Note
Click here to download the full example code
Compares implementations of Add#
This example compares the addition of numpy to onnxruntime implementation. Function numpy.add is repeated 3 times. This minimizes the cost of copying the data from python to an external library. If available, tensorflow and pytorch are included as well. The numpy implementation is not the best, it allocates more buffers than necessary because parameter out is not used to reuse buffers.
import numpy
import pandas
import matplotlib.pyplot as plt
from onnxruntime import InferenceSession
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx.algebra.onnx_ops import OnnxAdd
from cpyquickhelper.numbers import measure_time
from tqdm import tqdm
from mlprodict.testing.experimental_c_impl.experimental_c import code_optimisation
print(code_optimisation())
AVX-omp=8
Add implementations#
try:
from tensorflow.math import add as tf_add
from tensorflow import convert_to_tensor
except ImportError:
tf_add = None
try:
from torch import add as torch_add, from_numpy
except ImportError:
torch_add = None
def build_ort_add(op_version=12):
node1 = OnnxAdd('x', 'y', op_version=op_version)
node2 = OnnxAdd(node1, 'y', op_version=op_version)
node = OnnxAdd(node2, 'y', op_version=op_version, output_names=['z'])
onx = node.to_onnx(inputs=[('x', FloatTensorType()),
('y', FloatTensorType())],
target_opset=op_version)
sess = InferenceSession(onx.SerializeToString())
return lambda x, y: sess.run(None, {'x': x, 'y': y})
def loop_fct(fct, xs, ys):
for x, y in zip(xs, ys):
fct(x, y)
def benchmark_op(repeat=5, number=2, name="Add", shape_fcts=None):
if shape_fcts is None:
def shape_fct(dim):
return (5, dim, dim)
shape_fcts = (shape_fct, shape_fct)
ort_fct = build_ort_add()
res = []
for dim in tqdm([8, 16, 32, 64, 100, 128, 200,
256, 400, 512, 1024, 1536, 2048, 2560]):
shape1 = shape_fcts[0](dim)
shape2 = shape_fcts[1](dim)
n_arrays = (16 if dim < 512 else 4) if dim < 2048 else 4
if len(shape1) > 3:
n_arrays = int(n_arrays / 4)
xs = [numpy.random.rand(*shape1).astype(numpy.float32)
for _ in range(n_arrays)]
ys = [numpy.random.rand(*shape2).astype(numpy.float32)
for _ in range(n_arrays)]
info = dict(shape1=shape1, shape2=shape2)
# numpy
ctx = dict(
xs=xs, ys=ys,
fct=lambda x, y: numpy.add(numpy.add(numpy.add(x, y), y), y),
loop_fct=loop_fct)
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'numpy'
obs.update(info)
res.append(obs)
# onnxruntime
ctx['fct'] = ort_fct
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'ort'
obs.update(info)
res.append(obs)
if tf_add is not None:
# tensorflow
ctx['fct'] = lambda x, y: tf_add(tf_add(tf_add(x, y), y), y)
ctx['xs'] = [convert_to_tensor(x) for x in xs]
ctx['ys'] = [convert_to_tensor(y) for y in ys]
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'tf'
obs.update(info)
res.append(obs)
if torch_add is not None:
# torch
ctx['fct'] = lambda x, y: torch_add(
torch_add(torch_add(x, y), y), y)
ctx['xs'] = [from_numpy(x) for x in xs]
ctx['ys'] = [from_numpy(y) for y in ys]
obs = measure_time(
"loop_fct(fct, xs, ys)",
div_by_number=True, context=ctx, repeat=repeat, number=number)
obs['dim'] = dim
obs['fct'] = 'torch'
obs.update(info)
res.append(obs)
# Dataframes
shape1_name = str(shape1).replace(str(dim), "N")
shape2_name = str(shape2).replace(str(dim), "N")
df = pandas.DataFrame(res)
df.columns = [_.replace('dim', 'N') for _ in df.columns]
piv = df.pivot('N', 'fct', 'average')
rs = piv.copy()
for c in ['ort', 'torch', 'tf']:
if c in rs.columns:
rs[c] = rs['numpy'] / rs[c]
rs['numpy'] = 1.
# Graphs.
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
piv.plot(logx=True, logy=True, ax=ax[0],
title=f"{name} benchmark\n{shape1_name} + {shape2_name} lower better")
ax[0].legend(prop={"size": 9})
rs.plot(logx=True, logy=True, ax=ax[1],
title="%s Speedup, baseline=numpy\n%s + %s"
" higher better" % (name, shape1_name, shape2_name))
ax[1].plot([min(rs.index), max(rs.index)], [0.5, 0.5], 'g--')
ax[1].plot([min(rs.index), max(rs.index)], [2., 2.], 'g--')
ax[1].legend(prop={"size": 9})
return df, rs, ax
dfs = []
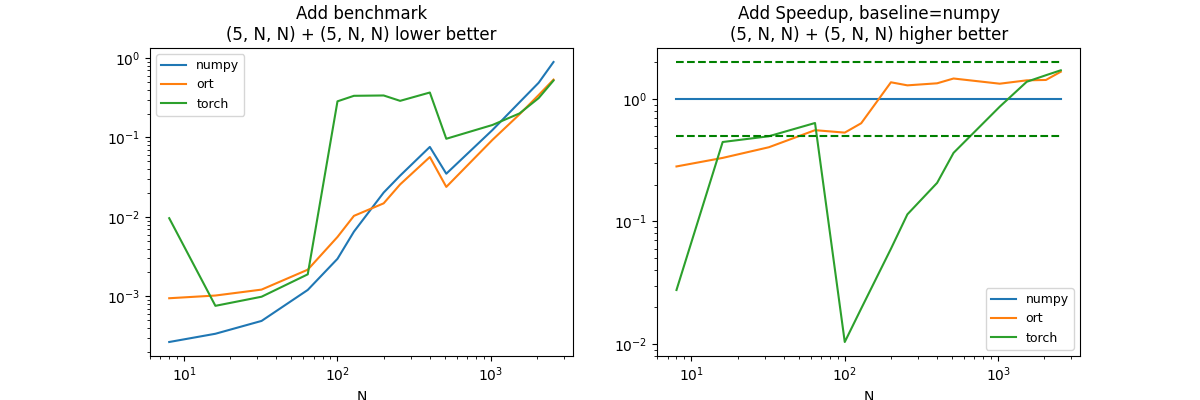
(5, N, N) + (5, N, N)#
df, piv, ax = benchmark_op()
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/14 [00:00<?, ?it/s]
7%|7 | 1/14 [00:00<00:02, 5.59it/s]
29%|##8 | 4/14 [00:00<00:00, 14.41it/s]
43%|####2 | 6/14 [00:06<00:11, 1.47s/it]
50%|##### | 7/14 [00:10<00:14, 2.04s/it]
57%|#####7 | 8/14 [00:14<00:14, 2.47s/it]
64%|######4 | 9/14 [00:20<00:16, 3.31s/it]
71%|#######1 | 10/14 [00:21<00:11, 2.90s/it]
79%|#######8 | 11/14 [00:26<00:10, 3.39s/it]
86%|########5 | 12/14 [00:35<00:10, 5.00s/it]
93%|#########2| 13/14 [00:51<00:08, 8.08s/it]
100%|##########| 14/14 [01:19<00:00, 14.11s/it]
100%|##########| 14/14 [01:19<00:00, 5.70s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:138: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:168: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
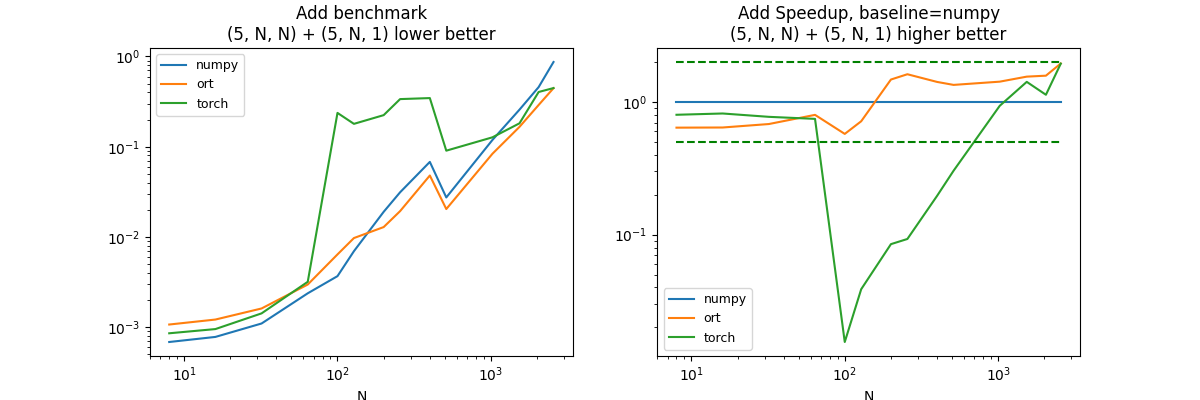
(5, N, N) + (5, N, 1)#
shape_fcts = (lambda dim: (5, dim, dim),
lambda dim: (5, dim, 1))
df, piv, ax = benchmark_op(shape_fcts=shape_fcts)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/14 [00:00<?, ?it/s]
21%|##1 | 3/14 [00:00<00:00, 27.51it/s]
43%|####2 | 6/14 [00:04<00:07, 1.09it/s]
57%|#####7 | 8/14 [00:11<00:10, 1.78s/it]
64%|######4 | 9/14 [00:16<00:12, 2.43s/it]
71%|#######1 | 10/14 [00:17<00:08, 2.22s/it]
79%|#######8 | 11/14 [00:21<00:07, 2.61s/it]
86%|########5 | 12/14 [00:28<00:07, 3.79s/it]
93%|#########2| 13/14 [00:42<00:06, 6.43s/it]
100%|##########| 14/14 [01:03<00:00, 10.53s/it]
100%|##########| 14/14 [01:03<00:00, 4.54s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:138: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:179: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
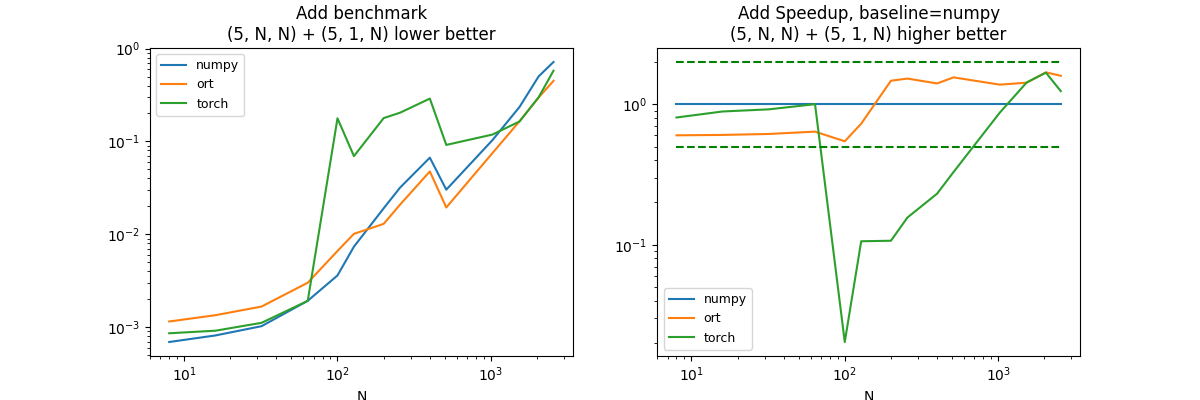
(5, N, N) + (5, 1, N)#
shape_fcts = (lambda dim: (5, dim, dim),
lambda dim: (5, 1, dim))
df, piv, ax = benchmark_op(shape_fcts=shape_fcts)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/14 [00:00<?, ?it/s]
21%|##1 | 3/14 [00:00<00:00, 26.68it/s]
43%|####2 | 6/14 [00:02<00:04, 1.72it/s]
57%|#####7 | 8/14 [00:07<00:07, 1.25s/it]
64%|######4 | 9/14 [00:12<00:09, 1.88s/it]
71%|#######1 | 10/14 [00:13<00:07, 1.81s/it]
79%|#######8 | 11/14 [00:17<00:06, 2.21s/it]
86%|########5 | 12/14 [00:24<00:06, 3.39s/it]
93%|#########2| 13/14 [00:37<00:05, 5.99s/it]
100%|##########| 14/14 [00:58<00:00, 10.15s/it]
100%|##########| 14/14 [00:58<00:00, 4.14s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:138: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:190: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
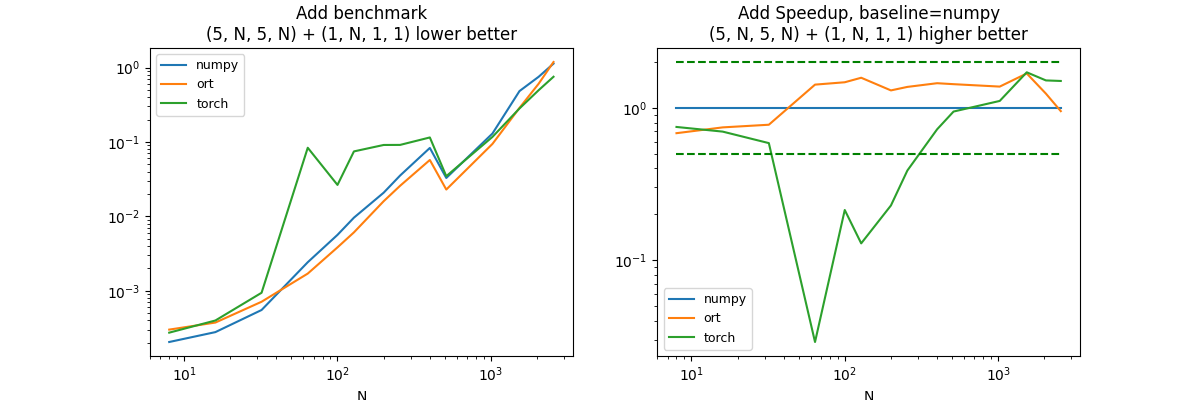
(5, N, 5, N) + (1, N, 1, 1)#
shape_fcts = (lambda dim: (5, dim, 5, dim),
lambda dim: (1, dim, 1, 1))
df, piv, ax = benchmark_op(shape_fcts=shape_fcts)
dfs.append(df)
df.pivot("fct", "N", "average")
0%| | 0/14 [00:00<?, ?it/s]
29%|##8 | 4/14 [00:00<00:02, 4.25it/s]
36%|###5 | 5/14 [00:01<00:02, 3.63it/s]
43%|####2 | 6/14 [00:02<00:03, 2.18it/s]
50%|##### | 7/14 [00:03<00:05, 1.39it/s]
57%|#####7 | 8/14 [00:05<00:05, 1.00it/s]
64%|######4 | 9/14 [00:08<00:07, 1.56s/it]
71%|#######1 | 10/14 [00:09<00:05, 1.42s/it]
79%|#######8 | 11/14 [00:13<00:06, 2.19s/it]
86%|########5 | 12/14 [00:25<00:10, 5.13s/it]
93%|#########2| 13/14 [00:48<00:10, 10.56s/it]
100%|##########| 14/14 [01:26<00:00, 18.77s/it]
100%|##########| 14/14 [01:27<00:00, 6.21s/it]
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:138: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
piv = df.pivot('N', 'fct', 'average')
somewhere/workspace/mlprodict/mlprodict_UT_39_std/_doc/examples/plot_op_add.py:201: FutureWarning: In a future version of pandas all arguments of DataFrame.pivot will be keyword-only.
df.pivot("fct", "N", "average")
Conclusion#
It is difficult to have a final conclusion as the addition of two vectors is of the same order of magnitude of a copy between python and the C++ code of onnxruntime, pytorch or tensorflow. numpy is much better of small vectors. onnxruntime, pytorch and tensorflow are not optimized on this case because it is not very common in deep learning.
merged = pandas.concat(dfs)
name = "add"
merged.to_csv(f"plot_{name}.csv", index=False)
merged.to_excel(f"plot_{name}.xlsx", index=False)
plt.savefig(f"plot_{name}.png")
plt.show()

Total running time of the script: ( 5 minutes 6.325 seconds)