Gradient et méthodes ensemblistes#
Le machine learning propose de nombreux modèles différents pour construire une relation entre deux grandeur X et Y mais l’idéal reste de constuire une relation la plus synthétique qui soit. Plus elle est simple, plus elle facile à interpréter.
On distingue deux grandes familles de modèles, ceux qui sont appris grâce à des méthodes dites ensemblistes et ceux appris grâce à des méthodes à base de gradient. La première famille suppose peu de choses sur les données elles-mêmes, la seconde suppose que la relation est une fonction dérivable.
Forces et différences#
Les méthodes ensemblistes sont douées pour trouver relations entre des valeurs précises de X et Y. X et Y sont en quelque sorte discrets mais cela fonctionne bien si ce nombre de valeurs discrets n’est pas trop grand sinon la liste des correspondances est très longue.
Les méthodes à base de gradient sont douées pour résumer une relation dérivable (et donc continue) : si X croît de tant, alors Y croît de tant.
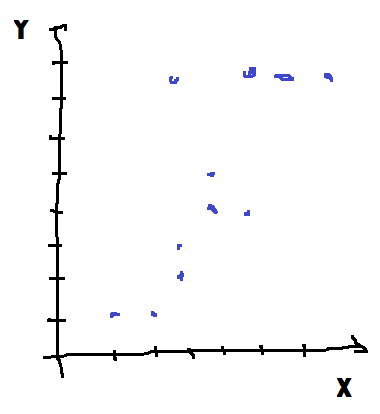
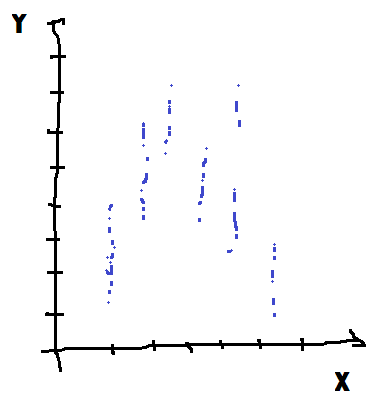
X discret |
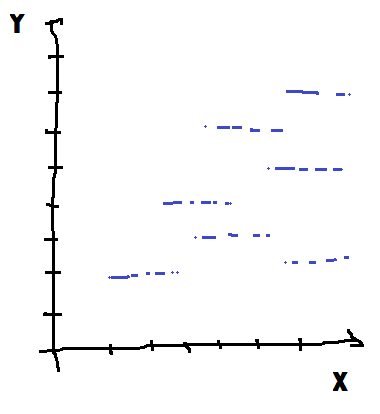
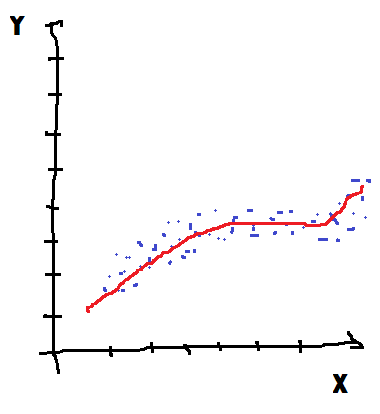
X continu |
|
|---|---|---|
Y discret |
|
|
Y continu |
|
|
Les deux cas sur la première diagonale sont les cas simples. Dans le premier, tout est discret et les méthodes ensemblistes sont plus performantes. Dans le dernier cas, tout est continu et un modèle à base de gradient sera plus approprié. Si les deux types de modèles obtiendront des performances similaires, les modèles ensemblistes seront plus synthétiques dans le premier, les modèles à base de gradient seront plus synthétiques et donc interprétables dans le second. Pour les deux cas sur l’autre diagonale, c’est souvent le caractère de Y qui détermine le meilleur choix : les méthodes ensemblistes pour le cas discret, les méthodes à gradient pour le cas continu. Il existe également des cas indécidables où la relation est dérivable par morceaux. Le meilleur modèle est alors un assemblage des deux.
La méthode ensembliste la plus connue est l”arbre de décision. Les autres modèles comme la forêt aléatoire sont des déclinaisons. Le modèle à base de gradient le plus simple est la régression linéaire. Les autres se caractérise par la forme de la relation qu’ils sont capables de modéliser. Le notebook suivant montre un cas où un arbre de décision, une méthode ensembliste.