2019-04-18 Jupyter, Spyder, ... and pyodide
It seems to be a good replacement for jupyter or spyder if you need to build complex animation. The logic is close to javascript and it does not suffer from a necessary complex bridge between python and javascript : pyodide. Why not...
2019-04-17 Sites pour parcourir les contributions au grand débat
C'est le premier site que je vois qui permet de parcourir les contributions au grand débat sous la forme d'un moteur de recherche et d'autres outils d'intelligence artificielle : Le grand débat national. La requête ENA illustre une forme de ressenti de la population vis à vis de cette école. Le site permet également de télécharger des données. Une autre requête sur le département qui m'a vu naître Ardennes donne un aperçu des contributions des citoyens qui y vivent. La requête Charleville montre que les carolos-macériens se plaignent du TGV qui s'arrête à Reims. Les Ardennes sont mal desservies en terme de transports publics.
Le second site La grande annotation donne l'opportunité à tous de reformuler les contributions au grand débat. La reformulation permet de d'agréger plus facilement les réponses comme le montre de façon explicite la page Les limites de l'intelligence artificielle. Il est par exemple très difficile d'agréger des réponses mal orthographiés.
Le premier site a été construit par deux anciens élèves de l'ENSAE : Découvrez quelles ont été les contributions au grand débat dans votre commune. On retrouve le second sur github/granddebat et on y retrouve des ENSAE aussi parmi les contributeurs.
2019-04-10 Are you able to solve a linear regression without computing a matrix inverse?
A linear regression is a solved problem: it finds B which minimizes the problem |y - (A + XB)|. The solution is known: B = (X'X)^(-1) X' y (see Ordinary least squares). Can we compute the solution without any matrix inverse, only with matrix products and additions? My solution is somewhere on my github account...
more...
2019-04-01 Determines close leaves in a decision tree
That's a problem I had in mind yesterday. When scikit-learn builds a decision tree, we might want to say which classes share a border with another one, which I translated by which couples of leaves of a decision tree share a border. The final node determines which feature to use to split between two leaves and two classes. What can we say about two leaves far away in the tree structure? Do they share a border? We could use the training data to build a kind of Voronoï diagram for points and group cells which belong to the same leave. What if we do not have the training data?
My answer is implemented somewhere on my website. This question was something I was looking into to imagine a way to build a continuous piecewise linear regression with at least two features... which is impossible but still finding close leaves seemed a good algorithmic problem.
2018-12-17 La COP 24, berceau des illusions
Greta Thunberg proteste à sa façon en refusant d'aller à l'école chaque vendredi pour protester contre l'inaction des gouvernements face au réchauffement climatique. Dans son discours lors de la COP 24, elle parle de justice climatique, elle dit aussi que si nous avons tant de fois échoué à réparer un système, c'est peut-être qu'il faut en changer.
more...
2018-12-15 La loi et le politique impatient
L'article induit quelque peu en erreur car le titre est comme d'habitude rédigé de façon à accrocher le lecteur tout en l'induisant dans l'erreur si jamais s'il s'arrêtait là : Le plafonnement des indemnités prud’homales jugé contraire au droit international. En substance, l'article aborde un cas où le jury prud'homal a donné raison à l'employé et a accordé des indemnités hors du plafond proposé par la loi. La loi plafonne les indemnités, l'employeur sait à l'avance ce qu'il va payer et cela peut être interprété comme si le jugement était connu à l'avance, ce qui est contraire à ce qu'on entend par Etat de droit. Le plafonnement des indemnités prud'homales n'est pas explicitement contraire à la loi mais pas tout à fait conforme à l'esprit de la loi. Voilà ce que j'ai retenu de cet article.
more...
2018-12-12 Les impôts payés en avance
Je suppose que beaucoup d'enseignants vacataires ont reçu un message des impôts comme celui que je recopie ci-dessous leur annonçant que les impôts seront prélevés dès le mois de janvier sur la base des revenus 2017 et corrigé en Septembre 2019 car le revenu 2018 ne sera connu qu'à cette date. Il est dit que le paiement à la source apporte beaucoup de souplesse... Je pense à tous les efforts pour mettre en place l'impôt à la source que l'Etat aurait pu utiliser pour réduire ce délai de 9 mois entre le début de l'année et la connaissance de mon revenu de 2018. Bref, si seulement on avait investi ces efforts dans la lutte contre la fraude plutôt que d'aller réformer une collecte qui marchait bien...
more...
2018-12-05 onnxruntime is open source
onnxruntime is meant to deploy machine learned models once they are converted to ONNX format. I did a presentation about it at PyParis and MSExperience. I went open source last night as expected. It aims at computing the prediction of many machine learned models or pipelines built with many machine learning frameworks. It does not take a dependency on the framework which produces the model, the runtime is optimized for CPU, GPU. I'm now working on a couple of projects, all open source, all on github. Interesting times.
2018-06-29 Le meilleur data scientist de France
C'est par un concours de circonstances pas si incroyable que ça d'ailleurs que le concours du meilleur datascientist de France s'est déroulé à station F avec les mêmes données que celles utilisées lors du hackathon de l'ENSAE Hackathon Ernst & Young / ENSAE / Genius / Latitudes / Label Emmaüs / 2017. La gagnant a partagé sa solution How I won Le Meilleur Data Scientist de France 2018, le dixième également Meilleur Data Scientist de France 2018. La vidéo de l'événement dans laquelle j'apparais très rapidement...
La présentation des solutions aura lieu le 4 juillet au meetup de FrenchData FrenchData Meetup #5 : les coulisses de 2 startups data et les solutions du MDSF.
2018-06-26 Data for Good #4
J'ai assisté à la quatrième session de Présentation des projets Data for Good (ou sur la page facebook) A noter, Cédric Villani faisait partie du jury. Il a partagé un peu de son expérience de la vie parlementaire, de la nécessité de convaincre qu'une idée est une bonne idée et que cette partie est au moins aussi importante que l'idée elle-même. C'était de mon point de vue une des sessions les plus réussies et pour la première fois les présentations ont été filmées et sont visibles sur le compte facebook.
Le premier projet hippocrate.tech a regroupé data scientist, philosophe et juriste pour traduire l'éthique sous la forme d'un code de bonne conduite pour les datascientist. Il n'est pas inutile d'y faire un détour.
J'ai découvert la base de données MIMIC qui contient les résultats de tests médicaux de 40.000 patients de services de réanimations. L'objectif d'un des projets était de construire un indicateur du caractère critique de l'état d'un patient. Après les présentations, la conversion m'a amené à Owkin, une startup qui construit des outils d'aide au diagnostique à partir d'intelligence artificielle. Elle a récemment effectué une levée de fond auprès de Otium : OWKIN, la pépite française spécialisée dans le machine learning lève 11 millions de dollars
Un dernier vers openfisca qui donne accès à de nombreuses données économiques et qui permet de faire des simulations pour mesurer l'impact d'une loi.
2018-05-03 Régression logistique et diagramme de Voronoï
Je retombe régulièrement sur le jeu de données Iris très souvent utilisé pour illustrer car il marche bien. J'aime bien aussi cette image :
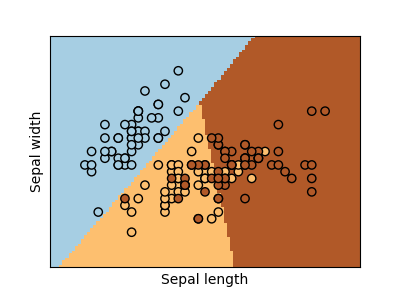
Elle me fait penser à un diagramme de Voronoï, le graphe qui dessine les zones d'influences de points dans un plan et plus généralement dans un espace vectoriel. Je me suis alors demandé s'il n'y avait pas d'équivalence entre les deux... La réponse est non dans le cas général mais cela n'empêche pas une petite promenade pour comprendre deux ou trois petites choses sur les problèmes que peut modéliser une régression logistique : Régression logistique, diagramme de Voronoï, k-Means. Vous y verrez une image comme celle-ci :
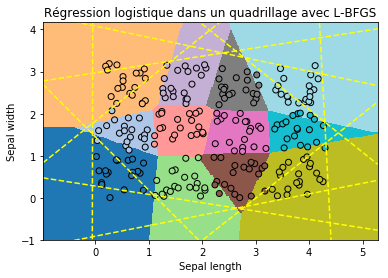
2018-03-31 Mettre un modèle de machine learning en production
J'écrivais un article il y a peu sur le sujet ONNX : apprendre et prédire sur différentes machines où j'évoquais deux pistes pour mettre en production un modèle de machine learning, essentiellement via une application web. Il n'y a pas d'ordre de préférence, certaines sont plus abouties que d'autres. La première tensorflow-serving propose tout clé en main mais elle repose sur l'utilisation de tensorflow. La seconde ONNX, onnxmltools, winmltools convertit un modèle dans un format commun. Il est ensuite exploité là où une librairie de prédiction (un runtime) existe (liste des runtime disponibles). Ce format commun n'est pas encore exploitable en C++ ou javascript mais ces options sont envisageables également. Tensorflow encore propose une façon d'exploiter les modèles en javascript directement avec tensorflow.js (voir https://js.tensorflow.org/tutorials/import-keras.html). ONNX réfléchit à une extension pour le langage C/C++ ONNX in C/C++ qu'il est possible de faire pour le moment pour un modèle de deep learning en convertissant un modèle appris pour la librairie caffe2 avec ONNX : ONNX: deploying a trained model in a C++ project. C'est une direction choisie par le module sklearn-porter qui propose des codes en Java, C++, Go, PhP, Ruby, Javascript pour certains des modèles implémenté par scikit-learn. Cela couvre nettement plus de modèles que ce que j'avais commencé à faire avec mlprodict. Il existe d'autres options comme Seldon, à moitié open source, à moitié tourné vers une proposition de services.
2018-03-19 ONNX : apprendre et prédire sur différentes machines
J'écrivais sur onnx il y a peu de temps. onnx, onnxmltools sont deux librairies qui permettent de convertir des modèles de deep learning mais aussi des modèles entraînés avec scikit-learn en un format unique. Lorsque cela est possible, cela permet d'utiliser avec une librairie un modèle appris avec une autre. C'est pratique si vous trouvez un modèle de deep learning appris avec Caffe et que vous souhaitez l'associé avec un autre appris avec pytorch. La suite n'a pas tardé, il est maintenant possible d'utilser ce format unique sur une machine qui dispose de l'algorithme de prédiction associé. Concrètement, on peut maintenant apprendre un modèle avec scikit-learn et l'utiliser depuis un programme écrit en C# sans faire appel à Python : How Three Lines of Code and Windows Machine Learning Empower .NET Developers to Run AI Locally on Windows 10 Devices. Quelques informations techniques supplémentaires : Windows Machine Learning overview.
On ne se pose plus la question de savoir s'il faut utiliser du deep learning mais plutôt comment le mettre en production. TensorFlow-Serving est une solution assez aboutie qui implémente certains besoins : prédiction temps réel, adaptation à un trafic élevé, capables de conserver de vieilles versions de modèles, de le comparer, de faire de l'A/B testing. Certains ont partagé leur expérience How Zendesk Serves TensorFlow Models in Production/ L'inconvénient est d'être plus ou moins lié à TensorFlow et personnellement je préfère PyTorch. La librairie est plus intuitive et séduit beaucoup les chercheurs : PyTorch or TensorFlow?. Elle est aussi rapide que TensorFlow voire un peu plus : Deep Learning Framework Examples. Il reste le problème de la mise en production. C'est là que le projet ONNX intervient en proposant de séparer l'apprentissage et l'exploitation en production. D'un côté l'apprentissage avec une librairie, une de celle supportée par ONNX, de l'autre une autre librairie ou runtime spécifique au la machine qui fera tourner les prédictions. Le reste du site web est composée de briques classiques. C'est une approche plus modulaire est moins dépendante d'un composant en particulier.
2018-03-13 Visualiser un arbre de décision
Je me suis amusé à essayer des libraires javascript pour représenter un arbre de décision. Amuser n'est pas vraiment le bon mot. C'est le genre de trucs que je n'aime pas faire plusieurs fois. Je l'ai emballé dans une fonction : Visualiser un arbre de décision. Le seul truc est que cela ne marche pas dans jupyterlab car l'exécution de javascript customisé est désactivée à moins d'en faire une extension ert mon courage s'est arrêté là.
2018-03-12 OpenFoodFacts et Google Summer of Code
La belle aventure de OpenFoodFacts continue. Elle fait partie des élus de Google Summer of Code. C'est un beau projet qui a permis de construire une base de données sur de nombreux produits alimentaires dans le monde entier. Si vous souhaitez connaître la qualité de ce que vous achetez, les produits équivalents mais sans additifs, c'est là qu'il faut aller. Les données sont accessibles et chacun peut imaginer une application. Et OpenFoodFacts cherche à automatiser la collecte et l'enrichissement de cette base. Vous trouverez de nombreux défis à résoudre : Student projects/GSOC/Proposals et certains requièrent l'utilisation du deep learning. Parfait pour un stage.
| --> |
Xavier Dupré
|