2015-05-09 Data Scientist à San Francisco
Clément, "data scientist" à San Francisco pour 5 950 euros par mois Avec ce salaire-là, on se place dans les 3% les mieux rémunérés en France. Je serai curieux d'avoir le même aperçu dans dix ans, avec les coûts liés à la garde des enfants, leur éducation.
2015-03-19 L'école à l'heure du numérique, Edmodo
MOOC, tablettes, réseaux sociaux, il y a chaque jour de nouveaux outils et pas assez de temps pour tous les essayer. L'article suivant Tablettes et cours inversés, équation gagnante dans un lycée pilote paru dans Le Monde partagent quelques expériences. J'ai retenu Edmodo une plateforme d'échanges entre professeurs et élèves, les petits MOOC avant d'assister au cours qui parle du sujet, la saisie de notes sur tablettes (l'enseignement poste ses notes de cours que les élèves annotent en cours). Pour finir, un peu de lecture : Apprentissage par enquête et Pédagogie inversée.
2015-01-15 Projets informatiques, ENSAE 1A
Liste des sujets suggérés. Le hors piste est encouragé.
2014-11-13 1981 : apprendre la programmation à l'école ?
En farfouillant sur Internet, je suis tombé sur un texte de Andreï Erschov : La programmation est un deuxième alphabétisme. C'est un exposé de 1981 sur l'utilisation des ordinateurs dans l'enseignement. C'est en Russe mais j'ai copié collé une traduction française faite par un moteur de traduction automatique et un peu retravaillée avec la traduction anglaise de meilleure qualité. J'espère que je n'ai pas déformé les propos de l'auteur, ce que je suis incapable de vérifier. Le texte a plus de trente ans mais il exprime déjà l'intuition que l'ordinateur et plus particulièrement la programmation vont considérablement changer la société, presque autant que l'écriture. Il est important que cette dernière fasse partie de l'enseignement afin de mieux préparer les enfants.
more...
2014-09-13 La programmation à l'école
J'écoutais l'émission Le téléphone sonne sur France Inter à propos du contenu des enseignements. Je faisais autre chose à côté donc je ne me souviens pas de tout et puis le ton du dialogue nous amène un peu partout sans vraiment construire une réflexion. Toutefois, au milieu de l'émisssion, Cédric Villani prend la parole pour dire que les enfants devraient pratiquer un sport, jouer d'un instrument de musique, apprendre un langage de programmation et puis l'anglais pour voyager.
Le plus étrange est qu'il a pris le temps de préciser que l'anglais était indispensable pour voyager sans justifier les autres ingrédients de la liste. En guise de réponse, je citerais une conférence de François Elie qu'un élève m'a fait découvrir.
Pourtant dans l'article Ces branchés qui débranchent (voir aussi La soeur du patron de Facebook conseille aux enfants de se déconnecter), on y apprend que les patrons des startups les plus célèbres désirent une éducation presque sans écran pour leurs enfants.
Peut-être faut-il en déduire que le numérique à l'école ne passe pas nécessairement par un écran.
2014-09-05 Rentrée scolaire
C'est reparti pour une année et je m'aperçois que beaucoup de choses ont changé en un an. Mes cours ont quitté Latex pour Sphinx et ont trouvé place sur GitHub. Toujours aussi peu désireux de répéter toujours les mêmes tâches, je n'ai que deux scripts à lancer pour compiler les cours et les mettre à jour sur mon site. J'ai testé pas mal de template (intraduisible en français) sphinx pour finalement un choisir un facile à lire sur ordinateur, tablette et téléphone portable : ENSAE - Programmation - Xavier Dupré. J'ai ajouté une présentation au format revealjs : ENSAE 1A - PROGRAMMATION qui passe tout aussi bien sur presque tous les téléphones. L'éditeur SciTE, tellement simple que je n'ai pas encore réussi à m'en passer, a pourtant laissé une grande place aux Notebook. J'ai commencé un module python pyensae afin d'y mettre les bouts de code que je transmets aux élèves. Il inclut une fonction download_data qui télécharge des données directement depuis mon site.
Je me souviens encore d'une discussion voici presque 10 ans avec un ami qui me disait : Il faut arrêter le C++, c'est trop compliqué pour une première découverte de la programmation. Il s'occupait des cours d'informatique à l'ENSAE. Un peu au même moment, un élève m'annonçait fièrement après les examens qu'il avait grandement contribué à sept projets. Mais pourquoi Python, lui demandais-je ? C'est le langage avec la plus petite spec, me répondit-il. Et il n'y a pas de point virgule, c'est l'indentation qui détermine les blocs. C'est vrai qu'un langage à point virgule mène souvent à des poèmes à la Prévert. J'ai acheté un livre et j'ai appris le Python trois semaines avant la rentrée et j'ai préparé mes cours dans le même temps. Plus de C++, voilà Python. Le nom du langage a également disparu de l'intitulé du cours. Il y a dix ans, Python, ça ne faisait pas assez sérieux.
Et aujourd'hui ? Python ne cache plus son nom. Le premier résultat de recherche fait référence au langage et non au serpent. Les chercheurs s'y mettent aussi. En deux ans, le langage s'est beaucoup étoffé. Et l'écart entre ce que j'enseigne et l'usage que j'ai du langage s'est considérablement réduit. Au quotidien, je notebooke beaucoup.
Mais si j'écris aujourd'hui, c'est ce que je suis stressé. C'est la rentrée.
2014-05-14 Deux ou trois choses à vérifier avant de rendre un projet informatique
Avant de remettre un programme informatique à un relecteur, il est deux ou trois petites choses qui facilitent le travail de relecture :
- Vérifier que le programme est transmis avec les fichiers supplémentaires dont il a besoin (données, images, ...)
- Vérifier que le programme n'inclut pas de noms de fichiers absolus mais relatifs (je n'ai pas de lecteur d:)
- Si le programme demande des valeurs que l'utilisateur doit rentrer, il faut ajouter dans l'intitulé de la question une valeur par défaut ou recommandée. C'est sans doute évident mais comme je relis plusieurs programmes à la fois, deviner la valeur qui fonctionne et qui ne fait pas planter le programme devient un exercice délicat. Je préfère également quelques lignes au début du programme spécifiant ces valeurs plutôt que d'avoir à les renseigner à chaque exécution.
Lorsqu'un programme ne marche pas et qu'on a passé beaucoup de temps à chercher l'erreur, quoi de plus naturel que d'envoyer un mail à son professeur : "Monsieur, je ne comprends pas, ça ne marche pas et ça devrait marcher". Une fois sur deux, je réponds qu'il me serait utile d'en savoir un peu plus :
- les valeurs des paramètres et les données afin que je puisse reproduire l'erreur,
- la raison pour laquelle vous pensez que cela ne marche pas (pas de convergence, le résultat attendu n'est pas là, ...),
- les directions que vous avez explorées pour comprendre l'erreur (sous-entendu elles se sont révélées infructueuses).
- mettre des print un peu partout pour afficher les valeurs intermédiaires,
- ajouter des tests à des endroits clés du programme pour m'assurer que les tableaux ont la bonne dimension, qu'il n'y a pas de valeurs nulles ou presque nulles lors d'une division, ...,
- réduire la taille du problème ou choisir des valeurs singulières pour obtenir un problème pour lequel je connais le résultat.
Un cas concret : un programme est censé minimiser la longueur du chemin passant par tous les noeuds d'un graphe (problème du voyageur de commerce). L'algorithme implémenté était tout-à-fait correct à ceci près que l'arc liant le dernier noeud au premier était oublié dans le calcul de la longueur du chemin (il ne bouclait pas). Je vous laisse imaginer ce que l'algorithme produisait comme solution et pourquoi ce que j'ai vu au fil des itérations m'a incité à aller inspecter le calcul de cette longueur.
2014-05-04 Données financières
Chaque année, je propose des sujets financiers aux étudiants de l'ENSAE et la question qui revient systématique est celle des données. Jusqu'à présent, j'utilisais Yahoo Finance!. L'inconvénient est qu'on ne peut récupérer que les cours daily des actions. Un ami m'a suggéré le site Quandl. Les historiques ne sont parfois pas aussi conséquent mais ce site aggrège différentes sources de données et les rend disponibles selon la même interface depuis de nombreux langages (Python, R, Julia, Clojure...).
L'interface est vraiment épurée, très réactive et très agréable à utiliser. Outre la multitude de séries financières qui est accessible, le site met à disposition des séries économiques comme le PIB pour de nombreux pays ou encore le cours du Bitcoin.
Le site stipule que l'accès est gratuit. Il faut s'authentifier si on dépasse un quota de 50 requêtes par jour. Le business model n'est pas encore bien défini (coming soon) contrairement à leur concurrent Datamarket. Ma préférence va pour Quandl, simple, accessible, gratuit et des objectifs ambitieux. Si une source de données ne fait pas partie du catalogue, il est même possible de leur demander de l'intégrer.
Quelques articles :
- In Praise of Quandl!
- Quandl: Wikipedia for data?
- Quantitative Finance Applications in R
- Retrieve Quandl's Data and Play with a Pandas
2014-02-12 Travailler à plusieurs sur le même projet informatique
La principale difficulté lorsqu'on travaille à plusieurs sur le même programme survient lorsqu'on doit agréger les modifications de plusieurs personnes. On part d'un même programme, on le modifie chacun de son côté et on essaye quelques jours plus tard de réconcilier les deux versions. C'est souvent laborieux et ça peut introduire quelques erreurs.
Une solution peut déjà être d'avoir un emplacement qui détient toujours la bonne version. Par exemple, hubiC vous propose d'avoir un répertoire distant (donc pas chez soi) synchronisé avec un répertoire local de son ordinateur. Ce même répertoire peut être synchronisé avec un autre répertoire local sur un autre ordinateur. De cette façon, dès que quelqu'un modifie un fichier, les autres contributeurs récupèrent les modifications (à condition d'être connecté).
Même si c'est pratique, ce genre de solution ne permet pas de revenir en arrière ni même de visualiser les modifications de chacun. Pour cela, on peut utiliser un système de suivi de source tel que GitHub, ce que j'ai fait pour pyensae, qui permet de voir les différences. Ce service n'est pas totalement gratuit (voir GitHub Pricing, BitBucket Pricing). Avant d'essayer, il est préférable de lire cette page : Fork A Repo. Si vous n'aimez pas trop les lignes de commande, il est possible de coupler cela avec TortoiseGit.
more...
2013-12-15 Quelques exercices de préparation à l'examen (5)
Lorsqu'on cherche un élément dans un tableau, c'est généralement pour retrouver sa position. Supposons maintenant que cet élément soit présent en plusieurs exemplaires et qu'on veuille toutes les positions où il est présent.
def positions(liste, element) :
...
return une liste
l = [ 4,3,3,6,4,3 ]
print ( positions(l, 3) ) # affiche [1,2,5]
Dans un second temps, on veut transformer la liste l en un dictionnaire de sorte que la fonction positions ne contienne plus de boucle. Quelle est la solution la plus rapide ?
more...
2013-12-14 Quelques exercices de préparation à l'examen (4)
On reprend le même texte que celui de l'exercice précédent. On veut connaître le nombre maximum de mots qu'on peut trouver entre deux mots commençant par une voyelle.
# source du texte : http://www.gutenberg.org/files/1567/1567-h/1567-h.htm#link2H_4_0017
texte = """They are rattling breakfast plates in basement kitchens,
And along the trampled edges of the street
I am aware of the damp souls of housemaids
Sprouting despondently at area gates.
The brown waves of fog toss up to me
Twisted faces from the bottom of the street,
And tear from a passer-by with muddy skirts
An aimless smile that hovers in the air
And vanishes along the level of the roofs.""".replace("\n"," ").lower().split()
def nombre_de_mot_maximum(mots) :
...
return un_nombre
more...
2013-12-13 Quelques exercices de préparation à l'examen (3)
On veut calculer la longueur moyenne des mots ayant le même nombre de voyelles. Le résultat est un dictionnaire où chaque élément vérifie :
- La clé est le nombre de voyelles.
- La valeur est la moyenne des mots du texte ayant le même nombre de voyelles.
# source du texte : http://www.gutenberg.org/files/1567/1567-h/1567-h.htm#link2H_4_0017
texte = """They are rattling breakfast plates in basement kitchens,
And along the trampled edges of the street
I am aware of the damp souls of housemaids
Sprouting despondently at area gates.
The brown waves of fog toss up to me
Twisted faces from the bottom of the street,
And tear from a passer-by with muddy skirts
An aimless smile that hovers in the air
And vanishes along the level of the roofs.""".replace("\n"," ").lower().split()
def moyenne_longueur_pour_chaque_nombre_de_voyelles(mots) :
...
return un dictionnaire
more...
2013-12-12 Quelques exercices de préparation à l'examen (2)
On veut écrire une fonction qui compte le nombre de voyelles dans un mot.
def compte_voyelles(mot):
...
return le nombre de voyelles
print (compte_voyelles("oui")) # doit afficher 3
print (compte_voyelles("non")) # doit afficher 1
more...
2013-12-11 Quelques exercices de préparation à l'examen (1)
On veut écrire une fonction qui détermine si une lettre est une voyelle.
def est_voyelle(c):
...
return 0 ou 1
print (est_voyelle("a")) # doit afficher 1
print (est_voyelle("b")) # doit afficher 0
Il faut écrire cette fonction de trois manières différentes :
- La fonction n'est composée que de tests.
- La fonction est composée d'un test et d'une liste.
- Il n'y a aucun test dans la fonction, on utilise seulement un dictionnaire.
more...
2013-12-07 Optimisation sous contraintes appliquée au calcul du report des voix
Entre les deux tours des élections présidentielles, on parle beaucoup du report des voix des élections. Dans la plupart des articles que j'ai trouvés (Les 1.139.316 voix qui ont fait la victoire d'Hollande), ces intentions sont estimées par sondage. Un blog parle d'une méthode d'estimation après seulement que les élections ont eu lieu : Estimation des reports de voix - explications techniques. La méthode proposée est bayésienne. Ici, j'ai utilisé l'optmisation sous contraintes car c'est la méthode que je souhaitais illustrer pour mes enseignements. J'ai pris les élections comme exemples d'application. Les données sont accessibles sur le site (data.gouv.fr , élections 2012). Elles incluent les chiffres aggrégés par départements et cantons dont je me suis servi et que j'ai regroupés ici : french_elections.zip).
On dispose donc des voix ventilées par candidats et disponibles pour chaque départements. On cherche à calculer une matrice de report de voix qui soit la même pour tous les départements.
| ARTHAUD | Abstentions | BAYROU | Blancs et nuls | CHEMINADE | Code dep | DUPONT-AIGNAN | HOLLANDE | JOLY | LE PEN | Département | MÉLENCHON | POUTOU | SARKOZY | total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1794 | 65996 | 32650 | 6453 | 860 | 1 | 7208 | 73096 | 7268 | 66540 | AIN | 30898 | 3323 | 97722 | 393808 |
| 2490 | 72928 | 19895 | 5196 | 738 | 2 | 5853 | 80751 | 3455 | 78452 | AISNE | 30360 | 3860 | 72090 | 376068 |
| 1482 | 45266 | 17814 | 5059 | 457 | 3 | 4068 | 61131 | 3232 | 37736 | ALLIER | 27969 | 2584 | 49477 | 256275 |
| 487 | 21034 | 7483 | 2111 | 283 | 4 | 1845 | 24551 | 2933 | 20875 | ALPES DE HAUTE PROVENCE | 15269 | 1394 | 25668 | 123933 |
| 1576 | 153383 | 38980 | 9063 | 1238 | 6 | 9241 | 111990 | 12556 | 136982 | ALPES MARITIMES | 49493 | 4048 | 216738 | 745288 |
| Abstentions | Blancs et nuls | Code | HOLLANDE | Département | SARKOZY | total |
|---|---|---|---|---|---|---|
| 67279 | 19513 | 1 | 131333 | AIN | 175741 | 393866 |
| 73997 | 21056 | 2 | 147260 | AISNE | 133760 | 376073 |
| 45079 | 14924 | 3 | 111615 | ALLIER | 84593 | 256211 |
| 20314 | 6639 | 4 | 49498 | ALPES DE HAUTE PROVENCE | 47444 | 123895 |
| 146254 | 30067 | 6 | 203117 | ALPES MARITIMES | 366055 | 745493 |
On cherche une matrice V qui permet d'obtenir les voix Y du second tour en fonction des voix du premier tour X :
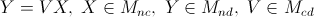
n est le nombre de départements, c est le nombre de candidats du premier tour (abstention et bulletin nuls inclus), d est le nombre de candidats du second tour. La matrice V définit le report des voix : Vij est la proportion des voix du candidat c allant au candidat d. Elle vérifie les contraintes suivantes :
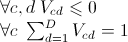
more...
| <-- --> |
Xavier Dupré
|