2013-05-26 Processing (big) data with Hadoop
Big Data becomes very popular nowadays. If the concept seems very simple - use many machines to process big chunks of data -, pratically, it takes a couple of hours before being ready to run the first script on the grid. Hopefully, this article will help you saving some times. Here are some directions I looked to create and submit a job map/reduce.
Unless you are very strong, there is very little chance that you develop a script without making any mistake on the first try. Every run on the grid has a cost, plus accessing a distant cluster might take some time. That's why it is convenient to be able to develop a script on a local machine. I looked into several ways: Cygwin, a virtual machine with Cloudera, a virtual machine with HortonWorks, a local installation of Hadoop on Windows. As you may have understood, my laptop OS is Windows. Setting up a virtual machine is more complex but it gives a better overview of how Hadoop works.
Here are the points I will develop:
- Develop a short script in Hue and Hive on this local machine,
- Install a virtual machine (VM) on a laptop,
- Run this script on the grid (using Amazon AWS).
Contents:
- Local run with Java
- Installation of a local server with HortonWorks
- Install a virtual machine (Cloudera)
- Files to download
- Only for French keyboards
- Upload, download files to the local grid
- Install the VMWare Tools and create a shared folder
- Final tweaks: change the repository
- Install Python 3.3, Numpy (optional)
- Install R and Rpy2
- Install a virtual machine (HortonWorks)
- Develop a short script
- Hadoop and Python
- Using Amazon AWS
- Errors you might face
more...
2013-05-25 Créer un GIF animé
Il y a quelques mois, j'ai écrit un article sur une façon de convertir des images en GIF animé. Il fallait télécharger deux fichiers. Maintenant, il suffit d'installer le module suivant : pyhome3 (il nécessite Python 3.3 et numpy). Ensuite, le code suivant fera le reste :
# coding: latin-1
# on prend les fichiers dans le répertoire
import os
files = os.listdir(".")
# on ne garde que les images
files = [ _ for _ in files if ".png" in _ ]
# on les tri : image_2.png doit être avant image_10.png
# (ce qui n'est pas l'ordre alphatétique)
# en enlève tout ce qui n'est pas un chiffre, on convertit un entier
# puis on trie une liste de couples ( numéro, images )
files = [ ( int (_.replace("image_","").replace(".png","")), _) for _ in files ]
files.sort()
files = [ _[1] for _ in files ]
# ici, on renomme les fichiers car ImageMagick utilise l'ordre alphabétique
files = [ ( "image_%03d.png" % i, _) for i,_ in enumerate(files) ]
for new_name, old_name in files :
if new_name != old_name :
os.rename(old_name, new_name)
# on reprend la nouvelle liste de fichiers
files = [ _ for _ in os.listdir(".") if ".png" in _ ]
files.sort()
# il faut supprimer ces lignes et installer le module disponible ici
# http://www.xavierdupre.fr/site2013/index_code.html (pyhome3)
# qui ne marche qu'avec python 3.3 + numpy
import sys
sys.path.append(r"D:\Dupre\_data\program\pyhome")
# on importe la fonction qu'il faut
from pyhome3 import create_animated_gif, HalLOG
# la fonction télécharge image magick et cela prend du temps, pour voir
# ce qu'il se passe, il faut utilise la fonction suivante
# le téléchargement n'est plus nécessaiire dès la seconde exécution
HalLOG(OutputPrint=True)
# et on l'exécute
create_animated_gif(files, "final.gif", resize = (400,300))
Si vous avez commencé votre programme avec Python 2.x, vous pouvez toujours exéctuer le programme comme ceci :
import os
os.system("c:\python33\python le_programme_precedent.py")
Afficher le GIF animé en utilisant Python n'est pas facile. On pourrait recréer l'animation manuellement en affichant les images les unes après les autres via tkinter, on pourrait utiliser d'autres modules de type pyQt. Par paresse, j'ai choisi le code suivant :
with open("image_res.html", "w") as f :
f.write("\n")
f.write("\n")
f.write('<img src="final.gif" />\n')
f.write("\n")
f.write("\n")
import os
os.system("image_res.html")
Il crée un fichier html puis l'exécute : le navigateur par défaut
se chargera de l'afficher.
2013-05-20 Quelques blogs intéressants pour la programmation Python
Le blog Les articles pour apprendre Python, dans le bon ordre regroupe de nombreux articles techniques sur la programmation Python. Les articles sont très détaillés autour d'un sujet précis :
- Les imports en Python
- L’encoding en Python, une bonne fois pour toute
- Mémoization d’une fonction Python
- Appeler du code C depuis Python avec ctypes
- Quelle valeur retourner quand on ne trouve rien en Python ?
2013-05-16 Modules for Python
I recently discovered this page Unofficial Windows Binaries for Python Extension Packages which provides a link to many Windows installer for Python extensions. It provides installer even when the official website does give any. It saved me sometimes while trying to build Rpy2 for Python 3.3. It was the only place I was able to find a Windows version for Python 3.3. I put here the official website for each module. The first page links to the latest installer for each of them. Here is a short not no short list of scientific extensions.
- pymvpa: Multivariate Pattern Analysis in Python
- pyminuit: Minuit numerical function minimization in Python
- gmpy: high precision computation (not limited to 64 bits)
- cvxopt: convex optimization (use the installer from the unofficial page)
- pywavelets: wavelets
- PyTables: data manipulations, many bridges between many formats, facilitates joins, visualization, ...
- CGAL: Computational Geometry Algorithms Library
- theano: machine learning, deep learning, uses CPU and GPU
- statsmodels: statistical models, linear regression, robust linear regression
- Orange: machine learning, kind of Weka but for Python, it is an python extension and a software where you can connect models through a graphical workflow
- sympy: symbolic mathematics
- qutib: The Quantum Toolbox in Python
- cartopy: use maps, maps of countries, counties, regions, ...
- pyproj: projection from geocodes to cartesian coordinates
- marthgl: 2D and 3D graphs
- PyQt: the best library for GUI (much better than tkinter)
- pyqwt: extension to PyQt
- IPython: gives Python a environement similar to R or MatLab one
- pygame: for games (2D games mostly)
- pyaudio: to play or record sound
- pyopengl: animation, 3D representation
- numpy: matrix computation
- MatPlobLib: drawings (MatLab style)
- SciPy: functionalities about statistics and machine learning
- IPython: between Python and MatLab, a kind of comfortable workspace
- pandas: data manipulation, cope with various data format
- scikit-learn: machine learning with Python
- pywin32: to manipulate Windows, Office components
- nose: unittesting in Python
- re2: extended version of re (regular expression), uses only algorithm in linear time
- pytz: to deal with timezones
- cffi: to include C function in Python
- pymongo: Python binding for Mongo
- pylzma: compression algorithm
- cx_Freeze: to build an exe from a Python program
2014/07/01 - an updated version of this page but in French: Modules intéressants (pour un ENSAE.
2013-05-15 Les bénéfices d'une thèse
Lorsqu'un de mes élèves me demandait si je lui conseille de faire une thèse, ma première réponse était de lui dire que le diplôme d'une grande école est souvent peu visible à l'étranger. Pour l'avoir vécu au sein d'une compagnie américaine, la thèse est un diplôme auquel les anglosaxons accordent de la valeur. La thèse ouvre plus de portes à l'international. Malgré tout, on me rétorque que l'image du thésards en France est plutôt celle d'un travailleur paresseux qui aime trop la recherche et pas assez les aspects techniques rébarbatifs mais incontournables. Aujourd'hui, je trouve ma réponse quelque peu réductrice.
Le monde change sans cesse. C'est sans doute une lapalissade que de dire cela mais je dirais qu'il change plus vite aujourd'hui d'hier. La plupart des boulots répétitifs est en train de disparaître, il ne s'agit pas de nouvelles techniques qui rendent les précédentes obsolètes mais de nouvelles techniques qui nous rendent obsolètes. L'économie n'est plus celle des produits mais celles des idées, ou elle mute progressivement en iconomie comme le souligne Michel Volle sur son blog. Il paraît naturel alors que la durée des études s'allonge et qu'elles se poursuivent par une thèse. D'ailleurs, peut-être un jour n'existera-t-il plus de limite entre les études et le travail.
De mon point de vue, faire une thèse est un choix qui se défend. Les grandes écoles françaises ont tendance à former des ingénieurs généralistes. Leur force réside avant tout dans le processus de sélection mis en place en amont. Bien sûr, chaque école est spécialisée mais des passerelles existent. Chaque diplômé a une grande latitude dans le choix de son futur boulot. Pourquoi faire une thèse si on considère que cette sélection est efficiente ? Si on exclue les technologies de pointe, la formation d'un étudiant en master recouvre bien souvent des aspects beaucoup plus techniques que ceux qu'il utilisera au quotidien dans son travail. Sa première tâche sera d'acquérir les codes et concepts d'un métier. Cette stratégie était valable il y a vingt ans mais aujourd'hui, on n'est plus assuré que son métier ne va pas disparaître d'ici cinq ans. Il est essentiel de ne pas cesser d'apprendre pour éviter de se retrouver sur le carreau.
Selon moi, la principale raison qui rend les sociétés réfractaires est la nature risquée de la recherche. Un thésard peut chercher trois ans - un temps long - sans rien trouver ou tout du moins sans compenser le temps perdu qu'il aurait pu passer à faire des choses plus utiles et surtout à la réussite plus certaine. Pourtant la thèse est l'occasion de se spécialiser, d'acquérir un savoir qu'on ne peut incorporer au cursus généraliste des grandes écoles. Ces trois années sont un apprentissage très poussé qui m'aura donné la capacité d'aller vite sur une grande multitude de problèmes par la suite. Le fait d'avoir pu explorer en détail, de faire des erreurs m'aura permis de me spécialiser dans un domaine et d'y exceller.
La thèse, c'est un peu comme si on me demandait de jouer des parties d'échecs rapides après avoir passé trois ans à jouer des parties longues : je joue des coups en deux secondes tout simplement parce que j'y ai réfléchi pendant des jours il y a cinq ans.
Je suis conscient qu'une compagnie privée peut voir d'un mauvais oeil le fait d'avoir à continuer à financer la formation d'un bac +5. Toute thèse comporte forcément un risque et elle peut considérer qu'il s'agit d'un devoir régalien. Concernant le risque financier, les thèses CIFRE sont subventionnées ainsi que l'emploi des jeunes docteurs pendant deux ans après la thèse via le crédit impôt recherche. Le risque risque financier est donc réduit. Accueillir un thésard au sein d'une entreprise veut dire aussi le former aux outils de la société, cela veut dire aussi encadrer une personne qui le sera également par son directeur de thèse, qui devra passer un à deux jours par semaine à l'université, qui devra continuer à aller de temps en temps en cours. Ce sont des contraintes qui ne s'inscrivent pas bien dans un contexte où la plupart des employés arrivent le matin et repartent le soir chaque jour de la semaine. Dans la mesure où les emplois sont de moins en moins répétitifs et nécessitent de plus en plus de réflexion, je dirais que les rythmes de travail vont devenir de moins en moins réguliers. Certaines compagnies proposent des vacances illimitées. Je pense que la formation continue occupera une place de plus en plus prépondérante. Elle sera autant nécessaire pour l'employé s'il ne veut pas se retrouver sans travail que pour la société qui doit conserver sa capacité à innover.
Je concluerai néanmoins par une note négative, pas forcément reliée à la thèse mais plutôt à l'évolution récente et rapide du système économique. Hannah Arendt a écrit dans Du mensonge à la violence :
Notre siècle est sans doute le premier au cours duquel les changements intervenus dans les choses de ce monde dépassent les changements intervenus parmi les habitants. [...] Il est bien connu que le révolutionnaire le plus extrémiste deviendra conservateur le lendemain de la révolution. L'aptitude au changement n'est pas plus illimitée dans l'espèce humaine que sa capacité de préservation, la première étant réduite par l'influence du passé sur le présent et l'autre par le caractère imprévisible de l'avenir.
Sommes-nous préparés ?
2013-05-14 Programmation : gagner du temps maintenant ou plus tard ?
Lorsqu'on programme, on veut avant tout arriver à construire un truc qui tourne et qui produise les résultats attendus. Ce faisant, certains raccourcis font parfois perdre du temps plus tard.
Par exemple, pour éviter que les élèves passent par des étapes intermédiaires fastidieuses (lecture de fichiers, récupération de données), je leur propose des fonctions toutes prêtes.
def download_data(dataset_name) :
...
return dataset
Comme il est parfois difficile d'écrire une fonction qui tourne
sur plusieurs environnement (chez moi, à l'école, sur différente
versions de Python), les élèves doivent parfois bidouiller, quitte à
aller au plus simple:
def download_data() :
...
... bidouille
...
return dataset_qui_marce
data1 = download_data()
Et puis, on a besoin d'un autre jeux de données, le programme devient :
def download_data() :
...
... bidouille
...
return dataset_qui_marce
data1 = download_data()
def download_data() :
...
... autre bidouille
...
return dataset_qui_marche
data2 = download_data()
Et puis un troisième...
Les élèves m'assurent que tout fonctionne comme prévu, je suggère de passer à l'étape suivante et de tester l'algorithme sur une dizaine de jeux de données. Comme je suppose qu'ils ont utilisé la fonction que je leur avais donnée, tester sur une dizaine de jeux de données revient dans mon esprit à écrire quelque chose de ce style :
datasetname = [ "data1.txt", ... ] datasets = [ download_data(name) for name in datasetname ]Mais dans leur cas, la première réaction fut un soupir devant ma requête quelque peu fastidieuse.
Je pense que c'est à ce moment-là qu'on retient le mieux une certaine façon d'organiser un programme qui fait perdre un peu de temps mais qui en fait gagner plus plus tard. L'inconvénient est que ce qu'on appris servira le plus souvent pour le projet suivant. Pour le projet courant, il est trop tard pour tout changer avant le rendu.
Laisser faire des erreurs ou donner une solution qui manquera de consistence tant qu'on n'aura pas saisi le fond du problème...
Ce n'est qu'un programme informatique. Cela dit, il faut parfois une grosse crise pour chacun prenne conscience de l'étendue du problème.
2013-05-13 Trie in Python
I was looking for extensions to use tries in Python and I found an interesting page: Fast Non-Standard Data Structures for Python. The winner seems to be MARISA-trie. The library is self contained and can be installed using pip (I did not try yet). The code can be compiled either in 32 or 64 bits.
2013-05-12 Les stations Vélib à Paris un jeudi soir
Les données Vélib sont ouvertes (depuis peu) et on peut disposer de l'état des stations (vélos et places disponibles) au moment où accède au service. J'ai collecté les données pendant plusieurs consécutives. Elles ressemblent à celles qui suivent.
| address | available bike stands | available bikes | banking | bike stands | bonus | last update | lat | lng | name | number | status |
| 3 AVENUE BOSQUET - 75007 PARIS | 57 | 12 | 0 | 69 | 0 | 2013-05-09 22:58:47 | 48.8616404995762 | 2.30225034417595 | 07022 - PONT DE L'ALMA | 7022 | OPEN |
| 18 RUE MARIE ANDREE LAGROUA - 75013 PARIS | 52 | 7 | 0 | 61 | 0 | 2013-05-09 22:53:34 | 48.8285952838574 | 2.38022060626611 | 13055 - LAGROUA | 13055 | OPEN |
| 25 RUE LOUIS LE GRAND - 75002 PARIS | 12 | 19 | 0 | 31 | 0 | 2013-05-09 22:55:38 | 48.8705089372039 | 2.33405446193933 | 02015 - OPERA - CAPUCINES | 2015 | OPEN |
| 2 RUE DE LA REPUBLIQUE - 92170 VANVES | 0 | 25 | 0 | 25 | 0 | 2013-05-09 23:01:03 | 48.8217026998931 | 2.28539562482839 | 21704 - REPUBLIQUE (VANVES) | 21704 | OPEN |
| 96 RUE DE LAGNY - 93100 MONTREUIL | 20 | 4 | 0 | 27 | 0 | 2013-05-09 22:55:21 | 48.8492303008648 | 2.42142994000703 | 31001 - LAGNY (MONTREUIL) | 31001 | OPEN |
Je me suis aperçu que l'état des stations est mis à jour de façon désynchronisée. A priori à chaque fois qu'un vélo arrive ou part et régulièrement toutes les dix minutes. Projeté sur un graphe, cela donne l'image suivante et pour voir l'animation, il suffit de cliquer sur le lien.
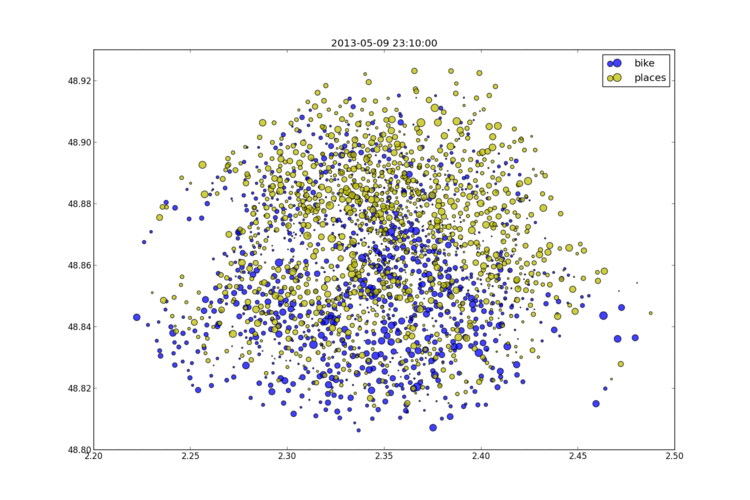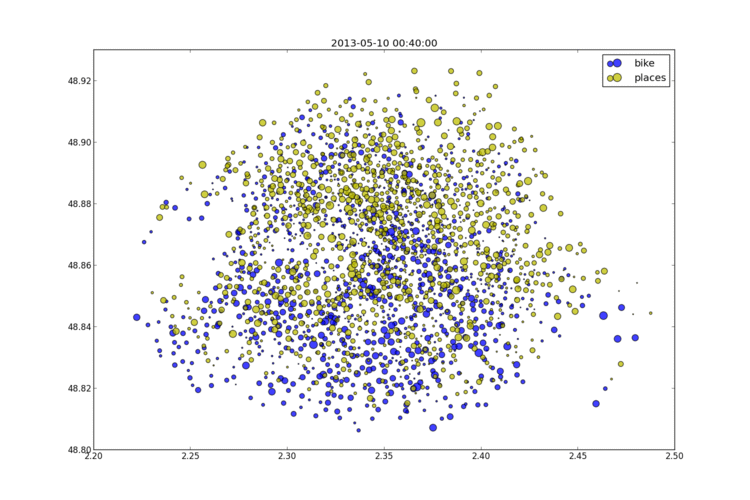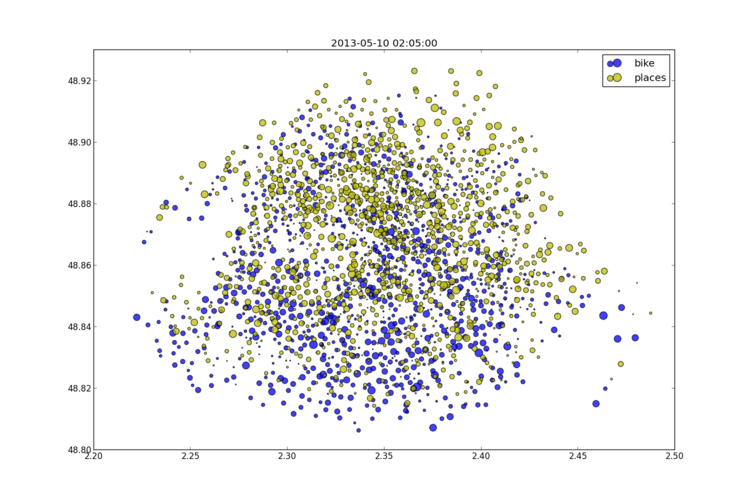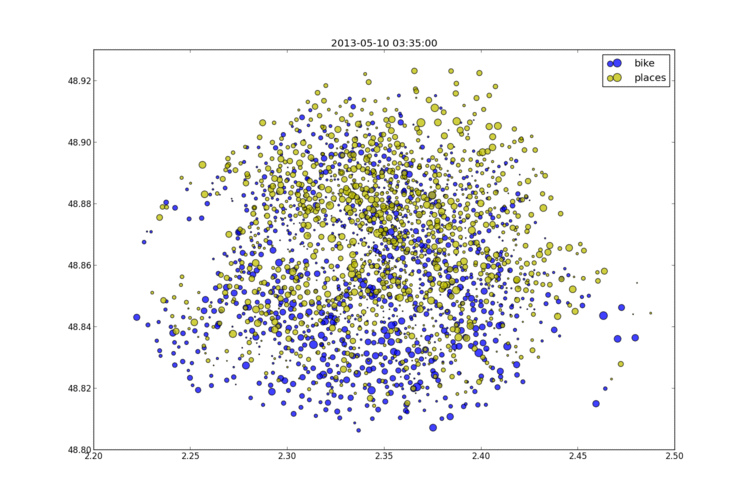
more...
2013-05-10 Installer un package simplement avec Python : pip
Pour installer les packages ou modules sous Python, il est possible d'utiliser un installer (.exe ou .msi sous Windows), de télécharger les sources puis de taper depuis une fenêtre de commande :
python setup.py installLorsque le package contient des extensions à compiler, il faut parfois taper. Par défaut, c'est le compilateur MingGW qui utilisé ou gcc sous Linux :
python setup.py build python setup.py install
Python facilite l'installation en évitant l'étape de téléchargement. Il faut pour cela d'abord intaller deux packages (comme mentionné ci-dessus) :
- distribute
- pip (ou ici pip from pypy)
pip install <module_name>L'avantage de cette méthode est la gestion automatique des dépedendances qui sont installées si besoin. (voir plus bas pour la sortie d'écran après l'exécution de la commande pip install jinja2).
Remarque : certains modules (numpy) contiennent des fichiers C++ qui devront être compilés. Cette compilation nécessite l'installation de MingGW et la définition de certaines variables environnement. Il est préférable d'utiliser les setups tout préparés qui incluent les mêmes fichiers déjà compilés.
Tester une installation
Parfois, on veut juste tester un module et ne pas dégrader son environnement. C'est possible avec le module virtualenv. Il faut d'abord l'installer :
pip install virtualenvEnsuite, on crée un répertoire pour les différents environnements virtuels :
mkdir c:\python33virOn crée un environnement virtuel :
virtualenv c:\python33vir\virt1 --system-site-packagesL'option --system-site-packages permet d'utiliser les modules déjà installés dans le répertoire de Python. Puis on va dans le répertoire python33vir/vir1/Script, on peut installer le module à tester :
pip install jinja2Si vous obtenez une erreur (bad sum), il est préférable de recommencer avant de chercher une autre erreur. Il suffit ensuite d'utiliser le programme python33vir/vir1/Script/python.exe (ou pythonw.exe) pour exécuter ses propres scripts.
more...
2013-05-09 Créer un site web en Python : Flask ou Django ou Pelican
Django est le framwork le plus connu quand il s'agit de créer un site web en Python. Le projet a démarré il y a plusieurs années (2005), il est robuste et il est maintenu. En contre partie, le coût d'entrée est assez lourd.
Récemment, j'ai découvert Flask qui est plus léger et suffit largement lorsqu'on veut construire un site internet à usage interne. Il nécessite l'installation des modules JinJa (disponible pour Python 3) et Werkzeug (non disponible pour Python 3). L'installation de ces modules se fait simplement avec pip (pip install <module>, voir article 2013-05-10 : Installer un package simplement avec Python : pip).
Pour démarrer avec Flash, il suffit de lire la page suivante : Introduction à Flask. Le code d'un service web hello world :
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Bonjour !"
if __name__ == "__main__":
app.run()
Qu'on lance de cette façon :
$ python hello.py * Running on http://localhost:5000/Si j'avais su, j'aurais probablement créé ce blog de cette façon en m'appuyant sur cet exemple. Flask permet l'utilisation d'une base de données de type SQLlite. Différentes configurations sont disponibles ici pour interacer Flask avec Heroku, MongoDB, CouchDB, OpenID...
Pour ceux qui souhaitent créer un blog en Python (et avec Python 2.7 ou 3), il existe aussi le package pelican. Il dépend des packages, feedgenerator, pygments, docutils, pytz, blinker, unidecode, six, automatiquement installé avec pip (pip install pelican).
Vous trouverez d'autres ressources pour créer un site sur ce blog : ScopArt.
2013-05-08 PCA, eigen values and numerical approximation
High dimensional data do not behave very well with linear computation, especially when coefficients are very different in order of magnitude.
Yesterday, I was playing with some observations trying to do a PCA. Usually, we do not look at very small eigen values because they do not explain the variance of the observations set. However, I was surprised to find negative values. My observations were described with 29 variables, let's denote them as a centered matrix X. Computing a PCA means extracting the eigen values of the covariance matrix: X'X / N (N is the number of centered observations). This matrix is symmetric so it is diagonalisable and its eigen values are positive or null. However, when I looked at them, the last ones were negative (as the determinant).
Getting negative eigen values for this kind of matrices is necessarily wrong and it is due to numerical approximations. To observe that, I computed the eigen values for the series of submatrices X'X [1:n,1:n]. I also compared the eigen values to the one I could get from the Jacobi algorithm. This algorithm cannot converge to a matrix having negative values on the diagonal (when the matrix is a covariance matrix). You can see the results below.
2013-05-06 Quelques références
Python XY est une compilation de modules Python utilisés pour le calcul scientifique. Il inclut également un environnement qui ressemble à Matlab où R studio. Je n'ai pas vraiment réussi à l'installer sans casse la dernière fois que j'ai essayé et il n'est pas disponible en version 3. La liste des modules est intéressante. On y trouve un module tel que swapy qui permet d'automatiser des clicks sur des applications Windows, pyMC pour faire de l'inférence bayésienne ou encore WinMerge un outil pour comparer des fichiers ou des arborescences de fichiers.
Le format de documentation (ReStructuredText) développé pour Sphinx est directement intégré à GitHub qui recueille de plus en plus de projets open source. Le livre Probabilistic Programming and Bayesian Methods for Hackers est écrit avec ce format et il s'affiche directement depuis GitHub.
Dans un autre ordre d'idées, lorsqu'on développe et qu'on veut tester l'installation d'un module ou d'avoir des versions différentes de modules, il est possible de créer un environnement virtuel avec VirtuelEnv. Pour déployer un site web avec un push sur GitHub, on peut utiliser Heroku qui prend en charge des tests basiques et le déploiement.
Enfin, JCDecaux a rendu certaines données temps réel publiques données vélib. On peut télécharger au moyen d'une interface des données sur la présence ou l'absence de vélos à toutes les stations à n'importe quelle heure.
|
Xavier Dupré
|