Note
Go to the end to download the full example code
Convert a pipeline with a LightGBM regressor#
The discrepancies observed when using float and TreeEnsemble operator (see Issues when switching to float) explains why the converter for LGBMRegressor may introduce significant discrepancies even when it is used with float tensors.
Library lightgbm is implemented with double. A random forest regressor
with multiple trees computes its prediction by adding the prediction of
every tree. After being converting into ONNX, this summation becomes
![\left[\sum\right]_{i=1}^F float(T_i(x))](../_images/math/a2d1c2f56276e05e34f6d2fc904dc71680fc1914.png) ,
where F is the number of trees in the forest,
,
where F is the number of trees in the forest,
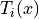 the output of tree i and
the output of tree i and ![\left[\sum\right]](../_images/math/c4db1c515ae99a7a1062382cd305c1692428c162.png) a float addition. The discrepancy can be expressed as
a float addition. The discrepancy can be expressed as
![D(x) = |\left[\sum\right]_{i=1}^F float(T_i(x)) -
\sum_{i=1}^F T_i(x)|](../_images/math/51210b969861f7df2fe22a76b7d03477a0aa7ce6.png) .
This grows with the number of trees in the forest.
.
This grows with the number of trees in the forest.
To reduce the impact, an option was added to split the node
TreeEnsembleRegressor into multiple ones and to do a summation
with double this time. If we assume the node if split into a nodes,
the discrepancies then become
![D'(x) = |\sum_{k=1}^a \left[\sum\right]_{i=1}^{F/a}
float(T_{ak + i}(x)) - \sum_{i=1}^F T_i(x)|](../_images/math/070692ac1405bf91a81a00816ad6fcaf5be87264.png) .
.
Train a LGBMRegressor#
import packaging.version as pv
import warnings
import timeit
import numpy
from pandas import DataFrame
import matplotlib.pyplot as plt
from tqdm import tqdm
from lightgbm import LGBMRegressor
from onnxruntime import InferenceSession
from skl2onnx import to_onnx, update_registered_converter
from skl2onnx.common.shape_calculator import calculate_linear_regressor_output_shapes # noqa
from onnxmltools import __version__ as oml_version
from onnxmltools.convert.lightgbm.operator_converters.LightGbm import convert_lightgbm # noqa
N = 1000
X = numpy.random.randn(N, 20)
y = (numpy.random.randn(N) +
numpy.random.randn(N) * 100 * numpy.random.randint(0, 1, 1000))
reg = LGBMRegressor(n_estimators=1000)
reg.fit(X, y)
Register the converter for LGBMClassifier#
The converter is implemented in onnxmltools: onnxmltools…LightGbm.py. and the shape calculator: onnxmltools…Regressor.py.
def skl2onnx_convert_lightgbm(scope, operator, container):
options = scope.get_options(operator.raw_operator)
if 'split' in options:
if pv.Version(oml_version) < pv.Version('1.9.2'):
warnings.warn(
"Option split was released in version 1.9.2 but %s is "
"installed. It will be ignored." % oml_version)
operator.split = options['split']
else:
operator.split = None
convert_lightgbm(scope, operator, container)
update_registered_converter(
LGBMRegressor, 'LightGbmLGBMRegressor',
calculate_linear_regressor_output_shapes,
skl2onnx_convert_lightgbm,
options={'split': None})
Convert#
We convert the same model following the two scenarios, one single TreeEnsembleRegressor node, or more. split parameter is the number of trees per node TreeEnsembleRegressor.
model_onnx = to_onnx(reg, X[:1].astype(numpy.float32),
target_opset={'': 14, 'ai.onnx.ml': 2})
model_onnx_split = to_onnx(reg, X[:1].astype(numpy.float32),
target_opset={'': 14, 'ai.onnx.ml': 2},
options={'split': 100})
Discrepancies#
sess = InferenceSession(model_onnx.SerializeToString())
sess_split = InferenceSession(model_onnx_split.SerializeToString())
X32 = X.astype(numpy.float32)
expected = reg.predict(X32)
got = sess.run(None, {'X': X32})[0].ravel()
got_split = sess_split.run(None, {'X': X32})[0].ravel()
disp = numpy.abs(got - expected).sum()
disp_split = numpy.abs(got_split - expected).sum()
print("sum of discrepancies 1 node", disp)
print("sum of discrepancies split node",
disp_split, "ratio:", disp / disp_split)
sum of discrepancies 1 node 0.00012932610302943083
sum of discrepancies split node 4.181837350948408e-05 ratio: 3.0925665485316083
The sum of the discrepancies were reduced 4, 5 times. The maximum is much better too.
disc = numpy.abs(got - expected).max()
disc_split = numpy.abs(got_split - expected).max()
print("max discrepancies 1 node", disc)
print("max discrepancies split node", disc_split, "ratio:", disc / disc_split)
max discrepancies 1 node 1.307127771354999e-06
max discrepancies split node 3.2222179946472806e-07 ratio: 4.056608750638187
Processing time#
The processing time is slower but not much.
print("processing time no split",
timeit.timeit(
lambda: sess.run(None, {'X': X32})[0], number=150))
print("processing time split",
timeit.timeit(
lambda: sess_split.run(None, {'X': X32})[0], number=150))
processing time no split 6.361445982940495
processing time split 6.967872331850231
Split influence#
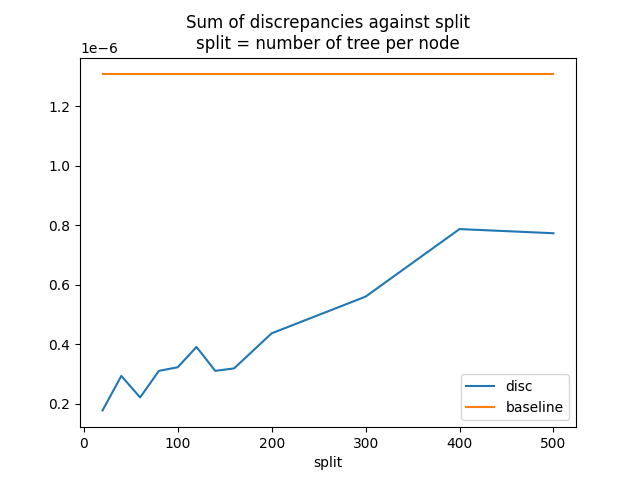
Let’s see how the sum of the discrepancies moves against the parameter split.
res = []
for i in tqdm(list(range(20, 170, 20)) + [200, 300, 400, 500]):
model_onnx_split = to_onnx(reg, X[:1].astype(numpy.float32),
target_opset={'': 14, 'ai.onnx.ml': 2},
options={'split': i})
sess_split = InferenceSession(model_onnx_split.SerializeToString())
got_split = sess_split.run(None, {'X': X32})[0].ravel()
disc_split = numpy.abs(got_split - expected).max()
res.append(dict(split=i, disc=disc_split))
df = DataFrame(res).set_index('split')
df["baseline"] = disc
print(df)
0%| | 0/12 [00:00<?, ?it/s]
8%|8 | 1/12 [00:16<03:01, 16.52s/it]
17%|#6 | 2/12 [00:31<02:38, 15.87s/it]
25%|##5 | 3/12 [00:47<02:22, 15.82s/it]
33%|###3 | 4/12 [01:02<02:04, 15.55s/it]
42%|####1 | 5/12 [01:18<01:49, 15.65s/it]
50%|##### | 6/12 [01:33<01:32, 15.47s/it]
58%|#####8 | 7/12 [01:48<01:16, 15.36s/it]
67%|######6 | 8/12 [02:04<01:01, 15.45s/it]
75%|#######5 | 9/12 [02:19<00:45, 15.26s/it]
83%|########3 | 10/12 [02:34<00:30, 15.33s/it]
92%|#########1| 11/12 [02:49<00:15, 15.19s/it]
100%|##########| 12/12 [03:04<00:00, 15.07s/it]
100%|##########| 12/12 [03:04<00:00, 15.38s/it]
disc baseline
split
20 1.771951e-07 0.000001
40 2.930574e-07 0.000001
60 2.208387e-07 0.000001
80 3.101587e-07 0.000001
100 3.222218e-07 0.000001
120 3.905435e-07 0.000001
140 3.101587e-07 0.000001
160 3.184264e-07 0.000001
200 4.363748e-07 0.000001
300 5.597714e-07 0.000001
400 7.869959e-07 0.000001
500 7.729833e-07 0.000001
Graph.
Total running time of the script: ( 8 minutes 19.778 seconds)