Galleries de notebooks#
Astuces de datascientist#

|
Insérer un menu en javascript. |
|

|
Les arbres de décision sont des modèles intéressants car ils peuvent être interprétés. Encore faut-il pouvoir les voir. |
Digressions machine learnesques#
|
Les k-means construisent des clusters qui ne sont pas forcément équilibrés. Comment modifier l’algorithme original pour que ce soit le cas ? |
Notebooks commencés en cours#

|
Notebook autour d’un cas de classification binaire. |
|
|
Le jeu de données Wine Quality Data Set recense les composants chimiques de vins ainsi que la note d’experts. Peut-on prédire cette note à partir des composants chimiques ? Peut-être que si on arrive à construire une fonction qui permet de prédire cette note, on pourra comprendre comment l’expert note les vins. |
|

|
Le jeu Titanic contient la liste des passages du Titanic, quelques informations comme le billet, la classe, et le fait qu’ils aient survécu. Il est possible d’utiliser le machine learning pour étudier la probabilité de survie ou plutôt de comprendre un peu mieux qui a eu la chance de survivre. S’il est possible de prédire, alors il existe une sorte de règle. |
|
|
Ce notebook présente la régression Ridge, Lasso, et l’API de scikit-learn. Il explique plus en détail pourquoi la régression Lasso contraint les coefficients de la régression à s’annuler. |
|
|
Un jeu de données, une régression linéaire et quelques trucs bizarres. Le jeu de données est Wine Data Set . |
Exemples et solutions#
|
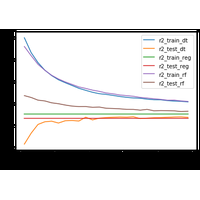
Le modèle est estimé sur une base d’apprentissage et évalué sur une base de test. |
|
|
Le texte est toujours délicat à traiter. La langue est importante et plus le vocabulaire est étendu, plus il faut de données. Le problème qui suit est classique, on cherche à catégoriser des phrases en sentiment positif ou négatif. Ce pourrait être aussi classer des spams. Le problème le plus simple : une phrase, un label. |
|

|
On cherche à prédire la note d’un vin avec un classifieur multi-classe. |
|

|
Plus il y a de classes, plus la classification est difficile car le nombre d’exemples par classe diminue. Voyons cela plus en détail sur des jeux artificiels produits mar make_blobs. |
|
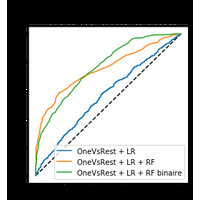
|
On cherche à prédire la note d’un vin avec un classifieur multi-classe puis à améliorer le score obtenu avec une méthode dite de stacking. |
|
|
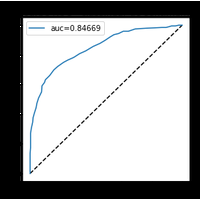
La courbe ROC est une façon de visualiser la performance d’un classifieur ou plutôt sa pertinence. Voyons comment. |
|
|
La tokenisation consiste à découper un texte en token, l’approche sac de mots consiste à compter les occurences de chaque mot dans chaque document de la base de données. |
|
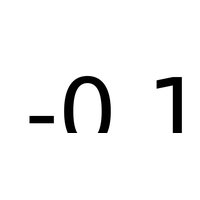
|
Lorsqu’une classe est sous-représentée, il y a peu de chances que la répartition apprentissage test conserve la distribution des classes. |
|
|
Le notebook utilise la factorisation de matrice pour calculer des recommandations sur la base movielens. On utilise le jeu de données ml-latest-small.zip. |
|

|
Le hashing est utilise lorsque le nombre de catégories est trop grand. |
|
|
Le notebook explore différentes façons d’interpréter la prédiction de la note d’un vin. |
|
|
La plupart des modèles de machine learning doivent être rafraîchi régulièrement. Quelques intuitions derrière ce phénomène. |
|

|
Le jeu de données Adult Data Set ne contient presque que des catégories. Ce notebook explore différentes moyens de les traiter. |
|
|
La normalisation des données est souvent inutile d’un point de vue mathématique. C’est une autre histoire d’un point de vue numérique où le fait d’avoir des données qui se ressemblent améliore la convergence des algorithmes et la précision des calculs. Voyons cela sur quelques exemples. |
|

|
On cherche à prédire la note d’un vin avec un modèle des plus proches voisins. |
|
|
On projette le jeu de données initiale selon les premiers axes d’une analyse en composantes principales (ACP). |
|
|
Comment évaluer la pertinence d’un modèle des plus proches voisins. |
|
|
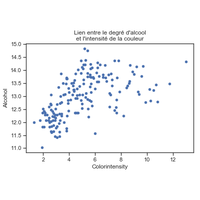
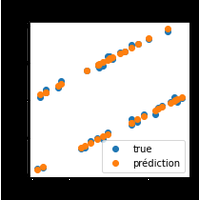
On cherche à prédire la note d’un vin mais on suppose que cette qualité est dépendante de la couleur et qu’il faudrait appliquer des modèles différents selon la couleur. |
|
|
Ce notebook cherche à prédire la durée de stockage de paquets préparés par un magasin. Chaque paquet met plus ou moins de temps à être préparé. Si la commande arrive le soir et ne peut être finie avant la fin de la journée, elle est reportée sur la journée suivante. C’est la particularité de ce jeu de données. |
|

|
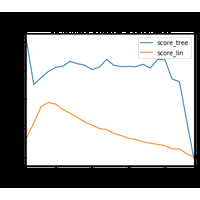
Le notebook compare plusieurs de modèles de régression. |
|
|
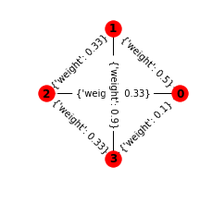
Si la méthode de factorisation de matrices est la méthode la plus connue pour faire des recommandations, ce n’est pas la seule. L’algorithme Random Walk with Restart s’appuie sur l’exploration locale des noeuds d’un graphe et produit des résultats plus facile à intepréter.)*. |
|
C’est un petit exemple de ranking avec un très petit jeu de données, trop petit pour que le modèle soit performant, mais le code peut être réutilisé pour des exemples de taille raisonnable. C’est à dire probablement pas pour apprendre un moteur de recherche. |
||
|
Prédire la couleur d’un vin à partir de ses composants. |
|
|
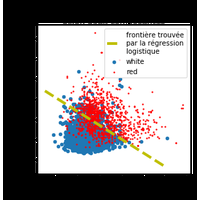
La régression logistique est un modèle de classification binaire, simple à interpréter mais limité dans la gamme des problèmes qu’il peut résoudre. Limité comment ? |
|
|
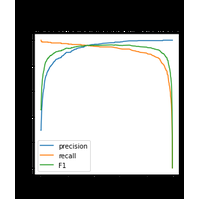
Prédire la couleur d’un vin à partir de ses composants et visualiser la performance avec une courbe ROC. |
|
|
Le notebook compare plusieurs de modèles de régression polynômiale. |
|
|
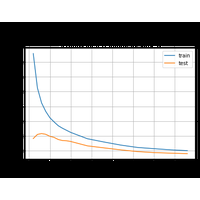
Le modèle des plus proches voisins KNeighborsRegressor est paramétrable. Le nombre de voisins est variables, la prédiction peut dépendre du plus proche voisins ou des $k$ plus proches proches. Comment choisir $k$ ? |
|

|
La tokenisation consiste à découper un texte en token, le plus souvent des mots. Le notebook utilise un extrait d’un article du monde. |
|
|
Ce notebook présenté des encoding différents de ceux implémentées dans scikit-learn. |
|
|
Ce notebook présente différentes options pour gérer les catégories au format entier ou texte. |
|
|
Il est acquis qu’un modèle doit être évalué sur une base de test différente de celle utilisée pour l’apprentissage. Mais la performance est peut-être juste l’effet d’une aubaine et d’un découpage particulièrement avantageux. Pour être sûr que le modèle est robuste, on recommence plusieurs fois. On appelle cela la validation croisée ou cross validation. |
Timeseries#
Ou séries temporelles.
|
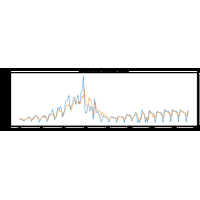
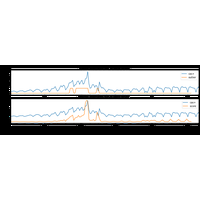
On s’intéresse aux séries temporelles de l’épidémie du COVID en France récupérées depuis data.gouv.fr : Chiffres-clés concernant l’épidémie de COVID19 en France. |
|
|
On s’intéresse aux séries temporelles de l’épidémie du COVID en France récupérées depuis data.gouv.fr : Chiffres-clés concernant l’épidémie de COVID19 en France. |
Visualisation#

|
Les données carroyées sont des données économiques agrégées sur tout le territoire français sur des carrés de 200m de côté. |
|
|
Le notebook propose plusieurs façons de tracer une carte en Python. |
|

|
bokeh permet de tracer une carte sur laquelle on peut zoomer, dézoomer et qui ne dépend pas d’un service extérieur comme folium. |