Note
Click here to download the full example code
Train a linear regression with onnxruntime-training on GPU
This example follows the same steps introduced in example Train a linear regression with onnxruntime-training but on GPU. This example works on CPU and GPU but automatically chooses GPU if it is available.
A simple linear regression with scikit-learn
This code begins like example Train a linear regression with onnxruntime-training on GPU. It creates a graph to train a linear regression initialized with random coefficients.
from pprint import pprint
import numpy as np
from pandas import DataFrame
from onnx import helper, numpy_helper, TensorProto
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
from onnxruntime import (
__version__ as ort_version, get_device, OrtValue,
TrainingParameters, SessionOptions, TrainingSession)
import matplotlib.pyplot as plt
from pyquickhelper.helpgen.graphviz_helper import plot_graphviz
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from tqdm import tqdm
X, y = make_regression(n_features=2, bias=2)
X = X.astype(np.float32)
y = y.astype(np.float32)
X_train, X_test, y_train, y_test = train_test_split(X, y)
def plot_dot(model):
pydot_graph = GetPydotGraph(
model.graph, name=model.graph.name, rankdir="TB",
node_producer=GetOpNodeProducer("docstring"))
return plot_graphviz(pydot_graph.to_string())
def onnx_linear_regression_training(coefs, intercept):
if len(coefs.shape) == 1:
coefs = coefs.reshape((1, -1))
coefs = coefs.T
# input
X = helper.make_tensor_value_info(
'X', TensorProto.FLOAT, [None, coefs.shape[0]])
# expected output
label = helper.make_tensor_value_info(
'label', TensorProto.FLOAT, [None, coefs.shape[1]])
# output
Y = helper.make_tensor_value_info(
'Y', TensorProto.FLOAT, [None, coefs.shape[1]])
# loss output
loss = helper.make_tensor_value_info('loss', TensorProto.FLOAT, [])
# inference
node_matmul = helper.make_node('MatMul', ['X', 'coefs'], ['y1'], name='N1')
node_add = helper.make_node('Add', ['y1', 'intercept'], ['Y'], name='N2')
# loss
node_diff = helper.make_node('Sub', ['Y', 'label'], ['diff'], name='L1')
node_square = helper.make_node(
'Mul', ['diff', 'diff'], ['diff2'], name='L2')
node_square_sum = helper.make_node(
'ReduceSum', ['diff2'], ['loss'], name='L3')
# initializer
init_coefs = numpy_helper.from_array(coefs, name="coefs")
init_intercept = numpy_helper.from_array(intercept, name="intercept")
# graph
graph_def = helper.make_graph(
[node_matmul, node_add, node_diff, node_square, node_square_sum],
'lrt',
[X, label], [loss, Y],
[init_coefs, init_intercept])
model_def = helper.make_model(
graph_def, producer_name='orttrainer', ir_version=7,
producer_version=ort_version,
opset_imports=[helper.make_operatorsetid('', 14)])
return model_def
onx_train = onnx_linear_regression_training(
np.random.randn(2).astype(np.float32),
np.random.randn(1).astype(np.float32))
plot_dot(onx_train)
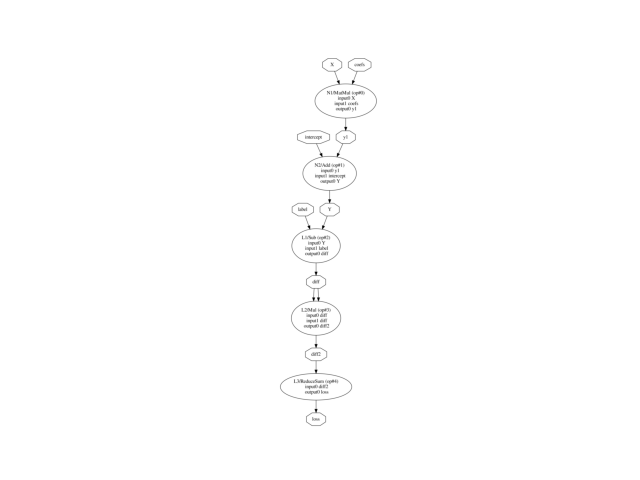
<AxesSubplot: >
First iterations of training on GPU
Prediction needs an instance of class InferenceSession, the training needs an instance of class TrainingSession. Next function creates this one.
device='cpu' get_device()='CPU'
Function creating the training session.
def create_training_session(
training_onnx, weights_to_train, loss_output_name='loss',
training_optimizer_name='SGDOptimizer', device='cpu'):
"""
Creates an instance of class `TrainingSession`.
:param training_onnx: ONNX graph used to train
:param weights_to_train: names of initializers to be optimized
:param loss_output_name: name of the loss output
:param training_optimizer_name: optimizer name
:param device: `'cpu'` or `'cuda'`
:return: instance of `TrainingSession`
"""
ort_parameters = TrainingParameters()
ort_parameters.loss_output_name = loss_output_name
ort_parameters.use_mixed_precision = False
# ort_parameters.world_rank = -1
# ort_parameters.world_size = 1
# ort_parameters.gradient_accumulation_steps = 1
# ort_parameters.allreduce_post_accumulation = False
# ort_parameters.deepspeed_zero_stage = 0
# ort_parameters.enable_grad_norm_clip = False
# ort_parameters.set_gradients_as_graph_outputs = False
# ort_parameters.use_memory_efficient_gradient = False
# ort_parameters.enable_adasum = False
output_types = {}
for output in training_onnx.graph.output:
output_types[output.name] = output.type.tensor_type
ort_parameters.weights_to_train = set(weights_to_train)
ort_parameters.training_optimizer_name = training_optimizer_name
# ort_parameters.lr_params_feed_name = lr_params_feed_name
ort_parameters.optimizer_attributes_map = {
name: {} for name in weights_to_train}
ort_parameters.optimizer_int_attributes_map = {
name: {} for name in weights_to_train}
session_options = SessionOptions()
session_options.use_deterministic_compute = True
if device == 'cpu':
provider = ['CPUExecutionProvider']
elif device.startswith("cuda"):
provider = ['CUDAExecutionProvider']
else:
raise ValueError("Unexpected device %r." % device)
session = TrainingSession(
training_onnx.SerializeToString(), ort_parameters, session_options,
providers=provider)
return session
train_session = create_training_session(
onx_train, ['coefs', 'intercept'], device=device)
print(train_session)
<onnxruntime.capi.training.training_session.TrainingSession object at 0x7f03188b1a90>
The coefficients.
state_tensors = train_session.get_state()
pprint(state_tensors)
{'coefs': array([[-1.7059902 ],
[ 0.05621672]], dtype=float32),
'intercept': array([-0.4933698], dtype=float32)}
We can now check the coefficients are updated after one iteration.
bind_x = OrtValue.ortvalue_from_numpy(X_train[:1], device, 0)
bind_y = OrtValue.ortvalue_from_numpy(y_train[:1].reshape((-1, 1)), device, 0)
bind_lr = OrtValue.ortvalue_from_numpy(np.array([0.01], dtype=np.float32), device, 0)
bind = train_session.io_binding()
bind.bind_input(
name='X', device_type=bind_x.device_name(), device_id=0,
element_type=np.float32, shape=bind_x.shape(),
buffer_ptr=bind_x.data_ptr())
bind.bind_input(
name='label', device_type=bind_y.device_name(), device_id=0,
element_type=np.float32, shape=bind_y.shape(),
buffer_ptr=bind_y.data_ptr())
bind.bind_input(
name='Learning_Rate', device_type=bind_lr.device_name(), device_id=0,
element_type=np.float32, shape=bind_lr.shape(),
buffer_ptr=bind_lr.data_ptr())
bind.bind_output('loss')
bind.bind_output('Y')
train_session.run_with_iobinding(bind)
outputs = bind.copy_outputs_to_cpu()
print(outputs)
[array([[23224.428]], dtype=float32), array([[2.247612]], dtype=float32)]
We check the coefficients have changed.
state_tensors = train_session.get_state()
pprint(state_tensors)
{'coefs': array([[3.3032565],
[3.4618416]], dtype=float32),
'intercept': array([-3.5412824], dtype=float32)}
Training on GPU
We still need to implement a gradient descent. Let’s wrap this into a class similar following scikit-learn’s API.
class DataLoaderDevice:
"""
Draws consecutive random observations from a dataset
by batch. It iterates over the datasets by drawing
*batch_size* consecutive observations.
:param X: features
:param y: labels
:param batch_size: batch size (consecutive observations)
:param device: `'cpu'` or `'cuda'`
:param device_idx: device index
"""
def __init__(self, X, y, batch_size=20, device='cpu', device_idx=0):
if len(y.shape) == 1:
y = y.reshape((-1, 1))
if X.shape[0] != y.shape[0]:
raise ValueError(
"Shape mismatch X.shape=%r, y.shape=%r." % (X.shape, y.shape))
self.X = np.ascontiguousarray(X)
self.y = np.ascontiguousarray(y)
self.batch_size = batch_size
self.device = device
self.device_idx = device_idx
def __len__(self):
"Returns the number of observations."
return self.X.shape[0]
def __iter__(self):
"""
Iterates over the datasets by drawing
*batch_size* consecutive observations.
"""
N = 0
b = len(self) - self.batch_size
while N < len(self):
i = np.random.randint(0, b)
N += self.batch_size
yield (
OrtValue.ortvalue_from_numpy(
self.X[i:i + self.batch_size],
self.device, self.device_idx),
OrtValue.ortvalue_from_numpy(
self.y[i:i + self.batch_size],
self.device, self.device_idx))
@property
def data(self):
"Returns a tuple of the datasets."
return self.X, self.y
data_loader = DataLoaderDevice(X_train, y_train, batch_size=2)
for i, batch in enumerate(data_loader):
if i >= 2:
break
print("batch %r: %r" % (i, batch))
batch 0: (<onnxruntime.capi.onnxruntime_inference_collection.OrtValue object at 0x7f03189d66a0>, <onnxruntime.capi.onnxruntime_inference_collection.OrtValue object at 0x7f03189d6d30>)
batch 1: (<onnxruntime.capi.onnxruntime_inference_collection.OrtValue object at 0x7f03189d6610>, <onnxruntime.capi.onnxruntime_inference_collection.OrtValue object at 0x7f03189d6bb0>)
The training algorithm.
class CustomTraining:
"""
Implements a simple :epkg:`Stochastic Gradient Descent`.
:param model_onnx: ONNX graph to train
:param weights_to_train: list of initializers to train
:param loss_output_name: name of output loss
:param max_iter: number of training iterations
:param training_optimizer_name: optimizing algorithm
:param batch_size: batch size (see class *DataLoader*)
:param eta0: initial learning rate for the `'constant'`, `'invscaling'`
or `'adaptive'` schedules.
:param alpha: constant that multiplies the regularization term,
the higher the value, the stronger the regularization.
Also used to compute the learning rate when set to *learning_rate*
is set to `'optimal'`.
:param power_t: exponent for inverse scaling learning rate
:param learning_rate: learning rate schedule:
* `'constant'`: `eta = eta0`
* `'optimal'`: `eta = 1.0 / (alpha * (t + t0))` where *t0* is chosen
by a heuristic proposed by Leon Bottou.
* `'invscaling'`: `eta = eta0 / pow(t, power_t)`
:param device: `'cpu'` or `'cuda'`
:param device_idx: device index
:param verbose: use :epkg:`tqdm` to display the training progress
"""
def __init__(self, model_onnx, weights_to_train, loss_output_name='loss',
max_iter=100, training_optimizer_name='SGDOptimizer',
batch_size=10, eta0=0.01, alpha=0.0001, power_t=0.25,
learning_rate='invscaling', device='cpu', device_idx=0,
verbose=0):
# See https://scikit-learn.org/stable/modules/generated/
# sklearn.linear_model.SGDRegressor.html
self.model_onnx = model_onnx
self.batch_size = batch_size
self.weights_to_train = weights_to_train
self.loss_output_name = loss_output_name
self.training_optimizer_name = training_optimizer_name
self.verbose = verbose
self.max_iter = max_iter
self.eta0 = eta0
self.alpha = alpha
self.power_t = power_t
self.learning_rate = learning_rate.lower()
self.device = device
self.device_idx = device_idx
def _init_learning_rate(self):
self.eta0_ = self.eta0
if self.learning_rate == "optimal":
typw = np.sqrt(1.0 / np.sqrt(self.alpha))
self.eta0_ = typw / max(1.0, (1 + typw) * 2)
self.optimal_init_ = 1.0 / (self.eta0_ * self.alpha)
else:
self.eta0_ = self.eta0
return self.eta0_
def _update_learning_rate(self, t, eta):
if self.learning_rate == "optimal":
eta = 1.0 / (self.alpha * (self.optimal_init_ + t))
elif self.learning_rate == "invscaling":
eta = self.eta0_ / np.power(t + 1, self.power_t)
return eta
def fit(self, X, y):
"""
Trains the model.
:param X: features
:param y: expected output
:return: self
"""
self.train_session_ = create_training_session(
self.model_onnx, self.weights_to_train,
loss_output_name=self.loss_output_name,
training_optimizer_name=self.training_optimizer_name,
device=self.device)
data_loader = DataLoaderDevice(
X, y, batch_size=self.batch_size, device=self.device)
lr = self._init_learning_rate()
self.input_names_ = [i.name for i in self.train_session_.get_inputs()]
self.output_names_ = [
o.name for o in self.train_session_.get_outputs()]
self.loss_index_ = self.output_names_.index(self.loss_output_name)
bind = self.train_session_.io_binding()
loop = (
tqdm(range(self.max_iter))
if self.verbose else range(self.max_iter))
train_losses = []
for it in loop:
bind_lr = OrtValue.ortvalue_from_numpy(
np.array([lr], dtype=np.float32), self.device, self.device_idx)
loss = self._iteration(data_loader, bind_lr, bind)
lr = self._update_learning_rate(it, lr)
if self.verbose > 1:
loop.set_description("loss=%1.3g lr=%1.3g" % (loss, lr))
train_losses.append(loss)
self.train_losses_ = train_losses
self.trained_coef_ = self.train_session_.get_state()
return self
def _iteration(self, data_loader, learning_rate, bind):
actual_losses = []
for batch_idx, (data, target) in enumerate(data_loader):
bind.bind_input(
name=self.input_names_[0],
device_type=self.device,
device_id=self.device_idx,
element_type=np.float32,
shape=data.shape(),
buffer_ptr=data.data_ptr())
bind.bind_input(
name=self.input_names_[1],
device_type=self.device,
device_id=self.device_idx,
element_type=np.float32,
shape=target.shape(),
buffer_ptr=target.data_ptr())
bind.bind_input(
name=self.input_names_[2],
device_type=learning_rate.device_name(), device_id=0,
element_type=np.float32, shape=learning_rate.shape(),
buffer_ptr=learning_rate.data_ptr())
bind.bind_output('loss')
self.train_session_.run_with_iobinding(bind)
outputs = bind.copy_outputs_to_cpu()
actual_losses.append(outputs[self.loss_index_])
return np.array(actual_losses).mean()
Let’s now train the model in a very similar way that it would be done with scikit-learn.
trainer = CustomTraining(onx_train, ['coefs', 'intercept'], verbose=1,
max_iter=10, device=device)
trainer.fit(X, y)
print("training losses:", trainer.train_losses_)
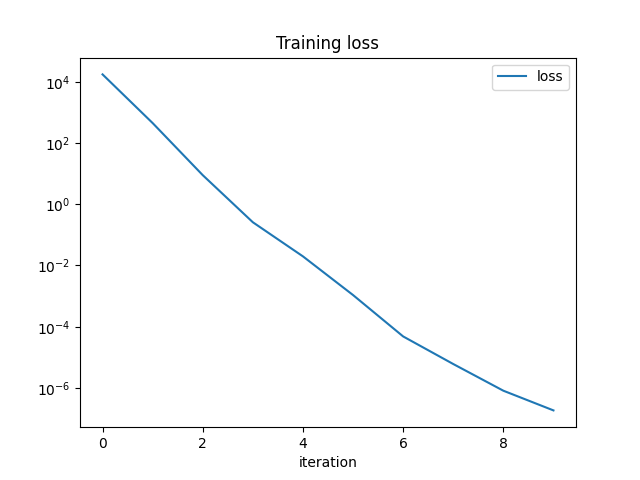
df = DataFrame({"iteration": np.arange(len(trainer.train_losses_)),
"loss": trainer.train_losses_})
df.set_index('iteration').plot(title="Training loss", logy=True)
0%| | 0/10 [00:00<?, ?it/s]
100%|##########| 10/10 [00:00<00:00, 150.71it/s]
training losses: [17326.672, 445.98785, 8.882076, 0.25754315, 0.019801162, 0.0010807887, 4.8141465e-05, 6.0500042e-06, 8.1356774e-07, 1.8512324e-07]
<AxesSubplot: title={'center': 'Training loss'}, xlabel='iteration'>
The final coefficients.
print("onnxruntime", trainer.trained_coef_)
onnxruntime {'coefs': array([[59.491734],
[48.662098]], dtype=float32), 'intercept': array([1.9999504], dtype=float32)}
Total running time of the script: ( 0 minutes 3.083 seconds)