Démonstration du théorème de la densité des réseaux de neurones#
Formulation du problème de la régression#
Soient deux variables aléatoires continues
 quelconque,
la résolution du problème de régression
est l’estimation de la fonction
quelconque,
la résolution du problème de régression
est l’estimation de la fonction  .
Pour cela, on dispose d’un ensemble de points
.
Pour cela, on dispose d’un ensemble de points
 .
.
Soit  une fonction, on définit
une fonction, on définit
 .
On appelle aussi
.
On appelle aussi  la valeur prédite pour
la valeur prédite pour  .
On pose alors
.
On pose alors
 .
.
Les résidus sont supposés
i.i.d. (identiquement et indépendemment distribués),
et suivant une loi normale
 La vraisemblance d’un échantillon
La vraisemblance d’un échantillon
 ,
où les
,
où les  sont indépendantes entre elles et suivent la loi de densité
sont indépendantes entre elles et suivent la loi de densité
 est la densité du vecteur
est la densité du vecteur  qu’on exprime
comme suit :
qu’on exprime
comme suit :

La log-vraisemblance de l’échantillon s’écrit
 .
Les estimateurs du maximum de vraisemblance
pour
.
Les estimateurs du maximum de vraisemblance
pour  et
et  sont (voir [Saporta1990]) :
sont (voir [Saporta1990]) :

L’estimateur de  désirée est de préférence
sans biais (
désirée est de préférence
sans biais ( ) et de variance minimum,
par conséquent, les paramètres
) et de variance minimum,
par conséquent, les paramètres  qui maximisent la vraisemblance
qui maximisent la vraisemblance  sont :
sont :
(1)#
Réciproquement, on vérifie que si  vérifie
l’équation (1) alors l’estimateur défini par
vérifie
l’équation (1) alors l’estimateur défini par
 est sans biais
Il suffit pour s’en convaincre de poser
est sans biais
Il suffit pour s’en convaincre de poser
 avec
avec
 et de vérifier que la valeur optimale pour
et de vérifier que la valeur optimale pour
 est
est
 .
L’estimateur minimise la vraisemblance .
Cette formule peut être généralisée en faisant une autre hypothèse
que celle de la normalité des résidus (l’indépendance étant conservée),
l’équation (1)
peut généralisée par (2).
.
L’estimateur minimise la vraisemblance .
Cette formule peut être généralisée en faisant une autre hypothèse
que celle de la normalité des résidus (l’indépendance étant conservée),
l’équation (1)
peut généralisée par (2).
(2)#
Où la fonction  est appelée fonction d’erreur.
est appelée fonction d’erreur.
Densité des réseaux de neurones#
L’utilisation de réseaux de neurones s’est considérablement développée depuis que l’algorithme de rétropropagation a été trouvé ([LeCun1985], [Rumelhart1986], [Bishop1995]). Ce dernier permet d’estimer la dérivée d’un réseau de neurones en un point donné et a ouvert la voie à des méthodes classiques de résolution pour des problèmes d’optimisation tels que la régression non linéaire.
Comme l’ensemble des fonctions polynômiales,
l’ensemble des fonctions engendrées par des réseaux de neurones
multi-couches possède des propriétés de densité
et sont infiniment dérivables. Les réseaux de neurones comme
les polynômes sont utilisés pour modéliser la fonction
de l’équation (2).
Ils diffèrent néanmoins sur certains points
Si une couche ne contient que des fonctions de transfert bornées comme la fonction sigmoïde, tout réseau de neurones incluant cette couche sera aussi borné. D’un point de vue informatique, il est préférable d’effectuer des calculs avec des valeurs du même ordre de grandeur. Pour un polynôme, les valeurs des termes de degré élevé peuvent être largement supérieurs à leur somme.
Un autre attrait est la symétrie dans l’architecture d’un réseau de neurones, les neurones qui le composent jouent des rôles symétriques (corollaire familles libres. Pour améliorer l’approximation d’une fonction, dans un cas, il suffit d’ajouter un neurone au réseau, dans l’autre, il faut inclure des polynômes de degré plus élevé que ceux déjà employés.
Théorème T1 : densité des réseaux de neurones (Cybenko1989)
[Cybenko1989]
Soit  l’espace des réseaux de neurones à
l’espace des réseaux de neurones à
 entrées et
entrées et  sorties, possédant une couche cachée dont la
fonction de seuil est une fonction sigmoïde
sorties, possédant une couche cachée dont la
fonction de seuil est une fonction sigmoïde
 ,
une couche de sortie dont la fonction de seuil est linéaire
Soit
,
une couche de sortie dont la fonction de seuil est linéaire
Soit  l’ensemble des fonctions continues de
l’ensemble des fonctions continues de
 avec
avec  compact muni de la norme
compact muni de la norme
 Alors est dense dans .
Alors est dense dans .
La démonstration de ce théorème nécessite deux lemmes.
Ceux-ci utilisent la définition usuelle du produit scalaire
sur  défini par
défini par
 .
et la norme infinie :
.
et la norme infinie :
 .
Toutes les normes sont
équivalentes
sur .
.
Toutes les normes sont
équivalentes
sur .
Corollaire C1 : approximation d’une fonction créneau
Soit  ,
alors :
,
alors :

Démonstration du corollaire
Partie 1
Soit  la fonction définie par :
la fonction définie par :
 avec
avec  et
et  .
A ,
.
A ,  fixé, ,
on cherche
fixé, ,
on cherche  tel que :
tel que :

Partie 2
Soit  et
et  ,
,
On pose  d’après sa définition,
d’après sa définition,  .
.
Pour  obtenu dans la partie précédente :
obtenu dans la partie précédente :

Partie 3
Soit  la fonction définie par :
la fonction définie par :

La fonction  est un polynôme en
est un polynôme en  dont le
discriminant est positif. Par conséquent la fraction
rationnelle
dont le
discriminant est positif. Par conséquent la fraction
rationnelle  admet une décomposition en éléments
simples du premier ordre
et il existe quatre réels
admet une décomposition en éléments
simples du premier ordre
et il existe quatre réels  ,
,  ,
,
 ,
,  tels que :
tels que :

Par conséquent :

Il existe  tel qu’il soit possible d’écrire sous la forme :
tel qu’il soit possible d’écrire sous la forme :

Corollaire C2 : approximation d’une fonction indicatrice
Soit  compact, alors :
compact, alors :

Démonstration du corollaire
Partie 1
Soit  et
et 
Le premier lemme suggère que la fonction cherchée pour ce lemme
dans le cas particulier  est :
est :
![\begin{array}{rcl}
f\left( y_{1},...,y_{p}\right) &=& \prod_{i=1}^p \dfrac
{1}{1+e^{-ky_{i}}} \prod_{i=1}^p\dfrac{1}{1+e^{-k\left( 1-y_{i}\right)
}}+ \\
&& \quad \left( \prod_{i \neq j}
\dfrac
{1}{1+e^{-ky_{i}}}\right) \left( \prod_{i \neq j}
\dfrac{1}{1+e^{-k\left( 1-y_{i}\right) }}\right)
\dfrac{1}{1+e^{k\left( 1-y_{j}\right) }}\dfrac{1}{1+e^{-k\left( 2-y_{j}\right)
}}\\
%
&=& \left( \prod_{i \neq j} \dfrac{1}{1+e^{-ky_{i}}}\right)
\left( \prod_{i \neq j} \dfrac{1}{1+e^{-k\left( 1-y_{i}\right)
}}\right) \\
&& \quad \left( \dfrac{1}{1+e^{-ky_{j}}}\dfrac{1}{1+e^{-k\left( 1-y_{j}\right) }}
+\dfrac {1}{1+e^{k\left( 1-y_{j}\right) }}
\dfrac{1}{1+e^{-k\left(2-y_{j}\right) }}\right)
\\
%
&=& \left( \prod_{i \neq j} \dfrac{1}{1+e^{-ky_{i}}}\right)
\left( \prod_{i \neq j} \dfrac{1}{1+e^{-k\left( 1-y_{i}\right) }}\right) \\
&& \quad \left[\dfrac{1}{1+e^{-ky_{j}}}\left( \dfrac{1}{1+e^{-k\left( 1-y_{j}\right) }
}+1-1\right) +\left( 1-\dfrac{1}{1+e^{-k\left( 1-y_{j}\right) }}\right)
\dfrac{1}{1+e^{-k\left( 2-y_{j}\right) }}\right]
\end{array}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTY4LjM2OTQ3M3B0JyB2ZXJzaW9uPScxLjEnIHZpZXdCb3g9JzQzLjgzNTYxNiA3OC43MDQ4NDUgNDcxLjIwNjI4MSAxNjguMzY5NDczJyB3aWR0aD0nNDcxLjIwNjI4MXB0JyB4bWxucz0naHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmcnIHhtbG5zOnhsaW5rPSdodHRwOi8vd3d3LnczLm9yZy8xOTk5L3hsaW5rJz4KPGRlZnM+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtMi43NDk2ODlDOC4wODE2OTQgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi45ODg3OTJTOC4wODE2OTQgLTMuMjI3ODk1IDcuODc4NDU2IC0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyIC0zLjIyNzg5NSAwLjk5MjI3OSAtMy4yMjc4OTUgMC45OTIyNzkgLTIuOTg4NzkyUzEuMjA3NDcyIC0yLjc0OTY4OSAxLjQxMDcxIC0yLjc0OTY4OUg3Ljg3ODQ1NlonIGlkPSdnMi0wJy8+CjxwYXRoIGQ9J00yLjA4MDE5OSAtMy43MzAwMTJDMi4wODAxOTkgLTMuODczNDc0IDEuOTcyNjAzIC0zLjk2OTExNiAxLjgzNTExOCAtMy45NjkxMTZDMS42NzM3MjQgLTMuOTY5MTE2IDEuNTAwMzc0IC0zLjgxMzY5OSAxLjUwMDM3NCAtMy42NDAzNDlDMS41MDAzNzQgLTMuNDkwOTA5IDEuNjA3OTcgLTMuNDAxMjQ1IDEuNzM5NDc3IC0zLjQwMTI0NUMxLjkzMDc2IC0zLjQwMTI0NSAyLjA4MDE5OSAtMy41ODA1NzMgMi4wODAxOTkgLTMuNzMwMDEyWk0xLjcyMTU0NCAtMS42NDM4MzZDMS43NDU0NTUgLTEuNzAzNjExIDEuNzk5MjUzIC0xLjg0NzA3MyAxLjgyMzE2MyAtMS45MDA4NzJDMS44NDEwOTYgLTEuOTU0NjcgMS44NjUwMDYgLTIuMDE0NDQ2IDEuODY1MDA2IC0yLjExNjA2NUMxLjg2NTAwNiAtMi40NTA4MDkgMS41NjYxMjcgLTIuNjM2MTE1IDEuMjY3MjQ4IC0yLjYzNjExNUMwLjY1NzUzNCAtMi42MzYxMTUgMC4zNjQ2MzMgLTEuODQ3MDczIDAuMzY0NjMzIC0xLjcxNTU2N0MwLjM2NDYzMyAtMS42ODU2NzkgMC4zODg1NDMgLTEuNjMxODggMC40NzIyMjkgLTEuNjMxODhTMC41NzM4NDggLTEuNjY3NzQ2IDAuNTkxNzgxIC0xLjcyMTU0NEMwLjc1OTE1MyAtMi4zMDEzNyAxLjA3NTk2NSAtMi40Mzg4NTQgMS4yNDMzMzcgLTIuNDM4ODU0QzEuMzYyODg5IC0yLjQzODg1NCAxLjQwNDczMiAtMi4zNjExNDYgMS40MDQ3MzIgLTIuMjIzNjYxQzEuNDA0NzMyIC0yLjEwNDExIDEuMzY4ODY3IC0yLjAxNDQ0NiAxLjM1NjkxMiAtMS45NzI2MDNMMS4wNDYwNzcgLTEuMjA3NDcyQzAuOTc0MzQ2IC0xLjAzNDEyMiAwLjk3NDM0NiAtMS4wMjIxNjcgMC44OTY2MzggLTAuODE4OTI5QzAuODE4OTI5IC0wLjYzOTYwMSAwLjc4OTA0MSAtMC41NjE4OTMgMC43ODkwNDEgLTAuNDYwMjc0QzAuNzg5MDQxIC0wLjE1NTQxNyAxLjA2NDAxIDAuMDU5Nzc2IDEuMzkyNzc3IDAuMDU5Nzc2QzEuOTk2NTEzIDAuMDU5Nzc2IDIuMjk1MzkyIC0wLjcyOTI2NSAyLjI5NTM5MiAtMC44NjA3NzJDMi4yOTUzOTIgLTAuODcyNzI3IDIuMjg5NDE1IC0wLjk0NDQ1OCAyLjE4MTgxOCAtMC45NDQ0NThDMi4wOTgxMzIgLTAuOTQ0NDU4IDIuMDkyMTU0IC0wLjkxNDU3IDIuMDU2Mjg5IC0wLjgwMDk5NkMxLjk2MDY0OCAtMC40OTYxMzkgMS43MTU1NjcgLTAuMTM3NDg0IDEuNDEwNzEgLTAuMTM3NDg0QzEuMzAzMTEzIC0wLjEzNzQ4NCAxLjI0OTMxNSAtMC4yMDkyMTUgMS4yNDkzMTUgLTAuMzUyNjc3QzEuMjQ5MzE1IC0wLjQ3MjIyOSAxLjI4NTE4MSAtMC41NjE4OTMgMS4zNjI4ODkgLTAuNzQ3MTk4TDEuNzIxNTQ0IC0xLjY0MzgzNlonIGlkPSdnMy0xMDUnLz4KPHBhdGggZD0nTTIuNzczNTk5IC0zLjczMDAxMkMyLjc3MzU5OSAtMy45MDkzNCAyLjYzMDEzNyAtMy45NjkxMTYgMi41MzQ0OTYgLTMuOTY5MTE2QzIuMzQzMjEzIC0zLjk2OTExNiAyLjE5Mzc3MyAtMy43ODM4MTEgMi4xOTM3NzMgLTMuNjQwMzQ5QzIuMTkzNzczIC0zLjUxNDgxOSAyLjI4OTQxNSAtMy40MDEyNDUgMi40Mzg4NTQgLTMuNDAxMjQ1QzIuNTk0MjcxIC0zLjQwMTI0NSAyLjc3MzU5OSAtMy41NTA2ODUgMi43NzM1OTkgLTMuNzMwMDEyWk0xLjUwMDM3NCAwLjI2ODk5MUMxLjM4NjggMC43MTczMSAxLjAzNDEyMiAxLjAyMjE2NyAwLjY4NzQyMiAxLjAyMjE2N0MwLjY2OTQ4OSAxLjAyMjE2NyAwLjUwMjExNyAxLjAxNjE4OSAwLjUwMjExNyAwLjk5MjI3OUMwLjUwMjExNyAwLjk4NjMwMSAwLjUyMDA1IDAuOTc0MzQ2IDAuNTIwMDUgMC45NjgzNjlDMC42MDk3MTQgMC44OTY2MzggMC42NTE1NTcgMC44MDA5OTYgMC42NTE1NTcgMC43MTEzMzNDMC42NTE1NTcgMC41MjAwNSAwLjQ5NjEzOSAwLjQ3ODIwNyAwLjQxMjQ1MyAwLjQ3ODIwN0MwLjI1MTA1OSAwLjQ3ODIwNyAwLjA3MTczMSAwLjYwOTcxNCAwLjA3MTczMSAwLjgzMDg4NEMwLjA3MTczMSAxLjE0NzY5NiAwLjQ0ODMxOSAxLjIxOTQyNyAwLjY5MzQgMS4yMTk0MjdDMS4wOTM4OTggMS4yMTk0MjcgMS44MTEyMDggMC45OTIyNzkgMS45OTA1MzUgMC4yNzQ5NjlMMi41Mjg1MTggLTEuODY1MDA2QzIuNTQwNDczIC0xLjkyNDc4MiAyLjU1ODQwNiAtMS45Nzg1OCAyLjU1ODQwNiAtMi4wNjIyNjdDMi41NTg0MDYgLTIuMzk3MDExIDIuMjU5NTI3IC0yLjYzNjExNSAxLjg3Njk2MSAtMi42MzYxMTVDMS4yMDE0OTQgLTIuNjM2MTE1IDAuNzgzMDY0IC0xLjgyOTE0MSAwLjc4MzA2NCAtMS43MTU1NjdDMC43ODMwNjQgLTEuNjc5NzAxIDAuODA2OTc0IC0xLjYzMTg4IDAuODkwNjYgLTEuNjMxODhTMC45ODAzMjQgLTEuNjU1NzkxIDEuMDIyMTY3IC0xLjczOTQ3N0MxLjE5NTUxNyAtMi4xMjgwMiAxLjUzMDI2MiAtMi40Mzg4NTQgMS44NTkwMjkgLTIuNDM4ODU0QzIuMDM4MzU2IC0yLjQzODg1NCAyLjA4MDE5OSAtMi4yODk0MTUgMi4wODAxOTkgLTIuMTM5OTc1QzIuMDgwMTk5IC0yLjA2MjI2NyAyLjA2ODI0NCAtMS45Nzg1OCAyLjA2MjI2NyAtMS45NjA2NDhMMS41MDAzNzQgMC4yNjg5OTFaJyBpZD0nZzMtMTA2Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzctNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c3LTQxJy8+CjxwYXRoIGQ9J000Ljc3MDExMiAtMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi45NzY4MzdDOC40NTIzMDQgLTMuMjAzOTg1IDguMjQ5MDY2IC0zLjIwMzk4NSA4LjA2OTczOCAtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyIC02LjY3MDk4NCA0Ljc3MDExMiAtNi44ODYxNzcgNC41NTQ5MTkgLTYuODg2MTc3QzQuMzI3NzcxIC02Ljg4NjE3NyA0LjMyNzc3MSAtNi42ODI5MzkgNC4zMjc3NzEgLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMwLjg2MDc3MiAtMy4yMDM5ODUgMC42NDU1NzkgLTMuMjAzOTg1IDAuNjQ1NTc5IC0yLjk4ODc5MkMwLjY0NTU3OSAtMi43NjE2NDQgMC44NDg4MTcgLTIuNzYxNjQ0IDEuMDI4MTQ0IC0yLjc2MTY0NEg0LjMyNzc3MVYwLjUzNzk4M0M0LjMyNzc3MSAwLjcwNTM1NSA0LjMyNzc3MSAwLjkyMDU0OCA0LjU0Mjk2NCAwLjkyMDU0OEM0Ljc3MDExMiAwLjkyMDU0OCA0Ljc3MDExMiAwLjcxNzMxIDQuNzcwMTEyIDAuNTM3OTgzVi0yLjc2MTY0NFonIGlkPSdnNy00MycvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzctNDknLz4KPHBhdGggZD0nTTguMDY5NzM4IC0zLjg3MzQ3NEM4LjIzNzExMSAtMy44NzM0NzQgOC40NTIzMDQgLTMuODczNDc0IDguNDUyMzA0IC00LjA4ODY2N0M4LjQ1MjMwNCAtNC4zMTU4MTYgOC4yNDkwNjYgLTQuMzE1ODE2IDguMDY5NzM4IC00LjMxNTgxNkgxLjAyODE0NEMwLjg2MDc3MiAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjEwMDYyM0MwLjY0NTU3OSAtMy44NzM0NzQgMC44NDg4MTcgLTMuODczNDc0IDEuMDI4MTQ0IC0zLjg3MzQ3NEg4LjA2OTczOFpNOC4wNjk3MzggLTEuNjQ5ODEzQzguMjM3MTExIC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS42NDk4MTMgOC40NTIzMDQgLTEuODY1MDA2QzguNDUyMzA0IC0yLjA5MjE1NCA4LjI0OTA2NiAtMi4wOTIxNTQgOC4wNjk3MzggLTIuMDkyMTU0SDEuMDI4MTQ0QzAuODYwNzcyIC0yLjA5MjE1NCAwLjY0NTU3OSAtMi4wOTIxNTQgMC42NDU1NzkgLTEuODc2OTYxQzAuNjQ1NTc5IC0xLjY0OTgxMyAwLjg0ODgxNyAtMS42NDk4MTMgMS4wMjgxNDQgLTEuNjQ5ODEzSDguMDY5NzM4WicgaWQ9J2c3LTYxJy8+CjxwYXRoIGQ9J00yLjE5OTc1MSAtMC41NzM4NDhDMi4xOTk3NTEgLTAuOTIwNTQ4IDEuOTEyODI3IC0xLjE1OTY1MSAxLjYyNTkwMyAtMS4xNTk2NTFDMS4yNzkyMDMgLTEuMTU5NjUxIDEuMDQwMSAtMC44NzI3MjcgMS4wNDAxIC0wLjU4NTgwM0MxLjA0MDEgLTAuMjM5MTAzIDEuMzI3MDI0IDAgMS42MTM5NDggMEMxLjk2MDY0OCAwIDIuMTk5NzUxIC0wLjI4NjkyNCAyLjE5OTc1MSAtMC41NzM4NDhaJyBpZD0nZzUtNTgnLz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2c1LTU5Jy8+CjxwYXRoIGQ9J00yLjEzOTk3NSAtMi43NzM1OTlDMi40NjI3NjUgLTIuNzczNTk5IDMuMjc1NzE2IC0yLjc5NzUwOSAzLjg0OTU2NCAtMy4wMTI3MDJDNC43NTgxNTcgLTMuMzU5NDAyIDQuODQxODQzIC00LjA1MjgwMiA0Ljg0MTg0MyAtNC4yNjc5OTVDNC44NDE4NDMgLTQuNzk0MDIyIDQuMzg3NTQ3IC01LjI3MjIyOSAzLjU5ODUwNiAtNS4yNzIyMjlDMi4zNDMyMTMgLTUuMjcyMjI5IDAuNTM3OTgzIC00LjEzNjQ4OCAwLjUzNzk4MyAtMi4wMDg0NjhDMC41Mzc5ODMgLTAuNzUzMTc2IDEuMjU1MjkzIDAuMTE5NTUyIDIuMzQzMjEzIDAuMTE5NTUyQzMuOTY5MTE2IDAuMTE5NTUyIDQuOTk3MjYgLTEuMTQ3Njk2IDQuOTk3MjYgLTEuMzAzMTEzQzQuOTk3MjYgLTEuMzc0ODQ0IDQuOTI1NTI5IC0xLjQzNDYyIDQuODc3NzA5IC0xLjQzNDYyQzQuODQxODQzIC0xLjQzNDYyIDQuODI5ODg4IC0xLjQyMjY2NSA0LjcyMjI5MSAtMS4zMTUwNjhDMy45NTcxNjEgLTAuMjk4ODc5IDIuODIxNDIgLTAuMTE5NTUyIDIuMzY3MTIzIC0wLjExOTU1MkMxLjY4NTY3OSAtMC4xMTk1NTIgMS4zMjcwMjQgLTAuNjU3NTM0IDEuMzI3MDI0IC0xLjU0MjIxN0MxLjMyNzAyNCAtMS43MDk1ODkgMS4zMjcwMjQgLTIuMDA4NDY4IDEuNTA2MzUxIC0yLjc3MzU5OUgyLjEzOTk3NVpNMS41NjYxMjcgLTMuMDEyNzAyQzIuMDgwMTk5IC00Ljg1Mzc5OCAzLjIxNTk0IC01LjAzMzEyNiAzLjU5ODUwNiAtNS4wMzMxMjZDNC4xMjQ1MzMgLTUuMDMzMTI2IDQuNDgzMTg4IC00LjcyMjI5MSA0LjQ4MzE4OCAtNC4yNjc5OTVDNC40ODMxODggLTMuMDEyNzAyIDIuNTcwMzYxIC0zLjAxMjcwMiAyLjA2ODI0NCAtMy4wMTI3MDJIMS41NjYxMjdaJyBpZD0nZzUtMTAxJy8+CjxwYXRoIGQ9J001LjMzMjAwNSAtNC44MDU5NzhDNS41NzExMDggLTQuODA1OTc4IDUuNjY2NzUgLTQuODA1OTc4IDUuNjY2NzUgLTUuMDMzMTI2QzUuNjY2NzUgLTUuMTUyNjc3IDUuNTcxMTA4IC01LjE1MjY3NyA1LjM1NTkxNSAtNS4xNTI2NzdINC4zODc1NDdDNC42MTQ2OTUgLTYuMzg0MDYgNC43ODIwNjcgLTcuMjMyODc3IDQuODc3NzA5IC03LjYxNTQ0MkM0Ljk0OTQ0IC03LjkwMjM2NiA1LjIwMDQ5OCAtOC4xNzczMzUgNS41MTEzMzMgLTguMTc3MzM1QzUuNzYyMzkxIC04LjE3NzMzNSA2LjAxMzQ1IC04LjA2OTczOCA2LjEzMzAwMSAtNy45NjIxNDJDNS42NjY3NSAtNy45MTQzMjEgNS41MjMyODggLTcuNTY3NjIxIDUuNTIzMjg4IC03LjM2NDM4NEM1LjUyMzI4OCAtNy4xMjUyOCA1LjcwMjYxNSAtNi45ODE4MTggNS45Mjk3NjMgLTYuOTgxODE4QzYuMTY4ODY3IC02Ljk4MTgxOCA2LjUyNzUyMiAtNy4xODUwNTYgNi41Mjc1MjIgLTcuNjM5MzUyQzYuNTI3NTIyIC04LjE0MTQ2OSA2LjAyNTQwNSAtOC40MTY0MzggNS40OTkzNzcgLTguNDE2NDM4QzQuOTg1MzA1IC04LjQxNjQzOCA0LjQ4MzE4OCAtOC4wMzM4NzMgNC4yNDQwODUgLTcuNTY3NjIxQzQuMDI4ODkyIC03LjE0OTE5MSAzLjkwOTM0IC02LjcxODgwNCAzLjYzNDM3MSAtNS4xNTI2NzdIMi44MzMzNzVDMi42MDYyMjcgLTUuMTUyNjc3IDIuNDg2Njc1IC01LjE1MjY3NyAyLjQ4NjY3NSAtNC45Mzc0ODRDMi40ODY2NzUgLTQuODA1OTc4IDIuNTU4NDA2IC00LjgwNTk3OCAyLjc5NzUwOSAtNC44MDU5NzhIMy41NjI2NEMzLjM0NzQ0NyAtMy42OTQxNDcgMi44NTcyODUgLTAuOTkyMjc5IDIuNTgyMzE2IDAuMjg2OTI0QzIuMzc5MDc4IDEuMzI3MDI0IDIuMTk5NzUxIDIuMTk5NzUxIDEuNjAxOTkzIDIuMTk5NzUxQzEuNTY2MTI3IDIuMTk5NzUxIDEuMjE5NDI3IDIuMTk5NzUxIDEuMDA0MjM0IDEuOTcyNjAzQzEuNjEzOTQ4IDEuOTI0NzgyIDEuNjEzOTQ4IDEuMzk4NzU1IDEuNjEzOTQ4IDEuMzg2OEMxLjYxMzk0OCAxLjE0NzY5NiAxLjQzNDYyIDEuMDA0MjM0IDEuMjA3NDcyIDEuMDA0MjM0QzAuOTY4MzY5IDEuMDA0MjM0IDAuNjA5NzE0IDEuMjA3NDcyIDAuNjA5NzE0IDEuNjYxNzY4QzAuNjA5NzE0IDIuMTc1ODQxIDEuMTM1NzQxIDIuNDM4ODU0IDEuNjAxOTkzIDIuNDM4ODU0QzIuODIxNDIgMi40Mzg4NTQgMy4zMjM1MzcgMC4yNTEwNTkgMy40NTUwNDQgLTAuMzQ2N0MzLjY3MDIzNyAtMS4yNjcyNDggNC4yNTYwNCAtNC40NDczMjMgNC4zMTU4MTYgLTQuODA1OTc4SDUuMzMyMDA1WicgaWQ9J2c1LTEwMicvPgo8cGF0aCBkPSdNMy4xNDQyMDkgMS4zMzg5NzlDMi44MjE0MiAxLjc5MzI3NSAyLjM1NTE2OCAyLjE5OTc1MSAxLjc2OTM2NSAyLjE5OTc1MUMxLjYyNTkwMyAyLjE5OTc1MSAxLjA1MjA1NSAyLjE3NTg0MSAwLjg3MjcyNyAxLjYyNTkwM0MwLjkwODU5MyAxLjYzNzg1OCAwLjk2ODM2OSAxLjYzNzg1OCAwLjk5MjI3OSAxLjYzNzg1OEMxLjM1MDkzNCAxLjYzNzg1OCAxLjU5MDAzNyAxLjMyNzAyNCAxLjU5MDAzNyAxLjA1MjA1NVMxLjM2Mjg4OSAwLjY4MTQ0NSAxLjE4MzU2MiAwLjY4MTQ0NUMwLjk5MjI3OSAwLjY4MTQ0NSAwLjU3Mzg0OCAwLjgyNDkwNyAwLjU3Mzg0OCAxLjQxMDcxQzAuNTczODQ4IDIuMDIwNDIzIDEuMDg3OTIgMi40Mzg4NTQgMS43NjkzNjUgMi40Mzg4NTRDMi45NjQ4ODIgMi40Mzg4NTQgNC4xNzIzNTQgMS4zMzg5NzkgNC41MDcwOTggMC4wMTE5NTVMNS42Nzg3MDUgLTQuNjUwNTZDNS42OTA2NiAtNC43MTAzMzYgNS43MTQ1NyAtNC43ODIwNjcgNS43MTQ1NyAtNC44NTM3OThDNS43MTQ1NyAtNS4wMzMxMjYgNS41NzExMDggLTUuMTUyNjc3IDUuMzkxNzgxIC01LjE1MjY3N0M1LjI4NDE4NCAtNS4xNTI2NzcgNS4wMzMxMjYgLTUuMTA0ODU3IDQuOTM3NDg0IC00Ljc0NjIwMkw0LjA1MjgwMiAtMS4yMzEzODJDMy45OTMwMjYgLTEuMDE2MTg5IDMuOTkzMDI2IC0wLjk5MjI3OSAzLjg5NzM4NSAtMC44NjA3NzJDMy42NTgyODEgLTAuNTI2MDI3IDMuMjYzNzYxIC0wLjExOTU1MiAyLjY4OTkxMyAtMC4xMTk1NTJDMi4wMjA0MjMgLTAuMTE5NTUyIDEuOTYwNjQ4IC0wLjc3NzA4NiAxLjk2MDY0OCAtMS4wOTk4NzVDMS45NjA2NDggLTEuNzgxMzIgMi4yODM0MzcgLTIuNzAxODY4IDIuNjA2MjI3IC0zLjU2MjY0QzIuNzM3NzMzIC0zLjkwOTM0IDIuODA5NDY1IC00LjA3NjcxMiAyLjgwOTQ2NSAtNC4zMTU4MTZDMi44MDk0NjUgLTQuODE3OTMzIDIuNDUwODA5IC01LjI3MjIyOSAxLjg2NTAwNiAtNS4yNzIyMjlDMC43NjUxMzEgLTUuMjcyMjI5IDAuMzIyNzkgLTMuNTM4NzMgMC4zMjI3OSAtMy40NDMwODhDMC4zMjI3OSAtMy4zOTUyNjggMC4zNzA2MSAtMy4zMzU0OTIgMC40NTQyOTYgLTMuMzM1NDkyQzAuNTYxODkzIC0zLjMzNTQ5MiAwLjU3Mzg0OCAtMy4zODMzMTMgMC42MjE2NjkgLTMuNTUwNjg1QzAuOTA4NTkzIC00LjU1NDkxOSAxLjM2Mjg4OSAtNS4wMzMxMjYgMS44MjkxNDEgLTUuMDMzMTI2QzEuOTM2NzM3IC01LjAzMzEyNiAyLjEzOTk3NSAtNS4wMzMxMjYgMi4xMzk5NzUgLTQuNjM4NjA1QzIuMTM5OTc1IC00LjMyNzc3MSAyLjAwODQ2OCAtMy45ODEwNzEgMS44MjkxNDEgLTMuNTI2Nzc1QzEuMjQzMzM3IC0xLjk2MDY0OCAxLjI0MzMzNyAtMS41NjYxMjcgMS4yNDMzMzcgLTEuMjc5MjAzQzEuMjQzMzM3IC0wLjE0MzQ2MiAyLjA1NjI4OSAwLjExOTU1MiAyLjY1NDA0NyAwLjExOTU1MkMzLjAwMDc0NyAwLjExOTU1MiAzLjQzMTEzMyAwLjAxMTk1NSAzLjg0OTU2NCAtMC40MzAzODZMMy44NjE1MTkgLTAuNDE4NDMxQzMuNjgyMTkyIDAuMjg2OTI0IDMuNTYyNjQgMC43NTMxNzYgMy4xNDQyMDkgMS4zMzg5NzlaJyBpZD0nZzUtMTIxJy8+CjxwYXRoIGQ9J00yLjY1NDA0NyAxLjk5MjUyOEMyLjcxNzgwOCAxLjk5MjUyOCAyLjgxMzQ1IDEuOTkyNTI4IDIuODEzNDUgMS44OTY4ODdDMi44MTM0NSAxLjg2NTAwNiAyLjgwNTQ3OSAxLjg1NzAzNiAyLjcwMTg2OCAxLjc1MzQyNUMxLjYwOTk2MyAwLjcyNTI4IDEuMzM4OTc5IC0wLjc1NzE2MSAxLjMzODk3OSAtMS45OTI1MjhDMS4zMzg5NzkgLTQuMjg3OTIgMi4yODc0MjIgLTUuMzYzODg1IDIuNjkzODk4IC01LjczMDUxMUMyLjgwNTQ3OSAtNS44MzQxMjIgMi44MTM0NSAtNS44NDIwOTIgMi44MTM0NSAtNS44ODE5NDNTMi43ODE1NjkgLTUuOTc3NTg0IDIuNzAxODY4IC01Ljk3NzU4NEMyLjU3NDM0NiAtNS45Nzc1ODQgMi4xNzU4NDEgLTUuNTcxMTA4IDIuMTEyMDggLTUuNDk5Mzc3QzEuMDQ0MDg1IC00LjM4MzU2MiAwLjgyMDkyMiAtMi45NDg5NDEgMC44MjA5MjIgLTEuOTkyNTI4QzAuODIwOTIyIC0wLjIwNzIyMyAxLjU3MDExMiAxLjIyNzM5NyAyLjY1NDA0NyAxLjk5MjUyOFonIGlkPSdnNi00MCcvPgo8cGF0aCBkPSdNMi40NjI3NjUgLTEuOTkyNTI4QzIuNDYyNzY1IC0yLjc0OTY4OSAyLjMzNTI0MyAtMy42NTgyODEgMS44NDEwOTYgLTQuNTk4NzU1QzEuNDUwNTYgLTUuMzMyMDA1IDAuNzI1MjggLTUuOTc3NTg0IDAuNTgxODE4IC01Ljk3NzU4NEMwLjUwMjExNyAtNS45Nzc1ODQgMC40NzgyMDcgLTUuOTIxNzkzIDAuNDc4MjA3IC01Ljg4MTk0M0MwLjQ3ODIwNyAtNS44NTAwNjIgMC40NzgyMDcgLTUuODM0MTIyIDAuNTczODQ4IC01LjczODQ4MUMxLjY4OTY2NCAtNC42Nzg0NTYgMS45NDQ3MDcgLTMuMjE5OTI1IDEuOTQ0NzA3IC0xLjk5MjUyOEMxLjk0NDcwNyAwLjI5NDg5NCAwLjk5NjI2NCAxLjM3ODgyOSAwLjU4OTc4OCAxLjc0NTQ1NUMwLjQ4NjE3NyAxLjg0OTA2NiAwLjQ3ODIwNyAxLjg1NzAzNiAwLjQ3ODIwNyAxLjg5Njg4N1MwLjUwMjExNyAxLjk5MjUyOCAwLjU4MTgxOCAxLjk5MjUyOEMwLjcwOTM0IDEuOTkyNTI4IDEuMTA3ODQ2IDEuNTg2MDUyIDEuMTcxNjA2IDEuNTE0MzIxQzIuMjM5NjAxIDAuMzk4NTA2IDIuNDYyNzY1IC0xLjAzNjExNSAyLjQ2Mjc2NSAtMS45OTI1MjhaJyBpZD0nZzYtNDEnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2c2LTQ5Jy8+CjxwYXRoIGQ9J00yLjI0NzU3MiAtMS42MjU5MDNDMi4zNzUwOTMgLTEuNzQ1NDU1IDIuNzA5ODM4IC0yLjAwODQ2OCAyLjgzNzM2IC0yLjEyMDA1QzMuMzMxNTA3IC0yLjU3NDM0NiAzLjgwMTc0MyAtMy4wMTI3MDIgMy44MDE3NDMgLTMuNzM3OTgzQzMuODAxNzQzIC00LjY4NjQyNiAzLjAwNDczMiAtNS4zMDAxMjUgMi4wMDg0NjggLTUuMzAwMTI1QzEuMDUyMDU1IC01LjMwMDEyNSAwLjQyMjQxNiAtNC41NzQ4NDQgMC40MjI0MTYgLTMuODY1NTA0QzAuNDIyNDE2IC0zLjQ3NDk2OSAwLjczMzI1IC0zLjQxOTE3OCAwLjg0NDgzMiAtMy40MTkxNzhDMS4wMTIyMDQgLTMuNDE5MTc4IDEuMjU5Mjc4IC0zLjUzODczIDEuMjU5Mjc4IC0zLjg0MTU5NEMxLjI1OTI3OCAtNC4yNTYwNCAwLjg2MDc3MiAtNC4yNTYwNCAwLjc2NTEzMSAtNC4yNTYwNEMwLjk5NjI2NCAtNC44Mzc4NTggMS41MzAyNjIgLTUuMDM3MTExIDEuOTIwNzk3IC01LjAzNzExMUMyLjY2MjAxNyAtNS4wMzcxMTEgMy4wNDQ1ODMgLTQuNDA3NDcyIDMuMDQ0NTgzIC0zLjczNzk4M0MzLjA0NDU4MyAtMi45MDkwOTEgMi40NjI3NjUgLTIuMzAzMzYyIDEuNTIyMjkxIC0xLjMzODk3OUwwLjUxODA1NyAtMC4zMDI4NjRDMC40MjI0MTYgLTAuMjE1MTkzIDAuNDIyNDE2IC0wLjE5OTI1MyAwLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMgLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2IC0xLjI2NzI0OCAzLjQ2Njk5OSAtMC44Njg3NDIgMy4zNzEzNTcgLTAuNzE3MzFDMy4zMjM1MzcgLTAuNjUzNTQ5IDIuNzE3ODA4IC0wLjY1MzU0OSAyLjU5MDI4NiAtMC42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzIgLTEuNjI1OTAzWicgaWQ9J2c2LTUwJy8+CjxwYXRoIGQ9J001LjgyNjE1MiAtMi42NTQwNDdDNS45NDU3MDQgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjY1NDA0NyA2LjEwNTEwNiAtMi44MzczNlM1LjkxMzgyMyAtMy4wMjA2NzIgNS43OTQyNzEgLTMuMDIwNjcySDAuNzgxMDcxQzAuNjYxNTE5IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMy4wMjA2NzIgMC40NzAyMzcgLTIuODM3MzZTMC42Mjk2MzkgLTIuNjU0MDQ3IDAuNzQ5MTkxIC0yLjY1NDA0N0g1LjgyNjE1MlpNNS43OTQyNzEgLTAuOTY0Mzg0QzUuOTEzODIzIC0wLjk2NDM4NCA2LjEwNTEwNiAtMC45NjQzODQgNi4xMDUxMDYgLTEuMTQ3Njk2UzUuOTQ1NzA0IC0xLjMzMTAwOSA1LjgyNjE1MiAtMS4zMzEwMDlIMC43NDkxOTFDMC42Mjk2MzkgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjMzMTAwOSAwLjQ3MDIzNyAtMS4xNDc2OTZTMC42NjE1MTkgLTAuOTY0Mzg0IDAuNzgxMDcxIC0wLjk2NDM4NEg1Ljc5NDI3MVonIGlkPSdnNi02MScvPgo8cGF0aCBkPSdNOC4zNjg2MTggMjguMDgyNjlDOC4zNjg2MTggMjguMDM0ODY5IDguMzQ0NzA3IDI4LjAxMDk1OSA4LjMyMDc5NyAyNy45NzUwOTNDNy44Nzg0NTYgMjcuNTMyNzUyIDcuMDc3NDYgMjYuNzMxNzU2IDYuMjc2NDYzIDI1LjQ0MDU5OEM0LjM1MTY4MSAyMi4zNTYxNjQgMy40Nzg5NTQgMTguNDcwNzM1IDMuNDc4OTU0IDEzLjg2Nzk5NUMzLjQ3ODk1NCAxMC42NTIwNTUgMy45MDkzNCA2LjUwMzYxMSA1Ljg4MTk0MyAyLjk0MDk3MUM2LjgyNjQwMSAxLjI0MzMzNyA3LjgwNjcyNSAwLjI2MzAxNCA4LjMzMjc1MiAtMC4yNjMwMTRDOC4zNjg2MTggLTAuMjk4ODc5IDguMzY4NjE4IC0wLjMyMjc5IDguMzY4NjE4IC0wLjM1ODY1NUM4LjM2ODYxOCAtMC40NzgyMDcgOC4yODQ5MzIgLTAuNDc4MjA3IDguMTE3NTU5IC0wLjQ3ODIwN1M3LjkyNjI3NiAtMC40NzgyMDcgNy43NDY5NDkgLTAuMjk4ODc5QzMuNzQxOTY4IDMuMzQ3NDQ3IDIuNDg2Njc1IDguODIyOTE0IDIuNDg2Njc1IDEzLjg1NjA0QzIuNDg2Njc1IDE4LjU1NDQyMSAzLjU2MjY0IDIzLjI4ODY2NyA2LjU5OTI1MyAyNi44NjMyNjNDNi44MzgzNTYgMjcuMTM4MjMyIDcuMjkyNjUzIDI3LjYyODM5NCA3Ljc4MjgxNCAyOC4wNTg3OEM3LjkyNjI3NiAyOC4yMDIyNDIgNy45NTAxODcgMjguMjAyMjQyIDguMTE3NTU5IDI4LjIwMjI0MlM4LjM2ODYxOCAyOC4yMDIyNDIgOC4zNjg2MTggMjguMDgyNjlaJyBpZD0nZzAtMTgnLz4KPHBhdGggZD0nTTYuMzAwMzc0IDEzLjg2Nzk5NUM2LjMwMDM3NCA5LjE2OTYxNCA1LjIyNDQwOCA0LjQzNTM2NyAyLjE4Nzc5NiAwLjg2MDc3MkMxLjk0ODY5MiAwLjU4NTgwMyAxLjQ5NDM5NiAwLjA5NTY0MSAxLjAwNDIzNCAtMC4zMzQ3NDVDMC44NjA3NzIgLTAuNDc4MjA3IDAuODM2ODYyIC0wLjQ3ODIwNyAwLjY2OTQ4OSAtMC40NzgyMDdDMC41MjYwMjcgLTAuNDc4MjA3IDAuNDE4NDMxIC0wLjQ3ODIwNyAwLjQxODQzMSAtMC4zNTg2NTVDMC40MTg0MzEgLTAuMzEwODM0IDAuNDY2MjUyIC0wLjI2MzAxNCAwLjQ5MDE2MiAtMC4yMzkxMDNDMC45MDg1OTMgMC4xOTEyODMgMS43MDk1ODkgMC45OTIyNzkgMi41MTA1ODUgMi4yODM0MzdDNC40MzUzNjcgNS4zNjc4NyA1LjMwODA5NSA5LjI1MzMgNS4zMDgwOTUgMTMuODU2MDRDNS4zMDgwOTUgMTcuMDcxOTggNC44Nzc3MDkgMjEuMjIwNDIzIDIuOTA1MTA2IDI0Ljc4MzA2NEMxLjk2MDY0OCAyNi40ODA2OTcgMC45NjgzNjkgMjcuNDcyOTc2IDAuNDY2MjUyIDI3Ljk3NTA5M0MwLjQ0MjM0MSAyOC4wMTA5NTkgMC40MTg0MzEgMjguMDQ2ODI0IDAuNDE4NDMxIDI4LjA4MjY5QzAuNDE4NDMxIDI4LjIwMjI0MiAwLjUyNjAyNyAyOC4yMDIyNDIgMC42Njk0ODkgMjguMjAyMjQyQzAuODM2ODYyIDI4LjIwMjI0MiAwLjg2MDc3MiAyOC4yMDIyNDIgMS4wNDAxIDI4LjAyMjkxNEM1LjA0NTA4MSAyNC4zNzY1ODggNi4zMDAzNzQgMTguOTAxMTIxIDYuMzAwMzc0IDEzLjg2Nzk5NVonIGlkPSdnMC0xOScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMjguMjAyMjQySDYuMTMzMDAxVjI3LjU0NDcwN0gzLjY0NjMyNlYwLjE3OTMyOEg2LjEzMzAwMVYtMC40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicgaWQ9J2cwLTIwJy8+CjxwYXRoIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdIMC4xNjczNzJWMjguMjAyMjQySDMuMzExNTgyVi0wLjQ3ODIwN0gwLjE2NzM3MlYwLjE3OTMyOEgyLjY1NDA0N1YyNy41NDQ3MDdaJyBpZD0nZzAtMjEnLz4KPHBhdGggZD0nTTQuMjkxOTA1IDExLjk1NTE2OFYxMS40NzY5NjFDMy4wNjA1MjMgMTEuNDc2OTYxIDMuMDYwNTIzIDEwLjg5MTE1OCAzLjA2MDUyMyAxMC41MzI1MDNWMC40NzgyMDdIOC4yMTMyVjEwLjUzMjUwM0M4LjIxMzIgMTAuODkxMTU4IDguMjEzMiAxMS40NzY5NjEgNi45ODE4MTggMTEuNDc2OTYxVjExLjk1NTE2OEgxMC42MDQyMzRWMTEuNDc2OTYxQzkuMzcyODUyIDExLjQ3Njk2MSA5LjM3Mjg1MiAxMC44OTExNTggOS4zNzI4NTIgMTAuNTMyNTAzVjEuNDIyNjY1QzkuMzcyODUyIDEuMDY0MDEgOS4zNzI4NTIgMC40NzgyMDcgMTAuNjA0MjM0IDAuNDc4MjA3VjBIMC42Njk0ODlWMC40NzgyMDdDMS45MDA4NzIgMC40NzgyMDcgMS45MDA4NzIgMS4wNjQwMSAxLjkwMDg3MiAxLjQyMjY2NVYxMC41MzI1MDNDMS45MDA4NzIgMTAuODkxMTU4IDEuOTAwODcyIDExLjQ3Njk2MSAwLjY2OTQ4OSAxMS40NzY5NjFWMTEuOTU1MTY4SDQuMjkxOTA1WicgaWQ9J2cwLTgxJy8+CjxwYXRoIGQ9J00yLjM3NTA5MyAtNC45NzMzNUMyLjM3NTA5MyAtNS4xNDg2OTIgMi4yNDc1NzIgLTUuMjc2MjE0IDIuMDY0MjU5IC01LjI3NjIxNEMxLjg1NzAzNiAtNS4yNzYyMTQgMS42MjU5MDMgLTUuMDg0OTMyIDEuNjI1OTAzIC00Ljg0NTgyOEMxLjYyNTkwMyAtNC42NzA0ODYgMS43NTM0MjUgLTQuNTQyOTY0IDEuOTM2NzM3IC00LjU0Mjk2NEMyLjE0Mzk2IC00LjU0Mjk2NCAyLjM3NTA5MyAtNC43MzQyNDcgMi4zNzUwOTMgLTQuOTczMzVaTTEuMjExNDU3IC0yLjA0ODMxOUwwLjc4MTA3MSAtMC45NDg0NDNDMC43NDEyMiAtMC44Mjg4OTIgMC43MDEzNyAtMC43MzMyNSAwLjcwMTM3IC0wLjU5Nzc1OEMwLjcwMTM3IC0wLjIwNzIyMyAxLjAwNDIzNCAwLjA3OTcwMSAxLjQyNjY1IDAuMDc5NzAxQzIuMTk5NzUxIDAuMDc5NzAxIDIuNTI2NTI2IC0xLjAzNjExNSAyLjUyNjUyNiAtMS4xMzk3MjZDMi41MjY1MjYgLTEuMjE5NDI3IDIuNDYyNzY1IC0xLjI0MzMzNyAyLjQwNjk3NCAtMS4yNDMzMzdDMi4zMTEzMzMgLTEuMjQzMzM3IDIuMjk1MzkyIC0xLjE4NzU0NyAyLjI3MTQ4MiAtMS4xMDc4NDZDMi4wODgxNjkgLTAuNDcwMjM3IDEuNzYxMzk1IC0wLjE0MzQ2MiAxLjQ0MjU5IC0wLjE0MzQ2MkMxLjM0Njk0OSAtMC4xNDM0NjIgMS4yNTEzMDggLTAuMTgzMzEzIDEuMjUxMzA4IC0wLjM5ODUwNkMxLjI1MTMwOCAtMC41ODk3ODggMS4zMDcwOTggLTAuNzMzMjUgMS40MTA3MSAtMC45ODAzMjRDMS40OTA0MTEgLTEuMTk1NTE3IDEuNTcwMTEyIC0xLjQxMDcxIDEuNjU3NzgzIC0xLjYyNTkwM0wxLjkwNDg1NyAtMi4yNzE0ODJDMS45NzY1ODggLTIuNDU0Nzk1IDIuMDcyMjI5IC0yLjcwMTg2OCAyLjA3MjIyOSAtMi44MzczNkMyLjA3MjIyOSAtMy4yMzU4NjYgMS43NTM0MjUgLTMuNTE0ODE5IDEuMzQ2OTQ5IC0zLjUxNDgxOUMwLjU3Mzg0OCAtMy41MTQ4MTkgMC4yMzkxMDMgLTIuMzk5MDA0IDAuMjM5MTAzIC0yLjI5NTM5MkMwLjIzOTEwMyAtMi4yMjM2NjEgMC4yOTQ4OTQgLTIuMTkxNzgxIDAuMzU4NjU1IC0yLjE5MTc4MUMwLjQ2MjI2NyAtMi4xOTE3ODEgMC40NzAyMzcgLTIuMjM5NjAxIDAuNDk0MTQ3IC0yLjMxOTMwM0MwLjcxNzMxIC0zLjA3NjQ2MyAxLjA4MzkzNSAtMy4yOTE2NTYgMS4zMjMwMzkgLTMuMjkxNjU2QzEuNDM0NjIgLTMuMjkxNjU2IDEuNTE0MzIxIC0zLjI1MTgwNiAxLjUxNDMyMSAtMy4wMjg2NDNDMS41MTQzMjEgLTIuOTQ4OTQxIDEuNTA2MzUxIC0yLjgzNzM2IDEuNDI2NjUgLTIuNTk4MjU3TDEuMjExNDU3IC0yLjA0ODMxOVonIGlkPSdnNC0xMDUnLz4KPHBhdGggZD0nTTMuMjkxNjU2IC00Ljk3MzM1QzMuMjkxNjU2IC01LjEyNDc4MiAzLjE3MjEwNSAtNS4yNzYyMTQgMi45ODA4MjIgLTUuMjc2MjE0QzIuNzQxNzE5IC01LjI3NjIxNCAyLjUzNDQ5NiAtNS4wNTMwNTEgMi41MzQ0OTYgLTQuODQ1ODI4QzIuNTM0NDk2IC00LjY5NDM5NiAyLjY1NDA0NyAtNC41NDI5NjQgMi44NDUzMyAtNC41NDI5NjRDMy4wODQ0MzMgLTQuNTQyOTY0IDMuMjkxNjU2IC00Ljc2NjEyNyAzLjI5MTY1NiAtNC45NzMzNVpNMS42MjU5MDMgMC4zOTg1MDZDMS41MDYzNTEgMC44ODQ2ODIgMS4xMTU4MTYgMS40MDI3NCAwLjYyOTYzOSAxLjQwMjc0QzAuNTAyMTE3IDEuNDAyNzQgMC4zODI1NjUgMS4zNzA4NTkgMC4zNjY2MjUgMS4zNjI4ODlDMC42MTM2OTkgMS4yNDMzMzcgMC42NDU1NzkgMS4wMjgxNDQgMC42NDU1NzkgMC45NTY0MTNDMC42NDU1NzkgMC43NjUxMzEgMC41MDIxMTcgMC42NjE1MTkgMC4zMzQ3NDUgMC42NjE1MTlDMC4xMDM2MTEgMC42NjE1MTkgLTAuMTExNTgyIDAuODYwNzcyIC0wLjExMTU4MiAxLjEyMzc4NkMtMC4xMTE1ODIgMS40MjY2NSAwLjE4MzMxMyAxLjYyNTkwMyAwLjYzNzYwOSAxLjYyNTkwM0MxLjEyMzc4NiAxLjYyNTkwMyAyLjAwMDQ5OCAxLjMyMzAzOSAyLjIzOTYwMSAwLjM2NjYyNUwyLjk1NjkxMiAtMi40ODY2NzVDMi45ODA4MjIgLTIuNTgyMzE2IDIuOTk2NzYyIC0yLjY0NjA3NyAyLjk5Njc2MiAtMi43NjU2MjlDMi45OTY3NjIgLTMuMjAzOTg1IDIuNjQ2MDc3IC0zLjUxNDgxOSAyLjE4MzgxMSAtMy41MTQ4MTlDMS4zMzg5NzkgLTMuNTE0ODE5IDAuODQ0ODMyIC0yLjM5OTAwNCAwLjg0NDgzMiAtMi4yOTUzOTJDMC44NDQ4MzIgLTIuMjIzNjYxIDAuOTAwNjIzIC0yLjE5MTc4MSAwLjk2NDM4NCAtMi4xOTE3ODFDMS4wNTIwNTUgLTIuMTkxNzgxIDEuMDYwMDI1IC0yLjIxNTY5MSAxLjExNTgxNiAtMi4zMzUyNDNDMS4zNTQ5MTkgLTIuODg1MTgxIDEuNzYxMzk1IC0zLjI5MTY1NiAyLjE1OTkgLTMuMjkxNjU2QzIuMzI3MjczIC0zLjI5MTY1NiAyLjQyMjkxNCAtMy4xODAwNzUgMi40MjI5MTQgLTIuOTE3MDYxQzIuNDIyOTE0IC0yLjgwNTQ3OSAyLjM5OTAwNCAtMi42OTM4OTggMi4zNzUwOTMgLTIuNTgyMzE2TDEuNjI1OTAzIDAuMzk4NTA2WicgaWQ9J2c0LTEwNicvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzQtMTA3Jy8+CjxwYXRoIGQ9J00wLjQxNDQ0NiAwLjk2NDM4NEMwLjM1MDY4NSAxLjIxOTQyNyAwLjMzNDc0NSAxLjI4MzE4OCAwLjAxNTk0IDEuMjgzMTg4Qy0wLjA5NTY0MSAxLjI4MzE4OCAtMC4xOTEyODMgMS4yODMxODggLTAuMTkxMjgzIDEuNDM0NjJDLTAuMTkxMjgzIDEuNTA2MzUxIC0wLjExOTU1MiAxLjU0NjIwMiAtMC4wNzk3MDEgMS41NDYyMDJDMCAxLjU0NjIwMiAwLjAzMTg4IDEuNTIyMjkxIDAuNjIxNjY5IDEuNTIyMjkxQzEuMTk1NTE3IDEuNTIyMjkxIDEuMzYyODg5IDEuNTQ2MjAyIDEuNDE4NjggMS41NDYyMDJDMS40NTA1NiAxLjU0NjIwMiAxLjU3MDExMiAxLjU0NjIwMiAxLjU3MDExMiAxLjM5NDc3QzEuNTcwMTEyIDEuMjgzMTg4IDEuNDU4NTMxIDEuMjgzMTg4IDEuMzYyODg5IDEuMjgzMTg4QzAuOTgwMzI0IDEuMjgzMTg4IDAuOTgwMzI0IDEuMjM1MzY3IDAuOTgwMzI0IDEuMTYzNjM2QzAuOTgwMzI0IDEuMTA3ODQ2IDEuMTIzNzg2IDAuNTQxOTY4IDEuMzYyODg5IC0wLjM5MDUzNUMxLjQ2NjUwMSAtMC4yMDcyMjMgMS43MTM1NzQgMC4wNzk3MDEgMi4xNDM5NiAwLjA3OTcwMUMzLjEyNDI4NCAwLjA3OTcwMSA0LjE0NDQ1OCAtMS4wNTIwNTUgNC4xNDQ0NTggLTIuMjA3NzIxQzQuMTQ0NDU4IC0yLjk5Njc2MiAzLjYzNDM3MSAtMy41MTQ4MTkgMi45OTY3NjIgLTMuNTE0ODE5QzIuNTE4NTU1IC0zLjUxNDgxOSAyLjEzNTk5IC0zLjE4ODA0NSAxLjkwNDg1NyAtMi45NDg5NDFDMS43Mzc0ODQgLTMuNTE0ODE5IDEuMjAzNDg3IC0zLjUxNDgxOSAxLjEyMzc4NiAtMy41MTQ4MTlDMC44MzY4NjIgLTMuNTE0ODE5IDAuNjM3NjA5IC0zLjMzMTUwNyAwLjUxMDA4NyAtMy4wODQ0MzNDMC4zMjY3NzUgLTIuNzI1Nzc4IDAuMjM5MTAzIC0yLjMxOTMwMyAwLjIzOTEwMyAtMi4yOTUzOTJDMC4yMzkxMDMgLTIuMjIzNjYxIDAuMjk0ODk0IC0yLjE5MTc4MSAwLjM1ODY1NSAtMi4xOTE3ODFDMC40NjIyNjcgLTIuMTkxNzgxIDAuNDcwMjM3IC0yLjIyMzY2MSAwLjUyNjAyNyAtMi40MzA4ODRDMC42Mjk2MzkgLTIuODM3MzYgMC43NzMxMDEgLTMuMjkxNjU2IDEuMDk5ODc1IC0zLjI5MTY1NkMxLjI5OTEyOCAtMy4yOTE2NTYgMS4zNTQ5MTkgLTMuMTA4MzQ0IDEuMzU0OTE5IC0yLjkxNzA2MUMxLjM1NDkxOSAtMi44MzczNiAxLjMyMzAzOSAtMi42NDYwNzcgMS4zMDcwOTggLTIuNTgyMzE2TDAuNDE0NDQ2IDAuOTY0Mzg0Wk0xLjg4MDk0NiAtMi40NTQ3OTVDMS45MjA3OTcgLTIuNTkwMjg2IDEuOTIwNzk3IC0yLjYwNjIyNyAyLjA0MDM0OSAtMi43NDk2ODlDMi4zNDMyMTMgLTMuMTA4MzQ0IDIuNjg1OTI4IC0zLjI5MTY1NiAyLjk3Mjg1MiAtMy4yOTE2NTZDMy4zNzEzNTcgLTMuMjkxNjU2IDMuNTIyNzkgLTIuOTAxMTIxIDMuNTIyNzkgLTIuNTQyNDY2QzMuNTIyNzkgLTIuMjQ3NTcyIDMuMzQ3NDQ3IC0xLjM5NDc3IDMuMTA4MzQ0IC0wLjkyNDUzM0MyLjkwMTEyMSAtMC40OTQxNDcgMi41MTg1NTUgLTAuMTQzNDYyIDIuMTQzOTYgLTAuMTQzNDYyQzEuNjAxOTkzIC0wLjE0MzQ2MiAxLjQ3NDQ3MSAtMC43NjUxMzEgMS40NzQ0NzEgLTAuODIwOTIyQzEuNDc0NDcxIC0wLjgzNjg2MiAxLjQ5MDQxMSAtMC45MjQ1MzMgMS40OTgzODEgLTAuOTQ4NDQzTDEuODgwOTQ2IC0yLjQ1NDc5NVonIGlkPSdnNC0xMTInLz4KPHBhdGggZD0nTTQuMTI4NTE4IC0zLjAwNDczMkM0LjE2MDM5OSAtMy4xMTYzMTQgNC4xNjAzOTkgLTMuMTMyMjU0IDQuMTYwMzk5IC0zLjE4ODA0NUM0LjE2MDM5OSAtMy4zODcyOTggNC4wMDA5OTYgLTMuNDM1MTE4IDMuOTA1MzU1IC0zLjQzNTExOEMzLjg2NTUwNCAtMy40MzUxMTggMy42ODIxOTIgLTMuNDI3MTQ4IDMuNTc4NTggLTMuMjE5OTI1QzMuNTYyNjQgLTMuMTgwMDc1IDMuNDkwOTA5IC0yLjg5MzE1MSAzLjQ1MTA1OSAtMi43MjU3NzhMMi45NzI4NTIgLTAuODEyOTUxQzIuOTY0ODgyIC0wLjc4OTA0MSAyLjYyMjE2NyAtMC4xNDM0NjIgMi4wNDAzNDkgLTAuMTQzNDYyQzEuNjQ5ODEzIC0wLjE0MzQ2MiAxLjUxNDMyMSAtMC40MzAzODYgMS41MTQzMjEgLTAuNzg5MDQxQzEuNTE0MzIxIC0xLjI1MTMwOCAxLjc4NTMwNSAtMS45NjA2NDggMS45Njg2MTggLTIuNDIyOTE0QzIuMDQ4MzE5IC0yLjYyMjE2NyAyLjA3MjIyOSAtMi42OTM4OTggMi4wNzIyMjkgLTIuODM3MzZDMi4wNzIyMjkgLTMuMjc1NzE2IDEuNzIxNTQ0IC0zLjUxNDgxOSAxLjM1NDkxOSAtMy41MTQ4MTlDMC41NjU4NzggLTMuNTE0ODE5IDAuMjM5MTAzIC0yLjM5MTAzNCAwLjIzOTEwMyAtMi4yOTUzOTJDMC4yMzkxMDMgLTIuMjIzNjYxIDAuMjk0ODk0IC0yLjE5MTc4MSAwLjM1ODY1NSAtMi4xOTE3ODFDMC40NjIyNjcgLTIuMTkxNzgxIDAuNDcwMjM3IC0yLjIzOTYwMSAwLjQ5NDE0NyAtMi4zMTkzMDNDMC43MDEzNyAtMy4wMTI3MDIgMS4wNDQwODUgLTMuMjkxNjU2IDEuMzMxMDA5IC0zLjI5MTY1NkMxLjQ1MDU2IC0zLjI5MTY1NiAxLjUyMjI5MSAtMy4yMTE5NTUgMS41MjIyOTEgLTMuMDI4NjQzQzEuNTIyMjkxIC0yLjg2MTI3IDEuNDU4NTMxIC0yLjY3Nzk1OCAxLjQwMjc0IC0yLjUzNDQ5NkMxLjA3NTk2NSAtMS42ODk2NjQgMC45NDA0NzMgLTEuMjgzMTg4IDAuOTQwNDczIC0wLjkwODU5M0MwLjk0MDQ3MyAtMC4xMjc1MjIgMS41MzAyNjIgMC4wNzk3MDEgMi4wMDA0OTggMC4wNzk3MDFDMi4zNzUwOTMgMC4wNzk3MDEgMi42NDYwNzcgLTAuMDg3NjcxIDIuODM3MzYgLTAuMjcwOTg0QzIuNzI1Nzc4IDAuMTc1MzQyIDIuNjQ2MDc3IDAuNDg2MTc3IDIuMzQzMjEzIDAuODY4NzQyQzIuMDgwMTk5IDEuMTk1NTE3IDEuNzYxMzk1IDEuNDAyNzQgMS40MDI3NCAxLjQwMjc0QzEuMjY3MjQ4IDEuNDAyNzQgMC45NjQzODQgMS4zNzg4MjkgMC44MDQ5ODEgMS4xMzk3MjZDMS4yMjczOTcgMS4xMDc4NDYgMS4yNTkyNzggMC43NDkxOTEgMS4yNTkyNzggMC43MDEzN0MxLjI1OTI3OCAwLjUxMDA4NyAxLjExNTgxNiAwLjQwNjQ3NiAwLjk0ODQ0MyAwLjQwNjQ3NkMwLjc3MzEwMSAwLjQwNjQ3NiAwLjQ5NDE0NyAwLjU0MTk2OCAwLjQ5NDE0NyAwLjkzMjUwM0MwLjQ5NDE0NyAxLjMwNzA5OCAwLjgzNjg2MiAxLjYyNTkwMyAxLjQwMjc0IDEuNjI1OTAzQzIuMjE1NjkxIDEuNjI1OTAzIDMuMTMyMjU0IDAuOTcyMzU0IDMuMzcxMzU3IDAuMDA3OTdMNC4xMjg1MTggLTMuMDA0NzMyWicgaWQ9J2c0LTEyMScvPgo8cGF0aCBkPSdNNS41NzExMDggLTEuODA5MjE1QzUuNjk4NjMgLTEuODA5MjE1IDUuODczOTczIC0xLjgwOTIxNSA1Ljg3Mzk3MyAtMS45OTI1MjhTNS42OTg2MyAtMi4xNzU4NDEgNS41NzExMDggLTIuMTc1ODQxSDEuMDA0MjM0QzAuODc2NzEyIC0yLjE3NTg0MSAwLjcwMTM3IC0yLjE3NTg0MSAwLjcwMTM3IC0xLjk5MjUyOFMwLjg3NjcxMiAtMS44MDkyMTUgMS4wMDQyMzQgLTEuODA5MjE1SDUuNTcxMTA4WicgaWQ9J2cxLTAnLz4KPHBhdGggZD0nTTUuMzM5OTc1IC01LjM2Mzg4NUM1LjQwMzczNiAtNS40Njc0OTcgNS40MDM3MzYgLTUuNDgzNDM3IDUuNDAzNzM2IC01LjUxNTMxOEM1LjQwMzczNiAtNS42MDI5ODkgNS4zMzIwMDUgLTUuNjk4NjMgNS4yMjA0MjMgLTUuNjk4NjNDNS4xMjQ3ODIgLTUuNjk4NjMgNS4wNzY5NjEgLTUuNjM0ODY5IDUuMDIxMTcxIC01LjUzOTIyOEwxLjIzNTM2NyAxLjM3ODgyOUMxLjE3MTYwNiAxLjQ4MjQ0MSAxLjE3MTYwNiAxLjQ5ODM4MSAxLjE3MTYwNiAxLjUzMDI2MkMxLjE3MTYwNiAxLjYxNzkzMyAxLjI0MzMzNyAxLjcxMzU3NCAxLjM1NDkxOSAxLjcxMzU3NEMxLjQ1MDU2IDEuNzEzNTc0IDEuNDk4MzgxIDEuNjQ5ODEzIDEuNTU0MTcyIDEuNTU0MTcyTDUuMzM5OTc1IC01LjM2Mzg4NVonIGlkPSdnMS01NCcvPgo8L2RlZnM+CjxnIGlkPSdwYWdlMSc+Cjx1c2UgeD0nNDMuODM1NjE2JyB4bGluazpocmVmPScjZzUtMTAyJyB5PSc5NC40OTcwNDYnLz4KPHVzZSB4PSc1Mi44NzQ1NTEnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nOTQuNDk3MDQ2Jy8+Cjx1c2UgeD0nNTcuNDI2ODc2JyB4bGluazpocmVmPScjZzUtMTIxJyB5PSc5NC40OTcwNDYnLz4KPHVzZSB4PSc2My4xMzQ1NzknIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nOTYuMjkwMzA5Jy8+Cjx1c2UgeD0nNjcuODY2ODk0JyB4bGluazpocmVmPScjZzUtNTknIHk9Jzk0LjQ5NzA0NicvPgo8dXNlIHg9JzczLjExMTA1MycgeGxpbms6aHJlZj0nI2c1LTU4JyB5PSc5NC40OTcwNDYnLz4KPHVzZSB4PSc3Ni4zNjI3MTQnIHhsaW5rOmhyZWY9JyNnNS01OCcgeT0nOTQuNDk3MDQ2Jy8+Cjx1c2UgeD0nNzkuNjE0Mzc2JyB4bGluazpocmVmPScjZzUtNTgnIHk9Jzk0LjQ5NzA0NicvPgo8dXNlIHg9JzgyLjg2NjAzNycgeGxpbms6aHJlZj0nI2c1LTU5JyB5PSc5NC40OTcwNDYnLz4KPHVzZSB4PSc4OC4xMTAxOTYnIHhsaW5rOmhyZWY9JyNnNS0xMjEnIHk9Jzk0LjQ5NzA0NicvPgo8dXNlIHg9JzkzLjgxNzg5OScgeGxpbms6aHJlZj0nI2c0LTExMicgeT0nOTYuMjkwMzA5Jy8+Cjx1c2UgeD0nOTguNTc4ODA4JyB4bGluazpocmVmPScjZzctNDEnIHk9Jzk0LjQ5NzA0NicvPgo8dXNlIHg9JzExMy4wOTM3NTEnIHhsaW5rOmhyZWY9JyNnNy02MScgeT0nOTQuNDk3MDQ2Jy8+Cjx1c2UgeD0nMTMyLjE2MTA0MycgeGxpbms6aHJlZj0nI2cwLTgxJyB5PSc4NS41MzA1OTQnLz4KPHVzZSB4PScxNDMuNDUyMDYnIHhsaW5rOmhyZWY9JyNnNC0xMTInIHk9Jzg4LjY4NTQzNScvPgo8dXNlIHg9JzE0My40NTIwNicgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nOTcuOTg0MDQ2Jy8+Cjx1c2UgeD0nMTQ2LjMzNTInIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nOTcuOTg0MDQ2Jy8+Cjx1c2UgeD0nMTUyLjkyMTcwNycgeGxpbms6aHJlZj0nI2c2LTQ5JyB5PSc5Ny45ODQwNDYnLz4KPHVzZSB4PScxODAuMjkwNjMxJyB4bGluazpocmVmPScjZzctNDknIHk9Jzg2LjQwOTI4NycvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNDQuNzUwMTcxJyB4PScxNjAuODQyMDMzJyB5PSc5MS4yNjkxNicvPgo8dXNlIHg9JzE2MC44NDIwMzMnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTAyLjY5NzcwOCcvPgo8dXNlIHg9JzE2OS4zNTE2ODcnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nMTAyLjY5NzcwOCcvPgo8dXNlIHg9JzE4MS4xMTMwMDInIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzEwMi42OTc3MDgnLz4KPHVzZSB4PScxODYuNTM4NDQyJyB4bGluazpocmVmPScjZzEtMCcgeT0nOTkuMjQ0Jy8+Cjx1c2UgeD0nMTkzLjEyNDk0OCcgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nOTkuMjQ0Jy8+Cjx1c2UgeD0nMTk3Ljc0NjU2NCcgeGxpbms6aHJlZj0nI2c0LTEyMScgeT0nOTkuMjQ0Jy8+Cjx1c2UgeD0nMjAxLjkzMjMxNCcgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nMTAwLjQ1OTA3OScvPgo8dXNlIHg9JzIwOC43ODAyMTUnIHhsaW5rOmhyZWY9JyNnMC04MScgeT0nODUuNTMwNTk0Jy8+Cjx1c2UgeD0nMjIwLjA3MTIzMycgeGxpbms6aHJlZj0nI2c0LTExMicgeT0nODguNjg1NDM1Jy8+Cjx1c2UgeD0nMjIwLjA3MTIzMycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nOTcuOTg0MDQ2Jy8+Cjx1c2UgeD0nMjIyLjk1NDM3MicgeGxpbms6aHJlZj0nI2c2LTYxJyB5PSc5Ny45ODQwNDYnLz4KPHVzZSB4PScyMjkuNTQwODc5JyB4bGluazpocmVmPScjZzYtNDknIHk9Jzk3Ljk4NDA0NicvPgo8dXNlIHg9JzI2NS42MTM0MDEnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nODYuNDA5Mjg3Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2Mi4xNTczNjcnIHg9JzIzNy40NjEyMDUnIHk9JzkxLjI2OTE2Jy8+Cjx1c2UgeD0nMjM3LjQ2MTIwNScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxMDIuNjk3NzA4Jy8+Cjx1c2UgeD0nMjQ1Ljk3MDg1OScgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxMDIuNjk3NzA4Jy8+Cjx1c2UgeD0nMjU3LjczMjE3NCcgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMTAyLjY5NzcwOCcvPgo8dXNlIHg9JzI2My4xNTc2MTQnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PSc5OS4yNDQnLz4KPHVzZSB4PScyNjkuNzQ0MTIxJyB4bGluazpocmVmPScjZzQtMTA3JyB5PSc5OS4yNDQnLz4KPHVzZSB4PScyNzQuMzY1NzM2JyB4bGluazpocmVmPScjZzYtNDAnIHk9Jzk5LjI0NCcvPgo8dXNlIHg9JzI3Ny42NTg5ODknIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nOTkuMjQ0Jy8+Cjx1c2UgeD0nMjgxLjg5MzE3MicgeGxpbms6aHJlZj0nI2cxLTAnIHk9Jzk5LjI0NCcvPgo8dXNlIHg9JzI4OC40Nzk2NzknIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9Jzk5LjI0NCcvPgo8dXNlIHg9JzI5Mi42NjU0MjknIHhsaW5rOmhyZWY9JyNnMy0xMDUnIHk9JzEwMC40NTkwNzknLz4KPHVzZSB4PScyOTUuODI3MTg3JyB4bGluazpocmVmPScjZzYtNDEnIHk9Jzk5LjI0NCcvPgo8dXNlIHg9JzMwMC44MTQwODYnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nOTQuNDk3MDQ2Jy8+Cjx1c2UgeD0nMTQzLjg2NzAyMycgeGxpbms6aHJlZj0nI2cwLTE4JyB5PScxMDQuMDg5MDk3Jy8+Cjx1c2UgeD0nMTUyLjY2NzM5NicgeGxpbms6aHJlZj0nI2cwLTgxJyB5PScxMTEuOTc5NTgyJy8+Cjx1c2UgeD0nMTYzLjk1ODQxMycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzE2Ni44NDE1NTMnIHhsaW5rOmhyZWY9JyNnMS01NCcgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzE2Ni44NDE1NTMnIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzE3My40MjgwNicgeGxpbms6aHJlZj0nI2c0LTEwNicgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzIwMC40NDY4MjYnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTEyLjg1ODI3NicvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNDQuNzUwMTcxJyB4PScxODAuOTk4MjI4JyB5PScxMTcuNzE4MTQ5Jy8+Cjx1c2UgeD0nMTgwLjk5ODIyOCcgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxMjkuMTQ2Njk3Jy8+Cjx1c2UgeD0nMTg5LjUwNzg4MicgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxMjkuMTQ2Njk3Jy8+Cjx1c2UgeD0nMjAxLjI2OTE5NycgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMTI5LjE0NjY5NycvPgo8dXNlIHg9JzIwNi42OTQ2MzcnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxMjUuNjkyOTg4Jy8+Cjx1c2UgeD0nMjEzLjI4MTE0NCcgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTI1LjY5Mjk4OCcvPgo8dXNlIHg9JzIxNy45MDI3NTknIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzEyNS42OTI5ODgnLz4KPHVzZSB4PScyMjIuMDg4NTA5JyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxMjYuOTA4MDY3Jy8+Cjx1c2UgeD0nMjI2Ljk0MzkxMycgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScxMDQuMDg5MDk3Jy8+Cjx1c2UgeD0nMjM3LjczNjc4MycgeGxpbms6aHJlZj0nI2cwLTE4JyB5PScxMDQuMDg5MDk3Jy8+Cjx1c2UgeD0nMjQ2LjUzNzE1NicgeGxpbms6aHJlZj0nI2cwLTgxJyB5PScxMTEuOTc5NTgyJy8+Cjx1c2UgeD0nMjU3LjgyODE3MycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzI2MC43MTEzMTMnIHhsaW5rOmhyZWY9JyNnMS01NCcgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzI2MC43MTEzMTMnIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nMTI0LjQzMzAzNCcvPgo8dXNlIHg9JzI2Ny4yOTc4MTknIHhsaW5rOmhyZWY9JyNnNC0xMDYnIHk9JzEyNC40MzMwMzQnLz4KPHVzZSB4PSczMDMuMDIwMTg0JyB4bGluazpocmVmPScjZzctNDknIHk9JzExMi44NTgyNzYnLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzYyLjE1NzM2NycgeD0nMjc0Ljg2Nzk4OCcgeT0nMTE3LjcxODE0OScvPgo8dXNlIHg9JzI3NC44Njc5ODgnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTI5LjE0NjY5NycvPgo8dXNlIHg9JzI4My4zNzc2NDEnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nMTI5LjE0NjY5NycvPgo8dXNlIHg9JzI5NS4xMzg5NTYnIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzEyOS4xNDY2OTcnLz4KPHVzZSB4PSczMDAuNTY0Mzk3JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTI1LjY5Mjk4OCcvPgo8dXNlIHg9JzMwNy4xNTA5MDMnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzEyNS42OTI5ODgnLz4KPHVzZSB4PSczMTEuNzcyNTE5JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEyNS42OTI5ODgnLz4KPHVzZSB4PSczMTUuMDY1NzcyJyB4bGluazpocmVmPScjZzYtNDknIHk9JzEyNS42OTI5ODgnLz4KPHVzZSB4PSczMTkuMjk5OTU1JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTI1LjY5Mjk4OCcvPgo8dXNlIHg9JzMyNS44ODY0NjInIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzEyNS42OTI5ODgnLz4KPHVzZSB4PSczMzAuMDcyMjEyJyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxMjYuOTA4MDY3Jy8+Cjx1c2UgeD0nMzMzLjIzMzk2OScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxMjUuNjkyOTg4Jy8+Cjx1c2UgeD0nMzM4LjIyMDg2OScgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScxMDQuMDg5MDk3Jy8+Cjx1c2UgeD0nMzc1LjQzODY5MycgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxMTIuODU4Mjc2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc1Ni4zMTE4NzEnIHg9JzM1MC4yMDkyNTMnIHk9JzExNy43MTgxNDknLz4KPHVzZSB4PSczNTAuMjA5MjUzJyB4bGluazpocmVmPScjZzctNDknIHk9JzEyOS4yNzI3MDQnLz4KPHVzZSB4PSczNTguNzE4OTA2JyB4bGluazpocmVmPScjZzctNDMnIHk9JzEyOS4yNzI3MDQnLz4KPHVzZSB4PSczNzAuNDgwMjIxJyB4bGluazpocmVmPScjZzUtMTAxJyB5PScxMjkuMjcyNzA0Jy8+Cjx1c2UgeD0nMzc1LjkwNTY2MScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTI1LjYwODQ4MicvPgo8dXNlIHg9JzM4MC41MjcyNzcnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nMTI1LjYwODQ4MicvPgo8dXNlIHg9JzM4My44MjA1MycgeGxpbms6aHJlZj0nI2c2LTQ5JyB5PScxMjUuNjA4NDgyJy8+Cjx1c2UgeD0nMzg4LjA1NDcxMycgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PSczOTQuNjQxMjInIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PSczOTguODI2OTcnIHhsaW5rOmhyZWY9JyNnMy0xMDYnIHk9JzEyNi44MjM1NicvPgo8dXNlIHg9JzQwMi43Mjk3MzgnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMTI1LjYwODQ4MicvPgo8dXNlIHg9JzQzNy40MzQ4NDUnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTEyLjg1ODI3NicvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNjIuODk4Mzc4JyB4PSc0MDguOTEyMTUxJyB5PScxMTcuNzE4MTQ5Jy8+Cjx1c2UgeD0nNDA4LjkxMjE1MScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxMjkuMjcyNzA0Jy8+Cjx1c2UgeD0nNDE3LjQyMTgwNScgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxMjkuMjcyNzA0Jy8+Cjx1c2UgeD0nNDI5LjE4MzEyJyB4bGluazpocmVmPScjZzUtMTAxJyB5PScxMjkuMjcyNzA0Jy8+Cjx1c2UgeD0nNDM0LjYwODU2JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTI1LjYwODQ4MicvPgo8dXNlIHg9JzQ0MS4xOTUwNjcnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PSc0NDUuODE2NjgyJyB4bGluazpocmVmPScjZzYtNDAnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PSc0NDkuMTA5OTM2JyB4bGluazpocmVmPScjZzYtNTAnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PSc0NTMuMzQ0MTE4JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTI1LjYwODQ4MicvPgo8dXNlIHg9JzQ1OS45MzA2MjUnIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PSc0NjQuMTE2Mzc1JyB4bGluazpocmVmPScjZzMtMTA2JyB5PScxMjYuODIzNTYnLz4KPHVzZSB4PSc0NjguMDE5MTQ0JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzEyNS42MDg0ODInLz4KPHVzZSB4PScxMTMuMDkzNzUxJyB4bGluazpocmVmPScjZzctNjEnIHk9JzE0OS42Mzg3MTQnLz4KPHVzZSB4PScxMzIuMTYxMDQzJyB4bGluazpocmVmPScjZzAtMTgnIHk9JzEzMi43ODE3NzcnLz4KPHVzZSB4PScxNDAuOTYxNDE1JyB4bGluazpocmVmPScjZzAtODEnIHk9JzE0MC42NzIyNjInLz4KPHVzZSB4PScxNTIuMjUyNDMzJyB4bGluazpocmVmPScjZzQtMTA1JyB5PScxNTMuMTI1NzE0Jy8+Cjx1c2UgeD0nMTU1LjEzNTU3MycgeGxpbms6aHJlZj0nI2cxLTU0JyB5PScxNTMuMTI1NzE0Jy8+Cjx1c2UgeD0nMTU1LjEzNTU3MycgeGxpbms6aHJlZj0nI2c2LTYxJyB5PScxNTMuMTI1NzE0Jy8+Cjx1c2UgeD0nMTYxLjcyMjA3OScgeGxpbms6aHJlZj0nI2c0LTEwNicgeT0nMTUzLjEyNTcxNCcvPgo8dXNlIHg9JzE4OC43NDA4NDUnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTQxLjU1MDk1NicvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNDQuNzUwMTcxJyB4PScxNjkuMjkyMjQ4JyB5PScxNDYuNDEwODI5Jy8+Cjx1c2UgeD0nMTY5LjI5MjI0OCcgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNTcuODM5Mzc3Jy8+Cjx1c2UgeD0nMTc3LjgwMTkwMScgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxNTcuODM5Mzc3Jy8+Cjx1c2UgeD0nMTg5LjU2MzIxNicgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMTU3LjgzOTM3NycvPgo8dXNlIHg9JzE5NC45ODg2NTYnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxNTQuMzg1NjY5Jy8+Cjx1c2UgeD0nMjAxLjU3NTE2MycgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTU0LjM4NTY2OScvPgo8dXNlIHg9JzIwNi4xOTY3NzknIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzE1NC4zODU2NjknLz4KPHVzZSB4PScyMTAuMzgyNTI5JyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxNTUuNjAwNzQ3Jy8+Cjx1c2UgeD0nMjE1LjIzNzkzMicgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScxMzIuNzgxNzc3Jy8+Cjx1c2UgeD0nMjI2LjAzMDgwMicgeGxpbms6aHJlZj0nI2cwLTE4JyB5PScxMzIuNzgxNzc3Jy8+Cjx1c2UgeD0nMjM0LjgzMTE3NScgeGxpbms6aHJlZj0nI2cwLTgxJyB5PScxNDAuNjcyMjYyJy8+Cjx1c2UgeD0nMjQ2LjEyMjE5MycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMTUzLjEyNTcxNCcvPgo8dXNlIHg9JzI0OS4wMDUzMzInIHhsaW5rOmhyZWY9JyNnMS01NCcgeT0nMTUzLjEyNTcxNCcvPgo8dXNlIHg9JzI0OS4wMDUzMzInIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nMTUzLjEyNTcxNCcvPgo8dXNlIHg9JzI1NS41OTE4MzknIHhsaW5rOmhyZWY9JyNnNC0xMDYnIHk9JzE1My4xMjU3MTQnLz4KPHVzZSB4PScyOTEuMzE0MjAzJyB4bGluazpocmVmPScjZzctNDknIHk9JzE0MS41NTA5NTYnLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzYyLjE1NzM2NycgeD0nMjYzLjE2MjAwNycgeT0nMTQ2LjQxMDgyOScvPgo8dXNlIHg9JzI2My4xNjIwMDcnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMTU3LjgzOTM3NycvPgo8dXNlIHg9JzI3MS42NzE2NjEnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nMTU3LjgzOTM3NycvPgo8dXNlIHg9JzI4My40MzI5NzYnIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzE1Ny44MzkzNzcnLz4KPHVzZSB4PScyODguODU4NDE2JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTU0LjM4NTY2OScvPgo8dXNlIHg9JzI5NS40NDQ5MjMnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzE1NC4zODU2NjknLz4KPHVzZSB4PSczMDAuMDY2NTM4JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzE1NC4zODU2NjknLz4KPHVzZSB4PSczMDMuMzU5NzkyJyB4bGluazpocmVmPScjZzYtNDknIHk9JzE1NC4zODU2NjknLz4KPHVzZSB4PSczMDcuNTkzOTc0JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTU0LjM4NTY2OScvPgo8dXNlIHg9JzMxNC4xODA0ODEnIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzE1NC4zODU2NjknLz4KPHVzZSB4PSczMTguMzY2MjMxJyB4bGluazpocmVmPScjZzMtMTA1JyB5PScxNTUuNjAwNzQ3Jy8+Cjx1c2UgeD0nMzIxLjUyNzk4OScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxNTQuMzg1NjY5Jy8+Cjx1c2UgeD0nMzI2LjUxNDg4OCcgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScxMzIuNzgxNzc3Jy8+Cjx1c2UgeD0nMTQzLjg2NzAyMycgeGxpbms6aHJlZj0nI2cwLTE4JyB5PScxNjEuNDc0NDU3Jy8+Cjx1c2UgeD0nMTczLjY4MjAwNScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNzAuMjQzNjM2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc0NS40OTExODInIHg9JzE1My44NjI5MScgeT0nMTc1LjEwMzUwOScvPgo8dXNlIHg9JzE1My44NjI5MScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxODYuNTMyMDU3Jy8+Cjx1c2UgeD0nMTYyLjM3MjU2MycgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxODYuNTMyMDU3Jy8+Cjx1c2UgeD0nMTc0LjEzMzg3OCcgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMTg2LjUzMjA1NycvPgo8dXNlIHg9JzE3OS41NTkzMTknIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxODIuODY3ODM0Jy8+Cjx1c2UgeD0nMTg2LjE0NTgyNScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTgyLjg2NzgzNCcvPgo8dXNlIHg9JzE5MC43Njc0NDEnIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzE4Mi44Njc4MzQnLz4KPHVzZSB4PScxOTQuOTUzMTkxJyB4bGluazpocmVmPScjZzMtMTA2JyB5PScxODQuMDgyOTEzJy8+Cjx1c2UgeD0nMjMwLjI2NzgxMycgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNzAuMjQzNjM2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2Mi44OTgzNzgnIHg9JzIwMS43NDUxMTknIHk9JzE3NS4xMDM1MDknLz4KPHVzZSB4PScyMDEuNzQ1MTE5JyB4bGluazpocmVmPScjZzctNDknIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PScyMTAuMjU0NzczJyB4bGluazpocmVmPScjZzctNDMnIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PScyMjIuMDE2MDg4JyB4bGluazpocmVmPScjZzUtMTAxJyB5PScxODYuNjU4MDY0Jy8+Cjx1c2UgeD0nMjI3LjQ0MTUyOCcgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PScyMzQuMDI4MDM1JyB4bGluazpocmVmPScjZzQtMTA3JyB5PScxODIuOTkzODQyJy8+Cjx1c2UgeD0nMjM4LjY0OTY1JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PScyNDEuOTQyOTAzJyB4bGluazpocmVmPScjZzYtNDknIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PScyNDYuMTc3MDg2JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTgyLjk5Mzg0MicvPgo8dXNlIHg9JzI1Mi43NjM1OTMnIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PScyNTYuOTQ5MzQzJyB4bGluazpocmVmPScjZzMtMTA2JyB5PScxODQuMjA4OTIxJy8+Cjx1c2UgeD0nMjYwLjg1MjExMicgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxODIuOTkzODQyJy8+Cjx1c2UgeD0nMjY4LjQ5NTY3NCcgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxNzguMzMxMzk1Jy8+Cjx1c2UgeD0nMzA2LjY4MTk0MycgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNzAuMjQzNjM2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc1Ni4zMTE4NzEnIHg9JzI4MS40NTI1MDMnIHk9JzE3NS4xMDM1MDknLz4KPHVzZSB4PScyODEuNDUyNTAzJyB4bGluazpocmVmPScjZzctNDknIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PScyODkuOTYyMTU3JyB4bGluazpocmVmPScjZzctNDMnIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PSczMDEuNzIzNDcyJyB4bGluazpocmVmPScjZzUtMTAxJyB5PScxODYuNjU4MDY0Jy8+Cjx1c2UgeD0nMzA3LjE0ODkxMicgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTgyLjk5Mzg0MicvPgo8dXNlIHg9JzMxMS43NzA1MjcnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nMTgyLjk5Mzg0MicvPgo8dXNlIHg9JzMxNS4wNjM3ODEnIHhsaW5rOmhyZWY9JyNnNi00OScgeT0nMTgyLjk5Mzg0MicvPgo8dXNlIHg9JzMxOS4yOTc5NjMnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScxODIuOTkzODQyJy8+Cjx1c2UgeD0nMzI1Ljg4NDQ3JyB4bGluazpocmVmPScjZzQtMTIxJyB5PScxODIuOTkzODQyJy8+Cjx1c2UgeD0nMzMwLjA3MDIyJyB4bGluazpocmVmPScjZzMtMTA2JyB5PScxODQuMjA4OTIxJy8+Cjx1c2UgeD0nMzMzLjk3Mjk4OScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxODIuOTkzODQyJy8+Cjx1c2UgeD0nMzY4LjY3ODA5NicgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxNzAuMjQzNjM2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2Mi44OTgzNzgnIHg9JzM0MC4xNTU0MDInIHk9JzE3NS4xMDM1MDknLz4KPHVzZSB4PSczNDAuMTU1NDAyJyB4bGluazpocmVmPScjZzctNDknIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PSczNDguNjY1MDU1JyB4bGluazpocmVmPScjZzctNDMnIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PSczNjAuNDI2MzcnIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzE4Ni42NTgwNjQnLz4KPHVzZSB4PSczNjUuODUxODExJyB4bGluazpocmVmPScjZzEtMCcgeT0nMTgyLjk5Mzg0MicvPgo8dXNlIHg9JzM3Mi40MzgzMTcnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PSczNzcuMDU5OTMzJyB4bGluazpocmVmPScjZzYtNDAnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PSczODAuMzUzMTg2JyB4bGluazpocmVmPScjZzYtNTAnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PSczODQuNTg3MzY5JyB4bGluazpocmVmPScjZzEtMCcgeT0nMTgyLjk5Mzg0MicvPgo8dXNlIHg9JzM5MS4xNzM4NzYnIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzE4Mi45OTM4NDInLz4KPHVzZSB4PSczOTUuMzU5NjI2JyB4bGluazpocmVmPScjZzMtMTA2JyB5PScxODQuMjA4OTIxJy8+Cjx1c2UgeD0nMzk5LjI2MjM5NCcgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScxODIuOTkzODQyJy8+Cjx1c2UgeD0nNDA0LjI0OTI5MycgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScxNjEuNDc0NDU3Jy8+Cjx1c2UgeD0nMTEzLjA5Mzc1MScgeGxpbms6aHJlZj0nI2c3LTYxJyB5PScyMDcuMDI0MDc1Jy8+Cjx1c2UgeD0nMTMyLjE2MTA0MycgeGxpbms6aHJlZj0nI2cwLTE4JyB5PScxOTAuMTY3MTM4Jy8+Cjx1c2UgeD0nMTQwLjk2MTQxNScgeGxpbms6aHJlZj0nI2cwLTgxJyB5PScxOTguMDU3NjIzJy8+Cjx1c2UgeD0nMTUyLjI1MjQzMycgeGxpbms6aHJlZj0nI2c0LTEwNScgeT0nMjEwLjUxMTA3NScvPgo8dXNlIHg9JzE1NS4xMzU1NzMnIHhsaW5rOmhyZWY9JyNnMS01NCcgeT0nMjEwLjUxMTA3NScvPgo8dXNlIHg9JzE1NS4xMzU1NzMnIHhsaW5rOmhyZWY9JyNnNi02MScgeT0nMjEwLjUxMTA3NScvPgo8dXNlIHg9JzE2MS43MjIwNzknIHhsaW5rOmhyZWY9JyNnNC0xMDYnIHk9JzIxMC41MTEwNzUnLz4KPHVzZSB4PScxODguNzQwODQ1JyB4bGluazpocmVmPScjZzctNDknIHk9JzE5OC45MzYzMTYnLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzQ0Ljc1MDE3MScgeD0nMTY5LjI5MjI0OCcgeT0nMjAzLjc5NjE4OScvPgo8dXNlIHg9JzE2OS4yOTIyNDgnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMjE1LjIyNDczNycvPgo8dXNlIHg9JzE3Ny44MDE5MDEnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nMjE1LjIyNDczNycvPgo8dXNlIHg9JzE4OS41NjMyMTYnIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzIxNS4yMjQ3MzcnLz4KPHVzZSB4PScxOTQuOTg4NjU2JyB4bGluazpocmVmPScjZzEtMCcgeT0nMjExLjc3MTAyOScvPgo8dXNlIHg9JzIwMS41NzUxNjMnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzIxMS43NzEwMjknLz4KPHVzZSB4PScyMDYuMTk2Nzc5JyB4bGluazpocmVmPScjZzQtMTIxJyB5PScyMTEuNzcxMDI5Jy8+Cjx1c2UgeD0nMjEwLjM4MjUyOScgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nMjEyLjk4NjEwNycvPgo8dXNlIHg9JzIxNS4yMzc5MzInIHhsaW5rOmhyZWY9JyNnMC0xOScgeT0nMTkwLjE2NzEzOCcvPgo8dXNlIHg9JzIyNi4wMzA4MDInIHhsaW5rOmhyZWY9JyNnMC0xOCcgeT0nMTkwLjE2NzEzOCcvPgo8dXNlIHg9JzIzNC44MzExNzUnIHhsaW5rOmhyZWY9JyNnMC04MScgeT0nMTk4LjA1NzYyMycvPgo8dXNlIHg9JzI0Ni4xMjIxOTMnIHhsaW5rOmhyZWY9JyNnNC0xMDUnIHk9JzIxMC41MTEwNzUnLz4KPHVzZSB4PScyNDkuMDA1MzMyJyB4bGluazpocmVmPScjZzEtNTQnIHk9JzIxMC41MTEwNzUnLz4KPHVzZSB4PScyNDkuMDA1MzMyJyB4bGluazpocmVmPScjZzYtNjEnIHk9JzIxMC41MTEwNzUnLz4KPHVzZSB4PScyNTUuNTkxODM5JyB4bGluazpocmVmPScjZzQtMTA2JyB5PScyMTAuNTExMDc1Jy8+Cjx1c2UgeD0nMjkxLjMxNDIwMycgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScxOTguOTM2MzE2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2Mi4xNTczNjcnIHg9JzI2My4xNjIwMDcnIHk9JzIwMy43OTYxODknLz4KPHVzZSB4PScyNjMuMTYyMDA3JyB4bGluazpocmVmPScjZzctNDknIHk9JzIxNS4yMjQ3MzcnLz4KPHVzZSB4PScyNzEuNjcxNjYxJyB4bGluazpocmVmPScjZzctNDMnIHk9JzIxNS4yMjQ3MzcnLz4KPHVzZSB4PScyODMuNDMyOTc2JyB4bGluazpocmVmPScjZzUtMTAxJyB5PScyMTUuMjI0NzM3Jy8+Cjx1c2UgeD0nMjg4Ljg1ODQxNicgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzIxMS43NzEwMjknLz4KPHVzZSB4PScyOTUuNDQ0OTIzJyB4bGluazpocmVmPScjZzQtMTA3JyB5PScyMTEuNzcxMDI5Jy8+Cjx1c2UgeD0nMzAwLjA2NjUzOCcgeGxpbms6aHJlZj0nI2c2LTQwJyB5PScyMTEuNzcxMDI5Jy8+Cjx1c2UgeD0nMzAzLjM1OTc5MicgeGxpbms6aHJlZj0nI2c2LTQ5JyB5PScyMTEuNzcxMDI5Jy8+Cjx1c2UgeD0nMzA3LjU5Mzk3NCcgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzIxMS43NzEwMjknLz4KPHVzZSB4PSczMTQuMTgwNDgxJyB4bGluazpocmVmPScjZzQtMTIxJyB5PScyMTEuNzcxMDI5Jy8+Cjx1c2UgeD0nMzE4LjM2NjIzMScgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nMjEyLjk4NjEwNycvPgo8dXNlIHg9JzMyMS41Mjc5ODknIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMjExLjc3MTAyOScvPgo8dXNlIHg9JzMyNi41MTQ4ODgnIHhsaW5rOmhyZWY9JyNnMC0xOScgeT0nMTkwLjE2NzEzOCcvPgo8dXNlIHg9JzE0My44NjcwMjMnIHhsaW5rOmhyZWY9JyNnMC0yMCcgeT0nMjE4Ljg1OTgxOCcvPgo8dXNlIHg9JzE3MS4xOTEzMycgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyMjcuNjI4OTk2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc0NS40OTExODInIHg9JzE1MS4zNzIyMzQnIHk9JzIzMi40ODg4NjknLz4KPHVzZSB4PScxNTEuMzcyMjM0JyB4bGluazpocmVmPScjZzctNDknIHk9JzI0My45MTc0MTcnLz4KPHVzZSB4PScxNTkuODgxODg4JyB4bGluazpocmVmPScjZzctNDMnIHk9JzI0My45MTc0MTcnLz4KPHVzZSB4PScxNzEuNjQzMjAzJyB4bGluazpocmVmPScjZzUtMTAxJyB5PScyNDMuOTE3NDE3Jy8+Cjx1c2UgeD0nMTc3LjA2ODY0MycgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzI0MC4yNTMxOTUnLz4KPHVzZSB4PScxODMuNjU1MTUnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzI0MC4yNTMxOTUnLz4KPHVzZSB4PScxODguMjc2NzY1JyB4bGluazpocmVmPScjZzQtMTIxJyB5PScyNDAuMjUzMTk1Jy8+Cjx1c2UgeD0nMTkyLjQ2MjUxNScgeGxpbms6aHJlZj0nI2czLTEwNicgeT0nMjQxLjQ2ODI3MycvPgo8dXNlIHg9JzIwMC4wNTE0MjgnIHhsaW5rOmhyZWY9JyNnMC0xOCcgeT0nMjE4Ljg1OTgxOCcvPgo8dXNlIHg9JzIzOC41NzAwMDgnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMjI3LjYyODk5NicvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNjIuODk4Mzc4JyB4PScyMTAuMDQ3MzE0JyB5PScyMzIuNDg4ODY5Jy8+Cjx1c2UgeD0nMjEwLjA0NzMxNCcgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyNDQuMDQzNDI1Jy8+Cjx1c2UgeD0nMjE4LjU1Njk2OCcgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScyNDQuMDQzNDI1Jy8+Cjx1c2UgeD0nMjMwLjMxODI4MycgeGxpbms6aHJlZj0nI2c1LTEwMScgeT0nMjQ0LjA0MzQyNScvPgo8dXNlIHg9JzIzNS43NDM3MjMnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nMjQyLjMzMDIzJyB4bGluazpocmVmPScjZzQtMTA3JyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nMjQ2Ljk1MTg0NScgeGxpbms6aHJlZj0nI2c2LTQwJyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nMjUwLjI0NTA5OCcgeGxpbms6aHJlZj0nI2c2LTQ5JyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nMjU0LjQ3OTI4MScgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzI0MC4zNzkyMDInLz4KPHVzZSB4PScyNjEuMDY1Nzg4JyB4bGluazpocmVmPScjZzQtMTIxJyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nMjY1LjI1MTUzOCcgeGxpbms6aHJlZj0nI2czLTEwNicgeT0nMjQxLjU5NDI4MScvPgo8dXNlIHg9JzI2OS4xNTQzMDcnIHhsaW5rOmhyZWY9JyNnNi00MScgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzI3Ni43OTc4NjknIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nMjM1LjcxNjc1NScvPgo8dXNlIHg9JzI4OC41NTkxODQnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMjM1LjcxNjc1NScvPgo8dXNlIHg9JzI5Ny4wNjg4MzgnIHhsaW5rOmhyZWY9JyNnMi0wJyB5PScyMzUuNzE2NzU1Jy8+Cjx1c2UgeD0nMzA5LjAyMzk5OCcgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyMzUuNzE2NzU1Jy8+Cjx1c2UgeD0nMzE0Ljg3Njk4OScgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScyMTguODU5ODE4Jy8+Cjx1c2UgeD0nMzI2LjMzNDAxNycgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScyMzUuNzE2NzU1Jy8+Cjx1c2UgeD0nMzM4LjA5NTMzMicgeGxpbms6aHJlZj0nI2cwLTE4JyB5PScyMTguODU5ODE4Jy8+Cjx1c2UgeD0nMzQ2Ljg5NTcwNScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyMzUuNzE2NzU1Jy8+Cjx1c2UgeD0nMzU1LjQwNTM1OScgeGxpbms6aHJlZj0nI2cyLTAnIHk9JzIzNS43MTY3NTUnLz4KPHVzZSB4PSczOTcuMDc4NzI3JyB4bGluazpocmVmPScjZzctNDknIHk9JzIyNy42Mjg5OTYnLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzYyLjg5ODM3OCcgeD0nMzY4LjU1NjAzMycgeT0nMjMyLjQ4ODg2OScvPgo8dXNlIHg9JzM2OC41NTYwMzMnIHhsaW5rOmhyZWY9JyNnNy00OScgeT0nMjQ0LjA0MzQyNScvPgo8dXNlIHg9JzM3Ny4wNjU2ODcnIHhsaW5rOmhyZWY9JyNnNy00MycgeT0nMjQ0LjA0MzQyNScvPgo8dXNlIHg9JzM4OC44MjcwMDInIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzI0NC4wNDM0MjUnLz4KPHVzZSB4PSczOTQuMjUyNDQyJyB4bGluazpocmVmPScjZzEtMCcgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzQwMC44Mzg5NDgnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzI0MC4zNzkyMDInLz4KPHVzZSB4PSc0MDUuNDYwNTY0JyB4bGluazpocmVmPScjZzYtNDAnIHk9JzI0MC4zNzkyMDInLz4KPHVzZSB4PSc0MDguNzUzODE3JyB4bGluazpocmVmPScjZzYtNDknIHk9JzI0MC4zNzkyMDInLz4KPHVzZSB4PSc0MTIuOTg4JyB4bGluazpocmVmPScjZzEtMCcgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzQxOS41NzQ1MDcnIHhsaW5rOmhyZWY9JyNnNC0xMjEnIHk9JzI0MC4zNzkyMDInLz4KPHVzZSB4PSc0MjMuNzYwMjU3JyB4bGluazpocmVmPScjZzMtMTA2JyB5PScyNDEuNTk0MjgxJy8+Cjx1c2UgeD0nNDI3LjY2MzAyNScgeGxpbms6aHJlZj0nI2c2LTQxJyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nNDMyLjY0OTkyNScgeGxpbms6aHJlZj0nI2cwLTE5JyB5PScyMTguODU5ODE4Jy8+Cjx1c2UgeD0nNDczLjE2MDk5NScgeGxpbms6aHJlZj0nI2c3LTQ5JyB5PScyMjcuNjI4OTk2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPSc2Mi44OTgzNzgnIHg9JzQ0NC42MzgzMDEnIHk9JzIzMi40ODg4NjknLz4KPHVzZSB4PSc0NDQuNjM4MzAxJyB4bGluazpocmVmPScjZzctNDknIHk9JzI0NC4wNDM0MjUnLz4KPHVzZSB4PSc0NTMuMTQ3OTU1JyB4bGluazpocmVmPScjZzctNDMnIHk9JzI0NC4wNDM0MjUnLz4KPHVzZSB4PSc0NjQuOTA5MjcnIHhsaW5rOmhyZWY9JyNnNS0xMDEnIHk9JzI0NC4wNDM0MjUnLz4KPHVzZSB4PSc0NzAuMzM0NzEnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nNDc2LjkyMTIxNicgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzQ4MS41NDI4MzInIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzQ4NC44MzYwODUnIHhsaW5rOmhyZWY9JyNnNi01MCcgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzQ4OS4wNzAyNjgnIHhsaW5rOmhyZWY9JyNnMS0wJyB5PScyNDAuMzc5MjAyJy8+Cjx1c2UgeD0nNDk1LjY1Njc3NScgeGxpbms6aHJlZj0nI2c0LTEyMScgeT0nMjQwLjM3OTIwMicvPgo8dXNlIHg9JzQ5OS44NDI1MjUnIHhsaW5rOmhyZWY9JyNnMy0xMDYnIHk9JzI0MS41OTQyODEnLz4KPHVzZSB4PSc1MDMuNzQ1Mjk0JyB4bGluazpocmVmPScjZzYtNDEnIHk9JzI0MC4zNzkyMDInLz4KPHVzZSB4PSc1MDguNzMyMTkzJyB4bGluazpocmVmPScjZzAtMjEnIHk9JzIxOC44NTk4MTgnLz4KPC9nPgo8L3N2Zz4=)
Pour , on a :

Par conséquent, il est facile de construire la fonction cherchée pour tout compact connexe par arc.
Partie 2
Si un compact n’est pas connexe par arc,
on peut le recouvrir par une somme finie de
compacts connexes par arcs et disjoints
 de telle sorte que :
de telle sorte que :

Démontration du théorème de densité des réseaux de neurones
Partie 1
On démontre le théorème dans le cas où  .
Soit une fonction continue du compact
.
Soit une fonction continue du compact
 et soit
et soit  .
.
On suppose également que est positive, dans le cas contraire, on pose
 .
.
Si est nulle, alors c’est fini, sinon, on pose  .
.
 existe car est continue et
est compact (de même,
existe car est continue et
est compact (de même,  existe également).
existe également).
On pose ![C_{k}=f^{-1}\left( \left[ k\varepsilon,M\right] \right)](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTIuNDYzNTMxcHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nMzguODU0Mjk2IDU2LjI3ODY4NiA5NC45OTIxMjYgMTIuNDYzNTMxJyB3aWR0aD0nOTQuOTkyMTI2cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTUuNTcxMTA4IC0xLjgwOTIxNUM1LjY5ODYzIC0xLjgwOTIxNSA1Ljg3Mzk3MyAtMS44MDkyMTUgNS44NzM5NzMgLTEuOTkyNTI4UzUuNjk4NjMgLTIuMTc1ODQxIDUuNTcxMTA4IC0yLjE3NTg0MUgxLjAwNDIzNEMwLjg3NjcxMiAtMi4xNzU4NDEgMC43MDEzNyAtMi4xNzU4NDEgMC43MDEzNyAtMS45OTI1MjhTMC44NzY3MTIgLTEuODA5MjE1IDEuMDA0MjM0IC0xLjgwOTIxNUg1LjU3MTEwOFonIGlkPSdnMC0wJy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzQtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c0LTQxJy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnNC02MScvPgo8cGF0aCBkPSdNMi45ODg3OTIgMi45ODg3OTJWMi41NDY0NTFIMS44MjkxNDFWLTguNTI0MDM1SDIuOTg4NzkyVi04Ljk2NjM3NkgxLjM4NjhWMi45ODg3OTJIMi45ODg3OTJaJyBpZD0nZzQtOTEnLz4KPHBhdGggZD0nTTEuODUzMDUxIC04Ljk2NjM3NkgwLjI1MTA1OVYtOC41MjQwMzVIMS40MTA3MVYyLjU0NjQ1MUgwLjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJyBpZD0nZzQtOTMnLz4KPHBhdGggZD0nTTEuNjYxNzY4IC0yLjcyNTc3OEMyLjA0NDMzNCAtMi41NzAzNjEgMi40NTA4MDkgLTIuNTcwMzYxIDIuNjc3OTU4IC0yLjU3MDM2MUMyLjk4ODc5MiAtMi41NzAzNjEgMy42MTA0NjEgLTIuNTcwMzYxIDMuNjEwNDYxIC0yLjkxNzA2MUMzLjYxMDQ2MSAtMy4xMzIyNTQgMy4zODMzMTMgLTMuMjE1OTQgMi43NzM1OTkgLTMuMjE1OTRDMi40NzQ3MiAtMy4yMTU5NCAyLjExNjA2NSAtMy4xODAwNzUgMS42OTc2MzQgLTMuMDAwNzQ3QzEuMzI3MDI0IC0zLjE4MDA3NSAxLjE4MzU2MiAtMy40NTUwNDQgMS4xODM1NjIgLTMuNzE4MDU3QzEuMTgzNTYyIC00LjQ1OTI3OCAyLjM1NTE2OCAtNC44ODk2NjQgMy40MTkxNzggLTQuODg5NjY0QzMuNjIyNDE2IC00Ljg4OTY2NCA0LjA1MjgwMiAtNC44ODk2NjQgNC41NTQ5MTkgLTQuNTE5MDU0QzQuNjI2NjUgLTQuNDcxMjMzIDQuNjYyNTE2IC00LjQzNTM2NyA0Ljc0NjIwMiAtNC40MzUzNjdDNC44ODk2NjQgLTQuNDM1MzY3IDUuMDQ1MDgxIC00LjU5MDc4NSA1LjA0NTA4MSAtNC43MzQyNDdDNS4wNDUwODEgLTQuOTQ5NDQgNC4zNTE2ODEgLTUuNDAzNzM2IDMuNTI2Nzc1IC01LjQwMzczNkMyLjE4Nzc5NiAtNS40MDM3MzYgMC45MjA1NDggLTQuNjAyNzQgMC45MjA1NDggLTMuNzE4MDU3QzAuOTIwNTQ4IC0zLjI3NTcxNiAxLjIwNzQ3MiAtMy4wMDA3NDcgMS40MTA3MSAtMi44NTcyODVDMC43MTczMSAtMi40NjI3NjUgMC4zMTA4MzQgLTEuODE3MTg2IDAuMzEwODM0IC0xLjIzMTM4MkMwLjMxMDgzNCAtMC40MDY0NzYgMS4wNTIwNTUgMC4yNTEwNTkgMi4xOTk3NTEgMC4yNTEwNTlDMy43Nzc4MzMgMC4yNTEwNTkgNC40MTE0NTcgLTAuODAwOTk2IDQuNDExNDU3IC0wLjk2ODM2OUM0LjQxMTQ1NyAtMS4wMjgxNDQgNC4zNjM2MzYgLTEuMDc1OTY1IDQuMzAzODYxIC0xLjA3NTk2NVM0LjIyMDE3NCAtMS4wNDAxIDQuMTcyMzU0IC0wLjk2ODM2OUM0LjA0MDg0NyAtMC43NDEyMiAzLjczMDAxMiAtMC4yNjMwMTQgMi4zMDczNDcgLTAuMjYzMDE0QzEuNTY2MTI3IC0wLjI2MzAxNCAwLjU4NTgwMyAtMC40NTQyOTYgMC41ODU4MDMgLTEuMzAzMTEzQzAuNTg1ODAzIC0xLjcwOTU4OSAwLjg4NDY4MiAtMi4zMTkzMDMgMS42NjE3NjggLTIuNzI1Nzc4Wk0yLjAzMjM3OSAtMi44NjkyNEMyLjM1NTE2OCAtMi45NzY4MzcgMi42NjYwMDIgLTIuOTc2ODM3IDIuNzQ5Njg5IC0yLjk3NjgzN0MzLjA4NDQzMyAtMi45NzY4MzcgMy4xNDQyMDkgLTIuOTUyOTI3IDMuMzM1NDkyIC0yLjkwNTEwNkMzLjEzMjI1NCAtMi44MDk0NjUgMy4xMDgzNDQgLTIuODA5NDY1IDIuNjc3OTU4IC0yLjgwOTQ2NUMyLjQ2Mjc2NSAtMi44MDk0NjUgMi4yNzE0ODIgLTIuODA5NDY1IDIuMDMyMzc5IC0yLjg2OTI0WicgaWQ9J2cyLTM0Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnMi01OScvPgo8cGF0aCBkPSdNOC45MzA1MTEgLTguMzA4ODQyQzguOTMwNTExIC04LjQxNjQzOCA4Ljg0NjgyNCAtOC40MTY0MzggOC44MjI5MTQgLTguNDE2NDM4UzguNzUxMTgzIC04LjQxNjQzOCA4LjY1NTU0MiAtOC4yOTY4ODdMNy44MzA2MzUgLTcuMjkyNjUzQzcuNDEyMjA0IC04LjAwOTk2MyA2Ljc1NDY3IC04LjQxNjQzOCA1Ljg1ODAzMiAtOC40MTY0MzhDMy4yNzU3MTYgLTguNDE2NDM4IDAuNTk3NzU4IC01Ljc5ODI1NyAwLjU5Nzc1OCAtMi45ODg3OTJDMC41OTc3NTggLTAuOTkyMjc5IDEuOTk2NTEzIDAuMjUxMDU5IDMuNzQxOTY4IDAuMjUxMDU5QzQuNjk4MzgxIDAuMjUxMDU5IDUuNTM1MjQzIC0wLjE1NTQxNyA2LjIyODY0MyAtMC43NDEyMkM3LjI2ODc0MiAtMS42MTM5NDggNy41Nzk1NzcgLTIuNzczNTk5IDcuNTc5NTc3IC0yLjg2OTI0QzcuNTc5NTc3IC0yLjk3NjgzNyA3LjQ4MzkzNSAtMi45NzY4MzcgNy40NDgwNyAtMi45NzY4MzdDNy4zNDA0NzMgLTIuOTc2ODM3IDcuMzI4NTE4IC0yLjkwNTEwNiA3LjMwNDYwOCAtMi44NTcyODVDNi43NTQ2NyAtMC45OTIyNzkgNS4xNDA3MjIgLTAuMDk1NjQxIDMuOTQ1MjA1IC0wLjA5NTY0MUMyLjY3Nzk1OCAtMC4wOTU2NDEgMS41NzgwODIgLTAuOTA4NTkzIDEuNTc4MDgyIC0yLjYwNjIyN0MxLjU3ODA4MiAtMi45ODg3OTIgMS42OTc2MzQgLTUuMDY4OTkxIDMuMDQ4NTY4IC02LjYzNTExOEMzLjcwNjEwMiAtNy40MDAyNDkgNC44Mjk4ODggLTguMDY5NzM4IDUuOTY1NjI5IC04LjA2OTczOEM3LjI4MDY5NyAtOC4wNjk3MzggNy44NjY1MDEgLTYuOTgxODE4IDcuODY2NTAxIC01Ljc2MjM5MUM3Ljg2NjUwMSAtNS40NTE1NTcgNy44MzA2MzUgLTUuMTg4NTQzIDcuODMwNjM1IC01LjE0MDcyMkM3LjgzMDYzNSAtNS4wMzMxMjYgNy45NTAxODcgLTUuMDMzMTI2IDcuOTg2MDUyIC01LjAzMzEyNkM4LjExNzU1OSAtNS4wMzMxMjYgOC4xMjk1MTQgLTUuMDQ1MDgxIDguMTc3MzM1IC01LjI2MDI3NEw4LjkzMDUxMSAtOC4zMDg4NDJaJyBpZD0nZzItNjcnLz4KPHBhdGggZD0nTTEwLjg1NTI5MyAtNy4yOTI2NTNDMTAuOTYyODg5IC03LjY5OTEyOCAxMC45ODY4IC03LjgxODY4IDExLjgzNTYxNiAtNy44MTg2OEMxMi4wNjI3NjUgLTcuODE4NjggMTIuMTcwMzYxIC03LjgxODY4IDEyLjE3MDM2MSAtOC4wNDU4MjhDMTIuMTcwMzYxIC04LjE2NTM4IDEyLjA4NjY3NSAtOC4xNjUzOCAxMS44NTk1MjcgLTguMTY1MzhIMTAuNDI0OTA3QzEwLjEyNjAyNyAtOC4xNjUzOCAxMC4xMTQwNzIgLTguMTUzNDI1IDkuOTgyNTY1IC03Ljk2MjE0Mkw1LjYxODkyOSAtMS4wNjQwMUw0LjcyMjI5MSAtNy45MDIzNjZDNC42ODY0MjYgLTguMTY1MzggNC42NzQ0NzEgLTguMTY1MzggNC4zNjM2MzYgLTguMTY1MzhIMi44ODExOTZDMi42NTQwNDcgLTguMTY1MzggMi41NDY0NTEgLTguMTY1MzggMi41NDY0NTEgLTcuOTM4MjMyQzIuNTQ2NDUxIC03LjgxODY4IDIuNjU0MDQ3IC03LjgxODY4IDIuODMzMzc1IC03LjgxODY4QzMuNTYyNjQgLTcuODE4NjggMy41NjI2NCAtNy43MjMwMzkgMy41NjI2NCAtNy41OTE1MzJDMy41NjI2NCAtNy41Njc2MjEgMy41NjI2NCAtNy40OTU4OSAzLjUxNDgxOSAtNy4zMTY1NjNMMS45ODQ1NTggLTEuMjE5NDI3QzEuODQxMDk2IC0wLjY0NTU3OSAxLjU2NjEyNyAtMC4zODI1NjUgMC43NjUxMzEgLTAuMzQ2N0MwLjcyOTI2NSAtMC4zNDY3IDAuNTg1ODAzIC0wLjMzNDc0NSAwLjU4NTgwMyAtMC4xMzE1MDdDMC41ODU4MDMgMCAwLjY5MzQgMCAwLjc0MTIyIDBDMC45ODAzMjQgMCAxLjU5MDAzNyAtMC4wMjM5MSAxLjgyOTE0MSAtMC4wMjM5MUgyLjQwMjk4OUMyLjU3MDM2MSAtMC4wMjM5MSAyLjc3MzU5OSAwIDIuOTQwOTcxIDBDMy4wMjQ2NTggMCAzLjE1NjE2NCAwIDMuMTU2MTY0IC0wLjIyNzE0OEMzLjE1NjE2NCAtMC4zMzQ3NDUgMy4wMzY2MTMgLTAuMzQ2NyAyLjk4ODc5MiAtMC4zNDY3QzIuNTk0MjcxIC0wLjM1ODY1NSAyLjIxMTcwNiAtMC40MzAzODYgMi4yMTE3MDYgLTAuODYwNzcyQzIuMjExNzA2IC0wLjk4MDMyNCAyLjIxMTcwNiAtMC45OTIyNzkgMi4yNTk1MjcgLTEuMTU5NjUxTDMuOTA5MzQgLTcuNzQ2OTQ5SDMuOTIxMjk1TDQuOTEzNTc0IC0wLjMyMjc5QzQuOTQ5NDQgLTAuMDM1ODY2IDQuOTYxMzk1IDAgNS4wNjg5OTEgMEM1LjIwMDQ5OCAwIDUuMjYwMjc0IC0wLjA5NTY0MSA1LjMyMDA1IC0wLjIwMzIzOEwxMC4xMjYwMjcgLTcuODA2NzI1SDEwLjEzNzk4M0w4LjQwNDQ4MyAtMC44ODQ2ODJDOC4yOTY4ODcgLTAuNDY2MjUyIDguMjcyOTc2IC0wLjM0NjcgNy40MzYxMTUgLTAuMzQ2N0M3LjIwODk2NiAtMC4zNDY3IDcuMDg5NDE1IC0wLjM0NjcgNy4wODk0MTUgLTAuMTMxNTA3QzcuMDg5NDE1IDAgNy4xOTcwMTEgMCA3LjI2ODc0MiAwQzcuNDcxOTggMCA3LjcxMTA4MyAtMC4wMjM5MSA3LjkxNDMyMSAtMC4wMjM5MUg5LjMyNTAzMUM5LjUyODI2OSAtMC4wMjM5MSA5Ljc3OTMyOCAwIDkuOTgyNTY1IDBDMTAuMDc4MjA3IDAgMTAuMjA5NzE0IDAgMTAuMjA5NzE0IC0wLjIyNzE0OEMxMC4yMDk3MTQgLTAuMzQ2NyAxMC4xMDIxMTcgLTAuMzQ2NyA5LjkyMjc5IC0wLjM0NjdDOS4xOTM1MjQgLTAuMzQ2NyA5LjE5MzUyNCAtMC40NDIzNDEgOS4xOTM1MjQgLTAuNTYxODkzQzkuMTkzNTI0IC0wLjU3Mzg0OCA5LjE5MzUyNCAtMC42NTc1MzQgOS4yMTc0MzUgLTAuNzUzMTc2TDEwLjg1NTI5MyAtNy4yOTI2NTNaJyBpZD0nZzItNzcnLz4KPHBhdGggZD0nTTUuMzMyMDA1IC00LjgwNTk3OEM1LjU3MTEwOCAtNC44MDU5NzggNS42NjY3NSAtNC44MDU5NzggNS42NjY3NSAtNS4wMzMxMjZDNS42NjY3NSAtNS4xNTI2NzcgNS41NzExMDggLTUuMTUyNjc3IDUuMzU1OTE1IC01LjE1MjY3N0g0LjM4NzU0N0M0LjYxNDY5NSAtNi4zODQwNiA0Ljc4MjA2NyAtNy4yMzI4NzcgNC44Nzc3MDkgLTcuNjE1NDQyQzQuOTQ5NDQgLTcuOTAyMzY2IDUuMjAwNDk4IC04LjE3NzMzNSA1LjUxMTMzMyAtOC4xNzczMzVDNS43NjIzOTEgLTguMTc3MzM1IDYuMDEzNDUgLTguMDY5NzM4IDYuMTMzMDAxIC03Ljk2MjE0MkM1LjY2Njc1IC03LjkxNDMyMSA1LjUyMzI4OCAtNy41Njc2MjEgNS41MjMyODggLTcuMzY0Mzg0QzUuNTIzMjg4IC03LjEyNTI4IDUuNzAyNjE1IC02Ljk4MTgxOCA1LjkyOTc2MyAtNi45ODE4MThDNi4xNjg4NjcgLTYuOTgxODE4IDYuNTI3NTIyIC03LjE4NTA1NiA2LjUyNzUyMiAtNy42MzkzNTJDNi41Mjc1MjIgLTguMTQxNDY5IDYuMDI1NDA1IC04LjQxNjQzOCA1LjQ5OTM3NyAtOC40MTY0MzhDNC45ODUzMDUgLTguNDE2NDM4IDQuNDgzMTg4IC04LjAzMzg3MyA0LjI0NDA4NSAtNy41Njc2MjFDNC4wMjg4OTIgLTcuMTQ5MTkxIDMuOTA5MzQgLTYuNzE4ODA0IDMuNjM0MzcxIC01LjE1MjY3N0gyLjgzMzM3NUMyLjYwNjIyNyAtNS4xNTI2NzcgMi40ODY2NzUgLTUuMTUyNjc3IDIuNDg2Njc1IC00LjkzNzQ4NEMyLjQ4NjY3NSAtNC44MDU5NzggMi41NTg0MDYgLTQuODA1OTc4IDIuNzk3NTA5IC00LjgwNTk3OEgzLjU2MjY0QzMuMzQ3NDQ3IC0zLjY5NDE0NyAyLjg1NzI4NSAtMC45OTIyNzkgMi41ODIzMTYgMC4yODY5MjRDMi4zNzkwNzggMS4zMjcwMjQgMi4xOTk3NTEgMi4xOTk3NTEgMS42MDE5OTMgMi4xOTk3NTFDMS41NjYxMjcgMi4xOTk3NTEgMS4yMTk0MjcgMi4xOTk3NTEgMS4wMDQyMzQgMS45NzI2MDNDMS42MTM5NDggMS45MjQ3ODIgMS42MTM5NDggMS4zOTg3NTUgMS42MTM5NDggMS4zODY4QzEuNjEzOTQ4IDEuMTQ3Njk2IDEuNDM0NjIgMS4wMDQyMzQgMS4yMDc0NzIgMS4wMDQyMzRDMC45NjgzNjkgMS4wMDQyMzQgMC42MDk3MTQgMS4yMDc0NzIgMC42MDk3MTQgMS42NjE3NjhDMC42MDk3MTQgMi4xNzU4NDEgMS4xMzU3NDEgMi40Mzg4NTQgMS42MDE5OTMgMi40Mzg4NTRDMi44MjE0MiAyLjQzODg1NCAzLjMyMzUzNyAwLjI1MTA1OSAzLjQ1NTA0NCAtMC4zNDY3QzMuNjcwMjM3IC0xLjI2NzI0OCA0LjI1NjA0IC00LjQ0NzMyMyA0LjMxNTgxNiAtNC44MDU5NzhINS4zMzIwMDVaJyBpZD0nZzItMTAyJy8+CjxwYXRoIGQ9J00zLjM1OTQwMiAtNy45OTgwMDdDMy4zNzEzNTcgLTguMDQ1ODI4IDMuMzk1MjY4IC04LjExNzU1OSAzLjM5NTI2OCAtOC4xNzczMzVDMy4zOTUyNjggLTguMjk2ODg3IDMuMjc1NzE2IC04LjI5Njg4NyAzLjI1MTgwNiAtOC4yOTY4ODdDMy4yMzk4NTEgLTguMjk2ODg3IDIuODA5NDY1IC04LjI2MTAyMSAyLjU5NDI3MSAtOC4yMzcxMTFDMi4zOTEwMzQgLTguMjI1MTU2IDIuMjExNzA2IC04LjIwMTI0NSAxLjk5NjUxMyAtOC4xODkyOUMxLjcwOTU4OSAtOC4xNjUzOCAxLjYyNTkwMyAtOC4xNTM0MjUgMS42MjU5MDMgLTcuOTM4MjMyQzEuNjI1OTAzIC03LjgxODY4IDEuNzQ1NDU1IC03LjgxODY4IDEuODY1MDA2IC03LjgxODY4QzIuNDc0NzIgLTcuODE4NjggMi40NzQ3MiAtNy43MTEwODMgMi40NzQ3MiAtNy41OTE1MzJDMi40NzQ3MiAtNy41NDM3MTEgMi40NzQ3MiAtNy41MTk4MDEgMi40MTQ5NDQgLTcuMzA0NjA4TDAuNzA1MzU1IC0wLjQ2NjI1MkMwLjY1NzUzNCAtMC4yODY5MjQgMC42NTc1MzQgLTAuMjYzMDE0IDAuNjU3NTM0IC0wLjE5MTI4M0MwLjY1NzUzNCAwLjA3MTczMSAwLjg2MDc3MiAwLjExOTU1MiAwLjk4MDMyNCAwLjExOTU1MkMxLjMxNTA2OCAwLjExOTU1MiAxLjM4NjggLTAuMTQzNDYyIDEuNDgyNDQxIC0wLjUxNDA3MkwyLjA0NDMzNCAtMi43NDk2ODlDMi45MDUxMDYgLTIuNjU0MDQ3IDMuNDE5MTc4IC0yLjI5NTM5MiAzLjQxOTE3OCAtMS43MjE1NDRDMy40MTkxNzggLTEuNjQ5ODEzIDMuNDE5MTc4IC0xLjYwMTk5MyAzLjM4MzMxMyAtMS40MjI2NjVDMy4zMzU0OTIgLTEuMjQzMzM3IDMuMzM1NDkyIC0xLjA5OTg3NSAzLjMzNTQ5MiAtMS4wNDAxQzMuMzM1NDkyIC0wLjM0NjcgMy43ODk3ODggMC4xMTk1NTIgNC4zOTk1MDIgMC4xMTk1NTJDNC45NDk0NCAwLjExOTU1MiA1LjIzNjM2NCAtMC4zODI1NjUgNS4zMzIwMDUgLTAuNTQ5OTM4QzUuNTgzMDY0IC0wLjk5MjI3OSA1LjczODQ4MSAtMS42NjE3NjggNS43Mzg0ODEgLTEuNzA5NTg5QzUuNzM4NDgxIC0xLjc2OTM2NSA1LjY5MDY2IC0xLjgxNzE4NiA1LjYxODkyOSAtMS44MTcxODZDNS41MTEzMzMgLTEuODE3MTg2IDUuNDk5Mzc3IC0xLjc2OTM2NSA1LjQ1MTU1NyAtMS41NzgwODJDNS4yODQxODQgLTAuOTU2NDEzIDUuMDMzMTI2IC0wLjExOTU1MiA0LjQyMzQxMiAtMC4xMTk1NTJDNC4xODQzMDkgLTAuMTE5NTUyIDQuMDI4ODkyIC0wLjIzOTEwMyA0LjAyODg5MiAtMC42OTM0QzQuMDI4ODkyIC0wLjkyMDU0OCA0LjA3NjcxMiAtMS4xODM1NjIgNC4xMjQ1MzMgLTEuMzYyODg5QzQuMTcyMzU0IC0xLjU3ODA4MiA0LjE3MjM1NCAtMS41OTAwMzcgNC4xNzIzNTQgLTEuNzMzNDk5QzQuMTcyMzU0IC0yLjQzODg1NCAzLjUzODczIC0yLjgzMzM3NSAyLjQzODg1NCAtMi45NzY4MzdDMi44NjkyNCAtMy4yMzk4NTEgMy4yOTk2MjYgLTMuNzA2MTAyIDMuNDY2OTk5IC0zLjg4NTQzQzQuMTQ4NDQzIC00LjY1MDU2IDQuNjE0Njk1IC01LjAzMzEyNiA1LjE2NDYzMyAtNS4wMzMxMjZDNS40Mzk2MDEgLTUuMDMzMTI2IDUuNTExMzMzIC00Ljk2MTM5NSA1LjU5NTAxOSAtNC44ODk2NjRDNS4xNTI2NzcgLTQuODQxODQzIDQuOTg1MzA1IC00LjUzMTAwOSA0Ljk4NTMwNSAtNC4yOTE5MDVDNC45ODUzMDUgLTQuMDA0OTgxIDUuMjEyNDUzIC0zLjkwOTM0IDUuMzc5ODI2IC0zLjkwOTM0QzUuNzAyNjE1IC0zLjkwOTM0IDUuOTg5NTM5IC00LjE4NDMwOSA1Ljk4OTUzOSAtNC41NjY4NzRDNS45ODk1MzkgLTQuOTEzNTc0IDUuNzE0NTcgLTUuMjcyMjI5IDUuMTc2NTg4IC01LjI3MjIyOUM0LjUxOTA1NCAtNS4yNzIyMjkgMy45ODEwNzEgLTQuODA1OTc4IDMuMTMyMjU0IC0zLjg0OTU2NEMzLjAxMjcwMiAtMy43MDYxMDIgMi41NzAzNjEgLTMuMjUxODA2IDIuMTI4MDIgLTMuMDg0NDMzTDMuMzU5NDAyIC03Ljk5ODAwN1onIGlkPSdnMi0xMDcnLz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2czLTQ5Jy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnMS0xMDcnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzM4Ljg1NDI5NicgeGxpbms6aHJlZj0nI2cyLTY3JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc0Ny4yMjkzNDInIHhsaW5rOmhyZWY9JyNnMS0xMDcnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzU1LjY2OTkxOScgeGxpbms6aHJlZj0nI2c0LTYxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2OC4wOTU0JyB4bGluazpocmVmPScjZzItMTAyJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3NS4xNDE4MzYnIHhsaW5rOmhyZWY9JyNnMC0wJyB5PSc2MS40MTQ5ODgnLz4KPHVzZSB4PSc4MS43MjgzNDMnIHhsaW5rOmhyZWY9JyNnMy00OScgeT0nNjEuNDE0OTg4Jy8+Cjx1c2UgeD0nODguNDUzMTU2JyB4bGluazpocmVmPScjZzQtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzkzLjAwNTQ4MScgeGxpbms6aHJlZj0nI2c0LTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5Ni4yNTcxNDMnIHhsaW5rOmhyZWY9JyNnMi0xMDcnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEwMi43NDY2NDcnIHhsaW5rOmhyZWY9JyNnMi0zNCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA4LjIyNDY3JyB4bGluazpocmVmPScjZzItNTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzExMy40Njg4MjknIHhsaW5rOmhyZWY9JyNnMi03NycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTI2LjA0MjQzNicgeGxpbms6aHJlZj0nI2c0LTkzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMjkuMjk0MDk3JyB4bGluazpocmVmPScjZzQtNDEnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) .
.
 est compact car il est l’image
réciproque d’un compact par une fonction continue et
est compact car il est l’image
réciproque d’un compact par une fonction continue et  compact.
compact.
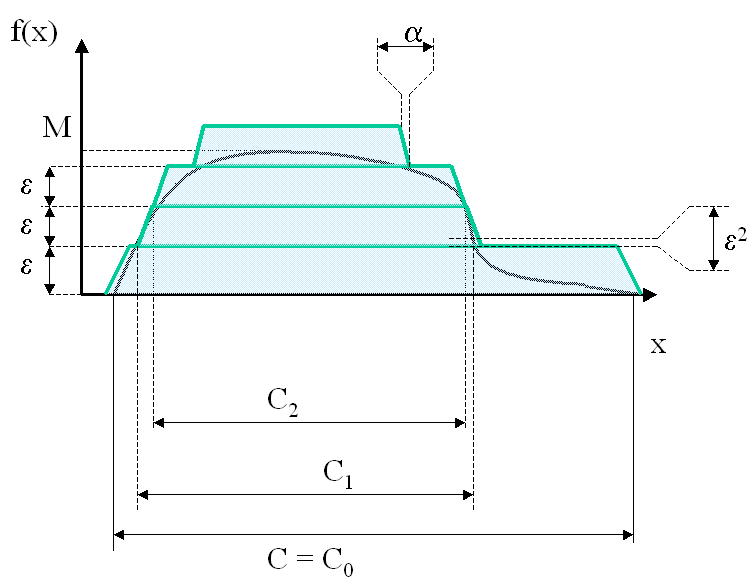
Par construction,  et
et  on définit~:
on définit~:

D’où~:
![\begin{eqnarray}
f\left( x\right) -g_{\varepsilon}\left( x\right) &=&
f\left( x\right)-\varepsilon\overset{\frac{M}{\varepsilon}}{\sum_{k=0}}
\indicatrice{x\in C_{k}} \nonumber
= f\left( x\right) -\varepsilon \overset{\frac{M}{\varepsilon}}
{\sum_{k=0}}\indicatrice
{ f\pa{x} \supegal k \varepsilon } \nonumber \\
&=& f\left( x\right) -\varepsilon\left[ \dfrac{f\left( x\right) }
{\varepsilon}\right] \quad \text{ (partie entière)}\nonumber \\
& \text{d'où }& 0\leqslant f\left( x\right) -g_{\varepsilon}\left( x\right) \leqslant \frac{\varepsilon}{4}
\end{eqnarray}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nOTcuNzQ2OTI5cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNjMuODMwMzM4IDc5LjkwMDM3MSAzNjMuNTY2OTIyIDk3Ljc0NjkyOScgd2lkdGg9JzM2My41NjY5MjJwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8dXNlIGlkPSdnMS01NCcgdHJhbnNmb3JtPSdzY2FsZSgxLjUpJyB4bGluazpocmVmPScjZzAtNTQnLz4KPHBhdGggZD0nTTQuNjMwNjM1IC0xLjgwOTIxNUM0Ljc1ODE1NyAtMS44MDkyMTUgNC45MzM0OTkgLTEuODA5MjE1IDQuOTMzNDk5IC0xLjk5MjUyOFM0Ljc1ODE1NyAtMi4xNzU4NDEgNC42MzA2MzUgLTIuMTc1ODQxSDEuMDc1OTY1QzEuMTc5NTc3IC0zLjI4MzY4NiAyLjEwNDExIC00LjEyODUxOCAzLjMxNTU2NyAtNC4xMjg1MThINC42MzA2MzVDNC43NTgxNTcgLTQuMTI4NTE4IDQuOTMzNDk5IC00LjEyODUxOCA0LjkzMzQ5OSAtNC4zMTE4MzFTNC43NTgxNTcgLTQuNDk1MTQzIDQuNjMwNjM1IC00LjQ5NTE0M0gzLjI5MTY1NkMxLjg1NzAzNiAtNC40OTUxNDMgMC43MDEzNyAtMy4zNzkzMjggMC43MDEzNyAtMS45OTI1MjhDMC43MDEzNyAtMC41OTc3NTggMS44NjUwMDYgMC41MTAwODcgMy4yOTE2NTYgMC41MTAwODdINC42MzA2MzVDNC43NTgxNTcgMC41MTAwODcgNC45MzM0OTkgMC41MTAwODcgNC45MzM0OTkgMC4zMjY3NzVTNC43NTgxNTcgMC4xNDM0NjIgNC42MzA2MzUgMC4xNDM0NjJIMy4zMTU1NjdDMi4xMDQxMSAwLjE0MzQ2MiAxLjE3OTU3NyAtMC43MDEzNyAxLjA3NTk2NSAtMS44MDkyMTVINC42MzA2MzVaJyBpZD0nZzMtNTAnLz4KPHBhdGggZD0nTTIuNDE0OTQ0IC00LjgyOTg4OEMyLjQxNDk0NCAtNS4wMjkxNDEgMi40MTQ5NDQgLTUuMjM2MzY0IDIuNjkzODk4IC01LjQ4MzQzN0MyLjc0OTY4OSAtNS41MjMyODggMi45ODA4MjIgLTUuNzIyNTQgMy40NzQ5NjkgLTUuNzU0NDIxQzMuNTcwNjEgLTUuNzYyMzkxIDMuNjM0MzcxIC01Ljc2MjM5MSAzLjYzNDM3MSAtNS44NjYwMDJDMy42MzQzNzEgLTUuOTc3NTg0IDMuNTU0NjcgLTUuOTc3NTg0IDMuNDQzMDg4IC01Ljk3NzU4NEMyLjU4MjMxNiAtNS45Nzc1ODQgMS44MjUxNTYgLTUuNTc5MDc4IDEuODE3MTg2IC00Ljk3MzM1Vi0yLjk0MDk3MUMxLjgwMTI0NSAtMi41MjY1MjYgMS40MDI3NCAtMi4xNDM5NiAwLjc0OTE5MSAtMi4xMDQxMUMwLjY1MzU0OSAtMi4wOTYxMzkgMC41ODk3ODggLTIuMDk2MTM5IDAuNTg5Nzg4IC0xLjk5MjUyOFMwLjY2MTUxOSAtMS44ODg5MTcgMC43MjUyOCAtMS44ODA5NDZDMS40ODI0NDEgLTEuODMzMTI2IDEuNzM3NDg0IC0xLjQyNjY1IDEuNzkzMjc1IC0xLjIwMzQ4N0MxLjgxNzE4NiAtMS4xMDc4NDYgMS44MTcxODYgLTEuMDkxOTA1IDEuODE3MTg2IC0wLjc5NzAxMVYwLjgyODg5MkMxLjgxNzE4NiAxLjA4MzkzNSAxLjgxNzE4NiAxLjQzNDYyIDIuMzI3MjczIDEuNzI5NTE0QzIuNjY5OTg4IDEuOTI4NzY3IDMuMTY0MTM0IDEuOTkyNTI4IDMuNDQzMDg4IDEuOTkyNTI4QzMuNTU0NjcgMS45OTI1MjggMy42MzQzNzEgMS45OTI1MjggMy42MzQzNzEgMS44ODA5NDZDMy42MzQzNzEgMS43NzczMzUgMy41NjI2NCAxLjc3NzMzNSAzLjQ5ODg3OSAxLjc2OTM2NUMyLjc1NzY1OSAxLjcyMTU0NCAyLjQ5NDY0NSAxLjM0Njk0OSAyLjQzODg1NCAxLjA5OTg3NUMyLjQxNDk0NCAxLjAyMDE3NCAyLjQxNDk0NCAxLjAwNDIzNCAyLjQxNDk0NCAwLjcyNTI4Vi0wLjk0ODQ0M0MyLjQxNDk0NCAtMS4xNjM2MzYgMi40MTQ5NDQgLTEuNzEzNTc0IDEuNDkwNDExIC0xLjk5MjUyOEMyLjA4ODE2OSAtMi4xNzU4NDEgMi4zMTEzMzMgLTIuNDYyNzY1IDIuMzkxMDM0IC0yLjc1NzY1OUMyLjQxNDk0NCAtMi44NTMzIDIuNDE0OTQ0IC0yLjkwOTA5MSAyLjQxNDk0NCAtMy4xNTYxNjRWLTQuODI5ODg4WicgaWQ9J2czLTEwMicvPgo8cGF0aCBkPSdNMi40MTQ5NDQgLTQuODEzOTQ4QzIuNDE0OTQ0IC01LjA0NTA4MSAyLjQxNDk0NCAtNS4zNzk4MjYgMS45OTI1MjggLTUuNjY2NzVDMS42NTc3ODMgLTUuODg5OTEzIDEuMTMxNzU2IC01Ljk3NzU4NCAwLjc4MTA3MSAtNS45Nzc1ODRDMC42Nzc0NiAtNS45Nzc1ODQgMC41ODk3ODggLTUuOTc3NTg0IDAuNTg5Nzg4IC01Ljg2NjAwMkMwLjU4OTc4OCAtNS43NjIzOTEgMC42NjE1MTkgLTUuNzYyMzkxIDAuNzI1MjggLTUuNzU0NDIxQzEuNDU4NTMxIC01LjcwNjYgMS43Mzc0ODQgLTUuMzU1OTE1IDEuODAxMjQ1IC01LjA2MTAyMUMxLjgxNzE4NiAtNC45ODEzMiAxLjgxNzE4NiAtNC45MjU1MjkgMS44MTcxODYgLTQuODEzOTQ4Vi0zLjE0MDIyNEMxLjgxNzE4NiAtMi43ODk1MzkgMS44MTcxODYgLTIuMjcxNDgyIDIuNzQxNzE5IC0xLjk5MjUyOEMyLjI5NTM5MiAtMS44NTcwMzYgMS45NTI2NzcgLTEuNjMzODczIDEuODQxMDk2IC0xLjIyNzM5N0MxLjgxNzE4NiAtMS4xMzE3NTYgMS44MTcxODYgLTEuMDc1OTY1IDEuODE3MTg2IC0wLjgyODg5MlYwLjYwNTcyOUMxLjgxNzE4NiAxLjEzOTcyNiAxLjgxNzE4NiAxLjIxMTQ1NyAxLjU1NDE3MiAxLjQ4MjQ0MUMxLjUzMDI2MiAxLjQ5ODM4MSAxLjMwNzA5OCAxLjcyOTUxNCAwLjc0OTE5MSAxLjc2OTM2NUMwLjY0NTU3OSAxLjc3NzMzNSAwLjU4OTc4OCAxLjc3NzMzNSAwLjU4OTc4OCAxLjg4MDk0NkMwLjU4OTc4OCAxLjk5MjUyOCAwLjY3NzQ2IDEuOTkyNTI4IDAuNzgxMDcxIDEuOTkyNTI4QzEuNjQxODQzIDEuOTkyNTI4IDIuNDA2OTc0IDEuNjAxOTkzIDIuNDE0OTQ0IDAuOTg4Mjk0Vi0wLjYxMzY5OUMyLjQxNDk0NCAtMS4xNTU2NjYgMi40MTQ5NDQgLTEuMzM4OTc5IDIuNjU0MDQ3IC0xLjU2MjE0MkMyLjkxNzA2MSAtMS43OTMyNzUgMy4yMDM5ODUgLTEuODU3MDM2IDMuNDc0OTY5IC0xLjg4MDk0NkMzLjU3ODU4IC0xLjg4ODkxNyAzLjYzNDM3MSAtMS44ODg5MTcgMy42MzQzNzEgLTEuOTkyNTI4UzMuNTYyNjQgLTIuMDk2MTM5IDMuNDk4ODc5IC0yLjEwNDExQzIuNjE0MTk3IC0yLjE1OTkgMi40MTQ5NDQgLTIuNzAxODY4IDIuNDE0OTQ0IC0yLjk0MDk3MVYtNC44MTM5NDhaJyBpZD0nZzMtMTAzJy8+CjxwYXRoIGQ9J00xLjY2MTc2OCAtMi43MjU3NzhDMi4wNDQzMzQgLTIuNTcwMzYxIDIuNDUwODA5IC0yLjU3MDM2MSAyLjY3Nzk1OCAtMi41NzAzNjFDMi45ODg3OTIgLTIuNTcwMzYxIDMuNjEwNDYxIC0yLjU3MDM2MSAzLjYxMDQ2MSAtMi45MTcwNjFDMy42MTA0NjEgLTMuMTMyMjU0IDMuMzgzMzEzIC0zLjIxNTk0IDIuNzczNTk5IC0zLjIxNTk0QzIuNDc0NzIgLTMuMjE1OTQgMi4xMTYwNjUgLTMuMTgwMDc1IDEuNjk3NjM0IC0zLjAwMDc0N0MxLjMyNzAyNCAtMy4xODAwNzUgMS4xODM1NjIgLTMuNDU1MDQ0IDEuMTgzNTYyIC0zLjcxODA1N0MxLjE4MzU2MiAtNC40NTkyNzggMi4zNTUxNjggLTQuODg5NjY0IDMuNDE5MTc4IC00Ljg4OTY2NEMzLjYyMjQxNiAtNC44ODk2NjQgNC4wNTI4MDIgLTQuODg5NjY0IDQuNTU0OTE5IC00LjUxOTA1NEM0LjYyNjY1IC00LjQ3MTIzMyA0LjY2MjUxNiAtNC40MzUzNjcgNC43NDYyMDIgLTQuNDM1MzY3QzQuODg5NjY0IC00LjQzNTM2NyA1LjA0NTA4MSAtNC41OTA3ODUgNS4wNDUwODEgLTQuNzM0MjQ3QzUuMDQ1MDgxIC00Ljk0OTQ0IDQuMzUxNjgxIC01LjQwMzczNiAzLjUyNjc3NSAtNS40MDM3MzZDMi4xODc3OTYgLTUuNDAzNzM2IDAuOTIwNTQ4IC00LjYwMjc0IDAuOTIwNTQ4IC0zLjcxODA1N0MwLjkyMDU0OCAtMy4yNzU3MTYgMS4yMDc0NzIgLTMuMDAwNzQ3IDEuNDEwNzEgLTIuODU3Mjg1QzAuNzE3MzEgLTIuNDYyNzY1IDAuMzEwODM0IC0xLjgxNzE4NiAwLjMxMDgzNCAtMS4yMzEzODJDMC4zMTA4MzQgLTAuNDA2NDc2IDEuMDUyMDU1IDAuMjUxMDU5IDIuMTk5NzUxIDAuMjUxMDU5QzMuNzc3ODMzIDAuMjUxMDU5IDQuNDExNDU3IC0wLjgwMDk5NiA0LjQxMTQ1NyAtMC45NjgzNjlDNC40MTE0NTcgLTEuMDI4MTQ0IDQuMzYzNjM2IC0xLjA3NTk2NSA0LjMwMzg2MSAtMS4wNzU5NjVTNC4yMjAxNzQgLTEuMDQwMSA0LjE3MjM1NCAtMC45NjgzNjlDNC4wNDA4NDcgLTAuNzQxMjIgMy43MzAwMTIgLTAuMjYzMDE0IDIuMzA3MzQ3IC0wLjI2MzAxNEMxLjU2NjEyNyAtMC4yNjMwMTQgMC41ODU4MDMgLTAuNDU0Mjk2IDAuNTg1ODAzIC0xLjMwMzExM0MwLjU4NTgwMyAtMS43MDk1ODkgMC44ODQ2ODIgLTIuMzE5MzAzIDEuNjYxNzY4IC0yLjcyNTc3OFpNMi4wMzIzNzkgLTIuODY5MjRDMi4zNTUxNjggLTIuOTc2ODM3IDIuNjY2MDAyIC0yLjk3NjgzNyAyLjc0OTY4OSAtMi45NzY4MzdDMy4wODQ0MzMgLTIuOTc2ODM3IDMuMTQ0MjA5IC0yLjk1MjkyNyAzLjMzNTQ5MiAtMi45MDUxMDZDMy4xMzIyNTQgLTIuODA5NDY1IDMuMTA4MzQ0IC0yLjgwOTQ2NSAyLjY3Nzk1OCAtMi44MDk0NjVDMi40NjI3NjUgLTIuODA5NDY1IDIuMjcxNDgyIC0yLjgwOTQ2NSAyLjAzMjM3OSAtMi44NjkyNFonIGlkPSdnNy0zNCcvPgo8cGF0aCBkPSdNNS4zMzIwMDUgLTQuODA1OTc4QzUuNTcxMTA4IC00LjgwNTk3OCA1LjY2Njc1IC00LjgwNTk3OCA1LjY2Njc1IC01LjAzMzEyNkM1LjY2Njc1IC01LjE1MjY3NyA1LjU3MTEwOCAtNS4xNTI2NzcgNS4zNTU5MTUgLTUuMTUyNjc3SDQuMzg3NTQ3QzQuNjE0Njk1IC02LjM4NDA2IDQuNzgyMDY3IC03LjIzMjg3NyA0Ljg3NzcwOSAtNy42MTU0NDJDNC45NDk0NCAtNy45MDIzNjYgNS4yMDA0OTggLTguMTc3MzM1IDUuNTExMzMzIC04LjE3NzMzNUM1Ljc2MjM5MSAtOC4xNzczMzUgNi4wMTM0NSAtOC4wNjk3MzggNi4xMzMwMDEgLTcuOTYyMTQyQzUuNjY2NzUgLTcuOTE0MzIxIDUuNTIzMjg4IC03LjU2NzYyMSA1LjUyMzI4OCAtNy4zNjQzODRDNS41MjMyODggLTcuMTI1MjggNS43MDI2MTUgLTYuOTgxODE4IDUuOTI5NzYzIC02Ljk4MTgxOEM2LjE2ODg2NyAtNi45ODE4MTggNi41Mjc1MjIgLTcuMTg1MDU2IDYuNTI3NTIyIC03LjYzOTM1MkM2LjUyNzUyMiAtOC4xNDE0NjkgNi4wMjU0MDUgLTguNDE2NDM4IDUuNDk5Mzc3IC04LjQxNjQzOEM0Ljk4NTMwNSAtOC40MTY0MzggNC40ODMxODggLTguMDMzODczIDQuMjQ0MDg1IC03LjU2NzYyMUM0LjAyODg5MiAtNy4xNDkxOTEgMy45MDkzNCAtNi43MTg4MDQgMy42MzQzNzEgLTUuMTUyNjc3SDIuODMzMzc1QzIuNjA2MjI3IC01LjE1MjY3NyAyLjQ4NjY3NSAtNS4xNTI2NzcgMi40ODY2NzUgLTQuOTM3NDg0QzIuNDg2Njc1IC00LjgwNTk3OCAyLjU1ODQwNiAtNC44MDU5NzggMi43OTc1MDkgLTQuODA1OTc4SDMuNTYyNjRDMy4zNDc0NDcgLTMuNjk0MTQ3IDIuODU3Mjg1IC0wLjk5MjI3OSAyLjU4MjMxNiAwLjI4NjkyNEMyLjM3OTA3OCAxLjMyNzAyNCAyLjE5OTc1MSAyLjE5OTc1MSAxLjYwMTk5MyAyLjE5OTc1MUMxLjU2NjEyNyAyLjE5OTc1MSAxLjIxOTQyNyAyLjE5OTc1MSAxLjAwNDIzNCAxLjk3MjYwM0MxLjYxMzk0OCAxLjkyNDc4MiAxLjYxMzk0OCAxLjM5ODc1NSAxLjYxMzk0OCAxLjM4NjhDMS42MTM5NDggMS4xNDc2OTYgMS40MzQ2MiAxLjAwNDIzNCAxLjIwNzQ3MiAxLjAwNDIzNEMwLjk2ODM2OSAxLjAwNDIzNCAwLjYwOTcxNCAxLjIwNzQ3MiAwLjYwOTcxNCAxLjY2MTc2OEMwLjYwOTcxNCAyLjE3NTg0MSAxLjEzNTc0MSAyLjQzODg1NCAxLjYwMTk5MyAyLjQzODg1NEMyLjgyMTQyIDIuNDM4ODU0IDMuMzIzNTM3IDAuMjUxMDU5IDMuNDU1MDQ0IC0wLjM0NjdDMy42NzAyMzcgLTEuMjY3MjQ4IDQuMjU2MDQgLTQuNDQ3MzIzIDQuMzE1ODE2IC00LjgwNTk3OEg1LjMzMjAwNVonIGlkPSdnNy0xMDInLz4KPHBhdGggZD0nTTQuMDQwODQ3IC0xLjUxODMwNkMzLjk5MzAyNiAtMS4zMjcwMjQgMy45NjkxMTYgLTEuMjc5MjAzIDMuODEzNjk5IC0xLjA5OTg3NUMzLjMyMzUzNyAtMC40NjYyNTIgMi44MjE0MiAtMC4yMzkxMDMgMi40NTA4MDkgLTAuMjM5MTAzQzIuMDU2Mjg5IC0wLjIzOTEwMyAxLjY4NTY3OSAtMC41NDk5MzggMS42ODU2NzkgLTEuMzc0ODQ0QzEuNjg1Njc5IC0yLjAwODQ2OCAyLjA0NDMzNCAtMy4zNDc0NDcgMi4zMDczNDcgLTMuODg1NDNDMi42NTQwNDcgLTQuNTU0OTE5IDMuMTkyMDMgLTUuMDMzMTI2IDMuNjk0MTQ3IC01LjAzMzEyNkM0LjQ4MzE4OCAtNS4wMzMxMjYgNC42Mzg2MDUgLTQuMDUyODAyIDQuNjM4NjA1IC0zLjk4MTA3MUw0LjYwMjc0IC0zLjgxMzY5OUw0LjA0MDg0NyAtMS41MTgzMDZaTTQuNzgyMDY3IC00LjQ4MzE4OEM0LjYyNjY1IC00LjgyOTg4OCA0LjI5MTkwNSAtNS4yNzIyMjkgMy42OTQxNDcgLTUuMjcyMjI5QzIuMzkxMDM0IC01LjI3MjIyOSAwLjkwODU5MyAtMy42MzQzNzEgMC45MDg1OTMgLTEuODUzMDUxQzAuOTA4NTkzIC0wLjYwOTcxNCAxLjY2MTc2OCAwIDIuNDI2ODk5IDBDMy4wNjA1MjMgMCAzLjYyMjQxNiAtMC41MDIxMTcgMy44Mzc2MDkgLTAuNzQxMjJMMy41NzQ1OTUgMC4zMzQ3NDVDMy40MDcyMjMgMC45OTIyNzkgMy4zMzU0OTIgMS4yOTExNTggMi45MDUxMDYgMS43MDk1ODlDMi40MTQ5NDQgMi4xOTk3NTEgMS45NjA2NDggMi4xOTk3NTEgMS42OTc2MzQgMi4xOTk3NTFDMS4zMzg5NzkgMi4xOTk3NTEgMS4wNDAxIDIuMTc1ODQxIDAuNzQxMjIgMi4wODAxOTlDMS4xMjM3ODYgMS45NzI2MDMgMS4yMTk0MjcgMS42Mzc4NTggMS4yMTk0MjcgMS41MDYzNTFDMS4yMTk0MjcgMS4zMTUwNjggMS4wNzU5NjUgMS4xMjM3ODYgMC44MTI5NTEgMS4xMjM3ODZDMC41MjYwMjcgMS4xMjM3ODYgMC4yMTUxOTMgMS4zNjI4ODkgMC4yMTUxOTMgMS43NTc0MUMwLjIxNTE5MyAyLjI0NzU3MiAwLjcwNTM1NSAyLjQzODg1NCAxLjcyMTU0NCAyLjQzODg1NEMzLjI2Mzc2MSAyLjQzODg1NCA0LjA2NDc1NyAxLjQ0NjU3NSA0LjIyMDE3NCAwLjgwMDk5Nkw1LjU0NzE5OCAtNC41NTQ5MTlDNS41ODMwNjQgLTQuNjk4MzgxIDUuNTgzMDY0IC00LjcyMjI5MSA1LjU4MzA2NCAtNC43NDYyMDJDNS41ODMwNjQgLTQuOTEzNTc0IDUuNDUxNTU3IC01LjA0NTA4MSA1LjI3MjIyOSAtNS4wNDUwODFDNC45ODUzMDUgLTUuMDQ1MDgxIDQuODE3OTMzIC00LjgwNTk3OCA0Ljc4MjA2NyAtNC40ODMxODhaJyBpZD0nZzctMTAzJy8+CjxwYXRoIGQ9J001LjY2Njc1IC00Ljg3NzcwOUM1LjI4NDE4NCAtNC44MDU5NzggNS4xNDA3MjIgLTQuNTE5MDU0IDUuMTQwNzIyIC00LjI5MTkwNUM1LjE0MDcyMiAtNC4wMDQ5ODEgNS4zNjc4NyAtMy45MDkzNCA1LjUzNTI0MyAtMy45MDkzNEM1Ljg5Mzg5OCAtMy45MDkzNCA2LjE0NDk1NiAtNC4yMjAxNzQgNi4xNDQ5NTYgLTQuNTQyOTY0QzYuMTQ0OTU2IC01LjA0NTA4MSA1LjU3MTEwOCAtNS4yNzIyMjkgNS4wNjg5OTEgLTUuMjcyMjI5QzQuMzM5NzI2IC01LjI3MjIyOSAzLjkzMzI1IC00LjU1NDkxOSAzLjgyNTY1NCAtNC4zMjc3NzFDMy41NTA2ODUgLTUuMjI0NDA4IDIuODA5NDY1IC01LjI3MjIyOSAyLjU5NDI3MSAtNS4yNzIyMjlDMS4zNzQ4NDQgLTUuMjcyMjI5IDAuNzI5MjY1IC0zLjcwNjEwMiAwLjcyOTI2NSAtMy40NDMwODhDMC43MjkyNjUgLTMuMzk1MjY4IDAuNzc3MDg2IC0zLjMzNTQ5MiAwLjg2MDc3MiAtMy4zMzU0OTJDMC45NTY0MTMgLTMuMzM1NDkyIDAuOTgwMzI0IC0zLjQwNzIyMyAxLjAwNDIzNCAtMy40NTUwNDRDMS40MTA3MSAtNC43ODIwNjcgMi4yMTE3MDYgLTUuMDMzMTI2IDIuNTU4NDA2IC01LjAzMzEyNkMzLjA5NjM4OSAtNS4wMzMxMjYgMy4yMDM5ODUgLTQuNTMxMDA5IDMuMjAzOTg1IC00LjI0NDA4NUMzLjIwMzk4NSAtMy45ODEwNzEgMy4xMzIyNTQgLTMuNzA2MTAyIDIuOTg4NzkyIC0zLjEzMjI1NEwyLjU4MjMxNiAtMS40OTQzOTZDMi40MDI5ODkgLTAuNzc3MDg2IDIuMDU2Mjg5IC0wLjExOTU1MiAxLjQyMjY2NSAtMC4xMTk1NTJDMS4zNjI4ODkgLTAuMTE5NTUyIDEuMDY0MDEgLTAuMTE5NTUyIDAuODEyOTUxIC0wLjI3NDk2OUMxLjI0MzMzNyAtMC4zNTg2NTUgMS4zMzg5NzkgLTAuNzE3MzEgMS4zMzg5NzkgLTAuODYwNzcyQzEuMzM4OTc5IC0xLjA5OTg3NSAxLjE1OTY1MSAtMS4yNDMzMzcgMC45MzI1MDMgLTEuMjQzMzM3QzAuNjQ1NTc5IC0xLjI0MzMzNyAwLjMzNDc0NSAtMC45OTIyNzkgMC4zMzQ3NDUgLTAuNjA5NzE0QzAuMzM0NzQ1IC0wLjEwNzU5NyAwLjg5NjYzOCAwLjExOTU1MiAxLjQxMDcxIDAuMTE5NTUyQzEuOTg0NTU4IDAuMTE5NTUyIDIuMzkxMDM0IC0wLjMzNDc0NSAyLjY0MjA5MiAtMC44MjQ5MDdDMi44MzMzNzUgLTAuMTE5NTUyIDMuNDMxMTMzIDAuMTE5NTUyIDMuODczNDc0IDAuMTE5NTUyQzUuMDkyOTAyIDAuMTE5NTUyIDUuNzM4NDgxIC0xLjQ0NjU3NSA1LjczODQ4MSAtMS43MDk1ODlDNS43Mzg0ODEgLTEuNzY5MzY1IDUuNjkwNjYgLTEuODE3MTg2IDUuNjE4OTI5IC0xLjgxNzE4NkM1LjUxMTMzMyAtMS44MTcxODYgNS40OTkzNzcgLTEuNzU3NDEgNS40NjM1MTIgLTEuNjYxNzY4QzUuMTQwNzIyIC0wLjYwOTcxNCA0LjQ0NzMyMyAtMC4xMTk1NTIgMy45MDkzNCAtMC4xMTk1NTJDMy40OTA5MDkgLTAuMTE5NTUyIDMuMjYzNzYxIC0wLjQzMDM4NiAzLjI2Mzc2MSAtMC45MjA1NDhDMy4yNjM3NjEgLTEuMTgzNTYyIDMuMzExNTgyIC0xLjM3NDg0NCAzLjUwMjg2NCAtMi4xNjM4ODVMMy45MjEyOTUgLTMuNzg5Nzg4QzQuMTAwNjIzIC00LjUwNzA5OCA0LjUwNzA5OCAtNS4wMzMxMjYgNS4wNTcwMzYgLTUuMDMzMTI2QzUuMDgwOTQ2IC01LjAzMzEyNiA1LjQxNTY5MSAtNS4wMzMxMjYgNS42NjY3NSAtNC44Nzc3MDlaJyBpZD0nZzctMTIwJy8+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtMi43NDk2ODlDOC4wODE2OTQgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi45ODg3OTJTOC4wODE2OTQgLTMuMjI3ODk1IDcuODc4NDU2IC0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyIC0zLjIyNzg5NSAwLjk5MjI3OSAtMy4yMjc4OTUgMC45OTIyNzkgLTIuOTg4NzkyUzEuMjA3NDcyIC0yLjc0OTY4OSAxLjQxMDcxIC0yLjc0OTY4OUg3Ljg3ODQ1NlonIGlkPSdnNC0wJy8+CjxwYXRoIGQ9J00xLjE2MzYzNiAtMS43ODUzMDVDMS40NDI1OSAtMS42NjU3NTMgMS42ODE2OTQgLTEuNjY1NzUzIDEuODk2ODg3IC0xLjY2NTc1M0MyLjE0Mzk2IC0xLjY2NTc1MyAyLjU5MDI4NiAtMS42NjU3NTMgMi41OTAyODYgLTEuOTUyNjc3QzIuNTkwMjg2IC0yLjE1OTkgMi4yODc0MjIgLTIuMTkxNzgxIDEuOTc2NTg4IC0yLjE5MTc4MUMxLjU2MjE0MiAtMi4xOTE3ODEgMS4zNDY5NDkgLTIuMTA0MTEgMS4xNzk1NzcgLTIuMDMyMzc5QzEuMDY3OTk1IC0yLjA4ODE2OSAwLjg2ODc0MiAtMi4yMzk2MDEgMC44Njg3NDIgLTIuNDYyNzY1QzAuODY4NzQyIC0yLjg4NTE4MSAxLjYwOTk2MyAtMy4xODAwNzUgMi40MDY5NzQgLTMuMTgwMDc1QzIuNjU0MDQ3IC0zLjE4MDA3NSAyLjkwMTEyMSAtMy4xNDAyMjQgMy4xODgwNDUgLTIuOTU2OTEyQzMuMjY3NzQ2IC0yLjkwMTEyMSAzLjI4MzY4NiAtMi44ODUxODEgMy4zNDc0NDcgLTIuODg1MTgxQzMuNDU5MDI5IC0yLjg4NTE4MSAzLjU4NjU1IC0zLjAwNDczMiAzLjU4NjU1IC0zLjEyNDI4NEMzLjU4NjU1IC0zLjI5MTY1NiAzLjI4MzY4NiAtMy40MTkxNzggMy4xNzIxMDUgLTMuNDY2OTk5QzIuODUzMyAtMy42MDI0OTEgMi42MDYyMjcgLTMuNjAyNDkxIDIuNDg2Njc1IC0zLjYwMjQ5MUMxLjUzODIzMiAtMy42MDI0OTEgMC42MjE2NjkgLTMuMDY4NDkzIDAuNjIxNjY5IC0yLjQ1NDc5NUMwLjYyMTY2OSAtMi4xNTk5IDAuODQ0ODMyIC0xLjk2ODYxOCAwLjkyNDUzMyAtMS45MTI4MjdDMC4zNjY2MjUgLTEuNTU0MTcyIDAuMjMxMTMzIC0xLjEyMzc4NiAwLjIzMTEzMyAtMC44NjA3NzJDMC4yMzExMzMgLTAuMzE4ODA0IDAuNzQxMjIgMC4xNjczNzIgMS42MjU5MDMgMC4xNjczNzJDMi43ODE1NjkgMC4xNjczNzIgMy4yMDM5ODUgLTAuNTU3OTA4IDMuMjAzOTg1IC0wLjY2OTQ4OUMzLjIwMzk4NSAtMC43MjUyOCAzLjE3MjEwNSAtMC43ODEwNzEgMy4xMDAzNzQgLTAuNzgxMDcxQzMuMDQ0NTgzIC0wLjc4MTA3MSAzLjAyMDY3MiAtMC43NDkxOTEgMi45ODg3OTIgLTAuNzAxMzdDMi44NjkyNCAtMC41MTAwODcgMi43MDE4NjggLTAuMjU1MDQ0IDEuNzEzNTc0IC0wLjI1NTA0NEMxLjUwNjM1MSAtMC4yNTUwNDQgMC40ODYxNzcgLTAuMjU1MDQ0IDAuNDg2MTc3IC0wLjkwODU5M0MwLjQ4NjE3NyAtMS4xNDc2OTYgMC42Njk0ODkgLTEuNTE0MzIxIDEuMTYzNjM2IC0xLjc4NTMwNVpNMi4zMDMzNjIgLTEuOTI4NzY3QzIuMTgzODExIC0xLjg4ODkxNyAyLjE2Nzg3IC0xLjg4ODkxNyAxLjg5Njg4NyAtMS44ODg5MTdDMS44MDkyMTUgLTEuODg4OTE3IDEuNjQxODQzIC0xLjg4ODkxNyAxLjUyMjI5MSAtMS45MTI4MjdDMS43MTM1NzQgLTEuOTYwNjQ4IDEuODg4OTE3IC0xLjk2ODYxOCAxLjk2MDY0OCAtMS45Njg2MThDMi4xMDQxMSAtMS45Njg2MTggMi4xOTk3NTEgLTEuOTUyNjc3IDIuMzAzMzYyIC0xLjkzNjczN1YtMS45Mjg3NjdaJyBpZD0nZzYtMzQnLz4KPHBhdGggZD0nTTYuMzQ0MjA5IC01LjM5NTc2NkM2LjM1MjE3OSAtNS40Mjc2NDYgNi4zNjgxMiAtNS40NzU0NjcgNi4zNjgxMiAtNS41MTUzMThDNi4zNjgxMiAtNS41NzExMDggNi4zMjAyOTkgLTUuNjEwOTU5IDYuMjY0NTA4IC01LjYxMDk1OVM2LjE4NDgwNyAtNS41ODcwNDkgNi4xMjEwNDYgLTUuNTE1MzE4TDUuNTYzMTM4IC00LjkwMTYxOUM1LjQ5MTQwNyAtNS4wMDUyMyA1LjA2ODk5MSAtNS42MTA5NTkgNC4xMzY0ODggLTUuNjEwOTU5QzIuMjg3NDIyIC01LjYxMDk1OSAwLjQyMjQxNiAtMy44OTczODUgMC40MjI0MTYgLTIuMDY0MjU5QzAuNDIyNDE2IC0wLjY3NzQ2IDEuNDc0NDcxIDAuMTY3MzcyIDIuNzQxNzE5IDAuMTY3MzcyQzMuNzg1ODAzIDAuMTY3MzcyIDQuNjcwNDg2IC0wLjQ3MDIzNyA1LjEwMDg3MiAtMS4wOTE5MDVDNS4zNjM4ODUgLTEuNDgyNDQxIDUuNDY3NDk3IC0xLjg2NTAwNiA1LjQ2NzQ5NyAtMS45MTI4MjdDNS40Njc0OTcgLTEuOTg0NTU4IDUuNDE5Njc2IC0yLjAxNjQzOCA1LjM0Nzk0NSAtMi4wMTY0MzhDNS4yNTIzMDQgLTIuMDE2NDM4IDUuMjM2MzY0IC0xLjk3NjU4OCA1LjIxMjQ1MyAtMS44ODg5MTdDNC44Nzc3MDkgLTAuNzg5MDQxIDMuODAxNzQzIC0wLjA5NTY0MSAyLjg0NTMzIC0wLjA5NTY0MUMyLjAzMjM3OSAtMC4wOTU2NDEgMS4xNzk1NzcgLTAuNTczODQ4IDEuMTc5NTc3IC0xLjc5MzI3NUMxLjE3OTU3NyAtMi4wNDgzMTkgMS4yNjcyNDggLTMuMzc5MzI4IDIuMTUxOTMgLTQuMzc1NTkyQzIuNzQ5Njg5IC01LjA0NTA4MSAzLjU2MjY0IC01LjM0Nzk0NSA0LjE5MjI3OSAtNS4zNDc5NDVDNS4xOTY1MTMgLTUuMzQ3OTQ1IDUuNjEwOTU5IC00LjU0Mjk2NCA1LjYxMDk1OSAtMy43ODU4MDNDNS42MTA5NTkgLTMuNjc0MjIyIDUuNTc5MDc4IC0zLjUyMjc5IDUuNTc5MDc4IC0zLjQyNzE0OEM1LjU3OTA3OCAtMy4zMjM1MzcgNS42ODI2OSAtMy4zMjM1MzcgNS43MTQ1NyAtMy4zMjM1MzdDNS44MTgxODIgLTMuMzIzNTM3IDUuODM0MTIyIC0zLjM1NTQxNyA1Ljg2NjAwMiAtMy40OTg4NzlMNi4zNDQyMDkgLTUuMzk1NzY2WicgaWQ9J2c2LTY3Jy8+CjxwYXRoIGQ9J00zLjA1MjU1MyAtMy4xNzIxMDVIMy43OTM3NzNDMy45NTMxNzYgLTMuMTcyMTA1IDQuMDQ4ODE3IC0zLjE3MjEwNSA0LjA0ODgxNyAtMy4zMjM1MzdDNC4wNDg4MTcgLTMuNDM1MTE4IDMuOTQ1MjA1IC0zLjQzNTExOCAzLjgwOTcxNCAtMy40MzUxMThIMy4xMDAzNzRDMy4yMjc4OTUgLTQuMTUyNDI4IDMuMzA3NTk3IC00LjYwNjcyNSAzLjM4NzI5OCAtNC45NjUzOEMzLjQxOTE3OCAtNS4xMDA4NzIgMy40NDMwODggLTUuMTg4NTQzIDMuNTYyNjQgLTUuMjg0MTg0QzMuNjY2MjUyIC01LjM3MTg1NiAzLjczMDAxMiAtNS4zODc3OTYgMy44MTc2ODQgLTUuMzg3Nzk2QzMuOTM3MjM1IC01LjM4Nzc5NiA0LjA2NDc1NyAtNS4zNjM4ODUgNC4xNjgzNjkgLTUuMzAwMTI1QzQuMTI4NTE4IC01LjI4NDE4NCA0LjA4MDY5NyAtNS4yNjAyNzQgNC4wNDA4NDcgLTUuMjM2MzY0QzMuOTA1MzU1IC01LjE2NDYzMyAzLjgwOTcxNCAtNS4wMjExNzEgMy44MDk3MTQgLTQuODYxNzY4QzMuODA5NzE0IC00LjY3ODQ1NiAzLjk1MzE3NiAtNC41NjY4NzQgNC4xMjg1MTggLTQuNTY2ODc0QzQuMzU5NjUxIC00LjU2Njg3NCA0LjU3NDg0NCAtNC43NjYxMjcgNC41NzQ4NDQgLTUuMDQ1MDgxQzQuNTc0ODQ0IC01LjQxOTY3NiA0LjE5MjI3OSAtNS42MTA5NTkgMy44MDk3MTQgLTUuNjEwOTU5QzMuNTM4NzMgLTUuNjEwOTU5IDMuMDM2NjEzIC01LjQ4MzQzNyAyLjc4MTU2OSAtNC43NTAxODdDMi43MDk4MzggLTQuNTY2ODc0IDIuNzA5ODM4IC00LjU1MDkzNCAyLjQ5NDY0NSAtMy40MzUxMThIMS44OTY4ODdDMS43Mzc0ODQgLTMuNDM1MTE4IDEuNjQxODQzIC0zLjQzNTExOCAxLjY0MTg0MyAtMy4yODM2ODZDMS42NDE4NDMgLTMuMTcyMTA1IDEuNzQ1NDU1IC0zLjE3MjEwNSAxLjg4MDk0NiAtMy4xNzIxMDVIMi40NDY4MjRMMS44NzI5NzYgLTAuMDc5NzAxQzEuNzIxNTQ0IDAuNzI1MjggMS42MDE5OTMgMS40MDI3NCAxLjE3OTU3NyAxLjQwMjc0QzEuMTU1NjY2IDEuNDAyNzQgMC45ODgyOTQgMS40MDI3NCAwLjgzNjg2MiAxLjMwNzA5OEMxLjIwMzQ4NyAxLjIxOTQyNyAxLjIwMzQ4NyAwLjg4NDY4MiAxLjIwMzQ4NyAwLjg3NjcxMkMxLjIwMzQ4NyAwLjY5MzQgMS4wNjAwMjUgMC41ODE4MTggMC44ODQ2ODIgMC41ODE4MThDMC42Njk0ODkgMC41ODE4MTggMC40MzgzNTYgMC43NjUxMzEgMC40MzgzNTYgMS4wNjc5OTVDMC40MzgzNTYgMS40MDI3NCAwLjc4MTA3MSAxLjYyNTkwMyAxLjE3OTU3NyAxLjYyNTkwM0MxLjY2NTc1MyAxLjYyNTkwMyAyLjAwMDQ5OCAxLjExNTgxNiAyLjEwNDExIDAuOTE2NTYzQzIuMzkxMDM0IDAuMzkwNTM1IDIuNTc0MzQ2IC0wLjYwNTcyOSAyLjU5MDI4NiAtMC42ODU0M0wzLjA1MjU1MyAtMy4xNzIxMDVaJyBpZD0nZzYtMTAyJy8+CjxwYXRoIGQ9J00yLjMyNzI3MyAtNS4yOTIxNTRDMi4zMzUyNDMgLTUuMzA4MDk1IDIuMzU5MTUzIC01LjQxMTcwNiAyLjM1OTE1MyAtNS40MTk2NzZDMi4zNTkxNTMgLTUuNDU5NTI3IDIuMzI3MjczIC01LjUzMTI1OCAyLjIzMTYzMSAtNS41MzEyNThDMi4xOTk3NTEgLTUuNTMxMjU4IDEuOTUyNjc3IC01LjUwNzM0NyAxLjc2OTM2NSAtNS40OTE0MDdMMS4zMjMwMzkgLTUuNDU5NTI3QzEuMTQ3Njk2IC01LjQ0MzU4NyAxLjA2Nzk5NSAtNS40MzU2MTYgMS4wNjc5OTUgLTUuMjkyMTU0QzEuMDY3OTk1IC01LjE4MDU3MyAxLjE3OTU3NyAtNS4xODA1NzMgMS4yNzUyMTggLTUuMTgwNTczQzEuNjU3NzgzIC01LjE4MDU3MyAxLjY1Nzc4MyAtNS4xMzI3NTIgMS42NTc3ODMgLTUuMDYxMDIxQzEuNjU3NzgzIC01LjAzNzExMSAxLjY1Nzc4MyAtNS4wMjExNzEgMS42MTc5MzMgLTQuODc3NzA5TDAuNDg2MTc3IC0wLjM0MjcxNUMwLjQ1NDI5NiAtMC4yMjMxNjMgMC40NTQyOTYgLTAuMTc1MzQyIDAuNDU0Mjk2IC0wLjE2NzM3MkMwLjQ1NDI5NiAtMC4wMzE4OCAwLjU2NTg3OCAwLjA3OTcwMSAwLjcxNzMxIDAuMDc5NzAxQzAuOTg4Mjk0IDAuMDc5NzAxIDEuMDUyMDU1IC0wLjE3NTM0MiAxLjA4MzkzNSAtMC4yODY5MjRDMS4xNjM2MzYgLTAuNjIxNjY5IDEuMzcwODU5IC0xLjQ2NjUwMSAxLjQ1ODUzMSAtMS44MDEyNDVDMS44OTY4ODcgLTEuNzUzNDI1IDIuNDMwODg0IC0xLjYwMTk5MyAyLjQzMDg4NCAtMS4xNDc2OTZDMi40MzA4ODQgLTEuMTA3ODQ2IDIuNDMwODg0IC0xLjA2Nzk5NSAyLjQxNDk0NCAtMC45ODgyOTRDMi4zOTEwMzQgLTAuODg0NjgyIDIuMzc1MDkzIC0wLjc3MzEwMSAyLjM3NTA5MyAtMC43MzMyNUMyLjM3NTA5MyAtMC4yNjMwMTQgMi43MjU3NzggMC4wNzk3MDEgMy4xODgwNDUgMC4wNzk3MDFDMy41MjI3OSAwLjA3OTcwMSAzLjczMDAxMiAtMC4xNjczNzIgMy44MzM2MjQgLTAuMzE4ODA0QzQuMDI0OTA3IC0wLjYxMzY5OSA0LjE1MjQyOCAtMS4wOTE5MDUgNC4xNTI0MjggLTEuMTM5NzI2QzQuMTUyNDI4IC0xLjIxOTQyNyA0LjA4ODY2NyAtMS4yNDMzMzcgNC4wMzI4NzcgLTEuMjQzMzM3QzMuOTM3MjM1IC0xLjI0MzMzNyAzLjkyMTI5NSAtMS4xOTU1MTcgMy44ODk0MTUgLTEuMDUyMDU1QzMuNzg1ODAzIC0wLjY3NzQ2IDMuNTc4NTggLTAuMTQzNDYyIDMuMjAzOTg1IC0wLjE0MzQ2MkMyLjk5Njc2MiAtMC4xNDM0NjIgMi45NDg5NDEgLTAuMzE4ODA0IDIuOTQ4OTQxIC0wLjUzMzk5OEMyLjk0ODk0MSAtMC42Mzc2MDkgMi45NTY5MTIgLTAuNzMzMjUgMi45OTY3NjIgLTAuOTE2NTYzQzMuMDA0NzMyIC0wLjk0ODQ0MyAzLjAzNjYxMyAtMS4wNzU5NjUgMy4wMzY2MTMgLTEuMTYzNjM2QzMuMDM2NjEzIC0xLjgxNzE4NiAyLjIxNTY5MSAtMS45NjA2NDggMS44MDkyMTUgLTIuMDE2NDM4QzIuMTA0MTEgLTIuMTkxNzgxIDIuMzc1MDkzIC0yLjQ2Mjc2NSAyLjQ3MDczNSAtMi41NjYzNzZDMi45MDkwOTEgLTIuOTk2NzYyIDMuMjY3NzQ2IC0zLjI5MTY1NiAzLjY1MDMxMSAtMy4yOTE2NTZDMy43NTM5MjMgLTMuMjkxNjU2IDMuODQ5NTY0IC0zLjI2Nzc0NiAzLjkxMzMyNSAtMy4xODgwNDVDMy40ODI5MzkgLTMuMTMyMjU0IDMuNDgyOTM5IC0yLjc1NzY1OSAzLjQ4MjkzOSAtMi43NDk2ODlDMy40ODI5MzkgLTIuNTc0MzQ2IDMuNjE4NDMxIC0yLjQ1NDc5NSAzLjc5Mzc3MyAtMi40NTQ3OTVDNC4wMDg5NjYgLTIuNDU0Nzk1IDQuMjQ4MDcgLTIuNjMwMTM3IDQuMjQ4MDcgLTIuOTU2OTEyQzQuMjQ4MDcgLTMuMjI3ODk1IDQuMDU2Nzg3IC0zLjUxNDgxOSAzLjY1ODI4MSAtMy41MTQ4MTlDMy4xOTYwMTUgLTMuNTE0ODE5IDIuNzgxNTY5IC0zLjE2NDEzNCAyLjMyNzI3MyAtMi43MDk4MzhDMS44NjUwMDYgLTIuMjU1NTQyIDEuNjY1NzUzIC0yLjE2Nzg3IDEuNTM4MjMyIC0yLjExMjA4TDIuMzI3MjczIC01LjI5MjE1NFonIGlkPSdnNi0xMDcnLz4KPHBhdGggZD0nTTMuOTkzMDI2IC0zLjE4MDA3NUMzLjY0MjM0MSAtMy4wOTI0MDMgMy42MjY0MDEgLTIuNzgxNTY5IDMuNjI2NDAxIC0yLjc0OTY4OUMzLjYyNjQwMSAtMi41NzQzNDYgMy43NjE4OTMgLTIuNDU0Nzk1IDMuOTM3MjM1IC0yLjQ1NDc5NVM0LjM4MzU2MiAtMi41OTAyODYgNC4zODM1NjIgLTIuOTMzMDAxQzQuMzgzNTYyIC0zLjM4NzI5OCAzLjg4MTQ0NSAtMy41MTQ4MTkgMy41ODY1NSAtMy41MTQ4MTlDMy4yMTE5NTUgLTMuNTE0ODE5IDIuOTA5MDkxIC0zLjI1MTgwNiAyLjcyNTc3OCAtMi45NDA5NzFDMi41NTA0MzYgLTMuMzYzMzg3IDIuMTM1OTkgLTMuNTE0ODE5IDEuODA5MjE1IC0zLjUxNDgxOUMwLjk0MDQ3MyAtMy41MTQ4MTkgMC40NTQyOTYgLTIuNTE4NTU1IDAuNDU0Mjk2IC0yLjI5NTM5MkMwLjQ1NDI5NiAtMi4yMjM2NjEgMC41MTAwODcgLTIuMTkxNzgxIDAuNTczODQ4IC0yLjE5MTc4MUMwLjY2OTQ4OSAtMi4xOTE3ODEgMC42ODU0MyAtMi4yMzE2MzEgMC43MDkzNCAtMi4zMjcyNzNDMC44OTI2NTMgLTIuOTA5MDkxIDEuMzcwODU5IC0zLjI5MTY1NiAxLjc4NTMwNSAtMy4yOTE2NTZDMi4wOTYxMzkgLTMuMjkxNjU2IDIuMjQ3NTcyIC0zLjA2ODQ5MyAyLjI0NzU3MiAtMi43ODE1NjlDMi4yNDc1NzIgLTIuNjIyMTY3IDIuMTUxOTMgLTIuMjU1NTQyIDIuMDg4MTY5IC0yLjAwMDQ5OEMyLjAzMjM3OSAtMS43NjkzNjUgMS44NTcwMzYgLTEuMDYwMDI1IDEuODE3MTg2IC0wLjkwODU5M0MxLjcwNTYwNCAtMC40NzgyMDcgMS40MTg2OCAtMC4xNDM0NjIgMS4wNjAwMjUgLTAuMTQzNDYyQzEuMDI4MTQ0IC0wLjE0MzQ2MiAwLjgyMDkyMiAtMC4xNDM0NjIgMC42NTM1NDkgLTAuMjU1MDQ0QzEuMDIwMTc0IC0wLjM0MjcxNSAxLjAyMDE3NCAtMC42Nzc0NiAxLjAyMDE3NCAtMC42ODU0M0MxLjAyMDE3NCAtMC44Njg3NDIgMC44NzY3MTIgLTAuOTgwMzI0IDAuNzAxMzcgLTAuOTgwMzI0QzAuNDg2MTc3IC0wLjk4MDMyNCAwLjI1NTA0NCAtMC43OTcwMTEgMC4yNTUwNDQgLTAuNDk0MTQ3QzAuMjU1MDQ0IC0wLjEyNzUyMiAwLjY0NTU3OSAwLjA3OTcwMSAxLjA1MjA1NSAwLjA3OTcwMUMxLjQ3NDQ3MSAwLjA3OTcwMSAxLjc2OTM2NSAtMC4yMzkxMDMgMS45MTI4MjcgLTAuNDk0MTQ3QzIuMDg4MTY5IC0wLjEwMzYxMSAyLjQ1NDc5NSAwLjA3OTcwMSAyLjgzNzM2IDAuMDc5NzAxQzMuNzA2MTAyIDAuMDc5NzAxIDQuMTg0MzA5IC0wLjkxNjU2MyA0LjE4NDMwOSAtMS4xMzk3MjZDNC4xODQzMDkgLTEuMjE5NDI3IDQuMTIwNTQ4IC0xLjI0MzMzNyA0LjA2NDc1NyAtMS4yNDMzMzdDMy45NjkxMTYgLTEuMjQzMzM3IDMuOTUzMTc2IC0xLjE4NzU0NyAzLjkyOTI2NSAtMS4xMDc4NDZDMy43Njk4NjMgLTAuNTczODQ4IDMuMzE1NTY3IC0wLjE0MzQ2MiAyLjg1MzMgLTAuMTQzNDYyQzIuNTkwMjg2IC0wLjE0MzQ2MiAyLjM5OTAwNCAtMC4zMTg4MDQgMi4zOTkwMDQgLTAuNjUzNTQ5QzIuMzk5MDA0IC0wLjgxMjk1MSAyLjQ0NjgyNCAtMC45OTYyNjQgMi41NTg0MDYgLTEuNDQyNTlDMi42MTQxOTcgLTEuNjgxNjk0IDIuNzg5NTM5IC0yLjM4MzA2NCAyLjgyOTM5IC0yLjUzNDQ5NkMyLjk0MDk3MSAtMi45NDg5NDEgMy4yMTk5MjUgLTMuMjkxNjU2IDMuNTc4NTggLTMuMjkxNjU2QzMuNjE4NDMxIC0zLjI5MTY1NiAzLjgyNTY1NCAtMy4yOTE2NTYgMy45OTMwMjYgLTMuMTgwMDc1WicgaWQ9J2c2LTEyMCcvPgo8cGF0aCBkPSdNNS4zNzk4MjYgLTQuNzM0MjQ3QzUuNDc1NDY3IC00Ljc4MjA2NyA1LjUzMTI1OCAtNC44MjE5MTggNS41MzEyNTggLTQuOTA5NTg5UzUuNDU5NTI3IC01LjA2ODk5MSA1LjM3MTg1NiAtNS4wNjg5OTFDNS4zMzIwMDUgLTUuMDY4OTkxIDUuMjYwMjc0IC01LjAzNzExMSA1LjIyODM5NCAtNS4wMjExNzFMMC44MjA5MjIgLTIuOTQwOTcxQzAuNjg1NDMgLTIuODc3MjEgMC42NjE1MTkgLTIuODIxNDIgMC42NjE1MTkgLTIuNzU3NjU5UzAuNjkzNCAtMi42MzgxMDcgMC44MjA5MjIgLTIuNTgyMzE2TDUuMjI4Mzk0IC0wLjUxMDA4N0M1LjMzMjAwNSAtMC40NTQyOTYgNS4zNDc5NDUgLTAuNDU0Mjk2IDUuMzcxODU2IC0wLjQ1NDI5NkM1LjQ1OTUyNyAtMC40NTQyOTYgNS41MzEyNTggLTAuNTI2MDI3IDUuNTMxMjU4IC0wLjYxMzY5OUM1LjUzMTI1OCAtMC43MTczMSA1LjQ1OTUyNyAtMC43NDkxOTEgNS4zNzE4NTYgLTAuNzg5MDQxTDEuMTk1NTE3IC0yLjc1NzY1OUw1LjM3OTgyNiAtNC43MzQyNDdaTTUuMjI4Mzk0IDEuMDM2MTE1QzUuMzMyMDA1IDEuMDkxOTA1IDUuMzQ3OTQ1IDEuMDkxOTA1IDUuMzcxODU2IDEuMDkxOTA1QzUuNDU5NTI3IDEuMDkxOTA1IDUuNTMxMjU4IDEuMDIwMTc0IDUuNTMxMjU4IDAuOTMyNTAzQzUuNTMxMjU4IDAuODI4ODkyIDUuNDU5NTI3IDAuNzk3MDExIDUuMzcxODU2IDAuNzU3MTYxTDAuOTcyMzU0IC0xLjMxNTA2OEMwLjg2ODc0MiAtMS4zNzA4NTkgMC44NTI4MDIgLTEuMzcwODU5IDAuODIwOTIyIC0xLjM3MDg1OUMwLjcyNTI4IC0xLjM3MDg1OSAwLjY2MTUxOSAtMS4yOTkxMjggMC42NjE1MTkgLTEuMjExNDU3QzAuNjYxNTE5IC0xLjE0NzY5NiAwLjY5MzQgLTEuMDkxOTA1IDAuODIwOTIyIC0xLjAzNjExNUw1LjIyODM5NCAxLjAzNjExNVonIGlkPSdnMC01NCcvPgo8cGF0aCBkPSdNNS4zNzE4NTYgLTIuNTgyMzE2QzUuNDk5Mzc3IC0yLjYzODEwNyA1LjUzMTI1OCAtMi42OTM4OTggNS41MzEyNTggLTIuNzU3NjU5QzUuNTMxMjU4IC0yLjg2MTI3IDUuNDc1NDY3IC0yLjg4NTE4MSA1LjM3MTg1NiAtMi45MzMwMDFMMC45ODAzMjQgLTUuMDEzMkMwLjg2ODc0MiAtNS4wNjg5OTEgMC44MzY4NjIgLTUuMDY4OTkxIDAuODIwOTIyIC01LjA2ODk5MUMwLjczMzI1IC01LjA2ODk5MSAwLjY2MTUxOSAtNC45OTcyNiAwLjY2MTUxOSAtNC45MDk1ODlDMC42NjE1MTkgLTQuODA1OTc4IDAuNzI1MjggLTQuNzgyMDY3IDAuODIwOTIyIC00LjczNDI0N0w0Ljk5NzI2IC0yLjc2NTYyOUwwLjgxMjk1MSAtMC43ODkwNDFDMC42OTM0IC0wLjczMzI1IDAuNjYxNTE5IC0wLjY4NTQzIDAuNjYxNTE5IC0wLjYxMzY5OUMwLjY2MTUxOSAtMC41MjYwMjcgMC43MzMyNSAtMC40NTQyOTYgMC44MjA5MjIgLTAuNDU0Mjk2QzAuODQ0ODMyIC0wLjQ1NDI5NiAwLjg2MDc3MiAtMC40NTQyOTYgMC45NjQzODQgLTAuNTEwMDg3TDUuMzcxODU2IC0yLjU4MjMxNlpNNS4zNzE4NTYgLTEuMDM2MTE1QzUuNDk5Mzc3IC0xLjA5MTkwNSA1LjUzMTI1OCAtMS4xNDc2OTYgNS41MzEyNTggLTEuMjExNDU3QzUuNTMxMjU4IC0xLjM3MDg1OSA1LjM3OTgyNiAtMS4zNzA4NTkgNS4zMjQwMzUgLTEuMzcwODU5TDAuODEyOTUxIDAuNzU3MTYxQzAuNzMzMjUgMC43OTcwMTEgMC42NjE1MTkgMC44NDQ4MzIgMC42NjE1MTkgMC45MzI1MDNTMC43MzMyNSAxLjA5MTkwNSAwLjgyMDkyMiAxLjA5MTkwNUMwLjg0NDgzMiAxLjA5MTkwNSAwLjg2MDc3MiAxLjA5MTkwNSAwLjk2NDM4NCAxLjAzNjExNUw1LjM3MTg1NiAtMS4wMzYxMTVaJyBpZD0nZzAtNjInLz4KPHBhdGggZD0nTTIuNjU0MDQ3IDEuOTkyNTI4QzIuNzE3ODA4IDEuOTkyNTI4IDIuODEzNDUgMS45OTI1MjggMi44MTM0NSAxLjg5Njg4N0MyLjgxMzQ1IDEuODY1MDA2IDIuODA1NDc5IDEuODU3MDM2IDIuNzAxODY4IDEuNzUzNDI1QzEuNjA5OTYzIDAuNzI1MjggMS4zMzg5NzkgLTAuNzU3MTYxIDEuMzM4OTc5IC0xLjk5MjUyOEMxLjMzODk3OSAtNC4yODc5MiAyLjI4NzQyMiAtNS4zNjM4ODUgMi42OTM4OTggLTUuNzMwNTExQzIuODA1NDc5IC01LjgzNDEyMiAyLjgxMzQ1IC01Ljg0MjA5MiAyLjgxMzQ1IC01Ljg4MTk0M1MyLjc4MTU2OSAtNS45Nzc1ODQgMi43MDE4NjggLTUuOTc3NTg0QzIuNTc0MzQ2IC01Ljk3NzU4NCAyLjE3NTg0MSAtNS41NzExMDggMi4xMTIwOCAtNS40OTkzNzdDMS4wNDQwODUgLTQuMzgzNTYyIDAuODIwOTIyIC0yLjk0ODk0MSAwLjgyMDkyMiAtMS45OTI1MjhDMC44MjA5MjIgLTAuMjA3MjIzIDEuNTcwMTEyIDEuMjI3Mzk3IDIuNjU0MDQ3IDEuOTkyNTI4WicgaWQ9J2c4LTQwJy8+CjxwYXRoIGQ9J00yLjQ2Mjc2NSAtMS45OTI1MjhDMi40NjI3NjUgLTIuNzQ5Njg5IDIuMzM1MjQzIC0zLjY1ODI4MSAxLjg0MTA5NiAtNC41OTg3NTVDMS40NTA1NiAtNS4zMzIwMDUgMC43MjUyOCAtNS45Nzc1ODQgMC41ODE4MTggLTUuOTc3NTg0QzAuNTAyMTE3IC01Ljk3NzU4NCAwLjQ3ODIwNyAtNS45MjE3OTMgMC40NzgyMDcgLTUuODgxOTQzQzAuNDc4MjA3IC01Ljg1MDA2MiAwLjQ3ODIwNyAtNS44MzQxMjIgMC41NzM4NDggLTUuNzM4NDgxQzEuNjg5NjY0IC00LjY3ODQ1NiAxLjk0NDcwNyAtMy4yMTk5MjUgMS45NDQ3MDcgLTEuOTkyNTI4QzEuOTQ0NzA3IDAuMjk0ODk0IDAuOTk2MjY0IDEuMzc4ODI5IDAuNTg5Nzg4IDEuNzQ1NDU1QzAuNDg2MTc3IDEuODQ5MDY2IDAuNDc4MjA3IDEuODU3MDM2IDAuNDc4MjA3IDEuODk2ODg3UzAuNTAyMTE3IDEuOTkyNTI4IDAuNTgxODE4IDEuOTkyNTI4QzAuNzA5MzQgMS45OTI1MjggMS4xMDc4NDYgMS41ODYwNTIgMS4xNzE2MDYgMS41MTQzMjFDMi4yMzk2MDEgMC4zOTg1MDYgMi40NjI3NjUgLTEuMDM2MTE1IDIuNDYyNzY1IC0xLjk5MjUyOFonIGlkPSdnOC00MScvPgo8cGF0aCBkPSdNMy44OTczODUgLTIuNTQyNDY2QzMuODk3Mzg1IC0zLjM5NTI2OCAzLjgwOTcxNCAtMy45MTMzMjUgMy41NDY3IC00LjQyMzQxMkMzLjE5NjAxNSAtNS4xMjQ3ODIgMi41NTA0MzYgLTUuMzAwMTI1IDIuMTEyMDggLTUuMzAwMTI1QzEuMTA3ODQ2IC01LjMwMDEyNSAwLjc0MTIyIC00LjU1MDkzNCAwLjYyOTYzOSAtNC4zMjc3NzFDMC4zNDI3MTUgLTMuNzQ1OTUzIDAuMzI2Nzc1IC0yLjk1NjkxMiAwLjMyNjc3NSAtMi41NDI0NjZDMC4zMjY3NzUgLTIuMDE2NDM4IDAuMzUwNjg1IC0xLjIxMTQ1NyAwLjczMzI1IC0wLjU3Mzg0OEMxLjA5OTg3NSAwLjAxNTk0IDEuNjg5NjY0IDAuMTY3MzcyIDIuMTEyMDggMC4xNjczNzJDMi40OTQ2NDUgMC4xNjczNzIgMy4xODAwNzUgMC4wNDc4MjEgMy41Nzg1OCAtMC43NDEyMkMzLjg3MzQ3NCAtMS4zMTUwNjggMy44OTczODUgLTIuMDI0NDA4IDMuODk3Mzg1IC0yLjU0MjQ2NlpNMi4xMTIwOCAtMC4wNTU3OTFDMS44NDEwOTYgLTAuMDU1NzkxIDEuMjkxMTU4IC0wLjE4MzMxMyAxLjEyMzc4NiAtMS4wMjAxNzRDMS4wMzYxMTUgLTEuNDc0NDcxIDEuMDM2MTE1IC0yLjIyMzY2MSAxLjAzNjExNSAtMi42MzgxMDdDMS4wMzYxMTUgLTMuMTg4MDQ1IDEuMDM2MTE1IC0zLjc0NTk1MyAxLjEyMzc4NiAtNC4xODQzMDlDMS4yOTExNTggLTQuOTk3MjYgMS45MTI4MjcgLTUuMDc2OTYxIDIuMTEyMDggLTUuMDc2OTYxQzIuMzgzMDY0IC01LjA3Njk2MSAyLjkzMzAwMSAtNC45NDE0NjkgMy4wOTI0MDMgLTQuMjE2MTg5QzMuMTg4MDQ1IC0zLjc3NzgzMyAzLjE4ODA0NSAtMy4xODAwNzUgMy4xODgwNDUgLTIuNjM4MTA3QzMuMTg4MDQ1IC0yLjE2Nzg3IDMuMTg4MDQ1IC0xLjQ1MDU2IDMuMDkyNDAzIC0xLjAwNDIzNEMyLjkyNTAzMSAtMC4xNjczNzIgMi4zNzUwOTMgLTAuMDU1NzkxIDIuMTEyMDggLTAuMDU1NzkxWicgaWQ9J2c4LTQ4Jy8+CjxwYXRoIGQ9J001LjgyNjE1MiAtMi42NTQwNDdDNS45NDU3MDQgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjY1NDA0NyA2LjEwNTEwNiAtMi44MzczNlM1LjkxMzgyMyAtMy4wMjA2NzIgNS43OTQyNzEgLTMuMDIwNjcySDAuNzgxMDcxQzAuNjYxNTE5IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMy4wMjA2NzIgMC40NzAyMzcgLTIuODM3MzZTMC42Mjk2MzkgLTIuNjU0MDQ3IDAuNzQ5MTkxIC0yLjY1NDA0N0g1LjgyNjE1MlpNNS43OTQyNzEgLTAuOTY0Mzg0QzUuOTEzODIzIC0wLjk2NDM4NCA2LjEwNTEwNiAtMC45NjQzODQgNi4xMDUxMDYgLTEuMTQ3Njk2UzUuOTQ1NzA0IC0xLjMzMTAwOSA1LjgyNjE1MiAtMS4zMzEwMDlIMC43NDkxOTFDMC42Mjk2MzkgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjMzMTAwOSAwLjQ3MDIzNyAtMS4xNDc2OTZTMC42NjE1MTkgLTAuOTY0Mzg0IDAuNzgxMDcxIC0wLjk2NDM4NEg1Ljc5NDI3MVonIGlkPSdnOC02MScvPgo8cGF0aCBkPSdNMS4xMTE4MzEgLTEuMzIxMDQ2QzEuMzU2OTEyIC0xLjIzMTM4MiAxLjYwMTk5MyAtMS4yMzEzODIgMS43MDM2MTEgLTEuMjMxMzgyQzEuODg4OTE3IC0xLjIzMTM4MiAyLjI3NzQ2IC0xLjIzMTM4MiAyLjI3NzQ2IC0xLjQ2NDUwOEMyLjI3NzQ2IC0xLjY1NTc5MSAxLjk3MjYwMyAtMS42NTU3OTEgMS43NzUzNDIgLTEuNjU1NzkxQzEuNjE5OTI1IC0xLjY1NTc5MSAxLjQxMDcxIC0xLjY1NTc5MSAxLjEyMzc4NiAtMS41NDIyMTdDMC45NTY0MTMgLTEuNjE5OTI1IDAuODcyNzI3IC0xLjcyNzUyMiAwLjg3MjcyNyAtMS44NDcwNzNDMC44NzI3MjcgLTIuMTU3OTA4IDEuNDg4NDE4IC0yLjM1NTE2OCAyLjA5ODEzMiAtMi4zNTUxNjhDMi4yMTE3MDYgLTIuMzU1MTY4IDIuNDY4NzQyIC0yLjM1NTE2OCAyLjc1NTY2NiAtMi4xODc3OTZDMi44MjE0MiAtMi4xNDU5NTMgMi44MjczOTcgLTIuMTM5OTc1IDIuODgxMTk2IC0yLjEzOTk3NUMyLjk4ODc5MiAtMi4xMzk5NzUgMy4wNzI0NzggLTIuMjQxNTk0IDMuMDcyNDc4IC0yLjMzMTI1OEMzLjA3MjQ3OCAtMi40MjY4OTkgMi45OTQ3NyAtMi40OTg2MyAyLjczMTc1NiAtMi42MDAyNDlDMi40NjI3NjUgLTIuNzAxODY4IDIuMjUzNTQ5IC0yLjcwMTg2OCAyLjE2Mzg4NSAtMi43MDE4NjhDMS4zOTg3NTUgLTIuNzAxODY4IDAuNjUxNTU3IC0yLjMxOTMwMyAwLjY1MTU1NyAtMS44NDEwOTZDMC42NTE1NTcgLTEuNTk2MDE1IDAuODg0NjgyIC0xLjQyODY0MyAwLjg5MDY2IC0xLjQyODY0M0MwLjU3Mzg0OCAtMS4yMzczNiAwLjM2NDYzMyAtMC45NjgzNjkgMC4zNjQ2MzMgLTAuNjYzNTEyQzAuMzY0NjMzIC0wLjI0NTA4MSAwLjc4OTA0MSAwLjEyNTUyOSAxLjUzMDI2MiAwLjEyNTUyOUMyLjU0MDQ3MyAwLjEyNTUyOSAyLjgxNTQ0MiAtMC40NDgzMTkgMi44MTU0NDIgLTAuNTE0MDcyQzIuODE1NDQyIC0wLjU3Mzg0OCAyLjc2NzYyMSAtMC42MDk3MTQgMi43MTk4MDEgLTAuNjA5NzE0UzIuNjQ4MDcgLTAuNTc5ODI2IDIuNjI0MTU5IC0wLjUzMjAwNUMyLjQ1MDgwOSAtMC4yNzQ5NjkgMi4xNTc5MDggLTAuMjIxMTcxIDEuNjE5OTI1IC0wLjIyMTE3MUMxLjQzNDYyIC0wLjIyMTE3MSAxLjE1MzY3NCAtMC4yMjExNzEgMC45MjA1NDggLTAuMzEwODM0QzAuNzUzMTc2IC0wLjM4MjU2NSAwLjU4NTgwMyAtMC41MDgwOTUgMC41ODU4MDMgLTAuNjk5Mzc3QzAuNTg1ODAzIC0wLjkyNjUyNiAwLjgzMDg4NCAtMS4xOTU1MTcgMS4xMTE4MzEgLTEuMzIxMDQ2Wk0xLjk4NDU1OCAtMS40NDY1NzVDMS45MTI4MjcgLTEuNDM0NjIgMS44NDcwNzMgLTEuNDI4NjQzIDEuNzA5NTg5IC0xLjQyODY0M0MxLjY5MTY1NiAtMS40Mjg2NDMgMS41MTgzMDYgLTEuNDI4NjQzIDEuNTE4MzA2IC0xLjQ0MDU5OEMxLjUxODMwNiAtMS40NTg1MzEgMS43NDU0NTUgLTEuNDU4NTMxIDEuNzY5MzY1IC0xLjQ1ODUzMUMxLjg5NDg5NCAtMS40NTg1MzEgMS45MDY4NDkgLTEuNDU4NTMxIDEuOTg0NTU4IC0xLjQ0NjU3NVonIGlkPSdnNS0zNCcvPgo8cGF0aCBkPSdNNi40Mzc4NTggLTMuNTk4NTA2QzYuNDg1Njc5IC0zLjc5NTc2NiA2LjQ5NzYzNCAtMy44NDM1ODcgNi45NzU4NDEgLTMuODQzNTg3QzcuMDgzNDM3IC0zLjg0MzU4NyA3LjE2NzEyMyAtMy44NDM1ODcgNy4xNjcxMjMgLTMuOTkzMDI2QzcuMTY3MTIzIC00LjA4MjY5IDcuMDg5NDE1IC00LjA4MjY5IDYuOTgxODE4IC00LjA4MjY5SDYuMTMzMDAxQzUuOTU5NjUxIC00LjA4MjY5IDUuOTQxNzE5IC00LjA3NjcxMiA1Ljg0NjA3NyAtMy45MzkyMjhMMy40Nzg5NTQgLTAuNTQ5OTM4TDIuODE1NDQyIC0zLjkyMTI5NUMyLjc4NTU1NCAtNC4wODI2OSAyLjc0OTY4OSAtNC4wODI2OSAyLjU5NDI3MSAtNC4wODI2OUgxLjY5NzYzNEMxLjU3ODA4MiAtNC4wODI2OSAxLjQ5NDM5NiAtNC4wODI2OSAxLjQ5NDM5NiAtMy45MzMyNUMxLjQ5NDM5NiAtMy44NDM1ODcgMS41ODQwNiAtMy44NDM1ODcgMS42OTE2NTYgLTMuODQzNTg3UzEuOTQ4NjkyIC0zLjg0MzU4NyAyLjA3NDIyMiAtMy44MDE3NDNDMi4wNzQyMjIgLTMuNzQxOTY4IDIuMDc0MjIyIC0zLjcwNjEwMiAyLjA1MDMxMSAtMy42MTA0NjFMMS4zMDkwOTEgLTAuNjYzNTEyQzEuMjQ5MzE1IC0wLjQxODQzMSAxLjE0MTcxOSAtMC4yNTcwMzYgMC42NTc1MzQgLTAuMjM5MTAzQzAuNTczODQ4IC0wLjIzMzEyNiAwLjUzMjAwNSAtMC4xNzMzNSAwLjUzMjAwNSAtMC4wODM2ODZDMC41Mzc5ODMgLTAuMDU5Nzc2IDAuNTQzOTYgMCAwLjYzMzYyNCAwQzAuNzc3MDg2IDAgMS4xMjk3NjMgLTAuMDIzOTEgMS4yNzMyMjUgLTAuMDIzOTFMMS42MDE5OTMgLTAuMDE3OTMzQzEuNzA5NTg5IC0wLjAxNzkzMyAxLjgzNTExOCAwIDEuOTM2NzM3IDBDMi4wNjIyNjcgMCAyLjA2ODI0NCAtMC4xMjU1MjkgMi4wNjgyNDQgLTAuMTU1NDE3QzIuMDUwMzExIC0wLjIzOTEwMyAxLjk5MDUzNSAtMC4yMzkxMDMgMS45MTg4MDQgLTAuMjM5MTAzQzEuNjQzODM2IC0wLjI0NTA4MSAxLjUyNDI4NCAtMC4zMjI3OSAxLjUyNDI4NCAtMC40NzgyMDdDMS41MjQyODQgLTAuNTE0MDcyIDEuNTMwMjYyIC0wLjUzNzk4MyAxLjU0ODE5NCAtMC42MDM3MzZMMi4zNDMyMTMgLTMuNzg5Nzg4SDIuMzQ5MTkxTDMuMDYwNTIzIC0wLjE2NzM3MkMzLjA4NDQzMyAtMC4wNTk3NzYgMy4xMDIzNjYgMCAzLjE5ODAwNyAwQzMuMjg3NjcxIDAgMy4zMzU0OTIgLTAuMDU5Nzc2IDMuMzc3MzM1IC0wLjEyNTUyOUw1Ljk3MTYwNiAtMy44NDM1ODdMNS45Nzc1ODQgLTMuODM3NjA5TDUuMTQwNzIyIC0wLjQ5NjEzOUM1LjA4NjkyNCAtMC4yODA5NDYgNS4wNzQ5NjkgLTAuMjM5MTAzIDQuNjI2NjUgLTAuMjM5MTAzQzQuNDk1MTQzIC0wLjIzOTEwMyA0LjQ4MzE4OCAtMC4yMzkxMDMgNC40NTkyNzggLTAuMjIxMTcxQzQuNDI5MzkgLTAuMTk3MjYgNC40MDU0NzkgLTAuMTE5NTUyIDQuNDA1NDc5IC0wLjA4MzY4NkM0LjQxMTQ1NyAtMC4wNTk3NzYgNC40MTc0MzUgMCA0LjUwNzA5OCAwQzQuNjI2NjUgMCA0Ljc1ODE1NyAtMC4wMTc5MzMgNC44Nzc3MDkgLTAuMDE3OTMzQzUuMDA5MjE1IC0wLjAxNzkzMyA1LjE0NjcgLTAuMDIzOTEgNS4yNzgyMDcgLTAuMDIzOTFDNS4yNzgyMDcgLTAuMDIzOTEgNS42OTA2NiAtMC4wMTc5MzMgNS42OTA2NiAtMC4wMTc5MzNDNS44MTAyMTIgLTAuMDE3OTMzIDUuOTUzNjc0IDAgNi4wNzMyMjUgMEM2LjEwOTA5MSAwIDYuMTUwOTM0IDAgNi4xNzQ4NDQgLTAuMDQxODQzQzYuMTg2OCAtMC4wNTk3NzYgNi4yMTA3MSAtMC4xMzE1MDcgNi4yMTA3MSAtMC4xNTU0MTdDNi4xOTI3NzcgLTAuMjM5MTAzIDYuMTM4OTc5IC0wLjIzOTEwMyA2LjAwMTQ5NCAtMC4yMzkxMDNDNS45Mjk3NjMgLTAuMjM5MTAzIDUuODQwMSAtMC4yNDUwODEgNS43NzQzNDYgLTAuMjUxMDU5QzUuNjY2NzUgLTAuMjYzMDE0IDUuNjI0OTA3IC0wLjI2MzAxNCA1LjYyNDkwNyAtMC4zMjg3NjdDNS42MjQ5MDcgLTAuMzUyNjc3IDUuNjMwODg0IC0wLjM3NjU4OCA1LjY0ODgxNyAtMC40MzYzNjRMNi40Mzc4NTggLTMuNTk4NTA2WicgaWQ9J2c1LTc3Jy8+CjxwYXRoIGQ9J00xLjk4NDU1OCAtMy45NjkxMTZDMS45OTA1MzUgLTMuOTkzMDI2IDIuMDAyNDkxIC00LjAyODg5MiAyLjAwMjQ5MSAtNC4wNTg3OEMyLjAwMjQ5MSAtNC4xNTQ0MjEgMS44ODI5MzkgLTQuMTQ4NDQzIDEuODExMjA4IC00LjE0MjQ2NkwxLjE0MTcxOSAtNC4wODg2NjdDMS4wNDAxIC00LjA4MjY5IDAuOTYyMzkxIC00LjA3NjcxMiAwLjk2MjM5MSAtMy45MzMyNUMwLjk2MjM5MSAtMy44NDM1ODcgMS4wNDAxIC0zLjg0MzU4NyAxLjEzNTc0MSAtMy44NDM1ODdDMS4zMDkwOTEgLTMuODQzNTg3IDEuMzUwOTM0IC0zLjgyNTY1NCAxLjQyODY0MyAtMy44MDE3NDNDMS40Mjg2NDMgLTMuNzMwMDEyIDEuNDI4NjQzIC0zLjcxODA1NyAxLjQwNDczMiAtMy42MjI0MTZMMC41Njc4NyAtMC4yODA5NDZDMC41NDM5NiAtMC4xODUzMDUgMC41NDM5NiAtMC4xNTU0MTcgMC41NDM5NiAtMC4xNDM0NjJDMC41NDM5NiAwLjAwNTk3OCAwLjY2MzUxMiAwLjA1OTc3NiAwLjc1MzE3NiAwLjA1OTc3NkMwLjgxMjk1MSAwLjA1OTc3NiAwLjkyMDU0OCAwLjAzNTg2NiAwLjk5ODI1NyAtMC4wNzc3MDlDMS4wNDAxIC0wLjE1NTQxNyAxLjI3OTIwMyAtMS4xNDc2OTYgMS4zMjEwNDYgLTEuMzM4OTc5QzEuNzIxNTQ0IC0xLjMwOTA5MSAyLjE1MTkzIC0xLjIxMzQ1IDIuMTUxOTMgLTAuODYwNzcyQzIuMTUxOTMgLTAuODMwODg0IDIuMTUxOTMgLTAuODAwOTk2IDIuMTMzOTk4IC0wLjczNTI0M0MyLjExNjA2NSAtMC42NDU1NzkgMi4xMTYwNjUgLTAuNjA5NzE0IDIuMTE2MDY1IC0wLjU2MTg5M0MyLjExNjA2NSAtMC4xNjczNzIgMi40NTA4MDkgMC4wNTk3NzYgMi43OTE1MzIgMC4wNTk3NzZDMy4zNzEzNTcgMC4wNTk3NzYgMy41ODA1NzMgLTAuODEyOTUxIDMuNTgwNTczIC0wLjg2MDc3MkMzLjU4MDU3MyAtMC44NzI3MjcgMy41NzQ1OTUgLTAuOTQ0NDU4IDMuNDY2OTk5IC0wLjk0NDQ1OEMzLjM4MzMxMyAtMC45NDQ0NTggMy4zNzEzNTcgLTAuOTA4NTkzIDMuMzQxNDY5IC0wLjgwNjk3NEMzLjI4MTY5NCAtMC41OTE3ODEgMy4xMTQzMjEgLTAuMTM3NDg0IDIuODA5NDY1IC0wLjEzNzQ4NEMyLjU4MjMxNiAtMC4xMzc0ODQgMi41ODIzMTYgLTAuMzk0NTIxIDIuNTgyMzE2IC0wLjQ2MDI3NEMyLjU4MjMxNiAtMC41NTU5MTUgMi41ODIzMTYgLTAuNTYxODkzIDIuNjEyMjA0IC0wLjY4MTQ0NUMyLjYxMjIwNCAtMC42ODc0MjIgMi42NDIwOTIgLTAuODA2OTc0IDIuNjQyMDkyIC0wLjg3ODcwNUMyLjY0MjA5MiAtMS4zMzg5NzkgMi4xMjIwNDIgLTEuNDgyNDQxIDEuNjYxNzY4IC0xLjUyNDI4NEMxLjgwNTIzIC0xLjYxMzk0OCAxLjkzMDc2IC0xLjcwOTU4OSAyLjE2OTg2MyAtMS45MTg4MDRDMi40Njg3NDIgLTIuMTgxODE4IDIuNzc5NTc3IC0yLjQzODg1NCAzLjEwODM0NCAtMi40Mzg4NTRDMy4xODYwNTIgLTIuNDM4ODU0IDMuMjU3NzgzIC0yLjQyMDkyMiAzLjMxMTU4MiAtMi4zNjExNDZDMy4xMDIzNjYgLTIuMzE5MzAzIDMuMDEyNzAyIC0yLjE1MTkzIDMuMDEyNzAyIC0yLjAyNjQwMUMzLjAxMjcwMiAtMS44MzUxMTggMy4xNjgxMiAtMS43OTMyNzUgMy4yNTE4MDYgLTEuNzkzMjc1QzMuMzgzMzEzIC0xLjc5MzI3NSAzLjU5ODUwNiAtMS44ODg5MTcgMy41OTg1MDYgLTIuMTg3Nzk2QzMuNTk4NTA2IC0yLjQ0NDgzMiAzLjQwNzIyMyAtMi42MzYxMTUgMy4xMTQzMjEgLTIuNjM2MTE1QzIuNzM3NzMzIC0yLjYzNjExNSAyLjM4NTA1NiAtMi4zNDkxOTEgMi4xMTAwODcgLTIuMTEwMDg3QzEuNzk5MjUzIC0xLjg0MTA5NiAxLjYxMzk0OCAtMS42ODU2NzkgMS4zOTI3NzcgLTEuNjAxOTkzTDEuOTg0NTU4IC0zLjk2OTExNlonIGlkPSdnNS0xMDcnLz4KPHBhdGggZD0nTTMuMjM5ODUxIC02LjEwOTA5MUwzLjQzMTEzMyAtNi4yODg0MThMMi4wMDg0NjggLTguMTI5NTE0QzEuOTQ4NjkyIC04LjIwMTI0NSAxLjg0MTA5NiAtOC4zMzI3NTIgMS42NzM3MjQgLTguMzMyNzUyQzEuNDcwNDg2IC04LjMzMjc1MiAxLjI2NzI0OCAtOC4xNTM0MjUgMS4yNjcyNDggLTcuOTM4MjMyQzEuMjY3MjQ4IC03LjgxODY4IDEuMzE1MDY4IC03LjcxMTA4MyAxLjQzNDYyIC03LjYxNTQ0MkwzLjIzOTg1MSAtNi4xMDkwOTFaJyBpZD0nZzktMTgnLz4KPHBhdGggZD0nTTIuMTA0MTEgLTcuMzc2MzM5QzIuMTE2MDY1IC03LjI5MjY1MyAyLjEyODAyIC03LjIzMjg3NyAyLjEyODAyIC03LjA3NzQ2QzIuMTI4MDIgLTYuOTEwMDg3IDIuMTI4MDIgLTUuOTQxNzE5IDEuMzAzMTEzIC01LjExNjgxMkMxLjE5NTUxNyAtNS4wMDkyMTUgMS4xOTU1MTcgLTQuOTg1MzA1IDEuMTk1NTE3IC00Ljk0OTQ0QzEuMTk1NTE3IC00Ljg4OTY2NCAxLjI1NTI5MyAtNC44Mjk4ODggMS4zMTUwNjggLTQuODI5ODg4QzEuNDIyNjY1IC00LjgyOTg4OCAyLjM2NzEyMyAtNS43MTQ1NyAyLjM2NzEyMyAtNy4wNzc0NkMyLjM2NzEyMyAtNy44MTg2OCAyLjA5MjE1NCAtOC4yOTY4ODcgMS42MTM5NDggLTguMjk2ODg3QzEuMjY3MjQ4IC04LjI5Njg4NyAxLjA0MDEgLTguMDMzODczIDEuMDQwMSAtNy43MjMwMzlDMS4wNDAxIC03LjQwMDI0OSAxLjI2NzI0OCAtNy4xMzcyMzUgMS42MjU5MDMgLTcuMTM3MjM1QzEuOTQ4NjkyIC03LjEzNzIzNSAyLjEwNDExIC03LjM2NDM4NCAyLjEwNDExIC03LjM3NjMzOVonIGlkPSdnOS0zOScvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2c5LTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnOS00MScvPgo8cGF0aCBkPSdNNS4zNTU5MTUgLTMuODI1NjU0QzUuMzU1OTE1IC00LjgxNzkzMyA1LjI5NjEzOSAtNS43ODYzMDEgNC44NjU3NTMgLTYuNjk0ODk0QzQuMzc1NTkyIC03LjY4NzE3MyAzLjUxNDgxOSAtNy45NTAxODcgMi45MjkwMTYgLTcuOTUwMTg3QzIuMjM1NjE2IC03Ljk1MDE4NyAxLjM4NjggLTcuNjAzNDg3IDAuOTQ0NDU4IC02LjYxMTIwOEMwLjYwOTcxNCAtNS44NTgwMzIgMC40OTAxNjIgLTUuMTE2ODEyIDAuNDkwMTYyIC0zLjgyNTY1NEMwLjQ5MDE2MiAtMi42NjYwMDIgMC41NzM4NDggLTEuNzkzMjc1IDEuMDA0MjM0IC0wLjk0NDQ1OEMxLjQ3MDQ4NiAtMC4wMzU4NjYgMi4yOTUzOTIgMC4yNTEwNTkgMi45MTcwNjEgMC4yNTEwNTlDMy45NTcxNjEgMC4yNTEwNTkgNC41NTQ5MTkgLTAuMzcwNjEgNC45MDE2MTkgLTEuMDY0MDFDNS4zMzIwMDUgLTEuOTYwNjQ4IDUuMzU1OTE1IC0zLjEzMjI1NCA1LjM1NTkxNSAtMy44MjU2NTRaTTIuOTE3MDYxIDAuMDExOTU1QzIuNTM0NDk2IDAuMDExOTU1IDEuNzU3NDEgLTAuMjAzMjM4IDEuNTMwMjYyIC0xLjUwNjM1MUMxLjM5ODc1NSAtMi4yMjM2NjEgMS4zOTg3NTUgLTMuMTMyMjU0IDEuMzk4NzU1IC0zLjk2OTExNkMxLjM5ODc1NSAtNC45NDk0NCAxLjM5ODc1NSAtNS44MzQxMjIgMS41OTAwMzcgLTYuNTM5NDc3QzEuNzkzMjc1IC03LjM0MDQ3MyAyLjQwMjk4OSAtNy43MTEwODMgMi45MTcwNjEgLTcuNzExMDgzQzMuMzcxMzU3IC03LjcxMTA4MyA0LjA2NDc1NyAtNy40MzYxMTUgNC4yOTE5MDUgLTYuNDA3OTdDNC40NDczMjMgLTUuNzI2NTI2IDQuNDQ3MzIzIC00Ljc4MjA2NyA0LjQ0NzMyMyAtMy45NjkxMTZDNC40NDczMjMgLTMuMTY4MTIgNC40NDczMjMgLTIuMjU5NTI3IDQuMzE1ODE2IC0xLjUzMDI2MkM0LjA4ODY2NyAtMC4yMTUxOTMgMy4zMzU0OTIgMC4wMTE5NTUgMi45MTcwNjEgMC4wMTE5NTVaJyBpZD0nZzktNDgnLz4KPHBhdGggZD0nTTMuNDQzMDg4IC03LjY2MzI2M0MzLjQ0MzA4OCAtNy45MzgyMzIgMy40NDMwODggLTcuOTUwMTg3IDMuMjAzOTg1IC03Ljk1MDE4N0MyLjkxNzA2MSAtNy42MjczOTcgMi4zMTkzMDMgLTcuMTg1MDU2IDEuMDg3OTIgLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OSAtNi44MzgzNTYgMS45NjA2NDggLTYuODM4MzU2IDIuNjE4MTgyIC03LjE0OTE5MVYtMC45MjA1NDhDMi42MTgxODIgLTAuNDkwMTYyIDIuNTgyMzE2IC0wLjM0NjcgMS41MzAyNjIgLTAuMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxIC0wLjAyMzkxIDIuNjQyMDkyIC0wLjAyMzkxIDMuMDM2NjEzIC0wLjAyMzkxUzQuNTc4ODI5IC0wLjAyMzkxIDQuOTAxNjE5IDBWLTAuMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NCAtMC4zNDY3IDMuNDQzMDg4IC0wLjQ5MDE2MiAzLjQ0MzA4OCAtMC45MjA1NDhWLTcuNjYzMjYzWicgaWQ9J2c5LTQ5Jy8+CjxwYXRoIGQ9J000LjMxNTgxNiAtNy43ODI4MTRDNC4zMTU4MTYgLTguMDA5OTYzIDQuMzE1ODE2IC04LjA2OTczOCA0LjE0ODQ0MyAtOC4wNjk3MzhDNC4wNTI4MDIgLTguMDY5NzM4IDQuMDE2OTM2IC04LjA2OTczOCAzLjkyMTI5NSAtNy45MjYyNzZMMC4zMjI3OSAtMi4zNDMyMTNWLTEuOTk2NTEzSDMuNDY2OTk5Vi0wLjkwODU5M0MzLjQ2Njk5OSAtMC40NjYyNTIgMy40NDMwODggLTAuMzQ2NyAyLjU3MDM2MSAtMC4zNDY3SDIuMzMxMjU4VjBDMi42MDYyMjcgLTAuMDIzOTEgMy41NTA2ODUgLTAuMDIzOTEgMy44ODU0MyAtMC4wMjM5MVM1LjE3NjU4OCAtMC4wMjM5MSA1LjQ1MTU1NyAwVi0wLjM0NjdINS4yMTI0NTNDNC4zNTE2ODEgLTAuMzQ2NyA0LjMxNTgxNiAtMC40NjYyNTIgNC4zMTU4MTYgLTAuOTA4NTkzVi0xLjk5NjUxM0g1LjUyMzI4OFYtMi4zNDMyMTNINC4zMTU4MTZWLTcuNzgyODE0Wk0zLjUyNjc3NSAtNi44NTAzMTFWLTIuMzQzMjEzSDAuNjIxNjY5TDMuNTI2Nzc1IC02Ljg1MDMxMVonIGlkPSdnOS01MicvPgo8cGF0aCBkPSdNOC4wNjk3MzggLTMuODczNDc0QzguMjM3MTExIC0zLjg3MzQ3NCA4LjQ1MjMwNCAtMy44NzM0NzQgOC40NTIzMDQgLTQuMDg4NjY3QzguNDUyMzA0IC00LjMxNTgxNiA4LjI0OTA2NiAtNC4zMTU4MTYgOC4wNjk3MzggLTQuMzE1ODE2SDEuMDI4MTQ0QzAuODYwNzcyIC00LjMxNTgxNiAwLjY0NTU3OSAtNC4zMTU4MTYgMC42NDU1NzkgLTQuMTAwNjIzQzAuNjQ1NTc5IC0zLjg3MzQ3NCAwLjg0ODgxNyAtMy44NzM0NzQgMS4wMjgxNDQgLTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOCAtMS42NDk4MTNDOC4yMzcxMTEgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjY0OTgxMyA4LjQ1MjMwNCAtMS44NjUwMDZDOC40NTIzMDQgLTIuMDkyMTU0IDguMjQ5MDY2IC0yLjA5MjE1NCA4LjA2OTczOCAtMi4wOTIxNTRIMS4wMjgxNDRDMC44NjA3NzIgLTIuMDkyMTU0IDAuNjQ1NTc5IC0yLjA5MjE1NCAwLjY0NTU3OSAtMS44NzY5NjFDMC42NDU1NzkgLTEuNjQ5ODEzIDAuODQ4ODE3IC0xLjY0OTgxMyAxLjAyODE0NCAtMS42NDk4MTNIOC4wNjk3MzhaJyBpZD0nZzktNjEnLz4KPHBhdGggZD0nTTQuNjE0Njk1IC0zLjE5MjAzQzQuNjE0Njk1IC0zLjgzNzYwOSA0LjYxNDY5NSAtNC4zMTU4MTYgNC4wODg2NjcgLTQuNzgyMDY3QzMuNjcwMjM3IC01LjE2NDYzMyAzLjEzMjI1NCAtNS4zMzIwMDUgMi42MDYyMjcgLTUuMzMyMDA1QzEuNjI1OTAzIC01LjMzMjAwNSAwLjg3MjcyNyAtNC42ODY0MjYgMC44NzI3MjcgLTMuOTA5MzRDMC44NzI3MjcgLTMuNTYyNjQgMS4wOTk4NzUgLTMuMzk1MjY4IDEuMzc0ODQ0IC0zLjM5NTI2OEMxLjY2MTc2OCAtMy4zOTUyNjggMS44NjUwMDYgLTMuNTk4NTA2IDEuODY1MDA2IC0zLjg4NTQzQzEuODY1MDA2IC00LjM3NTU5MiAxLjQzNDYyIC00LjM3NTU5MiAxLjI1NTI5MyAtNC4zNzU1OTJDMS41MzAyNjIgLTQuODc3NzA5IDIuMTA0MTEgLTUuMDkyOTAyIDIuNTgyMzE2IC01LjA5MjkwMkMzLjEzMjI1NCAtNS4wOTI5MDIgMy44Mzc2MDkgLTQuNjM4NjA1IDMuODM3NjA5IC0zLjU2MjY0Vi0zLjA4NDQzM0MxLjQzNDYyIC0zLjA0ODU2OCAwLjUyNjAyNyAtMi4wNDQzMzQgMC41MjYwMjcgLTEuMTIzNzg2QzAuNTI2MDI3IC0wLjE3OTMyOCAxLjYyNTkwMyAwLjExOTU1MiAyLjM1NTE2OCAwLjExOTU1MkMzLjE0NDIwOSAwLjExOTU1MiAzLjY4MjE5MiAtMC4zNTg2NTUgMy45MDkzNCAtMC45MzI1MDNDMy45NTcxNjEgLTAuMzcwNjEgNC4zMjc3NzEgMC4wNTk3NzYgNC44NDE4NDMgMC4wNTk3NzZDNS4wOTI5MDIgMC4wNTk3NzYgNS43ODYzMDEgLTAuMTA3NTk3IDUuNzg2MzAxIC0xLjA2NDAxVi0xLjczMzQ5OUg1LjUyMzI4OFYtMS4wNjQwMUM1LjUyMzI4OCAtMC4zODI1NjUgNS4yMzYzNjQgLTAuMjg2OTI0IDUuMDY4OTkxIC0wLjI4NjkyNEM0LjYxNDY5NSAtMC4yODY5MjQgNC42MTQ2OTUgLTAuOTIwNTQ4IDQuNjE0Njk1IC0xLjA5OTg3NVYtMy4xOTIwM1pNMy44Mzc2MDkgLTEuNjg1Njc5QzMuODM3NjA5IC0wLjUxNDA3MiAyLjk2NDg4MiAtMC4xMTk1NTIgMi40NTA4MDkgLTAuMTE5NTUyQzEuODY1MDA2IC0wLjExOTU1MiAxLjM3NDg0NCAtMC41NDk5MzggMS4zNzQ4NDQgLTEuMTIzNzg2QzEuMzc0ODQ0IC0yLjcwMTg2OCAzLjQwNzIyMyAtMi44NDUzMyAzLjgzNzYwOSAtMi44NjkyNFYtMS42ODU2NzlaJyBpZD0nZzktOTcnLz4KPHBhdGggZD0nTTMuNTg2NTUgLTguMTY1MzhWLTcuODE4NjhDNC4zOTk1MDIgLTcuODE4NjggNC40OTUxNDMgLTcuNzM0OTk0IDQuNDk1MTQzIC03LjE0OTE5MVYtNC41MDcwOThDNC4yNDQwODUgLTQuODUzNzk4IDMuNzMwMDEyIC01LjI3MjIyOSAzLjAwMDc0NyAtNS4yNzIyMjlDMS42MTM5NDggLTUuMjcyMjI5IDAuNDE4NDMxIC00LjEwMDYyMyAwLjQxODQzMSAtMi41NzAzNjFDMC40MTg0MzEgLTEuMDUyMDU1IDEuNTU0MTcyIDAuMTE5NTUyIDIuODY5MjQgMC4xMTk1NTJDMy43Nzc4MzMgMC4xMTk1NTIgNC4zMDM4NjEgLTAuNDc4MjA3IDQuNDcxMjMzIC0wLjcwNTM1NVYwLjExOTU1Mkw2LjE1NjkxMiAwVi0wLjM0NjdDNS4zNDM5NiAtMC4zNDY3IDUuMjQ4MzE5IC0wLjQzMDM4NiA1LjI0ODMxOSAtMS4wMTYxODlWLTguMjk2ODg3TDMuNTg2NTUgLTguMTY1MzhaTTQuNDcxMjMzIC0xLjM5ODc1NUM0LjQ3MTIzMyAtMS4xODM1NjIgNC40NzEyMzMgLTEuMTQ3Njk2IDQuMzAzODYxIC0wLjg4NDY4MkM0LjAxNjkzNiAtMC40NjYyNTIgMy41MjY3NzUgLTAuMTE5NTUyIDIuOTI5MDE2IC0wLjExOTU1MkMyLjYxODE4MiAtMC4xMTk1NTIgMS4zMjcwMjQgLTAuMjM5MTAzIDEuMzI3MDI0IC0yLjU1ODQwNkMxLjMyNzAyNCAtMy40MTkxNzggMS40NzA0ODYgLTMuODk3Mzg1IDEuNzMzNDk5IC00LjI5MTkwNUMxLjk3MjYwMyAtNC42NjI1MTYgMi40NTA4MDkgLTUuMDMzMTI2IDMuMDQ4NTY4IC01LjAzMzEyNkMzLjc4OTc4OCAtNS4wMzMxMjYgNC4yMDgyMTkgLTQuNDk1MTQzIDQuMzI3NzcxIC00LjMwMzg2MUM0LjQ3MTIzMyAtNC4xMDA2MjMgNC40NzEyMzMgLTQuMDc2NzEyIDQuNDcxMjMzIC0zLjg2MTUxOVYtMS4zOTg3NTVaJyBpZD0nZzktMTAwJy8+CjxwYXRoIGQ9J000LjU3ODgyOSAtMi43NzM1OTlDNC44NDE4NDMgLTIuNzczNTk5IDQuODY1NzUzIC0yLjc3MzU5OSA0Ljg2NTc1MyAtMy4wMDA3NDdDNC44NjU3NTMgLTQuMjA4MjE5IDQuMjIwMTc0IC01LjMzMjAwNSAyLjc3MzU5OSAtNS4zMzIwMDVDMS40MTA3MSAtNS4zMzIwMDUgMC4zNTg2NTUgLTQuMTAwNjIzIDAuMzU4NjU1IC0yLjYxODE4MkMwLjM1ODY1NSAtMS4wNDAxIDEuNTc4MDgyIDAuMTE5NTUyIDIuOTA1MTA2IDAuMTE5NTUyQzQuMzI3NzcxIDAuMTE5NTUyIDQuODY1NzUzIC0xLjE3MTYwNiA0Ljg2NTc1MyAtMS40MjI2NjVDNC44NjU3NTMgLTEuNDk0Mzk2IDQuODA1OTc4IC0xLjU0MjIxNyA0LjczNDI0NyAtMS41NDIyMTdDNC42Mzg2MDUgLTEuNTQyMjE3IDQuNjE0Njk1IC0xLjQ4MjQ0MSA0LjU5MDc4NSAtMS40MjI2NjVDNC4yNzk5NSAtMC40MTg0MzEgMy40Nzg5NTQgLTAuMTQzNDYyIDIuOTc2ODM3IC0wLjE0MzQ2MlMxLjI2NzI0OCAtMC40NzgyMDcgMS4yNjcyNDggLTIuNTQ2NDUxVi0yLjc3MzU5OUg0LjU3ODgyOVpNMS4yNzkyMDMgLTMuMDAwNzQ3QzEuMzc0ODQ0IC00Ljg3NzcwOSAyLjQyNjg5OSAtNS4wOTI5MDIgMi43NjE2NDQgLTUuMDkyOTAyQzQuMDQwODQ3IC01LjA5MjkwMiA0LjExMjU3OCAtMy40MDcyMjMgNC4xMjQ1MzMgLTMuMDAwNzQ3SDEuMjc5MjAzWicgaWQ9J2c5LTEwMScvPgo8cGF0aCBkPSdNMi4wODAxOTkgLTcuMzY0Mzg0QzIuMDgwMTk5IC03LjY3NTIxOCAxLjgyOTE0MSAtNy45NTAxODcgMS40OTQzOTYgLTcuOTUwMTg3QzEuMTgzNTYyIC03Ljk1MDE4NyAwLjkyMDU0OCAtNy42OTkxMjggMC45MjA1NDggLTcuMzc2MzM5QzAuOTIwNTQ4IC03LjAxNzY4NCAxLjIwNzQ3MiAtNi43OTA1MzUgMS40OTQzOTYgLTYuNzkwNTM1QzEuODY1MDA2IC02Ljc5MDUzNSAyLjA4MDE5OSAtNy4xMDEzNyAyLjA4MDE5OSAtNy4zNjQzODRaTTAuNDMwMzg2IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMzAzMTEzIC00LjcyMjI5MSAxLjMwMzExMyAtNC4xMzY0ODhWLTAuODg0NjgyQzEuMzAzMTEzIC0wLjM0NjcgMS4xNzE2MDYgLTAuMzQ2NyAwLjM5NDUyMSAtMC4zNDY3VjBDMC43MjkyNjUgLTAuMDIzOTEgMS4zMDMxMTMgLTAuMDIzOTEgMS42NDk4MTMgLTAuMDIzOTFDMS43ODEzMiAtMC4wMjM5MSAyLjQ3NDcyIC0wLjAyMzkxIDIuODgxMTk2IDBWLTAuMzQ2N0MyLjEwNDExIC0wLjM0NjcgMi4wNTYyODkgLTAuNDA2NDc2IDIuMDU2Mjg5IC0wLjg3MjcyN1YtNS4yNzIyMjlMMC40MzAzODYgLTUuMTQwNzIyWicgaWQ9J2c5LTEwNScvPgo8cGF0aCBkPSdNNS4zMjAwNSAtMi45MDUxMDZDNS4zMjAwNSAtNC4wMTY5MzYgNS4zMjAwNSAtNC4zNTE2ODEgNS4wNDUwODEgLTQuNzM0MjQ3QzQuNjk4MzgxIC01LjIwMDQ5OCA0LjEzNjQ4OCAtNS4yNzIyMjkgMy43MzAwMTIgLTUuMjcyMjI5QzIuNTcwMzYxIC01LjI3MjIyOSAyLjExNjA2NSAtNC4yNzk5NSAyLjAyMDQyMyAtNC4wNDA4NDdIMi4wMDg0NjhWLTUuMjcyMjI5TDAuMzgyNTY1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xOTU1MTcgLTQuNzk0MDIyIDEuMjkxMTU4IC00LjcxMDMzNiAxLjI5MTE1OCAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjkxMTU4IC0wLjM0NjcgMS4xNTk2NTEgLTAuMzQ2NyAwLjM4MjU2NSAtMC4zNDY3VjBDMC42OTM0IC0wLjAyMzkxIDEuMzM4OTc5IC0wLjAyMzkxIDEuNjczNzI0IC0wLjAyMzkxQzIuMDIwNDIzIC0wLjAyMzkxIDIuNjY2MDAyIC0wLjAyMzkxIDIuOTc2ODM3IDBWLTAuMzQ2N0MyLjIxMTcwNiAtMC4zNDY3IDIuMDY4MjQ0IC0wLjM0NjcgMi4wNjgyNDQgLTAuODg0NjgyVi0zLjEwODM0NEMyLjA2ODI0NCAtNC4zNjM2MzYgMi44OTMxNTEgLTUuMDMzMTI2IDMuNjM0MzcxIC01LjAzMzEyNlM0LjU0Mjk2NCAtNC40MjM0MTIgNC41NDI5NjQgLTMuNjk0MTQ3Vi0wLjg4NDY4MkM0LjU0Mjk2NCAtMC4zNDY3IDQuNDExNDU3IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2N1YwQzMuOTQ1MjA1IC0wLjAyMzkxIDQuNTkwNzg1IC0wLjAyMzkxIDQuOTI1NTI5IC0wLjAyMzkxQzUuMjcyMjI5IC0wLjAyMzkxIDUuOTE3ODA4IC0wLjAyMzkxIDYuMjI4NjQzIDBWLTAuMzQ2N0M1LjYzMDg4NCAtMC4zNDY3IDUuMzMyMDA1IC0wLjM0NjcgNS4zMjAwNSAtMC43MDUzNTVWLTIuOTA1MTA2WicgaWQ9J2c5LTExMCcvPgo8cGF0aCBkPSdNNS40ODc0MjIgLTIuNTU4NDA2QzUuNDg3NDIyIC00LjEwMDYyMyA0LjMxNTgxNiAtNS4zMzIwMDUgMi45MjkwMTYgLTUuMzMyMDA1QzEuNDk0Mzk2IC01LjMzMjAwNSAwLjM1ODY1NSAtNC4wNjQ3NTcgMC4zNTg2NTUgLTIuNTU4NDA2QzAuMzU4NjU1IC0xLjAyODE0NCAxLjU1NDE3MiAwLjExOTU1MiAyLjkxNzA2MSAwLjExOTU1MkM0LjMyNzc3MSAwLjExOTU1MiA1LjQ4NzQyMiAtMS4wNTIwNTUgNS40ODc0MjIgLTIuNTU4NDA2Wk0yLjkyOTAxNiAtMC4xNDM0NjJDMi40ODY2NzUgLTAuMTQzNDYyIDEuOTQ4NjkyIC0wLjMzNDc0NSAxLjYwMTk5MyAtMC45MjA1NDhDMS4yNzkyMDMgLTEuNDU4NTMxIDEuMjY3MjQ4IC0yLjE2Mzg4NSAxLjI2NzI0OCAtMi42NjYwMDJDMS4yNjcyNDggLTMuMTIwMjk5IDEuMjY3MjQ4IC0zLjg0OTU2NCAxLjYzNzg1OCAtNC4zODc1NDdDMS45NzI2MDMgLTQuOTAxNjE5IDIuNDk4NjMgLTUuMDkyOTAyIDIuOTE3MDYxIC01LjA5MjkwMkMzLjM4MzMxMyAtNS4wOTI5MDIgMy44ODU0MyAtNC44Nzc3MDkgNC4yMDgyMTkgLTQuNDExNDU3QzQuNTc4ODI5IC0zLjg2MTUxOSA0LjU3ODgyOSAtMy4xMDgzNDQgNC41Nzg4MjkgLTIuNjY2MDAyQzQuNTc4ODI5IC0yLjI0NzU3MiA0LjU3ODgyOSAtMS41MDYzNTEgNC4yNjc5OTUgLTAuOTQ0NDU4QzMuOTMzMjUgLTAuMzcwNjEgMy4zODMzMTMgLTAuMTQzNDYyIDIuOTI5MDE2IC0wLjE0MzQ2MlonIGlkPSdnOS0xMTEnLz4KPHBhdGggZD0nTTIuOTI5MDE2IDEuOTcyNjAzQzIuMTYzODg1IDEuOTcyNjAzIDIuMDIwNDIzIDEuOTcyNjAzIDIuMDIwNDIzIDEuNDM0NjJWLTAuNjQ1NTc5QzIuMjM1NjE2IC0wLjM0NjcgMi43MjU3NzggMC4xMTk1NTIgMy40OTA5MDkgMC4xMTk1NTJDNC44NjU3NTMgMC4xMTk1NTIgNi4wNzMyMjUgLTEuMDQwMSA2LjA3MzIyNSAtMi41ODIzMTZDNi4wNzMyMjUgLTQuMTAwNjIzIDQuOTQ5NDQgLTUuMjcyMjI5IDMuNjQ2MzI2IC01LjI3MjIyOUMyLjU5NDI3MSAtNS4yNzIyMjkgMi4wMzIzNzkgLTQuNTE5MDU0IDEuOTk2NTEzIC00LjQ3MTIzM1YtNS4yNzIyMjlMMC4zMzQ3NDUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE3MTYwNiAtNC43OTQwMjIgMS4yNDMzMzcgLTQuNzEwMzM2IDEuMjQzMzM3IC00LjE4NDMwOVYxLjQzNDYyQzEuMjQzMzM3IDEuOTcyNjAzIDEuMTExODMxIDEuOTcyNjAzIDAuMzM0NzQ1IDEuOTcyNjAzVjIuMzE5MzAzQzAuNjQ1NTc5IDIuMjk1MzkyIDEuMjkxMTU4IDIuMjk1MzkyIDEuNjI1OTAzIDIuMjk1MzkyQzEuOTcyNjAzIDIuMjk1MzkyIDIuNjE4MTgyIDIuMjk1MzkyIDIuOTI5MDE2IDIuMzE5MzAzVjEuOTcyNjAzWk0yLjAyMDQyMyAtMy44MTM2OTlDMi4wMjA0MjMgLTQuMDQwODQ3IDIuMDIwNDIzIC00LjA1MjgwMiAyLjE1MTkzIC00LjI0NDA4NUMyLjUxMDU4NSAtNC43ODIwNjcgMy4wOTYzODkgLTUuMDA5MjE1IDMuNTUwNjg1IC01LjAwOTIxNUM0LjQ0NzMyMyAtNS4wMDkyMTUgNS4xNjQ2MzMgLTMuOTIxMjk1IDUuMTY0NjMzIC0yLjU4MjMxNkM1LjE2NDYzMyAtMS4xNTk2NTEgNC4zNTE2ODEgLTAuMTE5NTUyIDMuNDMxMTMzIC0wLjExOTU1MkMzLjA2MDUyMyAtMC4xMTk1NTIgMi43MTM4MjMgLTAuMjc0OTY5IDIuNDc0NzIgLTAuNTAyMTE3QzIuMTk5NzUxIC0wLjc3NzA4NiAyLjAyMDQyMyAtMS4wMTYxODkgMi4wMjA0MjMgLTEuMzUwOTM0Vi0zLjgxMzY5OVonIGlkPSdnOS0xMTInLz4KPHBhdGggZD0nTTEuOTk2NTEzIC0yLjc4NTU1NEMxLjk5NjUxMyAtMy45NDUyMDUgMi40NzQ3MiAtNS4wMzMxMjYgMy4zOTUyNjggLTUuMDMzMTI2QzMuNDkwOTA5IC01LjAzMzEyNiAzLjUxNDgxOSAtNS4wMzMxMjYgMy41NjI2NCAtNS4wMjExNzFDMy40NjY5OTkgLTQuOTczMzUgMy4yNzU3MTYgLTQuOTAxNjE5IDMuMjc1NzE2IC00LjU3ODgyOUMzLjI3NTcxNiAtNC4yMzIxMyAzLjU1MDY4NSAtNC4xMDA2MjMgMy43NDE5NjggLTQuMTAwNjIzQzMuOTgxMDcxIC00LjEwMDYyMyA0LjIyMDE3NCAtNC4yNTYwNCA0LjIyMDE3NCAtNC41Nzg4MjlDNC4yMjAxNzQgLTQuOTM3NDg0IDMuODk3Mzg1IC01LjI3MjIyOSAzLjM4MzMxMyAtNS4yNzIyMjlDMi4zNjcxMjMgLTUuMjcyMjI5IDIuMDIwNDIzIC00LjE3MjM1NCAxLjk0ODY5MiAtMy45NDUyMDVIMS45MzY3MzdWLTUuMjcyMjI5TDAuMzM0NzQ1IC01LjE0MDcyMlYtNC43OTQwMjJDMS4xNDc2OTYgLTQuNzk0MDIyIDEuMjQzMzM3IC00LjcxMDMzNiAxLjI0MzMzNyAtNC4xMjQ1MzNWLTAuODg0NjgyQzEuMjQzMzM3IC0wLjM0NjcgMS4xMTE4MzEgLTAuMzQ2NyAwLjMzNDc0NSAtMC4zNDY3VjBDMC42Njk0ODkgLTAuMDIzOTEgMS4zMjcwMjQgLTAuMDIzOTEgMS42ODU2NzkgLTAuMDIzOTFDMi4wMDg0NjggLTAuMDIzOTEgMi44NTcyODUgLTAuMDIzOTEgMy4xMzIyNTQgMFYtMC4zNDY3SDIuODkzMTUxQzIuMDIwNDIzIC0wLjM0NjcgMS45OTY1MTMgLTAuNDc4MjA3IDEuOTk2NTEzIC0wLjkwODU5M1YtMi43ODU1NTRaJyBpZD0nZzktMTE0Jy8+CjxwYXRoIGQ9J00yLjAwODQ2OCAtNC44MDU5NzhIMy42OTQxNDdWLTUuMTUyNjc3SDIuMDA4NDY4Vi03LjM1MjQyOEgxLjc0NTQ1NUMxLjczMzQ5OSAtNi4yMjg2NDMgMS4zMDMxMTMgLTUuMDgwOTQ2IDAuMjE1MTkzIC01LjA0NTA4MVYtNC44MDU5NzhIMS4yMzEzODJWLTEuNDgyNDQxQzEuMjMxMzgyIC0wLjE1NTQxNyAyLjExNjA2NSAwLjExOTU1MiAyLjc0OTY4OSAwLjExOTU1MkMzLjUwMjg2NCAwLjExOTU1MiAzLjg5NzM4NSAtMC42MjE2NjkgMy44OTczODUgLTEuNDgyNDQxVi0yLjE2Mzg4NUgzLjYzNDM3MVYtMS41MDYzNTFDMy42MzQzNzEgLTAuNjQ1NTc5IDMuMjg3NjcxIC0wLjE0MzQ2MiAyLjgyMTQyIC0wLjE0MzQ2MkMyLjAwODQ2OCAtMC4xNDM0NjIgMi4wMDg0NjggLTEuMjU1MjkzIDIuMDA4NDY4IC0xLjQ1ODUzMVYtNC44MDU5NzhaJyBpZD0nZzktMTE2Jy8+CjxwYXRoIGQ9J00zLjYzNDM3MSAtNS4xNDA3MjJWLTQuNzk0MDIyQzQuNDQ3MzIzIC00Ljc5NDAyMiA0LjU0Mjk2NCAtNC43MTAzMzYgNC41NDI5NjQgLTQuMTI0NTMzVi0xLjk4NDU1OEM0LjU0Mjk2NCAtMC45NjgzNjkgNC4wMDQ5ODEgLTAuMTE5NTUyIDMuMTA4MzQ0IC0wLjExOTU1MkMyLjEyODAyIC0wLjExOTU1MiAyLjA2ODI0NCAtMC42ODE0NDUgMi4wNjgyNDQgLTEuMzE1MDY4Vi01LjI3MjIyOUwwLjM4MjU2NSAtNS4xNDA3MjJWLTQuNzk0MDIyQzEuMjkxMTU4IC00Ljc5NDAyMiAxLjI5MTE1OCAtNC43NTgxNTcgMS4yOTExNTggLTMuNjk0MTQ3Vi0xLjkwMDg3MkMxLjI5MTE1OCAtMS4xNTk2NTEgMS4yOTExNTggLTAuNzI5MjY1IDEuNjQ5ODEzIC0wLjMzNDc0NUMxLjkzNjczNyAtMC4wMjM5MSAyLjQyNjg5OSAwLjExOTU1MiAzLjAzNjYxMyAwLjExOTU1MkMzLjIzOTg1MSAwLjExOTU1MiAzLjYyMjQxNiAwLjExOTU1MiA0LjAyODg5MiAtMC4yMjcxNDhDNC4zNzU1OTIgLTAuNTAyMTE3IDQuNTY2ODc0IC0wLjk1NjQxMyA0LjU2Njg3NCAtMC45NTY0MTNWMC4xMTk1NTJMNi4yMjg2NDMgMFYtMC4zNDY3QzUuNDE1NjkxIC0wLjM0NjcgNS4zMjAwNSAtMC40MzAzODYgNS4zMjAwNSAtMS4wMTYxODlWLTUuMjcyMjI5TDMuNjM0MzcxIC01LjE0MDcyMlonIGlkPSdnOS0xMTcnLz4KPHBhdGggZD0nTTIuOTg4NzkyIDI4LjIwMjI0Mkg2LjEzMzAwMVYyNy41NDQ3MDdIMy42NDYzMjZWMC4xNzkzMjhINi4xMzMwMDFWLTAuNDc4MjA3SDIuOTg4NzkyVjI4LjIwMjI0MlonIGlkPSdnMi0yMCcvPgo8cGF0aCBkPSdNMi42NTQwNDcgMjcuNTQ0NzA3SDAuMTY3MzcyVjI4LjIwMjI0MkgzLjMxMTU4MlYtMC40NzgyMDdIMC4xNjczNzJWMC4xNzkzMjhIMi42NTQwNDdWMjcuNTQ0NzA3WicgaWQ9J2cyLTIxJy8+CjxwYXRoIGQ9J00xNS4xMzUyNDMgMTYuNzM3MjM1TDE2LjU4MTgxOCAxMi45MTE1ODJIMTYuMjgyOTM5QzE1LjgxNjY4NyAxNC4xNTQ5MTkgMTQuNTQ5NDQgMTQuOTY3ODcgMTMuMTc0NTk1IDE1LjMyNjUyNkMxMi45MjM1MzcgMTUuMzg2MzAxIDExLjc1MTkzIDE1LjY5NzEzNiA5LjQ1NjUzOCAxNS42OTcxMzZIMi4yNDc1NzJMOC4zMzI3NTIgOC41NTk5QzguNDE2NDM4IDguNDY0MjU5IDguNDQwMzQ5IDguNDI4Mzk0IDguNDQwMzQ5IDguMzY4NjE4QzguNDQwMzQ5IDguMzQ0NzA3IDguNDQwMzQ5IDguMzA4ODQyIDguMzU2NjYzIDguMTg5MjlMMi43ODU1NTQgMC41NzM4NDhIOS4zMzY5ODZDMTAuOTM4OTc5IDAuNTczODQ4IDEyLjAyNjg5OSAwLjc0MTIyIDEyLjEzNDQ5NiAwLjc2NTEzMUMxMi43ODAwNzUgMC44NjA3NzIgMTMuODIwMTc0IDEuMDY0MDEgMTQuNzY0NjMzIDEuNjYxNzY4QzE1LjA2MzUxMiAxLjg1MzA1MSAxNS44NzY0NjMgMi4zOTEwMzQgMTYuMjgyOTM5IDMuMzU5NDAySDE2LjU4MTgxOEwxNS4xMzUyNDMgMEgxLjAwNDIzNEMwLjcyOTI2NSAwIDAuNzE3MzEgMC4wMTE5NTUgMC42ODE0NDUgMC4wODM2ODZDMC42Njk0ODkgMC4xMTk1NTIgMC42Njk0ODkgMC4zNDY3IDAuNjY5NDg5IDAuNDc4MjA3TDYuOTkzNzczIDkuMTMzNzQ4TDAuODAwOTk2IDE2LjM5MDUzNUMwLjY4MTQ0NSAxNi41MzM5OTggMC42ODE0NDUgMTYuNTkzNzczIDAuNjgxNDQ1IDE2LjYwNTcyOUMwLjY4MTQ0NSAxNi43MzcyMzUgMC43ODkwNDEgMTYuNzM3MjM1IDEuMDA0MjM0IDE2LjczNzIzNUgxNS4xMzUyNDNaJyBpZD0nZzItODgnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzYzLjgzMDMzOCcgeGxpbms6aHJlZj0nI2c3LTEwMicgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzcyLjg2OTI3MycgeGxpbms6aHJlZj0nI2c5LTQwJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nNzcuNDIxNTk4JyB4bGluazpocmVmPScjZzctMTIwJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nODQuMDczNjg1JyB4bGluazpocmVmPScjZzktNDEnIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PSc5MS4yODI2NzUnIHhsaW5rOmhyZWY9JyNnNC0wJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMTAzLjIzNzgzNScgeGxpbms6aHJlZj0nI2c3LTEwMycgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzEwOC44NDMxNDMnIHhsaW5rOmhyZWY9JyNnNi0zNCcgeT0nMTA2LjA0MzcxMicvPgo8dXNlIHg9JzExNS4yNDQxNTcnIHhsaW5rOmhyZWY9JyNnOS00MCcgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzExOS43OTY0ODMnIHhsaW5rOmhyZWY9JyNnNy0xMjAnIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScxMjYuNDQ4NTcnIHhsaW5rOmhyZWY9JyNnOS00MScgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzE0OS40MTc4NDgnIHhsaW5rOmhyZWY9JyNnOS02MScgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzE3Ni45Mzk0NTknIHhsaW5rOmhyZWY9JyNnNy0xMDInIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScxODUuOTc4MzkzJyB4bGluazpocmVmPScjZzktNDAnIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScxOTAuNTMwNzE5JyB4bGluazpocmVmPScjZzctMTIwJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMTk3LjE4MjgwNicgeGxpbms6aHJlZj0nI2c5LTQxJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMjA0LjM5MTc5NScgeGxpbms6aHJlZj0nI2c0LTAnIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScyMTYuMzQ2OTU1JyB4bGluazpocmVmPScjZzctMzQnIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScyMjYuNjY1MTk2JyB4bGluazpocmVmPScjZzUtNzcnIHk9JzgzLjk4NTA1OScvPgo8cmVjdCBoZWlnaHQ9JzAuMzU4NjU2JyB3aWR0aD0nNy41ODgxODInIHg9JzIyNi42NjUxOTYnIHk9Jzg1LjA3MTYzNycvPgo8dXNlIHg9JzIyOC43MDU4MDcnIHhsaW5rOmhyZWY9JyNnNS0zNCcgeT0nOTAuMzY5MDkzJy8+Cjx1c2UgeD0nMjIxLjgyNDk3OScgeGxpbms6aHJlZj0nI2cyLTg4JyB5PSc5Mi44OTI5ODQnLz4KPHVzZSB4PScyMjIuNzM4MTM0JyB4bGluazpocmVmPScjZzYtMTA3JyB5PScxMTguMzUzMjAzJy8+Cjx1c2UgeD0nMjI3LjM1OTc1JyB4bGluazpocmVmPScjZzgtNjEnIHk9JzExOC4zNTMyMDMnLz4KPHVzZSB4PScyMzMuOTQ2MjU3JyB4bGluazpocmVmPScjZzgtNDgnIHk9JzExOC4zNTMyMDMnLz4KPHVzZSB4PScyMzkuMDkzNTk1JyB4bGluazpocmVmPScjZzktNDknIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScyNDAuOTYxNTknIHhsaW5rOmhyZWY9JyNnOS00OScgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzI0Ni44MTQ1ODEnIHhsaW5rOmhyZWY9JyNnMy0xMDInIHk9JzEwNi4xMTAxNTknLz4KPHVzZSB4PScyNTEuMDQ4NzYzJyB4bGluazpocmVmPScjZzYtMTIwJyB5PScxMDYuMTEwMTU5Jy8+Cjx1c2UgeD0nMjU1LjgxNTY2MicgeGxpbms6aHJlZj0nI2czLTUwJyB5PScxMDYuMTEwMTU5Jy8+Cjx1c2UgeD0nMjYxLjQ2MTIzOScgeGxpbms6aHJlZj0nI2c2LTY3JyB5PScxMDYuMTEwMTU5Jy8+Cjx1c2UgeD0nMjY3LjQ5Njc0MicgeGxpbms6aHJlZj0nI2c1LTEwNycgeT0nMTA3LjUxNjAwNCcvPgo8dXNlIHg9JzI3Mi4wNjk4MzQnIHhsaW5rOmhyZWY9JyNnMy0xMDMnIHk9JzEwNi4xMTAxNTknLz4KPHVzZSB4PScyODAuMTIyOTc4JyB4bGluazpocmVmPScjZzktNjEnIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PScyOTIuNTQ4NDU5JyB4bGluazpocmVmPScjZzctMTAyJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMzAxLjU4NzM5MycgeGxpbms6aHJlZj0nI2c5LTQwJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMzA2LjEzOTcxOScgeGxpbms6aHJlZj0nI2c3LTEyMCcgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzMxMi43OTE4MDYnIHhsaW5rOmhyZWY9JyNnOS00MScgeT0nMTA0LjI1MDQ0OScvPgo8dXNlIHg9JzMyMC4wMDA3OTUnIHhsaW5rOmhyZWY9JyNnNC0wJyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMzMxLjk1NTk1NicgeGxpbms6aHJlZj0nI2c3LTM0JyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMzQyLjI3NDE5NicgeGxpbms6aHJlZj0nI2c1LTc3JyB5PSc4My45ODUwNTknLz4KPHJlY3QgaGVpZ2h0PScwLjM1ODY1Nicgd2lkdGg9JzcuNTg4MTgyJyB4PSczNDIuMjc0MTk2JyB5PSc4NS4wNzE2MzcnLz4KPHVzZSB4PSczNDQuMzE0ODA3JyB4bGluazpocmVmPScjZzUtMzQnIHk9JzkwLjM2OTA5MycvPgo8dXNlIHg9JzMzNy40MzM5NzknIHhsaW5rOmhyZWY9JyNnMi04OCcgeT0nOTIuODkyOTg0Jy8+Cjx1c2UgeD0nMzM4LjM0NzEzNScgeGxpbms6aHJlZj0nI2c2LTEwNycgeT0nMTE4LjM1MzIwMycvPgo8dXNlIHg9JzM0Mi45Njg3NScgeGxpbms6aHJlZj0nI2c4LTYxJyB5PScxMTguMzUzMjAzJy8+Cjx1c2UgeD0nMzQ5LjU1NTI1NycgeGxpbms6aHJlZj0nI2c4LTQ4JyB5PScxMTguMzUzMjAzJy8+Cjx1c2UgeD0nMzU0LjcwMjU5NScgeGxpbms6aHJlZj0nI2c5LTQ5JyB5PScxMDQuMjUwNDQ5Jy8+Cjx1c2UgeD0nMzU2LjU3MDU5JyB4bGluazpocmVmPScjZzktNDknIHk9JzEwNC4yNTA0NDknLz4KPHVzZSB4PSczNjIuNDIzNTgxJyB4bGluazpocmVmPScjZzMtMTAyJyB5PScxMDYuMTEwMTU5Jy8+Cjx1c2UgeD0nMzY2LjY1Nzc2MycgeGxpbms6aHJlZj0nI2c2LTEwMicgeT0nMTA2LjExMDE1OScvPgo8dXNlIHg9JzM3MS42MDQ1MycgeGxpbms6aHJlZj0nI2c4LTQwJyB5PScxMDYuMTEwMTU5Jy8+Cjx1c2UgeD0nMzc0Ljg5Nzc4MycgeGxpbms6aHJlZj0nI2c2LTEyMCcgeT0nMTA2LjExMDE1OScvPgo8dXNlIHg9JzM3OS42NjQ2ODInIHhsaW5rOmhyZWY9JyNnOC00MScgeT0nMTA2LjExMDE1OScvPgo8dXNlIHg9JzM4Mi45NTc5MzUnIHhsaW5rOmhyZWY9JyNnMC02MicgeT0nMTA2LjExMDE1OScvPgo8dXNlIHg9JzM4OS4xNTY5MzMnIHhsaW5rOmhyZWY9JyNnNi0xMDcnIHk9JzEwNi4xMTAxNTknLz4KPHVzZSB4PSczOTMuNzc4NTQ5JyB4bGluazpocmVmPScjZzYtMzQnIHk9JzEwNi4xMTAxNTknLz4KPHVzZSB4PSczOTcuNjg4OTM0JyB4bGluazpocmVmPScjZzMtMTAzJyB5PScxMDYuMTEwMTU5Jy8+Cjx1c2UgeD0nMTQ5LjQxNzg0OCcgeGxpbms6aHJlZj0nI2c5LTYxJyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMTc2LjkzOTQ1OScgeGxpbms6aHJlZj0nI2c3LTEwMicgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzE4NS45NzgzOTMnIHhsaW5rOmhyZWY9JyNnOS00MCcgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzE5MC41MzA3MTknIHhsaW5rOmhyZWY9JyNnNy0xMjAnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PScxOTcuMTgyODA2JyB4bGluazpocmVmPScjZzktNDEnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PScyMDQuMzkxNzk1JyB4bGluazpocmVmPScjZzQtMCcgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzIxNi4zNDY5NTUnIHhsaW5rOmhyZWY9JyNnNy0zNCcgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzIyMy44MTc0NzYnIHhsaW5rOmhyZWY9JyNnMi0yMCcgeT0nMTI0LjAxMTk2Jy8+Cjx1c2UgeD0nMjMxLjMyMjY4NycgeGxpbms6aHJlZj0nI2c3LTEwMicgeT0nMTMyLjc4MTEzOScvPgo8dXNlIHg9JzI0MC4zNjE2MjInIHhsaW5rOmhyZWY9JyNnOS00MCcgeT0nMTMyLjc4MTEzOScvPgo8dXNlIHg9JzI0NC45MTM5NDcnIHhsaW5rOmhyZWY9JyNnNy0xMjAnIHk9JzEzMi43ODExMzknLz4KPHVzZSB4PScyNTEuNTY2MDM0JyB4bGluazpocmVmPScjZzktNDEnIHk9JzEzMi43ODExMzknLz4KPHJlY3QgaGVpZ2h0PScwLjQ3ODE4Nycgd2lkdGg9JzI0Ljc5NTY3MycgeD0nMjMxLjMyMjY4NycgeT0nMTM3LjY0MTAxMicvPgo8dXNlIHg9JzI0MC45ODE1MicgeGxpbms6aHJlZj0nI2c3LTM0JyB5PScxNDkuMDY5NTYnLz4KPHVzZSB4PScyNTcuMzEzODc0JyB4bGluazpocmVmPScjZzItMjEnIHk9JzEyNC4wMTE5NicvPgo8dXNlIHg9JzI4MS4yMjQwNDMnIHhsaW5rOmhyZWY9JyNnOS00MCcgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzI4NS43NzYzNjknIHhsaW5rOmhyZWY9JyNnOS0xMTInIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PScyOTIuMjc5NjkxJyB4bGluazpocmVmPScjZzktOTcnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PScyOTguMTMyNjgxJyB4bGluazpocmVmPScjZzktMTE0JyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMzAyLjY4NTAwNycgeGxpbms6aHJlZj0nI2c5LTExNicgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzMwNy4yMzczMzMnIHhsaW5rOmhyZWY9JyNnOS0xMDUnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PSczMTAuNDg4OTk0JyB4bGluazpocmVmPScjZzktMTAxJyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMzE5LjU5MzY0NicgeGxpbms6aHJlZj0nI2c5LTEwMScgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzMyNC43OTYzMDQnIHhsaW5rOmhyZWY9JyNnOS0xMTAnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PSczMzAuOTc0NDYnIHhsaW5rOmhyZWY9JyNnOS0xMTYnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PSczMzUuNTI2Nzg2JyB4bGluazpocmVmPScjZzktMTA1JyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMzM4LjQ1MzI4MScgeGxpbms6aHJlZj0nI2c5LTE4JyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMzM4Ljc3ODQ0NycgeGxpbms6aHJlZj0nI2c5LTEwMScgeT0nMTQwLjg2ODg5NycvPgo8dXNlIHg9JzM0My45ODExMDUnIHhsaW5rOmhyZWY9JyNnOS0xMTQnIHk9JzE0MC44Njg4OTcnLz4KPHVzZSB4PSczNDguNTMzNDMxJyB4bGluazpocmVmPScjZzktMTAxJyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMzUzLjczNjA4OScgeGxpbms6aHJlZj0nI2c5LTQxJyB5PScxNDAuODY4ODk3Jy8+Cjx1c2UgeD0nMTQwLjk2MzUyOCcgeGxpbms6aHJlZj0nI2c5LTEwMCcgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzE0Ny40NjY4NTEnIHhsaW5rOmhyZWY9JyNnOS0zOScgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzE1MC43MTg1MTInIHhsaW5rOmhyZWY9JyNnOS0xMTEnIHk9JzE2OS40NDY2MzcnLz4KPHVzZSB4PScxNTYuODk2NjY5JyB4bGluazpocmVmPScjZzktMTgnIHk9JzE2OS40NDY2MzcnLz4KPHVzZSB4PScxNTYuNTcxNTAyJyB4bGluazpocmVmPScjZzktMTE3JyB5PScxNjkuNDQ2NjM3Jy8+Cjx1c2UgeD0nMTc2LjkzOTQ1OScgeGxpbms6aHJlZj0nI2c5LTQ4JyB5PScxNjkuNDQ2NjM3Jy8+Cjx1c2UgeD0nMTg2LjExMzI3OCcgeGxpbms6aHJlZj0nI2cxLTU0JyB5PScxNjkuNDQ2NjM3Jy8+Cjx1c2UgeD0nMTk4LjczMjYwNScgeGxpbms6aHJlZj0nI2c3LTEwMicgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzIwNy43NzE1MzknIHhsaW5rOmhyZWY9JyNnOS00MCcgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzIxMi4zMjM4NjUnIHhsaW5rOmhyZWY9JyNnNy0xMjAnIHk9JzE2OS40NDY2MzcnLz4KPHVzZSB4PScyMTguOTc1OTUyJyB4bGluazpocmVmPScjZzktNDEnIHk9JzE2OS40NDY2MzcnLz4KPHVzZSB4PScyMjYuMTg0OTQxJyB4bGluazpocmVmPScjZzQtMCcgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzIzOC4xNDAxMDEnIHhsaW5rOmhyZWY9JyNnNy0xMDMnIHk9JzE2OS40NDY2MzcnLz4KPHVzZSB4PScyNDMuNzQ1NDA5JyB4bGluazpocmVmPScjZzYtMzQnIHk9JzE3MS4yMzk5Jy8+Cjx1c2UgeD0nMjUwLjE0NjQyNCcgeGxpbms6aHJlZj0nI2c5LTQwJyB5PScxNjkuNDQ2NjM3Jy8+Cjx1c2UgeD0nMjU0LjY5ODc0OScgeGxpbms6aHJlZj0nI2c3LTEyMCcgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzI2MS4zNTA4MzYnIHhsaW5rOmhyZWY9JyNnOS00MScgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzI2OS4yMjM5OTInIHhsaW5rOmhyZWY9JyNnMS01NCcgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzI4My4yMjYzMTUnIHhsaW5rOmhyZWY9JyNnNy0zNCcgeT0nMTYxLjM1ODg3OCcvPgo8cmVjdCBoZWlnaHQ9JzAuNDc4MTg3JyB3aWR0aD0nNS44NTI5OScgeD0nMjgzLjAzODgzMicgeT0nMTY2LjIxODc1MScvPgo8dXNlIHg9JzI4My4wMzg4MzInIHhsaW5rOmhyZWY9JyNnOS01MicgeT0nMTc3LjY0NzI5OScvPgo8dXNlIHg9JzQxMi40Mzk2MTknIHhsaW5rOmhyZWY9JyNnOS00MCcgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzQxNi45OTE5NDQnIHhsaW5rOmhyZWY9JyNnOS00OScgeT0nMTY5LjQ0NjYzNycvPgo8dXNlIHg9JzQyMi44NDQ5MzUnIHhsaW5rOmhyZWY9JyNnOS00MScgeT0nMTY5LjQ0NjYzNycvPgo8L2c+Cjwvc3ZnPg==)
Comme est continue sur un compact, elle est uniformément continue sur ce compact :

Par conséquent :

D’après le second lemme, on peut construire des fonctions  telles que :
telles que :

On en déduit que :
![\begin{array}{rcl}
\left| f\left( x\right) -\varepsilon\overset{\frac{M}{\varepsilon}}
{\sum_{k=0}}h_{k}\left( x\right) \right| &\leqslant&
\left| f\left( x\right) -g_{\varepsilon}\left( x\right) \right|
+\left|g_{\varepsilon}\left( x\right) -\varepsilon
\overset{\frac{M}{\varepsilon}}{\sum_{k=0}}h_{k}\left( x\right) \right| \\
&\leqslant& \varepsilon+ \varepsilon^2 \left[ \dfrac{M}{\varepsilon}\right] + 2\varepsilon^2 \\
&\leqslant& \varepsilon\left( M+3\right)
\end{array}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nNzcuMzEwNjg2cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNjEuODkyMDY2IDc5Ljc0MjE4MSAzNDIuNDY3NDQxIDc3LjMxMDY4Nicgd2lkdGg9JzM0Mi40Njc0NDFwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNOC4wNjk3MzggLTcuMTAxMzdDOC4yMTMyIC03LjE3MzEwMSA4LjI5Njg4NyAtNy4yMzI4NzcgOC4yOTY4ODcgLTcuMzY0Mzg0UzguMTg5MjkgLTcuNjAzNDg3IDguMDU3NzgzIC03LjYwMzQ4N0M3Ljk5ODAwNyAtNy42MDM0ODcgNy44OTA0MTEgLTcuNTU1NjY2IDcuODQyNTkgLTcuNTMxNzU2TDEuMjMxMzgyIC00LjQxMTQ1N0MxLjAyODE0NCAtNC4zMTU4MTYgMC45OTIyNzkgLTQuMjMyMTMgMC45OTIyNzkgLTQuMTM2NDg4UzEuMDQwMSAtMy45NTcxNjEgMS4yMzEzODIgLTMuODczNDc0TDcuODQyNTkgLTAuNzY1MTMxQzcuOTk4MDA3IC0wLjY4MTQ0NSA4LjAyMTkxOCAtMC42ODE0NDUgOC4wNTc3ODMgLTAuNjgxNDQ1QzguMTg5MjkgLTAuNjgxNDQ1IDguMjk2ODg3IC0wLjc4OTA0MSA4LjI5Njg4NyAtMC45MjA1NDhDOC4yOTY4ODcgLTEuMDc1OTY1IDguMTg5MjkgLTEuMTIzNzg2IDguMDU3NzgzIC0xLjE4MzU2MkwxLjc5MzI3NSAtNC4xMzY0ODhMOC4wNjk3MzggLTcuMTAxMzdaTTcuODQyNTkgMS41NTQxNzJDNy45OTgwMDcgMS42Mzc4NTggOC4wMjE5MTggMS42Mzc4NTggOC4wNTc3ODMgMS42Mzc4NThDOC4xODkyOSAxLjYzNzg1OCA4LjI5Njg4NyAxLjUzMDI2MiA4LjI5Njg4NyAxLjM5ODc1NUM4LjI5Njg4NyAxLjI0MzMzNyA4LjE4OTI5IDEuMTk1NTE3IDguMDU3NzgzIDEuMTM1NzQxTDEuNDU4NTMxIC0xLjk3MjYwM0MxLjMwMzExMyAtMi4wNTYyODkgMS4yNzkyMDMgLTIuMDU2Mjg5IDEuMjMxMzgyIC0yLjA1NjI4OUMxLjA4NzkyIC0yLjA1NjI4OSAwLjk5MjI3OSAtMS45NDg2OTIgMC45OTIyNzkgLTEuODE3MTg2QzAuOTkyMjc5IC0xLjcyMTU0NCAxLjA0MDEgLTEuNjM3ODU4IDEuMjMxMzgyIC0xLjU1NDE3Mkw3Ljg0MjU5IDEuNTU0MTcyWicgaWQ9J2cwLTU0Jy8+CjxwYXRoIGQ9J00zLjg5NzM4NSAtMi41NDI0NjZDMy44OTczODUgLTMuMzk1MjY4IDMuODA5NzE0IC0zLjkxMzMyNSAzLjU0NjcgLTQuNDIzNDEyQzMuMTk2MDE1IC01LjEyNDc4MiAyLjU1MDQzNiAtNS4zMDAxMjUgMi4xMTIwOCAtNS4zMDAxMjVDMS4xMDc4NDYgLTUuMzAwMTI1IDAuNzQxMjIgLTQuNTUwOTM0IDAuNjI5NjM5IC00LjMyNzc3MUMwLjM0MjcxNSAtMy43NDU5NTMgMC4zMjY3NzUgLTIuOTU2OTEyIDAuMzI2Nzc1IC0yLjU0MjQ2NkMwLjMyNjc3NSAtMi4wMTY0MzggMC4zNTA2ODUgLTEuMjExNDU3IDAuNzMzMjUgLTAuNTczODQ4QzEuMDk5ODc1IDAuMDE1OTQgMS42ODk2NjQgMC4xNjczNzIgMi4xMTIwOCAwLjE2NzM3MkMyLjQ5NDY0NSAwLjE2NzM3MiAzLjE4MDA3NSAwLjA0NzgyMSAzLjU3ODU4IC0wLjc0MTIyQzMuODczNDc0IC0xLjMxNTA2OCAzLjg5NzM4NSAtMi4wMjQ0MDggMy44OTczODUgLTIuNTQyNDY2Wk0yLjExMjA4IC0wLjA1NTc5MUMxLjg0MTA5NiAtMC4wNTU3OTEgMS4yOTExNTggLTAuMTgzMzEzIDEuMTIzNzg2IC0xLjAyMDE3NEMxLjAzNjExNSAtMS40NzQ0NzEgMS4wMzYxMTUgLTIuMjIzNjYxIDEuMDM2MTE1IC0yLjYzODEwN0MxLjAzNjExNSAtMy4xODgwNDUgMS4wMzYxMTUgLTMuNzQ1OTUzIDEuMTIzNzg2IC00LjE4NDMwOUMxLjI5MTE1OCAtNC45OTcyNiAxLjkxMjgyNyAtNS4wNzY5NjEgMi4xMTIwOCAtNS4wNzY5NjFDMi4zODMwNjQgLTUuMDc2OTYxIDIuOTMzMDAxIC00Ljk0MTQ2OSAzLjA5MjQwMyAtNC4yMTYxODlDMy4xODgwNDUgLTMuNzc3ODMzIDMuMTg4MDQ1IC0zLjE4MDA3NSAzLjE4ODA0NSAtMi42MzgxMDdDMy4xODgwNDUgLTIuMTY3ODcgMy4xODgwNDUgLTEuNDUwNTYgMy4wOTI0MDMgLTEuMDA0MjM0QzIuOTI1MDMxIC0wLjE2NzM3MiAyLjM3NTA5MyAtMC4wNTU3OTEgMi4xMTIwOCAtMC4wNTU3OTFaJyBpZD0nZzYtNDgnLz4KPHBhdGggZD0nTTIuMjQ3NTcyIC0xLjYyNTkwM0MyLjM3NTA5MyAtMS43NDU0NTUgMi43MDk4MzggLTIuMDA4NDY4IDIuODM3MzYgLTIuMTIwMDVDMy4zMzE1MDcgLTIuNTc0MzQ2IDMuODAxNzQzIC0zLjAxMjcwMiAzLjgwMTc0MyAtMy43Mzc5ODNDMy44MDE3NDMgLTQuNjg2NDI2IDMuMDA0NzMyIC01LjMwMDEyNSAyLjAwODQ2OCAtNS4zMDAxMjVDMS4wNTIwNTUgLTUuMzAwMTI1IDAuNDIyNDE2IC00LjU3NDg0NCAwLjQyMjQxNiAtMy44NjU1MDRDMC40MjI0MTYgLTMuNDc0OTY5IDAuNzMzMjUgLTMuNDE5MTc4IDAuODQ0ODMyIC0zLjQxOTE3OEMxLjAxMjIwNCAtMy40MTkxNzggMS4yNTkyNzggLTMuNTM4NzMgMS4yNTkyNzggLTMuODQxNTk0QzEuMjU5Mjc4IC00LjI1NjA0IDAuODYwNzcyIC00LjI1NjA0IDAuNzY1MTMxIC00LjI1NjA0QzAuOTk2MjY0IC00LjgzNzg1OCAxLjUzMDI2MiAtNS4wMzcxMTEgMS45MjA3OTcgLTUuMDM3MTExQzIuNjYyMDE3IC01LjAzNzExMSAzLjA0NDU4MyAtNC40MDc0NzIgMy4wNDQ1ODMgLTMuNzM3OTgzQzMuMDQ0NTgzIC0yLjkwOTA5MSAyLjQ2Mjc2NSAtMi4zMDMzNjIgMS41MjIyOTEgLTEuMzM4OTc5TDAuNTE4MDU3IC0wLjMwMjg2NEMwLjQyMjQxNiAtMC4yMTUxOTMgMC40MjI0MTYgLTAuMTk5MjUzIDAuNDIyNDE2IDBIMy41NzA2MUwzLjgwMTc0MyAtMS40MjY2NUgzLjU1NDY3QzMuNTMwNzYgLTEuMjY3MjQ4IDMuNDY2OTk5IC0wLjg2ODc0MiAzLjM3MTM1NyAtMC43MTczMUMzLjMyMzUzNyAtMC42NTM1NDkgMi43MTc4MDggLTAuNjUzNTQ5IDIuNTkwMjg2IC0wLjY1MzU0OUgxLjE3MTYwNkwyLjI0NzU3MiAtMS42MjU5MDNaJyBpZD0nZzYtNTAnLz4KPHBhdGggZD0nTTUuODI2MTUyIC0yLjY1NDA0N0M1Ljk0NTcwNCAtMi42NTQwNDcgNi4xMDUxMDYgLTIuNjU0MDQ3IDYuMTA1MTA2IC0yLjgzNzM2UzUuOTEzODIzIC0zLjAyMDY3MiA1Ljc5NDI3MSAtMy4wMjA2NzJIMC43ODEwNzFDMC42NjE1MTkgLTMuMDIwNjcyIDAuNDcwMjM3IC0zLjAyMDY3MiAwLjQ3MDIzNyAtMi44MzczNlMwLjYyOTYzOSAtMi42NTQwNDcgMC43NDkxOTEgLTIuNjU0MDQ3SDUuODI2MTUyWk01Ljc5NDI3MSAtMC45NjQzODRDNS45MTM4MjMgLTAuOTY0Mzg0IDYuMTA1MTA2IC0wLjk2NDM4NCA2LjEwNTEwNiAtMS4xNDc2OTZTNS45NDU3MDQgLTEuMzMxMDA5IDUuODI2MTUyIC0xLjMzMTAwOUgwLjc0OTE5MUMwLjYyOTYzOSAtMS4zMzEwMDkgMC40NzAyMzcgLTEuMzMxMDA5IDAuNDcwMjM3IC0xLjE0NzY5NlMwLjY2MTUxOSAtMC45NjQzODQgMC43ODEwNzEgLTAuOTY0Mzg0SDUuNzk0MjcxWicgaWQ9J2c2LTYxJy8+CjxwYXRoIGQ9J00xLjY2MTc2OCAtMi43MjU3NzhDMi4wNDQzMzQgLTIuNTcwMzYxIDIuNDUwODA5IC0yLjU3MDM2MSAyLjY3Nzk1OCAtMi41NzAzNjFDMi45ODg3OTIgLTIuNTcwMzYxIDMuNjEwNDYxIC0yLjU3MDM2MSAzLjYxMDQ2MSAtMi45MTcwNjFDMy42MTA0NjEgLTMuMTMyMjU0IDMuMzgzMzEzIC0zLjIxNTk0IDIuNzczNTk5IC0zLjIxNTk0QzIuNDc0NzIgLTMuMjE1OTQgMi4xMTYwNjUgLTMuMTgwMDc1IDEuNjk3NjM0IC0zLjAwMDc0N0MxLjMyNzAyNCAtMy4xODAwNzUgMS4xODM1NjIgLTMuNDU1MDQ0IDEuMTgzNTYyIC0zLjcxODA1N0MxLjE4MzU2MiAtNC40NTkyNzggMi4zNTUxNjggLTQuODg5NjY0IDMuNDE5MTc4IC00Ljg4OTY2NEMzLjYyMjQxNiAtNC44ODk2NjQgNC4wNTI4MDIgLTQuODg5NjY0IDQuNTU0OTE5IC00LjUxOTA1NEM0LjYyNjY1IC00LjQ3MTIzMyA0LjY2MjUxNiAtNC40MzUzNjcgNC43NDYyMDIgLTQuNDM1MzY3QzQuODg5NjY0IC00LjQzNTM2NyA1LjA0NTA4MSAtNC41OTA3ODUgNS4wNDUwODEgLTQuNzM0MjQ3QzUuMDQ1MDgxIC00Ljk0OTQ0IDQuMzUxNjgxIC01LjQwMzczNiAzLjUyNjc3NSAtNS40MDM3MzZDMi4xODc3OTYgLTUuNDAzNzM2IDAuOTIwNTQ4IC00LjYwMjc0IDAuOTIwNTQ4IC0zLjcxODA1N0MwLjkyMDU0OCAtMy4yNzU3MTYgMS4yMDc0NzIgLTMuMDAwNzQ3IDEuNDEwNzEgLTIuODU3Mjg1QzAuNzE3MzEgLTIuNDYyNzY1IDAuMzEwODM0IC0xLjgxNzE4NiAwLjMxMDgzNCAtMS4yMzEzODJDMC4zMTA4MzQgLTAuNDA2NDc2IDEuMDUyMDU1IDAuMjUxMDU5IDIuMTk5NzUxIDAuMjUxMDU5QzMuNzc3ODMzIDAuMjUxMDU5IDQuNDExNDU3IC0wLjgwMDk5NiA0LjQxMTQ1NyAtMC45NjgzNjlDNC40MTE0NTcgLTEuMDI4MTQ0IDQuMzYzNjM2IC0xLjA3NTk2NSA0LjMwMzg2MSAtMS4wNzU5NjVTNC4yMjAxNzQgLTEuMDQwMSA0LjE3MjM1NCAtMC45NjgzNjlDNC4wNDA4NDcgLTAuNzQxMjIgMy43MzAwMTIgLTAuMjYzMDE0IDIuMzA3MzQ3IC0wLjI2MzAxNEMxLjU2NjEyNyAtMC4yNjMwMTQgMC41ODU4MDMgLTAuNDU0Mjk2IDAuNTg1ODAzIC0xLjMwMzExM0MwLjU4NTgwMyAtMS43MDk1ODkgMC44ODQ2ODIgLTIuMzE5MzAzIDEuNjYxNzY4IC0yLjcyNTc3OFpNMi4wMzIzNzkgLTIuODY5MjRDMi4zNTUxNjggLTIuOTc2ODM3IDIuNjY2MDAyIC0yLjk3NjgzNyAyLjc0OTY4OSAtMi45NzY4MzdDMy4wODQ0MzMgLTIuOTc2ODM3IDMuMTQ0MjA5IC0yLjk1MjkyNyAzLjMzNTQ5MiAtMi45MDUxMDZDMy4xMzIyNTQgLTIuODA5NDY1IDMuMTA4MzQ0IC0yLjgwOTQ2NSAyLjY3Nzk1OCAtMi44MDk0NjVDMi40NjI3NjUgLTIuODA5NDY1IDIuMjcxNDgyIC0yLjgwOTQ2NSAyLjAzMjM3OSAtMi44NjkyNFonIGlkPSdnNS0zNCcvPgo8cGF0aCBkPSdNMTAuODU1MjkzIC03LjI5MjY1M0MxMC45NjI4ODkgLTcuNjk5MTI4IDEwLjk4NjggLTcuODE4NjggMTEuODM1NjE2IC03LjgxODY4QzEyLjA2Mjc2NSAtNy44MTg2OCAxMi4xNzAzNjEgLTcuODE4NjggMTIuMTcwMzYxIC04LjA0NTgyOEMxMi4xNzAzNjEgLTguMTY1MzggMTIuMDg2Njc1IC04LjE2NTM4IDExLjg1OTUyNyAtOC4xNjUzOEgxMC40MjQ5MDdDMTAuMTI2MDI3IC04LjE2NTM4IDEwLjExNDA3MiAtOC4xNTM0MjUgOS45ODI1NjUgLTcuOTYyMTQyTDUuNjE4OTI5IC0xLjA2NDAxTDQuNzIyMjkxIC03LjkwMjM2NkM0LjY4NjQyNiAtOC4xNjUzOCA0LjY3NDQ3MSAtOC4xNjUzOCA0LjM2MzYzNiAtOC4xNjUzOEgyLjg4MTE5NkMyLjY1NDA0NyAtOC4xNjUzOCAyLjU0NjQ1MSAtOC4xNjUzOCAyLjU0NjQ1MSAtNy45MzgyMzJDMi41NDY0NTEgLTcuODE4NjggMi42NTQwNDcgLTcuODE4NjggMi44MzMzNzUgLTcuODE4NjhDMy41NjI2NCAtNy44MTg2OCAzLjU2MjY0IC03LjcyMzAzOSAzLjU2MjY0IC03LjU5MTUzMkMzLjU2MjY0IC03LjU2NzYyMSAzLjU2MjY0IC03LjQ5NTg5IDMuNTE0ODE5IC03LjMxNjU2M0wxLjk4NDU1OCAtMS4yMTk0MjdDMS44NDEwOTYgLTAuNjQ1NTc5IDEuNTY2MTI3IC0wLjM4MjU2NSAwLjc2NTEzMSAtMC4zNDY3QzAuNzI5MjY1IC0wLjM0NjcgMC41ODU4MDMgLTAuMzM0NzQ1IDAuNTg1ODAzIC0wLjEzMTUwN0MwLjU4NTgwMyAwIDAuNjkzNCAwIDAuNzQxMjIgMEMwLjk4MDMyNCAwIDEuNTkwMDM3IC0wLjAyMzkxIDEuODI5MTQxIC0wLjAyMzkxSDIuNDAyOTg5QzIuNTcwMzYxIC0wLjAyMzkxIDIuNzczNTk5IDAgMi45NDA5NzEgMEMzLjAyNDY1OCAwIDMuMTU2MTY0IDAgMy4xNTYxNjQgLTAuMjI3MTQ4QzMuMTU2MTY0IC0wLjMzNDc0NSAzLjAzNjYxMyAtMC4zNDY3IDIuOTg4NzkyIC0wLjM0NjdDMi41OTQyNzEgLTAuMzU4NjU1IDIuMjExNzA2IC0wLjQzMDM4NiAyLjIxMTcwNiAtMC44NjA3NzJDMi4yMTE3MDYgLTAuOTgwMzI0IDIuMjExNzA2IC0wLjk5MjI3OSAyLjI1OTUyNyAtMS4xNTk2NTFMMy45MDkzNCAtNy43NDY5NDlIMy45MjEyOTVMNC45MTM1NzQgLTAuMzIyNzlDNC45NDk0NCAtMC4wMzU4NjYgNC45NjEzOTUgMCA1LjA2ODk5MSAwQzUuMjAwNDk4IDAgNS4yNjAyNzQgLTAuMDk1NjQxIDUuMzIwMDUgLTAuMjAzMjM4TDEwLjEyNjAyNyAtNy44MDY3MjVIMTAuMTM3OTgzTDguNDA0NDgzIC0wLjg4NDY4MkM4LjI5Njg4NyAtMC40NjYyNTIgOC4yNzI5NzYgLTAuMzQ2NyA3LjQzNjExNSAtMC4zNDY3QzcuMjA4OTY2IC0wLjM0NjcgNy4wODk0MTUgLTAuMzQ2NyA3LjA4OTQxNSAtMC4xMzE1MDdDNy4wODk0MTUgMCA3LjE5NzAxMSAwIDcuMjY4NzQyIDBDNy40NzE5OCAwIDcuNzExMDgzIC0wLjAyMzkxIDcuOTE0MzIxIC0wLjAyMzkxSDkuMzI1MDMxQzkuNTI4MjY5IC0wLjAyMzkxIDkuNzc5MzI4IDAgOS45ODI1NjUgMEMxMC4wNzgyMDcgMCAxMC4yMDk3MTQgMCAxMC4yMDk3MTQgLTAuMjI3MTQ4QzEwLjIwOTcxNCAtMC4zNDY3IDEwLjEwMjExNyAtMC4zNDY3IDkuOTIyNzkgLTAuMzQ2N0M5LjE5MzUyNCAtMC4zNDY3IDkuMTkzNTI0IC0wLjQ0MjM0MSA5LjE5MzUyNCAtMC41NjE4OTNDOS4xOTM1MjQgLTAuNTczODQ4IDkuMTkzNTI0IC0wLjY1NzUzNCA5LjIxNzQzNSAtMC43NTMxNzZMMTAuODU1MjkzIC03LjI5MjY1M1onIGlkPSdnNS03NycvPgo8cGF0aCBkPSdNNS4zMzIwMDUgLTQuODA1OTc4QzUuNTcxMTA4IC00LjgwNTk3OCA1LjY2Njc1IC00LjgwNTk3OCA1LjY2Njc1IC01LjAzMzEyNkM1LjY2Njc1IC01LjE1MjY3NyA1LjU3MTEwOCAtNS4xNTI2NzcgNS4zNTU5MTUgLTUuMTUyNjc3SDQuMzg3NTQ3QzQuNjE0Njk1IC02LjM4NDA2IDQuNzgyMDY3IC03LjIzMjg3NyA0Ljg3NzcwOSAtNy42MTU0NDJDNC45NDk0NCAtNy45MDIzNjYgNS4yMDA0OTggLTguMTc3MzM1IDUuNTExMzMzIC04LjE3NzMzNUM1Ljc2MjM5MSAtOC4xNzczMzUgNi4wMTM0NSAtOC4wNjk3MzggNi4xMzMwMDEgLTcuOTYyMTQyQzUuNjY2NzUgLTcuOTE0MzIxIDUuNTIzMjg4IC03LjU2NzYyMSA1LjUyMzI4OCAtNy4zNjQzODRDNS41MjMyODggLTcuMTI1MjggNS43MDI2MTUgLTYuOTgxODE4IDUuOTI5NzYzIC02Ljk4MTgxOEM2LjE2ODg2NyAtNi45ODE4MTggNi41Mjc1MjIgLTcuMTg1MDU2IDYuNTI3NTIyIC03LjYzOTM1MkM2LjUyNzUyMiAtOC4xNDE0NjkgNi4wMjU0MDUgLTguNDE2NDM4IDUuNDk5Mzc3IC04LjQxNjQzOEM0Ljk4NTMwNSAtOC40MTY0MzggNC40ODMxODggLTguMDMzODczIDQuMjQ0MDg1IC03LjU2NzYyMUM0LjAyODg5MiAtNy4xNDkxOTEgMy45MDkzNCAtNi43MTg4MDQgMy42MzQzNzEgLTUuMTUyNjc3SDIuODMzMzc1QzIuNjA2MjI3IC01LjE1MjY3NyAyLjQ4NjY3NSAtNS4xNTI2NzcgMi40ODY2NzUgLTQuOTM3NDg0QzIuNDg2Njc1IC00LjgwNTk3OCAyLjU1ODQwNiAtNC44MDU5NzggMi43OTc1MDkgLTQuODA1OTc4SDMuNTYyNjRDMy4zNDc0NDcgLTMuNjk0MTQ3IDIuODU3Mjg1IC0wLjk5MjI3OSAyLjU4MjMxNiAwLjI4NjkyNEMyLjM3OTA3OCAxLjMyNzAyNCAyLjE5OTc1MSAyLjE5OTc1MSAxLjYwMTk5MyAyLjE5OTc1MUMxLjU2NjEyNyAyLjE5OTc1MSAxLjIxOTQyNyAyLjE5OTc1MSAxLjAwNDIzNCAxLjk3MjYwM0MxLjYxMzk0OCAxLjkyNDc4MiAxLjYxMzk0OCAxLjM5ODc1NSAxLjYxMzk0OCAxLjM4NjhDMS42MTM5NDggMS4xNDc2OTYgMS40MzQ2MiAxLjAwNDIzNCAxLjIwNzQ3MiAxLjAwNDIzNEMwLjk2ODM2OSAxLjAwNDIzNCAwLjYwOTcxNCAxLjIwNzQ3MiAwLjYwOTcxNCAxLjY2MTc2OEMwLjYwOTcxNCAyLjE3NTg0MSAxLjEzNTc0MSAyLjQzODg1NCAxLjYwMTk5MyAyLjQzODg1NEMyLjgyMTQyIDIuNDM4ODU0IDMuMzIzNTM3IDAuMjUxMDU5IDMuNDU1MDQ0IC0wLjM0NjdDMy42NzAyMzcgLTEuMjY3MjQ4IDQuMjU2MDQgLTQuNDQ3MzIzIDQuMzE1ODE2IC00LjgwNTk3OEg1LjMzMjAwNVonIGlkPSdnNS0xMDInLz4KPHBhdGggZD0nTTQuMDQwODQ3IC0xLjUxODMwNkMzLjk5MzAyNiAtMS4zMjcwMjQgMy45NjkxMTYgLTEuMjc5MjAzIDMuODEzNjk5IC0xLjA5OTg3NUMzLjMyMzUzNyAtMC40NjYyNTIgMi44MjE0MiAtMC4yMzkxMDMgMi40NTA4MDkgLTAuMjM5MTAzQzIuMDU2Mjg5IC0wLjIzOTEwMyAxLjY4NTY3OSAtMC41NDk5MzggMS42ODU2NzkgLTEuMzc0ODQ0QzEuNjg1Njc5IC0yLjAwODQ2OCAyLjA0NDMzNCAtMy4zNDc0NDcgMi4zMDczNDcgLTMuODg1NDNDMi42NTQwNDcgLTQuNTU0OTE5IDMuMTkyMDMgLTUuMDMzMTI2IDMuNjk0MTQ3IC01LjAzMzEyNkM0LjQ4MzE4OCAtNS4wMzMxMjYgNC42Mzg2MDUgLTQuMDUyODAyIDQuNjM4NjA1IC0zLjk4MTA3MUw0LjYwMjc0IC0zLjgxMzY5OUw0LjA0MDg0NyAtMS41MTgzMDZaTTQuNzgyMDY3IC00LjQ4MzE4OEM0LjYyNjY1IC00LjgyOTg4OCA0LjI5MTkwNSAtNS4yNzIyMjkgMy42OTQxNDcgLTUuMjcyMjI5QzIuMzkxMDM0IC01LjI3MjIyOSAwLjkwODU5MyAtMy42MzQzNzEgMC45MDg1OTMgLTEuODUzMDUxQzAuOTA4NTkzIC0wLjYwOTcxNCAxLjY2MTc2OCAwIDIuNDI2ODk5IDBDMy4wNjA1MjMgMCAzLjYyMjQxNiAtMC41MDIxMTcgMy44Mzc2MDkgLTAuNzQxMjJMMy41NzQ1OTUgMC4zMzQ3NDVDMy40MDcyMjMgMC45OTIyNzkgMy4zMzU0OTIgMS4yOTExNTggMi45MDUxMDYgMS43MDk1ODlDMi40MTQ5NDQgMi4xOTk3NTEgMS45NjA2NDggMi4xOTk3NTEgMS42OTc2MzQgMi4xOTk3NTFDMS4zMzg5NzkgMi4xOTk3NTEgMS4wNDAxIDIuMTc1ODQxIDAuNzQxMjIgMi4wODAxOTlDMS4xMjM3ODYgMS45NzI2MDMgMS4yMTk0MjcgMS42Mzc4NTggMS4yMTk0MjcgMS41MDYzNTFDMS4yMTk0MjcgMS4zMTUwNjggMS4wNzU5NjUgMS4xMjM3ODYgMC44MTI5NTEgMS4xMjM3ODZDMC41MjYwMjcgMS4xMjM3ODYgMC4yMTUxOTMgMS4zNjI4ODkgMC4yMTUxOTMgMS43NTc0MUMwLjIxNTE5MyAyLjI0NzU3MiAwLjcwNTM1NSAyLjQzODg1NCAxLjcyMTU0NCAyLjQzODg1NEMzLjI2Mzc2MSAyLjQzODg1NCA0LjA2NDc1NyAxLjQ0NjU3NSA0LjIyMDE3NCAwLjgwMDk5Nkw1LjU0NzE5OCAtNC41NTQ5MTlDNS41ODMwNjQgLTQuNjk4MzgxIDUuNTgzMDY0IC00LjcyMjI5MSA1LjU4MzA2NCAtNC43NDYyMDJDNS41ODMwNjQgLTQuOTEzNTc0IDUuNDUxNTU3IC01LjA0NTA4MSA1LjI3MjIyOSAtNS4wNDUwODFDNC45ODUzMDUgLTUuMDQ1MDgxIDQuODE3OTMzIC00LjgwNTk3OCA0Ljc4MjA2NyAtNC40ODMxODhaJyBpZD0nZzUtMTAzJy8+CjxwYXRoIGQ9J00zLjM1OTQwMiAtNy45OTgwMDdDMy4zNzEzNTcgLTguMDQ1ODI4IDMuMzk1MjY4IC04LjExNzU1OSAzLjM5NTI2OCAtOC4xNzczMzVDMy4zOTUyNjggLTguMjk2ODg3IDMuMjc1NzE2IC04LjI5Njg4NyAzLjI1MTgwNiAtOC4yOTY4ODdDMy4yMzk4NTEgLTguMjk2ODg3IDIuNjU0MDQ3IC04LjI0OTA2NiAyLjU5NDI3MSAtOC4yMzcxMTFDMi4zOTEwMzQgLTguMjI1MTU2IDIuMjExNzA2IC04LjIwMTI0NSAxLjk5NjUxMyAtOC4xODkyOUMxLjY5NzYzNCAtOC4xNjUzOCAxLjYxMzk0OCAtOC4xNTM0MjUgMS42MTM5NDggLTcuOTM4MjMyQzEuNjEzOTQ4IC03LjgxODY4IDEuNzA5NTg5IC03LjgxODY4IDEuODc2OTYxIC03LjgxODY4QzIuNDYyNzY1IC03LjgxODY4IDIuNDc0NzIgLTcuNzExMDgzIDIuNDc0NzIgLTcuNTkxNTMyQzIuNDc0NzIgLTcuNTE5ODAxIDIuNDUwODA5IC03LjQyNDE1OSAyLjQzODg1NCAtNy4zODgyOTRMMC43MDUzNTUgLTAuNDY2MjUyQzAuNjU3NTM0IC0wLjI4NjkyNCAwLjY1NzUzNCAtMC4yNjMwMTQgMC42NTc1MzQgLTAuMTkxMjgzQzAuNjU3NTM0IDAuMDcxNzMxIDAuODYwNzcyIDAuMTE5NTUyIDAuOTgwMzI0IDAuMTE5NTUyQzEuMTgzNTYyIDAuMTE5NTUyIDEuMzM4OTc5IC0wLjAzNTg2NiAxLjM5ODc1NSAtMC4xNjczNzJMMS45MzY3MzcgLTIuMzMxMjU4QzEuOTk2NTEzIC0yLjU5NDI3MSAyLjA2ODI0NCAtMi44NDUzMyAyLjEyODAyIC0zLjEwODM0NEMyLjI1OTUyNyAtMy42MTA0NjEgMi4yNTk1MjcgLTMuNjIyNDE2IDIuNDg2Njc1IC0zLjk2OTExNlMzLjI1MTgwNiAtNS4wMzMxMjYgNC4xNzIzNTQgLTUuMDMzMTI2QzQuNjUwNTYgLTUuMDMzMTI2IDQuODE3OTMzIC00LjY3NDQ3MSA0LjgxNzkzMyAtNC4xOTYyNjRDNC44MTc5MzMgLTMuNTI2Nzc1IDQuMzUxNjgxIC0yLjIyMzY2MSA0LjA4ODY2NyAtMS41MDYzNTFDMy45ODEwNzEgLTEuMjE5NDI3IDMuOTIxMjk1IC0xLjA2NDAxIDMuOTIxMjk1IC0wLjg0ODgxN0MzLjkyMTI5NSAtMC4zMTA4MzQgNC4yOTE5MDUgMC4xMTk1NTIgNC44NjU3NTMgMC4xMTk1NTJDNS45Nzc1ODQgMC4xMTk1NTIgNi4zOTYwMTUgLTEuNjM3ODU4IDYuMzk2MDE1IC0xLjcwOTU4OUM2LjM5NjAxNSAtMS43NjkzNjUgNi4zNDgxOTQgLTEuODE3MTg2IDYuMjc2NDYzIC0xLjgxNzE4NkM2LjE2ODg2NyAtMS44MTcxODYgNi4xNTY5MTIgLTEuNzgxMzIgNi4wOTcxMzYgLTEuNTc4MDgyQzUuODIyMTY3IC0wLjYyMTY2OSA1LjM3OTgyNiAtMC4xMTk1NTIgNC45MDE2MTkgLTAuMTE5NTUyQzQuNzgyMDY3IC0wLjExOTU1MiA0LjU5MDc4NSAtMC4xMzE1MDcgNC41OTA3ODUgLTAuNTE0MDcyQzQuNTkwNzg1IC0wLjgyNDkwNyA0LjczNDI0NyAtMS4yMDc0NzIgNC43ODIwNjcgLTEuMzM4OTc5QzQuOTk3MjYgLTEuOTEyODI3IDUuNTM1MjQzIC0zLjMyMzUzNyA1LjUzNTI0MyAtNC4wMTY5MzZDNS41MzUyNDMgLTQuNzM0MjQ3IDUuMTE2ODEyIC01LjI3MjIyOSA0LjIwODIxOSAtNS4yNzIyMjlDMy41MjY3NzUgLTUuMjcyMjI5IDIuOTI5MDE2IC00Ljk0OTQ0IDIuNDM4ODU0IC00LjMyNzc3MUwzLjM1OTQwMiAtNy45OTgwMDdaJyBpZD0nZzUtMTA0Jy8+CjxwYXRoIGQ9J001LjY2Njc1IC00Ljg3NzcwOUM1LjI4NDE4NCAtNC44MDU5NzggNS4xNDA3MjIgLTQuNTE5MDU0IDUuMTQwNzIyIC00LjI5MTkwNUM1LjE0MDcyMiAtNC4wMDQ5ODEgNS4zNjc4NyAtMy45MDkzNCA1LjUzNTI0MyAtMy45MDkzNEM1Ljg5Mzg5OCAtMy45MDkzNCA2LjE0NDk1NiAtNC4yMjAxNzQgNi4xNDQ5NTYgLTQuNTQyOTY0QzYuMTQ0OTU2IC01LjA0NTA4MSA1LjU3MTEwOCAtNS4yNzIyMjkgNS4wNjg5OTEgLTUuMjcyMjI5QzQuMzM5NzI2IC01LjI3MjIyOSAzLjkzMzI1IC00LjU1NDkxOSAzLjgyNTY1NCAtNC4zMjc3NzFDMy41NTA2ODUgLTUuMjI0NDA4IDIuODA5NDY1IC01LjI3MjIyOSAyLjU5NDI3MSAtNS4yNzIyMjlDMS4zNzQ4NDQgLTUuMjcyMjI5IDAuNzI5MjY1IC0zLjcwNjEwMiAwLjcyOTI2NSAtMy40NDMwODhDMC43MjkyNjUgLTMuMzk1MjY4IDAuNzc3MDg2IC0zLjMzNTQ5MiAwLjg2MDc3MiAtMy4zMzU0OTJDMC45NTY0MTMgLTMuMzM1NDkyIDAuOTgwMzI0IC0zLjQwNzIyMyAxLjAwNDIzNCAtMy40NTUwNDRDMS40MTA3MSAtNC43ODIwNjcgMi4yMTE3MDYgLTUuMDMzMTI2IDIuNTU4NDA2IC01LjAzMzEyNkMzLjA5NjM4OSAtNS4wMzMxMjYgMy4yMDM5ODUgLTQuNTMxMDA5IDMuMjAzOTg1IC00LjI0NDA4NUMzLjIwMzk4NSAtMy45ODEwNzEgMy4xMzIyNTQgLTMuNzA2MTAyIDIuOTg4NzkyIC0zLjEzMjI1NEwyLjU4MjMxNiAtMS40OTQzOTZDMi40MDI5ODkgLTAuNzc3MDg2IDIuMDU2Mjg5IC0wLjExOTU1MiAxLjQyMjY2NSAtMC4xMTk1NTJDMS4zNjI4ODkgLTAuMTE5NTUyIDEuMDY0MDEgLTAuMTE5NTUyIDAuODEyOTUxIC0wLjI3NDk2OUMxLjI0MzMzNyAtMC4zNTg2NTUgMS4zMzg5NzkgLTAuNzE3MzEgMS4zMzg5NzkgLTAuODYwNzcyQzEuMzM4OTc5IC0xLjA5OTg3NSAxLjE1OTY1MSAtMS4yNDMzMzcgMC45MzI1MDMgLTEuMjQzMzM3QzAuNjQ1NTc5IC0xLjI0MzMzNyAwLjMzNDc0NSAtMC45OTIyNzkgMC4zMzQ3NDUgLTAuNjA5NzE0QzAuMzM0NzQ1IC0wLjEwNzU5NyAwLjg5NjYzOCAwLjExOTU1MiAxLjQxMDcxIDAuMTE5NTUyQzEuOTg0NTU4IDAuMTE5NTUyIDIuMzkxMDM0IC0wLjMzNDc0NSAyLjY0MjA5MiAtMC44MjQ5MDdDMi44MzMzNzUgLTAuMTE5NTUyIDMuNDMxMTMzIDAuMTE5NTUyIDMuODczNDc0IDAuMTE5NTUyQzUuMDkyOTAyIDAuMTE5NTUyIDUuNzM4NDgxIC0xLjQ0NjU3NSA1LjczODQ4MSAtMS43MDk1ODlDNS43Mzg0ODEgLTEuNzY5MzY1IDUuNjkwNjYgLTEuODE3MTg2IDUuNjE4OTI5IC0xLjgxNzE4NkM1LjUxMTMzMyAtMS44MTcxODYgNS40OTkzNzcgLTEuNzU3NDEgNS40NjM1MTIgLTEuNjYxNzY4QzUuMTQwNzIyIC0wLjYwOTcxNCA0LjQ0NzMyMyAtMC4xMTk1NTIgMy45MDkzNCAtMC4xMTk1NTJDMy40OTA5MDkgLTAuMTE5NTUyIDMuMjYzNzYxIC0wLjQzMDM4NiAzLjI2Mzc2MSAtMC45MjA1NDhDMy4yNjM3NjEgLTEuMTgzNTYyIDMuMzExNTgyIC0xLjM3NDg0NCAzLjUwMjg2NCAtMi4xNjM4ODVMMy45MjEyOTUgLTMuNzg5Nzg4QzQuMTAwNjIzIC00LjUwNzA5OCA0LjUwNzA5OCAtNS4wMzMxMjYgNS4wNTcwMzYgLTUuMDMzMTI2QzUuMDgwOTQ2IC01LjAzMzEyNiA1LjQxNTY5MSAtNS4wMzMxMjYgNS42NjY3NSAtNC44Nzc3MDlaJyBpZD0nZzUtMTIwJy8+CjxwYXRoIGQ9J00xLjczMzQ5OSA2Ljk4MTgxOEMxLjczMzQ5OSA3LjE3MzEwMSAxLjczMzQ5OSA3LjQyNDE1OSAxLjk4NDU1OCA3LjQyNDE1OUMyLjI0NzU3MiA3LjQyNDE1OSAyLjI0NzU3MiA3LjE4NTA1NiAyLjI0NzU3MiA2Ljk4MTgxOFYwLjE5MTI4M0MyLjI0NzU3MiAwIDIuMjQ3NTcyIC0wLjI1MTA1OSAxLjk5NjUxMyAtMC4yNTEwNTlDMS43MzM0OTkgLTAuMjUxMDU5IDEuNzMzNDk5IC0wLjAxMTk1NSAxLjczMzQ5OSAwLjE5MTI4M1Y2Ljk4MTgxOFonIGlkPSdnMS0xMicvPgo8cGF0aCBkPSdNMi45ODg3OTIgMjguMjAyMjQySDYuMTMzMDAxVjI3LjU0NDcwN0gzLjY0NjMyNlYwLjE3OTMyOEg2LjEzMzAwMVYtMC40NzgyMDdIMi45ODg3OTJWMjguMjAyMjQyWicgaWQ9J2cxLTIwJy8+CjxwYXRoIGQ9J00yLjY1NDA0NyAyNy41NDQ3MDdIMC4xNjczNzJWMjguMjAyMjQySDMuMzExNTgyVi0wLjQ3ODIwN0gwLjE2NzM3MlYwLjE3OTMyOEgyLjY1NDA0N1YyNy41NDQ3MDdaJyBpZD0nZzEtMjEnLz4KPHBhdGggZD0nTTUuMDMzMTI2IDYuMzg0MDZMMC43ODkwNDEgMTEuNjMyMzc5QzAuNjkzNCAxMS43NTE5MyAwLjY4MTQ0NSAxMS43NzU4NDEgMC42ODE0NDUgMTEuODIzNjYxQzAuNjgxNDQ1IDExLjk1NTE2OCAwLjc4OTA0MSAxMS45NTUxNjggMS4wMDQyMzQgMTEuOTU1MTY4SDEwLjkxNTA2OEwxMS45NDMyMTMgOC45NzgzMzFIMTEuNjQ0MzM0QzExLjM0NTQ1NSA5Ljg3NDk2OSAxMC41NDQ0NTggMTAuNjA0MjM0IDkuNTI4MjY5IDEwLjk1MDkzNEM5LjMzNjk4NiAxMS4wMTA3MSA4LjUxMjA4IDExLjI5NzYzNCA2Ljc1NDY3IDExLjI5NzYzNEgxLjY3MzcyNEw1LjgyMjE2NyA2LjE2ODg2N0M1LjkwNTg1MyA2LjA2MTI3IDUuOTI5NzYzIDYuMDI1NDA1IDUuOTI5NzYzIDUuOTc3NTg0UzUuOTE3ODA4IDUuOTE3ODA4IDUuODQ2MDc3IDUuODEwMjEyTDEuOTYwNjQ4IDAuNDc4MjA3SDYuNjk0ODk0QzguMDU3NzgzIDAuNDc4MjA3IDEwLjgwNzQ3MiAwLjU2MTg5MyAxMS42NDQzMzQgMi43OTc1MDlIMTEuOTQzMjEzTDEwLjkxNTA2OCAwSDEuMDA0MjM0QzAuNjgxNDQ1IDAgMC42Njk0ODkgMC4wMTE5NTUgMC42Njk0ODkgMC4zODI1NjVMNS4wMzMxMjYgNi4zODQwNlonIGlkPSdnMS04MCcvPgo8cGF0aCBkPSdNNy44Nzg0NTYgLTIuNzQ5Njg5QzguMDgxNjk0IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi43NDk2ODkgOC4yOTY4ODcgLTIuOTg4NzkyUzguMDgxNjk0IC0zLjIyNzg5NSA3Ljg3ODQ1NiAtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3MiAtMy4yMjc4OTUgMC45OTIyNzkgLTMuMjI3ODk1IDAuOTkyMjc5IC0yLjk4ODc5MlMxLjIwNzQ3MiAtMi43NDk2ODkgMS40MTA3MSAtMi43NDk2ODlINy44Nzg0NTZaJyBpZD0nZzItMCcvPgo8cGF0aCBkPSdNMS45MDA4NzIgLTguNTM1OTlDMS45MDA4NzIgLTguNzUxMTgzIDEuOTAwODcyIC04Ljk2NjM3NiAxLjY2MTc2OCAtOC45NjYzNzZTMS40MjI2NjUgLTguNzUxMTgzIDEuNDIyNjY1IC04LjUzNTk5VjIuNTU4NDA2QzEuNDIyNjY1IDIuNzczNTk5IDEuNDIyNjY1IDIuOTg4NzkyIDEuNjYxNzY4IDIuOTg4NzkyUzEuOTAwODcyIDIuNzczNTk5IDEuOTAwODcyIDIuNTU4NDA2Vi04LjUzNTk5WicgaWQ9J2cyLTEwNicvPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2c3LTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnNy00MScvPgo8cGF0aCBkPSdNNC43NzAxMTIgLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExIC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi43NjE2NDQgOC40NTIzMDQgLTIuOTc2ODM3QzguNDUyMzA0IC0zLjIwMzk4NSA4LjI0OTA2NiAtMy4yMDM5ODUgOC4wNjk3MzggLTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMiAtNi42NzA5ODQgNC43NzAxMTIgLTYuODg2MTc3IDQuNTU0OTE5IC02Ljg4NjE3N0M0LjMyNzc3MSAtNi44ODYxNzcgNC4zMjc3NzEgLTYuNjgyOTM5IDQuMzI3NzcxIC02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDMC44NjA3NzIgLTMuMjAzOTg1IDAuNjQ1NTc5IC0zLjIwMzk4NSAwLjY0NTU3OSAtMi45ODg3OTJDMC42NDU1NzkgLTIuNzYxNjQ0IDAuODQ4ODE3IC0yLjc2MTY0NCAxLjAyODE0NCAtMi43NjE2NDRINC4zMjc3NzFWMC41Mzc5ODNDNC4zMjc3NzEgMC43MDUzNTUgNC4zMjc3NzEgMC45MjA1NDggNC41NDI5NjQgMC45MjA1NDhDNC43NzAxMTIgMC45MjA1NDggNC43NzAxMTIgMC43MTczMSA0Ljc3MDExMiAwLjUzNzk4M1YtMi43NjE2NDRaJyBpZD0nZzctNDMnLz4KPHBhdGggZD0nTTUuMjYwMjc0IC0yLjAwODQ2OEg0Ljk5NzI2QzQuOTYxMzk1IC0xLjgwNTIzIDQuODY1NzUzIC0xLjE0NzY5NiA0Ljc0NjIwMiAtMC45NTY0MTNDNC42NjI1MTYgLTAuODQ4ODE3IDMuOTgxMDcxIC0wLjg0ODgxNyAzLjYyMjQxNiAtMC44NDg4MTdIMS40MTA3MUMxLjczMzQ5OSAtMS4xMjM3ODYgMi40NjI3NjUgLTEuODg4OTE3IDIuNzczNTk5IC0yLjE3NTg0MUM0LjU5MDc4NSAtMy44NDk1NjQgNS4yNjAyNzQgLTQuNDcxMjMzIDUuMjYwMjc0IC01LjY1NDc5NUM1LjI2MDI3NCAtNy4wMjk2MzkgNC4xNzIzNTQgLTcuOTUwMTg3IDIuNzg1NTU0IC03Ljk1MDE4N1MwLjU4NTgwMyAtNi43NjY2MjUgMC41ODU4MDMgLTUuNzM4NDgxQzAuNTg1ODAzIC01LjEyODc2NyAxLjExMTgzMSAtNS4xMjg3NjcgMS4xNDc2OTYgLTUuMTI4NzY3QzEuMzk4NzU1IC01LjEyODc2NyAxLjcwOTU4OSAtNS4zMDgwOTUgMS43MDk1ODkgLTUuNjkwNjZDMS43MDk1ODkgLTYuMDI1NDA1IDEuNDgyNDQxIC02LjI1MjU1MyAxLjE0NzY5NiAtNi4yNTI1NTNDMS4wNDAxIC02LjI1MjU1MyAxLjAxNjE4OSAtNi4yNTI1NTMgMC45ODAzMjQgLTYuMjQwNTk4QzEuMjA3NDcyIC03LjA1MzU0OSAxLjg1MzA1MSAtNy42MDM0ODcgMi42MzAxMzcgLTcuNjAzNDg3QzMuNjQ2MzI2IC03LjYwMzQ4NyA0LjI2Nzk5NSAtNi43NTQ2NyA0LjI2Nzk5NSAtNS42NTQ3OTVDNC4yNjc5OTUgLTQuNjM4NjA1IDMuNjgyMTkyIC0zLjc1MzkyMyAzLjAwMDc0NyAtMi45ODg3OTJMMC41ODU4MDMgLTAuMjg2OTI0VjBINC45NDk0NEw1LjI2MDI3NCAtMi4wMDg0NjhaJyBpZD0nZzctNTAnLz4KPHBhdGggZD0nTTIuMTk5NzUxIC00LjI5MTkwNUMxLjk5NjUxMyAtNC4yNzk5NSAxLjk0ODY5MiAtNC4yNjc5OTUgMS45NDg2OTIgLTQuMTYwMzk5QzEuOTQ4NjkyIC00LjA0MDg0NyAyLjAwODQ2OCAtNC4wNDA4NDcgMi4yMjM2NjEgLTQuMDQwODQ3SDIuNzczNTk5QzMuNzg5Nzg4IC00LjA0MDg0NyA0LjI0NDA4NSAtMy4yMDM5ODUgNC4yNDQwODUgLTIuMDU2Mjg5QzQuMjQ0MDg1IC0wLjQ5MDE2MiAzLjQzMTEzMyAtMC4wNzE3MzEgMi44NDUzMyAtMC4wNzE3MzFDMi4yNzE0ODIgLTAuMDcxNzMxIDEuMjkxMTU4IC0wLjM0NjcgMC45NDQ0NTggLTEuMTM1NzQxQzEuMzI3MDI0IC0xLjA3NTk2NSAxLjY3MzcyNCAtMS4yOTExNTggMS42NzM3MjQgLTEuNzIxNTQ0QzEuNjczNzI0IC0yLjA2ODI0NCAxLjQyMjY2NSAtMi4zMDczNDcgMS4wODc5MiAtMi4zMDczNDdDMC44MDA5OTYgLTIuMzA3MzQ3IDAuNDkwMTYyIC0yLjEzOTk3NSAwLjQ5MDE2MiAtMS42ODU2NzlDMC40OTAxNjIgLTAuNjIxNjY5IDEuNTU0MTcyIDAuMjUxMDU5IDIuODgxMTk2IDAuMjUxMDU5QzQuMzAzODYxIDAuMjUxMDU5IDUuMzU1OTE1IC0wLjgzNjg2MiA1LjM1NTkxNSAtMi4wNDQzMzRDNS4zNTU5MTUgLTMuMTQ0MjA5IDQuNDcxMjMzIC00LjAwNDk4MSAzLjMyMzUzNyAtNC4yMDgyMTlDNC4zNjM2MzYgLTQuNTA3MDk4IDUuMDMzMTI2IC01LjM3OTgyNiA1LjAzMzEyNiAtNi4zMTIzMjlDNS4wMzMxMjYgLTcuMjU2Nzg3IDQuMDUyODAyIC03Ljk1MDE4NyAyLjg5MzE1MSAtNy45NTAxODdDMS42OTc2MzQgLTcuOTUwMTg3IDAuODEyOTUxIC03LjIyMDkyMiAwLjgxMjk1MSAtNi4zNDgxOTRDMC44MTI5NTEgLTUuODY5OTg4IDEuMTgzNTYyIC01Ljc3NDM0NiAxLjM2Mjg4OSAtNS43NzQzNDZDMS42MTM5NDggLTUuNzc0MzQ2IDEuOTAwODcyIC01Ljk1MzY3NCAxLjkwMDg3MiAtNi4zMTIzMjlDMS45MDA4NzIgLTYuNjk0ODk0IDEuNjEzOTQ4IC02Ljg2MjI2NyAxLjM1MDkzNCAtNi44NjIyNjdDMS4yNzkyMDMgLTYuODYyMjY3IDEuMjU1MjkzIC02Ljg2MjI2NyAxLjIxOTQyNyAtNi44NTAzMTFDMS42NzM3MjQgLTcuNjYzMjYzIDIuNzk3NTA5IC03LjY2MzI2MyAyLjg1NzI4NSAtNy42NjMyNjNDMy4yNTE4MDYgLTcuNjYzMjYzIDQuMDI4ODkyIC03LjQ4MzkzNSA0LjAyODg5MiAtNi4zMTIzMjlDNC4wMjg4OTIgLTYuMDg1MTgxIDMuOTkzMDI2IC01LjQxNTY5MSAzLjY0NjMyNiAtNC45MDE2MTlDMy4yODc2NzEgLTQuMzc1NTkyIDIuODgxMTk2IC00LjMzOTcyNiAyLjU1ODQwNiAtNC4zMjc3NzFMMi4xOTk3NTEgLTQuMjkxOTA1WicgaWQ9J2c3LTUxJy8+CjxwYXRoIGQ9J00xLjExMTgzMSAtMS4zMjEwNDZDMS4zNTY5MTIgLTEuMjMxMzgyIDEuNjAxOTkzIC0xLjIzMTM4MiAxLjcwMzYxMSAtMS4yMzEzODJDMS44ODg5MTcgLTEuMjMxMzgyIDIuMjc3NDYgLTEuMjMxMzgyIDIuMjc3NDYgLTEuNDY0NTA4QzIuMjc3NDYgLTEuNjU1NzkxIDEuOTcyNjAzIC0xLjY1NTc5MSAxLjc3NTM0MiAtMS42NTU3OTFDMS42MTk5MjUgLTEuNjU1NzkxIDEuNDEwNzEgLTEuNjU1NzkxIDEuMTIzNzg2IC0xLjU0MjIxN0MwLjk1NjQxMyAtMS42MTk5MjUgMC44NzI3MjcgLTEuNzI3NTIyIDAuODcyNzI3IC0xLjg0NzA3M0MwLjg3MjcyNyAtMi4xNTc5MDggMS40ODg0MTggLTIuMzU1MTY4IDIuMDk4MTMyIC0yLjM1NTE2OEMyLjIxMTcwNiAtMi4zNTUxNjggMi40Njg3NDIgLTIuMzU1MTY4IDIuNzU1NjY2IC0yLjE4Nzc5NkMyLjgyMTQyIC0yLjE0NTk1MyAyLjgyNzM5NyAtMi4xMzk5NzUgMi44ODExOTYgLTIuMTM5OTc1QzIuOTg4NzkyIC0yLjEzOTk3NSAzLjA3MjQ3OCAtMi4yNDE1OTQgMy4wNzI0NzggLTIuMzMxMjU4QzMuMDcyNDc4IC0yLjQyNjg5OSAyLjk5NDc3IC0yLjQ5ODYzIDIuNzMxNzU2IC0yLjYwMDI0OUMyLjQ2Mjc2NSAtMi43MDE4NjggMi4yNTM1NDkgLTIuNzAxODY4IDIuMTYzODg1IC0yLjcwMTg2OEMxLjM5ODc1NSAtMi43MDE4NjggMC42NTE1NTcgLTIuMzE5MzAzIDAuNjUxNTU3IC0xLjg0MTA5NkMwLjY1MTU1NyAtMS41OTYwMTUgMC44ODQ2ODIgLTEuNDI4NjQzIDAuODkwNjYgLTEuNDI4NjQzQzAuNTczODQ4IC0xLjIzNzM2IDAuMzY0NjMzIC0wLjk2ODM2OSAwLjM2NDYzMyAtMC42NjM1MTJDMC4zNjQ2MzMgLTAuMjQ1MDgxIDAuNzg5MDQxIDAuMTI1NTI5IDEuNTMwMjYyIDAuMTI1NTI5QzIuNTQwNDczIDAuMTI1NTI5IDIuODE1NDQyIC0wLjQ0ODMxOSAyLjgxNTQ0MiAtMC41MTQwNzJDMi44MTU0NDIgLTAuNTczODQ4IDIuNzY3NjIxIC0wLjYwOTcxNCAyLjcxOTgwMSAtMC42MDk3MTRTMi42NDgwNyAtMC41Nzk4MjYgMi42MjQxNTkgLTAuNTMyMDA1QzIuNDUwODA5IC0wLjI3NDk2OSAyLjE1NzkwOCAtMC4yMjExNzEgMS42MTk5MjUgLTAuMjIxMTcxQzEuNDM0NjIgLTAuMjIxMTcxIDEuMTUzNjc0IC0wLjIyMTE3MSAwLjkyMDU0OCAtMC4zMTA4MzRDMC43NTMxNzYgLTAuMzgyNTY1IDAuNTg1ODAzIC0wLjUwODA5NSAwLjU4NTgwMyAtMC42OTkzNzdDMC41ODU4MDMgLTAuOTI2NTI2IDAuODMwODg0IC0xLjE5NTUxNyAxLjExMTgzMSAtMS4zMjEwNDZaTTEuOTg0NTU4IC0xLjQ0NjU3NUMxLjkxMjgyNyAtMS40MzQ2MiAxLjg0NzA3MyAtMS40Mjg2NDMgMS43MDk1ODkgLTEuNDI4NjQzQzEuNjkxNjU2IC0xLjQyODY0MyAxLjUxODMwNiAtMS40Mjg2NDMgMS41MTgzMDYgLTEuNDQwNTk4QzEuNTE4MzA2IC0xLjQ1ODUzMSAxLjc0NTQ1NSAtMS40NTg1MzEgMS43NjkzNjUgLTEuNDU4NTMxQzEuODk0ODk0IC0xLjQ1ODUzMSAxLjkwNjg0OSAtMS40NTg1MzEgMS45ODQ1NTggLTEuNDQ2NTc1WicgaWQ9J2czLTM0Jy8+CjxwYXRoIGQ9J002LjQzNzg1OCAtMy41OTg1MDZDNi40ODU2NzkgLTMuNzk1NzY2IDYuNDk3NjM0IC0zLjg0MzU4NyA2Ljk3NTg0MSAtMy44NDM1ODdDNy4wODM0MzcgLTMuODQzNTg3IDcuMTY3MTIzIC0zLjg0MzU4NyA3LjE2NzEyMyAtMy45OTMwMjZDNy4xNjcxMjMgLTQuMDgyNjkgNy4wODk0MTUgLTQuMDgyNjkgNi45ODE4MTggLTQuMDgyNjlINi4xMzMwMDFDNS45NTk2NTEgLTQuMDgyNjkgNS45NDE3MTkgLTQuMDc2NzEyIDUuODQ2MDc3IC0zLjkzOTIyOEwzLjQ3ODk1NCAtMC41NDk5MzhMMi44MTU0NDIgLTMuOTIxMjk1QzIuNzg1NTU0IC00LjA4MjY5IDIuNzQ5Njg5IC00LjA4MjY5IDIuNTk0MjcxIC00LjA4MjY5SDEuNjk3NjM0QzEuNTc4MDgyIC00LjA4MjY5IDEuNDk0Mzk2IC00LjA4MjY5IDEuNDk0Mzk2IC0zLjkzMzI1QzEuNDk0Mzk2IC0zLjg0MzU4NyAxLjU4NDA2IC0zLjg0MzU4NyAxLjY5MTY1NiAtMy44NDM1ODdTMS45NDg2OTIgLTMuODQzNTg3IDIuMDc0MjIyIC0zLjgwMTc0M0MyLjA3NDIyMiAtMy43NDE5NjggMi4wNzQyMjIgLTMuNzA2MTAyIDIuMDUwMzExIC0zLjYxMDQ2MUwxLjMwOTA5MSAtMC42NjM1MTJDMS4yNDkzMTUgLTAuNDE4NDMxIDEuMTQxNzE5IC0wLjI1NzAzNiAwLjY1NzUzNCAtMC4yMzkxMDNDMC41NzM4NDggLTAuMjMzMTI2IDAuNTMyMDA1IC0wLjE3MzM1IDAuNTMyMDA1IC0wLjA4MzY4NkMwLjUzNzk4MyAtMC4wNTk3NzYgMC41NDM5NiAwIDAuNjMzNjI0IDBDMC43NzcwODYgMCAxLjEyOTc2MyAtMC4wMjM5MSAxLjI3MzIyNSAtMC4wMjM5MUwxLjYwMTk5MyAtMC4wMTc5MzNDMS43MDk1ODkgLTAuMDE3OTMzIDEuODM1MTE4IDAgMS45MzY3MzcgMEMyLjA2MjI2NyAwIDIuMDY4MjQ0IC0wLjEyNTUyOSAyLjA2ODI0NCAtMC4xNTU0MTdDMi4wNTAzMTEgLTAuMjM5MTAzIDEuOTkwNTM1IC0wLjIzOTEwMyAxLjkxODgwNCAtMC4yMzkxMDNDMS42NDM4MzYgLTAuMjQ1MDgxIDEuNTI0Mjg0IC0wLjMyMjc5IDEuNTI0Mjg0IC0wLjQ3ODIwN0MxLjUyNDI4NCAtMC41MTQwNzIgMS41MzAyNjIgLTAuNTM3OTgzIDEuNTQ4MTk0IC0wLjYwMzczNkwyLjM0MzIxMyAtMy43ODk3ODhIMi4zNDkxOTFMMy4wNjA1MjMgLTAuMTY3MzcyQzMuMDg0NDMzIC0wLjA1OTc3NiAzLjEwMjM2NiAwIDMuMTk4MDA3IDBDMy4yODc2NzEgMCAzLjMzNTQ5MiAtMC4wNTk3NzYgMy4zNzczMzUgLTAuMTI1NTI5TDUuOTcxNjA2IC0zLjg0MzU4N0w1Ljk3NzU4NCAtMy44Mzc2MDlMNS4xNDA3MjIgLTAuNDk2MTM5QzUuMDg2OTI0IC0wLjI4MDk0NiA1LjA3NDk2OSAtMC4yMzkxMDMgNC42MjY2NSAtMC4yMzkxMDNDNC40OTUxNDMgLTAuMjM5MTAzIDQuNDgzMTg4IC0wLjIzOTEwMyA0LjQ1OTI3OCAtMC4yMjExNzFDNC40MjkzOSAtMC4xOTcyNiA0LjQwNTQ3OSAtMC4xMTk1NTIgNC40MDU0NzkgLTAuMDgzNjg2QzQuNDExNDU3IC0wLjA1OTc3NiA0LjQxNzQzNSAwIDQuNTA3MDk4IDBDNC42MjY2NSAwIDQuNzU4MTU3IC0wLjAxNzkzMyA0Ljg3NzcwOSAtMC4wMTc5MzNDNS4wMDkyMTUgLTAuMDE3OTMzIDUuMTQ2NyAtMC4wMjM5MSA1LjI3ODIwNyAtMC4wMjM5MUM1LjI3ODIwNyAtMC4wMjM5MSA1LjY5MDY2IC0wLjAxNzkzMyA1LjY5MDY2IC0wLjAxNzkzM0M1LjgxMDIxMiAtMC4wMTc5MzMgNS45NTM2NzQgMCA2LjA3MzIyNSAwQzYuMTA5MDkxIDAgNi4xNTA5MzQgMCA2LjE3NDg0NCAtMC4wNDE4NDNDNi4xODY4IC0wLjA1OTc3NiA2LjIxMDcxIC0wLjEzMTUwNyA2LjIxMDcxIC0wLjE1NTQxN0M2LjE5Mjc3NyAtMC4yMzkxMDMgNi4xMzg5NzkgLTAuMjM5MTAzIDYuMDAxNDk0IC0wLjIzOTEwM0M1LjkyOTc2MyAtMC4yMzkxMDMgNS44NDAxIC0wLjI0NTA4MSA1Ljc3NDM0NiAtMC4yNTEwNTlDNS42NjY3NSAtMC4yNjMwMTQgNS42MjQ5MDcgLTAuMjYzMDE0IDUuNjI0OTA3IC0wLjMyODc2N0M1LjYyNDkwNyAtMC4zNTI2NzcgNS42MzA4ODQgLTAuMzc2NTg4IDUuNjQ4ODE3IC0wLjQzNjM2NEw2LjQzNzg1OCAtMy41OTg1MDZaJyBpZD0nZzMtNzcnLz4KPHBhdGggZD0nTTEuMTYzNjM2IC0xLjc4NTMwNUMxLjQ0MjU5IC0xLjY2NTc1MyAxLjY4MTY5NCAtMS42NjU3NTMgMS44OTY4ODcgLTEuNjY1NzUzQzIuMTQzOTYgLTEuNjY1NzUzIDIuNTkwMjg2IC0xLjY2NTc1MyAyLjU5MDI4NiAtMS45NTI2NzdDMi41OTAyODYgLTIuMTU5OSAyLjI4NzQyMiAtMi4xOTE3ODEgMS45NzY1ODggLTIuMTkxNzgxQzEuNTYyMTQyIC0yLjE5MTc4MSAxLjM0Njk0OSAtMi4xMDQxMSAxLjE3OTU3NyAtMi4wMzIzNzlDMS4wNjc5OTUgLTIuMDg4MTY5IDAuODY4NzQyIC0yLjIzOTYwMSAwLjg2ODc0MiAtMi40NjI3NjVDMC44Njg3NDIgLTIuODg1MTgxIDEuNjA5OTYzIC0zLjE4MDA3NSAyLjQwNjk3NCAtMy4xODAwNzVDMi42NTQwNDcgLTMuMTgwMDc1IDIuOTAxMTIxIC0zLjE0MDIyNCAzLjE4ODA0NSAtMi45NTY5MTJDMy4yNjc3NDYgLTIuOTAxMTIxIDMuMjgzNjg2IC0yLjg4NTE4MSAzLjM0NzQ0NyAtMi44ODUxODFDMy40NTkwMjkgLTIuODg1MTgxIDMuNTg2NTUgLTMuMDA0NzMyIDMuNTg2NTUgLTMuMTI0Mjg0QzMuNTg2NTUgLTMuMjkxNjU2IDMuMjgzNjg2IC0zLjQxOTE3OCAzLjE3MjEwNSAtMy40NjY5OTlDMi44NTMzIC0zLjYwMjQ5MSAyLjYwNjIyNyAtMy42MDI0OTEgMi40ODY2NzUgLTMuNjAyNDkxQzEuNTM4MjMyIC0zLjYwMjQ5MSAwLjYyMTY2OSAtMy4wNjg0OTMgMC42MjE2NjkgLTIuNDU0Nzk1QzAuNjIxNjY5IC0yLjE1OTkgMC44NDQ4MzIgLTEuOTY4NjE4IDAuOTI0NTMzIC0xLjkxMjgyN0MwLjM2NjYyNSAtMS41NTQxNzIgMC4yMzExMzMgLTEuMTIzNzg2IDAuMjMxMTMzIC0wLjg2MDc3MkMwLjIzMTEzMyAtMC4zMTg4MDQgMC43NDEyMiAwLjE2NzM3MiAxLjYyNTkwMyAwLjE2NzM3MkMyLjc4MTU2OSAwLjE2NzM3MiAzLjIwMzk4NSAtMC41NTc5MDggMy4yMDM5ODUgLTAuNjY5NDg5QzMuMjAzOTg1IC0wLjcyNTI4IDMuMTcyMTA1IC0wLjc4MTA3MSAzLjEwMDM3NCAtMC43ODEwNzFDMy4wNDQ1ODMgLTAuNzgxMDcxIDMuMDIwNjcyIC0wLjc0OTE5MSAyLjk4ODc5MiAtMC43MDEzN0MyLjg2OTI0IC0wLjUxMDA4NyAyLjcwMTg2OCAtMC4yNTUwNDQgMS43MTM1NzQgLTAuMjU1MDQ0QzEuNTA2MzUxIC0wLjI1NTA0NCAwLjQ4NjE3NyAtMC4yNTUwNDQgMC40ODYxNzcgLTAuOTA4NTkzQzAuNDg2MTc3IC0xLjE0NzY5NiAwLjY2OTQ4OSAtMS41MTQzMjEgMS4xNjM2MzYgLTEuNzg1MzA1Wk0yLjMwMzM2MiAtMS45Mjg3NjdDMi4xODM4MTEgLTEuODg4OTE3IDIuMTY3ODcgLTEuODg4OTE3IDEuODk2ODg3IC0xLjg4ODkxN0MxLjgwOTIxNSAtMS44ODg5MTcgMS42NDE4NDMgLTEuODg4OTE3IDEuNTIyMjkxIC0xLjkxMjgyN0MxLjcxMzU3NCAtMS45NjA2NDggMS44ODg5MTcgLTEuOTY4NjE4IDEuOTYwNjQ4IC0xLjk2ODYxOEMyLjEwNDExIC0xLjk2ODYxOCAyLjE5OTc1MSAtMS45NTI2NzcgMi4zMDMzNjIgLTEuOTM2NzM3Vi0xLjkyODc2N1onIGlkPSdnNC0zNCcvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzQtMTA3Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc2MS44OTIwNjYnIHhsaW5rOmhyZWY9JyNnMS0xMicgeT0nNzkuNzQyMTgxJy8+Cjx1c2UgeD0nNjEuODkyMDY2JyB4bGluazpocmVmPScjZzEtMTInIHk9Jzg2LjkxNTM1NScvPgo8dXNlIHg9JzYxLjg5MjA2NicgeGxpbms6aHJlZj0nI2cxLTEyJyB5PSc5NC4wODg1MjgnLz4KPHVzZSB4PSc2MS44OTIwNjYnIHhsaW5rOmhyZWY9JyNnMS0xMicgeT0nMTAxLjI2MTcwMicvPgo8dXNlIHg9JzYxLjg5MjA2NicgeGxpbms6aHJlZj0nI2cxLTEyJyB5PScxMDguNDM0ODc2Jy8+Cjx1c2UgeD0nNjUuODc3MTIyJyB4bGluazpocmVmPScjZzUtMTAyJyB5PScxMDAuNjYzOTA3Jy8+Cjx1c2UgeD0nNzQuOTE2MDU2JyB4bGluazpocmVmPScjZzctNDAnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PSc3OS40NjgzODInIHhsaW5rOmhyZWY9JyNnNS0xMjAnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PSc4Ni4xMjA0NjknIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzkzLjMyOTQ1OCcgeGxpbms6aHJlZj0nI2cyLTAnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScxMDUuMjg0NjE4JyB4bGluazpocmVmPScjZzUtMzQnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScxMjEuMjQ4NDY2JyB4bGluazpocmVmPScjZzMtNzcnIHk9JzgzLjk4NTA1OScvPgo8cmVjdCBoZWlnaHQ9JzAuMzU4NjU2JyB3aWR0aD0nNy41ODgxODInIHg9JzEyMS4yNDg0NjYnIHk9Jzg1LjA3MTYzNycvPgo8dXNlIHg9JzEyMy4yODkwNzcnIHhsaW5rOmhyZWY9JyNnMy0zNCcgeT0nOTAuMzY5MDkzJy8+Cjx1c2UgeD0nMTEwLjc2MjY0MScgeGxpbms6aHJlZj0nI2cxLTgwJyB5PSc5MS42OTc0NTUnLz4KPHVzZSB4PScxMjMuMzgyMDIxJyB4bGluazpocmVmPScjZzQtMTA3JyB5PScxMDQuMTUwOTA3Jy8+Cjx1c2UgeD0nMTI4LjAwMzYzNycgeGxpbms6aHJlZj0nI2c2LTYxJyB5PScxMDQuMTUwOTA3Jy8+Cjx1c2UgeD0nMTM0LjU5MDE0MycgeGxpbms6aHJlZj0nI2c2LTQ4JyB5PScxMDQuMTUwOTA3Jy8+Cjx1c2UgeD0nMTM5LjMyMjQ1OCcgeGxpbms6aHJlZj0nI2c1LTEwNCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzE0Ni4wNjEwMTMnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzEwMi40NTcxNycvPgo8dXNlIHg9JzE1My4xNzMyNTgnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzE1Ny43MjU1ODQnIHhsaW5rOmhyZWY9JyNnNS0xMjAnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScxNjQuMzc3NjcxJyB4bGluazpocmVmPScjZzctNDEnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScxNjguOTI5OTk3JyB4bGluazpocmVmPScjZzEtMTInIHk9Jzc5Ljc0MjE4MScvPgo8dXNlIHg9JzE2OC45Mjk5OTcnIHhsaW5rOmhyZWY9JyNnMS0xMicgeT0nODYuOTE1MzU1Jy8+Cjx1c2UgeD0nMTY4LjkyOTk5NycgeGxpbms6aHJlZj0nI2cxLTEyJyB5PSc5NC4wODg1MjgnLz4KPHVzZSB4PScxNjguOTI5OTk3JyB4bGluazpocmVmPScjZzEtMTInIHk9JzEwMS4yNjE3MDInLz4KPHVzZSB4PScxNjguOTI5OTk3JyB4bGluazpocmVmPScjZzEtMTInIHk9JzEwOC40MzQ4NzYnLz4KPHVzZSB4PScxODIuODc3Njg1JyB4bGluazpocmVmPScjZzAtNTQnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyMDIuMTM4ODE1JyB4bGluazpocmVmPScjZzItMTA2JyB5PScxMDAuNjYzOTA3Jy8+Cjx1c2UgeD0nMjA1LjQ1OTcwNScgeGxpbms6aHJlZj0nI2c1LTEwMicgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzIxNC40OTg2MzknIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzIxOS4wNTA5NjUnIHhsaW5rOmhyZWY9JyNnNS0xMjAnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyMjUuNzAzMDUyJyB4bGluazpocmVmPScjZzctNDEnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyMzIuOTEyMDQxJyB4bGluazpocmVmPScjZzItMCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzI0NC44NjcyMDInIHhsaW5rOmhyZWY9JyNnNS0xMDMnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyNTAuNDcyNTA5JyB4bGluazpocmVmPScjZzQtMzQnIHk9JzEwMi40NTcxNycvPgo8dXNlIHg9JzI1Ni44NzM1MjQnIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzI2MS40MjU4NScgeGxpbms6aHJlZj0nI2c1LTEyMCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzI2OC4wNzc5MzcnIHhsaW5rOmhyZWY9JyNnNy00MScgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzI3Mi42MzAyNjMnIHhsaW5rOmhyZWY9JyNnMi0xMDYnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyNzguNjA3ODA5JyB4bGluazpocmVmPScjZzctNDMnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyOTAuMzY5MTI0JyB4bGluazpocmVmPScjZzEtMTInIHk9Jzc5Ljc0MjE4MScvPgo8dXNlIHg9JzI5MC4zNjkxMjQnIHhsaW5rOmhyZWY9JyNnMS0xMicgeT0nODYuOTE1MzU1Jy8+Cjx1c2UgeD0nMjkwLjM2OTEyNCcgeGxpbms6aHJlZj0nI2cxLTEyJyB5PSc5NC4wODg1MjgnLz4KPHVzZSB4PScyOTAuMzY5MTI0JyB4bGluazpocmVmPScjZzEtMTInIHk9JzEwMS4yNjE3MDInLz4KPHVzZSB4PScyOTAuMzY5MTI0JyB4bGluazpocmVmPScjZzEtMTInIHk9JzEwOC40MzQ4NzYnLz4KPHVzZSB4PScyOTQuMzU0MTgnIHhsaW5rOmhyZWY9JyNnNS0xMDMnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PScyOTkuOTU5NDg3JyB4bGluazpocmVmPScjZzQtMzQnIHk9JzEwMi40NTcxNycvPgo8dXNlIHg9JzMwNi4zNjA1MDInIHhsaW5rOmhyZWY9JyNnNy00MCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzMxMC45MTI4MjgnIHhsaW5rOmhyZWY9JyNnNS0xMjAnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PSczMTcuNTY0OTE1JyB4bGluazpocmVmPScjZzctNDEnIHk9JzEwMC42NjM5MDcnLz4KPHVzZSB4PSczMjQuNzczOTA0JyB4bGluazpocmVmPScjZzItMCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzMzNi43MjkwNjQnIHhsaW5rOmhyZWY9JyNnNS0zNCcgeT0nMTAwLjY2MzkwNycvPgo8dXNlIHg9JzM1Mi42OTI5MTInIHhsaW5rOmhyZWY9JyNnMy03NycgeT0nODMuOTg1MDU5Jy8+CjxyZWN0IGhlaWdodD0nMC4zNTg2NTYnIHdpZHRoPSc3LjU4ODE4MicgeD0nMzUyLjY5MjkxMicgeT0nODUuMDcxNjM3Jy8+Cjx1c2UgeD0nMzU0LjczMzUyMycgeGxpbms6aHJlZj0nI2czLTM0JyB5PSc5MC4zNjkwOTMnLz4KPHVzZSB4PSczNDIuMjA3MDg3JyB4bGluazpocmVmPScjZzEtODAnIHk9JzkxLjY5NzQ1NScvPgo8dXNlIHg9JzM1NC44MjY0NjcnIHhsaW5rOmhyZWY9JyNnNC0xMDcnIHk9JzEwNC4xNTA5MDcnLz4KPHVzZSB4PSczNTkuNDQ4MDgzJyB4bGluazpocmVmPScjZzYtNjEnIHk9JzEwNC4xNTA5MDcnLz4KPHVzZSB4PSczNjYuMDM0NTg5JyB4bGluazpocmVmPScjZzYtNDgnIHk9JzEwNC4xNTA5MDcnLz4KPHVzZSB4PSczNzAuNzY2OTA0JyB4bGluazpocmVmPScjZzUtMTA0JyB5PScxMDAuNjYzOTA3Jy8+Cjx1c2UgeD0nMzc3LjUwNTQ1OScgeGxpbms6aHJlZj0nI2c0LTEwNycgeT0nMTAyLjQ1NzE3Jy8+Cjx1c2UgeD0nMzg0LjYxNzcwNCcgeGxpbms6aHJlZj0nI2c3LTQwJyB5PScxMDAuNjYzOTA3Jy8+Cjx1c2UgeD0nMzg5LjE3MDAzJyB4bGluazpocmVmPScjZzUtMTIwJyB5PScxMDAuNjYzOTA3Jy8+Cjx1c2UgeD0nMzk1LjgyMjExNycgeGxpbms6aHJlZj0nI2c3LTQxJyB5PScxMDAuNjYzOTA3Jy8+Cjx1c2UgeD0nNDAwLjM3NDQ0MycgeGxpbms6aHJlZj0nI2cxLTEyJyB5PSc3OS43NDIxODEnLz4KPHVzZSB4PSc0MDAuMzc0NDQzJyB4bGluazpocmVmPScjZzEtMTInIHk9Jzg2LjkxNTM1NScvPgo8dXNlIHg9JzQwMC4zNzQ0NDMnIHhsaW5rOmhyZWY9JyNnMS0xMicgeT0nOTQuMDg4NTI4Jy8+Cjx1c2UgeD0nNDAwLjM3NDQ0MycgeGxpbms6aHJlZj0nI2cxLTEyJyB5PScxMDEuMjYxNzAyJy8+Cjx1c2UgeD0nNDAwLjM3NDQ0MycgeGxpbms6aHJlZj0nI2cxLTEyJyB5PScxMDguNDM0ODc2Jy8+Cjx1c2UgeD0nMTgyLjg3NzY4NScgeGxpbms6aHJlZj0nI2cwLTU0JyB5PScxMzIuOTQzMTc1Jy8+Cjx1c2UgeD0nMjAyLjEzODgxNScgeGxpbms6aHJlZj0nI2c1LTM0JyB5PScxMzIuOTQzMTc1Jy8+Cjx1c2UgeD0nMjEwLjI3MzUwMScgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxMzIuOTQzMTc1Jy8+Cjx1c2UgeD0nMjIyLjAzNDgxNicgeGxpbms6aHJlZj0nI2c1LTM0JyB5PScxMzIuOTQzMTc1Jy8+Cjx1c2UgeD0nMjI3LjUxMjgzOScgeGxpbms6aHJlZj0nI2c2LTUwJyB5PScxMjguNjA0NzM4Jy8+Cjx1c2UgeD0nMjM0LjIzNzY1MicgeGxpbms6aHJlZj0nI2cxLTIwJyB5PScxMTYuMDg2MjM3Jy8+Cjx1c2UgeD0nMjQxLjc0Mjg2MycgeGxpbms6aHJlZj0nI2c1LTc3JyB5PScxMjQuODU1NDE2Jy8+CjxyZWN0IGhlaWdodD0nMC40NzgxODcnIHdpZHRoPScxMi41NzM2MDcnIHg9JzI0MS43NDI4NjMnIHk9JzEyOS43MTUyODknLz4KPHVzZSB4PScyNDUuMjkwNjU1JyB4bGluazpocmVmPScjZzUtMzQnIHk9JzE0MS4xNDM4MzcnLz4KPHVzZSB4PScyNTUuNTExOTg0JyB4bGluazpocmVmPScjZzEtMjEnIHk9JzExNi4wODYyMzcnLz4KPHVzZSB4PScyNjQuNDc4MzQ1JyB4bGluazpocmVmPScjZzctNDMnIHk9JzEzMi45NDMxNzUnLz4KPHVzZSB4PScyNzYuMjM5NjYnIHhsaW5rOmhyZWY9JyNnNy01MCcgeT0nMTMyLjk0MzE3NScvPgo8dXNlIHg9JzI4Mi4wOTI2NScgeGxpbms6aHJlZj0nI2c1LTM0JyB5PScxMzIuOTQzMTc1Jy8+Cjx1c2UgeD0nMjg3LjU3MDY3MycgeGxpbms6aHJlZj0nI2c2LTUwJyB5PScxMjguNjA0NzM4Jy8+Cjx1c2UgeD0nMTgyLjg3NzY4NScgeGxpbms6aHJlZj0nI2cwLTU0JyB5PScxNTQuMDY0MDc1Jy8+Cjx1c2UgeD0nMjAyLjEzODgxNScgeGxpbms6aHJlZj0nI2c1LTM0JyB5PScxNTQuMDY0MDc1Jy8+Cjx1c2UgeD0nMjA5LjYwOTMzNScgeGxpbms6aHJlZj0nI2c3LTQwJyB5PScxNTQuMDY0MDc1Jy8+Cjx1c2UgeD0nMjE0LjE2MTY2MScgeGxpbms6aHJlZj0nI2c1LTc3JyB5PScxNTQuMDY0MDc1Jy8+Cjx1c2UgeD0nMjI5LjM5MTkzMicgeGxpbms6aHJlZj0nI2c3LTQzJyB5PScxNTQuMDY0MDc1Jy8+Cjx1c2UgeD0nMjQxLjE1MzI0NycgeGxpbms6aHJlZj0nI2c3LTUxJyB5PScxNTQuMDY0MDc1Jy8+Cjx1c2UgeD0nMjQ3LjAwNjIzNycgeGxpbms6aHJlZj0nI2c3LTQxJyB5PScxNTQuMDY0MDc1Jy8+CjwvZz4KPC9zdmc+)
Comme  est de la forme désirée, le théorème est démontré dans le cas .
est de la forme désirée, le théorème est démontré dans le cas .
Partie 2
Dans le cas  , on utilise la méthode précédente pour chacune des projections de
dans un repère orthonormé de
, on utilise la méthode précédente pour chacune des projections de
dans un repère orthonormé de  . Il suffit de
sommer sur chacune des dimensions.
. Il suffit de
sommer sur chacune des dimensions.
Ce théorème montre qu’il est judicieux de modéliser la fonction
dans l’équation (2)
par un réseau de neurones puisqu’il possible de s’approcher d’aussi
près qu’on veut de la fonction  ,
il suffit d’ajouter des neurones sur la couche cachée du réseau.
Ce théorème permet de déduire le corollaire suivant :
,
il suffit d’ajouter des neurones sur la couche cachée du réseau.
Ce théorème permet de déduire le corollaire suivant :
Corollaire C3 : famille libre de fonctions
Soit  l’ensemble des fonctions continues de
l’ensemble des fonctions continues de
 avec
compact muni de la norme :
Alors l’ensemble
avec
compact muni de la norme :
Alors l’ensemble  des fonctions sigmoïdes :
des fonctions sigmoïdes :

est une base de .
Démonstration du corollaire
Le théorème de densité montre que la famille
est une famille génératrice. Il reste à montrer que c’est une
famille libre. Soient  et
et
 vérifiant :
vérifiant :
 .
Soit
.
Soit  , il faut montrer que :
, il faut montrer que :
(3)#
C’est évidemment vrai pour  .
La démonstration est basée sur un raisonnement par récurrence,
on suppose qu’elle est vraie pour
.
La démonstration est basée sur un raisonnement par récurrence,
on suppose qu’elle est vraie pour  ,
démontrons qu’elle est vraie pour
,
démontrons qu’elle est vraie pour  .
On suppose donc
.
On suppose donc  .
S’il existe
.
S’il existe  tel que
tel que  ,
la fonction
,
la fonction  est une constante, par conséquent, dans ce cas le corollaire est
est vrai pour . Dans le cas contraire,
est une constante, par conséquent, dans ce cas le corollaire est
est vrai pour . Dans le cas contraire,
 .
On définit les vecteurs
.
On définit les vecteurs  et
et
 .
On cherche à résoude le système de équations à inconnues :
.
On cherche à résoude le système de équations à inconnues :
(4)#
On note le vecteur
 et la matrice :
et la matrice :

L’équation (4) est équivalente à l’équation matricielle :
 . On effectue une itération du pivot de Gauss.
(4) équivaut à :
. On effectue une itération du pivot de Gauss.
(4) équivaut à :

On note  et
et
 ,
,  les matrices :
les matrices :

Donc (4) est équivalent à :
(5)#
Il est possible de choisir  de telle sorte qu’il existe une suite
de telle sorte qu’il existe une suite  avec
avec  et vérifiant :
et vérifiant :

On définit :

On vérifie que :

On obtient, toujours pour (4) :
(6)#

On étudie la limite lorsque  :
:

Donc :
(7)#
D’après l’hypothèse de récurrence, (7) implique que :
 .
Il reste à montrer que
.
Il reste à montrer que  est nécessairement nul ce qui est le cas losque ,
alors
est nécessairement nul ce qui est le cas losque ,
alors  .
La récurrence est démontrée.
.
La récurrence est démontrée.
A chaque fonction sigmoïde du corollaire famille libre
correspond un neurone de la couche cachée. Tous ont des rôles
symétriques les uns par rapport aux autres ce qui ne serait
pas le cas si les fonctions de transfert étaient des polynômes.
C’est une des raisons pour lesquelles les réseaux de neurones
ont du succès. Le théorème densité
et le corollaire famille libre
sont aussi vraies pour des fonctions du type exponentielle :
 .
Maintenant qu’il est prouvé que les réseaux de neurones conviennent
pour modéliser dans l’équation (2),
il reste à étudier les méthodes qui permettent de trouver
les paramètres optimaux de cette fonction.
.
Maintenant qu’il est prouvé que les réseaux de neurones conviennent
pour modéliser dans l’équation (2),
il reste à étudier les méthodes qui permettent de trouver
les paramètres optimaux de cette fonction.