Custom DecisionTreeRegressor adapted to a linear regression#
Links: notebook, html, PDF, python, slides, GitHub
A DecisionTreeRegressor can be trained with a couple of possible criterions but it is possible to implement a custom one (see hellinger_distance_criterion). See also tutorial Cython example of exposing C-computed arrays in Python without data copies which describes a way to implement fast cython extensions.
from jyquickhelper import add_notebook_menu
add_notebook_menu()
%matplotlib inline
import warnings
warnings.simplefilter("ignore")
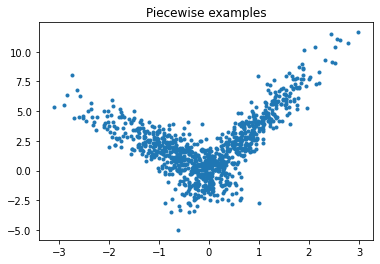
Piecewise data#
Let’s build a toy problem based on two linear models.
import numpy
import numpy.random as npr
X = npr.normal(size=(1000,4))
alpha = [4, -2]
t = (X[:, 0] + X[:, 3] * 0.5) > 0
switch = numpy.zeros(X.shape[0])
switch[t] = 1
y = alpha[0] * X[:, 0] * t + alpha[1] * X[:, 0] * (1-t) + X[:, 2]
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1)
ax.plot(X[:, 0], y, ".")
ax.set_title("Piecewise examples");
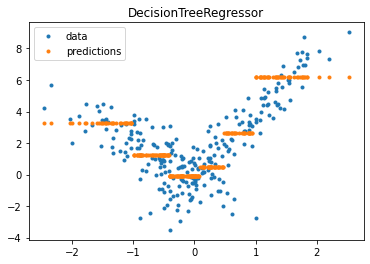
DecisionTreeRegressor#
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X[:, :1], y)
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(min_samples_leaf=100)
model.fit(X_train, y_train)
DecisionTreeRegressor(min_samples_leaf=100)
pred = model.predict(X_test)
pred[:5]
array([ 3.29436256, 0.50924806, -0.07129149, 0.50924806, 2.64957806])
fig, ax = plt.subplots(1, 1)
ax.plot(X_test[:, 0], y_test, ".", label='data')
ax.plot(X_test[:, 0], pred, ".", label="predictions")
ax.set_title("DecisionTreeRegressor")
ax.legend();
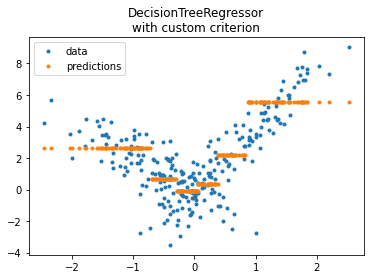
DecisionTreeRegressor with custom implementation#
import sklearn
from pyquickhelper.texthelper import compare_module_version
if compare_module_version(sklearn.__version__, '0.21') < 0:
print("Next step requires scikit-learn >= 0.21")
else:
print("sklearn.__version__ =", sklearn.__version__)
sklearn.__version__ = 1.1.dev0
from mlinsights.mlmodel.piecewise_tree_regression_criterion import SimpleRegressorCriterion
model2 = DecisionTreeRegressor(min_samples_leaf=100,
criterion=SimpleRegressorCriterion(X_train))
model2.fit(X_train, y_train)
DecisionTreeRegressor(criterion=<mlinsights.mlmodel.piecewise_tree_regression_criterion.SimpleRegressorCriterion object at 0x000001FC680A0BF0>,
min_samples_leaf=100)
pred = model2.predict(X_test)
pred[:5]
array([ 2.65757699, 0.37665413, -0.07967816, 0.37665413, 5.57229226])
fig, ax = plt.subplots(1, 1)
ax.plot(X_test[:, 0], y_test, ".", label='data')
ax.plot(X_test[:, 0], pred, ".", label="predictions")
ax.set_title("DecisionTreeRegressor\nwith custom criterion")
ax.legend();
Computation time#
The custom criterion is not really efficient but it was meant that way. The code can be found in piecewise_tree_regression_criterion. Bascially, it is slow because each time the algorithm optimizing the tree needs the class Criterion to evaluate the impurity reduction for a split, the computation happens on the whole data under the node being split. The implementation in _criterion.pyx does it once.
%timeit model.fit(X_train, y_train)
551 µs ± 93.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit model2.fit(X_train, y_train)
43.9 ms ± 2.21 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
A loop is involved every time the criterion of the node is involved
which raises a the computation cost of lot. The method _mse is
called each time the algorithm training the decision tree needs to
evaluate a cut, one cut involves elements betwee, position
[start, end[.
- cdef void _mean(self, SIZE_t start, SIZE_t end, DOUBLE_t *mean, DOUBLE_t *weight) nogil:
- if start == end:
mean[0] = 0. return
cdef DOUBLE_t m = 0. cdef DOUBLE_t w = 0. cdef int k for k in range(start, end):
m += self.sample_wy[k] w += self.sample_w[k]
weight[0] = w mean[0] = 0. if w == 0. else m / w
- cdef double _mse(self, SIZE_t start, SIZE_t end, DOUBLE_t mean, DOUBLE_t weight) nogil:
- if start == end:
return 0.
cdef DOUBLE_t squ = 0. cdef int k for k in range(start, end):
squ += (self.y[self.sample_i[k], 0] - mean) ** 2 * self.sample_w[k]
return 0. if weight == 0. else squ / weight
Better implementation#
I rewrote my first implementation to be closer to what scikit-learn is
doing. The criterion is computed once for all possible cut and then
retrieved on demand. The code is below, arrays sample_wy_left is the
cumulated sum of  starting from the left side (lower
Y). The loop disappeared.
starting from the left side (lower
Y). The loop disappeared.
- cdef void _mean(self, SIZE_t start, SIZE_t end, DOUBLE_t *mean, DOUBLE_t *weight) nogil:
- if start == end:
mean[0] = 0. return
cdef DOUBLE_t m = self.sample_wy_left[end-1] - (self.sample_wy_left[start-1] if start > 0 else 0) cdef DOUBLE_t w = self.sample_w_left[end-1] - (self.sample_w_left[start-1] if start > 0 else 0) weight[0] = w mean[0] = 0. if w == 0. else m / w
- cdef double _mse(self, SIZE_t start, SIZE_t end, DOUBLE_t mean, DOUBLE_t weight) nogil:
- if start == end:
return 0.
cdef DOUBLE_t squ = self.sample_wy2_left[end-1] - (self.sample_wy2_left[start-1] if start > 0 else 0) # This formula only holds if mean is computed on the same interval. # Otherwise, it is squ / weight - true_mean ** 2 + (mean - true_mean) ** 2. return 0. if weight == 0. else squ / weight - mean ** 2
from mlinsights.mlmodel.piecewise_tree_regression_criterion_fast import SimpleRegressorCriterionFast
model3 = DecisionTreeRegressor(min_samples_leaf=100,
criterion=SimpleRegressorCriterionFast(X_train))
model3.fit(X_train, y_train)
pred = model3.predict(X_test)
pred[:5]
array([ 2.65757699, 0.37665413, -0.07967816, 0.37665413, 5.57229226])
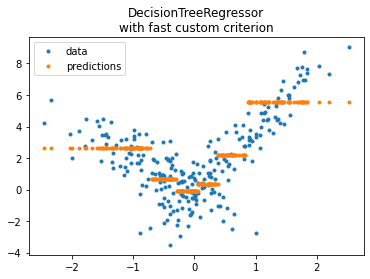
fig, ax = plt.subplots(1, 1)
ax.plot(X_test[:, 0], y_test, ".", label='data')
ax.plot(X_test[:, 0], pred, ".", label="predictions")
ax.set_title("DecisionTreeRegressor\nwith fast custom criterion")
ax.legend();
%timeit model3.fit(X_train, y_train)
676 µs ± 48.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Much better even though this implementation is currently 3, 4 times slower than scikit-learn’s. Let’s check with a datasets three times bigger to see if it is a fix cost or a cost.
import numpy
X_train3 = numpy.vstack([X_train, X_train, X_train])
y_train3 = numpy.hstack([y_train, y_train, y_train])
X_train.shape, X_train3.shape, y_train3.shape
((750, 1), (2250, 1), (2250,))
%timeit model.fit(X_train3, y_train3)
1.36 ms ± 57 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
The criterion needs to be reinstanciated since it depends on the features X. The computation does not but the design does. This was introduced to compare the current output with a decision tree optimizing for a piecewise linear regression and not a stepwise regression.
try:
model3.fit(X_train3, y_train3)
except Exception as e:
print(e)
X.shape=[750, 1, 0, 0, 0, 0, 0, 0] -- y.shape=[2250, 1, 0, 0, 0, 0, 0, 0]
model3 = DecisionTreeRegressor(min_samples_leaf=100,
criterion=SimpleRegressorCriterionFast(X_train3))
%timeit model3.fit(X_train3, y_train3)
2.03 ms ± 159 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Still almost 2 times slower but of the same order of magnitude. We could go further and investigate why or continue and introduce a criterion which optimizes a piecewise linear regression instead of a stepwise regression.
Criterion adapted for a linear regression#
The previous examples are all about decision trees which approximates a
function by a stepwise function. On every interval ![[r_1, r_2]](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDIuNi4xIC0tPgo8c3ZnIGhlaWdodD0nMTEuOTU1MTY4cHQnIHZlcnNpb249JzEuMScgdmlld0JveD0nNTYuNDEzMjY3IDU2Ljc4NzA0OSAzMS43NjI3MjYgMTEuOTU1MTY4JyB3aWR0aD0nMzEuNzYyNzI2cHQnIHhtbG5zPSdodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZycgeG1sbnM6eGxpbms9J2h0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsnPgo8ZGVmcz4KPHBhdGggZD0nTTIuNTAyNjE1IC01LjA3Njk2MUMyLjUwMjYxNSAtNS4yOTIxNTQgMi40ODY2NzUgLTUuMzAwMTI1IDIuMjcxNDgyIC01LjMwMDEyNUMxLjk0NDcwNyAtNC45ODEzMiAxLjUyMjI5MSAtNC43OTAwMzcgMC43NjUxMzEgLTQuNzkwMDM3Vi00LjUyNzAyNEMwLjk4MDMyNCAtNC41MjcwMjQgMS40MTA3MSAtNC41MjcwMjQgMS44NzI5NzYgLTQuNzQyMjE3Vi0wLjY1MzU0OUMxLjg3Mjk3NiAtMC4zNTg2NTUgMS44NDkwNjYgLTAuMjYzMDE0IDEuMDkxOTA1IC0wLjI2MzAxNEgwLjgxMjk1MVYwQzEuMTM5NzI2IC0wLjAyMzkxIDEuODI1MTU2IC0wLjAyMzkxIDIuMTgzODExIC0wLjAyMzkxUzMuMjM1ODY2IC0wLjAyMzkxIDMuNTYyNjQgMFYtMC4yNjMwMTRIMy4yODM2ODZDMi41MjY1MjYgLTAuMjYzMDE0IDIuNTAyNjE1IC0wLjM1ODY1NSAyLjUwMjYxNSAtMC42NTM1NDlWLTUuMDc2OTYxWicgaWQ9J2cxLTQ5Jy8+CjxwYXRoIGQ9J00yLjI0NzU3MiAtMS42MjU5MDNDMi4zNzUwOTMgLTEuNzQ1NDU1IDIuNzA5ODM4IC0yLjAwODQ2OCAyLjgzNzM2IC0yLjEyMDA1QzMuMzMxNTA3IC0yLjU3NDM0NiAzLjgwMTc0MyAtMy4wMTI3MDIgMy44MDE3NDMgLTMuNzM3OTgzQzMuODAxNzQzIC00LjY4NjQyNiAzLjAwNDczMiAtNS4zMDAxMjUgMi4wMDg0NjggLTUuMzAwMTI1QzEuMDUyMDU1IC01LjMwMDEyNSAwLjQyMjQxNiAtNC41NzQ4NDQgMC40MjI0MTYgLTMuODY1NTA0QzAuNDIyNDE2IC0zLjQ3NDk2OSAwLjczMzI1IC0zLjQxOTE3OCAwLjg0NDgzMiAtMy40MTkxNzhDMS4wMTIyMDQgLTMuNDE5MTc4IDEuMjU5Mjc4IC0zLjUzODczIDEuMjU5Mjc4IC0zLjg0MTU5NEMxLjI1OTI3OCAtNC4yNTYwNCAwLjg2MDc3MiAtNC4yNTYwNCAwLjc2NTEzMSAtNC4yNTYwNEMwLjk5NjI2NCAtNC44Mzc4NTggMS41MzAyNjIgLTUuMDM3MTExIDEuOTIwNzk3IC01LjAzNzExMUMyLjY2MjAxNyAtNS4wMzcxMTEgMy4wNDQ1ODMgLTQuNDA3NDcyIDMuMDQ0NTgzIC0zLjczNzk4M0MzLjA0NDU4MyAtMi45MDkwOTEgMi40NjI3NjUgLTIuMzAzMzYyIDEuNTIyMjkxIC0xLjMzODk3OUwwLjUxODA1NyAtMC4zMDI4NjRDMC40MjI0MTYgLTAuMjE1MTkzIDAuNDIyNDE2IC0wLjE5OTI1MyAwLjQyMjQxNiAwSDMuNTcwNjFMMy44MDE3NDMgLTEuNDI2NjVIMy41NTQ2N0MzLjUzMDc2IC0xLjI2NzI0OCAzLjQ2Njk5OSAtMC44Njg3NDIgMy4zNzEzNTcgLTAuNzE3MzFDMy4zMjM1MzcgLTAuNjUzNTQ5IDIuNzE3ODA4IC0wLjY1MzU0OSAyLjU5MDI4NiAtMC42NTM1NDlIMS4xNzE2MDZMMi4yNDc1NzIgLTEuNjI1OTAzWicgaWQ9J2cxLTUwJy8+CjxwYXRoIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonIGlkPSdnMi05MScvPgo8cGF0aCBkPSdNMS44NTMwNTEgLTguOTY2Mzc2SDAuMjUxMDU5Vi04LjUyNDAzNUgxLjQxMDcxVjIuNTQ2NDUxSDAuMjUxMDU5VjIuOTg4NzkySDEuODUzMDUxVi04Ljk2NjM3NlonIGlkPSdnMi05MycvPgo8cGF0aCBkPSdNMi4zMzEyNTggMC4wNDc4MjFDMi4zMzEyNTggLTAuNjQ1NTc5IDIuMTA0MTEgLTEuMTU5NjUxIDEuNjEzOTQ4IC0xLjE1OTY1MUMxLjIzMTM4MiAtMS4xNTk2NTEgMS4wNDAxIC0wLjg0ODgxNyAxLjA0MDEgLTAuNTg1ODAzUzEuMjE5NDI3IDAgMS42MjU5MDMgMEMxLjc4MTMyIDAgMS45MTI4MjcgLTAuMDQ3ODIxIDIuMDIwNDIzIC0wLjE1NTQxN0MyLjA0NDMzNCAtMC4xNzkzMjggMi4wNTYyODkgLTAuMTc5MzI4IDIuMDY4MjQ0IC0wLjE3OTMyOEMyLjA5MjE1NCAtMC4xNzkzMjggMi4wOTIxNTQgLTAuMDExOTU1IDIuMDkyMTU0IDAuMDQ3ODIxQzIuMDkyMTU0IDAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggMC4wNDc4MjFaJyBpZD0nZzAtNTknLz4KPHBhdGggZD0nTTQuNjUwNTYgLTQuODg5NjY0QzQuMjc5OTUgLTQuODE3OTMzIDQuMDg4NjY3IC00LjU1NDkxOSA0LjA4ODY2NyAtNC4yOTE5MDVDNC4wODg2NjcgLTQuMDA0OTgxIDQuMzE1ODE2IC0zLjkwOTM0IDQuNDgzMTg4IC0zLjkwOTM0QzQuODE3OTMzIC0zLjkwOTM0IDUuMDkyOTAyIC00LjE5NjI2NCA1LjA5MjkwMiAtNC41NTQ5MTlDNS4wOTI5MDIgLTQuOTM3NDg0IDQuNzIyMjkxIC01LjI3MjIyOSA0LjEyNDUzMyAtNS4yNzIyMjlDMy42NDYzMjYgLTUuMjcyMjI5IDMuMDk2Mzg5IC01LjA1NzAzNiAyLjU5NDI3MSAtNC4zMjc3NzFDMi41MTA1ODUgLTQuOTYxMzk1IDIuMDMyMzc5IC01LjI3MjIyOSAxLjU1NDE3MiAtNS4yNzIyMjlDMS4wODc5MiAtNS4yNzIyMjkgMC44NDg4MTcgLTQuOTEzNTc0IDAuNzA1MzU1IC00LjY1MDU2QzAuNTAyMTE3IC00LjIyMDE3NCAwLjMyMjc5IC0zLjUwMjg2NCAwLjMyMjc5IC0zLjQ0MzA4OEMwLjMyMjc5IC0zLjM5NTI2OCAwLjM3MDYxIC0zLjMzNTQ5MiAwLjQ1NDI5NiAtMy4zMzU0OTJDMC41NDk5MzggLTMuMzM1NDkyIDAuNTYxODkzIC0zLjM0NzQ0NyAwLjYzMzYyNCAtMy42MjI0MTZDMC44MTI5NTEgLTQuMzM5NzI2IDEuMDQwMSAtNS4wMzMxMjYgMS41MTgzMDYgLTUuMDMzMTI2QzEuODA1MjMgLTUuMDMzMTI2IDEuODg4OTE3IC00LjgyOTg4OCAxLjg4ODkxNyAtNC40ODMxODhDMS44ODg5MTcgLTQuMjIwMTc0IDEuNzY5MzY1IC0zLjc1MzkyMyAxLjY4NTY3OSAtMy4zODMzMTNMMS4zNTA5MzQgLTIuMDkyMTU0QzEuMzAzMTEzIC0xLjg2NTAwNiAxLjE3MTYwNiAtMS4zMjcwMjQgMS4xMTE4MzEgLTEuMTExODMxQzEuMDI4MTQ0IC0wLjgwMDk5NiAwLjg5NjYzOCAtMC4yMzkxMDMgMC44OTY2MzggLTAuMTc5MzI4QzAuODk2NjM4IC0wLjAxMTk1NSAxLjAyODE0NCAwLjExOTU1MiAxLjIwNzQ3MiAwLjExOTU1MkMxLjMzODk3OSAwLjExOTU1MiAxLjU2NjEyNyAwLjAzNTg2NiAxLjYzNzg1OCAtMC4yMDMyMzhDMS42NzM3MjQgLTAuMjk4ODc5IDIuMTE2MDY1IC0yLjEwNDExIDIuMTg3Nzk2IC0yLjM3OTA3OEMyLjI0NzU3MiAtMi42NDIwOTIgMi4zMTkzMDMgLTIuODkzMTUxIDIuMzc5MDc4IC0zLjE1NjE2NEMyLjQyNjg5OSAtMy4zMjM1MzcgMi40NzQ3MiAtMy41MTQ4MTkgMi41MTA1ODUgLTMuNjcwMjM3QzIuNTQ2NDUxIC0zLjc3NzgzMyAyLjg2OTI0IC00LjM2MzYzNiAzLjE2ODEyIC00LjYyNjY1QzMuMzExNTgyIC00Ljc1ODE1NyAzLjYyMjQxNiAtNS4wMzMxMjYgNC4xMTI1NzggLTUuMDMzMTI2QzQuMzAzODYxIC01LjAzMzEyNiA0LjQ5NTE0MyAtNC45OTcyNiA0LjY1MDU2IC00Ljg4OTY2NFonIGlkPSdnMC0xMTQnLz4KPC9kZWZzPgo8ZyBpZD0ncGFnZTEnPgo8dXNlIHg9JzU2LjQxMzI2NycgeGxpbms6aHJlZj0nI2cyLTkxJyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc1OS42NjQ5MjgnIHhsaW5rOmhyZWY9JyNnMC0xMTQnIHk9JzY1Ljc1MzQyNScvPgo8dXNlIHg9JzY0Ljk0MDIzNicgeGxpbms6aHJlZj0nI2cxLTQ5JyB5PSc2Ny41NDY2ODgnLz4KPHVzZSB4PSc2OS42NzI1NTEnIHhsaW5rOmhyZWY9JyNnMC01OScgeT0nNjUuNzUzNDI1Jy8+Cjx1c2UgeD0nNzQuOTE2NzA5JyB4bGluazpocmVmPScjZzAtMTE0JyB5PSc2NS43NTM0MjUnLz4KPHVzZSB4PSc4MC4xOTIwMTcnIHhsaW5rOmhyZWY9JyNnMS01MCcgeT0nNjcuNTQ2Njg4Jy8+Cjx1c2UgeD0nODQuOTI0MzMyJyB4bGluazpocmVmPScjZzItOTMnIHk9JzY1Ljc1MzQyNScvPgo8L2c+Cjwvc3ZnPg==) ,
the model optimizes
,
the model optimizes
 and finds the best constant (= the average) approxmating the function on
this interval. We would to like to approximate the function by a
regression line and not a constant anymore. It means minimizing
and finds the best constant (= the average) approxmating the function on
this interval. We would to like to approximate the function by a
regression line and not a constant anymore. It means minimizing
 .
Doing this require to change the criterion used to split the space of
feature into buckets and the prediction function of the decision tree
which now needs to return a dot product.
.
Doing this require to change the criterion used to split the space of
feature into buckets and the prediction function of the decision tree
which now needs to return a dot product.
from mlinsights.mlmodel.piecewise_tree_regression import PiecewiseTreeRegressor
piece = PiecewiseTreeRegressor(criterion='mselin', min_samples_leaf=100)
piece.fit(X_train, y_train)
PiecewiseTreeRegressor(min_samples_leaf=100)
pred = piece.predict(X_test)
pred[:5]
array([3.80559618, 0.45086204, 0.42563158, 0.44940565, 3.57423704])
fig, ax = plt.subplots(1, 1)
ax.plot(X_test[:, 0], y_test, ".", label='data')
ax.plot(X_test[:, 0], pred, ".", label="predictions")
ax.set_title("DecisionTreeRegressor\nwith criterion adapted to linear regression")
ax.legend();
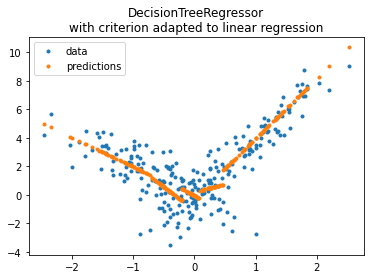
The coefficients for the linear regressions are kept into the following attribute:
piece.betas_
array([[-2.05163528, -0.07590713],
[-3.28097357, -1.07747849],
[-2.37373495, -0.05126022],
[ 1.10248486, 0.20358196],
[ 4.21766561, -0.2568136 ]])
Mapped to the following leaves:
piece.leaves_index_, piece.leaves_mapping_
([1, 4, 5, 7, 8], {1: 745, 4: 746, 3: 748, 0: 749, 2: 739})
We can get the leave each observation falls into:
piece.predict_leaves(X_test)[:5]
array([0, 3, 2, 3, 4])
The training is quite slow as it is training many linear regression each time a split is evaluated.
%timeit piece.fit(X_train, y_train)
26.9 ms ± 1.98 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit piece.fit(X_train3, y_train3)
105 ms ± 5.26 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
It works but it is slow, slower than the slow implementation of the standard criterion for decision tree regression.
Next#
PR Model trees (M5P and co) and issue Model trees (M5P) propose an implementation a piecewise regression with any kind of regression model. It is based on Building Model Trees. It fits many models to find the best splits and should be slower than this implementation in the case of a decision tree regressor associated with linear regressions.