Questions Projets 2014#
Quel type de problème pour quelles données ?#
Pour un problème de regréssion (linéaire ou non) ou de classification, on s’attend à ce que les données apparaissent dans une table classique, des colonnes pour les variables, une colonne contenant la cible (ou target) : une valeur numérique pour la régression, un label pour la classification. Dans cette configuration, les données sont supposées indépendantes.
Un problème, c’est aussi souvent plein de données de sources différentes et reliées entre elles :
Certaines données sont générées par les utilisateurs (données temps réels, …), d’autres sont créées manuellement (classification de livres, …).
Elles peuvent être liées par le temps (série temporelles), géographiques (données spatiables), par une structure de réseau (facebook).
On peut aussi passer d’une représentation à l’autre en ajoutant des concepts pour passer d’une structure à l’autre. Prenons l’exemple du jeu Amazon product co-purchasing network metadata. Ce jeu contient des commentaires d’utilisateurs à propos de produits. On sait aussi quand ce commentaire a été écrit. On dispose également d’une classification des produits (DVD, livres, vidéos…). C’est une taxonomie.
Un problème classique est d’essayer de prévoir si un utilisateur aimera
un produit ou non. C’est un
système de recommandation.
On veut prédire une sorte de score d’un produit  pour un utilisateur
pour un utilisateur  à l’instant
à l’instant  .
.
On peut voir cela comme un problème de régression et imaginer une table dans laquelle on regroupe des caractéristiques sur les utilisateurs et les produits pour prédire un score. On peut voir aussi cela comme un problème de classification en changeant le score par la probabilité que l’utilisateur achète aime produit (classe 0 : il n’aime pas, classe 1 : il aime).
Problème 1
Cela dit, le jeu de données ne contient pas beaucoup de caractéristiques à part des données agrégées : combien de produits l’utilisateur a aimé, combien de fois le produit a été apprécié, combien de fois il l’a été récemment. On peut ajouter des données agrégées par catégories. Ensuite, il suffit d’apprendre un modèle en utilisant les évaluations des utilisateurs dont on dispose. C’est le problème 1.
Problème 2, 2 bis
On peut aussi se dire qu’on n’a peu exploité le fait que les utilisateurs se ressemblent et que ceux qui se ressemblent aiment souvent les mêmes produits. On peut essayer de construire un clustering (donc non supervisé) des utilisateurs. C’est le problème 2. Ensuite, on utilise les probabilités d’appartenance des utilisateurs aux clusters comme caractéristiques pour le problème 1.
On peut se dire qu’on aurait pu faire de même sur les produits. C’est le problème 3, toujours pour améliorer les performances du modèle du problème 1.
L’inconvénient de ces deux approches est que le clustering opère sur des vecteurs de très grandes dimensions et creux. Cela ne les rend pas toujours facile à réaliser.
Problème 3
Pourquoi ne pas traiter les deux en même temps en décrivant le problème comme un système de recommandations. Les données sont structurées comme un graphe biparti. Un utilisateur d’un côté, un produit de l’autre, une évaluation pondère la relation entre les deux. Ce n’est pas toujours évident d’évaluer la pertinence d’un tel système. Une façon de faire est de transformer le résultat en caractéristiques pour revenir au problème 1.
Le système de recommandations peut être vu comme une façon de déterminer la proximité entre deux produits ou deux utilisateurs. C’est une forme de distance. Deux produits proches auront une distance en dessous d’un certain seuil. On peut par exemple ajouter comme caractéristiques le nombre de produits proches un utilisateur a rédigé un commentaire.
Problème 4
Et les catégories ? C’est souvent une information assez fiable car elle a été construite manuellement par ceux qui gèrent le service. Ils sont donc intéressés à ce que cette information soit de qualité. En comparaison, les commentaires sont parfois très bruités. Lorsqu’on manque d’information sur un produit en particulier (peu de commentaires), on peut regrouper les produits peu évalués par leur catégorie dans le problème 3. Il faut décider quels produits regrouper. On peut aussi les utiliser pour clusteriser les utilisateurs : le vecteur sera d’une dimension abordable.
Problème 5
Et le temps ? On peut rechercher si certains produits sont passés de mode ou si les utilisateurs découvrent les produits souvent dans le même ordre. On peut aussi considérer que les commentaires les plus vieux ont moins de valeurs et qu’il faut leur donner moins de poids. Comment choisir ce poids dépendant du temps ?
Problème 6
Une fois de retour au problème 1, on analyse les observations pour lesquelles on fait le plus d’erreurs. On en déduit que l’un des problème évoqués ci-dessous pourrait apporter la solution, une nouvelle caractéristique…
…
C’est un peu sans fin. Si l’objectif est de suggérer des produits qui pourraient plaire à un utilisateur, une façon de mesurer la pertinence des suggestions est de mesurer l’évolution du nombre d’achats par utilisateur, de calculer la moyenne des évaluations et de voir si ces deux mesures augmentent.
Remarque
Il est facile d’évaluer un système temps réel sur le court terme et très difficile sur le long terme. Recommander un best seller a beaucoup de chance de fonctionner à court terme. A long terme, les utilisateurs peuvent se lasser de ces recommandations qu’ils jugent peu-être un peu trop faciles.
A propos de l’évaluation d’un système de recommandation#
Un système de recommandations consiste par exemple à proposer à un utilisateur des livres qu’il n’a pas encore vu mais qu’il est susceptible d’apprécier. La seule information dont on dispose est ce que les utilisateurs ont acheté ou commenté. On la décrit sous forme de graphe bi-parti : d’un côté, les utilisateurs, de l’autre les livres, entre les deux des arcs qui représente un achat (ou un commentaire).
Pourquoi est tel système est-il difficile à évaluer ?
Pour calculer un taux d’erreur, il faut connaître la réponse attendue. Or le nombre de critiques est souvent bien inférieur à l’ensemble des critiques possibles (le nombre de livres multiplié par le nombre d’utilisateurs). Autrement dit, il est illusoire de compter sur cette information. On peut y remédier en supprimant quelques arcs du graphe pour vérifier que l’algorithme d’apprentissage arrive à retrouver cette information. On peut aussi demander à des juges humains d’évaluer certains recommandations, typiquement les meilleurs recommandations obtenues après un premier apprentissage.
Pour s’assurer qu’un modèle ne fait pas de surapprentissage, il est courant de garder une partie des données (base de test) pour évaluer le modèle appris sur le reste (base d’apprentissage). Dans le cas d’un système de recommandation, les données sont liées dans graphe. Il est impossible de diviser le problème simplement. On peut clusteriser mais il n’est pas dit que les sous-graphes obtenues soient homogènes.
On peut penser également que les données futures permettront de valider un modèle : une fois les recommandations en place, le taux d’achats des utilisateurs devrait augmenter. On appelle cette évaluation online. C’est souvent la plus fiable et elle est réalisé au moyen d’un test AB : on divise le traffic d’un site en deux, chaque partie reçoit un système de recommandation différent. Cette évaluation n’est cependant pas toujours disponibles.
L’article A Survey of Accuracy Evaluation Metrics of Recommendation Tasks recense d’autres directions.
Algorithmes de recommandations :
Algorithms de clustering :
Latent Dirichlet Association (détection de thèmes, topic detection)
Pourquoi la régression logistique marche bien lorsqu’une classe est sous-représentée ?#
Supposons qu’on doive constuire un classifieur binaire (deux classes). Lorsqu’une des classes est sous-représentée, les algorithmes d’apprentissages aboutissent parfois à des modèles qui retournent toujours la même réponse : la classe sur-représentée. Le taux d’erreur correspond à la proportion d’observations dans la classe sous-représentée.
L”analyse discriminante linéaire échappe à ce biais car elle consiste à trouver le meilleur hyperplan séparateur de deux nuages de points supposés gaussiens. Une classe peut être sous-représentée, le modèle produira toujours deux classes.
L’analyse discriminante linéaire de la régression logistique qui ne suppose plus les nuages de points gaussiens mais conserve toujours de bonnes propriétés.
La régression logistique est équivalente à un réseau de neurones de classification à une couche. Dans ce cas, l’algorithme d’apprentissage le plus courant est celui d’une descente de gradient stochastique. Celui-ci est moins robuste dans le cas d’une classe sous-représenté tout simplement parce que l’algorithme d’apprentissage utilisera plus beaucoup fréquemment les gradients calculés pour des observations de l’autre classe. Il est souvent conseillé dans ce cas de modifier la distribution des classes dans l’échantillon d’apprentissage de façon à ce qu’elle soit plus uniforme.
Il existe des algorithmes plus robustes comme gradient boosting, AdaBoost. Il s’agit de donner plus de poids aux exemples qui produisent les plus grosses erreurs.
Une autre approche consiste à conserver l’algorithme d’optimisation de la régression logistique et à multiplier les caractéristiques non linéaires constuires à partir des features existantes : Go non-linear with Vowpal Wabbit.
False positive, mais encore ?#
A vrai dire, je me trompe encore et je me tromperai probablement toujours. Le terme n’est pas très bien choisi. Je vous invite à lire l’introduction de l’exercice du TD 2A.ml - Machine Learning et Marketting.
La courbe ROC s’applique uniquement à un classifieur. Lorsqu’on présente des résultats, il faut faire attention si le cas True Positive correspond à :
un exemple de la classe A classé dans la classe A
un exemple d’une classe quelconque (A, B, …) classé dans la bonne classe
Aucun modèle ne fonctionne, que faire ? Des features ?#
Lorsque deux modèles différents retourne le même type de performance, on
est souvent tenté d’en utiliser un troisième voire de jouer avec les meta-paramètres
(voir la paramètre  de la régression lasso).
Que doit-on améliorer ? Le modèle, les features ?
de la régression lasso).
Que doit-on améliorer ? Le modèle, les features ?
Une première indication consiste à regarder si les deux modèles obtenus se trompent sur les mêmes observations. Dans ce cas, il est plus probable que les modèles manquent d’informations sur ces observations. Il faut alors se pencher sur ces observations pour imaginer des features qui les différencient du reste des données. On peut soit tirer un échantillon parmi ces erreurs, soit regarder en priorité les erreurs pour lesquelles le score de confiance est le plus élevé. Si c’est un problème de classification, on peut aussi regarder les classes pour lesquelles le taux d’erreur est le plus élevé.
Si les deux modèles ne se trompent pas aux mêmes endroits, il est possible qu’un mélange de modèles suffisent à améliorer la performance ou qu’un troisième parvienne finalement à tirer un meilleur parti des features.
A quoi doit ressembler une bonne courbe ROC ?#
La courbe ROC illustre la performance d’un classifieur si celui-ci retourne une classe et un score. Plus le score est élevé, plus la confiance dans le résultat est bonne : plus la probabilité qu’il se trompe est faible. Par conséquence, une bonne courbe ROC vérifie :
le taux de précision est croissant en fonction du score
le taux de rappel est décroissant
Ce sont souvent des fonctions concaves (la précision est en rouge, le rappel en bleu).
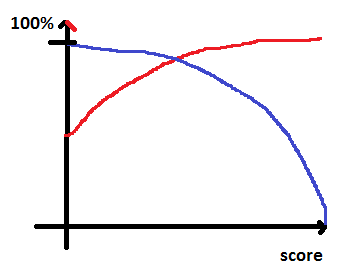
Lorsque le score est élevé, il ne reste que quelques points (rappel proche de zéros). On obtient quelque chose comme ceci :
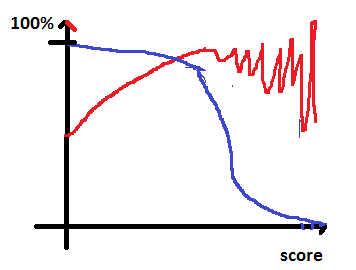
La courbe du rappel est directement relié à la distribution du score de confiance retournée par le modèle.
C’est presque une fonction de répartition :  .
.
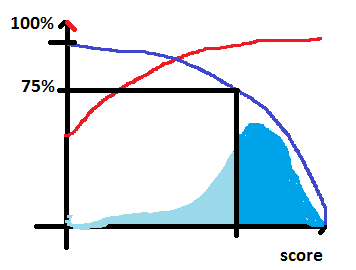
Si le score est pertinent, la probabilité de bien classer une observation augmente avec le score mais cela veut dire aussi qu’on rejette des observations (on ne le classe pas) dont le score est trop faible. Cela revient à faire un compromis entre le nombre d’exemples classés (= rappel) et la performance du modèle sur ces exemples (= précision).
Pourquoi le seuil de confiance retourné par le classifieur est-il important ?
Dans le cas d’une reconnaissance de chèques, l’erreur coûte très chère. On considère qu’il est préférable de traiter seulement les chèques pour lesquels on sait que le taux d’erreur ne sera pas très grand. Pour chaque chèque, on applique le modèle de reconnaissance, et si le seuil de confiance est inférieur à s, on traite le chèque manuellement. On a donc deux chaînes de traitements et deux coûts différents :
Si le seuil de confiance est
 , le coût est
, le coût est  où
où
 correspond au coût d’une erreur,
correspond au coût d’une erreur,  correspond
correspond au coût du traitement du chèque,
correspond
correspond au coût du traitement du chèque,  au taux d’erreur en fonction de s.
au taux d’erreur en fonction de s.Si le seuil de confiance est
 , le chèque est reconnu manuellement et on
suppose que le taux d’erreur
, le chèque est reconnu manuellement et on
suppose que le taux d’erreur  ne dépend pas du seuil.
Le coût est alors
ne dépend pas du seuil.
Le coût est alors  où
où  est le coût du traitement manuel.
est le coût du traitement manuel.
On cherche donc à minimiser le coût global
 ,
soit
,
soit ![R(s) \left[ c_1 + c_2 (1-P(s)) \right ] + (1-R(s)) \left[ c_1 + c_1' + c_2 e \right]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAyNTkuMTIzNTEzIDExLjk1NTE2OCcgd2lkdGg9JzI1OS4xMjM1MTNwdCcgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayc+CjxkZWZzPgo8cGF0aCBkPSdNMi4xMTIwOCAtMy43Nzc4MzNDMi4xNTE5MyAtMy44ODE0NDUgMi4xODM4MTEgLTMuOTM3MjM1IDIuMTgzODExIC00LjAxNjkzNkMyLjE4MzgxMSAtNC4yNzk5NSAxLjk0NDcwNyAtNC40NTUyOTMgMS43MjE1NDQgLTQuNDU1MjkzQzEuNDAyNzQgLTQuNDU1MjkzIDEuMzE1MDY4IC00LjE3NjMzOSAxLjI4MzE4OCAtNC4wNjQ3NTdMMC4yNzA5ODQgLTAuNjI5NjM5QzAuMjM5MTAzIC0wLjUzMzk5OCAwLjIzOTEwMyAtMC41MTAwODcgMC4yMzkxMDMgLTAuNTAyMTE3QzAuMjM5MTAzIC0wLjQzMDM4NiAwLjI4NjkyNCAtMC40MTQ0NDYgMC4zNjY2MjUgLTAuMzkwNTM1QzAuNTEwMDg3IC0wLjMyNjc3NSAwLjUyNjAyNyAtMC4zMjY3NzUgMC41NDE5NjggLTAuMzI2Nzc1QzAuNTY1ODc4IC0wLjMyNjc3NSAwLjYxMzY5OSAtMC4zMjY3NzUgMC42Njk0ODkgLTAuNDYyMjY3TDIuMTEyMDggLTMuNzc3ODMzWicgaWQ9J2cwLTQ4Jy8+CjxwYXRoIGQ9J003Ljg3ODQ1NiAtMi43NDk2ODlDOC4wODE2OTQgLTIuNzQ5Njg5IDguMjk2ODg3IC0yLjc0OTY4OSA4LjI5Njg4NyAtMi45ODg3OTJTOC4wODE2OTQgLTMuMjI3ODk1IDcuODc4NDU2IC0zLjIyNzg5NUgxLjQxMDcxQzEuMjA3NDcyIC0zLjIyNzg5NSAwLjk5MjI3OSAtMy4yMjc4OTUgMC45OTIyNzkgLTIuOTg4NzkyUzEuMjA3NDcyIC0yLjc0OTY4OSAxLjQxMDcxIC0yLjc0OTY4OUg3Ljg3ODQ1NlonIGlkPSdnMS0wJy8+CjxwYXRoIGQ9J00yLjUwMjYxNSAtNS4wNzY5NjFDMi41MDI2MTUgLTUuMjkyMTU0IDIuNDg2Njc1IC01LjMwMDEyNSAyLjI3MTQ4MiAtNS4zMDAxMjVDMS45NDQ3MDcgLTQuOTgxMzIgMS41MjIyOTEgLTQuNzkwMDM3IDAuNzY1MTMxIC00Ljc5MDAzN1YtNC41MjcwMjRDMC45ODAzMjQgLTQuNTI3MDI0IDEuNDEwNzEgLTQuNTI3MDI0IDEuODcyOTc2IC00Ljc0MjIxN1YtMC42NTM1NDlDMS44NzI5NzYgLTAuMzU4NjU1IDEuODQ5MDY2IC0wLjI2MzAxNCAxLjA5MTkwNSAtMC4yNjMwMTRIMC44MTI5NTFWMEMxLjEzOTcyNiAtMC4wMjM5MSAxLjgyNTE1NiAtMC4wMjM5MSAyLjE4MzgxMSAtMC4wMjM5MVMzLjIzNTg2NiAtMC4wMjM5MSAzLjU2MjY0IDBWLTAuMjYzMDE0SDMuMjgzNjg2QzIuNTI2NTI2IC0wLjI2MzAxNCAyLjUwMjYxNSAtMC4zNTg2NTUgMi41MDI2MTUgLTAuNjUzNTQ5Vi01LjA3Njk2MVonIGlkPSdnMy00OScvPgo8cGF0aCBkPSdNMi4yNDc1NzIgLTEuNjI1OTAzQzIuMzc1MDkzIC0xLjc0NTQ1NSAyLjcwOTgzOCAtMi4wMDg0NjggMi44MzczNiAtMi4xMjAwNUMzLjMzMTUwNyAtMi41NzQzNDYgMy44MDE3NDMgLTMuMDEyNzAyIDMuODAxNzQzIC0zLjczNzk4M0MzLjgwMTc0MyAtNC42ODY0MjYgMy4wMDQ3MzIgLTUuMzAwMTI1IDIuMDA4NDY4IC01LjMwMDEyNUMxLjA1MjA1NSAtNS4zMDAxMjUgMC40MjI0MTYgLTQuNTc0ODQ0IDAuNDIyNDE2IC0zLjg2NTUwNEMwLjQyMjQxNiAtMy40NzQ5NjkgMC43MzMyNSAtMy40MTkxNzggMC44NDQ4MzIgLTMuNDE5MTc4QzEuMDEyMjA0IC0zLjQxOTE3OCAxLjI1OTI3OCAtMy41Mzg3MyAxLjI1OTI3OCAtMy44NDE1OTRDMS4yNTkyNzggLTQuMjU2MDQgMC44NjA3NzIgLTQuMjU2MDQgMC43NjUxMzEgLTQuMjU2MDRDMC45OTYyNjQgLTQuODM3ODU4IDEuNTMwMjYyIC01LjAzNzExMSAxLjkyMDc5NyAtNS4wMzcxMTFDMi42NjIwMTcgLTUuMDM3MTExIDMuMDQ0NTgzIC00LjQwNzQ3MiAzLjA0NDU4MyAtMy43Mzc5ODNDMy4wNDQ1ODMgLTIuOTA5MDkxIDIuNDYyNzY1IC0yLjMwMzM2MiAxLjUyMjI5MSAtMS4zMzg5NzlMMC41MTgwNTcgLTAuMzAyODY0QzAuNDIyNDE2IC0wLjIxNTE5MyAwLjQyMjQxNiAtMC4xOTkyNTMgMC40MjI0MTYgMEgzLjU3MDYxTDMuODAxNzQzIC0xLjQyNjY1SDMuNTU0NjdDMy41MzA3NiAtMS4yNjcyNDggMy40NjY5OTkgLTAuODY4NzQyIDMuMzcxMzU3IC0wLjcxNzMxQzMuMzIzNTM3IC0wLjY1MzU0OSAyLjcxNzgwOCAtMC42NTM1NDkgMi41OTAyODYgLTAuNjUzNTQ5SDEuMTcxNjA2TDIuMjQ3NTcyIC0xLjYyNTkwM1onIGlkPSdnMy01MCcvPgo8cGF0aCBkPSdNMy41Mzg3MyAtMy44MDE3NDNINS41NDcxOThDNy4xOTcwMTEgLTMuODAxNzQzIDguODQ2ODI0IC01LjAyMTE3MSA4Ljg0NjgyNCAtNi4zODQwNkM4Ljg0NjgyNCAtNy4zMTY1NjMgOC4wNTc3ODMgLTguMTY1MzggNi41NTE0MzIgLTguMTY1MzhIMi44NTcyODVDMi42MzAxMzcgLTguMTY1MzggMi41MjI1NCAtOC4xNjUzOCAyLjUyMjU0IC03LjkzODIzMkMyLjUyMjU0IC03LjgxODY4IDIuNjMwMTM3IC03LjgxODY4IDIuODA5NDY1IC03LjgxODY4QzMuNTM4NzMgLTcuODE4NjggMy41Mzg3MyAtNy43MjMwMzkgMy41Mzg3MyAtNy41OTE1MzJDMy41Mzg3MyAtNy41Njc2MjEgMy41Mzg3MyAtNy40OTU4OSAzLjQ5MDkwOSAtNy4zMTY1NjNMMS44NzY5NjEgLTAuODg0NjgyQzEuNzY5MzY1IC0wLjQ2NjI1MiAxLjc0NTQ1NSAtMC4zNDY3IDAuOTA4NTkzIC0wLjM0NjdDMC42ODE0NDUgLTAuMzQ2NyAwLjU2MTg5MyAtMC4zNDY3IDAuNTYxODkzIC0wLjEzMTUwN0MwLjU2MTg5MyAwIDAuNjY5NDg5IDAgMC43NDEyMiAwQzAuOTY4MzY5IDAgMS4yMDc0NzIgLTAuMDIzOTEgMS40MzQ2MiAtMC4wMjM5MUgyLjgzMzM3NUMzLjA2MDUyMyAtMC4wMjM5MSAzLjMxMTU4MiAwIDMuNTM4NzMgMEMzLjYzNDM3MSAwIDMuNzY1ODc4IDAgMy43NjU4NzggLTAuMjI3MTQ4QzMuNzY1ODc4IC0wLjM0NjcgMy42NTgyODEgLTAuMzQ2NyAzLjQ3ODk1NCAtMC4zNDY3QzIuNzYxNjQ0IC0wLjM0NjcgMi43NDk2ODkgLTAuNDMwMzg2IDIuNzQ5Njg5IC0wLjU0OTkzOEMyLjc0OTY4OSAtMC42MDk3MTQgMi43NjE2NDQgLTAuNjkzNCAyLjc3MzU5OSAtMC43NTMxNzZMMy41Mzg3MyAtMy44MDE3NDNaTTQuMzk5NTAyIC03LjM1MjQyOEM0LjUwNzA5OCAtNy43OTQ3NyA0LjU1NDkxOSAtNy44MTg2OCA1LjAyMTE3MSAtNy44MTg2OEg2LjIwNDczMkM3LjEwMTM3IC03LjgxODY4IDcuODQyNTkgLTcuNTMxNzU2IDcuODQyNTkgLTYuNjM1MTE4QzcuODQyNTkgLTYuMzI0Mjg0IDcuNjg3MTczIC01LjMwODA5NSA3LjEzNzIzNSAtNC43NTgxNTdDNi45MzM5OTggLTQuNTQyOTY0IDYuMzYwMTQ5IC00LjA4ODY2NyA1LjI3MjIyOSAtNC4wODg2NjdIMy41ODY1NUw0LjM5OTUwMiAtNy4zNTI0MjhaJyBpZD0nZzItODAnLz4KPHBhdGggZD0nTTQuMzk5NTAyIC03LjM1MjQyOEM0LjUwNzA5OCAtNy43OTQ3NyA0LjU1NDkxOSAtNy44MTg2OCA1LjAyMTE3MSAtNy44MTg2OEg1Ljg4MTk0M0M2LjkxMDA4NyAtNy44MTg2OCA3LjY3NTIxOCAtNy41MDc4NDYgNy42NzUyMTggLTYuNTc1MzQyQzcuNjc1MjE4IC01Ljk2NTYyOSA3LjM2NDM4NCAtNC4yMDgyMTkgNC45NjEzOTUgLTQuMjA4MjE5SDMuNjEwNDYxTDQuMzk5NTAyIC03LjM1MjQyOFpNNi4wNjEyNyAtNC4wNjQ3NTdDNy41NDM3MTEgLTQuMzg3NTQ3IDguNzAzMzYyIC01LjM0Mzk2IDguNzAzMzYyIC02LjM3MjEwNUM4LjcwMzM2MiAtNy4zMDQ2MDggNy43NTg5MDQgLTguMTY1MzggNi4wOTcxMzYgLTguMTY1MzhIMi44NTcyODVDMi42MTgxODIgLTguMTY1MzggMi41MTA1ODUgLTguMTY1MzggMi41MTA1ODUgLTcuOTM4MjMyQzIuNTEwNTg1IC03LjgxODY4IDIuNTk0MjcxIC03LjgxODY4IDIuODIxNDIgLTcuODE4NjhDMy41Mzg3MyAtNy44MTg2OCAzLjUzODczIC03LjcyMzAzOSAzLjUzODczIC03LjU5MTUzMkMzLjUzODczIC03LjU2NzYyMSAzLjUzODczIC03LjQ5NTg5IDMuNDkwOTA5IC03LjMxNjU2M0wxLjg3Njk2MSAtMC44ODQ2ODJDMS43NjkzNjUgLTAuNDY2MjUyIDEuNzQ1NDU1IC0wLjM0NjcgMC45MjA1NDggLTAuMzQ2N0MwLjY0NTU3OSAtMC4zNDY3IDAuNTYxODkzIC0wLjM0NjcgMC41NjE4OTMgLTAuMTE5NTUyQzAuNTYxODkzIDAgMC42OTM0IDAgMC43MjkyNjUgMEMwLjk0NDQ1OCAwIDEuMTk1NTE3IC0wLjAyMzkxIDEuNDIyNjY1IC0wLjAyMzkxSDIuODMzMzc1QzMuMDQ4NTY4IC0wLjAyMzkxIDMuMjk5NjI2IDAgMy41MTQ4MTkgMEMzLjYxMDQ2MSAwIDMuNzQxOTY4IDAgMy43NDE5NjggLTAuMjI3MTQ4QzMuNzQxOTY4IC0wLjM0NjcgMy42MzQzNzEgLTAuMzQ2NyAzLjQ1NTA0NCAtMC4zNDY3QzIuNzI1Nzc4IC0wLjM0NjcgMi43MjU3NzggLTAuNDQyMzQxIDIuNzI1Nzc4IC0wLjU2MTg5M0MyLjcyNTc3OCAtMC41NzM4NDggMi43MjU3NzggLTAuNjU3NTM0IDIuNzQ5Njg5IC0wLjc1MzE3NkwzLjU1MDY4NSAtMy45NjkxMTZINC45ODUzMDVDNi4xMjEwNDYgLTMuOTY5MTE2IDYuMzM2MjM5IC0zLjI1MTgwNiA2LjMzNjIzOSAtMi44NTcyODVDNi4zMzYyMzkgLTIuNjc3OTU4IDYuMjE2Njg3IC0yLjIxMTcwNiA2LjEzMzAwMSAtMS45MDA4NzJDNi4wMDE0OTQgLTEuMzUwOTM0IDUuOTY1NjI5IC0xLjIxOTQyNyA1Ljk2NTYyOSAtMC45OTIyNzlDNS45NjU2MjkgLTAuMTQzNDYyIDYuNjU5MDI5IDAuMjUxMDU5IDcuNDYwMDI1IDAuMjUxMDU5QzguNDI4Mzk0IDAuMjUxMDU5IDguODQ2ODI0IC0wLjkzMjUwMyA4Ljg0NjgyNCAtMS4wOTk4NzVDOC44NDY4MjQgLTEuMTgzNTYyIDguNzg3MDQ5IC0xLjIxOTQyNyA4LjcxNTMxOCAtMS4yMTk0MjdDOC42MTk2NzYgLTEuMjE5NDI3IDguNTk1NzY2IC0xLjE0NzY5NiA4LjU3MTg1NiAtMS4wNTIwNTVDOC4yODQ5MzIgLTAuMjAzMjM4IDcuNzk0NzcgMC4wMTE5NTUgNy40OTU4OSAwLjAxMTk1NVM3LjAwNTcyOSAtMC4xMTk1NTIgNy4wMDU3MjkgLTAuNjU3NTM0QzcuMDA1NzI5IC0wLjk0NDQ1OCA3LjE0OTE5MSAtMi4wMzIzNzkgNy4xNjExNDYgLTIuMDkyMTU0QzcuMjIwOTIyIC0yLjUzNDQ5NiA3LjIyMDkyMiAtMi41ODIzMTYgNy4yMjA5MjIgLTIuNjc3OTU4QzcuMjIwOTIyIC0zLjU1MDY4NSA2LjUxNTU2NyAtMy45MjEyOTUgNi4wNjEyNyAtNC4wNjQ3NTdaJyBpZD0nZzItODInLz4KPHBhdGggZD0nTTQuNjc0NDcxIC00LjQ5NTE0M0M0LjQ0NzMyMyAtNC40OTUxNDMgNC4zMzk3MjYgLTQuNDk1MTQzIDQuMTcyMzU0IC00LjM1MTY4MUM0LjEwMDYyMyAtNC4yOTE5MDUgMy45NjkxMTYgLTQuMTEyNTc4IDMuOTY5MTE2IC0zLjkyMTI5NUMzLjk2OTExNiAtMy42ODIxOTIgNC4xNDg0NDMgLTMuNTM4NzMgNC4zNzU1OTIgLTMuNTM4NzNDNC42NjI1MTYgLTMuNTM4NzMgNC45ODUzMDUgLTMuNzc3ODMzIDQuOTg1MzA1IC00LjI1NjA0QzQuOTg1MzA1IC00LjgyOTg4OCA0LjQzNTM2NyAtNS4yNzIyMjkgMy42MTA0NjEgLTUuMjcyMjI5QzIuMDQ0MzM0IC01LjI3MjIyOSAwLjQ3ODIwNyAtMy41NjI2NCAwLjQ3ODIwNyAtMS44NjUwMDZDMC40NzgyMDcgLTAuODI0OTA3IDEuMTIzNzg2IDAuMTE5NTUyIDIuMzQzMjEzIDAuMTE5NTUyQzMuOTY5MTE2IDAuMTE5NTUyIDQuOTk3MjYgLTEuMTQ3Njk2IDQuOTk3MjYgLTEuMzAzMTEzQzQuOTk3MjYgLTEuMzc0ODQ0IDQuOTI1NTI5IC0xLjQzNDYyIDQuODc3NzA5IC0xLjQzNDYyQzQuODQxODQzIC0xLjQzNDYyIDQuODI5ODg4IC0xLjQyMjY2NSA0LjcyMjI5MSAtMS4zMTUwNjhDMy45NTcxNjEgLTAuMjk4ODc5IDIuODIxNDIgLTAuMTE5NTUyIDIuMzY3MTIzIC0wLjExOTU1MkMxLjU0MjIxNyAtMC4xMTk1NTIgMS4yNzkyMDMgLTAuODM2ODYyIDEuMjc5MjAzIC0xLjQzNDYyQzEuMjc5MjAzIC0xLjg1MzA1MSAxLjQ4MjQ0MSAtMy4wMTI3MDIgMS45MTI4MjcgLTMuODI1NjU0QzIuMjIzNjYxIC00LjM4NzU0NyAyLjg2OTI0IC01LjAzMzEyNiAzLjYyMjQxNiAtNS4wMzMxMjZDMy43Nzc4MzMgLTUuMDMzMTI2IDQuNDM1MzY3IC01LjAwOTIxNSA0LjY3NDQ3MSAtNC40OTUxNDNaJyBpZD0nZzItOTknLz4KPHBhdGggZD0nTTIuMTM5OTc1IC0yLjc3MzU5OUMyLjQ2Mjc2NSAtMi43NzM1OTkgMy4yNzU3MTYgLTIuNzk3NTA5IDMuODQ5NTY0IC0zLjAxMjcwMkM0Ljc1ODE1NyAtMy4zNTk0MDIgNC44NDE4NDMgLTQuMDUyODAyIDQuODQxODQzIC00LjI2Nzk5NUM0Ljg0MTg0MyAtNC43OTQwMjIgNC4zODc1NDcgLTUuMjcyMjI5IDMuNTk4NTA2IC01LjI3MjIyOUMyLjM0MzIxMyAtNS4yNzIyMjkgMC41Mzc5ODMgLTQuMTM2NDg4IDAuNTM3OTgzIC0yLjAwODQ2OEMwLjUzNzk4MyAtMC43NTMxNzYgMS4yNTUyOTMgMC4xMTk1NTIgMi4zNDMyMTMgMC4xMTk1NTJDMy45NjkxMTYgMC4xMTk1NTIgNC45OTcyNiAtMS4xNDc2OTYgNC45OTcyNiAtMS4zMDMxMTNDNC45OTcyNiAtMS4zNzQ4NDQgNC45MjU1MjkgLTEuNDM0NjIgNC44Nzc3MDkgLTEuNDM0NjJDNC44NDE4NDMgLTEuNDM0NjIgNC44Mjk4ODggLTEuNDIyNjY1IDQuNzIyMjkxIC0xLjMxNTA2OEMzLjk1NzE2MSAtMC4yOTg4NzkgMi44MjE0MiAtMC4xMTk1NTIgMi4zNjcxMjMgLTAuMTE5NTUyQzEuNjg1Njc5IC0wLjExOTU1MiAxLjMyNzAyNCAtMC42NTc1MzQgMS4zMjcwMjQgLTEuNTQyMjE3QzEuMzI3MDI0IC0xLjcwOTU4OSAxLjMyNzAyNCAtMi4wMDg0NjggMS41MDYzNTEgLTIuNzczNTk5SDIuMTM5OTc1Wk0xLjU2NjEyNyAtMy4wMTI3MDJDMi4wODAxOTkgLTQuODUzNzk4IDMuMjE1OTQgLTUuMDMzMTI2IDMuNTk4NTA2IC01LjAzMzEyNkM0LjEyNDUzMyAtNS4wMzMxMjYgNC40ODMxODggLTQuNzIyMjkxIDQuNDgzMTg4IC00LjI2Nzk5NUM0LjQ4MzE4OCAtMy4wMTI3MDIgMi41NzAzNjEgLTMuMDEyNzAyIDIuMDY4MjQ0IC0zLjAxMjcwMkgxLjU2NjEyN1onIGlkPSdnMi0xMDEnLz4KPHBhdGggZD0nTTIuNzI1Nzc4IC0yLjM5MTAzNEMyLjkyOTAxNiAtMi4zNTUxNjggMy4yNTE4MDYgLTIuMjgzNDM3IDMuMzIzNTM3IC0yLjI3MTQ4MkMzLjQ3ODk1NCAtMi4yMjM2NjEgNC4wMTY5MzYgLTIuMDMyMzc5IDQuMDE2OTM2IC0xLjQ1ODUzMUM0LjAxNjkzNiAtMS4wODc5MiAzLjY4MjE5MiAtMC4xMTk1NTIgMi4yOTUzOTIgLTAuMTE5NTUyQzIuMDQ0MzM0IC0wLjExOTU1MiAxLjE0NzY5NiAtMC4xNTU0MTcgMC45MDg1OTMgLTAuODEyOTUxQzEuMzg2OCAtMC43NTMxNzYgMS42MjU5MDMgLTEuMTIzNzg2IDEuNjI1OTAzIC0xLjM4NjhDMS42MjU5MDMgLTEuNjM3ODU4IDEuNDU4NTMxIC0xLjc2OTM2NSAxLjIxOTQyNyAtMS43NjkzNjVDMC45NTY0MTMgLTEuNzY5MzY1IDAuNjA5NzE0IC0xLjU2NjEyNyAwLjYwOTcxNCAtMS4wMjgxNDRDMC42MDk3MTQgLTAuMzIyNzkgMS4zMjcwMjQgMC4xMTk1NTIgMi4yODM0MzcgMC4xMTk1NTJDNC4xMDA2MjMgMC4xMTk1NTIgNC42Mzg2MDUgLTEuMjE5NDI3IDQuNjM4NjA1IC0xLjg0MTA5NkM0LjYzODYwNSAtMi4wMjA0MjMgNC42Mzg2MDUgLTIuMzU1MTY4IDQuMjU2MDQgLTIuNzM3NzMzQzMuOTU3MTYxIC0zLjAyNDY1OCAzLjY3MDIzNyAtMy4wODQ0MzMgMy4wMjQ2NTggLTMuMjE1OTRDMi43MDE4NjggLTMuMjg3NjcxIDIuMTg3Nzk2IC0zLjM5NTI2OCAyLjE4Nzc5NiAtMy45MzMyNUMyLjE4Nzc5NiAtNC4xNzIzNTQgMi40MDI5ODkgLTUuMDMzMTI2IDMuNTM4NzMgLTUuMDMzMTI2QzQuMDQwODQ3IC01LjAzMzEyNiA0LjUzMTAwOSAtNC44NDE4NDMgNC42NTA1NiAtNC40MTE0NTdDNC4xMjQ1MzMgLTQuNDExNDU3IDQuMTAwNjIzIC0zLjk1NzE2MSA0LjEwMDYyMyAtMy45NDUyMDVDNC4xMDA2MjMgLTMuNjk0MTQ3IDQuMzI3NzcxIC0zLjYyMjQxNiA0LjQzNTM2NyAtMy42MjI0MTZDNC42MDI3NCAtMy42MjI0MTYgNC45Mzc0ODQgLTMuNzUzOTIzIDQuOTM3NDg0IC00LjI1NjA0UzQuNDgzMTg4IC01LjI3MjIyOSAzLjU1MDY4NSAtNS4yNzIyMjlDMS45ODQ1NTggLTUuMjcyMjI5IDEuNTY2MTI3IC00LjA0MDg0NyAxLjU2NjEyNyAtMy41NTA2ODVDMS41NjYxMjcgLTIuNjQyMDkyIDIuNDUwODA5IC0yLjQ1MDgwOSAyLjcyNTc3OCAtMi4zOTEwMzRaJyBpZD0nZzItMTE1Jy8+CjxwYXRoIGQ9J00zLjg4NTQzIDIuOTA1MTA2QzMuODg1NDMgMi44NjkyNCAzLjg4NTQzIDIuODQ1MzMgMy42ODIxOTIgMi42NDIwOTJDMi40ODY2NzUgMS40MzQ2MiAxLjgxNzE4NiAtMC41Mzc5ODMgMS44MTcxODYgLTIuOTc2ODM3QzEuODE3MTg2IC01LjI5NjEzOSAyLjM3OTA3OCAtNy4yOTI2NTMgMy43NjU4NzggLTguNzAzMzYyQzMuODg1NDMgLTguODEwOTU5IDMuODg1NDMgLTguODM0ODY5IDMuODg1NDMgLTguODcwNzM1QzMuODg1NDMgLTguOTQyNDY2IDMuODI1NjU0IC04Ljk2NjM3NiAzLjc3NzgzMyAtOC45NjYzNzZDMy42MjI0MTYgLTguOTY2Mzc2IDIuNjQyMDkyIC04LjEwNTYwNCAyLjA1NjI4OSAtNi45MzM5OThDMS40NDY1NzUgLTUuNzI2NTI2IDEuMTcxNjA2IC00LjQ0NzMyMyAxLjE3MTYwNiAtMi45NzY4MzdDMS4xNzE2MDYgLTEuOTEyODI3IDEuMzM4OTc5IC0wLjQ5MDE2MiAxLjk2MDY0OCAwLjc4OTA0MUMyLjY2NjAwMiAyLjIyMzY2MSAzLjY0NjMyNiAzLjAwMDc0NyAzLjc3NzgzMyAzLjAwMDc0N0MzLjgyNTY1NCAzLjAwMDc0NyAzLjg4NTQzIDIuOTc2ODM3IDMuODg1NDMgMi45MDUxMDZaJyBpZD0nZzQtNDAnLz4KPHBhdGggZD0nTTMuMzcxMzU3IC0yLjk3NjgzN0MzLjM3MTM1NyAtMy44ODU0MyAzLjI1MTgwNiAtNS4zNjc4NyAyLjU4MjMxNiAtNi43NTQ2N0MxLjg3Njk2MSAtOC4xODkyOSAwLjg5NjYzOCAtOC45NjYzNzYgMC43NjUxMzEgLTguOTY2Mzc2QzAuNzE3MzEgLTguOTY2Mzc2IDAuNjU3NTM0IC04Ljk0MjQ2NiAwLjY1NzUzNCAtOC44NzA3MzVDMC42NTc1MzQgLTguODM0ODY5IDAuNjU3NTM0IC04LjgxMDk1OSAwLjg2MDc3MiAtOC42MDc3MjFDMi4wNTYyODkgLTcuNDAwMjQ5IDIuNzI1Nzc4IC01LjQyNzY0NiAyLjcyNTc3OCAtMi45ODg3OTJDMi43MjU3NzggLTAuNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IDAuNzc3MDg2IDIuNzM3NzMzQzAuNjU3NTM0IDIuODQ1MzMgMC42NTc1MzQgMi44NjkyNCAwLjY1NzUzNCAyLjkwNTEwNkMwLjY1NzUzNCAyLjk3NjgzNyAwLjcxNzMxIDMuMDAwNzQ3IDAuNzY1MTMxIDMuMDAwNzQ3QzAuOTIwNTQ4IDMuMDAwNzQ3IDEuOTAwODcyIDIuMTM5OTc1IDIuNDg2Njc1IDAuOTY4MzY5QzMuMDk2Mzg5IC0wLjI1MTA1OSAzLjM3MTM1NyAtMS41NDIyMTcgMy4zNzEzNTcgLTIuOTc2ODM3WicgaWQ9J2c0LTQxJy8+CjxwYXRoIGQ9J000Ljc3MDExMiAtMi43NjE2NDRIOC4wNjk3MzhDOC4yMzcxMTEgLTIuNzYxNjQ0IDguNDUyMzA0IC0yLjc2MTY0NCA4LjQ1MjMwNCAtMi45NzY4MzdDOC40NTIzMDQgLTMuMjAzOTg1IDguMjQ5MDY2IC0zLjIwMzk4NSA4LjA2OTczOCAtMy4yMDM5ODVINC43NzAxMTJWLTYuNTAzNjExQzQuNzcwMTEyIC02LjY3MDk4NCA0Ljc3MDExMiAtNi44ODYxNzcgNC41NTQ5MTkgLTYuODg2MTc3QzQuMzI3NzcxIC02Ljg4NjE3NyA0LjMyNzc3MSAtNi42ODI5MzkgNC4zMjc3NzEgLTYuNTAzNjExVi0zLjIwMzk4NUgxLjAyODE0NEMwLjg2MDc3MiAtMy4yMDM5ODUgMC42NDU1NzkgLTMuMjAzOTg1IDAuNjQ1NTc5IC0yLjk4ODc5MkMwLjY0NTU3OSAtMi43NjE2NDQgMC44NDg4MTcgLTIuNzYxNjQ0IDEuMDI4MTQ0IC0yLjc2MTY0NEg0LjMyNzc3MVYwLjUzNzk4M0M0LjMyNzc3MSAwLjcwNTM1NSA0LjMyNzc3MSAwLjkyMDU0OCA0LjU0Mjk2NCAwLjkyMDU0OEM0Ljc3MDExMiAwLjkyMDU0OCA0Ljc3MDExMiAwLjcxNzMxIDQuNzcwMTEyIDAuNTM3OTgzVi0yLjc2MTY0NFonIGlkPSdnNC00MycvPgo8cGF0aCBkPSdNMy40NDMwODggLTcuNjYzMjYzQzMuNDQzMDg4IC03LjkzODIzMiAzLjQ0MzA4OCAtNy45NTAxODcgMy4yMDM5ODUgLTcuOTUwMTg3QzIuOTE3MDYxIC03LjYyNzM5NyAyLjMxOTMwMyAtNy4xODUwNTYgMS4wODc5MiAtNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5IC02LjgzODM1NiAxLjk2MDY0OCAtNi44MzgzNTYgMi42MTgxODIgLTcuMTQ5MTkxVi0wLjkyMDU0OEMyLjYxODE4MiAtMC40OTAxNjIgMi41ODIzMTYgLTAuMzQ2NyAxLjUzMDI2MiAtMC4zNDY3SDEuMTU5NjUxVjBDMS40ODI0NDEgLTAuMDIzOTEgMi42NDIwOTIgLTAuMDIzOTEgMy4wMzY2MTMgLTAuMDIzOTFTNC41Nzg4MjkgLTAuMDIzOTEgNC45MDE2MTkgMFYtMC4zNDY3SDQuNTMxMDA5QzMuNDc4OTU0IC0wLjM0NjcgMy40NDMwODggLTAuNDkwMTYyIDMuNDQzMDg4IC0wLjkyMDU0OFYtNy42NjMyNjNaJyBpZD0nZzQtNDknLz4KPHBhdGggZD0nTTIuOTg4NzkyIDIuOTg4NzkyVjIuNTQ2NDUxSDEuODI5MTQxVi04LjUyNDAzNUgyLjk4ODc5MlYtOC45NjYzNzZIMS4zODY4VjIuOTg4NzkySDIuOTg4NzkyWicgaWQ9J2c0LTkxJy8+CjxwYXRoIGQ9J00xLjg1MzA1MSAtOC45NjYzNzZIMC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFIMC4yNTEwNTlWMi45ODg3OTJIMS44NTMwNTFWLTguOTY2Mzc2WicgaWQ9J2c0LTkzJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJz4KPHVzZSB4PSc1Ni40MTMyNjcnIHhsaW5rOmhyZWY9JyNnMi04MicgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNjUuNDIxNzgzJyB4bGluazpocmVmPScjZzQtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY5Ljk3NDEwOCcgeGxpbms6aHJlZj0nI2cyLTExNScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzUuNDg4MTE0JyB4bGluazpocmVmPScjZzQtNDEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzgyLjAzMjkzNycgeGxpbms6aHJlZj0nI2c0LTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4NS4yODQ1OTknIHhsaW5rOmhyZWY9JyNnMi05OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nOTAuMzIyNTg3JyB4bGluazpocmVmPScjZzMtNDknIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9Jzk3LjcxMTU2NScgeGxpbms6aHJlZj0nI2c0LTQzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMDkuNDcyODgnIHhsaW5rOmhyZWY9JyNnMi05OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTE0LjUxMDg2OScgeGxpbms6aHJlZj0nI2czLTUwJyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PScxMTkuMjQzMTg0JyB4bGluazpocmVmPScjZzQtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzEyMy43OTU1MScgeGxpbms6aHJlZj0nI2c0LTQ5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxMzIuMzA1MTYzJyB4bGluazpocmVmPScjZzEtMCcgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTQ0LjI2MDMyNCcgeGxpbms6aHJlZj0nI2cyLTgwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxNTMuNDMxNDIyJyB4bGluazpocmVmPScjZzQtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE1Ny45ODM3NDgnIHhsaW5rOmhyZWY9JyNnMi0xMTUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE2My40OTc3NTQnIHhsaW5rOmhyZWY9JyNnNC00MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTY4LjA1MDA4JyB4bGluazpocmVmPScjZzQtNDEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzE3Mi42MDI0MDUnIHhsaW5rOmhyZWY9JyNnNC05MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTc4LjUxMDcnIHhsaW5rOmhyZWY9JyNnNC00MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMTkwLjI3MjAxNScgeGxpbms6aHJlZj0nI2c0LTQwJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScxOTQuODI0MzQnIHhsaW5rOmhyZWY9JyNnNC00OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjAzLjMzMzk5NCcgeGxpbms6aHJlZj0nI2cxLTAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIxNS4yODkxNTUnIHhsaW5rOmhyZWY9JyNnMi04MicgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjI0LjI5NzY3JyB4bGluazpocmVmPScjZzQtNDAnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIyOC44NDk5OTYnIHhsaW5rOmhyZWY9JyNnMi0xMTUnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzIzNC4zNjQwMDInIHhsaW5rOmhyZWY9JyNnNC00MScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjM4LjkxNjMyNycgeGxpbms6aHJlZj0nI2c0LTQxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScyNDUuNDYxMTUxJyB4bGluazpocmVmPScjZzQtOTEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzI0OC43MTI4MTInIHhsaW5rOmhyZWY9JyNnMi05OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjUzLjc1MDgnIHhsaW5rOmhyZWY9JyNnMy00OScgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nMjYxLjEzOTc3OScgeGxpbms6aHJlZj0nI2c0LTQzJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PScyNzIuOTAxMDk0JyB4bGluazpocmVmPScjZzItOTknIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzI3Ny45MzkwODInIHhsaW5rOmhyZWY9JyNnMC00OCcgeT0nNjEuNDE0OTg4Jy8+Cjx1c2UgeD0nMjc3LjkzOTA4MicgeGxpbms6aHJlZj0nI2czLTQ5JyB5PSc2OC43MDg5NCcvPgo8dXNlIHg9JzI4NS4zMjgwNjEnIHhsaW5rOmhyZWY9JyNnNC00MycgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nMjk3LjA4OTM3NicgeGxpbms6aHJlZj0nI2cyLTk5JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSczMDIuMTI3MzY0JyB4bGluazpocmVmPScjZzMtNTAnIHk9JzY3LjU0NjY4OCcvPgo8dXNlIHg9JzMwNi44NTk2NzknIHhsaW5rOmhyZWY9JyNnMi0xMDEnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzMxMi4yODUxMTknIHhsaW5rOmhyZWY9JyNnNC05MycgeT0nNjUuNzUzNDI1Jy8+CjwvZz4KPC9zdmc+) .
.