2013-02-19 Petits scripts du quotidien en Python
Depuis qu'on m'a fait découvrir Python, je m'aperçois que j'écris un script dès que cela m'ennuie de répéter plusieurs fois la même opération. La plupart du temps, le script a une durée de vie de six mois. Mais parfois il résiste à l'usure du temps. J'ai commencé avec des scripts pour mes enseignements car je ne m'en sortais plus avec ces histoires d'index et le nettoyage des répertoires. D'autres tâches ont suivi :
- nettoyer les répertoires de leurs fichiers temporaires,
- mettre à jour mon blog,
- effectuer des copies de sauvergarde, synchroniser deux dossiers,
- compiler les index de mes documents latex (enseignements à l'ENSAE),
- virer les morceaux de musique que je n'écoute jamais,
- extraire tous les exemples de programmes Python utilisés durant mon cours et en faire une page HTML avec les numéros de page et les exemples,
- produire la documentation et les exécutables d'un module Python codé en C++ module Python,
- associer des groupes d'élèves et des sujets informatiques.
J'ai capitulé mais j'aimerais tant avoir ces boutons sur mon ordinateur que je pourrais même relier à mon téléphone. Je suis épaté aussi du temps qu'on perd à refaire les mêmes tâches au bureau. Copier/coller, faire un rapport, qu'on recommence même s'il ressemble beaucoup à celui qu'on a fait il y a six mois mais dont on a perdu la trace et puis l'en-tête officiel a changé de toute façon. Ou les vacances qu'on coordonne facilement quand on est cinq et qui devient un casse-tête lorsqu'on est plus nombreux. Un jour peut-être, j'aurais un bouton dès que ça me fera chier. Il existe une tradition qui veuille que ce bouton s'appelle un stagiaire mais uniquement l'été.
2013-02-18 Références, livres, articles, modules
Quelques livres qu'on m'a conseillé récemment de lire sur tel ou tel sujet ou quelques modules Python qui ont croisé ma route récemment.
Modules Python
- networkx : un module permettant d'afficher des graphes avec Graphviz, il a l'air plus simple que d'autres et ne nécessite pas l'installation préalable de Graphviz. Le module yapgvb ne semple plus maintenu.
- Pillow : le module PIL n'est plus maintenu, Pillow serait son remplaçant.
Livres
- Algorithms on Strings, Trees and Sequences: Computer Science and Computational Biology de Dan Gusfield, je cherchais un livre qui pourrait me donner des idées à propos de l'alignement entre deux graphes comme l'idée que j'ai developpée ici Graph matching and alignment.
- Random Graphs (Cambridge Studies in Advanced Mathematics) de Bela Ballobas, des étudiants me posaient des questions sur la génération de graphes aléatoires respectant certaines propriétés, ce livre contient quelques réponses.
- Compilers: Principles, Techniques, and Tools (connu sous le nom de Dragon book de Alfred V. Aho, Monica S. Lam, Ravi Sethi, Jeffrey D. Ullman, c'est la bible pour qui veut écrire un compilateur.
- Joel on Software: And on Diverse and Occasionally Related Matters That Will Prove of Interest to Software Developers, Designers, and Managers, and to Those Who, Whether by Good Fortune or Ill Luck, Work with Them in Some Capacity de Joel Spolsky, collections d'article autour de la programmation, C++ en particulier.
- exercices d'informatique : conseillé par un collègue
- types and programming languages, de Benjamin Pierce (site, un bouquin sur le lambda calcul
- Learn You a Haskell For Great Good, de Miran Lipovaca, livre sur le langage Haskell
- Purely functional data structures, de Chris Okasaki, livre sur les structures de données et comment les manipuler en langage fonctionnel (lazy interpretation) (version pdf)
- Machine Learning in Action, de Peter Harrington, contient un chapitre sur l'utilisation de Hadoop/Pig avec le service AWS d'Amazon.
2013-02-17 Harry Potter and the Einstein's enigma
When I read the first book of Harry Potter, my brain stopped when I faced the enigma solved by Hermione about finding the right potion. I want to solve it! I first realize that it would take me longer than reading the book but I'm still curious about how the author came up with this story. Maybe she read about Einstein's enigma which looks the same and can be solved using the same reasoning. Anyway, here is the Potter's enigma:
- One among us seven will let you move ahead.
- Another will transport the drinker back instead.
- Two among our number hold only nettle wine.
- Three of us are killers, waiting hidden in line.
- First, however slyly the poison tries to hide -- You will always find some on nettle wine's left side;
- Second, different are those who stand at either end, But if you would move onward, neither is your friend;
- Third, as you see clearly, all are different size, Neither dwarf nor giant holds death in their insides;,
- Fourth, the second left and the second on the right -- Are twins once you taste them, though different at first sight
- The Brit lives in a red house.
- The Swede keeps dogs as pets.
- The Dane drinks tea.
- The green house is next to, and on the left of the white house.
- The owner of the green house drinks coffee.
- The person who smokes Pall Mall rears birds.
- The owner of the yellow house smokes Dunhill.
- The man living in the centre house drinks milk.
- The Norwegian lives in the first house.
- The man who smokes Blends lives next to the one who keeps cats.
- The man who keeps horses lives next to the man who smokes Dunhill.
- The man who smokes Blue Master drinks beer.
- The German smokes Prince.
- The Norwegian lives next to the blue house.
- The man who smokes Blends has a neighbour who drinks water.
I won't probably Hermione's confidence while facing this kind of enigma but if cellphones continue to evolve in a machine you can command by implementing program, maybe I could do something about it.
more...
2013-02-16 Parser du XML
Traiter du XML peut s'avérer un cauchemar parfois. D'abord pour des problèmes d'encodings, je suis toujours ébahi devant la résistance que ces problèmes m'opposent. Je suis tout simplement incapable de comprendre dans quel sens opérer mes conversions, encoder, décoder, j'essaye tout et souvent sans succès comme cela est généralement le cas lorsqu'on essaye de réparer une erreur à l'aveugle. Bref, mon problème du jour revenait à ajouter un champ à une palanquée de fichiers HTML. J'ai donc choisi de coder le "truc".
J'ai choisi de parser le fichier en XML plutôt qu'en HTML parce qu'il est plus facile ensuite d'accéder aux noeuds du documents. J'ajoute mon noeud et je sauve le document. Manque de bol, tous les guillements de mon code javascript ont disparu et été remplacé par un code abominable. Je vais sur le net, je trouve que le module xml.dom.minidom que j'utilise ne permet pas de conserver les accents. J'adore. Je finis par écrire un code vraiment sale :
more...
2013-02-13 ENSAE Alumni, dossier Big Data du numéro 46 de Variance
Le dernier numéro de Variance est sorti (revue de l'association des Anciens de l'ENSAE (http://www.ensae.org/, Variance_46.pdf). Entre autres, il y a un focus sur Big Data auquel j'ai contribué en tant qu'auteur et en tant que rédacteur. Ce thème est amené à prendre plus d'espace dans les quelques années qui viennent et recouvre des secteurs économiques qui pourraient devenir demandeurs de statisticiens ou Data Scientist. Un forum sur ce sujet est dorénavant organisé chaque année (forum Big Data Paris). On se revoit dans cinq ans ?
2013-02-12 Graph using Javascript and D3.js
I don't remember how I found this library D3.js, probably while looking for something than Graphviz because I was not able to easily connect to draw a graph on a webpage. I discovered two days ago than a Python library (PIL) I used to recommend to my student was not maintained any more and had been replaced by another one (Pillow). To draw graph, I usually recommend Matplotlib but I was wondering why not trying another one and another language which allows animated graphs. So here are my first steps with D3.js which I intent to use to draw a very simple plot.
Before writing the script
The first step starts by create a spot on the webpage:
<div id="graphid"></div>It also requires data which I stored in a separate file marathon.txt:
city year time seconds PARIS 2011 02:06:29 7589 PARIS 2010 02:06:41 7601 PARIS 2009 02:05:47 7547 PARIS 2008 02:06:40 7600 PARIS 2007 02:07:17 7637 PARIS 2006 02:08:03 7683 ...I like the fact, every time I press F5, the browser opens up and show me my page. I use SciTE as a text editor. Simple but debugging is quite difficult. For that, I used Chrome to the error (look at option activate the debug console). Anyway, let's begin. It first requires to inclure the library:
<script src="http://d3js.org/d3.v3.js"></script>It can be placed in the header or in the body. You should then configure the style otherwise your graph may not have the look you are looking for:
2013-02-10 Edit distance and sequence alignment
Some algorithms, you cannot avoid implementing them a couple of times every year. When you work for a search company, you always deal with text. You use regular expressions almost every week. The edit distance is one of these algorithms you never find in the company's wiki or not in the programming language you expect. The code references some weird assembly you don't need and don't want. Or simply, this time, you don't need the distance but the path between the two sequences. You expect to find this algorithm to be somewhere present, accessible, somewhere you don't have to look for, somewhere on the company's wiki. But surprisingly, everybody did his own, not documented, including unexpected paramters. I wish I could even keep myself some versions I made but I often implemented the edit distance in a way that it was faster for my specific needs at that time. Even for this blog (How to normalize an edit distance ?), I did it again. I remember one time doing it to prove my students the edit distance was another versions of the shortest path in a graph. I did it again today: edit_distance_alignment.py. Maybe it will be the last time?
2013-02-09 Program to convert latex into gif picture in a html document
A couple of days ago, I wrote a blog (Insérer des formules en code Latex dans un blog) on how to insert Latex formulas in a blog post. Unfortunately, this way does not seem to work all the time. The browser will try to convert formulas using another site each somebody tries to read the post. And sometimes, the latex formula shows up instead of the picture. So, I decided to write a Python program to call http://latex.codecogs.com/latexit.js before publishing the blog post. I only push GIF images and let the latex code as comments. You will find this code latex_svg_gif.py. Basically, it looks for latex formulas, extract them, call the site mentioned below, stores the images, put the former latex code in a comments section and adds a link to the created image.
<div lang="latex_help">
N \frac{c^k-1}{c-1} \sim N \frac{\frac{S}{N}-1}{c-1} \sim \frac{S-N}{c-1}
</div>
Becomes:
<!--
<div lang="latex_help">
N \frac{c^k-1}{c-1} \sim N \frac{\frac{S}{N}-1}{c-1} \sim \frac{S-N}{c-1}
</div>
-->
<p class="latexcenter">
<img src="giflatex/blog_2013_2013-02-07.html__Nfracck1c1simNfracfracSN1c1simfracSNc1.gif"
alt=" N \frac{c^k-1}{c-1} \sim N \frac{\frac{S}{N}-1}{c-1} \sim \frac{S-N}{c-1} " />
</p>
The picture name is the concatenation of all symbols in [a-zA-Z0-9].
However, recently, I found another framework which seems to work better than this one. I did not try but it is available with wordpress for example: MathJax.
2013-02-07 How to extend a stack?
A common way to create a sizeable but continuous array is to use a stack mechanism. We start by allocating a buffer and when we need more space to store new elements, we often multiply the size of this buffer by 2. We copy the existing elements into the new space, we add the new one and we free the old buffer. If we follow that strategy for a long time, we end up by allocation memory blocks of size N, 2N, 4N, 8N, ... The major drawback of this approach is we cannot reuse the space we used for the first allocation. The reason is simple:
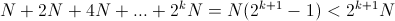
As a consequence, the new buffer is always larger than the sum of all previously allocated block. And we because, we need to keep the last one alive to copy the existing elements to the new block, this way of growing a stack cannot reuse the same memory space. This side effect could increase the memory fragmentation.
What does happen if we multiply the size of a block by a coefficient c smaller than 2:
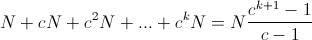
We need to compare that sum to:
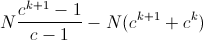
We can remove N from the equation:
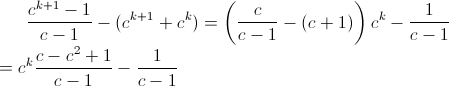
This expression is positive if and only if:
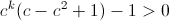
So first, we must have 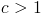 .
Second, we must also have
.
Second, we must also have 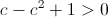 , which means:
, which means:
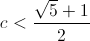
If that condition is fulfilled then, there will k for which the above expression becomes positive.
more...
2013-02-04 Insérer des formules en code Latex dans un blog
Ce blog est plus pour moi. Je cherchais un moyen de transcrire des documents Latex au format HTML. Je n'avais pas pensé à écrire mes formules directement dans un blog. J'ai suivi les instructions de ce site. On insère un lien vers un script au début du document :
<html>
<head>
<script type="text/javascript" src="
http://latex.codecogs.com/latexit.js"></script>
</head>
<body>
Puis on insère une formule :
<div lang="latex">
\frac{1+sin(x)}{y}
</div>
Et on regarde si ça marche :
\frac{1+sin(x)}{y}
Et si ça marche aussi lorsqu'on veut l'insérer dans le texte \frac{1+sin(x)}{x^3} en utilisant le code suivant :
<span lang="latex">\frac{1+sin(x)}{x^3}</span>
Dans quelques boîtes, il est désormais possible d'écrire ses propres blogs comme si finalement on avait
abandonné l'idée de structurer l'information interne dans une société. Chaque employé peut maintenant
faire circuler de l'information qu'on récupère en faisant des recherches par mots-clés. Quoiqu'il en soit,
on découvre la date à laquelle chacun à commencer à blogger car le premier blog s'appelle invariablement
Welcome to my blog, ce à quoi ce blog m'a fait penser.
2013-02-03 Quelques précisions sur les projets informatiques
Données textuelles, nuages de mots
Certains sujets traitent du traitement de texte et dans ce domaine, il est parfois important d'obtenir des données en grande quantité. La source la plus accessible et une des plus propres est Wikipedia dont il est possible de télécharger une copie dans n'importe quelle langue à partir de l'adresse suivante : wikipedia backups. Il faut chercher sur cette page un lien xxwiki ou xx sont les deux premières lettres d'une langue (frwiki par exemple). Il est possible de télécharger tout ou partie du site (cela peut prendre quelques heures).
Lire les informations présentes dans ces fichiers de plusieurs Go requiert quelques connaissances en XML, puis de comprendre la structure plutôt intuitive du document. Pour vous aider, vous pourrez lire l'article sur le parser XML en espérant que cela vous fasse gagner du temps.
La liste des sujets fournit quelques références concernant la construction des nuages de mots. Pour l'affichage, le language HTML est sans doute le plus simple. Il permet de composer des blocs de texte de différentes tailles et se charge de les disposer. Le code HTML suivant permet de modifier la taille du texte affiché par un navigateur (Firefox par exemple) :
<font size="6">This is some text!</font>
Taille 6Taille 16
Ce texte pourrait être la sorti d'un programme Python.
Données financières
more...
2013-02-02 Parser du XML
Parser du XML est toujours laborieux pour moi parce que je ne retiens jamais les librairies qu'il faut utiliser, le modèle SAX ou DOM. J'avais besoin de lire les fichiers issus du site Wikipedia qui sont organisés comme suit :
<root>
<page>
contenu d'une page
</page>
<page>
contenu d'une autre page
</page/>
...
</root>
Le fichier de Wikipedia fait malhreusement plusieurs gigaoctets, il est juste impossible
de tout charger en mémoire (sur la plupart des ordinateurs) sauf si on dispose d'au moins 20Go
de mémoire et qu'on ne veut pas s'occuper de Wikipedia en langue anglaise. En procédant
de la sorte, on est obligé de découper les fichiers.
Le programme suivant permet d'explorer les premiers objets d'un fichier Wikipedia ou de n'importe quel fichier XML pour peu qu'il contienne une collection d'objets.
from hal_xml_tree import *
file = r"c:\temp\ptwiki-20130125-pages-articles.xml"
f = open (file, "r")
parser = XMLIterParser ()
handler = XMLHandlerDict ()
parser.setContentHandler (handler)
nb = 0
for o in parser.parse(f) :
for a,b in o.iterfields() :
if len(b) > 0 :print [a,b]
print "---------------------"
nb += 1
if nb > 10: break
more...
2013-01-31 Quelques règles de survie pour travailler à plusieurs
Le document suivant décrit brièvement quelques règles qui peuvent aider si on les suit lorsqu'on se lance dans un programme informatique à plusieurs ou même seul. Elles ne sont pas ni difficiles ni agaçantes si on les applique dès le début du projet. En résumé :
- Ecrire des petites fonctions,
- Séparer les calculs, le chargement des données, l'interface graphique,
- Utiliser des fonctions de tests.
Si vous aimez les nouvelles technologiques type cloud, il devient relativement facile aujourd'hui de travailler à plusieurs sans avoir à s'échanger constamment des fichiers par emails. DropBox et TortoiseSVN permettent assez rapidement d'échanger des informations et de garder l'historique des modifications.
2013-01-30 Graph matching and alignment
Pipelines became a quite popular way to represent a workflow. Many tools such as RapidMiner, Orange or Weka use graphs to represent the sequence of processes data follow. Most of the time, between two experiments, we just copy paste a previous one, we add or delete a few nodes. After a while, it becomes uneasy to find out what modifications were made. I was wondering how it would be possible to automate such a task. How to find what modifications were introduced in a graph ?
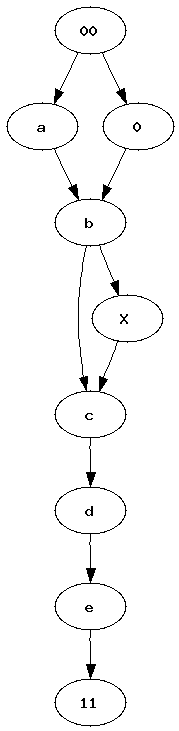 |
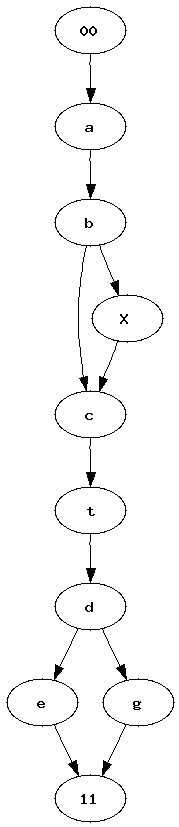 |
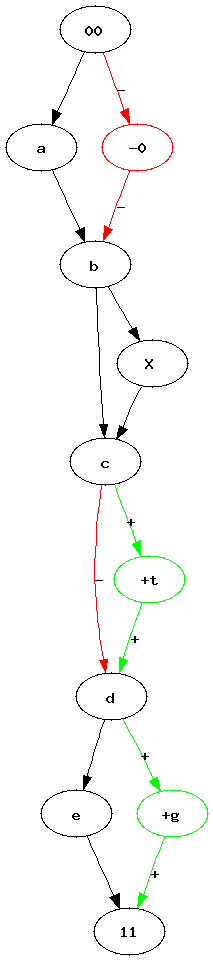 |
| Graph 1 | Graph 2 | Two graphs we would like to merge into a single one. Vertices 00 and 11 represents the only root and the only leave. |
more...
2013-01-28 Répéter les mêmes modifications sur une table
Excel est très pratique pour tracer des graphiques, écrire des formules dans une table. La seule contrainte vient parfois du fait qu'on se retrouve à faire la même chose plusieurs fois de suite. On doit produire les mêmes statistiques sur les mêmes données ou presque les mêmes : la matrice a deux colonnes en plus et trois lignes en moins. Ce n'est pas toujours évident d'adapter ses feuilles Excel. Aujourd'hui, je devais répéter la même formule sur dix colonnes différentes. J'ai donc décider de faire ça en Python. Je voulais écrire quelque chose comme ça :
table.add_column ( "has_A" + k, lambda v : 1 if "prenom" in v["name"] else 0 )L'avantage est que je peux maintenant écrire quelque chose comme :
for name in selection_colonnes :
table.add_column ( "has_" + name, lambda v : 1 if "mot clé" in v[name] else 0 )
ou encore
group = table.groupby ( lambda v: v["name"],
[ lambda v: v["d_a"],
lambda v: v["d_b"] ],
[ "name", "sum_d_a", "sum_d_b"] )
et
innerjoin = table.innerjoin (group, lambda v : v["name"],
lambda v : v["name"], "group" )
Il ne me reste plus qu'à récupérer le tout sous Excel pour faire des graphiques
ou faire de la mise en page. J'ai dû le coder plusieurs fois sous différentes
formes. Voici la dernière.
| <-- --> |
Xavier Dupré
|