2017-10-27 Entrepreneurs d'intérêt général : l'Etat comme source d'inspiration
J'ai assisté hier soir à la restitution des travaux menés par la première promotion des entrepreneurs d'intérêt général (EIG). La seconde promotion sera plus nombreuse et les candidatures sont encore ouvertes aujourd'hui jusque 17h. Il y a pas mal de sujets sur lesquels j'aimerais bien me pencher.
J'étais déjà enthousiaste sur le projet qui a découché sur la première promotion des EIG et ce qui m'avait incité à accepter la proposition de faire partie du jury qui a sélectionné les candidats. Je le suis tout autant en assistant la présentation des résultats. Cette promotion a tant que possible mis à disposition son travail sur github/eig-2017 et ce travail sera compléter durant les quelques semaines qui suivent. J'y ai découvert quelques outils développés par ces entrepreneurs addok-fr ou encore leaflet-geocoder-ban/demo (source) ou encore matchID, tous orientés vers le partage comme The Magical CSV Merge Machine, l'inventaire des orgues ou encore cette réflexion sur le parcours des données santés. Le rapport Des besoins d’information à la visualisation transcrit l'approche suivie sur un des challenges. Il illustre bien ce que peut être un projet datascience dans une institution qui n'a pas toujours l'habitude de ce type d'approche et porte sur un problème de données que tout le monde peut se représenter : les données de santé.
more...
2017-10-14 Python and javascript
I was doing some research on some other topic but I found this javascript library filbert which parses and converts a Python script into a javascript script. The output is quite verbose but follows the syntactic tree produced by the parser. Transcrypt is less verbose. I then became curious about pyjs which I saw in a conference. It did not get any update in two years so it seems to be discontinued but Brython is still alive and seems a better tool to run python from a javascript page. I also discovered pyduketape which wraps in Python a javascript engine. It is a different approach from the one followed by ghost.py which is relying on PySide.
2017-09-05 Retour sur la première séance
Les liens sont probablement une des informations les plus compliquées à prendre en note alors qu'ils sont si faciles à copier/coller. Tout d'abord les liens vers les contenus utilisés pour le cours :
- Exerices du cours principalement sous forme de notebooks, première année
- Langage Python, résumé de la syntaxe
- Quelques éléments théoriques autour du machine learning
- Challenges : problèmes algorithmes dont les solutions repose sur un assemblage d'algorithmes
- Exercices d'algorithmes
- Google Code Jam
- CodinGame : jeu de plateforme où le vaisseau se pilote avec un algorithme
- analyste ou ingénieur
- anciens examens et leurs corrections, autrement dit une idée de là où le cours se propose de vous emmener
Devinette extraite de la séance... Deux joueurs jouent aux dés. Un joueur a six dés à six faces, l'autre à neuf dés de quatre faces. Le gagnant est celui dont la somme des points sur chaque face est la plus grande. Comment calculer la probabilité de gagner ?
N'hésitez pas à commencer à installer Python sur vos ordinateurs et à les amener en cours si jamais un problème survient : Installer Python.
2017-08-28 Continuous integration
Maintaining notebooks is a lot of work. I consider a notebook is ok if it runs with the latest versions of the packages it uses and if it can be converted into HTML to be included on a website. Easy when you have one notebook but what if you have more than 200 hundred of them to verify for your teachings? I had to automate. I started by running a virtual machine on Azure wich Jenkins and everything I needed. This machine is still up and running and tests everything once in a week for all my python package. But my teachings are also open source so I decided to use continuous integration to test my package on other distributions. I first used travis and appveyor but I could not include the compilation of the notebooks into documentation. It requires a couple of huge dependencies as latex. appveyor is quite slow and stops any job after one hour. travis was using Ubuntu 12.04 when I started and 14.04 now. I recently tried CircleCI 2.0. The design is really nice, it offers Ubuntu 16.04, the configuration file config.yml is much easier to read and to write. One interesting feature is artifacts. The user can easily copy in a specific folder whatever he wants to keep from the build and make it available to download. The other interesting feature is caching. CircleCI automatically caches a docker which contains the dependencies of the package to test. The first run is slow and the following are faster due to this option plus renewing the cache can be easily done by changing a file. So I decided it was worth spending some time enabling CircleCI anywhere. I described here all the steps to create a Python package, with unit tests and documentation and to build it on CircleCI : Tests unitaires, setup et ingéniérie logiciel (French).
2017-08-25 Read paper, read git issues too!
Sometimes I go for a walk at scikit-learn/issues on radio github and I listened to this short news Random Forest Imputation and I discovered this package fancyimpute which is about filling missing values with many fancy ways and then knnimpute and downhill which implements a couple of gradient descent algorithms with theano. A little bit later: Thompson sampling with the online bootstrap.
2017-08-24 Remove big files from git history
Git repositories always get bigger. I noticed than one of GitHub repository was above 500Mb. I was wondering how I could make that size smaller. First, let see the size.
git count-objects -v
count: 0 size: 0 in-pack: 19644 packs: 1 size-pack: 222397 prune-packable: 0 garbage: 0 size-garbage: 0
The size is size-pack. To clean, the first option is to rebase the repository so basically to clean everything and to commit the current state of the content. One solution is to keep only the latest commits (see Reduce repository size).
git log -n N git reset --hard HEAD~N git push --force
more...
2017-08-17 L'inflation numérique
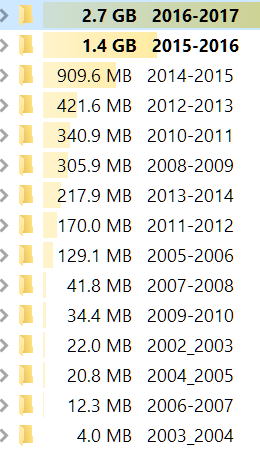
Chaque année, je reçois beaucoup de projets informatiques réalisés par des étudiants, plus d'une centaine l'année qui vient de se terminer. Je garde les projets principalement parce que des étudiants me demandent des lettres de recommandation. Chaque année cela grossit.
2017-08-03 PyData Seattle
Les vidéos des talks à PyData Seatle sont disponibles : PyData Seattle 2017. Quelques-unes à regarder pour les novices en Python :
- Keynote Jake VanderPlas (les outils du datascientiste)
- Stephanie Kim - How to be a 10x Data Scientist
- Tom Radcliffe - Robust Algorithms for Machine Learning
- Quentin Caudron - Introduction to data analytics with pandas
La datatascience, finalement, on passe son temps à chercher le bon graphe, celui qui nous montrera ce qu'il fallait voir dans ces données ou alors on cherche l'outils qui nous permettra de trouver le bon angle : Jeffrey Heer - Interactive Data Analysis: Visualization and Beyond. Pour les experts : Chris Fregly - High Performance Distributed Tensorflow, Jeff Fischer - Python and IoT: From Chips and Bits to Data Science, Stephen Hoover - Scaling Scikit Learn.
Pour les utilisateurs de Spark, cette vidéo pourrait vous intéresser : Raj Singh - PixieDust make Jupyter Notebooks with Apache Spark Faster, Flexible, and Easier to use (voir aussi PixieDust).
Si vous avez un vieux système à mettre à jour, Matt Braymer-Hayes, Erin Haswell - Upgrading Legacy Projects: Lessons Learned.
2017-07-02 Include output of a script in the Python documentation
The directive runpython runs a python script and insert the output in the documentation.
.. runpython::
import sys
print(sys.version_info)
Every printed information is added to the documntation :
sys.version_info(major=3, minor=6, micro=1, releaselevel='final', serial=0)
Two intersections options :
- :showcode: the code will be added to the documentation.
- :rst: the directive assumes the output is rst and is adding as such in the documentation. That options can be used to create repetitive documentation such as the list of imported mdules or to check that inserted examples still work.
extensions = ['sphinx.ext.intersphinx',
...
'pyquickhelper.sphinxext.sphinx_runpython_extension']
One example (in French) : demo runpython. The second one shows how I use to build content (still French): rendering and source.
2017-07-01 Python module with C functions
This a small module I created with C functions called from Python. The documentation is here cpyquickhelper and the code github/cpyquickhelper. Enabling travis took me some time but I got it finally working.
2017-05-11 PyParis
PyParis est la déclinaison parisienne du cycle de conférence pydata. Le programme de cette année est plutôt alléchant. Outre les sujets scientidiques, j'y ai découvert une palanquée de modules que je ne connaissais pas.
camisole est un module (documentatino) qui implémente un service de compilation et exécution de code. Ceci peut se réveler assez pratique pour l'enseignement. La liste des langages supportés est plutôt longue. Une machine virtuelle est mise à disposition. Le module implémente uniquement une API REST. Au détour de la documentation, on voit le package isolate (C). Je vous laisse découvrir ce qu'il fait.
Un talk parlera de PDF. Je n'avais pas imaginer qu'on puisse parler de PDF pendant tout un talk. Mais a priori, c'est possible. Quelques moduless : weasyprint, pdftk, reportlab.
Je ne vais pas assez souvent les extensions Unofficial Jupyter Notebook Extensions. Sans doute parce que qu'elles ne marchent pas toujours. Néanmoins, parmi celles que j'ai déjà utilisées, il y a execute_time, hide_input, ScratchPad (pratique celle-ci). Parmi celles que j'ai envie d'essayer, il y a nbTranslate, Table of Contents (2) (même si je rêverais de l'inclure en javascript plutôt que sous forme d'extension), tree filter, Collapsible Headings qui s'exporte aussi en HTML jupyter nbconvert --to html_ch FILE.ipynb.
Côté machine learning, nous avons Surprise pour construire des systèmes de recommandation (documentation). FreeDiscovery automatise quelques opérations standard d'analyse des données. Il y a pas mal de choses au niveau texte : Python API Reference. Un article Extremal Bootstrapping à propos de Conformal Field Theory. pomegranate qui implémente des modèles bayésiens tels que les Hidden Markov Models (à comparer avec hmmlearn.
Enième workflow engine MRQ mais il a l'air assez simple. FluidDyn est une autre option qui incluent également des fonctionalités de calculs numériques. L'objectif est de réaliser des simulations numériques.
Parmi ceux que je n'utiliserai pas tout de suite PySpice qui encapsule SPICE, un langage pour des circuits électroniques. Un bloq boontadata pour lire à propos de différentes architectures de workflow de données en temps réel.
Enfin Ch'ti code ou comment parler de programmation dans les écoles primaires.
Maintenant, il va falloir que j'aille regarder si tout cela s'installe facilement.
2017-05-10 Un vieux livre remis à jour
En 2009, le support de mon cours sortait sous forme de livre Programmation avec le langage PYTHON. Quand j'y pense ça fait huit ans et j'utilisais Python 2.5. En informatique, huit ans ressemblent à une éternité. Aujourd'hui, j'ai repris le contenu, je l'ai converti au format HTML et j'utilise Python 3.6 : Apprendre la programmation avec Python. J'ai commencé à faire pareil avec ma thèse mais ça risque de prendre un peu plus de temps : Les maths d’abord, la programmation ensuite. Et tout est sur GitHub.
2017-04-26 dotAI
J'ai passé l'après-midi à la conférence dotAI. J'ai vu neuf présentations aux théâtres des variétés. Un lieu insolite pour ce genre d'événements. J'ai pris quelques notes que j'ai intégrées aux références du cours que je donne à l'ENSAE. C'est pourquoi vous les trouverez sous la forme d'un commit dotAI.
Le deep learning était la star de la conférence. La moitié des orateurs ont parlé de transfer learning. Je terminerai par deux librairies javascript reinforcejs et synaptic qui ne sont pas aussi puissantes que les outils disponibles en python mais plus vivants depuis une page web.
Bref, ce post est plus m'inciter à y retourner l'année prochaine que pour vous.
2017-04-07 Sherlock Holmes le détective des marginales
Même si je ne suis pas convaincu par la dernière saison, les premiers épisodes contiennent quelques séquences de déductions statistiques symbolisées par les incrustations à l'écran.

Le dessin animé Basil le détective livre aussi quelques séquences de réflexions intéressantes. Sherlock sait où on a le plus de chance de trouver un taxi à telle heure, le nombre de voyageurs problables dans telle zone de Londres, la durée de transport moyenne en fonction du traffic.
Sherlock se penche sur le corps d'une femme. Son manteau est mouillé et n'a pas eu le temps de sécher. La météo indique qu'il a plus au Sud de Londres il y a quelques heures. C'est comme si Sherlock faisait de la traingulation. Chaque indice réduit l'ensemble des possibilités à quelques unes. Plusieurs indices finissent par lui donner une image précise de la personne qu'il ausculte.
Pourquoi les lois marginales... Une personne regarde facebook tous les matins avant de partir au boulot. Si elle ne le fait pas un jour, c'est qu'il s'est peut-être passé quelque chose d'important le matin. Si on n'en sait pas plus, alors on utilise ce qu'on sait des gens en général, les lois marginales. Que les gens le matin ? Ils vont travailler. La personne en question a dû arriver en retard. On vérifie. C'est le cas. Lorsque Sherlock n'a pas assez d'indice, il fait des hypothèses en partant de que feraient les gens qui ressemblent au sujet de son enquête.
2017-02-16 Pourquoi je n'aime pas l'informatique
Ca c'est tout ce qui pète en ce moment. J'utilise Jenkins pour vérifier tous les notebooks que j'utilise pour mes enseignements. Un site web a décidé de rendre l'âme et boom deux ronds rouges. Et bim Python 3.6 est sorti. Et plein de rouge à nouveau.
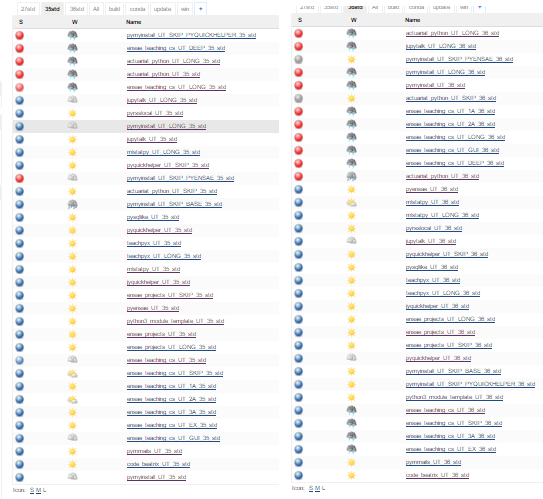
Fais chier !
J'en suis à plus de 150 notebooks et ça prend cinq à six heures de tout tester.
Les ronds rouges, ça fait chier.
| <-- --> |
Xavier Dupré
|