Map/Reduce avec PIG sur cloudera - énoncé#
Links: notebook, html, PDF, python, slides, GitHub
Manipulation de fichiers sur un cluster Hadoop Cloudera, premieer job map/reduce avec PIG. Lire aussi From Pig to Spark: An Easy Journey to Spark for Apache Pig Developers.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Données#
On considère le jeu de données suivant : Localization Data for Person Activity Data Set qu’on récupère comme suit :
import pyensae.datasource
import urllib.error
try:
# ce soir ça ne marche pas...
pyensae.datasource.download_data("ConfLongDemo_JSI.txt",
website="https://archive.ics.uci.edu/ml/machine-learning-databases/00196/")
except urllib.error.URLError:
# donc je récupère une vieille copie
pyensae.datasource.download_data("ConfLongDemo_JSI.zip")
On l’insère dans une base de données SQL.
columns = "sequence tag timestamp dateformat x y z activity".split()
import pandas, sqlite3, os
df = pandas.read_csv("ConfLongDemo_JSI.txt", sep=",", names=columns)
if os.path.exists("ConfLongDemo_JSI.db3"):
os.remove("ConfLongDemo_JSI.db3")
con = sqlite3.connect("ConfLongDemo_JSI.db3")
df.to_sql("person", con)
con.close()
df.head()
| sequence | tag | timestamp | dateformat | x | y | z | activity | |
|---|---|---|---|---|---|---|---|---|
| 0 | A01 | 010-000-024-033 | 633790226051280329 | 27.05.2009 14:03:25:127 | 4.062931 | 1.892434 | 0.507425 | walking |
| 1 | A01 | 020-000-033-111 | 633790226051820913 | 27.05.2009 14:03:25:183 | 4.291954 | 1.781140 | 1.344495 | walking |
| 2 | A01 | 020-000-032-221 | 633790226052091205 | 27.05.2009 14:03:25:210 | 4.359101 | 1.826456 | 0.968821 | walking |
| 3 | A01 | 010-000-024-033 | 633790226052361498 | 27.05.2009 14:03:25:237 | 4.087835 | 1.879999 | 0.466983 | walking |
| 4 | A01 | 010-000-030-096 | 633790226052631792 | 27.05.2009 14:03:25:263 | 4.324462 | 2.072460 | 0.488065 | walking |
On crée un petit exemple pour plus tard qu’on enregistre également dans la base de données.
columns = "sequence tag timestamp dateformat x y z activity".split()
import pandas
df = pandas.read_csv("ConfLongDemo_JSI.txt", sep=",", names=columns)
dfs = df[:1000]
dfs.to_csv("ConfLongDemo_JSI.small.txt", header=False)
import sqlite3
con = sqlite3.connect("ConfLongDemo_JSI.db3")
dfs.to_sql("person_small", con)
con.close()
[ _ for _ in os.listdir(".") if "db3" in _ ]
['ConfLongDemo_JSI.db3']
Partie 0 : aperçu du cluster Teralab#
Il faut se connecter au cluster avec l’url :
https://....datascience.fr/....&login=<login>.
from pyquickhelper.helpgen import NbImage
NbImage("cluster1.png", width=500)
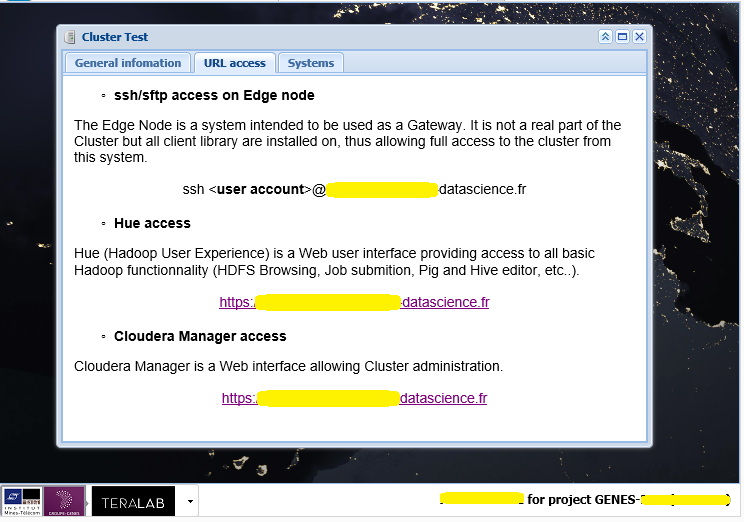
Il faut cliquer ensuite sur Hue Access une fenêtre s’ouvre. Il faut
ensuie trouver l’onglet qui permette d’obtenir l’image suivante et le
bouton Upload :
NbImage("hdfs1.png", width=900)
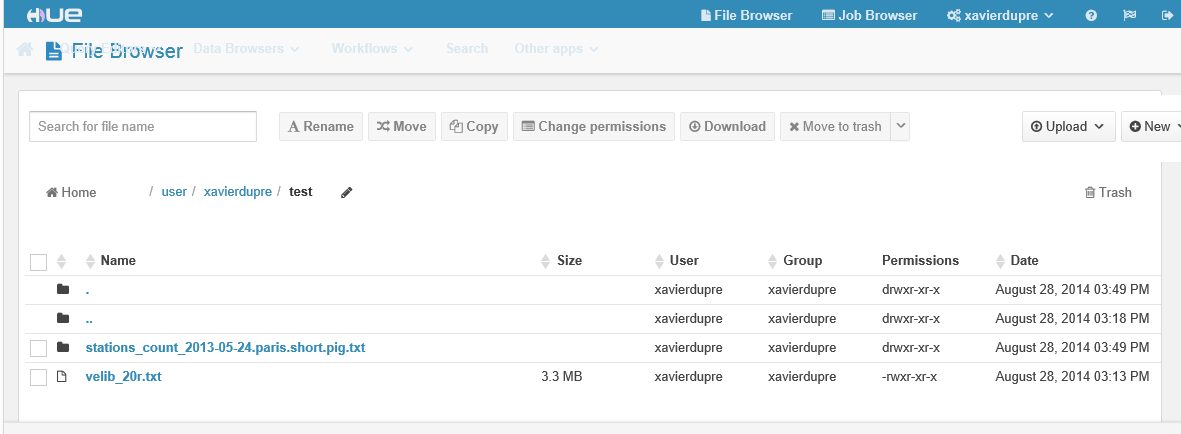
Les notebooks n’utiliseront que rarement cette interface qui est lente Hue extremely slow in running Hive Queries, hue is very slow.
Partie 1 : manipulation de fichiers#
Avant de commencer à déplacer des fichiers, il faut comprendre qu’il y a trois emplacements :
l’ordinateur local (celui dont vous vous servez)
la machine distante ou passerelle
le cluster
Les fichiers vont transiter sans cesse par cette passerelle. La passerelle est connectée à l’ordinateur local via SSH.
from pyquickhelper.helpgen import NbImage
NbImage("hdfspath.png")
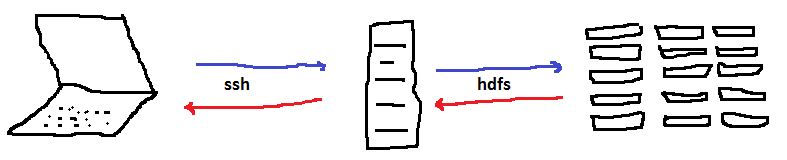
On uploade pour le chemin bleu, on downloade pour le chemin
rouge. La passerelle est sous linux et c’est par son intermédiaire qu’on
va communiquer avec le cluster. Toutes les commandes qui suivent vont
être exécutées depuis cette machine. L’outil le plus connu pour s’y
connecter est Putty. La commande magique
%remote_cmd imite le comportement d’une fenêtre putty.
from pyquickhelper.helpgen import NbImage
NbImage("putty1.png", width=400)
NbImage("putty2.png", width=600)
Le cluster Hadoop inclut un système de
fichiers
HDFS. Celui
fonctionne à peu près comme un système de fichiers linux avec les mêmes
commandes à ceci près qu’un fichier n’est plus nécessaire localisé sur
une seule machine mais peut-être réparti sur plusieurs. Pour éviter la
perte de données due à des machines défaillantes, les données sont
répliquées trois
fois.
Les opérations standard sont disponibles (copy, rename, delete)
auxquelles on ajoute deux opérations : upload, download. Les commandes
sont presque identiques à celles de linux mais précédées de hdfs.
Pour manipuler les données sur un cluster, il faut d’abord les uploader sur ce cluster. Pour les récupérer, il faut les downloader. Pour faciliter les choses, on va utiliser des commandes magiques implémentées dans le module pyensae (>= 0.8). La première tâche est d’enregistrer dans l’espace de travail le nom du server, votre alias et votre mot de passe dans le workspace du notebook.
Le code est avant tout destiné à ne pas laisser votre mot de passe en clair dans le notebook. S’il est en clair, tôt ou tard, vous oublierez de l’effacer avant de partager votre notebook. Dans ce cas, il faut changer de mot de passe sans tarder.
Le code suivant vérifie d’abord qu’il n’existe pas de variable
d’environnement CRTERALAB afin de ne pas avoir à rentrer les mot de
passe à chaque fois (voir Mettre ses mots de passe dans les variables
d’environnement).
Si cette variable existe, le notebook s’attend à trouver l’information
server**password**username.
import os
if "CRTERALAB" in os.environ:
spl = os.environ["CRTERALAB"].split("**")
params=dict(server=spl[0], password=spl[1], username=spl[2])
r = dict
else:
from pyquickhelper.ipythonhelper import open_html_form
params={"server":"", "username":"", "password":""}
r = open_html_form(params=params,title="server + credentials", key_save="params")
r
dict
On stocke le mot de passe dans trois variables de l’espace de travail afin que les commandes magiques trouvent ces informations.
password = params["password"]
server = params["server"]
username = params["username"]
On ouvre la connection SSH qui restera ouverte jusqu’à ce qu’on la ferme.
%load_ext pyensae
%load_ext pyenbc
%remote_open
<pyensae.remote.ssh_remote_connection.ASSHClient at 0xbb31f28>
On regarde le contenu du répertoire qui vous est associé sur la machine distante :
%remote_cmd ls -l
total 420 -rw-r--r-- 1 xavierdupre xavierdupre 132727 Oct 29 00:38 ConfLongDemo_JSI.small.example.is_back.txt -rw-rw-r-- 1 xavierdupre xavierdupre 132727 Oct 29 00:28 ConfLongDemo_JSI.small.example.txt -rw-rw-r-- 1 xavierdupre xavierdupre 0 Nov 24 18:00 dummy -rw-rw-r-- 1 xavierdupre xavierdupre 2222 Oct 29 00:57 empty.err -rw-rw-r-- 1 xavierdupre xavierdupre 0 Oct 29 00:57 empty.out -rw-rw-r-- 1 xavierdupre xavierdupre 2103 Oct 29 01:15 groupby.join.redirection.err -rw-rw-r-- 1 xavierdupre xavierdupre 0 Oct 29 01:15 groupby.join.redirection.out -rw-rw-r-- 1 xavierdupre xavierdupre 9049 Oct 29 01:10 groupby.redirection.err -rw-rw-r-- 1 xavierdupre xavierdupre 0 Oct 29 01:10 groupby.redirection.out -rw-rw-r-- 1 xavierdupre xavierdupre 2222 Oct 29 00:57 None.err -rw-rw-r-- 1 xavierdupre xavierdupre 0 Oct 29 00:57 None.out -rw-rw-r-- 1 xavierdupre xavierdupre 1449 Oct 29 00:41 pig_1446075664771.log -rw-rw-r-- 1 xavierdupre xavierdupre 3123 Oct 29 00:47 pig_1446076053872.log -rw-rw-r-- 1 xavierdupre xavierdupre 3123 Oct 29 00:49 pig_1446076194560.log -rw-rw-r-- 1 xavierdupre xavierdupre 3123 Oct 29 00:50 pig_1446076204158.log -rw-rw-r-- 1 xavierdupre xavierdupre 3123 Oct 29 00:50 pig_1446076211428.log -rw-rw-r-- 1 xavierdupre xavierdupre 1449 Oct 29 00:51 pig_1446076271184.log -rw-rw-r-- 1 xavierdupre xavierdupre 3153 Oct 29 00:56 pig_1446076561656.log -rw-rw-r-- 1 xavierdupre xavierdupre 3153 Oct 29 00:56 pig_1446076615152.log -rw-rw-r-- 1 xavierdupre xavierdupre 3153 Oct 29 00:57 pig_1446076628372.log -rw-rw-r-- 1 xavierdupre xavierdupre 3153 Oct 29 00:57 pig_1446076640389.log -rw-rw-r-- 1 xavierdupre xavierdupre 3153 Oct 29 00:59 pig_1446076767869.log -rw-rw-r-- 1 xavierdupre xavierdupre 3285 Oct 29 01:15 pig_1446077714461.log -rw-rw-r-- 1 xavierdupre xavierdupre 6296 Nov 24 18:00 pig_1448384434969.log -rw-rw-r-- 1 xavierdupre xavierdupre 659 Nov 24 18:00 pystream.pig -rw-rw-r-- 1 xavierdupre xavierdupre 382 Nov 24 18:00 pystream.py -rw-rw-r-- 1 xavierdupre xavierdupre 8432 Oct 29 00:52 redirection.err -rw-rw-r-- 1 xavierdupre xavierdupre 0 Oct 29 00:51 redirection.out -rw-rw-r-- 1 xavierdupre xavierdupre 8450 Oct 29 01:03 redirection.pig.err -rw-rw-r-- 1 xavierdupre xavierdupre 0 Oct 29 01:02 redirection.pig.out -rw-rw-r-- 1 xavierdupre xavierdupre 321 Oct 29 00:51 select1.pig -rw-rw-r-- 1 xavierdupre xavierdupre 344 Oct 29 00:59 select2.pig -rw-rw-r-- 1 xavierdupre xavierdupre 351 Oct 29 01:02 select3.pig -rw-rw-r-- 1 xavierdupre xavierdupre 428 Oct 29 01:15 solution_groupby_join.pig -rw-rw-r-- 1 xavierdupre xavierdupre 367 Oct 29 01:10 solution_groupby.pig -rw-r--r-- 1 xavierdupre xavierdupre 22166 Oct 29 01:06 toutenun.txt
On efface tout :
%remote_cmd rm -r *
%remote_cmd ls -l
total 0
C’est une commande linux. Les commandes les plus fréquentes sont accessibles décrites à Les commandes de base en console. L’instruction suivante consiste à uploader un fichier depuis l’ordinateur local vers la passerelle.
%remote_up ConfLongDemo_JSI.small.txt ConfLongDemo_JSI.small.example.txt
'ConfLongDemo_JSI.small.example.txt'
On vérifie que celui-ci a bien été transféré :
%remote_cmd ls -l
total 132 -rw-rw-r-- 1 xavierdupre xavierdupre 132727 Oct 29 00:28 ConfLongDemo_JSI.small.example.txt
Ensuite, on regarde le contenu du répertoire qui vous est associé sur le cluster :
%remote_cmd hdfs dfs -ls
Found 3 items drwx------ - xavierdupre xavierdupre 0 2015-10-28 01:09 .Trash drwx------ - xavierdupre xavierdupre 0 2015-10-28 01:08 .staging drwxr-xr-x - xavierdupre xavierdupre 0 2014-11-20 23:43 unitest2
On supprime les précédentes exécutions :
%remote_cmd hdfs dfs -rm -f -R ConfLong*
%remote_cmd hdfs dfs -ls
Found 3 items drwx------ - xavierdupre xavierdupre 0 2015-10-28 01:09 .Trash drwx------ - xavierdupre xavierdupre 0 2015-10-28 01:08 .staging drwxr-xr-x - xavierdupre xavierdupre 0 2014-11-20 23:43 unitest2
Les commandes HDFS décrite à Apache Hadoop 2.3.0. Elles sont très proches des commandes linux. Ensuite, on uploade le fichier sur le système de fichier distribué du cluster (HDFS) :
%remote_cmd hdfs dfs -put ConfLongDemo_JSI.small.example.txt ./ConfLongDemo_JSI.small.example.txt
Puis on vérifie que le fichier a bien été uploadé sur le cluster :
%remote_cmd hdfs dfs -ls
Found 4 items drwx------ - xavierdupre xavierdupre 0 2015-10-28 01:09 .Trash drwx------ - xavierdupre xavierdupre 0 2015-10-28 01:08 .staging -rw-r--r-- 3 xavierdupre xavierdupre 132727 2015-10-29 00:38 ConfLongDemo_JSI.small.example.txt drwxr-xr-x - xavierdupre xavierdupre 0 2014-11-20 23:43 unitest2
On regarde la fin du fichier sur le cluster :
%remote_cmd hdfs dfs -tail ConfLongDemo_JSI.small.example.txt
1,633790226377438480,27.05.2009 14:03:57:743,4.371500492095946,1.4781558513641355,0.5384233593940735,lying 993,A01,010-000-024-033,633790226377708776,27.05.2009 14:03:57:770,3.0621800422668457,1.0790562629699707,0.6795752048492432,lying 994,A01,020-000-032-221,633790226378519655,27.05.2009 14:03:57:853,4.36382532119751,1.4307395219802856,0.3206148743629456,lying 995,A01,010-000-024-033,633790226378789954,27.05.2009 14:03:57:880,3.0784008502960205,1.0197675228118896,0.6061218976974487,lying 996,A01,010-000-030-096,633790226379060251,27.05.2009 14:03:57:907,3.182415008544922,1.1020996570587158,0.29104289412498474,lying 997,A01,020-000-033-111,633790226379330550,27.05.2009 14:03:57:933,4.7574005126953125,1.285519003868103,-0.08946932852268219,lying 998,A01,020-000-032-221,633790226379600847,27.05.2009 14:03:57:960,4.3730292320251465,1.3821170330047607,0.38861045241355896,lying 999,A01,010-000-024-033,633790226379871138,27.05.2009 14:03:57:987,3.198556661605835,1.1257659196853638,0.3567752242088318,lying
Le fichier va suivre maintenant le chemin inverse. On le rapatrie depuis le cluster jusqu’à l’ordinateur local. Première étape : du cluster à la passerelle :
%remote_cmd hdfs dfs -get ConfLongDemo_JSI.small.example.txt ConfLongDemo_JSI.small.example.is_back.txt
On vérifie que le fichier est sur la passerelle :
%remote_cmd ls -l
total 264 -rw-r--r-- 1 xavierdupre xavierdupre 132727 Oct 29 00:38 ConfLongDemo_JSI.small.example.is_back.txt -rw-rw-r-- 1 xavierdupre xavierdupre 132727 Oct 29 00:28 ConfLongDemo_JSI.small.example.txt
On supprime le fichier de la précédente exécution :
import os
if os.path.exists("ConfLongDemo_JSI.small.example.is_back_local.txt") :
os.remove("ConfLongDemo_JSI.small.example.is_back_local.txt")
[ _ for _ in os.listdir(".") if "txt" in _ ]
['ConfLongDemo_JSI.small.txt', 'ConfLongDemo_JSI.txt']
Second transfert depuis la passerelle jusqu’à l’ordinateur local :
%remote_down ConfLongDemo_JSI.small.example.is_back.txt ConfLongDemo_JSI.small.example.is_back_local.txt
'ConfLongDemo_JSI.small.example.is_back_local.txt'
[ _ for _ in os.listdir(".") if "txt" in _ ]
['ConfLongDemo_JSI.small.example.is_back_local.txt',
'ConfLongDemo_JSI.small.txt',
'ConfLongDemo_JSI.txt']
%remote_close
True
Partie 2 : premier job map/reduce avec PIG#
Pour cette partie, l’idée d’exécuter des jobs Map/Reduce sur le fichier
ConfLongDemo_JSI.small.example.txt puis de vérifier qu’on obtient
bien les même résultats sur le même fichier en utilisant une requête
SQL. Le code pour créer la connexion à la passerelle est recopié
ci-dessous mais il n’est pas nécessaire de l’exécuter si la connexion
n’a pas été interrompue.
import pyensae
from pyquickhelper.ipythonhelper import open_html_form
open_html_form(params=params,title="server + credentials", key_save="params")
password
server
username
password = params["password"]
server = params["server"]
username = params["username"]
ssh = %remote_open
ssh
<pyensae.remote.ssh_remote_connection.ASSHClient at 0xa499908>
JOBS
Un job définit l’ensemble des traitements que vous souhaitez effectuer sur un ou plusieurs fichiers. Le langage PIG permet de décrire ces traitements. Le programme est ensuite interprété puis soumis à Hadoop qui s’occupe de répartir de traitements sur l’ensemble des resources dont il dispose. La commande suivante permet d’obtenir l’ensemble des tâches associés aux jobs :
%remote_cmd mapred --help
Usage: mapred [--config confdir] COMMAND
where COMMAND is one of:
pipes run a Pipes job
job manipulate MapReduce jobs
queue get information regarding JobQueues
classpath prints the class path needed for running
mapreduce subcommands
historyserver run job history servers as a standalone daemon
distcp copy file or directories recursively
archive -archiveName NAME -p * create a hadoop archive
hsadmin job history server admin interface
Most commands print help when invoked w/o parameters.
Et plus spécifiquement pour la commande mapred job :
- ::
- Usage: CLI <command> <args>
[-submit <job-file>] [-status <job-id>] [-counter <job-id> <group-name> <counter-name>] [-kill <job-id>] [-set-priority <job-id> <priority>]. Valid values for priorities are: VERY_HIGH HIGH NORMAL LOW VERY_LOW [-events <job-id> <from-event-#> <#-of-events>] [-history <jobHistoryFile>] [-list [all]] [-list-active-trackers] [-list-blacklisted-trackers] [-list-attempt-ids <job-id> <task-type> <task-state>]. Valid values for <task-type> are REDUCE MAP. Valid values for <task-state> are running, completed [-kill-task <task-attempt-id>] [-fail-task <task-attempt-id>] [-logs <job-id> <task-attempt-id>]
D’autres commandes sont disponibles avec la commande pig :
%remote_cmd pig --help
Apache Pig version 0.12.0-cdh5.0.2 (rexported)
compiled Jun 09 2014, 11:14:51
USAGE: Pig [options] [-] : Run interactively in grunt shell.
Pig [options] -e[xecute] cmd [cmd ...] : Run cmd(s).
Pig [options] [-f[ile]] file : Run cmds found in file.
options include:
-4, -log4jconf - Log4j configuration file, overrides log conf
-b, -brief - Brief logging (no timestamps)
-c, -check - Syntax check
-d, -debug - Debug level, INFO is default
-e, -execute - Commands to execute (within quotes)
-f, -file - Path to the script to execute
-g, -embedded - ScriptEngine classname or keyword for the ScriptEngine
-h, -help - Display this message. You can specify topic to get help for that topic.
properties is the only topic currently supported: -h properties.
-i, -version - Display version information
-l, -logfile - Path to client side log file; default is current working directory.
-m, -param_file - Path to the parameter file
-p, -param - Key value pair of the form param=val
-r, -dryrun - Produces script with substituted parameters. Script is not executed.
-t, -optimizer_off - Turn optimizations off. The following values are supported:
SplitFilter - Split filter conditions
PushUpFilter - Filter as early as possible
MergeFilter - Merge filter conditions
PushDownForeachFlatten - Join or explode as late as possible
LimitOptimizer - Limit as early as possible
ColumnMapKeyPrune - Remove unused data
AddForEach - Add ForEach to remove unneeded columns
MergeForEach - Merge adjacent ForEach
GroupByConstParallelSetter - Force parallel 1 for "group all" statement
All - Disable all optimizations
All optimizations listed here are enabled by default. Optimization values are case insensitive.
-v, -verbose - Print all error messages to screen
-w, -warning - Turn warning logging on; also turns warning aggregation off
-x, -exectype - Set execution mode: local|mapreduce, default is mapreduce.
-F, -stop_on_failure - Aborts execution on the first failed job; default is off
-M, -no_multiquery - Turn multiquery optimization off; default is on
-P, -propertyFile - Path to property file
-printCmdDebug - Overrides anything else and prints the actual command used to run Pig, including
any environment variables that are set by the pig command.
Le job suit le processus suivant :
Le job est soumis à Hadoop.
Il est ensuite placé dans une file d’attente avec une priorité qui détermine son ordre d’exécution (queue).
Il est exécuté.
SELECT … WHERE
import sqlite3
con = sqlite3.connect("ConfLongDemo_JSI.db3")
import pandas.io.sql as psql
sql = 'SELECT * FROM person_small WHERE activity == "walking"'
df = psql.read_sql(sql, con)
con.close()
df.tail()
| index | sequence | tag | timestamp | dateformat | x | y | z | activity | |
|---|---|---|---|---|---|---|---|---|---|
| 165 | 698 | A01 | 010-000-030-096 | 633790226277429870 | 27.05.2009 14:03:47:743 | 2.965434 | 1.782434 | 0.228563 | walking |
| 166 | 699 | A01 | 020-000-032-221 | 633790226277970452 | 27.05.2009 14:03:47:797 | 4.322405 | 1.571452 | 1.400499 | walking |
| 167 | 700 | A01 | 010-000-024-033 | 633790226278240749 | 27.05.2009 14:03:47:823 | 3.133065 | 1.769329 | -0.022590 | walking |
| 168 | 701 | A01 | 020-000-033-111 | 633790226278781331 | 27.05.2009 14:03:47:877 | 3.121254 | 1.549842 | 1.048139 | walking |
| 169 | 702 | A01 | 020-000-032-221 | 633790226279051629 | 27.05.2009 14:03:47:907 | 3.281498 | 1.498734 | 0.620412 | walking |
Avec PIG (syntaxe), le programme inclut trois étapes :
la déclaration de l’entrée (le fichier
ConfLongDemo_JSI.small.example.txt) (voir LOAD)la tâche à proprement parler (voir FILTER)
la création de la sortie (le fichier
ConfLongDemo_JSI.small.example.walking.txt) (voir STORE)
La commande magique permet d’écrire un fichier select1.pig avec
l’encoding utf-8 (les caractères accentuées sont possibles).
%%PIG select1.pig
myinput = LOAD 'ConfLongDemo_JSI.small.example.txt' USING PigStorage(',') AS
(index:long, sequence, tag, timestamp:long, dateformat, x:double,y:double, z:double, activity) ;
filt = FILTER myinput BY activity == "walking" ;
STORE filt INTO 'ConfLongDemo_JSI.small.example.walking_test.txt' USING PigStorage() ;
La commande suivante uploade le script et vérifie sa syntaxe (commande
pig -check <jobname>) :
%job_syntax select1.pig
2015-10-29 00:51:11,187 [main] INFO org.apache.pig.Main - Apache Pig version 0.12.0-cdh5.0.2 (rexported) compiled Jun 09 2014, 11:14:51 2015-10-29 00:51:11,188 [main] INFO org.apache.pig.Main - Logging error messages to: /home/xavierdupre/pig_1446076271184.log 2015-10-29 00:51:12,294 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/xavierdupre/.pigbootup not found 2015-10-29 00:51:12,536 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address 2015-10-29 00:51:12,537 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS 2015-10-29 00:51:12,537 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://nameservice1 2015-10-29 00:51:13,309 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFSUnexpected character '"' 2015-10-29 00:51:14,225 [main] ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1200: Unexpected character '"' Details at logfile: /home/xavierdupre/pig_1446076271184.log
Les guillemets ne font pas partie de la syntaxe du langage :
%%PIG select2.pig
myinput = LOAD 'ConfLongDemo_JSI.small.example.txt'
using PigStorage(',')
AS (index:long, sequence, tag, timestamp:long, dateformat, x:double,y:double, z:double, activity) ;
filt = FILTER myinput BY activity == 'walking' ;
STORE filt INTO 'ConfLongDemo_JSI.small.example2.walking_test20.txt' USING PigStorage() ;
La commande suivante fait deux choses : elle uploade le job sur la
passerelle et le soumet via la commande pig -execute -f <filenme>.
S’il n’y a pas d’erreur, il rejoint la file d’attente.
%pig_submit select2.pig -r None
2015-10-29 00:59:45,391 [main] INFO org.apache.pig.Main - Apache Pig version 0.12.0-cdh5.0.2 (rexported) compiled Jun 09 2014, 11:14:51
2015-10-29 00:59:45,392 [main] INFO org.apache.pig.Main - Logging error messages to: /home/xavierdupre/pig_1446076785387.log
2015-10-29 00:59:46,194 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/xavierdupre/.pigbootup not found
2015-10-29 00:59:46,430 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2015-10-29 00:59:46,430 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2015-10-29 00:59:46,431 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://nameservice1
2015-10-29 00:59:48,188 [main] WARN org.apache.pig.PigServer - Encountered Warning IMPLICIT_CAST_TO_CHARARRAY 1 time(s).
2015-10-29 00:59:48,211 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig features used in the script: FILTER
2015-10-29 00:59:48,285 [main] INFO org.apache.pig.newplan.logical.optimizer.LogicalPlanOptimizer - {RULES_ENABLED=[AddForEach, ColumnMapKeyPrune, DuplicateForEachColumnRewrite, GroupByConstParallelSetter, ImplicitSplitInserter, LimitOptimizer, LoadTypeCastInserter, MergeFilter, MergeForEach, NewPartitionFilterOptimizer, PartitionFilterOptimizer, PushDownForEachFlatten, PushUpFilter, SplitFilter, StreamTypeCastInserter], RULES_DISABLED=[FilterLogicExpressionSimplifier]}
2015-10-29 00:59:48,333 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.textoutputformat.separator is deprecated. Instead, use mapreduce.output.textoutputformat.separator
2015-10-29 00:59:48,511 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler - File concatenation threshold: 100 optimistic? false
2015-10-29 00:59:48,564 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size before optimization: 1
2015-10-29 00:59:48,565 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size after optimization: 1
2015-10-29 00:59:48,728 [main] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at ws09-sr1.tl.teralab-datascience.fr/10.200.209.11:8032
2015-10-29 00:59:48,926 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job
2015-10-29 00:59:49,021 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.reduce.markreset.buffer.percent is deprecated. Instead, use mapreduce.reduce.markreset.buffer.percent
2015-10-29 00:59:49,021 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3
2015-10-29 00:59:49,022 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.output.compress is deprecated. Instead, use mapreduce.output.fileoutputformat.compress
2015-10-29 00:59:49,025 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - creating jar file Job6897107947228914959.jar
2015-10-29 00:59:53,488 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - jar file Job6897107947228914959.jar created
2015-10-29 00:59:53,489 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.jar is deprecated. Instead, use mapreduce.job.jar
2015-10-29 00:59:53,538 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job
2015-10-29 00:59:53,556 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Key [pig.schematuple] is false, will not generate code.
2015-10-29 00:59:53,557 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Starting process to move generated code to distributed cache
2015-10-29 00:59:53,559 [main] INFO org.apache.pig.data.SchemaTupleFrontend - Setting key [pig.schematuple.classes] with classes to deserialize []
2015-10-29 00:59:53,654 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission.
2015-10-29 00:59:53,656 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker.http.address is deprecated. Instead, use mapreduce.jobtracker.http.address
2015-10-29 00:59:53,668 [JobControl] INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at ws09-sr1.tl.teralab-datascience.fr/10.200.209.11:8032
2015-10-29 00:59:53,752 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2015-10-29 00:59:55,086 [JobControl] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1
2015-10-29 00:59:55,086 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1
2015-10-29 00:59:55,127 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1
2015-10-29 00:59:55,999 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - number of splits:1
2015-10-29 00:59:56,108 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2015-10-29 00:59:56,748 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter - Submitting tokens for job: job_1444669880271_0036
2015-10-29 00:59:57,100 [JobControl] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1444669880271_0036
2015-10-29 00:59:57,172 [JobControl] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0036/
2015-10-29 00:59:57,173 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_1444669880271_0036
2015-10-29 00:59:57,173 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Processing aliases filt,myinput
2015-10-29 00:59:57,174 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - detailed locations: M: myinput[2,10],filt[6,7],myinput[-1,-1] C: R:
2015-10-29 00:59:57,233 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 0% complete
2015-10-29 01:00:15,280 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 50% complete
2015-10-29 01:00:22,643 [main] INFO org.apache.hadoop.mapred.ClientServiceDelegate - Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
2015-10-29 01:00:22,911 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
2015-10-29 01:00:22,984 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2015-10-29 01:00:22,988 [main] INFO org.apache.pig.tools.pigstats.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.3.0-cdh5.0.2 0.12.0-cdh5.0.2 xavierdupre 2015-10-29 00:59:48 2015-10-29 01:00:22 FILTER
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime MedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs
job_1444669880271_0036 1 0 4 4 4 4 n/a n/a n/a n/a filt,myinput MAP_ONLY hdfs://nameservice1/user/xavierdupre/ConfLongDemo_JSI.small.example2.walking_test20.txt,
Input(s):
Successfully read 1000 records (133117 bytes) from: "hdfs://nameservice1/user/xavierdupre/ConfLongDemo_JSI.small.example.txt"
Output(s):
Successfully stored 170 records (22166 bytes) in: "hdfs://nameservice1/user/xavierdupre/ConfLongDemo_JSI.small.example2.walking_test20.txt"
Counters:
Total records written : 170
Total bytes written : 22166
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_1444669880271_0036
2015-10-29 01:00:23,159 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
Derrière cette command magique, il y a la fonction pig_submit.
help(ssh.pig_submit)
Help on method pig_submit in module pyensae.remote.ssh_remote_connection:
pig_submit(pig_file, dependencies=None, params=None, redirection='redirection.pig', local=False, stop_on_failure=False, check=False, no_exception=True, fLOG=<function noLOG at 0x000000000573E620>) method of pyensae.remote.ssh_remote_connection.ASSHClient instance
submits a PIG script, it first upload the script
to the default folder and submit it
@param pig_file pig script (local)
@param dependencies others files to upload (still in the default folder)
@param params parameters to send to the job
@param redirection string empty or not
@param local local run or not (option -x local) (in that case, redirection will be empty)
@param stop_on_failure if True, add option -stop_on_failure on the command line
@param check if True, add option -check (in that case, redirection will be empty)
@param no_exception sent to @see me execute_command
@param fLOG logging function
@return out, err from @see me execute_command
If redirection is not empty, the job is submitted but
the function returns after the standard output and error were
redirected to redirection.out and redirection.err.
The first file will contain the results of commands
DESCRIBE
DUMP,
EXPLAIN.
The standard error receives logs and exceptions.
The function executes the command line::
pig -execute -f <filename>
With redirection::
pig -execute -f <filename> 2> redirection.pig.err 1> redirection.pig.out &
.. versionadded:: 1.1
On retrouve bien les mêmes résultats. Cependant, on n’a pas envie d’attendre la fin d’un job pour reprendre la main sur le notebook. Pour ce faire, on crée un second job.
%%PIG select3.pig
myinput = LOAD 'ConfLongDemo_JSI.small.example.txt'
using PigStorage(',')
AS (index:long, sequence, tag, timestamp:long, dateformat, x:double,y:double, z:double, activity) ;
filt = FILTER myinput BY activity == 'walking' ;
STORE filt INTO 'ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt' USING PigStorage() ;
%pig_submit select3.pig
%remote_cmd tail redirection.pig.err -n 15
Output(s): Successfully stored 170 records (22166 bytes) in: "hdfs://nameservice1/user/xavierdupre/ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt" Counters: Total records written : 170 Total bytes written : 22166 Spillable Memory Manager spill count : 0 Total bags proactively spilled: 0 Total records proactively spilled: 0 Job DAG: job_1444669880271_0037 2015-10-29 01:03:14,257 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
On vérifie le contenu du cluster :
%remote_cmd hdfs dfs -ls
Found 9 items drwx------ - xavierdupre xavierdupre 0 2015-10-29 01:00 .Trash drwx------ - xavierdupre xavierdupre 0 2015-10-29 01:03 .staging -rw-r--r-- 3 xavierdupre xavierdupre 132727 2015-10-29 00:38 ConfLongDemo_JSI.small.example.txt drwxr-xr-x - xavierdupre xavierdupre 0 2015-10-29 00:42 ConfLongDemo_JSI.small.example2.walking.txt drwxr-xr-x - xavierdupre xavierdupre 0 2015-10-29 00:52 ConfLongDemo_JSI.small.example2.walking_test.txt drwxr-xr-x - xavierdupre xavierdupre 0 2015-10-29 00:53 ConfLongDemo_JSI.small.example2.walking_test2.txt drwxr-xr-x - xavierdupre xavierdupre 0 2015-10-29 01:00 ConfLongDemo_JSI.small.example2.walking_test20.txt drwxr-xr-x - xavierdupre xavierdupre 0 2015-10-29 01:03 ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt drwxr-xr-x - xavierdupre xavierdupre 0 2014-11-20 23:43 unitest2
La sortie n’est pas un fichier mais un répertoire. Chaque partie provient d’une machine différente. Dans notre cas, les données étant de petite taille le calcul n’a pas été distribué.
%remote_cmd hdfs dfs -tail ConfLongDemo_JSI.small.example2.walking.txt/part-m-00000
6618983 27.05.2009 14:03:47:663 3.066070079803467 1.6573837995529177 1.0677484273910522 walking 696 A01 020-000-032-221 633790226276889279 27.05.2009 14:03:47:690 4.3041510581970215 1.6276369094848633 1.2260531187057495 walking 697 A01 010-000-024-033 633790226277159576 27.05.2009 14:03:47:717 3.1501431465148926 1.8083082437515257 -0.015722407028079033 walking 698 A01 010-000-030-096 633790226277429870 27.05.2009 14:03:47:743 2.9654340744018555 1.7824335098266602 0.2285633087158203 walking 699 A01 020-000-032-221 633790226277970452 27.05.2009 14:03:47:797 4.3224053382873535 1.5714523792266846 1.4004991054534912 walking 700 A01 010-000-024-033 633790226278240749 27.05.2009 14:03:47:823 3.1330645084381104 1.7693294286727903 -0.022590305656194687 walking 701 A01 020-000-033-111 633790226278781331 27.05.2009 14:03:47:877 3.121254205703736 1.5498417615890503 1.0481393337249756 walking 702 A01 020-000-032-221 633790226279051629 27.05.2009 14:03:47:907 3.281498432159424 1.4987335205078125 0.6204121708869934 walking
On retrouve bien les mêmes résultats. Cependant, on n’a pas envie d’attendre la fin d’un job pour reprendre la main sur le notebook. Pour ce faire, on crée un second job.
On regarde la liste des jobs en cours avec hadoop queue :
%remote_cmd hadoop queue -info root.xavierdupre -showJobs
======================
Queue Name : root.xavierdupre
Queue State : running
Scheduling Info : Capacity: 0.0, MaximumCapacity: UNDEFINED, CurrentCapacity: 0.0
Total jobs:0
JobId State StartTime UserName Queue Priority UsedContainers RsvdContainers UsedMem RsvdMem NeededMem AM info
%remote_cmd hdfs dfs -ls ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt
Found 2 items -rw-r--r-- 3 xavierdupre xavierdupre 0 2015-10-29 01:03 ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt/_SUCCESS -rw-r--r-- 3 xavierdupre xavierdupre 22166 2015-10-29 01:03 ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt/part-m-00000
C’est plus pratique mais la correction des erreurs quand elles se produisent n’est plus aussi pratique. On termine par une instruction qui permet de récupérer tous les fichiers d’un même repértoire en une seule fois :
%remote_cmd hdfs dfs -getmerge ConfLongDemo_JSI.small.example2.walking_test30_nowait.txt toutenun.txt
Le fichier est maintenant sur la passerelle.
%remote_cmd ls -l tout*
-rw-r--r-- 1 xavierdupre xavierdupre 22166 Oct 29 01:06 toutenun.txt
Lorsqu’on lance des jobs conséquent, il est important de savoir comment
les arrêter avec hadoop
job
-kill jobid :
%remote_cmd hadoop job -list all
Total jobs:28
JobId State StartTime UserName Queue Priority UsedContainers RsvdContainers UsedMem RsvdMem NeededMem AM info
job_1444669880271_0009 SUCCEEDED 1444779082040 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0009/jobhistory/job/job_1444669880271_0009
job_1444669880271_0010 SUCCEEDED 1444779114402 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0010/jobhistory/job/job_1444669880271_0010
job_1444669880271_0018 SUCCEEDED 1444781859339 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0018/jobhistory/job/job_1444669880271_0018
job_1444669880271_0033 SUCCEEDED 1446076296449 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0033/jobhistory/job/job_1444669880271_0033
job_1444669880271_0007 SUCCEEDED 1444778960311 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0007/jobhistory/job/job_1444669880271_0007
job_1444669880271_0025 SUCCEEDED 1444812309930 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0025/jobhistory/job/job_1444669880271_0025
job_1444669880271_0036 SUCCEEDED 1446076797029 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0036/jobhistory/job/job_1444669880271_0036
job_1444669880271_0022 SUCCEEDED 1444782235940 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0022/jobhistory/job/job_1444669880271_0022
job_1444669880271_0013 FAILED 1444780493283 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0013/jobhistory/job/job_1444669880271_0013
job_1444669880271_0008 SUCCEEDED 1444778993134 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0008/jobhistory/job/job_1444669880271_0008
job_1444669880271_0035 SUCCEEDED 1446076394207 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0035/jobhistory/job/job_1444669880271_0035
job_1444669880271_0001 SUCCEEDED 1444778245903 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0001/jobhistory/job/job_1444669880271_0001
job_1444669880271_0005 SUCCEEDED 1444778822775 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0005/jobhistory/job/job_1444669880271_0005
job_1444669880271_0028 SUCCEEDED 1444948433254 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0028/jobhistory/job/job_1444669880271_0028
job_1444669880271_0002 SUCCEEDED 1444778285584 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0002/jobhistory/job/job_1444669880271_0002
job_1444669880271_0030 SUCCEEDED 1445990873471 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0030/jobhistory/job/job_1444669880271_0030
job_1444669880271_0027 SUCCEEDED 1444948400340 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0027/jobhistory/job/job_1444669880271_0027
job_1444669880271_0024 SUCCEEDED 1444812276836 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0024/jobhistory/job/job_1444669880271_0024
job_1444669880271_0019 SUCCEEDED 1444781890983 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0019/jobhistory/job/job_1444669880271_0019
job_1444669880271_0003 SUCCEEDED 1444778547755 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0003/jobhistory/job/job_1444669880271_0003
job_1444669880271_0006 SUCCEEDED 1444778856950 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0006/jobhistory/job/job_1444669880271_0006
job_1444669880271_0032 SUCCEEDED 1446075704284 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0032/jobhistory/job/job_1444669880271_0032
job_1444669880271_0021 SUCCEEDED 1444782202256 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0021/jobhistory/job/job_1444669880271_0021
job_1444669880271_0037 SUCCEEDED 1446076967758 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0037/jobhistory/job/job_1444669880271_0037
job_1444669880271_0031 SUCCEEDED 1445990906117 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0031/jobhistory/job/job_1444669880271_0031
job_1444669880271_0004 SUCCEEDED 1444778575799 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0004/jobhistory/job/job_1444669880271_0004
job_1444669880271_0034 SUCCEEDED 1446076302576 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0034/jobhistory/job/job_1444669880271_0034
job_1444669880271_0012 SUCCEEDED 1444780465372 xavierdupre root.xavierdupre NORMAL 0 0 0M 0M 0M http://ws09-sr1.tl.teralab-datascience.fr:8088/proxy/application_1444669880271_0012/jobhistory/job/job_1444669880271_0012
On peut tuer un job lorsqu’il est dans la file d’attente ou en train de s’exécuter.
#%remote_cmd hadoop job -kill job_1414491244634_0002
Partie 3 : syntaxe PIG et exercices#
Dans cette partie, l’objectif est de transcrire un GROUP BY en PIG,
un JOIN et de combiner toutes ces opérations en un seul job au cours
du second exercice. Ces exemples utilisent de petits fichiers. Utiliser
un job Map/Reduce n’a pas beaucoup d’intérêt à moins que la taille de
ces fichiers n’atteigne un giga-octets. Les instructions sont à chercher
dans cette page : Pig Latin
Basics.
Exercice 1 : GROUP BY#
import pandas, sqlite3
con = sqlite3.connect("ConfLongDemo_JSI.db3")
df = pandas.read_sql("""SELECT activity, count(*) as nb FROM person GROUP BY activity""", con)
con.close()
df.head()
| activity | nb | |
|---|---|---|
| 0 | falling | 2973 |
| 1 | lying | 54480 |
| 2 | lying down | 6168 |
| 3 | on all fours | 5210 |
| 4 | sitting | 27244 |
Il faut maintenant le faire avec PIG.
Exercice 2 : JOIN#
con = sqlite3.connect("ConfLongDemo_JSI.db3")
df = pandas.read_sql("""SELECT person.*, A.nb FROM person INNER JOIN (
SELECT activity, count(*) as nb FROM person GROUP BY activity) AS A
ON person.activity == A.activity""", con)
con.close()
df.head()
| index | sequence | tag | timestamp | dateformat | x | y | z | activity | nb | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | A01 | 010-000-024-033 | 633790226051280329 | 27.05.2009 14:03:25:127 | 4.062931 | 1.892434 | 0.507425 | walking | 32710 |
| 1 | 1 | A01 | 020-000-033-111 | 633790226051820913 | 27.05.2009 14:03:25:183 | 4.291954 | 1.781140 | 1.344495 | walking | 32710 |
| 2 | 2 | A01 | 020-000-032-221 | 633790226052091205 | 27.05.2009 14:03:25:210 | 4.359101 | 1.826456 | 0.968821 | walking | 32710 |
| 3 | 3 | A01 | 010-000-024-033 | 633790226052361498 | 27.05.2009 14:03:25:237 | 4.087835 | 1.879999 | 0.466983 | walking | 32710 |
| 4 | 4 | A01 | 010-000-030-096 | 633790226052631792 | 27.05.2009 14:03:25:263 | 4.324462 | 2.072460 | 0.488065 | walking | 32710 |
Idem, maintenant il faut le faire avec PIG.