2015-03-26 Drawing in a notebook
My plan was quite simple : create a kind of small window in a notebook where I can click and mark some points. Once it is done, I retrieve the points and I run a simple algorithm to solve the Travelling Salesman Problem.
The notebook is there Voyageur de commerce and the javascript code is generated by the following function: display_canvas_point.
2015-03-07 Work on the features or the model
Sometimes, a machine learned model does not get it. It does not find any way to properly classify the data. Sometimes, you know it could work better with another model but it cannot be trained on such an amount of data. So what...
Another direction consists in looking for non linear combinations of existing features which could explain better the border between two classes. Let's consider this known difficult example:
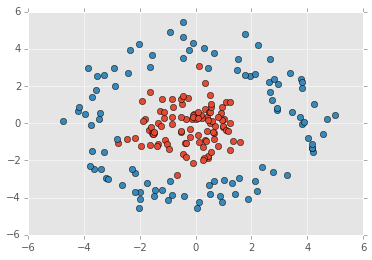
It cannot be linearly separated but it can with others kinds of models (k-NN, SVC). However, by adding simple multiplications between existing features, the problem becomes linear:
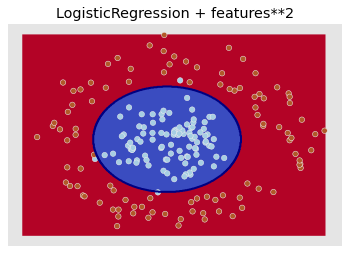
The point is: if you know that a complex features would really help your model, it is worth spending time implementing it rather that trying to approximating it by using a more complex model. (corresponding notebook).
2015-03-01 Automated build of pipelines on Jenkins
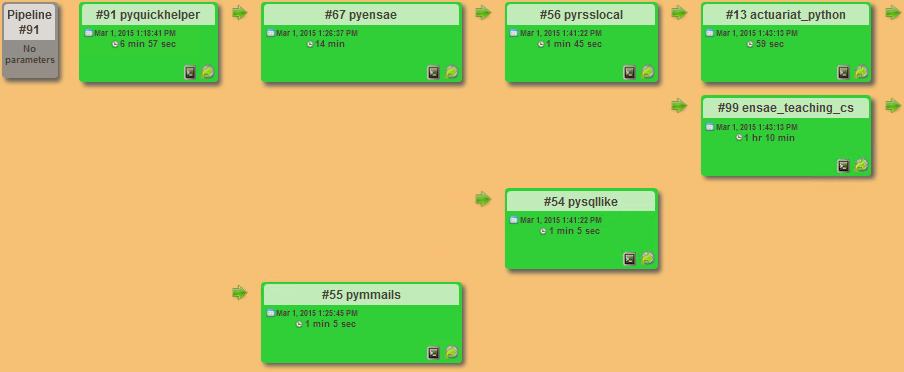
Jenkins is an interesting tools. You can schedule jobs, manage dependencies between or even display pipelines. Below follows the one I use for my teachings which consists in many helpers to generate documentation, proposes various magic commands for ipython, test all notebooks are working fine.
2015-02-28 Automated build on Travis for a python module
Many python modules display a small logo
which indicates the build status:
 .
I set up the same for the module
pyquickhelper which is held on github/pyquickhelper.
Travis installs packages before building the modules.
The first step is to gather all the dependencies:
.
I set up the same for the module
pyquickhelper which is held on github/pyquickhelper.
Travis installs packages before building the modules.
The first step is to gather all the dependencies:
pip freeze > requirements.txt
I replaced == by >= and removed some of them, I got:
Cython>=0.20.2 Flask>=0.10.1 Flask-SQLAlchemy>=2.0 Jinja2>=2.7.3 Markdown>=2.4.1 ...
more...
2015-02-26 Use scikit-learn with your own model
scikit-learn has a very simple API and it is quite simple to use its features with your own model. It just needs to be embbeded into a class which implements the methods fit, predict, decision_function, score. I wrote a simple model (kNN) which follows those guidelines: SkCustomKnn. A last method is needed for the cross validation scenario. This one needs to clone the machine learned model. It just calls the constructor with proper parameters. To do so, it needs to get a copy of those. That is the purpose of method get_params. You are all set.
2015-02-21 Distribution pour Python sous Windows
La distribution WinPython propose maintenant Python 3.4 mais aussi des versions customisées (ou flavors). L'une d'entre elles utilise Kivy. Une autre est particulièrement intéressante pour un datascientist puisqu'elle inclue R. On peut alors passer facilement de Python à R depuis le même notebooks sans étape d'installation supplémentaire ce qu'on teste aisément avec un notebook préinstallé. Comme le compilateur MinGW fait partie de la distribution, cython ne pose plus aucun problème.
Avec cette dernière version, le choix entre WinPython et Anaconda devient difficile sous Windows. Un seul bémol, l'installation du module paramiko est très simple avec Anaconda (avec conda install) mais se révèle compliquée avec WinPython. Donc, si vous avez besoin d'accéder à des ressources web de façon cryptée, Anaconda reste sans doute le plus sûr.
2015-02-16 Delay evaluation
The following class is meant to be a kind of repository of many tables. Its main issue it is loads everything first. It takes time and might not be necessary if not all the tables are required.
import pandas
class DataContainer:
def __init__( self, big_tables ):
self.big_tables = big_tables
def __getitem__(self, i):
return self.big_tables[i]
filenames = [ "file1.txt", "files2.txt" ]
def load(filename):
return pandas.read_csv(filename, sep="\t")
container = DataContainer ( [ load(f) for f in filenames ] )
So the goal is to load the data only when it is required. But I would like to avoid tweaking the interface of class. And the logic loading the data is held outside the container. However I would an access to the container to activate the loading of the data. Si instead of giving the class DataContainer the data itself, I give it a function able to load the data.
def memoize(f):
memo = {}
def helper(self, x):
if x not in memo:
memo[x] = f(self, x)
return memo[x]
return helper
class DataContainerDelayed:
def __init__( self, big_tables ):
self.big_tables = big_tables
@memoize
def __getitem__(self, i):
return self.big_tables[i]()
container = DataContainerDelayed ( [ lambda t=f : load(t) for f in filenames ] )
for i in range(0,2): print(container[i])
But I would like to avoid loading the data only one time. So I used a memoize mechanism.
2015-02-09 Jouer à Space Invaders à coup de ligne de code
Si vous ne me croyez pas, aller voir ici : codingame. Ce n'est pas vraiment un jeu d'arcade mais il s'agit d'implémenter une stratégie qui vous permette de résoudre un jeu sans joystick. Allez voir le blog.
2015-02-06 Quelques trucs à propos de PIG
PIG a besoin de connaître le nombre exact de colonnes. Supposons que vous ayez quatre colonnes :
c1 c2 c3 c3 1 2 3 4 6 7 8 9 ...
PIG ne dira rien si on écrit ceci :
A = LOAD '$CONTAINER/$PSEUDO/fichiers/ExportHDInsightutf8_noheader.txt'
USING PigStorage('\t')
AS (c1:chararray,c2:chararray,c3:chararray) ;
La dernière colonne sera forcément incluse avec une autre, ce entraînera une erreur plus tard dans l'exécution du script. Une autre erreur causée par inadvertance :
2015-02-05 23:40:54,964 [main] ERROR org.apache.pig.tools.pigstats.SimplePigStats - ERROR 0: Exception while executing [POUserFunc (Name: POUserFunc(org.apache.pig.builtin.YearsBetween)[long] - scope-380 Operator Key: scope-380) children: null at []]: java.lang.IllegalArgumentException: ReadableInstant objects must not be null
Cette erreur apparaît par exemple lors de la conversion d'une chaîne de caractères au format Date. Par ailleurs, on sait que les valeurs de cette colonne ne sont jamais nulles. Alors pourquoi ? Le fichier importé sur Hadoop provient en fait d'un fichier texte enregistré à l'aide de pandas. La première ligne contient le nom des colonnes. Or, sous Hadoop, le nom des colonnes n'est jamais précisé dans un fichier. Il n'y a pas de concept de première ligne sous Hadoop. Un gros fichier est stocké sur plusieurs machines et en plusieurs blocs. Chaque blocs a une première ligne mais l'ensemble des blocs n'en a pas vraiment. Ces blocs ne sont d'ailleurs pas ordonnés. On n'insère donc jamais le nom des colonnes dans un fichier sur Hadoop car il n'y a pas de première ligne.
2015-02-05 Run a IPython notebook offline
I intensively use notebooks for my teachings and I recently noticed that some of them fail because of I updated a module or I did some changes to my python installation. So I thought I looked for a way to run my notebooks in batch mode. I found runipy which runs a notebook and catches exception it raises. After a couple of tries, I decided to modify the code to get more infos when it fails. It ended up with a function run_notebook:
from pyquickhelper.ipythonhelper.notebook_helper import run_notebook
output = run_notebook(notebook_filename,
working_dir=folder,
outfilename=outfile)
I think it is going to save some time from one year to the next one.
2015-01-24 La donnée isolée et la moyenne
Les données sont légions et n'attendent que d'être intégrées à une histoire qui selon les personnes prend le nom d'interprétation, de modèle, d'analyse, de synthèse. Mais bien mystérieuse est la gestation de cette histoire. Mon premier témoignage d'une avalanche de chiffres remonte sans doute à Matrix où un programmateur fascinant interprétait un déluge de bits en temps réel sans aucune lampe stroboscopique dont tout humain normal aurait eu besoin pour espérer y voir quelque chose.
Nous ne sommes pas vraiment capables de donner un sens à une telle diarrhée numérique. Le plus souvent, on en fait la moyenne ou la médiane et on en garde que ce seul chiffre qui devient la seule chose à raconter. Personne n'aime affronter une tonne de chiffres mais savoir que celle-ci a accouché d'un seul nombre qui résume le tout, ça rassure et c'est simple à retenir. Le salaire médiane, le salaire moyen des ministres du gouvernement, le nombre d'élèves moyens par classe, le taux de chômages (moyen), le QI moyen, on fait une somme, on divise, on est content. On se sent même un peu savant dès qu'on parle d'écart type, un peu plus encore si on évoque les corrélations.
Et puis tout de suite, comme ces moyennes ont un poids certain, on se compare à elle. On est au dessus. On est heureux. On est en dessous, on se sent lésé. Tout à coup, on sait où on se trouve. On se sait rien du voisin mais on sait tout des français. Moi (donnée isolée) contre les autres (données agrégées), un grand classique. Lorsqu'on est du bon côté, on se repose, du mauvais, on a enfin trouvé l'objectif : la moyenne ou mieux encore, le premier quartile.
Et puis patatras, j'ai calculé le taux moyen de guérison de deux hôpitaux pour choisir le meilleur. Et je n'aurais pas pris toutes les données en considération, j'aurais raté un morceau de l'histoire ? C'est Le paradoxe de Simpson. J'hésite entre deux hôpitaux, le premier a un taux de succès de 98%, le second 90%. - Ah bon, tu hésites ? - Allez, on y va.
Un peu plus tard.
Tu lis quoi sur le fronton ? Euh... Chirurgie esthétique. - Tu n'aurais pas pu le dire avant ! - Mais tu m'as dit de prendre le meilleur. - Le meilleur pour ton type d'opération ! - J'ai oublié de regarder cette donnée.
2015-01-22 C'est quoi les données, c'est quoi le Big Data ?
Dans le film Bienvenue à Gattaca, le héros joué par Ethan Hawke doit non seulement faire disparaître ses traces mais aussi laisser celles de celui dont il usurpe l'identité. La moindre inattention peut jeter le doute voire dévoiler le stratagème. Une empreinte digitale inattendue interpelle immédiatement. Comme c'est inattendu, il faut lui trouver une explication.
La donnée : c'est une information juste avant qu'elle ne devienne partie intégrante d'une histoire, juste avant qu'on l'interprète. Et comme le suggère ce film, on en laisse partout et tout le temps. On en génère tellement qu'on est forcé de ne pas y prêter trop attention. La moindre connexion internet, la poussière sur le plancher, la température de l'eau, la fuite d'air à la fenêtre. C'est une donnée dès qu'on la décrit. Il y en a tellement qu'on les oublie rapidement. C'est juste un fait divers.
Mais pourquoi sont-elles si populaires maintenant ?
Une des raisons est qu'elles restent plus longtemps. La poussière sur mon plancher disparaît avec l'aspirateur. La connexion à un site internet restent plusieurs mois dans plusieurs fichiers de plusieurs machines différentes. Ces données numériques ont la vie dure. Ca n'explique pas pourquoi elles sont populaires. Seulement, du fait qu'elles restent plus longtemps, on a plus de temps pour les observer et leur donner du sens.
Comment donne-t-on du sens aux données ?
Les statistiques y sont pour beaucoup même si ce terme n'est pas une explication en soi. David Hume dans Enquête sur l'entendement humain nous apporte quelques éléments de réponses. Nous sommes tous très amnésiques mais une des façons qui nous permet de retenir est la répétition. Une observation, une donnée, commence à prendre du sens dès qu'elle se répète. Pour citer Hume :
De causes qui paraissent semblables, nous attendons des effets semblables. Telle est la somme de toutes nos conclusions expérimentales.
Les marins utilisaient les étoiles pour se repérer. Ils ont su associer la position d'une étoile dans le ciel (une donnée) de la même étoile à la même position une année plus tard (la donnée est répétée). C'est le début de la connaissance : chaque année, la même étoile est à la même position dans le ciel. On peut l'utiliser pour se repérer.
Et Big Data ?
La somme des données qui se rapporte à la même personne est quasiment infini. Seulement, aujourd'hui, elle persiste. Qu'en faire ? C'est tellement énorme que ce serait comme découvrir toute la voie lactée le même jour. Il faudrait une vie pour l'étudier... Sauf que... on a maintenant des ordinateurs qui font plein de calculs très rapidement. Alors on reprend notre cher Hume : on se répète beaucoup ! On fait presque tous les jours la même chose, et si ce n'est pas tous les jours, c'est toutes les semaines. Nous avons une vie rythmée - au sens musical -. Alors en comparant toutes les journées entre elles, et avec un bon ordinateur, on arrive à déterminer les habitudes et les goûts de chacun.
Et alors ?
Et bien c'est d'abord très drôle. On porte un bracelet au poignet qui enregistre les déplacements. On peut compter ses pas, enregistrer son poids tous les jours. C'est un peu comme si découvrait qu'on n'était plus intéressant que le voisin parce qu'on découvre plein de choses sur soi-même. Et le voisin, il n'est plus aussi intéressant ? Si si toujours, mais c'est lui qui nous montre sa courbe de poids, alors ce n'est plus aussi drôle. Et puis, quand on mange un carré de chocolat, on peut le mesurer tout de suite. Et ça c'est fun.
Autrefois si éphémères, les données sont quasi éternelles, et elles disent beaucoup de choses. Votre enfant sera peut-être dans 25 ans archéologue numérique. Les listes des relevés de cartes bleues pourraient permettre tout à la fois d'ajuster un régime alimentaire mal équilibré qu'à prédire la probabilité d'avoir un cancer (sauf si vous achetez toujours tout y compris votre whisky préféré en liquide).
Tu as vu le Monde aujourd'hui ? Les français prennent du poids à Noël ! - Incroyable, ils ont piraté ma balance numérique ! - Euh... tu es sûr ?
Les données, d'accord... et le bruit alors ?
C'est Agatha Christie qui nous apporte la réponse. Hercule Poirot avait coutume de dire que le meurtrier est un homme parfaitement normal qui cherche justement à l'être le seul jour où il ne l'est pas. Il pense à chaque instant à gommer tout ce qui pourrait éveiller les soupçons. S'il avait envie de manger une petite gâterie, il y renoncera car d'hatitude, il prend un jambon beurre à midi. Le meurtrier évacuera pour une journée toute fantaisie. Et pourtant, ce sont tous ces petits aléas qui font qu'une journée est parfaitement normale, tous ces petits détails qu'on n'est incapable de retenir, tous ces petits détails qui, parfois, sont remarqués par votre collègue car justement ils sortent de l'ordinaire. Mais si toute la journée, un meutrier pense à son crime, il n'y a plus de relâchement possible et il va chercher à gommer ces petits aléas qui attirent l'attention. En fin de compte, il aura paru tout à fait normal, bien trop normal pour être vrai, d'après Hercule Poirot. Le bruit, ce sont les fausses notes de la journée par rapport à une journée parfaitement normale, fausses notes délicieuses pour toute personne sensée, fausses notes malheureuses pour tout statisticien sensé.
2015-01-20 Download a file from Dropbox with Python
It is tempting to do everything from a IPython notebook such as downloading a file from DropBox. On the web interface, when a user click on a file, a button Download shows up. A second click on this button and the file will be downloaded it. To retrieve the file from a notebook, the url of the page which contains the button but it is close from the good one. This leads to the following example:
url = "https://www.dropbox.com/[something]/[filename]?dl=1" # dl=1 is important
import urllib.request
u = urllib.request.urlopen(url)
data = u.read()
u.close()
with open([filename], "wb") as f :
f.write(data)
It first downloads the data as bytes and then stores everything into a file.
2015-01-19 Install a Python module with Wheel
Wheel is going to be the new way to install modules with Python. According to pythonwheels.com, many packages are already available and the site Unofficial Windows Binaries for Python Extension Packages already proposes modules in wheel format.
Windows and Linux works the same way now. It requires to install wheel first:
pip install wheel
The next step consists in downloading a wheel file .whl. An example with pandas:
pip install pandas-0.15.2-cp27-none-win_amd64.whl
2015-01-15 Projets informatiques, ENSAE 1A
Liste des sujets suggérés. Le hors piste est encouragé.
| <-- --> |
Xavier Dupré
|