2017-09-19 Pourquoi pandas et numpy, pourquoi pas seulement pandas (2A) ?#
Voici quelques questions abordées durant la première séance.
L’instruction pandas.read_csv n’a pas toujours fonctionné.
Deux principales raisons à cela, la première à cause du chemin.
Un chemin peut être absolu, il commence par c:\ ou \ sous Windows
ou / sous Linux, ou relatif, il commence par un nom.
Le chemin absolu ne pose pas de difficulté en Python sauf dans
quelques cas où le chemin est un chemin réseau (commençant par \\).
Par défaut, Python cherche les données à partir de l’emplacement
du programme si le chemin est relatif. Cet emplacement est aussi l’emplacement
courant pour le programme. Il suffit de placer les fichiers dans ce répetoire
pour n’utiliser que le nom du fichier. On l’obtient en exécutant :
<<<
import os
print(os.getcwd())
>>>
/var/lib/jenkins/workspace/ensae_teaching_cs/ensae_teaching_cs_UT_39_std/_doc/sphinxdoc
Il est possible de vérifier le contenu d’un répertoire, en particulier du répertoire courent avec :
<<<
import os
for name in os.listdir("."):
print(name)
>>>
source
build
La seconde raison est l”encoding. Les caractères chinois nécessitent un encodage particulier car il faut plusieurs octets pour coder un des nombreux caractères. Il n’existe pas une seule façon d’associer un caractère chinois mais la façon commune est utf-8 qui est le standard du web. Il faut s’assurer que le code utilisée pour créer le fichier de données est le même que celui utilisé pour relire :
import pandas
df = pandas.read_csv("...", encoding="...")
Autre question, pourquoi numpy alors que pandas fait déjà tout. La réponse tient dans l’image qui suit :
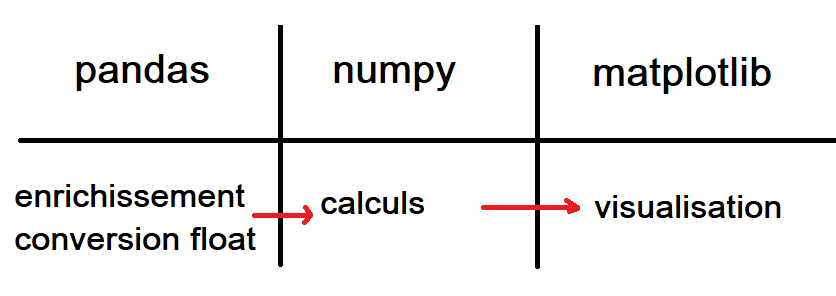
pandas sert à préparer les données, à transformer tout ce qui n’est pas numérique en nombres réelles, à enrichir les données en fusionnant avec d’autres bases. Une fois que cela est fait, on peut convertir toutes les données au format numérique, en matrice pour simplifier car les algorihmes numériques utilisant principalement cela. Des nombres réels sous forme de matrices, c’est ce que manipulent tous les algorithmes de machine learning. matplotlib conclue le processus en donnant les moyens de représenter le résultat de l’expérience.
Pour ceux qui ont commencé la compétition, les liens vers les données
sont cassés et seront réparés dès la publication de cet article. Un data leakage
ou expérience surprenante avec la dernière variable de la base qui contient
le nombre de valeurs non nulles parmi les colonnes dont le nom se termine pas
100g. La prise en compte de cette variable semble influencer beaucoup
la prédiction.