API de sciki-learn et modèles customisés#
Links: notebook, html, PDF, python, slides, GitHub
scikit-learn est devenu le module incontournable quand il s’agit de machine learning. Cela tient en partie à son API épurée qui permet à quiconque d’implémenter ses propres modèles tout permettant à scikit-learn de les manipuler comme s’il s’agissait des siens.
from jyquickhelper import add_notebook_menu
add_notebook_menu(last_level=3)
Cette présentation détaille l’API de scikit-learn, aborde la mise en production avec pickle, montre un exemple d’implémentation d’un modèle customisé appliqué à la sélection d’arbres dans une forêt aléatoire.
import matplotlib.pyplot as plt
from jupytalk.pres_helper import show_images
Design et API#
On peut penser que deux implémentations du même algorithme se valent à partir du moment où elles produisent les mêmes résultats. Voici deux chaises, vers laquelle votre instinct vous poussera-t-il ?
show_images("zigzag.jpg", "chaise.jpg", figsize=(14, 4), title2="Le Corbusier");

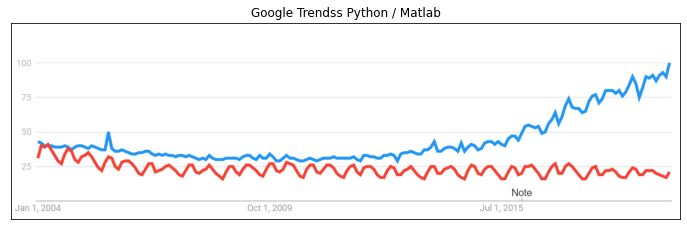
Quatre ou cinq librairies ont fait le succès de Python#
numpy: calcul matriciel - existait avant Python (matlab, R, …)
pandas: manipulation de données - existait avant Python (R, …)
matplotlib: graphes - existait avant Python - (matlab, R…)
scikit-learn: machine learning - innovation : design
jupyter: notebooks - innovation : mélange interactif code, texte, images
show_images("trends.png", title1="Google Trendss Python / Matlab");
Machine learning résumé#
Modèle de machine learning = résultat d’une optimisation
Cette optimisation dépend de paramètres (dimension, pas du gradient, …)
Optimisation = apprentissage
On s’en sert pour faire de la prédiction.
Ce que les codeurs imaginent#
Des designs souvent très jolis mais à usage unique.
show_images("coop.jpg", "coop2.jpg", title1="Coop Himeblau", title2="Rooftop", figsize=(16,8));

Vues incompatibles#
Les chercheurs aiment l’innonvation, cherchent de nouveaux modèles.
Les datascientist assemblent des modèles existants.
L’estimation d’un modèle arrivent à la toute fin.
On retient facilement ce qui est court et qui se répète.
Vocabulaire scikit-learn#
Predictor : modèle de machine learning qu’on apprend (
fit) et qui prédit (predict)Transformer : prétraitement de données qui précède un prédicteur, qu’on apprend (
fit) et qui transforme les données (transform)
Utilisation de classes : predictor#
- ::
- class Predictor:
- def __init__(self, **kwargs):
# kwargs sont les paramètres d’apprentissage
- def fit(self, X, y):
# apprentissage return self
- def predict(self, X):
# prédiction
Utilisation de classes : transformer#
- ::
- class Transformer:
- def __init__(self, **kwargs):
# kwargs sont les paramètres d’apprentissage
- def fit(self, X, y):
# apprentissage return self
- def transform(self, X):
# prédiction
pipeline (sandwitch en français)#
Normalisation + ACP + Régression Logistique
Classe |
Step 1 |
Step 2 |
Step 3 |
Step 4 |
|---|---|---|---|---|
Normalizer |
|
|
|
|
PCA |
. |
|
|
|
LogisticReg ression |
. |
. |
``fit(X3,y) `` |
|
En langage Python#
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Normalizer
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
pipe = Pipeline([
('norm', Normalizer()),
('pca', PCA()),
('lr', LogisticRegression())
])
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
pipe.fit(X_train, y_train)
Pipeline(steps=[('norm', Normalizer()), ('pca', PCA()),
('lr', LogisticRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('norm', Normalizer()), ('pca', PCA()),
('lr', LogisticRegression())])Normalizer()
PCA()
LogisticRegression()
prediction = pipe.predict(X_test)
prediction[:5]
array([0, 2, 0, 2, 2])
pipe.score(X_test, y_test)
0.6578947368421053
Raffinement#
show_images("church-of-light-1024x614.jpg", title1="Tadao Ando", figsize=(10, 6));

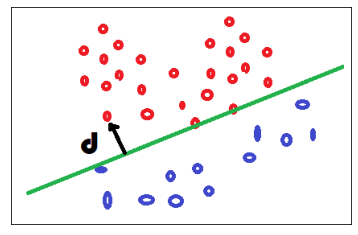
Un design commun aux régresseurs et classifieurs#
Les régresseurs sont les plus simples, ils modèlisent une fonction
 .
.Les classifieurs modélisent une fonction

Mais
Les classifieurs sont liés à la notion de distance par rapport à la frontière, distance qu’on relie ensuite à une probabilité mais pas toujours.
show_images('logreg.png');
Besoin d’un classifieur#
- ::
- class Classifier:
- def __init__(self, **kwargs):
# kwargs sont les paramètres d’apprentissage
- def fit(self, X, y):
# apprentissage return self
- def decision_function(self, X):
# distances
- def predict_proba(self, X):
# distances –> proba
- def predict(self, X):
# classes
Besoin d’un régresseur par mimétisme#
- ::
- class Classifier:
- def __init__(self, **kwargs):
# kwargs sont les paramètres d’apprentissage
- def fit(self, X, y):
# apprentissage return self
- def decision_function(self, X):
# une ou plusieurs régressions
- def predict(self, X):
# moyennes
Paramètres et résultats d’apprentissage#
Tout attribut terminé par
_est un résultat d’apprentissage.A l’opposé, tout ce qui ne se termine pas par
_est connu avant l’apprentissage
show_images("lasso.png");

Problèmes standards - moule commun#
show_images('sklearn_base.png');

Analyser ou prédire#
Certains modèles ne peuvent pas prédire, simplement analyser. C’est le cas du SpectralClustering.
- ::
- class NoPredictionButAnalysis:
- def __init__(self, **kwargs):
# kwargs sont les paramètres d’apprentissage
- def fit_predict(self, X, y=None):
# apprentissage et prédiction return self
Limites du concept#
Et si on veut réutiliser les sorties d’un prédicteur pour en faire autre chose ?
A suivre… dans la dernière partie.
Le design, c’est le design, le code, c’est de la bidouille.
pickle#
Un modèle c’est :
une classe, un pipeline, une liste de traitements définis avant apprentissage
des coefficients obtenus après apprentissage
Comment conserver le résultat ? –> pickle
Cas des dataframes#
from pandas import DataFrame, read_csv
df = DataFrame(X)
df['label'] = y
df.head()
| 0 | 1 | 2 | 3 | label | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
df.to_csv("data_iris.csv")
%timeit read_csv("data_iris.csv")
1.77 ms ± 117 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
import pickle
with open("data_iris.pickle", "wb") as f:
pickle.dump(df, f)
def load_from_pickle(name):
with open(name, "rb") as f:
return pickle.load(f)
%timeit load_from_pickle("data_iris.pickle")
264 µs ± 18.2 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
pickle est plus rapide#
read_csv : convertit un fichier texte en dataframe –> format intermédiaire csv
pickle : conserve des données comme elles sont stockées en mémoire –> pas de conversion
from jyquickhelper import RenderJsDot
RenderJsDot('''digraph{ rankdir="LR";
B [label="mémoire"]; C [label="csv"]; C2 [label="csv"];
D [label="disque"]; B -> C [label="to_csv", color="red"];
C -> D ; D -> C2 ;
C2 -> B [label="read_csv", color="red"];
B -> D [label="pickle.dump", color="blue"];
D -> B [label="pickle.load", color="blue"];
}''')
scikit-learn, pickle#
unique moyen de conserver les modèles
with open("pipe.pickle", "wb") as f:
pickle.dump(pipe, f)
with open("pipe.pickle", "rb") as f:
pipe2 = pickle.load(f)
from numpy.testing import assert_almost_equal
assert_almost_equal(pipe.predict(X_test), pipe2.predict(X_test))
Problème avec pickle#
L’état de la mémoire dépend très fortement des librairies installées
Changer de version scikit-learn –> l’état de la mémoire est différente
Analogie : pickle ne conserve que les coefficients en mémoire, ils sont cryptés en quelque sorte.
On ne peut les décrypter qu’avec le même code.
Dissocier les colonnes#
Toutes les colonnes subissent le même traitement.
pipe = Pipeline([
('norm', Normalizer()),
('pca', PCA()),
('lr', LogisticRegression())
])
Mais ce n’est pas forcément ce que l’on veut.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import MinMaxScaler
pipe2 = Pipeline([
('multi', ColumnTransformer([
('c01', Normalizer(), [0, 1]),
('c23', MinMaxScaler(), [2, 3]),
])),
('pca', PCA()),
('lr', LogisticRegression())
])
pipe2.fit(X_train, y_train);
from mlinsights.plotting import pipeline2dot
RenderJsDot(pipeline2dot(pipe2, X_train))
Concepts appliqués à un nouveau régresseur#
On construit une forêt d’arbres puis on réduit le nombre d’arbres à l’aide d’une régression Lasso.
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
data = load_diabetes()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
Sketch de l’algorithme#
import numpy
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import Lasso
# Apprentissage d'une forêt aléatoire
clr = RandomForestRegressor()
clr.fit(X_train, y_train)
# Récupération de la prédiction de chaque arbre
X_train_2 = numpy.zeros((X_train.shape[0], len(clr.estimators_)))
estimators = numpy.array(clr.estimators_).ravel()
for i, est in enumerate(estimators):
pred = est.predict(X_train)
X_train_2[:, i] = pred
# Apprentissage d'une régression Lasso
lrs = Lasso(max_iter=10000)
lrs.fit(X_train_2, y_train)
lrs.coef_
array([-0.00469714, 0.0221791 , -0.03849948, 0.00314431, 0.04879728,
-0.00045039, -0.0054841 , -0.01130761, -0.01956316, 0.05802847,
-0.00031975, -0.05406833, -0.04773371, 0.06614678, 0.00892759,
-0.06309655, 0.03340401, -0.04168602, 0.02377001, -0.03671289,
0.02627701, 0.00022712, -0.01083544, -0.04179967, 0.03231883,
-0.02245547, 0.00971713, 0.01600841, 0.01458184, -0.03772706,
0.02509486, -0.01068935, -0.04092312, 0.0541524 , 0.00537527,
-0.03710114, 0.017908 , 0.02937607, 0.04451909, 0.0013495 ,
-0.02321562, -0.04876043, -0.01734136, 0.03884741, 0.03373548,
0.00811501, 0.0169834 , -0.02234235, 0.05643999, 0.00889717,
-0.02046968, 0.00973609, 0.07077278, 0.01506631, 0.09280915,
0.01589242, -0.02673953, 0.02240294, -0.00475286, 0.01830085,
0.02026113, 0.03854988, 0.03195279, 0.0394844 , 0.02784215,
0.02402331, 0.06021017, 0.01825254, 0.01992086, 0.0188973 ,
0.01556557, 0.04059752, 0.04422221, 0.00365708, 0.00389476,
-0.00737055, 0.05960936, -0.04092342, 0.05995745, 0.06623417,
0.02395334, 0.01308198, 0.08500338, -0.01354122, 0.0357201 ,
0.01747697, 0.04941955, 0.05530153, 0.01663532, 0.04105603,
0.02831484, 0.00386307, -0.00450148, 0.03319402, -0.01291577,
-0.01517642, -0.0147378 , 0.05063852, -0.00490926, 0.00825488])
Ce que l’on veut#
- ::
- class LassoRandomForestRegressor:
- def fit(self, X, y):
# apprendre une random forest # sélectionner les arbres à garder avec un Lasso # supprimer les arbres associés à un poids nul return self
- def predict(self, X):
# retourner une moyenne pondérée des prédictions return …
Implémentation#
lasso_random_forest_regressor.py
import numpy
from sklearn.base import BaseEstimator, RegressorMixin, clone
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import Lasso
class LassoRandomForestRegressor(BaseEstimator, RegressorMixin):
def __init__(self, rf_estimator=None, lasso_estimator=None):
BaseEstimator.__init__(self)
RegressorMixin.__init__(self)
if rf_estimator is None:
rf_estimator = RandomForestRegressor()
if lasso_estimator is None:
lasso_estimator = Lasso()
self.rf_estimator = rf_estimator
self.lasso_estimator = lasso_estimator
def fit(self, X, y, sample_weight=None):
self.rf_estimator_ = clone(self.rf_estimator)
self.rf_estimator_.fit(X, y, sample_weight)
estims = self.rf_estimator_.estimators_
estimators = numpy.array(estims).ravel()
X2 = numpy.zeros((X.shape[0], len(estimators)))
for i, est in enumerate(estimators):
pred = est.predict(X)
X2[:, i] = pred
self.lasso_estimator_ = clone(self.lasso_estimator)
self.lasso_estimator_.fit(X2, y)
not_null = self.lasso_estimator_.coef_ != 0
self.intercept_ = self.lasso_estimator_.intercept_
self.estimators_ = estimators[not_null]
self.coef_ = self.lasso_estimator_.coef_[not_null]
return self
def predict(self, X):
prediction = None
for i, est in enumerate(self.estimators_):
pred = est.predict(X)
if prediction is None:
prediction = pred * self.coef_[i]
else:
prediction += pred * self.coef_[i]
return prediction + self.intercept_
ls = LassoRandomForestRegressor()
ls.fit(X_train, y_train)
C:xavierdupre__home_github_forkscikit-learnsklearnlinear_model_coordinate_descent.py:634: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 2.825e+04, tolerance: 1.935e+02 model = cd_fast.enet_coordinate_descent(
LassoRandomForestRegressor(lasso_estimator=Lasso(),
rf_estimator=RandomForestRegressor())In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LassoRandomForestRegressor(lasso_estimator=Lasso(),
rf_estimator=RandomForestRegressor())Lasso()
Lasso()
RandomForestRegressor()
RandomForestRegressor()
Résultats#
La forêt aléatoire seule.
clr.score(X_test, y_test)
0.5704306565411461
La forêt aléatoire réduite.
ls.score(X_test, y_test)
0.46294352058906363
Avec une réduction conséquente.
len(ls.estimators_), len(clr.estimators_)
(99, 100)
Critère AIC#
On peut même sélectionner le nombre d’arbres avec un critère AIC et le modèle LassoLarsIC.
from sklearn.linear_model import LassoLarsIC
ls_aic = LassoRandomForestRegressor(lasso_estimator=LassoLarsIC())
ls_aic.fit(X_train, y_train)
LassoRandomForestRegressor(lasso_estimator=LassoLarsIC(),
rf_estimator=RandomForestRegressor())In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LassoRandomForestRegressor(lasso_estimator=LassoLarsIC(),
rf_estimator=RandomForestRegressor())LassoLarsIC()
LassoLarsIC()
RandomForestRegressor()
RandomForestRegressor()
ls_aic.score(X_test, y_test)
0.4833526611115916
len(ls_aic.estimators_)
48
pickling#
A partir du moment où les conventions de l’API de scikit-learn sont respectées, tout est pris en charge.
from io import BytesIO
by = BytesIO()
pickle.dump(ls, by)
by2 = BytesIO(by.getvalue())
mod2 = pickle.load(by2)
p1 = ls.predict(X_test)
p2 = mod2.predict(X_test)
p1[:5], p2[:5]
(array([277.10103941, 221.38733112, 63.87889654, 205.27390858,
80.4188308 ]),
array([277.10103941, 221.38733112, 63.87889654, 205.27390858,
80.4188308 ]))
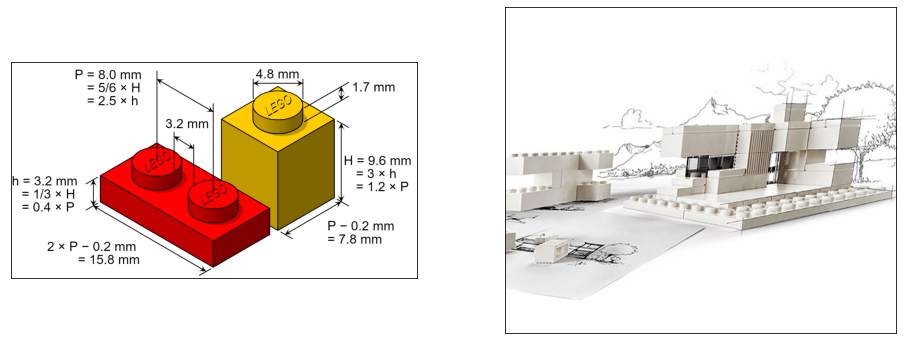
Conclusion#
L’API est une sorte de légo. Tout marche si on respecte les dimensions de départ.
show_images('lego.png', 'lego-architecture-studio-8804.jpg', figsize=(16,6));
show_images('vue-interieure-cite-de-musique-christian-de.jpg', 'PaulPoiret-7.jpg', figsize=(16,6));

show_images('lycee_chanzy_maquette.jpg', figsize=(16,10));
