Devinettes#
Cette page regroupe quelques questions et problèmes dont les solutions figurent dans les pages de ce site intéressante du point de vue d’un data scientiste.
Machine Learning#
Ces exercices abordent des sujets liés au machine learning, inventés pour des examens, un entretien d’embauche, ou tirés de l’expérience d’un data-scientiste.
Mathématiques#
Corrélations non linéaires#
Le coefficient de Pearson est sans aucun doute le coefficient de corrélation le plus connu. Le coefficient de Spearman mesure la corrélation entre deux variables à partir de leur rang. Et si on essayait de définir un coefficient de corrélation non linéaire ? A base d’arbre de décision ? Pas forcémenet symétrique ?
Décorrélation de variables#
On suppose que les variables  sont
corrélées avec une matrice variance coveriance égale à
sont
corrélées avec une matrice variance coveriance égale à  .
Comment construire des variables décorrélées à partir de
?
.
Comment construire des variables décorrélées à partir de
?
p-value et intervalle de confiance#
L’école anglaise a tendance à préférer les p-values, l’école française préfère les intervalles de confiance. Ces deux notions sont équivalentes mais connaissez-vous le lien qui les unit ?
Méthodologie#
Courbe ROC#
Voici deux courbes pour le même problème de prédiction de la couleur du vin en fonction de mesure sur sa composition chimique. La première répond à la question « Le vin est-il rouge ? » et le score utilisé est le score brut issu d’une régression logistique. La seconde courbe répond à la question « Le vin est-il bien classé ? », le score utilisé est soit le score du vin blanc, c’est-à-dire si le score est positif, soit l’opposé du score s’il est négatif et le prédicteur le classe dans la catégorie vin rouge.
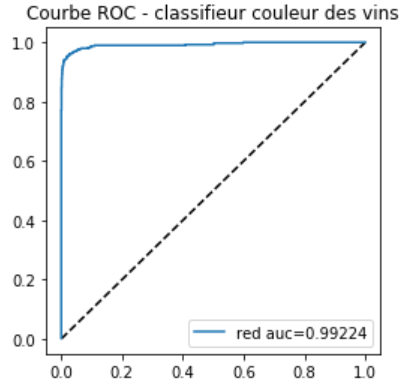
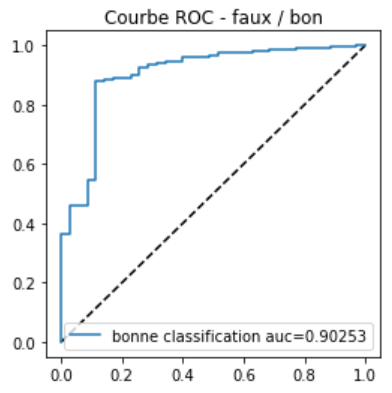
Pourquoi ces deux courbes ne sont-elles pas identiques ?
Naïve normalisation#
Le code suivant présente une erreur de méthodologie qui a souvent peu d’incidence mais qui n’en reste pas moins problématique.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
from sklearn.preprocessing import normalize
X_train_norm = normalize(X_train)
X_test_norm = normalize(X_test)
Quelle est-elle ?
Programmation#
Frontière polynomiale#
On considère un problème de classificatoin en deux dimensions. Comment tracer une frontière linéaire entre deux classes ? Et une frontière polynômiale ?
Implémenter un modèle de stacking#
Le stacking consiste à aggréger les sorties de plusieurs modèles de machine learning via un dernier modèle qui prend la décision en fonction des sorties de tous les autres. Il faut implémenter quelque chose de la sorte. La version 0.22 de scikit-learn implémente ce type de modèle StackingRegressor mais d’autres modules n’ont pas attendu comme mlxtend.regressor.StackingRegressor.