Plus proches voisins - évaluation#
Links: notebook, html, PDF, python, slides, GitHub
Comment évaluer la pertinence d’un modèle des plus proches voisins.
%matplotlib inline
from papierstat.datasets import load_wines_dataset
df = load_wines_dataset()
X = df.drop(['quality', 'color'], axis=1)
y = df['quality']
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(n_neighbors=1)
knn.fit(X, y)
KNeighborsRegressor(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
prediction = knn.predict(X)
Le modèle ne fait pas d’erreur sur tous les exemples de la base de vins. C’est normal puisque le plus proche voisin d’un vin est nécessairement lui-même, la note prédite et la sienne.
min(prediction - y), max(prediction - y)
(0.0, 0.0)
Il est difficile dans ces conditions de dire si la prédiction et de bonne qualité. On pourrait estimer la qualité de la prédiction sur un vin nouveau mais il n’y en a aucun pour le moment et ce n’est pas l’ordinateur qui va les fabriquer. On peut peut-être regarder combien de fois le plus proche voisin d’un vin autre que le vin lui-même partage la même note.
from sklearn.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors=2)
nn.fit(X)
NearestNeighbors(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=2, p=2, radius=1.0)
distance, index = nn.kneighbors(X)
proche = index[:, 1].ravel()
note_proche = [y[i] for i in proche]
Il ne reste plus qu’à calculer la différence entre la note d’un vin et celle de son plus proche voisin autre que lui-même.
diff = y - note_proche
ax = diff.hist(bins=20, figsize=(3,3))
ax.set_title('Histogramme des différences\nde prédiction')
Text(0.5,1,'Histogramme des différencesnde prédiction')
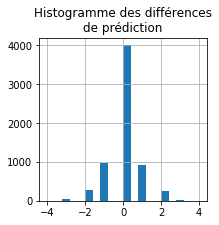
Ca marche pour les deux tiers de la base, pour le tiers restant, les notes diffèrent. On peut maintenant regarder si la distance entre ces deux voisins pourrait être corrélée à cette différence.
import pandas
dif = pandas.DataFrame(dict(dist=distance[:,1], diff=diff))
ax = dif.plot(x="dist", y="diff", kind='scatter', figsize=(3,3))
ax.set_title('Graphe XY - distance / différence');
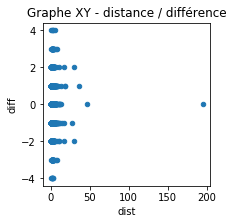
Ce n’est pas très lisible. Essayons un autre type de graphique.
from seaborn import violinplot, boxplot
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2, figsize=(8,3))
violinplot(x="diff", y="dist", data=dif, ax=ax[0])
ax[0].set_ylim([0,25])
ax[0].set_title('Violons distribution\ndifférence / distance')
boxplot(x="diff", y="dist", data=dif, ax=ax[1])
ax[1].set_title('Boxplots distribution\ndifférence / distance')
ax[1].set_ylim([0,25]);
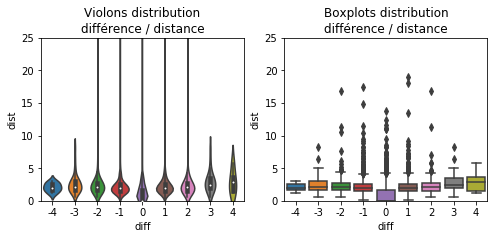
A priori le modèle n’est pas si mauvais, les voisins partageant la même note ont l’air plus proches que ceux qui ont des notes différentes.
import numpy
dif['abs_diff'] = numpy.abs(dif['diff'])
from seaborn import jointplot
ax = jointplot("dist", "abs_diff", data=dif[dif.dist <= 10],
kind="kde", space=0, color="g", size=4)
ax.ax_marg_y.set_title('Heatmap distribution distance / différence');
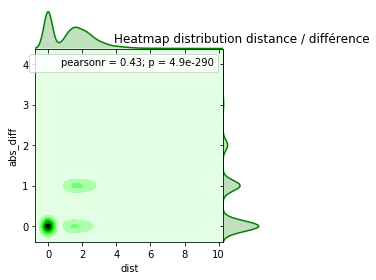
Les vins proches se ressemblent pour la plupart. C’est rassurant pour la suite. 61% des vins ont un voisin proche partageant la même note.
len(dif[dif['abs_diff'] == 0]) / dif.shape[0]
0.6152070186239803