1A.1 - Simuler une loi multinomiale#
Links: notebook, html, python, slides, GitHub
On part d’une loi uniforme et on simule une loi multinomiale.
%matplotlib inline
Populating the interactive namespace from numpy and matplotlib
from jyquickhelper import add_notebook_menu
add_notebook_menu()
Une variable qui suit une loi multinomiale est une variable à valeurs entières qui prend ses valeurs dans un ensemble fini, et chacune de ces valeurs a une probabilité différente.
import matplotlib.pyplot as plt
poids = [ 0.2, 0.15, 0.15, 0.1, 0.4 ]
valeur = [ 0,1,2,3,4 ]
plt.figure(figsize=(8,4))
plt.bar(valeur,poids)
<Container object of 5 artists>
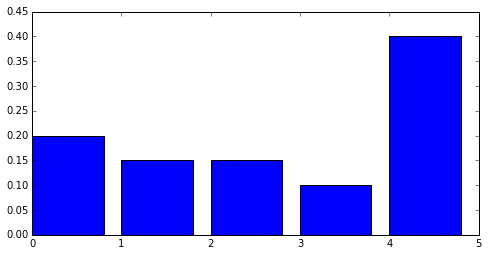
Lorsqu’on simule une telle loi, chaque valeur a une probabilité de sortir proportionnelle à chaque poids. La fonction numpy.random.multinomial permet de calculer cela.
import numpy.random as rnd
draw = rnd.multinomial(1000, poids)
draw / sum(draw)
array([ 0.211, 0.148, 0.15 , 0.089, 0.402])
Pour avoir 1000 tirages plutôt que l’aggrégation des 1000 tirages :
draw = rnd.multinomial(1, poids, 1000)
draw
array([[0, 0, 0, 1, 0],
[0, 0, 1, 0, 0],
[0, 1, 0, 0, 0],
...,
[0, 0, 0, 0, 1],
[0, 0, 1, 0, 0],
[0, 1, 0, 0, 0]])
Algorithme de simulation#
Tout d’abord, on calcule la distribution cumulée (ou fonction de répartition). Le calcule proposé utilise la fonction numpy.cumsum.
import numpy
cum = numpy.cumsum( poids ) # voir http://docs.scipy.org/doc/numpy/reference/generated/numpy.cumsum.html
print(cum)
plt.bar( valeur, cum)
[ 0.2 0.35 0.5 0.6 1. ]
<Container object of 5 artists>
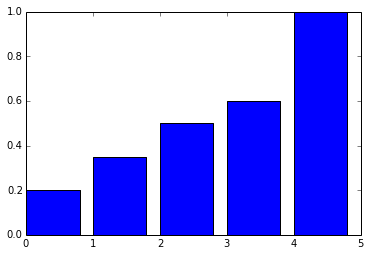
Cette fonction de répartition  est croissante. On
définit les cinq intervalles :
est croissante. On
définit les cinq intervalles : ![A_i=]F(i),F(i+1)]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAxMDEuMjAzOTQ3IDExLjk1NTE2OCcgd2lkdGg9JzEwMS4yMDM5NDdwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMy44ODU0MyAyLjkwNTEwNkMzLjg4NTQzIDIuODY5MjQgMy44ODU0MyAyLjg0NTMzIDMuNjgyMTkyIDIuNjQyMDkyQzIuNDg2Njc1IDEuNDM0NjIgMS44MTcxODYgLTAuNTM3OTgzIDEuODE3MTg2IC0yLjk3NjgzN0MxLjgxNzE4NiAtNS4yOTYxMzkgMi4zNzkwNzggLTcuMjkyNjUzIDMuNzY1ODc4IC04LjcwMzM2MkMzLjg4NTQzIC04LjgxMDk1OSAzLjg4NTQzIC04LjgzNDg2OSAzLjg4NTQzIC04Ljg3MDczNUMzLjg4NTQzIC04Ljk0MjQ2NiAzLjgyNTY1NCAtOC45NjYzNzYgMy43Nzc4MzMgLTguOTY2Mzc2QzMuNjIyNDE2IC04Ljk2NjM3NiAyLjY0MjA5MiAtOC4xMDU2MDQgMi4wNTYyODkgLTYuOTMzOTk4QzEuNDQ2NTc1IC01LjcyNjUyNiAxLjE3MTYwNiAtNC40NDczMjMgMS4xNzE2MDYgLTIuOTc2ODM3QzEuMTcxNjA2IC0xLjkxMjgyNyAxLjMzODk3OSAtMC40OTAxNjIgMS45NjA2NDggMC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicgaWQ9J2cyLTQwJy8+CjxwYXRoIGQ9J00zLjM3MTM1NyAtMi45NzY4MzdDMy4zNzEzNTcgLTMuODg1NDMgMy4yNTE4MDYgLTUuMzY3ODcgMi41ODIzMTYgLTYuNzU0NjdDMS44NzY5NjEgLTguMTg5MjkgMC44OTY2MzggLTguOTY2Mzc2IDAuNzY1MTMxIC04Ljk2NjM3NkMwLjcxNzMxIC04Ljk2NjM3NiAwLjY1NzUzNCAtOC45NDI0NjYgMC42NTc1MzQgLTguODcwNzM1QzAuNjU3NTM0IC04LjgzNDg2OSAwLjY1NzUzNCAtOC44MTA5NTkgMC44NjA3NzIgLTguNjA3NzIxQzIuMDU2Mjg5IC03LjQwMDI0OSAyLjcyNTc3OCAtNS40Mjc2NDYgMi43MjU3NzggLTIuOTg4NzkyQzIuNzI1Nzc4IC0wLjY2OTQ4OSAyLjE2Mzg4NSAxLjMyNzAyNCAwLjc3NzA4NiAyLjczNzczM0MwLjY1NzUzNCAyLjg0NTMzIDAuNjU3NTM0IDIuODY5MjQgMC42NTc1MzQgMi45MDUxMDZDMC42NTc1MzQgMi45NzY4MzcgMC43MTczMSAzLjAwMDc0NyAwLjc2NTEzMSAzLjAwMDc0N0MwLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAwLjk2ODM2OUMzLjA5NjM4OSAtMC4yNTEwNTkgMy4zNzEzNTcgLTEuNTQyMjE3IDMuMzcxMzU3IC0yLjk3NjgzN1onIGlkPSdnMi00MScvPgo8cGF0aCBkPSdNNC43NzAxMTIgLTIuNzYxNjQ0SDguMDY5NzM4QzguMjM3MTExIC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi43NjE2NDQgOC40NTIzMDQgLTIuOTc2ODM3QzguNDUyMzA0IC0zLjIwMzk4NSA4LjI0OTA2NiAtMy4yMDM5ODUgOC4wNjk3MzggLTMuMjAzOTg1SDQuNzcwMTEyVi02LjUwMzYxMUM0Ljc3MDExMiAtNi42NzA5ODQgNC43NzAxMTIgLTYuODg2MTc3IDQuNTU0OTE5IC02Ljg4NjE3N0M0LjMyNzc3MSAtNi44ODYxNzcgNC4zMjc3NzEgLTYuNjgyOTM5IDQuMzI3NzcxIC02LjUwMzYxMVYtMy4yMDM5ODVIMS4wMjgxNDRDMC44NjA3NzIgLTMuMjAzOTg1IDAuNjQ1NTc5IC0zLjIwMzk4NSAwLjY0NTU3OSAtMi45ODg3OTJDMC42NDU1NzkgLTIuNzYxNjQ0IDAuODQ4ODE3IC0yLjc2MTY0NCAxLjAyODE0NCAtMi43NjE2NDRINC4zMjc3NzFWMC41Mzc5ODNDNC4zMjc3NzEgMC43MDUzNTUgNC4zMjc3NzEgMC45MjA1NDggNC41NDI5NjQgMC45MjA1NDhDNC43NzAxMTIgMC45MjA1NDggNC43NzAxMTIgMC43MTczMSA0Ljc3MDExMiAwLjUzNzk4M1YtMi43NjE2NDRaJyBpZD0nZzItNDMnLz4KPHBhdGggZD0nTTMuNDQzMDg4IC03LjY2MzI2M0MzLjQ0MzA4OCAtNy45MzgyMzIgMy40NDMwODggLTcuOTUwMTg3IDMuMjAzOTg1IC03Ljk1MDE4N0MyLjkxNzA2MSAtNy42MjczOTcgMi4zMTkzMDMgLTcuMTg1MDU2IDEuMDg3OTIgLTcuMTg1MDU2Vi02LjgzODM1NkMxLjM2Mjg4OSAtNi44MzgzNTYgMS45NjA2NDggLTYuODM4MzU2IDIuNjE4MTgyIC03LjE0OTE5MVYtMC45MjA1NDhDMi42MTgxODIgLTAuNDkwMTYyIDIuNTgyMzE2IC0wLjM0NjcgMS41MzAyNjIgLTAuMzQ2N0gxLjE1OTY1MVYwQzEuNDgyNDQxIC0wLjAyMzkxIDIuNjQyMDkyIC0wLjAyMzkxIDMuMDM2NjEzIC0wLjAyMzkxUzQuNTc4ODI5IC0wLjAyMzkxIDQuOTAxNjE5IDBWLTAuMzQ2N0g0LjUzMTAwOUMzLjQ3ODk1NCAtMC4zNDY3IDMuNDQzMDg4IC0wLjQ5MDE2MiAzLjQ0MzA4OCAtMC45MjA1NDhWLTcuNjYzMjYzWicgaWQ9J2cyLTQ5Jy8+CjxwYXRoIGQ9J004LjA2OTczOCAtMy44NzM0NzRDOC4yMzcxMTEgLTMuODczNDc0IDguNDUyMzA0IC0zLjg3MzQ3NCA4LjQ1MjMwNCAtNC4wODg2NjdDOC40NTIzMDQgLTQuMzE1ODE2IDguMjQ5MDY2IC00LjMxNTgxNiA4LjA2OTczOCAtNC4zMTU4MTZIMS4wMjgxNDRDMC44NjA3NzIgLTQuMzE1ODE2IDAuNjQ1NTc5IC00LjMxNTgxNiAwLjY0NTU3OSAtNC4xMDA2MjNDMC42NDU1NzkgLTMuODczNDc0IDAuODQ4ODE3IC0zLjg3MzQ3NCAxLjAyODE0NCAtMy44NzM0NzRIOC4wNjk3MzhaTTguMDY5NzM4IC0xLjY0OTgxM0M4LjIzNzExMSAtMS42NDk4MTMgOC40NTIzMDQgLTEuNjQ5ODEzIDguNDUyMzA0IC0xLjg2NTAwNkM4LjQ1MjMwNCAtMi4wOTIxNTQgOC4yNDkwNjYgLTIuMDkyMTU0IDguMDY5NzM4IC0yLjA5MjE1NEgxLjAyODE0NEMwLjg2MDc3MiAtMi4wOTIxNTQgMC42NDU1NzkgLTIuMDkyMTU0IDAuNjQ1NTc5IC0xLjg3Njk2MUMwLjY0NTU3OSAtMS42NDk4MTMgMC44NDg4MTcgLTEuNjQ5ODEzIDEuMDI4MTQ0IC0xLjY0OTgxM0g4LjA2OTczOFonIGlkPSdnMi02MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMi05MycvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzEtNTknLz4KPHBhdGggZD0nTTIuMDMyMzc5IC0xLjMyNzAyNEMxLjYxMzk0OCAtMC42MjE2NjkgMS4yMDc0NzIgLTAuMzgyNTY1IDAuNjMzNjI0IC0wLjM0NjdDMC41MDIxMTcgLTAuMzM0NzQ1IDAuNDA2NDc2IC0wLjMzNDc0NSAwLjQwNjQ3NiAtMC4xMTk1NTJDMC40MDY0NzYgLTAuMDQ3ODIxIDAuNDY2MjUyIDAgMC41NDk5MzggMEMwLjc2NTEzMSAwIDEuMzAzMTEzIC0wLjAyMzkxIDEuNTE4MzA2IC0wLjAyMzkxQzEuODY1MDA2IC0wLjAyMzkxIDIuMjQ3NTcyIDAgMi41ODIzMTYgMEMyLjY1NDA0NyAwIDIuNzk3NTA5IDAgMi43OTc1MDkgLTAuMjI3MTQ4QzIuNzk3NTA5IC0wLjMzNDc0NSAyLjcwMTg2OCAtMC4zNDY3IDIuNjMwMTM3IC0wLjM0NjdDMi4zNTUxNjggLTAuMzcwNjEgMi4xMjgwMiAtMC40NjYyNTIgMi4xMjgwMiAtMC43NTMxNzZDMi4xMjgwMiAtMC45MjA1NDggMi4xOTk3NTEgLTEuMDUyMDU1IDIuMzU1MTY4IC0xLjMxNTA2OEwzLjI2Mzc2MSAtMi44MjE0Mkg2LjMxMjMyOUM2LjMyNDI4NCAtMi43MTM4MjMgNi4zMjQyODQgLTIuNjE4MTgyIDYuMzM2MjM5IC0yLjUxMDU4NUM2LjM3MjEwNSAtMi4xOTk3NTEgNi41MTU1NjcgLTAuOTU2NDEzIDYuNTE1NTY3IC0wLjcyOTI2NUM2LjUxNTU2NyAtMC4zNzA2MSA1LjkwNTg1MyAtMC4zNDY3IDUuNzE0NTcgLTAuMzQ2N0M1LjU4MzA2NCAtMC4zNDY3IDUuNDUxNTU3IC0wLjM0NjcgNS40NTE1NTcgLTAuMTMxNTA3QzUuNDUxNTU3IDAgNS41NTkxNTMgMCA1LjYzMDg4NCAwQzUuODM0MTIyIDAgNi4wNzMyMjUgLTAuMDIzOTEgNi4yNzY0NjMgLTAuMDIzOTFINi45NTc5MDhDNy42ODcxNzMgLTAuMDIzOTEgOC4yMTMyIDAgOC4yMjUxNTYgMEM4LjMwODg0MiAwIDguNDQwMzQ5IDAgOC40NDAzNDkgLTAuMjI3MTQ4QzguNDQwMzQ5IC0wLjM0NjcgOC4zMzI3NTIgLTAuMzQ2NyA4LjE1MzQyNSAtMC4zNDY3QzcuNDk1ODkgLTAuMzQ2NyA3LjQ4MzkzNSAtMC40NTQyOTYgNy40NDgwNyAtMC44MTI5NTFMNi43MTg4MDQgLTguMjcyOTc2QzYuNjk0ODk0IC04LjUxMjA4IDYuNjQ3MDczIC04LjUzNTk5IDYuNTE1NTY3IC04LjUzNTk5QzYuMzk2MDE1IC04LjUzNTk5IDYuMzI0Mjg0IC04LjUxMjA4IDYuMjE2Njg3IC04LjMzMjc1MkwyLjAzMjM3OSAtMS4zMjcwMjRaTTMuNDY2OTk5IC0zLjE2ODEyTDUuODY5OTg4IC03LjE4NTA1Nkw2LjI3NjQ2MyAtMy4xNjgxMkgzLjQ2Njk5OVonIGlkPSdnMS02NScvPgo8cGF0aCBkPSdNMy41NTA2ODUgLTMuODk3Mzg1SDQuNjk4MzgxQzUuNjA2OTc0IC0zLjg5NzM4NSA1LjY3ODcwNSAtMy42OTQxNDcgNS42Nzg3MDUgLTMuMzQ3NDQ3QzUuNjc4NzA1IC0zLjE5MjAzIDUuNjU0Nzk1IC0zLjAyNDY1OCA1LjU5NTAxOSAtMi43NjE2NDRDNS41NzExMDggLTIuNzEzODIzIDUuNTU5MTUzIC0yLjY1NDA0NyA1LjU1OTE1MyAtMi42MzAxMzdDNS41NTkxNTMgLTIuNTQ2NDUxIDUuNjA2OTc0IC0yLjQ5ODYzIDUuNjkwNjYgLTIuNDk4NjNDNS43ODYzMDEgLTIuNDk4NjMgNS43OTgyNTcgLTIuNTQ2NDUxIDUuODQ2MDc3IC0yLjczNzczM0w2LjUzOTQ3NyAtNS41MjMyODhDNi41Mzk0NzcgLTUuNTcxMTA4IDYuNTAzNjExIC01LjY0MjgzOSA2LjQxOTkyNSAtNS42NDI4MzlDNi4zMTIzMjkgLTUuNjQyODM5IDYuMzAwMzc0IC01LjU5NTAxOSA2LjI1MjU1MyAtNS4zOTE3ODFDNi4wMDE0OTQgLTQuNDk1MTQzIDUuNzYyMzkxIC00LjI0NDA4NSA0LjcyMjI5MSAtNC4yNDQwODVIMy42MzQzNzFMNC40MTE0NTcgLTcuMzQwNDczQzQuNTE5MDU0IC03Ljc1ODkwNCA0LjU0Mjk2NCAtNy43OTQ3NyA1LjAzMzEyNiAtNy43OTQ3N0g2LjYzNTExOEM4LjEyOTUxNCAtNy43OTQ3NyA4LjM0NDcwNyAtNy4zNTI0MjggOC4zNDQ3MDcgLTYuNTAzNjExQzguMzQ0NzA3IC02LjQzMTg4IDguMzQ0NzA3IC02LjE2ODg2NyA4LjMwODg0MiAtNS44NTgwMzJDOC4yOTY4ODcgLTUuODEwMjEyIDguMjcyOTc2IC01LjY1NDc5NSA4LjI3Mjk3NiAtNS42MDY5NzRDOC4yNzI5NzYgLTUuNTExMzMzIDguMzMyNzUyIC01LjQ3NTQ2NyA4LjQwNDQ4MyAtNS40NzU0NjdDOC40ODgxNjkgLTUuNDc1NDY3IDguNTM1OTkgLTUuNTIzMjg4IDguNTU5OSAtNS43Mzg0ODFMOC44MTA5NTkgLTcuODMwNjM1QzguODEwOTU5IC03Ljg2NjUwMSA4LjgzNDg2OSAtNy45ODYwNTIgOC44MzQ4NjkgLTguMDA5OTYzQzguODM0ODY5IC04LjE0MTQ2OSA4LjcyNzI3MyAtOC4xNDE0NjkgOC41MTIwOCAtOC4xNDE0NjlIMi44NDUzM0MyLjYxODE4MiAtOC4xNDE0NjkgMi40OTg2MyAtOC4xNDE0NjkgMi40OTg2MyAtNy45MjYyNzZDMi40OTg2MyAtNy43OTQ3NyAyLjU4MjMxNiAtNy43OTQ3NyAyLjc4NTU1NCAtNy43OTQ3N0MzLjUyNjc3NSAtNy43OTQ3NyAzLjUyNjc3NSAtNy43MTEwODMgMy41MjY3NzUgLTcuNTc5NTc3QzMuNTI2Nzc1IC03LjUxOTgwMSAzLjUxNDgxOSAtNy40NzE5OCAzLjQ3ODk1NCAtNy4zNDA0NzNMMS44NjUwMDYgLTAuODg0NjgyQzEuNzU3NDEgLTAuNDY2MjUyIDEuNzMzNDk5IC0wLjM0NjcgMC44OTY2MzggLTAuMzQ2N0MwLjY2OTQ4OSAtMC4zNDY3IDAuNTQ5OTM4IC0wLjM0NjcgMC41NDk5MzggLTAuMTMxNTA3QzAuNTQ5OTM4IDAgMC42NTc1MzQgMCAwLjcyOTI2NSAwQzAuOTU2NDEzIDAgMS4xOTU1MTcgLTAuMDIzOTEgMS40MjI2NjUgLTAuMDIzOTFIMi45NzY4MzdDMy4yMzk4NTEgLTAuMDIzOTEgMy41MjY3NzUgMCAzLjc4OTc4OCAwQzMuODk3Mzg1IDAgNC4wNDA4NDcgMCA0LjA0MDg0NyAtMC4yMTUxOTNDNC4wNDA4NDcgLTAuMzQ2NyAzLjk2OTExNiAtMC4zNDY3IDMuNzA2MTAyIC0wLjM0NjdDMi43NjE2NDQgLTAuMzQ2NyAyLjczNzczMyAtMC40MzAzODYgMi43Mzc3MzMgLTAuNjA5NzE0QzIuNzM3NzMzIC0wLjY2OTQ4OSAyLjc2MTY0NCAtMC43NjUxMzEgMi43ODU1NTQgLTAuODQ4ODE3TDMuNTUwNjg1IC0zLjg5NzM4NVonIGlkPSdnMS03MCcvPgo8cGF0aCBkPSdNMy4zODMzMTMgLTEuNzA5NTg5QzMuMzgzMzEzIC0xLjc2OTM2NSAzLjMzNTQ5MiAtMS44MTcxODYgMy4yNjM3NjEgLTEuODE3MTg2QzMuMTU2MTY0IC0xLjgxNzE4NiAzLjE0NDIwOSAtMS43ODEzMiAzLjA4NDQzMyAtMS41NzgwODJDMi43NzM1OTkgLTAuNDkwMTYyIDIuMjgzNDM3IC0wLjExOTU1MiAxLjg4ODkxNyAtMC4xMTk1NTJDMS43NDU0NTUgLTAuMTE5NTUyIDEuNTc4MDgyIC0wLjE1NTQxNyAxLjU3ODA4MiAtMC41MTQwNzJDMS41NzgwODIgLTAuODM2ODYyIDEuNzIxNTQ0IC0xLjE5NTUxNyAxLjg1MzA1MSAtMS41NTQxNzJMMi42ODk5MTMgLTMuNzc3ODMzQzIuNzI1Nzc4IC0zLjg3MzQ3NCAyLjgwOTQ2NSAtNC4wODg2NjcgMi44MDk0NjUgLTQuMzE1ODE2QzIuODA5NDY1IC00LjgxNzkzMyAyLjQ1MDgwOSAtNS4yNzIyMjkgMS44NjUwMDYgLTUuMjcyMjI5QzAuNzY1MTMxIC01LjI3MjIyOSAwLjMyMjc5IC0zLjUzODczIDAuMzIyNzkgLTMuNDQzMDg4QzAuMzIyNzkgLTMuMzk1MjY4IDAuMzcwNjEgLTMuMzM1NDkyIDAuNDU0Mjk2IC0zLjMzNTQ5MkMwLjU2MTg5MyAtMy4zMzU0OTIgMC41NzM4NDggLTMuMzgzMzEzIDAuNjIxNjY5IC0zLjU1MDY4NUMwLjkwODU5MyAtNC41NTQ5MTkgMS4zNjI4ODkgLTUuMDMzMTI2IDEuODI5MTQxIC01LjAzMzEyNkMxLjkzNjczNyAtNS4wMzMxMjYgMi4xMzk5NzUgLTUuMDIxMTcxIDIuMTM5OTc1IC00LjYzODYwNUMyLjEzOTk3NSAtNC4zMjc3NzEgMS45ODQ1NTggLTMuOTMzMjUgMS44ODg5MTcgLTMuNjcwMjM3TDEuMDUyMDU1IC0xLjQ0NjU3NUMwLjk4MDMyNCAtMS4yNTUyOTMgMC45MDg1OTMgLTEuMDY0MDEgMC45MDg1OTMgLTAuODQ4ODE3QzAuOTA4NTkzIC0wLjMxMDgzNCAxLjI3OTIwMyAwLjExOTU1MiAxLjg1MzA1MSAwLjExOTU1MkMyLjk1MjkyNyAwLjExOTU1MiAzLjM4MzMxMyAtMS42MjU5MDMgMy4zODMzMTMgLTEuNzA5NTg5Wk0zLjI4NzY3MSAtNy40NjAwMjVDMy4yODc2NzEgLTcuNjM5MzUyIDMuMTQ0MjA5IC03Ljg1NDU0NSAyLjg4MTE5NiAtNy44NTQ1NDVDMi42MDYyMjcgLTcuODU0NTQ1IDIuMjk1MzkyIC03LjU5MTUzMiAyLjI5NTM5MiAtNy4yODA2OTdDMi4yOTUzOTIgLTYuOTgxODE4IDIuNTQ2NDUxIC02Ljg4NjE3NyAyLjY4OTkxMyAtNi44ODYxNzdDMy4wMTI3MDIgLTYuODg2MTc3IDMuMjg3NjcxIC03LjE5NzAxMSAzLjI4NzY3MSAtNy40NjAwMjVaJyBpZD0nZzEtMTA1Jy8+CjxwYXRoIGQ9J00yLjM3NTA5MyAtNC45NzMzNUMyLjM3NTA5MyAtNS4xNDg2OTIgMi4yNDc1NzIgLTUuMjc2MjE0IDIuMDY0MjU5IC01LjI3NjIxNEMxLjg1NzAzNiAtNS4yNzYyMTQgMS42MjU5MDMgLTUuMDg0OTMyIDEuNjI1OTAzIC00Ljg0NTgyOEMxLjYyNTkwMyAtNC42NzA0ODYgMS43NTM0MjUgLTQuNTQyOTY0IDEuOTM2NzM3IC00LjU0Mjk2NEMyLjE0Mzk2IC00LjU0Mjk2NCAyLjM3NTA5MyAtNC43MzQyNDcgMi4zNzUwOTMgLTQuOTczMzVaTTEuMjExNDU3IC0yLjA0ODMxOUwwLjc4MTA3MSAtMC45NDg0NDNDMC43NDEyMiAtMC44Mjg4OTIgMC43MDEzNyAtMC43MzMyNSAwLjcwMTM3IC0wLjU5Nzc1OEMwLjcwMTM3IC0wLjIwNzIyMyAxLjAwNDIzNCAwLjA3OTcwMSAxLjQyNjY1IDAuMDc5NzAxQzIuMTk5NzUxIDAuMDc5NzAxIDIuNTI2NTI2IC0xLjAzNjExNSAyLjUyNjUyNiAtMS4xMzk3MjZDMi41MjY1MjYgLTEuMjE5NDI3IDIuNDYyNzY1IC0xLjI0MzMzNyAyLjQwNjk3NCAtMS4yNDMzMzdDMi4zMTEzMzMgLTEuMjQzMzM3IDIuMjk1MzkyIC0xLjE4NzU0NyAyLjI3MTQ4MiAtMS4xMDc4NDZDMi4wODgxNjkgLTAuNDcwMjM3IDEuNzYxMzk1IC0wLjE0MzQ2MiAxLjQ0MjU5IC0wLjE0MzQ2MkMxLjM0Njk0OSAtMC4xNDM0NjIgMS4yNTEzMDggLTAuMTgzMzEzIDEuMjUxMzA4IC0wLjM5ODUwNkMxLjI1MTMwOCAtMC41ODk3ODggMS4zMDcwOTggLTAuNzMzMjUgMS40MTA3MSAtMC45ODAzMjRDMS40OTA0MTEgLTEuMTk1NTE3IDEuNTcwMTEyIC0xLjQxMDcxIDEuNjU3NzgzIC0xLjYyNTkwM0wxLjkwNDg1NyAtMi4yNzE0ODJDMS45NzY1ODggLTIuNDU0Nzk1IDIuMDcyMjI5IC0yLjcwMTg2OCAyLjA3MjIyOSAtMi44MzczNkMyLjA3MjIyOSAtMy4yMzU4NjYgMS43NTM0MjUgLTMuNTE0ODE5IDEuMzQ2OTQ5IC0zLjUxNDgxOUMwLjU3Mzg0OCAtMy41MTQ4MTkgMC4yMzkxMDMgLTIuMzk5MDA0IDAuMjM5MTAzIC0yLjI5NTM5MkMwLjIzOTEwMyAtMi4yMjM2NjEgMC4yOTQ4OTQgLTIuMTkxNzgxIDAuMzU4NjU1IC0yLjE5MTc4MUMwLjQ2MjI2NyAtMi4xOTE3ODEgMC40NzAyMzcgLTIuMjM5NjAxIDAuNDk0MTQ3IC0yLjMxOTMwM0MwLjcxNzMxIC0zLjA3NjQ2MyAxLjA4MzkzNSAtMy4yOTE2NTYgMS4zMjMwMzkgLTMuMjkxNjU2QzEuNDM0NjIgLTMuMjkxNjU2IDEuNTE0MzIxIC0zLjI1MTgwNiAxLjUxNDMyMSAtMy4wMjg2NDNDMS41MTQzMjEgLTIuOTQ4OTQxIDEuNTA2MzUxIC0yLjgzNzM2IDEuNDI2NjUgLTIuNTk4MjU3TDEuMjExNDU3IC0yLjA0ODMxOVonIGlkPSdnMC0xMDUnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzU2LjQxMzI2NycgeGxpbms6aHJlZj0nI2cxLTY1JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc2NS4xODg2MTQnIHhsaW5rOmhyZWY9JyNnMC0xMDUnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzcxLjg5MDcxNScgeGxpbms6aHJlZj0nI2cyLTYxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MC45OTUzNjYnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nODQuMjQ3MDI4JyB4bGluazpocmVmPScjZzEtNzAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzkzLjQ1MDY0MycgeGxpbms6aHJlZj0nI2cyLTQwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc5OC4wMDI5NjgnIHhsaW5rOmhyZWY9JyNnMS0xMDUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEwMS45OTY0MDEnIHhsaW5rOmhyZWY9JyNnMi00MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTA2LjU0ODcyNicgeGxpbms6aHJlZj0nI2cxLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMTEuNzkyODg1JyB4bGluazpocmVmPScjZzEtNzAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyMC45OTY1JyB4bGluazpocmVmPScjZzItNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyNS41NDg4MjYnIHhsaW5rOmhyZWY9JyNnMS0xMDUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEzMi4xOTg5MjInIHhsaW5rOmhyZWY9JyNnMi00MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTQzLjk2MDIzNycgeGxpbms6aHJlZj0nI2cyLTQ5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNDkuODEzMjI3JyB4bGluazpocmVmPScjZzItNDEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE1NC4zNjU1NTMnIHhsaW5rOmhyZWY9JyNnMi05MycgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) . Pour simuler
une loi multinomiale, il suffit de tirer un nombre aléatoire dans
. Pour simuler
une loi multinomiale, il suffit de tirer un nombre aléatoire dans
![[0,1]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAyMy40NTM0NjIgMTEuOTU1MTY4JyB3aWR0aD0nMjMuNDUzNDYycHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuMzMxMjU4IDAuMDQ3ODIxQzIuMzMxMjU4IC0wLjY0NTU3OSAyLjEwNDExIC0xLjE1OTY1MSAxLjYxMzk0OCAtMS4xNTk2NTFDMS4yMzEzODIgLTEuMTU5NjUxIDEuMDQwMSAtMC44NDg4MTcgMS4wNDAxIC0wLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3IC0wLjA0NzgyMSAyLjAyMDQyMyAtMC4xNTU0MTdDMi4wNDQzMzQgLTAuMTc5MzI4IDIuMDU2Mjg5IC0wLjE3OTMyOCAyLjA2ODI0NCAtMC4xNzkzMjhDMi4wOTIxNTQgLTAuMTc5MzI4IDIuMDkyMTU0IC0wLjAxMTk1NSAyLjA5MjE1NCAwLjA0NzgyMUMyLjA5MjE1NCAwLjQ0MjM0MSAyLjAyMDQyMyAxLjIxOTQyNyAxLjMyNzAyNCAxLjk5NjUxM0MxLjE5NTUxNyAyLjEzOTk3NSAxLjE5NTUxNyAyLjE2Mzg4NSAxLjE5NTUxNyAyLjE4Nzc5NkMxLjE5NTUxNyAyLjI0NzU3MiAxLjI1NTI5MyAyLjMwNzM0NyAxLjMxNTA2OCAyLjMwNzM0N0MxLjQxMDcxIDIuMzA3MzQ3IDIuMzMxMjU4IDEuNDIyNjY1IDIuMzMxMjU4IDAuMDQ3ODIxWicgaWQ9J2cwLTU5Jy8+CjxwYXRoIGQ9J001LjM1NTkxNSAtMy44MjU2NTRDNS4zNTU5MTUgLTQuODE3OTMzIDUuMjk2MTM5IC01Ljc4NjMwMSA0Ljg2NTc1MyAtNi42OTQ4OTRDNC4zNzU1OTIgLTcuNjg3MTczIDMuNTE0ODE5IC03Ljk1MDE4NyAyLjkyOTAxNiAtNy45NTAxODdDMi4yMzU2MTYgLTcuOTUwMTg3IDEuMzg2OCAtNy42MDM0ODcgMC45NDQ0NTggLTYuNjExMjA4QzAuNjA5NzE0IC01Ljg1ODAzMiAwLjQ5MDE2MiAtNS4xMTY4MTIgMC40OTAxNjIgLTMuODI1NjU0QzAuNDkwMTYyIC0yLjY2NjAwMiAwLjU3Mzg0OCAtMS43OTMyNzUgMS4wMDQyMzQgLTAuOTQ0NDU4QzEuNDcwNDg2IC0wLjAzNTg2NiAyLjI5NTM5MiAwLjI1MTA1OSAyLjkxNzA2MSAwLjI1MTA1OUMzLjk1NzE2MSAwLjI1MTA1OSA0LjU1NDkxOSAtMC4zNzA2MSA0LjkwMTYxOSAtMS4wNjQwMUM1LjMzMjAwNSAtMS45NjA2NDggNS4zNTU5MTUgLTMuMTMyMjU0IDUuMzU1OTE1IC0zLjgyNTY1NFpNMi45MTcwNjEgMC4wMTE5NTVDMi41MzQ0OTYgMC4wMTE5NTUgMS43NTc0MSAtMC4yMDMyMzggMS41MzAyNjIgLTEuNTA2MzUxQzEuMzk4NzU1IC0yLjIyMzY2MSAxLjM5ODc1NSAtMy4xMzIyNTQgMS4zOTg3NTUgLTMuOTY5MTE2QzEuMzk4NzU1IC00Ljk0OTQ0IDEuMzk4NzU1IC01LjgzNDEyMiAxLjU5MDAzNyAtNi41Mzk0NzdDMS43OTMyNzUgLTcuMzQwNDczIDIuNDAyOTg5IC03LjcxMTA4MyAyLjkxNzA2MSAtNy43MTEwODNDMy4zNzEzNTcgLTcuNzExMDgzIDQuMDY0NzU3IC03LjQzNjExNSA0LjI5MTkwNSAtNi40MDc5N0M0LjQ0NzMyMyAtNS43MjY1MjYgNC40NDczMjMgLTQuNzgyMDY3IDQuNDQ3MzIzIC0zLjk2OTExNkM0LjQ0NzMyMyAtMy4xNjgxMiA0LjQ0NzMyMyAtMi4yNTk1MjcgNC4zMTU4MTYgLTEuNTMwMjYyQzQuMDg4NjY3IC0wLjIxNTE5MyAzLjMzNTQ5MiAwLjAxMTk1NSAyLjkxNzA2MSAwLjAxMTk1NVonIGlkPSdnMS00OCcvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzEtNDknLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2cxLTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2cxLTkzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHhsaW5rOmhyZWY9JyNnMS05MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNTkuNjY0OTI4JyB4bGluazpocmVmPScjZzEtNDgnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY1LjUxNzkxOScgeGxpbms6aHJlZj0nI2cwLTU5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc3MC43NjIwNzgnIHhsaW5rOmhyZWY9JyNnMS00OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzYuNjE1MDY4JyB4bGluazpocmVmPScjZzEtOTMnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) puis de trouver l’intervalle
puis de trouver l’intervalle  auquel il
appartient.
auquel il
appartient.  est le résultat cherché. Le calcul de la
distribution cumulée utilise une autre alternative :
functools.reduce.
est le résultat cherché. Le calcul de la
distribution cumulée utilise une autre alternative :
functools.reduce.
import functools, random
def simulation_multinomiale(poids):
# calcule la fonction de répartition
# voir https://docs.python.org/3.4/library/functools.html#functools.reduce
def agg(x,y):
x.append(y)
return x
cum = functools.reduce(agg, poids, [])
x = random.random()
s = 0
i = 0
while s <= x and i < len(cum):
s += cum[i]
i += 1
return i-1
alea = [ simulation_multinomiale(poids) for i in range(0,1000) ]
alea[:10]
[0, 4, 2, 4, 2, 3, 4, 4, 4, 4]
On vérifie que les probabilités d’apparition de chaque nombre sont celles attendues.
import collections
c = collections.Counter(alea)
c
Counter({4: 405, 0: 185, 2: 153, 1: 150, 3: 107})
Une première optimisation : tri des poids#
L’algorithme fait intervenir le calcul de la distribution cumulée.
Lorsqu’on tire un grand nombre de variable aléatoire, il est intéressant
de ne faire ce calcul qu’une seule fois puisqu’il ne change jamais. De
même, il est plus intéressant de mettre les valeurs de plus grand poids
en premier. La boucle de la fonction simulation_multinomiale
s’arrêtera plus tôt.
def simulation_multinomiale(pc):
x = random.random()
s = 0
i = 0
while s <= x and i < len(pc):
s += pc[i]
i += 1
return i-1
def agg(x,y):
x.append(y)
return x
poids_cumule = functools.reduce(agg, poids, [])
poids_cumule_trie = functools.reduce(agg, sorted(poids, reverse=True), [])
print(poids_cumule, poids_cumule_trie)
import time
for p in range(0,3):
print("passage",p)
a = time.perf_counter()
alea = [ simulation_multinomiale(poids_cumule) for i in range(0,10000) ]
b = time.perf_counter()
print(" non trié", b-a)
a = time.perf_counter()
alea = [ simulation_multinomiale(poids_cumule_trie) for i in range(0,10000) ]
b = time.perf_counter()
print(" trié", b-a)
[0.2, 0.15, 0.15, 0.1, 0.4] [0.4, 0.2, 0.15, 0.15, 0.1]
passage 0
non trié 0.052738262983552886
trié 0.026375759856477998
passage 1
non trié 0.04119122404517839
trié 0.01982565262665048
passage 2
non trié 0.025675719017215215
trié 0.020590266567126037
La seconde version est plus rapide.Son intérêt dépend du nombre
d’observations aléatoire à tirer. En effet, si  est le nombre
de valeurs distinctes, les coûts fixes des deux méthodes sont les
suivants :
est le nombre
de valeurs distinctes, les coûts fixes des deux méthodes sont les
suivants :
non trié :
 (distribution cumulative)
(distribution cumulative)trié :
 ((distribution cumulative + tri)
((distribution cumulative + tri)
Qu’en est-il pour la fonction numpy.random.multinomial ?
poids_trie = list(sorted(poids, reverse=True))
for p in range(0,3):
print("passage",p)
a = time.perf_counter()
rnd.multinomial(10000, poids)
b = time.perf_counter()
print(" non trié", b-a)
a = time.perf_counter()
rnd.multinomial(10000, poids_trie)
b = time.perf_counter()
print(" trié", b-a)
passage 0
non trié 0.00011246838175793528
trié 5.6020372539933305e-05
passage 1
non trié 4.96058262342558e-05
trié 4.704000753008586e-05
passage 2
non trié 7.483637568839185e-05
trié 4.8750553105492145e-05
C’est plus rapide aussi. On voit aussi que cette façon de faire est beaucoup plus rapide que la version implémentée en Python pur. Cela vient du faire que le module numpy est optimisé pour le calcul numérique et surtout implémenté en langages C++ et Fortran.
Optimisation bootstrap#
C’est une technique inspiré du
bootstrap
qui est un peu moins précise que la version précédente mais qui peut
suffire dans bien des cas. Elle est intéressante si on tire un grand
nomrbre d’observations aléatoire de la même loi et si est
grand ( = nombre de valeurs distinctes). L’idée consiste à
générer un premier grand vecteur de nombres aléatoires puis à tirer des
nombres aléatoire dans ce vecteur.
K = 100
poids = [ 1/K for i in range(0,K) ]
poids_cumule = functools.reduce(agg, poids, [])
vecteur = [ simulation_multinomiale(poids_cumule) for i in range(0,100000) ]
N = len(vecteur)-1
for p in range(0,3):
print("passage",p)
a = time.perf_counter()
alea = [ simulation_multinomiale(poids_cumule) for i in range(0,10000) ]
b = time.perf_counter()
print(" simulation_multinomiale", b-a)
a = time.perf_counter()
alea = [ vecteur [ random.randint(0,N) ] for i in range(0,10000) ]
b = time.perf_counter()
print(" bootstrap", b-a)
passage 0
simulation_multinomiale 0.20075264012029947
bootstrap 0.03310761256989281
passage 1
simulation_multinomiale 0.20289253282658137
bootstrap 0.033825186502781435
passage 2
simulation_multinomiale 0.22474218868592288
bootstrap 0.04704770498210564
Cette façon de faire implique le stockage d’un grand nombre de variables
aléatoires dans vecteur. Ce procédé est plus rapide car tirer un
nombre aléatoire entier est plus rapide que de simuler une variable de
loi multinomial.