Classification#
Vraisemblance d’un échantillon de variable suivant une loi multinomiale#
Soit  un échantillon de variables aléatoires i.i.d. suivant la loi multinomiale
un échantillon de variables aléatoires i.i.d. suivant la loi multinomiale
 .
On définit
.
On définit  .
La vraisemblance de l’échantillon est :
.
La vraisemblance de l’échantillon est :
(1)#
Cette fonction est aussi appelée distance de Kullback-Leiber ([Kullback1951]), elle mesure la distance entre deux distributions de variables aléatoires discrètes. L”estimateur de maximum de vraisemblance (emv) est la solution du problème suivant :
Problème P1 : estimateur du maximum de vraisemblance
Soit un vecteur  tel que :
tel que :

On cherche le vecteur  vérifiant :
vérifiant :

Théorème T1 : résolution du problème du maximum de vraisemblance
La solution du problème du maximum de vraisemblance est le vecteur :

Démonstration
Soit un vecteur  vérifiant les conditions :
vérifiant les conditions :

La fonction  est concave, d’où :
est concave, d’où :

La distance de KullBack-Leiber compare deux distributions de probabilités entre elles. C’est elle qui va faire le lien entre le problème de classification discret et les réseaux de neurones pour lesquels il faut impérativement une fonction d’erreur dérivable.
Problème de classification pour les réseaux de neurones#
Le problème de classification est un cas particulier de celui qui suit pour lequel il n’est pas nécessaire de connaître la classe d’appartenance de chaque exemple mais seulement les probabilités d’appartenance de cet exemple à chacune des classes.
Soient une variable aléatoire continue  et une variable aléatoire discrète multinomiale
et une variable aléatoire discrète multinomiale
 , on veut estimer la loi de :
, on veut estimer la loi de :

Le vecteur  est une fonction
est une fonction  de
de  où
où
 est l’ensemble des
est l’ensemble des  paramètres du modèle.
Cette fonction possède
paramètres du modèle.
Cette fonction possède  entrées et
entrées et  sorties.
Comme pour le problème de la régression, on cherche les
poids qui correspondent le mieux à l’échantillon :
sorties.
Comme pour le problème de la régression, on cherche les
poids qui correspondent le mieux à l’échantillon :

On suppose que les variables  suivent les lois respectives
suivent les lois respectives  et sont indépendantes entre elles, la vraisemblance du modèle
vérifie d’après l’équation (1) :
et sont indépendantes entre elles, la vraisemblance du modèle
vérifie d’après l’équation (1) :

La solution du problème  est celle d’un problème d’optimisation sous contrainte. Afin de contourner
ce problème, on définit la fonction :
est celle d’un problème d’optimisation sous contrainte. Afin de contourner
ce problème, on définit la fonction :

Les contraintes sur  sont bien vérifiées :
sont bien vérifiées :

On en déduit que :

D’où :
(2)#![\begin{eqnarray}
\begin{array}[c]{c}
\ln L_W \propto \sum_{i=1}^{N} \sum_{k=1}^{C} \eta_i^k f_k\pa{W,X_i} - \sum_{i=1}^{N}
\ln \cro{ \sum_{l=1}^{C} e^{f_l\pa{W,X_i} }}
\end{array} \nonumber
\end{eqnarray}](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMjEuNTE5NTIycHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNzIuMjY5Mjg5IDc3LjkwNzcyOSAzMDEuNzg3NzIyIDIxLjUxOTUyMicgd2lkdGg9JzMwMS43ODc3MjJwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMi4wODAxOTkgLTMuNzMwMDEyQzIuMDgwMTk5IC0zLjg3MzQ3NCAxLjk3MjYwMyAtMy45NjkxMTYgMS44MzUxMTggLTMuOTY5MTE2QzEuNjczNzI0IC0zLjk2OTExNiAxLjUwMDM3NCAtMy44MTM2OTkgMS41MDAzNzQgLTMuNjQwMzQ5QzEuNTAwMzc0IC0zLjQ5MDkwOSAxLjYwNzk3IC0zLjQwMTI0NSAxLjczOTQ3NyAtMy40MDEyNDVDMS45MzA3NiAtMy40MDEyNDUgMi4wODAxOTkgLTMuNTgwNTczIDIuMDgwMTk5IC0zLjczMDAxMlpNMS43MjE1NDQgLTEuNjQzODM2QzEuNzQ1NDU1IC0xLjcwMzYxMSAxLjc5OTI1MyAtMS44NDcwNzMgMS44MjMxNjMgLTEuOTAwODcyQzEuODQxMDk2IC0xLjk1NDY3IDEuODY1MDA2IC0yLjAxNDQ0NiAxLjg2NTAwNiAtMi4xMTYwNjVDMS44NjUwMDYgLTIuNDUwODA5IDEuNTY2MTI3IC0yLjYzNjExNSAxLjI2NzI0OCAtMi42MzYxMTVDMC42NTc1MzQgLTIuNjM2MTE1IDAuMzY0NjMzIC0xLjg0NzA3MyAwLjM2NDYzMyAtMS43MTU1NjdDMC4zNjQ2MzMgLTEuNjg1Njc5IDAuMzg4NTQzIC0xLjYzMTg4IDAuNDcyMjI5IC0xLjYzMTg4UzAuNTczODQ4IC0xLjY2Nzc0NiAwLjU5MTc4MSAtMS43MjE1NDRDMC43NTkxNTMgLTIuMzAxMzcgMS4wNzU5NjUgLTIuNDM4ODU0IDEuMjQzMzM3IC0yLjQzODg1NEMxLjM2Mjg4OSAtMi40Mzg4NTQgMS40MDQ3MzIgLTIuMzYxMTQ2IDEuNDA0NzMyIC0yLjIyMzY2MUMxLjQwNDczMiAtMi4xMDQxMSAxLjM2ODg2NyAtMi4wMTQ0NDYgMS4zNTY5MTIgLTEuOTcyNjAzTDEuMDQ2MDc3IC0xLjIwNzQ3MkMwLjk3NDM0NiAtMS4wMzQxMjIgMC45NzQzNDYgLTEuMDIyMTY3IDAuODk2NjM4IC0wLjgxODkyOUMwLjgxODkyOSAtMC42Mzk2MDEgMC43ODkwNDEgLTAuNTYxODkzIDAuNzg5MDQxIC0wLjQ2MDI3NEMwLjc4OTA0MSAtMC4xNTU0MTcgMS4wNjQwMSAwLjA1OTc3NiAxLjM5Mjc3NyAwLjA1OTc3NkMxLjk5NjUxMyAwLjA1OTc3NiAyLjI5NTM5MiAtMC43MjkyNjUgMi4yOTUzOTIgLTAuODYwNzcyQzIuMjk1MzkyIC0wLjg3MjcyNyAyLjI4OTQxNSAtMC45NDQ0NTggMi4xODE4MTggLTAuOTQ0NDU4QzIuMDk4MTMyIC0wLjk0NDQ1OCAyLjA5MjE1NCAtMC45MTQ1NyAyLjA1NjI4OSAtMC44MDA5OTZDMS45NjA2NDggLTAuNDk2MTM5IDEuNzE1NTY3IC0wLjEzNzQ4NCAxLjQxMDcxIC0wLjEzNzQ4NEMxLjMwMzExMyAtMC4xMzc0ODQgMS4yNDkzMTUgLTAuMjA5MjE1IDEuMjQ5MzE1IC0wLjM1MjY3N0MxLjI0OTMxNSAtMC40NzIyMjkgMS4yODUxODEgLTAuNTYxODkzIDEuMzYyODg5IC0wLjc0NzE5OEwxLjcyMTU0NCAtMS42NDM4MzZaJyBpZD0nZzItMTA1Jy8+CjxwYXRoIGQ9J00xLjc5MzI3NSAtMy45NjkxMTZDMS43OTkyNTMgLTMuOTkzMDI2IDEuODExMjA4IC00LjAyODg5MiAxLjgxMTIwOCAtNC4wNTg3OEMxLjgxMTIwOCAtNC4xNTQ0MjEgMS42OTE2NTYgLTQuMTQ4NDQzIDEuNjE5OTI1IC00LjE0MjQ2NkwwLjk1MDQzNiAtNC4wODg2NjdDMC44NDg4MTcgLTQuMDgyNjkgMC43NzExMDggLTQuMDc2NzEyIDAuNzcxMTA4IC0zLjkzMzI1QzAuNzcxMTA4IC0zLjg0MzU4NyAwLjg0ODgxNyAtMy44NDM1ODcgMC45NDQ0NTggLTMuODQzNTg3QzEuMTE3ODA4IC0zLjg0MzU4NyAxLjE1OTY1MSAtMy44MjU2NTQgMS4yMzczNiAtMy44MDE3NDNDMS4yMzczNiAtMy43MzAwMTIgMS4yMzczNiAtMy43MTgwNTcgMS4yMTM0NSAtMy42MjI0MTZMMC40ODQxODQgLTAuNzE3MzFDMC40NjYyNTIgLTAuNjUxNTU3IDAuNDU0Mjk2IC0wLjU5Nzc1OCAwLjQ1NDI5NiAtMC41MTQwNzJDMC40NTQyOTYgLTAuMTQ5NDQgMC43ODkwNDEgMC4wNTk3NzYgMS4xMjM3ODYgMC4wNTk3NzZDMS4zNzQ4NDQgMC4wNTk3NzYgMS41MTgzMDYgLTAuMTAxNjE5IDEuNjAxOTkzIC0wLjIzOTEwM0MxLjc2MzM4NyAtMC40OTYxMzkgMS44NDEwOTYgLTAuODM2ODYyIDEuODQxMDk2IC0wLjg2MDc3MkMxLjg0MTA5NiAtMC44NzI3MjcgMS44MzUxMTggLTAuOTQ0NDU4IDEuNzI3NTIyIC0wLjk0NDQ1OEMxLjYzNzg1OCAtMC45NDQ0NTggMS42MjU5MDMgLTAuOTAyNjE1IDEuNjAxOTkzIC0wLjgwNjk3NEMxLjQ5NDM5NiAtMC4zODI1NjUgMS4zNTY5MTIgLTAuMTM3NDg0IDEuMTQ3Njk2IC0wLjEzNzQ4NEMwLjkyNjUyNiAtMC4xMzc0ODQgMC45MjY1MjYgLTAuMzc2NTg4IDAuOTI2NTI2IC0wLjQzNjM2NEMwLjkyNjUyNiAtMC41MzIwMDUgMC45Mzg0ODEgLTAuNTc5ODI2IDAuOTU2NDEzIC0wLjY0NTU3OUwxLjc5MzI3NSAtMy45NjkxMTZaJyBpZD0nZzItMTA4Jy8+CjxwYXRoIGQ9J001LjY3ODcwNSAtMy4zMTE1ODJDNS43Mzg0ODEgLTMuNTUwNjg1IDUuNzc0MzQ2IC0zLjY5NDE0NyA1Ljc3NDM0NiAtNC4wMTY5MzZDNS43NzQzNDYgLTQuNzM0MjQ3IDUuMzU1OTE1IC01LjI3MjIyOSA0LjQ0NzMyMyAtNS4yNzIyMjlDMy4zODMzMTMgLTUuMjcyMjI5IDIuODIxNDIgLTQuNTE5MDU0IDIuNjA2MjI3IC00LjIyMDE3NEMyLjU3MDM2MSAtNC45MDE2MTkgMi4wODAxOTkgLTUuMjcyMjI5IDEuNTU0MTcyIC01LjI3MjIyOUMxLjIwNzQ3MiAtNS4yNzIyMjkgMC45MzI1MDMgLTUuMTA0ODU3IDAuNzA1MzU1IC00LjY1MDU2QzAuNDkwMTYyIC00LjIyMDE3NCAwLjMyMjc5IC0zLjQ5MDkwOSAwLjMyMjc5IC0zLjQ0MzA4OFMwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NDk5MzggLTMuMzM1NDkyIDAuNTYxODkzIC0zLjM0NzQ0NyAwLjYzMzYyNCAtMy42MjI0MTZDMC44MTI5NTEgLTQuMzI3NzcxIDEuMDQwMSAtNS4wMzMxMjYgMS41MTgzMDYgLTUuMDMzMTI2QzEuNzkzMjc1IC01LjAzMzEyNiAxLjg4ODkxNyAtNC44NDE4NDMgMS44ODg5MTcgLTQuNDgzMTg4QzEuODg4OTE3IC00LjIyMDE3NCAxLjc2OTM2NSAtMy43NTM5MjMgMS42ODU2NzkgLTMuMzgzMzEzTDEuMzUwOTM0IC0yLjA5MjE1NEMxLjMwMzExMyAtMS44NjUwMDYgMS4xNzE2MDYgLTEuMzI3MDI0IDEuMTExODMxIC0xLjExMTgzMUMxLjAyODE0NCAtMC44MDA5OTYgMC44OTY2MzggLTAuMjM5MTAzIDAuODk2NjM4IC0wLjE3OTMyOEMwLjg5NjYzOCAtMC4wMTE5NTUgMS4wMjgxNDQgMC4xMTk1NTIgMS4yMDc0NzIgMC4xMTk1NTJDMS4zNTA5MzQgMC4xMTk1NTIgMS41MTgzMDYgMC4wNDc4MjEgMS42MTM5NDggLTAuMTMxNTA3QzEuNjM3ODU4IC0wLjE5MTI4MyAxLjc0NTQ1NSAtMC42MDk3MTQgMS44MDUyMyAtMC44NDg4MTdMMi4wNjgyNDQgLTEuOTI0NzgyTDIuNDYyNzY1IC0zLjUwMjg2NEMyLjQ4NjY3NSAtMy41NzQ1OTUgMi43ODU1NTQgLTQuMTcyMzU0IDMuMjI3ODk1IC00LjU1NDkxOUMzLjUzODczIC00Ljg0MTg0MyAzLjk0NTIwNSAtNS4wMzMxMjYgNC40MTE0NTcgLTUuMDMzMTI2QzQuODg5NjY0IC01LjAzMzEyNiA1LjA1NzAzNiAtNC42NzQ0NzEgNS4wNTcwMzYgLTQuMTk2MjY0QzUuMDU3MDM2IC0zLjg0OTU2NCA1LjAwOTIxNSAtMy42NTgyODEgNC45NDk0NCAtMy40MzExMzNMMy41NjI2NCAyLjA2ODI0NEMzLjU1MDY4NSAyLjEyODAyIDMuNTI2Nzc1IDIuMTk5NzUxIDMuNTI2Nzc1IDIuMjcxNDgyQzMuNTI2Nzc1IDIuNDUwODA5IDMuNjcwMjM3IDIuNTcwMzYxIDMuODQ5NTY0IDIuNTcwMzYxQzMuOTU3MTYxIDIuNTcwMzYxIDQuMjA4MjE5IDIuNTIyNTQgNC4zMDM4NjEgMi4xNjM4ODVMNS42Nzg3MDUgLTMuMzExNTgyWicgaWQ9J2c0LTE3Jy8+CjxwYXRoIGQ9J00yLjMzMTI1OCAwLjA0NzgyMUMyLjMzMTI1OCAtMC42NDU1NzkgMi4xMDQxMSAtMS4xNTk2NTEgMS42MTM5NDggLTEuMTU5NjUxQzEuMjMxMzgyIC0xLjE1OTY1MSAxLjA0MDEgLTAuODQ4ODE3IDEuMDQwMSAtMC41ODU4MDNTMS4yMTk0MjcgMCAxLjYyNTkwMyAwQzEuNzgxMzIgMCAxLjkxMjgyNyAtMC4wNDc4MjEgMi4wMjA0MjMgLTAuMTU1NDE3QzIuMDQ0MzM0IC0wLjE3OTMyOCAyLjA1NjI4OSAtMC4xNzkzMjggMi4wNjgyNDQgLTAuMTc5MzI4QzIuMDkyMTU0IC0wLjE3OTMyOCAyLjA5MjE1NCAtMC4wMTE5NTUgMi4wOTIxNTQgMC4wNDc4MjFDMi4wOTIxNTQgMC40NDIzNDEgMi4wMjA0MjMgMS4yMTk0MjcgMS4zMjcwMjQgMS45OTY1MTNDMS4xOTU1MTcgMi4xMzk5NzUgMS4xOTU1MTcgMi4xNjM4ODUgMS4xOTU1MTcgMi4xODc3OTZDMS4xOTU1MTcgMi4yNDc1NzIgMS4yNTUyOTMgMi4zMDczNDcgMS4zMTUwNjggMi4zMDczNDdDMS40MTA3MSAyLjMwNzM0NyAyLjMzMTI1OCAxLjQyMjY2NSAyLjMzMTI1OCAwLjA0NzgyMVonIGlkPSdnNC01OScvPgo8cGF0aCBkPSdNNC4zODc1NDcgLTcuMjQ0ODMyQzQuNDk1MTQzIC03LjY5OTEyOCA0LjUzMTAwOSAtNy44MTg2OCA1LjU4MzA2NCAtNy44MTg2OEM1LjkwNTg1MyAtNy44MTg2OCA1Ljk4OTUzOSAtNy44MTg2OCA1Ljk4OTUzOSAtOC4wNDU4MjhDNS45ODk1MzkgLTguMTY1MzggNS44NTgwMzIgLTguMTY1MzggNS44MTAyMTIgLTguMTY1MzhDNS41NzExMDggLTguMTY1MzggNS4yOTYxMzkgLTguMTQxNDY5IDUuMDU3MDM2IC04LjE0MTQ2OUgzLjQ1NTA0NEMzLjIyNzg5NSAtOC4xNDE0NjkgMi45NjQ4ODIgLTguMTY1MzggMi43Mzc3MzMgLTguMTY1MzhDMi42NDIwOTIgLTguMTY1MzggMi41MTA1ODUgLTguMTY1MzggMi41MTA1ODUgLTcuOTM4MjMyQzIuNTEwNTg1IC03LjgxODY4IDIuNjE4MTgyIC03LjgxODY4IDIuNzk3NTA5IC03LjgxODY4QzMuNTI2Nzc1IC03LjgxODY4IDMuNTI2Nzc1IC03LjcyMzAzOSAzLjUyNjc3NSAtNy41OTE1MzJDMy41MjY3NzUgLTcuNTY3NjIxIDMuNTI2Nzc1IC03LjQ5NTg5IDMuNDc4OTU0IC03LjMxNjU2M0wxLjg2NTAwNiAtMC44ODQ2ODJDMS43NTc0MSAtMC40NjYyNTIgMS43MzM0OTkgLTAuMzQ2NyAwLjg5NjYzOCAtMC4zNDY3QzAuNjY5NDg5IC0wLjM0NjcgMC41NDk5MzggLTAuMzQ2NyAwLjU0OTkzOCAtMC4xMzE1MDdDMC41NDk5MzggMCAwLjYyMTY2OSAwIDAuODYwNzcyIDBINi4yMTY2ODdDNi40Nzk3MDEgMCA2LjQ5MTY1NiAtMC4wMTE5NTUgNi41NzUzNDIgLTAuMjI3MTQ4TDcuNDk1ODkgLTIuNzczNTk5QzcuNTE5ODAxIC0yLjgzMzM3NSA3LjU0MzcxMSAtMi45MDUxMDYgNy41NDM3MTEgLTIuOTQwOTcxQzcuNTQzNzExIC0zLjAxMjcwMiA3LjQ4MzkzNSAtMy4wNjA1MjMgNy40MjQxNTkgLTMuMDYwNTIzQzcuNDEyMjA0IC0zLjA2MDUyMyA3LjM1MjQyOCAtMy4wNjA1MjMgNy4zMjg1MTggLTMuMDEyNzAyQzcuMzA0NjA4IC0zLjAwMDc0NyA3LjMwNDYwOCAtMi45NzY4MzcgNy4yMDg5NjYgLTIuNzQ5Njg5QzYuODI2NDAxIC0xLjY5NzYzNCA2LjI4ODQxOCAtMC4zNDY3IDQuMjY3OTk1IC0wLjM0NjdIMy4xMjAyOTlDMi45NTI5MjcgLTAuMzQ2NyAyLjkyOTAxNiAtMC4zNDY3IDIuODU3Mjg1IC0wLjM1ODY1NUMyLjcyNTc3OCAtMC4zNzA2MSAyLjcxMzgyMyAtMC4zOTQ1MjEgMi43MTM4MjMgLTAuNDkwMTYyQzIuNzEzODIzIC0wLjU3Mzg0OCAyLjczNzczMyAtMC42NDU1NzkgMi43NjE2NDQgLTAuNzUzMTc2TDQuMzg3NTQ3IC03LjI0NDgzMlonIGlkPSdnNC03NicvPgo8cGF0aCBkPSdNMTAuNzk1NTE3IC02LjgzODM1NkMxMS4wNzA0ODYgLTcuMzA0NjA4IDExLjMzMzQ5OSAtNy43NDY5NDkgMTIuMDUwODA5IC03LjgxODY4QzEyLjE1ODQwNiAtNy44MzA2MzUgMTIuMjY2MDAyIC03Ljg0MjU5IDEyLjI2NjAwMiAtOC4wMzM4NzNDMTIuMjY2MDAyIC04LjE2NTM4IDEyLjE1ODQwNiAtOC4xNjUzOCAxMi4xMjI1NCAtOC4xNjUzOEMxMi4wOTg2MyAtOC4xNjUzOCAxMi4wMTQ5NDQgLTguMTQxNDY5IDExLjIyNTkwMyAtOC4xNDE0NjlDMTAuODY3MjQ4IC04LjE0MTQ2OSAxMC40OTY2MzggLTguMTY1MzggMTAuMTQ5OTM4IC04LjE2NTM4QzEwLjA3ODIwNyAtOC4xNjUzOCA5LjkzNDc0NSAtOC4xNjUzOCA5LjkzNDc0NSAtNy45MzgyMzJDOS45MzQ3NDUgLTcuODMwNjM1IDEwLjAzMDM4NiAtNy44MTg2OCAxMC4xMDIxMTcgLTcuODE4NjhDMTAuMzQxMjIgLTcuODA2NzI1IDEwLjcyMzc4NiAtNy43MzQ5OTQgMTAuNzIzNzg2IC03LjM2NDM4NEMxMC43MjM3ODYgLTcuMjA4OTY2IDEwLjY3NTk2NSAtNy4xMjUyOCAxMC41NTY0MTMgLTYuOTIyMDQyTDcuMjkyNjUzIC0xLjIwNzQ3Mkw2Ljg2MjI2NyAtNy40MzYxMTVDNi44NjIyNjcgLTcuNTc5NTc3IDYuOTkzNzczIC03LjgwNjcyNSA3LjY2MzI2MyAtNy44MTg2OEM3LjgxODY4IC03LjgxODY4IDcuOTM4MjMyIC03LjgxODY4IDcuOTM4MjMyIC04LjA0NTgyOEM3LjkzODIzMiAtOC4xNjUzOCA3LjgxODY4IC04LjE2NTM4IDcuNzU4OTA0IC04LjE2NTM4QzcuMzQwNDczIC04LjE2NTM4IDYuODk4MTMyIC04LjE0MTQ2OSA2LjQ2Nzc0NiAtOC4xNDE0NjlINS44NDYwNzdDNS42NjY3NSAtOC4xNDE0NjkgNS40NTE1NTcgLTguMTY1MzggNS4yNzIyMjkgLTguMTY1MzhDNS4yMDA0OTggLTguMTY1MzggNS4wNTcwMzYgLTguMTY1MzggNS4wNTcwMzYgLTcuOTM4MjMyQzUuMDU3MDM2IC03LjgxODY4IDUuMTQwNzIyIC03LjgxODY4IDUuMzQzOTYgLTcuODE4NjhDNS44OTM4OTggLTcuODE4NjggNS44OTM4OTggLTcuODA2NzI1IDUuOTQxNzE5IC03LjA3NzQ2TDUuOTc3NTg0IC02LjY0NzA3M0wyLjg4MTE5NiAtMS4yMDc0NzJMMi40Mzg4NTQgLTcuMzc2MzM5QzIuNDM4ODU0IC03LjUwNzg0NiAyLjQzODg1NCAtNy44MDY3MjUgMy4yNTE4MDYgLTcuODE4NjhDMy4zODMzMTMgLTcuODE4NjggMy41MTQ4MTkgLTcuODE4NjggMy41MTQ4MTkgLTguMDMzODczQzMuNTE0ODE5IC04LjE2NTM4IDMuNDA3MjIzIC04LjE2NTM4IDMuMzM1NDkyIC04LjE2NTM4QzIuOTE3MDYxIC04LjE2NTM4IDIuNDc0NzIgLTguMTQxNDY5IDIuMDQ0MzM0IC04LjE0MTQ2OUgxLjQyMjY2NUMxLjI0MzMzNyAtOC4xNDE0NjkgMS4wMjgxNDQgLTguMTY1MzggMC44NDg4MTcgLTguMTY1MzhDMC43NzcwODYgLTguMTY1MzggMC42MzM2MjQgLTguMTY1MzggMC42MzM2MjQgLTcuOTM4MjMyQzAuNjMzNjI0IC03LjgxODY4IDAuNzI5MjY1IC03LjgxODY4IDAuODk2NjM4IC03LjgxODY4QzEuNDU4NTMxIC03LjgxODY4IDEuNDcwNDg2IC03Ljc0Njk0OSAxLjQ5NDM5NiAtNy4zNjQzODRMMi4wMjA0MjMgLTAuMDIzOTFDMi4wMzIzNzkgMC4xNzkzMjggMi4wNDQzMzQgMC4yNTEwNTkgMi4xODc3OTYgMC4yNTEwNTlDMi4zMDczNDcgMC4yNTEwNTkgMi4zMzEyNTggMC4yMDMyMzggMi40Mzg4NTQgMC4wMjM5MUw2LjAwMTQ5NCAtNi4yMDQ3MzJMNi40NDM4MzYgLTAuMDIzOTFDNi40NTU3OTEgMC4xNzkzMjggNi40Njc3NDYgMC4yNTEwNTkgNi42MTEyMDggMC4yNTEwNTlDNi43MzA3NiAwLjI1MTA1OSA2Ljc2NjYyNSAwLjE5MTI4MyA2Ljg2MjI2NyAwLjAyMzkxTDEwLjc5NTUxNyAtNi44MzgzNTZaJyBpZD0nZzQtODcnLz4KPHBhdGggZD0nTTUuNjc4NzA1IC00Ljg1Mzc5OEw0LjU1NDkxOSAtNy40NzE5OEM0LjcxMDMzNiAtNy43NTg5MDQgNS4wNjg5OTEgLTcuODA2NzI1IDUuMjEyNDUzIC03LjgxODY4QzUuMjg0MTg0IC03LjgxODY4IDUuNDE1NjkxIC03LjgzMDYzNSA1LjQxNTY5MSAtOC4wMzM4NzNDNS40MTU2OTEgLTguMTY1MzggNS4zMDgwOTUgLTguMTY1MzggNS4yMzYzNjQgLTguMTY1MzhDNS4wMzMxMjYgLTguMTY1MzggNC43OTQwMjIgLTguMTQxNDY5IDQuNTkwNzg1IC04LjE0MTQ2OUgzLjg5NzM4NUMzLjE2ODEyIC04LjE0MTQ2OSAyLjY0MjA5MiAtOC4xNjUzOCAyLjYzMDEzNyAtOC4xNjUzOEMyLjUzNDQ5NiAtOC4xNjUzOCAyLjQxNDk0NCAtOC4xNjUzOCAyLjQxNDk0NCAtNy45MzgyMzJDMi40MTQ5NDQgLTcuODE4NjggMi41MjI1NCAtNy44MTg2OCAyLjY3Nzk1OCAtNy44MTg2OEMzLjM3MTM1NyAtNy44MTg2OCAzLjQxOTE3OCAtNy42OTkxMjggMy41Mzg3MyAtNy40MTIyMDRMNC45NjEzOTUgLTQuMDg4NjY3TDIuMzY3MTIzIC0xLjMxNTA2OEMxLjkzNjczNyAtMC44NDg4MTcgMS40MjI2NjUgLTAuMzk0NTIxIDAuNTM3OTgzIC0wLjM0NjdDMC4zOTQ1MjEgLTAuMzM0NzQ1IDAuMjk4ODc5IC0wLjMzNDc0NSAwLjI5ODg3OSAtMC4xMTk1NTJDMC4yOTg4NzkgLTAuMDgzNjg2IDAuMzEwODM0IDAgMC40NDIzNDEgMEMwLjYwOTcxNCAwIDAuNzg5MDQxIC0wLjAyMzkxIDAuOTU2NDEzIC0wLjAyMzkxSDEuNTE4MzA2QzEuOTAwODcyIC0wLjAyMzkxIDIuMzE5MzAzIDAgMi42ODk5MTMgMEMyLjc3MzU5OSAwIDIuOTE3MDYxIDAgMi45MTcwNjEgLTAuMjE1MTkzQzIuOTE3MDYxIC0wLjMzNDc0NSAyLjgzMzM3NSAtMC4zNDY3IDIuNzYxNjQ0IC0wLjM0NjdDMi41MjI1NCAtMC4zNzA2MSAyLjM2NzEyMyAtMC41MDIxMTcgMi4zNjcxMjMgLTAuNjkzNEMyLjM2NzEyMyAtMC44OTY2MzggMi41MTA1ODUgLTEuMDQwMSAyLjg1NzI4NSAtMS4zOTg3NTVMMy45MjEyOTUgLTIuNTU4NDA2QzQuMTg0MzA5IC0yLjgzMzM3NSA0LjgxNzkzMyAtMy41MjY3NzUgNS4wODA5NDYgLTMuNzg5Nzg4TDYuMzM2MjM5IC0wLjg0ODgxN0M2LjM0ODE5NCAtMC44MjQ5MDcgNi4zOTYwMTUgLTAuNzA1MzU1IDYuMzk2MDE1IC0wLjY5MzRDNi4zOTYwMTUgLTAuNTg1ODAzIDYuMTMzMDAxIC0wLjM3MDYxIDUuNzUwNDM2IC0wLjM0NjdDNS42Nzg3MDUgLTAuMzQ2NyA1LjU0NzE5OCAtMC4zMzQ3NDUgNS41NDcxOTggLTAuMTE5NTUyQzUuNTQ3MTk4IDAgNS42NjY3NSAwIDUuNzI2NTI2IDBDNS45Mjk3NjMgMCA2LjE2ODg2NyAtMC4wMjM5MSA2LjM3MjEwNSAtMC4wMjM5MUg3LjY4NzE3M0M3LjkwMjM2NiAtMC4wMjM5MSA4LjEyOTUxNCAwIDguMzMyNzUyIDBDOC40MTY0MzggMCA4LjU0Nzk0NSAwIDguNTQ3OTQ1IC0wLjIyNzE0OEM4LjU0Nzk0NSAtMC4zNDY3IDguNDI4Mzk0IC0wLjM0NjcgOC4zMjA3OTcgLTAuMzQ2N0M3LjYwMzQ4NyAtMC4zNTg2NTUgNy41Nzk1NzcgLTAuNDE4NDMxIDcuMzc2MzM5IC0wLjg2MDc3Mkw1Ljc5ODI1NyAtNC41NjY4NzRMNy4zMTY1NjMgLTYuMTkyNzc3QzcuNDM2MTE1IC02LjMxMjMyOSA3LjcxMTA4MyAtNi42MTEyMDggNy44MTg2OCAtNi43MzA3NkM4LjMzMjc1MiAtNy4yNjg3NDIgOC44MTA5NTkgLTcuNzU4OTA0IDkuNzc5MzI4IC03LjgxODY4QzkuODk4ODc5IC03LjgzMDYzNSAxMC4wMTg0MzEgLTcuODMwNjM1IDEwLjAxODQzMSAtOC4wMzM4NzNDMTAuMDE4NDMxIC04LjE2NTM4IDkuOTEwODM0IC04LjE2NTM4IDkuODYzMDE0IC04LjE2NTM4QzkuNjk1NjQxIC04LjE2NTM4IDkuNTE2MzE0IC04LjE0MTQ2OSA5LjM0ODk0MSAtOC4xNDE0NjlIOC43OTkwMDRDOC40MTY0MzggLTguMTQxNDY5IDcuOTk4MDA3IC04LjE2NTM4IDcuNjI3Mzk3IC04LjE2NTM4QzcuNTQzNzExIC04LjE2NTM4IDcuNDAwMjQ5IC04LjE2NTM4IDcuNDAwMjQ5IC03Ljk1MDE4N0M3LjQwMDI0OSAtNy44MzA2MzUgNy40ODM5MzUgLTcuODE4NjggNy41NTU2NjYgLTcuODE4NjhDNy43NDY5NDkgLTcuNzk0NzcgNy45NTAxODcgLTcuNjk5MTI4IDcuOTUwMTg3IC03LjQ3MTk4TDcuOTM4MjMyIC03LjQ0ODA3QzcuOTI2Mjc2IC03LjM2NDM4NCA3LjkwMjM2NiAtNy4yNDQ4MzIgNy43NzA4NTkgLTcuMTAxMzdMNS42Nzg3MDUgLTQuODUzNzk4WicgaWQ9J2c0LTg4Jy8+CjxwYXRoIGQ9J00yLjEzOTk3NSAtMi43NzM1OTlDMi40NjI3NjUgLTIuNzczNTk5IDMuMjc1NzE2IC0yLjc5NzUwOSAzLjg0OTU2NCAtMy4wMTI3MDJDNC43NTgxNTcgLTMuMzU5NDAyIDQuODQxODQzIC00LjA1MjgwMiA0Ljg0MTg0MyAtNC4yNjc5OTVDNC44NDE4NDMgLTQuNzk0MDIyIDQuMzg3NTQ3IC01LjI3MjIyOSAzLjU5ODUwNiAtNS4yNzIyMjlDMi4zNDMyMTMgLTUuMjcyMjI5IDAuNTM3OTgzIC00LjEzNjQ4OCAwLjUzNzk4MyAtMi4wMDg0NjhDMC41Mzc5ODMgLTAuNzUzMTc2IDEuMjU1MjkzIDAuMTE5NTUyIDIuMzQzMjEzIDAuMTE5NTUyQzMuOTY5MTE2IDAuMTE5NTUyIDQuOTk3MjYgLTEuMTQ3Njk2IDQuOTk3MjYgLTEuMzAzMTEzQzQuOTk3MjYgLTEuMzc0ODQ0IDQuOTI1NTI5IC0xLjQzNDYyIDQuODc3NzA5IC0xLjQzNDYyQzQuODQxODQzIC0xLjQzNDYyIDQuODI5ODg4IC0xLjQyMjY2NSA0LjcyMjI5MSAtMS4zMTUwNjhDMy45NTcxNjEgLTAuMjk4ODc5IDIuODIxNDIgLTAuMTE5NTUyIDIuMzY3MTIzIC0wLjExOTU1MkMxLjY4NTY3OSAtMC4xMTk1NTIgMS4zMjcwMjQgLTAuNjU3NTM0IDEuMzI3MDI0IC0xLjU0MjIxN0MxLjMyNzAyNCAtMS43MDk1ODkgMS4zMjcwMjQgLTIuMDA4NDY4IDEuNTA2MzUxIC0yLjc3MzU5OUgyLjEzOTk3NVpNMS41NjYxMjcgLTMuMDEyNzAyQzIuMDgwMTk5IC00Ljg1Mzc5OCAzLjIxNTk0IC01LjAzMzEyNiAzLjU5ODUwNiAtNS4wMzMxMjZDNC4xMjQ1MzMgLTUuMDMzMTI2IDQuNDgzMTg4IC00LjcyMjI5MSA0LjQ4MzE4OCAtNC4yNjc5OTVDNC40ODMxODggLTMuMDEyNzAyIDIuNTcwMzYxIC0zLjAxMjcwMiAyLjA2ODI0NCAtMy4wMTI3MDJIMS41NjYxMjdaJyBpZD0nZzQtMTAxJy8+CjxwYXRoIGQ9J001LjMzMjAwNSAtNC44MDU5NzhDNS41NzExMDggLTQuODA1OTc4IDUuNjY2NzUgLTQuODA1OTc4IDUuNjY2NzUgLTUuMDMzMTI2QzUuNjY2NzUgLTUuMTUyNjc3IDUuNTcxMTA4IC01LjE1MjY3NyA1LjM1NTkxNSAtNS4xNTI2NzdINC4zODc1NDdDNC42MTQ2OTUgLTYuMzg0MDYgNC43ODIwNjcgLTcuMjMyODc3IDQuODc3NzA5IC03LjYxNTQ0MkM0Ljk0OTQ0IC03LjkwMjM2NiA1LjIwMDQ5OCAtOC4xNzczMzUgNS41MTEzMzMgLTguMTc3MzM1QzUuNzYyMzkxIC04LjE3NzMzNSA2LjAxMzQ1IC04LjA2OTczOCA2LjEzMzAwMSAtNy45NjIxNDJDNS42NjY3NSAtNy45MTQzMjEgNS41MjMyODggLTcuNTY3NjIxIDUuNTIzMjg4IC03LjM2NDM4NEM1LjUyMzI4OCAtNy4xMjUyOCA1LjcwMjYxNSAtNi45ODE4MTggNS45Mjk3NjMgLTYuOTgxODE4QzYuMTY4ODY3IC02Ljk4MTgxOCA2LjUyNzUyMiAtNy4xODUwNTYgNi41Mjc1MjIgLTcuNjM5MzUyQzYuNTI3NTIyIC04LjE0MTQ2OSA2LjAyNTQwNSAtOC40MTY0MzggNS40OTkzNzcgLTguNDE2NDM4QzQuOTg1MzA1IC04LjQxNjQzOCA0LjQ4MzE4OCAtOC4wMzM4NzMgNC4yNDQwODUgLTcuNTY3NjIxQzQuMDI4ODkyIC03LjE0OTE5MSAzLjkwOTM0IC02LjcxODgwNCAzLjYzNDM3MSAtNS4xNTI2NzdIMi44MzMzNzVDMi42MDYyMjcgLTUuMTUyNjc3IDIuNDg2Njc1IC01LjE1MjY3NyAyLjQ4NjY3NSAtNC45Mzc0ODRDMi40ODY2NzUgLTQuODA1OTc4IDIuNTU4NDA2IC00LjgwNTk3OCAyLjc5NzUwOSAtNC44MDU5NzhIMy41NjI2NEMzLjM0NzQ0NyAtMy42OTQxNDcgMi44NTcyODUgLTAuOTkyMjc5IDIuNTgyMzE2IDAuMjg2OTI0QzIuMzc5MDc4IDEuMzI3MDI0IDIuMTk5NzUxIDIuMTk5NzUxIDEuNjAxOTkzIDIuMTk5NzUxQzEuNTY2MTI3IDIuMTk5NzUxIDEuMjE5NDI3IDIuMTk5NzUxIDEuMDA0MjM0IDEuOTcyNjAzQzEuNjEzOTQ4IDEuOTI0NzgyIDEuNjEzOTQ4IDEuMzk4NzU1IDEuNjEzOTQ4IDEuMzg2OEMxLjYxMzk0OCAxLjE0NzY5NiAxLjQzNDYyIDEuMDA0MjM0IDEuMjA3NDcyIDEuMDA0MjM0QzAuOTY4MzY5IDEuMDA0MjM0IDAuNjA5NzE0IDEuMjA3NDcyIDAuNjA5NzE0IDEuNjYxNzY4QzAuNjA5NzE0IDIuMTc1ODQxIDEuMTM1NzQxIDIuNDM4ODU0IDEuNjAxOTkzIDIuNDM4ODU0QzIuODIxNDIgMi40Mzg4NTQgMy4zMjM1MzcgMC4yNTEwNTkgMy40NTUwNDQgLTAuMzQ2N0MzLjY3MDIzNyAtMS4yNjcyNDggNC4yNTYwNCAtNC40NDczMjMgNC4zMTU4MTYgLTQuODA1OTc4SDUuMzMyMDA1WicgaWQ9J2c0LTEwMicvPgo8cGF0aCBkPSdNMi42NTQwNDcgMS45OTI1MjhDMi43MTc4MDggMS45OTI1MjggMi44MTM0NSAxLjk5MjUyOCAyLjgxMzQ1IDEuODk2ODg3QzIuODEzNDUgMS44NjUwMDYgMi44MDU0NzkgMS44NTcwMzYgMi43MDE4NjggMS43NTM0MjVDMS42MDk5NjMgMC43MjUyOCAxLjMzODk3OSAtMC43NTcxNjEgMS4zMzg5NzkgLTEuOTkyNTI4QzEuMzM4OTc5IC00LjI4NzkyIDIuMjg3NDIyIC01LjM2Mzg4NSAyLjY5Mzg5OCAtNS43MzA1MTFDMi44MDU0NzkgLTUuODM0MTIyIDIuODEzNDUgLTUuODQyMDkyIDIuODEzNDUgLTUuODgxOTQzUzIuNzgxNTY5IC01Ljk3NzU4NCAyLjcwMTg2OCAtNS45Nzc1ODRDMi41NzQzNDYgLTUuOTc3NTg0IDIuMTc1ODQxIC01LjU3MTEwOCAyLjExMjA4IC01LjQ5OTM3N0MxLjA0NDA4NSAtNC4zODM1NjIgMC44MjA5MjIgLTIuOTQ4OTQxIDAuODIwOTIyIC0xLjk5MjUyOEMwLjgyMDkyMiAtMC4yMDcyMjMgMS41NzAxMTIgMS4yMjczOTcgMi42NTQwNDcgMS45OTI1MjhaJyBpZD0nZzUtNDAnLz4KPHBhdGggZD0nTTIuNDYyNzY1IC0xLjk5MjUyOEMyLjQ2Mjc2NSAtMi43NDk2ODkgMi4zMzUyNDMgLTMuNjU4MjgxIDEuODQxMDk2IC00LjU5ODc1NUMxLjQ1MDU2IC01LjMzMjAwNSAwLjcyNTI4IC01Ljk3NzU4NCAwLjU4MTgxOCAtNS45Nzc1ODRDMC41MDIxMTcgLTUuOTc3NTg0IDAuNDc4MjA3IC01LjkyMTc5MyAwLjQ3ODIwNyAtNS44ODE5NDNDMC40NzgyMDcgLTUuODUwMDYyIDAuNDc4MjA3IC01LjgzNDEyMiAwLjU3Mzg0OCAtNS43Mzg0ODFDMS42ODk2NjQgLTQuNjc4NDU2IDEuOTQ0NzA3IC0zLjIxOTkyNSAxLjk0NDcwNyAtMS45OTI1MjhDMS45NDQ3MDcgMC4yOTQ4OTQgMC45OTYyNjQgMS4zNzg4MjkgMC41ODk3ODggMS43NDU0NTVDMC40ODYxNzcgMS44NDkwNjYgMC40NzgyMDcgMS44NTcwMzYgMC40NzgyMDcgMS44OTY4ODdTMC41MDIxMTcgMS45OTI1MjggMC41ODE4MTggMS45OTI1MjhDMC43MDkzNCAxLjk5MjUyOCAxLjEwNzg0NiAxLjU4NjA1MiAxLjE3MTYwNiAxLjUxNDMyMUMyLjIzOTYwMSAwLjM5ODUwNiAyLjQ2Mjc2NSAtMS4wMzYxMTUgMi40NjI3NjUgLTEuOTkyNTI4WicgaWQ9J2c1LTQxJy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnNS00OScvPgo8cGF0aCBkPSdNNS44MjYxNTIgLTIuNjU0MDQ3QzUuOTQ1NzA0IC0yLjY1NDA0NyA2LjEwNTEwNiAtMi42NTQwNDcgNi4xMDUxMDYgLTIuODM3MzZTNS45MTM4MjMgLTMuMDIwNjcyIDUuNzk0MjcxIC0zLjAyMDY3MkgwLjc4MTA3MUMwLjY2MTUxOSAtMy4wMjA2NzIgMC40NzAyMzcgLTMuMDIwNjcyIDAuNDcwMjM3IC0yLjgzNzM2UzAuNjI5NjM5IC0yLjY1NDA0NyAwLjc0OTE5MSAtMi42NTQwNDdINS44MjYxNTJaTTUuNzk0MjcxIC0wLjk2NDM4NEM1LjkxMzgyMyAtMC45NjQzODQgNi4xMDUxMDYgLTAuOTY0Mzg0IDYuMTA1MTA2IC0xLjE0NzY5NlM1Ljk0NTcwNCAtMS4zMzEwMDkgNS44MjYxNTIgLTEuMzMxMDA5SDAuNzQ5MTkxQzAuNjI5NjM5IC0xLjMzMTAwOSAwLjQ3MDIzNyAtMS4zMzEwMDkgMC40NzAyMzcgLTEuMTQ3Njk2UzAuNjYxNTE5IC0wLjk2NDM4NCAwLjc4MTA3MSAtMC45NjQzODRINS43OTQyNzFaJyBpZD0nZzUtNjEnLz4KPHBhdGggZD0nTTEuNDkwNDExIC0wLjExOTU1MkMxLjQ5MDQxMSAwLjM5ODUwNiAxLjM3ODgyOSAwLjg1MjgwMiAwLjg4NDY4MiAxLjM0Njk0OUMwLjg1MjgwMiAxLjM3MDg1OSAwLjgzNjg2MiAxLjM4NjggMC44MzY4NjIgMS40MjY2NUMwLjgzNjg2MiAxLjQ5MDQxMSAwLjkwMDYyMyAxLjUzODIzMiAwLjk1NjQxMyAxLjUzODIzMkMxLjA1MjA1NSAxLjUzODIzMiAxLjcxMzU3NCAwLjkwODU5MyAxLjcxMzU3NCAtMC4wMjM5MUMxLjcxMzU3NCAtMC41MzM5OTggMS41MjIyOTEgLTAuODg0NjgyIDEuMTcxNjA2IC0wLjg4NDY4MkMwLjg5MjY1MyAtMC44ODQ2ODIgMC43MzMyNSAtMC42NjE1MTkgMC43MzMyNSAtMC40NDYzMjZDMC43MzMyNSAtMC4yMjMxNjMgMC44ODQ2ODIgMCAxLjE3OTU3NyAwQzEuMzcwODU5IDAgMS40OTA0MTEgLTAuMTExNTgyIDEuNDkwNDExIC0wLjExOTU1MlonIGlkPSdnMy01OScvPgo8cGF0aCBkPSdNNi4zNDQyMDkgLTUuMzk1NzY2QzYuMzUyMTc5IC01LjQyNzY0NiA2LjM2ODEyIC01LjQ3NTQ2NyA2LjM2ODEyIC01LjUxNTMxOEM2LjM2ODEyIC01LjU3MTEwOCA2LjMyMDI5OSAtNS42MTA5NTkgNi4yNjQ1MDggLTUuNjEwOTU5UzYuMTg0ODA3IC01LjU4NzA0OSA2LjEyMTA0NiAtNS41MTUzMThMNS41NjMxMzggLTQuOTAxNjE5QzUuNDkxNDA3IC01LjAwNTIzIDUuMDY4OTkxIC01LjYxMDk1OSA0LjEzNjQ4OCAtNS42MTA5NTlDMi4yODc0MjIgLTUuNjEwOTU5IDAuNDIyNDE2IC0zLjg5NzM4NSAwLjQyMjQxNiAtMi4wNjQyNTlDMC40MjI0MTYgLTAuNjc3NDYgMS40NzQ0NzEgMC4xNjczNzIgMi43NDE3MTkgMC4xNjczNzJDMy43ODU4MDMgMC4xNjczNzIgNC42NzA0ODYgLTAuNDcwMjM3IDUuMTAwODcyIC0xLjA5MTkwNUM1LjM2Mzg4NSAtMS40ODI0NDEgNS40Njc0OTcgLTEuODY1MDA2IDUuNDY3NDk3IC0xLjkxMjgyN0M1LjQ2NzQ5NyAtMS45ODQ1NTggNS40MTk2NzYgLTIuMDE2NDM4IDUuMzQ3OTQ1IC0yLjAxNjQzOEM1LjI1MjMwNCAtMi4wMTY0MzggNS4yMzYzNjQgLTEuOTc2NTg4IDUuMjEyNDUzIC0xLjg4ODkxN0M0Ljg3NzcwOSAtMC43ODkwNDEgMy44MDE3NDMgLTAuMDk1NjQxIDIuODQ1MzMgLTAuMDk1NjQxQzIuMDMyMzc5IC0wLjA5NTY0MSAxLjE3OTU3NyAtMC41NzM4NDggMS4xNzk1NzcgLTEuNzkzMjc1QzEuMTc5NTc3IC0yLjA0ODMxOSAxLjI2NzI0OCAtMy4zNzkzMjggMi4xNTE5MyAtNC4zNzU1OTJDMi43NDk2ODkgLTUuMDQ1MDgxIDMuNTYyNjQgLTUuMzQ3OTQ1IDQuMTkyMjc5IC01LjM0Nzk0NUM1LjE5NjUxMyAtNS4zNDc5NDUgNS42MTA5NTkgLTQuNTQyOTY0IDUuNjEwOTU5IC0zLjc4NTgwM0M1LjYxMDk1OSAtMy42NzQyMjIgNS41NzkwNzggLTMuNTIyNzkgNS41NzkwNzggLTMuNDI3MTQ4QzUuNTc5MDc4IC0zLjMyMzUzNyA1LjY4MjY5IC0zLjMyMzUzNyA1LjcxNDU3IC0zLjMyMzUzN0M1LjgxODE4MiAtMy4zMjM1MzcgNS44MzQxMjIgLTMuMzU1NDE3IDUuODY2MDAyIC0zLjQ5ODg3OUw2LjM0NDIwOSAtNS4zOTU3NjZaJyBpZD0nZzMtNjcnLz4KPHBhdGggZD0nTTYuMzEyMzI5IC00LjU3NDg0NEM2LjQwNzk3IC00Ljk2NTM4IDYuNTgzMzEzIC01LjE1NjY2MyA3LjE1NzE2MSAtNS4xODA1NzNDNy4yMzY4NjIgLTUuMTgwNTczIDcuMzAwNjIzIC01LjIyODM5NCA3LjMwMDYyMyAtNS4zMzIwMDVDNy4zMDA2MjMgLTUuMzc5ODI2IDcuMjYwNzcyIC01LjQ0MzU4NyA3LjE4MTA3MSAtNS40NDM1ODdDNy4xMjUyOCAtNS40NDM1ODcgNi45NzM4NDggLTUuNDE5Njc2IDYuMzg0MDYgLTUuNDE5Njc2QzUuNzQ2NDUxIC01LjQxOTY3NiA1LjY0MjgzOSAtNS40NDM1ODcgNS41NzExMDggLTUuNDQzNTg3QzUuNDQzNTg3IC01LjQ0MzU4NyA1LjQxOTY3NiAtNS4zNTU5MTUgNS40MTk2NzYgLTUuMjkyMTU0QzUuNDE5Njc2IC01LjE4ODU0MyA1LjUyMzI4OCAtNS4xODA1NzMgNS41OTUwMTkgLTUuMTgwNTczQzYuMDgxMTk2IC01LjE2NDYzMyA2LjA4MTE5NiAtNC45NDk0NCA2LjA4MTE5NiAtNC44Mzc4NThDNi4wODExOTYgLTQuNzk4MDA3IDYuMDgxMTk2IC00Ljc1ODE1NyA2LjA0OTMxNSAtNC42MzA2MzVMNS4xNzI2MDMgLTEuMTM5NzI2TDMuMjUxODA2IC01LjMwMDEyNUMzLjE4ODA0NSAtNS40NDM1ODcgMy4xNzIxMDUgLTUuNDQzNTg3IDIuOTgwODIyIC01LjQ0MzU4N0gxLjk0NDcwN0MxLjgwMTI0NSAtNS40NDM1ODcgMS42OTc2MzQgLTUuNDQzNTg3IDEuNjk3NjM0IC01LjI5MjE1NEMxLjY5NzYzNCAtNS4xODA1NzMgMS43OTMyNzUgLTUuMTgwNTczIDEuOTYwNjQ4IC01LjE4MDU3M0MyLjAyNDQwOCAtNS4xODA1NzMgMi4yNjM1MTIgLTUuMTgwNTczIDIuNDQ2ODI0IC01LjEzMjc1MkwxLjM3ODgyOSAtMC44NTI4MDJDMS4yODMxODggLTAuNDU0Mjk2IDEuMDc1OTY1IC0wLjI3ODk1NCAwLjU0MTk2OCAtMC4yNjMwMTRDMC40OTQxNDcgLTAuMjYzMDE0IDAuMzk4NTA2IC0wLjI1NTA0NCAwLjM5ODUwNiAtMC4xMTE1ODJDMC4zOTg1MDYgLTAuMDYzNzYxIDAuNDM4MzU2IDAgMC41MTgwNTcgMEMwLjU0OTkzOCAwIDAuNzMzMjUgLTAuMDIzOTEgMS4zMDcwOTggLTAuMDIzOTFDMS45MzY3MzcgLTAuMDIzOTEgMi4wNTYyODkgMCAyLjEyODAyIDBDMi4xNTk5IDAgMi4yNzk0NTIgMCAyLjI3OTQ1MiAtMC4xNTE0MzJDMi4yNzk0NTIgLTAuMjQ3MDczIDIuMTkxNzgxIC0wLjI2MzAxNCAyLjEzNTk5IC0wLjI2MzAxNEMxLjg0OTA2NiAtMC4yNzA5ODQgMS42MDk5NjMgLTAuMzE4ODA0IDEuNjA5OTYzIC0wLjU5Nzc1OEMxLjYwOTk2MyAtMC42Mzc2MDkgMS42MzM4NzMgLTAuNzQ5MTkxIDEuNjMzODczIC0wLjc1NzE2MUwyLjY3Nzk1OCAtNC45MTc1NTlIMi42ODU5MjhMNC45MDE2MTkgLTAuMTQzNDYyQzQuOTU3NDEgLTAuMDE1OTQgNC45NjUzOCAwIDUuMDUzMDUxIDBDNS4xNjQ2MzMgMCA1LjE3MjYwMyAtMC4wMzE4OCA1LjIwNDQ4MyAtMC4xNjczNzJMNi4zMTIzMjkgLTQuNTc0ODQ0WicgaWQ9J2czLTc4Jy8+CjxwYXRoIGQ9J003Ljc4NjggLTQuNDg3MTczQzguMTQ1NDU1IC01LjA4NDkzMiA4LjQxNjQzOCAtNS4xNTY2NjMgOC42Nzk0NTIgLTUuMTgwNTczQzguNzUxMTgzIC01LjE4ODU0MyA4Ljg0NjgyNCAtNS4xOTY1MTMgOC44NDY4MjQgLTUuMzMyMDA1QzguODQ2ODI0IC01LjM4Nzc5NiA4Ljc5OTAwNCAtNS40NDM1ODcgOC43MzUyNDMgLTUuNDQzNTg3QzguNTk5NzUxIC01LjQ0MzU4NyA4LjcyNzI3MyAtNS40MTk2NzYgOC4wOTc2MzQgLTUuNDE5Njc2QzcuNTcxNjA2IC01LjQxOTY3NiA3LjM0MDQ3MyAtNS40NDM1ODcgNy4zMDA2MjMgLTUuNDQzNTg3QzcuMTczMTAxIC01LjQ0MzU4NyA3LjE0OTE5MSAtNS4zNTU5MTUgNy4xNDkxOTEgLTUuMjkyMTU0QzcuMTQ5MTkxIC01LjE4ODU0MyA3LjI2MDc3MiAtNS4xODA1NzMgNy4yODQ2ODIgLTUuMTgwNTczQzcuNTA3ODQ2IC01LjE3MjYwMyA3LjcwNzA5OCAtNS4wOTI5MDIgNy43MDcwOTggLTQuODkzNjQ5QzcuNzA3MDk4IC00Ljc5MDAzNyA3LjYyNzM5NyAtNC42NTQ1NDUgNy41ODc1NDcgLTQuNTkwNzg1TDUuMzc5ODI2IC0wLjg3NjcxMkw1LjAwNTIzIC00LjgzNzg1OEM0Ljk5NzI2IC00Ljg1Mzc5OCA0Ljk4OTI5IC00LjkwOTU4OSA0Ljk4OTI5IC00LjkzMzQ5OUM0Ljk4OTI5IC01LjA1MzA1MSA1LjE0MDcyMiAtNS4xODA1NzMgNS41MzEyNTggLTUuMTgwNTczQzUuNjUwODA5IC01LjE4MDU3MyA1Ljc0NjQ1MSAtNS4xODA1NzMgNS43NDY0NTEgLTUuMzMyMDA1QzUuNzQ2NDUxIC01LjM5NTc2NiA1LjY5ODYzIC01LjQ0MzU4NyA1LjYxODkyOSAtNS40NDM1ODdTNS4yNDQzMzQgLTUuNDI3NjQ2IDUuMTY0NjMzIC01LjQxOTY3Nkg0LjY4NjQyNkMzLjk3NzA4NiAtNS40MTk2NzYgMy44ODk0MTUgLTUuNDQzNTg3IDMuODI1NjU0IC01LjQ0MzU4N0MzLjc5Mzc3MyAtNS40NDM1ODcgMy42NjYyNTIgLTUuNDQzNTg3IDMuNjY2MjUyIC01LjI5MjE1NEMzLjY2NjI1MiAtNS4xODA1NzMgMy43Njk4NjMgLTUuMTgwNTczIDMuODg5NDE1IC01LjE4MDU3M0M0LjIyNDE1OSAtNS4xODA1NzMgNC4yNDgwNyAtNS4xMTY4MTIgNC4yNjQwMSAtNS4wMDUyM0M0LjI2NDAxIC00Ljk4OTI5IDQuMzExODMxIC00LjUyNzAyNCA0LjMxMTgzMSAtNC41MDMxMTNTNC4zMTE4MzEgLTQuNDM5MzUyIDQuMjU2MDQgLTQuMzUxNjgxTDIuMTgzODExIC0wLjg3NjcxMkwxLjgwOTIxNSAtNC43OTgwMDdDMS44MDkyMTUgLTQuODM3ODU4IDEuODAxMjQ1IC00LjkwMTYxOSAxLjgwMTI0NSAtNC45NDE0NjlDMS44MDEyNDUgLTUuMDA1MjMgMS44NjUwMDYgLTUuMTgwNTczIDIuMzUxMTgzIC01LjE4MDU3M0MyLjQzODg1NCAtNS4xODA1NzMgMi41NTA0MzYgLTUuMTgwNTczIDIuNTUwNDM2IC01LjMzMjAwNUMyLjU1MDQzNiAtNS4zOTU3NjYgMi40OTQ2NDUgLTUuNDQzNTg3IDIuNDIyOTE0IC01LjQ0MzU4N0MyLjM0MzIxMyAtNS40NDM1ODcgMi4wNDgzMTkgLTUuNDI3NjQ2IDEuOTY4NjE4IC01LjQxOTY3NkgxLjQ5MDQxMUMwLjc1NzE2MSAtNS40MTk2NzYgMC43MjUyOCAtNS40NDM1ODcgMC42Mjk2MzkgLTUuNDQzNTg3QzAuNTAyMTE3IC01LjQ0MzU4NyAwLjQ3ODIwNyAtNS4zNTU5MTUgMC40NzgyMDcgLTUuMjkyMTU0QzAuNDc4MjA3IC01LjE4MDU3MyAwLjU4OTc4OCAtNS4xODA1NzMgMC42Nzc0NiAtNS4xODA1NzNDMS4wNTIwNTUgLTUuMTgwNTczIDEuMDYwMDI1IC01LjEyNDc4MiAxLjA3NTk2NSAtNC45MjU1MjlMMS41MzgyMzIgLTAuMDYzNzYxQzEuNTU0MTcyIDAuMDg3NjcxIDEuNTYyMTQyIDAuMTY3MzcyIDEuNjk3NjM0IDAuMTY3MzcyQzEuNzYxMzk1IDAuMTY3MzcyIDEuODQxMDk2IDAuMTQzNDYyIDEuOTI4NzY3IDBMNC4zNTE2ODEgLTQuMDgwNjk3TDQuNzM0MjQ3IC0wLjA1NTc5MUM0Ljc1MDE4NyAwLjA4NzY3MSA0Ljc1ODE1NyAwLjE2NzM3MiA0Ljg4NTY3OSAwLjE2NzM3MkM1LjAyMTE3MSAwLjE2NzM3MiA1LjA2ODk5MSAwLjA3OTcwMSA1LjExNjgxMiAwTDcuNzg2OCAtNC40ODcxNzNaJyBpZD0nZzMtODcnLz4KPHBhdGggZD0nTTQuMTYwMzk5IC0zLjA0NDU4M0M0LjU0Mjk2NCAtMy40MzUxMTggNS42NzQ3MiAtNC41OTg3NTUgNS44NjYwMDIgLTQuNzUwMTg3QzYuMjAwNzQ3IC01LjAwNTIzIDYuNCAtNS4xNDg2OTIgNi45NzM4NDggLTUuMTgwNTczQzcuMDIxNjY5IC01LjE4ODU0MyA3LjA4NTQzIC01LjIyODM5NCA3LjA4NTQzIC01LjMzMjAwNUM3LjA4NTQzIC01LjQwMzczNiA3LjAxMzY5OSAtNS40NDM1ODcgNi45NzM4NDggLTUuNDQzNTg3QzYuODk0MTQ3IC01LjQ0MzU4NyA2Ljg0NjMyNiAtNS40MTk2NzYgNi4yMjQ2NTggLTUuNDE5Njc2QzUuNjI2ODk5IC01LjQxOTY3NiA1LjQxMTcwNiAtNS40NDM1ODcgNS4zNzE4NTYgLTUuNDQzNTg3QzUuMzM5OTc1IC01LjQ0MzU4NyA1LjIxMjQ1MyAtNS40NDM1ODcgNS4yMTI0NTMgLTUuMjkyMTU0QzUuMjEyNDUzIC01LjI4NDE4NCA1LjIxMjQ1MyAtNS4xODg1NDMgNS4zMzIwMDUgLTUuMTgwNTczQzUuMzg3Nzk2IC01LjE3MjYwMyA1LjYwMjk4OSAtNS4xNTY2NjMgNS42MDI5ODkgLTQuOTczMzVDNS42MDI5ODkgLTQuOTE3NTU5IDUuNTcxMTA4IC00LjgyOTg4OCA1LjUwNzM0NyAtNC43NjYxMjdMNS40ODM0MzcgLTQuNzI2Mjc2QzUuNDU5NTI3IC00LjcwMjM2NiA1LjQ1OTUyNyAtNC42ODY0MjYgNS4zNzk4MjYgLTQuNjE0Njk1TDQuMDQ4ODE3IC0zLjI2Nzc0NkwzLjIzNTg2NiAtNC45NTc0MUMzLjM0NzQ0NyAtNS4xNDg2OTIgMy41ODY1NSAtNS4xNzI2MDMgMy42ODIxOTIgLTUuMTgwNTczQzMuNzIyMDQyIC01LjE4MDU3MyAzLjgzMzYyNCAtNS4xODg1NDMgMy44MzM2MjQgLTUuMzI0MDM1QzMuODMzNjI0IC01LjM5NTc2NiAzLjc3NzgzMyAtNS40NDM1ODcgMy43MDYxMDIgLTUuNDQzNTg3QzMuNjI2NDAxIC01LjQ0MzU4NyAzLjMyMzUzNyAtNS40Mjc2NDYgMy4yNDM4MzYgLTUuNDI3NjQ2QzMuMTk2MDE1IC01LjQxOTY3NiAyLjkwMTEyMSAtNS40MTk2NzYgMi43MzM3NDggLTUuNDE5Njc2QzEuOTkyNTI4IC01LjQxOTY3NiAxLjg5Njg4NyAtNS40NDM1ODcgMS44MjUxNTYgLTUuNDQzNTg3QzEuNzkzMjc1IC01LjQ0MzU4NyAxLjY2NTc1MyAtNS40NDM1ODcgMS42NjU3NTMgLTUuMjkyMTU0QzEuNjY1NzUzIC01LjE4MDU3MyAxLjc2OTM2NSAtNS4xODA1NzMgMS44OTY4ODcgLTUuMTgwNTczQzIuMjk1MzkyIC01LjE4MDU3MyAyLjM2NzEyMyAtNS4xMDA4NzIgMi40Mzg4NTQgLTQuOTQ5NDRMMy40OTg4NzkgLTIuNzE3ODA4TDEuODY1MDA2IC0xLjA1MjA1NUMxLjM4NjggLTAuNTczODQ4IDEuMDEyMjA0IC0wLjI5NDg5NCAwLjQ0NjMyNiAtMC4yNjMwMTRDMC4zNTA2ODUgLTAuMjU1MDQ0IDAuMjU1MDQ0IC0wLjI1NTA0NCAwLjI1NTA0NCAtMC4xMTE1ODJDMC4yNTUwNDQgLTAuMDYzNzYxIDAuMjk0ODk0IDAgMC4zNzQ1OTUgMEMwLjQzMDM4NiAwIDAuNTE4MDU3IC0wLjAyMzkxIDEuMTIzNzg2IC0wLjAyMzkxQzEuNjk3NjM0IC0wLjAyMzkxIDEuOTQ0NzA3IDAgMS45NzY1ODggMEMyLjAxNjQzOCAwIDIuMTM1OTkgMCAyLjEzNTk5IC0wLjE1MTQzMkMyLjEzNTk5IC0wLjE2NzM3MiAyLjEyODAyIC0wLjI1NTA0NCAyLjAwODQ2OCAtMC4yNjMwMTRDMS44NTcwMzYgLTAuMjcwOTg0IDEuNzQ1NDU1IC0wLjMyNjc3NSAxLjc0NTQ1NSAtMC40NzAyMzdDMS43NDU0NTUgLTAuNTk3NzU4IDEuODQxMDk2IC0wLjcwMTM3IDEuOTYwNjQ4IC0wLjgyMDkyMkMyLjA5NjEzOSAtMC45NzIzNTQgMi41MTA1ODUgLTEuMzg2OCAyLjc5NzUwOSAtMS42NjU3NTNDMi45ODA4MjIgLTEuODQ5MDY2IDMuNDI3MTQ4IC0yLjMxMTMzMyAzLjYxMDQ2MSAtMi40ODY2NzVMNC41MjcwMjQgLTAuNTgxODE4QzQuNTY2ODc0IC0wLjUwMjExNyA0LjU2Njg3NCAtMC40OTQxNDcgNC41NjY4NzQgLTAuNDg2MTc3QzQuNTY2ODc0IC0wLjQxNDQ0NiA0LjM5OTUwMiAtMC4yNzg5NTQgNC4xMzY0ODggLTAuMjYzMDE0QzQuMDgwNjk3IC0wLjI2MzAxNCAzLjk3NzA4NiAtMC4yNTUwNDQgMy45NzcwODYgLTAuMTExNTgyQzMuOTc3MDg2IC0wLjEwMzYxMSAzLjk4NTA1NiAwIDQuMTEyNTc4IDBDNC4xOTIyNzkgMCA0LjQ4NzE3MyAtMC4wMTU5NCA0LjU2Njg3NCAtMC4wMjM5MUg1LjA3Njk2MUM1LjgxMDIxMiAtMC4wMjM5MSA1LjkyMTc5MyAwIDUuOTkzNTI0IDBDNi4wMjU0MDUgMCA2LjE0NDk1NiAwIDYuMTQ0OTU2IC0wLjE1MTQzMkM2LjE0NDk1NiAtMC4yNjMwMTQgNi4wNDEzNDUgLTAuMjYzMDE0IDUuOTIxNzkzIC0wLjI2MzAxNEM1LjQ5MTQwNyAtMC4yNjMwMTQgNS40NDM1ODcgLTAuMzU4NjU1IDUuMzg3Nzk2IC0wLjQ3ODIwN0w0LjE2MDM5OSAtMy4wNDQ1ODNaJyBpZD0nZzMtODgnLz4KPHBhdGggZD0nTTMuMDUyNTUzIC0zLjE3MjEwNUgzLjc5Mzc3M0MzLjk1MzE3NiAtMy4xNzIxMDUgNC4wNDg4MTcgLTMuMTcyMTA1IDQuMDQ4ODE3IC0zLjMyMzUzN0M0LjA0ODgxNyAtMy40MzUxMTggMy45NDUyMDUgLTMuNDM1MTE4IDMuODA5NzE0IC0zLjQzNTExOEgzLjEwMDM3NEMzLjIyNzg5NSAtNC4xNTI0MjggMy4zMDc1OTcgLTQuNjA2NzI1IDMuMzg3Mjk4IC00Ljk2NTM4QzMuNDE5MTc4IC01LjEwMDg3MiAzLjQ0MzA4OCAtNS4xODg1NDMgMy41NjI2NCAtNS4yODQxODRDMy42NjYyNTIgLTUuMzcxODU2IDMuNzMwMDEyIC01LjM4Nzc5NiAzLjgxNzY4NCAtNS4zODc3OTZDMy45MzcyMzUgLTUuMzg3Nzk2IDQuMDY0NzU3IC01LjM2Mzg4NSA0LjE2ODM2OSAtNS4zMDAxMjVDNC4xMjg1MTggLTUuMjg0MTg0IDQuMDgwNjk3IC01LjI2MDI3NCA0LjA0MDg0NyAtNS4yMzYzNjRDMy45MDUzNTUgLTUuMTY0NjMzIDMuODA5NzE0IC01LjAyMTE3MSAzLjgwOTcxNCAtNC44NjE3NjhDMy44MDk3MTQgLTQuNjc4NDU2IDMuOTUzMTc2IC00LjU2Njg3NCA0LjEyODUxOCAtNC41NjY4NzRDNC4zNTk2NTEgLTQuNTY2ODc0IDQuNTc0ODQ0IC00Ljc2NjEyNyA0LjU3NDg0NCAtNS4wNDUwODFDNC41NzQ4NDQgLTUuNDE5Njc2IDQuMTkyMjc5IC01LjYxMDk1OSAzLjgwOTcxNCAtNS42MTA5NTlDMy41Mzg3MyAtNS42MTA5NTkgMy4wMzY2MTMgLTUuNDgzNDM3IDIuNzgxNTY5IC00Ljc1MDE4N0MyLjcwOTgzOCAtNC41NjY4NzQgMi43MDk4MzggLTQuNTUwOTM0IDIuNDk0NjQ1IC0zLjQzNTExOEgxLjg5Njg4N0MxLjczNzQ4NCAtMy40MzUxMTggMS42NDE4NDMgLTMuNDM1MTE4IDEuNjQxODQzIC0zLjI4MzY4NkMxLjY0MTg0MyAtMy4xNzIxMDUgMS43NDU0NTUgLTMuMTcyMTA1IDEuODgwOTQ2IC0zLjE3MjEwNUgyLjQ0NjgyNEwxLjg3Mjk3NiAtMC4wNzk3MDFDMS43MjE1NDQgMC43MjUyOCAxLjYwMTk5MyAxLjQwMjc0IDEuMTc5NTc3IDEuNDAyNzRDMS4xNTU2NjYgMS40MDI3NCAwLjk4ODI5NCAxLjQwMjc0IDAuODM2ODYyIDEuMzA3MDk4QzEuMjAzNDg3IDEuMjE5NDI3IDEuMjAzNDg3IDAuODg0NjgyIDEuMjAzNDg3IDAuODc2NzEyQzEuMjAzNDg3IDAuNjkzNCAxLjA2MDAyNSAwLjU4MTgxOCAwLjg4NDY4MiAwLjU4MTgxOEMwLjY2OTQ4OSAwLjU4MTgxOCAwLjQzODM1NiAwLjc2NTEzMSAwLjQzODM1NiAxLjA2Nzk5NUMwLjQzODM1NiAxLjQwMjc0IDAuNzgxMDcxIDEuNjI1OTAzIDEuMTc5NTc3IDEuNjI1OTAzQzEuNjY1NzUzIDEuNjI1OTAzIDIuMDAwNDk4IDEuMTE1ODE2IDIuMTA0MTEgMC45MTY1NjNDMi4zOTEwMzQgMC4zOTA1MzUgMi41NzQzNDYgLTAuNjA1NzI5IDIuNTkwMjg2IC0wLjY4NTQzTDMuMDUyNTUzIC0zLjE3MjEwNVonIGlkPSdnMy0xMDInLz4KPHBhdGggZD0nTTIuMzc1MDkzIC00Ljk3MzM1QzIuMzc1MDkzIC01LjE0ODY5MiAyLjI0NzU3MiAtNS4yNzYyMTQgMi4wNjQyNTkgLTUuMjc2MjE0QzEuODU3MDM2IC01LjI3NjIxNCAxLjYyNTkwMyAtNS4wODQ5MzIgMS42MjU5MDMgLTQuODQ1ODI4QzEuNjI1OTAzIC00LjY3MDQ4NiAxLjc1MzQyNSAtNC41NDI5NjQgMS45MzY3MzcgLTQuNTQyOTY0QzIuMTQzOTYgLTQuNTQyOTY0IDIuMzc1MDkzIC00LjczNDI0NyAyLjM3NTA5MyAtNC45NzMzNVpNMS4yMTE0NTcgLTIuMDQ4MzE5TDAuNzgxMDcxIC0wLjk0ODQ0M0MwLjc0MTIyIC0wLjgyODg5MiAwLjcwMTM3IC0wLjczMzI1IDAuNzAxMzcgLTAuNTk3NzU4QzAuNzAxMzcgLTAuMjA3MjIzIDEuMDA0MjM0IDAuMDc5NzAxIDEuNDI2NjUgMC4wNzk3MDFDMi4xOTk3NTEgMC4wNzk3MDEgMi41MjY1MjYgLTEuMDM2MTE1IDIuNTI2NTI2IC0xLjEzOTcyNkMyLjUyNjUyNiAtMS4yMTk0MjcgMi40NjI3NjUgLTEuMjQzMzM3IDIuNDA2OTc0IC0xLjI0MzMzN0MyLjMxMTMzMyAtMS4yNDMzMzcgMi4yOTUzOTIgLTEuMTg3NTQ3IDIuMjcxNDgyIC0xLjEwNzg0NkMyLjA4ODE2OSAtMC40NzAyMzcgMS43NjEzOTUgLTAuMTQzNDYyIDEuNDQyNTkgLTAuMTQzNDYyQzEuMzQ2OTQ5IC0wLjE0MzQ2MiAxLjI1MTMwOCAtMC4xODMzMTMgMS4yNTEzMDggLTAuMzk4NTA2QzEuMjUxMzA4IC0wLjU4OTc4OCAxLjMwNzA5OCAtMC43MzMyNSAxLjQxMDcxIC0wLjk4MDMyNEMxLjQ5MDQxMSAtMS4xOTU1MTcgMS41NzAxMTIgLTEuNDEwNzEgMS42NTc3ODMgLTEuNjI1OTAzTDEuOTA0ODU3IC0yLjI3MTQ4MkMxLjk3NjU4OCAtMi40NTQ3OTUgMi4wNzIyMjkgLTIuNzAxODY4IDIuMDcyMjI5IC0yLjgzNzM2QzIuMDcyMjI5IC0zLjIzNTg2NiAxLjc1MzQyNSAtMy41MTQ4MTkgMS4zNDY5NDkgLTMuNTE0ODE5QzAuNTczODQ4IC0zLjUxNDgxOSAwLjIzOTEwMyAtMi4zOTkwMDQgMC4yMzkxMDMgLTIuMjk1MzkyQzAuMjM5MTAzIC0yLjIyMzY2MSAwLjI5NDg5NCAtMi4xOTE3ODEgMC4zNTg2NTUgLTIuMTkxNzgxQzAuNDYyMjY3IC0yLjE5MTc4MSAwLjQ3MDIzNyAtMi4yMzk2MDEgMC40OTQxNDcgLTIuMzE5MzAzQzAuNzE3MzEgLTMuMDc2NDYzIDEuMDgzOTM1IC0zLjI5MTY1NiAxLjMyMzAzOSAtMy4yOTE2NTZDMS40MzQ2MiAtMy4yOTE2NTYgMS41MTQzMjEgLTMuMjUxODA2IDEuNTE0MzIxIC0zLjAyODY0M0MxLjUxNDMyMSAtMi45NDg5NDEgMS41MDYzNTEgLTIuODM3MzYgMS40MjY2NSAtMi41OTgyNTdMMS4yMTE0NTcgLTIuMDQ4MzE5WicgaWQ9J2czLTEwNScvPgo8cGF0aCBkPSdNMi4zMjcyNzMgLTUuMjkyMTU0QzIuMzM1MjQzIC01LjMwODA5NSAyLjM1OTE1MyAtNS40MTE3MDYgMi4zNTkxNTMgLTUuNDE5Njc2QzIuMzU5MTUzIC01LjQ1OTUyNyAyLjMyNzI3MyAtNS41MzEyNTggMi4yMzE2MzEgLTUuNTMxMjU4QzIuMTk5NzUxIC01LjUzMTI1OCAxLjk1MjY3NyAtNS41MDczNDcgMS43NjkzNjUgLTUuNDkxNDA3TDEuMzIzMDM5IC01LjQ1OTUyN0MxLjE0NzY5NiAtNS40NDM1ODcgMS4wNjc5OTUgLTUuNDM1NjE2IDEuMDY3OTk1IC01LjI5MjE1NEMxLjA2Nzk5NSAtNS4xODA1NzMgMS4xNzk1NzcgLTUuMTgwNTczIDEuMjc1MjE4IC01LjE4MDU3M0MxLjY1Nzc4MyAtNS4xODA1NzMgMS42NTc3ODMgLTUuMTMyNzUyIDEuNjU3NzgzIC01LjA2MTAyMUMxLjY1Nzc4MyAtNS4wMzcxMTEgMS42NTc3ODMgLTUuMDIxMTcxIDEuNjE3OTMzIC00Ljg3NzcwOUwwLjQ4NjE3NyAtMC4zNDI3MTVDMC40NTQyOTYgLTAuMjIzMTYzIDAuNDU0Mjk2IC0wLjE3NTM0MiAwLjQ1NDI5NiAtMC4xNjczNzJDMC40NTQyOTYgLTAuMDMxODggMC41NjU4NzggMC4wNzk3MDEgMC43MTczMSAwLjA3OTcwMUMwLjk4ODI5NCAwLjA3OTcwMSAxLjA1MjA1NSAtMC4xNzUzNDIgMS4wODM5MzUgLTAuMjg2OTI0QzEuMTYzNjM2IC0wLjYyMTY2OSAxLjM3MDg1OSAtMS40NjY1MDEgMS40NTg1MzEgLTEuODAxMjQ1QzEuODk2ODg3IC0xLjc1MzQyNSAyLjQzMDg4NCAtMS42MDE5OTMgMi40MzA4ODQgLTEuMTQ3Njk2QzIuNDMwODg0IC0xLjEwNzg0NiAyLjQzMDg4NCAtMS4wNjc5OTUgMi40MTQ5NDQgLTAuOTg4Mjk0QzIuMzkxMDM0IC0wLjg4NDY4MiAyLjM3NTA5MyAtMC43NzMxMDEgMi4zNzUwOTMgLTAuNzMzMjVDMi4zNzUwOTMgLTAuMjYzMDE0IDIuNzI1Nzc4IDAuMDc5NzAxIDMuMTg4MDQ1IDAuMDc5NzAxQzMuNTIyNzkgMC4wNzk3MDEgMy43MzAwMTIgLTAuMTY3MzcyIDMuODMzNjI0IC0wLjMxODgwNEM0LjAyNDkwNyAtMC42MTM2OTkgNC4xNTI0MjggLTEuMDkxOTA1IDQuMTUyNDI4IC0xLjEzOTcyNkM0LjE1MjQyOCAtMS4yMTk0MjcgNC4wODg2NjcgLTEuMjQzMzM3IDQuMDMyODc3IC0xLjI0MzMzN0MzLjkzNzIzNSAtMS4yNDMzMzcgMy45MjEyOTUgLTEuMTk1NTE3IDMuODg5NDE1IC0xLjA1MjA1NUMzLjc4NTgwMyAtMC42Nzc0NiAzLjU3ODU4IC0wLjE0MzQ2MiAzLjIwMzk4NSAtMC4xNDM0NjJDMi45OTY3NjIgLTAuMTQzNDYyIDIuOTQ4OTQxIC0wLjMxODgwNCAyLjk0ODk0MSAtMC41MzM5OThDMi45NDg5NDEgLTAuNjM3NjA5IDIuOTU2OTEyIC0wLjczMzI1IDIuOTk2NzYyIC0wLjkxNjU2M0MzLjAwNDczMiAtMC45NDg0NDMgMy4wMzY2MTMgLTEuMDc1OTY1IDMuMDM2NjEzIC0xLjE2MzYzNkMzLjAzNjYxMyAtMS44MTcxODYgMi4yMTU2OTEgLTEuOTYwNjQ4IDEuODA5MjE1IC0yLjAxNjQzOEMyLjEwNDExIC0yLjE5MTc4MSAyLjM3NTA5MyAtMi40NjI3NjUgMi40NzA3MzUgLTIuNTY2Mzc2QzIuOTA5MDkxIC0yLjk5Njc2MiAzLjI2Nzc0NiAtMy4yOTE2NTYgMy42NTAzMTEgLTMuMjkxNjU2QzMuNzUzOTIzIC0zLjI5MTY1NiAzLjg0OTU2NCAtMy4yNjc3NDYgMy45MTMzMjUgLTMuMTg4MDQ1QzMuNDgyOTM5IC0zLjEzMjI1NCAzLjQ4MjkzOSAtMi43NTc2NTkgMy40ODI5MzkgLTIuNzQ5Njg5QzMuNDgyOTM5IC0yLjU3NDM0NiAzLjYxODQzMSAtMi40NTQ3OTUgMy43OTM3NzMgLTIuNDU0Nzk1QzQuMDA4OTY2IC0yLjQ1NDc5NSA0LjI0ODA3IC0yLjYzMDEzNyA0LjI0ODA3IC0yLjk1NjkxMkM0LjI0ODA3IC0zLjIyNzg5NSA0LjA1Njc4NyAtMy41MTQ4MTkgMy42NTgyODEgLTMuNTE0ODE5QzMuMTk2MDE1IC0zLjUxNDgxOSAyLjc4MTU2OSAtMy4xNjQxMzQgMi4zMjcyNzMgLTIuNzA5ODM4QzEuODY1MDA2IC0yLjI1NTU0MiAxLjY2NTc1MyAtMi4xNjc4NyAxLjUzODIzMiAtMi4xMTIwOEwyLjMyNzI3MyAtNS4yOTIxNTRaJyBpZD0nZzMtMTA3Jy8+CjxwYXRoIGQ9J00yLjA4ODE2OSAtNS4yOTIxNTRDMi4wOTYxMzkgLTUuMzA4MDk1IDIuMTIwMDUgLTUuNDExNzA2IDIuMTIwMDUgLTUuNDE5Njc2QzIuMTIwMDUgLTUuNDU5NTI3IDIuMDg4MTY5IC01LjUzMTI1OCAxLjk5MjUyOCAtNS41MzEyNThMMS4xODc1NDcgLTUuNDY3NDk3QzAuODkyNjUzIC01LjQ0MzU4NyAwLjgyODg5MiAtNS40MzU2MTYgMC44Mjg4OTIgLTUuMjkyMTU0QzAuODI4ODkyIC01LjE4MDU3MyAwLjk0MDQ3MyAtNS4xODA1NzMgMS4wMzYxMTUgLTUuMTgwNTczQzEuNDE4NjggLTUuMTgwNTczIDEuNDE4NjggLTUuMTMyNzUyIDEuNDE4NjggLTUuMDYxMDIxQzEuNDE4NjggLTUuMDM3MTExIDEuNDE4NjggLTUuMDIxMTcxIDEuMzc4ODI5IC00Ljg3NzcwOUwwLjM5MDUzNSAtMC45MjQ1MzNDMC4zNTg2NTUgLTAuNzk3MDExIDAuMzU4NjU1IC0wLjY3NzQ2IDAuMzU4NjU1IC0wLjY2OTQ4OUMwLjM1ODY1NSAtMC4xNzUzNDIgMC43NjUxMzEgMC4wNzk3MDEgMS4xNjM2MzYgMC4wNzk3MDFDMS41MDYzNTEgMC4wNzk3MDEgMS42ODk2NjQgLTAuMTkxMjgzIDEuNzc3MzM1IC0wLjM2NjYyNUMxLjkyMDc5NyAtMC42Mjk2MzkgMi4wNDAzNDkgLTEuMDk5ODc1IDIuMDQwMzQ5IC0xLjEzOTcyNkMyLjA0MDM0OSAtMS4xODc1NDcgMi4wMTY0MzggLTEuMjQzMzM3IDEuOTEyODI3IC0xLjI0MzMzN0MxLjg0MTA5NiAtMS4yNDMzMzcgMS44MTcxODYgLTEuMjAzNDg3IDEuODE3MTg2IC0xLjE5NTUxN0MxLjgwMTI0NSAtMS4xNzE2MDYgMS43NjEzOTUgLTEuMDI4MTQ0IDEuNzM3NDg0IC0wLjk0MDQ3M0MxLjYxNzkzMyAtMC40NzgyMDcgMS40NjY1MDEgLTAuMTQzNDYyIDEuMTc5NTc3IC0wLjE0MzQ2MkMwLjk4ODI5NCAtMC4xNDM0NjIgMC45MzI1MDMgLTAuMzI2Nzc1IDAuOTMyNTAzIC0wLjUxODA1N0MwLjkzMjUwMyAtMC42Njk0ODkgMC45NTY0MTMgLTAuNzU3MTYxIDAuOTgwMzI0IC0wLjg2MDc3MkwyLjA4ODE2OSAtNS4yOTIxNTRaJyBpZD0nZzMtMTA4Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzYtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c2LTQxJy8+CjxwYXRoIGQ9J00yLjA1NjI4OSAtOC4yOTY4ODdMMC4zOTQ1MjEgLTguMTY1MzhWLTcuODE4NjhDMS4yMDc0NzIgLTcuODE4NjggMS4zMDMxMTMgLTcuNzM0OTk0IDEuMzAzMTEzIC03LjE0OTE5MVYtMC44ODQ2ODJDMS4zMDMxMTMgLTAuMzQ2NyAxLjE3MTYwNiAtMC4zNDY3IDAuMzk0NTIxIC0wLjM0NjdWMEMwLjcyOTI2NSAtMC4wMjM5MSAxLjMxNTA2OCAtMC4wMjM5MSAxLjY3MzcyNCAtMC4wMjM5MVMyLjYzMDEzNyAtMC4wMjM5MSAyLjk2NDg4MiAwVi0wLjM0NjdDMi4xOTk3NTEgLTAuMzQ2NyAyLjA1NjI4OSAtMC4zNDY3IDIuMDU2Mjg5IC0wLjg4NDY4MlYtOC4yOTY4ODdaJyBpZD0nZzYtMTA4Jy8+CjxwYXRoIGQ9J001LjMyMDA1IC0yLjkwNTEwNkM1LjMyMDA1IC00LjAxNjkzNiA1LjMyMDA1IC00LjM1MTY4MSA1LjA0NTA4MSAtNC43MzQyNDdDNC42OTgzODEgLTUuMjAwNDk4IDQuMTM2NDg4IC01LjI3MjIyOSAzLjczMDAxMiAtNS4yNzIyMjlDMi41NzAzNjEgLTUuMjcyMjI5IDIuMTE2MDY1IC00LjI3OTk1IDIuMDIwNDIzIC00LjA0MDg0N0gyLjAwODQ2OFYtNS4yNzIyMjlMMC4zODI1NjUgLTUuMTQwNzIyVi00Ljc5NDAyMkMxLjE5NTUxNyAtNC43OTQwMjIgMS4yOTExNTggLTQuNzEwMzM2IDEuMjkxMTU4IC00LjEyNDUzM1YtMC44ODQ2ODJDMS4yOTExNTggLTAuMzQ2NyAxLjE1OTY1MSAtMC4zNDY3IDAuMzgyNTY1IC0wLjM0NjdWMEMwLjY5MzQgLTAuMDIzOTEgMS4zMzg5NzkgLTAuMDIzOTEgMS42NzM3MjQgLTAuMDIzOTFDMi4wMjA0MjMgLTAuMDIzOTEgMi42NjYwMDIgLTAuMDIzOTEgMi45NzY4MzcgMFYtMC4zNDY3QzIuMjExNzA2IC0wLjM0NjcgMi4wNjgyNDQgLTAuMzQ2NyAyLjA2ODI0NCAtMC44ODQ2ODJWLTMuMTA4MzQ0QzIuMDY4MjQ0IC00LjM2MzYzNiAyLjg5MzE1MSAtNS4wMzMxMjYgMy42MzQzNzEgLTUuMDMzMTI2UzQuNTQyOTY0IC00LjQyMzQxMiA0LjU0Mjk2NCAtMy42OTQxNDdWLTAuODg0NjgyQzQuNTQyOTY0IC0wLjM0NjcgNC40MTE0NTcgLTAuMzQ2NyAzLjYzNDM3MSAtMC4zNDY3VjBDMy45NDUyMDUgLTAuMDIzOTEgNC41OTA3ODUgLTAuMDIzOTEgNC45MjU1MjkgLTAuMDIzOTFDNS4yNzIyMjkgLTAuMDIzOTEgNS45MTc4MDggLTAuMDIzOTEgNi4yMjg2NDMgMFYtMC4zNDY3QzUuNjMwODg0IC0wLjM0NjcgNS4zMzIwMDUgLTAuMzQ2NyA1LjMyMDA1IC0wLjcwNTM1NVYtMi45MDUxMDZaJyBpZD0nZzYtMTEwJy8+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtMi43NDk2ODlDOC4wODE2OTQgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi45ODg3OTJTOC4wODE2OTQgLTMuMjI3ODk1IDcuODc4NDU2IC0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyIC0zLjIyNzg5NSAwLjk5MjI3OSAtMy4yMjc4OTUgMC45OTIyNzkgLTIuOTg4NzkyUzEuMjA3NDcyIC0yLjc0OTY4OSAxLjQxMDcxIC0yLjc0OTY4OUg3Ljg3ODQ1NlonIGlkPSdnMS0wJy8+CjxwYXRoIGQ9J004LjYzMTYzMSAtMC4zODI1NjVDOC41ODM4MTEgLTAuMzgyNTY1IDguMzkyNTI4IC0wLjM1ODY1NSA4LjM1NjY2MyAtMC4zNTg2NTVDNy40MTIyMDQgLTAuMzU4NjU1IDYuNzc4NTggLTEuMjkxMTU4IDYuMzcyMTA1IC0xLjkxMjgyN0M2LjI1MjU1MyAtMi4xMTYwNjUgNS45Mjk3NjMgLTIuNjA2MjI3IDUuNzk4MjU3IC0yLjgwOTQ2NUM2LjA4NTE4MSAtMy40NTUwNDQgNi44ODYxNzcgLTQuOTM3NDg0IDguMzA4ODQyIC00LjkzNzQ4NEM4LjM5MjUyOCAtNC45Mzc0ODQgOC41MDAxMjUgLTQuOTM3NDg0IDguNjMxNjMxIC00LjkwMTYxOUM4LjYzMTYzMSAtNS4yMTI0NTMgOC42MTk2NzYgLTUuMjI0NDA4IDguNTk1NzY2IC01LjI0ODMxOUM4LjUxMjA4IC01LjI3MjIyOSA4LjMzMjc1MiAtNS4yODQxODQgOC4yMjUxNTYgLTUuMjg0MTg0QzYuNzA2ODQ5IC01LjI4NDE4NCA1LjgyMjE2NyAtMy44MjU2NTQgNS41MzUyNDMgLTMuMjI3ODk1QzUuMDU3MDM2IC0zLjk1NzE2MSA0Ljg4OTY2NCAtNC4yMjAxNzQgNC40NDczMjMgLTQuNTkwNzg1QzMuNzE4MDU3IC01LjIyNDQwOCAzLjA2MDUyMyAtNS4yODQxODQgMi43NjE2NDQgLTUuMjg0MTg0QzEuNDM0NjIgLTUuMjg0MTg0IDAuNjY5NDg5IC0zLjk0NTIwNSAwLjY2OTQ4OSAtMi41NzAzNjFDMC42Njk0ODkgLTEuMjMxMzgyIDEuNDEwNzEgMC4xMzE1MDcgMi43MjU3NzggMC4xMzE1MDdDNC4yNDQwODUgMC4xMzE1MDcgNS4xMjg3NjcgLTEuMzI3MDI0IDUuNDE1NjkxIC0xLjkyNDc4MkM1Ljg5Mzg5OCAtMS4xOTU1MTcgNi4wNjEyNyAtMC45MzI1MDMgNi41MDM2MTEgLTAuNTYxODkzQzcuMjMyODc3IDAuMDcxNzMxIDcuODkwNDExIDAuMTMxNTA3IDguMTg5MjkgMC4xMzE1MDdDOC4zMzI3NTIgMC4xMzE1MDcgOC41MjQwMzUgMC4xMDc1OTcgOC42MzE2MzEgMC4wODM2ODZWLTAuMzgyNTY1Wk01LjE1MjY3NyAtMi4zNDMyMTNDNC44NjU3NTMgLTEuNjk3NjM0IDQuMDY0NzU3IC0wLjIxNTE5MyAyLjY0MjA5MiAtMC4yMTUxOTNDMS40ODI0NDEgLTAuMjE1MTkzIDAuOTMyNTAzIC0xLjQ4MjQ0MSAwLjkzMjUwMyAtMi41NzAzNjFDMC45MzI1MDMgLTMuNzUzOTIzIDEuNjAxOTkzIC00Ljc5NDAyMiAyLjU5NDI3MSAtNC43OTQwMjJDMy41Mzg3MyAtNC43OTQwMjIgNC4xNzIzNTQgLTMuODYxNTE5IDQuNTc4ODI5IC0zLjIzOTg1MUM0LjY5ODM4MSAtMy4wMzY2MTMgNS4wMjExNzEgLTIuNTQ2NDUxIDUuMTUyNjc3IC0yLjM0MzIxM1onIGlkPSdnMS00NycvPgo8cGF0aCBkPSdNNS4wMzMxMjYgNi4zODQwNkwwLjc4OTA0MSAxMS42MzIzNzlDMC42OTM0IDExLjc1MTkzIDAuNjgxNDQ1IDExLjc3NTg0MSAwLjY4MTQ0NSAxMS44MjM2NjFDMC42ODE0NDUgMTEuOTU1MTY4IDAuNzg5MDQxIDExLjk1NTE2OCAxLjAwNDIzNCAxMS45NTUxNjhIMTAuOTE1MDY4TDExLjk0MzIxMyA4Ljk3ODMzMUgxMS42NDQzMzRDMTEuMzQ1NDU1IDkuODc0OTY5IDEwLjU0NDQ1OCAxMC42MDQyMzQgOS41MjgyNjkgMTAuOTUwOTM0QzkuMzM2OTg2IDExLjAxMDcxIDguNTEyMDggMTEuMjk3NjM0IDYuNzU0NjcgMTEuMjk3NjM0SDEuNjczNzI0TDUuODIyMTY3IDYuMTY4ODY3QzUuOTA1ODUzIDYuMDYxMjcgNS45Mjk3NjMgNi4wMjU0MDUgNS45Mjk3NjMgNS45Nzc1ODRTNS45MTc4MDggNS45MTc4MDggNS44NDYwNzcgNS44MTAyMTJMMS45NjA2NDggMC40NzgyMDdINi42OTQ4OTRDOC4wNTc3ODMgMC40NzgyMDcgMTAuODA3NDcyIDAuNTYxODkzIDExLjY0NDMzNCAyLjc5NzUwOUgxMS45NDMyMTNMMTAuOTE1MDY4IDBIMS4wMDQyMzRDMC42ODE0NDUgMCAwLjY2OTQ4OSAwLjAxMTk1NSAwLjY2OTQ4OSAwLjM4MjU2NUw1LjAzMzEyNiA2LjM4NDA2WicgaWQ9J2cwLTgwJy8+CjxwYXRoIGQ9J00yLjcwMTg2OCAyMS4wMjkxNDFINS40MTU2OTFWMjAuNDY3MjQ4SDMuMjYzNzYxVjAuMDgzNjg2SDUuNDE1NjkxVi0wLjQ3ODIwN0gyLjcwMTg2OFYyMS4wMjkxNDFaJyBpZD0nZzAtMTA0Jy8+CjxwYXRoIGQ9J00yLjM2NzEyMyAyMC40NjcyNDhIMC4yMTUxOTNWMjEuMDI5MTQxSDIuOTI5MDE2Vi0wLjQ3ODIwN0gwLjIxNTE5M1YwLjA4MzY4NkgyLjM2NzEyM1YyMC40NjcyNDhaJyBpZD0nZzAtMTA1Jy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc3Mi4yNjkyODknIHhsaW5rOmhyZWY9JyNnNi0xMDgnIHk9JzkxLjY1NjI3NCcvPgo8dXNlIHg9Jzc1LjUyMDk1JyB4bGluazpocmVmPScjZzYtMTEwJyB5PSc5MS42NTYyNzQnLz4KPHVzZSB4PSc4NC4wMTY3NycgeGxpbms6aHJlZj0nI2c0LTc2JyB5PSc5MS42NTYyNzQnLz4KPHVzZSB4PSc5MS45ODEyNzYnIHhsaW5rOmhyZWY9JyNnMy04NycgeT0nOTMuNDQ5NTM3Jy8+Cjx1c2UgeD0nMTA0Ljk2NicgeGxpbms6aHJlZj0nI2cxLTQ3JyB5PSc5MS42NTYyNzQnLz4KPHVzZSB4PScxMTcuNTg1MzI3JyB4bGluazpocmVmPScjZzAtODAnIHk9JzgyLjY4OTgyMicvPgo8dXNlIHg9JzEzMC4yMDQ3MDYnIHhsaW5rOmhyZWY9JyNnMy03OCcgeT0nODUuODQ0NjYzJy8+Cjx1c2UgeD0nMTMwLjIwNDcwNicgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nOTUuMTQzMjc0Jy8+Cjx1c2UgeD0nMTMzLjA4Nzg0NicgeGxpbms6aHJlZj0nI2c1LTYxJyB5PSc5NS4xNDMyNzQnLz4KPHVzZSB4PScxMzkuNjc0MzUzJyB4bGluazpocmVmPScjZzUtNDknIHk9Jzk1LjE0MzI3NCcvPgo8dXNlIHg9JzE0Ni4zOTkxNjUnIHhsaW5rOmhyZWY9JyNnMC04MCcgeT0nODIuNjg5ODIyJy8+Cjx1c2UgeD0nMTU5LjAxODU0NScgeGxpbms6aHJlZj0nI2czLTY3JyB5PSc4NS44NDQ2NjMnLz4KPHVzZSB4PScxNTkuMDE4NTQ1JyB4bGluazpocmVmPScjZzMtMTA3JyB5PSc5NS4xNDMyNzQnLz4KPHVzZSB4PScxNjMuNjQwMTYnIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nOTUuMTQzMjc0Jy8+Cjx1c2UgeD0nMTcwLjIyNjY2NycgeGxpbms6aHJlZj0nI2c1LTQ5JyB5PSc5NS4xNDMyNzQnLz4KPHVzZSB4PScxNzYuOTUxNDc5JyB4bGluazpocmVmPScjZzQtMTcnIHk9JzkxLjY1NjI3NCcvPgo8dXNlIHg9JzE4My4xNTU5MzUnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9Jzg3LjMxNzgzNycvPgo8dXNlIHg9JzE4Mi43MjY5ODYnIHhsaW5rOmhyZWY9JyNnMy0xMDUnIHk9Jzk0LjYxMTc4OScvPgo8dXNlIHg9JzE4OC4yNzU2ODInIHhsaW5rOmhyZWY9JyNnNC0xMDInIHk9JzkxLjY1NjI3NCcvPgo8dXNlIHg9JzE5NC4wNDU2NzEnIHhsaW5rOmhyZWY9JyNnMy0xMDcnIHk9JzkzLjQ0OTUzNycvPgo8dXNlIHg9JzIwMS4xNTc5MTYnIHhsaW5rOmhyZWY9JyNnNi00MCcgeT0nOTEuNjU2Mjc0Jy8+Cjx1c2UgeD0nMjA1LjcxMDI0MicgeGxpbms6aHJlZj0nI2c0LTg3JyB5PSc5MS42NTYyNzQnLz4KPHVzZSB4PScyMTYuNDM2NTg1JyB4bGluazpocmVmPScjZzQtNTknIHk9JzkxLjY1NjI3NCcvPgo8dXNlIHg9JzIyMS42ODA3NDQnIHhsaW5rOmhyZWY9JyNnNC04OCcgeT0nOTEuNjU2Mjc0Jy8+Cjx1c2UgeD0nMjMxLjM5NTk3MScgeGxpbms6aHJlZj0nI2czLTEwNScgeT0nOTMuNDQ5NTM3Jy8+Cjx1c2UgeD0nMjM0Ljc3NzI0MycgeGxpbms6aHJlZj0nI2c2LTQxJyB5PSc5MS42NTYyNzQnLz4KPHVzZSB4PScyNDEuOTg2MjA5JyB4bGluazpocmVmPScjZzEtMCcgeT0nOTEuNjU2Mjc0Jy8+Cjx1c2UgeD0nMjUzLjk0MTM3JyB4bGluazpocmVmPScjZzAtODAnIHk9JzgyLjY4OTgyMicvPgo8dXNlIHg9JzI2Ni41NjA3NScgeGxpbms6aHJlZj0nI2czLTc4JyB5PSc4NS44NDQ2NjMnLz4KPHVzZSB4PScyNjYuNTYwNzUnIHhsaW5rOmhyZWY9JyNnMy0xMDUnIHk9Jzk1LjE0MzI3NCcvPgo8dXNlIHg9JzI2OS40NDM4ODknIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nOTUuMTQzMjc0Jy8+Cjx1c2UgeD0nMjc2LjAzMDM5NicgeGxpbms6aHJlZj0nI2c1LTQ5JyB5PSc5NS4xNDMyNzQnLz4KPHVzZSB4PScyODIuNzU1MjA4JyB4bGluazpocmVmPScjZzYtMTA4JyB5PSc5MS42NTYyNzQnLz4KPHVzZSB4PScyODYuMDA2ODcnIHhsaW5rOmhyZWY9JyNnNi0xMTAnIHk9JzkxLjY1NjI3NCcvPgo8dXNlIHg9JzI5NC41MDI2OScgeGxpbms6aHJlZj0nI2cwLTEwNCcgeT0nNzguMzg1OTIzJy8+Cjx1c2UgeD0nMzAwLjE0ODIwNicgeGxpbms6aHJlZj0nI2cwLTgwJyB5PSc4Mi42ODk4MjInLz4KPHVzZSB4PSczMTIuNzY3NTg2JyB4bGluazpocmVmPScjZzMtNjcnIHk9Jzg1Ljg0NDY2MycvPgo8dXNlIHg9JzMxMi43Njc1ODYnIHhsaW5rOmhyZWY9JyNnMy0xMDgnIHk9Jzk1LjE0MzI3NCcvPgo8dXNlIHg9JzMxNS4zODk3MTEnIHhsaW5rOmhyZWY9JyNnNS02MScgeT0nOTUuMTQzMjc0Jy8+Cjx1c2UgeD0nMzIxLjk3NjIxNycgeGxpbms6aHJlZj0nI2c1LTQ5JyB5PSc5NS4xNDMyNzQnLz4KPHVzZSB4PSczMjguNzAxMDMnIHhsaW5rOmhyZWY9JyNnNC0xMDEnIHk9JzkxLjY1NjI3NCcvPgo8dXNlIHg9JzMzNC4xMjY0NycgeGxpbms6aHJlZj0nI2czLTEwMicgeT0nODcuMzE3ODM3Jy8+Cjx1c2UgeD0nMzM4LjE5NDU4OCcgeGxpbms6aHJlZj0nI2cyLTEwOCcgeT0nODguNzIzNjgzJy8+Cjx1c2UgeD0nMzQxLjA5MzQ0NycgeGxpbms6aHJlZj0nI2c1LTQwJyB5PSc4Ny4zMTc4MzcnLz4KPHVzZSB4PSczNDQuMzg2NycgeGxpbms6aHJlZj0nI2czLTg3JyB5PSc4Ny4zMTc4MzcnLz4KPHVzZSB4PSczNTIuMTQxMDY4JyB4bGluazpocmVmPScjZzMtNTknIHk9Jzg3LjMxNzgzNycvPgo8dXNlIHg9JzM1NC40OTMzOTInIHhsaW5rOmhyZWY9JyNnMy04OCcgeT0nODcuMzE3ODM3Jy8+Cjx1c2UgeD0nMzYxLjQ1ODM0NycgeGxpbms6aHJlZj0nI2cyLTEwNScgeT0nODguNTMyOTE2Jy8+Cjx1c2UgeD0nMzY0LjYyMDEwNScgeGxpbms6aHJlZj0nI2c1LTQxJyB5PSc4Ny4zMTc4MzcnLz4KPHVzZSB4PSczNjguNDExNDkxJyB4bGluazpocmVmPScjZzAtMTA1JyB5PSc3OC4zODU5MjMnLz4KPC9nPgo8L3N2Zz4=)
Ceci mène à la définition du problème de classification suivant :
Problème P2 : classification
Soit  l’échantillon suivant :
l’échantillon suivant :

 représente la probabilité que l’élément
représente la probabilité que l’élément
 appartiennent à la classe
appartiennent à la classe  :
:

Le classifieur cherché est une fonction définie par :

Dont le vecteur de poids  est égal à :
est égal à :

Réseau de neurones adéquat#
Dans le problème précédent, la maximisation de
 aboutit au choix d’une fonction :
aboutit au choix d’une fonction :

Le réseau de neurones suivant
 choisi pour modéliser aura pour sorties :
choisi pour modéliser aura pour sorties :

Figure F1 : Réseau de neurones adéquat pour la classification
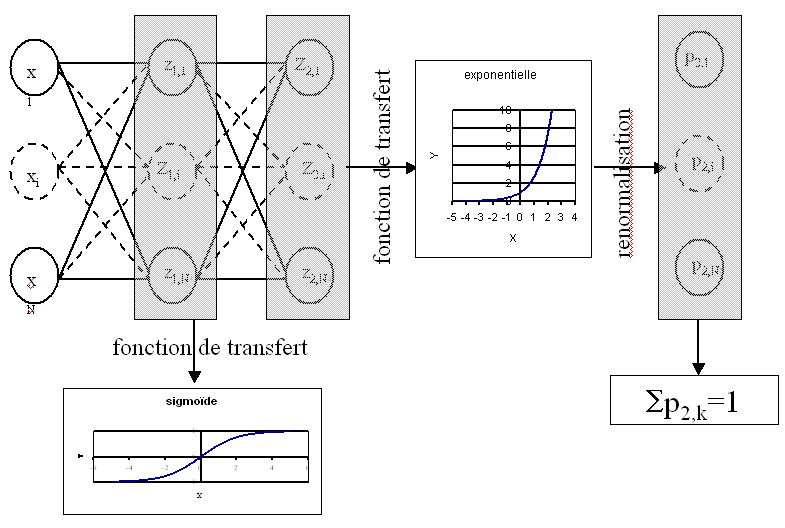
On en déduit que la fonction de transert des neurones de la couche de sortie est :
 .
La probabilité pour le vecteur
.
La probabilité pour le vecteur  d’appartenir à la classe
d’appartenir à la classe  est
est
 .
La fonction d’erreur à minimiser est l’opposé de la log-vraisemblance du modèle :
.
La fonction d’erreur à minimiser est l’opposé de la log-vraisemblance du modèle :

On note  le nombre de couches du réseau de neurones,
le nombre de couches du réseau de neurones,
 est la sortie avec
,
est la sortie avec
,
 où
où
 est le potentiel du neurone de la couche de sortie.
est le potentiel du neurone de la couche de sortie.
On calcule :

Cette équation permet d’adapter l’algorithme de la rétropropagation
décrivant rétropropagation pour le problème de la classification et pour
un exemple  .
Seule la couche de sortie change.
.
Seule la couche de sortie change.
Algorithme A1 : rétropropagation
Cet algorithme de rétropropagation est l’adaptation de
rétropropagation pour le problème
de la classification. Il suppose que l’algorithme de propagation
a été préalablement exécuté.
On note  ,
,
 et
et
 .
.
Initialiasation
 in
in 

Récurrence, Terminaison
Voir rétropropagation.
On vérifie que le gradient s’annule lorsque le réseau de neurones
retourne pour l’exemple  la
distribution de
la
distribution de  .
Cet algorithme de rétropropagation utilise un vecteur désiré de
probabilités
.
Cet algorithme de rétropropagation utilise un vecteur désiré de
probabilités  vérifiant
vérifiant
 .
L’expérience montre qu’il est préférable d’utiliser un vecteur vérifiant la contrainte :
.
L’expérience montre qu’il est préférable d’utiliser un vecteur vérifiant la contrainte :

Généralement,  est de l’ordre de
est de l’ordre de  ou
ou
 . Cette contrainte facilite le calcul de la vraisemblance
et évite l’obtention de gradients quasi-nuls qui freinent l’apprentissage
lorsque les fonctions exponnetielles sont saturées (voir [Bishop1995]).
. Cette contrainte facilite le calcul de la vraisemblance
et évite l’obtention de gradients quasi-nuls qui freinent l’apprentissage
lorsque les fonctions exponnetielles sont saturées (voir [Bishop1995]).