMjAyLjQ4ODA0NSA3NC41MDc5MTgnIHdpZHRoPScyMDIuNDg4MDQ1cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTEuNDUwNTYgLTUuNjgyNjlDMS40NTA1NiAtNS44MTAyMTIgMS40NTA1NiAtNS45Nzc1ODQgMS4yNjcyNDggLTUuOTc3NTg0UzEuMDgzOTM1IC01Ljc3ODMzMSAxLjA4MzkzNSAtNS42NTA4MDlWMS42NjU3NTNDMS4wODM5MzUgMS43OTMyNzUgMS4wODM5MzUgMS45OTI1MjggMS4yNjcyNDggMS45OTI1MjhTMS40NTA1NiAxLjgyNTE1NiAxLjQ1MDU2IDEuNjk3NjM0Vi01LjY4MjY5Wk0zLjE0MDIyNCAtNS42NTA4MDlDMy4xNDAyMjQgLTUuNzc4MzMxIDMuMTQwMjI0IC01Ljk3NzU4NCAyLjk1NjkxMiAtNS45Nzc1ODRTMi43NzM1OTkgLTUuODEwMjEyIDIuNzczNTk5IC01LjY4MjY5VjEuNjk3NjM0QzIuNzczNTk5IDEuODI1MTU2IDIuNzczNTk5IDEuOTkyNTI4IDIuOTU2OTEyIDEuOTkyNTI4UzMuMTQwMjI0IDEuNzkzMjc1IDMuMTQwMjI0IDEuNjY1NzUzVi01LjY1MDgwOVonIGlkPSdnMS0xMDcnLz4KPHBhdGggZD0nTTIuMDgwMTk5IC0zLjczMDAxMkMyLjA4MDE5OSAtMy44NzM0NzQgMS45NzI2MDMgLTMuOTY5MTE2IDEuODM1MTE4IC0zLjk2OTExNkMxLjY3MzcyNCAtMy45NjkxMTYgMS41MDAzNzQgLTMuODEzNjk5IDEuNTAwMzc0IC0zLjY0MDM0OUMxLjUwMDM3NCAtMy40OTA5MDkgMS42MDc5NyAtMy40MDEyNDUgMS43Mzk0NzcgLTMuNDAxMjQ1QzEuOTMwNzYgLTMuNDAxMjQ1IDIuMDgwMTk5IC0zLjU4MDU3MyAyLjA4MDE5OSAtMy43MzAwMTJaTTEuNzIxNTQ0IC0xLjY0MzgzNkMxLjc0NTQ1NSAtMS43MDM2MTEgMS43OTkyNTMgLTEuODQ3MDczIDEuODIzMTYzIC0xLjkwMDg3MkMxLjg0MTA5NiAtMS45NTQ2NyAxLjg2NTAwNiAtMi4wMTQ0NDYgMS44NjUwMDYgLTIuMTE2MDY1QzEuODY1MDA2IC0yLjQ1MDgwOSAxLjU2NjEyNyAtMi42MzYxMTUgMS4yNjcyNDggLTIuNjM2MTE1QzAuNjU3NTM0IC0yLjYzNjExNSAwLjM2NDYzMyAtMS44NDcwNzMgMC4zNjQ2MzMgLTEuNzE1NTY3QzAuMzY0NjMzIC0xLjY4NTY3OSAwLjM4ODU0MyAtMS42MzE4OCAwLjQ3MjIyOSAtMS42MzE4OFMwLjU3Mzg0OCAtMS42Njc3NDYgMC41OTE3ODEgLTEuNzIxNTQ0QzAuNzU5MTUzIC0yLjMwMTM3IDEuMDc1OTY1IC0yLjQzODg1NCAxLjI0MzMzNyAtMi40Mzg4NTRDMS4zNjI4ODkgLTIuNDM4ODU0IDEuNDA0NzMyIC0yLjM2MTE0NiAxLjQwNDczMiAtMi4yMjM2NjFDMS40MDQ3MzIgLTIuMTA0MTEgMS4zNjg4NjcgLTIuMDE0NDQ2IDEuMzU2OTEyIC0xLjk3MjYwM0wxLjA0NjA3NyAtMS4yMDc0NzJDMC45NzQzNDYgLTEuMDM0MTIyIDAuOTc0MzQ2IC0xLjAyMjE2NyAwLjg5NjYzOCAtMC44MTg5MjlDMC44MTg5MjkgLTAuNjM5NjAxIDAuNzg5MDQxIC0wLjU2MTg5MyAwLjc4OTA0MSAtMC40NjAyNzRDMC43ODkwNDEgLTAuMTU1NDE3IDEuMDY0MDEgMC4wNTk3NzYgMS4zOTI3NzcgMC4wNTk3NzZDMS45OTY1MTMgMC4wNTk3NzYgMi4yOTUzOTIgLTAuNzI5MjY1IDIuMjk1MzkyIC0wLjg2MDc3MkMyLjI5NTM5MiAtMC44NzI3MjcgMi4yODk0MTUgLTAuOTQ0NDU4IDIuMTgxODE4IC0wLjk0NDQ1OEMyLjA5ODEzMiAtMC45NDQ0NTggMi4wOTIxNTQgLTAuOTE0NTcgMi4wNTYyODkgLTAuODAwOTk2QzEuOTYwNjQ4IC0wLjQ5NjEzOSAxLjcxNTU2NyAtMC4xMzc0ODQgMS40MTA3MSAtMC4xMzc0ODRDMS4zMDMxMTMgLTAuMTM3NDg0IDEuMjQ5MzE1IC0wLjIwOTIxNSAxLjI0OTMxNSAtMC4zNTI2NzdDMS4yNDkzMTUgLTAuNDcyMjI5IDEuMjg1MTgxIC0wLjU2MTg5MyAxLjM2Mjg4OSAtMC43NDcxOThMMS43MjE1NDQgLTEuNjQzODM2WicgaWQ9J2czLTEwNScvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzItMCcvPgo8cGF0aCBkPSdNNi41NTE0MzIgLTIuNzQ5Njg5QzYuNzU0NjcgLTIuNzQ5Njg5IDYuOTY5ODYzIC0yLjc0OTY4OSA2Ljk2OTg2MyAtMi45ODg3OTJTNi43NTQ2NyAtMy4yMjc4OTUgNi41NTE0MzIgLTMuMjI3ODk1SDEuNDgyNDQxQzEuNjI1OTAzIC00LjgyOTg4OCAzLjAwMDc0NyAtNS45Nzc1ODQgNC42ODY0MjYgLTUuOTc3NTg0SDYuNTUxNDMyQzYuNzU0NjcgLTUuOTc3NTg0IDYuOTY5ODYzIC01Ljk3NzU4NCA2Ljk2OTg2MyAtNi4yMTY2ODdTNi43NTQ2NyAtNi40NTU3OTEgNi41NTE0MzIgLTYuNDU1NzkxSDQuNjYyNTE2QzIuNjE4MTgyIC02LjQ1NTc5MSAwLjk5MjI3OSAtNC45MDE2MTkgMC45OTIyNzkgLTIuOTg4NzkyUzIuNjE4MTgyIDAuNDc4MjA3IDQuNjYyNTE2IDAuNDc4MjA3SDYuNTUxNDMyQzYuNzU0NjcgMC40NzgyMDcgNi45Njk4NjMgMC40NzgyMDcgNi45Njk4NjMgMC4yMzkxMDNTNi43NTQ2NyAwIDYuNTUxNDMyIDBINC42ODY0MjZDMy4wMDA3NDcgMCAxLjYyNTkwMyAtMS4xNDc2OTYgMS40ODI0NDEgLTIuNzQ5Njg5SDYuNTUxNDMyWicgaWQ9J2cyLTUwJy8+CjxwYXRoIGQ9J002LjU4NzI5OCAtNy44NDI1OUM2LjY0NzA3MyAtNy45NzQwOTcgNi42NDcwNzMgLTcuOTk4MDA3IDYuNjQ3MDczIC04LjA1Nzc4M0M2LjY0NzA3MyAtOC4xNzczMzUgNi41NTE0MzIgLTguMjk2ODg3IDYuNDA3OTcgLTguMjk2ODg3QzYuMjUyNTUzIC04LjI5Njg4NyA2LjE4MDgyMiAtOC4xNTM0MjUgNi4xMzMwMDEgLTguMDIxOTE4TDUuMTQwNzIyIC01LjM5MTc4MUgxLjUwNjM1MUwwLjUxNDA3MiAtOC4wMjE5MThDMC40NTQyOTYgLTguMTg5MjkgMC4zOTQ1MjEgLTguMjk2ODg3IDAuMjM5MTAzIC04LjI5Njg4N0MwLjExOTU1MiAtOC4yOTY4ODcgMCAtOC4xNzczMzUgMCAtOC4wNTc3ODNDMCAtOC4wMzM4NzMgMCAtOC4wMDk5NjMgMC4wNzE3MzEgLTcuODQyNTlMMy4wNDg1NjggLTAuMDExOTU1QzMuMTA4MzQ0IDAuMTU1NDE3IDMuMTY4MTIgMC4yNjMwMTQgMy4zMjM1MzcgMC4yNjMwMTRDMy40OTA5MDkgMC4yNjMwMTQgMy41Mzg3MyAwLjEzMTUwNyAzLjU4NjU1IDAuMDExOTU1TDYuNTg3Mjk4IC03Ljg0MjU5Wk0xLjY5NzYzNCAtNC45MTM1NzRINC45NDk0NEwzLjMyMzUzNyAtMC42NTc1MzRMMS42OTc2MzQgLTQuOTEzNTc0WicgaWQ9J2cyLTU2Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnNS01OScvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTUuODIyMTY3QzguMDkzNjQ5IC01LjkxNzgwOCA4LjExNzU1OSAtNi4wMDE0OTQgOC4xMTc1NTkgLTYuMDczMjI1QzguMTE3NTU5IC02LjIwNDczMiA4LjAyMTkxOCAtNi4zMDAzNzQgNy44OTA0MTEgLTYuMzAwMzc0QzcuODY2NTAxIC02LjMwMDM3NCA3Ljg1NDU0NSAtNi4yODg0MTggNy42ODcxNzMgLTYuMjE2Njg3TDEuMjE5NDI3IC0zLjIzOTg1MUMxLjAwNDIzNCAtMy4xNDQyMDkgMC45ODAzMjQgLTMuMDYwNTIzIDAuOTgwMzI0IC0yLjk4ODc5MkMwLjk4MDMyNCAtMi45MDUxMDYgMC45OTIyNzkgLTIuODMzMzc1IDEuMjE5NDI3IC0yLjcyNTc3OEw3LjY4NzE3MyAwLjI1MTA1OUM3Ljg0MjU5IDAuMzIyNzkgNy44NjY1MDEgMC4zMzQ3NDUgNy44OTA0MTEgMC4zMzQ3NDVDOC4wMjE5MTggMC4zMzQ3NDUgOC4xMTc1NTkgMC4yMzkxMDMgOC4xMTc1NTkgMC4xMDc1OTdDOC4xMTc1NTkgMC4wMzU4NjYgOC4wOTM2NDkgLTAuMDQ3ODIxIDcuODc4NDU2IC0wLjE0MzQ2MkwxLjcyMTU0NCAtMi45NzY4MzdMNy44Nzg0NTYgLTUuODIyMTY3WicgaWQ9J2c1LTYwJy8+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtMi43MjU3NzhDOC4xMDU2MDQgLTIuODMzMzc1IDguMTE3NTU5IC0yLjkwNTEwNiA4LjExNzU1OSAtMi45ODg3OTJDOC4xMTc1NTkgLTMuMDYwNTIzIDguMDkzNjQ5IC0zLjE0NDIwOSA3Ljg3ODQ1NiAtMy4yMzk4NTFMMS40MTA3MSAtNi4yMTY2ODdDMS4yNTUyOTMgLTYuMjg4NDE4IDEuMjMxMzgyIC02LjMwMDM3NCAxLjIwNzQ3MiAtNi4zMDAzNzRDMS4wNjQwMSAtNi4zMDAzNzQgMC45ODAzMjQgLTYuMTgwODIyIDAuOTgwMzI0IC02LjA4NTE4MUMwLjk4MDMyNCAtNS45NDE3MTkgMS4wNzU5NjUgLTUuODkzODk4IDEuMjMxMzgyIC01LjgyMjE2N0w3LjM3NjMzOSAtMi45ODg3OTJMMS4yMTk0MjcgLTAuMTQzNDYyQzAuOTgwMzI0IC0wLjAzNTg2NiAwLjk4MDMyNCAwLjA0NzgyMSAwLjk4MDMyNCAwLjExOTU1MkMwLjk4MDMyNCAwLjIxNTE5MyAxLjA2NDAxIDAuMzM0NzQ1IDEuMjA3NDcyIDAuMzM0NzQ1QzEuMjMxMzgyIDAuMzM0NzQ1IDEuMjQzMzM3IDAuMzIyNzkgMS40MTA3MSAwLjI1MTA1OUw3Ljg3ODQ1NiAtMi43MjU3NzhaJyBpZD0nZzUtNjInLz4KPHBhdGggZD0nTTMuNTM4NzMgLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExIC0zLjgwMTc0MyA4Ljg0NjgyNCAtNS4wMjExNzEgOC44NDY4MjQgLTYuMzg0MDZDOC44NDY4MjQgLTcuMzE2NTYzIDguMDU3NzgzIC04LjE2NTM4IDYuNTUxNDMyIC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3IC04LjE2NTM4IDIuNTIyNTQgLTguMTY1MzggMi41MjI1NCAtNy45MzgyMzJDMi41MjI1NCAtNy44MTg2OCAyLjYzMDEzNyAtNy44MTg2OCAyLjgwOTQ2NSAtNy44MTg2OEMzLjUzODczIC03LjgxODY4IDMuNTM4NzMgLTcuNzIzMDM5IDMuNTM4NzMgLTcuNTkxNTMyQzMuNTM4NzMgLTcuNTY3NjIxIDMuNTM4NzMgLTcuNDk1ODkgMy40OTA5MDkgLTcuMzE2NTYzTDEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjY2OTQ4OSAwIDAuNzQxMjIgMEMwLjk2ODM2OSAwIDEuMjA3NDcyIC0wLjAyMzkxIDEuNDM0NjIgLTAuMDIzOTFIMi44MzMzNzVDMy4wNjA1MjMgLTAuMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4IC0wLjIyNzE0OEMzLjc2NTg3OCAtMC4zNDY3IDMuNjU4MjgxIC0wLjM0NjcgMy40Nzg5NTQgLTAuMzQ2N0MyLjc2MTY0NCAtMC4zNDY3IDIuNzQ5Njg5IC0wLjQzMDM4NiAyLjc0OTY4OSAtMC41NDk5MzhDMi43NDk2ODkgLTAuNjA5NzE0IDIuNzYxNjQ0IC0wLjY5MzQgMi43NzM1OTkgLTAuNzUzMTc2TDMuNTM4NzMgLTMuODAxNzQzWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4yMDQ3MzJDNy4xMDEzNyAtNy44MTg2OCA3Ljg0MjU5IC03LjUzMTc1NiA3Ljg0MjU5IC02LjYzNTExOEM3Ljg0MjU5IC02LjMyNDI4NCA3LjY4NzE3MyAtNS4zMDgwOTUgNy4xMzcyMzUgLTQuNzU4MTU3QzYuOTMzOTk4IC00LjU0Mjk2NCA2LjM2MDE0OSAtNC4wODg2NjcgNS4yNzIyMjkgLTQuMDg4NjY3SDMuNTg2NTVMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2c1LTgwJy8+CjxwYXRoIGQ9J000Ljk4NTMwNSAtNy4yOTI2NTNDNS4wNTcwMzYgLTcuNTc5NTc3IDUuMDgwOTQ2IC03LjY4NzE3MyA1LjI2MDI3NCAtNy43MzQ5OTRDNS4zNTU5MTUgLTcuNzU4OTA0IDUuNzUwNDM2IC03Ljc1ODkwNCA2LjAwMTQ5NCAtNy43NTg5MDRDNy4xOTcwMTEgLTcuNzU4OTA0IDcuNzU4OTA0IC03LjcxMTA4MyA3Ljc1ODkwNCAtNi43Nzg1OEM3Ljc1ODkwNCAtNi41OTkyNTMgNy43MTEwODMgLTYuMTQ0OTU2IDcuNjM5MzUyIC01LjcwMjYxNUw3LjYyNzM5NyAtNS41NTkxNTNDNy42MjczOTcgLTUuNTExMzMzIDcuNjc1MjE4IC01LjQzOTYwMSA3Ljc0Njk0OSAtNS40Mzk2MDFDNy44NjY1MDEgLTUuNDM5NjAxIDcuODY2NTAxIC01LjQ5OTM3NyA3LjkwMjM2NiAtNS42OTA2Nkw4LjI0OTA2NiAtNy44MDY3MjVDOC4yNzI5NzYgLTcuOTE0MzIxIDguMjcyOTc2IC03LjkzODIzMiA4LjI3Mjk3NiAtNy45NzQwOTdDOC4yNzI5NzYgLTguMTA1NjA0IDguMjAxMjQ1IC04LjEwNTYwNCA3Ljk2MjE0MiAtOC4xMDU2MDRIMS40MjI2NjVDMS4xNDc2OTYgLTguMTA1NjA0IDEuMTM1NzQxIC04LjA5MzY0OSAxLjA2NDAxIC03Ljg3ODQ1NkwwLjMzNDc0NSAtNS43MjY1MjZDMC4zMjI3OSAtNS43MDI2MTUgMC4yODY5MjQgLTUuNTcxMTA4IDAuMjg2OTI0IC01LjU1OTE1M0MwLjI4NjkyNCAtNS40OTkzNzcgMC4zMzQ3NDUgLTUuNDM5NjAxIDAuNDA2NDc2IC01LjQzOTYwMUMwLjUwMjExNyAtNS40Mzk2MDEgMC41MjYwMjcgLTUuNDg3NDIyIDAuNTczODQ4IC01LjY0MjgzOUMxLjA3NTk2NSAtNy4wODk0MTUgMS4zMjcwMjQgLTcuNzU4OTA0IDIuOTE3MDYxIC03Ljc1ODkwNEgzLjcxODA1N0M0LjAwNDk4MSAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNzU4OTA0IDQuMTI0NTMzIC03LjYyNzM5N0M0LjEyNDUzMyAtNy41OTE1MzIgNC4xMjQ1MzMgLTcuNTY3NjIxIDQuMDY0NzU3IC03LjM1MjQyOEwyLjQ2Mjc2NSAtMC45MzI1MDNDMi4zNDMyMTMgLTAuNDY2MjUyIDIuMzE5MzAzIC0wLjM0NjcgMS4wNTIwNTUgLTAuMzQ2N0MwLjc1MzE3NiAtMC4zNDY3IDAuNjY5NDg5IC0wLjM0NjcgMC42Njk0ODkgLTAuMTE5NTUyQzAuNjY5NDg5IDAgMC44MDA5OTYgMCAwLjg2MDc3MiAwQzEuMTU5NjUxIDAgMS40NzA0ODYgLTAuMDIzOTEgMS43NjkzNjUgLTAuMDIzOTFIMy42MzQzNzFDMy45MzMyNSAtMC4wMjM5MSA0LjI1NjA0IDAgNC41NTQ5MTkgMEM0LjY4NjQyNiAwIDQuODA1OTc4IDAgNC44MDU5NzggLTAuMjI3MTQ4QzQuODA1OTc4IC0wLjM0NjcgNC43MjIyOTEgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3QzMuMzM1NDkyIC0wLjM0NjcgMy4zMzU0OTIgLTAuNDU0Mjk2IDMuMzM1NDkyIC0wLjYzMzYyNEMzLjMzNTQ5MiAtMC42NDU1NzkgMy4zMzU0OTIgLTAuNzI5MjY1IDMuMzgzMzEzIC0wLjkyMDU0OEw0Ljk4NTMwNSAtNy4yOTI2NTNaJyBpZD0nZzUtODQnLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2c1LTg4Jy8+CjxwYXRoIGQ9J00zLjU5ODUwNiAtMS40MjI2NjVDMy41Mzg3MyAtMS4yMTk0MjcgMy41Mzg3MyAtMS4xOTU1MTcgMy4zNzEzNTcgLTAuOTY4MzY5QzMuMTA4MzQ0IC0wLjYzMzYyNCAyLjU4MjMxNiAtMC4xMTk1NTIgMi4wMjA0MjMgLTAuMTE5NTUyQzEuNTMwMjYyIC0wLjExOTU1MiAxLjI1NTI5MyAtMC41NjE4OTMgMS4yNTUyOTMgLTEuMjY3MjQ4QzEuMjU1MjkzIC0xLjkyNDc4MiAxLjYyNTkwMyAtMy4yNjM3NjEgMS44NTMwNTEgLTMuNzY1ODc4QzIuMjU5NTI3IC00LjYwMjc0IDIuODIxNDIgLTUuMDMzMTI2IDMuMjg3NjcxIC01LjAzMzEyNkM0LjA3NjcxMiAtNS4wMzMxMjYgNC4yMzIxMyAtNC4wNTI4MDIgNC4yMzIxMyAtMy45NTcxNjFDNC4yMzIxMyAtMy45NDUyMDUgNC4xOTYyNjQgLTMuNzg5Nzg4IDQuMTg0MzA5IC0zLjc2NTg3OEwzLjU5ODUwNiAtMS40MjI2NjVaTTQuMzYzNjM2IC00LjQ4MzE4OEM0LjIzMjEzIC00Ljc5NDAyMiAzLjkwOTM0IC01LjI3MjIyOSAzLjI4NzY3MSAtNS4yNzIyMjlDMS45MzY3MzcgLTUuMjcyMjI5IDAuNDc4MjA3IC0zLjUyNjc3NSAwLjQ3ODIwNyAtMS43NTc0MUMwLjQ3ODIwNyAtMC41NzM4NDggMS4xNzE2MDYgMC4xMTk1NTIgMS45ODQ1NTggMC4xMTk1NTJDMi42NDIwOTIgMC4xMTk1NTIgMy4yMDM5ODUgLTAuMzk0NTIxIDMuNTM4NzMgLTAuNzg5MDQxQzMuNjU4MjgxIC0wLjA4MzY4NiA0LjIyMDE3NCAwLjExOTU1MiA0LjU3ODgyOSAwLjExOTU1MlM1LjIyNDQwOCAtMC4wOTU2NDEgNS40Mzk2MDEgLTAuNTI2MDI3QzUuNjMwODg0IC0wLjkzMjUwMyA1Ljc5ODI1NyAtMS42NjE3NjggNS43OTgyNTcgLTEuNzA5NTg5QzUuNzk4MjU3IC0xLjc2OTM2NSA1Ljc1MDQzNiAtMS44MTcxODYgNS42Nzg3MDUgLTEuODE3MTg2QzUuNTcxMTA4IC0xLjgxNzE4NiA1LjU1OTE1MyAtMS43NTc0MSA1LjUxMTMzMyAtMS41NzgwODJDNS4zMzIwMDUgLTAuODcyNzI3IDUuMTA0ODU3IC0wLjExOTU1MiA0LjYxNDY5NSAtMC4xMTk1NTJDNC4yNjc5OTUgLTAuMTE5NTUyIDQuMjQ0MDg1IC0wLjQzMDM4NiA0LjI0NDA4NSAtMC42Njk0ODlDNC4yNDQwODUgLTAuOTQ0NDU4IDQuMjc5OTUgLTEuMDc1OTY1IDQuMzg3NTQ3IC0xLjU0MjIxN0M0LjQ3MTIzMyAtMS44NDEwOTYgNC41MzEwMDkgLTIuMTA0MTEgNC42MjY2NSAtMi40NTA4MDlDNS4wNjg5OTEgLTQuMjQ0MDg1IDUuMTc2NTg4IC00LjY3NDQ3MSA1LjE3NjU4OCAtNC43NDYyMDJDNS4xNzY1ODggLTQuOTEzNTc0IDUuMDQ1MDgxIC01LjA0NTA4MSA0Ljg2NTc1MyAtNS4wNDUwODFDNC40ODMxODggLTUuMDQ1MDgxIDQuMzg3NTQ3IC00LjYyNjY1IDQuMzYzNjM2IC00LjQ4MzE4OFonIGlkPSdnNS05NycvPgo8cGF0aCBkPSdNNi4wMTM0NSAtNy45OTgwMDdDNi4wMjU0MDUgLTguMDQ1ODI4IDYuMDQ5MzE1IC04LjExNzU1OSA2LjA0OTMxNSAtOC4xNzczMzVDNi4wNDkzMTUgLTguMjk2ODg3IDUuOTI5NzYzIC04LjI5Njg4NyA1LjkwNTg1MyAtOC4yOTY4ODdDNS44OTM4OTggLTguMjk2ODg3IDUuMzA4MDk1IC04LjI0OTA2NiA1LjI0ODMxOSAtOC4yMzcxMTFDNS4wNDUwODEgLTguMjI1MTU2IDQuODY1NzUzIC04LjIwMTI0NSA0LjY1MDU2IC04LjE4OTI5QzQuMzUxNjgxIC04LjE2NTM4IDQuMjY3OTk1IC04LjE1MzQyNSA0LjI2Nzk5NSAtNy45MzgyMzJDNC4yNjc5OTUgLTcuODE4NjggNC4zNjM2MzYgLTcuODE4NjggNC41MzEwMDkgLTcuODE4NjhDNS4xMTY4MTIgLTcuODE4NjggNS4xMjg3NjcgLTcuNzExMDgzIDUuMTI4NzY3IC03LjU5MTUzMkM1LjEyODc2NyAtNy41MTk4MDEgNS4xMDQ4NTcgLTcuNDI0MTU5IDUuMDkyOTAyIC03LjM4ODI5NEw0LjM2MzYzNiAtNC40ODMxODhDNC4yMzIxMyAtNC43OTQwMjIgMy45MDkzNCAtNS4yNzIyMjkgMy4yODc2NzEgLTUuMjcyMjI5QzEuOTM2NzM3IC01LjI3MjIyOSAwLjQ3ODIwNyAtMy41MjY3NzUgMC40NzgyMDcgLTEuNzU3NDFDMC40NzgyMDcgLTAuNTczODQ4IDEuMTcxNjA2IDAuMTE5NTUyIDEuOTg0NTU4IDAuMTE5NTUyQzIuNjQyMDkyIDAuMTE5NTUyIDMuMjAzOTg1IC0wLjM5NDUyMSAzLjUzODczIC0wLjc4OTA0MUMzLjY1ODI4MSAtMC4wODM2ODYgNC4yMjAxNzQgMC4xMTk1NTIgNC41Nzg4MjkgMC4xMTk1NTJTNS4yMjQ0MDggLTAuMDk1NjQxIDUuNDM5NjAxIC0wLjUyNjAyN0M1LjYzMDg4NCAtMC45MzI1MDMgNS43OTgyNTcgLTEuNjYxNzY4IDUuNzk4MjU3IC0xLjcwOTU4OUM1Ljc5ODI1NyAtMS43NjkzNjUgNS43NTA0MzYgLTEuODE3MTg2IDUuNjc4NzA1IC0xLjgxNzE4NkM1LjU3MTEwOCAtMS44MTcxODYgNS41NTkxNTMgLTEuNzU3NDEgNS41MTEzMzMgLTEuNTc4MDgyQzUuMzMyMDA1IC0wLjg3MjcyNyA1LjEwNDg1NyAtMC4xMTk1NTIgNC42MTQ2OTUgLTAuMTE5NTUyQzQuMjY3OTk1IC0wLjExOTU1MiA0LjI0NDA4NSAtMC40MzAzODYgNC4yNDQwODUgLTAuNjY5NDg5QzQuMjQ0MDg1IC0wLjcxNzMxIDQuMjQ0MDg1IC0wLjk2ODM2OSA0LjMyNzc3MSAtMS4zMDMxMTNMNi4wMTM0NSAtNy45OTgwMDdaTTMuNTk4NTA2IC0xLjQyMjY2NUMzLjUzODczIC0xLjIxOTQyNyAzLjUzODczIC0xLjE5NTUxNyAzLjM3MTM1NyAtMC45NjgzNjlDMy4xMDgzNDQgLTAuNjMzNjI0IDIuNTgyMzE2IC0wLjExOTU1MiAyLjAyMDQyMyAtMC4xMTk1NTJDMS41MzAyNjIgLTAuMTE5NTUyIDEuMjU1MjkzIC0wLjU2MTg5MyAxLjI1NTI5MyAtMS4yNjcyNDhDMS4yNTUyOTMgLTEuOTI0NzgyIDEuNjI1OTAzIC0zLjI2Mzc2MSAxLjg1MzA1MSAtMy43NjU4NzhDMi4yNTk1MjcgLTQuNjAyNzQgMi44MjE0MiAtNS4wMzMxMjYgMy4yODc2NzEgLTUuMDMzMTI2QzQuMDc2NzEyIC01LjAzMzEyNiA0LjIzMjEzIC00LjA1MjgwMiA0LjIzMjEzIC0zLjk1NzE2MUM0LjIzMjEzIC0zLjk0NTIwNSA0LjE5NjI2NCAtMy43ODk3ODggNC4xODQzMDkgLTMuNzY1ODc4TDMuNTk4NTA2IC0xLjQyMjY2NVonIGlkPSdnNS0xMDAnLz4KPHBhdGggZD0nTTIuMTM5OTc1IC0yLjc3MzU5OUMyLjQ2Mjc2NSAtMi43NzM1OTkgMy4yNzU3MTYgLTIuNzk3NTA5IDMuODQ5NTY0IC0zLjAxMjcwMkM0Ljc1ODE1NyAtMy4zNTk0MDIgNC44NDE4NDMgLTQuMDUyODAyIDQuODQxODQzIC00LjI2Nzk5NUM0Ljg0MTg0MyAtNC43OTQwMjIgNC4zODc1NDcgLTUuMjcyMjI5IDMuNTk4NTA2IC01LjI3MjIyOUMyLjM0MzIxMyAtNS4yNzIyMjkgMC41Mzc5ODMgLTQuMTM2NDg4IDAuNTM3OTgzIC0yLjAwODQ2OEMwLjUzNzk4MyAtMC43NTMxNzYgMS4yNTUyOTMgMC4xMTk1NTIgMi4zNDMyMTMgMC4xMTk1NTJDMy45NjkxMTYgMC4xMTk1NTIgNC45OTcyNiAtMS4xNDc2OTYgNC45OTcyNiAtMS4zMDMxMTNDNC45OTcyNiAtMS4zNzQ4NDQgNC45MjU1MjkgLTEuNDM0NjIgNC44Nzc3MDkgLTEuNDM0NjJDNC44NDE4NDMgLTEuNDM0NjIgNC44Mjk4ODggLTEuNDIyNjY1IDQuNzIyMjkxIC0xLjMxNTA2OEMzLjk1NzE2MSAtMC4yOTg4NzkgMi44MjE0MiAtMC4xMTk1NTIgMi4zNjcxMjMgLTAuMTE5NTUyQzEuNjg1Njc5IC0wLjExOTU1MiAxLjMyNzAyNCAtMC42NTc1MzQgMS4zMjcwMjQgLTEuNTQyMjE3QzEuMzI3MDI0IC0xLjcwOTU4OSAxLjMyNzAyNCAtMi4wMDg0NjggMS41MDYzNTEgLTIuNzczNTk5SDIuMTM5OTc1Wk0xLjU2NjEyNyAtMy4wMTI3MDJDMi4wODAxOTkgLTQuODUzNzk4IDMuMjE1OTQgLTUuMDMzMTI2IDMuNTk4NTA2IC01LjAzMzEyNkM0LjEyNDUzMyAtNS4wMzMxMjYgNC40ODMxODggLTQuNzIyMjkxIDQuNDgzMTg4IC00LjI2Nzk5NUM0LjQ4MzE4OCAtMy4wMTI3MDIgMi41NzAzNjEgLTMuMDEyNzAyIDIuMDY4MjQ0IC0zLjAxMjcwMkgxLjU2NjEyN1onIGlkPSdnNS0xMDEnLz4KPHBhdGggZD0nTTQuMDQwODQ3IC0xLjUxODMwNkMzLjk5MzAyNiAtMS4zMjcwMjQgMy45NjkxMTYgLTEuMjc5MjAzIDMuODEzNjk5IC0xLjA5OTg3NUMzLjMyMzUzNyAtMC40NjYyNTIgMi44MjE0MiAtMC4yMzkxMDMgMi40NTA4MDkgLTAuMjM5MTAzQzIuMDU2Mjg5IC0wLjIzOTEwMyAxLjY4NTY3OSAtMC41NDk5MzggMS42ODU2NzkgLTEuMzc0ODQ0QzEuNjg1Njc5IC0yLjAwODQ2OCAyLjA0NDMzNCAtMy4zNDc0NDcgMi4zMDczNDcgLTMuODg1NDNDMi42NTQwNDcgLTQuNTU0OTE5IDMuMTkyMDMgLTUuMDMzMTI2IDMuNjk0MTQ3IC01LjAzMzEyNkM0LjQ4MzE4OCAtNS4wMzMxMjYgNC42Mzg2MDUgLTQuMDUyODAyIDQuNjM4NjA1IC0zLjk4MTA3MUw0LjYwMjc0IC0zLjgxMzY5OUw0LjA0MDg0NyAtMS41MTgzMDZaTTQuNzgyMDY3IC00LjQ4MzE4OEM0LjYyNjY1IC00LjgyOTg4OCA0LjI5MTkwNSAtNS4yNzIyMjkgMy42OTQxNDcgLTUuMjcyMjI5QzIuMzkxMDM0IC01LjI3MjIyOSAwLjkwODU5MyAtMy42MzQzNzEgMC45MDg1OTMgLTEuODUzMDUxQzAuOTA4NTkzIC0wLjYwOTcxNCAxLjY2MTc2OCAwIDIuNDI2ODk5IDBDMy4wNjA1MjMgMCAzLjYyMjQxNiAtMC41MDIxMTcgMy44Mzc2MDkgLTAuNzQxMjJMMy41NzQ1OTUgMC4zMzQ3NDVDMy40MDcyMjMgMC45OTIyNzkgMy4zMzU0OTIgMS4yOTExNTggMi45MDUxMDYgMS43MDk1ODlDMi40MTQ5NDQgMi4xOTk3NTEgMS45NjA2NDggMi4xOTk3NTEgMS42OTc2MzQgMi4xOTk3NTFDMS4zMzg5NzkgMi4xOTk3NTEgMS4wNDAxIDIuMTc1ODQxIDAuNzQxMjIgMi4wODAxOTlDMS4xMjM3ODYgMS45NzI2MDMgMS4yMTk0MjcgMS42Mzc4NTggMS4yMTk0MjcgMS41MDYzNTFDMS4yMTk0MjcgMS4zMTUwNjggMS4wNzU5NjUgMS4xMjM3ODYgMC44MTI5NTEgMS4xMjM3ODZDMC41MjYwMjcgMS4xMjM3ODYgMC4yMTUxOTMgMS4zNjI4ODkgMC4yMTUxOTMgMS43NTc0MUMwLjIxNTE5MyAyLjI0NzU3MiAwLjcwNTM1NSAyLjQzODg1NCAxLjcyMTU0NCAyLjQzODg1NEMzLjI2Mzc2MSAyLjQzODg1NCA0LjA2NDc1NyAxLjQ0NjU3NSA0LjIyMDE3NCAwLjgwMDk5Nkw1LjU0NzE5OCAtNC41NTQ5MTlDNS41ODMwNjQgLTQuNjk4MzgxIDUuNTgzMDY0IC00LjcyMjI5MSA1LjU4MzA2NCAtNC43NDYyMDJDNS41ODMwNjQgLTQuOTEzNTc0IDUuNDUxNTU3IC01LjA0NTA4MSA1LjI3MjIyOSAtNS4wNDUwODFDNC45ODUzMDUgLTUuMDQ1MDgxIDQuODE3OTMzIC00LjgwNTk3OCA0Ljc4MjA2NyAtNC40ODMxODhaJyBpZD0nZzUtMTAzJy8+CjxwYXRoIGQ9J00zLjM4MzMxMyAtMS43MDk1ODlDMy4zODMzMTMgLTEuNzY5MzY1IDMuMzM1NDkyIC0xLjgxNzE4NiAzLjI2Mzc2MSAtMS44MTcxODZDMy4xNTYxNjQgLTEuODE3MTg2IDMuMTQ0MjA5IC0xLjc4MTMyIDMuMDg0NDMzIC0xLjU3ODA4MkMyLjc3MzU5OSAtMC40OTAxNjIgMi4yODM0MzcgLTAuMTE5NTUyIDEuODg4OTE3IC0wLjExOTU1MkMxLjc0NTQ1NSAtMC4xMTk1NTIgMS41NzgwODIgLTAuMTU1NDE3IDEuNTc4MDgyIC0wLjUxNDA3MkMxLjU3ODA4MiAtMC44MzY4NjIgMS43MjE1NDQgLTEuMTk1NTE3IDEuODUzMDUxIC0xLjU1NDE3MkwyLjY4OTkxMyAtMy43Nzc4MzNDMi43MjU3NzggLTMuODczNDc0IDIuODA5NDY1IC00LjA4ODY2NyAyLjgwOTQ2NSAtNC4zMTU4MTZDMi44MDk0NjUgLTQuODE3OTMzIDIuNDUwODA5IC01LjI3MjIyOSAxLjg2NTAwNiAtNS4yNzIyMjlDMC43NjUxMzEgLTUuMjcyMjI5IDAuMzIyNzkgLTMuNTM4NzMgMC4zMjI3OSAtMy40NDMwODhDMC4zMjI3OSAtMy4zOTUyNjggMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTYxODkzIC0zLjMzNTQ5MiAwLjU3Mzg0OCAtMy4zODMzMTMgMC42MjE2NjkgLTMuNTUwNjg1QzAuOTA4NTkzIC00LjU1NDkxOSAxLjM2Mjg4OSAtNS4wMzMxMjYgMS44MjkxNDEgLTUuMDMzMTI2QzEuOTM2NzM3IC01LjAzMzEyNiAyLjEzOTk3NSAtNS4wMjExNzEgMi4xMzk5NzUgLTQuNjM4NjA1QzIuMTM5OTc1IC00LjMyNzc3MSAxLjk4NDU1OCAtMy45MzMyNSAxLjg4ODkxNyAtMy42NzAyMzdMMS4wNTIwNTUgLTEuNDQ2NTc1QzAuOTgwMzI0IC0xLjI1NTI5MyAwLjkwODU5MyAtMS4wNjQwMSAwLjkwODU5MyAtMC44NDg4MTdDMC45MDg1OTMgLTAuMzEwODM0IDEuMjc5MjAzIDAuMTE5NTUyIDEuODUzMDUxIDAuMTE5NTUyQzIuOTUyOTI3IDAuMTE5NTUyIDMuMzgzMzEzIC0xLjYyNTkwMyAzLjM4MzMxMyAtMS43MDk1ODlaTTMuMjg3NjcxIC03LjQ2MDAyNUMzLjI4NzY3MSAtNy42MzkzNTIgMy4xNDQyMDkgLTcuODU0NTQ1IDIuODgxMTk2IC03Ljg1NDU0NUMyLjYwNjIyNyAtNy44NTQ1NDUgMi4yOTUzOTIgLTcuNTkxNTMyIDIuMjk1MzkyIC03LjI4MDY5N0MyLjI5NTM5MiAtNi45ODE4MTggMi41NDY0NTEgLTYuODg2MTc3IDIuNjg5OTEzIC02Ljg4NjE3N0MzLjAxMjcwMiAtNi44ODYxNzcgMy4yODc2NzEgLTcuMTk3MDExIDMuMjg3NjcxIC03LjQ2MDAyNVonIGlkPSdnNS0xMDUnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0zLjUwMjg2NEMyLjQ4NjY3NSAtMy41NzQ1OTUgMi43ODU1NTQgLTQuMTcyMzU0IDMuMjI3ODk1IC00LjU1NDkxOUMzLjUzODczIC00Ljg0MTg0MyAzLjk0NTIwNSAtNS4wMzMxMjYgNC40MTE0NTcgLTUuMDMzMTI2QzQuODg5NjY0IC01LjAzMzEyNiA1LjA1NzAzNiAtNC42NzQ0NzEgNS4wNTcwMzYgLTQuMTk2MjY0QzUuMDU3MDM2IC0zLjUxNDgxOSA0LjU2Njg3NCAtMi4xNTE5MyA0LjMyNzc3MSAtMS41MDYzNTFDNC4yMjAxNzQgLTEuMjE5NDI3IDQuMTYwMzk5IC0xLjA2NDAxIDQuMTYwMzk5IC0wLjg0ODgxN0M0LjE2MDM5OSAtMC4zMTA4MzQgNC41MzEwMDkgMC4xMTk1NTIgNS4xMDQ4NTcgMC4xMTk1NTJDNi4yMTY2ODcgMC4xMTk1NTIgNi42MzUxMTggLTEuNjM3ODU4IDYuNjM1MTE4IC0xLjcwOTU4OUM2LjYzNTExOCAtMS43NjkzNjUgNi41ODcyOTggLTEuODE3MTg2IDYuNTE1NTY3IC0xLjgxNzE4NkM2LjQwNzk3IC0xLjgxNzE4NiA2LjM5NjAxNSAtMS43ODEzMiA2LjMzNjIzOSAtMS41NzgwODJDNi4wNjEyNyAtMC41OTc3NTggNS42MDY5NzQgLTAuMTE5NTUyIDUuMTQwNzIyIC0wLjExOTU1MkM1LjAyMTE3MSAtMC4xMTk1NTIgNC44Mjk4ODggLTAuMTMxNTA3IDQuODI5ODg4IC0wLjUxNDA3MkM0LjgyOTg4OCAtMC44MTI5NTEgNC45NjEzOTUgLTEuMTcxNjA2IDUuMDMzMTI2IC0xLjMzODk3OUM1LjI3MjIyOSAtMS45OTY1MTMgNS43NzQzNDYgLTMuMzM1NDkyIDUuNzc0MzQ2IC00LjAxNjkzNkM1Ljc3NDM0NiAtNC43MzQyNDcgNS4zNTU5MTUgLTUuMjcyMjI5IDQuNDQ3MzIzIC01LjI3MjIyOUMzLjM4MzMxMyAtNS4yNzIyMjkgMi44MjE0MiAtNC41MTkwNTQgMi42MDYyMjcgLTQuMjIwMTc0QzIuNTcwMzYxIC00LjkwMTYxOSAyLjA4MDE5OSAtNS4yNzIyMjkgMS41NTQxNzIgLTUuMjcyMjI5QzEuMTcxNjA2IC01LjI3MjIyOSAwLjkwODU5MyAtNS4wNDUwODEgMC43MDUzNTUgLTQuNjM4NjA1QzAuNDkwMTYyIC00LjIwODIxOSAwLjMyMjc5IC0zLjQ5MDkwOSAwLjMyMjc5IC0zLjQ0MzA4OFMwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NDk5MzggLTMuMzM1NDkyIDAuNTYxODkzIC0zLjM0NzQ0NyAwLjYzMzYyNCAtMy42MjI0MTZDMC44MjQ5MDcgLTQuMzUxNjgxIDEuMDQwMSAtNS4wMzMxMjYgMS41MTgzMDYgLTUuMDMzMTI2QzEuNzkzMjc1IC01LjAzMzEyNiAxLjg4ODkxNyAtNC44NDE4NDMgMS44ODg5MTcgLTQuNDgzMTg4QzEuODg4OTE3IC00LjIyMDE3NCAxLjc2OTM2NSAtMy43NTM5MjMgMS42ODU2NzkgLTMuMzgzMzEzTDEuMzUwOTM0IC0yLjA5MjE1NEMxLjMwMzExMyAtMS44NjUwMDYgMS4xNzE2MDYgLTEuMzI3MDI0IDEuMTExODMxIC0xLjExMTgzMUMxLjAyODE0NCAtMC44MDA5OTYgMC44OTY2MzggLTAuMjM5MTAzIDAuODk2NjM4IC0wLjE3OTMyOEMwLjg5NjYzOCAtMC4wMTE5NTUgMS4wMjgxNDQgMC4xMTk1NTIgMS4yMDc0NzIgMC4xMTk1NTJDMS4zNTA5MzQgMC4xMTk1NTIgMS41MTgzMDYgMC4wNDc4MjEgMS42MTM5NDggLTAuMTMxNTA3QzEuNjM3ODU4IC0wLjE5MTI4MyAxLjc0NTQ1NSAtMC42MDk3MTQgMS44MDUyMyAtMC44NDg4MTdMMi4wNjgyNDQgLTEuOTI0NzgyTDIuNDYyNzY1IC0zLjUwMjg2NFonIGlkPSdnNS0xMTAnLz4KPHBhdGggZD0nTTAuNTE0MDcyIDEuNTE4MzA2QzAuNDMwMzg2IDEuODc2OTYxIDAuMzgyNTY1IDEuOTcyNjAzIC0wLjEwNzU5NyAxLjk3MjYwM0MtMC4yNTEwNTkgMS45NzI2MDMgLTAuMzcwNjEgMS45NzI2MDMgLTAuMzcwNjEgMi4xOTk3NTFDLTAuMzcwNjEgMi4yMjM2NjEgLTAuMzU4NjU1IDIuMzE5MzAzIC0wLjIyNzE0OCAyLjMxOTMwM0MtMC4wNzE3MzEgMi4zMTkzMDMgMC4wOTU2NDEgMi4yOTUzOTIgMC4yNTEwNTkgMi4yOTUzOTJIMC43NjUxMzFDMS4wMTYxODkgMi4yOTUzOTIgMS42MjU5MDMgMi4zMTkzMDMgMS44NzY5NjEgMi4zMTkzMDNDMS45NDg2OTIgMi4zMTkzMDMgMi4wOTIxNTQgMi4zMTkzMDMgMi4wOTIxNTQgMi4xMDQxMUMyLjA5MjE1NCAxLjk3MjYwMyAyLjAwODQ2OCAxLjk3MjYwMyAxLjgwNTIzIDEuOTcyNjAzQzEuMjU1MjkzIDEuOTcyNjAzIDEuMjE5NDI3IDEuODg4OTE3IDEuMjE5NDI3IDEuNzkzMjc1QzEuMjE5NDI3IDEuNjQ5ODEzIDEuNzU3NDEgLTAuNDA2NDc2IDEuODI5MTQxIC0wLjY4MTQ0NUMxLjk2MDY0OCAtMC4zNDY3IDIuMjgzNDM3IDAuMTE5NTUyIDIuOTA1MTA2IDAuMTE5NTUyQzQuMjU2MDQgMC4xMTk1NTIgNS43MTQ1NyAtMS42Mzc4NTggNS43MTQ1NyAtMy4zOTUyNjhDNS43MTQ1NyAtNC40OTUxNDMgNS4wOTI5MDIgLTUuMjcyMjI5IDQuMTk2MjY0IC01LjI3MjIyOUMzLjQzMTEzMyAtNS4yNzIyMjkgMi43ODU1NTQgLTQuNTMxMDA5IDIuNjU0MDQ3IC00LjM2MzYzNkMyLjU1ODQwNiAtNC45NjEzOTUgMi4wOTIxNTQgLTUuMjcyMjI5IDEuNjEzOTQ4IC01LjI3MjIyOUMxLjI2NzI0OCAtNS4yNzIyMjkgMC45OTIyNzkgLTUuMTA0ODU3IDAuNzY1MTMxIC00LjY1MDU2QzAuNTQ5OTM4IC00LjIyMDE3NCAwLjM4MjU2NSAtMy40OTA5MDkgMC4zODI1NjUgLTMuNDQzMDg4UzAuNDMwMzg2IC0zLjMzNTQ5MiAwLjUxNDA3MiAtMy4zMzU0OTJDMC42MDk3MTQgLTMuMzM1NDkyIDAuNjIxNjY5IC0zLjM0NzQ0NyAwLjY5MzQgLTMuNjIyNDE2QzAuODcyNzI3IC00LjMyNzc3MSAxLjA5OTg3NSAtNS4wMzMxMjYgMS41NzgwODIgLTUuMDMzMTI2QzEuODUzMDUxIC01LjAzMzEyNiAxLjk0ODY5MiAtNC44NDE4NDMgMS45NDg2OTIgLTQuNDgzMTg4QzEuOTQ4NjkyIC00LjE5NjI2NCAxLjkxMjgyNyAtNC4wNzY3MTIgMS44NjUwMDYgLTMuODYxNTE5TDAuNTE0MDcyIDEuNTE4MzA2Wk0yLjU4MjMxNiAtMy43MzAwMTJDMi42NjYwMDIgLTQuMDY0NzU3IDMuMDAwNzQ3IC00LjQxMTQ1NyAzLjE5MjAzIC00LjU3ODgyOUMzLjMyMzUzNyAtNC42OTgzODEgMy43MTgwNTcgLTUuMDMzMTI2IDQuMTcyMzU0IC01LjAzMzEyNkM0LjY5ODM4MSAtNS4wMzMxMjYgNC45Mzc0ODQgLTQuNTA3MDk4IDQuOTM3NDg0IC0zLjg4NTQzQzQuOTM3NDg0IC0zLjMxMTU4MiA0LjYwMjc0IC0xLjk2MDY0OCA0LjMwMzg2MSAtMS4zMzg5NzlDNC4wMDQ5ODEgLTAuNjkzNCAzLjQ1NTA0NCAtMC4xMTk1NTIgMi45MDUxMDYgLTAuMTE5NTUyQzIuMDkyMTU0IC0wLjExOTU1MiAxLjk2MDY0OCAtMS4xNDc2OTYgMS45NjA2NDggLTEuMTk1NTE3QzEuOTYwNjQ4IC0xLjIzMTM4MiAxLjk4NDU1OCAtMS4zMjcwMjQgMS45OTY1MTMgLTEuMzg2OEwyLjU4MjMxNiAtMy43MzAwMTJaJyBpZD0nZzUtMTEyJy8+CjxwYXRoIGQ9J000LjY1MDU2IC00Ljg4OTY2NEM0LjI3OTk1IC00LjgxNzkzMyA0LjA4ODY2NyAtNC41NTQ5MTkgNC4wODg2NjcgLTQuMjkxOTA1QzQuMDg4NjY3IC00LjAwNDk4MSA0LjMxNTgxNiAtMy45MDkzNCA0LjQ4MzE4OCAtMy45MDkzNEM0LjgxNzkzMyAtMy45MDkzNCA1LjA5MjkwMiAtNC4xOTYyNjQgNS4wOTI5MDIgLTQuNTU0OTE5QzUuMDkyOTAyIC00LjkzNzQ4NCA0LjcyMjI5MSAtNS4yNzIyMjkgNC4xMjQ1MzMgLTUuMjcyMjI5QzMuNjQ2MzI2IC01LjI3MjIyOSAzLjA5NjM4OSAtNS4wNTcwMzYgMi41OTQyNzEgLTQuMzI3NzcxQzIuNTEwNTg1IC00Ljk2MTM5NSAyLjAzMjM3OSAtNS4yNzIyMjkgMS41NTQxNzIgLTUuMjcyMjI5QzEuMDg3OTIgLTUuMjcyMjI5IDAuODQ4ODE3IC00LjkxMzU3NCAwLjcwNTM1NSAtNC42NTA1NkMwLjUwMjExNyAtNC4yMjAxNzQgMC4zMjI3OSAtMy41MDI4NjQgMC4zMjI3OSAtMy40NDMwODhDMC4zMjI3OSAtMy4zOTUyNjggMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTQ5OTM4IC0zLjMzNTQ5MiAwLjU2MTg5MyAtMy4zNDc0NDcgMC42MzM2MjQgLTMuNjIyNDE2QzAuODEyOTUxIC00LjMzOTcyNiAxLjA0MDEgLTUuMDMzMTI2IDEuNTE4MzA2IC01LjAzMzEyNkMxLjgwNTIzIC01LjAzMzEyNiAxLjg4ODkxNyAtNC44Mjk4ODggMS44ODg5MTcgLTQuNDgzMTg4QzEuODg4OTE3IC00LjIyMDE3NCAxLjc2OTM2NSAtMy43NTM5MjMgMS42ODU2NzkgLTMuMzgzMzEzTDEuMzUwOTM0IC0yLjA5MjE1NEMxLjMwMzExMyAtMS44NjUwMDYgMS4xNzE2MDYgLTEuMzI3MDI0IDEuMTExODMxIC0xLjExMTgzMUMxLjAyODE0NCAtMC44MDA5OTYgMC44OTY2MzggLTAuMjM5MTAzIDAuODk2NjM4IC0wLjE3OTMyOEMwLjg5NjYzOCAtMC4wMTE5NTUgMS4wMjgxNDQgMC4xMTk1NTIgMS4yMDc0NzIgMC4xMTk1NTJDMS4zMzg5NzkgMC4xMTk1NTIgMS41NjYxMjcgMC4wMzU4NjYgMS42Mzc4NTggLTAuMjAzMjM4QzEuNjczNzI0IC0wLjI5ODg3OSAyLjExNjA2NSAtMi4xMDQxMSAyLjE4Nzc5NiAtMi4zNzkwNzhDMi4yNDc1NzIgLTIuNjQyMDkyIDIuMzE5MzAzIC0yLjg5MzE1MSAyLjM3OTA3OCAtMy4xNTYxNjRDMi40MjY4OTkgLTMuMzIzNTM3IDIuNDc0NzIgLTMuNTE0ODE5IDIuNTEwNTg1IC0zLjY3MDIzN0MyLjU0NjQ1MSAtMy43Nzc4MzMgMi44NjkyNCAtNC4zNjM2MzYgMy4xNjgxMiAtNC42MjY2NUMzLjMxMTU4MiAtNC43NTgxNTcgMy42MjI0MTYgLTUuMDMzMTI2IDQuMTEyNTc4IC01LjAzMzEyNkM0LjMwMzg2MSAtNS4wMzMxMjYgNC40OTUxNDMgLTQuOTk3MjYgNC42NTA1NiAtNC44ODk2NjRaJyBpZD0nZzUtMTE0Jy8+CjxwYXRoIGQ9J001LjY2Njc1IC00Ljg3NzcwOUM1LjI4NDE4NCAtNC44MDU5NzggNS4xNDA3MjIgLTQuNTE5MDU0IDUuMTQwNzIyIC00LjI5MTkwNUM1LjE0MDcyMiAtNC4wMDQ5ODEgNS4zNjc4NyAtMy45MDkzNCA1LjUzNTI0MyAtMy45MDkzNEM1Ljg5Mzg5OCAtMy45MDkzNCA2LjE0NDk1NiAtNC4yMjAxNzQgNi4xNDQ5NTYgLTQuNTQyOTY0QzYuMTQ0OTU2IC01LjA0NTA4MSA1LjU3MTEwOCAtNS4yNzIyMjkgNS4wNjg5OTEgLTUuMjcyMjI5QzQuMzM5NzI2IC01LjI3MjIyOSAzLjkzMzI1IC00LjU1NDkxOSAzLjgyNTY1NCAtNC4zMjc3NzFDMy41NTA2ODUgLTUuMjI0NDA4IDIuODA5NDY1IC01LjI3MjIyOSAyLjU5NDI3MSAtNS4yNzIyMjlDMS4zNzQ4NDQgLTUuMjcyMjI5IDAuNzI5MjY1IC0zLjcwNjEwMiAwLjcyOTI2NSAtMy40NDMwODhDMC43MjkyNjUgLTMuMzk1MjY4IDAuNzc3MDg2IC0zLjMzNTQ5MiAwLjg2MDc3MiAtMy4zMzU0OTJDMC45NTY0MTMgLTMuMzM1NDkyIDAuOTgwMzI0IC0zLjQwNzIyMyAxLjAwNDIzNCAtMy40NTUwNDRDMS40MTA3MSAtNC43ODIwNjcgMi4yMTE3MDYgLTUuMDMzMTI2IDIuNTU4NDA2IC01LjAzMzEyNkMzLjA5NjM4OSAtNS4wMzMxMjYgMy4yMDM5ODUgLTQuNTMxMDA5IDMuMjAzOTg1IC00LjI0NDA4NUMzLjIwMzk4NSAtMy45ODEwNzEgMy4xMzIyNTQgLTMuNzA2MTAyIDIuOTg4NzkyIC0zLjEzMjI1NEwyLjU4MjMxNiAtMS40OTQzOTZDMi40MDI5ODkgLTAuNzc3MDg2IDIuMDU2Mjg5IC0wLjExOTU1MiAxLjQyMjY2NSAtMC4xMTk1NTJDMS4zNjI4ODkgLTAuMTE5NTUyIDEuMDY0MDEgLTAuMTE5NTUyIDAuODEyOTUxIC0wLjI3NDk2OUMxLjI0MzMzNyAtMC4zNTg2NTUgMS4zMzg5NzkgLTAuNzE3MzEgMS4zMzg5NzkgLTAuODYwNzcyQzEuMzM4OTc5IC0xLjA5OTg3NSAxLjE1OTY1MSAtMS4yNDMzMzcgMC45MzI1MDMgLTEuMjQzMzM3QzAuNjQ1NTc5IC0xLjI0MzMzNyAwLjMzNDc0NSAtMC45OTIyNzkgMC4zMzQ3NDUgLTAuNjA5NzE0QzAuMzM0NzQ1IC0wLjEwNzU5NyAwLjg5NjYzOCAwLjExOTU1MiAxLjQxMDcxIDAuMTE5NTUyQzEuOTg0NTU4IDAuMTE5NTUyIDIuMzkxMDM0IC0wLjMzNDc0NSAyLjY0MjA5MiAtMC44MjQ5MDdDMi44MzMzNzUgLTAuMTE5NTUyIDMuNDMxMTMzIDAuMTE5NTUyIDMuODczNDc0IDAuMTE5NTUyQzUuMDkyOTAyIDAuMTE5NTUyIDUuNzM4NDgxIC0xLjQ0NjU3NSA1LjczODQ4MSAtMS43MDk1ODlDNS43Mzg0ODEgLTEuNzY5MzY1IDUuNjkwNjYgLTEuODE3MTg2IDUuNjE4OTI5IC0xLjgxNzE4NkM1LjUxMTMzMyAtMS44MTcxODYgNS40OTkzNzcgLTEuNzU3NDEgNS40NjM1MTIgLTEuNjYxNzY4QzUuMTQwNzIyIC0wLjYwOTcxNCA0LjQ0NzMyMyAtMC4xMTk1NTIgMy45MDkzNCAtMC4xMTk1NTJDMy40OTA5MDkgLTAuMTE5NTUyIDMuMjYzNzYxIC0wLjQzMDM4NiAzLjI2Mzc2MSAtMC45MjA1NDhDMy4yNjM3NjEgLTEuMTgzNTYyIDMuMzExNTgyIC0xLjM3NDg0NCAzLjUwMjg2NCAtMi4xNjM4ODVMMy45MjEyOTUgLTMuNzg5Nzg4QzQuMTAwNjIzIC00LjUwNzA5OCA0LjUwNzA5OCAtNS4wMzMxMjYgNS4wNTcwMzYgLTUuMDMzMTI2QzUuMDgwOTQ2IC01LjAzMzEyNiA1LjQxNTY5MSAtNS4wMzMxMjYgNS42NjY3NSAtNC44Nzc3MDlaJyBpZD0nZzUtMTIwJy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzctNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c3LTQxJy8+CjxwYXRoIGQ9J00zLjQ0MzA4OCAtNy42NjMyNjNDMy40NDMwODggLTcuOTM4MjMyIDMuNDQzMDg4IC03Ljk1MDE4NyAzLjIwMzk4NSAtNy45NTAxODdDMi45MTcwNjEgLTcuNjI3Mzk3IDIuMzE5MzAzIC03LjE4NTA1NiAxLjA4NzkyIC03LjE4NTA1NlYtNi44MzgzNTZDMS4zNjI4ODkgLTYuODM4MzU2IDEuOTYwNjQ4IC02LjgzODM1NiAyLjYxODE4MiAtNy4xNDkxOTFWLTAuOTIwNTQ4QzIuNjE4MTgyIC0wLjQ5MDE2MiAyLjU4MjMxNiAtMC4zNDY3IDEuNTMwMjYyIC0wLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MSAtMC4wMjM5MSAyLjY0MjA5MiAtMC4wMjM5MSAzLjAzNjYxMyAtMC4wMjM5MVM0LjU3ODgyOSAtMC4wMjM5MSA0LjkwMTYxOSAwVi0wLjM0NjdINC41MzEwMDlDMy40Nzg5NTQgLTAuMzQ2NyAzLjQ0MzA4OCAtMC40OTAxNjIgMy40NDMwODggLTAuOTIwNTQ4Vi03LjY2MzI2M1onIGlkPSdnNy00OScvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzctNjEnLz4KPHBhdGggZD0nTTUuNzA2NiAtNC4xMTI1NzhDNS44MDIyNDIgLTQuMTYwMzk5IDUuODczOTczIC00LjIwODIxOSA1Ljg3Mzk3MyAtNC4zMTE4MzFTNS43OTQyNzEgLTQuNDk1MTQzIDUuNjkwNjYgLTQuNDk1MTQzQzUuNjY2NzUgLTQuNDk1MTQzIDUuNjUwODA5IC00LjQ5NTE0MyA1LjU0NzE5OCAtNC40MzkzNTJMMC44Njg3NDIgLTIuMTkxNzgxQzAuNzczMTAxIC0yLjE0Mzk2IDAuNzAxMzcgLTIuMDk2MTM5IDAuNzAxMzcgLTEuOTkyNTI4UzAuNzczMTAxIC0xLjg0MTA5NiAwLjg2ODc0MiAtMS43OTMyNzVMNS41NDcxOTggMC40NTQyOTZDNS42NTA4MDkgMC41MTAwODcgNS42NjY3NSAwLjUxMDA4NyA1LjY5MDY2IDAuNTEwMDg3QzUuNzk0MjcxIDAuNTEwMDg3IDUuODczOTczIDAuNDMwMzg2IDUuODczOTczIDAuMzI2Nzc1UzUuODAyMjQyIDAuMTc1MzQyIDUuNzA2NiAwLjEyNzUyMkwxLjMwNzA5OCAtMS45OTI1MjhMNS43MDY2IC00LjExMjU3OFonIGlkPSdnNC02MCcvPgo8cGF0aCBkPSdNMi4zNzUwOTMgLTQuOTczMzVDMi4zNzUwOTMgLTUuMTQ4NjkyIDIuMjQ3NTcyIC01LjI3NjIxNCAyLjA2NDI1OSAtNS4yNzYyMTRDMS44NTcwMzYgLTUuMjc2MjE0IDEuNjI1OTAzIC01LjA4NDkzMiAxLjYyNTkwMyAtNC44NDU4MjhDMS42MjU5MDMgLTQuNjcwNDg2IDEuNzUzNDI1IC00LjU0Mjk2NCAxLjkzNjczNyAtNC41NDI5NjRDMi4xNDM5NiAtNC41NDI5NjQgMi4zNzUwOTMgLTQuNzM0MjQ3IDIuMzc1MDkzIC00Ljk3MzM1Wk0xLjIxMTQ1NyAtMi4wNDgzMTlMMC43ODEwNzEgLTAuOTQ4NDQzQzAuNzQxMjIgLTAuODI4ODkyIDAuNzAxMzcgLTAuNzMzMjUgMC43MDEzNyAtMC41OTc3NThDMC43MDEzNyAtMC4yMDcyMjMgMS4wMDQyMzQgMC4wNzk3MDEgMS40MjY2NSAwLjA3OTcwMUMyLjE5OTc1MSAwLjA3OTcwMSAyLjUyNjUyNiAtMS4wMzYxMTUgMi41MjY1MjYgLTEuMTM5NzI2QzIuNTI2NTI2IC0xLjIxOTQyNyAyLjQ2Mjc2NSAtMS4yNDMzMzcgMi40MDY5NzQgLTEuMjQzMzM3QzIuMzExMzMzIC0xLjI0MzMzNyAyLjI5NTM5MiAtMS4xODc1NDcgMi4yNzE0ODIgLTEuMTA3ODQ2QzIuMDg4MTY5IC0wLjQ3MDIzNyAxLjc2MTM5NSAtMC4xNDM0NjIgMS40NDI1OSAtMC4xNDM0NjJDMS4zNDY5NDkgLTAuMTQzNDYyIDEuMjUxMzA4IC0wLjE4MzMxMyAxLjI1MTMwOCAtMC4zOTg1MDZDMS4yNTEzMDggLTAuNTg5Nzg4IDEuMzA3MDk4IC0wLjczMzI1IDEuNDEwNzEgLTAuOTgwMzI0QzEuNDkwNDExIC0xLjE5NTUxNyAxLjU3MDExMiAtMS40MTA3MSAxLjY1Nzc4MyAtMS42MjU5MDNMMS45MDQ4NTcgLTIuMjcxNDgyQzEuOTc2NTg4IC0yLjQ1NDc5NSAyLjA3MjIyOSAtMi43MDE4NjggMi4wNzIyMjkgLTIuODM3MzZDMi4wNzIyMjkgLTMuMjM1ODY2IDEuNzUzNDI1IC0zLjUxNDgxOSAxLjM0Njk0OSAtMy41MTQ4MTlDMC41NzM4NDggLTMuNTE0ODE5IDAuMjM5MTAzIC0yLjM5OTAwNCAwLjIzOTEwMyAtMi4yOTUzOTJDMC4yMzkxMDMgLTIuMjIzNjYxIDAuMjk0ODk0IC0yLjE5MTc4MSAwLjM1ODY1NSAtMi4xOTE3ODFDMC40NjIyNjcgLTIuMTkxNzgxIDAuNDcwMjM3IC0yLjIzOTYwMSAwLjQ5NDE0NyAtMi4zMTkzMDNDMC43MTczMSAtMy4wNzY0NjMgMS4wODM5MzUgLTMuMjkxNjU2IDEuMzIzMDM5IC0zLjI5MTY1NkMxLjQzNDYyIC0zLjI5MTY1NiAxLjUxNDMyMSAtMy4yNTE4MDYgMS41MTQzMjEgLTMuMDI4NjQzQzEuNTE0MzIxIC0yLjk0ODk0MSAxLjUwNjM1MSAtMi44MzczNiAxLjQyNjY1IC0yLjU5ODI1N0wxLjIxMTQ1NyAtMi4wNDgzMTlaJyBpZD0nZzQtMTA1Jy8+CjxwYXRoIGQ9J00zLjI5MTY1NiAtNC45NzMzNUMzLjI5MTY1NiAtNS4xMjQ3ODIgMy4xNzIxMDUgLTUuMjc2MjE0IDIuOTgwODIyIC01LjI3NjIxNEMyLjc0MTcxOSAtNS4yNzYyMTQgMi41MzQ0OTYgLTUuMDUzMDUxIDIuNTM0NDk2IC00Ljg0NTgyOEMyLjUzNDQ5NiAtNC42OTQzOTYgMi42NTQwNDcgLTQuNTQyOTY0IDIuODQ1MzMgLTQuNTQyOTY0QzMuMDg0NDMzIC00LjU0Mjk2NCAzLjI5MTY1NiAtNC43NjYxMjcgMy4yOTE2NTYgLTQuOTczMzVaTTEuNjI1OTAzIDAuMzk4NTA2QzEuNTA2MzUxIDAuODg0NjgyIDEuMTE1ODE2IDEuNDAyNzQgMC42Mjk2MzkgMS40MDI3NEMwLjUwMjExNyAxLjQwMjc0IDAuMzgyNTY1IDEuMzcwODU5IDAuMzY2NjI1IDEuMzYyODg5QzAuNjEzNjk5IDEuMjQzMzM3IDAuNjQ1NTc5IDEuMDI4MTQ0IDAuNjQ1NTc5IDAuOTU2NDEzQzAuNjQ1NTc5IDAuNzY1MTMxIDAuNTAyMTE3IDAuNjYxNTE5IDAuMzM0NzQ1IDAuNjYxNTE5QzAuMTAzNjExIDAuNjYxNTE5IC0wLjExMTU4MiAwLjg2MDc3MiAtMC4xMTE1ODIgMS4xMjM3ODZDLTAuMTExNTgyIDEuNDI2NjUgMC4xODMzMTMgMS42MjU5MDMgMC42Mzc2MDkgMS42MjU5MDNDMS4xMjM3ODYgMS42MjU5MDMgMi4wMDA0OTggMS4zMjMwMzkgMi4yMzk2MDEgMC4zNjY2MjVMMi45NTY5MTIgLTIuNDg2Njc1QzIuOTgwODIyIC0yLjU4MjMxNiAyLjk5Njc2MiAtMi42NDYwNzcgMi45OTY3NjIgLTIuNzY1NjI5QzIuOTk2NzYyIC0zLjIwMzk4NSAyLjY0NjA3NyAtMy41MTQ4MTkgMi4xODM4MTEgLTMuNTE0ODE5QzEuMzM4OTc5IC0zLjUxNDgxOSAwLjg0NDgzMiAtMi4zOTkwMDQgMC44NDQ4MzIgLTIuMjk1MzkyQzAuODQ0ODMyIC0yLjIyMzY2MSAwLjkwMDYyMyAtMi4xOTE3ODEgMC45NjQzODQgLTIuMTkxNzgxQzEuMDUyMDU1IC0yLjE5MTc4MSAxLjA2MDAyNSAtMi4yMTU2OTEgMS4xMTU4MTYgLTIuMzM1MjQzQzEuMzU0OTE5IC0yLjg4NTE4MSAxLjc2MTM5NSAtMy4yOTE2NTYgMi4xNTk5IC0zLjI5MTY1NkMyLjMyNzI3MyAtMy4yOTE2NTYgMi40MjI5MTQgLTMuMTgwMDc1IDIuNDIyOTE0IC0yLjkxNzA2MUMyLjQyMjkxNCAtMi44MDU0NzkgMi4zOTkwMDQgLTIuNjkzODk4IDIuMzc1MDkzIC0yLjU4MjMxNkwxLjYyNTkwMyAwLjM5ODUwNlonIGlkPSdnNC0xMDYnLz4KPHBhdGggZD0nTTAuNDE0NDQ2IDAuOTY0Mzg0QzAuMzUwNjg1IDEuMjE5NDI3IDAuMzM0NzQ1IDEuMjgzMTg4IDAuMDE1OTQgMS4yODMxODhDLTAuMDk1NjQxIDEuMjgzMTg4IC0wLjE5MTI4MyAxLjI4MzE4OCAtMC4xOTEyODMgMS40MzQ2MkMtMC4xOTEyODMgMS41MDYzNTEgLTAuMTE5NTUyIDEuNTQ2MjAyIC0wLjA3OTcwMSAxLjU0NjIwMkMwIDEuNTQ2MjAyIDAuMDMxODggMS41MjIyOTEgMC42MjE2NjkgMS41MjIyOTFDMS4xOTU1MTcgMS41MjIyOTEgMS4zNjI4ODkgMS41NDYyMDIgMS40MTg2OCAxLjU0NjIwMkMxLjQ1MDU2IDEuNTQ2MjAyIDEuNTcwMTEyIDEuNTQ2MjAyIDEuNTcwMTEyIDEuMzk0NzdDMS41NzAxMTIgMS4yODMxODggMS40NTg1MzEgMS4yODMxODggMS4zNjI4ODkgMS4yODMxODhDMC45ODAzMjQgMS4yODMxODggMC45ODAzMjQgMS4yMzUzNjcgMC45ODAzMjQgMS4xNjM2MzZDMC45ODAzMjQgMS4xMDc4NDYgMS4xMjM3ODYgMC41NDE5NjggMS4zNjI4ODkgLTAuMzkwNTM1QzEuNDY2NTAxIC0wLjIwNzIyMyAxLjcxMzU3NCAwLjA3OTcwMSAyLjE0Mzk2IDAuMDc5NzAxQzMuMTI0Mjg0IDAuMDc5NzAxIDQuMTQ0NDU4IC0xLjA1MjA1NSA0LjE0NDQ1OCAtMi4yMDc3MjFDNC4xNDQ0NTggLTIuOTk2NzYyIDMuNjM0MzcxIC0zLjUxNDgxOSAyLjk5Njc2MiAtMy41MTQ4MTlDMi41MTg1NTUgLTMuNTE0ODE5IDIuMTM1OTkgLTMuMTg4MDQ1IDEuOTA0ODU3IC0yLjk0ODk0MUMxLjczNzQ4NCAtMy41MTQ4MTkgMS4yMDM0ODcgLTMuNTE0ODE5IDEuMTIzNzg2IC0zLjUxNDgxOUMwLjgzNjg2MiAtMy41MTQ4MTkgMC42Mzc2MDkgLTMuMzMxNTA3IDAuNTEwMDg3IC0zLjA4NDQzM0MwLjMyNjc3NSAtMi43MjU3NzggMC4yMzkxMDMgLTIuMzE5MzAzIDAuMjM5MTAzIC0yLjI5NTM5MkMwLjIzOTEwMyAtMi4yMjM2NjEgMC4yOTQ4OTQgLTIuMTkxNzgxIDAuMzU4NjU1IC0yLjE5MTc4MUMwLjQ2MjI2NyAtMi4xOTE3ODEgMC40NzAyMzcgLTIuMjIzNjYxIDAuNTI2MDI3IC0yLjQzMDg4NEMwLjYyOTYzOSAtMi44MzczNiAwLjc3MzEwMSAtMy4yOTE2NTYgMS4wOTk4NzUgLTMuMjkxNjU2QzEuMjk5MTI4IC0zLjI5MTY1NiAxLjM1NDkxOSAtMy4xMDgzNDQgMS4zNTQ5MTkgLTIuOTE3MDYxQzEuMzU0OTE5IC0yLjgzNzM2IDEuMzIzMDM5IC0yLjY0NjA3NyAxLjMwNzA5OCAtMi41ODIzMTZMMC40MTQ0NDYgMC45NjQzODRaTTEuODgwOTQ2IC0yLjQ1NDc5NUMxLjkyMDc5NyAtMi41OTAyODYgMS45MjA3OTcgLTIuNjA2MjI3IDIuMDQwMzQ5IC0yLjc0OTY4OUMyLjM0MzIxMyAtMy4xMDgzNDQgMi42ODU5MjggLTMuMjkxNjU2IDIuOTcyODUyIC0zLjI5MTY1NkMzLjM3MTM1NyAtMy4yOTE2NTYgMy41MjI3OSAtMi45MDExMjEgMy41MjI3OSAtMi41NDI0NjZDMy41MjI3OSAtMi4yNDc1NzIgMy4zNDc0NDcgLTEuMzk0NzcgMy4xMDgzNDQgLTAuOTI0NTMzQzIuOTAxMTIxIC0wLjQ5NDE0NyAyLjUxODU1NSAtMC4xNDM0NjIgMi4xNDM5NiAtMC4xNDM0NjJDMS42MDE5OTMgLTAuMTQzNDYyIDEuNDc0NDcxIC0wLjc2NTEzMSAxLjQ3NDQ3MSAtMC44MjA5MjJDMS40NzQ0NzEgLTAuODM2ODYyIDEuNDkwNDExIC0wLjkyNDUzMyAxLjQ5ODM4MSAtMC45NDg0NDNMMS44ODA5NDYgLTIuNDU0Nzk1WicgaWQ9J2c0LTExMicvPgo8cGF0aCBkPSdNMy45OTMwMjYgLTMuMTgwMDc1QzMuNjQyMzQxIC0zLjA5MjQwMyAzLjYyNjQwMSAtMi43ODE1NjkgMy42MjY0MDEgLTIuNzQ5Njg5QzMuNjI2NDAxIC0yLjU3NDM0NiAzLjc2MTg5MyAtMi40NTQ3OTUgMy45MzcyMzUgLTIuNDU0Nzk1UzQuMzgzNTYyIC0yLjU5MDI4NiA0LjM4MzU2MiAtMi45MzMwMDFDNC4zODM1NjIgLTMuMzg3Mjk4IDMuODgxNDQ1IC0zLjUxNDgxOSAzLjU4NjU1IC0zLjUxNDgxOUMzLjIxMTk1NSAtMy41MTQ4MTkgMi45MDkwOTEgLTMuMjUxODA2IDIuNzI1Nzc4IC0yLjk0MDk3MUMyLjU1MDQzNiAtMy4zNjMzODcgMi4xMzU5OSAtMy41MTQ4MTkgMS44MDkyMTUgLTMuNTE0ODE5QzAuOTQwNDczIC0zLjUxNDgxOSAwLjQ1NDI5NiAtMi41MTg1NTUgMC40NTQyOTYgLTIuMjk1MzkyQzAuNDU0Mjk2IC0yLjIyMzY2MSAwLjUxMDA4NyAtMi4xOTE3ODEgMC41NzM4NDggLTIuMTkxNzgxQzAuNjY5NDg5IC0yLjE5MTc4MSAwLjY4NTQzIC0yLjIzMTYzMSAwLjcwOTM0IC0yLjMyNzI3M0MwLjg5MjY1MyAtMi45MDkwOTEgMS4zNzA4NTkgLTMuMjkxNjU2IDEuNzg1MzA1IC0zLjI5MTY1NkMyLjA5NjEzOSAtMy4yOTE2NTYgMi4yNDc1NzIgLTMuMDY4NDkzIDIuMjQ3NTcyIC0yLjc4MTU2OUMyLjI0NzU3MiAtMi42MjIxNjcgMi4xNTE5MyAtMi4yNTU1NDIgMi4wODgxNjkgLTIuMDAwNDk4QzIuMDMyMzc5IC0xLjc2OTM2NSAxLjg1NzAzNiAtMS4wNjAwMjUgMS44MTcxODYgLTAuOTA4NTkzQzEuNzA1NjA0IC0wLjQ3ODIwNyAxLjQxODY4IC0wLjE0MzQ2MiAxLjA2MDAyNSAtMC4xNDM0NjJDMS4wMjgxNDQgLTAuMTQzNDYyIDAuODIwOTIyIC0wLjE0MzQ2MiAwLjY1MzU0OSAtMC4yNTUwNDRDMS4wMjAxNzQgLTAuMzQyNzE1IDEuMDIwMTc0IC0wLjY3NzQ2IDEuMDIwMTc0IC0wLjY4NTQzQzEuMDIwMTc0IC0wLjg2ODc0MiAwLjg3NjcxMiAtMC45ODAzMjQgMC43MDEzNyAtMC45ODAzMjRDMC40ODYxNzcgLTAuOTgwMzI0IDAuMjU1MDQ0IC0wLjc5NzAxMSAwLjI1NTA0NCAtMC40OTQxNDdDMC4yNTUwNDQgLTAuMTI3NTIyIDAuNjQ1NTc5IDAuMDc5NzAxIDEuMDUyMDU1IDAuMDc5NzAxQzEuNDc0NDcxIDAuMDc5NzAxIDEuNzY5MzY1IC0wLjIzOTEwMyAxLjkxMjgyNyAtMC40OTQxNDdDMi4wODgxNjkgLTAuMTAzNjExIDIuNDU0Nzk1IDAuMDc5NzAxIDIuODM3MzYgMC4wNzk3MDFDMy43MDYxMDIgMC4wNzk3MDEgNC4xODQzMDkgLTAuOTE2NTYzIDQuMTg0MzA5IC0xLjEzOTcyNkM0LjE4NDMwOSAtMS4yMTk0MjcgNC4xMjA1NDggLTEuMjQzMzM3IDQuMDY0NzU3IC0xLjI0MzMzN0MzLjk2OTExNiAtMS4yNDMzMzcgMy45NTMxNzYgLTEuMTg3NTQ3IDMuOTI5MjY1IC0xLjEwNzg0NkMzLjc2OTg2MyAtMC41NzM4NDggMy4zMTU1NjcgLTAuMTQzNDYyIDIuODUzMyAtMC4xNDM0NjJDMi41OTAyODYgLTAuMTQzNDYyIDIuMzk5MDA0IC0wLjMxODgwNCAyLjM5OTAwNCAtMC42NTM1NDlDMi4zOTkwMDQgLTAuODEyOTUxIDIuNDQ2ODI0IC0wLjk5NjI2NCAyLjU1ODQwNiAtMS40NDI1OUMyLjYxNDE5NyAtMS42ODE2OTQgMi43ODk1MzkgLTIuMzgzMDY0IDIuODI5MzkgLTIuNTM0NDk2QzIuOTQwOTcxIC0yLjk0ODk0MSAzLjIxOTkyNSAtMy4yOTE2NTYgMy41Nzg1OCAtMy4yOTE2NTZDMy42MTg0MzEgLTMuMjkxNjU2IDMuODI1NjU0IC0zLjI5MTY1NiAzLjk5MzAyNiAtMy4xODAwNzVaJyBpZD0nZzQtMTIwJy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2c2LTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnNi05MycvPgo8cGF0aCBkPSdNNS4wMzMxMjYgNi4zODQwNkwwLjc4OTA0MSAxMS42MzIzNzlDMC42OTM0IDExLjc1MTkzIDAuNjgxNDQ1IDExLjc3NTg0MSAwLjY4MTQ0NSAxMS44MjM2NjFDMC42ODE0NDUgMTEuOTU1MTY4IDAuNzg5MDQxIDExLjk1NTE2OCAxLjAwNDIzNCAxMS45NTUxNjhIMTAuOTE1MDY4TDExLjk0MzIxMyA4Ljk3ODMzMUgxMS42NDQzMzRDMTEuMzQ1NDU1IDkuODc0OTY5IDEwLjU0NDQ1OCAxMC42MDQyMzQgOS41MjgyNjkgMTAuOTUwOTM0QzkuMzM2OTg2IDExLjAxMDcxIDguNTEyMDggMTEuMjk3NjM0IDYuNzU0NjcgMTEuMjk3NjM0SDEuNjczNzI0TDUuODIyMTY3IDYuMTY4ODY3QzUuOTA1ODUzIDYuMDYxMjcgNS45Mjk3NjMgNi4wMjU0MDUgNS45Mjk3NjMgNS45Nzc1ODRTNS45MTc4MDggNS45MTc4MDggNS44NDYwNzcgNS44MTAyMTJMMS45NjA2NDggMC40NzgyMDdINi42OTQ4OTRDOC4wNTc3ODMgMC40NzgyMDcgMTAuODA3NDcyIDAuNTYxODkzIDExLjY0NDMzNCAyLjc5NzUwOUgxMS45NDMyMTNMMTAuOTE1MDY4IDBIMS4wMDQyMzRDMC42ODE0NDUgMCAwLjY2OTQ4OSAwLjAxMTk1NSAwLjY2OTQ4OSAwLjM4MjU2NUw1LjAzMzEyNiA2LjM4NDA2WicgaWQ9J2cwLTgwJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScxMzEuNjMyNzA1JyB4bGluazpocmVmPScjZzItNTYnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzEzOC4yNzQ0ODUnIHhsaW5rOmhyZWY9JyNnNS0xMDUnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzE0NS41ODg3NDcnIHhsaW5rOmhyZWY9JyNnMi01MCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMTYzLjUyMTUxNCcgeGxpbms6aHJlZj0nI2c1LTExNCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMTY5LjEyMTk4OCcgeGxpbms6aHJlZj0nI2c1LTk3JyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxNzUuMjY2OTMyJyB4bGluazpocmVmPScjZzUtMTEwJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxODIuMjU0NTM4JyB4bGluazpocmVmPScjZzUtMTAzJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxODguMjg4Nzk0JyB4bGluazpocmVmPScjZzUtMTAxJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxOTMuNzE0MjM0JyB4bGluazpocmVmPScjZzctNDAnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzE5OC4yNjY1NicgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScyMDQuMTE5NTUnIHhsaW5rOmhyZWY9JyNnNS01OScgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMjA5LjM2MzcwOScgeGxpbms6aHJlZj0nI2c1LTEwMCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMjE1LjQ0NjQwMicgeGxpbms6aHJlZj0nI2c3LTQxJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxNjMuNTIxNTE0JyB4bGluazpocmVmPScjZzUtMTIwJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMTcwLjE3MzYwMScgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTA0LjIwOTE2MScvPgo8dXNlIHg9JzE3Ni44NzU3MDInIHhsaW5rOmhyZWY9JyNnNy02MScgeT0nMTAyLjQxNTg5OCcvPgo8dXNlIHg9JzE4OS4zMDExODMnIHhsaW5rOmhyZWY9JyNnNS04OCcgeT0nMTAyLjQxNTg5OCcvPgo8dXNlIHg9JzE5OS4wMTY0MScgeGxpbms6aHJlZj0nI2c2LTkxJyB5PScxMDQuMjc1NjA4Jy8+Cjx1c2UgeD0nMjAxLjM2ODczNCcgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTA0LjI3NTYwOCcvPgo8dXNlIHg9JzIwNC4yNTE4NzQnIHhsaW5rOmhyZWY9JyNnNi05MycgeT0nMTA0LjI3NTYwOCcvPgo8dXNlIHg9JzIwOS43NTg5OTMnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMjIxLjcxNDE1NCcgeGxpbms6aHJlZj0nI2cwLTgwJyB5PSc5My40NDk0NDYnLz4KPHVzZSB4PScyMzQuMzMzNTMzJyB4bGluazpocmVmPScjZzQtMTA2JyB5PScxMDUuOTAyODk4Jy8+Cjx1c2UgeD0nMjM4LjIxNzU1OCcgeGxpbms6aHJlZj0nI2c0LTYwJyB5PScxMDUuOTAyODk4Jy8+Cjx1c2UgeD0nMjQ0LjgwNDA2NScgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTA1LjkwMjg5OCcvPgo8dXNlIHg9JzI1MS41MDYxNjYnIHhsaW5rOmhyZWY9JyNnNS02MCcgeT0nMTAyLjQxNTg5OCcvPgo8dXNlIHg9JzI2My45MzE2NDcnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTAyLjQxNTg5OCcvPgo8dXNlIHg9JzI3MC43OTI2NTInIHhsaW5rOmhyZWY9JyNnNi05MScgeT0nMTA0LjI3NTYwOCcvPgo8dXNlIHg9JzI3My4xNDQ5NzYnIHhsaW5rOmhyZWY9JyNnNC0xMDYnIHk9JzEwNC4yNzU2MDgnLz4KPHVzZSB4PScyNzcuMDI5MDAxJyB4bGluazpocmVmPScjZzYtOTMnIHk9JzEwNC4yNzU2MDgnLz4KPHVzZSB4PScyNzkuODc5NDU3JyB4bGluazpocmVmPScjZzUtNTknIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScyODUuMTIzNjE2JyB4bGluazpocmVmPScjZzUtODgnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScyOTQuODM4ODQzJyB4bGluazpocmVmPScjZzYtOTEnIHk9JzEwNC4yNzU2MDgnLz4KPHVzZSB4PScyOTcuMTkxMTY3JyB4bGluazpocmVmPScjZzQtMTA1JyB5PScxMDQuMjc1NjA4Jy8+Cjx1c2UgeD0nMzAwLjA3NDMwNicgeGxpbms6aHJlZj0nI2c2LTkzJyB5PScxMDQuMjc1NjA4Jy8+Cjx1c2UgeD0nMzA2LjI0NTU5MScgeGxpbms6aHJlZj0nI2c1LTYyJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMzE4LjY3MTA3MicgeGxpbms6aHJlZj0nI2c1LTg0JyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMzI1LjUzMjA3OCcgeGxpbms6aHJlZj0nI2c2LTkxJyB5PScxMDQuMjc1NjA4Jy8+Cjx1c2UgeD0nMzI3Ljg4NDQwMScgeGxpbms6aHJlZj0nI2c0LTEwNicgeT0nMTA0LjI3NTYwOCcvPgo8dXNlIHg9JzMzMS43Njg0MjYnIHhsaW5rOmhyZWY9JyNnNi05MycgeT0nMTA0LjI3NTYwOCcvPgo8dXNlIHg9JzE2My41MjE1MTQnIHhsaW5rOmhyZWY9JyNnNS0xMTInIHk9JzExNy4yMTU5ODgnLz4KPHVzZSB4PScxNjkuMzk2NjU3JyB4bGluazpocmVmPScjZzQtMTA1JyB5PScxMTkuMDA5MjUxJy8+Cjx1c2UgeD0nMTc2LjA5ODc1OCcgeGxpbms6aHJlZj0nI2c3LTYxJyB5PScxMTcuMjE1OTg4Jy8+Cjx1c2UgeD0nMTg4LjUyNDIzOScgeGxpbms6aHJlZj0nI2c1LTgwJyB5PScxMTcuMjE1OTg4Jy8+Cjx1c2UgeD0nMTk2LjA2OTUwNycgeGxpbms6aHJlZj0nI2c2LTkxJyB5PScxMTkuMDc1Njk4Jy8+Cjx1c2UgeD0nMTk4LjQyMTgzMScgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTE5LjA3NTY5OCcvPgo8dXNlIHg9JzIwMS4zMDQ5NycgeGxpbms6aHJlZj0nI2c2LTkzJyB5PScxMTkuMDc1Njk4Jy8+Cjx1c2UgeD0nMjA2LjgxMjA5JyB4bGluazpocmVmPScjZzItMCcgeT0nMTE3LjIxNTk4OCcvPgo8dXNlIHg9JzIxOC43NjcyNScgeGxpbms6aHJlZj0nI2cwLTgwJyB5PScxMDguMjQ5NTM2Jy8+Cjx1c2UgeD0nMjMxLjM4NjYzJyB4bGluazpocmVmPScjZzQtMTA2JyB5PScxMjAuNzAyOTg4Jy8+Cjx1c2UgeD0nMjM1LjI3MDY1NScgeGxpbms6aHJlZj0nI2c0LTYwJyB5PScxMjAuNzAyOTg4Jy8+Cjx1c2UgeD0nMjQxLjg1NzE2MScgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTIwLjcwMjk4OCcvPgo8dXNlIHg9JzI0OC41NTkyNjInIHhsaW5rOmhyZWY9JyNnNS02MCcgeT0nMTE3LjIxNTk4OCcvPgo8dXNlIHg9JzI2MC45ODQ3NDMnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTE3LjIxNTk4OCcvPgo8dXNlIHg9JzI2Ny44NDU3NDknIHhsaW5rOmhyZWY9JyNnNi05MScgeT0nMTE5LjA3NTY5OCcvPgo8dXNlIHg9JzI3MC4xOTgwNzInIHhsaW5rOmhyZWY9JyNnNC0xMDYnIHk9JzExOS4wNzU2OTgnLz4KPHVzZSB4PScyNzQuMDgyMDk3JyB4bGluazpocmVmPScjZzYtOTMnIHk9JzExOS4wNzU2OTgnLz4KPHVzZSB4PScyNzYuOTMyNTUzJyB4bGluazpocmVmPScjZzUtNTknIHk9JzExNy4yMTU5ODgnLz4KPHVzZSB4PScyODIuMTc2NzEyJyB4bGluazpocmVmPScjZzUtODgnIHk9JzExNy4yMTU5ODgnLz4KPHVzZSB4PScyOTEuODkxOTM5JyB4bGluazpocmVmPScjZzYtOTEnIHk9JzExOS4wNzU2OTgnLz4KPHVzZSB4PScyOTQuMjQ0MjYzJyB4bGluazpocmVmPScjZzQtMTA1JyB5PScxMTkuMDc1Njk4Jy8+Cjx1c2UgeD0nMjk3LjEyNzQwMycgeGxpbms6aHJlZj0nI2c2LTkzJyB5PScxMTkuMDc1Njk4Jy8+Cjx1c2UgeD0nMzAzLjI5ODY4OCcgeGxpbms6aHJlZj0nI2c1LTYyJyB5PScxMTcuMjE1OTg4Jy8+Cjx1c2UgeD0nMzE1LjcyNDE2OScgeGxpbms6aHJlZj0nI2c1LTgwJyB5PScxMTcuMjE1OTg4Jy8+Cjx1c2UgeD0nMzIzLjI2OTQzNycgeGxpbms6aHJlZj0nI2c2LTkxJyB5PScxMTkuMDc1Njk4Jy8+Cjx1c2UgeD0nMzI1LjYyMTc2MScgeGxpbms6aHJlZj0nI2c0LTEwNicgeT0nMTE5LjA3NTY5OCcvPgo8dXNlIHg9JzMyOS41MDU3ODUnIHhsaW5rOmhyZWY9JyNnNi05MycgeT0nMTE5LjA3NTY5OCcvPgo8dXNlIHg9JzE2My41MjE1MTQnIHhsaW5rOmhyZWY9JyNnNS04NCcgeT0nMTMyLjAxNjA3OScvPgo8dXNlIHg9JzE3MC4zODI1MTknIHhsaW5rOmhyZWY9JyNnNi05MScgeT0nMTMzLjg3NTc4OScvPgo8dXNlIHg9JzE3Mi43MzQ4NDMnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzEzMy44NzU3ODknLz4KPHVzZSB4PScxNzUuNjE3OTgzJyB4bGluazpocmVmPScjZzYtOTMnIHk9JzEzMy44NzU3ODknLz4KPHVzZSB4PScxODEuNzg5MjY4JyB4bGluazpocmVmPScjZzctNjEnIHk9JzEzMi4wMTYwNzknLz4KPHVzZSB4PScxOTkuNjQ0NDQ2JyB4bGluazpocmVmPScjZzQtMTIwJyB5PScxMjcuMDk0OTI3Jy8+Cjx1c2UgeD0nMjA0LjQxMTM0NCcgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nMTI4LjMxMDAwNicvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nMTYuMzk3MDIzJyB4PScxOTUuNDEwMjYzJyB5PScxMjguNzg4MTkzJy8+Cjx1c2UgeD0nMTk1LjQxMDI2MycgeGxpbms6aHJlZj0nI2cxLTEwNycgeT0nMTM2LjEzODcxMScvPgo8dXNlIHg9JzE5OS42NDQ0NDYnIHhsaW5rOmhyZWY9JyNnNC0xMjAnIHk9JzEzNi4xMzg3MTEnLz4KPHVzZSB4PScyMDQuNDExMzQ0JyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxMzcuMzUzNzg5Jy8+Cjx1c2UgeD0nMjA3LjU3MzEwMicgeGxpbms6aHJlZj0nI2cxLTEwNycgeT0nMTM2LjEzODcxMScvPgo8dXNlIHg9JzE2My41MjE1MTQnIHhsaW5rOmhyZWY9JyNnNS04MCcgeT0nMTQ3Ljg5NDU4NCcvPgo8dXNlIHg9JzE3MS4wNjY3ODInIHhsaW5rOmhyZWY9JyNnNi05MScgeT0nMTQ5Ljc1NDI5NCcvPgo8dXNlIHg9JzE3My40MTkxMDYnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzE0OS43NTQyOTQnLz4KPHVzZSB4PScxNzYuMzAyMjQ1JyB4bGluazpocmVmPScjZzYtOTMnIHk9JzE0OS43NTQyOTQnLz4KPHVzZSB4PScxODIuNDczNTMxJyB4bGluazpocmVmPScjZzctNjEnIHk9JzE0Ny44OTQ1ODQnLz4KPHVzZSB4PScyMDAuMzI4NzA4JyB4bGluazpocmVmPScjZzQtMTEyJyB5PScxNDIuNjM4NzY1Jy8+Cjx1c2UgeD0nMjA0LjU5MTQ4NicgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nMTQzLjg1Mzg0MycvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nMTUuODkyOTAxJyB4PScxOTYuMDk0NTI1JyB5PScxNDQuNjY2Njk4Jy8+Cjx1c2UgeD0nMTk2LjA5NDUyNScgeGxpbms6aHJlZj0nI2cxLTEwNycgeT0nMTUyLjAxNzIxNicvPgo8dXNlIHg9JzIwMC4zMjg3MDgnIHhsaW5rOmhyZWY9JyNnNC0xMTInIHk9JzE1Mi4wMTcyMTYnLz4KPHVzZSB4PScyMDQuNTkxNDg2JyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxNTMuMjMyMjk0Jy8+Cjx1c2UgeD0nMjA3Ljc1MzI0MycgeGxpbms6aHJlZj0nI2cxLTEwNycgeT0nMTUyLjAxNzIxNicvPgo8L2c+Cjwvc3ZnPg==)
Théorème T1 : Régression linéaire après Gram-Schmidt
Soit une matrice avec
. Et un vecteur  .
D’après l”algorithme de Gram-Schmidt,
il existe deux matrices telles que
ou .
et .
La matrice T est triangulaire supérieure
et vérifie (
est la matrice identité). Alors
.
D’après l”algorithme de Gram-Schmidt,
il existe deux matrices telles que
ou .
et .
La matrice T est triangulaire supérieure
et vérifie (
est la matrice identité). Alors
 .
.
 est la solution du problème d’optimisation
est la solution du problème d’optimisation
 .
.
La démonstration est géométrique et reprend l’idée
du paragraphe précédent. La solution de la régression
peut être vu comme la projection du vecteur y
sur l’espace vectoriel engendré par les vecteurs
![X_{[1]}, ..., X_{[d]}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMDIxNjA0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU3LjU4NDA1OSA1OC4xNzI2ODMgMTIuMDIxNjA0JyB3aWR0aD0nNTguMTcyNjgzcHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTQuMjg3OTIgLTUuMjkyMTU0QzQuMjk1ODkgLTUuMzA4MDk1IDQuMzE5ODAxIC01LjQxMTcwNiA0LjMxOTgwMSAtNS40MTk2NzZDNC4zMTk4MDEgLTUuNDU5NTI3IDQuMjg3OTIgLTUuNTMxMjU4IDQuMTkyMjc5IC01LjUzMTI1OEM0LjE2MDM5OSAtNS41MzEyNTggMy45MTMzMjUgLTUuNTA3MzQ3IDMuNzMwMDEyIC01LjQ5MTQwN0wzLjI4MzY4NiAtNS40NTk1MjdDMy4xMDgzNDQgLTUuNDQzNTg3IDMuMDI4NjQzIC01LjQzNTYxNiAzLjAyODY0MyAtNS4yOTIxNTRDMy4wMjg2NDMgLTUuMTgwNTczIDMuMTQwMjI0IC01LjE4MDU3MyAzLjIzNTg2NiAtNS4xODA1NzNDMy42MTg0MzEgLTUuMTgwNTczIDMuNjE4NDMxIC01LjEzMjc1MiAzLjYxODQzMSAtNS4wNjEwMjFDMy42MTg0MzEgLTUuMDEzMiAzLjU1NDY3IC00Ljc1MDE4NyAzLjUxNDgxOSAtNC41OTA3ODVMMy4xMjQyODQgLTMuMDM2NjEzQzMuMDUyNTUzIC0zLjE3MjEwNSAyLjgyMTQyIC0zLjUxNDgxOSAyLjMzNTI0MyAtMy41MTQ4MTlDMS4zODY4IC0zLjUxNDgxOSAwLjM0MjcxNSAtMi40MDY5NzQgMC4zNDI3MTUgLTEuMjI3Mzk3QzAuMzQyNzE1IC0wLjM5ODUwNiAwLjg3NjcxMiAwLjA3OTcwMSAxLjQ5MDQxMSAwLjA3OTcwMUMyLjAwMDQ5OCAwLjA3OTcwMSAyLjQzODg1NCAtMC4zMjY3NzUgMi41ODIzMTYgLTAuNDg2MTc3QzIuNzI1Nzc4IDAuMDYzNzYxIDMuMjY3NzQ2IDAuMDc5NzAxIDMuMzYzMzg3IDAuMDc5NzAxQzMuNzMwMDEyIDAuMDc5NzAxIDMuOTEzMzI1IC0wLjIyMzE2MyAzLjk3NzA4NiAtMC4zNTg2NTVDNC4xMzY0ODggLTAuNjQ1NTc5IDQuMjQ4MDcgLTEuMTA3ODQ2IDQuMjQ4MDcgLTEuMTM5NzI2QzQuMjQ4MDcgLTEuMTg3NTQ3IDQuMjE2MTg5IC0xLjI0MzMzNyA0LjEyMDU0OCAtMS4yNDMzMzdTNC4wMDg5NjYgLTEuMTk1NTE3IDMuOTYxMTQ2IC0wLjk5NjI2NEMzLjg0OTU2NCAtMC41NTc5MDggMy42OTgxMzIgLTAuMTQzNDYyIDMuMzg3Mjk4IC0wLjE0MzQ2MkMzLjIwMzk4NSAtMC4xNDM0NjIgMy4xMzIyNTQgLTAuMjk0ODk0IDMuMTMyMjU0IC0wLjUxODA1N0MzLjEzMjI1NCAtMC42Njk0ODkgMy4xNTYxNjQgLTAuNzU3MTYxIDMuMTgwMDc1IC0wLjg2MDc3Mkw0LjI4NzkyIC01LjI5MjE1NFpNMi41ODIzMTYgLTAuODYwNzcyQzIuMTgzODExIC0wLjMxMDgzNCAxLjc2OTM2NSAtMC4xNDM0NjIgMS41MTQzMjEgLTAuMTQzNDYyQzEuMTQ3Njk2IC0wLjE0MzQ2MiAwLjk2NDM4NCAtMC40NzgyMDcgMC45NjQzODQgLTAuODkyNjUzQzAuOTY0Mzg0IC0xLjI2NzI0OCAxLjE3OTU3NyAtMi4xMjAwNSAxLjM1NDkxOSAtMi40NzA3MzVDMS41ODYwNTIgLTIuOTU2OTEyIDEuOTc2NTg4IC0zLjI5MTY1NiAyLjM0MzIxMyAtMy4yOTE2NTZDMi44NjEyNyAtMy4yOTE2NTYgMy4wMTI3MDIgLTIuNzA5ODM4IDMuMDEyNzAyIC0yLjYxNDE5N0MzLjAxMjcwMiAtMi41ODIzMTYgMi44MTM0NSAtMS44MDEyNDUgMi43NjU2MjkgLTEuNTk0MDIyQzIuNjYyMDE3IC0xLjIxOTQyNyAyLjY2MjAxNyAtMS4yMDM0ODcgMi41ODIzMTYgLTAuODYwNzcyWicgaWQ9J2cwLTEwMCcvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2cxLTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMS01OScvPgo8cGF0aCBkPSdNNS42Nzg3MDUgLTQuODUzNzk4TDQuNTU0OTE5IC03LjQ3MTk4QzQuNzEwMzM2IC03Ljc1ODkwNCA1LjA2ODk5MSAtNy44MDY3MjUgNS4yMTI0NTMgLTcuODE4NjhDNS4yODQxODQgLTcuODE4NjggNS40MTU2OTEgLTcuODMwNjM1IDUuNDE1NjkxIC04LjAzMzg3M0M1LjQxNTY5MSAtOC4xNjUzOCA1LjMwODA5NSAtOC4xNjUzOCA1LjIzNjM2NCAtOC4xNjUzOEM1LjAzMzEyNiAtOC4xNjUzOCA0Ljc5NDAyMiAtOC4xNDE0NjkgNC41OTA3ODUgLTguMTQxNDY5SDMuODk3Mzg1QzMuMTY4MTIgLTguMTQxNDY5IDIuNjQyMDkyIC04LjE2NTM4IDIuNjMwMTM3IC04LjE2NTM4QzIuNTM0NDk2IC04LjE2NTM4IDIuNDE0OTQ0IC04LjE2NTM4IDIuNDE0OTQ0IC03LjkzODIzMkMyLjQxNDk0NCAtNy44MTg2OCAyLjUyMjU0IC03LjgxODY4IDIuNjc3OTU4IC03LjgxODY4QzMuMzcxMzU3IC03LjgxODY4IDMuNDE5MTc4IC03LjY5OTEyOCAzLjUzODczIC03LjQxMjIwNEw0Ljk2MTM5NSAtNC4wODg2NjdMMi4zNjcxMjMgLTEuMzE1MDY4QzEuOTM2NzM3IC0wLjg0ODgxNyAxLjQyMjY2NSAtMC4zOTQ1MjEgMC41Mzc5ODMgLTAuMzQ2N0MwLjM5NDUyMSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjExOTU1MkMwLjI5ODg3OSAtMC4wODM2ODYgMC4zMTA4MzQgMCAwLjQ0MjM0MSAwQzAuNjA5NzE0IDAgMC43ODkwNDEgLTAuMDIzOTEgMC45NTY0MTMgLTAuMDIzOTFIMS41MTgzMDZDMS45MDA4NzIgLTAuMDIzOTEgMi4zMTkzMDMgMCAyLjY4OTkxMyAwQzIuNzczNTk5IDAgMi45MTcwNjEgMCAyLjkxNzA2MSAtMC4yMTUxOTNDMi45MTcwNjEgLTAuMzM0NzQ1IDIuODMzMzc1IC0wLjM0NjcgMi43NjE2NDQgLTAuMzQ2N0MyLjUyMjU0IC0wLjM3MDYxIDIuMzY3MTIzIC0wLjUwMjExNyAyLjM2NzEyMyAtMC42OTM0QzIuMzY3MTIzIC0wLjg5NjYzOCAyLjUxMDU4NSAtMS4wNDAxIDIuODU3Mjg1IC0xLjM5ODc1NUwzLjkyMTI5NSAtMi41NTg0MDZDNC4xODQzMDkgLTIuODMzMzc1IDQuODE3OTMzIC0zLjUyNjc3NSA1LjA4MDk0NiAtMy43ODk3ODhMNi4zMzYyMzkgLTAuODQ4ODE3QzYuMzQ4MTk0IC0wLjgyNDkwNyA2LjM5NjAxNSAtMC43MDUzNTUgNi4zOTYwMTUgLTAuNjkzNEM2LjM5NjAxNSAtMC41ODU4MDMgNi4xMzMwMDEgLTAuMzcwNjEgNS43NTA0MzYgLTAuMzQ2N0M1LjY3ODcwNSAtMC4zNDY3IDUuNTQ3MTk4IC0wLjMzNDc0NSA1LjU0NzE5OCAtMC4xMTk1NTJDNS41NDcxOTggMCA1LjY2Njc1IDAgNS43MjY1MjYgMEM1LjkyOTc2MyAwIDYuMTY4ODY3IC0wLjAyMzkxIDYuMzcyMTA1IC0wLjAyMzkxSDcuNjg3MTczQzcuOTAyMzY2IC0wLjAyMzkxIDguMTI5NTE0IDAgOC4zMzI3NTIgMEM4LjQxNjQzOCAwIDguNTQ3OTQ1IDAgOC41NDc5NDUgLTAuMjI3MTQ4QzguNTQ3OTQ1IC0wLjM0NjcgOC40MjgzOTQgLTAuMzQ2NyA4LjMyMDc5NyAtMC4zNDY3QzcuNjAzNDg3IC0wLjM1ODY1NSA3LjU3OTU3NyAtMC40MTg0MzEgNy4zNzYzMzkgLTAuODYwNzcyTDUuNzk4MjU3IC00LjU2Njg3NEw3LjMxNjU2MyAtNi4xOTI3NzdDNy40MzYxMTUgLTYuMzEyMzI5IDcuNzExMDgzIC02LjYxMTIwOCA3LjgxODY4IC02LjczMDc2QzguMzMyNzUyIC03LjI2ODc0MiA4LjgxMDk1OSAtNy43NTg5MDQgOS43NzkzMjggLTcuODE4NjhDOS44OTg4NzkgLTcuODMwNjM1IDEwLjAxODQzMSAtNy44MzA2MzUgMTAuMDE4NDMxIC04LjAzMzg3M0MxMC4wMTg0MzEgLTguMTY1MzggOS45MTA4MzQgLTguMTY1MzggOS44NjMwMTQgLTguMTY1MzhDOS42OTU2NDEgLTguMTY1MzggOS41MTYzMTQgLTguMTQxNDY5IDkuMzQ4OTQxIC04LjE0MTQ2OUg4Ljc5OTAwNEM4LjQxNjQzOCAtOC4xNDE0NjkgNy45OTgwMDcgLTguMTY1MzggNy42MjczOTcgLTguMTY1MzhDNy41NDM3MTEgLTguMTY1MzggNy40MDAyNDkgLTguMTY1MzggNy40MDAyNDkgLTcuOTUwMTg3QzcuNDAwMjQ5IC03LjgzMDYzNSA3LjQ4MzkzNSAtNy44MTg2OCA3LjU1NTY2NiAtNy44MTg2OEM3Ljc0Njk0OSAtNy43OTQ3NyA3Ljk1MDE4NyAtNy42OTkxMjggNy45NTAxODcgLTcuNDcxOThMNy45MzgyMzIgLTcuNDQ4MDdDNy45MjYyNzYgLTcuMzY0Mzg0IDcuOTAyMzY2IC03LjI0NDgzMiA3Ljc3MDg1OSAtNy4xMDEzN0w1LjY3ODcwNSAtNC44NTM3OThaJyBpZD0nZzEtODgnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2cyLTQ5Jy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2cyLTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnMi05MycvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMzguODU0Mjk2JyB4bGluazpocmVmPScjZzEtODgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzQ4LjU2OTUyNCcgeGxpbms6aHJlZj0nI2cyLTkxJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1MC45MjE4NDcnIHhsaW5rOmhyZWY9JyNnMi00OScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNTUuMTU2MDMnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNTguMDA2NDg2JyB4bGluazpocmVmPScjZzEtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYzLjI1MDY0NScgeGxpbms6aHJlZj0nI2cxLTU4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2Ni41MDIzMDYnIHhsaW5rOmhyZWY9JyNnMS01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNjkuNzUzOTY4JyB4bGluazpocmVmPScjZzEtNTgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzczLjAwNTYyOScgeGxpbms6aHJlZj0nI2cxLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3OC4yNDk3ODgnIHhsaW5rOmhyZWY9JyNnMS04OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODcuOTY1MDE1JyB4bGluazpocmVmPScjZzItOTEnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzkwLjMxNzMzOScgeGxpbms6aHJlZj0nI2cwLTEwMCcgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nOTQuNjc0NjU2JyB4bGluazpocmVmPScjZzItOTMnIHk9JzY3LjYxMzEzNScvPgo8L2c+Cjwvc3ZnPg==) .
Par construction, cet espace est le même que celui
engendré par
.
Par construction, cet espace est le même que celui
engendré par ![T_{[1]}, ..., T_{[d]}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMDIxNjA0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU3LjU4NDA1OSA1Mi40NjQyMzkgMTIuMDIxNjA0JyB3aWR0aD0nNTIuNDY0MjM5cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTQuMjg3OTIgLTUuMjkyMTU0QzQuMjk1ODkgLTUuMzA4MDk1IDQuMzE5ODAxIC01LjQxMTcwNiA0LjMxOTgwMSAtNS40MTk2NzZDNC4zMTk4MDEgLTUuNDU5NTI3IDQuMjg3OTIgLTUuNTMxMjU4IDQuMTkyMjc5IC01LjUzMTI1OEM0LjE2MDM5OSAtNS41MzEyNTggMy45MTMzMjUgLTUuNTA3MzQ3IDMuNzMwMDEyIC01LjQ5MTQwN0wzLjI4MzY4NiAtNS40NTk1MjdDMy4xMDgzNDQgLTUuNDQzNTg3IDMuMDI4NjQzIC01LjQzNTYxNiAzLjAyODY0MyAtNS4yOTIxNTRDMy4wMjg2NDMgLTUuMTgwNTczIDMuMTQwMjI0IC01LjE4MDU3MyAzLjIzNTg2NiAtNS4xODA1NzNDMy42MTg0MzEgLTUuMTgwNTczIDMuNjE4NDMxIC01LjEzMjc1MiAzLjYxODQzMSAtNS4wNjEwMjFDMy42MTg0MzEgLTUuMDEzMiAzLjU1NDY3IC00Ljc1MDE4NyAzLjUxNDgxOSAtNC41OTA3ODVMMy4xMjQyODQgLTMuMDM2NjEzQzMuMDUyNTUzIC0zLjE3MjEwNSAyLjgyMTQyIC0zLjUxNDgxOSAyLjMzNTI0MyAtMy41MTQ4MTlDMS4zODY4IC0zLjUxNDgxOSAwLjM0MjcxNSAtMi40MDY5NzQgMC4zNDI3MTUgLTEuMjI3Mzk3QzAuMzQyNzE1IC0wLjM5ODUwNiAwLjg3NjcxMiAwLjA3OTcwMSAxLjQ5MDQxMSAwLjA3OTcwMUMyLjAwMDQ5OCAwLjA3OTcwMSAyLjQzODg1NCAtMC4zMjY3NzUgMi41ODIzMTYgLTAuNDg2MTc3QzIuNzI1Nzc4IDAuMDYzNzYxIDMuMjY3NzQ2IDAuMDc5NzAxIDMuMzYzMzg3IDAuMDc5NzAxQzMuNzMwMDEyIDAuMDc5NzAxIDMuOTEzMzI1IC0wLjIyMzE2MyAzLjk3NzA4NiAtMC4zNTg2NTVDNC4xMzY0ODggLTAuNjQ1NTc5IDQuMjQ4MDcgLTEuMTA3ODQ2IDQuMjQ4MDcgLTEuMTM5NzI2QzQuMjQ4MDcgLTEuMTg3NTQ3IDQuMjE2MTg5IC0xLjI0MzMzNyA0LjEyMDU0OCAtMS4yNDMzMzdTNC4wMDg5NjYgLTEuMTk1NTE3IDMuOTYxMTQ2IC0wLjk5NjI2NEMzLjg0OTU2NCAtMC41NTc5MDggMy42OTgxMzIgLTAuMTQzNDYyIDMuMzg3Mjk4IC0wLjE0MzQ2MkMzLjIwMzk4NSAtMC4xNDM0NjIgMy4xMzIyNTQgLTAuMjk0ODk0IDMuMTMyMjU0IC0wLjUxODA1N0MzLjEzMjI1NCAtMC42Njk0ODkgMy4xNTYxNjQgLTAuNzU3MTYxIDMuMTgwMDc1IC0wLjg2MDc3Mkw0LjI4NzkyIC01LjI5MjE1NFpNMi41ODIzMTYgLTAuODYwNzcyQzIuMTgzODExIC0wLjMxMDgzNCAxLjc2OTM2NSAtMC4xNDM0NjIgMS41MTQzMjEgLTAuMTQzNDYyQzEuMTQ3Njk2IC0wLjE0MzQ2MiAwLjk2NDM4NCAtMC40NzgyMDcgMC45NjQzODQgLTAuODkyNjUzQzAuOTY0Mzg0IC0xLjI2NzI0OCAxLjE3OTU3NyAtMi4xMjAwNSAxLjM1NDkxOSAtMi40NzA3MzVDMS41ODYwNTIgLTIuOTU2OTEyIDEuOTc2NTg4IC0zLjI5MTY1NiAyLjM0MzIxMyAtMy4yOTE2NTZDMi44NjEyNyAtMy4yOTE2NTYgMy4wMTI3MDIgLTIuNzA5ODM4IDMuMDEyNzAyIC0yLjYxNDE5N0MzLjAxMjcwMiAtMi41ODIzMTYgMi44MTM0NSAtMS44MDEyNDUgMi43NjU2MjkgLTEuNTk0MDIyQzIuNjYyMDE3IC0xLjIxOTQyNyAyLjY2MjAxNyAtMS4yMDM0ODcgMi41ODIzMTYgLTAuODYwNzcyWicgaWQ9J2cwLTEwMCcvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2cxLTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMS01OScvPgo8cGF0aCBkPSdNNC45ODUzMDUgLTcuMjkyNjUzQzUuMDU3MDM2IC03LjU3OTU3NyA1LjA4MDk0NiAtNy42ODcxNzMgNS4yNjAyNzQgLTcuNzM0OTk0QzUuMzU1OTE1IC03Ljc1ODkwNCA1Ljc1MDQzNiAtNy43NTg5MDQgNi4wMDE0OTQgLTcuNzU4OTA0QzcuMTk3MDExIC03Ljc1ODkwNCA3Ljc1ODkwNCAtNy43MTEwODMgNy43NTg5MDQgLTYuNzc4NThDNy43NTg5MDQgLTYuNTk5MjUzIDcuNzExMDgzIC02LjE0NDk1NiA3LjYzOTM1MiAtNS43MDI2MTVMNy42MjczOTcgLTUuNTU5MTUzQzcuNjI3Mzk3IC01LjUxMTMzMyA3LjY3NTIxOCAtNS40Mzk2MDEgNy43NDY5NDkgLTUuNDM5NjAxQzcuODY2NTAxIC01LjQzOTYwMSA3Ljg2NjUwMSAtNS40OTkzNzcgNy45MDIzNjYgLTUuNjkwNjZMOC4yNDkwNjYgLTcuODA2NzI1QzguMjcyOTc2IC03LjkxNDMyMSA4LjI3Mjk3NiAtNy45MzgyMzIgOC4yNzI5NzYgLTcuOTc0MDk3QzguMjcyOTc2IC04LjEwNTYwNCA4LjIwMTI0NSAtOC4xMDU2MDQgNy45NjIxNDIgLTguMTA1NjA0SDEuNDIyNjY1QzEuMTQ3Njk2IC04LjEwNTYwNCAxLjEzNTc0MSAtOC4wOTM2NDkgMS4wNjQwMSAtNy44Nzg0NTZMMC4zMzQ3NDUgLTUuNzI2NTI2QzAuMzIyNzkgLTUuNzAyNjE1IDAuMjg2OTI0IC01LjU3MTEwOCAwLjI4NjkyNCAtNS41NTkxNTNDMC4yODY5MjQgLTUuNDk5Mzc3IDAuMzM0NzQ1IC01LjQzOTYwMSAwLjQwNjQ3NiAtNS40Mzk2MDFDMC41MDIxMTcgLTUuNDM5NjAxIDAuNTI2MDI3IC01LjQ4NzQyMiAwLjU3Mzg0OCAtNS42NDI4MzlDMS4wNzU5NjUgLTcuMDg5NDE1IDEuMzI3MDI0IC03Ljc1ODkwNCAyLjkxNzA2MSAtNy43NTg5MDRIMy43MTgwNTdDNC4wMDQ5ODEgLTcuNzU4OTA0IDQuMTI0NTMzIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy42MjczOTdDNC4xMjQ1MzMgLTcuNTkxNTMyIDQuMTI0NTMzIC03LjU2NzYyMSA0LjA2NDc1NyAtNy4zNTI0MjhMMi40NjI3NjUgLTAuOTMyNTAzQzIuMzQzMjEzIC0wLjQ2NjI1MiAyLjMxOTMwMyAtMC4zNDY3IDEuMDUyMDU1IC0wLjM0NjdDMC43NTMxNzYgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4zNDY3IDAuNjY5NDg5IC0wLjExOTU1MkMwLjY2OTQ4OSAwIDAuODAwOTk2IDAgMC44NjA3NzIgMEMxLjE1OTY1MSAwIDEuNDcwNDg2IC0wLjAyMzkxIDEuNzY5MzY1IC0wLjAyMzkxSDMuNjM0MzcxQzMuOTMzMjUgLTAuMDIzOTEgNC4yNTYwNCAwIDQuNTU0OTE5IDBDNC42ODY0MjYgMCA0LjgwNTk3OCAwIDQuODA1OTc4IC0wLjIyNzE0OEM0LjgwNTk3OCAtMC4zNDY3IDQuNzIyMjkxIC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2N0MzLjMzNTQ5MiAtMC4zNDY3IDMuMzM1NDkyIC0wLjQ1NDI5NiAzLjMzNTQ5MiAtMC42MzM2MjRDMy4zMzU0OTIgLTAuNjQ1NTc5IDMuMzM1NDkyIC0wLjcyOTI2NSAzLjM4MzMxMyAtMC45MjA1NDhMNC45ODUzMDUgLTcuMjkyNjUzWicgaWQ9J2cxLTg0Jy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnMi00OScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzItOTMnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cxLTg0JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0NS43MTUzMDInIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNDguMDY3NjI1JyB4bGluazpocmVmPScjZzItNDknIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzUyLjMwMTgwOCcgeGxpbms6aHJlZj0nI2cyLTkzJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1NS4xNTIyNjQnIHhsaW5rOmhyZWY9JyNnMS01OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNjAuMzk2NDIzJyB4bGluazpocmVmPScjZzEtNTgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYzLjY0ODA4NCcgeGxpbms6aHJlZj0nI2cxLTU4JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2Ni44OTk3NDUnIHhsaW5rOmhyZWY9JyNnMS01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzAuMTUxNDA3JyB4bGluazpocmVmPScjZzEtNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc1LjM5NTU2NicgeGxpbms6aHJlZj0nI2cxLTg0JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4Mi4yNTY1NzEnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nODQuNjA4ODk1JyB4bGluazpocmVmPScjZzAtMTAwJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc4OC45NjYyMTInIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+CjwvZz4KPC9zdmc+) . Dans cette base,
la projection de y a pour coordoonées
. Dans cette base,
la projection de y a pour coordoonées
![<y, T_{[1]}>, ..., <y, T_{[d]}> = T' y](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuNjE4NTI4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljk4NzEzNCAxNTUuMjY5OTY0IDEyLjYxODUyOCcgd2lkdGg9JzE1NS4yNjk5NjRwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMi4xMTIwOCAtMy43Nzc4MzNDMi4xNTE5MyAtMy44ODE0NDUgMi4xODM4MTEgLTMuOTM3MjM1IDIuMTgzODExIC00LjAxNjkzNkMyLjE4MzgxMSAtNC4yNzk5NSAxLjk0NDcwNyAtNC40NTUyOTMgMS43MjE1NDQgLTQuNDU1MjkzQzEuNDAyNzQgLTQuNDU1MjkzIDEuMzE1MDY4IC00LjE3NjMzOSAxLjI4MzE4OCAtNC4wNjQ3NTdMMC4yNzA5ODQgLTAuNjI5NjM5QzAuMjM5MTAzIC0wLjUzMzk5OCAwLjIzOTEwMyAtMC41MTAwODcgMC4yMzkxMDMgLTAuNTAyMTE3QzAuMjM5MTAzIC0wLjQzMDM4NiAwLjI4NjkyNCAtMC40MTQ0NDYgMC4zNjY2MjUgLTAuMzkwNTM1QzAuNTEwMDg3IC0wLjMyNjc3NSAwLjUyNjAyNyAtMC4zMjY3NzUgMC41NDE5NjggLTAuMzI2Nzc1QzAuNTY1ODc4IC0wLjMyNjc3NSAwLjYxMzY5OSAtMC4zMjY3NzUgMC42Njk0ODkgLTAuNDYyMjY3TDIuMTEyMDggLTMuNzc3ODMzWicgaWQ9J2cwLTQ4Jy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnNC02MScvPgo8cGF0aCBkPSdNMi4xOTk3NTEgLTAuNTczODQ4QzIuMTk5NzUxIC0wLjkyMDU0OCAxLjkxMjgyNyAtMS4xNTk2NTEgMS42MjU5MDMgLTEuMTU5NjUxQzEuMjc5MjAzIC0xLjE1OTY1MSAxLjA0MDEgLTAuODcyNzI3IDEuMDQwMSAtMC41ODU4MDNDMS4wNDAxIC0wLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MSAtMC4yODY5MjQgMi4xOTk3NTEgLTAuNTczODQ4WicgaWQ9J2cyLTU4Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMi01OScvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTUuODIyMTY3QzguMDkzNjQ5IC01LjkxNzgwOCA4LjExNzU1OSAtNi4wMDE0OTQgOC4xMTc1NTkgLTYuMDczMjI1QzguMTE3NTU5IC02LjIwNDczMiA4LjAyMTkxOCAtNi4zMDAzNzQgNy44OTA0MTEgLTYuMzAwMzc0QzcuODY2NTAxIC02LjMwMDM3NCA3Ljg1NDU0NSAtNi4yODg0MTggNy42ODcxNzMgLTYuMjE2Njg3TDEuMjE5NDI3IC0zLjIzOTg1MUMxLjAwNDIzNCAtMy4xNDQyMDkgMC45ODAzMjQgLTMuMDYwNTIzIDAuOTgwMzI0IC0yLjk4ODc5MkMwLjk4MDMyNCAtMi45MDUxMDYgMC45OTIyNzkgLTIuODMzMzc1IDEuMjE5NDI3IC0yLjcyNTc3OEw3LjY4NzE3MyAwLjI1MTA1OUM3Ljg0MjU5IDAuMzIyNzkgNy44NjY1MDEgMC4zMzQ3NDUgNy44OTA0MTEgMC4zMzQ3NDVDOC4wMjE5MTggMC4zMzQ3NDUgOC4xMTc1NTkgMC4yMzkxMDMgOC4xMTc1NTkgMC4xMDc1OTdDOC4xMTc1NTkgMC4wMzU4NjYgOC4wOTM2NDkgLTAuMDQ3ODIxIDcuODc4NDU2IC0wLjE0MzQ2MkwxLjcyMTU0NCAtMi45NzY4MzdMNy44Nzg0NTYgLTUuODIyMTY3WicgaWQ9J2cyLTYwJy8+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtMi43MjU3NzhDOC4xMDU2MDQgLTIuODMzMzc1IDguMTE3NTU5IC0yLjkwNTEwNiA4LjExNzU1OSAtMi45ODg3OTJDOC4xMTc1NTkgLTMuMDYwNTIzIDguMDkzNjQ5IC0zLjE0NDIwOSA3Ljg3ODQ1NiAtMy4yMzk4NTFMMS40MTA3MSAtNi4yMTY2ODdDMS4yNTUyOTMgLTYuMjg4NDE4IDEuMjMxMzgyIC02LjMwMDM3NCAxLjIwNzQ3MiAtNi4zMDAzNzRDMS4wNjQwMSAtNi4zMDAzNzQgMC45ODAzMjQgLTYuMTgwODIyIDAuOTgwMzI0IC02LjA4NTE4MUMwLjk4MDMyNCAtNS45NDE3MTkgMS4wNzU5NjUgLTUuODkzODk4IDEuMjMxMzgyIC01LjgyMjE2N0w3LjM3NjMzOSAtMi45ODg3OTJMMS4yMTk0MjcgLTAuMTQzNDYyQzAuOTgwMzI0IC0wLjAzNTg2NiAwLjk4MDMyNCAwLjA0NzgyMSAwLjk4MDMyNCAwLjExOTU1MkMwLjk4MDMyNCAwLjIxNTE5MyAxLjA2NDAxIDAuMzM0NzQ1IDEuMjA3NDcyIDAuMzM0NzQ1QzEuMjMxMzgyIDAuMzM0NzQ1IDEuMjQzMzM3IDAuMzIyNzkgMS40MTA3MSAwLjI1MTA1OUw3Ljg3ODQ1NiAtMi43MjU3NzhaJyBpZD0nZzItNjInLz4KPHBhdGggZD0nTTQuOTg1MzA1IC03LjI5MjY1M0M1LjA1NzAzNiAtNy41Nzk1NzcgNS4wODA5NDYgLTcuNjg3MTczIDUuMjYwMjc0IC03LjczNDk5NEM1LjM1NTkxNSAtNy43NTg5MDQgNS43NTA0MzYgLTcuNzU4OTA0IDYuMDAxNDk0IC03Ljc1ODkwNEM3LjE5NzAxMSAtNy43NTg5MDQgNy43NTg5MDQgLTcuNzExMDgzIDcuNzU4OTA0IC02Ljc3ODU4QzcuNzU4OTA0IC02LjU5OTI1MyA3LjcxMTA4MyAtNi4xNDQ5NTYgNy42MzkzNTIgLTUuNzAyNjE1TDcuNjI3Mzk3IC01LjU1OTE1M0M3LjYyNzM5NyAtNS41MTEzMzMgNy42NzUyMTggLTUuNDM5NjAxIDcuNzQ2OTQ5IC01LjQzOTYwMUM3Ljg2NjUwMSAtNS40Mzk2MDEgNy44NjY1MDEgLTUuNDk5Mzc3IDcuOTAyMzY2IC01LjY5MDY2TDguMjQ5MDY2IC03LjgwNjcyNUM4LjI3Mjk3NiAtNy45MTQzMjEgOC4yNzI5NzYgLTcuOTM4MjMyIDguMjcyOTc2IC03Ljk3NDA5N0M4LjI3Mjk3NiAtOC4xMDU2MDQgOC4yMDEyNDUgLTguMTA1NjA0IDcuOTYyMTQyIC04LjEwNTYwNEgxLjQyMjY2NUMxLjE0NzY5NiAtOC4xMDU2MDQgMS4xMzU3NDEgLTguMDkzNjQ5IDEuMDY0MDEgLTcuODc4NDU2TDAuMzM0NzQ1IC01LjcyNjUyNkMwLjMyMjc5IC01LjcwMjYxNSAwLjI4NjkyNCAtNS41NzExMDggMC4yODY5MjQgLTUuNTU5MTUzQzAuMjg2OTI0IC01LjQ5OTM3NyAwLjMzNDc0NSAtNS40Mzk2MDEgMC40MDY0NzYgLTUuNDM5NjAxQzAuNTAyMTE3IC01LjQzOTYwMSAwLjUyNjAyNyAtNS40ODc0MjIgMC41NzM4NDggLTUuNjQyODM5QzEuMDc1OTY1IC03LjA4OTQxNSAxLjMyNzAyNCAtNy43NTg5MDQgMi45MTcwNjEgLTcuNzU4OTA0SDMuNzE4MDU3QzQuMDA0OTgxIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNjI3Mzk3QzQuMTI0NTMzIC03LjU5MTUzMiA0LjEyNDUzMyAtNy41Njc2MjEgNC4wNjQ3NTcgLTcuMzUyNDI4TDIuNDYyNzY1IC0wLjkzMjUwM0MyLjM0MzIxMyAtMC40NjYyNTIgMi4zMTkzMDMgLTAuMzQ2NyAxLjA1MjA1NSAtMC4zNDY3QzAuNzUzMTc2IC0wLjM0NjcgMC42Njk0ODkgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4xMTk1NTJDMC42Njk0ODkgMCAwLjgwMDk5NiAwIDAuODYwNzcyIDBDMS4xNTk2NTEgMCAxLjQ3MDQ4NiAtMC4wMjM5MSAxLjc2OTM2NSAtMC4wMjM5MUgzLjYzNDM3MUMzLjkzMzI1IC0wLjAyMzkxIDQuMjU2MDQgMCA0LjU1NDkxOSAwQzQuNjg2NDI2IDAgNC44MDU5NzggMCA0LjgwNTk3OCAtMC4yMjcxNDhDNC44MDU5NzggLTAuMzQ2NyA0LjcyMjI5MSAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjdDMy4zMzU0OTIgLTAuMzQ2NyAzLjMzNTQ5MiAtMC40NTQyOTYgMy4zMzU0OTIgLTAuNjMzNjI0QzMuMzM1NDkyIC0wLjY0NTU3OSAzLjMzNTQ5MiAtMC43MjkyNjUgMy4zODMzMTMgLTAuOTIwNTQ4TDQuOTg1MzA1IC03LjI5MjY1M1onIGlkPSdnMi04NCcvPgo8cGF0aCBkPSdNMy4xNDQyMDkgMS4zMzg5NzlDMi44MjE0MiAxLjc5MzI3NSAyLjM1NTE2OCAyLjE5OTc1MSAxLjc2OTM2NSAyLjE5OTc1MUMxLjYyNTkwMyAyLjE5OTc1MSAxLjA1MjA1NSAyLjE3NTg0MSAwLjg3MjcyNyAxLjYyNTkwM0MwLjkwODU5MyAxLjYzNzg1OCAwLjk2ODM2OSAxLjYzNzg1OCAwLjk5MjI3OSAxLjYzNzg1OEMxLjM1MDkzNCAxLjYzNzg1OCAxLjU5MDAzNyAxLjMyNzAyNCAxLjU5MDAzNyAxLjA1MjA1NVMxLjM2Mjg4OSAwLjY4MTQ0NSAxLjE4MzU2MiAwLjY4MTQ0NUMwLjk5MjI3OSAwLjY4MTQ0NSAwLjU3Mzg0OCAwLjgyNDkwNyAwLjU3Mzg0OCAxLjQxMDcxQzAuNTczODQ4IDIuMDIwNDIzIDEuMDg3OTIgMi40Mzg4NTQgMS43NjkzNjUgMi40Mzg4NTRDMi45NjQ4ODIgMi40Mzg4NTQgNC4xNzIzNTQgMS4zMzg5NzkgNC41MDcwOTggMC4wMTE5NTVMNS42Nzg3MDUgLTQuNjUwNTZDNS42OTA2NiAtNC43MTAzMzYgNS43MTQ1NyAtNC43ODIwNjcgNS43MTQ1NyAtNC44NTM3OThDNS43MTQ1NyAtNS4wMzMxMjYgNS41NzExMDggLTUuMTUyNjc3IDUuMzkxNzgxIC01LjE1MjY3N0M1LjI4NDE4NCAtNS4xNTI2NzcgNS4wMzMxMjYgLTUuMTA0ODU3IDQuOTM3NDg0IC00Ljc0NjIwMkw0LjA1MjgwMiAtMS4yMzEzODJDMy45OTMwMjYgLTEuMDE2MTg5IDMuOTkzMDI2IC0wLjk5MjI3OSAzLjg5NzM4NSAtMC44NjA3NzJDMy42NTgyODEgLTAuNTI2MDI3IDMuMjYzNzYxIC0wLjExOTU1MiAyLjY4OTkxMyAtMC4xMTk1NTJDMi4wMjA0MjMgLTAuMTE5NTUyIDEuOTYwNjQ4IC0wLjc3NzA4NiAxLjk2MDY0OCAtMS4wOTk4NzVDMS45NjA2NDggLTEuNzgxMzIgMi4yODM0MzcgLTIuNzAxODY4IDIuNjA2MjI3IC0zLjU2MjY0QzIuNzM3NzMzIC0zLjkwOTM0IDIuODA5NDY1IC00LjA3NjcxMiAyLjgwOTQ2NSAtNC4zMTU4MTZDMi44MDk0NjUgLTQuODE3OTMzIDIuNDUwODA5IC01LjI3MjIyOSAxLjg2NTAwNiAtNS4yNzIyMjlDMC43NjUxMzEgLTUuMjcyMjI5IDAuMzIyNzkgLTMuNTM4NzMgMC4zMjI3OSAtMy40NDMwODhDMC4zMjI3OSAtMy4zOTUyNjggMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTYxODkzIC0zLjMzNTQ5MiAwLjU3Mzg0OCAtMy4zODMzMTMgMC42MjE2NjkgLTMuNTUwNjg1QzAuOTA4NTkzIC00LjU1NDkxOSAxLjM2Mjg4OSAtNS4wMzMxMjYgMS44MjkxNDEgLTUuMDMzMTI2QzEuOTM2NzM3IC01LjAzMzEyNiAyLjEzOTk3NSAtNS4wMzMxMjYgMi4xMzk5NzUgLTQuNjM4NjA1QzIuMTM5OTc1IC00LjMyNzc3MSAyLjAwODQ2OCAtMy45ODEwNzEgMS44MjkxNDEgLTMuNTI2Nzc1QzEuMjQzMzM3IC0xLjk2MDY0OCAxLjI0MzMzNyAtMS41NjYxMjcgMS4yNDMzMzcgLTEuMjc5MjAzQzEuMjQzMzM3IC0wLjE0MzQ2MiAyLjA1NjI4OSAwLjExOTU1MiAyLjY1NDA0NyAwLjExOTU1MkMzLjAwMDc0NyAwLjExOTU1MiAzLjQzMTEzMyAwLjAxMTk1NSAzLjg0OTU2NCAtMC40MzAzODZMMy44NjE1MTkgLTAuNDE4NDMxQzMuNjgyMTkyIDAuMjg2OTI0IDMuNTYyNjQgMC43NTMxNzYgMy4xNDQyMDkgMS4zMzg5NzlaJyBpZD0nZzItMTIxJy8+CjxwYXRoIGQ9J000LjI4NzkyIC01LjI5MjE1NEM0LjI5NTg5IC01LjMwODA5NSA0LjMxOTgwMSAtNS40MTE3MDYgNC4zMTk4MDEgLTUuNDE5Njc2QzQuMzE5ODAxIC01LjQ1OTUyNyA0LjI4NzkyIC01LjUzMTI1OCA0LjE5MjI3OSAtNS41MzEyNThDNC4xNjAzOTkgLTUuNTMxMjU4IDMuOTEzMzI1IC01LjUwNzM0NyAzLjczMDAxMiAtNS40OTE0MDdMMy4yODM2ODYgLTUuNDU5NTI3QzMuMTA4MzQ0IC01LjQ0MzU4NyAzLjAyODY0MyAtNS40MzU2MTYgMy4wMjg2NDMgLTUuMjkyMTU0QzMuMDI4NjQzIC01LjE4MDU3MyAzLjE0MDIyNCAtNS4xODA1NzMgMy4yMzU4NjYgLTUuMTgwNTczQzMuNjE4NDMxIC01LjE4MDU3MyAzLjYxODQzMSAtNS4xMzI3NTIgMy42MTg0MzEgLTUuMDYxMDIxQzMuNjE4NDMxIC01LjAxMzIgMy41NTQ2NyAtNC43NTAxODcgMy41MTQ4MTkgLTQuNTkwNzg1TDMuMTI0Mjg0IC0zLjAzNjYxM0MzLjA1MjU1MyAtMy4xNzIxMDUgMi44MjE0MiAtMy41MTQ4MTkgMi4zMzUyNDMgLTMuNTE0ODE5QzEuMzg2OCAtMy41MTQ4MTkgMC4zNDI3MTUgLTIuNDA2OTc0IDAuMzQyNzE1IC0xLjIyNzM5N0MwLjM0MjcxNSAtMC4zOTg1MDYgMC44NzY3MTIgMC4wNzk3MDEgMS40OTA0MTEgMC4wNzk3MDFDMi4wMDA0OTggMC4wNzk3MDEgMi40Mzg4NTQgLTAuMzI2Nzc1IDIuNTgyMzE2IC0wLjQ4NjE3N0MyLjcyNTc3OCAwLjA2Mzc2MSAzLjI2Nzc0NiAwLjA3OTcwMSAzLjM2MzM4NyAwLjA3OTcwMUMzLjczMDAxMiAwLjA3OTcwMSAzLjkxMzMyNSAtMC4yMjMxNjMgMy45NzcwODYgLTAuMzU4NjU1QzQuMTM2NDg4IC0wLjY0NTU3OSA0LjI0ODA3IC0xLjEwNzg0NiA0LjI0ODA3IC0xLjEzOTcyNkM0LjI0ODA3IC0xLjE4NzU0NyA0LjIxNjE4OSAtMS4yNDMzMzcgNC4xMjA1NDggLTEuMjQzMzM3UzQuMDA4OTY2IC0xLjE5NTUxNyAzLjk2MTE0NiAtMC45OTYyNjRDMy44NDk1NjQgLTAuNTU3OTA4IDMuNjk4MTMyIC0wLjE0MzQ2MiAzLjM4NzI5OCAtMC4xNDM0NjJDMy4yMDM5ODUgLTAuMTQzNDYyIDMuMTMyMjU0IC0wLjI5NDg5NCAzLjEzMjI1NCAtMC41MTgwNTdDMy4xMzIyNTQgLTAuNjY5NDg5IDMuMTU2MTY0IC0wLjc1NzE2MSAzLjE4MDA3NSAtMC44NjA3NzJMNC4yODc5MiAtNS4yOTIxNTRaTTIuNTgyMzE2IC0wLjg2MDc3MkMyLjE4MzgxMSAtMC4zMTA4MzQgMS43NjkzNjUgLTAuMTQzNDYyIDEuNTE0MzIxIC0wLjE0MzQ2MkMxLjE0NzY5NiAtMC4xNDM0NjIgMC45NjQzODQgLTAuNDc4MjA3IDAuOTY0Mzg0IC0wLjg5MjY1M0MwLjk2NDM4NCAtMS4yNjcyNDggMS4xNzk1NzcgLTIuMTIwMDUgMS4zNTQ5MTkgLTIuNDcwNzM1QzEuNTg2MDUyIC0yLjk1NjkxMiAxLjk3NjU4OCAtMy4yOTE2NTYgMi4zNDMyMTMgLTMuMjkxNjU2QzIuODYxMjcgLTMuMjkxNjU2IDMuMDEyNzAyIC0yLjcwOTgzOCAzLjAxMjcwMiAtMi42MTQxOTdDMy4wMTI3MDIgLTIuNTgyMzE2IDIuODEzNDUgLTEuODAxMjQ1IDIuNzY1NjI5IC0xLjU5NDAyMkMyLjY2MjAxNyAtMS4yMTk0MjcgMi42NjIwMTcgLTEuMjAzNDg3IDIuNTgyMzE2IC0wLjg2MDc3MlonIGlkPSdnMS0xMDAnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2czLTQ5Jy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2czLTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnMy05MycvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMzguODU0Mjk2JyB4bGluazpocmVmPScjZzItNjAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzUxLjI3OTc3NycgeGxpbms6aHJlZj0nI2cyLTEyMScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNTcuNDE2NDI5JyB4bGluazpocmVmPScjZzItNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYyLjY2MDU4OCcgeGxpbms6aHJlZj0nI2cyLTg0JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2OS41MjE1OTMnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNzEuODczOTE3JyB4bGluazpocmVmPScjZzMtNDknIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9Jzc2LjEwODEnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nODIuMjc5Mzg1JyB4bGluazpocmVmPScjZzItNjInIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzkxLjM4NDAzNicgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5Ni42MjgxOTUnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nOTkuODc5ODU3JyB4bGluazpocmVmPScjZzItNTgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEwMy4xMzE1MTgnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA2LjM4MzE3OScgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTEuNjI3MzM4JyB4bGluazpocmVmPScjZzItNjAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyNC4wNTI4MTknIHhsaW5rOmhyZWY9JyNnMi0xMjEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEzMC4xODk0NycgeGxpbms6aHJlZj0nI2cyLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMzUuNDMzNjI5JyB4bGluazpocmVmPScjZzItODQnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE0Mi4yOTQ2MzUnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nMTQ0LjY0Njk1OCcgeGxpbms6aHJlZj0nI2cxLTEwMCcgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nMTQ5LjAwNDI3NicgeGxpbms6aHJlZj0nI2czLTkzJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PScxNTUuMTc1NTYxJyB4bGluazpocmVmPScjZzItNjInIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE2NC4yODAyMTInIHhsaW5rOmhyZWY9JyNnNC02MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTc2LjcwNTY5MycgeGxpbms6aHJlZj0nI2cyLTg0JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxODUuMTkyNTI5JyB4bGluazpocmVmPScjZzAtNDgnIHk9JzYxLjQxNDk4OCcvPgo8dXNlIHg9JzE4Ny45ODc2MDUnIHhsaW5rOmhyZWY9JyNnMi0xMjEnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) .
On en déduit que la projection de y s’exprimer comme :
.
On en déduit que la projection de y s’exprimer comme :
![\hat{y} = \sum_{k=1}^d <y, T_{[k]}> T_{[k]}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMzQuNTgxNTc3cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMTc1LjQyNzg4NSA3OS45MDAzNzEgMTE0Ljg5NzY2NyAzNC41ODE1NzcnIHdpZHRoPScxMTQuODk3NjY3cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2czLTQ5Jy8+CjxwYXRoIGQ9J001LjgyNjE1MiAtMi42NTQwNDdDNS45NDU3MDQgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjY1NDA0NyA2LjEwNTEwNiAtMi44MzczNlM1LjkxMzgyMyAtMy4wMjA2NzIgNS43OTQyNzEgLTMuMDIwNjcySDAuNzgxMDcxQzAuNjYxNTE5IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMy4wMjA2NzIgMC40NzAyMzcgLTIuODM3MzZTMC42Mjk2MzkgLTIuNjU0MDQ3IDAuNzQ5MTkxIC0yLjY1NDA0N0g1LjgyNjE1MlpNNS43OTQyNzEgLTAuOTY0Mzg0QzUuOTEzODIzIC0wLjk2NDM4NCA2LjEwNTEwNiAtMC45NjQzODQgNi4xMDUxMDYgLTEuMTQ3Njk2UzUuOTQ1NzA0IC0xLjMzMTAwOSA1LjgyNjE1MiAtMS4zMzEwMDlIMC43NDkxOTFDMC42Mjk2MzkgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjMzMTAwOSAwLjQ3MDIzNyAtMS4xNDc2OTZTMC42NjE1MTkgLTAuOTY0Mzg0IDAuNzgxMDcxIC0wLjk2NDM4NEg1Ljc5NDI3MVonIGlkPSdnMy02MScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnMy05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzMtOTMnLz4KPHBhdGggZD0nTTE1LjEzNTI0MyAxNi43MzcyMzVMMTYuNTgxODE4IDEyLjkxMTU4MkgxNi4yODI5MzlDMTUuODE2Njg3IDE0LjE1NDkxOSAxNC41NDk0NCAxNC45Njc4NyAxMy4xNzQ1OTUgMTUuMzI2NTI2QzEyLjkyMzUzNyAxNS4zODYzMDEgMTEuNzUxOTMgMTUuNjk3MTM2IDkuNDU2NTM4IDE1LjY5NzEzNkgyLjI0NzU3Mkw4LjMzMjc1MiA4LjU1OTlDOC40MTY0MzggOC40NjQyNTkgOC40NDAzNDkgOC40MjgzOTQgOC40NDAzNDkgOC4zNjg2MThDOC40NDAzNDkgOC4zNDQ3MDcgOC40NDAzNDkgOC4zMDg4NDIgOC4zNTY2NjMgOC4xODkyOUwyLjc4NTU1NCAwLjU3Mzg0OEg5LjMzNjk4NkMxMC45Mzg5NzkgMC41NzM4NDggMTIuMDI2ODk5IDAuNzQxMjIgMTIuMTM0NDk2IDAuNzY1MTMxQzEyLjc4MDA3NSAwLjg2MDc3MiAxMy44MjAxNzQgMS4wNjQwMSAxNC43NjQ2MzMgMS42NjE3NjhDMTUuMDYzNTEyIDEuODUzMDUxIDE1Ljg3NjQ2MyAyLjM5MTAzNCAxNi4yODI5MzkgMy4zNTk0MDJIMTYuNTgxODE4TDE1LjEzNTI0MyAwSDEuMDA0MjM0QzAuNzI5MjY1IDAgMC43MTczMSAwLjAxMTk1NSAwLjY4MTQ0NSAwLjA4MzY4NkMwLjY2OTQ4OSAwLjExOTU1MiAwLjY2OTQ4OSAwLjM0NjcgMC42Njk0ODkgMC40NzgyMDdMNi45OTM3NzMgOS4xMzM3NDhMMC44MDA5OTYgMTYuMzkwNTM1QzAuNjgxNDQ1IDE2LjUzMzk5OCAwLjY4MTQ0NSAxNi41OTM3NzMgMC42ODE0NDUgMTYuNjA1NzI5QzAuNjgxNDQ1IDE2LjczNzIzNSAwLjc4OTA0MSAxNi43MzcyMzUgMS4wMDQyMzQgMTYuNzM3MjM1SDE1LjEzNTI0M1onIGlkPSdnMC04OCcvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzQtNjEnLz4KPHBhdGggZD0nTTIuOTI5MDE2IC04LjI5Njg4N0wxLjM2Mjg4OSAtNi42NzA5ODRMMS41NTQxNzIgLTYuNDkxNjU2TDIuOTE3MDYxIC03LjcyMzAzOUw0LjI5MTkwNSAtNi40OTE2NTZMNC40ODMxODggLTYuNjcwOTg0TDIuOTI5MDE2IC04LjI5Njg4N1onIGlkPSdnNC05NCcvPgo8cGF0aCBkPSdNNC4yODc5MiAtNS4yOTIxNTRDNC4yOTU4OSAtNS4zMDgwOTUgNC4zMTk4MDEgLTUuNDExNzA2IDQuMzE5ODAxIC01LjQxOTY3NkM0LjMxOTgwMSAtNS40NTk1MjcgNC4yODc5MiAtNS41MzEyNTggNC4xOTIyNzkgLTUuNTMxMjU4QzQuMTYwMzk5IC01LjUzMTI1OCAzLjkxMzMyNSAtNS41MDczNDcgMy43MzAwMTIgLTUuNDkxNDA3TDMuMjgzNjg2IC01LjQ1OTUyN0MzLjEwODM0NCAtNS40NDM1ODcgMy4wMjg2NDMgLTUuNDM1NjE2IDMuMDI4NjQzIC01LjI5MjE1NEMzLjAyODY0MyAtNS4xODA1NzMgMy4xNDAyMjQgLTUuMTgwNTczIDMuMjM1ODY2IC01LjE4MDU3M0MzLjYxODQzMSAtNS4xODA1NzMgMy42MTg0MzEgLTUuMTMyNzUyIDMuNjE4NDMxIC01LjA2MTAyMUMzLjYxODQzMSAtNS4wMTMyIDMuNTU0NjcgLTQuNzUwMTg3IDMuNTE0ODE5IC00LjU5MDc4NUwzLjEyNDI4NCAtMy4wMzY2MTNDMy4wNTI1NTMgLTMuMTcyMTA1IDIuODIxNDIgLTMuNTE0ODE5IDIuMzM1MjQzIC0zLjUxNDgxOUMxLjM4NjggLTMuNTE0ODE5IDAuMzQyNzE1IC0yLjQwNjk3NCAwLjM0MjcxNSAtMS4yMjczOTdDMC4zNDI3MTUgLTAuMzk4NTA2IDAuODc2NzEyIDAuMDc5NzAxIDEuNDkwNDExIDAuMDc5NzAxQzIuMDAwNDk4IDAuMDc5NzAxIDIuNDM4ODU0IC0wLjMyNjc3NSAyLjU4MjMxNiAtMC40ODYxNzdDMi43MjU3NzggMC4wNjM3NjEgMy4yNjc3NDYgMC4wNzk3MDEgMy4zNjMzODcgMC4wNzk3MDFDMy43MzAwMTIgMC4wNzk3MDEgMy45MTMzMjUgLTAuMjIzMTYzIDMuOTc3MDg2IC0wLjM1ODY1NUM0LjEzNjQ4OCAtMC42NDU1NzkgNC4yNDgwNyAtMS4xMDc4NDYgNC4yNDgwNyAtMS4xMzk3MjZDNC4yNDgwNyAtMS4xODc1NDcgNC4yMTYxODkgLTEuMjQzMzM3IDQuMTIwNTQ4IC0xLjI0MzMzN1M0LjAwODk2NiAtMS4xOTU1MTcgMy45NjExNDYgLTAuOTk2MjY0QzMuODQ5NTY0IC0wLjU1NzkwOCAzLjY5ODEzMiAtMC4xNDM0NjIgMy4zODcyOTggLTAuMTQzNDYyQzMuMjAzOTg1IC0wLjE0MzQ2MiAzLjEzMjI1NCAtMC4yOTQ4OTQgMy4xMzIyNTQgLTAuNTE4MDU3QzMuMTMyMjU0IC0wLjY2OTQ4OSAzLjE1NjE2NCAtMC43NTcxNjEgMy4xODAwNzUgLTAuODYwNzcyTDQuMjg3OTIgLTUuMjkyMTU0Wk0yLjU4MjMxNiAtMC44NjA3NzJDMi4xODM4MTEgLTAuMzEwODM0IDEuNzY5MzY1IC0wLjE0MzQ2MiAxLjUxNDMyMSAtMC4xNDM0NjJDMS4xNDc2OTYgLTAuMTQzNDYyIDAuOTY0Mzg0IC0wLjQ3ODIwNyAwLjk2NDM4NCAtMC44OTI2NTNDMC45NjQzODQgLTEuMjY3MjQ4IDEuMTc5NTc3IC0yLjEyMDA1IDEuMzU0OTE5IC0yLjQ3MDczNUMxLjU4NjA1MiAtMi45NTY5MTIgMS45NzY1ODggLTMuMjkxNjU2IDIuMzQzMjEzIC0zLjI5MTY1NkMyLjg2MTI3IC0zLjI5MTY1NiAzLjAxMjcwMiAtMi43MDk4MzggMy4wMTI3MDIgLTIuNjE0MTk3QzMuMDEyNzAyIC0yLjU4MjMxNiAyLjgxMzQ1IC0xLjgwMTI0NSAyLjc2NTYyOSAtMS41OTQwMjJDMi42NjIwMTcgLTEuMjE5NDI3IDIuNjYyMDE3IC0xLjIwMzQ4NyAyLjU4MjMxNiAtMC44NjA3NzJaJyBpZD0nZzEtMTAwJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMS0xMDcnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2cyLTU5Jy8+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtNS44MjIxNjdDOC4wOTM2NDkgLTUuOTE3ODA4IDguMTE3NTU5IC02LjAwMTQ5NCA4LjExNzU1OSAtNi4wNzMyMjVDOC4xMTc1NTkgLTYuMjA0NzMyIDguMDIxOTE4IC02LjMwMDM3NCA3Ljg5MDQxMSAtNi4zMDAzNzRDNy44NjY1MDEgLTYuMzAwMzc0IDcuODU0NTQ1IC02LjI4ODQxOCA3LjY4NzE3MyAtNi4yMTY2ODdMMS4yMTk0MjcgLTMuMjM5ODUxQzEuMDA0MjM0IC0zLjE0NDIwOSAwLjk4MDMyNCAtMy4wNjA1MjMgMC45ODAzMjQgLTIuOTg4NzkyQzAuOTgwMzI0IC0yLjkwNTEwNiAwLjk5MjI3OSAtMi44MzMzNzUgMS4yMTk0MjcgLTIuNzI1Nzc4TDcuNjg3MTczIDAuMjUxMDU5QzcuODQyNTkgMC4zMjI3OSA3Ljg2NjUwMSAwLjMzNDc0NSA3Ljg5MDQxMSAwLjMzNDc0NUM4LjAyMTkxOCAwLjMzNDc0NSA4LjExNzU1OSAwLjIzOTEwMyA4LjExNzU1OSAwLjEwNzU5N0M4LjExNzU1OSAwLjAzNTg2NiA4LjA5MzY0OSAtMC4wNDc4MjEgNy44Nzg0NTYgLTAuMTQzNDYyTDEuNzIxNTQ0IC0yLjk3NjgzN0w3Ljg3ODQ1NiAtNS44MjIxNjdaJyBpZD0nZzItNjAnLz4KPHBhdGggZD0nTTcuODc4NDU2IC0yLjcyNTc3OEM4LjEwNTYwNCAtMi44MzMzNzUgOC4xMTc1NTkgLTIuOTA1MTA2IDguMTE3NTU5IC0yLjk4ODc5MkM4LjExNzU1OSAtMy4wNjA1MjMgOC4wOTM2NDkgLTMuMTQ0MjA5IDcuODc4NDU2IC0zLjIzOTg1MUwxLjQxMDcxIC02LjIxNjY4N0MxLjI1NTI5MyAtNi4yODg0MTggMS4yMzEzODIgLTYuMzAwMzc0IDEuMjA3NDcyIC02LjMwMDM3NEMxLjA2NDAxIC02LjMwMDM3NCAwLjk4MDMyNCAtNi4xODA4MjIgMC45ODAzMjQgLTYuMDg1MTgxQzAuOTgwMzI0IC01Ljk0MTcxOSAxLjA3NTk2NSAtNS44OTM4OTggMS4yMzEzODIgLTUuODIyMTY3TDcuMzc2MzM5IC0yLjk4ODc5MkwxLjIxOTQyNyAtMC4xNDM0NjJDMC45ODAzMjQgLTAuMDM1ODY2IDAuOTgwMzI0IDAuMDQ3ODIxIDAuOTgwMzI0IDAuMTE5NTUyQzAuOTgwMzI0IDAuMjE1MTkzIDEuMDY0MDEgMC4zMzQ3NDUgMS4yMDc0NzIgMC4zMzQ3NDVDMS4yMzEzODIgMC4zMzQ3NDUgMS4yNDMzMzcgMC4zMjI3OSAxLjQxMDcxIDAuMjUxMDU5TDcuODc4NDU2IC0yLjcyNTc3OFonIGlkPSdnMi02MicvPgo8cGF0aCBkPSdNNC45ODUzMDUgLTcuMjkyNjUzQzUuMDU3MDM2IC03LjU3OTU3NyA1LjA4MDk0NiAtNy42ODcxNzMgNS4yNjAyNzQgLTcuNzM0OTk0QzUuMzU1OTE1IC03Ljc1ODkwNCA1Ljc1MDQzNiAtNy43NTg5MDQgNi4wMDE0OTQgLTcuNzU4OTA0QzcuMTk3MDExIC03Ljc1ODkwNCA3Ljc1ODkwNCAtNy43MTEwODMgNy43NTg5MDQgLTYuNzc4NThDNy43NTg5MDQgLTYuNTk5MjUzIDcuNzExMDgzIC02LjE0NDk1NiA3LjYzOTM1MiAtNS43MDI2MTVMNy42MjczOTcgLTUuNTU5MTUzQzcuNjI3Mzk3IC01LjUxMTMzMyA3LjY3NTIxOCAtNS40Mzk2MDEgNy43NDY5NDkgLTUuNDM5NjAxQzcuODY2NTAxIC01LjQzOTYwMSA3Ljg2NjUwMSAtNS40OTkzNzcgNy45MDIzNjYgLTUuNjkwNjZMOC4yNDkwNjYgLTcuODA2NzI1QzguMjcyOTc2IC03LjkxNDMyMSA4LjI3Mjk3NiAtNy45MzgyMzIgOC4yNzI5NzYgLTcuOTc0MDk3QzguMjcyOTc2IC04LjEwNTYwNCA4LjIwMTI0NSAtOC4xMDU2MDQgNy45NjIxNDIgLTguMTA1NjA0SDEuNDIyNjY1QzEuMTQ3Njk2IC04LjEwNTYwNCAxLjEzNTc0MSAtOC4wOTM2NDkgMS4wNjQwMSAtNy44Nzg0NTZMMC4zMzQ3NDUgLTUuNzI2NTI2QzAuMzIyNzkgLTUuNzAyNjE1IDAuMjg2OTI0IC01LjU3MTEwOCAwLjI4NjkyNCAtNS41NTkxNTNDMC4yODY5MjQgLTUuNDk5Mzc3IDAuMzM0NzQ1IC01LjQzOTYwMSAwLjQwNjQ3NiAtNS40Mzk2MDFDMC41MDIxMTcgLTUuNDM5NjAxIDAuNTI2MDI3IC01LjQ4NzQyMiAwLjU3Mzg0OCAtNS42NDI4MzlDMS4wNzU5NjUgLTcuMDg5NDE1IDEuMzI3MDI0IC03Ljc1ODkwNCAyLjkxNzA2MSAtNy43NTg5MDRIMy43MTgwNTdDNC4wMDQ5ODEgLTcuNzU4OTA0IDQuMTI0NTMzIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy42MjczOTdDNC4xMjQ1MzMgLTcuNTkxNTMyIDQuMTI0NTMzIC03LjU2NzYyMSA0LjA2NDc1NyAtNy4zNTI0MjhMMi40NjI3NjUgLTAuOTMyNTAzQzIuMzQzMjEzIC0wLjQ2NjI1MiAyLjMxOTMwMyAtMC4zNDY3IDEuMDUyMDU1IC0wLjM0NjdDMC43NTMxNzYgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4zNDY3IDAuNjY5NDg5IC0wLjExOTU1MkMwLjY2OTQ4OSAwIDAuODAwOTk2IDAgMC44NjA3NzIgMEMxLjE1OTY1MSAwIDEuNDcwNDg2IC0wLjAyMzkxIDEuNzY5MzY1IC0wLjAyMzkxSDMuNjM0MzcxQzMuOTMzMjUgLTAuMDIzOTEgNC4yNTYwNCAwIDQuNTU0OTE5IDBDNC42ODY0MjYgMCA0LjgwNTk3OCAwIDQuODA1OTc4IC0wLjIyNzE0OEM0LjgwNTk3OCAtMC4zNDY3IDQuNzIyMjkxIC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2N0MzLjMzNTQ5MiAtMC4zNDY3IDMuMzM1NDkyIC0wLjQ1NDI5NiAzLjMzNTQ5MiAtMC42MzM2MjRDMy4zMzU0OTIgLTAuNjQ1NTc5IDMuMzM1NDkyIC0wLjcyOTI2NSAzLjM4MzMxMyAtMC45MjA1NDhMNC45ODUzMDUgLTcuMjkyNjUzWicgaWQ9J2cyLTg0Jy8+CjxwYXRoIGQ9J00zLjE0NDIwOSAxLjMzODk3OUMyLjgyMTQyIDEuNzkzMjc1IDIuMzU1MTY4IDIuMTk5NzUxIDEuNzY5MzY1IDIuMTk5NzUxQzEuNjI1OTAzIDIuMTk5NzUxIDEuMDUyMDU1IDIuMTc1ODQxIDAuODcyNzI3IDEuNjI1OTAzQzAuOTA4NTkzIDEuNjM3ODU4IDAuOTY4MzY5IDEuNjM3ODU4IDAuOTkyMjc5IDEuNjM3ODU4QzEuMzUwOTM0IDEuNjM3ODU4IDEuNTkwMDM3IDEuMzI3MDI0IDEuNTkwMDM3IDEuMDUyMDU1UzEuMzYyODg5IDAuNjgxNDQ1IDEuMTgzNTYyIDAuNjgxNDQ1QzAuOTkyMjc5IDAuNjgxNDQ1IDAuNTczODQ4IDAuODI0OTA3IDAuNTczODQ4IDEuNDEwNzFDMC41NzM4NDggMi4wMjA0MjMgMS4wODc5MiAyLjQzODg1NCAxLjc2OTM2NSAyLjQzODg1NEMyLjk2NDg4MiAyLjQzODg1NCA0LjE3MjM1NCAxLjMzODk3OSA0LjUwNzA5OCAwLjAxMTk1NUw1LjY3ODcwNSAtNC42NTA1NkM1LjY5MDY2IC00LjcxMDMzNiA1LjcxNDU3IC00Ljc4MjA2NyA1LjcxNDU3IC00Ljg1Mzc5OEM1LjcxNDU3IC01LjAzMzEyNiA1LjU3MTEwOCAtNS4xNTI2NzcgNS4zOTE3ODEgLTUuMTUyNjc3QzUuMjg0MTg0IC01LjE1MjY3NyA1LjAzMzEyNiAtNS4xMDQ4NTcgNC45Mzc0ODQgLTQuNzQ2MjAyTDQuMDUyODAyIC0xLjIzMTM4MkMzLjk5MzAyNiAtMS4wMTYxODkgMy45OTMwMjYgLTAuOTkyMjc5IDMuODk3Mzg1IC0wLjg2MDc3MkMzLjY1ODI4MSAtMC41MjYwMjcgMy4yNjM3NjEgLTAuMTE5NTUyIDIuNjg5OTEzIC0wLjExOTU1MkMyLjAyMDQyMyAtMC4xMTk1NTIgMS45NjA2NDggLTAuNzc3MDg2IDEuOTYwNjQ4IC0xLjA5OTg3NUMxLjk2MDY0OCAtMS43ODEzMiAyLjI4MzQzNyAtMi43MDE4NjggMi42MDYyMjcgLTMuNTYyNjRDMi43Mzc3MzMgLTMuOTA5MzQgMi44MDk0NjUgLTQuMDc2NzEyIDIuODA5NDY1IC00LjMxNTgxNkMyLjgwOTQ2NSAtNC44MTc5MzMgMi40NTA4MDkgLTUuMjcyMjI5IDEuODY1MDA2IC01LjI3MjIyOUMwLjc2NTEzMSAtNS4yNzIyMjkgMC4zMjI3OSAtMy41Mzg3MyAwLjMyMjc5IC0zLjQ0MzA4OEMwLjMyMjc5IC0zLjM5NTI2OCAwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NjE4OTMgLTMuMzM1NDkyIDAuNTczODQ4IC0zLjM4MzMxMyAwLjYyMTY2OSAtMy41NTA2ODVDMC45MDg1OTMgLTQuNTU0OTE5IDEuMzYyODg5IC01LjAzMzEyNiAxLjgyOTE0MSAtNS4wMzMxMjZDMS45MzY3MzcgLTUuMDMzMTI2IDIuMTM5OTc1IC01LjAzMzEyNiAyLjEzOTk3NSAtNC42Mzg2MDVDMi4xMzk5NzUgLTQuMzI3NzcxIDIuMDA4NDY4IC0zLjk4MTA3MSAxLjgyOTE0MSAtMy41MjY3NzVDMS4yNDMzMzcgLTEuOTYwNjQ4IDEuMjQzMzM3IC0xLjU2NjEyNyAxLjI0MzMzNyAtMS4yNzkyMDNDMS4yNDMzMzcgLTAuMTQzNDYyIDIuMDU2Mjg5IDAuMTE5NTUyIDIuNjU0MDQ3IDAuMTE5NTUyQzMuMDAwNzQ3IDAuMTE5NTUyIDMuNDMxMTMzIDAuMDExOTU1IDMuODQ5NTY0IC0wLjQzMDM4NkwzLjg2MTUxOSAtMC40MTg0MzFDMy42ODIxOTIgMC4yODY5MjQgMy41NjI2NCAwLjc1MzE3NiAzLjE0NDIwOSAxLjMzODk3OVonIGlkPSdnMi0xMjEnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzE3Ni4yMjAwNDknIHhsaW5rOmhyZWY9JyNnNC05NCcgeT0nMTAwLjM3OTE5MycvPgo8dXNlIHg9JzE3NS40Mjc4ODUnIHhsaW5rOmhyZWY9JyNnMi0xMjEnIHk9JzEwMC4zNzkxOTMnLz4KPHVzZSB4PScxODQuODg1MzU0JyB4bGluazpocmVmPScjZzQtNjEnIHk9JzEwMC4zNzkxOTMnLz4KPHVzZSB4PScyMDMuNzY2NDg1JyB4bGluazpocmVmPScjZzEtMTAwJyB5PSc4NS40MzUxNzInLz4KPHVzZSB4PScxOTcuMzEwODM1JyB4bGluazpocmVmPScjZzAtODgnIHk9Jzg5LjAyMTcyOScvPgo8dXNlIHg9JzE5OC4yMjM5OTEnIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9JzExNC40ODE5NDgnLz4KPHVzZSB4PScyMDIuODQ1NjA2JyB4bGluazpocmVmPScjZzMtNjEnIHk9JzExNC40ODE5NDgnLz4KPHVzZSB4PScyMDkuNDMyMTEzJyB4bGluazpocmVmPScjZzMtNDknIHk9JzExNC40ODE5NDgnLz4KPHVzZSB4PScyMTcuOTAwMjgxJyB4bGluazpocmVmPScjZzItNjAnIHk9JzEwMC4zNzkxOTMnLz4KPHVzZSB4PScyMzAuMzI1NzYyJyB4bGluazpocmVmPScjZzItMTIxJyB5PScxMDAuMzc5MTkzJy8+Cjx1c2UgeD0nMjM2LjQ2MjQxNCcgeGxpbms6aHJlZj0nI2cyLTU5JyB5PScxMDAuMzc5MTkzJy8+Cjx1c2UgeD0nMjQxLjcwNjU3MycgeGxpbms6aHJlZj0nI2cyLTg0JyB5PScxMDAuMzc5MTkzJy8+Cjx1c2UgeD0nMjQ4LjU2NzU3OCcgeGxpbms6aHJlZj0nI2czLTkxJyB5PScxMDIuMjM4OTAzJy8+Cjx1c2UgeD0nMjUwLjkxOTkwMicgeGxpbms6aHJlZj0nI2cxLTEwNycgeT0nMTAyLjIzODkwMycvPgo8dXNlIHg9JzI1NS41NDE1MTcnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nMTAyLjIzODkwMycvPgo8dXNlIHg9JzI2MS43MTI4MDInIHhsaW5rOmhyZWY9JyNnMi02MicgeT0nMTAwLjM3OTE5MycvPgo8dXNlIHg9JzI3NC4xMzgyODMnIHhsaW5rOmhyZWY9JyNnMi04NCcgeT0nMTAwLjM3OTE5MycvPgo8dXNlIHg9JzI4MC45OTkyODgnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nMTAyLjIzODkwMycvPgo8dXNlIHg9JzI4My4zNTE2MTInIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9JzEwMi4yMzg5MDMnLz4KPHVzZSB4PScyODcuOTczMjI4JyB4bGluazpocmVmPScjZzMtOTMnIHk9JzEwMi4yMzg5MDMnLz4KPC9nPgo8L3N2Zz4=)
Il ne reste plus qu’à expremier cette projection
dans la base initial X. On sait que
![T_{[k]} = X P_{[k]}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMDIxNjA0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU3LjU4NDA1OSA1OS45NTgzNDkgMTIuMDIxNjA0JyB3aWR0aD0nNTkuOTU4MzQ5cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2czLTYxJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMC0xMDcnLz4KPHBhdGggZD0nTTMuNTM4NzMgLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExIC0zLjgwMTc0MyA4Ljg0NjgyNCAtNS4wMjExNzEgOC44NDY4MjQgLTYuMzg0MDZDOC44NDY4MjQgLTcuMzE2NTYzIDguMDU3NzgzIC04LjE2NTM4IDYuNTUxNDMyIC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3IC04LjE2NTM4IDIuNTIyNTQgLTguMTY1MzggMi41MjI1NCAtNy45MzgyMzJDMi41MjI1NCAtNy44MTg2OCAyLjYzMDEzNyAtNy44MTg2OCAyLjgwOTQ2NSAtNy44MTg2OEMzLjUzODczIC03LjgxODY4IDMuNTM4NzMgLTcuNzIzMDM5IDMuNTM4NzMgLTcuNTkxNTMyQzMuNTM4NzMgLTcuNTY3NjIxIDMuNTM4NzMgLTcuNDk1ODkgMy40OTA5MDkgLTcuMzE2NTYzTDEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjY2OTQ4OSAwIDAuNzQxMjIgMEMwLjk2ODM2OSAwIDEuMjA3NDcyIC0wLjAyMzkxIDEuNDM0NjIgLTAuMDIzOTFIMi44MzMzNzVDMy4wNjA1MjMgLTAuMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4IC0wLjIyNzE0OEMzLjc2NTg3OCAtMC4zNDY3IDMuNjU4MjgxIC0wLjM0NjcgMy40Nzg5NTQgLTAuMzQ2N0MyLjc2MTY0NCAtMC4zNDY3IDIuNzQ5Njg5IC0wLjQzMDM4NiAyLjc0OTY4OSAtMC41NDk5MzhDMi43NDk2ODkgLTAuNjA5NzE0IDIuNzYxNjQ0IC0wLjY5MzQgMi43NzM1OTkgLTAuNzUzMTc2TDMuNTM4NzMgLTMuODAxNzQzWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4yMDQ3MzJDNy4xMDEzNyAtNy44MTg2OCA3Ljg0MjU5IC03LjUzMTc1NiA3Ljg0MjU5IC02LjYzNTExOEM3Ljg0MjU5IC02LjMyNDI4NCA3LjY4NzE3MyAtNS4zMDgwOTUgNy4xMzcyMzUgLTQuNzU4MTU3QzYuOTMzOTk4IC00LjU0Mjk2NCA2LjM2MDE0OSAtNC4wODg2NjcgNS4yNzIyMjkgLTQuMDg4NjY3SDMuNTg2NTVMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2cxLTgwJy8+CjxwYXRoIGQ9J000Ljk4NTMwNSAtNy4yOTI2NTNDNS4wNTcwMzYgLTcuNTc5NTc3IDUuMDgwOTQ2IC03LjY4NzE3MyA1LjI2MDI3NCAtNy43MzQ5OTRDNS4zNTU5MTUgLTcuNzU4OTA0IDUuNzUwNDM2IC03Ljc1ODkwNCA2LjAwMTQ5NCAtNy43NTg5MDRDNy4xOTcwMTEgLTcuNzU4OTA0IDcuNzU4OTA0IC03LjcxMTA4MyA3Ljc1ODkwNCAtNi43Nzg1OEM3Ljc1ODkwNCAtNi41OTkyNTMgNy43MTEwODMgLTYuMTQ0OTU2IDcuNjM5MzUyIC01LjcwMjYxNUw3LjYyNzM5NyAtNS41NTkxNTNDNy42MjczOTcgLTUuNTExMzMzIDcuNjc1MjE4IC01LjQzOTYwMSA3Ljc0Njk0OSAtNS40Mzk2MDFDNy44NjY1MDEgLTUuNDM5NjAxIDcuODY2NTAxIC01LjQ5OTM3NyA3LjkwMjM2NiAtNS42OTA2Nkw4LjI0OTA2NiAtNy44MDY3MjVDOC4yNzI5NzYgLTcuOTE0MzIxIDguMjcyOTc2IC03LjkzODIzMiA4LjI3Mjk3NiAtNy45NzQwOTdDOC4yNzI5NzYgLTguMTA1NjA0IDguMjAxMjQ1IC04LjEwNTYwNCA3Ljk2MjE0MiAtOC4xMDU2MDRIMS40MjI2NjVDMS4xNDc2OTYgLTguMTA1NjA0IDEuMTM1NzQxIC04LjA5MzY0OSAxLjA2NDAxIC03Ljg3ODQ1NkwwLjMzNDc0NSAtNS43MjY1MjZDMC4zMjI3OSAtNS43MDI2MTUgMC4yODY5MjQgLTUuNTcxMTA4IDAuMjg2OTI0IC01LjU1OTE1M0MwLjI4NjkyNCAtNS40OTkzNzcgMC4zMzQ3NDUgLTUuNDM5NjAxIDAuNDA2NDc2IC01LjQzOTYwMUMwLjUwMjExNyAtNS40Mzk2MDEgMC41MjYwMjcgLTUuNDg3NDIyIDAuNTczODQ4IC01LjY0MjgzOUMxLjA3NTk2NSAtNy4wODk0MTUgMS4zMjcwMjQgLTcuNzU4OTA0IDIuOTE3MDYxIC03Ljc1ODkwNEgzLjcxODA1N0M0LjAwNDk4MSAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNzU4OTA0IDQuMTI0NTMzIC03LjYyNzM5N0M0LjEyNDUzMyAtNy41OTE1MzIgNC4xMjQ1MzMgLTcuNTY3NjIxIDQuMDY0NzU3IC03LjM1MjQyOEwyLjQ2Mjc2NSAtMC45MzI1MDNDMi4zNDMyMTMgLTAuNDY2MjUyIDIuMzE5MzAzIC0wLjM0NjcgMS4wNTIwNTUgLTAuMzQ2N0MwLjc1MzE3NiAtMC4zNDY3IDAuNjY5NDg5IC0wLjM0NjcgMC42Njk0ODkgLTAuMTE5NTUyQzAuNjY5NDg5IDAgMC44MDA5OTYgMCAwLjg2MDc3MiAwQzEuMTU5NjUxIDAgMS40NzA0ODYgLTAuMDIzOTEgMS43NjkzNjUgLTAuMDIzOTFIMy42MzQzNzFDMy45MzMyNSAtMC4wMjM5MSA0LjI1NjA0IDAgNC41NTQ5MTkgMEM0LjY4NjQyNiAwIDQuODA1OTc4IDAgNC44MDU5NzggLTAuMjI3MTQ4QzQuODA1OTc4IC0wLjM0NjcgNC43MjIyOTEgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3QzMuMzM1NDkyIC0wLjM0NjcgMy4zMzU0OTIgLTAuNDU0Mjk2IDMuMzM1NDkyIC0wLjYzMzYyNEMzLjMzNTQ5MiAtMC42NDU1NzkgMy4zMzU0OTIgLTAuNzI5MjY1IDMuMzgzMzEzIC0wLjkyMDU0OEw0Ljk4NTMwNSAtNy4yOTI2NTNaJyBpZD0nZzEtODQnLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2cxLTg4Jy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2cyLTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnMi05MycvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nMzguODU0Mjk2JyB4bGluazpocmVmPScjZzEtODQnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzQ1LjcxNTMwMicgeGxpbms6aHJlZj0nI2cyLTkxJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc0OC4wNjc2MjUnIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzUyLjY4OTI0MScgeGxpbms6aHJlZj0nI2cyLTkzJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1OC44NjA1MjYnIHhsaW5rOmhyZWY9JyNnMy02MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzEuMjg2MDA3JyB4bGluazpocmVmPScjZzEtODgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzgxLjk0MTExNScgeGxpbms6aHJlZj0nI2cxLTgwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4OS40ODYzODMnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nOTEuODM4NzA3JyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc5Ni40NjAzMjInIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjcuNjEzMTM1Jy8+CjwvZz4KPC9zdmc+) . On en déduit que ;
. On en déduit que ;
![\begin{array}{rcl}
\hat{y} &=& \sum_{k=1}^d <y, T_{[k]}> X P_{[k]} \\
&=& \sum_{k=1}^d <y, T_{[k]}> \sum_{l=1}^d X_{[l]} P_{lk} \\
&=& \sum_{l=1}^d X_{[l]} \sum_{k=1}^d <y, T_{[k]}> P_{lk} \\
&=& \sum_{l=1}^d X_{[l]} (T' y P_l) \\
&=& \sum_{l=1}^d X_{[l]} \beta_l
\end{array}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nNzcuMzIxNzA3cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMTM5Ljc5Njg4MyA3OC43MDQ4NTcgMTg2LjE1OTY4MiA3Ny4zMjE3MDcnIHdpZHRoPScxODYuMTU5NjgycHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTQuMjg3OTIgLTUuMjkyMTU0QzQuMjk1ODkgLTUuMzA4MDk1IDQuMzE5ODAxIC01LjQxMTcwNiA0LjMxOTgwMSAtNS40MTk2NzZDNC4zMTk4MDEgLTUuNDU5NTI3IDQuMjg3OTIgLTUuNTMxMjU4IDQuMTkyMjc5IC01LjUzMTI1OEM0LjE2MDM5OSAtNS41MzEyNTggMy45MTMzMjUgLTUuNTA3MzQ3IDMuNzMwMDEyIC01LjQ5MTQwN0wzLjI4MzY4NiAtNS40NTk1MjdDMy4xMDgzNDQgLTUuNDQzNTg3IDMuMDI4NjQzIC01LjQzNTYxNiAzLjAyODY0MyAtNS4yOTIxNTRDMy4wMjg2NDMgLTUuMTgwNTczIDMuMTQwMjI0IC01LjE4MDU3MyAzLjIzNTg2NiAtNS4xODA1NzNDMy42MTg0MzEgLTUuMTgwNTczIDMuNjE4NDMxIC01LjEzMjc1MiAzLjYxODQzMSAtNS4wNjEwMjFDMy42MTg0MzEgLTUuMDEzMiAzLjU1NDY3IC00Ljc1MDE4NyAzLjUxNDgxOSAtNC41OTA3ODVMMy4xMjQyODQgLTMuMDM2NjEzQzMuMDUyNTUzIC0zLjE3MjEwNSAyLjgyMTQyIC0zLjUxNDgxOSAyLjMzNTI0MyAtMy41MTQ4MTlDMS4zODY4IC0zLjUxNDgxOSAwLjM0MjcxNSAtMi40MDY5NzQgMC4zNDI3MTUgLTEuMjI3Mzk3QzAuMzQyNzE1IC0wLjM5ODUwNiAwLjg3NjcxMiAwLjA3OTcwMSAxLjQ5MDQxMSAwLjA3OTcwMUMyLjAwMDQ5OCAwLjA3OTcwMSAyLjQzODg1NCAtMC4zMjY3NzUgMi41ODIzMTYgLTAuNDg2MTc3QzIuNzI1Nzc4IDAuMDYzNzYxIDMuMjY3NzQ2IDAuMDc5NzAxIDMuMzYzMzg3IDAuMDc5NzAxQzMuNzMwMDEyIDAuMDc5NzAxIDMuOTEzMzI1IC0wLjIyMzE2MyAzLjk3NzA4NiAtMC4zNTg2NTVDNC4xMzY0ODggLTAuNjQ1NTc5IDQuMjQ4MDcgLTEuMTA3ODQ2IDQuMjQ4MDcgLTEuMTM5NzI2QzQuMjQ4MDcgLTEuMTg3NTQ3IDQuMjE2MTg5IC0xLjI0MzMzNyA0LjEyMDU0OCAtMS4yNDMzMzdTNC4wMDg5NjYgLTEuMTk1NTE3IDMuOTYxMTQ2IC0wLjk5NjI2NEMzLjg0OTU2NCAtMC41NTc5MDggMy42OTgxMzIgLTAuMTQzNDYyIDMuMzg3Mjk4IC0wLjE0MzQ2MkMzLjIwMzk4NSAtMC4xNDM0NjIgMy4xMzIyNTQgLTAuMjk0ODk0IDMuMTMyMjU0IC0wLjUxODA1N0MzLjEzMjI1NCAtMC42Njk0ODkgMy4xNTYxNjQgLTAuNzU3MTYxIDMuMTgwMDc1IC0wLjg2MDc3Mkw0LjI4NzkyIC01LjI5MjE1NFpNMi41ODIzMTYgLTAuODYwNzcyQzIuMTgzODExIC0wLjMxMDgzNCAxLjc2OTM2NSAtMC4xNDM0NjIgMS41MTQzMjEgLTAuMTQzNDYyQzEuMTQ3Njk2IC0wLjE0MzQ2MiAwLjk2NDM4NCAtMC40NzgyMDcgMC45NjQzODQgLTAuODkyNjUzQzAuOTY0Mzg0IC0xLjI2NzI0OCAxLjE3OTU3NyAtMi4xMjAwNSAxLjM1NDkxOSAtMi40NzA3MzVDMS41ODYwNTIgLTIuOTU2OTEyIDEuOTc2NTg4IC0zLjI5MTY1NiAyLjM0MzIxMyAtMy4yOTE2NTZDMi44NjEyNyAtMy4yOTE2NTYgMy4wMTI3MDIgLTIuNzA5ODM4IDMuMDEyNzAyIC0yLjYxNDE5N0MzLjAxMjcwMiAtMi41ODIzMTYgMi44MTM0NSAtMS44MDEyNDUgMi43NjU2MjkgLTEuNTk0MDIyQzIuNjYyMDE3IC0xLjIxOTQyNyAyLjY2MjAxNyAtMS4yMDM0ODcgMi41ODIzMTYgLTAuODYwNzcyWicgaWQ9J2cyLTEwMCcvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzItMTA3Jy8+CjxwYXRoIGQ9J00yLjA4ODE2OSAtNS4yOTIxNTRDMi4wOTYxMzkgLTUuMzA4MDk1IDIuMTIwMDUgLTUuNDExNzA2IDIuMTIwMDUgLTUuNDE5Njc2QzIuMTIwMDUgLTUuNDU5NTI3IDIuMDg4MTY5IC01LjUzMTI1OCAxLjk5MjUyOCAtNS41MzEyNThMMS4xODc1NDcgLTUuNDY3NDk3QzAuODkyNjUzIC01LjQ0MzU4NyAwLjgyODg5MiAtNS40MzU2MTYgMC44Mjg4OTIgLTUuMjkyMTU0QzAuODI4ODkyIC01LjE4MDU3MyAwLjk0MDQ3MyAtNS4xODA1NzMgMS4wMzYxMTUgLTUuMTgwNTczQzEuNDE4NjggLTUuMTgwNTczIDEuNDE4NjggLTUuMTMyNzUyIDEuNDE4NjggLTUuMDYxMDIxQzEuNDE4NjggLTUuMDM3MTExIDEuNDE4NjggLTUuMDIxMTcxIDEuMzc4ODI5IC00Ljg3NzcwOUwwLjM5MDUzNSAtMC45MjQ1MzNDMC4zNTg2NTUgLTAuNzk3MDExIDAuMzU4NjU1IC0wLjY3NzQ2IDAuMzU4NjU1IC0wLjY2OTQ4OUMwLjM1ODY1NSAtMC4xNzUzNDIgMC43NjUxMzEgMC4wNzk3MDEgMS4xNjM2MzYgMC4wNzk3MDFDMS41MDYzNTEgMC4wNzk3MDEgMS42ODk2NjQgLTAuMTkxMjgzIDEuNzc3MzM1IC0wLjM2NjYyNUMxLjkyMDc5NyAtMC42Mjk2MzkgMi4wNDAzNDkgLTEuMDk5ODc1IDIuMDQwMzQ5IC0xLjEzOTcyNkMyLjA0MDM0OSAtMS4xODc1NDcgMi4wMTY0MzggLTEuMjQzMzM3IDEuOTEyODI3IC0xLjI0MzMzN0MxLjg0MTA5NiAtMS4yNDMzMzcgMS44MTcxODYgLTEuMjAzNDg3IDEuODE3MTg2IC0xLjE5NTUxN0MxLjgwMTI0NSAtMS4xNzE2MDYgMS43NjEzOTUgLTEuMDI4MTQ0IDEuNzM3NDg0IC0wLjk0MDQ3M0MxLjYxNzkzMyAtMC40NzgyMDcgMS40NjY1MDEgLTAuMTQzNDYyIDEuMTc5NTc3IC0wLjE0MzQ2MkMwLjk4ODI5NCAtMC4xNDM0NjIgMC45MzI1MDMgLTAuMzI2Nzc1IDAuOTMyNTAzIC0wLjUxODA1N0MwLjkzMjUwMyAtMC42Njk0ODkgMC45NTY0MTMgLTAuNzU3MTYxIDAuOTgwMzI0IC0wLjg2MDc3MkwyLjA4ODE2OSAtNS4yOTIxNTRaJyBpZD0nZzItMTA4Jy8+CjxwYXRoIGQ9J001LjAzMzEyNiA2LjM4NDA2TDAuNzg5MDQxIDExLjYzMjM3OUMwLjY5MzQgMTEuNzUxOTMgMC42ODE0NDUgMTEuNzc1ODQxIDAuNjgxNDQ1IDExLjgyMzY2MUMwLjY4MTQ0NSAxMS45NTUxNjggMC43ODkwNDEgMTEuOTU1MTY4IDEuMDA0MjM0IDExLjk1NTE2OEgxMC45MTUwNjhMMTEuOTQzMjEzIDguOTc4MzMxSDExLjY0NDMzNEMxMS4zNDU0NTUgOS44NzQ5NjkgMTAuNTQ0NDU4IDEwLjYwNDIzNCA5LjUyODI2OSAxMC45NTA5MzRDOS4zMzY5ODYgMTEuMDEwNzEgOC41MTIwOCAxMS4yOTc2MzQgNi43NTQ2NyAxMS4yOTc2MzRIMS42NzM3MjRMNS44MjIxNjcgNi4xNjg4NjdDNS45MDU4NTMgNi4wNjEyNyA1LjkyOTc2MyA2LjAyNTQwNSA1LjkyOTc2MyA1Ljk3NzU4NFM1LjkxNzgwOCA1LjkxNzgwOCA1Ljg0NjA3NyA1LjgxMDIxMkwxLjk2MDY0OCAwLjQ3ODIwN0g2LjY5NDg5NEM4LjA1Nzc4MyAwLjQ3ODIwNyAxMC44MDc0NzIgMC41NjE4OTMgMTEuNjQ0MzM0IDIuNzk3NTA5SDExLjk0MzIxM0wxMC45MTUwNjggMEgxLjAwNDIzNEMwLjY4MTQ0NSAwIDAuNjY5NDg5IDAuMDExOTU1IDAuNjY5NDg5IDAuMzgyNTY1TDUuMDMzMTI2IDYuMzg0MDZaJyBpZD0nZzAtODAnLz4KPHBhdGggZD0nTTIuMTEyMDggLTMuNzc3ODMzQzIuMTUxOTMgLTMuODgxNDQ1IDIuMTgzODExIC0zLjkzNzIzNSAyLjE4MzgxMSAtNC4wMTY5MzZDMi4xODM4MTEgLTQuMjc5OTUgMS45NDQ3MDcgLTQuNDU1MjkzIDEuNzIxNTQ0IC00LjQ1NTI5M0MxLjQwMjc0IC00LjQ1NTI5MyAxLjMxNTA2OCAtNC4xNzYzMzkgMS4yODMxODggLTQuMDY0NzU3TDAuMjcwOTg0IC0wLjYyOTYzOUMwLjIzOTEwMyAtMC41MzM5OTggMC4yMzkxMDMgLTAuNTEwMDg3IDAuMjM5MTAzIC0wLjUwMjExN0MwLjIzOTEwMyAtMC40MzAzODYgMC4yODY5MjQgLTAuNDE0NDQ2IDAuMzY2NjI1IC0wLjM5MDUzNUMwLjUxMDA4NyAtMC4zMjY3NzUgMC41MjYwMjcgLTAuMzI2Nzc1IDAuNTQxOTY4IC0wLjMyNjc3NUMwLjU2NTg3OCAtMC4zMjY3NzUgMC42MTM2OTkgLTAuMzI2Nzc1IDAuNjY5NDg5IC0wLjQ2MjI2N0wyLjExMjA4IC0zLjc3NzgzM1onIGlkPSdnMS00OCcvPgo8cGF0aCBkPSdNMi41MDI2MTUgLTUuMDc2OTYxQzIuNTAyNjE1IC01LjI5MjE1NCAyLjQ4NjY3NSAtNS4zMDAxMjUgMi4yNzE0ODIgLTUuMzAwMTI1QzEuOTQ0NzA3IC00Ljk4MTMyIDEuNTIyMjkxIC00Ljc5MDAzNyAwLjc2NTEzMSAtNC43OTAwMzdWLTQuNTI3MDI0QzAuOTgwMzI0IC00LjUyNzAyNCAxLjQxMDcxIC00LjUyNzAyNCAxLjg3Mjk3NiAtNC43NDIyMTdWLTAuNjUzNTQ5QzEuODcyOTc2IC0wLjM1ODY1NSAxLjg0OTA2NiAtMC4yNjMwMTQgMS4wOTE5MDUgLTAuMjYzMDE0SDAuODEyOTUxVjBDMS4xMzk3MjYgLTAuMDIzOTEgMS44MjUxNTYgLTAuMDIzOTEgMi4xODM4MTEgLTAuMDIzOTFTMy4yMzU4NjYgLTAuMDIzOTEgMy41NjI2NCAwVi0wLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNiAtMC4yNjMwMTQgMi41MDI2MTUgLTAuMzU4NjU1IDIuNTAyNjE1IC0wLjY1MzU0OVYtNS4wNzY5NjFaJyBpZD0nZzQtNDknLz4KPHBhdGggZD0nTTUuODI2MTUyIC0yLjY1NDA0N0M1Ljk0NTcwNCAtMi42NTQwNDcgNi4xMDUxMDYgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjgzNzM2UzUuOTEzODIzIC0zLjAyMDY3MiA1Ljc5NDI3MSAtMy4wMjA2NzJIMC43ODEwNzFDMC42NjE1MTkgLTMuMDIwNjcyIDAuNDcwMjM3IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMi44MzczNlMwLjYyOTYzOSAtMi42NTQwNDcgMC43NDkxOTEgLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MSAtMC45NjQzODRDNS45MTM4MjMgLTAuOTY0Mzg0IDYuMTA1MTA2IC0wLjk2NDM4NCA2LjEwNTEwNiAtMS4xNDc2OTZTNS45NDU3MDQgLTEuMzMxMDA5IDUuODI2MTUyIC0xLjMzMTAwOUgwLjc0OTE5MUMwLjYyOTYzOSAtMS4zMzEwMDkgMC40NzAyMzcgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjE0NzY5NlMwLjY2MTUxOSAtMC45NjQzODQgMC43ODEwNzEgLTAuOTY0Mzg0SDUuNzk0MjcxWicgaWQ9J2c0LTYxJy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2c0LTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnNC05MycvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2c1LTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnNS00MScvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzUtNjEnLz4KPHBhdGggZD0nTTIuOTI5MDE2IC04LjI5Njg4N0wxLjM2Mjg4OSAtNi42NzA5ODRMMS41NTQxNzIgLTYuNDkxNjU2TDIuOTE3MDYxIC03LjcyMzAzOUw0LjI5MTkwNSAtNi40OTE2NTZMNC40ODMxODggLTYuNjcwOTg0TDIuOTI5MDE2IC04LjI5Njg4N1onIGlkPSdnNS05NCcvPgo8cGF0aCBkPSdNNi43NjY2MjUgLTYuOTU3OTA4QzYuNzY2NjI1IC03LjY3NTIxOCA2LjE1NjkxMiAtOC40MjgzOTQgNS4wNjg5OTEgLTguNDI4Mzk0QzMuNTI2Nzc1IC04LjQyODM5NCAyLjU0NjQ1MSAtNi41Mzk0NzcgMi4yMzU2MTYgLTUuMjk2MTM5TDAuMzQ2NyAyLjE5OTc1MUMwLjMyMjc5IDIuMjk1MzkyIDAuMzk0NTIxIDIuMzE5MzAzIDAuNDU0Mjk2IDIuMzE5MzAzQzAuNTM3OTgzIDIuMzE5MzAzIDAuNTk3NzU4IDIuMzA3MzQ3IDAuNjA5NzE0IDIuMjQ3NTcyTDEuNDQ2NTc1IC0xLjA5OTg3NUMxLjU2NjEyNyAtMC40MzAzODYgMi4yMjM2NjEgMC4xMTk1NTIgMi45MjkwMTYgMC4xMTk1NTJDNC42Mzg2MDUgMC4xMTk1NTIgNi4yNTI1NTMgLTEuMjE5NDI3IDYuMjUyNTUzIC0zLjAwMDc0N0M2LjI1MjU1MyAtMy40NTUwNDQgNi4xNDQ5NTYgLTMuOTA5MzQgNS44OTM4OTggLTQuMjkxOTA1QzUuNzUwNDM2IC00LjUxOTA1NCA1LjU3MTEwOCAtNC42ODY0MjYgNS4zNzk4MjYgLTQuODI5ODg4QzYuMjQwNTk4IC01LjI4NDE4NCA2Ljc2NjYyNSAtNi4wMTM0NSA2Ljc2NjYyNSAtNi45NTc5MDhaTTQuNjg2NDI2IC00Ljg0MTg0M0M0LjQ5NTE0MyAtNC43NzAxMTIgNC4zMDM4NjEgLTQuNzQ2MjAyIDQuMDc2NzEyIC00Ljc0NjIwMkMzLjkwOTM0IC00Ljc0NjIwMiAzLjc1MzkyMyAtNC43MzQyNDcgMy41Mzg3MyAtNC44MDU5NzhDMy42NTgyODEgLTQuODg5NjY0IDMuODM3NjA5IC00LjkxMzU3NCA0LjA4ODY2NyAtNC45MTM1NzRDNC4zMDM4NjEgLTQuOTEzNTc0IDQuNTE5MDU0IC00Ljg4OTY2NCA0LjY4NjQyNiAtNC44NDE4NDNaTTYuMTQ0OTU2IC03LjA2NTUwNEM2LjE0NDk1NiAtNi40MDc5NyA1LjgyMjE2NyAtNS40NTE1NTcgNS4wNDUwODEgLTUuMDA5MjE1QzQuODE3OTMzIC01LjA5MjkwMiA0LjUwNzA5OCAtNS4xNTI2NzcgNC4yNDQwODUgLTUuMTUyNjc3QzMuOTkzMDI2IC01LjE1MjY3NyAzLjI3NTcxNiAtNS4xNzY1ODggMy4yNzU3MTYgLTQuNzk0MDIyQzMuMjc1NzE2IC00LjQ3MTIzMyAzLjkzMzI1IC00LjUwNzA5OCA0LjEzNjQ4OCAtNC41MDcwOThDNC40NDczMjMgLTQuNTA3MDk4IDQuNzIyMjkxIC00LjU3ODgyOSA1LjAwOTIxNSAtNC42NjI1MTZDNS4zOTE3ODEgLTQuMzUxNjgxIDUuNTU5MTUzIC0zLjk0NTIwNSA1LjU1OTE1MyAtMy4zNDc0NDdDNS41NTkxNTMgLTIuNjU0MDQ3IDUuMzY3ODcgLTIuMDkyMTU0IDUuMTQwNzIyIC0xLjU3ODA4MkM0Ljc0NjIwMiAtMC42OTM0IDMuODEzNjk5IC0wLjExOTU1MiAyLjk4ODc5MiAtMC4xMTk1NTJDMi4xMTYwNjUgLTAuMTE5NTUyIDEuNjYxNzY4IC0wLjgxMjk1MSAxLjY2MTc2OCAtMS42MjU5MDNDMS42NjE3NjggLTEuNzMzNDk5IDEuNjYxNzY4IC0xLjg4ODkxNyAxLjcwOTU4OSAtMi4wNjgyNDRMMi40ODY2NzUgLTUuMjEyNDUzQzIuODgxMTk2IC02Ljc3ODU4IDMuODg1NDMgLTguMTg5MjkgNS4wNDUwODEgLTguMTg5MjlDNS45MDU4NTMgLTguMTg5MjkgNi4xNDQ5NTYgLTcuNTkxNTMyIDYuMTQ0OTU2IC03LjA2NTUwNFonIGlkPSdnMy0xMicvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzMtNTknLz4KPHBhdGggZD0nTTcuODc4NDU2IC01LjgyMjE2N0M4LjA5MzY0OSAtNS45MTc4MDggOC4xMTc1NTkgLTYuMDAxNDk0IDguMTE3NTU5IC02LjA3MzIyNUM4LjExNzU1OSAtNi4yMDQ3MzIgOC4wMjE5MTggLTYuMzAwMzc0IDcuODkwNDExIC02LjMwMDM3NEM3Ljg2NjUwMSAtNi4zMDAzNzQgNy44NTQ1NDUgLTYuMjg4NDE4IDcuNjg3MTczIC02LjIxNjY4N0wxLjIxOTQyNyAtMy4yMzk4NTFDMS4wMDQyMzQgLTMuMTQ0MjA5IDAuOTgwMzI0IC0zLjA2MDUyMyAwLjk4MDMyNCAtMi45ODg3OTJDMC45ODAzMjQgLTIuOTA1MTA2IDAuOTkyMjc5IC0yLjgzMzM3NSAxLjIxOTQyNyAtMi43MjU3NzhMNy42ODcxNzMgMC4yNTEwNTlDNy44NDI1OSAwLjMyMjc5IDcuODY2NTAxIDAuMzM0NzQ1IDcuODkwNDExIDAuMzM0NzQ1QzguMDIxOTE4IDAuMzM0NzQ1IDguMTE3NTU5IDAuMjM5MTAzIDguMTE3NTU5IDAuMTA3NTk3QzguMTE3NTU5IDAuMDM1ODY2IDguMDkzNjQ5IC0wLjA0NzgyMSA3Ljg3ODQ1NiAtMC4xNDM0NjJMMS43MjE1NDQgLTIuOTc2ODM3TDcuODc4NDU2IC01LjgyMjE2N1onIGlkPSdnMy02MCcvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzI1Nzc4QzguMTA1NjA0IC0yLjgzMzM3NSA4LjExNzU1OSAtMi45MDUxMDYgOC4xMTc1NTkgLTIuOTg4NzkyQzguMTE3NTU5IC0zLjA2MDUyMyA4LjA5MzY0OSAtMy4xNDQyMDkgNy44Nzg0NTYgLTMuMjM5ODUxTDEuNDEwNzEgLTYuMjE2Njg3QzEuMjU1MjkzIC02LjI4ODQxOCAxLjIzMTM4MiAtNi4zMDAzNzQgMS4yMDc0NzIgLTYuMzAwMzc0QzEuMDY0MDEgLTYuMzAwMzc0IDAuOTgwMzI0IC02LjE4MDgyMiAwLjk4MDMyNCAtNi4wODUxODFDMC45ODAzMjQgLTUuOTQxNzE5IDEuMDc1OTY1IC01Ljg5Mzg5OCAxLjIzMTM4MiAtNS44MjIxNjdMNy4zNzYzMzkgLTIuOTg4NzkyTDEuMjE5NDI3IC0wLjE0MzQ2MkMwLjk4MDMyNCAtMC4wMzU4NjYgMC45ODAzMjQgMC4wNDc4MjEgMC45ODAzMjQgMC4xMTk1NTJDMC45ODAzMjQgMC4yMTUxOTMgMS4wNjQwMSAwLjMzNDc0NSAxLjIwNzQ3MiAwLjMzNDc0NUMxLjIzMTM4MiAwLjMzNDc0NSAxLjI0MzMzNyAwLjMyMjc5IDEuNDEwNzEgMC4yNTEwNTlMNy44Nzg0NTYgLTIuNzI1Nzc4WicgaWQ9J2czLTYyJy8+CjxwYXRoIGQ9J00zLjUzODczIC0zLjgwMTc0M0g1LjU0NzE5OEM3LjE5NzAxMSAtMy44MDE3NDMgOC44NDY4MjQgLTUuMDIxMTcxIDguODQ2ODI0IC02LjM4NDA2QzguODQ2ODI0IC03LjMxNjU2MyA4LjA1Nzc4MyAtOC4xNjUzOCA2LjU1MTQzMiAtOC4xNjUzOEgyLjg1NzI4NUMyLjYzMDEzNyAtOC4xNjUzOCAyLjUyMjU0IC04LjE2NTM4IDIuNTIyNTQgLTcuOTM4MjMyQzIuNTIyNTQgLTcuODE4NjggMi42MzAxMzcgLTcuODE4NjggMi44MDk0NjUgLTcuODE4NjhDMy41Mzg3MyAtNy44MTg2OCAzLjUzODczIC03LjcyMzAzOSAzLjUzODczIC03LjU5MTUzMkMzLjUzODczIC03LjU2NzYyMSAzLjUzODczIC03LjQ5NTg5IDMuNDkwOTA5IC03LjMxNjU2M0wxLjg3Njk2MSAtMC44ODQ2ODJDMS43NjkzNjUgLTAuNDY2MjUyIDEuNzQ1NDU1IC0wLjM0NjcgMC45MDg1OTMgLTAuMzQ2N0MwLjY4MTQ0NSAtMC4zNDY3IDAuNTYxODkzIC0wLjM0NjcgMC41NjE4OTMgLTAuMTMxNTA3QzAuNTYxODkzIDAgMC42Njk0ODkgMCAwLjc0MTIyIDBDMC45NjgzNjkgMCAxLjIwNzQ3MiAtMC4wMjM5MSAxLjQzNDYyIC0wLjAyMzkxSDIuODMzMzc1QzMuMDYwNTIzIC0wLjAyMzkxIDMuMzExNTgyIDAgMy41Mzg3MyAwQzMuNjM0MzcxIDAgMy43NjU4NzggMCAzLjc2NTg3OCAtMC4yMjcxNDhDMy43NjU4NzggLTAuMzQ2NyAzLjY1ODI4MSAtMC4zNDY3IDMuNDc4OTU0IC0wLjM0NjdDMi43NjE2NDQgLTAuMzQ2NyAyLjc0OTY4OSAtMC40MzAzODYgMi43NDk2ODkgLTAuNTQ5OTM4QzIuNzQ5Njg5IC0wLjYwOTcxNCAyLjc2MTY0NCAtMC42OTM0IDIuNzczNTk5IC0wLjc1MzE3NkwzLjUzODczIC0zLjgwMTc0M1pNNC4zOTk1MDIgLTcuMzUyNDI4QzQuNTA3MDk4IC03Ljc5NDc3IDQuNTU0OTE5IC03LjgxODY4IDUuMDIxMTcxIC03LjgxODY4SDYuMjA0NzMyQzcuMTAxMzcgLTcuODE4NjggNy44NDI1OSAtNy41MzE3NTYgNy44NDI1OSAtNi42MzUxMThDNy44NDI1OSAtNi4zMjQyODQgNy42ODcxNzMgLTUuMzA4MDk1IDcuMTM3MjM1IC00Ljc1ODE1N0M2LjkzMzk5OCAtNC41NDI5NjQgNi4zNjAxNDkgLTQuMDg4NjY3IDUuMjcyMjI5IC00LjA4ODY2N0gzLjU4NjU1TDQuMzk5NTAyIC03LjM1MjQyOFonIGlkPSdnMy04MCcvPgo8cGF0aCBkPSdNNC45ODUzMDUgLTcuMjkyNjUzQzUuMDU3MDM2IC03LjU3OTU3NyA1LjA4MDk0NiAtNy42ODcxNzMgNS4yNjAyNzQgLTcuNzM0OTk0QzUuMzU1OTE1IC03Ljc1ODkwNCA1Ljc1MDQzNiAtNy43NTg5MDQgNi4wMDE0OTQgLTcuNzU4OTA0QzcuMTk3MDExIC03Ljc1ODkwNCA3Ljc1ODkwNCAtNy43MTEwODMgNy43NTg5MDQgLTYuNzc4NThDNy43NTg5MDQgLTYuNTk5MjUzIDcuNzExMDgzIC02LjE0NDk1NiA3LjYzOTM1MiAtNS43MDI2MTVMNy42MjczOTcgLTUuNTU5MTUzQzcuNjI3Mzk3IC01LjUxMTMzMyA3LjY3NTIxOCAtNS40Mzk2MDEgNy43NDY5NDkgLTUuNDM5NjAxQzcuODY2NTAxIC01LjQzOTYwMSA3Ljg2NjUwMSAtNS40OTkzNzcgNy45MDIzNjYgLTUuNjkwNjZMOC4yNDkwNjYgLTcuODA2NzI1QzguMjcyOTc2IC03LjkxNDMyMSA4LjI3Mjk3NiAtNy45MzgyMzIgOC4yNzI5NzYgLTcuOTc0MDk3QzguMjcyOTc2IC04LjEwNTYwNCA4LjIwMTI0NSAtOC4xMDU2MDQgNy45NjIxNDIgLTguMTA1NjA0SDEuNDIyNjY1QzEuMTQ3Njk2IC04LjEwNTYwNCAxLjEzNTc0MSAtOC4wOTM2NDkgMS4wNjQwMSAtNy44Nzg0NTZMMC4zMzQ3NDUgLTUuNzI2NTI2QzAuMzIyNzkgLTUuNzAyNjE1IDAuMjg2OTI0IC01LjU3MTEwOCAwLjI4NjkyNCAtNS41NTkxNTNDMC4yODY5MjQgLTUuNDk5Mzc3IDAuMzM0NzQ1IC01LjQzOTYwMSAwLjQwNjQ3NiAtNS40Mzk2MDFDMC41MDIxMTcgLTUuNDM5NjAxIDAuNTI2MDI3IC01LjQ4NzQyMiAwLjU3Mzg0OCAtNS42NDI4MzlDMS4wNzU5NjUgLTcuMDg5NDE1IDEuMzI3MDI0IC03Ljc1ODkwNCAyLjkxNzA2MSAtNy43NTg5MDRIMy43MTgwNTdDNC4wMDQ5ODEgLTcuNzU4OTA0IDQuMTI0NTMzIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy42MjczOTdDNC4xMjQ1MzMgLTcuNTkxNTMyIDQuMTI0NTMzIC03LjU2NzYyMSA0LjA2NDc1NyAtNy4zNTI0MjhMMi40NjI3NjUgLTAuOTMyNTAzQzIuMzQzMjEzIC0wLjQ2NjI1MiAyLjMxOTMwMyAtMC4zNDY3IDEuMDUyMDU1IC0wLjM0NjdDMC43NTMxNzYgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4zNDY3IDAuNjY5NDg5IC0wLjExOTU1MkMwLjY2OTQ4OSAwIDAuODAwOTk2IDAgMC44NjA3NzIgMEMxLjE1OTY1MSAwIDEuNDcwNDg2IC0wLjAyMzkxIDEuNzY5MzY1IC0wLjAyMzkxSDMuNjM0MzcxQzMuOTMzMjUgLTAuMDIzOTEgNC4yNTYwNCAwIDQuNTU0OTE5IDBDNC42ODY0MjYgMCA0LjgwNTk3OCAwIDQuODA1OTc4IC0wLjIyNzE0OEM0LjgwNTk3OCAtMC4zNDY3IDQuNzIyMjkxIC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2N0MzLjMzNTQ5MiAtMC4zNDY3IDMuMzM1NDkyIC0wLjQ1NDI5NiAzLjMzNTQ5MiAtMC42MzM2MjRDMy4zMzU0OTIgLTAuNjQ1NTc5IDMuMzM1NDkyIC0wLjcyOTI2NSAzLjM4MzMxMyAtMC45MjA1NDhMNC45ODUzMDUgLTcuMjkyNjUzWicgaWQ9J2czLTg0Jy8+CjxwYXRoIGQ9J001LjY3ODcwNSAtNC44NTM3OThMNC41NTQ5MTkgLTcuNDcxOThDNC43MTAzMzYgLTcuNzU4OTA0IDUuMDY4OTkxIC03LjgwNjcyNSA1LjIxMjQ1MyAtNy44MTg2OEM1LjI4NDE4NCAtNy44MTg2OCA1LjQxNTY5MSAtNy44MzA2MzUgNS40MTU2OTEgLTguMDMzODczQzUuNDE1NjkxIC04LjE2NTM4IDUuMzA4MDk1IC04LjE2NTM4IDUuMjM2MzY0IC04LjE2NTM4QzUuMDMzMTI2IC04LjE2NTM4IDQuNzk0MDIyIC04LjE0MTQ2OSA0LjU5MDc4NSAtOC4xNDE0NjlIMy44OTczODVDMy4xNjgxMiAtOC4xNDE0NjkgMi42NDIwOTIgLTguMTY1MzggMi42MzAxMzcgLTguMTY1MzhDMi41MzQ0OTYgLTguMTY1MzggMi40MTQ5NDQgLTguMTY1MzggMi40MTQ5NDQgLTcuOTM4MjMyQzIuNDE0OTQ0IC03LjgxODY4IDIuNTIyNTQgLTcuODE4NjggMi42Nzc5NTggLTcuODE4NjhDMy4zNzEzNTcgLTcuODE4NjggMy40MTkxNzggLTcuNjk5MTI4IDMuNTM4NzMgLTcuNDEyMjA0TDQuOTYxMzk1IC00LjA4ODY2N0wyLjM2NzEyMyAtMS4zMTUwNjhDMS45MzY3MzcgLTAuODQ4ODE3IDEuNDIyNjY1IC0wLjM5NDUyMSAwLjUzNzk4MyAtMC4zNDY3QzAuMzk0NTIxIC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMTE5NTUyQzAuMjk4ODc5IC0wLjA4MzY4NiAwLjMxMDgzNCAwIDAuNDQyMzQxIDBDMC42MDk3MTQgMCAwLjc4OTA0MSAtMC4wMjM5MSAwLjk1NjQxMyAtMC4wMjM5MUgxLjUxODMwNkMxLjkwMDg3MiAtMC4wMjM5MSAyLjMxOTMwMyAwIDIuNjg5OTEzIDBDMi43NzM1OTkgMCAyLjkxNzA2MSAwIDIuOTE3MDYxIC0wLjIxNTE5M0MyLjkxNzA2MSAtMC4zMzQ3NDUgMi44MzMzNzUgLTAuMzQ2NyAyLjc2MTY0NCAtMC4zNDY3QzIuNTIyNTQgLTAuMzcwNjEgMi4zNjcxMjMgLTAuNTAyMTE3IDIuMzY3MTIzIC0wLjY5MzRDMi4zNjcxMjMgLTAuODk2NjM4IDIuNTEwNTg1IC0xLjA0MDEgMi44NTcyODUgLTEuMzk4NzU1TDMuOTIxMjk1IC0yLjU1ODQwNkM0LjE4NDMwOSAtMi44MzMzNzUgNC44MTc5MzMgLTMuNTI2Nzc1IDUuMDgwOTQ2IC0zLjc4OTc4OEw2LjMzNjIzOSAtMC44NDg4MTdDNi4zNDgxOTQgLTAuODI0OTA3IDYuMzk2MDE1IC0wLjcwNTM1NSA2LjM5NjAxNSAtMC42OTM0QzYuMzk2MDE1IC0wLjU4NTgwMyA2LjEzMzAwMSAtMC4zNzA2MSA1Ljc1MDQzNiAtMC4zNDY3QzUuNjc4NzA1IC0wLjM0NjcgNS41NDcxOTggLTAuMzM0NzQ1IDUuNTQ3MTk4IC0wLjExOTU1MkM1LjU0NzE5OCAwIDUuNjY2NzUgMCA1LjcyNjUyNiAwQzUuOTI5NzYzIDAgNi4xNjg4NjcgLTAuMDIzOTEgNi4zNzIxMDUgLTAuMDIzOTFINy42ODcxNzNDNy45MDIzNjYgLTAuMDIzOTEgOC4xMjk1MTQgMCA4LjMzMjc1MiAwQzguNDE2NDM4IDAgOC41NDc5NDUgMCA4LjU0Nzk0NSAtMC4yMjcxNDhDOC41NDc5NDUgLTAuMzQ2NyA4LjQyODM5NCAtMC4zNDY3IDguMzIwNzk3IC0wLjM0NjdDNy42MDM0ODcgLTAuMzU4NjU1IDcuNTc5NTc3IC0wLjQxODQzMSA3LjM3NjMzOSAtMC44NjA3NzJMNS43OTgyNTcgLTQuNTY2ODc0TDcuMzE2NTYzIC02LjE5Mjc3N0M3LjQzNjExNSAtNi4zMTIzMjkgNy43MTEwODMgLTYuNjExMjA4IDcuODE4NjggLTYuNzMwNzZDOC4zMzI3NTIgLTcuMjY4NzQyIDguODEwOTU5IC03Ljc1ODkwNCA5Ljc3OTMyOCAtNy44MTg2OEM5Ljg5ODg3OSAtNy44MzA2MzUgMTAuMDE4NDMxIC03LjgzMDYzNSAxMC4wMTg0MzEgLTguMDMzODczQzEwLjAxODQzMSAtOC4xNjUzOCA5LjkxMDgzNCAtOC4xNjUzOCA5Ljg2MzAxNCAtOC4xNjUzOEM5LjY5NTY0MSAtOC4xNjUzOCA5LjUxNjMxNCAtOC4xNDE0NjkgOS4zNDg5NDEgLTguMTQxNDY5SDguNzk5MDA0QzguNDE2NDM4IC04LjE0MTQ2OSA3Ljk5ODAwNyAtOC4xNjUzOCA3LjYyNzM5NyAtOC4xNjUzOEM3LjU0MzcxMSAtOC4xNjUzOCA3LjQwMDI0OSAtOC4xNjUzOCA3LjQwMDI0OSAtNy45NTAxODdDNy40MDAyNDkgLTcuODMwNjM1IDcuNDgzOTM1IC03LjgxODY4IDcuNTU1NjY2IC03LjgxODY4QzcuNzQ2OTQ5IC03Ljc5NDc3IDcuOTUwMTg3IC03LjY5OTEyOCA3Ljk1MDE4NyAtNy40NzE5OEw3LjkzODIzMiAtNy40NDgwN0M3LjkyNjI3NiAtNy4zNjQzODQgNy45MDIzNjYgLTcuMjQ0ODMyIDcuNzcwODU5IC03LjEwMTM3TDUuNjc4NzA1IC00Ljg1Mzc5OFonIGlkPSdnMy04OCcvPgo8cGF0aCBkPSdNMy4xNDQyMDkgMS4zMzg5NzlDMi44MjE0MiAxLjc5MzI3NSAyLjM1NTE2OCAyLjE5OTc1MSAxLjc2OTM2NSAyLjE5OTc1MUMxLjYyNTkwMyAyLjE5OTc1MSAxLjA1MjA1NSAyLjE3NTg0MSAwLjg3MjcyNyAxLjYyNTkwM0MwLjkwODU5MyAxLjYzNzg1OCAwLjk2ODM2OSAxLjYzNzg1OCAwLjk5MjI3OSAxLjYzNzg1OEMxLjM1MDkzNCAxLjYzNzg1OCAxLjU5MDAzNyAxLjMyNzAyNCAxLjU5MDAzNyAxLjA1MjA1NVMxLjM2Mjg4OSAwLjY4MTQ0NSAxLjE4MzU2MiAwLjY4MTQ0NUMwLjk5MjI3OSAwLjY4MTQ0NSAwLjU3Mzg0OCAwLjgyNDkwNyAwLjU3Mzg0OCAxLjQxMDcxQzAuNTczODQ4IDIuMDIwNDIzIDEuMDg3OTIgMi40Mzg4NTQgMS43NjkzNjUgMi40Mzg4NTRDMi45NjQ4ODIgMi40Mzg4NTQgNC4xNzIzNTQgMS4zMzg5NzkgNC41MDcwOTggMC4wMTE5NTVMNS42Nzg3MDUgLTQuNjUwNTZDNS42OTA2NiAtNC43MTAzMzYgNS43MTQ1NyAtNC43ODIwNjcgNS43MTQ1NyAtNC44NTM3OThDNS43MTQ1NyAtNS4wMzMxMjYgNS41NzExMDggLTUuMTUyNjc3IDUuMzkxNzgxIC01LjE1MjY3N0M1LjI4NDE4NCAtNS4xNTI2NzcgNS4wMzMxMjYgLTUuMTA0ODU3IDQuOTM3NDg0IC00Ljc0NjIwMkw0LjA1MjgwMiAtMS4yMzEzODJDMy45OTMwMjYgLTEuMDE2MTg5IDMuOTkzMDI2IC0wLjk5MjI3OSAzLjg5NzM4NSAtMC44NjA3NzJDMy42NTgyODEgLTAuNTI2MDI3IDMuMjYzNzYxIC0wLjExOTU1MiAyLjY4OTkxMyAtMC4xMTk1NTJDMi4wMjA0MjMgLTAuMTE5NTUyIDEuOTYwNjQ4IC0wLjc3NzA4NiAxLjk2MDY0OCAtMS4wOTk4NzVDMS45NjA2NDggLTEuNzgxMzIgMi4yODM0MzcgLTIuNzAxODY4IDIuNjA2MjI3IC0zLjU2MjY0QzIuNzM3NzMzIC0zLjkwOTM0IDIuODA5NDY1IC00LjA3NjcxMiAyLjgwOTQ2NSAtNC4zMTU4MTZDMi44MDk0NjUgLTQuODE3OTMzIDIuNDUwODA5IC01LjI3MjIyOSAxLjg2NTAwNiAtNS4yNzIyMjlDMC43NjUxMzEgLTUuMjcyMjI5IDAuMzIyNzkgLTMuNTM4NzMgMC4zMjI3OSAtMy40NDMwODhDMC4zMjI3OSAtMy4zOTUyNjggMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTYxODkzIC0zLjMzNTQ5MiAwLjU3Mzg0OCAtMy4zODMzMTMgMC42MjE2NjkgLTMuNTUwNjg1QzAuOTA4NTkzIC00LjU1NDkxOSAxLjM2Mjg4OSAtNS4wMzMxMjYgMS44MjkxNDEgLTUuMDMzMTI2QzEuOTM2NzM3IC01LjAzMzEyNiAyLjEzOTk3NSAtNS4wMzMxMjYgMi4xMzk5NzUgLTQuNjM4NjA1QzIuMTM5OTc1IC00LjMyNzc3MSAyLjAwODQ2OCAtMy45ODEwNzEgMS44MjkxNDEgLTMuNTI2Nzc1QzEuMjQzMzM3IC0xLjk2MDY0OCAxLjI0MzMzNyAtMS41NjYxMjcgMS4yNDMzMzcgLTEuMjc5MjAzQzEuMjQzMzM3IC0wLjE0MzQ2MiAyLjA1NjI4OSAwLjExOTU1MiAyLjY1NDA0NyAwLjExOTU1MkMzLjAwMDc0NyAwLjExOTU1MiAzLjQzMTEzMyAwLjAxMTk1NSAzLjg0OTU2NCAtMC40MzAzODZMMy44NjE1MTkgLTAuNDE4NDMxQzMuNjgyMTkyIDAuMjg2OTI0IDMuNTYyNjQgMC43NTMxNzYgMy4xNDQyMDkgMS4zMzg5NzlaJyBpZD0nZzMtMTIxJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PScxNDAuNTg5MDQ4JyB4bGluazpocmVmPScjZzUtOTQnIHk9JzkwLjA1MTI3Jy8+Cjx1c2UgeD0nMTM5Ljc5Njg4MycgeGxpbms6aHJlZj0nI2czLTEyMScgeT0nOTAuMDUxMjcnLz4KPHVzZSB4PScxNTUuODk2MTYzJyB4bGluazpocmVmPScjZzUtNjEnIHk9JzkwLjA1MTI3Jy8+Cjx1c2UgeD0nMTc0Ljk2MzQ1NScgeGxpbms6aHJlZj0nI2cwLTgwJyB5PSc4MS4wODQ4MTcnLz4KPHVzZSB4PScxODcuNTgyODM1JyB4bGluazpocmVmPScjZzItMTAwJyB5PSc4NC4yMzk2NTknLz4KPHVzZSB4PScxODcuNTgyODM1JyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5My41MzgyNycvPgo8dXNlIHg9JzE5Mi4yMDQ0NScgeGxpbms6aHJlZj0nI2c0LTYxJyB5PSc5My41MzgyNycvPgo8dXNlIHg9JzE5OC43OTA5NTcnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nOTMuNTM4MjcnLz4KPHVzZSB4PScyMDYuODQ0MTAxJyB4bGluazpocmVmPScjZzMtNjAnIHk9JzkwLjA1MTI3Jy8+Cjx1c2UgeD0nMjE5LjI2OTU4MicgeGxpbms6aHJlZj0nI2czLTEyMScgeT0nOTAuMDUxMjcnLz4KPHVzZSB4PScyMjUuNDA2MjMzJyB4bGluazpocmVmPScjZzMtNTknIHk9JzkwLjA1MTI3Jy8+Cjx1c2UgeD0nMjMwLjY1MDM5MicgeGxpbms6aHJlZj0nI2czLTg0JyB5PSc5MC4wNTEyNycvPgo8dXNlIHg9JzIzNy41MTEzOTgnIHhsaW5rOmhyZWY9JyNnNC05MScgeT0nOTEuOTEwOTgnLz4KPHVzZSB4PScyMzkuODYzNzIxJyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5MS45MTA5OCcvPgo8dXNlIHg9JzI0NC40ODUzMzcnIHhsaW5rOmhyZWY9JyNnNC05MycgeT0nOTEuOTEwOTgnLz4KPHVzZSB4PScyNTAuNjU2NjIyJyB4bGluazpocmVmPScjZzMtNjInIHk9JzkwLjA1MTI3Jy8+Cjx1c2UgeD0nMjYzLjA4MjEwMycgeGxpbms6aHJlZj0nI2czLTg4JyB5PSc5MC4wNTEyNycvPgo8dXNlIHg9JzI3My43MzcyMTEnIHhsaW5rOmhyZWY9JyNnMy04MCcgeT0nOTAuMDUxMjcnLz4KPHVzZSB4PScyODEuMjgyNDc5JyB4bGluazpocmVmPScjZzQtOTEnIHk9JzkxLjkxMDk4Jy8+Cjx1c2UgeD0nMjgzLjYzNDgwMicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nOTEuOTEwOTgnLz4KPHVzZSB4PScyODguMjU2NDE4JyB4bGluazpocmVmPScjZzQtOTMnIHk9JzkxLjkxMDk4Jy8+Cjx1c2UgeD0nMTU1Ljg5NjE2MycgeGxpbms6aHJlZj0nI2c1LTYxJyB5PScxMDUuNTgyMDM0Jy8+Cjx1c2UgeD0nMTc0Ljk2MzQ1NScgeGxpbms6aHJlZj0nI2cwLTgwJyB5PSc5Ni42MTU1ODInLz4KPHVzZSB4PScxODcuNTgyODM1JyB4bGluazpocmVmPScjZzItMTAwJyB5PSc5OS43NzA0MjMnLz4KPHVzZSB4PScxODcuNTgyODM1JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMDkuMDY5MDM0Jy8+Cjx1c2UgeD0nMTkyLjIwNDQ1JyB4bGluazpocmVmPScjZzQtNjEnIHk9JzEwOS4wNjkwMzQnLz4KPHVzZSB4PScxOTguNzkwOTU3JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEwOS4wNjkwMzQnLz4KPHVzZSB4PScyMDYuODQ0MTAxJyB4bGluazpocmVmPScjZzMtNjAnIHk9JzEwNS41ODIwMzQnLz4KPHVzZSB4PScyMTkuMjY5NTgyJyB4bGluazpocmVmPScjZzMtMTIxJyB5PScxMDUuNTgyMDM0Jy8+Cjx1c2UgeD0nMjI1LjQwNjIzMycgeGxpbms6aHJlZj0nI2czLTU5JyB5PScxMDUuNTgyMDM0Jy8+Cjx1c2UgeD0nMjMwLjY1MDM5MicgeGxpbms6aHJlZj0nI2czLTg0JyB5PScxMDUuNTgyMDM0Jy8+Cjx1c2UgeD0nMjM3LjUxMTM5OCcgeGxpbms6aHJlZj0nI2c0LTkxJyB5PScxMDcuNDQxNzQ0Jy8+Cjx1c2UgeD0nMjM5Ljg2MzcyMScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTA3LjQ0MTc0NCcvPgo8dXNlIHg9JzI0NC40ODUzMzcnIHhsaW5rOmhyZWY9JyNnNC05MycgeT0nMTA3LjQ0MTc0NCcvPgo8dXNlIHg9JzI1MC42NTY2MjInIHhsaW5rOmhyZWY9JyNnMy02MicgeT0nMTA1LjU4MjAzNCcvPgo8dXNlIHg9JzI2My4wODIxMDMnIHhsaW5rOmhyZWY9JyNnMC04MCcgeT0nOTYuNjE1NTgyJy8+Cjx1c2UgeD0nMjc1LjcwMTQ4MicgeGxpbms6aHJlZj0nI2cyLTEwMCcgeT0nOTkuNzcwNDIzJy8+Cjx1c2UgeD0nMjc1LjcwMTQ4MicgeGxpbms6aHJlZj0nI2cyLTEwOCcgeT0nMTA5LjA2OTAzNCcvPgo8dXNlIHg9JzI3OC4zMjM2MDcnIHhsaW5rOmhyZWY9JyNnNC02MScgeT0nMTA5LjA2OTAzNCcvPgo8dXNlIHg9JzI4NC45MTAxMTQnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTA5LjA2OTAzNCcvPgo8dXNlIHg9JzI5MS42MzQ5MjcnIHhsaW5rOmhyZWY9JyNnMy04OCcgeT0nMTA1LjU4MjAzNCcvPgo8dXNlIHg9JzMwMS4zNTAxNTQnIHhsaW5rOmhyZWY9JyNnNC05MScgeT0nMTA3LjQ0MTc0NCcvPgo8dXNlIHg9JzMwMy43MDI0NzgnIHhsaW5rOmhyZWY9JyNnMi0xMDgnIHk9JzEwNy40NDE3NDQnLz4KPHVzZSB4PSczMDYuMzI0NjAzJyB4bGluazpocmVmPScjZzQtOTMnIHk9JzEwNy40NDE3NDQnLz4KPHVzZSB4PSczMDkuMTc1MDU5JyB4bGluazpocmVmPScjZzMtODAnIHk9JzEwNS41ODIwMzQnLz4KPHVzZSB4PSczMTYuNzIwMzI2JyB4bGluazpocmVmPScjZzItMTA4JyB5PScxMDcuMzc1Mjk3Jy8+Cjx1c2UgeD0nMzE5LjM0MjQ1MScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTA3LjM3NTI5NycvPgo8dXNlIHg9JzE1NS44OTYxNjMnIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nMTIxLjExMjc5OCcvPgo8dXNlIHg9JzE3NC45NjM0NTUnIHhsaW5rOmhyZWY9JyNnMC04MCcgeT0nMTEyLjE0NjM0NicvPgo8dXNlIHg9JzE4Ny41ODI4MzUnIHhsaW5rOmhyZWY9JyNnMi0xMDAnIHk9JzExNS4zMDExODcnLz4KPHVzZSB4PScxODcuNTgyODM1JyB4bGluazpocmVmPScjZzItMTA4JyB5PScxMjQuNTk5Nzk4Jy8+Cjx1c2UgeD0nMTkwLjIwNDk2JyB4bGluazpocmVmPScjZzQtNjEnIHk9JzEyNC41OTk3OTgnLz4KPHVzZSB4PScxOTYuNzkxNDY2JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEyNC41OTk3OTgnLz4KPHVzZSB4PScyMDMuNTE2Mjc5JyB4bGluazpocmVmPScjZzMtODgnIHk9JzEyMS4xMTI3OTgnLz4KPHVzZSB4PScyMTMuMjMxNTA2JyB4bGluazpocmVmPScjZzQtOTEnIHk9JzEyMi45NzI1MDgnLz4KPHVzZSB4PScyMTUuNTgzODMnIHhsaW5rOmhyZWY9JyNnMi0xMDgnIHk9JzEyMi45NzI1MDgnLz4KPHVzZSB4PScyMTguMjA1OTU1JyB4bGluazpocmVmPScjZzQtOTMnIHk9JzEyMi45NzI1MDgnLz4KPHVzZSB4PScyMjMuMDQ4OTA4JyB4bGluazpocmVmPScjZzAtODAnIHk9JzExMi4xNDYzNDYnLz4KPHVzZSB4PScyMzUuNjY4Mjg4JyB4bGluazpocmVmPScjZzItMTAwJyB5PScxMTUuMzAxMTg3Jy8+Cjx1c2UgeD0nMjM1LjY2ODI4OCcgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTI0LjU5OTc5OCcvPgo8dXNlIHg9JzI0MC4yODk5MDMnIHhsaW5rOmhyZWY9JyNnNC02MScgeT0nMTI0LjU5OTc5OCcvPgo8dXNlIHg9JzI0Ni44NzY0MScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMjQuNTk5Nzk4Jy8+Cjx1c2UgeD0nMjU0LjkyOTU1NCcgeGxpbms6aHJlZj0nI2czLTYwJyB5PScxMjEuMTEyNzk4Jy8+Cjx1c2UgeD0nMjY3LjM1NTAzNScgeGxpbms6aHJlZj0nI2czLTEyMScgeT0nMTIxLjExMjc5OCcvPgo8dXNlIHg9JzI3My40OTE2ODcnIHhsaW5rOmhyZWY9JyNnMy01OScgeT0nMTIxLjExMjc5OCcvPgo8dXNlIHg9JzI3OC43MzU4NDYnIHhsaW5rOmhyZWY9JyNnMy04NCcgeT0nMTIxLjExMjc5OCcvPgo8dXNlIHg9JzI4NS41OTY4NTEnIHhsaW5rOmhyZWY9JyNnNC05MScgeT0nMTIyLjk3MjUwOCcvPgo8dXNlIHg9JzI4Ny45NDkxNzUnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEyMi45NzI1MDgnLz4KPHVzZSB4PScyOTIuNTcwNzknIHhsaW5rOmhyZWY9JyNnNC05MycgeT0nMTIyLjk3MjUwOCcvPgo8dXNlIHg9JzI5OC43NDIwNzUnIHhsaW5rOmhyZWY9JyNnMy02MicgeT0nMTIxLjExMjc5OCcvPgo8dXNlIHg9JzMxMS4xNjc1NTYnIHhsaW5rOmhyZWY9JyNnMy04MCcgeT0nMTIxLjExMjc5OCcvPgo8dXNlIHg9JzMxOC43MTI4MjQnIHhsaW5rOmhyZWY9JyNnMi0xMDgnIHk9JzEyMi45MDYwNjEnLz4KPHVzZSB4PSczMjEuMzM0OTQ5JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMjIuOTA2MDYxJy8+Cjx1c2UgeD0nMTU1Ljg5NjE2MycgeGxpbms6aHJlZj0nI2c1LTYxJyB5PScxMzYuNjQzNTYyJy8+Cjx1c2UgeD0nMTc0Ljk2MzQ1NScgeGxpbms6aHJlZj0nI2cwLTgwJyB5PScxMjcuNjc3MTEnLz4KPHVzZSB4PScxODcuNTgyODM1JyB4bGluazpocmVmPScjZzItMTAwJyB5PScxMzAuODMxOTUxJy8+Cjx1c2UgeD0nMTg3LjU4MjgzNScgeGxpbms6aHJlZj0nI2cyLTEwOCcgeT0nMTQwLjEzMDU2MicvPgo8dXNlIHg9JzE5MC4yMDQ5NicgeGxpbms6aHJlZj0nI2c0LTYxJyB5PScxNDAuMTMwNTYyJy8+Cjx1c2UgeD0nMTk2Ljc5MTQ2NicgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxNDAuMTMwNTYyJy8+Cjx1c2UgeD0nMjAzLjUxNjI3OScgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxMzYuNjQzNTYyJy8+Cjx1c2UgeD0nMjEzLjIzMTUwNicgeGxpbms6aHJlZj0nI2c0LTkxJyB5PScxMzguNTAzMjcyJy8+Cjx1c2UgeD0nMjE1LjU4MzgzJyB4bGluazpocmVmPScjZzItMTA4JyB5PScxMzguNTAzMjcyJy8+Cjx1c2UgeD0nMjE4LjIwNTk1NScgeGxpbms6aHJlZj0nI2c0LTkzJyB5PScxMzguNTAzMjcyJy8+Cjx1c2UgeD0nMjIxLjA1NjQxMScgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxMzYuNjQzNTYyJy8+Cjx1c2UgeD0nMjI1LjYwODczNicgeGxpbms6aHJlZj0nI2czLTg0JyB5PScxMzYuNjQzNTYyJy8+Cjx1c2UgeD0nMjM0LjA5NTU3MicgeGxpbms6aHJlZj0nI2cxLTQ4JyB5PScxMzIuMzA1MTI1Jy8+Cjx1c2UgeD0nMjM2Ljg5MDY0OCcgeGxpbms6aHJlZj0nI2czLTEyMScgeT0nMTM2LjY0MzU2MicvPgo8dXNlIHg9JzI0My4wMjczJyB4bGluazpocmVmPScjZzMtODAnIHk9JzEzNi42NDM1NjInLz4KPHVzZSB4PScyNTAuNTcyNTY4JyB4bGluazpocmVmPScjZzItMTA4JyB5PScxMzguNDM2ODI1Jy8+Cjx1c2UgeD0nMjUzLjY5MjgyNScgeGxpbms6aHJlZj0nI2c1LTQxJyB5PScxMzYuNjQzNTYyJy8+Cjx1c2UgeD0nMTU1Ljg5NjE2MycgeGxpbms6aHJlZj0nI2c1LTYxJyB5PScxNTIuMTc0MzI2Jy8+Cjx1c2UgeD0nMTc0Ljk2MzQ1NScgeGxpbms6aHJlZj0nI2cwLTgwJyB5PScxNDMuMjA3ODc0Jy8+Cjx1c2UgeD0nMTg3LjU4MjgzNScgeGxpbms6aHJlZj0nI2cyLTEwMCcgeT0nMTQ2LjM2MjcxNScvPgo8dXNlIHg9JzE4Ny41ODI4MzUnIHhsaW5rOmhyZWY9JyNnMi0xMDgnIHk9JzE1NS42NjEzMjYnLz4KPHVzZSB4PScxOTAuMjA0OTYnIHhsaW5rOmhyZWY9JyNnNC02MScgeT0nMTU1LjY2MTMyNicvPgo8dXNlIHg9JzE5Ni43OTE0NjYnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTU1LjY2MTMyNicvPgo8dXNlIHg9JzIwMy41MTYyNzknIHhsaW5rOmhyZWY9JyNnMy04OCcgeT0nMTUyLjE3NDMyNicvPgo8dXNlIHg9JzIxMy4yMzE1MDYnIHhsaW5rOmhyZWY9JyNnNC05MScgeT0nMTU0LjAzNDAzNicvPgo8dXNlIHg9JzIxNS41ODM4MycgeGxpbms6aHJlZj0nI2cyLTEwOCcgeT0nMTU0LjAzNDAzNicvPgo8dXNlIHg9JzIxOC4yMDU5NTUnIHhsaW5rOmhyZWY9JyNnNC05MycgeT0nMTU0LjAzNDAzNicvPgo8dXNlIHg9JzIyMS4wNTY0MTEnIHhsaW5rOmhyZWY9JyNnMy0xMicgeT0nMTUyLjE3NDMyNicvPgo8dXNlIHg9JzIyNy42NjQ4OTknIHhsaW5rOmhyZWY9JyNnMi0xMDgnIHk9JzE1My45Njc1ODknLz4KPC9nPgo8L3N2Zz4=)
D’où  .
L’implémentation suit :
.
L’implémentation suit :
<<<
import numpy
X = numpy.array([[1., 2., 3., 4.],
[5., 6., 6., 6.],
[5., 6., 7., 8.]]).T
Xt = X.T
Tt = numpy.empty(Xt.shape)
Pt = numpy.identity(X.shape[1])
for i in range(0, Xt.shape[0]):
Tt[i, :] = Xt[i, :]
for j in range(0, i):
d = numpy.dot(Tt[j, :], Xt[i, :])
Tt[i, :] -= Tt[j, :] * d
Pt[i, :] -= Pt[j, :] * d
d = numpy.dot(Tt[i, :], Tt[i, :])
if d > 0:
d **= 0.5
Tt[i, :] /= d
Pt[i, :] /= d
print("X")
print(X)
print("T")
print(Tt.T)
print("X P")
print(X @ Pt.T)
print("T T'")
print(Tt @ Tt.T)
y = numpy.array([0.1, 0.2, 0.19, 0.29])
beta1 = numpy.linalg.inv(Xt @ X) @ Xt @ y
beta2 = Tt @ y @ Pt
print("beta1")
print(beta1)
print("beta2")
print(beta2)
>>>
X
[[1. 5. 5.]
[2. 6. 6.]
[3. 6. 7.]
[4. 6. 8.]]
T
[[ 0.183 0.736 0.651]
[ 0.365 0.502 -0.67 ]
[ 0.548 0.024 -0.181]
[ 0.73 -0.453 0.308]]
X P
[[ 0.183 0.736 0.651]
[ 0.365 0.502 -0.67 ]
[ 0.548 0.024 -0.181]
[ 0.73 -0.453 0.308]]
T T'
[[ 1.000e+00 3.886e-16 9.021e-16]
[ 3.886e-16 1.000e+00 -1.110e-14]
[ 9.021e-16 -1.110e-14 1.000e+00]]
beta1
[ 0.077 0.037 -0.032]
beta2
[ 0.077 0.037 -0.032]
La librairie implémente ces deux algorithmes de manière un peu
plus efficace dans les fonctions
gram_schmidt et
linear_regression.
Streaming#
Streaming Gram-Schmidt#
Je ne sais pas vraiment comment le dire en français,
peut-être régression linéaire mouvante. Même Google ou Bing
garde le mot streaming dans leur traduction…
C’est néanmoins l’idée qu’il faut
réussir à mettre en place d’une façon ou d’une autre car pour
choisir le bon point de coupure pour un arbre de décision.
On note  la matrice composée
des lignes
la matrice composée
des lignes  et le vecteur colonne
et le vecteur colonne
 .
L’apprentissage de l’arbre de décision
faut calculer des régressions pour les problèmes
.
L’apprentissage de l’arbre de décision
faut calculer des régressions pour les problèmes
 .
L’idée que je propose n’est pas parfaite mais elle fonctionne
pour l’idée de l’algorithme avec Gram-Schmidt.
.
L’idée que je propose n’est pas parfaite mais elle fonctionne
pour l’idée de l’algorithme avec Gram-Schmidt.
Tout d’abord, il faut imaginer un algorithme
de Gram-Schmidt version streaming. Pour la matrice
 , celui-ci produit deux matrices
, celui-ci produit deux matrices
 et
et  telles que :
telles que :
 . On note d la dimension
des observations. Comment faire pour ajouter une observation
. On note d la dimension
des observations. Comment faire pour ajouter une observation
 ? L’idée d’un algorithme au format streaming
est que le coût de la mise à jour pour l’itération k+1
ne dépend pas de k.
? L’idée d’un algorithme au format streaming
est que le coût de la mise à jour pour l’itération k+1
ne dépend pas de k.
On suppose donc que  sont les deux matrices
retournées par l’algorithme de algo_gram_schmidt.
On construit la matrice
sont les deux matrices
retournées par l’algorithme de algo_gram_schmidt.
On construit la matrice ![V_{k+1} = [ T_k, X_{k+1} P_k ]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSAxMDAuNTYwMDExIDExLjk1NTE2OCcgd2lkdGg9JzEwMC41NjAwMTFwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzMtNjEnLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2czLTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2czLTkzJy8+CjxwYXRoIGQ9J00zLjQ3NDk2OSAtMS44MDkyMTVINS44MTgxODJDNS45Mjk3NjMgLTEuODA5MjE1IDYuMTA1MTA2IC0xLjgwOTIxNSA2LjEwNTEwNiAtMS45OTI1MjhTNS45Mjk3NjMgLTIuMTc1ODQxIDUuODE4MTgyIC0yLjE3NTg0MUgzLjQ3NDk2OVYtNC41MjcwMjRDMy40NzQ5NjkgLTQuNjM4NjA1IDMuNDc0OTY5IC00LjgxMzk0OCAzLjI5MTY1NiAtNC44MTM5NDhTMy4xMDgzNDQgLTQuNjM4NjA1IDMuMTA4MzQ0IC00LjUyNzAyNFYtMi4xNzU4NDFIMC43NTcxNjFDMC42NDU1NzkgLTIuMTc1ODQxIDAuNDcwMjM3IC0yLjE3NTg0MSAwLjQ3MDIzNyAtMS45OTI1MjhTMC42NDU1NzkgLTEuODA5MjE1IDAuNzU3MTYxIC0xLjgwOTIxNUgzLjEwODM0NFYwLjU0MTk2OEMzLjEwODM0NCAwLjY1MzU0OSAzLjEwODM0NCAwLjgyODg5MiAzLjI5MTY1NiAwLjgyODg5MlMzLjQ3NDk2OSAwLjY1MzU0OSAzLjQ3NDk2OSAwLjU0MTk2OFYtMS44MDkyMTVaJyBpZD0nZzItNDMnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2cyLTQ5Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMS01OScvPgo8cGF0aCBkPSdNMy41Mzg3MyAtMy44MDE3NDNINS41NDcxOThDNy4xOTcwMTEgLTMuODAxNzQzIDguODQ2ODI0IC01LjAyMTE3MSA4Ljg0NjgyNCAtNi4zODQwNkM4Ljg0NjgyNCAtNy4zMTY1NjMgOC4wNTc3ODMgLTguMTY1MzggNi41NTE0MzIgLTguMTY1MzhIMi44NTcyODVDMi42MzAxMzcgLTguMTY1MzggMi41MjI1NCAtOC4xNjUzOCAyLjUyMjU0IC03LjkzODIzMkMyLjUyMjU0IC03LjgxODY4IDIuNjMwMTM3IC03LjgxODY4IDIuODA5NDY1IC03LjgxODY4QzMuNTM4NzMgLTcuODE4NjggMy41Mzg3MyAtNy43MjMwMzkgMy41Mzg3MyAtNy41OTE1MzJDMy41Mzg3MyAtNy41Njc2MjEgMy41Mzg3MyAtNy40OTU4OSAzLjQ5MDkwOSAtNy4zMTY1NjNMMS44NzY5NjEgLTAuODg0NjgyQzEuNzY5MzY1IC0wLjQ2NjI1MiAxLjc0NTQ1NSAtMC4zNDY3IDAuOTA4NTkzIC0wLjM0NjdDMC42ODE0NDUgLTAuMzQ2NyAwLjU2MTg5MyAtMC4zNDY3IDAuNTYxODkzIC0wLjEzMTUwN0MwLjU2MTg5MyAwIDAuNjY5NDg5IDAgMC43NDEyMiAwQzAuOTY4MzY5IDAgMS4yMDc0NzIgLTAuMDIzOTEgMS40MzQ2MiAtMC4wMjM5MUgyLjgzMzM3NUMzLjA2MDUyMyAtMC4wMjM5MSAzLjMxMTU4MiAwIDMuNTM4NzMgMEMzLjYzNDM3MSAwIDMuNzY1ODc4IDAgMy43NjU4NzggLTAuMjI3MTQ4QzMuNzY1ODc4IC0wLjM0NjcgMy42NTgyODEgLTAuMzQ2NyAzLjQ3ODk1NCAtMC4zNDY3QzIuNzYxNjQ0IC0wLjM0NjcgMi43NDk2ODkgLTAuNDMwMzg2IDIuNzQ5Njg5IC0wLjU0OTkzOEMyLjc0OTY4OSAtMC42MDk3MTQgMi43NjE2NDQgLTAuNjkzNCAyLjc3MzU5OSAtMC43NTMxNzZMMy41Mzg3MyAtMy44MDE3NDNaTTQuMzk5NTAyIC03LjM1MjQyOEM0LjUwNzA5OCAtNy43OTQ3NyA0LjU1NDkxOSAtNy44MTg2OCA1LjAyMTE3MSAtNy44MTg2OEg2LjIwNDczMkM3LjEwMTM3IC03LjgxODY4IDcuODQyNTkgLTcuNTMxNzU2IDcuODQyNTkgLTYuNjM1MTE4QzcuODQyNTkgLTYuMzI0Mjg0IDcuNjg3MTczIC01LjMwODA5NSA3LjEzNzIzNSAtNC43NTgxNTdDNi45MzM5OTggLTQuNTQyOTY0IDYuMzYwMTQ5IC00LjA4ODY2NyA1LjI3MjIyOSAtNC4wODg2NjdIMy41ODY1NUw0LjM5OTUwMiAtNy4zNTI0MjhaJyBpZD0nZzEtODAnLz4KPHBhdGggZD0nTTQuOTg1MzA1IC03LjI5MjY1M0M1LjA1NzAzNiAtNy41Nzk1NzcgNS4wODA5NDYgLTcuNjg3MTczIDUuMjYwMjc0IC03LjczNDk5NEM1LjM1NTkxNSAtNy43NTg5MDQgNS43NTA0MzYgLTcuNzU4OTA0IDYuMDAxNDk0IC03Ljc1ODkwNEM3LjE5NzAxMSAtNy43NTg5MDQgNy43NTg5MDQgLTcuNzExMDgzIDcuNzU4OTA0IC02Ljc3ODU4QzcuNzU4OTA0IC02LjU5OTI1MyA3LjcxMTA4MyAtNi4xNDQ5NTYgNy42MzkzNTIgLTUuNzAyNjE1TDcuNjI3Mzk3IC01LjU1OTE1M0M3LjYyNzM5NyAtNS41MTEzMzMgNy42NzUyMTggLTUuNDM5NjAxIDcuNzQ2OTQ5IC01LjQzOTYwMUM3Ljg2NjUwMSAtNS40Mzk2MDEgNy44NjY1MDEgLTUuNDk5Mzc3IDcuOTAyMzY2IC01LjY5MDY2TDguMjQ5MDY2IC03LjgwNjcyNUM4LjI3Mjk3NiAtNy45MTQzMjEgOC4yNzI5NzYgLTcuOTM4MjMyIDguMjcyOTc2IC03Ljk3NDA5N0M4LjI3Mjk3NiAtOC4xMDU2MDQgOC4yMDEyNDUgLTguMTA1NjA0IDcuOTYyMTQyIC04LjEwNTYwNEgxLjQyMjY2NUMxLjE0NzY5NiAtOC4xMDU2MDQgMS4xMzU3NDEgLTguMDkzNjQ5IDEuMDY0MDEgLTcuODc4NDU2TDAuMzM0NzQ1IC01LjcyNjUyNkMwLjMyMjc5IC01LjcwMjYxNSAwLjI4NjkyNCAtNS41NzExMDggMC4yODY5MjQgLTUuNTU5MTUzQzAuMjg2OTI0IC01LjQ5OTM3NyAwLjMzNDc0NSAtNS40Mzk2MDEgMC40MDY0NzYgLTUuNDM5NjAxQzAuNTAyMTE3IC01LjQzOTYwMSAwLjUyNjAyNyAtNS40ODc0MjIgMC41NzM4NDggLTUuNjQyODM5QzEuMDc1OTY1IC03LjA4OTQxNSAxLjMyNzAyNCAtNy43NTg5MDQgMi45MTcwNjEgLTcuNzU4OTA0SDMuNzE4MDU3QzQuMDA0OTgxIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNjI3Mzk3QzQuMTI0NTMzIC03LjU5MTUzMiA0LjEyNDUzMyAtNy41Njc2MjEgNC4wNjQ3NTcgLTcuMzUyNDI4TDIuNDYyNzY1IC0wLjkzMjUwM0MyLjM0MzIxMyAtMC40NjYyNTIgMi4zMTkzMDMgLTAuMzQ2NyAxLjA1MjA1NSAtMC4zNDY3QzAuNzUzMTc2IC0wLjM0NjcgMC42Njk0ODkgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4xMTk1NTJDMC42Njk0ODkgMCAwLjgwMDk5NiAwIDAuODYwNzcyIDBDMS4xNTk2NTEgMCAxLjQ3MDQ4NiAtMC4wMjM5MSAxLjc2OTM2NSAtMC4wMjM5MUgzLjYzNDM3MUMzLjkzMzI1IC0wLjAyMzkxIDQuMjU2MDQgMCA0LjU1NDkxOSAwQzQuNjg2NDI2IDAgNC44MDU5NzggMCA0LjgwNTk3OCAtMC4yMjcxNDhDNC44MDU5NzggLTAuMzQ2NyA0LjcyMjI5MSAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjdDMy4zMzU0OTIgLTAuMzQ2NyAzLjMzNTQ5MiAtMC40NTQyOTYgMy4zMzU0OTIgLTAuNjMzNjI0QzMuMzM1NDkyIC0wLjY0NTU3OSAzLjMzNTQ5MiAtMC43MjkyNjUgMy4zODMzMTMgLTAuOTIwNTQ4TDQuOTg1MzA1IC03LjI5MjY1M1onIGlkPSdnMS04NCcvPgo8cGF0aCBkPSdNNy40MDAyNDkgLTYuODM4MzU2QzcuODA2NzI1IC03LjQ4MzkzNSA4LjE3NzMzNSAtNy43NzA4NTkgOC43ODcwNDkgLTcuODE4NjhDOC45MDY2IC03LjgzMDYzNSA5LjAwMjI0MiAtNy44MzA2MzUgOS4wMDIyNDIgLTguMDQ1ODI4QzkuMDAyMjQyIC04LjA5MzY0OSA4Ljk3ODMzMSAtOC4xNjUzOCA4Ljg3MDczNSAtOC4xNjUzOEM4LjY1NTU0MiAtOC4xNjUzOCA4LjE0MTQ2OSAtOC4xNDE0NjkgNy45MjYyNzYgLTguMTQxNDY5QzcuNTc5NTc3IC04LjE0MTQ2OSA3LjIyMDkyMiAtOC4xNjUzOCA2Ljg4NjE3NyAtOC4xNjUzOEM2Ljc5MDUzNSAtOC4xNjUzOCA2LjY3MDk4NCAtOC4xNjUzOCA2LjY3MDk4NCAtNy45MzgyMzJDNi42NzA5ODQgLTcuODMwNjM1IDYuNzc4NTggLTcuODE4NjggNi44MjY0MDEgLTcuODE4NjhDNy4yNjg3NDIgLTcuNzgyODE0IDcuMzE2NTYzIC03LjU2NzYyMSA3LjMxNjU2MyAtNy40MjQxNTlDNy4zMTY1NjMgLTcuMjQ0ODMyIDcuMTQ5MTkxIC02Ljk2OTg2MyA3LjEzNzIzNSAtNi45NTc5MDhMMy4zODMzMTMgLTEuMDA0MjM0TDIuNTQ2NDUxIC03LjQ0ODA3QzIuNTQ2NDUxIC03Ljc5NDc3IDMuMTY4MTIgLTcuODE4NjggMy4yOTk2MjYgLTcuODE4NjhDMy40Nzg5NTQgLTcuODE4NjggMy41ODY1NSAtNy44MTg2OCAzLjU4NjU1IC04LjA0NTgyOEMzLjU4NjU1IC04LjE2NTM4IDMuNDU1MDQ0IC04LjE2NTM4IDMuNDE5MTc4IC04LjE2NTM4QzMuMjE1OTQgLTguMTY1MzggMi45NzY4MzcgLTguMTQxNDY5IDIuNzczNTk5IC04LjE0MTQ2OUgyLjEwNDExQzEuMjMxMzgyIC04LjE0MTQ2OSAwLjg3MjcyNyAtOC4xNjUzOCAwLjg2MDc3MiAtOC4xNjUzOEMwLjc4OTA0MSAtOC4xNjUzOCAwLjY0NTU3OSAtOC4xNjUzOCAwLjY0NTU3OSAtNy45NTAxODdDMC42NDU1NzkgLTcuODE4NjggMC43MjkyNjUgLTcuODE4NjggMC45MjA1NDggLTcuODE4NjhDMS41MzAyNjIgLTcuODE4NjggMS41NjYxMjcgLTcuNzExMDgzIDEuNjAxOTkzIC03LjQxMjIwNEwyLjU1ODQwNiAtMC4wMzU4NjZDMi41OTQyNzEgMC4yMTUxOTMgMi41OTQyNzEgMC4yNTEwNTkgMi43NjE2NDQgMC4yNTEwNTlDMi45MDUxMDYgMC4yNTEwNTkgMi45NjQ4ODIgMC4yMTUxOTMgMy4wODQ0MzMgMC4wMjM5MUw3LjQwMDI0OSAtNi44MzgzNTZaJyBpZD0nZzEtODYnLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2cxLTg4Jy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMC0xMDcnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cxLTg2JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0NS42Nzg2NDYnIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzUwLjMwMDI2MicgeGxpbms6aHJlZj0nI2cyLTQzJyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PSc1Ni44ODY3NjgnIHhsaW5rOmhyZWY9JyNnMi00OScgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nNjQuOTM5OTEzJyB4bGluazpocmVmPScjZzMtNjEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc3LjM2NTM5NCcgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MC42MTcwNTUnIHhsaW5rOmhyZWY9JyNnMS04NCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODcuNDc4MDYnIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzkyLjU5NzgwOCcgeGxpbms6aHJlZj0nI2cxLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5Ny44NDE5NjYnIHhsaW5rOmhyZWY9JyNnMS04OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA3LjU1NzE5NCcgeGxpbms6aHJlZj0nI2cwLTEwNycgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nMTEyLjE3ODgwOScgeGxpbms6aHJlZj0nI2cyLTQzJyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PScxMTguNzY1MzE2JyB4bGluazpocmVmPScjZzItNDknIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzEyMy40OTc2MzEnIHhsaW5rOmhyZWY9JyNnMS04MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTMxLjA0Mjg5OScgeGxpbms6aHJlZj0nI2cwLTEwNycgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nMTM2LjE2MjY0NicgeGxpbms6aHJlZj0nI2czLTkzJyB5PSc2NS43NTM0MjUnLz4KPC9nPgo8L3N2Zz4=) :
on ajoute une ligne à la matrice
:
on ajoute une ligne à la matrice  . On applique
une itération de algorithme de algo_gram_schmidt
pour obtenir
. On applique
une itération de algorithme de algo_gram_schmidt
pour obtenir  . On en déduit que
. On en déduit que
 . L’expression
de la régression ne change pas mais il reste à l’expression
de telle sorte que les expressions ne dépendent pas de k.
Comme
. L’expression
de la régression ne change pas mais il reste à l’expression
de telle sorte que les expressions ne dépendent pas de k.
Comme ![T_k = X_{[1..k]} P_k](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMDIxNjA0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU3LjU4NDA1OSA2OC4zNzIzOTkgMTIuMDIxNjA0JyB3aWR0aD0nNjguMzcyMzk5cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2cyLTQ5Jy8+CjxwYXRoIGQ9J00yLjE1OTkgMS45OTI1MjhWMS42MjU5MDNIMS4zNTQ5MTlWLTUuNjEwOTU5SDIuMTU5OVYtNS45Nzc1ODRIMC45ODgyOTRWMS45OTI1MjhIMi4xNTk5WicgaWQ9J2cyLTkxJy8+CjxwYXRoIGQ9J00xLjM1NDkxOSAtNS45Nzc1ODRIMC4xODMzMTNWLTUuNjEwOTU5SDAuOTg4Mjk0VjEuNjI1OTAzSDAuMTgzMzEzVjEuOTkyNTI4SDEuMzU0OTE5Vi01Ljk3NzU4NFonIGlkPSdnMi05MycvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzMtNjEnLz4KPHBhdGggZD0nTTMuNTM4NzMgLTMuODAxNzQzSDUuNTQ3MTk4QzcuMTk3MDExIC0zLjgwMTc0MyA4Ljg0NjgyNCAtNS4wMjExNzEgOC44NDY4MjQgLTYuMzg0MDZDOC44NDY4MjQgLTcuMzE2NTYzIDguMDU3NzgzIC04LjE2NTM4IDYuNTUxNDMyIC04LjE2NTM4SDIuODU3Mjg1QzIuNjMwMTM3IC04LjE2NTM4IDIuNTIyNTQgLTguMTY1MzggMi41MjI1NCAtNy45MzgyMzJDMi41MjI1NCAtNy44MTg2OCAyLjYzMDEzNyAtNy44MTg2OCAyLjgwOTQ2NSAtNy44MTg2OEMzLjUzODczIC03LjgxODY4IDMuNTM4NzMgLTcuNzIzMDM5IDMuNTM4NzMgLTcuNTkxNTMyQzMuNTM4NzMgLTcuNTY3NjIxIDMuNTM4NzMgLTcuNDk1ODkgMy40OTA5MDkgLTcuMzE2NTYzTDEuODc2OTYxIC0wLjg4NDY4MkMxLjc2OTM2NSAtMC40NjYyNTIgMS43NDU0NTUgLTAuMzQ2NyAwLjkwODU5MyAtMC4zNDY3QzAuNjgxNDQ1IC0wLjM0NjcgMC41NjE4OTMgLTAuMzQ2NyAwLjU2MTg5MyAtMC4xMzE1MDdDMC41NjE4OTMgMCAwLjY2OTQ4OSAwIDAuNzQxMjIgMEMwLjk2ODM2OSAwIDEuMjA3NDcyIC0wLjAyMzkxIDEuNDM0NjIgLTAuMDIzOTFIMi44MzMzNzVDMy4wNjA1MjMgLTAuMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4IC0wLjIyNzE0OEMzLjc2NTg3OCAtMC4zNDY3IDMuNjU4MjgxIC0wLjM0NjcgMy40Nzg5NTQgLTAuMzQ2N0MyLjc2MTY0NCAtMC4zNDY3IDIuNzQ5Njg5IC0wLjQzMDM4NiAyLjc0OTY4OSAtMC41NDk5MzhDMi43NDk2ODkgLTAuNjA5NzE0IDIuNzYxNjQ0IC0wLjY5MzQgMi43NzM1OTkgLTAuNzUzMTc2TDMuNTM4NzMgLTMuODAxNzQzWk00LjM5OTUwMiAtNy4zNTI0MjhDNC41MDcwOTggLTcuNzk0NzcgNC41NTQ5MTkgLTcuODE4NjggNS4wMjExNzEgLTcuODE4NjhINi4yMDQ3MzJDNy4xMDEzNyAtNy44MTg2OCA3Ljg0MjU5IC03LjUzMTc1NiA3Ljg0MjU5IC02LjYzNTExOEM3Ljg0MjU5IC02LjMyNDI4NCA3LjY4NzE3MyAtNS4zMDgwOTUgNy4xMzcyMzUgLTQuNzU4MTU3QzYuOTMzOTk4IC00LjU0Mjk2NCA2LjM2MDE0OSAtNC4wODg2NjcgNS4yNzIyMjkgLTQuMDg4NjY3SDMuNTg2NTVMNC4zOTk1MDIgLTcuMzUyNDI4WicgaWQ9J2cxLTgwJy8+CjxwYXRoIGQ9J000Ljk4NTMwNSAtNy4yOTI2NTNDNS4wNTcwMzYgLTcuNTc5NTc3IDUuMDgwOTQ2IC03LjY4NzE3MyA1LjI2MDI3NCAtNy43MzQ5OTRDNS4zNTU5MTUgLTcuNzU4OTA0IDUuNzUwNDM2IC03Ljc1ODkwNCA2LjAwMTQ5NCAtNy43NTg5MDRDNy4xOTcwMTEgLTcuNzU4OTA0IDcuNzU4OTA0IC03LjcxMTA4MyA3Ljc1ODkwNCAtNi43Nzg1OEM3Ljc1ODkwNCAtNi41OTkyNTMgNy43MTEwODMgLTYuMTQ0OTU2IDcuNjM5MzUyIC01LjcwMjYxNUw3LjYyNzM5NyAtNS41NTkxNTNDNy42MjczOTcgLTUuNTExMzMzIDcuNjc1MjE4IC01LjQzOTYwMSA3Ljc0Njk0OSAtNS40Mzk2MDFDNy44NjY1MDEgLTUuNDM5NjAxIDcuODY2NTAxIC01LjQ5OTM3NyA3LjkwMjM2NiAtNS42OTA2Nkw4LjI0OTA2NiAtNy44MDY3MjVDOC4yNzI5NzYgLTcuOTE0MzIxIDguMjcyOTc2IC03LjkzODIzMiA4LjI3Mjk3NiAtNy45NzQwOTdDOC4yNzI5NzYgLTguMTA1NjA0IDguMjAxMjQ1IC04LjEwNTYwNCA3Ljk2MjE0MiAtOC4xMDU2MDRIMS40MjI2NjVDMS4xNDc2OTYgLTguMTA1NjA0IDEuMTM1NzQxIC04LjA5MzY0OSAxLjA2NDAxIC03Ljg3ODQ1NkwwLjMzNDc0NSAtNS43MjY1MjZDMC4zMjI3OSAtNS43MDI2MTUgMC4yODY5MjQgLTUuNTcxMTA4IDAuMjg2OTI0IC01LjU1OTE1M0MwLjI4NjkyNCAtNS40OTkzNzcgMC4zMzQ3NDUgLTUuNDM5NjAxIDAuNDA2NDc2IC01LjQzOTYwMUMwLjUwMjExNyAtNS40Mzk2MDEgMC41MjYwMjcgLTUuNDg3NDIyIDAuNTczODQ4IC01LjY0MjgzOUMxLjA3NTk2NSAtNy4wODk0MTUgMS4zMjcwMjQgLTcuNzU4OTA0IDIuOTE3MDYxIC03Ljc1ODkwNEgzLjcxODA1N0M0LjAwNDk4MSAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNzU4OTA0IDQuMTI0NTMzIC03LjYyNzM5N0M0LjEyNDUzMyAtNy41OTE1MzIgNC4xMjQ1MzMgLTcuNTY3NjIxIDQuMDY0NzU3IC03LjM1MjQyOEwyLjQ2Mjc2NSAtMC45MzI1MDNDMi4zNDMyMTMgLTAuNDY2MjUyIDIuMzE5MzAzIC0wLjM0NjcgMS4wNTIwNTUgLTAuMzQ2N0MwLjc1MzE3NiAtMC4zNDY3IDAuNjY5NDg5IC0wLjM0NjcgMC42Njk0ODkgLTAuMTE5NTUyQzAuNjY5NDg5IDAgMC44MDA5OTYgMCAwLjg2MDc3MiAwQzEuMTU5NjUxIDAgMS40NzA0ODYgLTAuMDIzOTEgMS43NjkzNjUgLTAuMDIzOTFIMy42MzQzNzFDMy45MzMyNSAtMC4wMjM5MSA0LjI1NjA0IDAgNC41NTQ5MTkgMEM0LjY4NjQyNiAwIDQuODA1OTc4IDAgNC44MDU5NzggLTAuMjI3MTQ4QzQuODA1OTc4IC0wLjM0NjcgNC43MjIyOTEgLTAuMzQ2NyA0LjQxMTQ1NyAtMC4zNDY3QzMuMzM1NDkyIC0wLjM0NjcgMy4zMzU0OTIgLTAuNDU0Mjk2IDMuMzM1NDkyIC0wLjYzMzYyNEMzLjMzNTQ5MiAtMC42NDU1NzkgMy4zMzU0OTIgLTAuNzI5MjY1IDMuMzgzMzEzIC0wLjkyMDU0OEw0Ljk4NTMwNSAtNy4yOTI2NTNaJyBpZD0nZzEtODQnLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2cxLTg4Jy8+CjxwYXRoIGQ9J00xLjYxNzkzMyAtMC40MzgzNTZDMS42MTc5MzMgLTAuNzA5MzQgMS4zOTQ3NyAtMC44ODQ2ODIgMS4xNzk1NzcgLTAuODg0NjgyQzAuOTI0NTMzIC0wLjg4NDY4MiAwLjczMzI1IC0wLjY3NzQ2IDAuNzMzMjUgLTAuNDQ2MzI2QzAuNzMzMjUgLTAuMTc1MzQyIDAuOTU2NDEzIDAgMS4xNzE2MDYgMEMxLjQyNjY1IDAgMS42MTc5MzMgLTAuMjA3MjIzIDEuNjE3OTMzIC0wLjQzODM1NlonIGlkPSdnMC01OCcvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzAtMTA3Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMS04NCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDUuNzE1MzAyJyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PSc1NC4xNTU4NzgnIHhsaW5rOmhyZWY9JyNnMy02MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNjYuNTgxMzU5JyB4bGluazpocmVmPScjZzEtODgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9Jzc2LjI5NjU4NycgeGxpbms6aHJlZj0nI2cyLTkxJyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc3OC42NDg5MScgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc4Mi44ODMwOTMnIHhsaW5rOmhyZWY9JyNnMC01OCcgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nODUuMjM1NDE3JyB4bGluazpocmVmPScjZzAtNTgnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9Jzg3LjU4Nzc0MScgeGxpbms6aHJlZj0nI2cwLTEwNycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nOTIuMjA5MzU2JyB4bGluazpocmVmPScjZzItOTMnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9Jzk1LjA1OTgxMicgeGxpbms6aHJlZj0nI2cxLTgwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMDIuNjA1MDgnIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8L2c+Cjwvc3ZnPg==) , la seule matrice qui nous intéresse
véritablement est
, la seule matrice qui nous intéresse
véritablement est  .
.
Maintenant, on considère la matrice ![T_{[1..k]}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuMDIxNjA0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU3LjU4NDA1OSAyNS4xMjYwOTkgMTIuMDIxNjA0JyB3aWR0aD0nMjUuMTI2MDk5cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTEuNjE3OTMzIC0wLjQzODM1NkMxLjYxNzkzMyAtMC43MDkzNCAxLjM5NDc3IC0wLjg4NDY4MiAxLjE3OTU3NyAtMC44ODQ2ODJDMC45MjQ1MzMgLTAuODg0NjgyIDAuNzMzMjUgLTAuNjc3NDYgMC43MzMyNSAtMC40NDYzMjZDMC43MzMyNSAtMC4xNzUzNDIgMC45NTY0MTMgMCAxLjE3MTYwNiAwQzEuNDI2NjUgMCAxLjYxNzkzMyAtMC4yMDcyMjMgMS42MTc5MzMgLTAuNDM4MzU2WicgaWQ9J2cwLTU4Jy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMC0xMDcnLz4KPHBhdGggZD0nTTQuOTg1MzA1IC03LjI5MjY1M0M1LjA1NzAzNiAtNy41Nzk1NzcgNS4wODA5NDYgLTcuNjg3MTczIDUuMjYwMjc0IC03LjczNDk5NEM1LjM1NTkxNSAtNy43NTg5MDQgNS43NTA0MzYgLTcuNzU4OTA0IDYuMDAxNDk0IC03Ljc1ODkwNEM3LjE5NzAxMSAtNy43NTg5MDQgNy43NTg5MDQgLTcuNzExMDgzIDcuNzU4OTA0IC02Ljc3ODU4QzcuNzU4OTA0IC02LjU5OTI1MyA3LjcxMTA4MyAtNi4xNDQ5NTYgNy42MzkzNTIgLTUuNzAyNjE1TDcuNjI3Mzk3IC01LjU1OTE1M0M3LjYyNzM5NyAtNS41MTEzMzMgNy42NzUyMTggLTUuNDM5NjAxIDcuNzQ2OTQ5IC01LjQzOTYwMUM3Ljg2NjUwMSAtNS40Mzk2MDEgNy44NjY1MDEgLTUuNDk5Mzc3IDcuOTAyMzY2IC01LjY5MDY2TDguMjQ5MDY2IC03LjgwNjcyNUM4LjI3Mjk3NiAtNy45MTQzMjEgOC4yNzI5NzYgLTcuOTM4MjMyIDguMjcyOTc2IC03Ljk3NDA5N0M4LjI3Mjk3NiAtOC4xMDU2MDQgOC4yMDEyNDUgLTguMTA1NjA0IDcuOTYyMTQyIC04LjEwNTYwNEgxLjQyMjY2NUMxLjE0NzY5NiAtOC4xMDU2MDQgMS4xMzU3NDEgLTguMDkzNjQ5IDEuMDY0MDEgLTcuODc4NDU2TDAuMzM0NzQ1IC01LjcyNjUyNkMwLjMyMjc5IC01LjcwMjYxNSAwLjI4NjkyNCAtNS41NzExMDggMC4yODY5MjQgLTUuNTU5MTUzQzAuMjg2OTI0IC01LjQ5OTM3NyAwLjMzNDc0NSAtNS40Mzk2MDEgMC40MDY0NzYgLTUuNDM5NjAxQzAuNTAyMTE3IC01LjQzOTYwMSAwLjUyNjAyNyAtNS40ODc0MjIgMC41NzM4NDggLTUuNjQyODM5QzEuMDc1OTY1IC03LjA4OTQxNSAxLjMyNzAyNCAtNy43NTg5MDQgMi45MTcwNjEgLTcuNzU4OTA0SDMuNzE4MDU3QzQuMDA0OTgxIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNjI3Mzk3QzQuMTI0NTMzIC03LjU5MTUzMiA0LjEyNDUzMyAtNy41Njc2MjEgNC4wNjQ3NTcgLTcuMzUyNDI4TDIuNDYyNzY1IC0wLjkzMjUwM0MyLjM0MzIxMyAtMC40NjYyNTIgMi4zMTkzMDMgLTAuMzQ2NyAxLjA1MjA1NSAtMC4zNDY3QzAuNzUzMTc2IC0wLjM0NjcgMC42Njk0ODkgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4xMTk1NTJDMC42Njk0ODkgMCAwLjgwMDk5NiAwIDAuODYwNzcyIDBDMS4xNTk2NTEgMCAxLjQ3MDQ4NiAtMC4wMjM5MSAxLjc2OTM2NSAtMC4wMjM5MUgzLjYzNDM3MUMzLjkzMzI1IC0wLjAyMzkxIDQuMjU2MDQgMCA0LjU1NDkxOSAwQzQuNjg2NDI2IDAgNC44MDU5NzggMCA0LjgwNTk3OCAtMC4yMjcxNDhDNC44MDU5NzggLTAuMzQ2NyA0LjcyMjI5MSAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjdDMy4zMzU0OTIgLTAuMzQ2NyAzLjMzNTQ5MiAtMC40NTQyOTYgMy4zMzU0OTIgLTAuNjMzNjI0QzMuMzM1NDkyIC0wLjY0NTU3OSAzLjMzNTQ5MiAtMC43MjkyNjUgMy4zODMzMTMgLTAuOTIwNTQ4TDQuOTg1MzA1IC03LjI5MjY1M1onIGlkPSdnMS04NCcvPgo8cGF0aCBkPSdNMi41MDI2MTUgLTUuMDc2OTYxQzIuNTAyNjE1IC01LjI5MjE1NCAyLjQ4NjY3NSAtNS4zMDAxMjUgMi4yNzE0ODIgLTUuMzAwMTI1QzEuOTQ0NzA3IC00Ljk4MTMyIDEuNTIyMjkxIC00Ljc5MDAzNyAwLjc2NTEzMSAtNC43OTAwMzdWLTQuNTI3MDI0QzAuOTgwMzI0IC00LjUyNzAyNCAxLjQxMDcxIC00LjUyNzAyNCAxLjg3Mjk3NiAtNC43NDIyMTdWLTAuNjUzNTQ5QzEuODcyOTc2IC0wLjM1ODY1NSAxLjg0OTA2NiAtMC4yNjMwMTQgMS4wOTE5MDUgLTAuMjYzMDE0SDAuODEyOTUxVjBDMS4xMzk3MjYgLTAuMDIzOTEgMS44MjUxNTYgLTAuMDIzOTEgMi4xODM4MTEgLTAuMDIzOTFTMy4yMzU4NjYgLTAuMDIzOTEgMy41NjI2NCAwVi0wLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNiAtMC4yNjMwMTQgMi41MDI2MTUgLTAuMzU4NjU1IDIuNTAyNjE1IC0wLjY1MzU0OVYtNS4wNzY5NjFaJyBpZD0nZzItNDknLz4KPHBhdGggZD0nTTIuMTU5OSAxLjk5MjUyOFYxLjYyNTkwM0gxLjM1NDkxOVYtNS42MTA5NTlIMi4xNTk5Vi01Ljk3NzU4NEgwLjk4ODI5NFYxLjk5MjUyOEgyLjE1OTlaJyBpZD0nZzItOTEnLz4KPHBhdGggZD0nTTEuMzU0OTE5IC01Ljk3NzU4NEgwLjE4MzMxM1YtNS42MTA5NTlIMC45ODgyOTRWMS42MjU5MDNIMC4xODMzMTNWMS45OTI1MjhIMS4zNTQ5MTlWLTUuOTc3NTg0WicgaWQ9J2cyLTkzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSczOC44NTQyOTYnIHhsaW5rOmhyZWY9JyNnMS04NCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDUuNzE1MzAyJyB4bGluazpocmVmPScjZzItOTEnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzQ4LjA2NzYyNScgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PSc1Mi4zMDE4MDgnIHhsaW5rOmhyZWY9JyNnMC01OCcgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNTQuNjU0MTMyJyB4bGluazpocmVmPScjZzAtNTgnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzU3LjAwNjQ1NicgeGxpbms6aHJlZj0nI2cwLTEwNycgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nNjEuNjI4MDcxJyB4bGluazpocmVmPScjZzItOTMnIHk9JzY3LjYxMzEzNScvPgo8L2c+Cjwvc3ZnPg==) qui vérifie
qui vérifie
 et on ajoute une ligne
et on ajoute une ligne
 pour former
pour former
![[ [T_k] [X_{k+1} P_k] ] = [ [X_{[1..k]} P_k] [X_{k+1} P_k] ]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuODE4NjE0cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2Ljc4NzA0OSAxODQuNTMxODI1IDEyLjgxODYxNCcgd2lkdGg9JzE4NC41MzE4MjVwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMy40NzQ5NjkgLTEuODA5MjE1SDUuODE4MTgyQzUuOTI5NzYzIC0xLjgwOTIxNSA2LjEwNTEwNiAtMS44MDkyMTUgNi4xMDUxMDYgLTEuOTkyNTI4UzUuOTI5NzYzIC0yLjE3NTg0MSA1LjgxODE4MiAtMi4xNzU4NDFIMy40NzQ5NjlWLTQuNTI3MDI0QzMuNDc0OTY5IC00LjYzODYwNSAzLjQ3NDk2OSAtNC44MTM5NDggMy4yOTE2NTYgLTQuODEzOTQ4UzMuMTA4MzQ0IC00LjYzODYwNSAzLjEwODM0NCAtNC41MjcwMjRWLTIuMTc1ODQxSDAuNzU3MTYxQzAuNjQ1NTc5IC0yLjE3NTg0MSAwLjQ3MDIzNyAtMi4xNzU4NDEgMC40NzAyMzcgLTEuOTkyNTI4UzAuNjQ1NTc5IC0xLjgwOTIxNSAwLjc1NzE2MSAtMS44MDkyMTVIMy4xMDgzNDRWMC41NDE5NjhDMy4xMDgzNDQgMC42NTM1NDkgMy4xMDgzNDQgMC44Mjg4OTIgMy4yOTE2NTYgMC44Mjg4OTJTMy40NzQ5NjkgMC42NTM1NDkgMy40NzQ5NjkgMC41NDE5NjhWLTEuODA5MjE1WicgaWQ9J2cyLTQzJy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnMi00OScvPgo8cGF0aCBkPSdNMi4xNTk5IDEuOTkyNTI4VjEuNjI1OTAzSDEuMzU0OTE5Vi01LjYxMDk1OUgyLjE1OTlWLTUuOTc3NTg0SDAuOTg4Mjk0VjEuOTkyNTI4SDIuMTU5OVonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS4zNTQ5MTkgLTUuOTc3NTg0SDAuMTgzMzEzVi01LjYxMDk1OUgwLjk4ODI5NFYxLjYyNTkwM0gwLjE4MzMxM1YxLjk5MjUyOEgxLjM1NDkxOVYtNS45Nzc1ODRaJyBpZD0nZzItOTMnLz4KPHBhdGggZD0nTTEuNjE3OTMzIC0wLjQzODM1NkMxLjYxNzkzMyAtMC43MDkzNCAxLjM5NDc3IC0wLjg4NDY4MiAxLjE3OTU3NyAtMC44ODQ2ODJDMC45MjQ1MzMgLTAuODg0NjgyIDAuNzMzMjUgLTAuNjc3NDYgMC43MzMyNSAtMC40NDYzMjZDMC43MzMyNSAtMC4xNzUzNDIgMC45NTY0MTMgMCAxLjE3MTYwNiAwQzEuNDI2NjUgMCAxLjYxNzkzMyAtMC4yMDcyMjMgMS42MTc5MzMgLTAuNDM4MzU2WicgaWQ9J2cwLTU4Jy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMC0xMDcnLz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2czLTYxJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnMy05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMy05MycvPgo8cGF0aCBkPSdNMy41Mzg3MyAtMy44MDE3NDNINS41NDcxOThDNy4xOTcwMTEgLTMuODAxNzQzIDguODQ2ODI0IC01LjAyMTE3MSA4Ljg0NjgyNCAtNi4zODQwNkM4Ljg0NjgyNCAtNy4zMTY1NjMgOC4wNTc3ODMgLTguMTY1MzggNi41NTE0MzIgLTguMTY1MzhIMi44NTcyODVDMi42MzAxMzcgLTguMTY1MzggMi41MjI1NCAtOC4xNjUzOCAyLjUyMjU0IC03LjkzODIzMkMyLjUyMjU0IC03LjgxODY4IDIuNjMwMTM3IC03LjgxODY4IDIuODA5NDY1IC03LjgxODY4QzMuNTM4NzMgLTcuODE4NjggMy41Mzg3MyAtNy43MjMwMzkgMy41Mzg3MyAtNy41OTE1MzJDMy41Mzg3MyAtNy41Njc2MjEgMy41Mzg3MyAtNy40OTU4OSAzLjQ5MDkwOSAtNy4zMTY1NjNMMS44NzY5NjEgLTAuODg0NjgyQzEuNzY5MzY1IC0wLjQ2NjI1MiAxLjc0NTQ1NSAtMC4zNDY3IDAuOTA4NTkzIC0wLjM0NjdDMC42ODE0NDUgLTAuMzQ2NyAwLjU2MTg5MyAtMC4zNDY3IDAuNTYxODkzIC0wLjEzMTUwN0MwLjU2MTg5MyAwIDAuNjY5NDg5IDAgMC43NDEyMiAwQzAuOTY4MzY5IDAgMS4yMDc0NzIgLTAuMDIzOTEgMS40MzQ2MiAtMC4wMjM5MUgyLjgzMzM3NUMzLjA2MDUyMyAtMC4wMjM5MSAzLjMxMTU4MiAwIDMuNTM4NzMgMEMzLjYzNDM3MSAwIDMuNzY1ODc4IDAgMy43NjU4NzggLTAuMjI3MTQ4QzMuNzY1ODc4IC0wLjM0NjcgMy42NTgyODEgLTAuMzQ2NyAzLjQ3ODk1NCAtMC4zNDY3QzIuNzYxNjQ0IC0wLjM0NjcgMi43NDk2ODkgLTAuNDMwMzg2IDIuNzQ5Njg5IC0wLjU0OTkzOEMyLjc0OTY4OSAtMC42MDk3MTQgMi43NjE2NDQgLTAuNjkzNCAyLjc3MzU5OSAtMC43NTMxNzZMMy41Mzg3MyAtMy44MDE3NDNaTTQuMzk5NTAyIC03LjM1MjQyOEM0LjUwNzA5OCAtNy43OTQ3NyA0LjU1NDkxOSAtNy44MTg2OCA1LjAyMTE3MSAtNy44MTg2OEg2LjIwNDczMkM3LjEwMTM3IC03LjgxODY4IDcuODQyNTkgLTcuNTMxNzU2IDcuODQyNTkgLTYuNjM1MTE4QzcuODQyNTkgLTYuMzI0Mjg0IDcuNjg3MTczIC01LjMwODA5NSA3LjEzNzIzNSAtNC43NTgxNTdDNi45MzM5OTggLTQuNTQyOTY0IDYuMzYwMTQ5IC00LjA4ODY2NyA1LjI3MjIyOSAtNC4wODg2NjdIMy41ODY1NUw0LjM5OTUwMiAtNy4zNTI0MjhaJyBpZD0nZzEtODAnLz4KPHBhdGggZD0nTTQuOTg1MzA1IC03LjI5MjY1M0M1LjA1NzAzNiAtNy41Nzk1NzcgNS4wODA5NDYgLTcuNjg3MTczIDUuMjYwMjc0IC03LjczNDk5NEM1LjM1NTkxNSAtNy43NTg5MDQgNS43NTA0MzYgLTcuNzU4OTA0IDYuMDAxNDk0IC03Ljc1ODkwNEM3LjE5NzAxMSAtNy43NTg5MDQgNy43NTg5MDQgLTcuNzExMDgzIDcuNzU4OTA0IC02Ljc3ODU4QzcuNzU4OTA0IC02LjU5OTI1MyA3LjcxMTA4MyAtNi4xNDQ5NTYgNy42MzkzNTIgLTUuNzAyNjE1TDcuNjI3Mzk3IC01LjU1OTE1M0M3LjYyNzM5NyAtNS41MTEzMzMgNy42NzUyMTggLTUuNDM5NjAxIDcuNzQ2OTQ5IC01LjQzOTYwMUM3Ljg2NjUwMSAtNS40Mzk2MDEgNy44NjY1MDEgLTUuNDk5Mzc3IDcuOTAyMzY2IC01LjY5MDY2TDguMjQ5MDY2IC03LjgwNjcyNUM4LjI3Mjk3NiAtNy45MTQzMjEgOC4yNzI5NzYgLTcuOTM4MjMyIDguMjcyOTc2IC03Ljk3NDA5N0M4LjI3Mjk3NiAtOC4xMDU2MDQgOC4yMDEyNDUgLTguMTA1NjA0IDcuOTYyMTQyIC04LjEwNTYwNEgxLjQyMjY2NUMxLjE0NzY5NiAtOC4xMDU2MDQgMS4xMzU3NDEgLTguMDkzNjQ5IDEuMDY0MDEgLTcuODc4NDU2TDAuMzM0NzQ1IC01LjcyNjUyNkMwLjMyMjc5IC01LjcwMjYxNSAwLjI4NjkyNCAtNS41NzExMDggMC4yODY5MjQgLTUuNTU5MTUzQzAuMjg2OTI0IC01LjQ5OTM3NyAwLjMzNDc0NSAtNS40Mzk2MDEgMC40MDY0NzYgLTUuNDM5NjAxQzAuNTAyMTE3IC01LjQzOTYwMSAwLjUyNjAyNyAtNS40ODc0MjIgMC41NzM4NDggLTUuNjQyODM5QzEuMDc1OTY1IC03LjA4OTQxNSAxLjMyNzAyNCAtNy43NTg5MDQgMi45MTcwNjEgLTcuNzU4OTA0SDMuNzE4MDU3QzQuMDA0OTgxIC03Ljc1ODkwNCA0LjEyNDUzMyAtNy43NTg5MDQgNC4xMjQ1MzMgLTcuNjI3Mzk3QzQuMTI0NTMzIC03LjU5MTUzMiA0LjEyNDUzMyAtNy41Njc2MjEgNC4wNjQ3NTcgLTcuMzUyNDI4TDIuNDYyNzY1IC0wLjkzMjUwM0MyLjM0MzIxMyAtMC40NjYyNTIgMi4zMTkzMDMgLTAuMzQ2NyAxLjA1MjA1NSAtMC4zNDY3QzAuNzUzMTc2IC0wLjM0NjcgMC42Njk0ODkgLTAuMzQ2NyAwLjY2OTQ4OSAtMC4xMTk1NTJDMC42Njk0ODkgMCAwLjgwMDk5NiAwIDAuODYwNzcyIDBDMS4xNTk2NTEgMCAxLjQ3MDQ4NiAtMC4wMjM5MSAxLjc2OTM2NSAtMC4wMjM5MUgzLjYzNDM3MUMzLjkzMzI1IC0wLjAyMzkxIDQuMjU2MDQgMCA0LjU1NDkxOSAwQzQuNjg2NDI2IDAgNC44MDU5NzggMCA0LjgwNTk3OCAtMC4yMjcxNDhDNC44MDU5NzggLTAuMzQ2NyA0LjcyMjI5MSAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjdDMy4zMzU0OTIgLTAuMzQ2NyAzLjMzNTQ5MiAtMC40NTQyOTYgMy4zMzU0OTIgLTAuNjMzNjI0QzMuMzM1NDkyIC0wLjY0NTU3OSAzLjMzNTQ5MiAtMC43MjkyNjUgMy4zODMzMTMgLTAuOTIwNTQ4TDQuOTg1MzA1IC03LjI5MjY1M1onIGlkPSdnMS04NCcvPgo8cGF0aCBkPSdNNS42Nzg3MDUgLTQuODUzNzk4TDQuNTU0OTE5IC03LjQ3MTk4QzQuNzEwMzM2IC03Ljc1ODkwNCA1LjA2ODk5MSAtNy44MDY3MjUgNS4yMTI0NTMgLTcuODE4NjhDNS4yODQxODQgLTcuODE4NjggNS40MTU2OTEgLTcuODMwNjM1IDUuNDE1NjkxIC04LjAzMzg3M0M1LjQxNTY5MSAtOC4xNjUzOCA1LjMwODA5NSAtOC4xNjUzOCA1LjIzNjM2NCAtOC4xNjUzOEM1LjAzMzEyNiAtOC4xNjUzOCA0Ljc5NDAyMiAtOC4xNDE0NjkgNC41OTA3ODUgLTguMTQxNDY5SDMuODk3Mzg1QzMuMTY4MTIgLTguMTQxNDY5IDIuNjQyMDkyIC04LjE2NTM4IDIuNjMwMTM3IC04LjE2NTM4QzIuNTM0NDk2IC04LjE2NTM4IDIuNDE0OTQ0IC04LjE2NTM4IDIuNDE0OTQ0IC03LjkzODIzMkMyLjQxNDk0NCAtNy44MTg2OCAyLjUyMjU0IC03LjgxODY4IDIuNjc3OTU4IC03LjgxODY4QzMuMzcxMzU3IC03LjgxODY4IDMuNDE5MTc4IC03LjY5OTEyOCAzLjUzODczIC03LjQxMjIwNEw0Ljk2MTM5NSAtNC4wODg2NjdMMi4zNjcxMjMgLTEuMzE1MDY4QzEuOTM2NzM3IC0wLjg0ODgxNyAxLjQyMjY2NSAtMC4zOTQ1MjEgMC41Mzc5ODMgLTAuMzQ2N0MwLjM5NDUyMSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjExOTU1MkMwLjI5ODg3OSAtMC4wODM2ODYgMC4zMTA4MzQgMCAwLjQ0MjM0MSAwQzAuNjA5NzE0IDAgMC43ODkwNDEgLTAuMDIzOTEgMC45NTY0MTMgLTAuMDIzOTFIMS41MTgzMDZDMS45MDA4NzIgLTAuMDIzOTEgMi4zMTkzMDMgMCAyLjY4OTkxMyAwQzIuNzczNTk5IDAgMi45MTcwNjEgMCAyLjkxNzA2MSAtMC4yMTUxOTNDMi45MTcwNjEgLTAuMzM0NzQ1IDIuODMzMzc1IC0wLjM0NjcgMi43NjE2NDQgLTAuMzQ2N0MyLjUyMjU0IC0wLjM3MDYxIDIuMzY3MTIzIC0wLjUwMjExNyAyLjM2NzEyMyAtMC42OTM0QzIuMzY3MTIzIC0wLjg5NjYzOCAyLjUxMDU4NSAtMS4wNDAxIDIuODU3Mjg1IC0xLjM5ODc1NUwzLjkyMTI5NSAtMi41NTg0MDZDNC4xODQzMDkgLTIuODMzMzc1IDQuODE3OTMzIC0zLjUyNjc3NSA1LjA4MDk0NiAtMy43ODk3ODhMNi4zMzYyMzkgLTAuODQ4ODE3QzYuMzQ4MTk0IC0wLjgyNDkwNyA2LjM5NjAxNSAtMC43MDUzNTUgNi4zOTYwMTUgLTAuNjkzNEM2LjM5NjAxNSAtMC41ODU4MDMgNi4xMzMwMDEgLTAuMzcwNjEgNS43NTA0MzYgLTAuMzQ2N0M1LjY3ODcwNSAtMC4zNDY3IDUuNTQ3MTk4IC0wLjMzNDc0NSA1LjU0NzE5OCAtMC4xMTk1NTJDNS41NDcxOTggMCA1LjY2Njc1IDAgNS43MjY1MjYgMEM1LjkyOTc2MyAwIDYuMTY4ODY3IC0wLjAyMzkxIDYuMzcyMTA1IC0wLjAyMzkxSDcuNjg3MTczQzcuOTAyMzY2IC0wLjAyMzkxIDguMTI5NTE0IDAgOC4zMzI3NTIgMEM4LjQxNjQzOCAwIDguNTQ3OTQ1IDAgOC41NDc5NDUgLTAuMjI3MTQ4QzguNTQ3OTQ1IC0wLjM0NjcgOC40MjgzOTQgLTAuMzQ2NyA4LjMyMDc5NyAtMC4zNDY3QzcuNjAzNDg3IC0wLjM1ODY1NSA3LjU3OTU3NyAtMC40MTg0MzEgNy4zNzYzMzkgLTAuODYwNzcyTDUuNzk4MjU3IC00LjU2Njg3NEw3LjMxNjU2MyAtNi4xOTI3NzdDNy40MzYxMTUgLTYuMzEyMzI5IDcuNzExMDgzIC02LjYxMTIwOCA3LjgxODY4IC02LjczMDc2QzguMzMyNzUyIC03LjI2ODc0MiA4LjgxMDk1OSAtNy43NTg5MDQgOS43NzkzMjggLTcuODE4NjhDOS44OTg4NzkgLTcuODMwNjM1IDEwLjAxODQzMSAtNy44MzA2MzUgMTAuMDE4NDMxIC04LjAzMzg3M0MxMC4wMTg0MzEgLTguMTY1MzggOS45MTA4MzQgLTguMTY1MzggOS44NjMwMTQgLTguMTY1MzhDOS42OTU2NDEgLTguMTY1MzggOS41MTYzMTQgLTguMTQxNDY5IDkuMzQ4OTQxIC04LjE0MTQ2OUg4Ljc5OTAwNEM4LjQxNjQzOCAtOC4xNDE0NjkgNy45OTgwMDcgLTguMTY1MzggNy42MjczOTcgLTguMTY1MzhDNy41NDM3MTEgLTguMTY1MzggNy40MDAyNDkgLTguMTY1MzggNy40MDAyNDkgLTcuOTUwMTg3QzcuNDAwMjQ5IC03LjgzMDYzNSA3LjQ4MzkzNSAtNy44MTg2OCA3LjU1NTY2NiAtNy44MTg2OEM3Ljc0Njk0OSAtNy43OTQ3NyA3Ljk1MDE4NyAtNy42OTkxMjggNy45NTAxODcgLTcuNDcxOThMNy45MzgyMzIgLTcuNDQ4MDdDNy45MjYyNzYgLTcuMzY0Mzg0IDcuOTAyMzY2IC03LjI0NDgzMiA3Ljc3MDg1OSAtNy4xMDEzN0w1LjY3ODcwNSAtNC44NTM3OThaJyBpZD0nZzEtODgnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0Mi4xMDU5NTgnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNDUuMzU3NjE5JyB4bGluazpocmVmPScjZzEtODQnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzUyLjIxODYyNCcgeGxpbms6aHJlZj0nI2cwLTEwNycgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nNTcuMzM4MzcyJyB4bGluazpocmVmPScjZzMtOTMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzYwLjU5MDAzMycgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2My44NDE2OTQnIHhsaW5rOmhyZWY9JyNnMS04OCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzMuNTU2OTIxJyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PSc3OC4xNzg1MzcnIHhsaW5rOmhyZWY9JyNnMi00MycgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nODQuNzY1MDQ0JyB4bGluazpocmVmPScjZzItNDknIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9Jzg5LjQ5NzM1OCcgeGxpbms6aHJlZj0nI2cxLTgwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5Ny4wNDI2MjYnIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzEwMi4xNjIzNzQnIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA1LjQxNDAzNScgeGxpbms6aHJlZj0nI2czLTkzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTEuOTg2NTI2JyB4bGluazpocmVmPScjZzMtNjEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyNC40MTIwMDYnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTI3LjY2MzY2OCcgeGxpbms6aHJlZj0nI2czLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMzAuOTE1MzI5JyB4bGluazpocmVmPScjZzEtODgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE0MC42MzA1NTYnIHhsaW5rOmhyZWY9JyNnMi05MScgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nMTQyLjk4Mjg4JyB4bGluazpocmVmPScjZzItNDknIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzE0Ny4yMTcwNjMnIHhsaW5rOmhyZWY9JyNnMC01OCcgeT0nNjcuNjEzMTM1Jy8+Cjx1c2UgeD0nMTQ5LjU2OTM4NycgeGxpbms6aHJlZj0nI2cwLTU4JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PScxNTEuOTIxNzExJyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny42MTMxMzUnLz4KPHVzZSB4PScxNTYuNTQzMzI2JyB4bGluazpocmVmPScjZzItOTMnIHk9JzY3LjYxMzEzNScvPgo8dXNlIHg9JzE1OS4zOTM3ODInIHhsaW5rOmhyZWY9JyNnMS04MCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTY2LjkzOTA1JyB4bGluazpocmVmPScjZzAtMTA3JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PScxNzIuMDU4Nzk3JyB4bGluazpocmVmPScjZzMtOTMnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE3NS4zMTA0NTgnIHhsaW5rOmhyZWY9JyNnMy05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTc4LjU2MjEyJyB4bGluazpocmVmPScjZzEtODgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE4OC4yNzczNDcnIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzE5Mi44OTg5NjInIHhsaW5rOmhyZWY9JyNnMi00MycgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nMTk5LjQ4NTQ2OScgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PScyMDQuMjE3Nzg0JyB4bGluazpocmVmPScjZzEtODAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIxMS43NjMwNTInIHhsaW5rOmhyZWY9JyNnMC0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzIxNi44ODI3OTknIHhsaW5rOmhyZWY9JyNnMy05MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjIwLjEzNDQ2MScgeGxpbms6aHJlZj0nI2czLTkzJyB5PSc2NS43NTM0MjUnLz4KPC9nPgo8L3N2Zz4=) .
La fonction
.
La fonction streaming_gram_schmidt_update
implémente la mise à jour. Le coût de la fonction est en
 .
.
<<<
import numpy
from mlstatpy.ml.matrices import streaming_gram_schmidt_update, gram_schmidt
X = numpy.array([[1, 0.5, 10., 5., -2.],
[0, 0.4, 20, 4., 2.],
[0, 0.7, 20, 4., 2.]], dtype=float).T
Xt = X.T
Tk, Pk = gram_schmidt(X[:3].T, change=True)
print("k={}".format(3))
print(Pk)
Tk = X[:3] @ Pk.T
print(Tk.T @ Tk)
k = 3
while k < X.shape[0]:
streaming_gram_schmidt_update(Xt[:, k], Pk)
k += 1
print("k={}".format(k))
print(Pk)
Tk = X[:k] @ Pk.T
print(Tk.T @ Tk)
>>>
k=3
[[ 0.099 0. 0. ]
[-0.953 0.482 0. ]
[-0.287 -3.338 3.481]]
[[ 1.000e+00 -1.749e-15 -2.234e-15]
[-1.749e-15 1.000e+00 1.387e-14]
[-2.234e-15 1.387e-14 1.000e+00]]
k=4
[[ 0.089 0. 0. ]
[-0.308 0.177 0. ]
[-0.03 -3.334 3.348]]
[[ 1.000e+00 -4.441e-16 -1.793e-15]
[-4.441e-16 1.000e+00 2.377e-15]
[-1.793e-15 2.377e-15 1.000e+00]]
k=5
[[ 0.088 0. 0. ]
[-0.212 0.128 0. ]
[-0.016 -3.335 3.342]]
[[ 1.000e+00 -9.714e-17 -6.210e-15]
[-9.714e-17 1.000e+00 1.978e-16]
[-6.210e-15 1.978e-16 1.000e+00]]
Streaming Linear Regression#
Je reprends l’idée introduite dans l’article
Efficient online linear regression.
On cherche à minimiser  et le vecteur
solution annuler le gradient :
et le vecteur
solution annuler le gradient :  .
On note le vecteur
.
On note le vecteur  qui vérifie
qui vérifie
 .
Qu’en est-il de
.
Qu’en est-il de  ?
On note
?
On note  .
.
![\begin{array}{rcl}
\nabla(\beta_{k+1}) &=& -2X_{1..k+1}'(y_{1..k+1} - X_{1..k+1}(\beta_k + d\beta)) \\
&=& -2 [ X_{1..k}' X_{k+1}' ] ( [ y_{1..k} y_{k+1} ] - [ X_{1..k} X_{k+1} ]'(\beta_k + d\beta)) \\
&=& -2 X_{1..k}' ( y_{1..k} - X_{1..k} (\beta_k + d\beta))
-2 X_{k+1}' ( y_{k+1} - X_{k+1} (\beta_k + d\beta)) \\
&=& 2 X_{1..k}' X_{1..k} d\beta -2 X_{k+1}' ( y_{k+1} - X_{k+1} (\beta_k + d\beta)) \\
&=& 2 (X_{1..k}' X_{1..k} + X_{k+1}' X_{k+1}) d\beta - 2 X_{k+1}' (y_{k+1} - X_{k+1} \beta_k)
\end{array}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nNjguNjk2NTM1cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNDMuODM1NjE2IDc5LjUwMTgyNSAzOTEuMTc4NDUxIDY4LjY5NjUzNScgd2lkdGg9JzM5MS4xNzg0NTFwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMi4xMTIwOCAtMy43Nzc4MzNDMi4xNTE5MyAtMy44ODE0NDUgMi4xODM4MTEgLTMuOTM3MjM1IDIuMTgzODExIC00LjAxNjkzNkMyLjE4MzgxMSAtNC4yNzk5NSAxLjk0NDcwNyAtNC40NTUyOTMgMS43MjE1NDQgLTQuNDU1MjkzQzEuNDAyNzQgLTQuNDU1MjkzIDEuMzE1MDY4IC00LjE3NjMzOSAxLjI4MzE4OCAtNC4wNjQ3NTdMMC4yNzA5ODQgLTAuNjI5NjM5QzAuMjM5MTAzIC0wLjUzMzk5OCAwLjIzOTEwMyAtMC41MTAwODcgMC4yMzkxMDMgLTAuNTAyMTE3QzAuMjM5MTAzIC0wLjQzMDM4NiAwLjI4NjkyNCAtMC40MTQ0NDYgMC4zNjY2MjUgLTAuMzkwNTM1QzAuNTEwMDg3IC0wLjMyNjc3NSAwLjUyNjAyNyAtMC4zMjY3NzUgMC41NDE5NjggLTAuMzI2Nzc1QzAuNTY1ODc4IC0wLjMyNjc3NSAwLjYxMzY5OSAtMC4zMjY3NzUgMC42Njk0ODkgLTAuNDYyMjY3TDIuMTEyMDggLTMuNzc3ODMzWicgaWQ9J2cwLTQ4Jy8+CjxwYXRoIGQ9J00xLjYxNzkzMyAtMC40MzgzNTZDMS42MTc5MzMgLTAuNzA5MzQgMS4zOTQ3NyAtMC44ODQ2ODIgMS4xNzk1NzcgLTAuODg0NjgyQzAuOTI0NTMzIC0wLjg4NDY4MiAwLjczMzI1IC0wLjY3NzQ2IDAuNzMzMjUgLTAuNDQ2MzI2QzAuNzMzMjUgLTAuMTc1MzQyIDAuOTU2NDEzIDAgMS4xNzE2MDYgMEMxLjQyNjY1IDAgMS42MTc5MzMgLTAuMjA3MjIzIDEuNjE3OTMzIC0wLjQzODM1NlonIGlkPSdnMi01OCcvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzItMTA3Jy8+CjxwYXRoIGQ9J002Ljc2NjYyNSAtNi45NTc5MDhDNi43NjY2MjUgLTcuNjc1MjE4IDYuMTU2OTEyIC04LjQyODM5NCA1LjA2ODk5MSAtOC40MjgzOTRDMy41MjY3NzUgLTguNDI4Mzk0IDIuNTQ2NDUxIC02LjUzOTQ3NyAyLjIzNTYxNiAtNS4yOTYxMzlMMC4zNDY3IDIuMTk5NzUxQzAuMzIyNzkgMi4yOTUzOTIgMC4zOTQ1MjEgMi4zMTkzMDMgMC40NTQyOTYgMi4zMTkzMDNDMC41Mzc5ODMgMi4zMTkzMDMgMC41OTc3NTggMi4zMDczNDcgMC42MDk3MTQgMi4yNDc1NzJMMS40NDY1NzUgLTEuMDk5ODc1QzEuNTY2MTI3IC0wLjQzMDM4NiAyLjIyMzY2MSAwLjExOTU1MiAyLjkyOTAxNiAwLjExOTU1MkM0LjYzODYwNSAwLjExOTU1MiA2LjI1MjU1MyAtMS4yMTk0MjcgNi4yNTI1NTMgLTMuMDAwNzQ3QzYuMjUyNTUzIC0zLjQ1NTA0NCA2LjE0NDk1NiAtMy45MDkzNCA1Ljg5Mzg5OCAtNC4yOTE5MDVDNS43NTA0MzYgLTQuNTE5MDU0IDUuNTcxMTA4IC00LjY4NjQyNiA1LjM3OTgyNiAtNC44Mjk4ODhDNi4yNDA1OTggLTUuMjg0MTg0IDYuNzY2NjI1IC02LjAxMzQ1IDYuNzY2NjI1IC02Ljk1NzkwOFpNNC42ODY0MjYgLTQuODQxODQzQzQuNDk1MTQzIC00Ljc3MDExMiA0LjMwMzg2MSAtNC43NDYyMDIgNC4wNzY3MTIgLTQuNzQ2MjAyQzMuOTA5MzQgLTQuNzQ2MjAyIDMuNzUzOTIzIC00LjczNDI0NyAzLjUzODczIC00LjgwNTk3OEMzLjY1ODI4MSAtNC44ODk2NjQgMy44Mzc2MDkgLTQuOTEzNTc0IDQuMDg4NjY3IC00LjkxMzU3NEM0LjMwMzg2MSAtNC45MTM1NzQgNC41MTkwNTQgLTQuODg5NjY0IDQuNjg2NDI2IC00Ljg0MTg0M1pNNi4xNDQ5NTYgLTcuMDY1NTA0QzYuMTQ0OTU2IC02LjQwNzk3IDUuODIyMTY3IC01LjQ1MTU1NyA1LjA0NTA4MSAtNS4wMDkyMTVDNC44MTc5MzMgLTUuMDkyOTAyIDQuNTA3MDk4IC01LjE1MjY3NyA0LjI0NDA4NSAtNS4xNTI2NzdDMy45OTMwMjYgLTUuMTUyNjc3IDMuMjc1NzE2IC01LjE3NjU4OCAzLjI3NTcxNiAtNC43OTQwMjJDMy4yNzU3MTYgLTQuNDcxMjMzIDMuOTMzMjUgLTQuNTA3MDk4IDQuMTM2NDg4IC00LjUwNzA5OEM0LjQ0NzMyMyAtNC41MDcwOTggNC43MjIyOTEgLTQuNTc4ODI5IDUuMDA5MjE1IC00LjY2MjUxNkM1LjM5MTc4MSAtNC4zNTE2ODEgNS41NTkxNTMgLTMuOTQ1MjA1IDUuNTU5MTUzIC0zLjM0NzQ0N0M1LjU1OTE1MyAtMi42NTQwNDcgNS4zNjc4NyAtMi4wOTIxNTQgNS4xNDA3MjIgLTEuNTc4MDgyQzQuNzQ2MjAyIC0wLjY5MzQgMy44MTM2OTkgLTAuMTE5NTUyIDIuOTg4NzkyIC0wLjExOTU1MkMyLjExNjA2NSAtMC4xMTk1NTIgMS42NjE3NjggLTAuODEyOTUxIDEuNjYxNzY4IC0xLjYyNTkwM0MxLjY2MTc2OCAtMS43MzM0OTkgMS42NjE3NjggLTEuODg4OTE3IDEuNzA5NTg5IC0yLjA2ODI0NEwyLjQ4NjY3NSAtNS4yMTI0NTNDMi44ODExOTYgLTYuNzc4NTggMy44ODU0MyAtOC4xODkyOSA1LjA0NTA4MSAtOC4xODkyOUM1LjkwNTg1MyAtOC4xODkyOSA2LjE0NDk1NiAtNy41OTE1MzIgNi4xNDQ5NTYgLTcuMDY1NTA0WicgaWQ9J2czLTEyJy8+CjxwYXRoIGQ9J001LjY3ODcwNSAtNC44NTM3OThMNC41NTQ5MTkgLTcuNDcxOThDNC43MTAzMzYgLTcuNzU4OTA0IDUuMDY4OTkxIC03LjgwNjcyNSA1LjIxMjQ1MyAtNy44MTg2OEM1LjI4NDE4NCAtNy44MTg2OCA1LjQxNTY5MSAtNy44MzA2MzUgNS40MTU2OTEgLTguMDMzODczQzUuNDE1NjkxIC04LjE2NTM4IDUuMzA4MDk1IC04LjE2NTM4IDUuMjM2MzY0IC04LjE2NTM4QzUuMDMzMTI2IC04LjE2NTM4IDQuNzk0MDIyIC04LjE0MTQ2OSA0LjU5MDc4NSAtOC4xNDE0NjlIMy44OTczODVDMy4xNjgxMiAtOC4xNDE0NjkgMi42NDIwOTIgLTguMTY1MzggMi42MzAxMzcgLTguMTY1MzhDMi41MzQ0OTYgLTguMTY1MzggMi40MTQ5NDQgLTguMTY1MzggMi40MTQ5NDQgLTcuOTM4MjMyQzIuNDE0OTQ0IC03LjgxODY4IDIuNTIyNTQgLTcuODE4NjggMi42Nzc5NTggLTcuODE4NjhDMy4zNzEzNTcgLTcuODE4NjggMy40MTkxNzggLTcuNjk5MTI4IDMuNTM4NzMgLTcuNDEyMjA0TDQuOTYxMzk1IC00LjA4ODY2N0wyLjM2NzEyMyAtMS4zMTUwNjhDMS45MzY3MzcgLTAuODQ4ODE3IDEuNDIyNjY1IC0wLjM5NDUyMSAwLjUzNzk4MyAtMC4zNDY3QzAuMzk0NTIxIC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4zMzQ3NDUgMC4yOTg4NzkgLTAuMTE5NTUyQzAuMjk4ODc5IC0wLjA4MzY4NiAwLjMxMDgzNCAwIDAuNDQyMzQxIDBDMC42MDk3MTQgMCAwLjc4OTA0MSAtMC4wMjM5MSAwLjk1NjQxMyAtMC4wMjM5MUgxLjUxODMwNkMxLjkwMDg3MiAtMC4wMjM5MSAyLjMxOTMwMyAwIDIuNjg5OTEzIDBDMi43NzM1OTkgMCAyLjkxNzA2MSAwIDIuOTE3MDYxIC0wLjIxNTE5M0MyLjkxNzA2MSAtMC4zMzQ3NDUgMi44MzMzNzUgLTAuMzQ2NyAyLjc2MTY0NCAtMC4zNDY3QzIuNTIyNTQgLTAuMzcwNjEgMi4zNjcxMjMgLTAuNTAyMTE3IDIuMzY3MTIzIC0wLjY5MzRDMi4zNjcxMjMgLTAuODk2NjM4IDIuNTEwNTg1IC0xLjA0MDEgMi44NTcyODUgLTEuMzk4NzU1TDMuOTIxMjk1IC0yLjU1ODQwNkM0LjE4NDMwOSAtMi44MzMzNzUgNC44MTc5MzMgLTMuNTI2Nzc1IDUuMDgwOTQ2IC0zLjc4OTc4OEw2LjMzNjIzOSAtMC44NDg4MTdDNi4zNDgxOTQgLTAuODI0OTA3IDYuMzk2MDE1IC0wLjcwNTM1NSA2LjM5NjAxNSAtMC42OTM0QzYuMzk2MDE1IC0wLjU4NTgwMyA2LjEzMzAwMSAtMC4zNzA2MSA1Ljc1MDQzNiAtMC4zNDY3QzUuNjc4NzA1IC0wLjM0NjcgNS41NDcxOTggLTAuMzM0NzQ1IDUuNTQ3MTk4IC0wLjExOTU1MkM1LjU0NzE5OCAwIDUuNjY2NzUgMCA1LjcyNjUyNiAwQzUuOTI5NzYzIDAgNi4xNjg4NjcgLTAuMDIzOTEgNi4zNzIxMDUgLTAuMDIzOTFINy42ODcxNzNDNy45MDIzNjYgLTAuMDIzOTEgOC4xMjk1MTQgMCA4LjMzMjc1MiAwQzguNDE2NDM4IDAgOC41NDc5NDUgMCA4LjU0Nzk0NSAtMC4yMjcxNDhDOC41NDc5NDUgLTAuMzQ2NyA4LjQyODM5NCAtMC4zNDY3IDguMzIwNzk3IC0wLjM0NjdDNy42MDM0ODcgLTAuMzU4NjU1IDcuNTc5NTc3IC0wLjQxODQzMSA3LjM3NjMzOSAtMC44NjA3NzJMNS43OTgyNTcgLTQuNTY2ODc0TDcuMzE2NTYzIC02LjE5Mjc3N0M3LjQzNjExNSAtNi4zMTIzMjkgNy43MTEwODMgLTYuNjExMjA4IDcuODE4NjggLTYuNzMwNzZDOC4zMzI3NTIgLTcuMjY4NzQyIDguODEwOTU5IC03Ljc1ODkwNCA5Ljc3OTMyOCAtNy44MTg2OEM5Ljg5ODg3OSAtNy44MzA2MzUgMTAuMDE4NDMxIC03LjgzMDYzNSAxMC4wMTg0MzEgLTguMDMzODczQzEwLjAxODQzMSAtOC4xNjUzOCA5LjkxMDgzNCAtOC4xNjUzOCA5Ljg2MzAxNCAtOC4xNjUzOEM5LjY5NTY0MSAtOC4xNjUzOCA5LjUxNjMxNCAtOC4xNDE0NjkgOS4zNDg5NDEgLTguMTQxNDY5SDguNzk5MDA0QzguNDE2NDM4IC04LjE0MTQ2OSA3Ljk5ODAwNyAtOC4xNjUzOCA3LjYyNzM5NyAtOC4xNjUzOEM3LjU0MzcxMSAtOC4xNjUzOCA3LjQwMDI0OSAtOC4xNjUzOCA3LjQwMDI0OSAtNy45NTAxODdDNy40MDAyNDkgLTcuODMwNjM1IDcuNDgzOTM1IC03LjgxODY4IDcuNTU1NjY2IC03LjgxODY4QzcuNzQ2OTQ5IC03Ljc5NDc3IDcuOTUwMTg3IC03LjY5OTEyOCA3Ljk1MDE4NyAtNy40NzE5OEw3LjkzODIzMiAtNy40NDgwN0M3LjkyNjI3NiAtNy4zNjQzODQgNy45MDIzNjYgLTcuMjQ0ODMyIDcuNzcwODU5IC03LjEwMTM3TDUuNjc4NzA1IC00Ljg1Mzc5OFonIGlkPSdnMy04OCcvPgo8cGF0aCBkPSdNNi4wMTM0NSAtNy45OTgwMDdDNi4wMjU0MDUgLTguMDQ1ODI4IDYuMDQ5MzE1IC04LjExNzU1OSA2LjA0OTMxNSAtOC4xNzczMzVDNi4wNDkzMTUgLTguMjk2ODg3IDUuOTI5NzYzIC04LjI5Njg4NyA1LjkwNTg1MyAtOC4yOTY4ODdDNS44OTM4OTggLTguMjk2ODg3IDUuMzA4MDk1IC04LjI0OTA2NiA1LjI0ODMxOSAtOC4yMzcxMTFDNS4wNDUwODEgLTguMjI1MTU2IDQuODY1NzUzIC04LjIwMTI0NSA0LjY1MDU2IC04LjE4OTI5QzQuMzUxNjgxIC04LjE2NTM4IDQuMjY3OTk1IC04LjE1MzQyNSA0LjI2Nzk5NSAtNy45MzgyMzJDNC4yNjc5OTUgLTcuODE4NjggNC4zNjM2MzYgLTcuODE4NjggNC41MzEwMDkgLTcuODE4NjhDNS4xMTY4MTIgLTcuODE4NjggNS4xMjg3NjcgLTcuNzExMDgzIDUuMTI4NzY3IC03LjU5MTUzMkM1LjEyODc2NyAtNy41MTk4MDEgNS4xMDQ4NTcgLTcuNDI0MTU5IDUuMDkyOTAyIC03LjM4ODI5NEw0LjM2MzYzNiAtNC40ODMxODhDNC4yMzIxMyAtNC43OTQwMjIgMy45MDkzNCAtNS4yNzIyMjkgMy4yODc2NzEgLTUuMjcyMjI5QzEuOTM2NzM3IC01LjI3MjIyOSAwLjQ3ODIwNyAtMy41MjY3NzUgMC40NzgyMDcgLTEuNzU3NDFDMC40NzgyMDcgLTAuNTczODQ4IDEuMTcxNjA2IDAuMTE5NTUyIDEuOTg0NTU4IDAuMTE5NTUyQzIuNjQyMDkyIDAuMTE5NTUyIDMuMjAzOTg1IC0wLjM5NDUyMSAzLjUzODczIC0wLjc4OTA0MUMzLjY1ODI4MSAtMC4wODM2ODYgNC4yMjAxNzQgMC4xMTk1NTIgNC41Nzg4MjkgMC4xMTk1NTJTNS4yMjQ0MDggLTAuMDk1NjQxIDUuNDM5NjAxIC0wLjUyNjAyN0M1LjYzMDg4NCAtMC45MzI1MDMgNS43OTgyNTcgLTEuNjYxNzY4IDUuNzk4MjU3IC0xLjcwOTU4OUM1Ljc5ODI1NyAtMS43NjkzNjUgNS43NTA0MzYgLTEuODE3MTg2IDUuNjc4NzA1IC0xLjgxNzE4NkM1LjU3MTEwOCAtMS44MTcxODYgNS41NTkxNTMgLTEuNzU3NDEgNS41MTEzMzMgLTEuNTc4MDgyQzUuMzMyMDA1IC0wLjg3MjcyNyA1LjEwNDg1NyAtMC4xMTk1NTIgNC42MTQ2OTUgLTAuMTE5NTUyQzQuMjY3OTk1IC0wLjExOTU1MiA0LjI0NDA4NSAtMC40MzAzODYgNC4yNDQwODUgLTAuNjY5NDg5QzQuMjQ0MDg1IC0wLjcxNzMxIDQuMjQ0MDg1IC0wLjk2ODM2OSA0LjMyNzc3MSAtMS4zMDMxMTNMNi4wMTM0NSAtNy45OTgwMDdaTTMuNTk4NTA2IC0xLjQyMjY2NUMzLjUzODczIC0xLjIxOTQyNyAzLjUzODczIC0xLjE5NTUxNyAzLjM3MTM1NyAtMC45NjgzNjlDMy4xMDgzNDQgLTAuNjMzNjI0IDIuNTgyMzE2IC0wLjExOTU1MiAyLjAyMDQyMyAtMC4xMTk1NTJDMS41MzAyNjIgLTAuMTE5NTUyIDEuMjU1MjkzIC0wLjU2MTg5MyAxLjI1NTI5MyAtMS4yNjcyNDhDMS4yNTUyOTMgLTEuOTI0NzgyIDEuNjI1OTAzIC0zLjI2Mzc2MSAxLjg1MzA1MSAtMy43NjU4NzhDMi4yNTk1MjcgLTQuNjAyNzQgMi44MjE0MiAtNS4wMzMxMjYgMy4yODc2NzEgLTUuMDMzMTI2QzQuMDc2NzEyIC01LjAzMzEyNiA0LjIzMjEzIC00LjA1MjgwMiA0LjIzMjEzIC0zLjk1NzE2MUM0LjIzMjEzIC0zLjk0NTIwNSA0LjE5NjI2NCAtMy43ODk3ODggNC4xODQzMDkgLTMuNzY1ODc4TDMuNTk4NTA2IC0xLjQyMjY2NVonIGlkPSdnMy0xMDAnLz4KPHBhdGggZD0nTTMuMTQ0MjA5IDEuMzM4OTc5QzIuODIxNDIgMS43OTMyNzUgMi4zNTUxNjggMi4xOTk3NTEgMS43NjkzNjUgMi4xOTk3NTFDMS42MjU5MDMgMi4xOTk3NTEgMS4wNTIwNTUgMi4xNzU4NDEgMC44NzI3MjcgMS42MjU5MDNDMC45MDg1OTMgMS42Mzc4NTggMC45NjgzNjkgMS42Mzc4NTggMC45OTIyNzkgMS42Mzc4NThDMS4zNTA5MzQgMS42Mzc4NTggMS41OTAwMzcgMS4zMjcwMjQgMS41OTAwMzcgMS4wNTIwNTVTMS4zNjI4ODkgMC42ODE0NDUgMS4xODM1NjIgMC42ODE0NDVDMC45OTIyNzkgMC42ODE0NDUgMC41NzM4NDggMC44MjQ5MDcgMC41NzM4NDggMS40MTA3MUMwLjU3Mzg0OCAyLjAyMDQyMyAxLjA4NzkyIDIuNDM4ODU0IDEuNzY5MzY1IDIuNDM4ODU0QzIuOTY0ODgyIDIuNDM4ODU0IDQuMTcyMzU0IDEuMzM4OTc5IDQuNTA3MDk4IDAuMDExOTU1TDUuNjc4NzA1IC00LjY1MDU2QzUuNjkwNjYgLTQuNzEwMzM2IDUuNzE0NTcgLTQuNzgyMDY3IDUuNzE0NTcgLTQuODUzNzk4QzUuNzE0NTcgLTUuMDMzMTI2IDUuNTcxMTA4IC01LjE1MjY3NyA1LjM5MTc4MSAtNS4xNTI2NzdDNS4yODQxODQgLTUuMTUyNjc3IDUuMDMzMTI2IC01LjEwNDg1NyA0LjkzNzQ4NCAtNC43NDYyMDJMNC4wNTI4MDIgLTEuMjMxMzgyQzMuOTkzMDI2IC0xLjAxNjE4OSAzLjk5MzAyNiAtMC45OTIyNzkgMy44OTczODUgLTAuODYwNzcyQzMuNjU4MjgxIC0wLjUyNjAyNyAzLjI2Mzc2MSAtMC4xMTk1NTIgMi42ODk5MTMgLTAuMTE5NTUyQzIuMDIwNDIzIC0wLjExOTU1MiAxLjk2MDY0OCAtMC43NzcwODYgMS45NjA2NDggLTEuMDk5ODc1QzEuOTYwNjQ4IC0xLjc4MTMyIDIuMjgzNDM3IC0yLjcwMTg2OCAyLjYwNjIyNyAtMy41NjI2NEMyLjczNzczMyAtMy45MDkzNCAyLjgwOTQ2NSAtNC4wNzY3MTIgMi44MDk0NjUgLTQuMzE1ODE2QzIuODA5NDY1IC00LjgxNzkzMyAyLjQ1MDgwOSAtNS4yNzIyMjkgMS44NjUwMDYgLTUuMjcyMjI5QzAuNzY1MTMxIC01LjI3MjIyOSAwLjMyMjc5IC0zLjUzODczIDAuMzIyNzkgLTMuNDQzMDg4QzAuMzIyNzkgLTMuMzk1MjY4IDAuMzcwNjEgLTMuMzM1NDkyIDAuNDU0Mjk2IC0zLjMzNTQ5MkMwLjU2MTg5MyAtMy4zMzU0OTIgMC41NzM4NDggLTMuMzgzMzEzIDAuNjIxNjY5IC0zLjU1MDY4NUMwLjkwODU5MyAtNC41NTQ5MTkgMS4zNjI4ODkgLTUuMDMzMTI2IDEuODI5MTQxIC01LjAzMzEyNkMxLjkzNjczNyAtNS4wMzMxMjYgMi4xMzk5NzUgLTUuMDMzMTI2IDIuMTM5OTc1IC00LjYzODYwNUMyLjEzOTk3NSAtNC4zMjc3NzEgMi4wMDg0NjggLTMuOTgxMDcxIDEuODI5MTQxIC0zLjUyNjc3NUMxLjI0MzMzNyAtMS45NjA2NDggMS4yNDMzMzcgLTEuNTY2MTI3IDEuMjQzMzM3IC0xLjI3OTIwM0MxLjI0MzMzNyAtMC4xNDM0NjIgMi4wNTYyODkgMC4xMTk1NTIgMi42NTQwNDcgMC4xMTk1NTJDMy4wMDA3NDcgMC4xMTk1NTIgMy40MzExMzMgMC4wMTE5NTUgMy44NDk1NjQgLTAuNDMwMzg2TDMuODYxNTE5IC0wLjQxODQzMUMzLjY4MjE5MiAwLjI4NjkyNCAzLjU2MjY0IDAuNzUzMTc2IDMuMTQ0MjA5IDEuMzM4OTc5WicgaWQ9J2czLTEyMScvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzEtMCcvPgo8cGF0aCBkPSdNOS4zMjUwMzEgLTcuOTAyMzY2QzkuMzQ4OTQxIC03LjkzODIzMiA5LjM4NDgwNyAtOC4wMjE5MTggOS4zODQ4MDcgLTguMDY5NzM4QzkuMzg0ODA3IC04LjE1MzQyNSA5LjM3Mjg1MiAtOC4xNjUzOCA5LjA5Nzg4MyAtOC4xNjUzOEgwLjg0ODgxN0MwLjU3Mzg0OCAtOC4xNjUzOCAwLjU2MTg5MyAtOC4xNTM0MjUgMC41NjE4OTMgLTguMDY5NzM4QzAuNTYxODkzIC04LjAyMTkxOCAwLjU5Nzc1OCAtNy45MzgyMzIgMC42MjE2NjkgLTcuOTAyMzY2TDQuNjUwNTYgMC4xNjczNzJDNC43MzQyNDcgMC4zMjI3OSA0Ljc3MDExMiAwLjM5NDUyMSA0Ljk3MzM1IDAuMzk0NTIxUzUuMjEyNDUzIDAuMzIyNzkgNS4yOTYxMzkgMC4xNjczNzJMOS4zMjUwMzEgLTcuOTAyMzY2Wk0yLjA0NDMzNCAtNy4zMDQ2MDhIOC42MDc3MjFMNS4zMzIwMDUgLTAuNzI5MjY1TDIuMDQ0MzM0IC03LjMwNDYwOFonIGlkPSdnMS0xMTQnLz4KPHBhdGggZD0nTTMuNDc0OTY5IC0xLjgwOTIxNUg1LjgxODE4MkM1LjkyOTc2MyAtMS44MDkyMTUgNi4xMDUxMDYgLTEuODA5MjE1IDYuMTA1MTA2IC0xLjk5MjUyOFM1LjkyOTc2MyAtMi4xNzU4NDEgNS44MTgxODIgLTIuMTc1ODQxSDMuNDc0OTY5Vi00LjUyNzAyNEMzLjQ3NDk2OSAtNC42Mzg2MDUgMy40NzQ5NjkgLTQuODEzOTQ4IDMuMjkxNjU2IC00LjgxMzk0OFMzLjEwODM0NCAtNC42Mzg2MDUgMy4xMDgzNDQgLTQuNTI3MDI0Vi0yLjE3NTg0MUgwLjc1NzE2MUMwLjY0NTU3OSAtMi4xNzU4NDEgMC40NzAyMzcgLTIuMTc1ODQxIDAuNDcwMjM3IC0xLjk5MjUyOFMwLjY0NTU3OSAtMS44MDkyMTUgMC43NTcxNjEgLTEuODA5MjE1SDMuMTA4MzQ0VjAuNTQxOTY4QzMuMTA4MzQ0IDAuNjUzNTQ5IDMuMTA4MzQ0IDAuODI4ODkyIDMuMjkxNjU2IDAuODI4ODkyUzMuNDc0OTY5IDAuNjUzNTQ5IDMuNDc0OTY5IDAuNTQxOTY4Vi0xLjgwOTIxNVonIGlkPSdnNC00MycvPgo8cGF0aCBkPSdNMi41MDI2MTUgLTUuMDc2OTYxQzIuNTAyNjE1IC01LjI5MjE1NCAyLjQ4NjY3NSAtNS4zMDAxMjUgMi4yNzE0ODIgLTUuMzAwMTI1QzEuOTQ0NzA3IC00Ljk4MTMyIDEuNTIyMjkxIC00Ljc5MDAzNyAwLjc2NTEzMSAtNC43OTAwMzdWLTQuNTI3MDI0QzAuOTgwMzI0IC00LjUyNzAyNCAxLjQxMDcxIC00LjUyNzAyNCAxLjg3Mjk3NiAtNC43NDIyMTdWLTAuNjUzNTQ5QzEuODcyOTc2IC0wLjM1ODY1NSAxLjg0OTA2NiAtMC4yNjMwMTQgMS4wOTE5MDUgLTAuMjYzMDE0SDAuODEyOTUxVjBDMS4xMzk3MjYgLTAuMDIzOTEgMS44MjUxNTYgLTAuMDIzOTEgMi4xODM4MTEgLTAuMDIzOTFTMy4yMzU4NjYgLTAuMDIzOTEgMy41NjI2NCAwVi0wLjI2MzAxNEgzLjI4MzY4NkMyLjUyNjUyNiAtMC4yNjMwMTQgMi41MDI2MTUgLTAuMzU4NjU1IDIuNTAyNjE1IC0wLjY1MzU0OVYtNS4wNzY5NjFaJyBpZD0nZzQtNDknLz4KPHBhdGggZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2IC0wLjUzNzk4MyAxLjgxNzE4NiAtMi45NzY4MzdDMS44MTcxODYgLTUuMjk2MTM5IDIuMzc5MDc4IC03LjI5MjY1MyAzLjc2NTg3OCAtOC43MDMzNjJDMy44ODU0MyAtOC44MTA5NTkgMy44ODU0MyAtOC44MzQ4NjkgMy44ODU0MyAtOC44NzA3MzVDMy44ODU0MyAtOC45NDI0NjYgMy44MjU2NTQgLTguOTY2Mzc2IDMuNzc3ODMzIC04Ljk2NjM3NkMzLjYyMjQxNiAtOC45NjYzNzYgMi42NDIwOTIgLTguMTA1NjA0IDIuMDU2Mjg5IC02LjkzMzk5OEMxLjQ0NjU3NSAtNS43MjY1MjYgMS4xNzE2MDYgLTQuNDQ3MzIzIDEuMTcxNjA2IC0yLjk3NjgzN0MxLjE3MTYwNiAtMS45MTI4MjcgMS4zMzg5NzkgLTAuNDkwMTYyIDEuOTYwNjQ4IDAuNzg5MDQxQzIuNjY2MDAyIDIuMjIzNjYxIDMuNjQ2MzI2IDMuMDAwNzQ3IDMuNzc3ODMzIDMuMDAwNzQ3QzMuODI1NjU0IDMuMDAwNzQ3IDMuODg1NDMgMi45NzY4MzcgMy44ODU0MyAyLjkwNTEwNlonIGlkPSdnNS00MCcvPgo8cGF0aCBkPSdNMy4zNzEzNTcgLTIuOTc2ODM3QzMuMzcxMzU3IC0zLjg4NTQzIDMuMjUxODA2IC01LjM2Nzg3IDIuNTgyMzE2IC02Ljc1NDY3QzEuODc2OTYxIC04LjE4OTI5IDAuODk2NjM4IC04Ljk2NjM3NiAwLjc2NTEzMSAtOC45NjYzNzZDMC43MTczMSAtOC45NjYzNzYgMC42NTc1MzQgLTguOTQyNDY2IDAuNjU3NTM0IC04Ljg3MDczNUMwLjY1NzUzNCAtOC44MzQ4NjkgMC42NTc1MzQgLTguODEwOTU5IDAuODYwNzcyIC04LjYwNzcyMUMyLjA1NjI4OSAtNy40MDAyNDkgMi43MjU3NzggLTUuNDI3NjQ2IDIuNzI1Nzc4IC0yLjk4ODc5MkMyLjcyNTc3OCAtMC42Njk0ODkgMi4xNjM4ODUgMS4zMjcwMjQgMC43NzcwODYgMi43Mzc3MzNDMC42NTc1MzQgMi44NDUzMyAwLjY1NzUzNCAyLjg2OTI0IDAuNjU3NTM0IDIuOTA1MTA2QzAuNjU3NTM0IDIuOTc2ODM3IDAuNzE3MzEgMy4wMDA3NDcgMC43NjUxMzEgMy4wMDA3NDdDMC45MjA1NDggMy4wMDA3NDcgMS45MDA4NzIgMi4xMzk5NzUgMi40ODY2NzUgMC45NjgzNjlDMy4wOTYzODkgLTAuMjUxMDU5IDMuMzcxMzU3IC0xLjU0MjIxNyAzLjM3MTM1NyAtMi45NzY4MzdaJyBpZD0nZzUtNDEnLz4KPHBhdGggZD0nTTQuNzcwMTEyIC0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMSAtMi43NjE2NDQgOC40NTIzMDQgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjk3NjgzN0M4LjQ1MjMwNCAtMy4yMDM5ODUgOC4yNDkwNjYgLTMuMjAzOTg1IDguMDY5NzM4IC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTIgLTYuNjcwOTg0IDQuNzcwMTEyIC02Ljg4NjE3NyA0LjU1NDkxOSAtNi44ODYxNzdDNC4zMjc3NzEgLTYuODg2MTc3IDQuMzI3NzcxIC02LjY4MjkzOSA0LjMyNzc3MSAtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0QzAuODYwNzcyIC0zLjIwMzk4NSAwLjY0NTU3OSAtMy4yMDM5ODUgMC42NDU1NzkgLTIuOTg4NzkyQzAuNjQ1NTc5IC0yLjc2MTY0NCAwLjg0ODgxNyAtMi43NjE2NDQgMS4wMjgxNDQgLTIuNzYxNjQ0SDQuMzI3NzcxVjAuNTM3OTgzQzQuMzI3NzcxIDAuNzA1MzU1IDQuMzI3NzcxIDAuOTIwNTQ4IDQuNTQyOTY0IDAuOTIwNTQ4QzQuNzcwMTEyIDAuOTIwNTQ4IDQuNzcwMTEyIDAuNzE3MzEgNC43NzAxMTIgMC41Mzc5ODNWLTIuNzYxNjQ0WicgaWQ9J2c1LTQzJy8+CjxwYXRoIGQ9J001LjI2MDI3NCAtMi4wMDg0NjhINC45OTcyNkM0Ljk2MTM5NSAtMS44MDUyMyA0Ljg2NTc1MyAtMS4xNDc2OTYgNC43NDYyMDIgLTAuOTU2NDEzQzQuNjYyNTE2IC0wLjg0ODgxNyAzLjk4MTA3MSAtMC44NDg4MTcgMy42MjI0MTYgLTAuODQ4ODE3SDEuNDEwNzFDMS43MzM0OTkgLTEuMTIzNzg2IDIuNDYyNzY1IC0xLjg4ODkxNyAyLjc3MzU5OSAtMi4xNzU4NDFDNC41OTA3ODUgLTMuODQ5NTY0IDUuMjYwMjc0IC00LjQ3MTIzMyA1LjI2MDI3NCAtNS42NTQ3OTVDNS4yNjAyNzQgLTcuMDI5NjM5IDQuMTcyMzU0IC03Ljk1MDE4NyAyLjc4NTU1NCAtNy45NTAxODdTMC41ODU4MDMgLTYuNzY2NjI1IDAuNTg1ODAzIC01LjczODQ4MUMwLjU4NTgwMyAtNS4xMjg3NjcgMS4xMTE4MzEgLTUuMTI4NzY3IDEuMTQ3Njk2IC01LjEyODc2N0MxLjM5ODc1NSAtNS4xMjg3NjcgMS43MDk1ODkgLTUuMzA4MDk1IDEuNzA5NTg5IC01LjY5MDY2QzEuNzA5NTg5IC02LjAyNTQwNSAxLjQ4MjQ0MSAtNi4yNTI1NTMgMS4xNDc2OTYgLTYuMjUyNTUzQzEuMDQwMSAtNi4yNTI1NTMgMS4wMTYxODkgLTYuMjUyNTUzIDAuOTgwMzI0IC02LjI0MDU5OEMxLjIwNzQ3MiAtNy4wNTM1NDkgMS44NTMwNTEgLTcuNjAzNDg3IDIuNjMwMTM3IC03LjYwMzQ4N0MzLjY0NjMyNiAtNy42MDM0ODcgNC4yNjc5OTUgLTYuNzU0NjcgNC4yNjc5OTUgLTUuNjU0Nzk1QzQuMjY3OTk1IC00LjYzODYwNSAzLjY4MjE5MiAtMy43NTM5MjMgMy4wMDA3NDcgLTIuOTg4NzkyTDAuNTg1ODAzIC0wLjI4NjkyNFYwSDQuOTQ5NDRMNS4yNjAyNzQgLTIuMDA4NDY4WicgaWQ9J2c1LTUwJy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnNS02MScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzUtOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzUtOTMnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzQzLjgzNTYxNicgeGxpbms6aHJlZj0nI2cxLTExNCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nNTMuNzk4Mjg3JyB4bGluazpocmVmPScjZzUtNDAnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzU4LjM1MDYxMycgeGxpbms6aHJlZj0nI2czLTEyJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PSc2NC45NTkxMDEnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzY5LjU4MDcxNycgeGxpbms6aHJlZj0nI2c0LTQzJyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PSc3Ni4xNjcyMjMnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nOTAuMjYxNDY1Jy8+Cjx1c2UgeD0nODAuODk5NTM4JyB4bGluazpocmVmPScjZzUtNDEnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9Jzk1LjQxNDUwNCcgeGxpbms6aHJlZj0nI2c1LTYxJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxMTQuNDgxNzk2JyB4bGluazpocmVmPScjZzEtMCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMTIzLjc4MDI5MycgeGxpbms6aHJlZj0nI2c1LTUwJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxMjkuNjMzMjgzJyB4bGluazpocmVmPScjZzMtODgnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzE0MC4yODgzOTEnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nODQuMTI5NzY1Jy8+Cjx1c2UgeD0nMTM5LjM0ODUxJyB4bGluazpocmVmPScjZzQtNDknIHk9JzkxLjU3NzMxNicvPgo8dXNlIHg9JzE0My41ODI2OTMnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTEuNTc3MzE2Jy8+Cjx1c2UgeD0nMTQ1LjkzNTAxNycgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc5MS41NzczMTYnLz4KPHVzZSB4PScxNDguMjg3MzQxJyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5MS41NzczMTYnLz4KPHVzZSB4PScxNTIuOTA4OTU2JyB4bGluazpocmVmPScjZzQtNDMnIHk9JzkxLjU3NzMxNicvPgo8dXNlIHg9JzE1OS40OTU0NjMnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nOTEuNTc3MzE2Jy8+Cjx1c2UgeD0nMTY0LjIyNzc3OCcgeGxpbms6aHJlZj0nI2c1LTQwJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxNjguNzgwMTAzJyB4bGluazpocmVmPScjZzMtMTIxJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScxNzQuNDg3ODA2JyB4bGluazpocmVmPScjZzQtNDknIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzE3OC43MjE5ODknIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTAuMjYxNDY1Jy8+Cjx1c2UgeD0nMTgxLjA3NDMxMycgeGxpbms6aHJlZj0nI2cyLTU4JyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PScxODMuNDI2NjM3JyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PScxODguMDQ4MjUyJyB4bGluazpocmVmPScjZzQtNDMnIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzE5NC42MzQ3NTknIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nOTAuMjYxNDY1Jy8+Cjx1c2UgeD0nMjAyLjAyMzczNycgeGxpbms6aHJlZj0nI2cxLTAnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzIxMy45Nzg4OTgnIHhsaW5rOmhyZWY9JyNnMy04OCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMjIzLjY5NDEyNScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PScyMjcuOTI4MzA4JyB4bGluazpocmVmPScjZzItNTgnIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzIzMC4yODA2MzInIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nOTAuMjYxNDY1Jy8+Cjx1c2UgeD0nMjMyLjYzMjk1NicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nOTAuMjYxNDY1Jy8+Cjx1c2UgeD0nMjM3LjI1NDU3MScgeGxpbms6aHJlZj0nI2c0LTQzJyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PScyNDMuODQxMDc4JyB4bGluazpocmVmPScjZzQtNDknIHk9JzkwLjI2MTQ2NScvPgo8dXNlIHg9JzI0OC41NzMzOTMnIHhsaW5rOmhyZWY9JyNnNS00MCcgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMjUzLjEyNTcxOCcgeGxpbms6aHJlZj0nI2czLTEyJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScyNTkuNzM0MjA3JyB4bGluazpocmVmPScjZzItMTA3JyB5PSc5MC4yNjE0NjUnLz4KPHVzZSB4PScyNjcuNTEwNjE4JyB4bGluazpocmVmPScjZzUtNDMnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzI3OS4yNzE5MzMnIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9JzI4NS4zNTQ2MjYnIHhsaW5rOmhyZWY9JyNnMy0xMicgeT0nODguNDY4MjAyJy8+Cjx1c2UgeD0nMjkyLjYyNTg5NycgeGxpbms6aHJlZj0nI2c1LTQxJyB5PSc4OC40NjgyMDInLz4KPHVzZSB4PScyOTcuMTc4MjIyJyB4bGluazpocmVmPScjZzUtNDEnIHk9Jzg4LjQ2ODIwMicvPgo8dXNlIHg9Jzk1LjQxNDUwNCcgeGxpbms6aHJlZj0nI2c1LTYxJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMTE0LjQ4MTc5NicgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxMjMuNzgwMjkzJyB4bGluazpocmVmPScjZzUtNTAnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxMjkuNjMzMjgzJyB4bGluazpocmVmPScjZzUtOTEnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxMzIuODg0OTQ0JyB4bGluazpocmVmPScjZzMtODgnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxNDMuNTQwMDUyJyB4bGluazpocmVmPScjZzAtNDgnIHk9Jzk4LjA3NzQ2MScvPgo8dXNlIHg9JzE0Mi42MDAxNzEnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTA1LjUyNTAxMicvPgo8dXNlIHg9JzE0Ni44MzQzNTQnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nMTA1LjUyNTAxMicvPgo8dXNlIHg9JzE0OS4xODY2NzgnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nMTA1LjUyNTAxMicvPgo8dXNlIHg9JzE1MS41MzkwMDInIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEwNS41MjUwMTInLz4KPHVzZSB4PScxNTYuNjU4NzQ5JyB4bGluazpocmVmPScjZzMtODgnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxNjcuMzEzODU3JyB4bGluazpocmVmPScjZzAtNDgnIHk9Jzk4LjA3NzQ2MScvPgo8dXNlIHg9JzE2Ni4zNzM5NzcnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEwNS41MjUwMTInLz4KPHVzZSB4PScxNzAuOTk1NTkyJyB4bGluazpocmVmPScjZzQtNDMnIHk9JzEwNS41MjUwMTInLz4KPHVzZSB4PScxNzcuNTgyMDk5JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEwNS41MjUwMTInLz4KPHVzZSB4PScxODIuMzE0NDE0JyB4bGluazpocmVmPScjZzUtOTMnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxODUuNTY2MDc1JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxOTAuMTE4NDAxJyB4bGluazpocmVmPScjZzUtOTEnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScxOTMuMzcwMDYyJyB4bGluazpocmVmPScjZzMtMTIxJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMTk5LjA3Nzc2NScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjAzLjMxMTk0OCcgeGxpbms6aHJlZj0nI2cyLTU4JyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjA1LjY2NDI3MicgeGxpbms6aHJlZj0nI2cyLTU4JyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjA4LjAxNjU5NScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTA0LjIwOTE2MScvPgo8dXNlIHg9JzIxMy4xMzYzNDMnIHhsaW5rOmhyZWY9JyNnMy0xMjEnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScyMTguODQ0MDQ2JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjIzLjQ2NTY2MScgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjMwLjA1MjE2OCcgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjM0Ljc4NDQ4MycgeGxpbms6aHJlZj0nI2c1LTkzJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMjQwLjY5MjgwOCcgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScyNTIuNjQ3OTY4JyB4bGluazpocmVmPScjZzUtOTEnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScyNTUuODk5NjI5JyB4bGluazpocmVmPScjZzMtODgnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PScyNjUuNjE0ODU3JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEwNC4yMDkxNjEnLz4KPHVzZSB4PScyNjkuODQ5MDM5JyB4bGluazpocmVmPScjZzItNTgnIHk9JzEwNC4yMDkxNjEnLz4KPHVzZSB4PScyNzIuMjAxMzYzJyB4bGluazpocmVmPScjZzItNTgnIHk9JzEwNC4yMDkxNjEnLz4KPHVzZSB4PScyNzQuNTUzNjg3JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMDQuMjA5MTYxJy8+Cjx1c2UgeD0nMjc5LjY3MzQzNScgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMjg5LjM4ODY2MicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTA0LjIwOTE2MScvPgo8dXNlIHg9JzI5NC4wMTAyNzcnIHhsaW5rOmhyZWY9JyNnNC00MycgeT0nMTA0LjIwOTE2MScvPgo8dXNlIHg9JzMwMC41OTY3ODQnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTA0LjIwOTE2MScvPgo8dXNlIHg9JzMwNS4zMjkwOTknIHhsaW5rOmhyZWY9JyNnNS05MycgeT0nMTAyLjQxNTg5OCcvPgo8dXNlIHg9JzMwOC41ODA3NicgeGxpbms6aHJlZj0nI2cwLTQ4JyB5PSc5OC4wNzc0NjEnLz4KPHVzZSB4PSczMTEuMzc1ODM2JyB4bGluazpocmVmPScjZzUtNDAnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PSczMTUuOTI4MTYyJyB4bGluazpocmVmPScjZzMtMTInIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PSczMjIuNTM2NjUnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEwNC4yMDkxNjEnLz4KPHVzZSB4PSczMzAuMzEzMDYxJyB4bGluazpocmVmPScjZzUtNDMnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PSczNDIuMDc0Mzc2JyB4bGluazpocmVmPScjZzMtMTAwJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMzQ4LjE1NzA2OScgeGxpbms6aHJlZj0nI2czLTEyJyB5PScxMDIuNDE1ODk4Jy8+Cjx1c2UgeD0nMzU1LjQyODM0JyB4bGluazpocmVmPScjZzUtNDEnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PSczNTkuOTgwNjY2JyB4bGluazpocmVmPScjZzUtNDEnIHk9JzEwMi40MTU4OTgnLz4KPHVzZSB4PSc5NS40MTQ1MDQnIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzExNC40ODE3OTYnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMTIzLjc4MDI5MycgeGxpbms6aHJlZj0nI2c1LTUwJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMTI5LjYzMzI4MycgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMTQwLjI4ODM5MScgeGxpbms6aHJlZj0nI2cwLTQ4JyB5PScxMTIuMDI1MTU3Jy8+Cjx1c2UgeD0nMTM5LjM0ODUxJyB4bGluazpocmVmPScjZzQtNDknIHk9JzExOS40NzI3MDgnLz4KPHVzZSB4PScxNDMuNTgyNjkzJyB4bGluazpocmVmPScjZzItNTgnIHk9JzExOS40NzI3MDgnLz4KPHVzZSB4PScxNDUuOTM1MDE3JyB4bGluazpocmVmPScjZzItNTgnIHk9JzExOS40NzI3MDgnLz4KPHVzZSB4PScxNDguMjg3MzQxJyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMTkuNDcyNzA4Jy8+Cjx1c2UgeD0nMTUzLjQwNzA4OCcgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMTU3Ljk1OTQxNCcgeGxpbms6aHJlZj0nI2czLTEyMScgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzE2My42NjcxMTcnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTE4LjE1Njg1NycvPgo8dXNlIHg9JzE2Ny45MDEzJyB4bGluazpocmVmPScjZzItNTgnIHk9JzExOC4xNTY4NTcnLz4KPHVzZSB4PScxNzAuMjUzNjIzJyB4bGluazpocmVmPScjZzItNTgnIHk9JzExOC4xNTY4NTcnLz4KPHVzZSB4PScxNzIuNjA1OTQ3JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMTgwLjM4MjM1OCcgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PScxOTIuMzM3NTE5JyB4bGluazpocmVmPScjZzMtODgnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PScyMDIuMDUyNzQ2JyB4bGluazpocmVmPScjZzQtNDknIHk9JzExOC4xNTY4NTcnLz4KPHVzZSB4PScyMDYuMjg2OTI5JyB4bGluazpocmVmPScjZzItNTgnIHk9JzExOC4xNTY4NTcnLz4KPHVzZSB4PScyMDguNjM5MjUzJyB4bGluazpocmVmPScjZzItNTgnIHk9JzExOC4xNTY4NTcnLz4KPHVzZSB4PScyMTAuOTkxNTc3JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMjE2LjExMTMyNCcgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMjIwLjY2MzY1JyB4bGluazpocmVmPScjZzMtMTInIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PScyMjcuMjcyMTM4JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMjM1LjA0ODU0OScgeGxpbms6aHJlZj0nI2c1LTQzJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMjQ2LjgwOTg2NCcgeGxpbms6aHJlZj0nI2czLTEwMCcgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzI1Mi44OTI1NTcnIHhsaW5rOmhyZWY9JyNnMy0xMicgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzI2MC4xNjM4MjgnIHhsaW5rOmhyZWY9JyNnNS00MScgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzI2NC43MTYxNTQnIHhsaW5rOmhyZWY9JyNnNS00MScgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzI3MS45MjUxNDMnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMjgzLjg4MDMwNCcgeGxpbms6aHJlZj0nI2c1LTUwJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMjg5LjczMzI5NCcgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMzAwLjM4ODQwMicgeGxpbms6aHJlZj0nI2cwLTQ4JyB5PScxMTIuMDI1MTU3Jy8+Cjx1c2UgeD0nMjk5LjQ0ODUyMScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTE5LjQ3MjcwOCcvPgo8dXNlIHg9JzMwNC4wNzAxMzcnIHhsaW5rOmhyZWY9JyNnNC00MycgeT0nMTE5LjQ3MjcwOCcvPgo8dXNlIHg9JzMxMC42NTY2NDMnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTE5LjQ3MjcwOCcvPgo8dXNlIHg9JzMxNS4zODg5NTgnIHhsaW5rOmhyZWY9JyNnNS00MCcgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzMxOS45NDEyODQnIHhsaW5rOmhyZWY9JyNnMy0xMjEnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSczMjUuNjQ4OTg3JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMzMwLjI3MDYwMicgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMzM2Ljg1NzEwOScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMzQ0LjI0NjA4NycgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSczNTYuMjAxMjQ4JyB4bGluazpocmVmPScjZzMtODgnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSczNjUuOTE2NDc1JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMzcwLjUzODA5MScgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMzc3LjEyNDU5NycgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMTguMTU2ODU3Jy8+Cjx1c2UgeD0nMzgxLjg1NjkxMicgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMzg2LjQwOTIzOCcgeGxpbms6aHJlZj0nI2czLTEyJyB5PScxMTYuMzYzNTk0Jy8+Cjx1c2UgeD0nMzkzLjAxNzcyNicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTE4LjE1Njg1NycvPgo8dXNlIHg9JzQwMC43OTQxMzcnIHhsaW5rOmhyZWY9JyNnNS00MycgeT0nMTE2LjM2MzU5NCcvPgo8dXNlIHg9JzQxMi41NTU0NTInIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSc0MTguNjM4MTQ1JyB4bGluazpocmVmPScjZzMtMTInIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSc0MjUuOTA5NDE2JyB4bGluazpocmVmPScjZzUtNDEnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSc0MzAuNDYxNzQyJyB4bGluazpocmVmPScjZzUtNDEnIHk9JzExNi4zNjM1OTQnLz4KPHVzZSB4PSc5NS40MTQ1MDQnIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nMTMwLjMxMTI5Jy8+Cjx1c2UgeD0nMTE0LjQ4MTc5NicgeGxpbms6aHJlZj0nI2c1LTUwJyB5PScxMzAuMzExMjknLz4KPHVzZSB4PScxMjAuMzM0Nzg2JyB4bGluazpocmVmPScjZzMtODgnIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9JzEzMC45ODk4OTQnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nMTI1Ljk3Mjg1MycvPgo8dXNlIHg9JzEzMC4wNTAwMTMnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTMzLjQyMDQwNCcvPgo8dXNlIHg9JzEzNC4yODQxOTYnIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nMTMzLjQyMDQwNCcvPgo8dXNlIHg9JzEzNi42MzY1MicgeGxpbms6aHJlZj0nI2cyLTU4JyB5PScxMzMuNDIwNDA0Jy8+Cjx1c2UgeD0nMTM4Ljk4ODg0NCcgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTMzLjQyMDQwNCcvPgo8dXNlIHg9JzE0NC4xMDg1OTEnIHhsaW5rOmhyZWY9JyNnMy04OCcgeT0nMTMwLjMxMTI5Jy8+Cjx1c2UgeD0nMTUzLjgyMzgxOCcgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMTU4LjA1ODAwMScgeGxpbms6aHJlZj0nI2cyLTU4JyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMTYwLjQxMDMyNScgeGxpbms6aHJlZj0nI2cyLTU4JyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMTYyLjc2MjY0OScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTMyLjEwNDU1MycvPgo8dXNlIHg9JzE2Ny44ODIzOTYnIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9JzE3My45NjUwODknIHhsaW5rOmhyZWY9JyNnMy0xMicgeT0nMTMwLjMxMTI5Jy8+Cjx1c2UgeD0nMTgzLjg5MzAyNCcgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9JzE5NS44NDgxODQnIHhsaW5rOmhyZWY9JyNnNS01MCcgeT0nMTMwLjMxMTI5Jy8+Cjx1c2UgeD0nMjAxLjcwMTE3NCcgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxMzAuMzExMjknLz4KPHVzZSB4PScyMTIuMzU2MjgyJyB4bGluazpocmVmPScjZzAtNDgnIHk9JzEyNS45NzI4NTMnLz4KPHVzZSB4PScyMTEuNDE2NDAyJyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMzMuNDIwNDA0Jy8+Cjx1c2UgeD0nMjE2LjAzODAxNycgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxMzMuNDIwNDA0Jy8+Cjx1c2UgeD0nMjIyLjYyNDUyNCcgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMzMuNDIwNDA0Jy8+Cjx1c2UgeD0nMjI3LjM1NjgzOScgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxMzAuMzExMjknLz4KPHVzZSB4PScyMzEuOTA5MTY0JyB4bGluazpocmVmPScjZzMtMTIxJyB5PScxMzAuMzExMjknLz4KPHVzZSB4PScyMzcuNjE2ODY4JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMjQyLjIzODQ4MycgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMjQ4LjgyNDk5JyB4bGluazpocmVmPScjZzQtNDknIHk9JzEzMi4xMDQ1NTMnLz4KPHVzZSB4PScyNTYuMjEzOTY4JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTMwLjMxMTI5Jy8+Cjx1c2UgeD0nMjY4LjE2OTEyOCcgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxMzAuMzExMjknLz4KPHVzZSB4PScyNzcuODg0MzU2JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMjgyLjUwNTk3MScgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMjg5LjA5MjQ3OCcgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxMzIuMTA0NTUzJy8+Cjx1c2UgeD0nMjkzLjgyNDc5MycgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxMzAuMzExMjknLz4KPHVzZSB4PScyOTguMzc3MTE5JyB4bGluazpocmVmPScjZzMtMTInIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9JzMwNC45ODU2MDcnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzEzMi4xMDQ1NTMnLz4KPHVzZSB4PSczMTIuNzYyMDE4JyB4bGluazpocmVmPScjZzUtNDMnIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9JzMyNC41MjMzMzMnIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9JzMzMC42MDYwMjYnIHhsaW5rOmhyZWY9JyNnMy0xMicgeT0nMTMwLjMxMTI5Jy8+Cjx1c2UgeD0nMzM3Ljg3NzI5NycgeGxpbms6aHJlZj0nI2c1LTQxJyB5PScxMzAuMzExMjknLz4KPHVzZSB4PSczNDIuNDI5NjIzJyB4bGluazpocmVmPScjZzUtNDEnIHk9JzEzMC4zMTEyOScvPgo8dXNlIHg9Jzk1LjQxNDUwNCcgeGxpbms6aHJlZj0nI2c1LTYxJyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMTE0LjQ4MTc5NicgeGxpbms6aHJlZj0nI2c1LTUwJyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMTIwLjMzNDc4NicgeGxpbms6aHJlZj0nI2c1LTQwJyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMTI0Ljg4NzExMicgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMTM1LjU0MjIxOScgeGxpbms6aHJlZj0nI2cwLTQ4JyB5PScxMzkuOTIwNTQ5Jy8+Cjx1c2UgeD0nMTM0LjYwMjMzOScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxNDcuMzY4MScvPgo8dXNlIHg9JzEzOC44MzY1MjInIHhsaW5rOmhyZWY9JyNnMi01OCcgeT0nMTQ3LjM2ODEnLz4KPHVzZSB4PScxNDEuMTg4ODQ2JyB4bGluazpocmVmPScjZzItNTgnIHk9JzE0Ny4zNjgxJy8+Cjx1c2UgeD0nMTQzLjU0MTE2OScgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTQ3LjM2ODEnLz4KPHVzZSB4PScxNDguNjYwOTE3JyB4bGluazpocmVmPScjZzMtODgnIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PScxNTguMzc2MTQ0JyB4bGluazpocmVmPScjZzQtNDknIHk9JzE0Ni4wNTIyNDknLz4KPHVzZSB4PScxNjIuNjEwMzI3JyB4bGluazpocmVmPScjZzItNTgnIHk9JzE0Ni4wNTIyNDknLz4KPHVzZSB4PScxNjQuOTYyNjUxJyB4bGluazpocmVmPScjZzItNTgnIHk9JzE0Ni4wNTIyNDknLz4KPHVzZSB4PScxNjcuMzE0OTc1JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxNDYuMDUyMjQ5Jy8+Cjx1c2UgeD0nMTc1LjA5MTM4NicgeGxpbms6aHJlZj0nI2c1LTQzJyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMTg2Ljg1MjcwMScgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMTk3LjUwNzgwOCcgeGxpbms6aHJlZj0nI2cwLTQ4JyB5PScxMzkuOTIwNTQ5Jy8+Cjx1c2UgeD0nMTk2LjU2NzkyOCcgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTQ3LjM2ODEnLz4KPHVzZSB4PScyMDEuMTg5NTQzJyB4bGluazpocmVmPScjZzQtNDMnIHk9JzE0Ny4zNjgxJy8+Cjx1c2UgeD0nMjA3Ljc3NjA1JyB4bGluazpocmVmPScjZzQtNDknIHk9JzE0Ny4zNjgxJy8+Cjx1c2UgeD0nMjEyLjUwODM2NScgeGxpbms6aHJlZj0nI2czLTg4JyB5PScxNDQuMjU4OTg2Jy8+Cjx1c2UgeD0nMjIyLjIyMzU5MicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTQ2LjA1MjI0OScvPgo8dXNlIHg9JzIyNi44NDUyMDgnIHhsaW5rOmhyZWY9JyNnNC00MycgeT0nMTQ2LjA1MjI0OScvPgo8dXNlIHg9JzIzMy40MzE3MTQnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nMTQ2LjA1MjI0OScvPgo8dXNlIHg9JzIzOC4xNjQwMjknIHhsaW5rOmhyZWY9JyNnNS00MScgeT0nMTQ0LjI1ODk4NicvPgo8dXNlIHg9JzI0Mi43MTYzNTUnIHhsaW5rOmhyZWY9JyNnMy0xMDAnIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PScyNDguNzk5MDQ4JyB4bGluazpocmVmPScjZzMtMTInIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PScyNTguNzI2OTgyJyB4bGluazpocmVmPScjZzEtMCcgeT0nMTQ0LjI1ODk4NicvPgo8dXNlIHg9JzI3MC42ODIxNDMnIHhsaW5rOmhyZWY9JyNnNS01MCcgeT0nMTQ0LjI1ODk4NicvPgo8dXNlIHg9JzI3Ni41MzUxMzMnIHhsaW5rOmhyZWY9JyNnMy04OCcgeT0nMTQ0LjI1ODk4NicvPgo8dXNlIHg9JzI4Ny4xOTAyNDEnIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nMTM5LjkyMDU0OScvPgo8dXNlIHg9JzI4Ni4yNTAzNicgeGxpbms6aHJlZj0nI2cyLTEwNycgeT0nMTQ3LjM2ODEnLz4KPHVzZSB4PScyOTAuODcxOTc2JyB4bGluazpocmVmPScjZzQtNDMnIHk9JzE0Ny4zNjgxJy8+Cjx1c2UgeD0nMjk3LjQ1ODQ4MicgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxNDcuMzY4MScvPgo8dXNlIHg9JzMwMi4xOTA3OTcnIHhsaW5rOmhyZWY9JyNnNS00MCcgeT0nMTQ0LjI1ODk4NicvPgo8dXNlIHg9JzMwNi43NDMxMjMnIHhsaW5rOmhyZWY9JyNnMy0xMjEnIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PSczMTIuNDUwODI2JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxNDYuMDUyMjQ5Jy8+Cjx1c2UgeD0nMzE3LjA3MjQ0MicgeGxpbms6aHJlZj0nI2c0LTQzJyB5PScxNDYuMDUyMjQ5Jy8+Cjx1c2UgeD0nMzIzLjY1ODk0OCcgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PScxNDYuMDUyMjQ5Jy8+Cjx1c2UgeD0nMzMxLjA0NzkyNycgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PSczNDMuMDAzMDg3JyB4bGluazpocmVmPScjZzMtODgnIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PSczNTIuNzE4MzE0JyB4bGluazpocmVmPScjZzItMTA3JyB5PScxNDYuMDUyMjQ5Jy8+Cjx1c2UgeD0nMzU3LjMzOTkzJyB4bGluazpocmVmPScjZzQtNDMnIHk9JzE0Ni4wNTIyNDknLz4KPHVzZSB4PSczNjMuOTI2NDM2JyB4bGluazpocmVmPScjZzQtNDknIHk9JzE0Ni4wNTIyNDknLz4KPHVzZSB4PSczNjguNjU4NzUxJyB4bGluazpocmVmPScjZzMtMTInIHk9JzE0NC4yNTg5ODYnLz4KPHVzZSB4PSczNzUuMjY3MjQnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzE0Ni4wNTIyNDknLz4KPHVzZSB4PSczODAuMzg2OTg3JyB4bGluazpocmVmPScjZzUtNDEnIHk9JzE0NC4yNTg5ODYnLz4KPC9nPgo8L3N2Zz4=)
On en déduit la valeur  qui annule le gradient.
On peut décliner cette formule en version streaming.
C’est ce qu’implémente la fonction
qui annule le gradient.
On peut décliner cette formule en version streaming.
C’est ce qu’implémente la fonction
streaming_linear_regression_update.
Le coût de l’algorithme est en  .
L’inconvénient de cet algorithme est qu’il requiert des
matrices inversibles. C’est souvent le cas et la probabilité
que cela ne le soit pas décroît avec k. C’est un petit
inconvénient compte tenu de la simplicité de l’implémentation.
On vérifie que tout fonction bien sur un exemple.
.
L’inconvénient de cet algorithme est qu’il requiert des
matrices inversibles. C’est souvent le cas et la probabilité
que cela ne le soit pas décroît avec k. C’est un petit
inconvénient compte tenu de la simplicité de l’implémentation.
On vérifie que tout fonction bien sur un exemple.
<<<
import numpy
def linear_regression(X, y):
inv = numpy.linalg.inv(X.T @ X)
return inv @ (X.T @ y)
def streaming_linear_regression_update(Xk, yk, XkXk, bk):
Xk = Xk.reshape((1, XkXk.shape[0]))
xxk = Xk.T @ Xk
XkXk += xxk
err = Xk.T * (yk - Xk @ bk)
bk[:] += (numpy.linalg.inv(XkXk) @ err).flatten()
def streaming_linear_regression(mat, y, start=None):
if start is None:
start = mat.shape[1]
Xk = mat[:start]
XkXk = Xk.T @ Xk
bk = numpy.linalg.inv(XkXk) @ (Xk.T @ y[:start])
yield bk
k = start
while k < mat.shape[0]:
streaming_linear_regression_update(mat[k], y[k:k + 1], XkXk, bk)
yield bk
k += 1
X = numpy.array([[1, 0.5, 10., 5., -2.],
[0, 0.4, 20, 4., 2.],
[0, 0.7, 20, 4., 3.]], dtype=float).T
y = numpy.array([1., 0.3, 10, 5.1, -3.])
for i, bk in enumerate(streaming_linear_regression(X, y)):
bk0 = linear_regression(X[:i + 3], y[:i + 3])
print("iteration", i, bk, bk0)
>>>
iteration 0 [ 1. 0.667 -0.667] [ 1. 0.667 -0.667]
iteration 1 [ 1.03 0.682 -0.697] [ 1.03 0.682 -0.697]
iteration 2 [ 1.036 0.857 -0.875] [ 1.036 0.857 -0.875]
Streaming Linear Regression version Gram-Schmidt#
L’algorithme reprend le théorème
Régression linéaire après Gram-Schmidt
et l’algorithme Streaming Gram-Schmidt. Tout tient dans cette formule :
 qu’on écrit différemment
en considérent l’associativité de la multiplication des matrices :
qu’on écrit différemment
en considérent l’associativité de la multiplication des matrices :
 . La matrice centrale
a pour dimension d. L’exemple suivant implémente cette idée.
Il s’appuie sur les fonctions
. La matrice centrale
a pour dimension d. L’exemple suivant implémente cette idée.
Il s’appuie sur les fonctions streaming_gram_schmidt_update et
gram_schmidt.
<<<
import numpy
from mlstatpy.ml.matrices import gram_schmidt, streaming_gram_schmidt_update
def linear_regression(X, y):
inv = numpy.linalg.inv(X.T @ X)
return inv @ (X.T @ y)
def streaming_linear_regression_gram_schmidt_update(Xk, yk, Xkyk, Pk, bk):
Xk = Xk.T
streaming_gram_schmidt_update(Xk, Pk)
Xkyk += (Xk * yk).reshape(Xkyk.shape)
bk[:] = Pk @ Xkyk @ Pk
def streaming_linear_regression_gram_schmidt(mat, y, start=None):
if start is None:
start = mat.shape[1]
Xk = mat[:start]
xyk = Xk.T @ y[:start]
_, Pk = gram_schmidt(Xk.T, change=True)
bk = Pk @ xyk @ Pk
yield bk
k = start
while k < mat.shape[0]:
streaming_linear_regression_gram_schmidt_update(
mat[k], y[k], xyk, Pk, bk)
yield bk
k += 1
X = numpy.array([[1, 0.5, 10., 5., -2.],
[0, 0.4, 20, 4., 2.],
[0, 0.7, 20, 4., 3.]], dtype=float).T
y = numpy.array([1., 0.3, 10, 5.1, -3.])
for i, bk in enumerate(streaming_linear_regression_gram_schmidt(X, y)):
bk0 = linear_regression(X[:i + 3], y[:i + 3])
print("iteration", i, bk, bk0)
>>>
iteration 0 [ 1. 0.667 -0.667] [ 1. 0.667 -0.667]
iteration 1 [ 1.03 0.682 -0.697] [ 1.03 0.682 -0.697]
iteration 2 [ 1.036 0.857 -0.875] [ 1.036 0.857 -0.875]
Ces deux fonctions sont implémentées dans le module par
streaming_linear_regression_gram_schmidt_update
et streaming_linear_regression_gram_schmidt.
Le coût de l’algorithme est en mais n’inclut pas
d’inversion de matrices.
Digressions#
L’article An Efficient Two Step Algorithm for High DimensionalChange Point Regression Models Without Grid Search propose un cadre théorique pour déterminer une frontière dans un nuage de données qui délimite un changement de modèle linéaire. Le suivant étudie des changements de paramètres Change Surfaces for Expressive MultidimensionalChangepoints and Counterfactual Prediction d’une façon plus générique.
Notebooks#
Implémentations#
Bilbiographie#
Fast Algorithms for Segmented Regression, Jayadev Acharya, Ilias Diakonikolas, Jerry Li, Ludwig Schmidt, ICML 2016
Online Sufficient Dimension Reduction Through Sliced Inverse Regression, Zhanrui Cai, Runze Li, Liping Zhu
Online PCA with Optimal Regret, Jiazhong Nie, Wojciech Kotlowski, Manfred K. Warmuth
The NIPALS Algorithm for Missing Functional Data, Cristian Preda, Gilbert Saporta, Mohamed Hadj Mbarek, Revue roumaine de mathématiques pures et appliquées 2010, 55 (4), pp.315-326.
Voir aussi The NIPALS algorithm.