2013-12-02 Distance d'édition et programmation dynamique
La distance d'édition (ou distance de Levenstein) est un algorithme très connu qui sert à comparer deux mots, deux chaînes de caractères et, plus généralement, deux séquences. La distance est définie comme le nombre d'opérations minimum qui permet de passer du premier mot au second sachant qu'il n'existe que trois opérations possibles :
- le remplacement d'un caractère par un autre,
- la suppression d'un caractère,
- l'insertion d'un caractère.
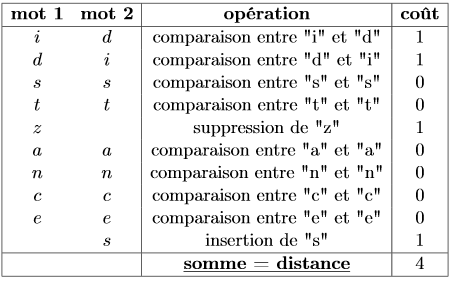
Dans l'exemple qui précède, ces trois opérations ont un coût identique. Mais il pourrait tout-à-fait dépendre du caractère inséré ou supprimé ou de la comparaison entre les deux caractères. La distance est alors la somme de ces coûts.
Trouver le nombre minimal d'opérations est un problème classique qu'on peut résoudre à l'aide de la programmation dynamique. Cela veut dire que le problème vérifie la propriété suivante : Toute solution optimale s'appuie elle-même sur des sous-problèmes résolus localement de façon optimale (Wikipedia). Cela veut souvent dire qu'il existe une façon de trouver la solution du problème par récurrence. Ou alors, si on trouve une façon de couper le problème en deux, la solution optimale sera la combinaison des deux solutions optimales sur chacune des deux parties.
more...
2013-12-01 Recherche dichotomique, récursive, itérative et le logarithme
Lorsqu'on décrit n'importe quel algorithme, on évoque toujours son coût, souvent une formule de ce style :
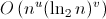
u et v sont des entiers. v est souvent soit 0, soit 1. Mais d'où vient ce logarithme ? Le premier algorithme auquel on pense et dont le coût correspond au cas u=0 et v=1 est la recherche dichotomique. Il consiste à chercher un élément dans une liste triée. Le logarithme vient du fait qu'on réduit l'espace de recherche par deux à chaque itération. Fatalement, on trouve très vite l'élément à chercher. Et le logarithme, dans la plupart des algorithmes, vient du fait qu'on divise la dimension du problème par un nombre entier à chaque itération, ici 2.
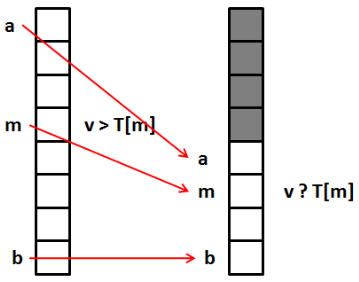
La recherche dichotomique est assez simple : on part d'une liste triée T et on cherche l'élément v (on suppose qu'il s'y trouve). On procède comme suit :
- On compare v à l'élément du milieu de la liste.
- S'il est égal à v, on a fini.
- Sinon, s'il est inférieur, il faut chercher dans la première moitié de la liste. On retourne à l'étape 1 avec la liste réduite.
- S'il est supérieur, on fait de même avec la seconde moitié de la liste.
more...
2013-11-30 More about interactive graphs using Python, d3.js, R, shiny, IPython, vincent, d3py, python-nvd3
I recently found this url The Big List of D3.js Examples. As d3.js is getting popular - their website is pretty nice -, I was curious if I could easily use it through Python. After a couple of searches (many in fact), I discovered vincent and some others. It ended up doing a quick review. Every script was tested with Python 3.
Contents:
- Graphs with IPython and QtConsole
- Graphs with IPython Notebook
- Graph with d3.js and IPython Notebook
- Graphs with Python and vincent
- Graphs with Python and d3py
- Graphs with IPython and nvd3
- R with shiny
- Alternatives
- How will you share the graph? (no share, image, web + HTML and Javascript, web + R)
- Can you see the graph you want to do in galleries?
Use of IPython (qt)console
The QtConsole looks like a command line window but is able to display images inline using matplotlib:
more...
2013-11-29 Python avec la Khan Academy
La Khan Academy propose des leçons de 10 minutes sur de nombreux sujets parmi lesquels Python. Voici quelques pointeurs (en anglais):
- Introduction (programmes, variables)
- Listes
- Chaînes de caractères
- Boucle for
- Boucle while
- Versions itérative et récursive de la fonction factorielle
- Les dictionnaires, lire notamment la section Construction d'un histogramme à l'aide d'un dictionnaire
- Les fonctions
2014-05-28 - Les liens vers la Khan Academy sont cassés et je n'ai pas réussi à les retrouver sur leur site. Ils sont néanmoins accessibles sur YouTube : listes. Les autres vidéos sont accessibles depuis les suggestions.
2013-11-09 Compter les pièces de monnaie pour obtenir un montant
On est amené presque tous les jours à compter les pièces dans son porte-monnaie pour payer la baguette, le fromage ou la bouteille de vin. Comment écrire un algorithme qui donne la liste des pièces qu'il faut piocher dans son porte-monnaie pour payer ? On s'intéressera seulement au cas où on cherche à composer le montant juste. Cela revient à chercher un sous-ensemble S de pièces dans l'ensemble P des pièces du portefeuille pour composer le montant M :
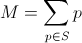
Une façon naïve de construire l'ensemble S est de procéder comme on le fait souvent, c'est-à-dire à prendre la pièce la plus grosse, de voir si elle dépasse le montant N puis de passer à la seconde plus grande et ainsi de suite. Soit :
- On trie les pièces par ordre décroissant.
- Au début, l'ensembe S est vide.
- On prend les pièces dans l'ordre décroissant et on les ajoute à l'ensemble S si la somme de l'ensemble n'est pas plus grand que M.
more...
2013-11-08 De l'idée au programme informatique
Lorsqu'on apprend à programmer, on a souvent une idée précise de l'objectif à atteindre et pourtant, on reste perplexe devant l'écran ne sachant pas par où commencer. Par exemple, si on dispose d'une matrice de trois colonnes :
| x | y | poids |
| A | C | 3 |
| A | D | 1 |
| A | E | 4 |
| B | D | 6 |
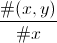
Par exemple, si x=A et y=D, on aura 1 / (3 + 1 + 4) = 0.125. Maintenant, comment s'y prend-on ?
Tout d'abord, on cherche à calculer un ratio de trucs qui ne sont pas des nombres entiers. Un dictionnaire est tout indiqué pour stocker ces trucs car il permet d'associer n'importe quoi (valeur) à presque n'importe quoi (clé). La valeur est une somme d'entiers, la clé est un couple de lettres ou une lettre. Sans me soucier des petits détails, voilà ce que j'ai envie d'écrire comme premier jet :
l = [ ['A','B', 3], ['A','C', 1],
['A','E', 4], ['B','D', 6], ]
def transition(l):
d = {}
for x,y,n in l :
d [x,y] += n # erreur ici : KeyError: ('A', 'B')
d [x] += n
for x,y in d :
d[x,y] /= d [x]
return d
print (transition(l))
Bien sûr ça ne marche pas (voir l'erreur ci-dessus). Mais j'ai foi en moi. La logique est bonne. Lorsque j'écris d [a,b] += n, je suppose que le couple (x,y) existe dans le dictionnaire même la toute première fois. Et c'est pas possible ! Il est vide au début.
more...
2013-09-21 Le profile online d'un développeur
Beaucoup de sociétés recherchent de bons développeurs et les dernières années ont changé les façons de les trouver. Il y a d'abord les réseaux sociaux Linkedin, Viadeo, Facebook. Mais ce n'est pas tout, les bons développeurs ont souvent partagé leur code ou contribué à des projets open source. On retrouve leurs traces sur GitHub. Certains ont aussi tenté de résoudre certains des problèmes proposés par kaggle. Ajoutons, un site web, un petit blog pour commenter tous les défis techniques auquel un développeur s'attaque.
Il y a dix ans, le CV et la lettre de motivation était la façon de se vendre. Le CV est aujourd'hui sur Linkedin ou Viadeo, la motivation dans le nombre de commit sur GitHub.
2013-08-15 L'économie, à quoi ça sert ?
C'est l'histoire que j'aurais voulu entendre avant de commencer mes cours d'économie à l'ENSAE. Elle est tirée du livre Pourquoi les crises reviennent toujours ? de Paul Krugman dont je recommande la lecture. Il est bien écrit et très clair. L'histoire de la coopérative de baby-sitting du Capital Hill (en) sert d'exemple illustratif tout au long du livre. L'économie prend un tout autre sens qu'une liste de modèle macro/micro économiques. Je reprends ici les différents passages du livre qui ont trait à ce petit univers fort passionnant du Capitol Hill. Les derniers paragraphes relatifs à la dépréciation du coupon d'hiver sont fictifs mais ils permettent à l'auteur de transposer la récession économique du Japon des années 1990 dans ce microcosme.
Pendant les années 1970, les Sweeney étaient membres d'une coopérative de baby-sitting : une association constitutée de jeunes couples, travaillant presque tous au Congrès, qui désiraient prendre en charge mutuellement la garde de leurs enfants. Cette coopérative d'un genre particulier avait une taille peu commune, près de cent cinquante couples ; c'est dire le nombre de baby-sitters potentiels, mais aussi la difficulté d'exploitation d'une telle structure - il faut assurer en particulier que chaque couple s'acquitte de sa quote-part.
A l'instar de nombreuses institutions de ce genre (et d'autres formes de troc), la coopérative de Capitol Hill résolut le problème en émettant ses propres titres : des coupons donnant droit au porteur à des heures de baby-sitting. Lorsqu'ils gardaient des bébés, les baby-sitters recevaient un nombre de coupons correspondant au nombre d'enfants. Le système était conçu pour empêcher le resquillage : il assurait automatiquement que chaque couple, en fin de compte, fournirait autant d'heures de baby-sitting qu'il en aurait lui-même utilisé.
Mais ce n'était pas si simple, un tel système requiert la circulation d'une quantité considérable de bons. Les couples disposant de plusieurs soirées libres d'affilée, et sans projet immédiat de sortie, allaient essayer de se constituer des réserves pour les utiliser ultérieurement ; cette accumulation se ferait aux dépens des réserves des autres couples, mais il était probable que chaque couple chercherait à détenir suffisamment de coupons pour sortir plusieurs fois entre les épisodes de baby-sitting qu'il assurerait. L'émission de coupons dans la coopérative de Capitol Hill était compliquée : les couples recevaient des coupons lorsqu'ils adhéraient, ils étaient censés les rembourser lorsqu'ils la quittaient ; mais ces coupons leur servaient également à payer des cotisations pour rémunérer les administrateurs, etc. Les détails ne sont pas importants ; le fait est est qu'il arriva un moment où il y eut trop peu de coupons en circulation - trop peu pour couvrir les besoins de la coopérative.
Le résultat fut surprenant. Les couples qui jugeaient leur réserve de coupons insuffisante se montrèrent plus désireux de faire du baby-sitting et réticents pour sortir. Mais il fallait qu'un couple décide de sortir pour qu'un autre couple puisse faire du baby-sitting. Dans ces conditions, les occasions d'en faire devinrent rares, ce qui rendit les couples encore plus hésitants à utiliser leur réserve, sauf pour des occasions exceptionnelles, attitude qui contribua à raréfier encore davantage les occasions de faire du baby-sitting...
Bref, la coopérative était entrée en récession.
more...
2013-08-11 pyensae
Exchanging code with students through emails is easy but after a couple of years, looking into my database of emails became difficult. Plus, it is difficult to maintain pieces of code inside emails.
pyensae is the module I will use from now on to exchange code for my teachings. So far, it only contains a function to download materials I put on my website. It should grow over the next years. The module can be obtained:
Having students contributing will be another story. Let's see after a year.2013-05-15 Les bénéfices d'une thèse
Lorsqu'un de mes élèves me demandait si je lui conseille de faire une thèse, ma première réponse était de lui dire que le diplôme d'une grande école est souvent peu visible à l'étranger. Pour l'avoir vécu au sein d'une compagnie américaine, la thèse est un diplôme auquel les anglosaxons accordent de la valeur. La thèse ouvre plus de portes à l'international. Malgré tout, on me rétorque que l'image du thésards en France est plutôt celle d'un travailleur paresseux qui aime trop la recherche et pas assez les aspects techniques rébarbatifs mais incontournables. Aujourd'hui, je trouve ma réponse quelque peu réductrice.
Le monde change sans cesse. C'est sans doute une lapalissade que de dire cela mais je dirais qu'il change plus vite aujourd'hui d'hier. La plupart des boulots répétitifs est en train de disparaître, il ne s'agit pas de nouvelles techniques qui rendent les précédentes obsolètes mais de nouvelles techniques qui nous rendent obsolètes. L'économie n'est plus celle des produits mais celles des idées, ou elle mute progressivement en iconomie comme le souligne Michel Volle sur son blog. Il paraît naturel alors que la durée des études s'allonge et qu'elles se poursuivent par une thèse. D'ailleurs, peut-être un jour n'existera-t-il plus de limite entre les études et le travail.
De mon point de vue, faire une thèse est un choix qui se défend. Les grandes écoles françaises ont tendance à former des ingénieurs généralistes. Leur force réside avant tout dans le processus de sélection mis en place en amont. Bien sûr, chaque école est spécialisée mais des passerelles existent. Chaque diplômé a une grande latitude dans le choix de son futur boulot. Pourquoi faire une thèse si on considère que cette sélection est efficiente ? Si on exclue les technologies de pointe, la formation d'un étudiant en master recouvre bien souvent des aspects beaucoup plus techniques que ceux qu'il utilisera au quotidien dans son travail. Sa première tâche sera d'acquérir les codes et concepts d'un métier. Cette stratégie était valable il y a vingt ans mais aujourd'hui, on n'est plus assuré que son métier ne va pas disparaître d'ici cinq ans. Il est essentiel de ne pas cesser d'apprendre pour éviter de se retrouver sur le carreau.
Selon moi, la principale raison qui rend les sociétés réfractaires est la nature risquée de la recherche. Un thésard peut chercher trois ans - un temps long - sans rien trouver ou tout du moins sans compenser le temps perdu qu'il aurait pu passer à faire des choses plus utiles et surtout à la réussite plus certaine. Pourtant la thèse est l'occasion de se spécialiser, d'acquérir un savoir qu'on ne peut incorporer au cursus généraliste des grandes écoles. Ces trois années sont un apprentissage très poussé qui m'aura donné la capacité d'aller vite sur une grande multitude de problèmes par la suite. Le fait d'avoir pu explorer en détail, de faire des erreurs m'aura permis de me spécialiser dans un domaine et d'y exceller.
La thèse, c'est un peu comme si on me demandait de jouer des parties d'échecs rapides après avoir passé trois ans à jouer des parties longues : je joue des coups en deux secondes tout simplement parce que j'y ai réfléchi pendant des jours il y a cinq ans.
Je suis conscient qu'une compagnie privée peut voir d'un mauvais oeil le fait d'avoir à continuer à financer la formation d'un bac +5. Toute thèse comporte forcément un risque et elle peut considérer qu'il s'agit d'un devoir régalien. Concernant le risque financier, les thèses CIFRE sont subventionnées ainsi que l'emploi des jeunes docteurs pendant deux ans après la thèse via le crédit impôt recherche. Le risque risque financier est donc réduit. Accueillir un thésard au sein d'une entreprise veut dire aussi le former aux outils de la société, cela veut dire aussi encadrer une personne qui le sera également par son directeur de thèse, qui devra passer un à deux jours par semaine à l'université, qui devra continuer à aller de temps en temps en cours. Ce sont des contraintes qui ne s'inscrivent pas bien dans un contexte où la plupart des employés arrivent le matin et repartent le soir chaque jour de la semaine. Dans la mesure où les emplois sont de moins en moins répétitifs et nécessitent de plus en plus de réflexion, je dirais que les rythmes de travail vont devenir de moins en moins réguliers. Certaines compagnies proposent des vacances illimitées. Je pense que la formation continue occupera une place de plus en plus prépondérante. Elle sera autant nécessaire pour l'employé s'il ne veut pas se retrouver sans travail que pour la société qui doit conserver sa capacité à innover.
Je concluerai néanmoins par une note négative, pas forcément reliée à la thèse mais plutôt à l'évolution récente et rapide du système économique. Hannah Arendt a écrit dans Du mensonge à la violence :
Notre siècle est sans doute le premier au cours duquel les changements intervenus dans les choses de ce monde dépassent les changements intervenus parmi les habitants. [...] Il est bien connu que le révolutionnaire le plus extrémiste deviendra conservateur le lendemain de la révolution. L'aptitude au changement n'est pas plus illimitée dans l'espèce humaine que sa capacité de préservation, la première étant réduite par l'influence du passé sur le présent et l'autre par le caractère imprévisible de l'avenir.
Sommes-nous préparés ?
2013-03-26 L'informatique, une matière moins noble
Quand j'ai soutenu ma thèse, j'ai découvert que mon doctorat m'offrirait moins de portes académiques tout simplement parce celui-ci me désignait comme docteur en informatique et non en mathématiques. Je ne sais pas si c'est toujours le cas mais l'informatique a toujours eu en France un côté moins noble parce que très appliqué. Aujourd'hui, des phénomènes comme Big Data, Data Scientist prennent de l'ampleur et avec eux l'utilisation de l'informatique. Il est pratiquement impossible de se passer des ordinateurs, dès qu'on aborde un sujet un tant soit peu appliqué, il faut savoir coder, ce que j'ai très peu fait dans un cadre scolaire, ce que j'ai beaucoup fait en dehors de l'école et surtout au travail. On peut prétendre que cela s'apprend facilement, que comprendre les maths est plus difficile, et qu'avec un peu de pratique, on saura faire. Il me serait difficile de réfuter ça, c'est comme ça que j'ai appris. Toutefois, c'est un peu comme les gammes au piano, plus on en fait, plus on est à l'aise.
Cette division math/info est beaucoup moins présente dans les pays anglosaxons où les mathématiques appliquées et l'informatique s'appellent computer science. Lors des entretiens d'embauche, il est rare de passer au travers d'exercices de codes. C'est parfois même le premier filtre écrit préalable au premier entretien. Entre quelqu'un que cela ne rebute pas et quelqu'un qui prend la chose de haut, les sociétés n'hésitent pas longtemps. Même s'il est prétendument facile de devenir programmeur, de nombreuses compagnies ont tendance à rejeter des candidats qui n'ont jamais beaucoup programmé si c'est un élément important du poste à pourvoir.
Les smartphones sont aussi de petits ordinateurs programmables. Il est probable que d'autres objets du quotidien gagneront en complexité et deviendront à leur tour pilotables à l'aide un langage de programmation. Je pense que c'est un outil dont il faudrait commencer l'apprentissage plus tôt. Il en serait moins rébarbatif et, accessoirement, n'en limiterait plus l'usage aux seuls geeks. C'est d'ailleurs le cas dans certains pays de l'est comme la Roumanie. Maîtriser la programmation pourrait faire gagner beaucoup de temps à quiconque se sert d'Excel au quotidien.
Lorsqu'on doit pondre un algorithme qui doit tourner en production 24h sur 24, savoir coder est très important. Il peut y avoir des facteurs 10 ou 100 sur le même algorithme programmé de façon plus ou moins efficace. Savoir programmer n'est pas tout, il est utile d'apprendre les tournures de phrases les plus fréquentes, d'acquérir une sorte de culture générale du domaine, savoir ce que sont des tableaux, des arbres, savoir quand il est préférable d'utiliser l'un plutôt que l'autre, savoir pourquoi quand on divise un problème en deux, on passe d'un coût en O(n) à un coût en O(ln(n)), comprendre pourquoi il vaut mieux utiliser un index lorsqu'on fait une jointure sur deux tables SQL...
En ce qui concerne l'informatique, j'ai quasiment tout appris en pratiquant, parce que terminer un programme signifie aussi l'avoir compris. La pratique permet aussi de comprendre qu'il existe rarement un programme optimal en toute circonstance et qu'on choisira une façon de coder plutôt qu'une autre en fonction du volume, de la nature des données qu'on manipule. De ce fait, beaucoup de programmes sont une compilation complexe de recettes simples. On s'aperçoit aussi parfois qu'on retrouve le même algorithme sous différents visages, plus court chemin dans un graphe de Djikstra, distance d'édition de Levenstein, séquence la plus probable de Viterbi.
Je manipule tellement de données qu'en regarder quelques-unes ne suffit plus à donner une vue d'ensemble. Il faut sans cesse agrégrer, classifier, régresser. Ce travail est quasiment impossible si on ne sait pas programmer. Cette culture algorithmique me permet bien souvent d'aller plus vite, d'obtenir les mêmes résultats en un temps moindre avec, parfois, une certaine élégance.
Pour finir, je conseille l'écoute d'une émission de radio que j'ai découverte après avoir écrit ceci : L'éloge du savoir, Algorithmes, machines et langages (entretien avec Gérard Berry) L'informatique est train de changer la façon d'organiser nos vies et il est mal enseigné aujourd'hui et surtout trop tard. Que sera notre monde dans les prochaines années (et non les prochaines décennies) ? Nos dirigeants ne prennent la mesure des changements que l'informatique n'a pas fini d'apporter comme le dit Michelle Volle dans cet article : Pour comprendre l'iconomie.
2013-03-11 Big Data, Data Scientist, quelques repères
En rejoignant Yahoo il y a déjà cinq ans, j'ai découvert le langage PIG. Ce n'était pour moi qu'un nouveau langage très proche de SQL dont le seul attrait était de pouvoir accéder aux logs de recherches puis de les aggréger de différentes manières avant de pouvoir enfin les poser sur une machine isolée où je pouvais travailler simplement et rapidement. Aujourd'hui, cette technique est étiqueté Big Data et s'est considérablement étoffée. En passant chez Microsoft, j'ai découvert son équivalent chez Microsoft avec Scope. Google a developpé un langage Sawzall dont la syntaxe est plus proche d'un langage fonctionnel. Aujourd'hui, au fur et à mesure de mes discussions sur le Big Data, je garde quelques références sur le sujet, des idées. Cela n'a rien d'exhaustif mais je suis étonné qu'autant de projets fleurissent étant donné l'investissement que chacun d'entre eux nécessite. Ce billet rassemble quelques idées, termes, liens.
Quelques remarques sur l'utilité de ces techniques
- Les données Big Data sont souvent plus bruitées que d'autres données car il n'est plus possible de les nettoyer manuellement. Le nettoyage est forcément statistique ou il nécessite l'utilisation de modèles robustes au bruit.
- Le machine learning est souvent associé à BigData (voir plus bas). Machine learning = apprentissage statistique en français. La raison est qu'il est quasiment impossible de visualiser les données sans un traitement préalable.
- Il est aussi une chose qui rend le BigData très attractif, c'est la possibilité de croiser les données : données clients avec clics internet. Ces croisements n'étaient pas possibles avant tout à cause de la taille des bases concernées. Il devient maintenant possible en un temps raisonnable car il est distribué
- Les gens sont connectés en permanence (téléphone, tablette, recherche internet, connexion à un site internet), il y a une accumulation de données variées sur les gens que les sociétés utilisent de plus en plus.
Hadoop/PIG et ses extensions open sources
more...
2013-03-05 Importer des modules directement depuis ce site
Lorsqu'on prépare une séance de travaux pratiques, on prévoit parfois de travailler sur des données non disponibles à l'école. Pour éviter de perdre du temps sur des choses déjà et rébarbatives telles que lire un fichier de données et construire une matrice, je prépare un fichier qui permet de lire ces données directement. Un fichier zip nécessite qu'on décompresse le fichier quelque part, qu'on vérifie que tout marche bien. Finalement, j'ai opté pour le programme que voici : importme.py. Il me permet à l'aide d'une instruction de télécharger les fichiers dont les élèves ont besoin. Il me suffit alors de leur donner quelques unes des lignes suivantes pour qu'ils puissent commencer à travailler.
import importme
use_graphviz = importme.import_module("use_graphviz")
tableformula = importme.import_module("tableformula")
tableformulagraph = importme.import_module("tableformulagraph")
file = importme.import_module("donnes_banque_mondiale.txt")
files = importme.import_module("equipements_sportif_2011.zip")
Si un fichier téléchargé est un fichier zip,
il décompresse tous les fichiers
au même endroit.
2013-02-13 ENSAE Alumni, dossier Big Data du numéro 46 de Variance
Le dernier numéro de Variance est sorti (revue de l'association des Anciens de l'ENSAE (http://www.ensae.org/, Variance_46.pdf). Entre autres, il y a un focus sur Big Data auquel j'ai contribué en tant qu'auteur et en tant que rédacteur. Ce thème est amené à prendre plus d'espace dans les quelques années qui viennent et recouvre des secteurs économiques qui pourraient devenir demandeurs de statisticiens ou Data Scientist. Un forum sur ce sujet est dorénavant organisé chaque année (forum Big Data Paris). On se revoit dans cinq ans ?
2013-02-03 Quelques précisions sur les projets informatiques
Données textuelles, nuages de mots
Certains sujets traitent du traitement de texte et dans ce domaine, il est parfois important d'obtenir des données en grande quantité. La source la plus accessible et une des plus propres est Wikipedia dont il est possible de télécharger une copie dans n'importe quelle langue à partir de l'adresse suivante : wikipedia backups. Il faut chercher sur cette page un lien xxwiki ou xx sont les deux premières lettres d'une langue (frwiki par exemple). Il est possible de télécharger tout ou partie du site (cela peut prendre quelques heures).
Lire les informations présentes dans ces fichiers de plusieurs Go requiert quelques connaissances en XML, puis de comprendre la structure plutôt intuitive du document. Pour vous aider, vous pourrez lire l'article sur le parser XML en espérant que cela vous fasse gagner du temps.
La liste des sujets fournit quelques références concernant la construction des nuages de mots. Pour l'affichage, le language HTML est sans doute le plus simple. Il permet de composer des blocs de texte de différentes tailles et se charge de les disposer. Le code HTML suivant permet de modifier la taille du texte affiché par un navigateur (Firefox par exemple) :
<font size="6">This is some text!</font>
Taille 6Taille 16
Ce texte pourrait être la sorti d'un programme Python.
Données financières
more...
| <-- --> |
Xavier Dupré
|