|
blog post, blogs, javascript, programming, python, rss reader, web server
|
2013-07-28 my RSS Reader
When Google Reader died, I was reluctant to move to something different. Not because others solutions are worse or anything like that, but more because I needed to create a new account, a new password, eventually to pay if the number of blogs I wanted to follow was above a given threshold. With Google, I did not have to do anything like that. I would argue that giving everything to a single company which can monitor every single move you do on the net is not a good idea.
But if I push this reasoning to its extreme, why not having a tool on my laptop which allows me to read blog posts? That way, I would download myself the blog content, I would keep any statistics about my own uage for myself. And if the design is not good enough, I just have to change it. Well, the only argument against that is the time I will need to build that tool (and to maintain it).
Well, to be honest, I also did it because I wanted to learn about some python and javascript figures of programming which I talk about in previous blogs. The tools looks that way:
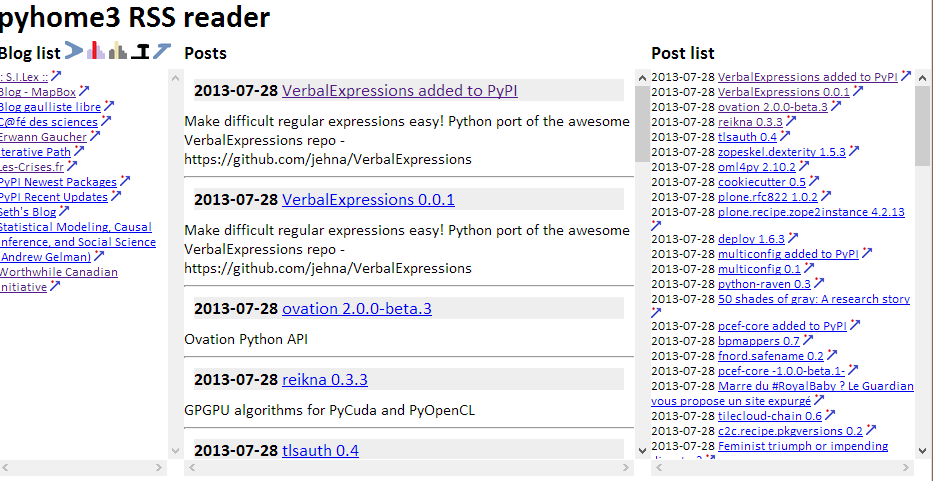
The tool goes through the list of blogs you want to read at will. It stores everything in a SQLite database, it launches a very simple local server written in Python and launches the default browser to get the previous page. On the top of the page, you can see the following images:
A click on them will let you know:
- the list of all posts,
- the list of blogs which publish many posts a day
- the list of blogs which publish less than a post a day
- the list of blogs which published during the last day
- the list of blogs which published during the last wek
<div class="divpostsext" id="divpostsext" onscroll="savePosition('divpostsext')">
<script type="text/python">
for post in dbrss.enumerate_posts(blog_selection = blog_selected,
post_selection = post_selected,
specific = search,
first = 20) :
action = "__link__"
if search != None : action += "?search=%s" % search
print (post.html(action = action, extended = True))
</script>
</div>
Installation: it requires a python module I wrote pyhome3 (see also dependencies). Then, it just needs to create a shortcut on the desktop:
C:\Python33\pythonw.exe C:\Python33\Lib\site-packages\pyhome3\pyhome3_gui.pyIt should work on Linux but I did not test every thing.
Usage: when you execute the link, you will see a window:
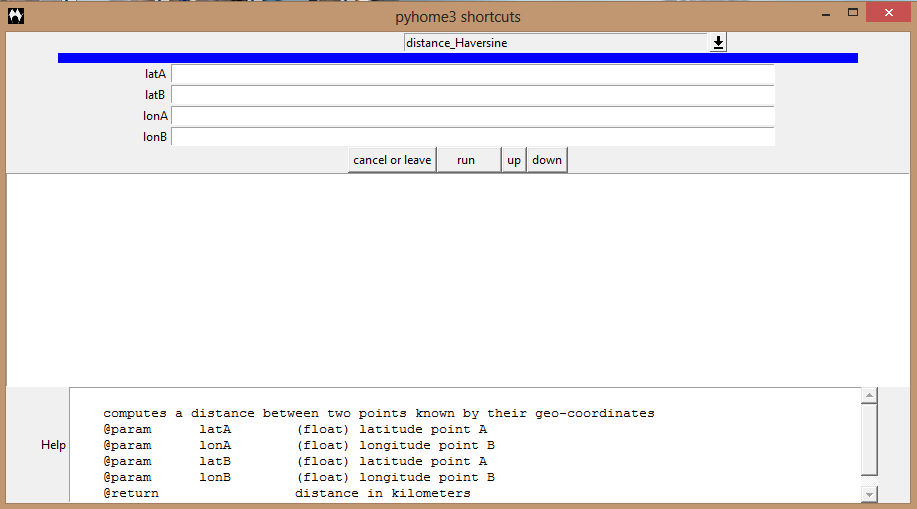
You need to choose the function rss_update_run_server.
You need to fill two parameters: the list of blogs you want to follow and the file (SQLite format) the function will fill with the downloaded data. For example:

The list of blogs is defined by an XML file which uses Google Reader dump format:
<?xml version="1.0" encoding="UTF-8"?>
<opml version="1.0">
<head>
<title>Xavier subscriptions in Google Reader</title>
</head>
<body>
<outline title="libraries" text="libraries">
<outline text="The Overview Project"
title="The Overview Project" type="rss"
xmlUrl="http://overview.ap.org/feed/" htmlUrl="http://overview.ap.org"/>
</outline>
<outline text=":: S.I.Lex ::" title=":: S.I.Lex ::" type="rss"
xmlUrl="http://scinfolex.wordpress.com/feed/" htmlUrl="https://scinfolex.wordpress.com"/>
</body>
</opml>
It starts displaying many information you do not care about (except if there is an error
which should not happen).
2013-07-28 17:15:41 SQL 'SELECT * FROM blogs WHERE xmlUrl="http://aboudjaffar.blog.lemonde.fr/feed/";' 2013-07-28 17:15:41 SQL 'SELECT * FROM blogs WHERE xmlUrl="http://feeds.feedburner.com/TheMouseVsThePython";' 2013-07-28 17:15:41 SQL 'SELECT * FROM blogs WHERE xmlUrl="http://blog.mozilla.org/feed/";' 2013-07-28 17:15:41 SQL 'SELECT * FROM blogs WHERE xmlUrl="http://worthwhile.typepad.com/worthwhile_canadian_initi/atom.xml";' 2013-07-28 17:15:41 SQL 'SELECT * FROM blogs WHERE xmlUrl="http://www.xavierdupre.fr/blog/xdbrss.xml";' 2013-07-28 17:15:41 SQL 'SELECT * FROM blogs' 2013-07-28 17:15:41 reading post from rss: :: S.I.Lex :: (http://scinfolex.wordpress.com/feed/) 2013-07-28 17:15:49 reading post from rss: Andrej Karpathy: Blog (http://karpathy.ca/myblog/feed/) 2013-07-28 17:15:52 reading post from rss: Les-Crises.fr (http://feeds.feedburner.com/les-crises-fr) 2013-07-28 17:15:53 reading post from rss: Regards Citoyens (http://www.regardscitoyens.org/feed/)It ends by launching the default brownser and you can start reading blog posts. You need to click on Cancel or Leave to terminate the server when you are done. When you come back the next day, you will not have to type again the parameters.
Next steps: I have some ideas but maybe not enough time to implement them. Some features are missing on the webpage (the title of the blog next to each post). I would like to compute some statistics on the background, add a link to make the server update the blog. For the time being, you can do that yoursel by looking at the database it creates to store the post. A tool such as SQLiteSpy will easily allow you to query the database.
The code is now available at pymmails.
| <-- --> |
Xavier Dupré
|