Training Tutorial#
The tutorial assumes there exist an ONNX graph saved and introduces two ways to train this model assuming a gradient can be computed for every node of this graph.
First part looks into the first API of onnxruntime-training based on class TrainingSession. This class assumes the loss function is part of the graph to train. The tutorial shows how to do that.
Second part relies on class TrainingAgent. It builds a new ONNX graph to compute the gradient. This design gives more freedom to the user but it requires to write more code to implement the whole training.
Both parts rely on classes this package (onnxcustom) implements to simplify the code.
main difference between the two approaches
The second API handles less than the first one by letting the user implement the weight updating. However, this freedom gives more possibilities to the user. The first API is faster than second one mostly because all the computation happens in a single ONNX graph. onnxruntime can better optimize if everything takes place in a single graph. It minimizes round trips between C++ and python. The major drawback of this approach is every change in the way weights are updated requires a code change.
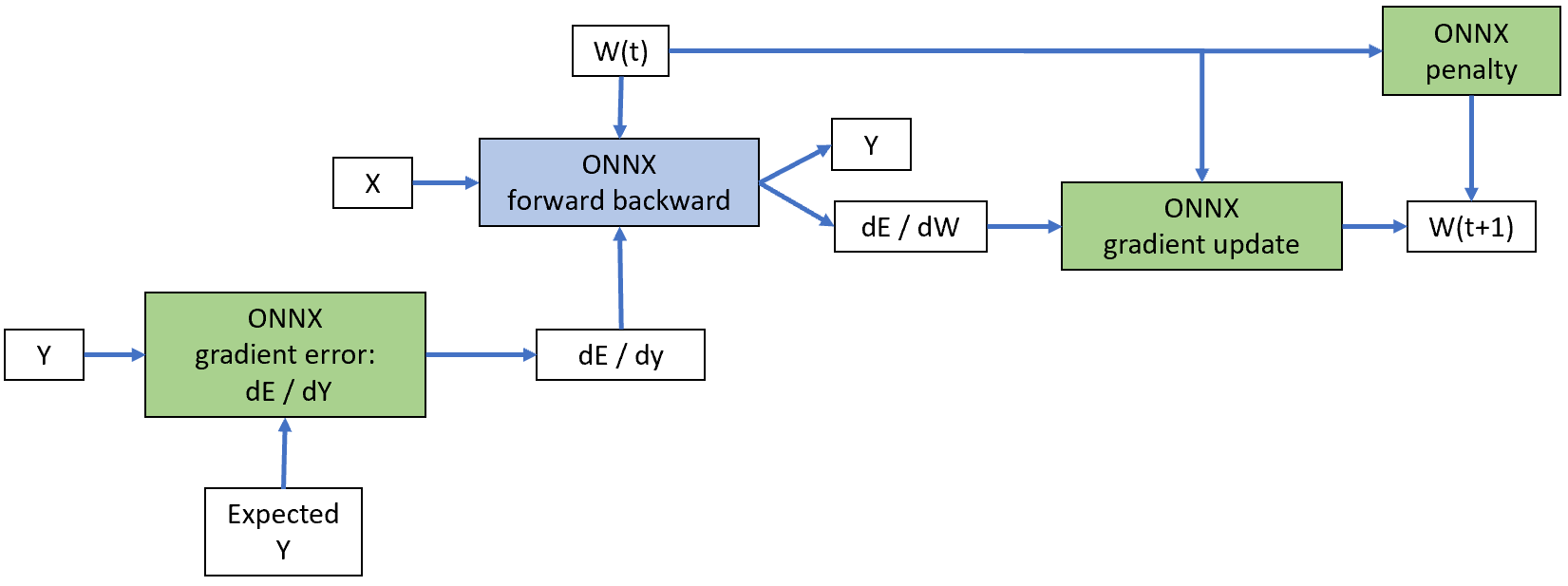
The second API works with multiple ONNX graph, one to update the weights,
one to compute the loss and its gradients, one to compute the
regularization and its gradient, one to compute the gradient of the model.
The implementation tries to avoid copies when a tensor goes from
one graph to the next one. The freedom provided by this API
can be used to implement Nesterov method to update the weight.
It can even stick to scikit-learn API to leverage
some of the functionalities of this packages such as
sklearn.model_selection.GridSearchCV.
Following picture shows the four onnx graphs
of this second approach.
The tutorial was tested with following version:
<<<
import sys
import numpy
import scipy
import onnx
import onnxruntime
import lightgbm
import xgboost
import sklearn
import onnxconverter_common
import onnxmltools
import skl2onnx
import pyquickhelper
import mlprodict
import onnxcustom
import torch
print("python {}".format(sys.version_info))
mods = [numpy, scipy, sklearn, lightgbm, xgboost,
onnx, onnxmltools, onnxruntime, onnxcustom,
onnxconverter_common,
skl2onnx, mlprodict, pyquickhelper,
torch]
mods = [(m.__name__, m.__version__) for m in mods]
mx = max(len(_[0]) for _ in mods) + 1
for name, vers in sorted(mods):
print("{}{}{}".format(name, " " * (mx - len(name)), vers))
>>>
python sys.version_info(major=3, minor=9, micro=1, releaselevel='final', serial=0)
lightgbm 3.3.4
mlprodict 0.9.1887
numpy 1.24.1
onnx 1.13.0
onnxconverter_common 1.13.0
onnxcustom 0.4.344
onnxmltools 1.11.1
onnxruntime 1.14.92+cpu
pyquickhelper 1.11.3801
scipy 1.10.0
skl2onnx 1.13.1
sklearn 1.2.0
torch 1.13.1+cu117
xgboost 1.7.3