2013-02-09 Program to convert latex into gif picture in a html document
A couple of days ago, I wrote a blog (Insérer des formules en code Latex dans un blog) on how to insert Latex formulas in a blog post. Unfortunately, this way does not seem to work all the time. The browser will try to convert formulas using another site each somebody tries to read the post. And sometimes, the latex formula shows up instead of the picture. So, I decided to write a Python program to call http://latex.codecogs.com/latexit.js before publishing the blog post. I only push GIF images and let the latex code as comments. You will find this code latex_svg_gif.py. Basically, it looks for latex formulas, extract them, call the site mentioned below, stores the images, put the former latex code in a comments section and adds a link to the created image.
<div lang="latex_help">
N \frac{c^k-1}{c-1} \sim N \frac{\frac{S}{N}-1}{c-1} \sim \frac{S-N}{c-1}
</div>
Becomes:
<!--
<div lang="latex_help">
N \frac{c^k-1}{c-1} \sim N \frac{\frac{S}{N}-1}{c-1} \sim \frac{S-N}{c-1}
</div>
-->
<p class="latexcenter">
<img src="giflatex/blog_2013_2013-02-07.html__Nfracck1c1simNfracfracSN1c1simfracSNc1.gif"
alt=" N \frac{c^k-1}{c-1} \sim N \frac{\frac{S}{N}-1}{c-1} \sim \frac{S-N}{c-1} " />
</p>
The picture name is the concatenation of all symbols in [a-zA-Z0-9].
However, recently, I found another framework which seems to work better than this one. I did not try but it is available with wordpress for example: MathJax.
2013-02-07 How to extend a stack?
A common way to create a sizeable but continuous array is to use a stack mechanism. We start by allocating a buffer and when we need more space to store new elements, we often multiply the size of this buffer by 2. We copy the existing elements into the new space, we add the new one and we free the old buffer. If we follow that strategy for a long time, we end up by allocation memory blocks of size N, 2N, 4N, 8N, ... The major drawback of this approach is we cannot reuse the space we used for the first allocation. The reason is simple:
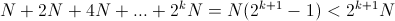
As a consequence, the new buffer is always larger than the sum of all previously allocated block. And we because, we need to keep the last one alive to copy the existing elements to the new block, this way of growing a stack cannot reuse the same memory space. This side effect could increase the memory fragmentation.
What does happen if we multiply the size of a block by a coefficient c smaller than 2:
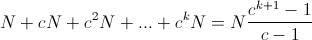
We need to compare that sum to:
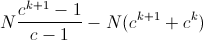
We can remove N from the equation:
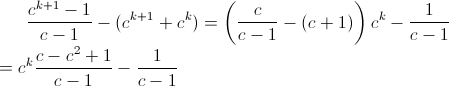
This expression is positive if and only if:
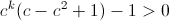
So first, we must have 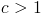 .
Second, we must also have
.
Second, we must also have 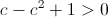 , which means:
, which means:
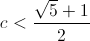
If that condition is fulfilled then, there will k for which the above expression becomes positive.
more...
2013-02-04 Insérer des formules en code Latex dans un blog
Ce blog est plus pour moi. Je cherchais un moyen de transcrire des documents Latex au format HTML. Je n'avais pas pensé à écrire mes formules directement dans un blog. J'ai suivi les instructions de ce site. On insère un lien vers un script au début du document :
<html>
<head>
<script type="text/javascript" src="
http://latex.codecogs.com/latexit.js"></script>
</head>
<body>
Puis on insère une formule :
<div lang="latex">
\frac{1+sin(x)}{y}
</div>
Et on regarde si ça marche :
\frac{1+sin(x)}{y}
Et si ça marche aussi lorsqu'on veut l'insérer dans le texte \frac{1+sin(x)}{x^3} en utilisant le code suivant :
<span lang="latex">\frac{1+sin(x)}{x^3}</span>
Dans quelques boîtes, il est désormais possible d'écrire ses propres blogs comme si finalement on avait
abandonné l'idée de structurer l'information interne dans une société. Chaque employé peut maintenant
faire circuler de l'information qu'on récupère en faisant des recherches par mots-clés. Quoiqu'il en soit,
on découvre la date à laquelle chacun à commencer à blogger car le premier blog s'appelle invariablement
Welcome to my blog, ce à quoi ce blog m'a fait penser.
2013-02-03 Quelques précisions sur les projets informatiques
Données textuelles, nuages de mots
Certains sujets traitent du traitement de texte et dans ce domaine, il est parfois important d'obtenir des données en grande quantité. La source la plus accessible et une des plus propres est Wikipedia dont il est possible de télécharger une copie dans n'importe quelle langue à partir de l'adresse suivante : wikipedia backups. Il faut chercher sur cette page un lien xxwiki ou xx sont les deux premières lettres d'une langue (frwiki par exemple). Il est possible de télécharger tout ou partie du site (cela peut prendre quelques heures).
Lire les informations présentes dans ces fichiers de plusieurs Go requiert quelques connaissances en XML, puis de comprendre la structure plutôt intuitive du document. Pour vous aider, vous pourrez lire l'article sur le parser XML en espérant que cela vous fasse gagner du temps.
La liste des sujets fournit quelques références concernant la construction des nuages de mots. Pour l'affichage, le language HTML est sans doute le plus simple. Il permet de composer des blocs de texte de différentes tailles et se charge de les disposer. Le code HTML suivant permet de modifier la taille du texte affiché par un navigateur (Firefox par exemple) :
<font size="6">This is some text!</font>
Taille 6Taille 16
Ce texte pourrait être la sorti d'un programme Python.
Données financières
more...
2013-02-02 Parser du XML
Parser du XML est toujours laborieux pour moi parce que je ne retiens jamais les librairies qu'il faut utiliser, le modèle SAX ou DOM. J'avais besoin de lire les fichiers issus du site Wikipedia qui sont organisés comme suit :
<root>
<page>
contenu d'une page
</page>
<page>
contenu d'une autre page
</page/>
...
</root>
Le fichier de Wikipedia fait malhreusement plusieurs gigaoctets, il est juste impossible
de tout charger en mémoire (sur la plupart des ordinateurs) sauf si on dispose d'au moins 20Go
de mémoire et qu'on ne veut pas s'occuper de Wikipedia en langue anglaise. En procédant
de la sorte, on est obligé de découper les fichiers.
Le programme suivant permet d'explorer les premiers objets d'un fichier Wikipedia ou de n'importe quel fichier XML pour peu qu'il contienne une collection d'objets.
from hal_xml_tree import *
file = r"c:\temp\ptwiki-20130125-pages-articles.xml"
f = open (file, "r")
parser = XMLIterParser ()
handler = XMLHandlerDict ()
parser.setContentHandler (handler)
nb = 0
for o in parser.parse(f) :
for a,b in o.iterfields() :
if len(b) > 0 :print [a,b]
print "---------------------"
nb += 1
if nb > 10: break
more...
2013-01-31 Quelques règles de survie pour travailler à plusieurs
Le document suivant décrit brièvement quelques règles qui peuvent aider si on les suit lorsqu'on se lance dans un programme informatique à plusieurs ou même seul. Elles ne sont pas ni difficiles ni agaçantes si on les applique dès le début du projet. En résumé :
- Ecrire des petites fonctions,
- Séparer les calculs, le chargement des données, l'interface graphique,
- Utiliser des fonctions de tests.
Si vous aimez les nouvelles technologiques type cloud, il devient relativement facile aujourd'hui de travailler à plusieurs sans avoir à s'échanger constamment des fichiers par emails. DropBox et TortoiseSVN permettent assez rapidement d'échanger des informations et de garder l'historique des modifications.
2013-01-30 Graph matching and alignment
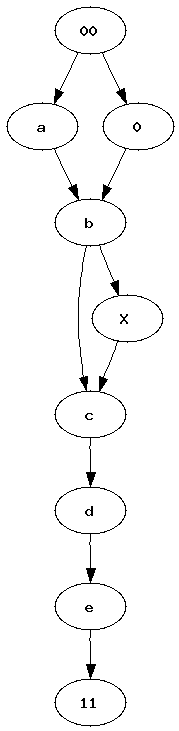
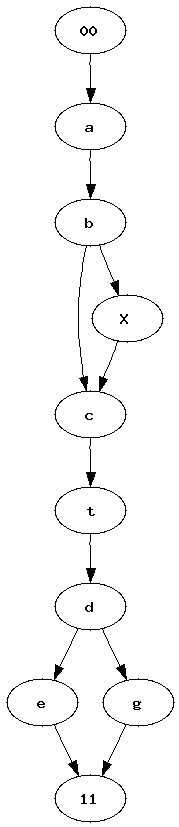
Pipelines became a quite popular way to represent a workflow. Many tools such as RapidMiner, Orange or Weka use graphs to represent the sequence of processes data follow. Most of the time, between two experiments, we just copy paste a previous one, we add or delete a few nodes. After a while, it becomes uneasy to find out what modifications were made. I was wondering how it would be possible to automate such a task. How to find what modifications were introduced in a graph ?
 |
 |
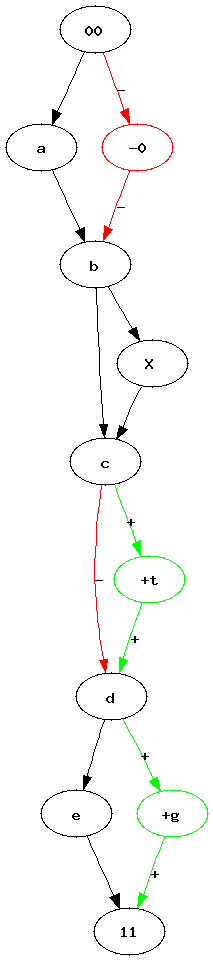 |
| Graph 1 | Graph 2 | Two graphs we would like to merge into a single one. Vertices 00 and 11 represents the only root and the only leave. |
more...
2013-01-28 Répéter les mêmes modifications sur une table
Excel est très pratique pour tracer des graphiques, écrire des formules dans une table. La seule contrainte vient parfois du fait qu'on se retrouve à faire la même chose plusieurs fois de suite. On doit produire les mêmes statistiques sur les mêmes données ou presque les mêmes : la matrice a deux colonnes en plus et trois lignes en moins. Ce n'est pas toujours évident d'adapter ses feuilles Excel. Aujourd'hui, je devais répéter la même formule sur dix colonnes différentes. J'ai donc décider de faire ça en Python. Je voulais écrire quelque chose comme ça :
table.add_column ( "has_A" + k, lambda v : 1 if "prenom" in v["name"] else 0 )L'avantage est que je peux maintenant écrire quelque chose comme :
for name in selection_colonnes :
table.add_column ( "has_" + name, lambda v : 1 if "mot clé" in v[name] else 0 )
ou encore
group = table.groupby ( lambda v: v["name"],
[ lambda v: v["d_a"],
lambda v: v["d_b"] ],
[ "name", "sum_d_a", "sum_d_b"] )
et
innerjoin = table.innerjoin (group, lambda v : v["name"],
lambda v : v["name"], "group" )
Il ne me reste plus qu'à récupérer le tout sous Excel pour faire des graphiques
ou faire de la mise en page. J'ai dû le coder plusieurs fois sous différentes
formes. Voici la dernière.
2013-01-26 Compter le nombre de cellules d'une couleur sous Excel
On cherche à compter le nombre de cellules d'une couleur spécifique sous Excel dans une plage de données. On peut considérer l'exemple suivant qui fait apparaître un rectangle contenant des cases de couleurs différentes. La première ligne contient toutes les couleurs une seule fois, la seconde ligne contient le nombre de cellules dans le rectangle de la même couleur que la case du dessus.

On veut pouvoir écrire une formule du type :
=NbColorSameAs($B$6:$D$11;B1)Il n'est pas possible de s'en sortir sans programmer soit même cette fonction. Pour cela, il faut :
- créer une document Excel qui accepte les macros,
- ouvrir l'éditeur Visual Basic (ALT + F11),
- ajouter un module (clic droit de la souris)
- copier/coller le code qui suit
Function NbColor(ByRef Plage As Range, Couleur As Byte) As Long
Dim c As Range
Dim nb As Long
nb = 0
For Each c In Plage
If c.Interior.ColorIndex = Couleur Then
nb = nb + 1
End If
Next c
NbColor = nb
End Function
Function NbColorSameAs(ByRef Plage As Range, ByRef Cellule As Range) As Long
NbColorSameAs = NbColor(Plage, Cellule.Interior.ColorIndex)
End Function
Le document Excel est maintenant prêt, il suffit d'insérer
la première formule insérée plus haut dans ce blog (vous pourrez trouver un
exemple ici).
more...
2013-01-25 How to normalize an edit distance ?
An edit distance is usually used to compute a distance between two words. The basic version gives the same weight to every mistake or operation which means every comparison, every insertion or deletion between two words weight the same. The sum of all these errors gives a integer score and most of time, it is better to keep that score within an interval such as [0,1].
Most of the time, we divide the edit distance by the length of the longest word involved in that distance. This score is not a distance anymore in a sense it does not verify the triangular inequality. There are many option and the following document studies some aspects of normalizations. Based on that, the maximum length is not the best option, the minimum length is not very good either. A third option studied in that document seems to be the best, especially if this distance is used by a machine learned model as a feature.
2012-12-22 ENSAE, initiation à la programmation, suggestions de projets
Voici la liste des suggestions de projets. proposées cette année dans le cadre du projet informatique du second semestre. Ce projet doit être effectué de préférence par groupe de deux élèves. Chaque groupe sera suivi par un enseignant, à raison de quatre suivis d'une demi-heure entre février et avril. Une soutenance aura lieu au mois de mai.
Le projet consiste en la réalisation d'un programme informatique, d'un rapport expliquant la démarche et les résultats obtenus et d'une soutenance orale. La note dépend de ces trois exercices (elle ne dépend pas de la taille du programme informatique). Le programme peut être réalisé dans un autre langage que Python. Chaque groupe est encouragé à proposer un sujet de son choix.
Le document lié plus haut contient toutes les références nécessaires autour des sujets suivants :
- Puissance 4, Othello, Awalé, Poker, Belotte
- Nuages de mots, Recherche exacte d'un motif, d'une expression, Recherche approximative d’un motif, d'une expression
- Pentomino, Apprentissage par renforcement, Construction d'une texture, Algorithme génétique : les fourmis, Evolution de la population française, La méthode de Louvain, Détection d'événements sur Twitter
- Trend following, Optimisation de portefeuille
2012-01-27 Relationship between p-values and confidence interval
I grew up in France, I studied statistics but I only heard the term p-Value for the first time a couple of years ago when I started to work on search engines. I was used to hear about confidence intervals at 95%. But we are talking about the same thing as explained here.
It goes on with the specific case of a binomial law. Assuming we want to determine whether or not two binomial laws are significantly different, how many observations we need to get the p-value under a given threshold.
2011-11-13 Résoudre un puzzle
C'est un cadeau que j'ai reçu à Noël sous forme de puzzle. A vrai dire, je n'ai même pas essayé de résoudre le puzzle moi-même. mais je me suis qu'en scannant les pièces du puzzle (au nombre de neuf), je devrais être en mesure d'écrire un programme pour le résoudre à ma place. Il contient neuf pièces carrées avec des haut et des bas de girafes de couleurs différentes et qu'il faut recoller. Ce document décrit comment je m'y suis pris.

Vous trouverez dans ce fichier zip tous les fichiers nécessaires pour résoudre le puzzle. Le programme est aussi visible ici : girage_affichage.py.
2008-06-27 Décomposition d'une fraction rationnelle en éléments simples
Ce document décrit une façon de décomposer une fraction rationnelle en élément simple. La solution est implémentée en langage C.
| <-- |
Xavier Dupré
|