Galleries de notebooks#
Cette page reprend tous les notebooks disponibles pour ces enseignements et les classes par thèmes. Beaucoup de notebooks se présentent par pairs énoncé - correction car ils servent de supports à des séances de travaux dirigés. Il est préférable de lire l’énoncé d’abord.
1A - Exposés, exercices pour apprendre la programmation et les algorithmes#
Ces exercices sont utiles pour apprendre la programmation et les algorithmes.
Un exercice typique posé lors des entretiens d’embauche est celui
sur le calcul de  où
où  est entier. D’autres notebooks
exposent des notions algorithmiques au travers de courts exemples.
Les notebooks s’adressent en premier lieu à ceux qui apprennent
à programmer.
est entier. D’autres notebooks
exposent des notions algorithmiques au travers de courts exemples.
Les notebooks s’adressent en premier lieu à ceux qui apprennent
à programmer.
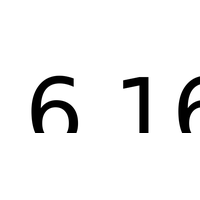
|
$chi_2$ et tableau de contingence, avec numpy, avec scipy ou sans. |
|

|
Ce notebook s’amuse à passer d’une structure de données à une autre, d’une liste à un dictionnaire, d’une liste de liste à un dictionnaire, avec toujours les mêmes données : list, dict, tuple. |
|
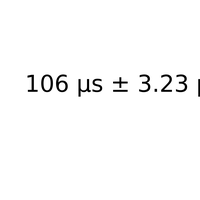
|
Compter les occurences de nombres dans une liste est assez facile avec un dictionnaire et on peut l’écrire de plusieurs manières différentes. |
|

|
1A.1 - Liste, tuple, ensemble, dictionnaire, liste chaînée, coût des opérations |
Exemples de containers, list, tuple, set, dict. |
|
On part d’une loi uniforme et on simule une loi multinomiale. |
|

|
1A.algo - Calculer le nombre de façons de monter une échelle. |
Une grenouille monte une échelle. Elle peut faire des bonds de un ou deux barreaux. Combien a-t-elle de façons de monter une échelle de treize barreaux ? Notion abordée : fonction récursive. |

|
C’est un exercice courant lors des entretiens d’embauche. Il faut savoir ce qu’est la dichotomie et la notation binaire d’un nombre. |
|

|
Le code Morse était utilisé au siècle dernier pour les transmissions. Chaque lettre est représentée par une séquence de points et tirets. Comment décoder ce code ? Notion abordée : graphe, programmation dynamique, trie. |
|
|
Ce problème est connu sur le nom de Maximum subarray problem. Notion abordée : programmation dynamique. |
|
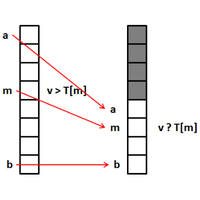
|
Recherche dichotomique illustrée. Extrait de Recherche dichotomique, récursive, itérative et le logarithme. |
|
|
Dans le cas général, le coût d’un algorithme de tri est en $O(n ln n)$. Mais il existe des cas particuliers pour lesquels on peut faire plus court. Par exemple, on suppose que l’ensemble à trier contient plein de fois le même élément. |
|

|
Profiling et fonction pdf. Le profiling est utilisé pour mesurer le temps que passe un programme dans chaque fonction. |
|
|
La structure heap ou tas en français est utilisée pour trier. Elle peut également servir à obtenir les k premiers éléments d’une liste. |
|
|
Le notebook explore quelques problèmes de géométrie dans un carré. |
|
|
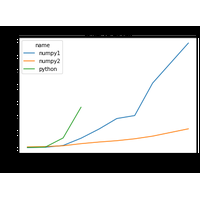
Etape par étape, le pivote de Gauss implémenté en python puis avec numpy. |
2A - Exposés, techniques de data scientiste#
Ces notebooks abordent peu de théorie, en majorité des astuces pour améliorer son quotidien de data scientiste.

|
Une table dans une base de données est déjà le résultat d’une réflexion sur la façon de les représenter. |
|

|
2A.i - Données non structurées, programmation fonctionnelle : dask |
dask est une sorte de mélange entre pandas et map/reduce. Le module implémente un sous-ensemble des possibilités de pandas sur des données qui ne tiennent pas nécessairement en mémoire. |
|
Lire un dataframe avec un itérateur quand on ne connaît pas sa taille, lire un array avec un itérateur. |
|

|
Itérateur, générateur, programmation fonctionnelle, tout pour éviter de charger l’intégralité des données en mémoire et commencer les calculs le plus vite possible. |
|

|
Modèles de mélanges de lois. Statistiques bayésiennes. bayespy, scikit-learn. |
|
|
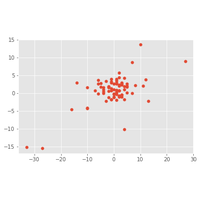
Série temporelle et prédiction. Module statsmodels. |
|

|
A couple of tricks to convert notebook such as convert a notebook into RST or HTML, get the notebook name. |
|

|
The following example shows how to define custom logic to your notebooks. You will find more details here: Defining your own magics. It works pretty simple. I just defined the magic commands |
|
|
Git est un logiciel de suivi de source décentralisé qui permet de travailler à plusieurs sur les mêmes fichiers. Aujourd’hui, on ne crée plus de logiciels sans ce type d’outil qui permet de garder l’historique des modifications apportées à un programme. Git a supplanté tous les autres logiciels du même type. |
|

|
L’idée est de recoder une fonction en C. On prend comme exemple la fonction de prédiction de la régression linéaire de scikit-learn et de prévoir le gain de temps qu’on obtient en recodant la fonction dans un langage plus rapide. |
|
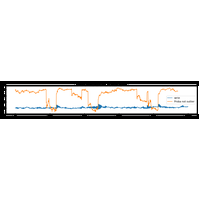
|
Illustration de la méthode SSA pour les séries temporelles appliquée à la détection de points aberrants. La méthode est décrite dans Singular Spectrum Analysis: Methodology and Comparison. Voir aussi Automated outlier detection in Singular Spectrum Analysis. |
Compétitions de machine learning#
Une compétition de machine learning a été organisé sur plusieurs semaines pour le cours de Python pour un data scientiste. On trouve dans cette section différents matériaux pour débuter et quelques solutions des étudiants.
Année 2016#
L’objectif est de prédire la probabilité de défaut de paiement d’utilisateurs. On dispose de 23 variables et la variable à prédire est binaire. Chaque participant est évalué avec la métrique AUC qui est une métrique standard dans un problème de classification binaire. Les données sont issues de default of credit card clients Data Set et ont été un peu modifiées pour la compétition : apprentissage (X,Y) et test (X). Les étudiants avaient quelques notebooks pour les aider à démarrer. Un notebook présente la solution de l’un d’eux.
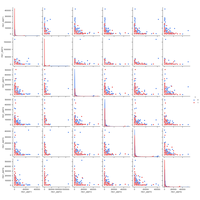
|
Une compétition était proposée dans le cadre du cours Python pour un Data Scientist à l’ENSAE. Ce notebook facilite la prise en main des données et étudie les données avec des méthodes de statistiques descriptives. |
|
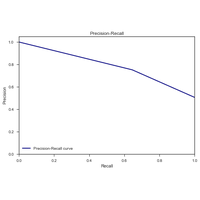
|
Une compétition était proposée dans le cadre du cours Python pour un Data Scientist à l’ENSAE. Ce notebook facilite la prise en main des données et montre comment comparer plusieurs classifieurs avec la courbe ROC. |
|
|
Une compétition était proposée dans le cadre du cours Python pour un Data Scientist à l’ENSAE. Ce notebook facilite la prise en main des données et propose de mettre en oeuvre un modèle logit. |
Année 2017#
L’objectif est de prédire la probabilité de défaut de paiement d’utilisateurs. On dispose de 23 variables et la variable à prédire est binaire. Chaque participant est évalué avec la métrique AUC qui est une métrique standard dans un problème de classification binaire. Les données sont issues de default of credit card clients Data Set et ont été un peu modifiées pour la compétition : apprentissage (X,Y) et test (X). Les étudiants avaient quelques notebooks pour les aider à démarrer. Un notebook présente la solution de l’un d’eux.
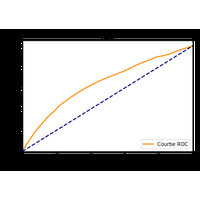
|
Ce notebook explique comment les données de la compétation 2017 ont été préparées. On récupére d’abord les données depuis le site OpenFoodFacts. |
Données#
Ces données peuvent être utilisées lors de projets, de TDs, ils montrent comment les récupérer.
|
Ce jeu de données est proposé pour la réalisation d’un projet de module python pour partager une fonction de graphe. Un exemple de ce projet est proposé : td2a_plotting. |
|
|
Ce jeu de données est disponible sous le nombre Registre des émissions polluantes. |
1A - Examens et solutions#
Le cours d’introduction à l’algorithmie est conclu par une séance de TD noté. Ces notebooks implémentent les solutions.
|
Correction de l’examen du 15 novembre 2021. |
|
|
Correction de l’examen du 24 novembre 2020. |
|

|
Correction de l’examen du 26 octobre 2022. |
|

|
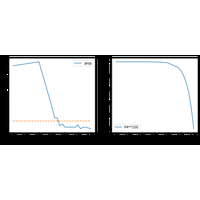
Correction de l’examen du 3 mars 2022. L’objectif est de construire un arbre de façon algorithmique. |
|
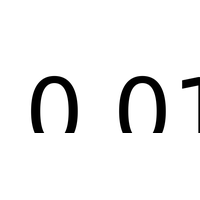
|
Correction de l’examen du 3 novembre 2021. |
|

|
1A.e - Correction de l’interrogation écrite du 10 octobre 2014 |
dictionnaire et coût algorithmique |

|
1A.e - Correction de l’interrogation écrite du 14 novembre 2014 |
coût algorithmique, calcul de séries mathématiques |

|
1A.e - Correction de l’interrogation écrite du 14 novembre 2014 |
dictionnaires |
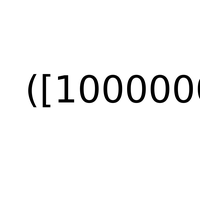
|
1A.e - Correction de l’interrogation écrite du 26 septembre 2014 |
chaîne de caractères, tri, fonction |

|
1A.e - Correction de l’interrogation écrite du 26 septembre 2015 |
tests, boucles, fonctions |
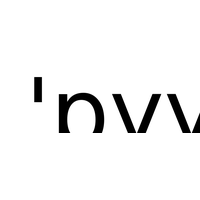
|
1A.e - Correction de l’interrogation écrite du 6 novembre 2015 |
listes et dictionnaires |
|
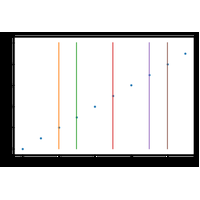
Correction du premier énoncé de l’examen du 12 décembre 2017. Celui-ci mène à l’implémentation d’un algorithme qui permet de retrouver une fonction $f$ en escalier à partir d’un ensemble de points $(X_i, f(X_i))$. |
|

|
Correction du premier énoncé de l’examen du 12 décembre 2017. Celui-ci mène à l’implémentation d’un algorithme qui permet d’approximer une fonction $f$ par une fonction en escalier à partir d’un ensemble de points $(X_i, f(X_i))$. |
|
|
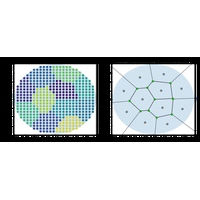
Correction du premier énoncé de l’examen du 22 octobre 2019. L’énoncé propose une façon de disposer des tables rondes dans une salle ronde. |
|

|
Correction du second énoncé de l’examen du 22 octobre 2019. L’énoncé propose une façon de disposer des tables carrées dans une salle carrée. |
|
|
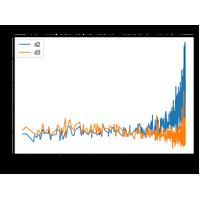
Correction du premier énoncé de l’examen du 23 octobre 2018. L’énoncé propose une méthode pour renseigner les valeurs manquantes dans une base de deux variables. |
|
|
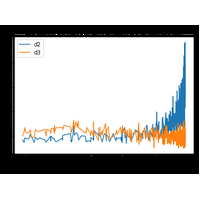
Correction du second énoncé de l’examen du 23 octobre 2018. L’énoncé propose une méthode pour renseigner les valeurs manquantes dans une base de deux variables. |
|
|
Questions posées à l’oral autour du jeu 2048 et d’un exercice Google Jam sur le position de carreaux dans un plus grand carré : Problem D. Cut Tiles. |
|

|
Calcul des intérêt d’un emprunt pour acheter un appartement, stratégie d’investissement. |
|

|
Régression linéaire avec des variables catégorielles. |
|

|
Solution du TD noté, celui-ci présente un algorithme pour calculer les coefficients d’une régression quantile et par extension d’une médiane dans un espace à plusieurs dimensions. |
|
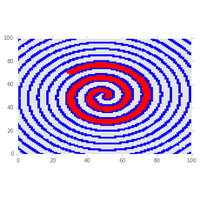
|
Coloriage d’une image, dessin d’une spirale avec matplotlib. |
|
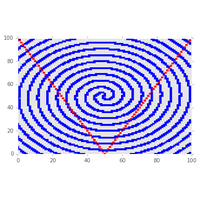
|
1A.e - TD noté, 27 novembre 2012 (éléments de code pour le coloriage) |
Coloriage d’une image, dessin d’une spirale avec matplotlib : éléments de code données avec l’énoncé. |

|
Parcours de chemins dans un graphe acyclique (arbre). |
Exposés#
Ces notebooks ne sont pas des exercices. Ils viennent principalement illuster la partie Découvrir et abordent des problèmes algorithmiques dont quelques solutions sont implémentées.

|
La lettre la plus fréquente en français est la lettre E. Cette information permet de casser le code de César en calculant le décalage entre la lettre la plus fréquente du message codé et E. Mais cette même méthode ne marchera pas pour casser le code de Vigenère. Babbage a contourné cet obstacle en étudiant la fréquence des groupes de trois lettres. |
|
|
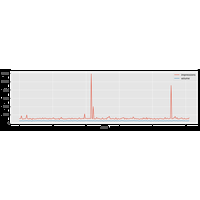
Les streams (flux) de données sont aujourd’hui présents dans de nombreux domaines (réseaux sociaux, e-commerce, logs de connexion Internet, etc.). L’analyse rapide et pertinente de ces flux est motivée par l’immensité des données qui ne peuvent souvent pas être stockés (du moins facilement) et dont le traitement serait trop lourd (penser au calcul de l’âge moyen des 1,86 milliards utilisateurs de Facebook pour s’en convaincre). Ce notebook s’intéresse particulièrement à l’algorithme BJKST. |
|
|
Une fonction de hash a pour propriété statistiques de transformer une distribution quelconque en distribution uniforme. C’est pour cela que beaucoup d’algorithmes utilisent ce type de fonction avant tout traitement pour répartir les données de manières uniformes plutôt que d’utiliser une variable une colonne telle quelle. |
|

|
Résolution de l’énigme L’énigme d’Einstein. Implémentatin d’une solution à base de règles. |
|
|
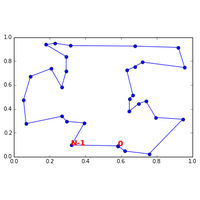
Algorithme de plus courts chemins dans un graphe. Calcul d’un chemin comparé au calcul de tous les chemins les plus courts. |
|
|
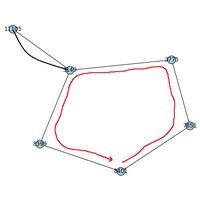
Le problème du voyageur de commerce consiste à trouver le plus court chemin passant par toutes les villes. On parle aussi de circuit hamiltonien qui consiste à trouver le plus court chemin passant par tous les noeuds d’un graphe. Le notebook explore quelques solutions approchées et intuitives. |
|
|
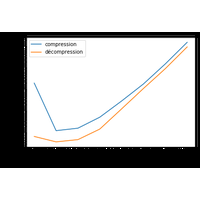
L’exemple Building a huge numpy array using pytables montre créer une grande matrice qui ne tient pourtant pas en mémoire. Il existe des modules qui permet de faire des calcul à partir de données stockées sur disque comme si elles étaient en mémoire. |
|
|
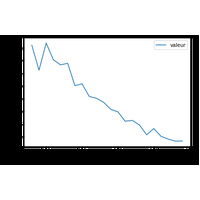
Pas de calcul d’espérence de vie, seulement différentes façons de lire les données d’une table de mortalité. |
|

|
On se pose toujours la question du modèle de machine learning qui conviendrait le mieux à notre problème. Faut-il choisir un modèle complexe avec des features brutes ou plutôt un modèle simple avec des features retravaillées ? |
|
|
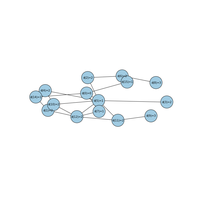
Les graphes sont des structures de données difficiles à manipuler avec des concepts map/reduce car les données ne sont pas indépendantes et la notion de voisinage est importante. Ce notebook explore ces difficultés. |
|
|
3A.mr - Random Walk with Restart (système de recommandations) |
Si la méthode de factorisation de matrices est la méthode la plus connue pour faire des recommandations, ce n’est pas la seule. L’algorithme Random Walk with Restart s’appuie sur l’exploration locale des noeuds d’un graphe et produit des résultats plus facile à intepréter. |
Notebooks des étudiants#
Ces notebooks viennent des étudiants et illustrent certains aspects du cours.
Année 2016-2017#
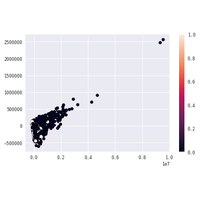
Une compétition a été lancée lors de la première année. Ce notebook a été proposé comme solution par un étudiant.
|
Ce notebook a été proposé par un étudiant pour la compétition organisée pour ce cours : classification binaire. |
Année 2017-2018#
Les étudiants contribuent au cours.

|
On peut souhaiter réduire de nombre de dimensions d’un jeu de données : |
Année 2018-2019#
Notebooks écrits par les étudiants ou écrits pendant les cours.

|
Présentation de l’API de scikit-learn et implémentation d’un prédicteur fait maison. On utilise le jeu du Titanic qu’on peut récupérer sur opendatasoft ou awesome-public-datasets. |
|

|
Notebooks écrit durant la séance du 18 septembre 2018 à propos du langage Python. |
|
|
Manipulation de données autour du jeu des passagers du Titanic qu’on peut récupérer sur opendatasoft ou awesome-public-datasets. |
|

|
La distance proposée est naïve puisqu’elle considère uniquement les lettres communes entre deux mots. |
|

|
Le notebook suivant récupère le contenu d’une page du journal Le Monde, extrait les urls d’images à l’aide d’une expression régulière puis télécharge les images pour les stocker dans un répertoire. Le notebook extrait les images d’une personnalité. |
|
|
Le noteboook explore quelques particularités des algorithmes d’apprentissage pour expliquer certains résultats numériques. L’algoithme AdaBoost surpondère les exemples sur lequel un modèle fait des erreurs. |
Année 2022-2023#
Notebooks pendant les cours.

|
## Initialization |
2A - sklearn_ensae_course#
Ces exemples viennent des lectures proposées par Gaël Varoquaux A l”ENSAE : sklearn_ensae_course/notebooks/figures.
|
Machine Learning is about building programs with tunable parameters that are adjusted automatically so as to improve their behavior by adapting to previously seen data. |
|
|
2A.ML101.1: Introduction to data manipulation with scientific Python |
In this section we’ll go through the basics of the scientific Python stack for data manipulation: using numpy and matplotlib. |
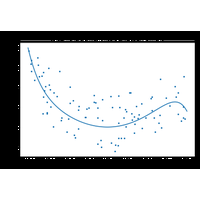
|
2A.ML101.2: Basic principles of machine learning with scikit-learn |
Classification and regression. |

|
2A.ML101.3: Supervised Learning: Classification of Handwritten Digits |
In this section we’ll apply scikit-learn to the classification of handwritten digits. This will go a bit beyond the iris classification we saw before: we’ll discuss some of the metrics which can be used in evaluating the effectiveness of a classification model. |
|
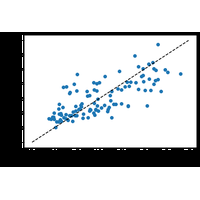
Here we’ll do a short example of a regression problem: learning a continuous value from a set of features. |
|
|
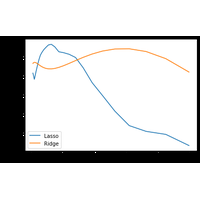
Source: Course on machine learning with scikit-learn by Gaël Varoquaux |
|
|
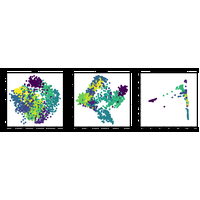
2A.ML101.6: Unsupervised Learning: Dimensionality Reduction and Visualization |
Unsupervised learning is interested in situations in which X is available, but not y: data without labels. A typical use case is to find hiden structure in the data. |

|
Here we’ll take a look at a simple facial recognition example. |
|
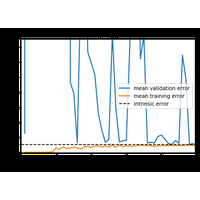
|
The content in this section is adapted from Andrew Ng’s excellent Coursera course. |
1A - Travaux dirigés - Introductions#
Tous les énoncés et les corrections des séances d’introduction à la programmation et aux algorithmes.

|
Questions très simples pour ceux qui savent coder, quelques éléments principaux du langage Python pour les autres. |
|

|
La partie 1 ne nécessite pas de correction. |
|
|
Notebook sur un des premiers programmes qu’on écrit quand on apprend à programmer. Une boucle, un test. |
|

|
On reprend la fonction introduite dans l’énoncé et qui permet de saisir un nombre. |
|

|
Le dictionnaire est une structure de données très utilisée. Elle est illustrée pour un problème de décryptage. |
|

|
1A.1 - Dictionnaires, fonctions, code de Vigenère (correction) |
Le notebook ne fait que crypter et décrypter un message sachant le code connu. Casser le code requiert quelques astuces décrites dnas ce notebook : casser le code de Vigenère. |
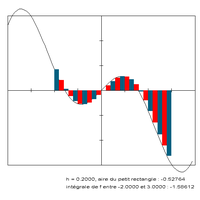
|
Approximation du calcul d’une intégrale par la méthode des rectangles |
|
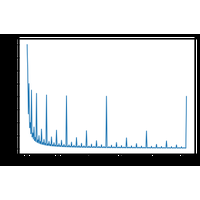
|
Approximation du calcul d’une intégrale par la méthode des rectangles. |
|
|
Cet exercice est inspirée de l’article 2015-04-07 Motif, optimisation, biodiversité. Il s’agit de dessiner un motif. |
|
|
Cet exercice est inspirée de l’article 2015-04-07 Motif, optimisation, biodiversité. Il s’agit de dessiner un motif. Correction. |
|
|
Répétitions de code, exécuter une partie plutôt qu’une autre. |
|
|
Boucles, tests, correction. |
|

|
Le jeu 2048 est assez simple et fut populaire en son temps. Comment imaginer une stratégie qui dépasser le 2048 ? |
|

|
Le jeu 2048 est assez simple et fut populaire en son temps. Comment imaginer une stratégie qui dépasser le 2048 ? |
|

|
L’héritage permet de réécrire certaines parties du code sans pour autant enlever les anciennes versions toujours utilisées. |
|

|
Correction. |
|

|
1A.2 - Classes, méthodes, attributs, opérateurs et carré magique |
Les classes proposent une façon différente de structurer un programme informatique. Pas indispensable mais souvent élégant. |
|
1A.2 - Classes, méthodes, attributs, opérateurs et carré magique (correction) |
Correction. |

|
Comment deviner la langue d’un texte sans savoir lire la langue ? Ce notebook aborde les dictionnaires, les fichiers et les graphiques. |
|
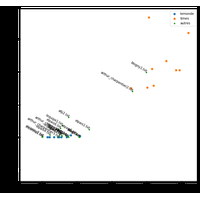
|
Calcul d’un score pour détecter la langue d’un texte. Ce notebook aborde les dictionnaires, les fichiers et les graphiques (correction). |
|
|
Le langage Python est défini par un ensemble de règle, une grammaire. Seul, il n’est bon qu’à faire des calculs. Les modules sont des collections de fonctionnalités pour interagir avec des capteurs ou des écrans ou pour faire des calculs plus rapides ou plus complexes. |
|

|
1A.2 - Modules, fichiers, expressions régulières (correction) |
Correction. |
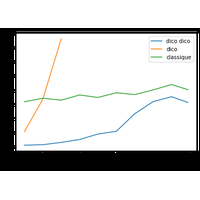
|
Les dictionnaires sont une façon assez de représenter les matrices creuses en ne conservant que les coefficients non nuls. Comment écrire alors le produit matriciel ? |
1A - Travaux dirigés autour des algorithmes#
Problèmes de graphes, d’optimisation, ces notebooks traitent principalement d’algorithmes.
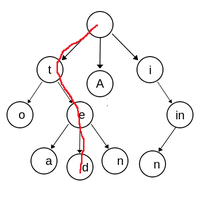
|
Le mot trie est anglais et se prononce traïlle. Il sera défini plus bas. Cette structure de données est très adaptée à la recherche d’un mot dans une liste ordonnée. C’est aussi une histoire de dictionnaires imbriqués. |
|

|
Correction. |
|

|
Comment calculer le nombre d’éléments distincts d’un ensemble de données quand celui-ci est trop grand pour tenir en mémoire. C’est ce que fait l’algorithme BJKST. |
|
|
Découvrir les graphes avec des problèmes pas trop compliqués. Composantes connexes, plus court chemin et… |
|

|
La distance d’édition ou de Levenshtein calcule une distance entre deux séquences. L’algorithme utilise la programmation dynamique. |
|

|
Correction. |
|

|
L’optimisation sous contrainte est un problème résolu. Ce notebook utilise une librairie externe et la compare avec l’algorithme Arrow-Hurwicz qu’il faudra implémenter. Plus de précision dans cet article Damped Arrow-Hurwicz algorithm for sphere packing. |
|

|
Un peu plus de détails dans cet article : Damped Arrow-Hurwicz algorithm for sphere packing. |
|

|
Parcourir le graphe formé par les liens wikipédia… Le notebook explore également le web scrapping. |
|

|
Correction du notebook du même titre. On part d’une page, on explore les liens des pages liées à la première et on continue. On utilise le module beautifulsoup4 (web scrapping pour parser les pages. |
|
|
On veut compter les arcs, les noeuds d’un graphe. On utilise également les classes. |
|
|
Algorithme assez simple sur les graphes (correction). |
|

|
La programmation dynamique est une façon des calculs qui revient dans beaucoup d’algorithmes. Elle s’applique dès que ceux-ci peuvent s’écrire de façon récurrente. |
|
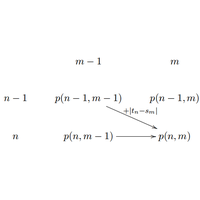
|
1A.algo - Programmation dynamique et plus court chemin (correction) |
Correction. |
|
Cet énoncé a pour objectif de présenter l’algorithme de tri quicksort qui permet de trier par ordre croissant un ensemble d’éléments (ici des chaînes de caractères) avec un coût moyen. |
|
|
On veut couper un graphe en deux en coupant le moindre d’arcs possible. C’est un algorithme de clustering. |
|
|
On veut couper un graphe en deux en coupant le moindre d’arcs possible. C’est un algorithme de clustering. Correction du notebook qui contient l’énoncé. |
|

|
Le notebook part du problème qui consiste à construire une distance entre deux chaînes de caractères en partant d’une idée naïve pour aller jusque la distance d’édition. distance de Jaccard. |
|

|
De la distance de Jaccard à la distance de Levenshtein. |
|

|
Le filtre de Sobel est utilisé pour calculer des gradients dans une image. L’image ainsi filtrée révèle les forts contrastes. |
|

|
Correction. |
|

|
Un exercice classique : trouver la plus grande sous-séquence croissante. Celle-ci n’est pas nécessairement un bloc contigü de la liste initiale mais les entiers apparaissent dans le même ordre. |
|

|
1A.algo - la plus grande sous-séquence croissante - correction |
Un exercice classique : trouver la plus grande sous-séquence croissante. Celle-ci n’est pas nécessairement un bloc contigü de la liste initiale mais les entiers apparaissent dans le même ordre. |
|
Implémentation du quicksort façon graphe. |
1A - Travaux dirigés autour des données#
Ces notebooks s’intéresse principalement à ceux qui découvre la manipulation des données avec des dataframes.

|
Les DataFrame se sont imposés pour manipuler les données avec le module pandas. Le module va de la manipulation des données jusqu’au calcul d’une régresion linéaire. |
|
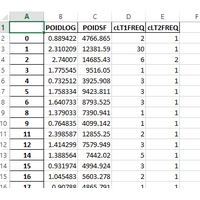
|
Correction. |
|

|
On construit des variables corrélées gaussiennes et on cherche à construire des variables décorrélées en utilisant le calcul matriciel. |
|

|
1A.data - Décorrélation de variables aléatoires - correction |
On construit des variables corrélées gaussiennes et on cherche à construire des variables décorrélées en utilisant le calcul matriciel. (correction) |
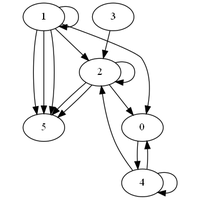
|
Les tableaux et les graphes sont deux outils incontournables des statisticiens. Petite revue des graphes. |
|
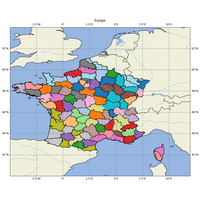
|
Les cartes sont probablement les graphes les plus longs à mettre en place. Si les coordonnées longitude lattitude sont les plus utilisées, il est possible de les considérer comme des coordonnées carthésiennes sur une grande surface (sphérique). Il faut passer par une projection spécifique dans le plan. Il faut également ajouter des repères géographiques pour lire efficacement une carte comme les frontières des pays, les rivières… Tout ça prend du temps. |
|
|
Les graphiques interactif permettent d’afficher plus d’information sur le même graphe mais comme le lecteur ne peut déchiffrer des graphes trop chargés, il interagit pour restreindre sa lecture à une zone précise. Le zoom est indispensable pour visualiser des données très localisées sur de grandes zones géographiques mais ce n’est pas la seule. |
|
|
Correction. |
td1a_home#
|
Le jeu 2048 est assez addictif mais peut-on imaginer une stratégie qui joue à notre place est maximise le gain… Le jeu se joue sur une matrice 4x4. |
|
|
Le voyageur de commerce ou Travelling Salesman Problem en anglais est le problème NP-complet emblématique : il n’existe pas d’algorithme capable de trouver la solution optimale en temps polynômial. La seule option est de parcourir toutes les configurations pour trouver la meilleure. Ce notebook ne fait qu’aborder le problème. |
|
|
C’est l’histoire d’une boucle, puis d’une autre, puis enfin d’un couple de boucles, voire d’un triplé. |
|
|
Les graphes sont un outil très utilisé pour modéliser un ensemble de relations entre personnes, entre produits, entre consommateurs. Les utilisations sont nombreuses, systèmes de recommandations, modélisation de la propagation d’une épidémie, modélisation de flux, plus court chemin dans un graphe. |
|
|
Un problème d’ordonnancement est un problème dans lequel il faut déterminer le meilleur moment de démarrer un travail, une tâche alors que celles-ci ont des durées bien précises et dépendent les unes des autres. |
|
|
TSP, Traveling Salesman Problem ou Problème du Voyageur de Commerce est un problème classique. Il s’agit de trouver le plus court chemin passant par des villes en supposant qu’il existe une route entre chaque paire de villes. |
|
|
La distance d’édition ou distance de Levenshtein permet de calculer une distance entre deux mots et par extension entre deux séquences. |
|
|
Comment générer un graphe aléatoire… Générer une séquence de nombres aléatoires indépendants est un problème connu et plutôt bien résolu. Générer une structure aléatoire comme une graphe est aussi facile. En revanche, générer un graphe aléatoire vérifiant une propriété - la distribution des degrés - n’est pas aussi simple qu’anticipé. |
|

|
Les dictionnaires sont très utilisés pour associer des choses entre elles, surtout quand ces choses ne sont pas entières. Le notebook montre l’intérêt de perdre un peu de temps pour transformer les données et rendre un calcul plus rapide. |
|
|
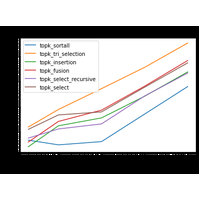
Rechercher les k premiers éléments est un exercice classique d’algorithmie, souvent appelé *top-k*et qu’on peut résoudre à l’aide d’un algorithme de sélection. C’est très utile en machine learning pour retourner les 3, 4, ou 5 premiers résultats d’un modèle prédictif. |
|
|
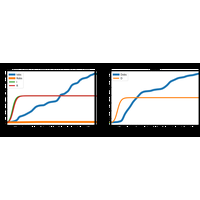
Ou comment utiliser les mathématiques pour comprendre la propagation de l’épidémie. |
|

|
Distance entre deux mots de même longueur et tests unitaires |
Calculer une distance entre deux mots n’est pas le plus intuitif des problèmes. Dans ce notebook, on se permet de tâtonner pour faire évoluer quelques idées autour du sujet. C’est l’occasion aussi de montrer à quoi servent les tests unitaires et pourquoi ils sont utiles lorsqu’on tâtonne. |

|
Une convolution est une opération très fréquente en deep learning lorsqu’il s’agit d’interpréter des images. Elle est aussi coûteuse et c’est pour ça que beaucoup essayent d’accélérer son calcul à défaut de s’en passer. |
|
|
Il est facile de répartir des élèves en quatre groupe après les avoir triés par ordre croissant, les élèves dont les noms de famille commencent par A dans le premier groupe et ainsi de suite… Cette répartition peut poser un problème éthique parfois. On souhaite écrire une fonction de répartition qui affecte les étudiants dans un groupe parmi quatre : |
|
|
Ce notebook aborde les sujets évoqués dans le titre. |
|

|
Certains sites web actuels font appels à de nombreux modèles de machine learning. Un moteur de recherche affiche beaucoup de résultats différents, des suggestions, des résultats de recherches, des recherches associées, des informations, des résultats locaux. Chacun d’entre eux fait appel à un ou plusieurs modèles de machine learning plus ou moins complexes. Le modèle classique d’un site web, ce sont deux machines : * le client : la machine de celui qui consiste le site web * le server : la machine qui retourne la page pour celui qui consiste le site web |
|
|
Transmettre l’information d’une machine à une autre, d’un logiciel à un autre, d’une base de données à une autre est un problème récurrent. Le format le plus simple pour des données est le format csv. Ca marche bien pour les tables mais cela ne permet de transmettre aisément des données non structurées. |
|

|
La sérialisation répond à un problème simple : comment échanger des données complexes autres que des tableaux ? |
|
|
numpy est la librairie incontournable pour faire des calculs en Python. Ces fonctionnalités sont disponibles dans tous les langages et utilisent les optimisations processeurs. Il est hautement improbable d’écrire un code aussi rapide sans l’utiliser. |
|
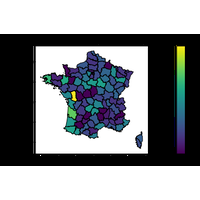
|
Faire une carte, c’est toujours compliqué. C’est simple jusqu’à ce qu’on s’aperçoive qu’on doit récupérer la description des zones administratives d’un pays, fournies parfois dans des coordonnées autres que longitude et latitude. Quelques modules utiles : |
|

|
Les expressions régulières sont utilisées pour rechercher des motifs dans un texte tel que des mots, des dates, des nombres… |
|
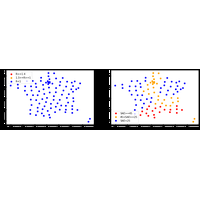
|
pandas est la librairie incontournable pour manipuler les données. Elle permet de manipuler aussi bien les données sous forme de tables qu’elle peut récupérer ou exporter en différents formats. Elle permet également de créer facilement des graphes. |
|
|
Le profilage de code ou profiling en anglais signifie qu’on mesure le temps passé dans chaque partie d’un programme pour en découvrir les parties les plus coûteuses et les améliorer. On souhaite toujours accélérer un programme trop lent, le profiling permet de savoir sur quelles parties se concentrer. |
|

|
Les tests unitaires sont l’élément clé pour créer un programme fiable. Il est impensable de s’en passer. Un test unitaire est une fonction qui s’assure qu’une autre fonction retourne le résultat souhaité pour les mêmes entrées. Ils sont présents dans tous les langages. |
|
|
Les classes ou la programmation objet est une façon différente d’écrire et d’organiser un programme informatique. Cela ne permet rien de plus que les fonctions mais ça permet de le faire souvent de façon plus élégante. |
1A - Travaux dirigés autour des pratiques logiciels#
Il est difficile de construire un logiciel qui tiennent la route lorsqu’il est conçu à plusieurs, que certains des auteurs ne sont plus là. Ces notebooks sont un guide des bonnes pratiques.

|
Python est très lent. Il est possible d’écrire certains parties en C mais le dialogue entre les deux langages est fastidieux. Cython propose un mélange de C et Python qui accélère la conception. |
|

|
||
|
Premiers pas avec le langage SQL. |
|
|
Correction des exercices du premier notebooks relié au SQL. |
|

|
On vérifie toujours qu’un code fonctionne quand on l’écrit mais cela ne veut pas dire qu’il continuera à fonctionner à l’avenir. La robustesse d’un code vient de tout ce qu’on fait autour pour s’assurer qu’il continue d’exécuter correctement. |
2A - Travaux dirigés - Data Scientiste / Economiste#
Enoncés communs aux data scientistes et aux économistes pour le cours Python pour un Data Scientist / Economiste.
|
numpy arrays sont la première chose à considérer pour accélérer un algorithme. Les matrices sont présentes dans la plupart des algorithmes et numpy optimise les opérations qui s’y rapporte. Ce notebook est un parcours en diagonal. |
|
|
Calcul matriciel (numpy. |
|

|
Les Dataframe se sont imposés pour manipuler les données. Avec cette façon de représenter les données, associée à des méthodes couramment utilisées, ce qu’on faisait en une ou deux boucles se fait maintenant en une seule fonction. Le module pandas est très utilisé, il existe de nombreux tutoriels, ou page de recettes pour les usages les plus fréquents : cookbook. |
|
|
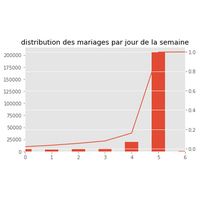
Opérations standards sur les dataframes (pandas et les matrices (numpy. Graphiques avec matplotlib. |
|

|
Tutoriel sur matplotlib. |
|
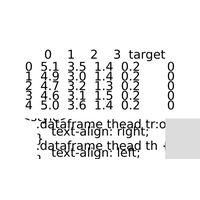
|
pandas a tendance a prendre beaucoup d’espace mémoire pour charger les données, environ trois fois plus que sa taille sur disque. Quand la mémoire n’est pas assez grande, que peut-on faire ? |
|

|
pandas a tendance a prendre beaucoup d’espace mémoire pour charger les données, environ trois fois plus que sa taille sur disque. Quand la mémoire n’est pas assez grande, que peut-on faire ? |
|

|
2A.i - Données non structurées et programmation fonctionnelle |
Calculs de moyennes et autres statistiques sur une base twitter au format JSON avec de la programmation fonctionnelle (module cytoolz. |

|
2A.i - Données non structurées, programmation fonctionnelle - correction |
Calculs de moyennes et autres statistiques sur une base twitter au format JSON avec de la programmation fonctionnelle (module cytoolz. |
|
Jupyter a été découpé en plusieurs extensions comme ipyparallel qui permet de distribuer un calcul sur plusieurs processus. Ce notebook montre comment faire sur une seule machine. |
|

|
2A.i - Modèle relationnel, analyse d’incidents dans le transport aérien |
Base de données relationnelles, logique SQL. |

|
2A.i - Modèle relationnel, analyse d’incidents dans le transport aérien - correction |
Manipulation de données avec les dataframes, jointures. Correction inachevée… |
|
Parallélisation avec joblib. |
|

|
L’idée de ce notebook n’est pas de se servir de faire du machine learning mais de modifier la fonction fit pour afficher une barre d’avancement dans le notebook. Lorsque les affichages (print) sont trop nombreux et prennent tout l’écran, une barre de défilement est une solution pratique et efficace. On applique cela à un assemblage de random forest. |
|

|
Eléments de réflexion autour des jeux de données trop grands pour tenir en mémoire. |
|
|
Charger un dataframe depuis un fichier texte prend du temps car il faut convertir le texte en nombre. La sérialisation permet de copier le contenu depuis la mémoire vers le disque. A la prochaine utilisation, Python a juste besoin de recopier le bloc depuis le disque et de le copier sans trop le modifier en mémoire. Sérialiser un dataframe permet de le récupérer beaucoup plus vite. |
|

|
Sérialisation d’objets, en particulier de dataframes. Mesures de vitesse. |
|
|
Ce notebook propose de voir comment incorporer des features pour voir l’amélioration des performances sur une classification binaire. |
|
|
2A.ml - Classification binaire avec features textuelles - correction |
Ce notebook propose de voir comment incorporer des features pour voir l’amélioration des performances sur une classification binaire. |

|
Comment faire du machine learning avec des données cryptées ? Ce notebook propose d’en montrer un principe exposé dans CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. |
|
|
Comment faire du machine learning avec des données cryptées ? Ce notebook propose d’en montrer un principe exposés CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. Correction. |
|

|
Revue de méthodes de word embedding statistiques (~ NLP ou comment transformer une information textuelle en vecteurs dans un espace vectoriel (features) ? Deux exercices sont ajoutés à la fin. |
|
|
Aperçu des commandes magiques pour automatiser un peu plus les tâches courantes. |
|

|
Pour être inventif, il faut être un peu paresseux. Cela explique parfois la syntaxe peu compréhensible mais réduite de certaines instructions. Cela explique sans doute aussi que Jupyter offre la possibilité de définir des commandes magiques qu’on peut interpréter comme des raccourcis. |
2A - Travaux dirigés - Algorithmes#
Enoncés algorithmiques pour le cours Python pour un Data Scientist / Economiste.

|
La méthodes des plus proches voisins est un algorithme assez simple. Que se passe-t-il quand la dimension de l’espace des features augmente ? Comment y remédier ? Le profiling memory_profiler ou cprofile sont des outils utiles pour savoir où le temps est perdu. |
|

|
2A.algo - Plus proches voisins en grande dimension - correction |
La méthodes des plus proches voisins est un algorithme assez simple qui devient très lent en grande dimension. Ce notebook propose un moyen d’aller plus vite (ACP) mais en perdant un peu en performance. |

|
Eléments de réponses pour des puzzles algorithmiques tirés de Google Code Jam et autres sites équivalents, produits scalaires, problèmes de recouvrements, soudoyer les prisonniers, découpage stratifié. |
|

|
Eléments de réponses pour des puzzles algorithmiques tirés de Google Code Jam et autres sites équivalents, nombres premiers, écoulement d’eau, séparation des bagarreurs, formation de binômes. |
|

|
Puzzles algorithmiques tirés de Google Code Jam et autres sites équivalents, produits scalaires, problèmes de recouvrements, soudoyer les prisonniers, découpage stratifié. |
|

|
Puzzles algorithmiques tirés de Google Code Jam et autres sites équivalents, nombres premiers, écoulement d’eau, séparation des bagarreurs, formation de binômes. |
|

|
Un cryptage homomorphe préserve l’addition et la multiplication : une addition sur des nombres cryptés est égale au résultat crypté de l’addition sur les nombres non cryptées. Craig Gentry a proposé un tel cryptage dans son article Fully Homomorphic Encryption over the Integers. Le système de cryptage encrypte et décrypte des bits (0 ou 1). |
|

|
Un cryptage homomorphe préserve l’addition et la multiplication : une addition sur des nombres cryptés est égale au résultat crypté de l’addition sur les nombres non cryptées. Craig Gentry a proposé un tel cryptage dans son article Fully Homomorphic Encryption over the Integers. Le système de cryptage encrypte et décrypte des bits (0 ou 1). Correction. |
2A - Travaux dirigés - Economistes (1)#
Enoncés plutôt dédiés aux économistes pour le cours Python pour un Data Scientist / Economiste.

|
Petite revue d’API REST. |
|
|
Pour aller vite, Flask est un framework de développement web en Python. Il en existe d’autres, le plus connu d’entre eux est Django. Ce notebook la création d’un site web à usage principalement privé. |
|

|
Manipulation d’une API REST, celle de la SNCF est prise comme exemple. Exercices. |
|

|
Manipulation d’une API REST, celle de la SNCF est prise comme exemple. Correction d’exercices. |
|

|
Voici un petit exercice qui nous permet de voir à peu près toutes les opérations standards sur les dataframes avec un jeu de données issus des élections. |
|
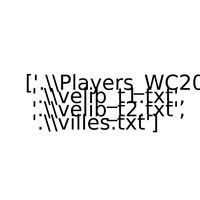
|
2A.eco - Mise en pratique des séances 1 et 2 - Utilisation de pandas et visualisation |
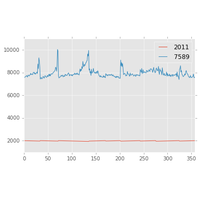
Trois exercices pour manipuler les donner, manipulation de texte, données vélib. |

|
2A.eco - Mise en pratique des séances 1 et 2 - Utilisation de pandas et visualisation - correction |
Correction d’un exercice sur la manipulation des données. |

|
2A.eco - Mise en pratique des séances 1 et 2 - Utilisation de pandas et visualisation - correction |
Correction de l’exercice 2 et manipulations classiques de texte. |

|
2A.eco - Mise en pratique des séances 1 et 2 - Utilisation de pandas et visualisation - correction |
Correction de l’exercice 3 et disponibilités des velibs. |

|
SQL permet de créer des tables, de rechercher, d’ajouter, de modifier ou de supprimer des données dans les bases de données. Un peu ce que vous ferez bientôt tous les jours. C’est un langage de management de données, pas de nettoyage, d’analyse ou de statistiques avancées. |
|

|
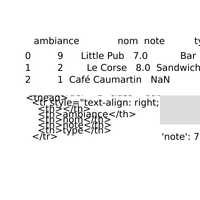
Correction d’exercices sur SQL. |
|
|
2A.eco - Rappel de ce que vous savez déjà mais avez peut-être oublié |
pandas et numpy sont essentiels pour manipuler les données. C’est ce que rappelle ce notebook. Voir aussi Essential Cheat Sheets for Machine Learning and Deep Learning Engineers. |
|
Aperçu de ce qu’est le traitement automatique du langage naturel (NLP et quelques exercices. |
|

|
2A.eco - Traitement automatique de la langue en Python - correction |
Correction d’exercices liés au traitement automatique du langage naturel. |

|
Sous ce nom se cache une pratique très utile pour toute personne souhaitant travailler sur des informations disponibles en ligne, mais n’existant pas forcément sous la forme d’un tableau Excel… Bref, il s’agit de récupérer des informations depuis Internet. |
|

|
Il faut récupérer automatiquement des images de pokémon depuis le site pokemondb.net. |
|
|
On peut réaliser des régressions linéaires de beaucoup de manières avec Python. On en a retenu 2, statsmodels et scikit-learn. Les deux librairies ont chacunes leurs qualités et leurs défauts, sachez que l’une est plus orienté data science et l’autre plus pour des économistes. |
2A - Travaux dirigés - Economistes (2)#
Enoncés plutôt dédiés aux économistes pour le cours Python pour un Data Scientist / Economiste. Ces énoncés sont également moins testés et peuvent ne plus être à jour.
|
Dans ce TD, nous allons voir comment travailler avec du texte, à partir d’extraits de textes de trois auteurs, Edgar Allan Poe, (EAP), HP Lovecraft (HPL), et Mary Wollstonecraft Shelley (MWS). |
|
|
Chercher un mot dans un texte est une tâche facile, c’est l’objectif de la méthode find attachée aux chaînes de caractères, elle suffit encore lorsqu’on cherche un mot au pluriel ou au singulier mais il faut l’appeler au moins deux fois pour chercher ces deux formes. Pour des expressions plus compliquées, il est conseillé d’utiliser les expressions régulières. C’est une fonctionnalité qu’on retrouve dans beaucoup de langages. C’est une forme de grammaire qui permet de rechercher des expressions. |
|
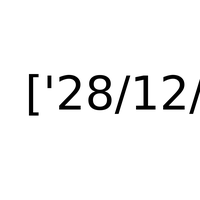
|
2A.eco - Les expressions régulières : à quoi ça sert ? (correction) |
Chercher un mot dans un texte est une tâche facile, c’est l’objectif de la méthode find attachée aux chaînes de caractères, elle suffit encore lorsqu’on cherche un mot au pluriel ou au singulier mais il faut l’appeler au moins deux fois pour chercher ces deux formes. Pour des expressions plus compliquées, il est conseillé d’utiliser les expressions régulières. C’est une fonctionnalité qu’on retrouve dans beaucoup de langages. C’est une forme de grammaire qui permet de rechercher des expressions. |

|
Analyse de texte, TF-IDF, LDA, moteur de recherche, expressions régulières. |
|

|
Analyse de texte, TF-IDF, LDA, moteur de recherche, expressions régulières (correction). |
2A - Travaux dirigés - Machine Learning#
Enoncés plutôt dédiés aux data scientistes pour le cours Python pour un Data Scientist / Economiste.
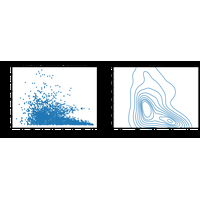
|
2A.data - Classification, régression, anomalies - correction |
Le jeu de données Wine Quality Data Set contient 5000 vins décrits par leurs caractéristiques chimiques et évalués par un expert. Peut-on s’approcher de l’expert à l’aide d’un modèle de machine learning. |

|
Le jeu de données Wine Quality Data Set contient 5000 vins décrits par leurs caractéristiques chimiques et évalués par un expert. Peut-on s’approcher de l’expert à l’aide d’un modèle de machine learning. |
|

|
C’est désormais un problème classique de machine learning. D’un côté, du texte, de l’autre une appréciation, le plus souvent binaire, positive ou négative mais qui pourrait être graduelle. |
|
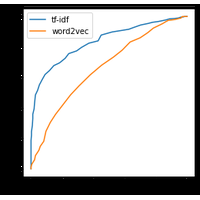
|
C’est désormais un problème classique de machine learning. D’un côté, du texte, de l’autre une appréciation, le plus souvent binaire, positive ou négative mais qui pourrait être graduelle. |
|
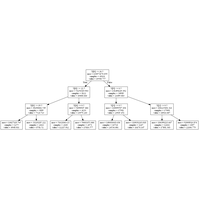
|
Classification, régression, visualisation avec des méthodes ensemblistes (arbres, forêts, …). |
|

|
Méthodes ensemblistes, features importance, correction. |
|
|
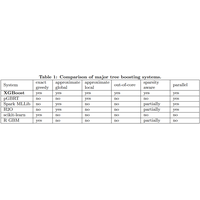
2A.ml - Boosting, random forest, gradient - les features qu’ils aiment |
Avantages et inconvénients des méthodes à gradient. Exercice sur la rotation de features avant l’utilisation d’une random forest. |

|
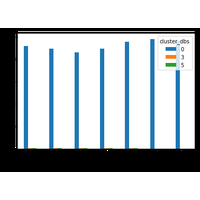
Ce notebook utilise les données des vélos de Chicago Divvy Data. Il s’inspire du challenge créée pour découvrir les habitudes des habitantes de la ville City Bike. L’idée est d’explorer plusieurs algorithmes de clustering et de voire comment trafiquer les données pour les faire marcher et en tirer quelques apprentissages. |
|
|
Ce notebook utilise les données des vélos de Chicago Divvy Data. Il s’inspire du challenge créée pour découvrir les habitudes des habitantes de la ville City Bike. L’idée est d’explorer plusieurs algorithmes de clustering et comment trafiquer les données pour les faire marcher. |
|
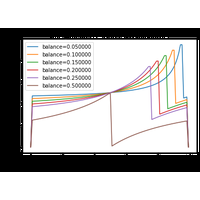
|
Un jeu de données imbalanced signifie qu’une classe est sous représentée dans un problème de classification. Lire 8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset. |
|
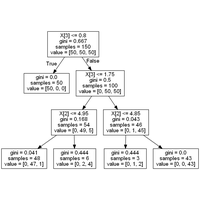
|
Plus un modèle de machine learning contient de coefficients, moins sa décision peut être interprétée. Comment contourner cet obstacle et comprendre ce que le modèle a appris ? Notion de feature importance. |
|

|
Prédire la souscription d’un contrat sur le jeu de données Bank Marketing Data Set . |
|
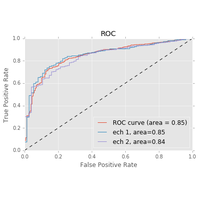
|
Classification binaire, correction. |
|
|
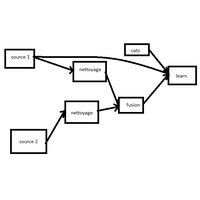
2A.ml - Pipeline pour un réduction d’une forêt aléatoire - correction |
Le modèle Lasso permet de sélectionner des variables, une forêt aléatoire produit une prédiction comme étant la moyenne d’arbres de régression. Cet aspect a été abordé dans le notebook Reduction d’une forêt aléatoire. On cherche à automatiser le processus. |

|
2A.ml - Pipeline pour un réduction d’une forêt aléatoire - énoncé |
Le modèle Lasso permet de sélectionner des variables, une forêt aléatoire produit une prédiction comme étant la moyenne d’arbres de régression. Cet aspect a été abordé dans le notebook Reduction d’une forêt aléatoire. On cherche à automatiser le processus. |
|
Revue des problèmes classiques de machines learning, classification, régression, ranking. Exercices sur la classification multi-classes. |
|
|
Le modèle Lasso permet de sélectionner des variables, une forêt aléatoire produit une prédiction comme étant la moyenne d’arbres de régression. Et si on mélangeait les deux ? |
|

|
Le modèle Lasso permet de sélectionner des variables, une forêt aléatoire produit une prédiction comme étant la moyenne d’arbres de régression. Et si on mélangeait les deux ? |
|
|
ACP, CAH, régression lineaire. |
|
|
2A.ml - Statistiques descriptives avec scikit-learn - correction |
ACP, CAH, régression linéaire, correction. |
|
Prédictions sur des séries temporelles et autres opérations classiques. |
|
|
Prédictions sur des séries temporelles. |
|
|
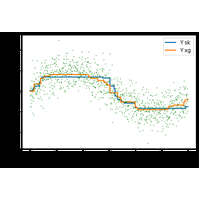
L’overfitting ou surapprentissage apparaît lorsque les prédictions sur de nouvelles données sont nettement moins bonnes que celles obtenus sur la base d’apprentissage. Les forêts aléatoires sont moins sujettes à l’overfitting que les arbres de décisions qui les composent. Quelques illustrations. |
|

|
Le notebook explore l’algorithme du Gradient Boosting. |
|
|
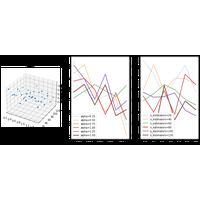
Hyperparamètres, LassoRandomForestRregressor et grid_search (correction) |
Le notebook explore l’optimisation des hyper paramaètres du modèle LassoRandomForestRegressor, et fait varier le nombre d’arbre et le paramètres alpha. |

|
Hyperparamètres, LassoRandomForestRregressor et grid_search (énoncé) |
Le notebook explore l’optimisation des hyper paramaètres du modèle LassoRandomForestRegressor, et fait varier le nombre d’arbre et le paramètres alpha. |

|
Ce notebook est inspiré de l’article FairTest: Discovering Unwarranted Associations in Data-Driven Applications et propose d’étudier une façon de vérifier qu’un modèle ou une métrique n’est pas biaisé par rapport à certains critères. |
|

|
Ce notebook est inspiré de l’article FairTest: Discovering Unwarranted Associations in Data-Driven Applications et propose d’étudier une façon de vérifier qu’un modèle ou une métrique n’est pas biaisé par rapport à certains critères. |
|

|
Quelques exercices simples sur scikit-learn. Le notebook est long pour ceux qui débutent en machine learning et sans doute sans suspens pour ceux qui en ont déjà fait. |
|
|
Rappels sur scikit-learn et le machine learning (correction) |
Quelques exercices simples sur scikit-learn. Le notebook est long pour ceux qui débutent en machine learning et sans doute sans suspens pour ceux qui en ont déjà fait. |
|
Ce notebook présente quelques étapes simples pour une série temporelle. La plupart utilise le module statsmodels.tsa. |