2015-04-07 Text and machine learning
How can we automatically translate text into another language? You can find some intuitive explanations of how that works from the video by Peter Norvig included in the blog post Being good at programming competitions correlates negatively with being good on the job. It introduces to machine learning, bag of words, Statistical Machine Translation. The conference is quite easy to follow and gives insight on how much data these system require.
2015-03-07 Work on the features or the model
Sometimes, a machine learned model does not get it. It does not find any way to properly classify the data. Sometimes, you know it could work better with another model but it cannot be trained on such an amount of data. So what...
Another direction consists in looking for non linear combinations of existing features which could explain better the border between two classes. Let's consider this known difficult example:
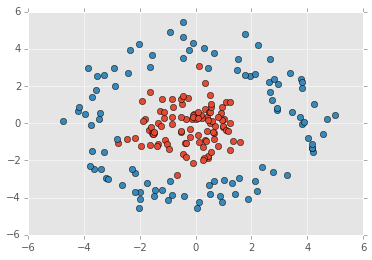
It cannot be linearly separated but it can with others kinds of models (k-NN, SVC). However, by adding simple multiplications between existing features, the problem becomes linear:
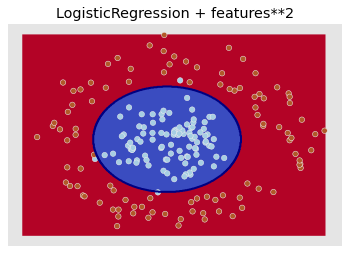
The point is: if you know that a complex features would really help your model, it is worth spending time implementing it rather that trying to approximating it by using a more complex model. (corresponding notebook).
2015-02-26 Use scikit-learn with your own model
scikit-learn has a very simple API and it is quite simple to use its features with your own model. It just needs to be embbeded into a class which implements the methods fit, predict, decision_function, score. I wrote a simple model (kNN) which follows those guidelines: SkCustomKnn. A last method is needed for the cross validation scenario. This one needs to clone the machine learned model. It just calls the constructor with proper parameters. To do so, it needs to get a copy of those. That is the purpose of method get_params. You are all set.
2014-10-11 Machine learning et algorithme
Il existe plein d'outils pour manipuler les données, pandas, R, Excel, ... Ces outils font la plupart des choses pour nous et pourtant parfois, on a besoin de calculer un indicateur imprévu. C'est la cas du drawdown qui est un indicateur financier qu'on calcule parfois sur la performance d'un produit financier. Naïvement, on implémente une solution qui n'est pas toujours optimale et pourtant son calcul est identique à celui de la sous-séquence de plus grande somme qui est un algorithme classique.
2014-07-11 Why Python?
Python recently became very popular. It can do pretty much everything. The language is very slow but extensions can be fast because their implementation can be done in C++. Python is also very popular at schools as mentioned in this paper: Python is Now the Most Popular Introductory Teaching Language at Top U.S. Universities. This page also references many schools using Python: Schools using Python.
It might be difficult to find a perfect setup for your own use. There are usually many libraries doing the same thing. If you do not know Python, it might be difficult to navigate through the big repository pypi. However, there exists distribution which does everything for you: WinPython. We can argue R is a better fit or Julia might be easier to start with. However, I think there are two reasons why Python is a good choice:
- I think the Python language is easier to learn.
- R, Julia have their own way to do matrix computation, it cannot be changed. numpy is the most used package to do matrix computation on Python but it can be changed if some others ways were proved to be better (see blaze).
2014-06-30 Machine Learning with Python
Two very interesting blogs which illustrate how to do machine learning with Python:
I suggest the two following blog posts:
- Data Science in Python
- Using Python's sci-packages to prepare data for Machine Learning tasks and other data analyses
- Implementing simple sequential feature selection algorithms in Python
2014-04-02 References for Statistics with R
Python does not offer all the functionalities in one module, you need to look for them sometimes. In my case, I was looking for a statistical test on coefficients obtained with a linear regression. The module I was looking for is statmodels. While looking for that, I found this interesting blog Glowing Python. But I finally decided to switch to R where I know for sure I would find what I need. And because I'm not fluent in R, I need something like that : StatMethods.
2014-03-28 Quelques astuces pour faire du machine learning
On a parfois l'impression qu'il suffit de choisir un modèle (réseau de neurones, SVM, random forests, ou autres scikit-learn), de l'entraîner puis de l'appliquer pour obtenir un prédicteur de bonne qualité. Mais ça ne marche pas toujours... Voici quelques raisons qui pourraient l'expliquer.
more...
2013-09-15 Python extensions to do machine learning
I started to compare the functionalities of some Python extensions (the list is not exhaustive) :
- scikit-learn
- mlpy
- Modular toolkit for Data Processing (MDP)
- PyBrain
- Theano
- MILK
- Gensim
- NLTK
- Orange
- statsmodels
- pyMVPA
A couple of forums, kind of FAQ for machine learning:
It would be difficult to do machine learning without using visualization tools. matplotlib and ggplot would be a good way to start. We also manipulate tables: numpy and pandas. For a command line: ipython or bpython are two common options.
If you are looking for data UC Irvine Machine Learning Repository. If you work with Windows, many of the presented modules can be downloaded from Unofficial Windows Binaries for Python Extension Packages. It also gives a clear view of what package is available on which Python's version.
more...
2013-08-10 Machine Learning with Python
Here is the list of modules you should install:
All modules can be installed from Unofficial Windows Binaries for Python Extension Packages except IPython which should be installed with pip (+ setuptools) because it has may dependencies (see installation guidelines) to get a command line windows with colors and copy/paste functionalities. IPython is very interesting for auto-completion. Press TAB and you will get a list of possible options.
Some others modules can be useful:
2013-08-01 Datamining avec R ou Python
Il est devenu assez facile de travailler avec R. Même si je trouve toujours le langage compliqué, il faut avouer que des outils comme RStudio rendent l'outil indispensable et de moins en moins difficile d'accès. On peut importer ses données depuis une grande variété de format, créer des rapports en utilisant knitr ou encore créer une application web avec shiny. Il existe un package pour presque tout comme pour faire des tests unitaires avec RUnit.
J'ai pour habitude de faire le plus de choses possibles en Python, de passer au C++ quand c'est vraiment nécessaire et d'utiliser R pour tout ce qui statistiques. R a l'avantage d'avoir une modèle suivi par tous les packages alors que les modules Python suivent leur propre logique le plus souvent.
Un exemple sur les méthodes à noyau : sous R, il faudrait utiliser le package kernlab, sous Python, on se dirigerait vers scikit-learn. Les packages sous Python sont souvent plus gros car les auteurs auront voulu intégrer de nombreux algorithmes selon la même logique. Sous R, chaque package a un périmètre plus réduit et suit les mêmes conventions. Comme Python s'interface avec à peu près tout y compris R, je préfère ce langage dont la syntaxe me paraît plus facile même si je n'hésite pas à repasser à R dès qu'il le faut.
C++
Les deux langages permettent d'inclure des morceau de C++ si nécessaire. Python dispose de diverses façons~: Cython, Boost.Python, ou cffi. Avec R, il y a Rcpp (tutoriel sur Rcpp, il faut aussi installer devtools). Est-ce que le langage C va disparaître ? Pour le moment, si les langages de scripts sont beaucoup plus utilisés, les compilateurs sont la plupart du temps écrits en C++. De nombreuses extensions ont été écrites en C++ (voir Eigen par exemple). Ce langage est souvent un choix raisonnable lorsqu'on veut écrire du code très rapide.
Graphiques
L'outil qui prend un peu plus d'importance ces temps-ci est d3.js car il permet de réaliser des graphiques facilement intégrables sur un site web, un journal en ligne, qu'il permet de faire plus facilement des animations et surtout, comme il est écrit en javascript, il permet de créer des graphes qui réagissent à la souris ou au clavier. Je n'arrive pas encore à trouver un module qui le rende facilement utilisable depuis Python. L'article Method: Data visualization with D3.js and python - part 1 décrit comment s'y prendre sans toutefois citer de module dédié à cet usage. Ca ne devrait pas tarder. Sous R, sans être javascript, il existe ggplot2 qui propose des graphes assez jolis.
Big Data
Enfin, dans le domaine des Big Data, les solutions lourdes type Map/Reduce Hadoop sont de plus en plus fréquentes lorsqu'on traite des données qui arrivent en continu (internet, téléphone, consommation d'énergie...). Pour le reste, un ordinateur portable avec quelques giga octets de mémoire et un disque dur conséquent suffit. Des outils existent pour ne pas avoir à charger une base complète en mémoire. C'est le cas de ff et ffbase (ou ça bigvis) sous R. Sous Python, l'environnement de travail le plus approprié est IPython. Pour manipuler les données, on trouve pandas ou PyTables.
2013-05-26 Processing (big) data with Hadoop
Big Data becomes very popular nowadays. If the concept seems very simple - use many machines to process big chunks of data -, pratically, it takes a couple of hours before being ready to run the first script on the grid. Hopefully, this article will help you saving some times. Here are some directions I looked to create and submit a job map/reduce.
Unless you are very strong, there is very little chance that you develop a script without making any mistake on the first try. Every run on the grid has a cost, plus accessing a distant cluster might take some time. That's why it is convenient to be able to develop a script on a local machine. I looked into several ways: Cygwin, a virtual machine with Cloudera, a virtual machine with HortonWorks, a local installation of Hadoop on Windows. As you may have understood, my laptop OS is Windows. Setting up a virtual machine is more complex but it gives a better overview of how Hadoop works.
Here are the points I will develop:
- Develop a short script in Hue and Hive on this local machine,
- Install a virtual machine (VM) on a laptop,
- Run this script on the grid (using Amazon AWS).
Contents:
- Local run with Java
- Installation of a local server with HortonWorks
- Install a virtual machine (Cloudera)
- Files to download
- Only for French keyboards
- Upload, download files to the local grid
- Install the VMWare Tools and create a shared folder
- Final tweaks: change the repository
- Install Python 3.3, Numpy (optional)
- Install R and Rpy2
- Install a virtual machine (HortonWorks)
- Develop a short script
- Hadoop and Python
- Using Amazon AWS
- Errors you might face
more...
| <-- |
Xavier Dupré
|