2013-12-11 Quelques exercices de préparation à l'examen (1)
On veut écrire une fonction qui détermine si une lettre est une voyelle.
def est_voyelle(c):
...
return 0 ou 1
print (est_voyelle("a")) # doit afficher 1
print (est_voyelle("b")) # doit afficher 0
Il faut écrire cette fonction de trois manières différentes :
- La fonction n'est composée que de tests.
- La fonction est composée d'un test et d'une liste.
- Il n'y a aucun test dans la fonction, on utilise seulement un dictionnaire.
more...
2013-12-07 Optimisation sous contraintes appliquée au calcul du report des voix
Entre les deux tours des élections présidentielles, on parle beaucoup du report des voix des élections. Dans la plupart des articles que j'ai trouvés (Les 1.139.316 voix qui ont fait la victoire d'Hollande), ces intentions sont estimées par sondage. Un blog parle d'une méthode d'estimation après seulement que les élections ont eu lieu : Estimation des reports de voix - explications techniques. La méthode proposée est bayésienne. Ici, j'ai utilisé l'optmisation sous contraintes car c'est la méthode que je souhaitais illustrer pour mes enseignements. J'ai pris les élections comme exemples d'application. Les données sont accessibles sur le site (data.gouv.fr , élections 2012). Elles incluent les chiffres aggrégés par départements et cantons dont je me suis servi et que j'ai regroupés ici : french_elections.zip).
On dispose donc des voix ventilées par candidats et disponibles pour chaque départements. On cherche à calculer une matrice de report de voix qui soit la même pour tous les départements.
| ARTHAUD | Abstentions | BAYROU | Blancs et nuls | CHEMINADE | Code dep | DUPONT-AIGNAN | HOLLANDE | JOLY | LE PEN | Département | MÉLENCHON | POUTOU | SARKOZY | total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1794 | 65996 | 32650 | 6453 | 860 | 1 | 7208 | 73096 | 7268 | 66540 | AIN | 30898 | 3323 | 97722 | 393808 |
| 2490 | 72928 | 19895 | 5196 | 738 | 2 | 5853 | 80751 | 3455 | 78452 | AISNE | 30360 | 3860 | 72090 | 376068 |
| 1482 | 45266 | 17814 | 5059 | 457 | 3 | 4068 | 61131 | 3232 | 37736 | ALLIER | 27969 | 2584 | 49477 | 256275 |
| 487 | 21034 | 7483 | 2111 | 283 | 4 | 1845 | 24551 | 2933 | 20875 | ALPES DE HAUTE PROVENCE | 15269 | 1394 | 25668 | 123933 |
| 1576 | 153383 | 38980 | 9063 | 1238 | 6 | 9241 | 111990 | 12556 | 136982 | ALPES MARITIMES | 49493 | 4048 | 216738 | 745288 |
| Abstentions | Blancs et nuls | Code | HOLLANDE | Département | SARKOZY | total |
|---|---|---|---|---|---|---|
| 67279 | 19513 | 1 | 131333 | AIN | 175741 | 393866 |
| 73997 | 21056 | 2 | 147260 | AISNE | 133760 | 376073 |
| 45079 | 14924 | 3 | 111615 | ALLIER | 84593 | 256211 |
| 20314 | 6639 | 4 | 49498 | ALPES DE HAUTE PROVENCE | 47444 | 123895 |
| 146254 | 30067 | 6 | 203117 | ALPES MARITIMES | 366055 | 745493 |
On cherche une matrice V qui permet d'obtenir les voix Y du second tour en fonction des voix du premier tour X :
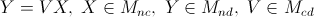
n est le nombre de départements, c est le nombre de candidats du premier tour (abstention et bulletin nuls inclus), d est le nombre de candidats du second tour. La matrice V définit le report des voix : Vij est la proportion des voix du candidat c allant au candidat d. Elle vérifie les contraintes suivantes :
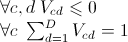
more...
2013-12-06 Extend the exception stack in Python
Most of the time, message given by exception are not enough precise to quickly understand the error. To add more information, I used to catch it and throw a new one:
try :
# something
except Exception as e :
message = "my message with more information \n" + str(e)
raise Exception(message)
However, it is possible to do this:
try :
# something
except Exception as e :
message = "my message with more information"
raise Exception(message) from e
It does not break the exception stack as before. The new exception is just added to it.
more...
2013-12-02 Distance d'édition et programmation dynamique
La distance d'édition (ou distance de Levenstein) est un algorithme très connu qui sert à comparer deux mots, deux chaînes de caractères et, plus généralement, deux séquences. La distance est définie comme le nombre d'opérations minimum qui permet de passer du premier mot au second sachant qu'il n'existe que trois opérations possibles :
- le remplacement d'un caractère par un autre,
- la suppression d'un caractère,
- l'insertion d'un caractère.
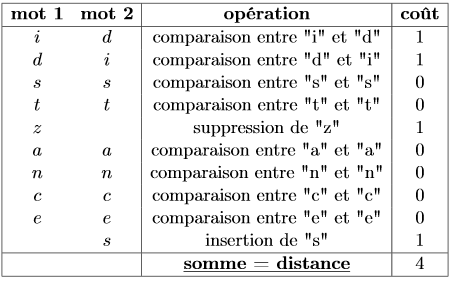
Dans l'exemple qui précède, ces trois opérations ont un coût identique. Mais il pourrait tout-à-fait dépendre du caractère inséré ou supprimé ou de la comparaison entre les deux caractères. La distance est alors la somme de ces coûts.
Trouver le nombre minimal d'opérations est un problème classique qu'on peut résoudre à l'aide de la programmation dynamique. Cela veut dire que le problème vérifie la propriété suivante : Toute solution optimale s'appuie elle-même sur des sous-problèmes résolus localement de façon optimale (Wikipedia). Cela veut souvent dire qu'il existe une façon de trouver la solution du problème par récurrence. Ou alors, si on trouve une façon de couper le problème en deux, la solution optimale sera la combinaison des deux solutions optimales sur chacune des deux parties.
more...
2013-12-01 Recherche dichotomique, récursive, itérative et le logarithme
Lorsqu'on décrit n'importe quel algorithme, on évoque toujours son coût, souvent une formule de ce style :
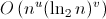
u et v sont des entiers. v est souvent soit 0, soit 1. Mais d'où vient ce logarithme ? Le premier algorithme auquel on pense et dont le coût correspond au cas u=0 et v=1 est la recherche dichotomique. Il consiste à chercher un élément dans une liste triée. Le logarithme vient du fait qu'on réduit l'espace de recherche par deux à chaque itération. Fatalement, on trouve très vite l'élément à chercher. Et le logarithme, dans la plupart des algorithmes, vient du fait qu'on divise la dimension du problème par un nombre entier à chaque itération, ici 2.
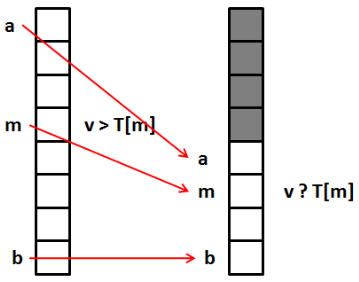
La recherche dichotomique est assez simple : on part d'une liste triée T et on cherche l'élément v (on suppose qu'il s'y trouve). On procède comme suit :
- On compare v à l'élément du milieu de la liste.
- S'il est égal à v, on a fini.
- Sinon, s'il est inférieur, il faut chercher dans la première moitié de la liste. On retourne à l'étape 1 avec la liste réduite.
- S'il est supérieur, on fait de même avec la seconde moitié de la liste.
more...
2013-11-30 More about interactive graphs using Python, d3.js, R, shiny, IPython, vincent, d3py, python-nvd3
I recently found this url The Big List of D3.js Examples. As d3.js is getting popular - their website is pretty nice -, I was curious if I could easily use it through Python. After a couple of searches (many in fact), I discovered vincent and some others. It ended up doing a quick review. Every script was tested with Python 3.
Contents:
- Graphs with IPython and QtConsole
- Graphs with IPython Notebook
- Graph with d3.js and IPython Notebook
- Graphs with Python and vincent
- Graphs with Python and d3py
- Graphs with IPython and nvd3
- R with shiny
- Alternatives
- How will you share the graph? (no share, image, web + HTML and Javascript, web + R)
- Can you see the graph you want to do in galleries?
Use of IPython (qt)console
The QtConsole looks like a command line window but is able to display images inline using matplotlib:
more...
2013-11-29 Python avec la Khan Academy
La Khan Academy propose des leçons de 10 minutes sur de nombreux sujets parmi lesquels Python. Voici quelques pointeurs (en anglais):
- Introduction (programmes, variables)
- Listes
- Chaînes de caractères
- Boucle for
- Boucle while
- Versions itérative et récursive de la fonction factorielle
- Les dictionnaires, lire notamment la section Construction d'un histogramme à l'aide d'un dictionnaire
- Les fonctions
2014-05-28 - Les liens vers la Khan Academy sont cassés et je n'ai pas réussi à les retrouver sur leur site. Ils sont néanmoins accessibles sur YouTube : listes. Les autres vidéos sont accessibles depuis les suggestions.
2013-11-25 Edit distance and weights
I often had to implement an edit distance and I most of time chose to use uniform weights : every modification costs 1. That's the easy solution. However, I was looking for a quick way to give different weights to every comparison between twwo characters.
So I went to the site Gutenberg and downloaded a few texts. I then did the following:
- I split the text into lower case words.
- I grouped them by length.
- For all words having the same length, I looked for words with one letter difference.
- I counted the number of times the same pair was that differences.
- I normalized by the number of pairs and took 1-p where p the frequency of a pair.
more...
2013-11-21 Fusionner deux tableaux
L'exercice est le suivant : on récupère deux tableaux depuis le site http://www.data.gouv.fr/. On récupère les deux fichiers suivants :
- PLF 2014 - ETP DU BUDGET GÉNÉRAL (BG) PAR MINISTÈRE ET CATÉGORIE D'EMPLOI (ou a2012.csv)
- LFI 2012 DOTATION BG EN ETP PAR MINISTÈRE (ou a2012.csv)
Ministère Libellé Catégorie d'emploi Emploi ETPPLF 1 Affaires étrangères 1101 Titulaires et CDI en administration centrale 3 059 1 Affaires étrangères 1102 Titulaires et CDI dans le réseau 2 895 1 Affaires étrangères 1103 CDD et volontaires internationaux 2 877 1 Affaires étrangères 1104 Militaires 712 1 Affaires étrangères 1105 Agents de droit local 4 962 ...
On cherche à mesurer l'évolution des effectifs entre ces deux années même si la liste des ministères et des catégories évolue.
more...
2013-11-09 Compter les pièces de monnaie pour obtenir un montant
On est amené presque tous les jours à compter les pièces dans son porte-monnaie pour payer la baguette, le fromage ou la bouteille de vin. Comment écrire un algorithme qui donne la liste des pièces qu'il faut piocher dans son porte-monnaie pour payer ? On s'intéressera seulement au cas où on cherche à composer le montant juste. Cela revient à chercher un sous-ensemble S de pièces dans l'ensemble P des pièces du portefeuille pour composer le montant M :
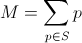
Une façon naïve de construire l'ensemble S est de procéder comme on le fait souvent, c'est-à-dire à prendre la pièce la plus grosse, de voir si elle dépasse le montant N puis de passer à la seconde plus grande et ainsi de suite. Soit :
- On trie les pièces par ordre décroissant.
- Au début, l'ensembe S est vide.
- On prend les pièces dans l'ordre décroissant et on les ajoute à l'ensemble S si la somme de l'ensemble n'est pas plus grand que M.
more...
2013-11-08 De l'idée au programme informatique
Lorsqu'on apprend à programmer, on a souvent une idée précise de l'objectif à atteindre et pourtant, on reste perplexe devant l'écran ne sachant pas par où commencer. Par exemple, si on dispose d'une matrice de trois colonnes :
| x | y | poids |
| A | C | 3 |
| A | D | 1 |
| A | E | 4 |
| B | D | 6 |
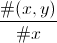
Par exemple, si x=A et y=D, on aura 1 / (3 + 1 + 4) = 0.125. Maintenant, comment s'y prend-on ?
Tout d'abord, on cherche à calculer un ratio de trucs qui ne sont pas des nombres entiers. Un dictionnaire est tout indiqué pour stocker ces trucs car il permet d'associer n'importe quoi (valeur) à presque n'importe quoi (clé). La valeur est une somme d'entiers, la clé est un couple de lettres ou une lettre. Sans me soucier des petits détails, voilà ce que j'ai envie d'écrire comme premier jet :
l = [ ['A','B', 3], ['A','C', 1],
['A','E', 4], ['B','D', 6], ]
def transition(l):
d = {}
for x,y,n in l :
d [x,y] += n # erreur ici : KeyError: ('A', 'B')
d [x] += n
for x,y in d :
d[x,y] /= d [x]
return d
print (transition(l))
Bien sûr ça ne marche pas (voir l'erreur ci-dessus). Mais j'ai foi en moi. La logique est bonne. Lorsque j'écris d [a,b] += n, je suppose que le couple (x,y) existe dans le dictionnaire même la toute première fois. Et c'est pas possible ! Il est vide au début.
more...
2013-11-05 Python, SQL, pandas and frustration
When I try to avoid coding and to use existing tools, I usually decompose my problem in smaller ones I think people already solved. I usually skip the documentation until I find an example for each of them. That's how I proceed to use pandas. I imagine how I would do it using SQL and I try to write it using this module. My problem was the following one:
SELECT location, MIN(commute) AS minc, MAX(commute) AS maxc FROM data
Which I was able to solve this way (after a couple of tries and a glass of wine to avoid losing my temper):
data = [
{ "name":"hugo", "location":"paris", "commute":55 },
{ "name":"marcel", "location":"paris", "commute":45 },
{ "name":"jack", "location":"lyon", "commute":25 },
{ "name":"hugo", "location":"lyon", "commute":20 }, ]
df = pandas.DataFrame(data)
agg = df.groupby ( "location", as_index=False).agg (
{ "commute": [ ("minc",min), ("maxc", max) ] } ) # first glass of wine
print (agg)
Then, I wanted to write this:
SELECT A.*, B.minc, B.maxc FROM data AS A INNER JOIN (
SELECT location, MIN(commute) AS minc, MAX(commute) AS maxc FROM data) AS B
Which I converted into after a second glass of wine:
agg = df.groupby ( "location", as_index=False).agg (
{ "commute": [ ("minc",min), ("maxc", max) ] } )
agg.columns = ["minc", "maxc"] # the second glass of wine
join = df.merge (agg, left_on="location", right_on = "location")
print (join)
But you could write it that way:
agg = df.groupby ( "location").agg (
{ "commute": [ ("minc",min), ("maxc", max) ] } )
agg.columns=["minc","maxc"]
join = df.merge (agg, left_on="location", right_index= True)
print (join)
Last precision: the instruction agg.columns=["minc","maxc"] rename the column name. However, it works in this case just because we aggregated only one column (commute). When several columns are aggregated, the order of the column in the resulting matrix is not always the same. So do not do the following:
def sums(l) : return ",".join(l)
agg = df.groupby ( "location", as_index=False).agg (
{ "name":sums,
"commute": [ ("minc",min), ("maxc", max) ] } )
agg.columns=["name","minc","maxc"] # glass of whisky
I often get frustrated about tools, it takes me so many tries to get the data the way I want before I start working on an algorithm using them. Then, you try to apply it on a much bigger dataset and it fails for a couple of bad rows which cannot be parsed because of a string including tabs. After, I got the accent problem... I hate those days.
2013-11-02 Stop a thread in Python
I was writing a simple GUI in Python, a button start to start a function from a thread, another one to stop the execution. I then realized my program did not stop.
import threading, time
class MyThread(threading.Thread):
def run(self):
while True:
time.sleep(1)
th = MyThread()
th.start()
There are two ways to avoid that issue. The first one is to set up daemon to True.
th = MyThread() th.daemon = True th.start()
The second way is to use a kind of hidden function _stop(not documented). But this function might disappear in the next version of python.
th = MyThread() th.start() th._stop()
2013-10-31 Choisir des couleurs pour un graphe
J'ai parfois besoin de pas mal de couleurs sur un graphique (avec matplotlib par exemple) et je ne sais jamais quelles couleurs choisir après rouge, vert, bleu. Bref, j'imagine que dans la liste suivante, si chaque couleur porte un nom, c'est qu'on peut les reconnaître.
more...
2013-10-27 Convert HTML into JSON
I needed to convert a HTML string into JSON. After looking for results without any success, I thought doing it myself should be faster than searching. As an exemple:
content = '<html><body><div class="an_example"><p>one paragraph</p></div></body></html>' js = HTMLtoJSONParser.to_json(content) print (js)Will produce this:
{'html': {'body': {'div': {'p': {'': 'one paragraph'}, '#class': 'an_example'}}}}
The implementation of HTMLtoJSONParser follows:
more...
| <-- --> |
Xavier Dupré
|